
Abstract
This paper presents a new feature selection method for learning based single image super-resolution (SR). The performance of learning based SR strongly depends on the quality of the feature. Better features produce better co-occurrence relationship between low-resolution (LR) and high-resolution (HR) patches, which share the same local geometry in the manifold. In this paper, Zernike moment is used for feature selection. To generate a better feature vector, the luminance norm with three Zernike moments are considered, which preserves the global structure. Additionally, a global neighborhood selection method is used to overcome the problem of blurring effect due to over-fitting and under-fitting during K-nearest neighbor (KNN) search. Experimental analysis shows that the proposed scheme yields better recovery quality during HR reconstruction.
Access provided by CONRICYT-eBooks. Download conference paper PDF
Similar content being viewed by others

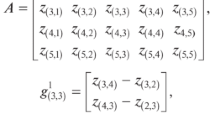
Keywords
- Super-resolution
- Zernike moment
- Luminance norm
- Manifold learning
- Global neighborhood selection
- Locally linear embedding
1 Introduction
Visual pattern recognition and analysis plays a vital role in image processing and computer vision. However, it has several limitations due to image acquisition in the unfavorable condition. Super-resolution (SR) technique is used to overcome the limitations of the sensors and optics [1]. Super-resolution is a useful signal processing technique to obtain a high-resolution (HR) image from an input low-resolution (LR) image. In this work, we have modeled a learning based super-resolution approach to generate a HR image from a single LR image.
The problem of learning based SR was introduced by Freeman et al. [2] called example-based super-resolution (EBSR). In their work, a training set has been used to learn the fine details that correspond to the region of low-resolution using the one-pass algorithm. Later, Kim et al. [3] extended their formulation by considering kernel ridge regression which combines the idea of gradient descent and matching pursuit. Afterward, Li et al. [4] have proposed example-based single frame SR using support vector regression (SVR) to illustrate the local similarity. However, due to lack of similarities in local geometry and neighborhood preservation, aliasing effect is generated during HR reconstruction. To preserve the neighborhood information, a neighbor embedding based SR (SRNE) was introduced by Chang et al. [5]. Thereafter, in [6,7,8,9,10] an extended neighbor embedding based SR is used by considering different feature selection methods. Chan et al. [8] have proposed a neighbor embedding based super-resolution algorithm through edge detection and feature selection (NeedFS), where a combination of luminance norm and the first-order gradient feature is introduced for edge preservation and smoothening the color region. To preserve the edge, Liao et al. [9] have proposed a new feature selection using stationary wavelet transform (SWT) coefficient. Mishra et al. [10] have emphasized on neighborhood preservation and reduction of sensitivity to noise. Therefore, they have proposed an incremental feature selection method by combining the first-order gradient and residual luminance inspired by image pyramid. Gao et al. [11] have proposed a method to project the original HR and LR patch onto the jointly learning unified feature subspace. Further, they have introduced sparse neighbor selection method to generate a SR image [12]. Bevilacqua et al. [13] have introduced a new algorithm based on external dictionary and non-negative embedding. They have used the iterative back-projection (IBP) to refine the LR image patches and a joint K-means clustering (JKC) technique to optimize the dictionary. In [14], a new Zernike moment based SR has been proposed for multi-frame super-resolution. Due to orthogonality, rotation invariance, and information compaction of Zernike moment, they have formulated a new weight value for HR image reconstruction.
However, in practice, preserving the fine details in the image is inaccurate in embedding space, which is still an open problem. For better local compatibility and smoothness constraints between adjacent patches, a better feature selection is necessary. Hence, we have proposed a new feature selection method inspired by Zernike moment [15]. In our work, a feature vector has been generated by the combination of three Zernike moments and luminance norm. In addition, a global neighborhood selection method is used to generate the K value for neighborhood search to overcome the problem of over-fitting and under-fitting. The proposed approach is verified through the different performance measures. The experimental results indicate that proposed scheme preserves more fine details than the state-of-the-art methods.
The remainder of the paper is organized as follows. Section 2 describes the problem statement. Section 3 presents an overall idea about Zernike moment. Section 4 discusses the proposed algorithm for single image super-resolution using Zernike moment. Experimental results and analysis are discussed in Sect. 5 and the concluding remarks are outlined in Sect. 6.
2 Problem Statement
In this section, the objective of single image super-resolution problem is defined and formulated. Let us consider a set of n low-resolution images of size \(M \times N\). Theoretically each low-resolution image can be viewed as a single high-resolution image of size \(DM \times DN\) that has been blurred and down sampled by a factor of D. A particular low-resolution image \(X_l\) is represented as
where \(X_h\) is a \(DM \times DN\) high-resolution image, B is \(5 \times 5\) Gaussian blur kernel and D is the down sampling factor. In the proposed scheme, we consider a neighbor embedding approach to generate a SR image for a given LR image. Hence, a set of LR and its corresponding HR training image is required to find out a co-occurrence relationship between LR and HR patches.
3 Background
In the field of image processing and pattern recognition, moment-based features play a vital role. The use of the Zernike moments in image analysis was introduced by Teague [15]. Zernike moments are basically projections of the image information to a set of complex polynomials, that from a complete orthogonal set over the interior of a unit circle, i.e. \(\sqrt{{x^2} + {y^2}} \le 1\).
The two-dimensional Zernike moments of an image intensity function f(x, y) of order n and repetition m are defined as
where \(\frac{{n + 1}}{\pi }\) is a normalization factor. In discrete form \(Z_{nm}\) can be expressed as
The kernel of these moments is a set of orthogonal polynomials, where the complex polynomial \(V_{nm}\) can be expressed in polar coordinates \(\left( {\rho ,\theta } \right) \) as
where \(n \ge 0\) and \(n - \left| m \right| \) is an even positive integer.
In (4), \(R_{nm}(\rho )\) is radial polynomial and is defined as
The real and imaginary masks are deduced by a circular integral of complex polynomials. On the whole, edge detection is conducted at the pixel level. At each edge point, orthogonal moment method is used to calculate accurately gradient direction. Mostly, the higher-order moments are more sensitive to noise. Therefore, first three 2nd order moments has been employed for feature selection. The real and imaginary \(7\times 7\) homogeneous mask of \(M_{11}\) and \(M_{20}\) should be deduced by circular integral of \(V^*_{11}\) and \(V^*_{20}\) [16]. Hence, three Zernike moments are \(Z_{11}R\), \(Z_{11}I\) and \(Z_{20}\).
4 Neighbor Embedding Based SR Using Zernike Moment
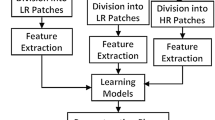
In this section, a new feature selection method is proposed using Zernike moments for neighbor embedding based super-resolution. The feature vector is generated by combining the three Zernike moments with luminance norm. Moreover, neighborhood size for K-nearest neighbor (KNN) search is generated by global neighborhood selection [17]. The overall block diagram of the proposed scheme is shown in Fig. 1.

Block diagram of proposed scheme
4.1 Neighbor Embedding Based SR
To perform neighbor embedding based SR, luminance component of each image is split into a set of overlapping patches. \(X_L=\left\{ x_l^t\right\} _{t=1}^T\) is the training LR image and \(X_H=\left\{ x_h^s\right\} _{s=1}^S\) is the corresponding HR image. To preserve the inter-patch relationship between the LR and HR patch, if the patch size of LR image is \(s\times s\) then the patch size of corresponding HR image will be \(fs\times fs\), where f is the magnification factor. The input LR image \(Y_L=\left\{ y_l^t\right\} _{t=1}^T\) and expected HR image \(Y_H=\left\{ y_h^s\right\} _{s=1}^S\) pair should have same number of patches.
In training process, for each LR patch K-nearest neighbors search among all training LR patches and the optimal reconstruction weight vector \(W_{t}\) calculated by minimizing the local reconstruction error as
subject to two constrains, i.e., \(\sum \nolimits _{y_l^s \in {N_t}} {{w_{ts}}} = 1\) and \(w_{ts}=0\) for any \(y_l^s \notin {N_t}\). This is generally used for normalization of the optimal weight vector, where \(N_{t}\) is the set of neighborhood of \(y_l^t\) in training set \(X_{L}\).
The local Gram matrix \({G_t}\) plays an important role to calculate the weight \(w_{t}\) associated to \(y_l^t\), which is defined as
where one’s column vectors are considered to match the dimensionality with X. The dimension of X is \(D \times K\), where its columns represent the neighbors of \(y_l^t\). The optimal weight vector \(W_{t}\) for \(y_l^t\) having the weights of each neighbors \(w_{ts}\) are reordered by s. The weight is calculated as
After solving \(w_{t}\) efficiently, the high-resolution target patch \(y_h^t\) is computed as follows:
Then the HR patches are stitched according to the corresponding coordinates by averaging the overlapping regions. The detailed procedure of the proposed scheme is given in Algorithm 1.

4.2 Zernike Moment Based Feature Selection
In this section, an efficient feature selection method for neighbor embedding based super-resolution method is proposed. In [5, 7, 8], several features are used for better geometry preservation in the manifold. But, consistency in structure between the neighborhood patches embedding still is an issue. To overcome the problem like sensitivity of noise, recovery quality, and neighborhood preservation among the patches, Zernike moment feature descriptor is used as appropriate feature selection. Due to robustness to noise and orthogonal properties of Zernike moment, a perfect representation of information is done. Basically, the features are selected from the luminance channel because it is sensitive to the human visual system. Luminance norm is also considered as a part of the features because it represent the global structure of the image. For each pixel, there are four components of a feature vector i.e., \([LN, Z_{11}R, Z_{11}I\,, and \, Z_{20}]\). As the learning based SR perform on the patch, feature vector of each patch size is \(4p^2\), where p is the patch size.
4.3 Global Neighborhood Selection
Choosing the neighborhood size for locally linear embedding has great influence on HR image reconstruction because the neighborhood size K determines the local and global structure in the embedding space. Moreover, fixed neighborhood size leads to over-fitting or under-fitting. To preserve the local and global structure, the neighbor embedding method search a transformation. Hence, global neighborhood selection method is used. The reason for global neighborhood selection is to preserve the small scale structures in manifold. To get the best reconstructed HR image, well representation of high dimensional structure is required in the embedding space.
This method has been introduced by Kouropteva et al. [17], where Residual Variance is used as a quantitative measure that estimate the quality of the input-output mapping in embedding space. The residual variance [18] is defined as
where \(\rho \) is the standard linear correlation coefficient, takes over all entries of \(d_X\) and \(d_Y\) matrices; The element of \(d_X\) and \(d_Y\) matrices having size \(m \times m\) represents the Euclidean distance between pair of patches in X and Y. According to [17] lower is the residual variance better is the high dimensional data representation. Hence, optimal neighborhood size \(K=(k_{opt})\) computed by hierarchical method as
The overall mechanism of global neighborhood selection is summarized in Algorithm 2


Test images
5 Experimental Results
5.1 Experimental Setting
To validate the proposed algorithm, simulations are carried out on some standard images of different size like Parrot, Peppers, Lena, Tiger, Biker, and Lotus. In this experiment, a set of LR and HR pairs are required for training. Hence, LR images are generated from the ideal images by blurring each image using (\(5 \times 5\)) Gaussian kernel and decimation using 3 : 1 decimation ratio in each axis. A comparative analysis has been made with respect to two performance measures, namely, pick signal to noise ratio (PSNR) and feature similarity index (FSIM) [19]. The value of FSIM lies between 0 to 1. The larger value of PSNR and FSIM indicates better performance.
5.2 Experimental Analysis
To evaluate the performance of the proposed scheme, we compare our results with four schemes namely, Bicubic interpolation, EBSR [2], SRNE [5], and NeedFS [8]. The test images are shown in Fig. 2. Table 1 lists the PSNR and FSIM values for all test images. The 1st row and 2nd row in the table indicates PSNR and FSIM values respectively. The features generated by Zernike moment for Lena image are shown in Fig. 3. The visual comparison for Lena and Tiger image are shown in Figs. 4 and 5 respectively. To validate the performance of the proposed scheme, we compare the results with state-of-the-art approaches with different K value. In SRNE [5], the K value is fixed which leads to blurring effect in the expected HR image; whereas in NeedFS [8] two different K values are provided according to the patches having edge. In our scheme, the K value lies between 1 to 15. Due to global neighborhood selection, our method gives a better results in terms of both PSNR and FSIM as shown in Fig. 6. It shows the graph is increased gradually between the K value 5 to 9. However, it gives only good results for a certain K value in the state-of-the-arts.

Three Zernike moments of Lena image

Comparison of SR results(\(3\times \)) of Lena image

Comparison of SR results(\(3\times \)) of Tiger image

PSNR and FSIM comparison of Lena image
6 Conclusion
In this paper, we have proposed a new feature selection method for neighbor embedding based super-resolution. The feature vector is generated by combining three Zernike moments with the luminance norm of the image. The global neighborhood size selection technique is used to find the K value for K-nearest neighbor search. Both qualitative and quantitative comparison of the proposed method is carried out with the state-of- the-art methods. The results show that the proposed method is superior to the other methods in terms of PSNR and FSIM values. However, for texture based image edge preservation is still an issue that will be addressed in our future work.
References
Park, S.C., Park, M.K., Kang, M.G.: Super-resolution image reconstruction: a technical overview. IEEE Signal Processing Magazine 20(3) (2003) 21–36
Freeman, W.T., Jones, T.R., Pasztor, E.C.: Example-based super-resolution. IEEE Computer Graphics and Applications 22(2) (2002) 56–65
Kim, K.I., Kwon, Y.: Example-based learning for single-image super-resolution. In: Proceedings of the 30th DAGM Symposium on Pattern Recognition. (2008) 456–465
Li, D., Simske, S.: Example based single-frame image super-resolution by support vector regression. Journal of Pattern Recognition Research 1 (2010) 104–118
Chang, H., Yeung, D.Y., Xiong, Y.: Super-resolution through neighbor embedding. In: IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Volume 1. (2004) 275–282
Chan, T.M., Zhang, J.: Improved super-resolution through residual neighbor embedding. Journal of Guangxi Normal University 24(4) (2006)
Fan, W., Yeung, D.Y.: Image hallucination using neighbor embedding over visual primitive manifolds. In: IEEE Conference on Computer Vision and Pattern Recognition. (June 2007) 1–7
Chan, T.M., Zhang, J., Pu, J., Huang, H.: Neighbor embedding based super-resolution algorithm through edge detection and feature selection. Pattern Recognition Letters 30(5) (2009) 494–502
Liao, X., Han, G., Wo, Y., Huang, H., Li, Z.: New feature selection for neighbor embedding based super-resolution. In: International Conference on Multimedia Technology. (July 2011) 441–444
Mishra, D., Majhi, B., Sa, P.K.: Neighbor embedding based super-resolution using residual luminance. In: IEEE India Conference. (2014) 1–6
Gao, X., Zhang, K., Tao, D., Li, X.: Joint learning for single-image super-resolution via a coupled constraint. IEEE Transactions on Image Processing 21(2) (2012) 469–480
Gao, X., Zhang, K., Tao, D., Li, X.: Image super-resolution with sparse neighbor embedding. IEEE Transactions on Image Processing 21(7) (2012) 3194–3205
Bevilacqua, M., Roumy, A., Guillemot, C., Morel, M.L.A.: Super-resolution using neighbor embedding of back-projection residuals. In: International Conference on Digital Signal Processing. (2013) 1–8
Gao, X., Wang, Q., Li, X., Tao, D., Zhang, K.: Zernike-moment-based image super resolution. IEEE Transactions on Image Processing 20(10) (2011) 2738–2747
Teague, M.R.: Image analysis via the general theory of moments. Journal of the Optical Society of America 70 (1980) 920–930
Xiao-Peng, Z., Yuan-Wei, B.: Improved algorithm about subpixel edge detection based on zernike moments and three-grayscale pattern. In: International Congress on Image and Signal Processing. (2009) 1–4
Kouropteva, O., Okun, O., Pietikinen, M.: Selection of the optimal parameter value for the locally linear embedding algorithm. In: International Conference on Fuzzy Systems and Knowledge Discovery. (2002) 359–363
Roweis, S.T., Saul, L.K.: Nonlinear dimensionality reduction by locally linear embedding. Science 290(5500) (2000) 2323–2326
Zhang, L., Zhang, D., Mou, X., Zhang, D.: Fsim: A feature similarity index for image quality assessment. IEEE Transactions on Image Processing 20(8) (2011) 2378–2386
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer Science+Business Media Singapore
About this paper
Cite this paper
Mishra, D., Majhi, B., Sa, P.K. (2017). Improved Feature Selection for Neighbor Embedding Super-Resolution Using Zernike Moments. In: Raman, B., Kumar, S., Roy, P., Sen, D. (eds) Proceedings of International Conference on Computer Vision and Image Processing. Advances in Intelligent Systems and Computing, vol 460. Springer, Singapore. https://doi.org/10.1007/978-981-10-2107-7_2
Download citation
DOI: https://doi.org/10.1007/978-981-10-2107-7_2
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-10-2106-0
Online ISBN: 978-981-10-2107-7
eBook Packages: EngineeringEngineering (R0)