
Abstract
Data acquisition and data processing are at the core of pavement management systems. Nowadays, traditional methods of data collection are rarely used in developed countries due to the considerable disadvantages of the traditional methods compared to the automated ones, such as the slow pace of data collection, endangering the safety of the human operators collecting the data, considerable cost, collecting data from only a limited section of road networks, and inconsistency among the data collected by different operators. In contrast, automated methods alleviate the majority of these problems. However, the main drawback of the automated methods is the high cost of purchase, implementation, and maintenance of the equipment, which has deterred their use in developing countries with limited financial resources. To address this problem, developing a new automated method that reduces the production costs while keeping the required accuracy and performance seems imperative. The goal of this research is to investigate the use of microphones, as inexpensive equipment with acceptable accuracy, for collecting pavement macrotexture data, which is an input to the pavement management system. The proposed method is based on the tire/road interaction noise. To this end, a review of the previous researches on audio-based monitoring of various pavement features is presented. By considering the results of the related researches and the goals of this work, a new setup for data collection and an accompanying signal processing method is proposed. To develop and evaluate the proposed method, data from six standard road sections of a test field are collected. To process the collected data, PCA, Cepstrum, LPC, LSF, PSD, and Wavelet methods are employed. The SVM and KNN classification methods are used to evaluate the results of the signal processing step, which is performed in various frequency bands. The best results are obtained by using the Cepstrum signal processing method along with the SVM classifier in the 3000–5000 Hz frequency band resulting in an accuracy of 95% on the test data and the precision error of 1%.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Road pavements are one of the main parts of the public infrastructure and are designed to have long service life while providing a safe and smooth surface in various weather conditions. To maintain these conditions and meet the needs of the transportation system, regular monitoring and maintenance is a necessity.
The equipment used to evaluate and monitor the road surface conditions have been improving at a fast pace. This equipment has been improved from simple visual inspection to novel, sophisticated automated methods. The challenges associated with the performance and outcomes of such equipment have also been diminished over time. The constant need for improved performance has been the driving force behind the development of complicated systems with the ability to collect various road features in on passing by using high precision and inexpensive sensors and processing the collected data using various signal processing techniques [1].
In general, road surface condition data are used for the following purposes:
-
Evaluating the quality of the constructed road
-
Assessing the present-day quality
-
Assessing the change in performance over time and estimating the future state of the road surface
-
Providing metrics for evaluating the performance of the road network
-
Assessing the performance of road construction companies
-
Providing data for optimum road maintenance and repair planning
There are various metrics for evaluating road surface condition. Some of the most important of these metrics are Pavement Condition Index (PCI), Mean Texture Depth (MTD), Mean Profile Depth (MPD), Estimated Texture Depth (ETD), International Roughness Index (IRI), Rut Depth, Friction Index and Structural Index.
Pavement macrotexture is a technical parameter of the road surface, which is used for developing various important indexes related to different road features such as road safety (road surface friction), environmental effects (tire/road interaction noise), construction and maintenance of the road (assessing the quality after construction and during service life by using MTD).
On the other hand, pavement defects have considerable effects on the number of car accidents. One of the most important defects is the road surface slipperiness. Resistance to slipperiness is affected by various factors such as traffic, road surface, vehicle, and environment, with the road surface being the most important. Road pavement is studied on both micro and macro scales. A combination of both scales in the asphalt mixture provides the necessary resistance to friction for a vehicle under various conditions [2]. Pavement macrotexture plays a significant role in providing road safety and preventing accidents due to the slipperiness of the road surface in rainy weather, and as a result, is one of the most important factors in evaluating the safety of the wet surface of the road [3].
Evaluating the friction of the road surface, detecting low friction sections, and implementing methods for increasing the needed sections friction result in increased road safety. One of the friction assessment methods is to evaluate the texture of the pavement and the resistance to slipperiness [2]. The road safety enhancement road through maintenance treatment allocation is of significant importance from an economic perspective. Every year a portion of fatal car accidents which occur during the rainy weather, which in part is due to the slipperiness of the wet surface of the road [4]. Hence it is imperative to evaluate the pavement texture, which is not only an important factor in determining the safety of the road but also an important indicator of the quality and homogeneity of the constructed pavement [3]. The most common indexes used for quantifying road surface texture are MTD and MPD [1]. Other, less common, indexes based on the analysis of the spectrum of the texture amplitude have also been used in the literature [1].
The technology used for data collection, and especially the pavement macrotexture data in the pavement management systems and safety management systems, has been advancing at a significant pace. Development and implementation of data collection systems based on technologies such as laser sensors, ultrasound beam, high precision cameras, high precision microphones, and computers with high processing speed have played a significant role in improving the quality and relevance of the collected data. In general, the methods used for collecting the pavement macrotexture data can be divided into static and dynamic methods [3]. The most common static data collection methods are the sand patch method and the circular texture meter method [3]. Dynamic data collection is usually performed at high speeds of the collecting vehicle (80 to 100 km/h), with the most common method being the profilometer, which is equipped with laser sensors. Besides these methods, other less common methods such as outflow meter, image processing based methods, and profilometers with 3D lasers have also been implemented for evaluating the pavement macrotexture [1].
2 Audio-based Pavement Evaluation
One of the main approaches for evaluating the pavement texture is an audio-based method that applies a microphone to collect data. Evaluating the pavement texture comprises of determining the pavement characteristics such as the condition of the road surface (e.g., dry, wet, and moist), characteristics of the road surface (e.g., texture, roughness, and cracking), and depth characteristics (e.g., thickness, layer conditions). To evaluate these various characteristics, different data collection systems have been developed, a summary of which is presented herein.
As can be seen in Table 1, various researches have employed microphones and audio signals to evaluate different pavement characteristics. One of these characteristics that has been considered in various researches is pavement macrotexture. Various data collection and signal processing methods have been developed for collecting the pavement macrotexture data; however, only the method developed by Ganji et al. [10] has been able to distinguish surfaces with close macrotexture characteristics. To this end, Ganji et al. [10] have developed a piece of custom equipment for collecting the tire/road interaction noise. However, the main drawback of the developed equipment is that data collection has to be performed at relatively low vehicle speed.
3 Problem Definition
The purpose of this work is to develop equipment with high vehicle speed and assessing various combinations of different signal processing and modeling techniques, to distinguish surfaces with close macrotexture characteristics using the tire/road interaction noise. Doing so will not only increase the data collection speed compared to the work done in [10] but also further increase the possibility of using microphones as an inexpensive sensor in the automated data collection equipment. To this end, by considering the various processing methods presented in the literature, the PSD, Wavelet, Cepstrum, LPC, PCA, and LSF methods were selected. Also, the SVM and KNN methods were considered as classifiers. The scope of this work is limited to non-porous asphaltic pavements with no defects.
4 Methodology
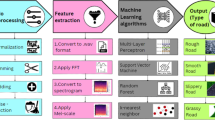
In this work, as a first step, various data collection methods based on the tire/road interaction noise were identified. By considering the drawbacks of the existing methods, new audio-based equipment for evaluating the pavement macrotexture was developed. Standard road sections were used for collecting the interaction noise. The collected interaction noise data were first preprocessed, and then the DWT, LPC, LSF, Cepstrum, PCA, and PSD signal processing methods were employed to extract macrotexture data. After the processing step, and to select the best method, the SVM and KNN classifiers were applied. The flowchart of the approach presented in this work is shown in Fig. 1.

The employed research method
5 Developing the Equipment
There are various methods for measuring the tire/road interaction noise, which in general can be divided into three main categories: (1) on-board measurement (2) measurement from the side of the road (3) measurement in the laboratory.
Given that the goal of this research is to measure pavement macrotexture dynamically, the onboard measurement methods were considered. The CPX and OBSI methods are the two standard onboard measurement methods in practice. The setup and configuration of these two standards are presented in Table 2.
Besides the two aforementioned standard methods, various other onboard methods have also been presented by researchers. A summary of which is expressed in Table 3.
Having assessed the mechanisms affecting the interaction noise and the present methods, it was decided to develop new equipment with an associated microphone set up to be able to collect the interaction noise at a higher quality, which has been presented in [11]. To this end, some modifications to the microphone array relative to the CPX standard were performed. In this setup, microphones (Beyerdynamic TG I53c) are closer to the tire and further apart from each other, and are also directed towards the tire/road interaction surface. This modified setup can better capture the tire/road interaction noise [11]. The vehicle on which this setup was mounted is compatible with the ISO/DIS 11819-2 standard.
To be able to evaluate the interaction noise in different directions, three microphones were utilized. The first microphone was placed near to the front of the tire, the second one was located in the center of the tire, and the third microphone was positioned near to the back of the tire. The reason for this placement is that in each direction, some noise mechanisms can be better monitored. The mechanisms involved in the production of the tire/road interaction noise are depicted in Fig. 2.

There are various mechanisms responsible for the production and emission of the interaction noise, which can be divided into two general categories: noise generation and noise amplification. Noise generation mechanisms include stick-snap, slip-stick, air pumping, and tread impact, while noise amplification mechanisms encompass horn effect, organ pipes, Helmholtz resonators, carcass vibration, mechanical impedance, and cavity resonance.
Based on the nature of the source of the generated noise, noise generation mechanisms can be divided into two categories of vibration and air pumping. Each of these mechanisms are effective in a different frequency band. The effective frequency range of these mechanisms is shown in Fig. 3 [47]. The vibration-based mechanisms are effective in the frequency range of below 1000 Hz, while the air pumping based mechanisms are most effective in the frequency range of 1000–2500 Hz [48].

The effective frequency range of noise generation mechanisms [47]
In the majority of the researches conducted on the pavement macrotexture using interaction noise, the selected frequency band has been below 2000 Hz, and the results obtained show that the developed methods are not capable of differentiating between pavements with close macrotexture levels. In this work, various frequency bands with various signal processing methods were considered to evaluate the possibility of using interaction noise to differentiate pavements with close macrotexture levels. The reason for selecting various frequency bands is to observe various mechanisms active in the frequency band of above 2000 Hz, which have not been considered in previous works.
6 Data Collection and Experiment Design
Six pavement sections with almost similar macrotexture levels from the BAREZ test track were selected. The road/tire interaction noise of these sections was collected. The macrotexture of these sections is shown in Fig. 4. The MTD of these pavements was measured by using the sand patch method according to the ASTM E965 standard, and the results are presented in Table 4.

Macrotexture of the selected pavement sections
In the experiment design, the pavement macrotexture, vehicle speed, and the ambient temperature were chosen as parameters/factors, while the other relevant factors were tried to be constant such as tire pressure, wind speed, tire type, ambient moisture, and vehicle operator. The descriptions/levels for each factor are expressed in Table 5.
7 Signal Processing
As mentioned in the literature review, various signal processing methods have been used on the audio data for evaluating the pavement surface. However, the range of signal processing methods employed in the area of pavement macrotexture monitoring by using interaction noise has been relatively limited. As a result, in this section, the signal processing methods used on the audio data have been tried to find the best method for obtaining macrotexture related data. To process the interaction noise, first, a preprocessing step, which is comprised of bandpass filtering, was performed on the audio signal. The filtered signal was then processed by PCA, DWT, PSD, LPC, LSF, and Cepstrum signal processing methods in various frequency bands. After processing the SVM and KNN classifiers were employed to evaluate the extracted features. To this end, 80% of the collected data was used for training the classifiers, and 20% was deployed for testing the trained models (Fig. 5).

Flowchart of the Processing methods
7.1 Preprocessing
Since different mechanisms perform differently at various frequency bands are affected by macrotexture, it is imperative to process the audio signal at different frequency bands. To implement bandpass filtering, first, the upper and lower cutoff frequency ranges were determined. The wind noise and the macrotexture effects are the most important factors in the lower cutoff range. Given that the physical principle behind the sound transmission and microphone performance is sound pressure, the wind blowing in the data collection environment or the wind pressure produced due to the speed of the moving vehicle can have negative effects on the quality of the recorded data. Having analyzed the data collected in this research and also by considering the results obtained in [33], it was understood that the main effects of wind blowing and wind pressure are in the lower frequency ranges, and they don’t have significant components in the middle and higher frequency ranges. Having considered these two effects and observed the experimental results (maximum distinguishability between pavements), the lower frequency range of 500 Hz was selected.
Macrotexture characteristics also play an important role in determining the upper cutoff frequency range. The effects of these characteristics, in this case, are similar to their effects in determining the lower cutoff frequency range, i.e., the interaction noise generated due to macrotexture characteristics has limited effective frequency range and does not have significant components in very high-frequency ranges. The other important factor in determining the upper cutoff frequency range is the thermal noise. Thermal noise is an inherent phenomenon present in all electronic devices such as microphones and amplifiers and has almost equal components in a very wide frequency range. As a result, regarding the fact that the recorded interaction noise does not have significant components in higher frequency ranges, the signal to noise ratio becomes very low in these frequencies. If it is not filtered out, it can have degrading effects on the relevance of the extracted features in the processing step and on the overall performance of the proposed system. Regarding these two effects and observing the experimental results (maximum distinguishability between pavements), the upper-frequency range of 5000 Hz was chosen.
To analyze the effects of the mechanisms involved in the interaction noise generation, the frequency band of 500–5000 Hz was divided into three smaller regions. These regions which were selected based on the effective frequency ranges of the involved mechanisms are (1) 500–1500 Hz in which vibration is the dominant mechanism, (2) 1500–3000 Hz in which air pumping is the dominant mechanism, and (3) 3000–5000 Hz in which the slipping mechanism is dominant. A sample of the raw audio data and the filtering results are shown in Fig. 6.

A sample of raw audio data and the spectrum of the filtered results
For each of the frequency, as mentioned above, ranges, the signal processing, and model training steps were performed. However, it should be noted that for the wavelet case, due to the inherently applied filter bank, the 500–5000 Hz audio data has been employed as input.
8 Signal Processing and Model Development
Given the variety of tested signal processing and classification methods, several models were obtained. For every signal processing method, 18 models were trained, which is the result of training over three microphones in three different frequency bands using two classifiers. The precision error was used for evaluating the resulting models, the formula of which is given in Eq. 1.
If the precision error calculated using Eq. 1 is exceeding 100%, it is replaced with the value of 100%. The difference between the two measurements of the same homogenous pavement section using the sand patch method can vary by as much as 27% [49]. Given the prevalence of using laser devices for measuring MPD, some relations for estimating MTD using MPD were proposed, which resulted in dynamic MTD measurements and were called ETD relations. According to the ISO 13473-1 standard [50], which is one of the main standards for estimating MPD, for a given 150-meter-long section, the difference between MPD of various data collections can vary by as much as 20% of the mean value. This error can result from software errors, operator errors, and the fact that data are collected from different lines during different data collection replications. It is quite hard to track the same line on the pavement during every data collection replication. By considering the above standard, the 20% threshold was considered for the precision error results and the acceptability of the trained models. In the following sections, the accuracy and the precision error of the trained models are presented, which can be used to compare the results of different models. For training the models, data with different speed and temperature conditions were utilized, reducing the sensitivity of the trained model to such variations.
8.1 Classification using SVM
Support vector machines are one of the supervised learning methods which can be used for both classification and regression purposes. In the training phase of this method, the aim was to find a hyperplane that separated the existing classes as much as possible. This training was carried out by trying to find a hyperplane that had the maximum possible distance from existing classes. During the classification phase, new data was assigned to a class based on which side of the hyperplane it fell. The optimization problem formulated for finding the best hyperplane is as follows
In the above equations, C is a tuning parameter and \(\epsilon_{i}\) are called the stack variables. Together, they determine the sensitivity of the trained hyperplane to outliers in the data. By solving the above equations, the \(\alpha\) parameters were obtained, which were then applied to classify new data by using the relation given in Eq. 3 [51].
The original SVM method was introduced for two classes: the one-versus-one and one-versus-all [51]. Both methods were tested for training an SVM model, and the best result was reported. 80% of the available data were used for training the models, while 20% of the data were used for testing the performance of the trained models.
8.2 Classification using KNN
The k nearest neighbor method is a classification algorithm that classifies new inputs based on the majority voting amongst the class labels of the k nearest neighbors of this input. As a result, the output function is only computed locally, and during the classification step, this type of learning is also referred to as lazy learning in computer science literature.
During the training phase, the input feature space is partitioned into regions in which one class is dominant. The partitioned regions vary based on the selected value for k. For a given test, inputs are calculated using the conditional probability formula given in Eq. 4.
Similar to the SVM case, 80% of the available data were employed for training the models, while 20% were used for testing the performance of the trained models.
8.3 Wavelet
The wavelet transform is a method for obtaining signal representations in the time–frequency domain. The main difference between this method and the Fourier transform is that in the wavelet transform, the length of the applied window is dependent on the central frequency. The continuous wavelet transform was proposed as an alternative to the STFT transform for solving the time–frequency resolution problem. To calculate the wavelet coefficients, the input signal is multiplied by a wavelet function, which is similar to the windowing function applied in the STFT method. The formula for calculating the continuous wavelet transform is given in Eq. 5 [27].
As can be seen from Eq. 5, the obtained coefficient is a parameter of the \(\tau\) and s variables, which are called the translation and dilation parameters, respectively. \(\varPsi \left( t \right)\) is the transformation function and is also called the mother wavelet.
In practice, the dilation and translation parameters are discrete, which results in the discrete wavelet transform (DWT). In this case, the wavelet function is given by Eq. 6 [52].
Similar to the CWT case, the DWT coefficients are also calculated using the inner product between the signal and the wavelet function, which results in the relation given in Eq. 7. In this equation, j and k are dilation and translation parameters, respectively.
DWT, in effect, divides the signal into two frequency regions recursively, which is shown in Fig. 7.

Decomposition using DWT
For developing models using the DWT method, after preprocessing, the signal was decomposed into six levels using a one-dimensional DWT algorithm. For every level, the three parameters of mean value, power mean, and standard deviation were calculated for the obtained DWT coefficients resulted in 18 total parameters. These parameters were later fed as input to the two aforementioned classifiers. A sample of the obtained features is shown in Figs. 8 and 9.

Obtained wavelet features

The separation of the obtained wavelet features for different sections
The results of testing the trained SVM and KNN models are presented in Table 6.
As can be seen in Table 6, the classification accuracy for the frontal microphone using the KNN classifier and the rear microphone using the SVM classifier are similar, which verifies the difference like the received signal in these directions.
8.4 Cepstral Signal Processing
This processing method is used by Ganji et al. [11], and this method is used here to be compared with the other methods. The cepstral analysis is a very common processing method in audio signal processing due to possessing three useful features which are, data compression, separation of the audio source from the transmission channel in the cepstral space, and negligible correlation (reduced redundancy) between resulting cepstrum coefficients [53]. To obtain the cepstrum coefficients, the signal is first divided into small time frames using hamming windowing. After this step, the Fourier transform of each window is obtained, and then the logarithm operator is applied to the amplitude of the resulting Fourier coefficients. The logarithm operator transforms the multiplication of the signal source and transmission channel in the frequency domain into addition to the cepstral domain. The formula for obtaining the cepstrum coefficients is presented in Eq. 8 [53].
The separation of the signal source and transmission channel in the cepstral domain is the result of applying the logarithm operator, and the reason for this is that in the audio case the signal source and the transmission channel occupy different cepstral ranges, which makes it possible to separate them in this space using the liftering operation easily. After the logarithm operator, coefficients are normalized by removing the mean value; there are divided by their standards deviation. This step reduces the dependence of the final coefficients on the intensity levels of the input audio and helps increase the classification accuracy of the trained model. The last step is to apply the Discrete Cosine Transform (DCT) on the normalized coefficients. The DCT transform relation is given in Eq. 9.
In Eq. 9, the \(x\left[ j \right]\) is the \(j\) th Fourier coefficient, \(i\) is the index of the cepstrum coefficient, and \(N\) is the number of data samples in each time frame. The compression and negligible correlation features of the cepstrum coefficients are the results of applying the DCT transform. After applying the above steps, the final cepstrum coefficients are obtained.
Through testing the accuracy of the trained models by changing the number of selected cepstrum coefficients and observing the decreasing trend in the amplitude of these coefficients, the first 50 cepstrum coefficients were selected. A sample of the resulting cepstrum coefficients are illuminated in Figs. 10 and 11.

A sample cepstrum coefficients

The separation of the obtained cepstrum coefficients for different sections
The results of testing the trained SVM and KNN models are shown in Table 7.
It can be observed in Table 7 that although all of the developed models using the cepstrum coefficients have acceptable performance, the best results were obtained in the 3000–5000 Hz frequency band. The reason for this was the presence of a slipping mechanism, which is a source of interaction noise generation, in this frequency range, and the deconvolve property of the cepstrum coefficients. The result of the combination of these two effects was that the first few cepstrum coefficients represented the transmission channel, which in this case, was associated with the pavement macrotexture, which also reduced the sensitivity of the model to the temperature and vehicle speed variations. For the models developed in other frequency ranges, due to the presence of low-frequency interaction noise generation mechanism, the separation in the cepstrum coefficients was not clear, resulting in their degraded performance.
8.5 Principle Component Analysis
This method is used by Saykin et al. [6], and this method is used here again to be compared with the other methods. The PCA method is mainly used for reducing the dimensionality of data. The PCA applies an orthogonal transformation on the input vector space to create a new vector space such that the variance of the data is the highest for the first component of the new vector space, second-highest for the second component and so on. The reduction in dimension is the result of selecting only the first few components of the new vector space, which entail a fixed percentage of variations in the data as representative vectors for the input data. The first principle component can be written as a normalized linear combination of the input vectors, as presented in Eq. 10.
in which
The coefficients in Eq. 10 comprise the coefficients vector for the first principle component [51].
To apply the PCA method in determining the pavement macrotexture, after the preprocessing step, the input signal was divided into short time windows and the sub-band energies of each time window which resulted in the following matrix representation [6].
After forming the matrix in Eq. 13, the PCA was applied to obtain feature representations from the input signal. The obtained principal components for a sample data from each pavement section type employed herein are illustrated in Figs. 12 and 13. Having considered the percentage of the variance covered by each principal component, the first principle components were selected as signal representatives.

Principle components for different sections

The separation of the obtained principal components for different sections
The results of testing the trained SVM and KNN models are presented in Table 8.
Table 8 expresses that the PCA results for all tested speeds and temperatures are out of the accepted range; hence, the PCA is not a suitable method for evaluating the pavement macrotexture.
8.6 Power Spectral Density
The power spectral density represents the energy spread of a signal in its comprising frequency components. In other words, the power spectral density represents how much power is in each frequency component of a signal. There are various methods for estimating the power spectral density of a given signal from its samples, such as the Periodogram or the Welch method. The Welch method, which is a common way of obtaining the PSD of a signal, was employed in this study, and a summary of it is described as follows [54].
In this method, for every section of length L of the input signal, a modified periodogram is calculated. To this end, the selected section is first multiplied by a window, and then the FFT of the results is obtained.
After the above step, the modified periodogram is derived as follows.
in which
and
After calculating the modified periodograms, the individual periodograms are then averaged, which reduce the variance of the individual power measurements. The average result is the desired PSD using the Welch method.
The obtained PSD coefficients for a sample from each pavement section, are depicted in Figs. 14 and 15.

PSD coefficients for different sections

The separation of the obtained PSD coefficients for different sections
The results of testing the trained SVM and KNN models are presented in Table 9.
As observed in Table 9, the best results in this method are provided using the KNN classifier for the frequency range of 1500–3000 Hz.
8.7 Linear Predictive Coding [55]
The LPC method has been widely used in speech coding, speech synthesis, speech recognition, speaker recognition, speaker identification, and speech saving. The main idea in this method is to estimate the \(n\) th sample of the desired signal using the previous samples and the current and previous values of an input signal by using the relation given in Eq. 19.
where,
In Eq. 19, \(u\left( n \right)\) is the input signal, and \(G\) is the applied gain on the input. Taking the Z-transform of Eq. 19 results in:
Hence the transfer function of the above set of equations becomes:
Considering an all-pole model or, i.e., discarding the dependency in the past input values we have:
Equation 23 tries to estimate the current sample of the desired signal using its previous values and the current input value. The error of using this estimate is calculated using Eq. 25.
With the resulting error transfer function of
The LPC method aims to find the \(a_{k}\) coefficients to minimize the error \(e_{n}\). The most common number of considered past signal values in the speech processing literature is 14. Therefore, 14 coefficients were also considered in this research. A sample of the obtained LPC coefficients is illustrated in Figs. 16 and 17.

LPC coefficients for different sections

The separation of the obtained LPC coefficients for different sections
The results of testing the trained SVM and KNN models are shown in Table 10.
It can be observed from Table 10 that the KNN classifier does not yield acceptable results for this method, while the SVM results are acceptable. The best result in this method is associated with the rear microphone and in the frequency range of 500–1500 Hz.
8.8 Line Spectral Frequencies
Line spectral frequencies are a representation for linear predictive coefficients. They are obtained by decomposing the LPC transfer function into symmetric and an antisymmetric section, which correspond to vocal tract with the glottis closed and with the glottis open, respectively (Fig. 18). The line spectral frequencies are computed as follows.

LSF decomposition procedure
where
The roots of the \(P\left( z \right){\text{and }}Q\left( z \right)\) and polynomials lie on the unit circle, which are the desired spectral frequencies. In this study, 10 LSF coefficients were deployed as signal representatives. A sample of the obtained LSF coefficients is shown in Figs. 19 and 20.

LSF coefficients for different sections

The separation of the obtained LSF coefficients for different sections
The results of testing the trained SVM and KNN models are expressed in Table 11.
The line spectral frequencies represent the frequencies with peak values in the spectrum of the audio signal, and the interaction noise also has a peak value at around the frequency of 1000 Hz. As a result, the best performance by this method is obtained in the frequency band of 500–1500 Hz. It should be noted that the results obtained by using the LSF coefficients are acceptable in all frequency ranges using any of the microphones in either of the classifiers.
The best results for each signal processing method are expressed in Table 12. This table is a comparison table to compare all methods that have been used.
As can be seen, the best model was obtained using the cepstral signal processing in the frequency range of 3000–5000 Hz. This result is due to the nature of the interaction noise in this frequency band and the inner workings of the applied processing method.
9 Conclusion
Using inexpensive equipment for measuring various pavement characteristics in an automated manner is an optimal solution for developing countries. The focus of this research was to implement the microphones and tire/road interaction noise to evaluate pavement macrotexture. According to recent related literature, present measurement methods were modified, and novel equipment was developed. In the processing step, the efficiency of various signal processing methods in different frequency bands and using different classifiers for evaluating pavement macrotexture were assessed, and the best results were presented. The important achievements of this study can be summarized as follows.
-
Using the developed equipment, it was possible to obtain the pavement macrotexture with high accuracy
-
The cepstrum analysis was the best method for processing the tire/road interaction noise
-
The best model was obtained using the cepstrum coefficients in the frequency range of 3000–5000 Hz. This result is due to the nature of the interaction noise in this frequency band and the inner workings of the applied processing method.
-
Not only the cepstrum coefficients were suitable signal features for macrotexture analysis, but also, they had little sensitivity to variations in the temperature and the vehicle speed.
-
Different processing methods yielded different results in various frequency bands which were due to the different nature of the interaction noise in these bands
References
PIARC (2015) State of the art in monitoring road condition, 1–70. https://www.piarc.org/en/order-library/25113-en-State of the art in monitoring road condition and road/vehicle interaction.htm (accessed February 1, 2017)
PIARC (2004) Road Safety manual, https://roadsafety.piarc.org/en (accessed July 8, 2017)
Flintsch G, de León E, McGhee K, AI-Qadi I (2003) Pavement surface macrotexture measurement and applications. Transp Res Rec 1860:168–177. https://doi.org/10.3141/1860-19
Smith HA (1977) Pavement contributions to wet-weather skidding accident reduction, Transportation Research Record. pp 51–59. http://onlinepubs.trb.org/Onlinepubs/trr/1976/622/622-004.pdf (accessed March 1, 2016)
Saykin VV, Zhang Y, Cao Y, Wang ML, McDaniel JG (2012) Pavement macrotexture monitoring through sound generated by tire-pavement interaction. J Eng Mech 139:264–271. https://doi.org/10.1061/(ASCE)EM.1943-7889.0000485
Zhang Y, Mcdaniel JG, Wang ML (2013) Estimation of pavement macrotexture by principal component analysis of acoustic measurements. J Transp Eng 140:1–12. https://doi.org/10.1061/(ASCE)TE.1943-5436.0000617
Masino J, Foitzik M-J, Frey M, Gauterin F (2017) Pavement type and wear condition classification from tire cavity acoustic measurements with artificial neural networks. J Acoust Soc Am 141:4220–4229. https://doi.org/10.1121/1.4983757
Masino J, Pinay J, Reischl M, Gauterin F (2017) Road surface prediction from acoustical measurements in the tire cavity using support vector machine. Appl Acoust 125:41–48. https://doi.org/10.1016/j.apacoust.2017.03.018
Mendes R, Trichês G, Vergara EF, Gerges SNY (2019) Characterization of tire-road noise from Brazilian roads using the CPX trailer method. Appl Acoust 151:206–214. https://doi.org/10.1016/j.apacoust.2019.03.013
Ganji MR, Golroo A, Sheikhzadeh H, Ghelmani A (2019) Dense-graded asphalt pavement macrotexture measurement using tire/road noise monitoring. Autom Constr 106:102887. https://doi.org/10.1016/j.autcon.2019.102887
Reza M, Ghelmani A, Golroo A, Sheikhzadeh H (2020) Mean texture depth measurement with an acoustical-based apparatus using cepstral signal processing and support vector machine. Appl Acoust 161:107168. https://doi.org/10.1016/j.apacoust.2019.107168
Zhang Y, McDaniel JG, Wang ML (2015) Pavement macrotexture measurement using tire/road noise. J Civil Struct Health Monit 5:253–261. https://doi.org/10.1007/s13349-015-0100-4
Zhao Y, Wu HF, McDaniel JG, Wang ML, Evaluating road surface conditions using tire generated noise. In: Proceeding SPIE 8694, nondestructive characterization for composite materials, aerospace engineering, civil infrastructure, and homeland security, 2013. https://doi.org/10.1117/12.2012269
Ramos-romero C, León-ríos P, Al-hadithi BM, Sigcha L, De Arcas G, Asensio C (2019) Identification and mapping of asphalt surface deterioration by tyre-pavement interaction noise measurement. Measurement 146:718–727. https://doi.org/10.1016/j.measurement.2019.06.034
Mednis A, Strazdins G, Liepins M, Gordjusins A, Selavo L, RoadMic (2010) Road Surface Monitoring Using Vehicular Sensor Networks with Microphones. In: International conference on networked digital technologies, Springer, Heidelberg: pp 417–429
Masino J, Wohnhas B, Frey M, Gauterin F (2017) Identification and prediction of road features and their contribution on tire road noise. WSEAS Trans Syst Control 12:201–212
Fedele R, Pratico FG, Carotenuto R, Giuseppe Della Corte F (2017) Instrumented infrastructures for damage detection and management, in: 5th IEEE international conference on models and technologies for intelligent transportation systems (MT-ITS), IEEE, pp 526–531. https://doi.org/10.1109/mtits.2017.8005729
Paje SE, Bueno M, Terán F, Viñuela U (2007) Monitoring road surfaces by close proximity noise of the tire/road interaction. J Acoust Soc Am 122:2636–2641. https://doi.org/10.1121/1.2766777
Paulo JP, Coelho JLB, Figueiredo MAT (2010) Statistical classification of road pavements using near field vehicle rolling noise measurements. J Acoust Soc Am 128(2010):1747–1754. https://doi.org/10.1121/1.3466870
Kongrattanaprasert W, Nomura H, Kamakura T, Ueda K (2010) Detection of road surface states from tire noise using neural network analysis. IEEJ Trans Ind Appl 130:920–925. https://doi.org/10.1541/ieejias.130.920
Yunha K, Oh S, Hori Y (2010) Road condition estimation using acoustic method for electric vehicles. In: 10th FISITA Student Congress
Alonso J, López JM, Pavón I, Recuero M, Asensio C, Arcas G, Bravo A (2014) On-board wet road surface identification using tyre/road noise and Support Vector Machines. Appl Acoust 76:407–415. https://doi.org/10.1016/j.apacoust.2013.09.011
Ishihama M, Matsumoto K, Miyoshi K, Yoshii K, Kanda M (2016) Tire cavity sound measurement for identifying characters of road surfaces and tire structures. In: INTER-NOISE 2016—45th international congress and exposition on noise control engineering: towards a quieter future, pp 7017–7027
Doğan D (2017) Road-Types classification using audio signal processing and SVM method. In: 25th signal processing and communications applications conference (SIU), IEEE, 2017: pp 3–6
David J, Van Hauwermeiren L, Wout Dekoninck, De Pessemier Toon W, Joseph, Filipan K, De Coensel D, Bert Botteldooren, Martens L (2019) Rolling-noise-relevant classification of pavement based on opportunistic sound and vibration monitoring in cars, In: INTER-NOISE 2019, Spain, Madrid
Dogan D, Boyraz P (2019) Smart traction control systems for electric vehicles using acoustic road-type estimation. IEEE Trans Intell Veh 4(3):486–496
Atibi M, Atouf I, Boussaa M, Bennis A (2016) Comparison between the MFCC and DWT applied to the roadway classification. In: 7th international conference on computer science and information technology (CSIT), IEEE, 2016, pp 1–6
Hayashi K, Shin S (2008) Road type estimation by wavelet analysis of running tire sound. In: Proceedings of the 2008 international conference on wavelet analysis and pattern recognition, pp 30–31 https://doi.org/10.1109/icwapr.2008.4635859
Akama S, Tabaru T, Shin S (2004) Bayes estimation of road surface using road noise, In: 30th annual conference of the IEEE industrial electronics society, https://doi.org/10.1109/iecon.2004.1432274
Zofka A, Maliszewski M, Zofka E, Mechowski T (2017) Pavement assessment using on-board sound intensity system. In: 10th International Conference, Environmental Engineering, pp. 27–28
Johnsson R, Odelius J (2012) Methods for road texture estimation using vehicle measurements. In: International conference on noise and vibration engineering, pp 1573–1582
Boyraz P (2014) Acoustic road-type estimation for intelligent vehicle safety applications. Int J Veh Saf 7:209–222
Zhao R, Gregory J, Ming L, Estimation IRI, Probabilistic U (2016) IRI estimation using probabilistic analysis of acoustic measurements. Mater Perform Charact 2:339–359. https://doi.org/10.1520/MPC20130018
Ambrosini L, Gabrielli L, Vesperini F, Squartini S, Cattani L (2018) Deep neural networks for road surface roughness classification from acoustic signals In: Audio Engineering Society Convention, Milan, Italy
Lu Y, Zhang Y, Cao Y, Mcdaniel JG, Wang ML (2013) A mobile acoustic subsurface sensing (MASS) system for rapid roadway assessment. Sensors 13:5881–5896. https://doi.org/10.3390/s130505881
Ibarra D, Ramírez-Mendoza R, Ibarra S (2016) Characterization of the road surfaces in real time. Appl Acoust 105:93–98. https://doi.org/10.1016/j.apacoust.2015.10.023
Groschup R, Grosse CU (2016) Development of an efficient air-coupled impact—echo scanner for concrete pavements. In: World conference on non-destructive testing, Munich, Germany
Moghadas Nejad F, Karimi S, Zakeri H (2019) A brief review on acoustic analysis in quality evaluation and a new method for determining bulk density of aggregate. Arch Comput Methods Eng 26(5):1577–1591
Ryden N, Lowe MJS, Cawley P (2009) Non-contact surface wave testing of pavements using a rolling microphone array. In: AIP Conference Proceedings, Nantes, France
Bjurström H, Ryden N, Bjurström H (2017) Non-contact rolling surface wave measurements on asphalt concrete. Road Mater Pavement Des 20:334–346. https://doi.org/10.1080/14680629.2017.1390491
Mioduszewski P, Gardziejczyk W (2016) Inhomogeneity of low-noise wearing courses evaluated by tire/road noise measurements using the close-proximity method. Appl Acoust 111:58–66. https://doi.org/10.1016/j.apacoust.2016.04.006
Sandberg U, Bühlmann E, Conter M, Mioduszewski P (2016) Improving the CPX method by specifying reference tyres and including corrections for rubber hardness and temperature. In: INTER-NOISE and NOISE-CON congress and conference proceedings., Institute of noise control engineering, Hamburg, pp 4913–4923 http://www.diva-portal.org/smash/record.jsf?pid=diva2%3A1049612&dswid=9956 (accessed June 1, 2017)
ISO 11819-2 (2017) Acoustics: measurement of the influence of road surfaces on traffic noise: part 2: the close-proximity method https://www.iso.org/standard/39675.html (accessed June 2, 2017)
AASHTO TP 76 (2015) Standard method of test for measurement of tire/pavement noise using the on-board sound intensity (OBSI) Method https://standards.globalspec.com/std/9945275/AASHTO TP 76 (accessed July 12, 2017)
Masino J, Daubner B, Frey M, Gauterin F (2016) Development of a tire cavity sound measurement system for the application of field operational tests. In: 10th Annual International Systems Conference, SysCon 2016—Proceedings, https://doi.org/10.1109/syscon.2016.7490624
Sandberg U, Ejsmont JA (2002) Tyre/road noise reference book, 2002. isbn: 91-631-2610-9
Kuijpers A, van Blokland G (2001) Tyre/road noise models in the last two decades: a critical evaluation. In: Proceedings of Inter-Noise 2001, The Hague, Holland. 2494
Dare TP (2013) Generation mechanisms of tire-pavement noise, https://docs.lib.purdue.edu/dissertations/AAI3544123/ (accessed April 3, 2018)
ASTM E965-15 (2015) Standard test method for measuring pavement macrotexture depth using a volumetric technique, ASTM International, West Conshohocken, PA. www.astm.org
IS013473-1 (1997) Characterization of pavement texture by use of surface profiles - Part 1: Determination of Mean Profile Depth. https://www.iso.org/standard/25637.html (accessed April 10, 2017)
Casella G, Fienberg S, Olkin I (2013) An introduction to statistical learning, vol 1. springer, New York. https://doi.org/10.1016/j.peva.2007.06.006
Truchetet F, Laligant O (2008) Review of industrial applications of wavelet and multiresolution-based signal and image processing. J Electr Imag doi 10(1117/1):2957606
John J, Deller R, Hansen JHL, Proakis JG (1993) Discrete-Time processing of speech signals, Prentice Hall PTR. isbn: 978-0780353862
Welch PD (1967) The use of fast Fourier transform for the estimation of power spectra: a method based on time averaging over short, modified periodograms. IEEE Trans Audio Electroacoust 15:70–73. https://doi.org/10.1109/TAU.1967.1161901
Lawrence B-HJ (1993) Fundamental of Speech Recognition. Prentice-hall International, Upper Saddle River
Acknowledgements
The authors would like to thank Mr. Mohammad Arbabpour and Mr. Mohammad Ali Ghasemiyeh for their help in developing the measurement platform.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Ganji, M.R., Ghelmani, A., Golroo, A. et al. A Brief Review on the Application of Sound in Pavement Monitoring and Comparison of Tire/Road Noise Processing Methods for Pavement Macrotexture Assessment. Arch Computat Methods Eng 28, 2977–3000 (2021). https://doi.org/10.1007/s11831-020-09484-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11831-020-09484-4