
Abstract
Parameter estimation has wide applications in one-dimensional and multidimensional signal processing and filtering. This paper focuses on the parameter estimation problem of multivariate output-error autoregressive systems. Based on the data filtering technique and the auxiliary model identification idea, we derive a filtering based auxiliary model generalized stochastic gradient algorithm. The key is to choose an appropriate filter to filter the input-output data and to study a novel method to get the system model parameters and noise model parameters respectively. By employing the multi-innovation identification theory, a filtering based auxiliary model multi-innovation generalized stochastic gradient algorithm is proposed. Compared with the auxiliary model generalized stochastic gradient algorithm, the proposed algorithms can generate more accurate parameter estimates. Finally, an illustrative example is provided to verify the effectiveness of the proposed algorithms.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
With the development of control theory and the demand of engineering practices, the multivariable systems widely exist in all kinds of control processes (Cheng and Ugrinovskii 2016) and signal processing (Li and Zhang 2015). Compared with single variable systems, multivariable systems have more complex structures (Saikrishna et al. 2017) and uncertain disturbances (Xing et al. 2016; Jafari et al. 2014). As a consequence, the identification problems for multivariable systems have attracted a lot of attention (Mercère and Bako 2011; Mu and Chen 2013; Cham et al. 2017). Katayama and Ase (2016) considered the linear approximation and identification of multi-input multi-output (MIMO) Wiener–Hammerstein systems and applied the separable least squares algorithm to estimate the parameters. In order to improve the estimation accuracy, Wang and Ding (2016) proposed an auxiliary model based recursive least squares parameter estimation algorithm for MIMO systems by filtering input-output data. Cheng et al. (2017) proposed the subspace identification methods for two-dimensional causal, recursive, and separable-in-denominator systems, which are applicable to both open-loop and closed-loop data. Recently, a gradient based parameter estimation method has been proposed for multivariate pseudo-linear systems using the multi-innovation and the data filtering (Ma and Ding 2017). In this paper, we use the multidimensional input and output signals to study the parameter identification problems for the multivariate system.
The data filtering technique is used to eliminate noises and outliers to reduce the noise-to-signal ratio in signal processing (Dhabal and Venkateswaran 2017; Ding et al. 2017; Tseng and Lee 2017; Zhao et al. 2017b), and has been employed to deal with the parameter estimation problem of systems which contains colored noises (Afshari et al. 2017). Differing from eliminating noises, the data filtering method in system identification only changes the structure of the system and does not change the relationship between the inputs and outputs (Pan et al. 2016; Ding et al. 2017a). Pan et al. (2017) used the filtering technique and the multi-innovation identification theory to identify the multivariable system with moving average noise, and proposed the filtering based multi-innovation extended stochastic gradient algorithm for improving the parameter estimation accuracy.
Many identification methods has been studied for linear systems and nonlinear systems (Li et al. 2017a, b, c), such as the least squares (Wan et al. 2016), the Newton iteration (Xu 2016, 2015; Xu et al. 2015) and the stochastic methods (Xu and Ding 2017b). Compared with the recursive least square algorithm (Wang et al. 2016; Zhang and Mao 2107), the stochastic gradient algorithm requires less computational cost and has been applied in parameter estimation (Liang et al. 2014; Levanony and Berman 2004). However, the stochastic gradient algorithm has a slow convergence rate and can not reach a satisfactory estimation accuracy (Li et al. 2014). To solve this problem, we use the multi-innovation identification theory to improve the performance of the stochastic gradient algorithm (Xu and Ding 2017c; Xu et al. 2017). Ding et al. (2017) presented a filtering based multi-innovation gradient algorithm for linear state space systems with time-delay by adopting the data filtering technique.
This paper studies the parameter estimation methods for multivariate output-error systems whose disturbance is an autoregressive noise (Aslam 2016) using the data filtering and the auxiliary model (Ding et al. 2017b; Jin et al. 2015). The main idea is to use a filter to filter the input-output data, then the system can be transformed into two identification models: a multivariate output-error model with white noise and an autoregressive noise model. The difficulty is that the two models have unmeasurable variables. We employ the auxiliary model identification idea to establish the auxiliary models and replace the unknown variables with the outputs of the auxiliary models. The main contributions of this paper are in the following aspects.
-
A filtering based auxiliary model generalized stochastic gradient algorithm is derived for multivariate output-error autoregressive systems by using the data filter technique and the auxiliary model. Compared with the auxiliary model based generalized stochastic gradient algorithm, the proposed algorithm can generate more accurate estimates.
-
A filtering based auxiliary model multi-innovation generalized stochastic gradient algorithm is proposed in order to improve the performance of the filtering based auxiliary model generalized stochastic gradient algorithm and it can get more accurate parameter estimates than the auxiliary model multi-innovation generalized stochastic gradient algorithm for the same innovation length.
The rest of this paper is organized as follows. In Sect. 2, we give some definitions and the identification model for multivariate output-error autoregressive systems. Section 3 gives the auxiliary model based stochastic gradient algorithm and the auxiliary model based multi-innovation stochastic gradient algorithm for comparisons. Section 4 derives the filtering identification model and presents the filtering based auxiliary model generalized stochastic gradient algorithm and the filtering based auxiliary model multi-innovation generalized stochastic gradient algorithm. An illustrative example is shown to verify the effectiveness of the proposed algorithms in Sect. 5. Finally, we offer some concluding remarks in Sect. 6.
2 The system description
Some notation is introduced. “\(A=:X\)” or “\(X:=A\)” stands for “A is defined as X”; the superscript T stands for the vector/matrix transpose; the symbol \(\varvec{I}_n\) denotes an identity matrix of appropriate size (\(n\times n\)); \(\hat{\varvec{{\vartheta }}}(t)\) denotes the estimate of \(\varvec{{\vartheta }}\) at time t; \(\mathbf{1}_n\) stands for an n-dimensional column vector whose elements are 1; the norm of a matrix (or a column vector) \(\varvec{X}\) is defined by \(\Vert \varvec{X}\Vert ^2:=\mathrm{tr}[\varvec{X}\varvec{X}^{\tiny \text{ T }}]\).
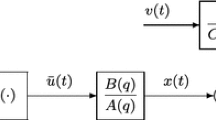
Consider the following multivariate output-error autoregressive (M-OEAR) system in Fig. 1,
where \(\varvec{y}(t):=[y_1(t), y_2(t),\ldots , y_m(t)]^{\tiny \text{ T }}\in {\mathbb R}^{m}\) is the output vector of the system, \(\varvec{\varPhi }_{\mathrm{s}}(t)\in {\mathbb R}^{m\times n}\) is the information matrix consisting of the input signals \(\varvec{u}(t)=[u_1(t), u_2(t), \ldots , u_r(t)]\in {\mathbb R}^{r}\) and output signals \(\varvec{y}(t)\), \(\varvec{{\theta }}\in {\mathbb R}^{n}\) is the parameter vector to be identified and \(\varvec{v}(t):=[v_1(t), v_2(t), \ldots , v_m(t)]^{\tiny \text{ T }}\in {\mathbb R}^{m}\) is a white noise vector with zero mean, A(z) and C(z) are the polynomials in the unit backward shift operator \(z^{-1}\) [\(z^{-1}y(t)=y(t-1)\)], and defined as
Assume that the orders m, n, \(n_a\) and \(n_c\) are known and \(\varvec{y}(t)=\mathbf{0}\), \(\varvec{\varPhi }_{\mathrm{s}}(t)=\mathbf{0}\) and \(\varvec{v}(t)=\mathbf{0}\) for \(t\leqslant 0\).

A multivariate output-error autoregressive system
Define the parameter vectors:
and the information matrices:
Define the intermediate variables:
Equation (3) is the noise identification model.
Substituting (2) and (3) into (1) gives
Equation (5) is the identification model for the M-OEAR system and the parameter vector \(\varvec{{\vartheta }}\) contains all the parameters to be estimated. The object of this paper is to derive a new algorithm for the M-OEAR system by using the data filtering technique and the multi-innovation theory, which can generate more accurate estimates.
This paper studies the parameter estimation problem for the multivariate system by using the multidimensional input and output signals. The information matrix \(\varvec{\varPhi }_{\mathrm{s}}(t)\) is composed of the m-dimensional output signals and the r-dimensional input signals. Therefore, the problem under consideration belongs to the multidimensional signal processing and estimation.
3 The auxiliary model based generalized stochastic gradient identification algorithm
In this section, we give the generalized stochastic gradient (AM-GSG) identification algorithm based on the auxiliary model identification idea. In order to improve the convergence rate and parameter estimation accuracy, an auxiliary model based multi-innovation stochastic gradient (AM-MI-GSG) algorithm is derived.
3.1 The AM-GSG algorithm
The stochastic gradient algorithm has been used to identify the multivariable system, and its convergence has been analyzed under weak conditions (Ding et al. 2008). On the basis of the work in Ding et al. (2008), we derive the AM-GSG algorithm for M-OEAR systems.
According to the identification model (5), we can define a gradient criterion function
Using the negative gradient search and minimizing the criterion function \(J_1(\varvec{{\vartheta }})\) give
Here, some problems arise. The information matrix \(\varvec{\varPhi }(t)\) contains the unknown terms \(\{\varvec{x}(t-i)\), \(i=1, 2, \ldots , n_a\}\) and \(\{\varvec{w}(t-i)\), \(i=1, 2, \ldots , n_c\}\), thus the estimate \(\hat{\varvec{{\vartheta }}}(t)\) in (6–7) is impossible to compute. An effective method to solve this problem is to employ the auxiliary model identification idea. Establish the appropriate auxiliary models, use their outputs \(\varvec{x}_{\mathrm{a}}(t-i)\) and \(\hat{\varvec{w}}(t-i)\) to replace the unknown variables \(\varvec{x}(t-i)\) and \(\varvec{w}(t-i)\). The estimates \(\hat{\varvec{{\phi }}}_a(t)\) and \(\hat{\varvec{{\phi }}}_c(t)\) of \(\varvec{{\phi }}_a(t)\) and \(\varvec{{\phi }}_c(t)\) can be formed by \(\varvec{x}_{\mathrm{a}}(t-i)\) and \(\hat{\varvec{w}}(t-i)\). Then we can get the estimate \(\hat{\varvec{\varPhi }}(t)\) by using \(\varvec{\varPhi }_{\mathrm{s}}(t)\), \(\hat{\varvec{{\phi }}}_a(t)\) and \(\hat{\varvec{{\phi }}}_c(t)\). Define
According to (2), replacing the \(\varvec{{\phi }}_a(t)\), \(\varvec{{\theta }}\) and \(\varvec{a}\) with their estimates \(\hat{\varvec{{\phi }}}_a(t)\), \(\hat{\varvec{{\theta }}}(t)\) and \(\hat{\varvec{a}}(t)\), the output \(\varvec{x}_{\mathrm{a}}(t)\) of the auxiliary model can be computed by
Similarly, from (4), \(\hat{\varvec{w}}(t)\) can be computed through
For convenience, define the innovation vector
Replacing \(\varvec{\varPhi }(t)\) in (6–7) with its estimate \(\hat{\varvec{\varPhi }}(t)\), we can obtain the auxiliary model based generalized stochastic gradient (AM-GSG) algorithm:
The procedure for computing the parameter estimation vector \(\hat{\varvec{{\vartheta }}}(t)\) in the AM-GSG algorithm (8–16) is as follows.
-
1.
Set the initial values: let \(t=1\), \(\hat{\varvec{{\vartheta }}}(0)=\mathbf{1}_{n+n_a+n_c}/p_0\), \(r(0)=1\), \(\varvec{x}_{\mathrm{a}}(t-i)=\mathbf{1}_m/p_0\), \(\hat{\varvec{w}}(t-i)=\mathbf{1}_m/p_0\), \(i=1\), 2, \(\ldots \), \(\max [n_a,n_c]\), \(p_0=10^6\) and set a small positive number \(\varepsilon \).
-
2.
Collect the observation data \(\varvec{y}(t)\) and \(\varvec{\varPhi }_{\mathrm{s}}(t)\), and construct the information matrices \(\hat{\varvec{{\phi }}}_a(t)\), \(\hat{\varvec{{\phi }}}_c(t)\) and \(\hat{\varvec{\varPhi }}(t)\) using (12–13) and (11).
-
3.
Compute the innovation vector \(\varvec{e}(t)\) and the step-size r(t) according to (9) and (10).
-
4.
Update the parameter estimation vector \(\hat{\varvec{{\vartheta }}}(t)\) using (8).
-
5.
Compute \(\varvec{x}_{\mathrm{a}}(t)\) and \(\hat{\varvec{w}}(t)\) using (14–15).
-
6.
Compare \(\hat{\varvec{{\vartheta }}}(t)\) with \(\hat{\varvec{{\vartheta }}}(t-1)\): if \(\Vert \hat{\varvec{{\vartheta }}}(t)-\hat{\varvec{{\vartheta }}}(t-1)\Vert <\varepsilon \), terminate recursive calculation procedure and obtain \(\hat{\varvec{{\vartheta }}}(t)\); otherwise, increase t by 1 and go to Step 2.
Remark 1
: In order to improve the transient performance and parameter estimation accuracy of the AM-GSG algorithm, we can introduce a forgetting factor (FF) \(\lambda \) in (10):
Equations (8–9), (11–16) and (17) form the auxiliary model based forgetting factor gradient stochastic gradient (AM-FF-GSG) algorithm for the M-OEAR system. When \(\lambda \)=1, the AM-FF-GSG algorithm reduces to the AM-GSG algorithm (8–16).
Remark 2
In order to improve the stable state performance, a convergence index \(\varepsilon \) can be introduced in (8),
Then Eqs. (9–16) and (18) form the Modified AM-GSG (M-AM-GSG) algorithm. When \(\varepsilon =1\), the M-AM-GSG algorithm reduces to the AM-GSG algorithm in (8–16).
3.2 The AM-MI-GSG algorithm
In order to improve the convergence rate and parameter estimation accuracy of the AM-GSG algorithm, we expand the dimension of the innovation vector \(\varvec{e}(t)\) by employing the multi-innovation identification theory and derive the auxiliary model based multi-innovation generalized stochastic gradient algorithm for the M-OEAR system.
Let p represents the innovation length, consider p data from \(j=t-p+1\) to \(j=t\) and define a new multi-innovation vector:
It is usually considered that the estimate \(\hat{\varvec{{\vartheta }}}(t-1)\) is more closer to the true value than \(\hat{\varvec{{\vartheta }}}(t-i)\) and \(\varvec{E}(p,t)\) is modified as
Define the stacked output vector \(\varvec{Y}(p,t)\) and the stacked information matrix \(\hat{{{\varvec{\varGamma }}}}(p,t)\) as
Then the innovation vector \(\varvec{E}(p,t)\) can be equivalently expressed as
Thus, we have
Equations (19–23) and (11–16) consist the AM-MI-GSG algorithm. When the innovation length \(p=1\), the AM-MI-GSG algorithm reduces to the AM-GSG algorithm in (8–16). That is to say, the AM-GSG is a special case of the AM-MI-GSG algorithm. Similarly, a forgetting factor \(\lambda \) can be introduced in (21),
Equations (19–20), (24), (22–23) and (11–16) form the auxiliary model based forgetting factor multi-innovation stochastic generalized gradient (AM-FF-MI-GSG) algorithm for the M-OEAR system.
To initialize the AM-MI-GSG algorithm, we should set the innovation length p and some initial values, e.g., \(\hat{\varvec{{\vartheta }}}(0)=\mathbf{1}_{n+n_a+n_c}/p_0\), \(\varvec{x}_{\mathrm{a}}(t-i)=\mathbf{1}_m/p_0\), \(\hat{\varvec{w}}(t-i)=\mathbf{1}_m/p_0\), \(i=1\), 2, \(\ldots \), \(\max [n_a,n_c]\) and \(p_0=10^6\). The flowchart of computing \(\hat{\varvec{{\vartheta }}}(t)\) in the AM-MI-GSG algorithm is shown in Fig. 2.

The flowchart of computing the AM-MI-GSG parameter estimates \(\hat{\varvec{{\vartheta }}}(t)\)
4 The filtering based AM-GSG identification algorithm
In this section, a linear filter L(z) is introduced to deal with the colored noises. We derive two identification models by filtering the input and output data including a system model and a noise model, and identify each subsystems respectively. A filtering base AM-GSG (F-AM-GSG) and a filtering base AM-MI-GSG (F-AM-MI-GSG) identification algorithms are proposed in order to improve the convergence rate and parameter estimation accuracy.
4.1 The F-AM-GSG algorithm
For the M-OEAR model in (1), choose the polynomial C(z) as the filter, that is to say, \(L(z)=C(z)\). Multiplying the both sides of (1) by C(z) gives
Define the filtered output vector \(\varvec{y}_{\mathrm{f}}(t)\) and the filtered information matrix \(\varvec{\varPhi }_{\mathrm{f}}(t)\) as
which can be expressed as the following recursive forms:
From (25), we have
Define an inner variable
where
Then Eq. (30) can be rewritten as
For the filter identification model in (32) and the noise identification model in (3), defining and minimizing the two gradient criterion functions
result in the following gradient recursive relations:
As we can see, Eqs. (33–36) cannot generate the estimates of \(\hat{\varvec{{\theta }}}_{\mathrm{f}}(t)\) and \(\hat{\varvec{c}}(t)\), because the filter C(z) is unknown, then the filtered matrix \(\varvec{\varPhi }_{\mathrm{f}}\) is unknown, in addition, \(\varvec{x}(t-i)\) and \(\varvec{w}(t-i)\) are unmeasurable, the information matrices \(\varvec{{\phi }}_a(t)\) and \(\varvec{{\phi }}_c(t)\) contain those unknown terms. In order to solve those difficulties, we employ the auxiliary model method to replace the unknown variables with the output of the auxiliary model.
Use the outputs of the auxiliary models \(\varvec{x}_{\mathrm{a}}(t-i)\) and \(\hat{\varvec{w}}(t-i)\) to construct the estimates
Similarly, we use the estimate \(\varvec{x}_{\mathrm{f}\mathrm{a}}(t-i)\) of \(\varvec{x}_{\mathrm{f}}(t-i)\) and the estimate \(\hat{\varvec{{\phi }}}_{\mathrm{f}}(t)\) of \(\varvec{\varPhi }_{\mathrm{f}}(t)\) to define
From (2), (4) and (31), we can compute the outputs \(\varvec{x}_{\mathrm{a}}(t)\), \(\hat{\varvec{w}}(t)\) and \(\varvec{x}_{\mathrm{f}\mathrm{a}}(t)\) of the auxiliary models by
Use the parameter estimates of the noise model
to construct the estimate of C(z):
Replacing the C(z) in (26) and (27) with \(\hat{C}(t,z)\), the estimates of the filtered output vector \(\varvec{y}_{\mathrm{f}}(t)\) and the filtered information matrix \(\varvec{{\phi }}_{\mathrm{f}}(t)\) can be computed by
Replace the unknown information matrix \(\varvec{\varPhi }_{\mathrm{f}}(t)\) in (33–34) with its estimate \(\hat{\varvec{\varPhi }}_{\mathrm{f}}(t)\), \(\varvec{{\phi }}_c(t)\) in (35–36) with \(\hat{\varvec{{\phi }}}_c(t)\), \(\varvec{{\phi }}_a(t)\) in (36) with \(\hat{\varvec{{\phi }}}_a(t)\), and the filtered output \(\varvec{y}_{\mathrm{f}}(t)\) in (33) with \(\hat{\varvec{y}}_{\mathrm{f}}(t)\), the parameter vector \(\varvec{{\theta }}\) and \(\varvec{a}\) in (36) with \(\hat{\varvec{{\theta }}}(t-1)\) and \(\hat{\varvec{a}}(t-1)\) respectively. Furthermore, define the innovation vectors:
Then, we can derive a filtering based auxiliary model generalized stochastic gradient (F-AM-GSG) algorithm to estimate the parameter vectors \(\hat{\varvec{{\theta }}}_{\mathrm{f}}(t)\) and \(\hat{\varvec{c}}(t)\) for the M-OEAR system:
The steps involved in the F-AM-GSG algorithm are listed as follows.
-
1.
Set the initial values: let \(t=1\), \(\hat{\varvec{{\theta }}}_{\mathrm{f}}(0)=\mathbf{1}_{n+n_a}/p_0\), \(\hat{\varvec{c}}(0)=\mathbf{1}_{n_c}/p_0\), \(r_1(0)=1\), \(r_2(0)=1\), \(\varvec{x}_{\mathrm{f}\mathrm{a}}(t-i)=\mathbf{1}_m/p_0\), \(\varvec{x}_{\mathrm{a}}(t-i)=\mathbf{1}_m/p_0\), \(\hat{\varvec{w}}(t-i)=\mathbf{1}_m/p_0\), \(i=1\), 2, \(\ldots \), \(\max [n_a,n_c]\), \(p_0=10^6\), and set a small positive number \(\varepsilon \).
-
2.
Collect the observation data \(\varvec{y}(t)\) and \(\varvec{\varPhi }_{\mathrm{s}}(t)\), construct the information matrices \(\hat{\varvec{{\phi }}}_a(t)\) and \(\hat{\varvec{{\phi }}}_c(t)\) by (46) and (47).
- 3.
-
4.
Update the parameter estimate \(\hat{\varvec{c}}(t)\) by (40).
-
5.
Compute the filtered output vector \(\hat{\varvec{y}}_{\mathrm{f}}(t)\) by (44) and the filtered information matrix \(\hat{\varvec{{\phi }}}_{\mathrm{f}}(t)\) by (45), and form \(\hat{\varvec{\varPhi }}_{\mathrm{f}}(t)\) by (43).
- 6.
-
7.
Update the parameter estimate \(\hat{\varvec{{\theta }}}_{\mathrm{f}}(t)\) by (37).
-
8.
Compute \(\varvec{x}_{\mathrm{f}\mathrm{a}}(t)\) by (48). Read \(\hat{\varvec{{\theta }}}(t)\) and \(\hat{\varvec{a}}(t)\) from \(\hat{\varvec{{\theta }}}_{\mathrm{f}}(t)\) and compute \(\varvec{x}_{\mathrm{a}}(t)\) and \(\hat{\varvec{w}}(t)\) by (49–50).
-
9.
Compare \(\hat{\varvec{{\theta }}}_{\mathrm{f}}(t)\) with \(\hat{\varvec{{\theta }}}_{\mathrm{f}}(t-1)\) and compare \(\hat{\varvec{c}}(t)\) with \(\hat{\varvec{c}}(t-1)\): if \(\Vert \hat{\varvec{{\theta }}}_{\mathrm{f}}(t)-\hat{\varvec{{\theta }}}_{\mathrm{f}}(t-1)\Vert <\varepsilon \) and \(\Vert \hat{\varvec{c}}(t)-\hat{\varvec{c}}(t-1)\Vert <\varepsilon \), terminate recursive calculation procedure and obtain \(\hat{\varvec{{\vartheta }}}(t)\); otherwise, increase t by 1 and go to Step 2.
4.2 The F-AM-MI-GSG algorithm
The F-AM-GSG algorithm can identify the parameter vectors \(\hat{\varvec{{\theta }}}_{\mathrm{f}}(t)\) and \(\hat{\varvec{c}}(t)\), but has slow convergence speed. To improve the convergence rate and parameter estimation accuracy of the F-AM-GSG algorithm, according to the multi-innovation identification theory, we expand the innovation vectors \(\varvec{e}_1(t)=\hat{\varvec{y}}_{\mathrm{f}}(t)-\hat{\varvec{\varPhi }}_{\mathrm{f}}(t)\hat{\varvec{{\theta }}}_{\mathrm{f}}(t-1)\in {\mathbb R}^{m}\) in (38) and \(\varvec{e}_2(t)=\varvec{y}(t)-\varvec{\varPhi }_{\mathrm{s}}(t)\hat{\varvec{{\theta }}}(t-1)-\hat{\varvec{{\phi }}}_a(t)\hat{\varvec{a}}(t-1)-\hat{\varvec{{\phi }}}_c(t)\hat{\varvec{c}}(t-1)\in {\mathbb R}^{m}\) in (41) into large innovation vectors (p represents the innovation length):
Define the stacked filtered output vector \(\hat{\varvec{Y}}_{\mathrm{f}}(p,t)\), the stacked filtered information matrix \(\hat{{{\varvec{\varGamma }}}}_{\mathrm{f}}(p,t)\), the stacked output vector \(\varvec{Y}(p,t)\), the stacked information matrices \({{\varvec{\varGamma }}}_{\mathrm{s}}(p,t)\), \(\hat{\varvec{\varOmega }}_a(p,t)\) and \(\hat{\varvec{\varOmega }}_c(p,t)\) as
Then \(\varvec{E}_1(p,t)\) and \(\varvec{E}_2(p,t)\) can be equivalently expressed as
According to the F-AM-GSG algorithm in (37–51), we can obtain the following equations:
The equations above and (43–51) form the data filtering based auxiliary model multi-innovation generalized stochastic gradient (F-AM-MI-GSG) algorithm. When \(p=1\), the F-AM-MI-GSG algorithm reduce to the F-AM-GSG algorithm in (37–51). The proposed method in this paper can be extended to study the parameter estimation of transfer functions (Xu 2014; Xu and Ding 2017a), time-varying systems (Ding et al. 2016) and signal models (Xu 2017; Wang et al. 2018), and applied to other fields (Feng et al. 2016; Li et al. 2017d; Ji and Ding 2017; Cao and Zhu 2017; Chu et al. 2017; Zhao et al. 2017a).
5 Example
Consider the following multivariate output-error autoregressive system:
In simulation, the inputs \(\{u_1(t)\}\) and \(\{u_2(t)\}\) are taken as two independent persistent excitation signal sequences with zero mean and unit variances, \(\{v_1(t)\}\) and \(\{v_2(t)\}\) are taken as two white noise sequences with zero mean and variances \(\sigma ^2_1\) for \(v_1(t)\) and \(\sigma ^2_2\) for \(v_2(t)\). Taking \(\sigma ^2_1=\sigma ^2_2=\sigma ^2=0.50^2\) and based on the above model, we generate the system’s output signals \(\varvec{y}(t)=[y_1(t),y_2(t)]^{\tiny \text{ T }}\). By using \(u_1(t)\), \(u_2(t)\), \(y_1(t)\) and \(y_2(t)\) and applying the AM-MI-GSG algorithm and the F-AM-MISG algorithm to estimate the parameters of this system, the parameter estimates and errors are shown in Tables 1 and 2 with \(p=1\), 2, 4, 6 and 12. The estimation errors \(\delta :=\Vert \hat{\varvec{{\vartheta }}}(t)-\varvec{{\vartheta }}\Vert /\Vert \varvec{{\vartheta }}\Vert \) versus t are shown in Figs. 3 and 4.

The AM-MI-GSG parameter estimation errors \(\delta \) versus t

The F-AM-MI-GSG parameter estimation errors \(\delta \) versus t
From Tables 1 and 2 and Figs. 3 and 4, we can draw the following conclusions.
-
1.
The parameter estimation errors of the AM-MI-GSG and the F-AM-MI-GSG algorithms become smaller with the data length t increasing – see the estimation errors of the last columns in Tables 1 and 2.
-
2.
A larger innovation length p leads to smaller parameter estimation errors both for the AM-MI-GSG algorithm and the F-AM-MI-GSG algorithm–see from Figs. 3 and 4. The estimation errors can almost converge to zero if the innovation length p is large enough and the data length goes to infinity.
-
3.
Under the same innovation length p, the F-AM-MI-GSG algorithm can give more accurate parameter estimates than the AM-MI-GSG algorithm.
6 Conclusions
In this paper, we employ the data filtering technique to propose an F-AM-GSG algorithm for M-OEAR systems and derive an F-AM-MI-GSG algorithm by adopting the multi-innovation identification theory, taking account into an autoregressive noise. This work can be extended to the case with an autoregressive moving average noise. Compared with the AM-MI-GSG algorithm, the F-AM-MI-GSG algorithm has smaller estimation errors under the same innovation length. The proposed filtering based identification method can be applied to study the parameter estimation of other multivariate systems with different structures and disturbance noise, e.g., nonlinear multidimensional multivariate systems with colored noise. These are worth further studying in multidimensional multivariate systems in the future.
References
Afshari, H. H., Gadsden, S. A., & Habibi, S. (2017). Gaussian filters for parameter and state estimation: A general review of theory and recent trends. Signal Processing, 135, 218–238.
Aslam, M. S. (2016). Maximum likelihood least squares identification method for active noise control systems with autoregressive moving average noise. Automatica, 69, 1–11.
Cao, X., & Zhu, D. Q. (2017). Multi-AUV task assignment and path planning with ocean current based on biological inspired self-organizing map and velocity synthesis algorithm. Intelligent Automation and Soft Computing, 23(1), 31–39.
Cham, C. L., Tan, A. H., & Tan, W. H. (2017). Identification of a multivariable nonlinear and time-varying mist reactor system. Control Engineering Practice, 63, 13–23.
Cheng, J. X., Fang, M. Q., & Wang, Y. Q. (2017). Subspace identification for closed-loop 2-D separable-in-denominator systems. Multidimensional Systems and Signal Processing, 28(4), 1499–1521.
Cheng, Y., & Ugrinovskii, V. (2016). Event-triggered leader-following tracking control for multivariable multi-agent systems. Automatica, 70, 204–210.
Chu, Z. Z., Zhu, D. Q., & Yang, S. X. (2017). Adaptive sliding mode control for depth trajectory tracking of remotely operated vehicle with thruster nonlinearity. Journal of Navigation, 70(1), 149–164.
Dhabal, S., & Venkateswaran, P. (2017). A novel accelerated artificial bee colony algorithm for optimal design of two dimensional FIR filter. Multidimensional Systems and Signal Processing, 28(2), 471–493.
Ding, D. R., Wang, Z. D., Ho, D. W. C., et al. (2017). Distributed recursive filtering for stochastic systems under uniform quantizations and deception attacks through sensor networks. Automatica, 78, 231–240.
Ding, F., Wang, F. F., Xu, L., et al. (2017a). Decomposition based least squares iterative identification algorithm for multivariate pseudo-linear ARMA systems using the data filtering. Journal of the Franklin Institute, 354(3), 1321–1339.
Ding, F., Wang, F. F., Xu, L., et al. (2017b). Parameter estimation for pseudo-linear systems using the auxiliary model and the decomposition technique. IET Control Theory and Applications, 11(3), 390–400.
Ding, F., Wang, X. H., Mao, L., et al. (2017). Joint state and multi-innovation parameter estimation for time-delay linear systems and its convergence based on the Kalman filtering. Digital Signal Processing, 62, 211–223.
Ding, F., Xu, L., & Zhu, Q. M. (2016). Performance analysis of the generalised projection identification for time-varying systems. IET Control Theory and Applications, 10(18), 2506–2514.
Ding, F., Yang, H. Z., & Liu, F. (2008). Performance analysis of stochastic gradient algorithms under weak conditions. Science in China Series F-Information Sciences, 51(9), 1269–1280.
Feng, L., Wu, M. H., Li, Q. X., et al. (2016). Array factor forming for image reconstruction of one-dimensional nonuniform aperture synthesis radiometers. IEEE Geoscience and Remote Sensing Letters, 13(2), 237–241.
Jafari, M., Salimifard, M., & Dehghani, M. (2014). Identification of multivariable nonlinear systems in the presence of colored noises using iterative hierarchical least squares algorithm. ISA Transactions, 53(4), 1243–1252.
Ji, Y., & Ding, F. (2017). Multiperiodicity and exponential attractivity of neural networks with mixed delays. Circuits, Systems and Signal Processing, 36(6), 2558–2573.
Jin, Q. B., Wang, Z., & Liu, X. P. (2015). Auxiliary model-based interval-varying multi-innovation least squares identification for multivariable OE-like systems with scarce measurements. Journal of Process Control, 35, 154–168.
Katayama, T., & Ase, H. (2016). Linear approximation and identification of MIMO Wiener-Hammerstein systems. Automatica, 71, 118–124.
Levanony, D., & Berman, N. (2004). Recursive nonlinear system identification by a stochastic gradient algorithm: Stability, performance, and model nonlinearity considerations. IEEE Transactions on Signal Processing, 52(9), 2540–2550.
Liang, J. L., Wang, Z. D., & Liu, X. H. (2014). Robust state estimation for two-dimensional stochastic time-delay systems with missing measurements and sensor saturation. Multidimensional Systems and Signal Processing, 25(1), 157–177.
Li, J. F., & Zhang, X. F. (2015). Sparse representation-based joint angle and Doppler frequency estimation for MIMO radar. Multidimensional Systems and Signal Processing, 26(1), 179–192.
Li, J. P., Hua, C. C., Tang, Y. J., et al. (2014). A time-varying forgetting factor stochastic gradient combined with Kalman filter algorithm for parameter identification of dynamic systems. Nonlinear Dynamics, 78(3), 1943–1952.
Li, M. H., Liu, X. M., & Ding, F. (2017a). Least-squares-based iterative and gradient-based iterative estimation algorithms for bilinear systems. Nonlinear Dynamics, 89(1), 197–211.
Li, M. H., Liu, X. M., & Ding, F. (2017b). The maximum likelihood least squares based iterative estimation algorithm for bilinear systems with autoregressive moving average noise. Journal of the Franklin Institute, 354(12), 4861–4881.
Li, M. H., Liu, X. M., & Ding, F. (2017c). The gradient based iterative estimation algorithms for bilinear systems with autoregressive noise. Circuits, Systems and Signal Processing, 36(11), 4541–4568.
Li, X. F., Chu, Y. D., Leung, A. Y. T., & Zhang, H. (2017d). Synchronization of uncertain chaotic systems via complete-adaptive-impulsive controls. Chaos Solitons & Fractals, 100, 24–30.
Ma, P., & Ding, F. (2017). New gradient based identification methods for multivariate pseudo-linear systems using the multi-innovation and the data filtering. Journal of the Franklin Institute, 354(3), 1568–1583.
Mercère, G., & Bako, L. (2011). Parameterization and identification of multivariable state-space systems: A canonical approach. Automatica, 47(8), 1547–1555.
Mu, B. Q., & Chen, H. F. (2013). Recursive identification of MIMO Wiener systems. IEEE Transactions on Automatic Control, 58(3), 802–808.
Pan, J., Jiang, X., Wan, X. K., et al. (2017). A filtering based multi-innovation extended stochastic gradient algorithm for multivariable control systems. International Journal of Control, Automation and Systems, 15(3), 1189–1197.
Pan, J., Yang, X. H., Cai, H. F., et al. (2016). Image noise smoothing using a modified Kalman filter. Neurocomputing, 173, 1625–1629.
Saikrishna, P. S., Pasumarthy, R., & Bhatt, N. P. (2017). Identification and multivariable gain-scheduling control for cloud computing systems. IEEE Transactions on Control Systems Technology, 25(3), 792–807.
Tseng, C. C., & Lee, S. L. (2017). Closed-form designs of digital fractional order Butterworth filters using discrete transforms. Signal Processing, 137, 80–97.
Wan, X. K., Li, Y., Xia, C., et al. (2016). A T-wave alternans assessment method based on least squares curve fitting technique. Measurement, 86, 93–100.
Wang, Y. J., & Ding, F. (2016). Novel data filtering based parameter identification for multiple-input multiple-output systems using the auxiliary model. Automatica, 71, 308–313.
Wang, Y.J., Ding, F., & Xu, L. (2018) Some new results of designing an IIR filter with colored noise for signal processing. Digital Signal Processing, 72, 44–58.
Wang, Z., Jin, Q. B., & Liu, X. P. (2016). Recursive least squares identification of hybrid Box-Jenkins model structure in open-loop and closed-loop. Journal of the Franklin Institute, 353(2), 265–278.
Xing, H. L., Li, D. H., Li, J., et al. (2016). Linear extended state observer based sliding mode disturbance decoupling control for nonlinear multivariable systems with uncertainty. International Journal of Control, Automation and Systems, 14(4), 967–976.
Xu, L. (2014). A proportional differential control method for a time-delay system using the Taylor expansion approximation. Applied Mathematics and Computation, 236, 391–399.
Xu, L. (2015). Application of the Newton iteration algorithm to the parameter estimation for dynamical systems. Journal of Computational and Applied Mathematics, 288, 33–43.
Xu, L. (2016). The damping iterative parameter identification method for dynamical systems based on the sine signal measurement. Signal Processing, 120, 660–667.
Xu L. (2017). The parameter estimation algorithms based on the dynamical response measurement data. Advances in Mechanical Engineering, 9. https://dx.doi.org/10.1177/1687814017730003.
Xu, L., Chen, L., & Xiong, W. L. (2015). Parameter estimation and controller design for dynamic systems from the step responses based on the Newton iteration. Nonlinear Dynamics, 79(3), 2155–2163.
Xu, L., & Ding, F. (2017a). Parameter estimation for control systems based on impulse responses. International Journal of Control, Automation and Systems, 15(6). https://dx.doi.org/10.1007/s12555-016-0224-2.
Xu, L., & Ding, F. (2017b). Recursive least squares and multi-innovation stochastic gradient parameter estimation methods for signal modeling. Circuits, Systems and Signal Processing, 36(4), 1735–1753.
Xu, L., & Ding, F. (2017c). Parameter estimation algorithms for dynamical response signals based on the multi-innovation theory and the hierarchical principle. IET Signal Processing, 11(2), 228–237.
Xu, L., Ding, F., Gu, Y., et al. (2017). A multi-innovation state and parameter estimation algorithm for a state space system with d-step state-delay. Signal Processing, 140, 97–103.
Zhang, B., & Mao, Z. Z. (2107). Bias compensation principle based recursive least squares identification method for Hammerstein nonlinear systems. Journal of the Franklin Institute, 354(3), 1340–1355.
Zhao, N., Chen, Y., Liu, R., Wu, M. H., & Xiong, W. (2017a). Monitoring strategy for relay incentive mechanism in cooperative communication networks. Computers & Electrical Engineering, 60, 14–29.
Zhao, N., Wu, M. H., & Chen, J. J. (2017b). Android-based mobile educational platform for speech signal processing. International Journal of Electrical Engineering Education, 54(1), 3–16.
Acknowledgements
This work was supported by the National Natural Science Foundation of China (No. 61273194) and the Fundamental Research Funds for the Central Universities (JUSRP51733B).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Liu, Q., Ding, F. The data filtering based generalized stochastic gradient parameter estimation algorithms for multivariate output-error autoregressive systems using the auxiliary model. Multidim Syst Sign Process 29, 1781–1800 (2018). https://doi.org/10.1007/s11045-017-0529-1
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11045-017-0529-1