
Abstract
Between 2011 and 2013, convenience store retail business grew dramatically in Thailand. As a result, most companies have increasingly been choosing the application of performance measurement systems. This significantly results in poor performance measurement regarding future business lagging measure. To solve this problem, this research presents a hybrid predictive performance measurement system (PPMS) using the neuro-fuzzy approach based on particle swarm optimization (ANFIS-PSO). It is constructed from many leading aspects of convenience store performance measures and projects the competitive level of future business lagging measure. To do so, monthly store performance measures were first congregated from the case study value chains. Second, data cleaning and preparations by headquarter accounting verification were carried out before the proposed model construction. Third, these results were used as the learning dataset to derive a predictive performance measurement system based on ANFIS-PSO. The fuzzy value of each leading input was optimized by parallel processing PSO, before feeding to the neuro-fuzzy system. Finally, the model provides a future performance for the next month’s sales and expense to managers who focused on managing a store using desirability function (\(D_{i})\). It boosted the sales growth in 2012 by ten percentages using single PPMS. Additionally, the composite PPMS was also boosted by the same growth rate for the store in the blind test (July 2013–February 2014). From the experimental results, it can be concluded that ANFIS-PSO delivers high-accuracy modeling, delivering much smaller error and computational time compared to artificial neural network model and supports vector regression but its component searching time differs significantly because of the complexity of each model.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Retail convenience stores are crucial drivers of the Thai economy. These stores proved that they can generate great value to the tunes of approximately tens of billions of baht, in 2012 (Department Of Industrial Promotion 2012). This directly results in an increase in Thai economic wealth (Evans 2011). Modern retailing practices are in full bloom in many countries around the world, especially in the Asia region. This has come about from the ongoing principal revolution in retailing business over the past 20 years. In Asia, old-style, local retail businesses cannot compete easily with modern retailing. To survive, they must adopt a rounded performance management strategy, reflecting current and projected marketplace constraints, while focusing on sales growth, rather than past performance. Soft computing and data mining have been broadly applied as analytic tools in this domain, and these include scheduling, product assortment, product characteristic design, and location management. The relevance of fuzzy logic, artificial neural network, and other evolutionary algorithms to the data mining problem is established by the parameter or output optimization concept based on randomized search and reasoning approximation of input and output factors. The hybrid approach offers a much more powerful model for data mining by integrating optimization and learning, feature selection, representation features in data mining models such as the simplified hybrid algorithm mixing Nelder–Mead, and PSO methods to improve the training process of neural network especially in neural network parameter optimization (Liao et al. 2014).
In the middle of the 2000s, performance measurement failed to connect the then current strategies and to take forward the result of the improvement; it was also too inward looking (Gunasekaran and Kobu 2007). Furthermore, PMS often identified the improvement of the key performance indicator to be improvement in individual financial indicators, without addressing the interaction between them and the other operational indicators (Gunasekaran and Ngai 2004).
Most companies and academic research groups have also concentrated on the results of the historical performance measurement interpretation and relied on the things that have already happened (Unahabhokha et al. 2007). This is in accordance with general PMS manners where there are only guidelines on how to manage and control performance based on previous reported outputs. The results are the scarce concern on performance inclination and the lack of well-rounded performance planning improvement in the long term.
Furthermore, there have a few of effort to integrated the prediction capacity to performance measurement system (PMS) for examples in manufacturing industry such as Mehrabad et al. (2011) and Unahabhokha et al. (2007) and for instance in supply chain management such as Ganga and Carpinetti (2011); however, most of them were focused on only one output based on fuzzy rule approach rather than multiple output. The proposed modeling approach was initially extended and fulfilled this research gap by PPMS with multiple output with priority to action of each business unit.
Today, soft computing and data mining are used not only in marketing but also in many different areas in performance management and measurement in manufacturing and the other industries to retrieve useful knowledge based on many models and methodologies (Mariscal et al. 2010) such as knowledge discovery by neuro-fuzzy modeling framework to knowledge in the format of fuzzy rules (Castellano et al. 2005), a decision rule-based soft computing model for supporting financial performance improvement of the banking industry (Shen and Tzeng 2015) and neuro-fuzzy for air conditioning systems to reduce electricity consumption (Costa and La Neve 2015).
Recently, an evolutionary algorithm (EA) and PSO have caught the continuous attention of the research community (Bonabeau and Meyer 2001) for instances two-stage hybrid swarm intelligence optimization algorithm development (Deng et al. 2012), two-layer surrogate-assisted particle swarm optimization algorithm (Sun et al. 2014). Moreover, some researches focused on dynamic hybrid framework for constrained evolutionary optimization which can extend to optimization engine in another model (Wang and Cai 2012). Both EA and PSO have shown promise in tackling a wide variety of engineering and supply chain difficulties, such as forecast of off-season longan supply (Leksakul et al. 2015), agricultural products logistics (Yao et al. 2009), value creation through collaborative supply chain: holistic performance enhancement road map (Holimchayachotikul et al. 2014), solving a garbage and recycling collection problem (Pessin et al. 2013), the permutation flowshop scheduling problem (Marinakis and Marinaki 2013) and emergency transportation planning in disaster relief supply chain management (Zheng and Ling 2013).
Currently, the most common research technologies associated with soft computing and data mining have a few number of the fusion of soft computing and evolutionary optimization algorithms such as a directed search strategy for evolutionary dynamic multi-objective optimization (Liu et al. 2009). Internationally, its application took over gradually not only production and operations management but also performance development. To draw from the powerful business lagging performance increment solution of Thai local retail case study and fill the research gaps, a predictive performance measurement model was derived from integrating modern convenience store performance measurement with a soft computing model such as the neuro-fuzzy system and particle swarm intelligence bases on predictive model concept in data mining.
In this paper, the primary research question investigated in this thesis is as follows: how can we integrate the concept of soft computing and data mining with PMS to offer a predictive performance measurement and management model (PPMS) for potential PMS improvement? Since this question could become too valuable; a novel alternative approach via integrated performance measurement system together with multiple decision making and neuro-fuzzy approach based on particle swarm optimization (ANFIS-PSO) was developed in a systematic manner to forecast future performance with priority to action of each business unit rather than the traditional PMS and recognize latent problems in their business unit performance improvement.
This paper is organized as follows. In Sect. 2, simple additive weighting, ANFIS, and particle swarm optimization are described in brief and summed up. In Sect. 3, the methodology of the proposed approach is drawn out. Single PPMS and composite PPMS results and discussion of the proposed framework deployment and the extended model development are discussed in Sect. 4. Finally, the conclusions are provided in Sect. 5.
2 Background
2.1 Literature review
Since the 2000s, businesses and the production domain have broadly accepted and utilized the extension of data mining using soft computing based on heuristic theory or evolutionary approaches. Currently, many different areas of business, performance management, supply chain, and logistics engineering use computational intelligence and hybrid data mining for demand forecasting system modeling (Harding and Popplewell 2006; Mariscal et al. 2010), supply chain improvement roadmap rule extraction (Linh et al. 2003), quality assurance, scheduling, and decision support systems. At the turn of the 2000s, the blooming of fusion theory among data mining, soft computing, and modern business performance study was gradually used in business performance management to choose the suitable and agile solution in real practical deployment. In recent times, there have been a few attempts to bring about an integration between modern business performance studies and evolutionary approaches to carry out the final lagging performance boosting up in terms of business performance measurement and management, for example, a soft computing framework using the neuro-fuzzy inference system for software effort estimation that is directly related with the cost and quality of the software in terms of project management and risk analysis (Huang et al. 2006).
Over the past ten years, soft computing in terms of fuzzy logic systems and neural networks is being increasingly applied in the internal functions of industries (Tirian et al. 2010; Shen and Tzeng 2015), particularly in forecasting, inventory control, quality control, group technology, scheduling, and planning.
Most prior research focusing on neural networks and fuzzy logic systems have taken five approaches: (1) neural network in system management such as wind speed prediction to operate wind farms by neural network Gnana Sheela and Deepa (2014), medium-term sales forecasting in fashion retail supply chains (Deng et al. 2012; 2) spending neural networks to generate membership functions in fuzzy logic systems; (3) applying neural networks to substitute fuzzy rule evaluation in fuzzy logic systems; (4) blending neural networks and fuzzy logic systems; and (5) opting for neural networks for the learning process of fuzzy types of data. This is under the umbrella of the past ten years of neural networks and/or fuzzy logic research (Gumus and Guneri 2009; Gumus et al. 2009; Paladini 2009). In the last five years, the most common research technologies that have integrated the fuzzy set theory procedure are neural networks and evolutionary algorithms. Internationally, its application gradually found employment in not only production and operations management but also supply chain management and performance measurement (Wong and Lai 2010). Table 1 shows the trend of application of the neuro-fuzzy logic in terms of modeling solutions for problems in many industries since the 1990s. There are many linkages between the applications of the neuro-fuzzy logic, namely business, engineering, knowledge management, medicine, and others, but only a small number between performance measurement and neuro-fuzzy application.
2.2 Neuro-fuzzy system
A fuzzy inference system (FIS) employing fuzzy “if-then” rules can be constructed as a model to put together the qualitative aspects of human knowledge and reasoning process without employing a precise measurable analyzer (Jang 1993). Moreover, adaptive neuro-fuzzy inference system (ANFIS) has been accepted as a potential technique that can facilitate effective development of models by linking information from different sources, such as empirical models, heuristics, and data.

The ANFIS architecture Fuzzy Logic Toolbox User’s Guide (2015)
Hence, in most cases, neuro-fuzzy models, rather than totally black box models such as neural networks, can be improved and used to elucidate solutions to users. Figure 1. shows the ANFIS architecture.
According to Sugeno fuzzy model, the rule sets are as follows:
Layer 1: Layer 1 is the input and fuzzification layer. Every node i in this layer is an adaptive node with a node function.
Layer 2: Layer 2 is the rule layer. Each node in this layer calculates the firing strength of each rule via multiplication
Layer 3: Layer 3 is the normalization layer. Each neuron in this layer calculates the normalized firing strength of a given rule.
Layer 4: Parameters in this layer are referred to as consequent parameters.
Layer 5: This layer is designed to calculate the summation of output of all incoming signals.
2.3 Particle swarm optimization
Particle swarm optimization (PSO) is a social behavior-based, stochastic optimization method constructed by Eberhart and Kennedy (1995), inspired by the social behavior of bird flocking. PSO has many similarities with evolutionary computation techniques. It is initialized with a population of random solutions and then solved for optima by updating generations. In PSO, the possible solutions, called particles, fly over the problem space by following the current optimum particles. Each particle records track of its coordinates in the problem space, which are associated with the best solution (fitness) it has achieved so far. (The fitness value is also stored.) This value is called \(p_{\mathrm{best}}\). Another “best” value that is tracked by the particle swarm optimizer is the best value obtained thus far by any particle in the neighborhood of the particle. This location is called \(l_{\mathrm{best}}(P_{{id}}\).). When a particle takes the entire population as its topological neighbor, the global best is called \(g_{\mathrm{best}}(P_{{gd}})\). PSO consists of, at each time step, changing the velocity of (accelerating) each particle toward its \(p_{\mathrm{best}}\) and \(l_{\mathrm{best}}\) locations (local version of PSO). The acceleration is weighted by a random term, with separate random numbers being generated for acceleration toward the \(p_{\mathrm{best}}\) and the \(l_{\mathrm{best}}\) locations. The updating equations are as follows:

The methodology of ANFIS-PSO for predictive performance measurement system
2.4 Case study company
4600 examples were collected monthly in 2011 and 2012 from the strategic stores of the biggest modern retail value chain in northern Thailand. The single PPMS is demonstrated using these data. To illustrate the composite PPMS model construction process and result, the dataset of the period from July 2012 to February 2014 was determined as learning data and test data. Its mother chain had approximately 6700 branches. As far as its retail value chain is concerned, the operating store is crucial to driving their retail value chains. The operating store has three store types such as company stores, individual franchise stores, and sub-area stores. Due to confidentiality issues, the case study company transformed all continuous attributes such as sales and number of transactions to an appropriated scale. Store business performance depends on five core measures: past store sales (the same month in the previous year), present store sales (the current month in the present year), monthly expected number of customers from the store department manager teams, present store expenses, and present store quality score in terms of service, environment, and other store quality factors of concern in each month following the headquarter policies. These play a crucial role in modern retailing. The results of these monthly core measures were used as the input for store performance grouping. Each group was targeted for the next month’s sales by comparing the mean of its group. The management team carried out a store-by-store consideration to assign a sales target based on the group and its performance.
3 Methodology
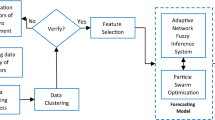
In this study, ANFIS-PSO is developed for predictive performance measurement system (PPMS), where a strong relationship exists between the leading measures and the lagging business result. PPMS is of two types (single PPMS and composite PPMS) as shown in Fig. 3. The main methodology is presented in Fig. 2.
The selected leading measures include two parts from 4600 examples. The first part includes four measures of past performances: store sales, number of customers, store quality score, and store expenses. The second part is the expected number of customers, which is assigned by the case study company. In addition, the future business result is the next month’s sales. The data were cleaned by applying the logical accounting consistency validation provided by the head office of the case study company. To prepare the learning dataset, the primary dataset (with regard to single PPMS) was randomly rearranged in the order of records with “1234567” of seed numbers. The single PPMS model structure, based on the leading and lagging KPIs is shown in Fig. 3. Its concept will be drawn in Sect. 4.7.1.

The proposed PPMS type
Then, the simple PPMS model with one output was run using a tenfold cross validation dataset, which comprised of a training set and a test set from the present dataset. These data, consisting of input parameters and the corresponding output, are then used to train and test ANFIS-PSO, support vector regression (SVR), and artificial neural network (ANN) based on grid search, concurrently.
In deep, mean absolute percentage error was used as accuracy measurement of the predictive model. PPMS learning process is done at specified iterations with the accepted error. The so-called best PPMS model in current generation is used to generate predictive performance values. Performance of predictive values can be improved by adjusting PPMS model using potential scenarios from early the fuzzy rule simulation in Matlab tool box from expert participation. Hence, ANFIS based on PSO was chosen to conduct PPMS model by its ability to learn data while giving human-like style of fuzzy system. By passing this enhancement back into PPMS model, the model then recalculate its optimal initial values and generate better predictive performance values in next generation. Ultimately, the core objective of this phase is answered to “How can organizations ensure the expected results if they design the action follow the predictive performance from PPMS?”.
After computational learning, the prediction accuracy of the testing data of each fold in terms of mean absolute percentage error (MAPE), standard deviation of MAPE (SD), and runtime in cross validation process was used to compare the performances of the ANFIS-PSO, SVR, and ANN based on grid search (ANN-grid search) models. At this stage, simple additive weighting (Fishburn 1997) was applied to calculate the overall score of the model. The weights of MAPE, SD, and runtime in the second unit were assigned to be 55, 25, and 20 %, respectively, in the SAW process. The highest overall score from SAW was the criterion for selecting the best model. Finally, the potential leading scenarios, that is, the scenarios that can acquire the high level of each strategic store result, as obtained from the domain manager, were fed into the best model. The scenario inputs included two parts: (1) past performance based on store sales and number of customers and (2) the expected number of customers, store quality score, and store expenses, as assigned by the case study company. Moreover, the desirability function was applied to illustrate the focused store management in Sect. 4.7. \(D_{i}\) which played the role as the predictive output integrator.
4 Results and discussion
4.1 Learning dataset construction
Subsequently, the primary dataset was collected from the case study company. Next, data cleaning and input–output format following the ANFIS-PSO structure were conducted to prepare the learning data. Eighty percent of the learning dataset is randomly assigned as dataset for the cross validation process. The rest of the dataset is chosen as the unseen test dataset. In addition, the blind dataset is also used for the final performance model test. Additionally, it is used for the model evaluation process as well.
4.2 Artificial neural network model construction
All computations were performed on an Intel® Core(TM) i7-3540M, 3.0 GHz CPU computer with 4 GB of memory. The learning dataset of ANFIS-PSO and ANN-grid search set for each learning step came from the dataset prepared as discussed in Sect. 4.1. To achieve the best setting with minimum error, the network parameters were identified by exhaustive search (3000 iterations and two retrainings for each combination). The testing error fitness criterion was used: the smaller the error, the more accurate the network. The space search of two hidden layers was carried out from 1 to 40 hidden nodes in each layer, with the search step as one by one. The best topology obtained from the search was the 4-12-15-1 network, as depicted in Fig. 4. The Quickprop algorithm was used in the training. The network was trained with sigmoid transfer function for both the hidden and the output layers. A coefficient term of 1.75 was used for fast convergence. Consequently, the number of training iterations was 50,000 epochs and the initial values of weights and biases were random.

The ANN model with four inputs and its next month sales output

The particle architecture (the array $swarm)
4.3 Support vector regression construction
The same dataset as the one that was used to train and test the neural network was used with the support vector regression. Firstly, the input data were mapped from the input space into a high-dimensional feature space using radial basic function kernel (RBF). This function was deservedly used for regression problems. It can be defined as follows:
The amplitude of RBF was controlled by the vital parameter \(\gamma \). In this research, we found that a \(\gamma \) value of 0.2 provides the best predictive results. In addition, \(\varepsilon =0.001\) and \(c=500{,}000\) were used.

The ANFIS-PSO process flow
4.4 ANFIS-PSO construction
The same dataset as the one that was used to train and test the neural network was used with ANFIS-PSO. This dataset comprised of the input vectors and the corresponding output vector. In PSO, the numbers of particles were assigned as 4, 8, 16, 32, and 64. Each ANFIS-PSO model was set parameter values by following 40 iterations of PSO, 10 iterations of ANFIS, 0.9 of \(_{\mathrm{max}}\), 0.4 of \(W_{\mathrm{min}}\), and 1.2 for both C1 and C2. Initially, the triangular membership with three levels was assigned the value of each level according to the center value. Each particle swarm plays a crucial role as the value optimizer of the membership for each input. It provides the best value of the membership for each input that is related to the error objective function of ANFIS. In addition, the particle storage pattern is designed to collect the optimized value of each membership function element.
An example of particle architecture is shown in Fig. 4. A swarm is created and stored in the array $swarm. This swarm comprises a group of particles structured as illustrated in Fig. 5. To explain the array $swarm, if the ANFIS-PSO model has three inputs and uses two levels of membership function which are optimized by ten particles, one particle will have three nodes of two membership functions in which each one of them also has three parameters.
This vital process is performed in ten steps, as demonstrated in Fig. 6. The MAPE was used as the objective function with regard to minimization based on the iterations.
Normally, one particle of the swarm of PSO is assigned to find the optimized value of the membership function in one iteration of ANFIS. This is due to the trade-off problem between the complexity of the model and the time to the next month target management. The concept of parallel processing with multi-thread in Fig. 7 was applied to the PSO part in ANFIS-PSO to overcome the limitation of the computational resource problem. After ANFIS-PSO learning, the best triangular membership functions of each input were determined as shown in Fig. 8.

The concept of parallel processing
However, parallel processing of PSO would use the number of particles by following the real core CPU of the laptop. In this study, four particles of the swarm were opted for one iteration of ANFIS-PSO. This can reduce the computational runtime from 1000 s of the existing ANFIS-PSO to 10 s, approximately. The results are presented in Table 2.

The best triangular membership functions of the inputs
4.5 Model evaluation
The overall score of the model from SAW was calculated based on the results of the blind dataset to find the suitable model with the highest overall score. The results from ANFIS-PSO, SVR, and ANN-grid search are presented in Table 2.
All performance investigation was calculated by the mean absolute percentage error (MAPE). The equation of MAPE is
The performance investigation used the overall performance index aggregated from the three measures (MAPE, SD, and runtime) of the blind dataset. Based on the overall score, it is evident that ANFIS-PSO with tenfold cross validation and 16 particles had the lowest error. ANN-grid search had the highest error. ANFIS-PSO provided good results and was suitable for use with the real problem (targeting the next month in the case study). Therefore, ANFIS-PSO was selected for predictive performance measurement. In addition, it was found that the MAPE of the testing set from the final model was less than 15 %; this can be observed in the acceptance error from the domain expert assumption. Comparison of the desired output of the next month’s sales (blind test dataset) with the results obtained from ANFIS-PSO with tenfold cross validation and 16 particles is presented in Fig. 9.

The results of single PPMS.
From analysis of variance (ANOVA) study in Table 3 for MAPE and Model, there is evidence at 95 percentage of confidence interval that MAPE of ANFIS-PSO do differ from the traditional targeting.
In this study, the convergence graph of the ANFIS-PSO is shown in Fig. 10. This graph was onefold in tenfold cross validation using 19.23 s of CPU processing time. MAPE converges to 15 % of MAPE after 32nd iteration from 400th iteration. Furthermore, MAPE and CPU processing time of tenfold cross validation are also illustrated in Fig. 11.
4.6 Model deployment means
As regards practical deployment, the domain users tried it using the following steps:
-
1.
Prepare their store performance data according to the input–output model format and then feed it into the ANFIS-PSO model.
-
2.
Use the results from ANFIS-PSO as the next month’s sales target.
-
3.
Provide the monthly predictive sales as the monthly sales target KPI to each manager.
-
4.
Analyze the ANFIS-PSO model performance for sales, targeting error monitoring.
-
5.
Develop a suitable management policy to make the stores of interest shift the focus from their current performance to reach higher or same level of sales target.
The predictive sales and expense from single PPMS will target the next month’s performance of the store with priority to act by taking a cue from the result of composite PPMS. The experimental results reveal that the error of the store in the blind test (from July 2013 to February 2014) has been decreased by approximately fifteen percent, which compares with the existing approach.

Convergence graph of the ANFIS-PSO

MAPE and CPU processing time of tenfold cross validation
4.7 Extended model development and deployment means
4.7.1 Single PPMS
Practically, the priority is that target deployment is of vital consideration to the area managers in the case study company on the grounds of resource limitation as regards focused management (“less and focused” resources return better results). Derringer and Suich proposed the desirability function in 1980, and it is also used in the multi-response surface optimization application (He et al. 2012). The predictive output from the model discussed in Sect. 4.4 was used as the input variable in the desirability function for \(D_{i}\). The predictive output from the next month’s sales model is to be maximized, instead; individual desirability is defined as

Let \(L_{{i}}\), \(U_{{i}}\), and \(T_{{i}}\) be the lower, the upper, and the target values, respectively, that are desired for response \(Y_{{i}}\) (predictive output), with \(L_{i}\le T_{i}\le U_{{i}}\). The lower and the target values for the present model are 30,000 and 85,000 of sales, respectively. \(D_{{i}}\) from the single PPMS model is as shown in Fig. 3. The area managers can sort the \(D_{{i}}\) and then assign the management order of the top store and the bottom store. The priority to action (\(D_{{i}})\) is as shown in Fig. 3. For example, if the area manager receives the closed predictive value from ANFIS-PSO, it is hard for the management to make a decision or to take action. \(D_{{i}}\) will contribute to resolve this problem by the order of \(D_{{i}}\).
Suppose the area manager wants to develop the \(D_{{i}}\) for the next month’s expense (the small value is better). The predictive output of the next month’s expense model is to be minimized; the individual desirability is defined as follows:
The upper and the target values for the present model are 25,000 and 5000 of sales, respectively. Equation 12 will be used in Sect. 4.7.2 to construct the \(d_{2}\) for the next month’s expense. It is used as the component of the composite \(D_{i}\) for the composite PPMS.

The results of the feature selection for each model
4.7.2 Composite PPMS
To construct the composite PPMS, as illustrated in Fig. 8, the database of data from July of 2012 to February of 2014 was collected and chosen as the composite PPMS database. The data record from June 2012 to June 2013 were assigned as the learning dataset while the rest of the dataset was apportioned as the test dataset. The descriptive statistics of the learning dataset are presented in Table 4.
To illustrate the PPMS model construction process and result, the dataset of the period from July 2012 to January 2014 was designated as the learning dataset and the dataset of February 2014 was defined as the test dataset. These show one loop of the PPMS model construction process and result. The incremental learning data process was used to raise the learning dataset month by month, for instance the dataset of February 2014 was combined with the dataset of the period from July 2012 to January 2014 as the learning dataset for March 2014. The explanation for each of the attributes in terms of average per day per store is as follows: Sale_LM (Last month’s sales), Sale_TY_LY (Current month’s sales in last year), SupplyUse (Last month’s supply use), ExpenseLM (Last month’s expense), ExpenseNextMonthInLastYear (Next month’s expense in last year),ExpenseNextMonth (Next month’s expense), TC_LM (Last month’s customer transaction),TCNextMonthInLastYear (Next month’s customer transaction in last year) and SaleNextMonth (Next month’s sales).
In this session, we have two main lagging business results, which are the sales of the next month and the expense of the next month. These are considered as the predictive output for the PPMS model based on ANFIS-PSO. According to the PPMS model complexity from the number of assigned membership functions of each input, genetic algorithm input feature selection was applied to the learning dataset using Optimized Weights (Evolutionary) in Rappid Minner 6.0. It was used to reduce the input redundancies from ten inputs and choose only five crucial inputs which have strong relationship with each of the lagging outputs. The initial parameters of data processing were configured for 100 % of sampling. However, GA was also ascribed to follow 50 of the population size, 50 of the generation, 0.9 of the crossover rate, and 0.1 of the mutation.
Due to the heuristic nature of genetic algorithm (GA), GA with the same configuration was performed more than 100 times. Those combinations which had a fitness value more than 0.5 were taken into account as candidate combinations, as illustrated in Fig. 12. At the conclusion of this step, the winner combination was used as the input combination of the next month’s sales model. It consisted of Sale_LM, TC_LM, Sale_TY_LY, SupplyUse, and ExpenseLM, whereas the input combination of the next month’s expense model consisted of ExpenseNextMonthInLastYear, TCNextMonthInLastYear, Sale_LM, TC_LM, Sale_TY_LY, and ExpenseLM.
The composite PPMS can be assembled from the next month’s sales model and the next month’s expense using the desirability function. Its computational condition and ANFIS-PSO condition are performed in the manner discussed in Sects. 4.2 and 4.3.
Initially, the triangular membership with three levels was assigned the value of each level by the center value. Each model generates 234 fuzzy rules. After the learning process, the best triangular membership functions of each input were determined, as illustrated in Figs. 13 and 14. The MAPE of the blind dataset (July 2013–February 2014) is as shown in Fig. 15.

The best triangular membership functions for the next month’s sales model

The best triangular membership functions for the next month’s expense

The MAPE of the blind dataset
The averages of the blind dataset (February 2014) of the next month’s sales model and the next month’s expense model are 10.88 and 10.68 %, respectively. These can be verified by the performance of the PPMS where the MAPE achieved was less than 15 %, which, again, is better than that of the traditional sales and expense targets of the case study company. The desired output values of the next month’s sales and the next month’s expense (actual values) from the high-performance store group of the case study company were compared with their results, as demonstrated in Fig. 15. From the policy of the headquarters, the next month’s sales and the next month’s expense targets were assigned as 10–15 % of the growth of the next month’s sales in last year and the next month’s expense in last year. This traditional approach generates MAPE to an approximation of 20–25 %.
In the main calculation process of the composite PPMS model, each input of each single, simple PPMS from one store data point is fed to each composite PPMS, data point by data point.
\(Y_{1}\) (predictive next month’s sales value for suggested sales target for measurement) and \(Y_{2}\) (predictive next month’s expense value for suggested sales target for measurement) are received, respectively, from the next month’s sales model output and the next month’s expense model output. The value of \(d_{i}\) was calculated using Eqs. 12, 13 and their \(L_{i},U_{i}\) and \(T_{i}\) were also found to be the values discussed in Sect. 4.6. These values can be fed into the final desirability function, as follows:
Let \(D_{i}\), \(d_{1}, d_{2}, w_{1}\), and \(w_{2}\) be the final desirability value, the desirability value of the predictive next month’s sales value, the desirability value of the predictive next month’s expense value, the weight of \(d_{1}\), and the weight of \(d_{2}\).
Due to the business lagging performance’s focus on management, \(w_{1}\) and \(w_{2}\) were assigned the values of 0.8 and 0.2, respectively. Practically, the \(D_{i}\) of each record in each model can help the area manager to prioritize the store instead giving the same priority to all. Moreover, the \(D_{i}\) from the composite PPMS can resolve and perform conflict management of the trade-off business lagging outputs such as sales and expense, based on the fact that the traditional store management looks, sees, asks, and acts in the step-by-step manner of business lagging output by business lagging output, without it concerning the top and the bottom stores. They cannot make the decision to act based on one factor; however, \(D_{i}\) from the composite PPMS can fulfill this requirement and bridge the critical management gap.
Basically, \(D_{i}\) from each model will be decently ordered to provide the management the order of the top store and the bottom store. The \(D_{i}\) from each model is as shown in Fig. 16.

The results of the composite PPMS
4.7.3 Composite PPMS model deployment means
As regards the practical composite PPMS deployment, the domain users tried it using the following steps:
-
1.
Prepare their PPM (store department managers) data according to the input–output model format and then feed it into the ANFIS-PSO model.
-
2.
Consider the results from ANFIS-PSO as the next month’s sales target and the next month’s expense.
-
3.
Consider the Di value of each store as the priority to manage the top store and the bottom store.
-
4.
Provide monthly predictive suggested sales and expense as the monthly sales target KPI to each division manager.
-
5.
Analyze the ANFIS-PSO model performance for sales and expense, targeting error monitoring.
-
6.
Develop management policies to focus on the stores of interest, as a shift from its current performance, to reach higher or same level of sales target.
After applied PPMS, the next month’s sales and expense targeting were manipulated based on ANFIS-PSO. It was observed (from July 2013 to February 2014) that the sales growth was approximately 10–15 % for the blind store. This evidence proved the potential of the proposed PPMS.
5 Conclusion
This paper has described a new predictive performance measurement system (PPMS) to create competitive advantages with regard to high-accuracy lagging business performance targeting and smart business performance understanding. The PPMS was proposed concerning how to construct logical and sequential integration between ANFIS and PSO and the retailing performance measurement system. Data collected for the period from February 2011 to February 2014 of the biggest retailing value chain in northern Thailand were used to demonstrate both single PPMS and composite PPMS. The integration of ANFIS and PSO was developed as PPMS based on each vital business attribute to each model output from store the performance measurement database. This approach provides the next month’s sales and expense targets to each store and helps it to keep its focus on the right sales performance. The results obtained from the single PPMS of the next month’s sale suggest that ANFIS-PSO outperforms SVR and ANN based on grid search. Last but not least, division managers can use the predicted sales from the single PPMS to develop performance-boosting strategies for each store via focused store management by the order of \(D_{i}.\) This is in connection with multiple business output management.
There could be conflicting performances; therefore, the single PPMS by ANFIS-PSO will be used as the primary model of the composite PPMS. This would combine the output from each single PPMS based on the desirability function concept. The composite PPMS (\(D_{i})\) changes the performance measurement from targeting and late measurement to predictive measurement based on the future performance target with priority being given to action. The PPMS by ANFIS-PSO can greatly reduce the time required for the next month’s sales and the next month’s expense targeting performance on the grounds that each store can know the reasonable and the challenging sales and expense targets. From the results given in Sect. 4, we can conclude that the proposed PPMS and its elements are successfully fulfilling the design requirement and developing an effective predictive performance measurement system using the hybrid model for the retail industry.
The ANFIS-PSO model has potential advantages: it is not disruptive and is relatively inexpensive as it utilizes historical and current data to incrementally construct PPMS. However, ANFIS-PSO has limitations, too. The computational resource usage performance depends on the number of particles in the PSO and its iterations. In addition, if data have high variations between each trial, the modeling performance would become poor. Further research potential includes applying the parallel processing in both the ANFIS part and PSO to overcome the limitation of the computational resource problem or applying the clustering function of data mining to construct the performance store group before performing PPMS using the ANFIS-PSO model. This is to reduce the variations in the performance of the different stores. Additionally, local events, seasonal campaigns, and promotional measures of each store can be used as inputs to PPMS by the ANFIS-PSO model.
References
Almejalli K, Dahal K, Hossain MA (2008) Real time identification of road traffic control measures. Advances in computational intelligence in transport, logistics, and supply chain management, vol 144. Springer, Berlin
Asiltürk I et al (2012) An intelligent system approach for surface roughness and vibrations prediction in cylindrical grinding. Int J Comput Integr Manuf 25:750–759
Bonabeau E, Meyer C (2001) Swarm intelligence. A whole new way to think about business. Harv Bus Rev 79:106–114, 165
Castellano G, Castiello C, Fanelli AM, Mencar C (2005) Knowledge discovery by a neuro-fuzzy modeling framework. Fuzzy Sets Syst 149:187–207
Cheng JH, Chen SS, Chuang YW (2008) An application of fuzzy delphi and Fuzzy AHP for multi-criteria evaluation model of fourth party logistics. WSEAS Trans Syst 7:466–478
Costa HRN, La Neve A (2015) Study on application of a neuro-fuzzy models in air conditioning systems. Soft Comput 19:929–937
Deng W, Chen R, He B, Liu YQ, Yin LF, Guo JH (2012) A novel two-stage hybrid swarm intelligence optimization algorithm and application. Soft Comput 16(10):1707–1722
Department of Industrial Promotion (2012). http://www.dip.go.th/
Du TCT, Wolfe PM (1997) Implementation of fuzzy logic systems and neural networks in industry. Comput Ind 32:261–272
Eberhart R, Kennedy J (1995) New optimizer using particle swarm theory. In: Proceedings of the international symposium on micro machine and human science, pp 39–43
Efendigil T, Önüt S, Kahraman C (2009) A decision support system for demand forecasting with artificial neural networks and neuro-fuzzy models: a comparative analysis. Expert Syst Appl 36:6697–6707
Evans JR (2011) Retailing in perspective: the past is a prologue to the future. Int Rev Retail Distrib Consum Res 21:1–31
Firat M, Turan ME, Yurdusev MA (2009) Comparative analysis of fuzzy inference systems for water consumption time series prediction. J Hydrol 374:235–241
Fishburn PC (1997) Method for estimating addtive utilities. Manag Sci 13–17:435–453
Fuzzy Logic Toolbox User’s Guide, MATLAB 7.9 (2015)
Ganga GMD, Carpinetti LCR (2011) A fuzzy logic approach to supply chain performance management. Int J Prod Econ 134:177–187
Garcia Infante JC, Medel Juarez JJ, Sanchez Garcia JC (2010) Evolutive neural fuzzy filtering: an approach. WSEAS Trans Syst Control 5:164–173
Gnana Sheela K, Deepa SN (2014) Performance analysis of modeling framework for prediction in wind farms employing artificial neural networks. Soft Comput 18:607–615
Gumus AT, Guneri AF, Keles S (2009) Supply chain network design using an integrated neuro-fuzzy and MILP approach: a comparative design study. Expert Syst Appl 36:12570–12577
Gumus AT, Guneri AF (2009) A multi-echelon inventory management framework for stochastic and fuzzy supply chains. Expert Syst Appl 36:5565–5575
Gunasekaran A, Kobu B (2007) Performance measures and metrics in logistics and supply chain management: a review of recent literature (1995–2004) for research and applications. Int J Prod Res 45:2819–2840
Gunasekaran A, Ngai EWT (2004) Information systems in supply chain integration and management. Eur J Oper Res 159:269–295
Harding JA, Popplewell K (2006) Knowledge reuse and sharing through data mining manufacturing data. In: 2006 IIE annual conference and exhibition
He Z, Zhu P, Park S (2012) A robust desirability function method for multi-response surface optimization considering model uncertainty. Eur J Oper Res 221:241–247
Holimchayachotikul P et al (2014) Value creation through collaborative supply chain: holistic performance enhancement road map. Prod Plan Control 25:912–922
Huang X, Ho D, Ren J, Capretz LF (2006) A soft computing framework for software effort estimation. Soft Comput 10:170–177
Jang JSR (1993) ANFIS: adaptive network based fuzzy inference system. IEEE Trans Syst Man Cybern 23(3):665–684
Jilani TA, Burney SMA (2007) New method of learning and knowledge management in type-I fuzzy neural networks. Adv Soft Comput 42:730–740
Krzysztof S (2014) Neuro-fuzzy system with weighted attributes. Soft Comput 18:285–297
Leksakul K et al (2015) Forecast of off-season longan supply using fuzzy support vector regression and fuzzy artificial neural network. Comput Electron Agric 118:259–269
Liao SH et al (2014) Training neural networks via simplified hybrid algorithm mixing Nelder-Mead and particle swarm optimization methods. Soft Comput 19:679–689
Linh TH, Osowski S, Stodolski M (2003) On-line heart beat recognition using hermite polynomials and neuro-fuzzy network. IEEE Trans Instrum Meas 52:1224–1231
Liu ZQ et al (2009) Self-spawning neuro-fuzzy system for rule extraction. Soft Comput 13:1013–1025
Lopez-Cruz IL, Hernandez-Larragoiti L (2010) Neuro-fuzzy models for air temperature and humidity of arched and venlo type greenhouses in central Maxico. Modelos neuro-difusos para temperatura y humedad del aire en invernaderos tipo cenital y capilla en el centro de maxico. Agrociencia 44:791–805
Marinakis Y, Marinaki M (2013) Particle swarm optimization with expanding neighborhood topology for the permutation flowshop scheduling problem. Soft Comput 17:1159–1173
Mariscal G, Marban O, Fernandez C (2010) A survey of data mining and knowledge discovery process models and methodologies. Knowl Eng Rev 25:137–166
Marx-Gómez J, Rautenstrauch C, Nurnberger A, Kruse R (2002) Neuro-fuzzy approach to forecast returns of scrapped products to recycling and remanufacturing. Knowl Based Syst 15:119–128
Mehrabad MS et al (2011) Targeting performance measures based on performance prediction. Int J Product Perform Manag 61:46–68
Mohandes M et al (2011) Estimation of wind speed profile using adaptive neuro-fuzzy inference system (ANFIS). Appl Energy 88:4024–4032
Paladini EP (2009) A fuzzy approach to compare human performance in industrial plants and service-providing companies. WSEAS Trans Bus Econ 6:557–569
Pessin G et al (2013) Swarm intelligence and the quest to solve a garbage and recycling collection problem. Soft Comput 17:2311–2325
Shen KY, Tzeng GH (2015) A decision rule-based soft computing model for supporting financial performance improvement of the banking industry. Soft Comput 19:859–874
Sheu JB (2008) A hybrid neuro-fuzzy analytical approach to mode choice of global logistics management. Eur J Oper Res 189:971–986
Sun C et al (2014) A two-layer surrogate-assisted particle swarm optimization algorithm. Soft Comput 19:1461–1475
Svalina I et al (2013) An adaptive network-based fuzzy inference system (ANFIS) for the forecasting: the case of close price indices. Expert Syst Appl 40:6055–6063
Tirian GO, Pinca CB, Cristea D, Topor M (2010) Applications of fuzzy logic in continuous casting. WSEAS Trans Syst Control 5:133–142
Unahabhokha C et al (2007) Predictive performance measurement system: a fuzzy expert system approach. Benchmarking 14:77–91
Vukadinovic K, Teodorovic D, Pavkovic G (1999) An application of neurofuzzy modeling: the vehicle assignment problem. Eur J Oper Res 114:474–488
Wang Y, Cai ZX (2012) A dynamic hybrid framework for constrained evolutionary optimization. IEEE Trans Syst Man Cybern Part B Cybern 42(1):203–217
Wong BK, Lai VS (2010) A survey of the application of fuzzy set theory in production and operations management: 1998–2009. Int J Prod Econ 129:157–168
Yao X, Xu G, Cui Y, Fan S, Wei J (2009) Application of the swarm intelligence in the organization of agricultural products logistics. In: Proceedings of 2009 4th international conference on computer science and education, ICCSE 2009, pp 77–80
Zheng YJ, Ling HF (2013) Emergency transportation planning in disaster relief supply chain management: a cooperative fuzzy optimization approach. Soft Comput 17:1301–1314
Acknowledgments
The Thailand Research Fund (TRF) through the Royal Golden Jubilee (RGJ) PhD Program (PHD/0090/2553) and Chiang Mai University (CMU) through our Excellence Center in Logistics and Supply Chain Management (E-LSCM) provided the financial support.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Communicated by V. Loia.
This paper should not be disseminated without the written permission of the authors.
Rights and permissions
About this article

Cite this article
Holimchayachotikul, P., Leksakul, K. Predictive performance measurement system for retail industry using neuro-fuzzy system based on swarm intelligence. Soft Comput 21, 1895–1912 (2017). https://doi.org/10.1007/s00500-016-2082-5
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00500-016-2082-5