
Abstract
Recently, traditional manufacturing industries have faced two serious gaps and problems in line with effective product-line sales forecasting methods to balance the negative impacts on the performance of the subjective experience, including (1) arbitrary judgment, such as growth rate of expectancy, manager’s experiences, and historical sales data, may cause inaccurately predictive results and severe negative effects, and (2) sales forecasting is a key priority and challenge in the context of considerable product lines that have different properties and need specific models for supporting decision analytics. This study is motivated to propose an advanced hybrid model to utilize the advantages of variation for methods of fuzzy time series (FTS), exponential smoothing (ES), moving average (MA), and regression analysis (RA). To analyze the four product lines—stably growing product (SGP), declining product (DP), irregularly growing product (IGP), and special sales product (SSP)—this study is based on empirical sales data from a leading traditional manufacturer to accurately identify the high potentials of decisive key factors and objectively evaluate the model. Two evaluation standards—the mean absolute percentage error (MAPE) and root mean square error (RMSE), a parameter sensitivity analysis, and comparative analysis—are measured. After implementing the data from the case study, four key reports were conclusively identified. (1) Purely for the RMSE, the best one (10.32) is the ES method in the SGP line. (2) In the DP line, the better one is the RA(2) method, with a relatively low MAPE of 17.78% and RMSE of 26.46. (3) The FTS method is the best choice (MAPE 12.41% and RMSE 18.98) for the IGP line. (4) For the SSP line, the better one (MAPE 24.05 and RMSE 29.34) is the MA method. According to the above reports, although the proposed hybrid model has a general performance for the SSP line, it still has a superior predictor when compared to manager subjective prediction. Interestingly, the proposed model is rarely used, has a new trial with an innovative solution for the traditional manufacturer, and thus realizes applicable values. The study concludes with acceptable and satisfactory results and yields seven important findings and three managerial implications that significantly contribute to decision-making reference for complete sales-production planning for interested parties. Thus, this study benefits and values a conventional industry upgrade from novel application techniques.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
This section initially describes the study issue related to research background and research question, research motivation, and the significance and purposes of the study addressed and highlighted.
1.1 Research background and research question
First, highlighting a decision-making practice in sales forecasting for concerns of various industries from big data profits is an interesting and important practical topic for the main purpose of supporting sustainable business management under a circular economy (Wen et al., 2023) in traditional industries manufacturing for the achievement of better business operating performance and engineering applicable values. Next, traditional industries manufacture general products for daily life, which can supply domestic demand and are even exported to foreign countries, play important roles in steady economic growth with the purposes of a circular economy and free from waste, particularly for committing to the environmental, social, and governance (ESG) policy for a circular economy and for sustainability of both efficient use and protection of environmental resources (Yu et al., 2023), and benefit employees in Taiwan. Interestingly, it will face an unintended consequence if enterprises neglect ESG importance within their sustainable business management in the world (Yu et al., 2023); thus, it is obvious that the issue of sustainable business management under the circular economy is very important for the continuous development of enterprises, and in particular, the sustainable performance of the enterprise’s ESG has become a benchmark indicator to measure the environmental and social obligation responsibility of enterprises. Successively, when we turn back to reviewing traditional industries for actual operating conditions, customer demand might not always be practical or cost-oriented but rather might consist of the pursuit of high-quality and creative merchandise. Thus, the context of customer demand is continually changing, and smaller companies or those with fewer products might be unable to cope with the changing environment. Observing traditional domestic industries reveals a few companies with long histories or larger scales that insist on producing and selling a variety of product lines. However, they always meet with a serious problem of operating performance, such as inventory management and excessive waste (Nozari et al., 2023; Teerasoponpong & Sopadang, 2022). Lack of production capacity can lead to loss of orders, poor inventory, and other operational problems. Heizer and Render (2011) pointed out that customers are more likely to stop buying their goods whenever a company encounters a shortage of goods. In contrast, in cases of manufacturing too many products, there are inventory problems (Feng & Shanthikumar, 2022) but fewer problems of capacity. Given the above heavy dilemma problems faced for sales and production issues, it has emerged to guide effective decision-making in practice from the key priority of benefiting from the use of AI-based machine learning techniques (Gupta et al., 2022; Jiang et al., 2022; Yazici et al., 2022) on enhancing innovative knowledge management to offer sustainable products that traditional industries manufacture. However, it has a research gap because no researchers focus on studying the AI-based machine learning techniques to match up specific characteristics of different product lines from the limited literature review; thus, it should be first bridged. A key research question is hereby triggered with how to solve such an adverse condition to develop an effective forecasting mechanism to employ optimal alternative methods for making a pair with different product lines in the traditional manufacturing industry for further pursuing the realization of sustainable development under the background of the circular economy (Wan et al., 2023).
1.2 Research motivation
Furthermore, response capability is likely to become a decisive key factor for the customer. Response capability helps a company match the competition, except for production quantity. In order to deliver the product on time, the company must have sufficient quantities of inventory as well as meet each customer's order requirement on time. Production volume and storage space are so limited that how to balance sales, production quantities, and reaction capacity is a key point in sales forecasts. To increase profits, manufacturers should maintain the correct mix of the correct product lines at the correct time relevant to market demands based on sales forecasting strategies. Practically speaking, manufacturers can base sales forecasts for product lines on the personal and subjective experiences of a manager. This approach depends heavily on individual opinion, historical sales data, and the expectancy of future growth rates, which might cause inaccurate results that result in negative effects. For these reasons, sales forecasting is a key priority and an interesting challenge for sustainable inventory management in particular, because various product lines have different specific properties and backgrounds that need different forecasting models that can be applied in various application fields (Fang & Chen, 2022; Golmohammadi & Radnia, 2016; Jiang & Dai, 2015; Kamaraj et al., 2015; Lu et al., 2015; van Donselaar et al., 2016; Wang et al., 2022; Yuan et al., 2015). Forecasting models can have a significant effect on product lines. Thus, the research gap with the key research question to model a suitable and effective sales forecasting tool and effectively identify the decisive key factors based on characteristics for various product lines applied in the traditional manufacturing industry is required to be filled and is particularly of concern. To bridge the research gap and question, this research is motivated by the search for optimal alternative methods for machine learning to pursue an effective decision-making methodology to highlight integrating AI into processing decision-making mechanisms for supporting the achievement of better sustainable business management from the perspectives of industry-engineering applications highlighted in this study. That is, the study aims at providing a reasonable justification of technique for addressing and adding academic values to strengthen the novelty of traditional industry application.
1.3 Significance and purposes of the study
Lastly, this study thus proposes a hybrid model to build four key techniques and use their advantages to support the manufacture of the correct quantity of products by predicting the quantity of sales accurately. The study further organizes fuzzy time series (FTS) models (Chan et al., 2015; Efendi et al., 2015; Yang et al., 2022), exponential smoothing (ES) methods (Sadeghi, 2015; Udenio et al., 2022; Yang et al., 2015), moving average (MA) methods (Lin et al., 2023; Marshall et al., 2017), and regression analysis (RA) models (Fumo & Biswas, 2015; Tang et al., 2023; Thrane, 2016) to help manufacturers lower total stock costs and improve sales performance. To evaluate model performance through objective analysis, this study collects practical sales data from a leading traditional manufacturer in Taiwan for various product lines. The product lines are varied based on specific characteristics, such as long-term or periodic, to select representative products from various categories. In particular, there is no better model applicable to a variety of product lines. Thus, it is a key significance of the study to achieve a crucial strategy for finding out a better model for different product lines. Meanwhile, this study has the following four significant objectives: (1) Construct four models to predict and determine the related conditions of sales quantity in manufacturing and their decisive factors. (2) Estimate the effect of the four models by comparing the artificial-subjective approach and the technical-objective approach. (3) Identify the problems of sales forecasting, make recommendations, and propose improvements to provide more-precise sales quantity data for back-end production units. (4) Provide empirical results as a reference for near-range purposes in supporting business sales forecasting decision-making and in key interests of the remote target of addressing sustainable business management under the circular economy in order to achieve the core goal of further protecting the Earth due to the limited resources.
Importantly and interestingly, it is worth mentioning that the base of concepts and ideas of this study is emphasized on structurally modeling the scientific-technical research based on machine learning techniques with the advantages for an industrial application in the traditional manufacturer. Thus, from the well-established literature on the related research for the FTS method (Cagcag Yolcu et al., 2020), for the ES method (Gallina et al., 2021; Jayant et al., 2021), for the MA method (Hanggara, 2021), and for the RA method (Zheng et al., 2023), for the time series prediction of good manufacturing industry applications, this study provides the equivalent research or works of intellectuals to build a citadel for well designing the learning architecture of the proposed hybrid model, which can justify the adaptability and applicability of the proposed methods employed. Moreover, regarding the applicability of the proposed hybrid model, it is basically acceptable to the generally traditional manufacturing industry for identifying sales forecasting, but it is inapplicable that the sales quantity has outbreaking and slumping situations, and it will be a challengeable issue for the black swan effect, such as in the COVID-19 case. Furthermore, the proposed hybrid model is rarely used, and a new trial with an innovative solution for the traditional manufacturer is conducted after reviewing the related literature and thus realizing applicable values for academic research purposes. Thus, this study benefits and values a conventional industry for the technical upgrade of prediction models from novel application techniques, with a significant contribution of industry application for interested parties.
The remainder of the paper is presented as follows: Sect. 2 reviews sales forecasting literature and four models for quantitative analysis. The proposed model is described in Sect. 3 by using an empirical case to compare its errors under two useful criteria. Section 4 displays comparison, verification, and related comparative studies. Section 5 explores the study findings and management implications, and introduces discussions and limitations. Finally, Sect. 6 concludes and defines the future direction.
2 Related studies
This section summarizes the work related to sales forecasting and its applications, including FTS, ES, MA, and RA.
2.1 Sales forecasting and its applications
Prediction (or forecasting) information is important for helping policymakers (or decision-makers) make appropriate decisions and can be found in a variety of applications (Fang & Chen, 2022; Gokulachandran & Mohandas, 2015; Sarkheyli et al., 2015; Wu et al., 2013; Zeroudi & Fontaine, 2015). Accurate forecasting results can provide more useful and truer information for proper reactions against encountered problems; however, each of the constructed methods has its pros and cons that derive from some of the data’s characteristics. Thus, effective methods for modeling and identifying related activities are a top-priority concern for academicians and practitioners. Concerning previous forecasting research, many researchers used various models or methods to predict, with the aim of addressing and analyzing relevant problems in various fields of applications. For example, Yu and Huarng (2008) and Yang et al. (2022) indicated that FTS is suitable for applicable forecasting in a variety of fields. Their research model combined neural networks (NNs) with FTS to build a binary model for predicting stock market indices; experimental results showed that this model was better at prediction accuracy than other models. Wang and Hsu (2008) used FTS to model and predict tourism demand and analyze tourism data for 1991–2001, and their findings showed that this model is suitable for short-term forecasts in the tourism industry. Udenio et al. (2022) used the ES method to forecast and control the bullwhip effect problem. Liu et al. (2010) used the ES method to predict the development trend of water environmental safety in Zhejiang. Thomassey (2010) conducted a study of the current practice of the garment industry, which is characterized by short-cycle and seasonal product problems. He uses FTS, NNs, and other data mining methods to build predictive models that enable the supply chain to react faster to market changes and reduce the impact of addressing the bullwhip effect. Moraes et al. (2013) studied the electricity demand forecast and used fuzzy theories as the basis for this application. They found it was more accurate when given a small amount of input. Aladag et al. (2014) presented an advanced predictive model for high-order seasonal FTS by integrating the model with the NNs; they also applied this approach to Turkey's international tourism needs and found that the experience of this proposed model was better than that of a normal seasonal FTS for a tourism service system. Carpio et al. (2014) used a multi-variable ES and dynamic factor model applied to the hourly electricity price analysis, and they showed the advantages of its multi-variant version and introduced the performance of the model through applications in previous markets, such as Omel, Powernext, and Nord Pool. Jónsson et al. (2014) incorporated the seasonal and dynamic nature of real-time prices into the ES methodology for predicting real-time electricity markets, and subsequent empirical surveys of the Nord pool, imitating practical forecasts for the 4-year period of 2008–2011, proved that the proposed approach was superior to several common benchmarks. Marshall et al. (2017) applied time-series momentum and moving averages (MAs) to trading rules, and their experimental findings showed that the MA rule often gives early signals that lead to meaningful returns. Zhang et al. (2014) used a seasonal autoregressive integrated MA model to forecast the mortality of road traffic injuries in China and had significant results. Fumo and Biswas (2015) performed RA to predict residential energy consumption, and when compared to other methods, it showed promising results due to its reasonable accuracy and relatively simple implementation. Thrane (2016) employed a logistic RA to examine how certain independent variables explained a tendency to choose package travel rather than independent travel. Yang et al. (2015) combined an extensive ES model of knowledge-based precise time series decomposition approaches to forecast global horizontal irradiance; the results showed that their proposed method performs as a persistence model. Wang et al. (2016) used an intuitive FTS forecast model on admission to the University of Alabama and the Taiwan Stock Exchange capitalized weighted stock index. Yolcu and Lam (2017) presented an integrated, powerful model (C-R-FTSM) to evaluate the outliers and analytical predictive performance of the methods used. Overall, Table 1 lists the above-mentioned studies related to forecasting issues in chronological order.
According to Yang et al. (2022), Udenio et al. (2022), Lin et al. (2023), and Tang et al. (2023), FTS, ES, MA, and RA not only have a noted and distinguished role but also have received widespread attention in recent years due to the invention of the national space design. (Ramos & Oliveira, 2016; Ramos et al., 2015), which delivers a satisfactory performance in many studies. Although a variety of composite models (or hybrid models) of these methods are further proposed for use in a wide variety of application fields, the models still provide a basic theoretical form and structure, providing advantages for numerous studies. Moreover, based on a limited literature review, these models are less applied in the sales forecasting of the traditional manufacturing industry in Taiwan than in other application contexts. Based on these reasons, this study thus combines these methods with knowledge-based prediction modeling and identification models to improve prediction accuracy and efficiency for sales forecasting issues in the traditional manufacturing industry.
Furthermore, it is a hot issue to address and evaluate the ESG sustainable performance to save resource efficiency and avoid waste for industrial companies worldwide (Yu et al., 2023) due to the increasingly serious problem of global warming, particularly for the traditional manufacturing industry; thus, the main objective is highlighted on matching the program of sales and production by effective sales forecasting models and achieving the reduction of waste free from overproduction, over-inventory, oversupply, and over-material and over-labor in this study.
2.2 Fuzzy time series
In applied time series analysis, observing trends in data, such as seasonal cycles, increasing, and decreasing, can help to assess events and then choose the most appropriate model. In the modeling process of time series, various time-series modeling analyses can be combined into a composite model in a more effective framework. The three basic, well-known forms of this approach are auto regressive moving average (ARMA; Huang, 2015), auto regressive integrated moving average (ARIMA; Wei et al., 2016), and seasonal auto regressive integrated moving average (SARIMA; Zhang et al., 2014). Due to errors or obstacles in data collection, time delays, and the interaction effects of these models, the researchers used only single numerical parameters for measurement; however, doing so might incur the danger of overfitting. Accordingly, Jain et al. (2012) provided a data dredging approach through a fuzzy concept to extract relevant data from the reduction of a massive amount of time-series data in a stock market, which can help investors decide when to buy and sell their products. The authors’ experimental results indicated satisfactory progress. Thus, this research focuses on the FTS model to solve the above errors, obstacles, and real-life sales forecasting problems encountered. Zadeh (1965) proposed a fuzzy set theory that uses mathematical models to describe the vague information provided, which should be represented by the probability distribution. Zadeh (1996) further introduced possibility theory as a part of the modeling of fuzzy information that can be expressed in natural language. Fuzzy set theory can help imitate human thinking processes, specifically by extending each element from binary logic to multivariate logic. Yager et al. (1987) used fuzzy set concepts to express the definition of fuzzy set characteristics as follows: Let X be the universal set. A is a fuzzy set, and x is the generic element of X. \({\varvec{\mu}}{\varvec{A}}\left({\varvec{x}}\right)\) calls the membership function of group A, and \({\varvec{\mu}}{\varvec{A}}\left({\varvec{x}}\right)\) assigns the value between 0 and 1. The definitions are defined as Eqs. (1) and (2).
Zadeh (1965) used membership functions to introduce the characteristics of fuzzy sets. Fuzzy sets of data can be quantified, analyzed, and accurately processed through the membership function, and the value between 0 and 1 represents the fuzzy membership degree. The membership function is divided into two main types: a discrete membership function (DMF) and a continuous membership function (CMF). DMF directly gives a member a grade for each member in a finite fuzzy set, whereas CMF uses different forms of functions to describe fuzzy sets. Membership functions include triangular, trapezoidal, and Gaussian functions. Determining the appropriate member function is often one of the most important factors in practical examples of fuzzy theory; it is mostly demonstrated by experience or statistical methods.
In a further application analysis for FTS, Arora and Saini (2013) suggested that FTS applied fuzzy logic to time series analysis processes to solve fuzzy issues of data provided in the real world. Chen (2014) further adopted a new high-order FTS method to address nonlinearity and complexity issues, predicting good performance for the Taiwan Stock Index and the University of Alabama student enrollment record. The definition of FTS is as follows:
Let {X(t)}\(\in\) R, t = 1, 2, …, n} be a time series. U is its domain. Since U is an orderly partition set, the linguistic variable of {Pi; i = 1, 2, …, r,\(\bigcup\nolimits_{i = 1}^{r} {P_{i} }\) = U} is corresponded to {Li; i = 1, 2, …, r} if there has {Li; i = 1, 2, …, r} corresponding to F(t) of X(t); then, F(t) is called as a FTS on X(t) (t = 1, 2, …, n). Given the above description of theory, F(t) is called a linguistic variable. The membership function of F(t) is {\({{\varvec{\mu}}}_{1}\)(X(t)), \({{\varvec{\mu}}}_{2}\)(X(t)), …, \({{\varvec{\mu}}}_{{\varvec{r}}}\)(X(t))}, 0 ≤ \({{\varvec{\mu}}}_{{\varvec{i}}}\)(t) ≤ 1, and i = 1, 2, …, r. This definition is used to define the set on FTS of {F(t)} as Eq. (3).
In this equation, \({{\varvec{\mu}}}_{1}\): R → [0, 1], \(\sum\nolimits_{i = 1}^{r} {}\) \({{\varvec{\mu}}}_{{\varvec{i}}}\)(X(t)) = 1, for each t = 1, 2, …, n.
Based on Egrioglu (2014) and Song and Chissom (1993), the FTS models are detailed as follows.
-
(1)
p-th order on fuzzy auto-regressive method: For a notation FAR(p), it is generalized as an autoregressive FTS method for order p, and the formation is defined as Eq. (4). Equation (4) shows that R refers to a relationship of fuzzy set among \({\varvec{F}}\left({\varvec{t}}\right)\), \({\varvec{F}}\left({\varvec{t}}-1\right)\), \({\varvec{F}}\left({\varvec{t}}-2\right)\), …, and \({\varvec{F}}\left({\varvec{t}}-{\varvec{p}}\right)\).
$$ {\varvec{F}}\left( {\varvec{t}} \right) = {\varvec{F}}\left( {{\varvec{t}} - 1} \right) \cdot {\varvec{F}}\left( {{\varvec{t}} - 2} \right) \cdot \cdots \cdot {\varvec{F}}\left( {{\varvec{t}} - {\varvec{p}}} \right) \cdot {\varvec{R}} $$(4) -
(2)
First order of fuzzy auto-regressive method: In a particular case, the notation FAR(1) indicates an autoregressive FTS method of first order when p = 1, and the equation is defined as Eq. (5). Afterwards, R has a relationship of fuzzy set between \({\varvec{F}}\left({\varvec{t}}\right)\) and \({\varvec{F}}\left({\varvec{t}}-1\right)\).
$$ {\varvec{F}}\left( {\varvec{t}} \right) = {\varvec{F}}\left( {{\varvec{t}} - 1} \right) \cdot {\varvec{R}}. $$(5)
2.3 Exponential smoothing
Exponential smoothing was suggested by Brown (1956) in the statistical literature. ES is suitable for forecasting issues, such as sales forecasting for both individual and multiple items. That is, it is also appropriate for forecasting time series data with or without seasonal patterns or trends. In particular, the ES method has better effectiveness when the data values to describe the time series are changed slowly because it can assign larger weights to more recent data. This method is intuitional, computable, and resilient; thus, it benefits from the advantages of requiring less data storage property, assigning more weight to recent observations, and having the easier-to-change responsiveness of a forecast that the decision-maker desires for the parameter alpha (\({\alpha }\)). Given these merits, it is widely applied in various domains, such as the electricity industry (Carpio et al., 2014; Jónsson et al., 2014) and the shoe manufacturing industry (Singh et al., 2015). However, this method still has a significant lack (or disadvantage) of statistical theory and does not contain explainable exogenous variables. Based on the study of Brown (1956, 1960), the ES model is usually classified into the following two different types:
-
(1)
Simple ES: It calculates the difference between the actual and forecast values of the previous year and the preceding year and adds the result to the expected value of the prior year. Higher smooth constant weights mean that recent data is more important; conversely, lower smooth regular weights mean that historical data is more important. Simple ES is defined as Eq. (6). For example, if \({{\varvec{A}}}_{{\varvec{t}}-1}\) is 585, \({{\varvec{F}}}_{{\varvec{t}}-1}\) is 472, and \(\boldsymbol{\alpha }\) is set with a suitable value of 0.9, then the forecasting value for \({{\varvec{F}}}_{{\varvec{t}}}\) is rounded to 574.
$$ {\varvec{F}}_{{\varvec{t}}} = {\varvec{F}}_{{{\varvec{t}} - 1}} + {\varvec{\alpha}}\left( {{\varvec{A}}_{{{\varvec{t}} - 1}} - {\varvec{F}}_{{{\varvec{t}} - 1}} } \right) $$(6)where \({{\varvec{F}}}_{{\varvec{t}}}\) refers to the forecasting data of the ES model in the period t, \({{\varvec{A}}}_{{\varvec{t}}-1}\) refers to the actual sales value for period \({\varvec{t}}-1\), and \(\boldsymbol{\alpha }\) is the value of smooth constant between 0 and 1.
-
(2)
Trend-adjusted ES method: Use a simple ES method to reach the predicted value, and then use the second ES value to reach the final predictable value. This approach could lead us to a major trend shift. Equations (7) and (8) of trend-adjusted ES are expressed as follows:
$$ {\varvec{F}}_{{\varvec{t}}} = {\varvec{\alpha}}\left( {{\varvec{A}}_{{{\varvec{t}} - 1}} } \right) + \left( {1 - {\varvec{\alpha}}} \right)\left( {{\varvec{F}}_{{{\varvec{t}} - 1}} + {\varvec{T}}_{{{\varvec{t}} - 1}} } \right), $$(7)$$ {\varvec{T}}_{{\varvec{t}}} = {\varvec{\beta}}\left( {{\varvec{F}}_{{\varvec{t}}} - {\varvec{F}}_{{{\varvec{t}} - 1}} } \right) + \left( {1 - {\varvec{\beta}}} \right){\varvec{T}}_{{{\varvec{t}} - 1}} , $$(8)where \({{\varvec{F}}}_{{\varvec{t}}}\) refers to the forecasting data of the ES model in the period t; \({{\varvec{T}}}_{{\varvec{t}}}\) refers to the trend-adjusted data of the ES method in the period t; \({{\varvec{A}}}_{{\varvec{t}}}\) is an actual demand in the period t; \(\boldsymbol{\alpha }\) is a value of smooth constant; \({\varvec{\beta}}\) refers to a trend constant, and values of both \(\boldsymbol{\alpha }\) and \({\varvec{\beta}}\) are between 0 and 1.
2.4 Moving average
Granville (1976) pointed out that MA is the use of recent actual data to predict data for the next period, which can help companies predict demand for products or production capacity. In statistical applications, the MA method is also suitable for sales forecasting issues used in the shoe industry (Singh and Borah 2014) and in fresh food sales (Lee et al., 2012). The MA method is simply divided into two modes: simple MA and weighted MA. First, in its simplest form, this method is properly used with time-series data in a calculation to analyze the actual given data by computing a series of averages of different subsets with equal weights, each containing a certain number of items for the full dataset, and these average data can show a short-term fluctuation and reflect a long-term trend. This approach is called simple MA; in particular, the weight of each element for simple MA should be equal. Second, for weighted MA, the points of this approach are that each period of historical data used to forecast future demand should be set up with different weights, with n viewed as a periodically changing value. The changing variables are not important if they are away from the target period; thus, the weight is low. For the MA method, the generalized equation in the form of generic weights is formatted as Eq. (9).
where \({{\varvec{F}}}_{{\varvec{t}}}\) refers to the predicted value for the next period; n refers to the periods number of MA model; \({{\varvec{A}}}_{{\varvec{t}}-1}\) refers to the actual value from the previous period; \({{\varvec{A}}}_{{\varvec{t}}-2}\), \({{\varvec{A}}}_{{\varvec{t}}-3}\), and \({{\varvec{A}}}_{{\varvec{t}}-{\varvec{n}}}\) refer to the real value for the first two periods, the first three periods, and until the previous n periods, respectively; \({{\varvec{w}}}_{1}\) refers to the weight for the actual value of sales quantity during the period \({\varvec{t}}-1\); \({{\varvec{w}}}_{2}\) refers to the weight for the actual value of sales quantity during the period \({\varvec{t}}-2\), etc.; \({{\varvec{w}}}_{{\varvec{n}}}\) refers to the weight for the actual value of sales quantity during the period \({\varvec{t}}-{\varvec{n}}\); and \({{\varvec{w}}}_{1}+{{\varvec{w}}}_{2}+\cdots +{{\varvec{w}}}_{{\varvec{n}}}\) is a total of 1.
Concerning the MA method, some characteristics are defined for sales forecasting topics. (1) The fewer the data periods, the greater the responsiveness for the decision-maker (e.g., sales and production managers setting appropriate weights). (2) As an analytical tool, the MA method can be used quickly and easily to identify a current uptrend or downtrend change for smoothing out the volatility of the sales or production quantity in a given dataset. (3) Measure the effects of different timeframes in short and long terms. The longer the timeframes, the smoother the simple MA; in other words, a shorter-term MA is more volatile than a longer-term MA for sales and production quantities.
2.5 Regression analysis
Regression analysis uses statistical theory to construct and explore the forms of these relationships between variables and is used in equations to prove the effect between each variable and the product formula. Allen and Fildes (2001) and Scott (2012) found sufficient evidence to suggest that RA often provides useful predictions for data analysis and modeling. Thus, this RA method is also widely applied, with many practical usages and research studies, and is used for forecasting or prediction, as in the automobile industry (Sharma & Sinha, 2012) and grocery store sales (Morphet, 1991). This approach has the following two main types of RA: (1) According to the difference between the independent variables, there are two RA classifications: simple RA and multiple RA. Simple RA has only one independent variable; conversely, multiple RA has more than two independent variables. (2) Based on the relationship between the dependent variables and the independent variables, the RA model can be divided into linear and non-linear methods.
As Schneider et al. (2010) described, a linear RA model means that one or more independent variables and dependent variables are based on the variability and linearity of the independent variable in order to predict the average trend development of the dependent variable. Particularly, the linear regression prediction model is always used for sales prediction, as is frequently shown in previous studies (Palia & Roussos, 2004; Rogers, 1992). In the study of practical problems, the dependent variable of multiple linear regressions is often affected by several important factors. Assume that X refers to an independent variable and Y is a dependent variable. X and Y have existed in a linear relationship. Specifically, the details of generalized multiple linear regression models can be referenced in Uyanık and Güler (2013) and are defined as in Eq. (10).
where \({{\varvec{b}}}_{0}\) refers to a constant, and \({{\varvec{b}}}_{1}\), \({{\varvec{b}}}_{2}\), …, \({{\varvec{b}}}_{{\varvec{k}}}\) are the coefficients of regression.
The RA method to analyze data can help production managers forecast future demands to support sufficient sales quantities in operations management and provide new insights to move the production plans toward a more profitable solution. Some advantages associated with the high performance of the RA method used by academicians and practitioners as a forecasting model are as follows: (1) The method can provide an efficient forecast. (2) Using a suitable slope for an RA model can increase forecasting accuracy because there is less variability in the forecasting processes. (3) The model lends an objective and scientific view to measuring the relative correlation of one or more independent variables to the dependent values. (4) It has the ability to determine outliers. However, disadvantages of the RA method can include (Osborne & Waters, 2002): (1) It needs typical assumptions, such as no error measurement and linear independence with the independent variables; and (2) the performance of the RA method is highly dependent upon the form of how the data are used in the data-generating process.
3 The proposed model
This section introduces the concepts and algorithms for the proposed model with the introduction of an empirical case study.
3.1 Concepts of the proposed hybrid model with an empirical case study
Concerning the relevant research on creative forecasting from key technical tools for the interests of better sustainable business management in traditional manufacturing industries, although there are many approaches to sales forecasting for various products, no existing model is suitable for every product because of differences between product lines. The authors have experienced the effects of losses in traditional manufacturing industries when sales forecasting is wrong. Moreover, the authors’ work in traditional industries triggered an empirical case study. The research object is a large-scale manufacturing company (hereafter referred to as L-Company) with four manufacturing product lines: a stably growing product (SGP), a declining product (DP), an irregularly growing product (IGP), and a special sales product (SSP) from big data application analytics. The company manufactures and sells an enormous number of stock-keeping unit (SKU) products and plans to produce similar make-to-stock (MTS) products. In a detailed estimation in 2008–2012, a review of the total inventory of products sold by L-Company in Taiwan found approximately 500, 90, 1200, and 220 products belonged to SGP, DP, IGP, and SSP, respectively. The company is also a leading one in Taiwan’s traditional industry. How L-Company estimates its sales rates is based on subjective predictions. Administrators use historical sales data and expected sales growth rates (SGRs) to forecast the sales rate for the next year. Such subjective experiences and prediction standards might be changed frequently and dramatically by a manager; such negative activity would affect production plans provided by the back-end production unit severely and persistently. The activity might cause a significant reduction in operating performance and increases in sales and inventory costs due to subjective forecasting results being different from actual demand quantities. This research benefits objective and smart technologies for sales forecasting: (1) It facilitates sales quantity forecasting based on the characteristics of product lines more accurately and then arranges production plans more appropriately to avoid creating excessive inventory quantities; and (2) it helps production supply to avoid delays and enhances the competitive advantage of L-Company for a good decisional support model.
Given these reasons, this study develops a hybrid sales forecasting model for each type of product line in an empirical case study using L-Company and collects the sales data as an experimental dataset to use for calculation and decision analysis. The processes of modeling the proposed model are divided into three phases, as follows: (1) Three procedures are conducted in the following three steps: (a) Choose the research items of products; (b) catalogize the four product lines by type according to product property; and (c) organize and collect the data on sales quantity for each product line. (2) Build FTS, ES, MA, and RA in the proposed model for sales forecasting, defining and training the various parameters of each model. (3) Calculate the performance of each proposed method and compare the four empirical results with actual and predicted values from the subjective forecasting of managers. Figure 1 describes the flow chart of the proposed hybrid model.

Flow chart of the proposed models
3.2 Implementing algorithms for the proposed hybrid model using the L-Company case
The computational processes of the proposed hybrid model comprise the seven steps for L-Company as follows: (Note: For ease of presentation, the empirical results are unified and described in the next section.)
Step 1: Select the research item from the products.
Initially, this study selects historical sales data on the products from L-Company to conduct modeling and identify processes. The experimental dataset was collected as monthly data in 2008–2012.
Step 2: Classify products by their line types.
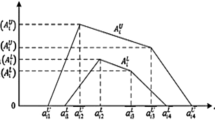
Categorize the product item based on product properties, such as trends in sales quantity and frequency of sales. One alternative means of determining the stage of the sales cycle for product lines is based on the SGR method because the SGR approach shows a high relationship to product sales cycles (Harrell & Taylor, 1981). This method helps this study judge, based on changes in SGR, the stage of the sales cycle of the products being analyzed. SGR is used to divide the stages of product life cycles based on the annual growth rate in sales quantity. The four types of product lines for L-Company are classified by SGR (Harrell & Taylor, 1981) as follows:
-
(1)
SGP line: It is identified as the SGP line, which meets the definition of the continuous growth type life cycle for the products in the last 5 years. This type of product line is a popular group applicable to writing, painting, and designing. Practically speaking, the SGP line can be applicable to the surface of a variety of materials for a wide range of uses and for having a specific property with steady demand for sales quantity when SGR is greater than 10%. The company needs an effective production plan to produce a product line that meets growing sales quantities continuously. Forecasting sales demand for this line accurately is important and attracts much attention at L-Company.
-
(2)
DP line: Art painting materials belong primarily to the DP line and are often bought by schoolchildren. Their sales quantity and sales profit present a declining trend in which SGR is less than 0%, with a prolonged recession in 2008–2012. This product line has the following characteristics: First, such products exist on the market as long as they are spread and standardized. Second, there are many competitors selling the same types of alternatives. Third, consumer demand for the product line has changed, and this change is characterized as time-descending. Although there are promotional activities for the product line, the line generates insufficient sales. Concerning management implications, the DP line should not be overstocked. Therefore, to prevent an accumulation of potential inventory and losses, L-Company clearly must control the inventory level rigorously and appropriately based on correct sales forecasting models.
-
(3)
IGP line: According to expert opinion in the manufacturing field, an IGP line has problems with a certain irregularity of pattern rules and unsteady sales. On the one hand, an IGP line can be a growing trend, and when no similar type of product is competing in the market, the product can become a potential mainstream product with a massive quantity of sales. On the other hand, the IGP line can enter a decline for unknown reasons. Specifically, a product line is considered an IGP when its SGR is between 0 and 10%. Thus, if this study can analyze the sales logic of this product line or identify the potential reasons for and growth method of its irregular rules, this product line can be converted from a potential product to a major, popular product that will achieve better profits for L-Company. This situation motivates the research.
-
(4)
SSP line: Experts from the manufacturing company have indicated that the SSP line (SGR is always lower than 10%) is primarily coordinated with a property of specific activities on particular days, such as the beginning of the school season or a particular exhibition with a significant sales quantity. An experienced business will address group demand for semester activities with suitable product sets for enhancing sales quantity. It is an interesting process for L-Company to make an accurate prediction for this product line.
Step 3: Gather and organize the data describing the sales quantities of products.
Select a representative product from each of the different types of products based on two criteria: the SGR (Harrell & Taylor, 1981) and the property of specific activities on particular days, based on a consensus reached by three professional experts at L-Company, and then collect the historical sales data for the product. There is an existing drift, non-linear relationship, and uncertainty for the given data; thus, it is a key point to do sales forecasting by using similar fuzzy data dredging (Jain et al., 2012). To address these problems, this study preprocesses the data based on the following two sub-steps: (1) Implement and evaluate the adjustment according to the best intervals of data, and (2) generate corresponding datasets. The preprocessed data applied to the related fuzzy models can greatly improve forecasting accuracy (Bang & Lee, 2008). This study preprocesses the data based on the experts’ recommendations before conducting each technique of the proposed model. Any abnormal, special features caused by specific unit events, such as an increase in expected price that is contingent on anticipated price changes for oil and electricity, i.e., anything that might generate pseudo-needs or fictitious demands that could cause unusual or inaccurate sales information for that period, should be removed or adjusted in this preprocessing stage before being used in this study. Furthermore, testing for autocorrelation (also known as serial correlation) (Sun et al., 2018) for the given linear RA method and other models used is a common and necessary task for researchers because the accuracy of the forecast method used depends upon the right selection of explanatory variables. An autocorrelation test is a mathematical representation of the degree of similarity between observations that acts as a function of identifying the time lag to find repeating patterns over the forecasting horizon in the experimental time intervals. The test for detecting the presence of first-order auto-correlation is to apply the statistic of Durbin Watson (DW) for a measure of autocorrelation in the residuals from an RA method or other model. The test value of the DW statistic should be between 0 and 4. The DW statistic is thus run to test the autocorrelation problem of the data used in this study; testing results of 1.01, 1.32, 1.47, and 2.08 for these data of the four representative products are obtained, respectively. Field (2013) suggested that a definite concern about autocorrelation should exist when the test values of DW are less than 1 or greater than 3. Thus, there appears to be no autocorrelation problem of concern based on the testing results of the four given experimental samples.
Step 4: Model sales forecasting methods.
This step selects four representative products for the four corresponding product lines based on the suggestions of experts at L-Company. Accordingly, we model the four sales forecasting methods (FTS, ES, MA, and RA methods) with the four representative products.
Step 5: Build forecasting models.
This step first introduces building the FTS method to model and analyze the empirical case data collected from L-Company because the type of fuzzified data can yield better results for the numerical values of the data used. Accordingly, the constructs of the other three models are used to determine suitable methods for various types of representative products. First, in the building process, a recognition of the order in FTS analysis is useful to handle the variables associated with data trends and to build a mathematical method to show the real world. In general, the existence of an increasing or decreasing trend shows that the raw data can be processed with different actions. The calculative processes for the FTS model are divided into seven sub-steps, as follows: (1) Build the domains for fuzzy sets and subsequently fuzzify their data. (2) Employ the principle of a hypothetical test to judge whether the data is fuzzy; otherwise, return to sub-step (1). Afterwards, execute the difference conversion of the given data; otherwise, proceed to the next step. (3) Identify the order of the FTS method. (4) Compute fuzzy relationships by matrix. (5) Choose the best FTS method. (6) Apply the FTS method to make a forecast. (7) Defuzzify the data to obtain the experimental results. Second, in the ES building process, based on Eqs. (6) and (7), various smoothing constants (α) between 0 and 1 are adjusted to model better results for different product lines. Third, in using the MA method, various numbers of moving-period times are measured based on Eq. (9) to obtain the predicted value for the next period. Finally, in the RA building process, the key task is initially based on the experts’ recommendations to identify the decisive key factors influencing sales quantity and then calculate the forecasting results based on Eq. (10).
Step 6: Generate forecasting values.
In fact, the data from the sales quantities of the product lines have an interval value at L-Company; thus, this step fuzzifies data with the same interval value into the same fuzzy sets. There are two advantages to this approach. The first is that it could decrease the data complexity; the second is that the processed data could be supplied as the input values for each forecasting method. Accordingly, this step generates the forecasting results to further verify the empirical results of the proposed model. Additionally, based on the other models modeled in previous steps, their forecasting results are accordingly calculated and created. For brevity, the empirical results will be uniformly presented in the next section.
Step 7: Make a comparison of empirical results and deal with an error analysis.
To assess the performance of the proposed model, the step compares the predicted value with the actual value, both of which are based on a mean absolute percentage error (MAPE) (Zhang et al., 2023a), which prevents the proportion of inaccuracy caused by large differences in product sales quantity. However, error analysis with only one percentage indicator for MAPE is not sufficient to verify a forecasting model. Thus, the root mean square error (RMSE) (Zhang et al., 2023a) should be employed when the forecasting value is critical and the unit price is high. Additionally, this approach can convert error values to a percentage of the actual values. The greater the MAPE and RMSE, the poorer the performance of the method in terms of the size of the error for the forecast horizon required. The equations of MAPE and RMSE are defined as Eqs. (11) and (12), respectively.
where \(x(k) - x^{\prime}(k) = \varepsilon_{k}\), \(x(k)\) refers to an actual value, \(x^{\prime}(k)\) refers to an estimated value, \(\varepsilon_{k}\) refers to the difference of the above two values, and M is sample size. The calculation yields a perfect performance measure for the predicted results if their values of both the MAPE and RMSE achieve 0% and 0, respectively.
4 Experimental results and comparisons
This section shows the verification of the case study for four product-line datasets and summarizes the experiments, comparable methods with internal and external comparisons of four product lines by using the FTS, ES, MA, and RA methods, and the Wilcoxon signed-rank test to model and identify related sales forecasting for the experimental time periods during 2008–2012.
4.1 Empirical study results using the four product lines
The verification of an empirical study for L-Company on the four product lines and using the proposed model is described in bullet points, and in particular, a parameter sensitivity analysis to core parameters is needed to make more validation for the experimental results of mathematical time series models. For brevity, the main experimental results with tables and figures, and their illustrations are listed as follows:
4.1.1 For the SGP line
-
(1)
FTS method: In the FTS building process of time series forecasting, there is the minimum value of 360, the maximum value of 3204, interval values from 10 to 200, and fuzzy auto-similarity examined from 1 to 15 periods for the parameter sensitivity analysis of periods in order to find out the best empirical results in the SGP line. Interestingly, parameter sensitivity analysis (Ganaie et al., 2023; Singhal et al., 2023) is specifically a vital necessity for measuring mathematical models constructed with solving a real-life problem, and the detailed parameters of sensitivity analysis can determine a broad set of predictions to see how different values affect the mathematical method outputs under a given set of data in a time series model. Table 2 lists the experimental results by the FTS method with different periods, and from Table 2, it is shown that the best similarity of fuzzy is found behind 1 period having 20 intervals; at the same time, the best similarity is 0.9527 using the FAR(1) adaptive value. Accordingly, the determination method of order number was 1; thus, the predicted result of the FTS model for the SGP line was MAPE = 7.768% and RMSE = 10.342. From the results of the evaluation indicators, this study provides the meaningful fact that it is acceptable and has a good reason for benefiting the rationality of the proposed hybrid model.
-
(2)
ES method: In the ES building process, the smoothing constant α is an important parameter. In accordance with the SGP line, this step conducts a parameter sensitivity analysis and adjusts the smoothing constant α from 0.1 to 0.9 to see how this detailed parameter affects the forecasting outputs of the mathematical ES model. Table 3 shows the experimental results of this ES method with different values of the core parameter α. Consequently, the prediction results have a lowest value of 7.692% in terms of the MAPE when the α value is 0.8 and a lowest RMSE value of 10.323 when the α value is equal to 0.9. From Table 3, it is understandable that the MAPE and RMSE show a good performance for sales prediction of the ES method in the SGP line.
-
(3)
MA method: In the average of the volume of sales in the previous period, the MA method is used as the predicted value for the next period. The MA method, similar to the previous building process, also runs a parameter sensitivity analysis of periods for a mathematical model. Table 4 lists the experimental results for the MA method with different time periods in 2–4 periods. From Table 4, it is shown that the moving-period number increases with both the MAPE and RMSE values, and the comparison results of MAPE 7.682% and RMSE 10.455 for this method show two moving periods with better performance than that of the other periods; importantly, the empirical results also show a clear performance advantage of the MA method.
-
(4)
RA method: In the RA building process, the most important work is to identify decisive key factors that significantly affect sales quantity. In an interview with three experts at L-Company, three core factors were noted as follows: (a) Seasons are divided into two types: peak (the first and third seasons) and low (the second and fourth seasons). The peak season means before and after the beginning of the school season, and sales quantity will increase; in other words, sales quantity will decrease in the other seasons. (b) The price is a vital factor affecting sales quantity distinctively. The price will increase with the cost of the SGP line. However, when the price is increasing, retailers might decrease the purchase quantity and charge customers higher prices, resulting in a decrease in sales quantity during this increase period. (c) The frequency of product exposure increases when there are promotional events (such as TV ads or exhibitions). Promotions will attract the attention of customers and encourage them to purchase the product. However, from the sales records of L-Company, there were no promotional activities for the SGP line in 2008–2012. Thus, the promotion factor could be removed from the RA method for the SGP line. Table 5 lists the partial RA data. Tables 6, 7 and 8 list the experimental results after conducting the RA method sequentially. Table 8 shows that season and price have significance levels of 0.1 and 0.001, respectively; thus, the RA equation is constructed for the SGP line below, and its calculated error value from 2008 to 2012 has the values of MAPE 31.203% and RMSE 45.690. From Table 8, it is clear that both the factors of season and price have a significant impact on influencing sales quantity, particularly the core factor of price. However, only from the MAPE of 31.203%, the forecasting result seems to have just a general mediocre performance.
$$ {\varvec{Y}} = - {2}0,{314}.00{5} - {156}.{896}{\varvec{X}}_{1} + {2},{85}0.{187}{\varvec{X}}_{2} \left( {{\varvec{X}}_{1} :{\text{ Season factor and }}{\varvec{X}}_{2} :{\text{ Price factor}}} \right). $$
After implementing the above four methods for the SGP line, this study just selected Fig. 2 to show its curve details between the actual and predicted values by a MAPE of 31.203% when using the RA method for the SGP line. From Fig. 2, it is clear that the two curves seem to not be quite suitable in some graphs for the SGP line due to its relatively high MAPE of 31.203%; however, it is acceptable if the RA method is compared to manager subjective (MS) prediction.

Curve details between the actual and predicted values for the SGP line by RA method
This study omits some complicated content, such as figures and tables, and uses text to narrate the following three types of product lines for brevity. The comparative studies after conducting parameter sensitivity analyses are distinctly summarized for convenience and ease of interpretation in the next subsection.
4.1.2 For the DP line
-
(1)
FTS method: Similarly, the minimum value of 4 and the maximum value of 3124 were determined. Several intervals from 10 to 200 and behind 1–15 periods were identified for a parameter sensitivity analysis of periods in the FTS modeling process. Table 9 lists the fuzzy similarity of behind periods with different values for the DP line by the FTS method. From Table 9, the empirical results show the best similarity of fuzzy sets remains behind 1 period with 30 intervals; its best similarity is 0.9772; and the order number of determinations still indicates 1. Subsequently, the empirical results of the FTS model using an adaptive FAR(1) have values of MAPE 27.037% and RMSE 58.169. From the above empirical results, it is clear that MAPE 27.037% and RMSE 58.169 seem to have less than the ideal performance expected for the FTS method.
-
(2)
ES method: Subsequently, the experimental results in the building process of the ES method are also run with a parameter sensitivity analysis of key α. Table 10 shows the experimental results of different values for parameter α (adjusted from 0.1 to 0.9) in this ES method for the DP line. It is indicated that when the smoothing constant α value is 0.9, it has the lowest values of MAPE 22.948% and RMSE 34.294. Figure 3 shows information on the curve details between the actual and predicted values for achieving a MAPE of 22.948% for the DP line by the ES method. Likewise, it seems that a general effect is identified for MAPE 22.948% for the ES method.
-
(3)
MA model: Moreover, the experimental results for running the moving average from different 2–4 periods with a parameter sensitivity analysis are conducted from the building process of the MA model. Table 11 lists the analytical results of MAPE in the MA method for the sensitivity analysis from two periods to four periods for the DP line. It is shown that the number of moving periods increases with both the MAPE and RMSE values. This information in the DP line is similar to that in the SGP line. The MA method also shows that two-periods have better performance and effective models than do other periods. The method has a slightly higher MAPE of 31.893% and an RMSE of 48.670. When compared to all the previous results, the MAPE of 31.893% seems to specifically disappoint the MA method; however, it is also acceptable when compared to the MS method.
-
(4)
RA model: With the coefficient results of the regression analysis method, the RA mathematical equation of the DP line is defined as RA(1). After the experiment, Table 12 shows the experimental result on regression coefficients using the RA method for the data of the DP line. From Table 12, it is clear that only the promotion factor has a significant level of 0.01 for influencing the consequence of the sales quantity of the DP line.
$$\begin{aligned} &{\text{RA}}\left( {1} \right):{\varvec{Y}} = { 266}.{112 } + { 35}.{271}{\varvec{X}}_{1} + \, 0.{78}0{\varvec{X}}_{2} + { 577}.{16}0{\varvec{X}}_{3} \big({\varvec{X}}_{1} \\ &\quad :{\text{ Season factor}},{\varvec{X}}_{2} :{\text{ Price factor}},{\text{ and }}{\varvec{X}}_{3} :{\text{ Promotion factor}} \big).\end{aligned} $$

Curve details between the actual and predicted values for the DP line by ES method
Surprisingly, an ultra-high error rate of MAPE 644.000% and RMSE 1813.704 is achieved for the above equation; thus, this equation should be reconsidered and reconstructed. Based on the professional knowledge of experts from L-Company, this model should consider the enrollment number of elementary school students for the past 5 years (i.e., 2008–2012) as a decisive key factor; the RA equation is then reformatted as RA(2) below. Table 13 shows the error results with the enrollment number of elementary school students in 2008–2012 for the DP line by using the RA(2) method. This refined equation yields a significantly lower average MAPE of 17.780% than the MAPE of 644.000%. Similarly, the RMSE value is significantly reduced from 1,813.704 to 26.457. This refined result clearly shows that the DP line is affected significantly by the enrollment numbers at elementary schools. Thus, this decisive key factor of enrollment numbers at elementary schools is found and identified in this study. Moreover, it is an impressive feature that the error rate has a lower 1.07% for the data in 2008 for the DP line when using the RA method from Table 13.
4.1.3 For the IGP line
-
(1)
FTS method: The IGP line has a large range, with a minimum value of 181,136 and a maximum value of 727,093. Similarly, a larger interval from 1000 to 10,000 with behind 1–15 periods of a parameter sensitivity analysis is defined for implementing a time series model. Table 14 lists the fuzzy similarity of different values on behind periods for the IGP line by the FTS method. The best similarity for fuzzy sets has 1 period and 5000 intervals, and the value of 0.8981 is determined as the best similarity. The order number for determinations remains 1. Thus, the analytical results for the FTS model by the FAR(1) adaptive value are a low value of MAPE 12.412% and RMSE 18.980. From both the testing results of MAPE 12.412% and RMSE 18.980, it is determined that the FTS method can be used as the prediction model for the IGP line.
-
(2)
ES method: Similarly, the analytical results of this ES method in the IGP line are executed with a parameter sensitivity analysis of the core parameter α. Table 15 shows the experimental results of different α values in this method for the IGP line. It is shown that when the adjusted constant α value achieves 0.9, it has a lowest value of MAPE 13.429% and RMSE 19.469; importantly, this outcome is an acceptable bottom line for a prediction model based on the expert opinions in the case study.
-
(3)
MA method: Moreover, given the 2–4 moving periods for a parameter sensitivity analysis, the experiment is run. Table 16 lists the analytical results of the MA method with different values from two periods to four periods in terms of the MAPE for the IGP line. The empirical results of the MA method still show better performance in the two moving periods, with MAPE 13.974% and RMSE 19.777. Importantly, it was found that the values of MAPE and RMSE are greater when the number of moving periods is greater. Figure 4 shows information on the curve details between the actual and predicted values by a MAPE of 13.974% for the IGP line using the MA method. From the above evidence-based results in prediction, it is also an acceptable outcome for the MA method in the IGP line.
-
(4)
RA method: The RA equation for the IGP line is also constructed below, and the calculated error results in 2008–2012 are MAPE 18.220% and RMSE 22.638. Importantly, although the IGP line has the property of having no certain rule and can vary dramatically up or down in sales quantity, its error rate between the actual value and the predicted value is controlled within less than 20% in this study. Thus, the piloted curve of the predicted values from the RA equation still has some degree of approaching the centerline to indicate the middle of the actual values in this representative product of the IGP line. Table 17 presents the experimental results on regression coefficients for the RA method using the data from the IGP line. It is also very clear that only the promotion factor from Table 17 has a significant level of 0.01, which means that this factor is a critical variable for influencing the sales quantity of the consequent result Y in the IGP line.

Curve details between the actual and predicted values for the IGP line by MA method
4.1.4 For the SSP line
For promotional purposes, L-Company chooses new items that can be expected to receive much attention or existing items that were always used by customers and assembles them as an on-sale item package.
-
(1)
FTS method: Similarly, the minimum and maximum values of 1016 and 5076 for the SSP line are defined. The behind 1–15 periods with 10–200 intervals with a parameter sensitivity analysis are handled in building the FTS model. Table 18 lists the fuzzy similarity of different values on behind periods for the SSP line by the FTS method. From Table 18, it is clear that the best similarity for fuzzy sets is set behind 3 periods; twenty intervals are classified into 202 types of items, and the best similarity has a value of 0.8994. The empirical results of the FTS method for the FAR(3) adaptive value achieve an error value of MAPE 36.211% and RMSE 53.520. From the above results, both the values of MAPE 36.211% and RMSE 53.520 have a higher error rate, and that seems to be a relatively unacceptable outcome when compared to the previous three product lines for the FTS method.
-
(2)
ES method: The empirical results for this model with a parameter sensitivity analysis of key values for parameter α were run and obtained. Table 19 shows the experimental results of different α values in this ES method for the SSP line. It is shown that when the adjusted α value is 0.3, the lowest MAPE and RMSE values reach 34.076% and 43.947, respectively, in accordance with the SSP line by the ES model. Similarly, from the lowest values of both MAPE 34.076% and RMSE 43.947, it is also not a good result when compared to the previous three product lines for the ES method.
-
(3)
MA method: For this SSP line, the MA method with a parameter sensitivity analysis of different periods for a mathematical model is run. Table 20 lists the analytical results from two periods to six periods in terms of MAPE in the MA method for the SSP line. Interestingly, using the MA model, we find that when the moving periods decrease, the MAPE and RMSE values increase. This phenomenon is converse to other product lines. In the given 2–6 periods, this study provides empirical results that have the lowest MAPE of 24.047% and RMSE of 29.342 in the four moving periods. This method performs better and more effectively than do other moving periods. Only for the SSP line does the MA method have less error when compared to the other three methods. This result seems to imply that the MA method is more suitable for application in this product line.
-
(4)
RA method: The same three key factors from experts are used. Consequently, the values of MAPE 32.485% and RMSE 39.953 in 2008–2012 are obtained from the RA method, and its regression equation is expressed as follows: Table 21 shows the regression coefficient results of the experiment using the RA method for the data from the SSP line. From Table 21, it is clear that both the price and promotion factors have a significant level of 0.01 for significantly influencing the consequence of sales quantity in the SSP line.
$$ {\varvec{Y}} = { 2},{385}.{918 } + { 77}.{945}{\varvec{X}}_{1} {-} \, 0.{3}0{5}{\varvec{X}}_{2} + { 1},{195}.{599}{\varvec{X}}_{3} \left( {{\varvec{X}}_{1} :{\text{ Season factor}},{\varvec{X}}_{2} :{\text{ Price factor}},{\text{ and }}{\varvec{X}}_{3} :{\text{ Promotion factor}}} \right). $$
4.2 Comparable studies
This subsection describes aggregate MAPE and RMSE for internal comparison (i.e., the component comparison inside the proposed model) and external comparison (i.e., the proposed model and MS method) of the four product lines by the proposed model from the above empirical results with the main tables and figures of the study. This part discusses the significance of each independent variable for sales quantity forecasting.
4.2.1 Comparisons of MAPE and RMSE
In order to further compare the performance of subjective artificial and objective machine methods, this study discusses L-Company performance forecasts of MS (i.e., manager subjects) for four product lines. Table 22 lists the summary of the error rates in terms of MAPE and RMSE for internal and external comparisons of the four types of product lines by the proposed model and an additional MS method from the empirical results.
Table 22 shows that the five key points determined for the details of internal and external comparison results of the MAPE and RMSE are slightly small for MAPE and RMSE, respectively. These details are identified from the empirical results and conclusively described as follows: (1) In the SGP line, performance differences for the first three methods, i.e., 7.68, 7.69, and 7.77% vs. 10.32, 10.3%, and 10.46%. The ranking order of model components for the proposed hybrid model in terms of the MAPE performance has been defined as MA → ES → FTS → RA(1) → MS, and in terms of the RMSE performance, it is ranked as ES → FTS →MA → RA(1) → MS. The independent factors include season and price. (2) Interestingly, the ES method has the best original performance in the DP line for both MAPE and RMSE. In particular, the RA method has an extra unsatisfied result (MAPE 644.00% and RMSE 1813.70) based on the three factors season, promotion, and price; however, the RA method yields a significant result of MAPE 17.78% and RMSE 26.46 when a decisive key factor of the enrollment number of elementary schools is considered in the regression equation. Similarly, the ranking order in terms of the MAPE performance becomes RA(2) → ES → FTS → MA → MS → RA(1), and in terms of the RMSE, it becomes RA(2) → ES → MA → FTS → MS → RA(1). (3) Importantly, in a specific characteristic of the IGP line, the FTS model has the best prediction performance for both the MAPE and RMSE performances. The ranking order in terms of both the MAPE and RMSE performances shows the same: FTS → ES → MA → RA(1) → MS. Notably, the proposed model performs well in the IGP line (Table 22), and the independent factors are season, promotion, and price. (4) More interestingly, the MA method has a lower error rate for MAPE and RMSE than do the other three models in the SSP line. The ranking order for both the MAPE and RMSE performances is also the same: MA → RA(1) → ES → FTS → MS, and its independent factors also include season, promotion, and price. (5) In the MS method of artificial forecasting of external comparison, the error rate of the subjective analysis was higher than that of the proposed model (Table 22). All types of technological sales forecasting models in this study were more accurate than any subjective method. For the MS worst performance, a reasonable explanation is provided; the manager in the empirical L-Company case has the difficult responsibility of controlling an extensive variety of 2010 SKU products. Thus, it is clear that, in the empirical case, the company needs a more intelligent method to process the sales forecasting work effectively and efficiently. Interestingly, this information also implies that if L-Company can use the proposed model as an intelligent sales forecasting tool instead of using a traditional forecasting method, it can benefit from correct and accurate sales forecasting to decrease operating costs and provide a completely effective production plan for downstream production units.
Moreover, to provide complete information in relation to internal and external comparison results in graphic format, Figs. 5, 6, 7 and 8 show their curve details of actual and predicted values for the four product lines by the four techniques of the proposed method with the MS method, respectively. Clearly, these comparison curves support the empirical results from Table 22. The MS method has the worst performance.

Comparison curve for the actual and predicted values for the SGP line by the four methods and MS

Comparison curve for the actual and predicted values for the DP line by the four methods and MS

Comparison curve for the actual and predicted values for the IGP line by the four methods and MS

Comparison curve for the actual and predicted values for the SSP line by the four methods and MS
4.2.2 Effect of independent variables
To identify key factors for the three variables further, Table 23 highlights the significance of each independent variable on sales forecasting by using the RA method for the four product lines. Table 23 shows that this study characterizes the following four directions according to the achieved RA equation: (1) For the SGP line, the key factor price practically shows a significant relationship to the sales quantity from the analysis in Table 23. In particular, this SGP product is defined as an increasing-demand product with a high market share rate. Thus, this useful information implies that the expected higher prices might have a higher sales quantity due to consumers’ psychological expectations, with panic behavior for downstream customers. A reasonable explanation is that when wholesalers, dealers, sellers, or even retailers worry about the expected increasing cost of goods purchased, they might move to make larger purchases to stock in advance. Therefore, it is an interesting and special case that this type of product will have some influence and attraction on the consumer market. Specifically, the experts also support this thought-provoking phenomenon in interviews. (2) Practically speaking, although many of the same types of competitive products in the manufacturing industry might exist, only promotional factors can affect and improve the sales quantity of the DP line. In particular, the SGP product does not actually need a promotional activity to promote sales quantity in the empirical L-Company because it has good sales in practice (please see Table 5). (3) Similar to the DP line, only the factor of promotion significantly affects the sales quantity of the IGP line. This type of product has great potential to experience increased sales volume from improved marketing capabilities. Moreover, this information implies that if L-Company makes a promotional activity and introduces a new product, the volumes of sales will specifically increase. (4) For the SSP line, the main factors include promotion and price. Most product sets are derived from a combination of marketing activity and special sales, such as at the product exhibition of the World Trade Center in Taipei, Taiwan. Thus, when these types of products go on sale, the sales quantities will increase statistically and significantly.
4.3 Wilcoxon signed-rank test
A Wilcoxon signed-rank is a test of a non-parametric statistical hypothesis that can identify the difference in values between two related samples and assess whether population averages differ when groups are not necessarily distributed properly (Wilcoxon, 1945). Thus, the study adopts and extends it to evaluate MAPE and RMSE further for the proposed model. In Wilcoxon statistics, the values 1, 0, and − 1 indicate that the first method outperformed, performed equally to, or underperformed the other methods, respectively, for addressing a two-tailed test method at a ± 5% level of significance. Tables 24 and 25 simply summarize the internal comparison results of the Wilcoxon test under the MAPE and RMSE of the proposed model for the four product lines, respectively. Tables 24 and 25 show the related results of both the used models and the product lines in alphabetical order. Interestingly, the test results show that the best model is the ES method and the worst model is the RA method under both the MAPE and RMSE criteria. Conclusively, the ranking order of prediction performance from Table 24 and 25 is ES → MA → FTS → RA in this study.
5 Findings and discussions
This section includes related findings, discussions, research contributions, and research limitations from the above experimental results.
5.1 Findings and management implications
The study yields seven findings for academicians and practitioners from the empirical results of internal comparisons, as follows:
-
(1)
The MA method works well for the SGP line on the MAPE criterion and the SSP line on both the MAPE and RMSE criteria, according to the empirical results (Table 22).
-
(2)
The DP line performed well with the ES model on both the MAPE and RMSE criteria; nevertheless, if decisive key factors are identified and considered in the modeling process, the RA method has the best forecasting results (Table 22).
-
(3)
For the IGP line, the FTS method has better forecasting performance than the other proposed models on both the MAPE and RMSE criteria in cases of the unpredictability of sales data and unknown factors (Table 13).
-
(4)
Empirical results prove that the ES model has the most accurate forecasting model, and the RA method is the worst (Tables 24 and 25).
-
(5)
In using the MA model, the number of moving periods had a positive correlation with the MAPE and RMSE values for the SGP, DP, and IGP lines; however, for the SSP line, the number of moving periods had negative effects on the MAPE and RMSE values.
-
(6)
This study further proves that the most decisive key factor for the DP line when using the RA method is the student enrollment numbers in elementary school because of the low rate of birth in Taiwan (Table 13). The meaningful information can provide relevant types of products as a helpful reference for decision-making in sales and production planning for L-Company.
-
(7)
Although Table 23 shows that the factor price is an important variable in this empirical case, different types of product lines lead to different pricing performance for decision-making. First, if the products dominate the market or sell well, retailers are willing to agree to a higher purchase price in the future; on the contrary, when the expected price increases, retailers remain willing to order more products to increase sales quantity. Second, the market gives a lot of attention to the same competitive products, and customers have many choices to choose from. A price decrease will attract customers to buy the product and thus generate increased sales.
Furthermore, how to utilize the findings of the study to allocate a product to a suitable model is an important concern. This allocation activity can simply use the following three sub-steps: First, select the target product. Second, classify this product into an appropriate line type (i.e., SGP, DP, IGP, or SSP) based on the SGR (Harrell & Taylor, 1981) and a property of specific activities on particular days. Third, select a suitable model (i.e., FTS, ES, MA, or RA) as a forecasting method that corresponds to this product based on the above findings and Table 22. Following the above three sub-steps, we can simplify and standardize the proposed hybrid model and effectively learn the seven findings yielded from the empirical evidence. Thus, it is worthy of further exploring the issue of the applicability of these findings. Theoretically and practically, the proposed model has no need to further train data if it has a similar product line type in the same traditional manufacturing industry; however, it is necessary to re-train and re-test the data for the proposed hybrid model if it is employed in other application fields or other industries.
Regarding the impact of implicit experiences on management from a perspective, the study highlights the following three valuable lessons learned and presents a summary of the core titles.
-
(1)
Defining clear and objective forecasting methods for sales forecasts: To overcome overstock or out-of-stock conditions caused by a manager’s subjective forecasting, it is necessary for L-Company to use the proposed model in its sales forecasting plans to control and manage inventory strategies seriously. Therefore, it is important for a manufacturing company to have a clear and objective means of modeling an optimal sales forecasting model and identifying the decisive key factors for effective decision-making.
-
(2)
Each product has a suitable prediction method: There are thousands of types of products; however, different products have different characteristics and thus require different management methods. The study therefore provides suitable prediction methods for an appropriate case of homogeneous products to predict sales quantities more accurately for L-Company. The proposed model provides L-Company with sufficient information to sell potential commodities at the right price, in the right place, at the appropriate time, and in the appropriate quantity.
-
(3)
Attention to variables affecting sales volumes significantly: The variables of three key trends for season, price, and promotion can potentially affect sales quantity, particularly price. Price affects sales quantity significantly in most product lines. More interestingly, key variables occasionally affect sales quantity positively but occasionally affect it negatively due to the properties of product lines. Thus, it is a requirement for L-Company to categorize its product line types properly. A reasonable explanation for this issue is based on differences in product type. L-Company should focus more on setting correct forecasting models for product lines based on the empirical results of this study.
5.2 Discussions
In this study, six meaningful issues, including two additional methods of classifying types of product lines for L-Company in the future, a problematic issue for making decisions, sustainable business management under a circular economy, strengths and rationality of the proposed model, innovative contribution of industry application, and a significant challenge of corporate social responsibility (CSR), with their abstract summary, can be further addressed and discussed, respectively.
-
(1)
Two additional methods: First, except for the SGR, product life cycle and sales frequency can be good alternatives for contributing to this classification. Second, choose the representative products by a specific classification principle, such as rare materials or new items, as a practical research objective. Moreover, the gap in sales quantity between peak and low seasons is enormous in the manufacturing industry; nevertheless, Taiwan's birth rate has become one of the lowest in the world in recent years, which has become a serious problem for future development. For the above reasons, overall sales for domestic consumption have decreased for years, in particular in 2015. L-Company now faces serious challenges. To solve these emerging challenges and problems, L-Company must make flexible use of the proposed model and its empirical results to match production-sales behaviors completely and simultaneously consider and use different marketing strategies, such as cross-industry collaboration and group buying, to promote its products. This promotional strategy can also increase company and product reputations simultaneously. Although this research cannot measure how marketing methods affect sales quantity, this study considers this activity a key variable that affects sales quantity. Issues involving marketing methods influencing sales quantity can be explored in future studies.
-
(2)
A problematic issue for making decisions from managers: Although this study has provided four forecasting lines (SGP, DP, IGP, and SSP) conducted by the collected data of case L-Company and used different models to predict them, this study will face a dilemma of decision-making for future sales if the manager "cannot" make sure which line will occur (four possible lines may happen) in the next season or next year and employ a proper model to forecast it. Although the dilemma may have a problematic issue for sales and production managers, the traditional manufacturing industry always has a higher probability of making some basic daily necessities or some basic components and parts for further use by upstream and downstream industry chains or end customers than other industries, and basically, the product line will have a sustainability of requirements, production, and consumption for the case company. Thus, the case study has very few problems causing decision-making difficulty; reversely, sustainable manufacturing under sustainable development goals (SDGs) with a consideration for circular economy is really a crucial concern for the case study of L-Company.
-
(3)
Sustainable business management under a circular economy according to the empirical results: For this topic of sustainable business management and the empirical results of this study, there are three main directions determined for discussion and improvement. (a) It is necessary to define the circular economy. A circular economy can be one of the renewable systems to reduce the amount of used and disposed resources in the natural environment, finally reaching the highest goal of zero waste. From the perspective of the well-use of limited resources, it is a better solution to turn a directional linear economy (i.e., take → manufacturing → use → dispose) into the recycling of a circular economy (i.e., materials → manufacturing → product → use → recycling), which can effectively and significantly reduce the rate of resource waste. (b) For the traditional manufacturing industry, the issue of sustainable manufacturing is the better use of manufactured products via circular economy-based processes to maximize the use of limited resources and natural energy and minimize the negative effect on the environment. (c) As mentioned above, for the good use of the goals of sustainable manufacturing under the circular economy in the case study of L-Company, two crucial benefits are identified. First, it is suggested that the higher the probability of prediction for the proposed hybrid model, the better the key target achievement for sustainable manufacturing and sustainable business management under a circular economy for L-Company. In particular, in the case study of the company, the current use of managers' artificial subjective predictions makes the differences between actual and predicted values too large, becoming a waste of overstocking with overtime, which results in a gap unable to obtain the intended goal of the ESG’s sustainable development and sustainable business management (Yu et al., 2023) and exempting from all waste as soon as possible. Thus, it is clear and implied that the proposed hybrid model can just provide a key advantage in bridging this gap. Second, given the above concerns, for promptly achieving the case of good corporate governance in order to achieve the top goal of sustainable business management under a circular economy, it is implied and also suggested that the ES method or MA method can be used for the SGP line, the RA(2) method with a decisive key factor of enrollment numbers is better used for the DP line, the ES method is more suitable for the IGP line, and the MA method is used for the SSP line more than the MS method. Thus, this study makes a strong recommendation against the use of the MS method, which cannot be used for sales forecasting in the future.
-
(4)
Strengths and rationality of the proposed model: Two directions are addressed for the strengths and rationality of the study objectives. (a) For Industry 4.0, some new technologies, such as machine learning and AI techniques, are used to completely integrate and improve the manufacturing process of a company throughout its production operations for the advantages of smart production innovation goals. In taking into consideration Industry 4.0, this study has used machine learning techniques, including FTS, ES, MA, and RA, to effectively identify four representative products with the strengths of simplicity, usability, applicability, and justifiability from the practical results of experiencing the proposed hybrid model. (b) Productively, we can learn from empirical results, evidence-based practice, research findings, and management implications to benefit from the proposed hybrid model for the traditional manufacturing industry, which provides the rationality to motivate this study in using a variety of time-series models and to highlight the practical outcomes of the case study.
-
(5)
Innovative contribution of industry application: In particular, the motivation of the study was to organize well techniques to provide sales ‘applications’ that can meet expectations for a specific function and to properly identify suitable forecasting models that increase performance for industry applications. This novel approach was not the sole objective in this study; instead, the ‘industry applications’ of the key advanced prediction techniques and the methods that were used were primarily intensified to improve forecasting accuracy. Although the methodology used in this research is not new, original, or an impressive technique, the proposed hybrid model has undergone a new trial in the manufacturing field with satisfactory results for L-Company and other interested parties. Thus, this research contributed to the integration of appropriate models in planning as a feasible method with industry innovation to explain sales information and to mine hidden information and knowledge from the collected four datasets.
-
(6)
A significant challenge in CSR, accompanied by new technological improvements: Although the rapid development of new technology, such as machine learning, the internet of things, or artificial intelligence, achieves positive performance and accomplishment for people, it is relative to negatively causing pollution of the environment and damage to the Earth from the industrial sector; that is, technological development implies collaterally considerable destruction to directly impact the environment. Thus, exploring and facing their social responsibility to industries while benefiting sustainable business management is another meaningful challenge. In particular, it is expected that the possible drawbacks of technological improvements for society should be confronted by businesses and decision-makers through some strategies, such as Industry 5.0, Society 5.0, and responsible research and innovation (RRI), and any successful industrial policy is also expected to follow such strategies to relate how the industrial models can help solve society's difficulties when adopting new technologies. Moreover, according to the study of Isik et al. (2023), it is indicated that the use of new technologies in Industry 4.0 is to mainly highlight the quality improvements and cost advantages over the manufacturing process, but it doesn’t care about social and environmental effects; thus, Industry 5.0 just bridges this gap. Industry 5.0 has a compounded set of strategies: one solution brings the new technologies to create competitive advantages for industries, and concurrently, another solution provides the transformation process for society and the main operations to lessen the detrimental results of climate change and to simultaneously devote sustainable development. Besides, Society 5.0 has the core purpose of expanding and transforming the digitalization of economic manufacturing to meet social challenges like the aging society’s needs; more importantly, the activities of RRI just support seamless integration in the transformation of Industry 4.0 into Industry 5.0, and the RRI opportunely matches an instrumental role between Industry 4.0 and Industry 5.0 strategies (Isik et al., 2023). Thus, these issues should be a key priority for L-Company to achieve sustainable business management.
5.3 Research contributions
The study offers an alternative approach to analyzing sales experience for L-Company and uses the benefits of the proposed hybrid model for academicians and practitioners, with empirically useful outcomes from the four product line datasets. Although this study is not the main concern of innovation technique, we have successfully organized a hybrid method of four forecasting models just for four different characteristics of product lines and just provide a good case of application research; in particular, such a hybrid model suitable for traditional manufacturing industry is yet to be seen in reviewing the limited references. Thus, this study has innovative industry application research with an applicable contribution. In general, the research contribution can be highlighted in the following six directions with its main heading abstract.
-
(1)
Savings—a cost–benefit analysis: By constructing four hybrid sales forecasting models to address the issues with cost savings, the 'manufacturing application’ focus of this research was to prevent the squandering of manufacturing resources and properly combine and reconcile the flexible use of technological and artificial methods with efficient operating performance for managers. The study conducts a forecasting analysis for product sales information, and the empirical results prove that the proposed hybrid model is convenient and accurate with its use of historical sales data for predictive decision-making. Thus, they can effectively reduce the costs of inventory for L-Company.
-
(2)
A new architecture and trial: This study supports an advanced sales forecasting approach and technique that reflects a new architecture and trial for improving sales forecasting accuracy (or error rate) in manufacturing services for managers and their suppliers and customers.
-
(3)
Identifying the determinants influencing sales quantity: The application of such a hybrid forecasting model based on linear RA to identify the determinants influencing sales quantity has been limited in the literature for L-Company until now.
-
(4)
Rare experience in the real-life dataset describing manufacturing fields: This study further explores the relationships between forecasting models and product lines, which were rarely examined based on real-life datasets in previous studies.
-
(5)
Benefits of aiding decision-making policy: Importantly, analysis of the behavioral differences (Figs. 5, 6, 7, and 8) between actual sales value and predicted sales value is important for experiments when using the proposed model for the practical purposes of decision-making policy. The differences between the achieved accuracies of the proposed model have been disclosed, which is a benefit for aiding decision-making policy for managers. Practically speaking, the four forecasting lines represent the four product types. Managers determine the type of product based on past (or last season) sales for the product and then produce the forecasted quantity based on the appropriate forecasting method from the proposed model. This study offers decision-making significantly more effective than a manager’s subjective decision-making for future sales because a manager can ensure which line will occur based on last-season sales and employ a proper model to forecast it.
-
(6)
Bridging the knowledge gap: Empirically, none of the differences distorts the experimental results in favor of the constructed sales forecasting models in this study. From the limited literature, the knowledge gap concerning the identification of sales quantity and related factors of forecasting models between sales managers and production managers and their customers remains to be identified; thus, this study just fills the gaps for L-Company.
According to the contributions mentioned above, this study highlights the importance of these factors and provides a rationale for the proposed hybrid model.
5.4 Research limitations
This study makes the following six directions of core research constraints with a key abstract summary for the proposed hybrid model, which restrict the general reference range and use:
-
(1)
Constraints of company and industry: The data used in the four product datasets are limited to a specific Taiwanese real database; thus, further investigations are needed to verify whether the results reported here are suitable for applications in additional companies and countries and whether the proposed model can be used in generalized applications in other companies or industries.
-
(2)
Constraints of scale and time period of data: Re-training and re-testing of the experimental datasets is also necessary due to the limited case when applying the proposed model to different scales and time periods of data, such as regional or district companies vs. international companies, and different years due to potential changes in the industry environment, respectively.
-
(3)
Constraints of background knowledge: Users of the models must understand the appropriate sales terms and background for the pre-selected conditional and decisional attributes determined in real situations.
-
(4)
Constraints of professional data: Forecasting methods must be more tailored to various features of data to make an informed model selection when encountering a few data points or when new data is available.
-
(5)
Constraints of methods: In addition, the proposed model is limited to the four forecasting methods, FTS, ES, MA, and RA, and it is needed to re-model the proposed hybrid model if the new components are inserted and used.
-
(6)
Constraints of implementation challenges: When we implement the proposed hybrid model, two types of challenges are encountered, including data problems and background problems. (a) The first challenge includes the difficulty problems of data collection, the correctness problems of data, and personnel errors in work, causing subjective identification of personnel to overwhelm objective model predictions. (b) For the second challenge, when we face possible changes in future background environments, such as influencing variables like the COVID-19 pandemic or industrial upgrades for future Industry 5.0, they can distort the prediction results of the proposed hybrid model; thus, timely adjustment or the addition of new impact variables for the proposed hybrid model is imperative.
6 Conclusions and future directions
This section majorly describes the related issues, including conclusions, policy implications, and subsequent research, concerned with all the study results.
6.1 Conclusions from the study results
Given the important results, the study conclusively addresses four main areas of analytical outcomes with critical abstract explanations to interested parties for beneficial concerns in inspiring constructive references as follows:
-
(1)
AI-based machine learning modeling techniques for overcoming real-life problems: According to the study of Sarker (2022), a comprehensive review of the principles and capabilities of “AI-based modeling” has an important role in developing an intelligent system for solving various real-life industry application problems, such as manufacturing, health care, and financial management, particularly for addressing the current era of the Fourth Industrial Revolution (called Industry 4.0) in the manufacturing industry. Overall, this paper provides an effective guide for AI-based machine learning modeling techniques to address various real-life scenarios and apply applicable values to decision-making processes for academics and practitioners. With the above AI-based modeling methods, various types of AI are applied to upraise and carry out the capabilities of an application and intelligently sustainable operating management under the background of circular economy (Wan et al., 2023); optimal sustainable intelligence can match specific operating management achieved in the benefits of achieving environmental, economic, and cost-efficiency to facilitate a more optimal decision-making process in order to reach a circular economy and sustainable business resources (Wen et al., 2023). Thus, it is a valuable issue to effectively use intelligent tools for processing and overcoming real-life problems in a wide industry, particularly the traditional manufacturing industry.
-
(2)
An alternative practical industry application case: In Taiwan, the traditional manufacturing industry has encountered the following problems: a low birth rate, a sustained economic recession, and the effects of prevailing advanced information technology, particularly for the COVID-19 pandemic outbreak. These serious problems are related to a rapidly declining demand for traditional products. To break through the above limitations, a manufacturing company expects to adopt new strategies effectively, such as enhancing promotional activities, adjusting sales prices, and developing creative products, to meet customer requirements and further increase sales quantity. Thus, the above potential factors and new strategies should be considered for the future of sales forecasting processes by L-Company to obtain better predicting performances than past subjective experiences for managers. This study is of importance to empirically explain the proposed model and provide a better understanding of how to address the related issue of sales forecasting for the decision analytics approach. This study has used practical sales data with four product lines: steadily growing, declining, irregularly growing, and special sales. L-Company evaluated the forecasting performance of the proposed model as an empirical case for a variety of big data application analytics. The empirical results indicated that the study performed satisfactorily and was a successful case study to provide the manufacturing industry with a useful reference to identify a suitable forecasting method to model sales quantity forecasting processes and accurately identify the decisive determinants. This study can be considered an alternative to and a good example of a complete sales forecasting model that is more accurate for arranging feasible back-end production units of demanded quantities in advance. Although this study does not propose a real novel approach, it has a new structure and trial to support ‘sales applications’ with a significant experience of alternative approaches to well-formed key and advanced techniques and to address the main purpose of the need to adapt forecasting models for different product lines showing different behaviors to particular L-Company needs. Subsequently, the study focuses on seven important findings and three managerial implications, with good business case use of these models from the sales forecasting application field in the traditional manufacturing industry from big data application solutions of the decision analytics approach.
-
(3)
Five important recommendations: Based on the conclusive and significant management implications of the implied empirical results, this study offers the following five recommendations: (a) Set an alternative to objective forecasting methods for sales quantity forecasting. The negative effects of inaccurate predictions often result in serious inventory problems, causing business gains, losses, and cost increases. (b) Each product has a specific property; thus, searching for an appropriate prediction model and a useful manufacturing plan is necessary. If the prediction model can be reconciled with the timing control of L-Company’s manufacturing items, the forecast can help the company provide sufficient inventory to serve customers during peak seasons. (c) Be concerned about the season, price, promotion, and enrollment number of elementary schools, which affect sales quantity forecasting. (d) The empirical results and findings offer interested parties useful information for future forecasting directions. (e) Moreover, as referred to in two previous studies with objectives similar to those of this study, two conclusions are formed. First, Kang et al. (2017) indicated that when evaluating the advantages of different prediction models for well-studied time series datasets using time series techniques with controllable characteristics, studying the unique strengths and weaknesses of the methods for generalizing about robust performances with respect to diverse and challenging issues is important. Second, Petropoulos et al. (2014) showed that identifying the key factors of the prediction accuracy of 14 popular prediction models and combinations of them, seven time-series features, and one strategic decision on the forecasting horizon is influenced by a variety of data characteristics, such as for fast-moving data, for intermittent data, and for all types of data.
-
(4)
Seeking a suitable method for different product lines in the case of L-Company: Thus, based on the advanced, previously mentioned identifications and the empirical results in this study, it is concluded that no single forecasting method is perfect to match all practical data because there are horses for courses (Petropoulos et al., 2014). We remain unable to answer a very simple question: “Which one is the best method to use with my data?” when discussing this topic with practitioners and researchers. In general, forecasting methods must exist that are more tailored to specific types of data, enabling interested parties to select an informed method when facing new data. More importantly, this study result is consistent with Petropoulos et al. (2014) for 'horses for courses' in a demand prediction method. This objective is significant when seeking a suitable method for the products of different product lines at L-Company in this study. In addition, another consideration to match the ideas of Industry 4.0 activity is that the components of the proposed model consist of machine learning technology and conform to new traditional industry applications for trending the concepts of new technologies; thus, this study has a pace of opening up milestones on providing sales forecasting issues.
6.2 Policy implications
To further help rule the sales-production policy for decision-makers in the case of L-Company, four effective strategies are implied and identified according to this study’s performance metrics and empirical results towards the sustainability of the ESG commitments as well as CSR and RRI issues, as follows:
-
(1)
The first strategy for ruling policy of decision-making is implied and defined that the prediction method of MS artificial subjectivity for future sales forecasting should be abandoned, and the objective intelligent time series method proposed from this study should be adopted as a useful alternative for identifying characteristics of different product lines.
-
(2)
The second strategy is also implied by the fact that ruling the policy on promotion activity is absolutely needed for the DP, IGP, and SSP lines; conversely, the promotion policy is not a good strategy for the SGP line because it doesn't work well. Moreover, for the SGP and SSP lines, the pricing policy is effective and necessary; however, it is ineffective and unnecessary for the others. Ruling the policy about seasonal variables is efficient and effective only for the SGP line, and the others don’t have the effect of improving sales forecasting.
-
(3)
For achieving the goals of sustainable business management under a circular economy, it is the last strategy that the company needs and continues to dedicate to seeking AI-based decision support systems, such as art-of-the-state techniques, for further committing the complete sales-production plans.
-
(4)
For well-addressing sustainable business management for L-Company, it will be an effective policy that the top management should positively face and adopt the CSR and RRI issues from Industry 4.0 to Industry 5.0, and it should effectively follow efforts to transform its existing production functions and sales methods into an organized, environmentally friendly, sustainability-focused system to create a competitive advantage by tempting consumers’ attention for a new feature of future challenges (Isik et al., 2023).
6.3 Subsequent research
The study performs well with the four constructed methods to predict the four product lines. Several directions and areas remain that can be extended and applied in future research. These efforts can be expressed as follows: (1) Further conduct sales quantity work, applying different forecasting methods for various products. (2) It is a good solution to search for appropriately deformable models of ARIMA, such as ARMA-GARCH (autoregressive moving average-autoregressive conditional heteroscedasticity), SARIMA (seasonal ARIMA), and SARIMAX (seasonal ARIMA with eXogenous factors), for addressing and identifying different characteristics of the four product lines in the subsequent research, respectively. (3) Identify different key factors that can affect sales quantity for a wide range of marketing purposes. (4) Combine back-end production and logistics management into the proposed model for production forecasting and inventory management predictions. (5) Apply the proposed model to other industries, such as high-tech, biotech, and medicine. (6) Extend this work with various hybrid soft computing approaches in the form of applications for other sectors. (7) It might be a feasible alternative to further merge more recently developed intelligent application methods, such as the generative adversarial network (GAN)-based scheme (Zhang et al., 2023b; Zhou et al., 2022) and the wavelet transform model (WTM) (Guido, 2022), into the proposed hybrid model for addressing the related manufacturing forecasting problems. In particular, the WTM has two sophisticated but useful types of categories: discrete wavelet transform and continuous wavelet transform; thus, it can be widely used in a variety of industrial applications. Moreover, due to the complexity and variety of experiments in this study and according to the review of Guido (2022), we can understand that the WTM is a powerful tool for identifying uncertain and random data in the classification application of time series (e.g., ARIMA) and images, particularly for signal and video compression algorithms, which can be well executed for the convolutional neural network (CNN) method; thus, it can be further merged into the proposed hybrid model for further measuring its performance in the future.
References
Aladag, C. H., Egrioglu, E., Yolcu, U., & Uslu, V. R. (2014). A high order seasonal fuzzy time series model and application to international tourism demand of Turkey. Journal of Intelligent and Fuzzy Systems, 26(1), 295–302.
Allen, P. G., & Fildes, R. (2001). Econometric forecasting. In J. S. Armstrong (Ed.). Principles of Forecasting. Kluwer Academic Publishers.
Arora, N., & Saini, J. R. (2013). Time series model for bankruptcy prediction via adaptive neuro-fuzzy inference system. International Journal of Hybrid Information Technology, 6(2), 51–64.
Bang, Y. K., & Lee, C. H. (2008). Fuzzy time series prediction with data preprocessing and error compensation based on correlation analysis. Convergence and Hybrid Information Technology, 2, 714–721.
Brown, R. G. (1956). Exponential smoothing for predicting demand (p. 15). Arthur D. Little Inc.
Brown, R. G. (1960). The fundamental theorem of exponential smoothing. Operations Research, 9, 673–685.
Cagcag Yolcu, O., Bas, E., Egrioglu, E., & Yolcu, U. (2020). A new intuitionistic fuzzy functions approach based on hesitation margin for time-series prediction. Soft Computing, 24, 8211–8222.
Carpio, J., Juan, J., & López, D. (2014). Multivariate exponential smoothing and dynamic factor model applied to hourly electricity price analysis. Technometrics, 56(4), 494–503.
Chan, F. T., Samvedi, A., & Chung, S. H. (2015). Fuzzy time series forecasting for supply chain disruptions. Industrial Management & Data Systems, 115(3), 419–435.
Chen, M. Y. (2014). A high-order fuzzy time series forecasting model for internet stock trading. Future Generation Computer Systems, 37, 461–467.
Chen, S. M., Zou, X. Y., & Gunawan, G. C. (2019). Fuzzy time series forecasting based on proportions of intervals and particle swarm optimization techniques. Information Sciences, 500, 127–139.
Efendi, R., Ismail, Z., & Deris, M. M. (2015). A new linguistic out-sample approach of fuzzy time series for daily forecasting of Malaysian electricity load demand. Applied Soft Computing, 28, 422–430.
Egrioglu, E. (2014). PSO-based high order time invariant fuzzy time series method: Application to stock exchange data. Economic Modelling, 38, 633–639.
Fang, X., & Chen, H. C. (2022). Using vendor management inventory system for goods inventory management in IoT manufacturing. Enterprise Information Systems, 16(7), 1885743.
Feng, Q., & Shanthikumar, J. G. (2022). Applications of stochastic orders and stochastic functions in inventory and pricing problems. Production and Operations Management, 31(4), 1433–1453.
Field, A. P. (2013). Discovering statistics using IBM SPSS Statistics: And sex and drugs and rock ‘n’ roll (4th ed.). Sage.
Fumo, N., & Biswas, M. R. (2015). Regression analysis for prediction of residential energy consumption. Renewable and Sustainable Energy Reviews, 47, 332–343.
Gallina, V., Lingitz, L., Breitschopf, J., Zudor, E., & Sihn, W. (2021). Work in progress level prediction with long short-term memory recurrent neural network. Procedia Manufacturing, 54, 136–141.
Ganaie, M. A., Tanveer, M., & Jangir, J. (2023). EEG signal classification via pinball universum twin support vector machine. Annals of Operations Research, 328(1), 451–492.
Gokulachandran, J., & Mohandas, K. (2015). Comparative study of two soft computing techniques for the prediction of remaining useful life of cutting tools. Journal of Intelligent Manufacturing, 26(2), 255–268.
Golmohammadi, D., & Radnia, N. (2016). Prediction modeling and pattern recognition for patient readmission. International Journal of Production Economics, 171(1), 151–161.
Granville, J. E. (1976). Granville’s new strategy of daily stock market timing for maximum profit. Prentice-Hall.
Guido, R. C. (2022). Wavelets behind the scenes: Practical aspects, insights, and perspectives. Physics Reports, 985, 1–23.
Gupta, S., Modgil, S., Bhattacharyya, S., & Bose, I. (2022). Artificial intelligence for decision support systems in the field of operations research: Review and future scope of research. Annals of Operations Research, 308, 215–274. https://doi.org/10.1007/s10479-020-03856-6
Hanggara, F. D. (2021). Forecasting car demand in Indonesia with moving average method. Journal of Engineering Science and Technology Management (JES-TM), 1(1), 1–6.
Harrell, S. G., & Taylor, E. D. (1981). Modeling the product life cycle for consumer durables. Journal of Marketing, 45(4), 68–75.
Heizer, J., & Render, B. (2011). Operations management flexible version with lecture guide & activities manual package. Pearson Higher Ed.
Huang, L. (2015). Auto regressive moving average (ARMA) modeling method for Gyro random noise using a robust Kalman filter. Sensors, 15(10), 25277–25286.
Isik, M., Akay, G. H., & Arslan, R. N. (2023). From Industry 4.0 to Industry 5.0: The role of responsible research and innovation. In Implications of Industry 5.0 on Environmental Sustainability. IGI Global, pp. 1–24. https://doi.org/10.4018/978-1-6684-6113-6.ch001.
Jain, V., Rathi, R., & Gautam, A. K. (2012). Time-series data prediction using fuzzy data dredging. In: IEEE 2012 Nirma University International Conference on Engineering (NUiCONE), pp. 1–6.
Jayant, A., Agarwal, A., & Gupta, V. (2021). Application of Machine Learning Technique for Demand Forecasting: A Case Study of the Manufacturing Industry. In Advances in Production and Industrial Engineering: Select Proceedings of ICETMIE 2019, pp. 403–421. Springer.
Jiang, H.-J., & Dai, H.-L. (2015). A novel model to predict U-bending springback and time-dependent springback for a HSLA steel plate. International Journal of Advanced Manufacturing Technology, 81(5), 1055–1066.
Jiang, M., Jia, L., Chen, Z., & Chen, W. (2022). The two-stage machine learning ensemble models for stock price prediction by combining mode decomposition, extreme learning machine and improved harmony search algorithm. Annals of Operations Research, 309, 553–585. https://doi.org/10.1007/s10479-020-03690-w
Jónsson, T., Pinson, P., Nielsen, H. A., & Madsen, H. (2014). Exponential smoothing approaches for prediction in real-time electricity markets. Energies, 7(6), 3710–3732.
Kamaraj, A. B., Jui, S. K., Cai, Z., & Sundaram, M. M. (2015). A mathematical model to predict overcut during electrochemical discharge machining. International Journal of Advanced Manufacturing Technology, 81(1), 685–691.
Kang, Y., Hyndman, R. J., & Smith-Miles, K. (2017). Visualising forecasting algorithm performance using time series instance spaces. International Journal of Forecasting, 33(2), 345–358.
Lee, W. I., Chen, C. W., Chen, K. H., Chen, T. H., & Liu, C. C. (2012). Comparative study on the forecast of fresh food sales using logistic regression, moving average and BPNN methods. Journal of Marine Science and Technology, 20(2), 142–152.
Lin, R. F. Y., Wu, J., Tseng, K. K., Tang, Y. M., & Liu, L. (2023). Applied sentiment analysis on a real estate advertisement recommendation model. Enterprise Information Systems, 17(6), 2037158. https://doi.org/10.1080/17517575.2022.2037158
Liu, H., Liu, Y., & Li, L. (2010). Study on application of exponential smoothing method to water environment safety forecasting. In 2010 International Conference on E-Product E-Service and E-Entertainment (ICEEE), pp. 1–3, Henan, China, November 7–9, 2010.
Lu, X., Jia, Z., Wang, X., Li, G., & Ren, Z. (2015). Three-dimensional dynamic cutting forces prediction model during micro-milling nickel-based superalloy. International Journal of Advanced Manufacturing Technology, 81(9), 2067–2086.
Marshall, B. R., Nguyen, N. H., & Visaltanachoti, N. (2017). Time series momentum and moving average trading rules. Quantitative Finance, 17(3), 405–421.
Moraes, L. A., Flauzino, R. A., Araujo, M. A., & Batista, O. E. (2013). A fuzzy methodology to improve time series forecast of power demand in distribution systems. In 2013 IEEE Power & Energy Society General Meeting, pp. 1–5. https://doi.org/10.1109/PESMG.2013.6672491.
Morphet, C. S. (1991). Applying multiple regression analysis to the forecasting of grocery store sales: An application and critical appraisal. International Review of Retail, Distribution and Consumer Research, 1(3), 329–351.
Nozari, H., Ghahremani-Nahr, J., & Szmelter-Jarosz, A. (2023). A multi-stage stochastic inventory management model for transport companies including several different transport modes. International Journal of Management Science and Engineering Management, 18(2), 134–144. https://doi.org/10.1080/17509653.2022.2042747
Osborne, J., & Waters, E. (2002). Four assumptions of multiple regression that researchers should always test. Practical Assessment, Research & Evaluation, 8(2), 1–9.
Ottaviani, F. M., & De Marco, A. (2022). Multiple linear regression model for improved project cost forecasting. Procedia Computer Science, 196, 808–815.
Palia, A. P., & Roussos, D. S. (2004). Online sales forecasting with the multiple regression analysis data matrices package. Developments in Business Simulation and Experiential Learning, 31, 53–57.
Petropoulos, F., Makridakis, S., Assimakopoulos, V., & Nikolopoulos, K. (2014). “horses for courses” in demand forecasting. European Journal of Operational Research, 237(1), 152–163.
Ramos, P., & Oliveira, J. M. (2016). A procedure for identification of appropriate state space and ARIMA models based on time-series cross-validation. Algorithms, 9(4), 76–89.
Ramos, P., Santos, N., & Rebelo, R. (2015). Performance of state space and ARIMA models for consumer retail sales forecasting. Robotics and Computer-Integrated Manufacturing, 34, 151–163.
Rogers, D. (1992). A review of sales forecasting models most commonly applied in retail site evaluation. International Journal of Retail & Distribution Management, 20(4), 3–11.
Sadeghi, A. (2015). Providing a measure for bullwhip effect in a two-product supply chain with exponential smoothing forecasts. International Journal of Production Economics, 169, 44–54.
Sarker, I. H. (2022). AI-Based modeling: Techniques, applications and research issues towards automation, intelligent and smart systems. SN Computer Science, 3, 158. https://doi.org/10.1007/s42979-022-01043-x
Sarkheyli, A., Zain, A. M., & Sharif, S. (2015). A multi-performance prediction model based on ANFIS and new modified-GA for machining processes. Journal of Intelligent Manufacturing, 26(4), 703–716.
Schneider, A., Hommel, G., & Blettner, M. (2010). Linear regression analysis: Part 14 of a series on evaluation of scientific publications. Deutsches Ärzteblatt International, 107(44), 776–782.
Scott, A. J. (2012). Illusions in regression analysis. International Journal of Forecasting, 28(3), 689–694.
Sharma, R., & Sinha, A. K. (2012). Sales forecast of an automobile industry. International Journal of Computer Applications, 53(12), 25–28.
Singh, P., & Borah, B. (2014). An effective neural network and fuzzy time series-based hybridized model to handle forecasting problems of two factors. Knowledge and Information Systems, 38(3), 669–690.
Singh, A. P., Gaur, M. K., KumarKasdekar, D., & Agrawal, S. (2015). A study of time series model for forecasting of boot in shoe industry. International Journal of Hybrid Information Technology, 8(8), 143–152.
Singhal, S., Kapur, P. K., Kumar, V., & Panwar, S. (2023). Stochastic debugging based reliability growth models for Open Source Software project. Annals of Operations Research, 1–39. https://doi.org/10.1007/s10479-023-05240-6.
Smyl, S. (2020). A hybrid method of exponential smoothing and recurrent neural networks for time series forecasting. International Journal of Forecasting, 36(1), 75–85.
Song, Q., & Chissom, B. S. (1993). Fuzzy time series and its models. Fuzzy Sets and Systems, 54(3), 269–277.
Sun, Y., Wang, Q., & Yan, T. (2018). The exact autocorrelation distribution and 2-adic complexity of a class of binary sequences with almost optimal autocorrelation. Cryptography and Communications, 10, 467–477. https://doi.org/10.1007/s12095-017-0233-x
Tang, Y. M., Chau, K. Y., Ip, Y. K., & Ji, J. (2023). Empirical research on the impact of customer integration and information sharing on supply chain performance in community-based homestays in China. Enterprise Information Systems, 17(7), 2037161. https://doi.org/10.1080/17517575.2022.2037161
Teerasoponpong, S., & Sopadang, A. (2022). Decision support system for adaptive sourcing and inventory management in small-and medium-sized enterprises. Robotics and Computer-Integrated Manufacturing, 73(C), 102226. https://doi.org/10.1016/j.rcim.2021.102226.
Thomassey, S. (2010). Sales forecasts in clothing industry: The key success factor of the supply chain management. International Journal of Production Economics, 128(2), 470–483.
Thrane, C. (2016). Norwegian students’ package trip propensity in 2007 and 2014–a logistic regression analysis. Tourism Economics, 22(5), 1141–1150. https://doi.org/10.5367/te.2015.0471
Udenio, M., Vatamidou, E., & Fransoo, J. C. (2022). Exponential smoothing forecasts: Taming the bullwhip effect when demand is seasonal. International Journal of Production Research, 61(6), 1796–1813. https://doi.org/10.1080/00207543.2022.2048114
Uyanık, G. K., & Güler, N. (2013). A study on multiple linear regression analysis. Procedia-Social and Behavioral Sciences, 106, 234–240.
van Donselaar, K. H., Peters, J., de Jong, A., & Broekmeulen, R. A. C. M. (2016). Analysis and forecasting of demand during promotions for perishable items. International Journal of Production Economics, 172, 65–75.
Wan, X., Teng, Z., Zhang, Z., Liu, X., & Du, Z. (2023). Equity financing risk assessment based on PLTS-ER approach in marine ranching from the ecological and circular economy perspectives. Annals of Operations Research, 1–46. https://doi.org/10.1007/s10479-023-05222-8.
Wang, C. H., & Hsu, L. C. (2008). Constructing and applying an improved fuzzy time series model: Taking the tourism industry for example. Expert Systems with Applications, 34(4), 2732–2738.
Wang, Y., Lei, Y., Fan, X., & Wang, Y. (2016). Intuitionistic fuzzy time series forecasting model based on intuitionistic fuzzy reasoning. Mathematical Problems in Engineering, 2016, 5035160. https://doi.org/10.1155/2016/5035160
Wang, D., Wang, Z., Zhang, B., & Zhu, L. (2022). Vendor-managed inventory supply chain coordination based on commitment-penalty contracts with bilateral asymmetric information. Enterprise Information Systems, 16(3), 508–525.
Wei, W., Jiang, J., Liang, H., Gao, L., Liang, B., Huang, J., Zang, N., Liao, Y., Yu, J., Lai, J., Qin, F., Su, J., Ye, L., & Chen, H. (2016). Application of a combined model with autoregressive integrated moving average (ARIMA) and generalized regression neural network (GRNN) in forecasting hepatitis incidence in Heng County. China. Plos One, 11(6), e0156768. https://doi.org/10.1371/journal.pone.0156768
Wen, X., Chung, S. H., Ma, H. L., & Khan, W. A. (2023). Airline crew scheduling with sustainability enhancement by data analytics under circular economy. Annals of Operations Research, 1–27. https://doi.org/10.1007/s10479-023-05312-7.
Wilcoxon, F. (1945). Individual comparisons by ranking methods. Biometrics, 1(6), 80–83.
Wu, L., Liu, S., Yao, L., Yan, S., & Liu, D. (2013). Grey system model with the fractional order accumulation. Communications in Nonlinear Science and Numerical Simulation, 18(7), 1775–1785.
Wu, H., Long, H., Wang, Y., & Wang, Y. (2021). Stock index forecasting: A new fuzzy time series forecasting method. Journal of Forecasting, 40(4), 653–666.
Yager, R. R. S., Ovchinnikov, R. M. T., & Nguyen, H. T. (1987). Fuzzy sets and applications. Wiley, pp. 46–79.
Yang, D., Sharma, V., Ye, Z., Lim, L. I., Zhao, L., & Aryaputera, A. W. (2015). Forecasting of global horizontal irradiance by exponential smoothing, using decompositions. Energy, 81, 111–119.
Yang, H., Li, P., & Li, H. (2022). An oil imports dependence forecasting system based on fuzzy time series and multi-objective optimization algorithm: Case for China. Knowledge-Based Systems, 246, 108687.
Yazici, I., Beyca, O. F., Gurcan, O. F., Zaim, H., Delen, D., & Zaim, S. (2022). A comparative analysis of machine learning techniques and fuzzy analytic hierarchy process to determine the tacit knowledge criteria. Annals of Operations Research, 308, 753–776. https://doi.org/10.1007/s10479-020-03697-3
Yolcu, O. C., & Lam, H. K. (2017). A combined robust fuzzy time series method for prediction of time series. Neurocomputing, 247, 87–101.
Yu, K., Wu, Q., Chen, X., Wang, W., & Mardani, A. (2023). An integrated MCDM framework for evaluating the environmental, social, and governance (ESG) sustainable business performance. Annals of Operations Research, 1–32. https://doi.org/10.1007/s10479-023-05616-8.
Yu, T. H. K., & Huarng, K. H. (2008). A bivariate fuzzy time series model to forecast the TAIEX. Expert Systems with Applications, 34(4), 2945–2952.
Yuan, S., Zhang, C., Amin, M., Fan, H., & Liu, M. (2015). Development of a cutting force prediction model based on brittle fracture for carbon fiber reinforced polymers for rotary ultrasonic drilling. International Journal of Advanced Manufacturing Technology, 81(5), 1223–1231.
Zadeh, L. A. (1965). Fuzzy sets. Information and Control, 8, 338–353.
Zadeh, L. A. (1996). Possibility theory and soft data analysis. in Klir, G.J. & Yuan, B. (editors) Fuzzy Sets, Fuzzy Logic, and Fuzzy Systems, World Scientific Press, Vol. 6, pp. 481–541.
Zeroudi, N., & Fontaine, M. (2015). Prediction of tool deflection and tool path compensation in ball-end milling. Journal of Intelligent Manufacturing, 26(3), 425–445.
Zhang, X., Pang, Y., Cui, M., Stallones, L., & Xiang, H. (2014). Forecasting mortality of road traffic injuries in China using seasonal autoregressive integrated moving average model. Annals of Epidemiology, 25(2), 101–106.
Zhang, J., Yan, Q., Zhu, X., & Yu, K. (2023a). Smart industrial IoT empowered crowd sensing for safety monitoring in coal mine. Digital Communications and Networks, 9(2), 296–305.
Zhang, J., Zhao, L., Yu, K., Min, G., Al-Dubai, A. Y., & Zomaya, A. Y. (2023b). A novel federated learning scheme for generative adversarial networks. IEEE Transactions on Mobile Computing, 2023, 1–17. https://doi.org/10.1109/TMC.2023.3278668.(earlyaccess,May22,2023)
Zhao, J., & Liu, X. (2018). A hybrid method of dynamic cooling and heating load forecasting for office buildings based on artificial intelligence and regression analysis. Energy and Buildings, 174, 293–308.
Zheng, J., Shi, J., Lin, F., Hu, X., Pan, Q., Qi, T., Ren, Y., Guan, A., Zhang, Z., & Ling, W. (2023). Reducing manufacturing carbon emissions: Optimal low carbon production strategies respect to product structures and batches. Science of the Total Environment, 858(3), 159916. https://doi.org/10.1016/j.scitotenv.2022.159916
Zhou, Z., Li, Y., Li, J., Yu, K., Kou, G., Wang, M., & Gupta, B. B. (2022). Gan-siamese network for cross-domain vehicle re-identification in intelligent transport systems. IEEE Transactions on Network Science and Engineering, 10(5), 2779–2790. https://doi.org/10.1109/TNSE.2022.3199919
Acknowledgements
The authors would like to sincerely thank the National Science and Technology Council of Taiwan for partially supporting this study under Grant No. NSTC 111-2221-E-167-036-MY2. In particular, the authors also cordially thank the Editor-in-Chief, Managing Guest Editor, and five anonymous referees for their useful comments and suggestions, which have significantly improved the quality of this study.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
Authors declare that there is no conflict of interest.
Research involving human participants and/or animals
This article does not contain any studies with human participants or animals performed by any of the authors.
Informed consent
This study is not funded.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Chen, YS., Sangaiah, A.K. & Lin, YP. Hyperautomation on fuzzy data dredging on four advanced industrial forecasting models to support sustainable business management. Ann Oper Res (2024). https://doi.org/10.1007/s10479-024-05882-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10479-024-05882-0