
Abstract
Efficient trade-off between the reconstruction qualities and the processing time of any single-image super-resolution reconstruction (SISRR) approach is critically influenced by two major aspects. These aspects are (i) appropriate representation of image patch in feature space and (ii) effective searching of candidate patches from the pool of training patches or learned dictionary. This paper proposes a neighbor embedding-based SISRR method. Novelties of our work include integration of (i) efficient feature mapping scheme which fuses multiple correlated features naturally, (ii) faster searching of candidate patches by measuring the patch correlation in non-Euclidean space and (iii) adaptive selection of neighborhood size using patch characteristic. Correlation among features is modeled via global covariance matrix, and the fusion process enables to preserve sufficient structural, spatial correlation among patches. Distance functions based on notion of generalized eigenvalue are used for measuring patch similarity which support faster searching of candidate patches. Performance analysis of the suggested method is compared with some of the competent state-of-the-art methodologies. From the simulated result analysis, proposed work is found to be outperforming in terms of sharpened image details with diminished effect of artifacts at a reasonable computational burden.
Similar content being viewed by others

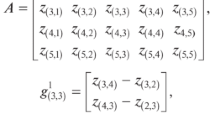

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Machine vision systems (MVSs) have a wide range of applications in various industry, academia, etc. Usually, MVSs are assembled around the right camera resolution and utilize sensors with well-specialized optics to capture high-quality images. These images are further processed, analyzed and measured by any other hardware or software techniques for decision making. It can effortlessly inspect the image details that are hard to be seen by human eye. However, current imaging system generates images with limited resolution and needs to be enhanced for obtaining high resolution (HR) images. Resolution of a digital image is defined as the detail information contained in that image. HR images contain high pixel density, encompass essential and critical image details and hence offer enhanced visual perception. Thus, HR images become essential in various imaging applications such as forensic image analysis, video surveillance [1], medical imaging, image security analysis [2] and many more. However, the resolution of an image is exclusively influenced by the properties and specification of the capturing device. Possible reasons for the limited resolution may be due to different physical constraints, insufficient amount of photodetectors, inferior spatial sampling rate and inappropriate image capturing process. Moreover, images captured in poor environmental condition get contaminated with different degradations such as fog, haze and smog. Consequently, quality of images gets degraded and results in low resolution (LR) images. Various dehazing and defogging techniques [3, 4] have been suggested in the literature to reinstate the visibility and to diminish the artifacts. These methods works efficiently as the preprocessing step to the reconstruction process but hardly improve the perceived resolution. Possible approaches to boost up the spatial resolution of the captured LR images are either by redesigning the hardware (by integrating adequate number of photodetector or by increasing pixel density per unit area) or by increasing the chip size. However, resolution enhancement by redesigning the hardware is critically challenging, costly and time-consuming in nature. As an alternative, image reconstruction is a mathematical process which generates images from the acquired projections captured at different angles or at different times. It aims at retrieving information that has been lost or obscured in the imaging process without sacrificing the quality of the image. Basically, reconstruction process is intended to model the degradation phenomenon and utilizes the reverse process to retrieve the original images from the degraded, noisy, blurred and aliased images. Over the few decades, Super-resolution reconstruction (SRR) has been recognized as one of the evolving and cost effective off-line technology to enrich the resolution of the LR images. This process aims at estimating HR image by fusing the non-redundant information in the single or multiple LR images of the same scene. SRR methods overcome the limitations associated with the optics and sensor technology and efficiently enhance the resolution.
SRR methodologies have been widely used in various imaging applications such as remote sensing [5], medical imaging [6] and machine vision. In the age of advanced space technology, commercial remote sensors capture images of better spatial resolution. However, quality of images degrades due to various atmospheric effects. Consequently, results in nonaligned LR images. In that scenario, SRR techniques behave as adaptive and low-risk solutions which will effectively enhance the resolution of the archive of remotely sensed LR images. In medical imaging, resolution of the captured multimodal images of a particular patient using the same imaging device at different times may not be consistent. This is due to several physical constraints, environmental conditions and also due to the respiratory behavior of the patient. Consequently, captured images are of limited resolution. SRR methodologies help to increase the resolution of captured images for better diagnostic analysis and proper treatment planning. Another important application of SRR is in the field of video surveillance [7]. Coding of surveillance video for various application needs large volume of memory and storage. As an alternative, we can compress the original video sequences into its lower version to store them effectively. Their resolution can be further improved via SRR techniques at the user end.
SRR of a HR image by using multiple number of LR images is referred as multi-image SRR (MISRR), whereas reconstruction of a HR image with single LR image is referred as single-image SRR (SISRR). Performance of the MISRR methods relies on the accuracy of motion estimation among the LR observations which is again an open research problem. Moreover, error in the registration process affects a lot to the reconstruction process. Furthermore, availability of a series of LR observations of a particular scene encompassing sub-pixel shift among each other is not an easy task. All these limitations necessitate the use of SISRR in reconstructing a HR image. SISRR aims at estimating a pleasant HR solution with enhanced image detail from its LR image. Learning-based approaches have been drawing widespread attention in SISRR as these types of reconstruction process provide better reconstruction capability even at higher magnification factors. These approaches exploit some image priors extracted from external training image datasets to recover the missing image details in the HR image.
Figure 1 depicts the basic flowchart of learning-based single-image super-resolution reconstruction (LBSISRR) methods. Estimation of the output HR image is performed by utilizing two basic steps such as training stage followed by reconstruction stage. Training stage aims at learning the co-occurrence priors or correlation among the training image patches via some learning models. This stage involves two subsequent steps such as feature extraction step and learning step. Training stage starts with the input LR image whose resolution is to be enhanced and a set of training images. Training images contain various HR images and their corresponding LR images. Prior to feature extraction step, the training/testing HR and LR images are divided into overlapped patches. In the feature extraction step, each training/testing HR and LR image patches are represented in feature space, i.e., any predefined feature extraction operator is used to represent each image patch in terms of feature vectors. Next, the learning step involves different learning models to preserve the co-occurrence prior among images patches. This phase aims at providing potential candidate HR patches corresponding to each input LR image patch for the reconstruction process. Candidate patches are selected by measuring the patch similarity in feature space. After the successful implementation of training stage, the reconstruction stage integrates the learned knowledge as a priori term with the input LR image to preserve the missing details in the estimation process. Finally, the estimated HR patches are stitched to generate the super-resolved output image. Basic steps followed in the reconstruction process are summarized as follows:
-
Generation of training image dataset containing HR images and their corresponding LR images
-
Division of training images into overlapped patches
-
Extraction of features for training image patches
-
Division of input LR image into several patches
-
Extraction of feature for the input LR image patches
-
Establishment of learning model to learn the co-occurrence priors among patches
-
Utilization of appropriate searching method to select candidate patches for each LR patch
-
Estimation of HR image by utilizing the priors obtained from the learning models.

Flowchart of LBSISRR method
Based on the variety of learning models available in the literature, LBSISRR methods are categorized as example-based single-image SRR (EX-SISRR) [8,9,10,11,12,13,14,15] methods, neighbor-embedding-based single-image SRR (NE-SISRR) methods [16,17,18,19,20,21,22,23,24], and sparse coding-based single-image super-resolution (SC-SISRR) [25,26,27,28,29,30,31,32,33,34,35] methods. Now-a-days, deep learning-based SRR methods have been successfully implemented for providing fast and high-quality super-resolution (SR) results [36,37,38,39,40].
EX-SISRR methods [8,9,10,11,12,13,14] depend on a numerous amount of example training patches for the reconstruction process. Prediction of HR patch is achieved by learning the Markov random field (MRF) model solved by belief propagation (BP) algorithm. Spatial relationship between the LR patches and their corresponding HR patches is learned from the example images using the Markov network. Despite the recent advances, these methods suffer from heavy computational overload and have a weak generality property in preserving the boundary between two highly contrasted patches [14, 15]. All these bottlenecks make these methods often too slow for practical use [29]. A detailed analysis about some of the significant EX-SISRR methods is provided in Sect. 2.1. Several NE-SISRR and SC-SISRR methods have been proposed to overcome these issues.
NE-SISRR methodologies are based on the idea of local linear embedding (LLE) from the manifold learning and estimate the HR image by linearly combining the neighboring candidate HR patches. Existing state-of-the-art NE-SISRR methodologies utilize two independent steps: (1) searching of K numbers of candidate patches for each input patch in its feature space and (2) obtaining the reconstruction weights of patches for estimating the HR image. Popularly, size of K is chosen randomly or by means of any distance function [18, 23], whereas the weight of each patch is selected by least-squares minimization of reconstruction error. Reconstruction quality of the estimated HR image solely depends on the quality and spatial compatibility among the K number of candidate patches. Computational overload of the estimation process is contributed mainly due to searching of candidate patches using Euclidean distance (Eud) measure. As compared to EX-SISRR methods, NE-SISRR methods exhibit much stronger generalization capability for a range of images [21]. These methods can estimate a high-quality HR solution by utilizing relatively limited training image patches. Some important aspects which influence the performance of NE-SISRR methods are
-
To obtain efficient feature mapping scheme in a low dimensional feature space which will help to preserve the missing details in the reconstruction process by selecting relevant candidate patches
-
To choose the optimal size of K which will enable faithful reconstruction. As reconstruction of a HR image with fixed number of neighboring patches causes over or under-fitting of data, thus yields blurred output.
-
To use a faster searching scheme to get the neighboring patches which will reduce the computational overload of the whole reconstruction process
So far, many improved NE-SISRR methods have been proposed in the literature. The detail description about these methods is provided in Sect. 2.2.
SC-SISRR methods exploit the sparsity prior to solve the reconstruction problem. These methods are based on the assumption that the LR image patch and its corresponding HR patch shares the same sparse representations. As the initial step, these methods aim at learning dictionaries from the external image datasets. Next step aims at searching the dictionary for each image patch to obtain the optimal match. Performance of these methods solely relies on dictionary learning in its feature space and main time-consuming step is the searching mechanism for obtaining the similar candidate patches from the dictionary. In the literature, a number of advanced SC-SISRR methods have been proposed by learning compact dictionaries and/or by utilizing faster searching schemes. A brief description about some of these methods is provided in Sect. 2.3.
1.1 Gaps in the Literature and Solutions to Break Them
Varieties of SISRR approaches have been suggested in the literature (refer Tables 1, 2, 3) to enable an efficient trade-off between reconstruct quality and processing time. An appropriate balance between the quality of HR solutions and the computational speed highly depends upon the selection of training image dataset, feature extraction operation to represent each patch, searching of candidate patches and the learning model to learn the co-occurrence prior among patches. Selection of an efficient training image dataset or an over-complete dictionary from a set of example image patches plays an important role in the successful accomplishment of the reconstruction task. Quality of reconstruction gets enhanced when the training image patches encompass structural as well as statistical similarity with the input image to be super-resolved [15]. However, learning of training dataset or dictionary is performed only once for any reconstruction problem, hence may not contribute more toward the computational overload of the method. Irrespective of the type of learning model, trade-off process is critically influenced by two major aspects such as (1) selection of appropriate feature type to represent image patch and (2) searching of candidate patches from the pool of training image dataset or learned dictionary. A brief discussion about these two aspects is discussed below.
1.1.1 Selection of Feature Type
After doing a critical review from Tables 1, 2 and 3, it observed that most of the SISRR methods [14, 16, 18, 20, 23, 25, 26] commonly use first- and second-order gradient operator to represent each patch. These operators individually preserve the local edge information of patches, but their combination may not preserve the local neighborhood compatibility. Moreover, second-order gradients are sensitive to noises. As compared to them, feature vectors using norm luminance (NL) [18, 24] efficiently preserve the low frequency information but fail to capture the high frequency information of the patch. Zernike moment (ZM)-based feature vectors [24] are insensitive to noise, efficiently preserve the global compatibility, but have limited reconstruction capability. Field-of-experts (FoE)-based feature vectors in [22] and histograms of oriented gradients (HoG)-based feature vectors in [19, 21] help to preserve more image details for images rich in edge information but provide limited performance to images rich in structural and geometrical contents. Methods in [15, 28, 32, 34, 35] utilize pixel intensity to represent image patch. However, intensity values of the patches are much sensitive to noise and contrast variation. Hence, a small disturbance in intensity value may result a significant change in further processing. Methods in [30, 31] use texture of the image as the feature vector to represent image patch. However, this feature vector cannot preserve the structural and statistical correlation among patches, consequently provide limited performance for images rich in geometrical and structural content. Disadvantages of these aforementioned methods necessitate selecting a state-of-the-art feature extraction operator which will fit to variety of image types in preserving high frequency information and spatial correlation in both LR and HR space.
1.1.2 Searching of Candidate Patches
About the searching of candidate patches, almost all the EX-SISRR and NE-SISRR methods unexceptionally utilize KNN-based searching scheme where EuD or its variants are used for measuring the patch similarity [21, 35]. EuD makes the searching process computationally intensive, does not preserve sufficient spatial relationship among patches and is sensitive to small amount of disturbances, hence may not select potential candidate patches. Consequently, estimated HR image suffers from various artifacts. Similarly, almost all SC-SISRR methods popularly use orthogonal matching pursuit (OMP) or linear programming (LP) to search the dictionary. This searching process utilizes \(l_2\) norm for minimizing the error which is again computationally prohibitive. However, methods in [21, 26, 29, 32] utilizes some faster searching techniques which results in reducing the computational complexity of the reconstruction process with an compromise with the reconstruction quality. All these aspects motivated us to propose a SISRR method which will provide an efficient trade-off between reconstruction quality and processing speed.
This paper proposes an enhanced yet computationally efficient NE-SISRR method which will enable faster searching of potential candidate patches and will facilitate better preservation of image details with diminished effect of artifacts. Major contributions and novelty of the work include
-
Proposition of a low-dimensional feature mapping scheme to represent image patch in its feature space. Each patch is represented as a combination of several raw feature attributes such as intensity profile, texture, edge, statistical and spatial information. Fusion of these feature attributes enable to preserve sufficient structural, statistical and spatial homogeneity among patches in the reconstruction process.
-
(2) Development of a faster searching scheme to get potential candidate patches by measuring the similarity in non-Euclidean space. Patch similarity is measured by distance function based on eigenvalues rather than Eud which speeds up the searching process
-
(3) Implication of an automotive scheme to choose the neighborhood size of K based on the input patch characteristic. Neighborhood size of each input patch is adaptive in nature and is decided by the patch characteristics.
Afterward, the reconstruction weights are obtained by minimizing the reconstruction error. Finally, the output HR image is estimated by the linear combination of neighboring candidate HR patches. Performance analysis of the suggested method is compared in some of the significant state-of-the-art learning-based methodologies and found to be outperforming in terms of image quality as well as faster searching speed.
Rest of the paper is organized as follows: Sect. 2 provides a brief discussion about some of the significant LBSISRR methods in the literature. Detailed description of the proposed reconstruction method is provided in Sect. 3. Performance evaluation and analysis of the proposed method compared with some of the state-of-the-art LBSISRR methods along with some faster SISRR methods are performed in Sect. 4. Section 5 concludes the paper.
2 Related LBSISRR Methods
2.1 Example-Based Single-Image SRR (EX-SISRR) Methodologies
Freeman et al. [8] pioneered the concept of example-based SRR of single image. In this method, authors select numerous amount of training patches for the reconstruction process. Band-pass filtered feature map is used to represent each patch. Nearest neighbor (NN) search method is used to find candidate patches for each input patch and Eud is used to measure the patch similarity. MRF network is used to learn the correlation among related HR-LR image patches. BP algorithm is used to train the MRF network. Maximum a posteriori (MAP) approach is used to estimate the HR patch by utilizing the learned prior knowledge. However, this method fails to preserve sufficient spatial correlation among patches due to integration of Gaussian smoothness functions in the computation of compatibility functions. Moreover, heavy computational overload, slow rate of convergence make this method prohibitive in practical applications [14]. Number of methods have been proposed in the literature to address these limitations. Authors in [9, 10] proposed example-based methods which enable faster convergence rate, whereas methods in [12,13,14,15] aim at preserving more image details in the reconstructed output image. In method [9], each image patch is represented by Gaussian derivative. Position constraint operation is used to compute compatibility function and squared difference is used as the patch similarity measure, whereas primal sketch priors are used to represent patch in its feature space. In [11], searching of candidate patches is done via K-means algorithm to improve the rate of convergence of the reconstruction process. In [12], authors employ Contourlet coefficients to represent raw image patches and weighted Euclidean distance is used to measure the patch similarity. Method in [13] utilizes structural contents to represent each patch and patch similarity is measured via modified Chi-square distance. In [14, 15], authors utilize image Euclidean distance (IMED) to measure patch similarity. Method in [15] uses a probability way of searching candidate patches and utilizes edge preserving compatibility functions to preserve more image details. Table 1 provides a brief comparative analysis of the popularly used EX-SISRR methods. From the critical review of the literature, it is observed that EX-SISRR methodologies provide sharper output images by selecting appropriate compatibility functions. But computational burden of these methods remain high due to utilization of numerous amount of example images for the reconstruction process and EuD to measure patch similarity. Hence, these methods remain unsuitable for real-time applications.
2.2 NE-Based Single-Image SRR (NE-SISRR) Methodologies
NE-SISRR methodologies are based on the idea of LLE from the manifold learning. These methods presume that HR and LR image patches share identical local geometry and estimate the HR image as the linear combination of K nearest neighboring patches. In [16], authors introduce the concept of LLE based SRR of image. This method utilizes first- and second-order gradient to represent each patch and uses the fixed size of K for the reconstruction process. The reconstructed output cannot well preserve the high frequency details in the images and sometimes produces too much blurry output images. Afterward, a variety of NE-SISRR methodologies [17,18,19,20,21,22,23,24] are proposed in the literature. In [17], histogram-based matching is used to select efficient training images and image residuals generated by image pyramid are used as feature vectors. Method in [18] emphasizes the importance of edge and neighborhood size in the reconstruction process. This method utilizes edge detection and feature selection to generate discriminate training patches. Combination of first-order gradient and NL feature vectors is used to represent each patch. Method in [19], proposes a partially-supervised neighbor embedding (NE)-based SRR (NE-SRR) process and uses the notion of multi-manifold assumption. In this method, each image patch is represented by means HoG feature vectors. K-mean algorithm via unsupervised Gaussian mixture model is employed to assign class labels in the searching of neighboring patches. In [20], discrete-cosine-transform (DCT) coefficients are used as feature vectors. Neighborhood size is selected based on K-means algorithm. In [21], each image patch is represented by HoG features. The initial training dataset is divided into a set of training subsets via K-means clustering. \(L_2\) norm is used as the distance measure in the clustering process. With the HoG, training image pairs in a particular subset carry similar geometry. In this method, searching of candidate neighboring patches and reconstruction weights are performed simultaneously via variants of Robust-SL0 algorithm. This algorithm diminishes the limitation of the KNN searching with EuD and enhances the speed of reconstruction process. In [22], a new feature extraction operator, i.e., FoE is utilized to represent each image patch. Non-local similarity constraint is considered to find the optimal weight in the reconstruction process. K-means clustering using GMM is performed to divide the initial training dataset into 32 number of sub clusters. KNN searching process via EuD is utilized for measuring patch similarity. In [23], a NE-SRR method is proposed which is robust to the outliers present in the input image. This method employs histogram-based matching criterion to select training image dataset and global neighborhood size is selected based on Euclidean and geodesic distance measure. Each patch is represented by eight feature vectors based on gradients along different orientations. In [24], a new feature vectors based on combination of ZM and NL is employed to preserve global structure in the reconstruction process. Hierarchical method using residual variance is used to select the global size of K in the searching process. Table 2 describes a brief analysis of some of the state-of-art NE-SISRR methods.
2.3 Sparse Coding-Based Single-Image Super-Resolution (SC-SISRR) Methodologies
SC-SISRR methods have been widely used in recent years. These methods assume that the LR, HR patches have the similar sparse representation. Any LR patch can be reconstructed as a sparse linear combination of different atoms from an appropriately chosen dictionary. They do not work directly on the raw training image patches rather different compact dictionaries are learned from the set of training patches to capture the co-occurrence priors. In the training step, different learning techniques are utilized to learn the dictionaries followed by the sparse coding (SC) algorithm to obtain the optimal sparse representation (\({\alpha ^ * }\)) of each LR patch with respect to the learned over complete dictionary. In the reconstruction step, learned \({\alpha ^ * }\) of each LR serves as sparse priors for the reconstruction of its HR patch. In the final step, the estimated HR patches are merged by averaging the overlapping area to obtain the output HR image. Later, various regularization constrains are further used to provide sharpened output by minimizing the effect of reconstruction error. Yang et al. in [25] applied the SC algorithm for both generic and face image SR. In this method, probabilistic approach is used to learn the over-complete dictionary pairs. Linear programming algorithm is used to find the sparse coefficients. This method founds to be outperforming in providing high-quality SR images but computational time of this method is very high. As an advancement, Zeyde et al. in [26] proposes a faster sparse representation based method. Instead of simultaneous learning of dictionary pairs, authors utilize K-SVD to learn the LR dictionary and pseudo-inverse to learn the HR dictionary. Principal component analysis (PCA) is used for dimension reduction of patch features and orthogonal matching pursuit (OMP) is utilized as the SC algorithm. This SC algorithm enables faster rate of convergence than the SC approach in [25]. Afterward, a variety of methods have been proposed in the literature based on different dictionary learning (DL) strategy as well as SC algorithms to maintain an efficient balance between the computational time and the image quality. In [28], authors utilize semi-coupled dictionary learning (SCDL) approach for cross-style image SRR. In [28], the proposed learning approach enables simultaneous learning of dictionary pairs as well as mapping functions to preserve better compatibility between two style domains. Moreover, K-means clustering as well as image nonlocal-redundancy is also integrated in the SCDL model to enhance its stability. The proposed method serves as an effective alternative for photo-sketch synthesis problems at a cost of computational overload. Authors in [29] propose a faster yet efficient SRR method using anchored neighborhood regression approach by integrating the notion of NE with SC. Dictionary is learned by sparse model and the dictionary atoms are grouped into neighborhoods based on the correlation among the atoms. The SC model is modified as a least-square regression problem. Estimation of HR patch is achieved by performing mapping of projection matrix of its nearest neighborhood atoms in the dictionary. Eud is used to measure the distance between anchored atoms and trained samples. In [30], an improved ODL approach is used as the dictionary learning purpose. Particle swarm optimization (PSO) is used in the dictionary training stage to provide the information about atom updating and direction of optimization process. This helps to speed up the reconstruction rate. In [31], authors utilize Gabor filtered feature vectors to represent each image patch. In [32], an evolutionary SC based method is proposed. This method utilizes the adaptive Genetic algorithm as the SC model to obtain \({\alpha ^ * }\) of each LR patch. This evolutionary SC model speeds up the reconstruction process than by using the conventional \(l_0\)- or \(l_1\)-based SC models. In [33], a super-pixel based sparse representation model is proposed for hyper-spectral (HS) image SRR. This method constructs two dictionaries such as a spectral dictionary from HS image and a transformed dictionary from multispectral image. The generalized simultaneous OMP (G-SOMP+) is used to solve the sparse representation. Fractional abundance coefficient matrix is used for the reconstruction of final HS HR image. In [34], authors propose multiple dictionary pairs based on different structural contents of image via improved fuzzy C-means (IFCM) clustering method. A weighted SC model is used to obtain \({\alpha ^* }\) of each LR patch. Method proposed in [35] enables a faster searching of candidate patches by utilizing KNN-based dictionary pair for each patch rather than the unified dictionary pair. Binary encoding scheme is used to accelerate the KNN retrieval process. Moreover, the proposed method uses large sized patches which encompass more information and hence preserves more image details in the reconstruction process. The proposed method enhances the processing speed as well as reconstruction quality. A brief discussion about some of the significant state-of-the-art SC-SISRR methods is provided in Table 3. Some of the parameter and abbreviations used in this table are given in.Footnote 1
2.4 Deep Learning-Based SRR
In recent years, deep learning-based SRR of image [36,37,38,39] has made excellent breakthroughs in providing high-quality reconstruction. The reconstruction process preforms end to end mapping of a LR image into a HR image either via convolutional neural network (CNN) model [36, 37] or by Generative-Adversarial-Nets (GAN) model [38] or by deep shallow convolutional network [39]. Generally, the state-of-the-art deep learning-based methodologies diverge from each other in terms of: varieties of network architectures, variants of loss functions and most importantly different types of learning strategies. Wang et al. [40] provide an excellent survey in the context of SRR via deep leaning models. Irrespective of the great accomplishment of these methods in terms of reconstruction accuracy with reduced computational burden, they suffer from some critical bottlenecks which should be solved carefully. To design an optimal network which will efficiently combine local as well as global along with low as well as high-level information at a reduced spatial and temporal cost is still an open problem [40]. The next difficult aspect of implementing these methods is selecting an appropriate loss function which will guide to optimize the model parameters. In [38], Ledig et al. have utilized cross-entropy based adversarial loss in the reconstruction process to provide an enhanced output. However, training the GAN architecture is quite difficult and sometimes unstable in nature [40].
3 Proposed Method
In this section, we will discuss about the proposed NE-SISRR method known as efficient neighbor embedding-based SRR (ENESR) method. The proposed work is based on the idea of the work in method [16] with several important modifications. Both of these methods are based on the concept of LLE which aims at estimating the HR image by linearly combining the neighboring candidate HR patches. Method in [16] utilizes first- and second-order gradient to represent each patch and employs fixed neighborhood size K for the reconstruction process. Consequently, the estimated output cannot well preserve the high frequency details in the reconstruction process. Sometimes, produces too much blurry output solutions. Moreover, this method exploits distance function based Eud to measure patch similarity. Hence, searching of candidate patches from the pool of training image patches consumes more time. On the contrary, proposed work fuses a number of feature attributes naturally to represent each image patch. The fusion process helps to preserve sufficient structural, spatial and statistical correlation among image patches. An automotive scheme is proposed to choose adaptive neighborhood size K for each image patch. Aiding to that, distance functions based on the notion of generalized eigenvalue which lies in computationally cheap non-Euclidean space is exploited to measure patch similarity. Detailed description on the contributions and novelty of the proposed work are discussed as follows:
-
Proposition of a low-dimensional feature mapping scheme to represent image patch in its feature space.
-
1.
To the best of our knowledge, till now the LBSISRR methods either use edge information or combination of edge and smoothness information to represent the image patch. Consequently, reconstruction solutions well preserve the high frequency information in the reconstruction process, but provides limited performance for images rich in structural and statistical content. This necessitates selecting an efficient feature extraction operator which will preserve not only the high frequency information but also the spatial and structural correlation in both LR and HR space.
-
2.
To accomplish this, a low-dimensional feature mapping scheme is proposed which enables compact yet informative way of representing a patch in its feature space. Each patch is represented by a set of discriminative feature attributes. Correlation among these feature attributes is modeled via global covariance matrix. The matrix enables to fuse multiple correlated features naturally. This fusion process helps to preserve sufficient structural, spatial and statistical correlation among each other. Hence, allows faithful reconstruction of HR patch.
-
3.
Moreover, unlike individual raw feature the unified feature attributes are insensitive to noise; invariant to scale and illumination variations, consequently provides robust performance.
-
1.
-
Development of a faster searching scheme to get potential candidate patches by measuring the similarity in non-Euclidean space
-
1.
In the searching of candidate neighbors, unexceptionally, almost all methods use the Eud or its variants to measure the patch similarity. Eud-based measure utilizes intensity profile of the patch for its computation hence there is no provision to preserve the spatial correlation among pixels. Nevertheless, this measure is much sensitive to noise and suffers from curse of dimensionality.
-
2.
In this work, the patch similarity is measured in non-Euclidean space. Each patch is modeled as a global co-variance matrix which lie in a Riemannian manifold [41]. This matrix is symmetric and positive definite in nature. Most importantly, the diagonal and off-diagonal elements of this matrix possess variance and correlation among feature attributes.
-
3.
Inter-variance gap and inter-correlation map among feature vectors are measured by distance functions based on generalized eigenvalues which surely do not lie on Euclidean space, thus enables a faster searching process.
-
1.
-
Implication of an automotive scheme to choose the neighborhood size of K based on the input patch characteristic
-
1.
In the literature, various strategies such as K-mean clustering [19,20,21] or by distance measure [23] have been suggested to select the global size of K in the NE-SISRR methods. However, all these strategies aid additional computational load to the reconstruction process. However, our proposed work uses a cheap strategy to do that.
-
2.
Similarity values of the input patch with its candidate HR patches are sorted in descending order. Sorted similarity values are plotted with respect to the patch index. Next, gradient of this similarity curve is plotted. The global minima point of the gradient curve is considered as the threshold value \(\varsigma \). Training image patch index whose gradient values are lesser than equal to the threshold value \(\varsigma \) are considered as the K number of neighboring patches
-
1.
Processing time of any LBSISRR approach is critically influenced by effective searching of candidate patches from the pool of training patches. Selection of K number of candidate patches is performed by matching the similarity among patches. Each image patch is represented in its feature space. State-of-the-art LBSISRR methods utilize several raw image statistics such as gradient, pixel intensity, filter responses, DCT, HoG and FoE features to represent each image patch. Let us consider the popularly used feature extraction operator such as first- and second-order gradients along vertical and horizontal direction of an image patch of size \((z \times \) z). Now, each patch is represented by \((4 z^2 \times 1)\) length of feature vector. Patch similarity is determined by measuring similarity among two \((4 z^2 \times 1)\) feature vectors using Eud-based functions. Dimensionality of the feature representation of an image patch depends on the patch size selected. Consequently, complexity of the searching process increases with increase in patch size. On the other hand, proposed low-dimensional feature mapping scheme enables to fuse d dimension of raw feature attributes to a covariance matrix of size \((d\times d)\). The fusion process preserves sufficient image details in the reconstruction process. Instead of working on the high-dimensional feature vectors of image patches, proposed work employs distance functions using eigenvalues of \((d\times d)\) matrix to measure the patch similarity. Distance functions based on generalized eigenvalues lie in non-Euclidean space and hence converge faster that the Eud-based functions. Hence, through the proposed low-dimensional feature mapping scheme, we can effectively reduce the computational time of the searching process while enhancing the SR quality of the reconstructed solution.
\({Y_{L}}\) is the input LR image to be super-resolved to obtain the final HR image \({{\hat{X}}_{H}}\). \({X_{H}}\) is the ground truth HR image. \({Y_{L}}\) image is up-sampled by P-spline interpolation scheme [42] by a factor of u to obtain \({Y_{U}}\) so as to make its size equal to the size of final HR image \({\hat{X}_{H}}\). \(\left\{ {y_{U}^j} \right\} _{j = 1}^N\) are the N number of overlapped patches of \({Y_{U}}\) image and \(\left\{ {{\hat{x}}_{H}^j} \right\} _{j = 1}^N\) are the corresponding N number of HR patches to be estimated. \(TR _{optimal}\) is the optimal training image dataset consisting of HR images \({H_{TRbest}}\) and LR images \({L_{TRbest}}\). \( \left\{ {l_{TRbest}^p} \right\} _{p = 1}^M\) and \(\left\{ {h_{TRbest}^p} \right\} _{p = 1}^M\) are M number of overlapped LR and HR training image patches, respectively. \(\left\{ {NE(y_{L}^j)} \right\} _{j = 1}^K\) is K number of neighboring LR training patches of the input LR patch \((y_{L}^j)\) and \(\left\{ {NE(x_{H}^j)} \right\} _{j = 1}^K\) are their corresponding HR patches, respectively. Equation (1) represents the mathematical formulation of the imaging model which is used to generate the LR counterpart image \({Y_{L}}\) of the HR image \({X_{H}}\).
where De is the decimation matrix, Br is the blurring operation, Wa performs the warping operation to generate the LR image from its corresponding HR image. \(\eta \) is the amount of AWGN which corrupts the imaging model. Terminologies and notations utilized in this paper are described in Table 4 and pseudo-code of the proposed ENESR method is depicted in Algorithm 1.

3.1 Selection of \(TR _{optimal}\)
Proposed work utilizes the methodology used in [15] for the selection of optimal training image dataset \(TR _{optimal}\). Selection of \(TR _{optimal}\) via spatiogram-based matching criterion preserves sufficient statistical and structural similarity with the input test image.
3.2 Selection of Features
This subsection describes the representation of each image patch as a compact set of feature attributes. \({Y_{U}}\) and \({H_{TRbest}}\) \(\in \) \(TR _{optimal}\) are divided into patches of size \(\left( {z \times z} \right) \) with 2 pixel overlapping. Each patch is represented by a set of preferably compact and discriminative feature attributes. The raw feature attributes exhibit some correlation among each other. This correlation among feature vectors is modeled by a global covariance matrix. The covariance matrix enables to fuse multiple correlated features naturally [41]. Nevertheless, it is robust to noise and invariant to variations of scale, rotation and illumination level [41]. Correlation between two patches is based on measuring the similarity between their corresponding global covariance matrices. The global covariance matrices lie on non-Euclidean space [41]. Hence, the notion of a generalized eigenvalue is considered for measuring the similarity which enables a faster matching process.
Let a patch p of size \(\left( {z \times z} \right) \) is represented by a d dimensional attribute vector \({\left\{ {{A_i}} \right\} _{i = 1,2\ldots n}}\). Equation (2) represents the formulation of its corresponding \(\left( {d \times d} \right) \) covariance matrix \({C_p}(x,y)\). \((x,y)^{th}\) component of the \({C_p}\) matrix is described in Eq. (3) [41].
where \(\mu \) is the mean of the feature attribute vector \({A_i}\).
In this work, we integrate 9 different feature vectors in the formation of vector \({A_i}\) and is represented in Eq. (4).
where (x, y) represents the pixel location, \(\left| {{I_p}} \right| \) is the absolute intensity profile of the patch p, \({G_I}\) are the multi-scale and multi-orientation Gabor features and \({S_j}\) are the first-order and second-order statistical information of the patch p. SC and O are the total number of scales and orientations of the Gabor filter, respectively.
The pixel locations (x, y) in the vector \({A_i}\) are correlated to other features which contribute toward the non-diagonal entries of the covariance matrix. Gabor features are used because they capture geometrical as well as textural information effectively. The low-frequency Gabor filters often behave as a local image smoother and represent image patch at coarse resolution. The high-frequency Gabor filters often act as efficient edge detectors irrespective of the nature of underlying intensity distributions [43]. Unlike conventional edge detectors, the multi-oriented Gabor features easily differentiate edges in horizontal as well as vertical directions [43]. However, computational cost for the computation of Gabor features is high. To reduce the computational cost, the approximate method provided in [44] are adopted in this work. The first- and second-order statistical information such as mean and co-variance measure of the patch are embedded to make the vector \({A_i}\) adequate to characterize image patch efficiently. With these 9 raw feature vectors, each patch p is represented by a \(\left( {9\times 9} \right) \) covariance matrix \({C_p}(x,y)\).
Some basic properties of the covariance matrix \({C_p}(x,y)\) are presented as follows:
-
it is symmetric and positive definite which lie in Riemannian manifold
-
unlike individual raw features, it is robust to noise, insensitive to change in scale, rotation and illumination
-
it enables to integrate multiple correlated features
-
diagonal elements exhibit the variance of the raw feature vectors
-
off-diagonal elements of the matrix hold the correlation among feature vectors
3.3 Selection of Candidate Patches
In this section, candidate HR patches for each input LR patch are searched over the image patches of \({H_{TRbest}}\) \(\in \) \(TR _{optimal}\). Given two patches p, q with their corresponding global covariance matrices \({C_p}(x,y)\), \({C_q}(x,y)\), measurement of similarity between two patches is done w.r.t their covariance matrices. Similarity between two patches will be maximum when inter-variance gap of feature attributes will be minimum and the inter-correlation of feature attributes will be maximum. Measurement of both inter-variance gap and inter-correlation map is guided by specified distance function and minimization of distance measure signifies the maximization of the similarity between two patches. As the covariance matrices do not lie in Euclidean space, distance function is based on generalized eigenvalues which follow the Lie group structure of positive definite matrices [41]. Equation (5) defines the formulation of similarity between patches p and q using their covariance matrices \({C_p}(x,y)\) and \({C_q}(x,y)\), respectively.
where \({\rho _1}( \cdot ), {\rho _2}( \cdot )\) are the distance functions to measure the inter-variance gap and inter-correlation map, respectively. Equations (6) and (7) provide the formulation of \({\rho _1}( \cdot ), {\rho _2}( \cdot )\), respectively.
where \({{C_{pD}}(x,y), {C_{qD}}(x,y)}\) are the diagonal matrices of \({C_p}(x,y)\), \({C_q}(x,y)\), respectively. \({{C_{pND}}(x,y),{C_{qND}}(x,y)}\) are same as the \({C_p}(x,y)\), \({C_q}(x,y)\) matrices by keeping all the off-diagonal entries unchanged and replacing all the diagonal entries by one. \({\lambda _i}\left( {{C_{pD}},{C_{qD}}} \right) = {\lambda _1},{\lambda _2}\ldots {\lambda _n}\) are joint eigenvalues of the matrices of \({C_{pD}}\),\({C_{qD}}\) by solving the equation \(\det (\lambda {C_{pD}} - {C_{qD}}) = 0\). \({\left\| \cdot \right\| _F}\) is the Frobenius norm. Frobenius norm of a \(m\times n\) matrix A is defined as the square root of the sum of the absolute squares of its elements. \({\left\| A \right\| _F} = \sqrt{\sum \nolimits _{i = 1}^m {\sum \nolimits _{j = 1}^n {{{\left| {{a_{ij}}} \right| }^2}} } }\).
3.4 Selection of Size K
Size of K is adaptively chosen according to the patch similarity values. After measuring the patch similarity (Sim) of the input patch \({y_{L}^j}\) with respect to the training image patches \(\left\{ {h_{TRbest}^p} \right\} _{p = 1}^M\) by using the formulation given in Eq. (5), the Sim values of patches are sorted in descending order. Sorted similarity values are plotted with respect to the patch index. Next, gradient of this similarity curve is plotted. The global minima point of the gradient curve is considered as the threshold value \(\varsigma \). Training image patch index whose gradient values are lesser than equal to the threshold value \(\varsigma \) is considered as the K number of neighboring patches for \({y_{L}^j}\) patch. Figure 2 shows the graphical representation of the selection of size K of an arbitrary patch \({y_{L}^j}\).

Selection of size K
First row shows the plot of sorted Sim values against the training image patch index. Second row shows the gradient of the above curve. Global minima of the curve is shown in circle and \(\varsigma \) value is marked by the arrow mark. Here, the \(\varsigma \) is lying at the 10th number training image patch index and hence the size of K is 10. Top most 10 training image patches are serving as the neighborhood candidate patches for the input patch \({y_{L}^j}\). Likewise, size of K is different for each LR patch and it depends on the patch similarity of that particular patch with the training image patches \(\left\{ {h_{TRbest}^p} \right\} _{p = 1}^M\). Consequently, neighborhood size K for the reconstruction process is adaptive in nature and diminishes the effect of over and under fitting of data. The overall steps for selecting the optimal candidate patches for each input LR patch are described in Algorithm 2.
Algorithm 2 discusses about the steps to select K number of candidate HR patches for each input patch. Input to this searching process is N number of input patches \(\left\{ {y_{U}^j} \right\} _{j = 1}^N\) and M number of training HR patches \(\left\{ {h_{TRbest}^p} \right\} _{p = 1}^M\). Searching process aims at selecting K number of HR training patches \(\left\{ {h_{TRbest}^i} \right\} _{i = 1}^K \) from M number of training HR patches in \(\left\{ {h_{TRbest}^p} \right\} _{p = 1}^M\) for each input patch \({y_{U}^j}\) in \(\left\{ {y_{U}^j} \right\} _{j = 1}^N\). \({y_{U}^j}\) is the \(j^th\) patch of up-sampled image \({Y_{U}}\). \({Y_{U}}\) is obtained by up-sampling the input LR image \({Y_{L}}\) by a factor of u using P-spline interpolation [42]. Image \({Y_{U}}\) is divided into N number of patches \(\left\{ {y_{U}^j} \right\} _{j = 1}^N\) with the same size as that of the each \({h_{TRbest}^p}\) patch. Now, feature vector \(A_i\) and its corresponding co-variance matrix for each input patch \({y_{UR}^j}\) and each training HR image patches \(\left\{ {h_{TRbest}^p} \right\} _{p = 1}^M\) are computed using Eqs. (3) and (4), respectively. Correlation among the co-variance matrix of input patch \({y_{U}^j}\) and M number of co-variance matrix of training patches \(\left\{ {h_{TRbest}^p} \right\} _{p = 1}^M\) are measured using Eq. (5). Now we are available with M number of correlated values which are termed as Sim values. By using the procedure as discussed in Sect. 3.4, K number of candidate training patches \(\left\{ {h_{TRbest}^i} \right\} _{i = 1}^K \) for the input patch \({y_{U}^j}\) are selected. This process is continued till each patch of \(\left\{ {y_{U}^j} \right\} _{j = 1}^N\) selects its corresponding K number of candidate HR patches. Afterward, reconstruction weights are computed for the linear embedding process to estimate the final HR image.

3.5 Computation of Reconstruction Weight and Estimation of HR Image \(\left\{ {{\hat{x}}_{H}^j} \right\} _{j = 1}^N\)
Optimal reconstruction weights \(W{_K}\) of the neighboring patches are computed by minimizing the local reconstruction error as performed in [16, 18]. For each \({y_{U}^j}\), K nearest neighbor patches \(\left\{ {NE(Y_{U}^j)} \right\} _{j = 1}^K\) are searched. \(W{_K}\) is achieved by minimizing the error for \({y_{U}^j}\) as given in Eq. (8).
subject to constraint \(\sum \nolimits _{Y_U^P \in N{E_j}} {{W_{jp}} = 1}\) and \({W_{jp}} = 0\) for any patch \(Y_U^P \notin N{E_j}\). \(N{E_j}\) is the nearest neighbor patches of \({y_{U}^j}\). Estimation of \({{\hat{x}}_{H}^j}\) is done by following the formulation as described in Eq. (9).
\({{\hat{X}}_{H}}\) is estimated by stitching the estimated HR patches \(\left\{ {{\hat{x}}_{H}^j} \right\} _{j = 1}^N\) by preserving the local compatibility and smoothness priors among patches. The overlapped region of patches are averaged in the stitching process to preserve better inter-patch compatibility.

a, b HR and LR images of ‘butterfly.bmp,’ c, d HR and LR images of ‘ppt3.bmp,’ e, f HR and LR images of ‘189080.jpg’



4 Simulations and Result Analysis
Effectiveness of the proposed method in providing an efficient trade-off between reconstruction quality and the processing speed is validated through simulation data experiments for both synthetic and real-time images. Performance evaluation of the proposed work is compared with some of the existing state-of-the-art LBSISRR methodologies [15, 21,22,23,24, 35] along with the deep learning-based method proposed in [38]. Along with visual perception, several subjective image quality measures such as PSNR, SSIM, FSIM, ringing measure (RM) and blur measure (BM) [45] are used to quantify the reconstruction quality for synthetic data experiments. To have a fair comparison, several objective quality measures such as Spearman rank order correlation coefficient (SRCC), Pearson linear correlation coefficient (PLCC) and root mean square error (RMSE) are also computed to quantify the reconstruction quality of the estimated HR images. We have used the methodology used in [46] for the computation of these parameters. Reconstruction process is carried out for 2\(\times \), 3\(\times \) and 4\(\times \) magnification factors. For synthetic-data experiments, images used in [15, 25] are used for training purpose and images from ‘Set5’ [47], ‘Set14’ [26] and ‘BSD200’ [48] are utilized for testing purpose. For real-time experiments, images from MDSP [49] dataset are used. Each of the images in the MDSP dataset contains a sequence of image frames with some global and local motion with each other. For the simulation purpose, one of the image sequence is used as the testing image while rest of the frames are utilized for training purpose. The blind image quality index (BIQI) [50] and natural image quality evaluator (NIQE) [51] indices are used to quantify the reconstruction accuracy for real-time data experiments. Higher value signifies better reconstruction quality.
4.1 Experimental Setting
In the reconstruction process, \(TR _{optimal}\) is generated as done in [15]. Size of K is chosen adaptively as described in Sect. 3.4. The degradation process as defined in Eq. (1) utilizes the blurring matrix Br as (5\(\times \)5) Gaussian LPF with smoothing parameter 0.1. Warping matrix Wa executes [\(-1\) to 1] translation along both x and y directions along with 2 degrees of rotation. Down-sampling operation is performed by an amount of 2 to 4. Noise \(\eta \) is added to make the SNR as 20 dB. In the real-time experiments, the degradation process ignores the warping operation as the image sequences comprise of local as well as global shift among each other. Size of LR patch \(z\times z\) is taken as \((5\times 5)\) with two pixels overlapping. For extracting the Gabor features of patches, scale \(SC = 1\) and orientation \(O=4\), i.e., \(O = \left\{ {\frac{\pi }{4},\frac{\pi }{2},\frac{{3\pi }}{4},\pi } \right\} \) are used. Parameters of the compared LBSISRR methods are chosen in the similar fashion as provided in their original work.
4.2 Performance Analysis of Synthetic Data Experiments
In this section, we have discussed the performance analysis of the proposed work with some of the existing state-of-the art methods by performing experimentation on synthetic test images from the ‘Set5,’ ‘Set14’ and ‘BSD200’ datasets at different magnification factors. For objective quality analysis, reconstructed HR solutions of some test images from these datasets are also provided.
Figure 3 depicts the original HR and their corresponding LR versions of ‘butterfly.bmp,’ ‘ppt3.bmp’ and ‘189080.jpg’ images from the ‘Set5,’ ‘Set14’ and ‘BSD200’ datasets, respectively.
Reconstructed HR solutions of these there test images at 3\(\times \) magnification factor are presented in Figs. 4, 5 and 6. Corresponding subjective quality measures of the reconstructed images are given in Table 5.
From the visual analysis as perceived from images in Figs. 4, 5 and 6g and tabular data analysis, it is observed that the deep learning-based SRR method in [38] provides superior performance. However, here our soul aim is to propose a faster and efficient LBSISRR method as compared to the existing ones. Hence, we will analyze the effectiveness of our proposed work with respect to the compared LBSISRR methods. The reconstructed HR images using the method in [21] well preserves the image details by utilizing the HOG feature. However, reconstruction quality of this method degrades for images rich in textural contents as observed in Fig. 6a for ‘189080.jpg’ image. However, method in [22] utilizes FoE features and non-local based constraints, consequently produces enhanced output even for images rich in textural content. But, measuring patch similarity by means of EuD among feature vector makes the method time-consuming in nature. Likewise, method in [24] is also providing some pleasant output by utilizing ZM based features. This method well preserves the global structure of image and robust to noise but have limited reconstruction capability for large-scale reconstruction. Consequently, some unwanted artifacts dominant in the reconstructed solutions as observed in Fig. 5d for ‘ppt3.bmp’ image. As compared to the above discussed methods, method in [23] is quite robust to noise and outliers present. This method also suggests an automated scheme for selecting the global size K for the reconstruction process. The estimated solutions as shown in Figs. 4, 5 and 6c show the efficacy of this method in producing the enhanced output. However, utilization of geodesic and EuD makes the reconstruction process computationally expensive. Method in [15] proposes edge preserving compatibility functions to well preserve the compatibility among neighboring patches and hence produces better HR results than the methods in [21, 22, 24]. This can be observed from the images in Figs. 4, 5 and 6e. However, utilization of intensity profile to represent patch in its feature space makes this method sensitive to noise and outliers. Nevertheless, computational complexity of this method is too high due to epitomic-based neighborhood searching process. Reconstructed solutions as shown in Figs. 4, 5 and 6f via the method in [35] produce sharper HR images by utilizing SC-based learning and KNN-based dictionary instead of unified dictionaries. Consequently, this method provides enhanced image quality at a lesser computational overload. From visual perception of reconstructed HR images as shown in Figs. 4, 5 and 6h, it is clearly seen that the proposed method produces sharp image details with diminished effect of artifacts than the other methods. Improvement of reconstruction quality of the proposed work is due to the integration of several raw image features which in turn provides an unified framework to preserve the complete set of high frequency components in the reconstruction process. To provide a fair comparative analysis, average values of different subjective quality measures of the reconstructed solutions for three image datasets at different magnification factors are provided in Tables 6, 7 and 8. Quality measure values using the method in [38] are shown in boldfaces and the values by using the proposed ENESR method are shown in italic and boldfaces.
Tables 9 and 10 show the average values of the objective quality assessment parameters of the reconstructed HR solutions at magnification factors of 3\(\times \) and 4\(\times \), respectively, for different dataset images. By analyzing the data present in Tables 6, 7, 8, 9 and 10, it is observed that, both the subjective and objective quality measures are consistent with the visual perception and our proposed ENESR method outperforms the compared methods. However, methods in [23, 35] are providing comparable results with the ENESR method.
Tables 11 and 12 provide the improvement of different subjective and objective quality measures of the proposed method compared to the two comparable methods in [23, 35] at different magnification factors for the three test image datasets. From the above tabular data analysis, it is observed that, improvement in different quality measures of the proposed method decreases with increase in magnification factors. However, our proposed method provides remarkable improvement in image quality even at higher magnification factor which signifies the efficacy of the method in providing high-quality image details.
Table 13 provides the average processing time for dataset images, whereas Table 14 provides the average processing time in reconstructing the HR images in three ‘Set5,’ ‘Set14’ and ‘BSD100’ datasets.
4.2.1 Comparison with the State-of-the-Art Faster LBSISRR Methods
In this subsection, performance of our proposed method is compared with some of the existing state-of-the-art faster LBSISRR methods [21, 26, 29, 32, 35] to show its superiority in providing a high-quality solution at a faster processing speed. Figure 7 shows the HR solutions of the ‘butterfly.bmp,’ ‘ppt3.bmp’ and ‘189080.jpg’ images by using the above mentioned reconstruction methods.

Table 15 describes both subjective and objective image quality assessment parameters of these reconstructed solutions at a magnification factor 3\(\times \). Table 16 describes the average values of both subjective and objective image quality assessment parameters along with average processing speed (in seconds) of the reconstructed solutions at different magnification factors. Averaging process takes the quality measure values and processing time for reconstructing the images in ‘Set5,’ ‘Set14’ and ‘BSD100’ datasets. From the visual perception and tabular data analysis, it is observed that, proposed ENESR method outperforms the compared faster LBSISRR methods. This is because, our proposed method efficiently fuses several raw image features to preserve sufficient amount of structural, statistical and spatial image details in the estimated solutions with reduced effect of artifacts. However, method in [29] provides comparable results with the proposed method. This method utilizes the combination of sparse coding and neighbor embedding to learn the dictionary. Unlike, conventional EuD-based measures, candidate patches are searched by considering the correlation with the dictionary atoms and hence sufficient spatial correlation have been preserved among neighboring patches. Consequently, yields a better quality of reconstruction and considered as the next state-of-the-art faster LBSISRR method.
4.2.2 Entropy of Reconstructed HR Solutions
Along with the above mentioned subjective and objective quality measures, entropy of the LR and its corresponding reconstructed HR images using different LBSISRR methods are also provided here to show the information content in the reconstructed solutions. Entropy values of the reconstructed ‘butterfly.bmp,’ ‘ppt3.bmp’ and ‘189080.jpg’ images at a magnification factor of 3\(\times \) are plotted in Fig. 8.

Bar plot of the entropy values of different SISRR methods for estimating ‘butterfly.bmp,’ ‘ppt3.bmp’ and ‘189080.jpg’ images at a zooming factor of 3\(\times \)
Formulation for the calculation of entropy and information gain is provided in Eq. (10).
where M, N are size of images, p(i, j) pixel values and \({\log _2}p(i,j)\) probability density.
From Fig. 8, it is quite evident that, for each of the images the HR solutions contain higher information than its corresponding LR images. However, our proposed ENESR method outperforms the compared methods and methods in [29, 35] provide comparable results. Information gain (IG) of a method is computed by taking the ratio of the entropy values of the reconstructed HR solution to its corresponding LR image. Higher value of IG signifies more information content. Values of IG for ‘butterfly.bmp,’ ‘ppt3.bmp’ and ‘189080.jpg’ images of the proposed method are: 1.82, 1.63, 1.70. Values of IG for the method in [35] are: 1.70, 1.54, 1.55, whereas values for the method in [29] are: 1.72, 1.56, 1.70, respectively. Thus, average improvement of the proposed ENESR method over the methods in [29, 35] is around 6.98% and 5.81 %, respectively.
4.2.3 Reconstruction Quality Versus Processing Speed
This section discusses about the trade-off between the reconstruction accuracy and the processing speed behavior of the reconstruction process. This is demonstrated by plotting the average computational speed (in seconds) against the avg. PSNR(dB) of the reconstructed HR solutions. The plot is provided for the proposed, compared state-of-the-art LBSISRR methods and faster SRR methods at different magnification factors. Figures 9 and 10 show the plot of average running time Vs average PSNR at 3\(\times \) and 4\(\times \), respectively.

Avg. processing speed (s) versus Avg. PSNR (dB) of the proposed and the state-of-the-art LBSISRR methods at a magnification factor of 3\(\times \). Blue color represents the proposed ENESR method

Avg. processing speed (s) versus Avg. PSNR (dB) of the proposed and the state-of-the-art LBSISRR methods at a zooming factor 4\(\times \). Blue color represents the proposed ENESR method

Reconstructed HR solutions of ‘Foreman’ sequence using different methods at a magnification factor 3\(\times \) along with the BIQI/NIQE values a Gao et al. [21] (19.46/.5612), b Zhu et al. [22] (20.01/.5718), c Mishra et al. [23] (22.43/.6013), d Mishra et al. [24] (20.68/.5819), e Nayak et al. [15] (20.86/.5867), f Liu et al. [35] (23.60/.6312), g Ledig et al. [38] (32.24/.6615), h ENESR (proposed) (25.01/.6519)

Reconstructed HR solutions of ‘Foreman’ sequence using proposed and compared faster LBSISRR methods at a magnification factor 3\(\times \) along with their BIQI/NIQE values a Zeyde. et al. (19.90/.5703), b Gao et al. [21] (19.46/.5612), c Timofte et al. [29] (24.11/.6410), d Ahmadi et al. [32] (19.97/.5711), e Liu et al. [35] (23.60/.6312), f ENESR (proposed) (25.01/.6519)
From the plot, it is observed that the methods in [15, 22] consume more processing time to converge. This is due to the integration of EuD-based measure to compute the compatibility functions and patch similarity. As compared to other methods, method in [29, 35] outperforms in terms of computational speed. Integration of SC based learning method by utilizing the KNN-based dictionary clusters enables faster convergence in method [35]. However, method in [29] utilizes an off-line anchored regression process to obtain the neighborhood by measuring the correlation with the dictionary atoms. Most importantly, this method integrates the notion of SC along with neighbor embedding approach to interpret the learned dictionary in a smaller space. Consequently, the method enables to preserve sufficient image details and converges at a faster rate than the methods using SC only [26, 32, 35]. However, our proposed method is consuming a little more time than the comparable methods in [29, 35] but yields high-quality reconstruction accuracy. This is due to the use of covariance-based feature representation of image patches. At higher magnification factors, i.e., at 3\(\times \) 4\(\times \), proposed ENESR method achieves an average gain of PSNR value by .45 dB to .64 dB at a cost of 4 to 6 seconds more computational time than the next state-of-the-art LBSISRR methods in [29, 35]. Hence, methods in [29, 35] can be efficiently used for applications where the computation speed is a major concern with the sacrifice in image quality. On the contrary, our proposed ENESR method maintains an efficient trade-off between computational speed and reconstruction accuracy. Hence, it can be successfully applied in various real-time applications.
4.3 Performance Analysis for Real-Time Data Experiments
In this section, we have provided the performance analysis of real-time test images for different magnification factors. Figure 11 depicts the reconstructed HR solutions of the Foreman sequence along with their corresponding BIQE and NIQE values at a magnification factor of 3\(\times \).
Figure 12 depicts the reconstructed HR solutions of the Foreman sequence along with their corresponding BIQE and NIQE values when compared with faster reconstruction methods at zooming factor of 3\(\times \).
Table 17 provides the average values of BIQI and NIQE measures of the reconstructed HR solutions from MDSP dataset [49] at different magnification factors. From the visual perception and tabular data analysis, it is observed that, even for real-time data analysis also, our proposed method is providing superior reconstruction quality than the other methods. Methods in [29] and [35] are providing comparable results to the proposed work. But, with increase in magnification factor, the reconstruction accuracy of these methods severely degrades and artifacts dominant. On the other hand, our proposed method maintains its reconstruction accuracy even at larger magnification factors.
Table 18 provides the average improvement of BIQI and NIQE measures of the proposed method over the methods in [29] and [35] at different magnification factors for MDSP dataset.
5 Conclusion
In this paper, we have presented an efficient neighbor embedding-based super-resolution reconstruction scheme by utilizing an enhanced way of representing image patch in feature space and a faster way of searching candidate patches. Each patch is efficiently represented by fusing a number of low- and high-level feature attributes which in turn provides sufficient essential information for reconstructing high-quality image details. Moreover, this unified means of patch representation makes the reconstruction process robust to noise. Size of K is chosen adaptively and patch similarity is measured in non-Euclidean space. This overcomes the bottleneck of Euclidean distance-based similarity measures. Qualitative and quantitative analysis of reconstruction process suggests that methods in [29, 35] provide comparable results with the proposed method and hence considered as the next two state-of-the-art methods. Our proposed work produces an average gain in PSNR by 0.37-0.68 dB, average improvements of SSIM, FSIM, RM, BM, SRCC and IG measures are by 0.91–1.08%, 1.09–1.94%, 6.45–12%, 11.26–17.54%, 10.13–18.10% and 6.98%, respectively, over the method in [35] at a cost of 3–5 s more processing time. Moreover, as compared to method in [29], our method achieves an average gain in PSNR by .30–.60 dB, average gain in SSIM, FSIM, RM, BM, SRCC and IG measures are by .64–.8%, .73–1.62%, 4.31–10.78%, 2.7–9.7%, 7.15–17.9% and 5.8% at a cost of 4–6 s processing time. All these analysis suggest that the proposed work produces a better trade-off between sharper image details and running time than the compared state-of-the-art methods.
Notes
\({\alpha ^* }\), optimal sparse coefficient; LASSO, least absolute shrinkage and selection operator, NCC, normalized cross-correlation, G-SOMP+, generalized simultaneous OMP, HSI, hyper-spectral image, IFCM, improved fuzzy C-means.
References
Hamza, R.; Hassan, A.; Huang, T.; Ke, L.; Yan, H.: An efficient cryptosystem for video surveillance in the internet of things environment. Complexity 2019, (2019)
Hamza, R.; Hewage, C.; Titouna, F.: Investigation of three-dimentional image security based on improved image randomised encryption method. NED Univ. J. Res. (2018)
Singh, D.; Kumar, V.; Kaur, M.: Single image dehazing using gradient channel prior. Appl. Intell. 49(12), 4276–4293 (2019)
Singh, D.; Kumar, V.: Single image defogging by gain gradient image filter. Sci. China Inf. Sci. 62(7), 79101 (2019)
Jiang, K.; Wang, Z.; Yi, P.; Jiang, J.: A progressively enhanced network for video satellite imagery superresolution. IEEE Signal Process. Lett. 25(11), 1630–1634 (2018)
Jurek, J.; Kociński, M.; Materka, A.; Elgalal, M.; Majos, A.: Cnn-based superresolution reconstruction of 3D MR images using thick-slice scans. Biocybernet. Biomed. Eng. 40(1), 111–125 (2020)
Zhang, L.; Zhang, H.; Shen, H.; Li, P.: A super-resolution reconstruction algorithm for surveillance images. Signal Process. 90(3), 848–859 (2010)
Freeman, W.T.; Jones, T.R.; Pasztor, E.C.: Example-based super-resolution. IEEE Comput. Graph. Appl. 22(2), 56–65 (2002)
Sun, J.; Zheng, N.-N.; Tao, H.; Shum, H.-Y.: Image hallucination with primal sketch priors. In: 2003 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2003. Proceedings, vol. 2, pp. II–729 IEEE (2003)
Huang, D.J.; Siebert, J.P.; Cockshott, W.P.; Xiao, Y.J.: Super-resolution of face images based on adaptive markov network. In: Third International IEEE Conference on Signal-Image Technologies and Internet-Based System, 2007, pp. 742–747. IEEE (2007)
Banerjee, J.; Namboodiri, A.M.; Jawahar, C.; Contextual restoration of severely degraded document images. In: IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2009, vol. 2009, 517–524. IEEE (2009)
Wu, W.; Liu, Z.; Gueaieb, W.; He, X.: Single-image super-resolution based on markov random field and contourlet transform. J. Electron. Imaging 20(2), 023005–023005 (2011)
Chen, X.; Qi, C.: Document image super-resolution using structural similarity and markov random field. IET Image Process. 8(12), 687–698 (2014)
Nayak, R.; Krishna, L.S.; Patra, D.: Enhanced super-resolution image reconstruction using MRF model. In: Progress in Intelligent Computing Techniques: Theory, Practice, and Applications, pp. 207–215. Springer (2018)
Nayak, R.; Patra, D.: New single-image super-resolution reconstruction using MRF model. Neurocomputing 293, 108–129 (2018)
Chang, H.; Yeung, D.-Y.; Xiong, Y.: Super-resolution through neighbor embedding. In: Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2004. CVPR 2004, vol. 1, pp. I–I. IEEE (2004)
Chan, T.-M.; Zhang, J.: Improved super-resolution through residual neighbor embedding. J. Guangxi Normal Univ. 24(4), 1–8 (2006)
Chan, T.-M.; Zhang, J.; Pu, J.; Huang, H.: Neighbor embedding based super-resolution algorithm through edge detection and feature selection. Pattern Recognit. Lett. 30(5), 494–502 (2009)
Zhang, K.; Gao, X.; Li, X.; Tao, D.: Partially supervised neighbor embedding for example-based image super-resolution. IEEE J. Sel. Top. Signal Process. 5(2), 230–239 (2010)
Cao, M.; Gan, Z.; Zhu, X.: Super-resolution algorithm through neighbor embedding with new feature selection and example training. In: 2012 IEEE 11th International Conference on Signal Processing (ICSP), vol. 2, pp. 825–828. IEEE (2012)
Gao, X.; Zhang, K.; Tao, D.; Li, X.: Image super-resolution with sparse neighbor embedding. IEEE Trans. Image Process. 21(7), 3194–3205 (2012)
Zhu, Q.; Sun, L.; Cai, C.: Non-local neighbor embedding for image super-resolution through FoE features. Neurocomputing 141, 211–222 (2014)
Mishra, D.; Majhi, B.; Sa, P.K.; Dash, R.: Development of robust neighbor embedding based super-resolution scheme. Neurocomputing 202, 49–66 (2016)
Mishra, D.; Majhi, B.; Sa, P.K.: Improved feature selection for neighbor embedding super-resolution using zernike moments. In: Proceedings of International Conference on Computer Vision and Image Processing, pp. 13–24. Springer (2017)
Yang, J.; Wright, J.; Huang, T.S.; Ma, Y.: Image super-resolution via sparse representation. IEEE Trans. Image Process. 19(11), 2861–2873 (2010)
Zeyde, R.; Elad, M.; Protter, M.: On single image scale-up using sparse-representations. In: International Conference on Curves and Surfaces, pp. 711–730. Springer, Berlin (2010)
Yang, J.; Wang, Z.; Lin, Z.; Cohen, S.; Huang, T.: Coupled dictionary training for image super-resolution. IEEE Trans. Image Process. 21(8), 3467–3478 (2012)
Wang, S.; Zhang, L.; Liang, Y.; Pan, Q.: Semi-coupled dictionary learning with applications to image super-resolution and photo-sketch synthesis. In: 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2216–2223. IEEE (2012)
Timofte, R.; De Smet, V.; Van Gool, L.: A+: Adjusted anchored neighborhood regression for fast super-resolution. In: Asian Conference on Computer Vision, pp. 111–126. Springer, Berlin (2014)
Wang, L.; Geng, H.; Liu, P.; Lu, K.; Kolodziej, J.; Ranjan, R.; Zomaya, A.Y.: Particle swarm optimization based dictionary learning for remote sensing big data. Knowl.-Based Syst. 79, 43–50 (2015)
Nayak, R.; Patra, D.; Harshavardhan, S.: Sparse representation based image super resolution reconstruction. In: TENCON 2015–2015 IEEE Region 10 Conference, pp. 1–6. IEEE (2015)
Ahmadi, K.; Salari, E.: Single-image super resolution using evolutionary sparse coding technique. IET Image Process. 11(1), 13–21 (2016)
Fang, L.; Zhuo, H.; Li, S.: Super-resolution of hyperspectral image via superpixel-based sparse representation. Neurocomputing 273, 171–177 (2018)
Yang, X.; Wu, W.; Liu, K.; Chen, W.; Zhou, Z.: Multiple dictionary pairs learning and sparse representation-based infrared image super-resolution with improved fuzzy clustering. Soft Comput. 22(5), 1385–1398 (2018)
Liu, N.; Xu, X.; Li, Y.; Zhu, A.: Sparse representation based image super-resolution on the knn based dictionaries. Optics Laser Technol. 110, 135–144 (2019)
Dong, C.; Loy, C.C.; He, K.; Tang, X.: Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 38(2), 295–307 (2015)
Kim, J.; Lee, J.K.; Lee, K.M.: Accurate image super-resolution using very deep convolutional networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1646–1654 (2016)
Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al.: Photo-realistic single image super-resolution using a generative adversarial network. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4681–4690 (2017)
Wang, Y.; Wang, L.; Wang, H.; Li, P.: End-to-end image super-resolution via deep and shallow convolutional networks. IEEE Access 7, 31959–31970 (2019)
Wang, Z.; Chen, J.; Hoi, S.C.: Deep learning for image super-resolution: a survey. arXiv preprint arXiv:1902.06068 (2019)
Tuzel, O.; Porikli, F.; Meer, P.: Region covariance: A fast descriptor for detection and classification. In: Computer Vision-ECCV, vol. 2006, pp. 589–600 (2006)
Nayak, R.; Patra, D.: Super resolution image reconstruction using penalized-spline and phase congruency. Comput. Electr. Eng. 62, 232–248 (2017)
Ou, Y.; Sotiras, A.; Paragios, N.; Davatzikos, C.: Dramms: deformable registration via attribute matching and mutual-saliency weighting. Medical Image Anal. 15(4), 622–639 (2011)
Zhan, Y.; Shen, D.: Deformable segmentation of 3-D ultrasound prostate images using statistical texture matching method. IEEE Trans. Med. Imaging 25(3), 256–272 (2006)
Marziliano, P.; Dufaux, F.; Winkler, S.; Ebrahimi, T.: Perceptual blur and ringing metrics: application to jpeg2000. Signal Process. Image Commun. 19(2), 163–172 (2004)
Tang, L.; Sun, K.; Liu, L.; Wang, G.; Liu, Y.: A reduced-reference quality assessment metric for super-resolution reconstructed images with information gain and texture similarity. Signal Process. Image Commun. 79, 32–39 (2019)
Bevilacqua, M.; Roumy, A.; Guillemot, C.; Alberi-Morel, M.L.: Low-complexity single-image super-resolution based on nonnegative neighbor embedding (2012)
Martin, D.; Fowlkes, C.; Tal, D.; Malik J.; et al.: A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. Iccv Vancouver (2001)
Milanfar, P.; Farsiu, S., Robinson, D.: MDSP super-resolution and demosaicing datasets (2016)
Moorthy, A.K.; Bovik, A.C.: A two-step framework for constructing blind image quality indices. IEEE Signal Process Lett. 17(5), 513–516 (2010)
Mittal, A.; Soundararajan, R.; Bovik, A.C.: Making a “completely blind” image quality analyzer. IEEE Signal Process. Lett. 20(3), 209–212 (2012)
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Nayak, R., Balabantaray, B.K. & Patra, D. A New Single-Image Super-Resolution Using Efficient Feature Fusion and Patch Similarity in Non-Euclidean Space. Arab J Sci Eng 45, 10261–10285 (2020). https://doi.org/10.1007/s13369-020-04662-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13369-020-04662-9