
Abstract
In this paper, an M–EEMD–ELM model (modified ensemble empirical mode decomposition (EEMD)-based extreme learning machine (ELM) ensemble learning paradigm) is proposed for landslide displacement prediction. The nonlinear original surface displacement deformation monitoring time series of landslide is first decomposed into a limited number of intrinsic mode functions (IMFs) and one residual series using EEMD technique for a deep insight into the data structure. Then, these sub-series except the high frequency are forecasted, respectively, by establishing appropriate ELM models. At last, the prediction results of the modeled IMFs and residual series are summed to formulate an ensemble forecast for the original landslide displacement series. A case study of Baishuihe landslide in the Three Gorges reservoir area of China is presented to illustrate the capability and merit of our model. Empirical results reveal that the prediction using M–EEMD–ELM model is consistently better than basic artificial neural networks (ANNs) and unmodified EEMD–ELM in terms of the same measurements.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
In the Three Gorges Reservoir area, which is located at the upper reaches of the Yangtze River in China, frequent landslides often result in significant casualties and property losses. So, the prediction of landslide-prone regions is essential for carrying out quicker and safer mitigation programs, as well as future planning of the area. It is well known that landslide hazard is a complex nonlinear dynamical system with the uncertainty (Chen and Zeng 2011; Msilimba 2010; Qin et al. 2001, 2002; Sorbino et al. 2010). The landslide displacement is basically determined by the potential energy and constraint condition of the slope, but it is also strongly influenced by rainfall and reservoir level fluctuation (Guzzetti et al. 2005; Kawabata and Bandibas 2009).
In recent years, a number of methods have been tried in the problem of displacement of landslide forecasting, such as autoregression (AR) (Xu et al. 2011), linear regression (Kaunda 2010), and artificial neural networks (ANNs) (e.g., Chen and Zeng 2011; Pradhan and Lee 2009, 2010; Melchiorre et al. 2008; Nefeslioglu et al. 2008). In particular, ANNs have become one of the frequent modeling approaches among these techniques, because of the characteristics of adaptability and they can approximate any continuous nonlinear function with arbitrary precision (Hornik 1991). However, most ANN-based landslide forecasting methods used gradient-based learning algorithms such as back-propagation neural network (BPNN), which are relatively slow in learning and may easily get into local minima points (Jaroudi and Makhoul 1990; Drucker and Cun 1992). Recently, a novel learning algorithm for single-hidden-layer feedforward neural networks (SLFNs) called extreme learning machine (ELM) has been proposed (Huang et al. 2006a, b; Zhu et al. 2005). ELM not only learns much faster with higher generalization performance than the traditional gradient-based learning algorithms but also avoids many difficulties faced by gradient-based learning methods such as stoping criteria, learning rate, learning epochs, and local minimum (Huang 2003; Huang and Babri 1998; Huang et al. 2006a, b; Tamura and Tateishi 1997). ELM has been successfully applied in many fields such as sales forecasting (Sun et al. 2008; Chen and Ou 2011), face recognition (Zong and Huang 2011), and reversible watermarking (Feng et al. 2012).
Inspired by the idea of “decomposition and ensemble” (Yu et al. 2008; Guo et al. 2012), the original time series can be decomposed into several sub-series. Each component can be predicted with the purpose of simplifying the predication tasks, and the final predicted value can be obtained by summing the predictive value of each sub-series. Considering the displacement deformation monitoring time series of landslide is unsystematic and nonlinear, the ensemble empirical mode decomposition (EEMD), which is introduced by Wu and Huang (2009), is used to decompose the accumulative displacement of landslide series. In this paper, a modified EEMD–ELM model is proposed for landslide displacement prediction. The first step is to decompose the displacement of landslide series into several sub-series with EEMD. The second step is to choose appropriate ELM model for each decomposed sub-series’s forecasting. At last, the final predicted value is obtained by summing the each component forecasting results. It should be pointed out that the change of landslide displacement is considered as one of the most difficult natural parameters to model and forecast due to the complex structures of factors which affect landslide displacement such as tectonic, rainfall, reservoir level fluctuation, difference in temperature of day and night, and even earthquake. Considering these influencing factors relate intricately and interact complexly, we only consider original landslide displacement time series in this paper because of landslide displacement time series contain the information of the interaction of these influencing factors which happened in the past.
2 Methodology formulation
2.1 EMD and EEMD
The empirical mode decomposition (EMD) is an adaptive and efficient time series decomposition technique applied to decompose nonlinear and non-stationary signals using the Hilbert–Huang transform (HHT) (Huang et al. 1998). The key innovation of EMD is the establishment of the concept of intrinsic mode function (IMF), each contains the local information embedded in the data series. Using EMD, any complex time series can be decomposed into several IMF components and a residue component which contains the main trend of the original series. According to Huang et al. (1998), IMFs must satisfy the following conditions:
-
1.
In the whole data series, the number of extrema (sum of maxima and minima) and the number of zero crossings must be equal, or differ at most by one.
-
2.
At any point, the mean value of the envelope defined by local maxima and local maxima must be zero.
With the above definition for IMF, any signal series s(t) (t = 1, 2,…, l), t is the time index and l is the total number of observations, can be decomposed as follows:
-
Step (1.1) Identify all the local extrema of original signal s(t). Use a cubic spline line that connects all local maxima (minima) to obtain the upper (lower) envelopes and calculate the point-by-point envelope mean m 1(t) of the upper and lower envelopes. Calculate the difference between s(t) and m 1(t), obtain the first component h 1(t):
$$ h_1(t)=s(t)-m_1(t) $$(1)Step (1.2) To treat h 1(t) as the original signal series s(t) in the next iteration:
$$ h_{11}(t)=h_1(t)-m_{11}(t) $$(2)
where m 11(t) is the mean of upper and low envelope values of h 1(t). This step will be repeated for k times, until h 1k (t) satisfy the definition of an IMF,
Designate it as c 1(t) = h 1k (t). A suggested stoppage criterion (Huang et al. 1998), which is determined by using a Cauchy type of convergence test, is defined as follows:
Here, SD k is less than a predetermined value.
Step (1.3) Once c 1(t) is determined, the residue r 1(t) can be obtained by separating c 1(t) from the rest of the data,
To replace s(t) with r 1(t), and repeating the steps (1.1) and (1.2), the second IMF and residue [c 2(t) and r 2(t)] can be obtained. If c 1(t) or r 1(t) is smaller than a predetermined value, or r 1(t) becomes a monotone function, the sifting process is stopped. Thus, a series of IMFs can be obtained. The original signal s(t) can be expressed as follows.
where c i (t) (i = 1, …, μ) are the μ number of IMFs, and r μ (t) is the residue after repeating the sifting procedure μ times.
However, there are also some shortcomings in EMD, and one of the most significant problem is the mode mixing, which means either some signals consisting of disparate scales exist in the same IMF or the signals with the same scale exist in different IMFs. In order to eliminate the mode mixing problem, a new noise-assisted analysis method, called EEMD was proposed. The EEMD algorithm can be described as follows:
-
Step (2.1) Add a white noise to the original signal series.
-
Step (2.2) Decompose the signal with added white noise into IMFs using EMD.
-
Step (2.3) Repeat steps (2.1) and (2.2) again and again, with different white noise each time.
-
Step (2.4) Obtain the means of corresponding IMFs of the decompositions as the final result.
-
Step (2.5) Obtain the mean of corresponding residue of the decomposition as the final result.
2.2 ELM
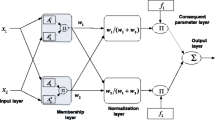
ELM is a single-hidden-layer feedforward neural network (SLFN) with randomly generated hidden nodes independent of the training data. Input weights and biases can be randomly chosen and the output weights can be analytically determined using the Moore–Penrose (MP) generalized inverse. Compared with traditional popular gradient-based learning algorithms for SLFNs, ELM not only learns much faster with higher generalization ability but also avoids many difficulties, such as the stopping criteria, learning rate, learning epochs, and local minima. The structure of ELM is demonstrated in Fig. 1. For N distinct samples (x i , t i ), where x i = [x i1, x i2, …, x in]T ∈ R n and t i = [t i1, t i2, …, t im]T ∈ R m, standard SLFNs with \(\tilde{N}\) hidden neurons and activation function g(x) are mathematically modeled as
where w i = [w i1, w i2, …, w in]T is the weight of the connection from the input neurons to the ith hidden neuron, β i = [β i1, β i2, …, β im]T is the weight vector connecting the ith hidden neuron and the output neurons, o j = [o j1, o j2, …, o jm]T is the jth output vector of the SLFN and b i is the threshold of the ith hidden neuron. w i ·x j denotes the inner product of w i and x j . The above N equations can be written compactly as:
where
where H is called the hidden-layer output matrix of the neural network. The ith column of H is the ith hidden neuron’s output vector with respect to inputs \({\bf x}_1, {\bf x}_2,\ldots,{\bf x}_N.\)

The structure of ELM
ELM theories claim that the input weights w i and hidden biases b i can be randomly generated instead of tuned. To minimize the cost function \(\|{\bf O}-{\bf T}\|,\) where \({\bf T}=[{\bf t}_1,{\bf t}_2,\ldots,{\bf t}_N]^T\) is the target value matrix, the output weights is as simple as finding the least−square (LS) solution to the linear system H β = T, as follows:
where \({\bf H}^{\dag}\) is the Moore−Penrose (MP) generalized inverse of the matrix H. The minimum norm LS solution is unique and has the smallest norm among all the LS solutions. In addition, before the ELM training, the input and output data set should be firstly normalized as follows:
and the unnormalized method for the input and output data set is given as follows:
2.3 Overall process of the modified EEMD-based ELM ensemble paradigm
An original displacement deformation monitoring time series of landslide can be decomposed into various frequency IMFs by EEMD. Inspired by Guo et al. (2012), the highest frequency component (IMF1) is always so small that has little contribution to model fitting, while it always gives a great disturbance for the forecasting precision of displacement of landslide. In order to improve the prediction precision, we remove IMF1 and the model is called M-EEND-ELM, where “M” represents “Modified.”
Suppose there are the displacement deformation monitoring time series of landslide \(s(t)(t=1,2,\ldots, \ell), \) in which one wants to make the η-step ahead prediction, that is, s(t + η). For example, η = 1 means forecasting one step head in advance and η = 5 means forecasting five steps head in advance. Based on the previous methods, the modified EEMD-based ELM ensemble paradigm is illustrated in Fig. 2.

The scheme of M–EEMD–ELM ensemble methodology
The steps of constructing the landslide displacement prediction model are described as follows:
-
1.
The displacement deformation monitoring time series of landslide \(s(t)(t=1,2,\ldots, \ell)\) is decomposed into μ IMFs, \(c_i(t) (i=1,\ldots, \mu), \) and one residual component r μ (t) by EEMD.
-
2.
To forecast all extracted IMFs and one residual component but IMF1, by establishing appropriate ELM model.
-
3.
The final predicted value can be obtained through the superposition of all IMFs and one residual component forecasting results but IMF1.
In order to illustrate the effectiveness of the proposed modified EEMD-based ELM ensemble methodology, a case study of Baishuihe landslide in the Three Gorges reservoir area is presented in the next section.
3 Experiments
3.1 Date collection
Baishuihe landslide is located on the south bank of Yantze River and its 56 km away from the Three Gorges Dam of China. The bedrock geology of the study area consists mainly of sandstone and mudstone, which is an easy slip stratum. The slope is of the category of bedding slopes. Figure 3 shows the scene of landslide collapse along roads on June 30, 2007 and Fig. 4 shows parts of landslide fissure in the warning zone. Fig. 5 shows the schematic diagram of monitoring arrangement in Baishuihe landslide. There are eleven GPS deformation monitoring points layout in the landslide surface. The monitoring data of landslide accumulative displacement at ZG118 monitoring point is selected as a case study. Figure 6 shows the monitoring data of landslide accumulative displacement at ZG118 monitoring point.

The scene of landslide collapse along roads on June 30, 2007

Landslide fissure in the warning zone

Schematic diagram of monitoring arrangement in Baishuihe landslide

Monitoring curves of landslide accumulative displacement at ZG118 monitoring point
The total number of data at ZG118 monitoring point is 101 observations from August 2003 to December 2011. The data between August 2003 and November 2009 are selected as training data in order to construct the forecasting model and the rest of 25 observations of data from December 2009 to December 2011 are selected as predicting data. Note that only one-step-ahead prediction is performed in the experiments. Actually, multi-step-ahead prediction can also be performed, but the prediction performance in such cases is unsatisfactory. And 1 month ahead prediction is enough to provide early warnings in the landslide prediction.
3.2 Evaluation of forecast performance
In order to measure the prediction performance, three loss functions are used as the criteria to evaluate the proposed models. The loss functions are the root mean square error (RMSE), mean absolute error (MAE), and mean absolute percentage error (MAPE) which are defined by:
where \(e(t)=s(t)-\hat{s}(t), s(t)\) is the actual value for the time period \(t, \hat{s}(t)\) is the predicted value for the same period, and ρ is the number of predictions.
In addition, one ensemble model, EEMD–ELM without modified, and four single ANN models, BPNN, RBF neural network (RBFNN), support vector regression (SVR), and ELM, are also used to predict landslide displacement for comparison purposes.
3.3 Experimental results
We use the mean monthly landslide accumulative displacement for prediction. The original time series is first decomposed into several IMFs and one residue using EEMD decomposition tool. The amplitude of add noise we used is 0.2, the number of ensemble is 100. The decomposition results with EEMD can be seen in Fig. 7.

EEMD decomposition of the monthly accumulative displacement
Then, we choose appropriate ELM model to forecast all extracted IMFs. The input and output data should firstly normalized using Eq. (10). The activation function of all ELM model we used is the sigmoidal function g(x) = 1/(1 + e −x). With the output variable x(t), the other parameters, which can be determined by trial and error, used in ELMs are shown in Table 1, where the series of x(i) represents those six normalized series, respectively.
Using the above settings, the forecasting results for IMFs and residue are shown in Fig. 8. As shown in Fig. 8, the predicted values and extracted values for each sub-series are very close for every calculation except IFM1. As mentioned previously, IMF1 mainly reflects the random component of the original sequence, which is the most disorder and unsystematic part of the landslide displacement sequence. ELM can approach any continuous nonlinear function with arbitrary precision and fit IMF1 well, but the prediction is unpredictable and even may reduce the accuracy of prediction.

Comparison of predicted and extracted values of each sub-series
The final predicted value is obtained by adding the predictive values of IMFs (except IMF1) and one residual. The final predicted values are shown in Fig. 9.

The comparison among six forecast models
As shown in Fig. 9, we can find that only two ensemble models successfully predict the obvious deformation from the 19th month to the 20th month, and there is an obvious predict time delay in the other single ANN models. In Table 2, the comparison of different methods for the landslide displacement prediction is given via RMSE, MAE, MAPE, maximum error, minimum error.
Obviously, the results obtained from Table 2 indicate that the prediction performance of the two ensemble model, EEMD–ELM and M–EEMD–ELM, is better than those of the single ANN model. And the prediction precision of M–EEMD–ELM has an appropriate improvement to EEMD–ELM where the MSE, MAE, and MAPE reduce by 1.0961, 0.0387, and 0.1898 %, respectively; especially, we can see that M–EEMD–ELM model produces better results than the other five models in terms of getting the smallest maximum error and minimum error. And two ensemble models, EEMD–ELM and M–EEMD–ELM, have a big reducing in the maximum error. So, we can draw the conclusion that the proposed M–EEMD–ELM model is superior to the single ANN models and EEMD–ELM model. This illustrates that the idea of “decomposition and ensemble,” which is achieved using EEMD decomposition, can effectively improve the performance of landslide displacement prediction.
4 Conclusions
This study proposes a modified EEMD-based ELM ensemble paradigm to obtain accurate prediction results and improve landslide displacement prediction quality further. In terms of different criteria, RMSE, MAE, and MAPE, we can find that across different models for the test case of Baishuihe landslide, our proposed M–EEMD–ELM method performs the best. In comparison with the other classic single ANN models, only two ensemble models, EEMD–ELM and M–EEMD–ELM, successfully predict the obvious deformation without time delay, which is very important in landslide forecast warning. In conclusion, the M–EEMD–ELM prediction paradigm can effectively improve landslide displacement prediction and help make future planning of the area.
References
Chen FL, Ou TY (2011) Sales forecasting system based on Gray extreme learning machine with Taguchi method in retail industry. Expert Systems with Applications 38:1336–1345
Chen HQ, Zeng ZG (2011) Deformation prediction of landslide based on genetic-simulated annealing algorithm and BP neural network. In: Proceedings of the fourth international workshop on advanced computational intelligence, Wuhan, China, pp 675–679
Drucker H, Cun YL (1992) Improving generalization performance using double backpropagation. IEEE Trans Neural Netw 3(6):991–997
Feng GR, Qian ZX, Dai NJ (2012) Reversible watermarking via extreme learning machine prediction. Neurocomputing 82:62–68
Guo ZH, Zhao WG, Lu HY, Wang JZ (2012) Multi-step forecasting for wind speed using a modified EMD-based artificial neural network model. Renew Energy 37:241–249
Guzzetti F, Reichenbach P, Cardinali M, Galli M, Ardizzone F (2005) Probabilistic landslide hazard assessment at the basin scale. Geomorphology 72:272–299
Hornik K (1991) Approximation capabilities of multilayer feedforward networks. Neural Netw 4(2):251–257
Huang GB (2003) Learning capability and storage capacity of two-hidden-layer feedforward networks. IEEE Trans Neural Netw 14(2):274–281
Huang GB, Babri HA (1998) Upper bounds on the number of hidden neurons in feedforward networks with arbitrary bounded nonlinear activation functions. IEEE Trans Neural Netw 9(1):224–229
Huang GB, Chen L, Siew CK (2006a) Universal approximation using incremental constructive feedforward networks with random hidden nodes. IEEE Trans Neural Netw 17(4):879–892
Huang GB, Zhu QY, Siew CK (2006b) Extreme learning machine: theory and applications. Neurocomputing 70(1–3):489–501
Huang NE, Shen Z, Long SR, Wu MC, Shih HH, Zheng Q, Yen NC, Tung CC, Liu HH (1998) The empirical mode decomposition and the Hilbert spectrum for nonlinear and nonstationary time series analysis. Proc R Soc A Math Phys Eng Sci 454:903–995
Jaroudi AE, Makhoul J (1990) A new error criterion for posterior probability estimation with neural nets. In: Proceedings of iteration joint conference on neural networks, pp 185–192
Kaunda RB (2010) A linear regression framework for predicting subsurface geometries and displacement rates in deep-seated, slow-moving landslides. Eng Geol 114:1–9
Kawabata D, Bandibas J (2009) Landslide susceptibility mapping using geological data, a DEM from ASTER images and an artificial neural network (ANN). Geomorphology 113:97–109
Melchiorre C, Matteucci M, Azzoni A, Zanchi A (2008) Artificial neural networks and cluster analysis in landslide susceptibility zonation. Geomorphology 94:379–400
Msilimba GG (2010) The socioeconomic and environmental effects of the 2003 landslides in the Rumphi and Ntcheu Districts (Malawi). Nat Hazards 53:347–360
Nefeslioglu HA, Gokceoglu C, Sonmez H (2008) An assessment on the use of logistic regression and artificial neural networks with different sampling strategies for the preparation of landslide susceptibility maps. Eng Geol 97:171–191
Pradhan B, Lee S (2009) Landslide risk analysis using artificial neural network model focussing on different training sites. Int J Phys Sci 4(1):1–15
Pradhan B, Lee S, Buchroithner MF (2010) A GIS-based back-propagation neural network model and its cross-application and validation for landslide susceptibility analyses. Comput Environ Urban Syst 34:216–235
Qin SQ, Jiao JJ, Wang SJ (2001) The predictable time scale of landslides. Bull Eng Geol Environ 59(4):307–312
Qin SQ, Jiao JJ, Wang SJ (2002) A nonlinear dynamical model of landslide evolution. Geomorphology 43:77–85
Sun ZL, Choi TM, Au KF, Yu Y (2008) Sales forecasting using extreme learning machine with applications in fashion retailing. Decision Support Syst 46:411–419
Sorbino G, Sica C, Cascini L (2010) Susceptibility analysis of shallow landslides source areas using physically based models. Nat Hazards 53:313–332
Tamura S, Tateishi M (1997) Capabilities of a four-layered feedforward neural network: four layers versus three. IEEE Trans Neural Netw 8(2):251–255
Wu ZH, Huang NE (2009) Ensemble empirical mode decomposition: a noise-assisted data analysis method. Adv Adapt Data Anal 1(1):1–41
Xu F, Wang Y, Du J, Ye J (2011) Study of displacement prediction model of landslide based on time series analysis. Chin J Rock Mechan Eng 30(4):746–751
Yu L, Wang SY, Lai KK (2008) Forecasting crude oil price with an EMD-based neural network ensemble learning paradigm. Energy Econ 30:2623–2635
Zhu QY, Qin AK, Suganthan PN, Huang GB (2005) Evolutionary extreme learning machine. Pattern Recogn 38(10):1759–1763
Zong WW, Huang GB (2011) Face recognition based on extreme learning machine. Neurocomputing 74:2541–2551
Acknowledgments
The work is supported by the Natural Science Foundation of China under Grant 60974021 and 61203286, the 973 Program of China under Grant 2011CB710606, the Specialized Research Fund for the Doctoral Program of Higher Education of China under Grant 20100142110021.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Lian, C., Zeng, Z., Yao, W. et al. Displacement prediction model of landslide based on a modified ensemble empirical mode decomposition and extreme learning machine. Nat Hazards 66, 759–771 (2013). https://doi.org/10.1007/s11069-012-0517-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11069-012-0517-6