
Abstract
Precise and efficient landslide displacement prediction is crucial for improving the effectiveness of landslide warning systems. Numerous time series decomposition and machine learning (ML) methods have been proposed and applied in landslide displacement prediction. Nevertheless, most ML methods display individual biases when applied to landslide displacement datasets, and the effect of different methods for time series decomposition on prediction results has not been systematically studied. Therefore, this paper adopts four methods commonly used for time series decomposition to decompose the accumulated displacement into a trend term and a periodic term. The double exponential smoothing is utilized to predict the trend displacement. After the grey relation analysis between the periodic displacement and the external cyclical influencing factors, the ensemble algorithm is used to integrate six commonly used ML algorithms for the prediction of periodic displacement, so as to eliminate the bias of individual artificial intelligence method and enhance the accuracy and stability of prediction results. Furthermore, Bayesian optimization is employed to optimize the base-learners, ensuring the integration fairness. The typical step-like landslides (i.e., Bazimen landslide, Caojiatuo landslide) in the Three Gorges area are selected to compare the performance of different methods for time series decomposition and illustrate the effectiveness of the framework of the ensemble algorithm with the evaluation indices of mean absolute error, mean absolute percentage error and root mean square error. The prediction results indicate that the ICEEMDAN method has the best performance in displacement decomposition. In addition, the prediction results of Bayesian optimized ensemble method are more robust than those of individual ML method, facilitating more accurate and stable landslide displacement prediction and more effective reference for landslide early warning.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Step-like landslides are a type of rainfall reservoir-induced landslide with step-like deformation characteristics, which are affected by periodic external factors (Lu et al. 2021; Zhang et al. 2021a). These landslides are widely distributed in the Three Gorges area of China and pose great potential safety hazards to the lives and property of the local people (Miao et al. 2022). As such, the disaster warning and prevention of step-like landslides are particularly important (Lin et al. 2022). Globally, landslide early warning systems are crucial for mitigating landslide hazards (Naidu et al. 2018; Fan et al. 2019). Within these systems, precise and efficient prediction of landslide displacement is essential for early detection of landslide event, understanding landslide progression, and providing reliable data for early warning initiatives (Yao et al. 2015). Hence, developing methods to accurately and efficiently predict displacement in step-like landslides holds significant value.
The methods of landslide displacement prediction have been developed over the past five decades. So far, various methods have emerged (Miao et al. 2018; Wang et al. 2023), broadly classified into four categories based on their underlying principles and modeling processes: empirical model, numerical simulation, statistical model and nonlinear prediction model. The empirical model is mainly based on the creep theory, and the rheological function describing the landslide deformation is constructed according to the physical simulation results of the laboratory creep experiment (Saito 1969; Tavenas and Leroueil 1981; Voight 1988; Li et al. 2012). The numerical simulation of the landslide is primarily using the methods like finite element or material point methods based on geometric model to calculate the deformation (Wang et al. 2016; Kardani et al. 2021), which is associated with high computational costs and low modeling efficiency (Augarde et al. 2021; Liu and Wang 2021). The statistical model predicts the displacement mainly by analyzing the statistical trend of landslide evolution (Li et al. 2012), which is constrained when considering the complexities in the landslide evolution under the influence of multiple factors (Gao et al. 2020). The nonlinear prediction model mainly predict the landslide displacement based on the nonlinear relationship between landslide displacement and influencing factors (Cao et al. 2016). Herein, due to the robust nonlinear prediction capability (Liu et al. 2021a, 2021b), the machine learning (ML) has been widely used in the field of landslide displacement prediction. (Liu et al. 2014; Li et al. 2015; Hu et al. 2021; Zhang et al. 2024). Due to the variety of linear and nonlinear factors in the evolution process of landslides, the landslide displacement is mainly composed of trend, periodic and random displacement (Zhou et al. 2016), which is influenced by different external factors. Generally, the displacement prediction process that decomposing the cumulative displacement into different components firstly and then predict them respectively is conformed to the evolution mechanism of landslide displacement, which has been widely applied in landslide displacement prediction (Yang et al. 2019). Although some studies have attempted to predict random displacement (Miao et al. 2018), the minimal impact and inherent randomness of these displacements cast doubt on the reliability of such predictions. Consequently, this paper omits consideration of random displacement terms.
The signal of cumulative displacement can be expressed as the sum of trend and periodic displacement due to the independence of different components (Du et al. 2013; Zhang et al. 2021c). The moving average (MA) technique, a conventional approach for time series decomposition in landslide displacement analysis, is simple and convenient but has limitations in processing the initial and final data points, and the smoothing order requires manual determination (Zhou et al. 2016; Zhang et al. 2021d). As spectrum analysis technology advances, wavelet analysis (WA) has gained popularity for its ability to decompose landslide displacement, although it necessitates manual selection of successive wavelet (Cai et al. 2016; Huang et al. 2016). Furthermore, empirical mode decomposition techniques, such as empirical mode decomposition (EMD), ensemble EMD (EEMD), and improved complete ensemble EMD with adaptive noise (ICEEMDAN), offer substantial versatility and reduce manual intervention based on the principle of signal decomposition. Despite their utility, EMD and EEMD sometimes exhibit issues with local oscillations and residual noise in their results (Lian et al. 2014). The ICEEMDAN method refines this by improving the noise addition in the EMD process, achieving more uniform and precise decomposition (Colominas et al. 2014). While these methods have been applied in landslide displacement decomposition, the characteristics of their decompositions, such as the number of components, vary across methods. The impact of choosing different decomposition methods on landslide displacement prediction has not been thoroughly explored and compared in the literature.
Trend displacement, indicative of the landslide's long-term internal evolutionary trend, typically follows a relatively stable developmental law. Generally, the polynomial fitting method is employed for predicting trend displacement due to its ease of operation and straightforward principle (Xu and Niu 2018; Zhang et al. 2021d). However, as polynomials are fundamentally unbounded oscillating functions, they may not be ideal for predicting monotonically increasing trend displacements. Beyond polynomial fitting, the double exponential smoothing (DES) is another viable method for predicting the landslide trend displacement (Huang et al. 2017; Xing et al. 2020). In the context of predicting periodic displacement, ML methods are increasingly being utilized, leveraging the nonlinear mapping relationship between periodic displacement and seasonal influencing factors. These methods include support vector machine, artificial neural network, decision tree regression (DTR), extreme learning machine, among other advanced technologies (Hochreiter and Schmidhuber 1997; Ma et al. 2017, 2018; Li et al. 2018, 2019; Wang et al. 2022; Xing et al. 2019). In this context, seasonal influencing factors are typically identified using methods such as grey relation analysis (GRA) (Zhang et al. 2020b). Due to variations in data characteristics and the potential for ML models to be biased, excellent performance achieved by an individual ML method on a specific sample dataset does not guarantee the same level of performance on other datasets in different research cases (Kardani et al. 2021). The predictive performance of landslide displacement varies depending on the ML method used, and there exists an individual bias associated with each method's generalization ability. In addition, to improve the prediction performance of ML algorithms, various metaheuristic algorithms are used to optimize the hyperparameters of the prediction model (Ma et al. 2022), such as genetic algorithm, artificial bee colony algorithm, particle swarm optimization algorithm and grey wolf algorithm (Li and Kong 2014; Cai et al. 2016; Zhu et al. 2018; Zhang et al. 2021b; Zeng et al. 2022). However, these algorithms often gravitate towards local optimum and may suffer from lower computational efficiency.
This paper proposes a displacement prediction model for step-like landslide based on ensemble framework, aiming to overcome the bias of individual ML model to different landslide datasets and improve the prediction accuracy and generalization ability. To highlight the effectiveness of the ensemble framework, six commonly used ML models are selected to construct the learner pool of ensemble algorithm. The Bayesian optimization method is employed to optimize the hyperparameters of base-learners in the ensemble model to ensure the fairness in the process of ensemble. In addition, four conventional techniques of time series decomposition are utilized to decompose the time series of landslide displacement, and their respective effects on landslide displacement prediction are compared. For practical application, two typical step-like landslides in the Three Gorges area, Bazimen landslide and Caojiatuo landslide, are chosen as case studies. To assess and contrast the various time series decomposition and displacement prediction methodologies, evaluation metrics such as mean absolute error (MAE), mean absolute percentage error (MAPE) and root mean square error (RMSE) are calculated.
2 Methodology
2.1 Decomposing the displacement time series into trend and periodic term
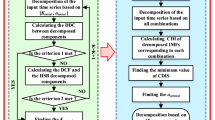
As the value of the random displacement is relatively small and unpredictable due to its inherent randomness, the time series of cumulative displacement are decomposed the into two components: trend displacement and periodic displacement (Lin et al. 2022; Zhou et al. 2022), as shown in Eq. (1). To analyze the influence of different time series decomposition methods on the landslide displacement prediction, the methods of MA, WA, EMD and ICEEMDAN, which are the major methods used widely in landslide displacement prediction at present, are selected to decompose the cumulative displacement of landslide.
where \({Y}_{t}\) donates the original time series of total displacement; \({T}_{t}\) donates the time series of trend displacement; \({C}_{t}\) donates the time series of periodic displacement.
2.1.1 Moving average
The MA method operates by sliding a fixed-size time window across the time series data. Within this window, it calculates the average value of a specified number of data points, effectively highlighting the long-term trend of the time series. This averaging approach is particularly effective at mitigating the impact of random fluctuations, making it well-suited for time series with periodic variations, such as landslide displacement. The primary formula for the MA calculation is as follows:
where M is the order of MA, which is relevant to the data frequency and the impact cycle of the external factors. Due to the annual variation of the landslide influencing factors (i.e., rainfall), the M is set to 12 to represent the time scale of one year (Yang et al. 2019; Zhang et al. 2021c).
2.1.2 Wavelet analysis
The WA method decomposes the time series of landslide displacement into components with varying frequencies. This decomposition is achieved by calculating wavelet coefficients. These coefficients are determined through the interaction between successive, artificially selected wavelets and the total displacement. In essence, each component analyzed matches the frequency of the current wavelet basis function (Huang et al. 2016). The general form of wavelet basis function utilized is as follows:
where \({\psi }_{a, b}\left(t\right)\) donates the successive wavelet; \(a\) donates the frequency factor of wavelet basis function; \(b\) donates the time factor of wavelet basis function.
The calculation formula of wavelet coefficients is as follows:
Figure 1 illustrates the process of continuous translation and expansion of the successive wavelet, achieved through altering parameters a and b, which in turn transforms the frequency. The wavelet coefficients, computed between the original signal and the successive wavelet, facilitate the analysis of different frequency components present in the time series of the original signal, specifically for landslide displacement.

Principle diagram of wavelet analysis (WA)
2.1.3 EMD
The EMD method identifies all vibration modes in a time series using the characteristic time scale. Subsequently, it decomposes the complex time series into a finite number of intrinsic mode functions (IMF). These IMFs encapsulate local characteristic sequences at different frequencies from the original time series (Chen and Chou 2012; Xu and Niu 2018). The process of EMD to decompose the time series of landslide displacement is as follows:
where \({m}_{1}\left(t\right)\) donates the average envelope of the original time series; \({Y}_{tmax}\) donates the fitting curve of the maximum point on the original time series (upper envelope); \({Y}_{tmin}\) donates the fitting curve of the minimum point on the original time series (lower envelope); \({d}_{1}\left(t\right)\) donates the remaining sequence.
When \({d}_{1}\left(t\right)\) satisfies the stopping condition for obtaining the IMF, which means that the number of local extreme points and zero-crossing points of \({d}_{1}\left(t\right)\) are equal to 1 or the quantity gap between the two types of points is less than 1, and the average values of the upper envelope and the lower envelope at different times are equal to zero, then the \({d}_{1}\left(t\right)\) can be regarded as the first IMF obtained by the decomposition of the original time series. Otherwise, Eqs. (6) and (7) are repeated until the stopping condition is satisfied. After the first IMF is obtained, the original sequence is subtracted to obtain the first-order residual quantity, which is used to replace the original time series. The n-order modal component is obtained after repeating the steps above for n times. The IMF with the lowest frequency is regarded as the trend displacement, and the remaining IMF components are cumulated to obtain the periodic displacement.
2.1.4 ICEEMDAN
The ICEEMDAN method employs EMD to decompose Gaussian white noise, which has a zero mean, into J IMF components. These components are then added to the original landslide displacement time series for sequence reconstruction. Consequently, J time series of landslide displacement are created for decomposition. The IMF of each order is determined by calculating the mean of the IMFs derived from the decomposition of the J -times reconstructed time series. This process, including the separation of trend and periodic displacement components, is consistent with the EMD approach (Colominas et al. 2014).
2.2 Predicting the trend displacement
The DES is employed to predict the trend displacement derived from time series decomposition. This method utilizes a specialized weighted average approach, where greater weight is assigned to historical data closer to the forecast period, and less weight to data further away. The weights assigned decrease exponentially with distance from the prediction period. This characteristic makes DES particularly effective for predicting linear trend displacement (Xing et al. 2020). The primary calculation formula of DES is as follows:
where \({S}_{t}^{1}\) donates the first exponential smoothing value of the \(t\) period; \({S}_{t}^{2}\) donates the second exponential smoothing value of the \(t\) period; \(\alpha\) donates the smoothing constant, which is set to 0.5 appropriately generally. The prediction results are given by the following formula:
where \({F}_{t+Q}\) donates the predicted value of the \(t+Q\) period; \(Q\) donates the number of periods predicted for the future; \({a}_{t}\) and \({b}_{t}\) donate the model parameters respectively.
2.3 Predicting the periodic displacement
2.3.1 Grey relation analysis
When the base-learners of the ensemble algorithm are utilized to predict the periodic displacement, the input original data includes the periodic displacement and its external influencing factors. Herein, GRA is used to select the influencing factors closely related to the periodic displacement to improve the prediction accuracy. GRA is a multi-factor statistical analysis method. By calculating the correlation coefficient between the mother sequence (periodic displacement) and the sub-sequence (time series of influencing factors, such as rainfall, etc.) and sorting, the relation degree between the influencing factors and the periodic displacement is measured (Miao et al. 2018; Zeng et al. 2022). The correlation coefficient is calculated according to Eq. (13).
where \({\zeta }_{t}\left(k\right)\) donates the correlation coefficient between the sequence of influencing factors \({I}_{t}\left(k\right)\) at time k and the displacement sequence \({C}_{t}\left(k\right)\), which is generally between 0 ~ 1. The relation degree increases with the growth of correlation coefficient; \({min}_{i}{min}_{k}\left|{C}_{t}\left(k\right)-{I}_{t}\left(k\right)\right|\) donates the absolute value of the second-order minimum difference between the sub-sequence and the mother sequence at time k; \({max}_{i}{max}_{k}\left|{C}_{t}\left(k\right)-{I}_{t}\left(k\right)\right|\) donates the absolute value of the second-order maximum difference between the sub-sequence and the mother sequence at time k; \(\rho\) donates the gray resolution coefficient, which is set to 0.5 appropriately generally.
2.3.2 Ensemble algorithm
The ensemble algorithm is used to predict the periodic displacement obtained by time series decomposition, which can eliminate the individual bias of different ML methods to improve the accuracy and generalization ability of the prediction model by integrating multiple individual learners, that means the overall learner is superior to the individual learner (Jena et al. 2020; Kardani et al. 2021; Rong et al. 2023). Figure 2 shows the operation process of the ensemble algorithm. The ensemble algorithm generally includes two parts: the base-learners (the first layer) and the meta-learner (the second layer). In the training process of ensemble model, the K-Fold cross-validation method is introduced to train the base-learners firstly. By dividing the training dataset of ensemble into K parts on average, each part is used as the testing data of each Fold, and the remaining data is used as the training data of the current Fold, then the base-learners Mi can be trained based on the training data and obtain the periodic displacement based on the testing data Mi, k. The prediction results of periodic displacement on each Fold through training and testing of one base-learner are spliced in turn to obtain a complete prediction result of periodic displacement of each base-learner on the original dataset. The prediction results of individual base-learner are used as the input features and the periodic displacement obtained by time series decomposition are used as the target output to train the meta-learner, then the training of the ensemble model is completed. In this study, we focus on the effectiveness of the ensemble framework rather than the performance of a single artificial intelligence approach. Hence, six commonly used ML regression algorithms (i.e., DTR, multilayer perceptron (MLP), random forest (RF), extreme gradient boosting (XGBoost), support vector regression (SVR) and Ridge), are selected to construct the learner pool of the ensemble algorithm.

The operation process of the ensemble algorithm
In general, the traditional evaluation of the performance of ML model is mainly carried out by quantifying the accuracy of the prediction results of test dataset after the model training on the training set. However, the results of this performance evaluation are easily affected by the division of the training and testing dataset, while the original dataset is not fully utilized. Hence, a 5-Fold cross-validation method is used to evaluate the performance of the prediction models in this study, which shows the advantages of reducing over-fitting and fully utilizing the original dataset. The original dataset mainly incorporates the time series of periodic displacement obtained by time series decomposition and the corresponding influence factors. After dividing the training dataset of ensemble into 5 parts on average, each part is utilized as the testing dataset of ensemble model on the current Fold, and the remaining data is used as the training dataset of ensemble model on the current Fold. Hence, the prediction results of periodic displacement on each Fold through training and testing of the ensemble model on the original dataset are spliced in turn to obtain a complete prediction result of periodic displacement. The basic process of cross-validation has been described in the training process of the base-learners above.
2.3.3 Bayesian optimization algorithm
The Bayesian optimization algorithm, recognized as one of the best methods in ML for efficiently balancing optimization efficiency and accuracy in hyperparameter tuning, is utilized in this study to optimize the hyperparameters of base-learners, aiming to ensure the fairness in model integration and enhance the modeling efficiency (Huang et al. 2022; Li and Yang 2022; Yang et al. 2022). Figure 3 shows the main process of Bayesian optimization, where \(x\) donates the parameter space of the ML models, and \(f\left(x\right)\) donates the objective function. The objective function is typically a regression evaluation index such as mean square error. The optimal parameters are determined when the objective function obtains the minimum value. In this optimization process, the surrogate function is utilized to fit to the real objective function based on randomly sampled points along the x-axis. This surrogate function is continually refined by collecting more data points near the minimum value or in unsampled areas, so as to approximate the true objective function progressively. The goal is to find the optimal solution corresponding to the minimum value of the objective function, and this process is guided by the sampling function.

The process of Bayesian optimization
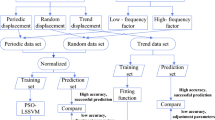
2.4 Flowchart of the proposed model for landslide displacement prediction
To evaluate the performance of different methods of landslide displacement prediction and time series decomposition, three indices of regression evaluation, MAE (Eq. (14)), MAPE (Eq. (15)) and RMSE (Eq. (16)) are adopted. Figure 4 shows the main process of the displacement prediction model proposed in this paper, which mainly includes three parts: time series decomposition, trend displacement prediction and periodic displacement prediction.

Flowchart of the proposed prediction model of landslide displacement
Part 1. Decompose the monitoring data of landslide cumulative displacement by the methods for time series decomposition to obtain the landslide periodic displacement and trend displacement.
Part 2. Predict the trend displacement by the method of DES, and the predicted trend displacement will be added to the predicted period displacement to obtain the total displacement.
Part 3. Confirm the influencing factors of landslide preliminarily by analyzing the monitoring data of landslide cumulative displacement. The GRA method is used to select the most influential factors related to the periodic displacement. The time series of these selected factors are used as inputs, while the time series of periodic displacement serves as the output for training the base-learners. The prediction results of each base-learner on the periodic displacement are obtained by cross-validation, which are used as the input of the meta-learner to establish the ensemble model. To ensure the fairness in the ensemble, Bayesian optimization is used to optimize the base-learners' parameters. The primary steps of Bayesian optimization include:
-
(I)
Initialization of the surrogate function;
-
(II)
Sampling using the sampling function;
-
(III)
Training learners based on parameters from the sampled points to obtain the objective function value;
-
(IV)
Updating the surrogate function;
-
(V)
Repeating the above steps until the maximum number of iterations is reached.
Based on the theory of time series analysis, the predicted total displacement is obtained by adding the predicted trend and periodic displacement, and the performance of landslide displacement prediction is evaluated according to the statistical results of evaluation index.
where \({Y}_{t}\) donates the original time series of total displacement; \({Y}_{p}\) donates the predicted time series of total displacement, N represents the quantity of total monitoring periods.
3 Results
3.1 Case 1: Bazimen landslide
3.1.1 Geological conditions and monitoring data
The Bazimen landslide is located in Guizhou Town, Zigui County, Hubei Province, which is on the right bank of the Xiangxi River, a tributary of the northern bank of the Yangtze River. The bank slope is in north–south direction, and the landslide body is distributed at the foot of the bank slope in a dustpan shape with 139 ~ 280 m distribution elevation, the slope of the landslide body is 10 ~ 30°, and the volume of the landslide is about 2 million m3. The types of monitoring data mainly include landslide surface displacement, rainfall and reservoir water level. The distribution of GPS monitoring points of surface displacement is shown in Fig. 5.

The diagram of the distribution about the GPS monitoring points of surface displacement on Bazimen landslide
Figure 6 displays the monitoring data for the Bazimen landslide, showing that from October 2013 to October 2020, there were multiple step-like uplifts in the landslide. Among them, a significant trend was observed where the largest uplifts in the Bazimen landslide coincided with the highest rainfall each June, with this pattern being particularly pronounced in June of 2015, 2016, and 2017. This correlation suggests a substantial relationship between the landslide deformation and both the rainfall and the fluctuations in the water level of the Three Gorges Reservoir. It is important to note that the monitoring period for the Bazimen landslide was set at one-month intervals, and thus, the displacement predictions made in this study were conducted on a monthly basis.

Monitoring data of Bazimen landslide
3.1.2 Displacement decomposition
Figure 6 indicates that among the Bazimen landslide's GPS monitoring points, GPS-3 exhibits the largest surface displacement with a pronounced step-like feature. Consequently, the monitoring data from GPS-3 is selected as the sample data for landslide displacement prediction. Various methods, including the MA, WA, EMD, and ICEEMDAN, are adopted to decompose the landslide displacement into trend and periodic components. Figure 7 presents the decomposition results using these methods. It is observed that while the results from EMD and its improved version ICEEMDAN are similar, the trend and periodic displacements derived from other methods show differences. Notably, the trend displacement obtained through WA is the smoothest and most stable, yet this does not necessarily imply that WA's decompositions accurately reflect the actual scenario. The effectiveness of these decomposition methods needs further verification through the testing results of the total displacement prediction.

Displacement decomposition of Bazimen landslide based on different methods for time series decomposition
3.1.3 Trend displacement prediction
The DES method is used to predict the trend displacement derived from various time series decomposition methods. Figure 8 shows the prediction results of the trend displacement and the corresponding prediction error. It can be observed that DES effectively predicts the trend displacement, accurately reflecting the evolution characteristic of steady growth based on historical data up to the prediction point, thus offering practical significance in forecasting. Moreover, the average prediction errors for the trend displacement, derived from various time series decomposition methods, exhibit relative uniformity, predominantly between 11 to 13 mm. A noteworthy observation is that a decrease in the slope of the trend displacement curve is associated with a reduction in prediction error.

Trend displacement prediction of Bazimen landslide based on different methods for time series decomposition
3.1.4 Periodic displacement and total displacement prediction
Determination of influencing factors
The ensemble algorithm predicts the periodic displacement by extracting the nonlinear relation between the periodic displacement and seasonal influencing factors. To improve the accuracy of these predictions, it is necessary to select the influencing factors closely related to the periodic displacement (Xu and Niu 2018). Based on the Bazimen landslide monitoring data, eight influencing factors have been identified: the 1-month cumulative antecedent rainfall, the 2-month cumulative antecedent rainfall, the 3-month cumulative antecedent rainfall, the average elevation of reservoir level in the current month, reservoir level change in 1-month period, reservoir level change in 2-month period, the displacement over the past 1 month, the displacement over the past 2 months and the displacement over the past 3 months (Zhang et al. 2021d; Ma et al. 2022). The correlation coefficient between different influencing factors and the periodic displacement is calculated by the GRA method. Then, factors with high correlation coefficients are selected as inputs for the ensemble algorithm. Figure 9 illustrates the grey relational analysis process, showing the correlation between periodic displacement (obtained through different time series decomposition methods) and the selected influencing factors. A correlation coefficient closer to 1 indicates a more significant impact of the influencing factors on the periodic displacement. As depicted in Fig. 9, the correlation between past displacement and the periodic displacement decreases over time.

The results of GRA of Bazimen landslide based on different methods for time series decomposition: (a) MA; (b) WA; (c) EMD; (d) ICEEMDAN
Table 1 presents the average values of the correlation coefficients, calculated by the GRA method, which quantify the relationship between periodic displacement and influencing factors. These coefficients range from 0.5 to 1, signifying a notable correlation between the periodic displacement, derived from diverse time series decomposition methods, and external influencing factors. Significantly, factors pertaining to rainfall and reservoir levels demonstrate a substantial impact on periodic displacement, as evidenced by higher correlation coefficients. Conversely, factors related to displacement in recent months exhibit a lesser influence, with correlation coefficients showing a decreasing trend over longer time intervals. Following the principle that a higher correlation coefficient indicates a stronger relation degree (Miao et al. 2018; Yang et al. 2019; Zhang et al. 2020b), factors with coefficients exceeding 0.9 were selected as input features for the ensemble algorithm to forecast periodic displacement.
Periodic displacement prediction
The selected influencing factors and periodic displacement are used as the original sample data for the ensemble algorithm to predict the periodic displacement. Herein, six commonly used ML algorithms are chosen to construct the learner pool of the ensemble algorithm: DTR, MLP, RF, XGBoost, SVR and Ridge. Generally, increasing the variety of base-learners in the ensemble algorithm can improve the prediction effect. Hence, all models in the learner pool are selected as the base-learners. To ensure the fairness of the ensemble, the Bayesian optimization method is used to obtain the optimal parameters of each base-learner. The prediction results from base-learners on the original sample data, validated through K-fold cross-validation, are then used as inputs for the meta-learner. Considering the need for reasonable sample division, choosing 5 as the value of K in this study. Each individual model in the learner pool is regarded as meta-learner and combined with the base-learners to establish the ensemble model. Figure 10 shows the prediction results of the periodic displacement obtained by different time series decomposition methods, based on the ensemble algorithms with various meta-learners.

Prediction of periodic displacement of Bazimen landslide based on different methods for time series decomposition
According to the prediction results, it can be observed that the Bayesian optimized ensemble algorithm model has a good performance on the periodic displacement prediction of Bazimen landslide, which can correctly reflect the annual fluctuation of the periodic displacement. Among them, the prediction performance of the periodic displacement based on the ICEEMDAN method is the best compared with other methods for time series decomposition, indicating that the periodic displacement decomposed by the ICEEMDAN method are the most realistic and consistent with the actual situation.
Total displacement prediction
Figure 11 shows the prediction results for the total displacement of the Bazimen landslide, achieved by various time series decomposition methods and ensemble algorithms with different meta-learners. These results represent the sum of the predicted trend displacement and periodic displacement predictions. The proposed method, combining time series decomposition and Bayesian optimized ensemble algorithm, shows excellent performance, aligning well with the step-like deformation characteristics of Bazimen landslide. Notably, the ICEEMDAN method outperforms other time series decomposition methods in predicting total displacement. Additionally, the prediction results vary significantly across local time periods when different decomposition methods are used. This variation is attributed to the significant impact of the time series decomposition results on the predictions. If there is a major discrepancy between the decomposed components (trend and periodic terms) and the actual components, the ML methods may fail to accurately map the relationship between influencing factors with seasonal fluctuations and periodic displacement. This can adversely affect displacement prediction accuracy. Therefore, selecting the most appropriate time series decomposition method is crucial for accurately predicting landslide displacement, particularly when dealing with low-frequency and simple signal scenarios.

Prediction of total displacement of Bazimen landslide based on different methods for time series decomposition
Figure 12 shows the evaluation indices for the total displacement predictions based on various time series decomposition methods and ensemble algorithms with different meta-learners, including MAE, MAPE and RMSE.Footnote 1 The results indicate that the ensemble algorithms with different meta-learners yield relatively stable and accurate predictions, demonstrating the proposed model has better generalization ability. Among them, the ICEEMDAN method consistently shows the lowest values across all three evaluation indices, suggesting its exceptional performance in landslide displacement prediction.

Evaluation of error in total displacement prediction of Bazimen landslide based on different methods for time series decomposition
To further verify the advantages of the proposed method, the paired t-test is conducted based on the prediction results related to different time series decomposition. According to the paired t-test, the significance level is achieved when the p-value < 0.05, indicating that the difference of the compared time series is significant. As shown in Table 2, the most p-value related to ICEEMDAN vs. the other time series decomposition are less than 0.05, suggesting the superiority of the proposed prediction model. Besides, the significant difference between ICEEMDAN and EMD are smaller than the other pairwise comparison, which is consistent with expectations according to the results of time series decomposition in Fig. 7.
3.2 Case 2: Caojiatuo landslide
3.2.1 Geological conditions and monitoring data
The Caojiatuo landslide is located in Wushan area of Three Gorges, north bank of Yangtze River, with dustpan shape, and there are many large gullies on both sides of the landslide boundary. The landslide mainly produces sliding deformation in the direction of the Yangtze River with 187° sliding direction, and the distribution elevation is between 125 and 275 m. The length and width of the landslide are about 900 m and 500 m, respectively. The thickness of the sliding body is about 25 m, which belongs to the large soil landslide. The monitoring types of Caojiatuo landslide incorporate multiple monitoring points of landslide surface displacement, meteorological and hydrological. Here, the distribution of GPS monitoring points of surface displacement is shown in Fig. 13.

The diagram of the distribution about the GPS monitoring points of surface displacement on Caojiatuo landslide
Figure 14 shows the displacement monitoring data of Caojiatuo landslide that from February 2007 to November 2013. It can be seen that the deformation of Caojiatuo landslide is related to the change of rainfall and reservoir water level. After the end of each water impoundment period (i.e., the reservoir water level declined to the minimum), the deformation of the landslide would uplift in the several few months, which exhibits the annual variation features of step-like deformation generally. Notably, the first large-scale deformation was observed in 2009 after the first wider fluctuation of reservoir water level. The fluctuation of reservoir water level generally affects the stability of the front edge of the landslide. With the periodic change of reservoir water level, the front edge of the landslide is constantly washed away, forming multiple local small bank collapses and constantly developing to the trailing edge and causing the Caojiatuo landslide to present the deformation characteristics as the retrogressive landslide. The displacement prediction for the Caojiatuo landslide was conducted monthly, aligned with the established monthly monitoring schedule.

Monitoring data of Caojiatuo landslide
3.2.2 Displacement decomposition
The GPS-6 monitoring data is selected as the sample data for the modelling of landslide displacement prediction due to the most obvious step-like deformation characteristics, and the four methods for time series decomposition selected in this study are utilized to decompose the cumulative displacement to obtain the trend displacement and periodic displacement. Figure 15 shows the decomposition results of GPS-6 monitoring data, which indicates that the decomposition characteristics of the four methods for time series decomposition are similar to the decomposition results of Bazimen landslide. Herein, the curve of trend displacement obtained by WA is the smoothest, while the decomposition results of EMD and ICEEMDAN methods are similar. In general, the decomposition results of other methods are quite different.

Monitoring data of Caojiatuo landslide based on different methods for time series decomposition
3.2.3 Trend displacement prediction
Figure 16 shows the prediction results of the trend displacement of Caojiatuo landslide. The pattern of prediction errors over different time periods closely resembles that observed in the Bazimen landslide, where the prediction error diminishes as the slope of the trend displacement curve decreases. Furthermore, the prediction results show that the DES method is also suitable for the prediction of trend displacement. Although obviously smoother than those obtained by other decomposition methods, the trend displacement results from the WA method show little difference compared to those based on the DES method.

Trend displacement prediction of Caojiatuo landslide based on different methods for time series decomposition
3.2.4 Periodic displacement and total displacement prediction
Determination of influencing factors
The initial influencing factors selected for the displacement prediction of Caojiatuo landslide are the same as those of Bazimen landslide, owing to the similar geological similarities and deformation characteristics between the two cases. Figure 17 and Table 3 show the calculation process of GRA and the average value of the calculation results of correlation coefficient between periodic displacement and influencing factors in the different monitoring periods. Generally, the features of the calculation results of the correlation coefficient between the influencing factors and periodic displacement of Caojiatuo landslide are roughly same as that of Bazimen landslide. Notably, the correlation coefficient between cumulative rainfall and periodic displacement of Caojiatuo landslide is lower than that of Bazimen landslide. According to the calculation results in Fig. 17 and Table 3, the influencing factors with the correlation coefficient larger than 0.9 are selected as the input features of the ensemble algorithm, which are the same as those of the Bazimen landslide.

The results of GRA of Caojiatuo landslide based on different methods for time series decomposition: (a) MA; (b) WA; (c) EMD; (d) ICEEMDAN
Periodic displacement prediction
After the determination of the influencing factors, the prediction of periodic displacement of Caojiatuo landslide adopts the same ensemble pattern as that of the Bazimen landslide. The selected six ML algorithms in the learner pool are regarded as base-learners to be combined with individual ML methods (meta-learner) in the learner pool to establish the ensemble model, and the Bayesian optimization is adopted to optimize the hyperparameters of each base-learner in the ensemble model to obtain the optimal base-learner, so as to ensure the fairness of the ensemble. During the ensemble process, the prediction results of the base-learners are used as the input of the meta-learner by 5-Fold cross-validation. Using the established ensemble prediction model, the periodic displacement of Caojiatuo landslide is predicted based on the input of the influencing factors determined by GRA.
Figure 18 shows the prediction results of the periodic displacement obtained by different methods for time series decomposition of Caojiatuo landslide by the ensemble model with different meta-learners. It can be observed that the ensemble model exhibits a good performance in predicting the periodic displacement of Caojiatuo landslide, which is consistent with the seasonal fluctuation characteristics of the monitored periodic displacement. In addition, the prediction results of the periodic displacement obtained by different methods for time series decomposition are quite different. Among them, the prediction results based on the WA method produce a large prediction error when the periodic displacement changes greatly. Although the WA method can obtain a relatively smooth trend displacement (Fig. 16), it does not mean that the components obtained by the WA method are consistent with the actual situation, that means the effect of time series decomposition on the landslide displacement prediction needs to be evaluated according to the final predictive performance. In addition, the prediction performance based on the MA method in Caojiatuo landslide is better than the prediction performance based on the MA method in Bazimen landslide. The possible reason is due to the fact that, with the decomposition properties of the MA method, the initial and final data points of the time series of periodic displacement obtained by the MA method are always zero according to Eq. (2). When the seasonal fluctuation of landslide evolution is small, it can produce better prediction results.

Prediction of periodic displacement of Caojiatuo landslide based on different methods for time series decomposition
Total displacement prediction
The total displacement prediction results are obtained by summing the prediction results of periodic trend displacement of Caojiatuo landslide obtained by the different methods for time series decomposition (Fig. 19). It can be observed that the proposed prediction model in this paper shows a good performance in predicting the displacement of step-like landslide. In addition, the prediction results of landslide displacement based on different methods for time series decomposition are quite different. Herein, the displacement prediction results based on ICEEMDAN are the closest to the actual landslide displacement, indicating that the ICEEMDAN method is the most suitable for the decomposition of the accumulative displacement, which is the same as the displacement prediction of Bazimen landslide.

Prediction of total displacement of Caojiatuo landslide based on different methods for time series decomposition
Figure 20 shows the statistical results of MAE, MAPE and RMSEFootnote 2 of total displacement predicted based on different time series decomposition and ensemble model. Among them, the calculation results of MAPE are quite different from those of Bazimen landslide. That is because the initial displacement value of Caojiatuo landslide is close to zero. According to Eq. (15), the prediction error in the initial stage will be amplified. Hence, due to the first data of the trend displacement obtained by the MA is close to zero, the MAPE of the prediction results of landslide displacement obtained by the MA is significantly smaller than other methods for time series decomposition. In addition, according to the calculation results of MAE and RMSE shown in Fig. 20, the accuracy of the prediction results based on the ICEEMDAN method is the highest compared with the other methods for time series decomposition, which indicates that the ICEEMDAN can produce the best decomposition performance on the cumulative displacement of the step-like landslide. Furthermore, it can be seen from Table 4 that the results of the paired t-test of the prediction results of Caojiatuo landslide are similar to that of Bazimen landslide, the prediction performance based on the ICEEMDAN are significantly better than other time series decomposition, while the significant difference between ICEEMDAN and EMD are smaller than the other pairwise comparison.

Error evaluation indices of total displacement prediction of Caojiatuo landslide
4 Discussions
4.1 Comparison with individual ML models
To verify the superiority of the proposed ensemble model in estimating the individual bias of different artificial intelligence models, the prediction results of the Bazimen landslide and the Caojiatuo landslide from the optimized individual ML model and the ensemble model with the optimized base-learners are compared. It should be noted that evaluation of individual ML model is based on the fivefold cross-validation method. Figure 21 shows the statistical results of distribution range of the evaluation indices of the prediction results based on different methods for time series decomposition. It should be noted that the upper and lower bounds of each index represent the maximum and minimum values of the calculation results respectively based on different prediction models. According to the statistical results in Fig. 21, the distribution range of each evaluation index of the ensemble algorithms with the optimized base-learners is generally lower and smaller than individual optimized ML models based on Bayesian optimization, especially for the MAE and RMSE, indicating that the prediction results of the ensemble algorithm with the optimized base-learners are more accurate and robust. In addition, due to the error amplification effect of the MAPE index in the initial and final monitoring periods when the displacement value is close to zero, the MAPE of the displacement prediction results of Caojiatuo landslide is unstable. Hence, it is necessary to select appropriate evaluation index according to the characteristics of the data itself when evaluating the accuracy of regression prediction of time series.

The range of error indices for the predicted displacements by the ensemble and the individual ML algorithms, both based on Bayesian optimization
4.2 Influence of the Bayesian optimization algorithm on the proposed ensemble model
In this study, the Bayesian optimization method is used to obtain the optimal base-learners to ensure the fairness of ensemble and enhance the predictive performance, which means that the predictive performance of the base-learners will influence the final prediction results of the ensemble model. To verify the significance of the Bayesian optimization algorithm to the ensemble model, the prediction results of the two research cases based on the ensemble model with optimized base-learners and the ensemble model without optimized base-learners are compared. Figure 22 shows the distribution range of the statistical results of evaluation indices based on different methods for time series decomposition. It can be observed that the distribution range and upper limit of each evaluation index are reduced obviously after the optimization of the base-learners in the ensemble model. Although the statistical results of MAPE of the prediction results of the Caojiatuo landslide show the error amplification effect, the Bayesian optimization algorithm can improve the accuracy and robustness of ensemble model in predicting the landslide displacement. Furthermore, the focus of this paper is whether the Bayesian optimization algorithm can improve the performance of the ensemble model, rather than finding the optimal hyperparameter optimization algorithm, whereas the choice of optimization algorithm should be one of the important factors affecting the model performance. Hence, it is worthy to conduct systematic comparative studies on different types of optimization algorithms in the future.

The range of error indices of prediction results by the ensemble model with optimized base-learners by Bayesian optimization and unoptimized base-learners
4.3 Comparison with other studies of the step-like landslide displacement prediction of Bazimen landslide and Caojiatuo landslide
In order to eliminate the contingency inherent in a single case and enhance the persuasiveness of the conclusion, this research focuses on the Bazimen and Caojiatuo landslides, chosen for their sufficient monitoring data and typical step-like deformation characteristics. While numerous studies have investigated landslide displacement predictions for these cases, as summarized in Table 5, they predominantly emphasize the superior efficacy of deep learning methods over traditional ML models and highlight the role of hyperparameter optimization in enhancing prediction accuracy. However, these studies lack the exploration of the influence of time series decomposition on the prediction results of landslide displacement, and the individual bias of different artificial intelligence models on landslide datasets is not considered. In this study, the framework of ensemble learning is used to eliminate the individual bias of different artificial intelligence models to obtain more robust prediction results, and the prediction results of landslide displacement based on different methods of time series decomposition are analyzed. To explore the effectiveness of the framework of ensemble learning and compare the displacement prediction results of different methods of time series decomposition, six traditional ML algorithms are selected to be applied to the proposed prediction method for landslide displacement. In the future, the application of the framework of ensemble learning in deep learning can be studied, so as to establish displacement prediction models with better performance, combing them with the time series decomposition method that is more suitable for landslide deformation.
4.4 Discussion of the impact of rainfall factors on the prediction results
To comprehensively illustrate the possible impact of rainfall factors on the prediction results, the prediction results related to the Bazimen and Caojiatuo landslide with and without the input factors of rainfall are compared. Herein, the method of ICEEMDAN with the best performance is utilized to decompose the landslide accumulate displacement. The trend displacement is predicted by the double exponential smoothing, and the periodic displacement is predicted by ensemble learning with different ML models optimized by the Bayesian optimization algorithm as the meta-model. the Tables 6 and 7 present the comparison of the prediction results of the Bazimen and Caojiatuo landslides with and without the inputs factors of rainfall. In general, it can be observed that the accuracy of the prediction results with the rainfall factors as the input factors is higher than that without the rainfall factors as the input factors, verifying the strong correlation between the rainfall and landslide displacement. Furthermore, the difference of the prediction results with and without the rainfall factors as input of the Bazimen landslide are larger than that of the Caojiatuo landslide. The possible reason is that the regional location and geological conditions of the two landslide cases are not exactly the same, resulting in different responses of landslide deformation to rainfall.
5 Conclusions
In this paper, a novel method for predicting step-like landslide displacement based on time series decomposition and Bayesian optimized ensemble model is proposed to eliminate the individual bias of different artificial intelligence models. Additionally, a systematic comparative analysis is performed on various methods for time series decomposition. Two typical step-like landslides, namely Bazimen landslide and Caojiatuo landslide in the Three Gorges area, are selected as research cases. The main findings of this study can be summarized as follows:
-
(1)
The evolution of landslides is a system affected by a variety of linear and nonlinear factors, which means that the deformation characteristics are usually controlled by the imposition pattern of influencing factors. According to the monitoring data of the research cases in this paper, the landslide displacement is affected by the combined action of periodic fluctuation factors, such as rainfall and reservoir water level, which cause the step-like displacement change. These deformation characteristics can provide a basis for intelligent algorithm to predict landslide displacement.
-
(2)
The accuracy of landslide displacement prediction is influenced by the choice of time series decomposition method. For the Bazimen and Caojiatuo landslides, the MAE and RMSE of predictions based on the Bayesian optimized ensemble learning and ICEEMDAN method range between 19 mm—23 mm and 25—29 mm, respectively. This represents a decrease around 30%—60% compared to the other time series decomposition methods. Overall, the experimental results indicate that the ICEEMDAN approach is the most effective for decomposing landslide deformation monitoring data for displacement prediction purposes.
-
(3)
The ensemble algorithm efficiently mitigates individual biases of the different ML models, enhancing the predictive performance for landslide displacement. The distribution range of the evaluation indices of the displacement prediction results based on the ensemble framework is smaller than that of the individual ML method. Meanwhile, the ensemble framework reduces prediction errors related to the individual ML method. Besides, the Bayesian optimization technique refines the parameters of each base-learner in the ensemble algorithm, thereby improving the performance of ensemble models with smaller prediction errors, while ensuring fairness within the ensemble. Therefore, the Bayesian optimized ensemble model exhibits significant potential for landslide displacement prediction.
Notes
Mean absolute error (MAE), mean absolute percentage error (MAPE) and root mean square error (RMSE).
Mean absolute error (MAE), mean absolute percentage error (MAPE) and root mean square error (RMSE).
Abbreviations
- Bi:
-
Bidirectional
- BPNN:
-
Back propagation neural network
- DBi:
-
Deep bidirectional
- DES:
-
Double exponential smoothing
- DTR:
-
Decision tree regression
- EEMD:
-
Ensemble EMD
- ELM:
-
Extreme learning machine
- EMD:
-
Empirical mode decomposition
- FC:
-
Fully connected
- FOA:
-
Fruit fly optimization algorithm
- GA:
-
Genetic algorithm
- GRA:
-
Grey relation analysis
- GRU:
-
Gate recurrent unit
- GWO:
-
Grey wolf optimizer
- ICEEMDAN:
-
Improved complete ensemble EMD with adaptive noise
- IMF:
-
Intrinsic mode functions
- LSTM:
-
Long short-term memory
- MA:
-
Moving average
- ML:
-
Machine learning
- MLP:
-
Multilayer perceptron
- MFIT:
-
Multi-feature fusion transfer learning
- NARX:
-
Nonlinear autoregressive neural network with exogenous inputs
- PSO:
-
Particle swarm optimization
- RF:
-
Random forest
- RNN:
-
Recurrent neural network
- SSSC:
-
Soft screening stopping criteria
- SVR:
-
Support vector regression
- VMD:
-
Variational mode decomposition
- WA:
-
Wavelet analysis
- WMA:
-
Weighted moving average
- XGBoost:
-
Extreme gradient boosting
- \({Y}_{t}\) :
-
Original time series of total displacement
- \({T}_{t}\) :
-
Time series of trend displacement
- \({C}_{t}\) :
-
Time series of periodic displacement
- \(M\) :
-
The order of MA
- \({\psi }_{a, b}\left(t\right)\) :
-
Successive wavelet of WA
- \(a\) :
-
The frequency factor of wavelet basis function
- \(b\) :
-
The time factor of wavelet basis function
- \({W}_{a, b}\) :
-
Wavelet coefficients of WA
- \({m}_{1}(t)\) :
-
The average envelope of the original time series \({Y}_{t}\)
- \({d}_{1}(t)\) :
-
Remaining sequence corresponding to \({m}_{1}(t)\)
- \(J\) :
-
The quantity of the decomposed IMF of the Gaussian white noise of ICEEMDAN
- \({S}_{t}^{1}\) :
-
The first exponential smoothing value of the \(t\) period of DES
- \({S}_{t}^{2}\) :
-
The second exponential smoothing value of the \(t\) period of DES
- \(\alpha\) :
-
Smoothing constant of DES
- \({a}_{t},\) \({b}_{t}\) :
-
Model parameters of DES
- \(Q\) :
-
The number of periods predicted for the future
- \({F}_{t+Q}\) :
-
Predicted value of the \(t+Q\) period of DES
- \({\zeta }_{t}\left(k\right)\) :
-
The correlation coefficient between the sequence of influencing factors and the displacement sequence
- \({C}_{t}\left(k\right)\) :
-
The sequence of landslide displacement
- \({I}_{t}\left(k\right)\) :
-
The sequence of influencing factors
- \(\rho\) :
-
The gray resolution coefficient
- \(K\) :
-
The dividing quantity of the cross-validation of ensemble algorithm
- \(x\) :
-
The parameter space of the machine learning models
- \(f(x)\) :
-
The objective function in the optimization process of the machine learning models
References
Augarde CE, Lee SJ, Loukidis D (2021) Numerical modelling of large deformation problems in geotechnical engineering: A state-of-the-art review. Soils Found 61(6):1718–1735
Cai ZL, Xu WY, Meng YD, Shi C, Wang RB (2016) Prediction of landslide displacement based on GA-LSSVM with multiple factors. Bull Eng Geol Environ 75(2):637–646
Cao Y, Yin KL, David EA, Zhou C (2016) Using an extreme learning machine to predict the displacement of step-like landslides in relation to controlling factors. Landslides 13(4):725–736
Chen, S.Y., Chou, W.Y., 2012. Short-term traffic flow prediction using emd-based recurrent hermite neural network approach, in: International IEEE Conference on Intelligent Transportation Systems, Anchorage, Alaska, USA
Colominas MA, Schlotthauer G, Torres ME (2014) Improved complete ensemble EMD: A suitable tool for biomedical signal processing. Biomed Signal Process Control 14:19–29
Du J, Yin KL, Lacasse S (2013) Displacement prediction in colluvial landslides, ThreeGorges Reservoir, China. Landslides 10:203–218
Fan XM, Xu Q, Liu J, Subramanian SS, He CY, Zhu X (2019) Successful early warning and emergency response of a disastrous rockslide in Guizhou province China. Landslides 16(4):2445–2457
Gao W, Dai S, Chen X (2020) Landslide prediction based on a combination intelligent method using the GM and ENN: two cases of landslides in the Three Gorges Reservoir China. Landslides 17(1):111–126
Hochreiter S, Schmidhuber J (1997) Long short-term memory. Neural Comput 9(8):1735
Hu XL, Wu SS, Zhang GC, Zheng WB, Liu C, He CC (2021) Landslide displacement prediction using kinematics-based random forests method: A case study in Jinping Reservoir Area. China. Eng Geol 283:105975
Huang C, Tian L, Zhang T, Chen J, Wu J, Wang H (2022) Globally optimized machine-learning framework for CO2-hydrocarbon minimum miscibility pressure calculations. Fuel 329:125312
Huang FM, Huang JS, Jiang SH, Zhou CB (2017) Landslide displacement prediction based on multivariate chaotic model and extreme learning machine. Eng Geol 218:173–186
Huang F, Yin K, Zhang G, Gui L, Yang B, Liu L (2016) Landslide displacement prediction using discrete wavelet transform and extreme learning machine based on chaos theory. Environ Earth Sci 75(20):1376
Jena R, Pradhan B, Beydoun G, Nizamuddin A, Sofyan H (2020) Integrated model for earthquake risk assessment using neural network and analytic hierarchy process: Aceh province Indonesia. Geosci Front 11(2):613–634
Jiang YH, Wang W, Zou LF, Wang RB, Liu SF, Duan XL (2022) Research on dynamic prediction model of landslide displacement based on particle swarm optimization-variational mode decomposition, nonlinear autoregressive neural network with exogenous inputs and gated recurrent unit. Rock Soil Mech 43:601–612
Kardani N, Zhou A, Nazem M, Shen SL (2021) Improved prediction of slope stability using a hybrid stacking ensemble method based on finite element analysis and field data. J Rock Mech Geotech Eng 13(1):188–201
Li C, Zeng ZG, Yao W, Tang HM (2015) Multiple neural networks switched prediction for landslide displacement. Eng Geol 186:91–99
Li DY, Sun YQ, Yin KL, Miao FS, Thomas G, Chin L (2019) Displacement characteristics and prediction of Baishuihe landslide in the Three Gorges Reservoir. J Mt Sci 16(9):2203–2214
Li HJ, Xu Q, He YS, Deng JH (2018) Prediction of landslide displacement with an ensemble-based extreme learning machine and copula models. Landslides 15(6):2047–2059
Li S, Wu N (2021) A new grey prediction model and its application in landslide displacement prediction. Chaos Solitons Fractals 147:110969
Li S, Yang J (2022) Modelling of suspended sediment load by Bayesian optimized machine learning methods with seasonal adjustment. Eng Appl Comput Fluid Mech 16(1):1883–1901
Li XZ, Kong JM (2014) Application of GA–SVM method with parameter optimization for landslide development prediction. Nat Hazards Earth Syst Sci 14(3):525–533
Li XZ, Kong JM, Wang ZY (2012) Landslide displacement prediction based on combining method with optimal weight. Nat Hazards 61:635–646
Lian C, Zeng ZG, Yao W, Tang HM (2014) Extreme learning machine for the displacement prediction of landslide under rainfall and reservoir level. Stoch Environ Res Risk Assess 28(8):1957–1972
Lin Z, Sun X, Ji Y (2022) Landslide Displacement Prediction Model Using Time Series Analysis Method and Modified LSTM Model. Electronics 11(10):1519
Liu LL, Yang C, Huang FM, Wang XM (2021a) Landslide susceptibility mapping by attentional factorization machines considering feature interactions. Geomat Nat Hazards Risk 12(1):1837–1861
Liu LL, Yang C, Wang XM (2021b) Landslide susceptibility assessment using feature selection-based machine learning models. Geomech Eng 25:1
Liu X, Wang Y (2021) Probabilistic simulation of entire process of rainfall-induced landslides using random finite element and material point methods with hydro-mechanical coupling. Comput Geosci 132:103989
Liu ZB, Shao JF, Xu WY, Chen HJ, Shi C (2014) Comparison on landslide nonlinear displacement analysis and prediction with computational intelligence approaches. Landslides 11(5):889–896
Long J, Li C, Liu Y, Feng P, Zuo Q (2022) A multi-feature fusion transfer learning method for displacement prediction of rainfall reservoir-induced landslide with step-like deformation characteristics. Eng Geol 297:106494
Lu X, Miao F, Xie X, Li D, Xie Y (2021) A new method for displacement prediction of “step-like” landslides based on VMD-FOA-SVR model. Environ Earth Sci 80(17):542
Ma J, Xia D, Guo H, Wang Y, Niu X, Liu Z (2022) Metaheuristic-based support vector regression for landslide displacement prediction: a comparative study. Landslides 19(10):2489–2511
Ma JW, Tang HM, Liu X, Hu XL, Sun MJ, Song YJ (2017) Establishment of a deformation forecasting model for a step-like landslide based on decision tree C5.0 and two-step cluster algorithms: a case study in the Three Gorges Reservoir area China. Landslides 14(3):1275–1281
Ma JW, Tang HM, Liu X, Wen T, Zhang JR, Tan QW (2018) Probabilistic forecasting of landslide displacement accounting for epistemic uncertainty: a case study in the Three Gorges Reservoir area China. Landslides 15(3):1145–1153
Miao F, Wu Y, Török Á, Li L, Xue Y (2022) Centrifugal model test on a riverine landslide in the Three Gorges Reservoir induced by rainfall and water level fluctuation. Geosci Front 13(3):101378
Miao FS, Wu YP, Xie YH, Li YN (2018) Prediction of landslide displacement with step-like behavior based on multialgorithm optimization and a support vector regression model. Landslides 15(3):475–488
Naidu S, Sajinkumar KS, Oommen T, Anuja VJ, Samuel RA, Muraleedharan C (2018) Early warning system for shallow landslides using rainfall threshold and slope stability analysis. Geosci Front 9(6):1871–1882
Rong G, Li K, Tong Z, Liu X, Zhang J, Zhang Y (2023) Population amount risk assessment of extreme precipitation-induced landslides based on integrated machine learning model and scenario simulation. Geosci Front 14(3):101541
Saito M 1969. Forecasting time of slope failure by tertiary creep, in: Proceedings of the 7th International Conference on Soil Mechanics and Foundation Engineering, Mexico City, 677–683
Tavenas F, Leroueil S (1981) Creep and failure of slopes in clays. Can Geotech J 18(1):106–120
Voight B (1988) A method for prediction of volcanic eruptions. Nature 332(6160):125–130
Wang B, Hicks M, Vardon P (2016) Slope failure analysis using the random material point method. Geotech Lett 6:1–6
Wang L, Xiao T, Liu S, Zhang W, Yang B, Chen L (2023) Quantification of model uncertainty and variability for landslide displacement prediction based on Monte Carlo simulation. Gondwana Res 123:27–40
Wang Y, Tang H, Huang J, Wen T, Ma J, Zhang J (2022) A comparative study of different machine learning methods for reservoir landslide displacement prediction. Eng Geol 298:106544
Xing Y, Yue J, Chen C, Qin Y, Hu J (2020) A hybrid prediction model of landslide displacement with risk-averse adaptation. Comput Geosci 141:104527
Xing Y, Yue JP, Chen C, Cong KL, Zhu SL, Bian YK (2019) Dynamic displacement forecasting of dashuitian landslide in china using variational mode decomposition and stack long short-term memory network. Appl Sci 9:1–12
Xu SL, Niu RQ (2018) Displacement prediction of Baijiabao landslide based on empirical mode decomposition and long short-term memory neural network in Three Gorges area China. Comput Geosci 111:87–96
Yang BB, Yin KL, Lacasse S, Liu ZQ (2019) Time series analysis and long short-term memory neural network to predict landslide displacement. Landslides 16:677–694
Yang C, Liu LL, Huang FM, Huang L, Wang XM (2022) Machine learning-based landslide susceptibility assessment with optimized ratio of landslide to non-landslide samples. Gondwana Res 123:198–216
Yao W, Zeng ZG, Lian C, Tang HM (2015) Training enhanced reservoir computing predictor for landslide displacement. Eng Geol 188:101–109
Zeng TR, Jiang HG, Liu QL, Yin KL (2022) Landslide displacement prediction based on Variational mode decomposition and MIC-GWO-LSTM model. Landslides 17(11):567–583
Zhang J, Lin C, Tang H, Wen T, Tannant DD, Zhang B (2024) Input-parameter optimization using a SVR based ensemble model to predict landslide displacements in a reservoir area – A comparative study. Appl Soft Comput 150:111107
Zhang K, Zhang K, Cai C, Liu W, Xie J (2021a) Displacement prediction of step-like landslides based on feature optimization and VMD-Bi-LSTM: a case study of the Bazimen and Baishuihe landslides in the Three Gorges China. Bull Eng Geol Environ 80(11):8481–8502
Zhang L, Chen X, Zhang Y, Wu F, Chen F, Wang W (2020) Application of GWO-ELM Model to Prediction of Caojiatuo Landslide Displacement in the Three Gorge Reservoir Area. Water 12(7):1860
Zhang L, Shi B, Zhu HH, Yu XB, Han HM, Fan XD (2021b) PSO-SVM-based deep displacement prediction of Majiagou landslide considering the deformation hysteresis effect. Landslides 18(1):179–193
Zhang LG, Chen XQ, Zhang YG, Wu FW, Chen F, Wang WT (2020) Application of GWO-ELM Model to Prediction of Caojiatuo Landslide Displacement in the Three Gorge Reservoir Area. Water 12:1860
Zhang Y, Tang J, Cheng Y, Huang L, Guo F, Yin X (2022) Prediction of landslide displacement with dynamic features using intelligent approaches. Int J Min Sci Technol 32(3):539–549
Zhang YG, Chen XQ, Liao RP, Wan JL, He ZY, Zhao ZX (2021c) Research on displacement prediction of step-type landslide under the infuence of various environmental factors based on intelligent WCA-ELM in the Three Gorges Reservoir area. Nat Hazards Earth Syst Sci 107:1709–1729
Zhang YG, Tang J, He ZY, Tan JK, Li C (2021d) A novel displacement prediction method using gated recurrent unit model with time series analysis in the Erdaohe landslide. Nat Hazards Earth Syst Sci 105:783–813
Zhou C, Yin KL, Cao Y, Ahmed B (2016) Application of time series analysis and PSO–SVM model in predicting the Bazimen landslide in the Three Gorges Reservoir China. Eng Geol 204:108–120
Zhou LS, Fu YH, Berto F (2022) Prediction of Landslide Displacement by the Novel Coupling Method of HP Filtering Method and Extreme Gradient Boosting. Strength Mater 54(5):942–958
Zhu X, Ma SQ, Q, Xu, WD, Liu (2018) A WD-GA-LSSVM model for rainfall-triggered landslide displacement prediction. J Mt Sci 15(1):156–166
Acknowledgements
The work described in this paper was funded by grants from the National Natural Science Foundation of China (Project No. 41902291), the Natural Science Foundation of Hunan Province, China (Project No. 2020JJ5704 and 2022JJ20058), the Research Project of Geological Bureau of Hunan Province (Project No. HNGSTP202106), and the Special Fund for Safety Production Prevention and Emergency of Hunan Province (Project No. 2021YJ009). the Fundamental Research Funds for Central Universities of the Central South University (Project No. 2023ZZTS0470). The financial support is greatly acknowledged.
Author information
Authors and Affiliations
Contributions
L.L. L: Conceptualization; Methodology; Validation; Resources; Funding acquisition; Writing - Original Draft, Review & Editing. H.D. Y: Methodology; Software; Formal analysis; Investigation; Writing - Original Draft. T. X: Resources; Supervision; Project administration; Visualization; Writing - Review & Editing. B.B. Y: Formal analysis; Visualization; Writing - Review & Editing. S. L: Methodology; Formal analysis; Visualization; Writing - Review & Editing.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Liu, L., Yin, H., Xiao, T. et al. Ensemble learning for landslide displacement prediction: A perspective of Bayesian optimization and comparison of different time series analysis methods. Stoch Environ Res Risk Assess 38, 3031–3058 (2024). https://doi.org/10.1007/s00477-024-02730-2
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00477-024-02730-2