
Abstract
This paper considers the complex mixing matrix estimation in under-determined blind source separation problems. The proposed estimation algorithm is based on single source points contributed by only one source. First, the problem of complex matrix estimation is transformed to that of real matrix estimation to lay the foundation for detecting single source points. Secondly, a detection algorithm is adopted to detect single source points. Then, a potential function clustering method is proposed to process single source points in order to get better performance. Finally, we can get the complex mixing matrix after derivation and calculation. The algorithm can estimate the complex mixing matrix when the number of sources is more than that of sensors, which proves it can solve the problem of under-determined blind source separation. The experimental results validate the efficiency of the proposed algorithm.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
In recent years, as a hot issue of many fields, blind source separation (BSS) techniques have been applied to speech signal processing [1], biomedical engineering [2], array signal processing [3], mechanical fault diagnosis [4], image processing [5], and so on. BSS can be classified into normal blind source separation (NBSS), overdetermined blind source separation (OBSS) and under-determined blind source separation (UBSS) based on the number of sources and sensors. In NBSS, the number of sources is equal to that of sensors. In OBSS, there are more sensors than sources. In UBSS, there are less sensors than sources. Independent component analysis (ICA) [6, 7] is a main method to handle BSS problems. The ICA algorithms solving the OBSS problems and those solving the UBSS problems are called overdetermined ICA and under-determined ICA, respectively. ICA is always applied to solve OBSS problems and NBSS problems [8–13] that include image processing, biomedical application and speech recognition. ICA is also applied to UBSS problems [14–16]. However, ICA is usually unsatisfactory for solving UBSS problems, so the research on UBSS receives more attention. As the most representative method of UBSS, sparse component analysis (SCA) [17, 18] can yield better separation results than traditional ICA. The SCA method includes two steps: mixing matrix estimation and sources recovery. The mixing matrix estimation is the basis of sources recovery. In other words, the estimation precision of the mixing matrix has an important effect on sources recovery. Therefore, the mixing matrix estimation gets particularly important. In SCA methods, the performance is up to the sparsity of signals. A signal is sparse if only a small number of samples have valid values and other samples are nearly zero. However, many signals are not sparse in real life. We must make transformations such as short-time Fourier transform (STFT) [19, 20] and wavelet transform (WT) [21] to make signals sparser. This paper focuses on complex mixing matrix estimation of UBSS problems by utilizing the sparse time-frequency (TF) representations that are obtained by STFT.
Many methods have been proposed to estimate the mixing matrix. In these algorithms, the algorithms based on single source points where only one source occurs can improve the accuracy of estimating the mixing matrix and then receive more attention. Some scholars [22–26] detected single source points with various methods and then estimated the mixing matrix by utilizing single source points. Xu [27] extended the algorithm of single source points to images and estimated the mixing matrix faster and more accurately. The above methods based on single source points can obtain good performance for estimating the mixing matrix, and they are all applicable to UBSS. However, these methods aim at real mixing matrix estimation. In other words, they are invalid for estimating the complex mixing matrix. If the mixing model of BSS is the instantaneous mixing model, the mixing matrix is real. However, if the mixing model is the anechoic mixing model, the mixing matrix is complex. The instantaneous mixing model is sometimes restrictive, and the anechoic mixing model is closer to the actual application. Some algorithms consider the complex mixing matrix estimation. The algorithm in Li et al. [28] estimated the complex mixing matrix with more sources than sensors. It utilized the probability density distribution of single source points and the K-means clustering algorithm. In [29], the mixing matrix was estimated based on single source points and agglomerative hierarchical clustering. These two algorithms proposed the similar and specific model about single source points. In this paper, we propose a more general model to transform complex mixing matrix estimation to real mixing matrix estimation. As a result, all detection algorithms of single source points for real matrix estimation can be applied. What is more, we combine the single source points detection with the potential function clustering algorithm to improve the algorithm performance.
The rest of this paper is organized as follows. In Sect. 2, we introduce the basic model of our method. Our algorithm is derived in Sect. 3. Section 4 describes the simulation results and analysis, and conclusions are drawn in Sect. 5.
2 The basic model
In the algorithms described in Li et al. [28] and Zhang et al. [29], the mixing matrix is estimated when the antenna array is the uniform linear array. In order to present our algorithm better and compare with other algorithms more intuitively, we take the uniform linear array as the research priority.
This paper assumes that sources come from the far-field of the array. Assume there are M sources \(\mathbf{{s}}(t) = {[{s_1}(t),{s_2}(t),\ldots ,{s_M}(t)]^\mathrm{T}}\) and N mixed signals \(\mathbf{{x}}(t) = {[{x_1}(t),{x_2}(t),\ldots ,{x_N}(t)]^\mathrm{T}}\). \({s_i}(t)(i = 1,\ldots ,\) M) denotes the ith source signal at the time instant t. \({x_i}(t)(i = 1,\ldots ,N)\) denotes the ith mixed signal at the time instant t. M is larger than N. The linear mixing model of UBSS can be described as
where the mixing matrix \(\mathbf{{H}}\) can also be written as
The distance between two sensors is d, and the angle between the mth source and the normal is \({\theta _m}( -\pi /2<{\theta _m} < \pi /2)\). The schematic of the uniform linear array is shown in Fig. 1.

Schematic of the uniform linear array
If the first sensor is chosen as the reference, the delay from the nth sensor to the first sensor for the mth source can be denoted as
where \(\lambda \) is the signal wavelength and w is the signal frequency. If the complex expression of the mth source is denoted as \({s_m}(t) = {a_m}(t){e^{j[wt + \varphi (t)]}}\), the mth source received by the nth sensor can be written as
where \({H_{nm}}\) is called amplitude dis-accommodation factor. If we assume that the modulation components \({a_m}(t)\) and \(\varphi (t)\) are narrow-band signals and take no account of the effect of the amplitude fading, the above formula can be simplified as
Based on the above formula, the mixed signal that includes M sources in the nth sensor can be denoted as
It can also be written with the matrix form
For the uniform linear array, the corresponding mixing matrix is
In order to guarantee that there is no ambiguity in DOA estimation, the assumption \(d \le \lambda /2\) is usually satisfied. Meanwhile, the angle measurement error gets lower when d gets larger. Therefore, d is usually equal to \(\lambda /2\). Besides, the articles [28, 29] assume d as \(\lambda /2\). In order to compare our algorithm with other algorithms, d is set to \(\lambda /2\) in this paper. Equation (8) can be simplified as
3 The proposed algorithm
In order to make signals sparser, STFT is adopted. The STFT of the nth mixed signal is as follows
where \(h(\;)\) denotes the window function. Similarly, the STFT of the mth source signal is denoted as
Applying STFT on Eq. (1), we can obtain the following formula
where \({\mathbf{{X}}'}(t,f) = {[X_1'(t,f),X_2'(t,f),\ldots ,X_N'(t,f)]^\mathrm{T}}\) and \(\mathbf{{S}}(t,f) = {[{S_1}(t,f), {S_2}(t,f),\ldots ,{S_M}(t,f)]^\mathrm{T}}\) refer to the STFT coefficients of mixtures and sources, respectively.
Two assumptions need to be satisfied like other UBSS algorithms. On one hand, any \(N \times N\) sub-matrix of the mixing matrix should be of full rank. Even if we only estimate the mixing matrix, the condition that any two columns of the mixing matrix are uncorrelated is also needed. On the other hand, some TF points where only one source occurs must exist.
We consider two mixed signals that include the mixed signal \({x_1}(t)\) received by the first sensor and the mixed signal \({x_n}(t)\) received by the nth sensor. Combining Eq. (7), we can obtain
If \({\psi _m} = \pi (n - 1)\sin {\theta _m}(m = 1,2,\ldots ,M)\) is assumed, Eq. (13) can be simplified as
Because the above mixing matrix is complex, most algorithms based on single source points are not applicable. In other words, the algorithms cannot present the linear clustering feature. Therefore, the goal of this paper is getting the linear clustering feature through transformation and then estimating the mixing matrix.
A matrix \(\mathbf{{T}}\) is denoted as
where b is an angle. Utilizing Eqs. (14) and (15), we obtain the following formula
After this procedure, the new STFT coefficients of mixtures \(\mathbf{{X}}(t,f) = [X_1(t,f),X_2(t,f),\ldots ,X_N(t,f)]\) are obtained. When only one source \({s_1}\) occurs at some TF point \(\left( {{t_p},{f_p}} \right) \), Eq. (16) can be denoted as
From the above formula, we can get
Because the above ratio is real, two equations can be obtained based on Eq. (18)
Utilizing the above two equations and forcing the sign of the first element of the two vectors to be positive, we can get
Consider some TF point \(({t_q},{f_q})\) where two sources \({s_1}\) and \({s_2}\) occur. If we want to realize
the following conditions must be satisfied
These conditions are so strict that the probability of Eq. (22) is very low. Meanwhile, when three or more sources occur at some TF point, the probability of similar equations will get lower. For identifying single source points, the authors in [26] develop a rule as
where \({\varepsilon _1}\) is a threshold value that is close to 0. After single source points detection, the points that are close to the origin still have bad effect on estimation. In order to improve performance, these points should be removed if they satisfy the following formula
where \({\varepsilon _2}\) is a threshold value. After above procedures, we use the residual points to estimate the mixing matrix. In this paper, we adapt a potential function clustering algorithm. The number and the set of the residual single source points are set to T and B, respectively. We first normalize the data in the set B and then define the potential function as
where \({\mathbf{{b}}_k}\) and \({\mathbf{{b}}_j}\) are the elements of the set B, \(\widehat{{\mathbf{{b}}_k},{\mathbf{{b}}_j}}\) denotes the included angle of \({\mathbf{{b}}_k}\) and \({\mathbf{{b}}_j}\), \(\beta \) and \(\gamma \) are the parameters that adjust the attenuation of the objective function at the non-maximum points. \({\mathbf{{b}}_k}\) can be denoted as \(({b_{k1}},{b_{k2}})\), so we can calculate the potential function values of different \({\mathbf{{b}}_k}\) and get the three-dimensional scatter plot of \(J({\mathbf{{b}}_k})\). In the figure, there are some peaks occurring and the number of the peaks is equal to that of sources. The amplitude of each point is \(P(k)(k = 1,\ldots ,T)\). Because of the effect of noises, there will be some false peaks. In order to remove these false peaks, the normalization is first adopted as follows
where \(\max [\;]\) denotes the maximum and \(\hat{P}(k)\) is the normalization amplitude. Then, the smooth function is utilized and defined as
where \({{p_k}}\) is the new amplitude. In order to get the locations of the peaks accurately, the following rules are set
Based on the above rules, corresponding peak locations help us find the corresponding \({\mathbf{{b}}_k}\) that are considered to be clustering centers. After these procedures, we get M clustering centers \(\left( {{Y_m},{Z_m}} \right) (1 \le m \le M)\). Combining with Eq. (18), we obtain the following formula
According to the above equation, we need to exchange positions of the numerator and the denominator if \(\cos [(b - {\psi _m})/2]\) is equal to 0. In order to calculate simply, we set b as \(\pi /2\). Then, Eq. (32) can be simplified as
Based on the above description, \({\psi _m} = \pi (n - 1)\sin {\theta _m}(1 < n \le N)\) and \( - \pi /2< {\theta _m} < \pi /2\) are known. For a uniform linear array, the least number of sensors is 2. Meanwhile, only utilizing two sensors can help us estimate the mixing matrix. Therefore , we can only set n as 2 and obtain
According to Eqs. (32) and (33), we can know
Through the calculation, \({\psi _m}\) is denoted as
Based on Eq. (34) and the range of \({\theta _m}\), \({\theta _m}\) is calculated as
After getting all \({\theta _m}\), we can get the final mixing matrix.
In this paper and some other papers, there is permutation ambiguity in the algorithms of estimating the mixing matrix. However, sources recovery is not affected by this permutation ambiguity.
The steps of our algorithm are as follows:
-
Step 1 Transform the problem of complex mixing matrix estimation to the problem of real mixing matrix estimation.
-
Step 2 Detect single source points and remove the points that are close to the origin.
-
Step 3 Get the clustering centers through the potential function clustering algorithm.
-
Step 4 Calculate the corresponding angles and then get the mixing matrix.
4 Simulation results and analysis
In the simulation, four females speech sources are chosen from the Web page of SiSEC2011. The angles of sources and the normal are \( - \pi /12\), \( - \pi /36\), \(5\pi /36\) and \(\pi /18\). The number of sampling points is 80,000. The STFT size is 1024. The overlapping is 256. The Hanning window is chosen as the weighting function. The signals are received by a uniform linear array whose sensors interval is the half of the wavelength. The number of the sensors is 2, so the mixing matrix \(\mathbf{{H}}\) can be written as
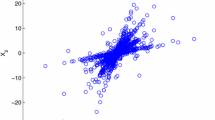
In noiseless case, the scatter plot based on the above equations is shown in Fig. 2.

Scatter plot before detecting single source points
It is shown that the points present obvious clustering property, but some multiple source points affect this property. Direct clustering will lead to bad performance because of the influence of multiple source points. The measure of detecting single source points aims at eliminating the multiple source points and getting better performance. Meanwhile, eliminating the points that are close to the origin has good effect on improving the performance. Figure 3 is the scatter plot after detecting single source points and eliminating the points that are close to the origin.

Scatter plot after detecting single source points and eliminating the points that are close to the origin
It is shown from Fig. 3 that the points that affect the performance have been removed. In order to lay the foundation for the clustering process, we make the normalizing procedure and force the sign of the first element of the normalized point to be positive for the points in Figs. 2 and 3. After these procedures, the scatter plot comparison before detecting single source points and after detecting single source points is shown in Figs. 4 and 5.

Scatter plot through the normalizing procedure and the sign procedure before detecting single source points

Scatter plot through the normalizing procedure and the sign procedure after detecting single source points
From Figs. 4 and 5, It is easy to find the superiority of detecting single source points and eliminating the points that are close to the origin. After above procedures, necessary clustering is needed. A potential function clustering algorithm is utilized to process these points in this paper. Figure 6 is the three-dimensional plot of \(J({\mathbf{{b}}_k})\).

Three-dimensional plot of \(J({\mathbf{{b}}_k})\)
As shown in Fig. 6, several peaks occur and the number of the peaks is equal to that of sources. The locations of the peaks correspond to the clustering centers. Finally, through this clustering algorithm, the final complex mixing matrix can be estimated as
The original mixing matrix is as follows
Comparing \({\tilde{\mathbf{H}}}\) with \(\mathbf{{H}}\), we can know that the proposed algorithm is effective and accurate in the noiseless situation.
To demonstrate that this algorithm is also suitable for other sources and other mixing matrix, three speech utterances are selected referring to Reju et al. [24]. The angles of sources and the normal are \( - \pi /18\),\(\pi /9\) and \(\pi /36\). The other conditions remain unchanged. The original mixing matrix and the estimated mixing matrix are as follows.
According to \(\mathbf{{H}}\) and \({\tilde{\mathbf{H}}}\), we can know that the algorithm is also effective for other sources.
In the noisy situation, an index must be chosen in order to measure the performance of the proposed algorithm and other algorithms. Mean square error (MSE) is suitable for these purposes. It is described as
where \({\tilde{\theta }_m}\) is the estimated value of \({\theta _m}\).
Gaussian white noise is used to demonstrate the robustness of the proposed algorithm and the comparison algorithms that include Li’s algorithm in [28] and Zhang’s algorithm in [29]. In this paper, \({\varepsilon _1}\) is 0.02 and \({\varepsilon _2}\) is 0.1. All parameters of the comparison algorithms are selected based on the references. The average results of 100 Monte Carlo trials about three algorithms are shown in Fig. 7.

Performance comparison of the proposed algorithm with other algorithms
From Fig. 7, we can know that our algorithm has better performance than the comparison algorithms.
5 Conclusions
In this paper, a new algorithm is proposed to estimate the complex mixing matrix in the UBSS problem. The algorithms based on single source points can get good performance in the estimation of the real mixing matrix. However, the detection method of single source points cannot be directly applied to the estimation of the complex mixing matrix. In this paper, we first transform complex mixing matrix estimation to real mixing matrix estimation through modeling and calculating. Following that, a detection algorithm of single source points is adopted to get the single source points and remove the points that are close to the origin. Then, we propose a potential function clustering process in order to get better clustering results. Finally, the complex mixing matrix is obtained through derivation and calculation. The simulation experiments show efficiency and practicability of the proposed algorithm. Meanwhile, they show that our algorithm owns higher accuracy than other algorithms. The paper is about the estimation problem of the complex mixing matrix. The problem belongs to the anechoic mixing model of BSS. The research of this mixing model is meaningful and promising.
References
Pedersen, M., Wang, D.L., Larsen, J., Kjems, U.: Two-microphone separation of speech mixtures. IEEE Trans. Neural Netw. 19(3), 475–492 (2008)
Abolghasemi, V., Ferdowsi, S., Sanei, S.: Fast and incoherent dictionary learning algorithms with application to fMRI. Signal Image Video Process. 9(1), 147–158 (2015)
Wang, X., Huang, Z.T., Zhou, Y.Y.: Semi-blind signal extraction for communication signals by combining independent component analysis and spatial constraints. Sensors 12(7), 9024–9045 (2012)
Wang, H.Q., Li, R.T., Tang, G., Yuan, H.F., Zhao, Q.L., Cao, X.: A compound fault diagnosis for rolling bearings method based on blind source separation and ensemble empirical mode decomposition. PLoS One 9(10), 1–13 (2014)
Abd, E.A., Mohamed, K.W.: Nonnegative matrix factorization based on projected hybrid conjugate gradient algorithm. Signal Image Video Process. 9(8), 1825–1831 (2015)
Naik, G.R., Kumar, D.K.: An overview of independent component analysis and its applications. Int. J. Comput. Inf. 35(1), 63–81 (2011)
Hyvarinen, A.: Testing the ICA mixing matrix based on inter-subject or inter-session consistency. NeuroImage 58(1), 122–136 (2011)
Naik, G.R., Dinesh, K.K., Marimuthu, P.: Signal processing evaluation of myoelectric sensor placement in low-level gestures: sensitivity analysis using independent component analysis. Expert Syst. 31(1), 91–99 (2014)
Pendharkar, G., Naik, G.R., Nguyen, H.T.: Using blind source separation on accelerometry data to analyze and distinguish the toe walking gait from normal gait in ITW children. Biomed. Signal Process. Control 13, 41–49 (2014)
Naik, G.R., Baker, K.G., Nguyen, H.T.: Dependency Independency measure for posterior and anterior EMG sensors used in simple and complex finger flexion movements: Evaluation using SDICA. IEEE J. Biomed. Health Inf. 19(5), 1689–1696 (2014)
Li, M., Liu, Y.D., Chen, F.L., Hu, D.W.: Including signal intensity increases the performance of blind source separation on brain imaging data. IEEE Trans. Med. Imaging 34(2), 551–563 (2015)
Illner, K., Miettinen, J., Fuchs, C., et al.: Model selection using limiting distributions of second-order blind source separation algorithms. Signal Process. 113, 95–103 (2015)
Chen, D.F., Liang, J.M., Guo K.: Temporal unmixing of dynamic fluorescent images by blind source separation method with a convex framework. Comput. Math. Methods Med. Article ID 713424(2015)
Guo, Y.N., Huang, S.H., Li, Y.T., Naik, G.R., et al.: Edge effect elimination in single-mixture blind source separation. Circuits Syst. Signal Process. 32(5), 2317–2334 (2013)
Naik, G.R., Selvan S., Hung N.: Single-channel EMG classification with ensemble empirical mode decomposition based ICA for diagnosing neuromuscular disorders. IEEE Trans. Neural Syst. Rehabil. Eng. doi:10.1109/TNSRE.2015.2454503 (2015)
Chen, X.A., Liu, X., Dong, S.J., Liu, J.F.: Single-channel bearing vibration signal blind source separation method based on morphological filter and optimal matching pursuit (MP) algorithm. J. Vib. Control. 21(9), 1757–1768 (2015)
Georgiev, P., Theis, F., Cichocki, A.: Sparse component analysis and blind source separation of under-determined mixtures. IEEE Trans. Neural Netw. 16(4), 992–996 (2005)
Hattay, J., Belaid, S., Lebrun, D., Naanaa, W.: Digital in-line particle holography: twin-image suppression using sparse blind source separation. Signal Image Video Process. 9(8), 1767–1774 (2015)
Xiao, M., Xie, S.L., Fu, Y.L.: Undetermined blind delayed source separation based on single source intervals in frequency domain. Acta Electron. Sin. 35(12), 2367–2373 (2007)
Thiagarajan, J.J., Ramamurthy, K.N., Spanias, A.: Mixing matrix estimation using discriminative clustering for blind source separation. Digit. Signal Process. 23(1), 9–18 (2013)
Yu, X.C., Xu, J.D., Hu, D., Xing, H.H.: A new blind image source separation algorithm based on feedback sparse component analysis. Signal Process. 93(1), 288–296 (2013)
Abrard, F., Deville, Y.: A time-frequency blind signal separation method applicate to under-determined mixtures of dependent sources. Signal Process. 85(7), 1389–1403 (2005)
Liu, K., Du, L.M., Wang, J.L.: Underdetermined blind source separation based on single dominant source areas. Sci. China Ser. E-technol. Sci. 38(8), 1284–1301 (2008)
Reju, V.G., Koh, S.N., Soon, I.Y.: An algorithm for mixing matrix estimation in instantaneous blind source separation. Signal Process. 89(9), 1762–1773 (2009)
Kim, S.G., Yoo, C.D.: Under-determined blind source separation based on subspace representation. IEEE Trans. Signal Process. 57(7), 2604–2614 (2009)
Dong, T.B., Lei, Y.K., Yang, J.S.: An algorithm for under-determined mixing matrix estimation. Neurocomputing 104(15), 26–34 (2013)
Xu, J.D., Yu, X.C., Hu, D., Zhang, L.B.: A fast mixing matrix estimation method in the wavelet domain. Signal Process. 95, 58–66 (2014)
Li, H., Shen, Y.H., Wang, J.G., Ren, X.S.: Estimation of the complex-valued mixing matrix by single-source-points detection with less sensors than sources. Trans. Emerg. Telecommun. Technol. 23, 137–147 (2012)
Zhang, L.J., Yang, J., Lu, K.W., Zhang, Q.N.: Modified subspace method based on convex model for underdetermined blind speech separation. IEEE Trans. Consum. Electron. 60(2), 225–232 (2014)
Acknowledgments
This work is supported by National Natural Science Foundation of China (No. 51509049), the Heilongjiang Province Natural Science Foundation (Nos. F201345 and QC2016081) and the Fundamental Research Funds for the Central Universities of China (No. GK2080260140).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Li, Y., Nie, W., Ye, F. et al. A complex mixing matrix estimation algorithm in under-determined blind source separation problems. SIViP 11, 301–308 (2017). https://doi.org/10.1007/s11760-016-0937-y
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11760-016-0937-y