
Abstract
The main focus of this paper is on the reliability modelling of a computer system considering the concepts of redundancy, preventive maintenance and priority in repair activities. Two identical units of a computer system are taken—one unit is initially operative and the other is kept as spare in cold standby. In each unit h/w and s/w work together and may fail independently from normal mode. There is a single server who visits the system immediately as and when needed. Server conducts preventive maintenance of the unit (computer system) after a maximum operation time. Repair of the h/w is done at its failure while s/w is upgraded from time to time as per requirements. If server unable to repair the h/w in a pre-specific time (called maximum repair time), h/w is replaced by new one giving some replacement time. Priority to h/w repair is given over s/w up gradation if, in one unit s/w is under up-gradation and h/w fails in another operative unit. The failure time of h/w and s/w follows negative exponential distributions while the distributions of preventive maintenance, h/w repair/replacement and s/w up-gradation times are taken as arbitrary with different probability density functions. The expressions for several reliability and economic measures are derived in steady state using semi-Markov process and regenerative point technique. The graphical study of mean time to system failure (MTSF) and profit function has also been made giving particular values to various parameters and costs.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Now a day’s computer systems are of growing importance because of their wide use in many areas such as aerospace, transportation, automobiles, home appliances as well as in most of the clerical works. In computer systems, h/w and s/w work together to complete various tasks in a given period of time with full efficiency. In spite of increasing development and availability of new computer technologies, a little work has been dedicated to the reliability modeling of computer systems with independent failures of h/w and s/w components. And, most of the research work has been carried out either considering h/w or s/w alone. Friedman and Tran (1992) tried to establish a combined reliability model for the whole system including both hardware and software. But the technique of redundancy was not used in that paper in order to improve the performance and reliability of the system. First time, Malik and Anand [2010] developed a reliability model for a computer system with independent h/w and s/w failures using the technique of redundancy.
It is observed that continued operation and ageing of operable systems reduce their performance, reliability and safety. Thus, to slow the deterioration process as well as to restore the system in a younger age or state, the preventive maintenance can be conducted after a maximum operation time. Malik and Nandal (2010) analyzed a cold standby system introducing the concept of preventive maintenance after a maximum operation time. Further, the availability of the system can be increased by making replacement of the failed components by new one in case their repair times are too long. Kumar et al. (2012) discussed a computer system with the aspects of maximum operation and repair times. Furthermore, sometimes it becomes necessary to give priority in repair disciplines to one unit over the other not only to reduce the down time but also to minimize the operating cost. Malik and Sureria (2012) studied probabilistically a computer system with priority to h/w repair over s/w replacement.
While considering above observations and facts in mind, here a reliability model for a computer system is developed using the concepts of redundancy, preventive maintenance and priority. Two identical units of a computer system are taken up—one unit is initially operative and the other is kept as spare in cold standby. In each unit h/w and s/w work together and may fail independently from normal mode. There is a single server who visits the system immediately to conduct preventive maintenance of the unit after a maximum operation time as well as to do h/w repair/replacement and s/w up-gradation. If server unable to repair the h/w in a pre-specific time (called maximum repair time), h/w is replaced by new one giving some replacement time. However, only up-gradation of the s/w is made as per requirements giving some up-gradation time. Priority to h/w repair is given over s/w up gradation if, in one unit s/w is under up-gradation and h/w fails in another operative unit. The failure time of h/w and s/w follows negative exponential distributions while the distributions of preventive maintenance, h/w repair/replacement and s/w up-gradation times are taken as arbitrary with different probability density functions. All random variables are statistically independent to each other. The repairs and switch devices are perfect. The expressions for various reliability measures such as mean time to system failure, availability, busy period of the server due to preventive maintenance, busy period of the server due to h/w repair/replacement, busy period of the server due to software up-gradation, expected number of software up-gradations, expected number of hardware replacements and expected number of visits of the server are derived by using semi-Markov process and regenerative point technique. The graphical study of mean time to system failure (MTSF) and profit function has been made giving particular values to various parameters and costs.
2 Transition probabilities and mean sojourn times
Using Fig. 1, simple probabilistic considerations yield the following expressions for the non-zero elements
\( {\text{p}}_{0 1} = \frac{{\mathop \alpha \nolimits_{0} }}{A} \), \( {\text{p}}_{0 2} = \frac{{\mathop {a\lambda }\nolimits_{1} }}{A} \), \( {\text{p}}_{0 3} = \frac{{\mathop {b\lambda }\nolimits_{2} }}{A} \), \( {\text{p}}_{ 10} = f^{*} \left( {\text{A}} \right),{\text{ p}}_{ 1 6} = \;\frac{{\mathop {a\lambda }\nolimits_{1} }}{A}\left[ {{ 1} - f^{*} \left( {\text{A}} \right)} \right] \, = {\text{ p}}_{ 1 2. 6} \), \( {\text{p}}_{ 1 8} = \frac{{\mathop {b\lambda }\nolimits_{2} }}{A}\,\left[ {{ 1} - f^{*} \left( {\text{A}} \right)} \right] = {\text{ p}}_{ 1 3. 8, } \) \( {\text{p}}_{ 1. 1 3} = \frac{{\mathop \alpha \nolimits_{0} }}{A}\left[ {{ 1} - f^{*} \left( {\text{A}} \right)} \right] \, = {\text{p}}_{ 1 1. 1 3} \), \( {\text{p}}_{ 20} = g^{*} \left( {\text{B}} \right) \), \( {\text{p}}_{ 2 4} = \frac{{\mathop \beta \nolimits_{0} }}{B}\left[ {{ 1} - g^{*} \left( {\text{B}} \right)} \right] \), \( {\text{p}}_{ 2 5} = \frac{{\mathop \alpha \nolimits_{0} }}{B}\left[ {{ 1} - g^{*} \left( {\text{ B}} \right)} \right]{\text{p}}_{ 2. 1 1} = \) \( \frac{{\mathop {b\lambda }\nolimits_{2} }}{B}\left[ {{ 1} - g^{*} \left( {\text{B}} \right)} \right] \), \( {\text{p}}_{ 2. 1 2} = \frac{{\mathop {a\lambda }\nolimits_{1} }}{B}\left[ {{ 1} - g^{*} \left( {\text{B}} \right)} \right] \), \( {\text{p}}_{ 30} = h^{*} \left( {\text{A}} \right),{\text{ p}}_{ 3 7} = \frac{{\mathop {a\lambda }\nolimits_{1} }}{A}\left[ {{ 1} - h^{*} \left( {\text{A}} \right)} \right] \) , \( {\text{p}}_{ 3 9} = \frac{{\mathop \alpha \nolimits_{0} }}{A}\left[ {{ 1} - h^{*} \left( {\text{A}} \right)} \right] = {\text{ p}}_{ 3, 1. 9} \), \( {\text{p}}_{ 40} = m^{*} \left( {\text{A}} \right) \), \( {\text{p}}_{ 3, 10} = \frac{{\mathop {b\lambda }\nolimits_{2} }}{A}\left[ {{ 1} - h^{*} \left( {\text{A}} \right)} \right] = {\text{ p}}_{ 3 3. 10} \) , \( {\text{p}}_{ 5 1} = g^{*} \left( {{{\upbeta}}_{0} } \right) \), \( {\text{p}}_{ 5, 1 6} = { 1} - g^{*} \left( {{{\upbeta}}_{0} } \right) \), \( {\text{p}}_{ 4. 1 7} = \frac{{\mathop \alpha \nolimits_{0} }}{A}\left[ {{ 1} - m^{*} \left( {\text{A}} \right)} \right] = {\text{ p}}_{ 4, 1. 1 7} \), \( {\text{p}}_{ 6 2} = f^{*} \left( 0 \right) \), \( {\text{p}}_{ 7 3} = {\text{g}}^{*} \left( 0 \right) \), \( {\text{p}}_{ 8 3} = f^{*} \left( 0 \right) \), \( {\text{p}}_{ 9 1} = {\text{ h}}^{*} \left( 0 \right) \), \( {\text{p}}_{ 10. 3} = h^{*} \left( 0 \right) \), \( {\text{p}}_{ 1 1. 3} = g^{*} \left( {{{\upbeta}}_{0} } \right) \), \( {\text{p}}_{ 1 1. 1 4} = { 1} - g^{*} \left( {{{\upbeta}}_{0} } \right) \), \( {\text{p}}_{ 4, 1 8} = \frac{{\mathop {b\lambda }\nolimits_{2} }}{A}\left[ {{ 1} - m^{*} \left( {\text{A}} \right)} \right] \, = {\text{ p}}_{ 4 3. 1 8} \), \( {\text{p}}_{ 1 2. 2} = g^{*} \left( {{{\upbeta}}_{0} } \right) \), \( {\text{p}}_{ 1 2. 1 5} = { 1} - g^{*} \left( {{{\upbeta}}_{0} } \right) \), \( {\text{p}}_{ 1 3. 1} = f^{*} \left( 0 \right) \),\( {\text{p}}_{ 1 4. 3} = m^{*} \left( 0 \right) \), \( {\text{p}}_{ 4 2. 1 9} = {\text{p}}_{ 4. 1 9} = \frac{{\mathop {a\lambda }\nolimits_{1} }}{A}\left[ {{ 1} - m^{*} \left( {\text{A}} \right)} \right] \), \( {\text{p}}_{ 1 5. 2} = m^{*} \left( 0 \right) \), \( {\text{p}}_{ 1 6. 1} = m^{*} \left( 0 \right) \),\( {\text{p}}_{ 1 7. 1} = m^{*} \left( 0 \right) \), \( {\text{p}}_{ 1 8. 3} = m^{*} \left( 0 \right) \), \( {\text{P}}_{19.2} = m^{*} \left( 0 \right) \), \( {\text{p}}_{ 2 1. 5} = \frac{{\mathop \alpha \nolimits_{0} }}{B}\left[ {{ 1} - g^{*} \left( {\text{B}} \right)} \right]g^{*} \left( {{{\upbeta}}_{0} } \right) \), \( {\text{p}}_{ 2 1. 1 6, 5} = \frac{{\mathop \alpha \nolimits_{0} }}{B}\left[ {{ 1} - g^{*} \left( {\text{B}} \right)} \right]\left[ { 1- g^{*} \left( {{{\upbeta}}_{0} } \right)} \right] \), \( {\text{p}}_{ 2 3. 1 1} = \frac{{\mathop {b\lambda }\nolimits_{2} }}{B}\left[ {{ 1} - g^{*} \left( {\text{B}} \right)} \right]\left[ {g^{*} \left( {{{\upbeta}}_{0} } \right)} \right] \), \( {\text{p}}_{ 2 3. 1 1, 1 4} = \frac{{\mathop {b\lambda }\nolimits_{2} }}{B}\left[ {{ 1} - g^{*} \left( {\text{B}} \right)} \right]\left[ { 1- g^{*} \left( {{{\upbeta}}_{0} } \right)} \right] \), \( {\text{p}}_{ 2 2. 1 2} = \frac{{\mathop {a\lambda }\nolimits_{1} }}{B}\left[ {{ 1} - g^{*} \left( {\text{B}} \right)} \right]g^{*} \left( {{{\upbeta}}_{0} } \right) \), \( {\text{p}}_{ 2 2. 1 2, 1 5} = \frac{{\mathop {a\lambda }\nolimits_{1} }}{B}\left[ {{ 1} - g^{*} \left( {\text{B}} \right)} \right]\left[ { 1- g^{*} \left( {{{\upbeta}}_{0} } \right)} \right] \)

.
where
It can be easily verified that \( {\text{p}}_{0 1} + {\text{p}}_{0 2} + {\text{p}}_{0 3} = {\text{ p}}_{ 10} + {\text{p}}_{ 1 6} + {\text{p}}_{ 1 8} + {\text{p}}_{ 1. 1 3} = {\text{ p}}_{ 20} + {\text{p}}_{ 2 4} + {\text{p}}_{ 2 5} + {\text{ p}}_{ 2, 1 1} + {\text{p}}_{ 2. 1 2} \)
The Mean Sojourn Times (μi) in the state Si are
3 Reliability and Mean Time to System Failure (MTSF)
Let ϕi(t) be the cdf of first passage time from the regenerative state i to a failed state. Regarding the failed state as absorbing state, we have the following recursive relations for
ϕi (t) as
where j is an un-failed regenerative state to which the given regenerative state i can transit and k is a failed state to which the state i can transit directly.
Taking LT of above relation (5) and solving for \( \tilde{\phi }_{0} (s) \)
We have
The reliability of the system model can be obtained by taking Laplace inverse transform of (6).
The mean time to system failure (MTSF) is given by
\( {\text{N}}_{ 1} = \mu_{0} + p_{01} \mu_{1} + p_{02} \mu_{2} + p_{03} \mu_{3} + p_{24} p_{02} \mu_{4} \) and \( {\text{D}}_{ 1} = 1 - p_{01} p_{10} - p_{02} p_{20} - p_{03} p_{30} - p_{02} p_{24} p_{40} \)
4 Steady state availability
Let Ai(t) be the probability that the system is in up-state at instant ‘t’ given that the system entered regenerative state i at t = 0. The recursive relations for Ai (t) are given as
where j is any successive regenerative state to which the regenerative state i can transit through n transitions. Mi(t) is the probability that the system is up initially in state \( S_{i} \in E \) is up at time t without visiting to any other regenerative state, we have
Taking LT of above relations (8) and solving for \( A_{0}^{*} (s) \), the steady state availability is given by
N2 = μ0 {(1 − p11.13) [(1 − p33.10 − p73 p37) (1 − p22.12 − p22.12.15 − p24p42.19)] − p12.6 [(1 − p33.10 − p73 p37) (p22.5 + p21.5.16 + p41.17p24) + p31.9(p23.11 + p23.11,14 + p43.18p24)] − p13.8[(1 − p22.12 − p22.12.15 − p24p42.19)p31.9]} + \( \mu_{1} \) {p01 (1 − p33.10 − p73 p37) (1 − p22.12 − p22.12.15 − p24p42.19) + p02 [(1 − p33.10 − p73 p37) (p21.5 + p21.5.16 + p41.17p24) + p31.9(p23.11 + p23.11,14 + p43.18p24)] + p03[(1 − p22.12 − p22.12.15 − p24p42.19)p31.9]} + (\( \mu_{2} \)+p24 \( \mu_{4} \)){p01 [(1 − p33.10 − p73 p37)p12.6 + p02{(1 − p11.13) (1 − p33.10 − p73 p37) − p13.8p31.9] + p03 p31.9p12.6} + (\( \mu_{3} \)){p01 [p12.6(p23.11 + p23.11,14 + p43.18p24) + (1 − p22.12 − p22.12.15 − p24p42.19)p13.8] + p02[(1 − p11.13) (p23.11 + p23.11,14 + p43.18p24) + p13.8 (p21.5 + p21.5.16 + p41.17p24)] + p03[(1 − p11.13) (1 − p22.12 − p22.12.15 − p24p42.19) − p12.6 (p21.5 + p21.5.16 + p41.17p24)]}
and
D2 = μ0 {(1 − p11.13) [(1 − p33.10 − p73 p37) (1 − p22.12 − p22.12.15 − p24p42.19)] − p12.6 [(1 − p33.10 − p73 p37) (p22.5 + p21.5.16 + p41.17p24) + p31.9(p23.11 + p23.11,14 + p43.18p24)] − p13.8[(1 − p22.12 − p22.12.15 − p24p42.19)p31.9]} + \( \mu^{\prime}_{1} \) {p01 (1 − p33.10 − p73 p37) (1 − p22.12 − p22.12.15 − p24p42.19) + p02 [(1 − p33.10 − p73 p37) (p21.5 + p21.5.16 + p41.17p24) + p31.9(p23.11 + p23.11,14 + p43.18p24)] + p03[(1 − p22.12 − p22.12.15 − p24p42.19)p31.9]} + (\( \mu^{\prime}_{2} \)+p24 \( \mu^{\prime}_{4} \)){p01 [(1 − p33.10 − p73 p37)p12.6 + p02{(1 − p11.13) (1 − p33.10 − p73 p37) − p13.8p31.9] + p03 p31.9p12.6} + (\( \mu^{\prime}_{3} \)+p37 \( \mu_{7} \)){p01 [p12.6(p23.11 + p23.11,14 + p43.18p24) + (1 − p22.12 − p22.12.15 − p24p42.19)p13.8] + p02[(1 − p11.13) (p23.11 + p23.11,14 + p43.18p24) + p13.8 (p21.5 + p21.5.16 + p41.17p24)] + p03[(1 − p11.13) (1 − p22.12 − p22.12.15 − p24p42.19) − p12.6 (p21.5 + p21.5.16 + p41.17p24)]}
5 Busy period analysis for server
Let \( B_{i}^{P} (t), \) \( B_{i}^{R} (t), \,\) \( B_{i}^{S} (t)\,\,{\text{and}} \) \( B_{i}^{HRp} (t) \)be the probabilities that the server is busy in preventive maintenance of the system, repairing the unit due to hardware failure, up-gradation of the software and hardware replacement at an instant ‘t’ given that the system entered state i at t = 0. The recursive relations for \( B_{i}^{P} (t), \) \( B_{i}^{R} (t), \,\) \( B_{i}^{S} (t)\,\,{\text{and}} \) \( B_{i}^{HRp} (t) \) are as follows
where j is any successive regenerative state to which the regenerative state i can transit through n transitions. Let Wi(t) be the probability that the server is busy in state Si due to preventive maintenance, hardware and software failure up to time t without making any transition to any other regenerative state or returning to the same via one or more non-regenerative states. We have\( W_{1}^{{}} = e^{{ - (a\lambda_{1} + b\lambda_{2} + \alpha_{0} )t}} \overline{F} (t) + (\alpha_{0} e^{{ - (a\lambda_{1} + b\lambda_{2} + \alpha_{0} )t}} \copyright{ 1)}\overline{{{\text{F}}_{{}} }} (t) + (a\lambda_{1} e^{{ - (a\lambda_{1} + b\lambda_{2} + \alpha_{0} )t}} \copyright{ 1)}\overline{F} (t) + (b\lambda_{2} e^{{ - (a\lambda_{1} + b\lambda_{2} + \alpha_{0} )t}} \copyright{ 1)}\overline{F} (t) \) \( W_{2}^{{}} = e^{{ - (a\lambda_{1} + b\lambda_{2} + \alpha_{0} + \beta_{0} )t}} \overline{G} (t) + (\alpha_{0} e^{{ - (a\lambda_{1} + b\lambda_{2} + \alpha_{0} + \beta_{0} )t}} )\overline{{{\text{G}}_{{}} }} (t) + (a\lambda_{1} e^{{ - (a\lambda_{1} + b\lambda_{2} + \alpha_{0} + \beta_{0} )t}} \copyright{ 1)}\overline{G} (t) + (b\lambda_{2} e^{{ - (a\lambda_{1} + b\lambda_{2} + \alpha_{0} + \beta_{0} )t}} \copyright{ 1)}\overline{G} (t) \) \( W_{3}^{{}} = e^{{ - (a\lambda_{1} + b\lambda_{2} + \alpha_{0} )t}} \overline{H} (t) + (\alpha_{0} e^{{ - (a\lambda_{1} + b\lambda_{2} + \alpha_{0} )t}} \copyright 1 )\overline{{{\text{H}}_{{}} }} (t) + (a\lambda_{1} e^{{ - (a\lambda_{1} + b\lambda_{2} + \alpha_{0} )t}} )\overline{H} (t) + (b\lambda_{2} e^{{ - (a\lambda_{1} + b\lambda_{2} + \alpha_{0} )t}} \copyright 1 )\overline{H} (t) \) \( W_{4}^{{}} = e^{{ - (a\lambda_{1} + b\lambda_{2} + \alpha_{0} )t}} \overline{M} (t) + (\alpha_{0} e^{{ - (a\lambda_{1} + b\lambda_{2} + \alpha_{0} )t}} \copyright{ 1)}\overline{{{\text{M}}_{{}} }} (t) + (a\lambda_{1} e^{{ - (a\lambda_{1} + b\lambda_{2} + \alpha_{0} )t}} \copyright{ 1)}\overline{M} (t) + (b\lambda_{2} e^{{ - (a\lambda_{1} + b\lambda_{2} + \alpha_{0} )t}} \copyright{ 1)}\overline{M} (t) \), Taking LT of above relations (11). And, solving for \( B_{i}^{*P} (s) \),\( B_{i}^{*R} (s) \), \( B_{i}^{*S} (s)\,\,{\text{and}} \) \( B_{i}^{*HRp} (s) \), the time for which server is busy due to preventive maintenance, h/w repair/replacement and s/w up-gradation respectively is given by
And
where
6 Expected number of h/w replacements and s/w up-gradations
Let \( R_{i}^{H} (t)\,\,{\text{and}} \) \( R_{i}^{S} (t) \)the expected number of h/w replacements and software up-gradations by the server in (0, t] given that the system entered the regenerative state i at t = 0. The recursive relations for \( R_{i}^{H} (t)\,\,{\text{and}} \) \( R_{i}^{S} (t) \) are given as
where j is any regenerative state to which the given regenerative state i transits and \( \delta j \) = 1, if j is the regenerative state where the server does job afresh, otherwise \( \delta j \) = 0.
Taking LST of relations and, solving for \( \tilde{R}_{0}^{H} (s) \) and \( \tilde{R}_{0}^{S} (s) \). The expected numbers of h/w replacements per unit time and software up-gradations per unit time are respectively given by
where D2 is already mentioned.
7 Expected number of visits by the server
Let Ni(t) be the expected number of visits by the server in (0, t] given that the system entered the regenerative state i at t = 0. The recursive relations for Ni(t) are given as
where j is any regenerative state to which the given regenerative state i transits and \( \delta j \) = 1, if j is the regenerative state where the server does job afresh, otherwise \( \delta j \) = 0. Taking LST of relation (15) and solving for \( \tilde{N}_{0} (s) \). The expected number of visit per unit time by the server are given by
N5 = (p01 + p02 + p03){(1 − p11.13) [(1 − p33.10 − p73 p37) (1 − p22.12 − p22.12.15 − p24p42.19)] − p12.6 [(1 − p33.10 − p73 p37) (p22.5 + p21.5.16 + p41.17p24) + p31.9(p23.11 + p23.11,14 + p43.18p24)] − p13.8[(1 − p22.12 − p22.12.15 − p24p42.19)p31.9]}
8 Profit analysis
The profit incurred to the system model in steady state can be obtained as
- K0 :
-
Revenue per unit up-time of the system
- K1 :
-
Cost per unit time for which server is busy due preventive maintenance
- K2 :
-
Cost per unit time for which server is busy due to hardware failure
- K3 :
-
Cost per unit time for which server is busy in software up-gradation
- K4 :
-
Cost per unit time for which server is busy in h/w replacement
- K5 :
-
Cost per unit time h/w replacement
- K6 :
-
Cost per unit time s/w up-gradation
- K7 :
-
Cost per unit time visit by the server
9 Conclusion
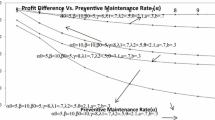
In the present study, the numerical results for mean time to system failure (MTSF) and profit are obtained giving some particular values to various parameters and costs taking \( g(t) = \theta e^{ - \theta t} \), \( h(t) = \beta e^{ - \beta t} \), \( f(t) = \alpha e^{ - \alpha t} \) and \( m(t) = \gamma e^{ - \gamma t} \). The graphs for MTSF and profit are drawn with respect to preventive maintenance rate (α) for fixed values of other parameters including a = 0.7 and b = 0.3 as shown respectively in Figs. 2 and 3. These figures indicate that MTSF and profit increase with the increase of preventive maintenance rate (α), maximum repair time (β0), and h/w repair rate (θ). But the values of these measures decrease with the increase of maximum operation time (α0). Thus finally it is concluded that a computer system in which chances of h/w failure are high can be made more reliable and profitable to use

.

.
-
(i)
By taking one more unit (computer system) in cold standby.
-
(ii)
By conducting preventive maintenance of the system after a specific period of operation.
-
(iii)
By giving maximum repair time to the server for h/w repair in case priority is given to the h/w repair over s/w up-gradation.
-
(iv)
By making s/w up-gradation immediately as per requirements in case s/w fails to execute the desired functions properly
Abbreviations
- E:
-
The set of regenerative states
- NO:
-
The unit is operative and in normal mode
- Cs:
-
The unit is cold standby
- a/b:
-
Probability that the system has hardware/software failure
- \( \lambda_{1} /\lambda_{2} \) :
-
Constant hardware/software failure rate
- α0 :
-
Maximum operation time
- β0 :
-
Maximum repair time
- Pm/PM:
-
The unit is under preventive maintenance/under preventive maintenance continuously from previous state
- WPm/WPM:
-
The unit is waiting for preventive maintenance/waiting for preventive maintenance from previous state
- HFur/HFUR:
-
The unit is failed due to hardware and is under repair/under repair continuously from previous state
- HFurp/HFURP:
-
The unit is failed due to hardware and is under replacement/under replacement continuously from previous state
- HFwr/HFWR:
-
The unit is failed due to hardware and is waiting for repair/waiting for repair continuously from previous state
- SFurp/SFURP:
-
The unit is failed due to the software and is under up-gradation/under up-gradation continuously from previous state
- SFwrp/SFWRP:
-
The unit is failed due to the software and is waiting for up-gradation/waiting for up-gradation continuously from previous state
- h(t)/H(t):
-
pdf/cdf of up-gradation time of unit due to software
- g(t)/G(t):
-
pdf/cdf of repair time of the hardware
- m(t)/M(t):
-
pdf/cdf of replacement time of the hardware
- f(t)/F(t):
-
pdf/cdf of the time for PM of the unit
- qij(t)/Qij(t):
-
pdf/cdf of passage time from regenerative state i to a regenerative state j or to a failed state j without visiting any other regenerative state in (0, t]
- pdf/cdf:
-
Probability density function/Cumulative density function
- qij.kr (t)/Qij.kr(t):
-
pdf/cdf of direct transition time from regenerative state i to a regenerative state j or to a failed state j visiting state k, r once in (0, t]
- μi(t):
-
Probability that the system up initially in state Si ∈ E is up at time t without visiting to any regenerative state
- Wi(t):
-
Probability that the server is busy in the state Si up to time ‘t’ without making any transition to any other regenerative state or returning to the same state via one or more non-regenerative states
- mij :
-
Contribution to mean sojourn time (μi) in state Si when system transit directly to state Sj so that \( \mu_{i} = \sum\limits_{j} {m_{ij} } \) and mij = \( \int {tdQ_{ij} (t) = - q_{ij}^{*} \prime (0)} \)
- \( \circledS \)/©:
-
Symbol for Laplace-Stieltjes convolution/Laplace convolution
- ~/*:
-
Symbol for Laplace Steiltjes Transform/Laplace Transform
- ‘(desh):
-
Used to represent alternative result
References
Friedman MA, Tran P (1992) Reliability techniques for combined hardware/software systems. In: Proceedings of annual reliability and maintability symposiym, pp 290–293
Kumar A, Malik SC, Barak MS (2012) Reliability modeling of a computer system with independent H/W and S/W failures subject to maximum operation and repair times. Int J Math Arch 3(7):2622–2630
Malik SC, Anand J (2010) Reliability and economic analysis of a computer system with independent hardware and software failures. Bull Pure Appl Sci 29E (Math. & Stat.)(1):141–153
Malik SC, Nandal P (2010) Cost-analysis of stochastic models with priority to repair over preventive maintenance subject to maximum operation time. Learning manual on modeling, optimization and their applications, Edited Book. Excel India Publishers, pp 165–178
Malik SC, Sureria JK (2012) Reliability and economic analysis of a computer system with priority to H/w repair over S/W replacement. Int J Stat Anal 2(4):379–389
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Malik, S.C. Reliability modeling of a computer system with preventive maintenance and priority subject to maximum operation and repair times. Int J Syst Assur Eng Manag 4, 94–100 (2013). https://doi.org/10.1007/s13198-013-0144-y
Received:
Revised:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13198-013-0144-y
Keywords
- Computer system
- Cold standby
- Preventive maintenance
- Maximum operation and repair times
- H/w repair and replacement
- S/w up-gradation
- Reliability measures
- Profit function