
Abstract
This paper focuses on the parameter estimation problem of multivariate output-error autoregressive systems. Based on the data filtering technique and the auxiliary model identification idea, we derive a filtering-based auxiliary model recursive generalized least squares algorithm. The key is to filter the input–output data and to derive two identification models, one of which includes the system parameters and the other contains the noise parameters. Compared with the auxiliary model-based recursive generalized least squares algorithm, the proposed algorithm requires less computational burden and can generate more accurate parameter estimates. Finally, an illustrative example is provided to verify the effectiveness of the proposed algorithm.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Parameter estimation and system identification can be used to many areas [2, 16, 18, 53] such as signal modeling [41, 42]. Modeling is always the first step when one tries to design a control system [54], and the model quality directly affects the performance of the entire control system [9, 46]. System identification, which mainly includes the parameter identification [6, 43, 44] and the state estimation and filtering [12, 17, 57], is the methodology of system modeling and has been used in linear systems and nonlinear systems [5, 19, 40]. Recently, Greblicki, and Pawlak presented a nearest neighbor algorithm for Hammerstein systems and established the optimal convergence rate which is independent of the shape of the input density [14]. Li et al. gave the input–output representation of a bilinear system through eliminating the state variables and derived an iterative algorithm by using the maximum likelihood principle [21]. Other methods can be found in [3, 10, 11, 22, 24, 34, 37, 55]. It is well known that multivariable systems, i.e., multi-input multi-output (MIMO) systems, are frequently encountered in practical engineering. However, multivariable systems have large dimensions, complex strictures and coupled relations between inputs and outputs [39]. Therefore, the identification for multivariable systems is important and has attracted a lot of attention [33, 56]. For MIMO systems with unknown inner variables, an auxiliary model-based algorithm was studied by means of the iterative search principle [4]. Multivariable systems have many categories and multivariate systems are a class of multivariable systems, which can describe not only linear systems but also nonlinear systems.
The least squares is a conventional method and plays an important role in system identification [1, 45]. The basic idea is to define and minimize a quadratic function and to get the minimum solution [35]. However, the recursive least squares (RLS) algorithm has a heavy computational burden due to the calculation of the inversion of the covariance matrix. In this paper, we employ the data filtering technique to improve the performance of the RLS algorithm [8]. By filtering the input–output data, the original system is divided into two subsystems with fewer variables. Then the dimensions of the involved covariance matrices in each subsystem become smaller than the original system [20]. Moreover, the filtering technique can reduce the parameter estimation errors [38]. For example, a decomposition-based iterative algorithm was developed for multivariate pseudo-linear autoregressive moving average systems using the data filtering, and this algorithm had less computational burden and higher estimation accuracy compared with the least squares-based iterative algorithm [7]. In the previous work [31], we combined the data filtering technique and the multi-innovation theory to improve the performance of the stochastic gradient algorithm.
This paper studies the parameter estimation methods for multivariate output-error systems with autoregressive noise (i.e., colored noise). In order to reduce the influence of the colored noise on the parameter estimation accuracy, we modify the RLS algorithm by employing the data filtering technique and the auxiliary model. In addition, the data filtering technique can improve the computational efficiency. The main idea is to use a filter to filter the input–output data; then the system can be transformed into two models: a multivariate output-error model with white noise and an autoregressive noise model. To cope with the unknown variables in the identification models, we establish the auxiliary models and replace the unknown variables in the algorithm with the outputs of the auxiliary models. The main contributions of this paper are in the following aspects.
-
A filtering-based auxiliary model recursive generalized least squares (F-AM-RGLS) algorithm is derived for multivariate output-error autoregressive systems by using the data filtering and the auxiliary model.
-
The F-AM-RGLS algorithm has smaller parameter estimation errors than the auxiliary model-based recursive generalized least squares (AM-RGLS) algorithm under the same noise levels.
-
The F-AM-RGLS algorithm has higher computational efficiency than the AM-RGLS algorithm.
The rest of this paper is organized as follows. In Sect. 2, we give some definitions and the identification model for multivariate output-error autoregressive systems. Section 3 employs the data filtering technique to derive two identification models and presents the F-AM-RGLS algorithm. Section 4 proposes the AM-RGLS algorithm for comparison. An illustrative example is shown to verify the effectiveness of the proposed algorithms in Sect. 5. Finally, we offer some concluding remarks in Sect. 6.
2 The System Description
Some symbols are introduced. \(``A=:X''\) or \(``X:=A''\) stands for “A is defined as \(X''\); the superscript T stands for the vector/matrix transpose; the symbol \({\varvec{I}}_n\) denotes an identity matrix of size \(n\times n\); \(\mathbf{1}_n\) stands for an n-dimensional column vector whose elements are 1; \(\mathbf{1}_{m\times n}\) represents a matrix of size \(m\times n\) whose elements are 1; the symbol \(\otimes \) represents the Kronecker product, for example, \({\varvec{A}}:=a_{ij}\in {\mathbb R}^{m\times n}\), \({\varvec{B}}:=b_{ij}\in {\mathbb R}^{p\times q}\), \({\varvec{A}}\otimes {\varvec{B}}= [a_{ij}{\varvec{B}}]\in {\mathbb R}^{(mp)\times (nq)}\), in general, \({\varvec{A}}\otimes {\varvec{B}}\ne {\varvec{B}}\otimes {\varvec{A}}\); \(\mathrm{col}[{\varvec{X}}]\) is defined as a vector consisting of all columns of matrix \({\varvec{X}}\) arranged in order, for example, \({\varvec{X}}:=[{\varvec{x}}_1,{\varvec{x}}_2,\ldots ,{\varvec{x}}_n]\in {\mathbb R}^{m\times n}\), \({\varvec{x}}_i\in {\mathbb R}^{m}\)\((i=1,2,\ldots ,n)\), \(\mathrm{col}[{\varvec{X}}]:=[{\varvec{x}}^{\tiny \text{ T }}_1,{\varvec{x}}^{\tiny \text{ T }}_2,\ldots ,{\varvec{x}}^{\tiny \text{ T }}_n]\in {\mathbb R}^{mn}\); \(\hat{{\varvec{{\vartheta }}}}(t)\) denotes the estimate of \({\varvec{{\vartheta }}}\) at time t; the norm of a matrix (or a column vector) \({\varvec{X}}\) is defined by \(\Vert {\varvec{X}}\Vert ^2:=\mathrm{tr}[{\varvec{X}}{\varvec{X}}^{\tiny \text{ T }}]\).
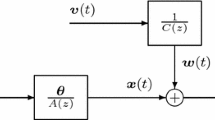
Consider the following multivariate output-error system,
where \({\varvec{y}}(t):=[y_1(t), y_2(t),\ldots , y_m(t)]^{\tiny \text{ T }}\in {\mathbb R}^{m}\) is the output vector of the system, \({\varvec{\varPhi }}_{\mathrm{s}}(t)\in {\mathbb R}^{m\times n}\) is the information matrix which can be linear or nonlinear function of the past input–output data \({\varvec{u}}(t-i)\) and \({\varvec{y}}(t-i)\), \({\varvec{{\theta }}}\in {\mathbb R}^{n}\) is the parameter vector to be identified and A(z) is a polynomial in the unit backward shift operator \(z^{-1}\) [\(z^{-1}y(t)=y(t-1)\)], and
\({\varvec{w}}(t):=[w_1(t), w_2(t), \ldots , w_m(t)]^{\tiny \text{ T }}\in {\mathbb R}^{m}\) is a disturbance vector. In general, \({\varvec{w}}(t)\) includes several special cases, (a) \({\varvec{w}}(t)\) is a stochastic white noise process with zero mean; (b) \({\varvec{w}}(t)\) is an autoregressive (AR) process; (c) \({\varvec{w}}(t)\) is a moving average (MA) process; (d) \({\varvec{w}}(t)\) is an ARMA process. In this paper, \({\varvec{w}}(t)\) is taken as an AR process of the white noise vector \({\varvec{v}}(t):=[v_1(t),v_2(t),\ldots ,v_m(t)]^{\tiny \text{ T }}\in {\mathbb R}^{m}\), and there are still two cases for the description of the AR noise term,
Case 1: \({\varvec{w}}(t):=\frac{1}{C(z)}{\varvec{v}}(t)\), where C(z) is a scalar polynomial and expressed as
Case 2: \({\varvec{w}}(t):={\varvec{C}}^{-1}(z){\varvec{v}}(t)\), where \({\varvec{C}}(z)\) is a matrix polynomial and expressed as
Case 2 is chosen to derive the identification models and identification algorithms in this paper. Assume that the orders m, n, \(n_a\), and \(n_c\) are known and \({\varvec{y}}(t)=\mathbf{0}\), \({\varvec{\varPhi }}_{\mathrm{s}}(t)=\mathbf{0}\) and \({\varvec{v}}(t)=\mathbf{0}\) for \(t\leqslant 0\).
Define the parameter vectors \({\varvec{a}}\) and \({\varvec{{\theta }}}_{\mathrm{s}}\) and parameter matrix \({\varvec{{\theta }}}_c\) as
and the information matrices \({{{\phi }}}_a(t)\) and \({\varvec{\varPhi }}(t)\), and parameter vector \({{{\phi }}}_c(t)\) as
Then \({\varvec{w}}(t)\) in Case 2 can be expressed as
Define an intermediate variable:
Substituting (2)–(4) into (1), we can obtain
Equation (7) is the hierarchical identification model for the multivariate output-error autoregressive (M-OEAR) system in (1). Observing (7), we can see that there is not only a system parameter vector \({\varvec{{\theta }}}_{\mathrm{s}}\) to be identified, but also a noise model parameter matrix \({\varvec{{\theta }}}_c\) to be identified. The objective of this paper is to derive a new recursive algorithm for the M-OEAR system by using the auxiliary model and the data filtering.
3 The Filtering-Based Auxiliary Model Recursive Generalized Least Squares Algorithm
From (5), we can see that the output \({\varvec{y}}(t)\) contains the colored noise \({\varvec{w}}(t)\), which leads to large parameter estimation errors. In this section, we use a filter \({\varvec{L}}(z)={\varvec{C}}(z)\) to filter the input and output data and derive an F-AM-RGLS algorithm for the M-OEAR system to improve the parameter estimation accuracy.
For the M-OEAR system in (1), multiplying the both sides of (1) by \({\varvec{C}}(z)\) gives
Define the filtered output vector \({\varvec{y}}_{\mathrm{f}}(t)\) and the filtered information matrix \({\varvec{\varPhi }}_{\mathrm{f}\mathrm{s}}(t)\) as
which can be expressed as the following recursive forms:
where
Then Eq. (8) can be rewritten as
Define an inner variable:
where
Substituting (12) into (11) gives
For the filtered identification model (13) and the noise identification model (3), define two quadratic functions:
Based on the least squares principle [32], minimizing \(J_1({\varvec{{\theta }}}_{\mathrm{s}})\) and \(J_2({\varvec{{\theta }}}_c)\) gives
As we can see, Eqs. (14)–(19) cannot generate the estimates \(\hat{{\varvec{{\theta }}}}_{\mathrm{s}}(t)\) and \(\hat{{\varvec{{\theta }}}}_c(t)\), because the filter \({\varvec{C}}(z)\) is unknown, then the filtered output vector \({\varvec{y}}_{\mathrm{f}}(t)\) and the filtered matrix \({\varvec{\varPhi }}_{\mathrm{f}}(t)\) are unknown. In addition, the information matrix \({{{\phi }}}_a(t)\) and the information vector \({{{\phi }}}_c(t)\) contain the unknown terms \({\varvec{x}}(t-i)\) and \({\varvec{w}}(t-i)\). Here, we establish the appropriate auxiliary models and use their outputs \({\varvec{x}}_{\mathrm{a}}(t-i)\), \(\hat{{\varvec{w}}}(t-i)\), and \({\varvec{x}}_{\mathrm{f}\mathrm{a}}(t-i)\) to replace the unknown variables \({\varvec{x}}(t-i)\), \({\varvec{w}}(t-i)\), and \({\varvec{x}}_{\mathrm{f}}(t-i)\). Then the estimates \(\hat{{{{\phi }}}}_a(t)\) and \(\hat{{{{\phi }}}}_c(t)\) of \({{{\phi }}}_a(t)\) and \({{{\phi }}}_c(t)\) can be formed by \({\varvec{x}}_{\mathrm{a}}(t-i)\) and \(\hat{{\varvec{w}}}(t-i)\) as
Similarly, we use \({\varvec{x}}_{\mathrm{f}\mathrm{a}}(t-i)\) and the estimate \(\hat{{\varvec{\varPhi }}}_{\mathrm{f}\mathrm{s}}(t)\) of \({\varvec{\varPhi }}_{\mathrm{f}\mathrm{s}}(t)\) to define
Then we can get the estimate of \({\varvec{\varPhi }}(t)\):
According to (4)–(6), replacing \({\varvec{\varPhi }}(t)\) and \({\varvec{{\theta }}}_{\mathrm{s}}\) with their estimates \(\hat{{\varvec{\varPhi }}}(t)\) and \(\hat{{\varvec{{\theta }}}}_{\mathrm{s}}(t)\) in (4), the outputs \({\varvec{x}}_{\mathrm{a}}(t)\) and \(\hat{{\varvec{w}}}(t)\) of the auxiliary models can be computed by
From (12), we can obtain \({\varvec{x}}_{\mathrm{f}\mathrm{a}}(t)\) through
Use the parameter estimates \(\hat{{\varvec{{\theta }}}}_c(t):=[\hat{{\varvec{C}}}_1(t),\hat{{\varvec{C}}}_2(t),\ldots ,\hat{{\varvec{C}}}_{n_c}(t)]^{\tiny \text{ T }}\in {\mathbb R}^{(mn_c)\times m}\) of the noise model to construct the estimate of \({\varvec{C}}(z)\) as
Replacing \({\varvec{C}}(z)\) in (9), (10) with \(\hat{{\varvec{C}}}(t,z)\), the estimates of the filtered output vector \({\varvec{y}}_{\mathrm{f}}(t)\) and the filtered information matrix \({\varvec{\varPhi }}_{\mathrm{f}\mathrm{s}}(t)\) can be obtained by
Replace the unknown information matrix \({\varvec{\varPhi }}(t)\), the information vector \({{{\phi }}}_c(t)\), the filtered output vector \({\varvec{y}}_{\mathrm{f}}(t)\), and the filtered information matrix \({\varvec{\varPhi }}_{\mathrm{f}}(t)\) with their estimates \(\hat{{\varvec{\varPhi }}}(t)\), \(\hat{{{{\phi }}}}_c(t)\), \(\hat{{\varvec{y}}}_{\mathrm{f}}(t)\), and \(\hat{{\varvec{\varPhi }}}_{\mathrm{f}}(t)\) in (14)–(19), respectively. For convenience, define two innovation vectors:
Then, we can obtain the filtering-based auxiliary model recursive generalized least squares (F-AM-RGLS) algorithm:
The steps involved in the F-AM-RGLS algorithm in (20)–(40) are listed as follows.
-
1.
Set the initial values: let \(t=1\), \(\hat{{\varvec{{\theta }}}}_{\mathrm{s}}(0)=\mathbf{1}_{n+n_a}/p_0\), \(\hat{{\varvec{{\theta }}}}_c(0)=\mathbf{1}_{(mn_c)\times m}\), \({\varvec{P}}_1(0)=p_0{\varvec{I}}_{n+n_a}\), \({\varvec{P}}_2(0)=p_0{\varvec{I}}_{mn_c}\), \({\varvec{x}}_{\mathrm{f}\mathrm{a}}(t-i)=\mathbf{1}_m/p_0\), \({\varvec{x}}_{\mathrm{a}}(t-i)=\mathbf{1}_m/p_0\), \(\hat{{\varvec{w}}}(t-i)=\mathbf{1}_m/p_0\), \(i=1\), 2, \(\ldots \), \(\max [n_a,n_c]\), \(p_0=10^6\) and set a small positive number \(\varepsilon \).
-
2.
Collect the observation data \({\varvec{y}}(t)\) and \({\varvec{\varPhi }}_{\mathrm{s}}(t)\), and construct the information vectors and matrices \({{{\phi }}}_y(t)\), \({\varvec{\varPsi }}_{\mathrm{s}}(t)\), \(\hat{{{{\phi }}}}_a(t)\), \(\hat{{{{\phi }}}}_c(t)\) and \(\hat{{\varvec{\varPhi }}}(t)\) using (31), (32), (34), (35), and (33).
-
3.
Compute \({\varvec{L}}_2(t)\), \({\varvec{P}}_2\), and \({\varvec{e}}_2(t)\) using (26), (27), and (25).
-
4.
Update the parameter estimation matrix \(\hat{{\varvec{{\theta }}}}_c(t)\) using (24).
-
5.
Compute the filtered output vector \(\hat{{\varvec{y}}}_{\mathrm{f}}(t)\) by (29) and the filtered information matrix \(\hat{{\varvec{\varPhi }}}_{\mathrm{f}\mathrm{s}}(t)\) by (30), and form \(\hat{{\varvec{\varPhi }}}_{\mathrm{f}}(t)\) by (28).
-
6.
Compute \({\varvec{L}}_1(t)\), \({\varvec{P}}_1(t)\), and \({\varvec{e}}_1(t)\) by (22), (23), and (21).
-
7.
Update the parameter estimate \(\hat{{\varvec{{\theta }}}}_{\mathrm{s}}(t)\) by (20).
-
8.
Compute the outputs \({\varvec{x}}_{\mathrm{f}\mathrm{a}}(t)\), \({\varvec{x}}_{\mathrm{a}}(t)\), and \(\hat{{\varvec{w}}}(t)\) by (36)–(38).
-
9.
Compare \(\hat{{\varvec{{\theta }}}}_{\mathrm{s}}(t)\) with \(\hat{{\varvec{{\theta }}}}_{\mathrm{s}}(t-1)\) and compare \(\hat{{\varvec{{\theta }}}}_c(t)\) with \(\hat{{\varvec{{\theta }}}}_c(t-1)\): if \(\Vert \hat{{\varvec{{\theta }}}}_{\mathrm{s}}(t)-\hat{{\varvec{{\theta }}}}_{\mathrm{s}}(t-1)\Vert <\varepsilon \) and \(\Vert \hat{{\varvec{{\theta }}}}_c(t)-\hat{{\varvec{{\theta }}}}_c(t-1)\Vert <\varepsilon \), terminate recursive calculation procedure and obtain \(\hat{{\varvec{{\theta }}}}_{\mathrm{s}}(t)\) and \(\hat{{\varvec{{\theta }}}}_c(t)\); otherwise, increase t by 1 and go to Step 2.
The flowchart of computing \(\hat{{\varvec{{\theta }}}}_{\mathrm{s}}(t)\) and \(\hat{{\varvec{{\theta }}}}_c(t)\) in the F-AM-RGLS algorithm is shown in Fig. 1.

The flowchart of computing the F-AM-RGLS parameter estimates \(\hat{{\varvec{{\theta }}}}_{\mathrm{s}}(t)\) and \(\hat{{\varvec{{\theta }}}}_c(t)\)
Remark 1
To obtain the F-AM-RGLS algorithm in (20)–(40), we use the matrix polynomial \(\hat{{\varvec{C}}}(t,z)\) to filter the input–output data and derive a filtered model with the white noise and a noise model. As for the calculation procedure, the F-AM-RGLS algorithm identifies the noise parameter matrix \(\hat{{\varvec{{\theta }}}}_c(t)\) first and constructs the filtered output vector \(\hat{{\varvec{y}}}_{\mathrm{f}}(t)\) and the filtered information matrix \(\hat{{\varvec{\varPhi }}}_{\mathrm{f}\mathrm{s}}(t)\) before calculating the system parameter vector \(\hat{{\varvec{{\theta }}}}_{\mathrm{s}}(t)\).
4 The Auxiliary Model-Based Recursive Generalized Least Squares Algorithm
As a comparison, this section gives the AM-RGLS algorithm to show the advantages of the F-AM-RLS algorithm in (20)–(40). For the identification model in (7), combine the information matrix \({\varvec{\varPhi }}(t)\) and the information vector \({{{\phi }}}_c(t)\) into a new information matrix \({\varvec{\varPsi }}(t)\), and the parameter vector \({\varvec{{\theta }}}_{\mathrm{s}}\) and the parameter matrix \({\varvec{{\theta }}}_c\) into a parameter vector \({\varvec{{\vartheta }}}\):
Then, we have the following identification model
The parameter vector \({\varvec{{\vartheta }}}\) contains all parameters to be estimated. Referring to the derivation of the F-AM-RGLS algorithm in (20)–(40), we can obtain the following AM-RGLS algorithm:
The procedure for computing the parameter estimation vector \(\hat{{\varvec{{\vartheta }}}}(t)\) in the AM-RGLS algorithm in (42)–(52) is listed as follows.
-
1.
Set the initial values: let \(t=1\), \(\hat{{\varvec{{\vartheta }}}}(0)=\mathbf{1}_{n_1}/p_0\), \({\varvec{P}}(0)=p_0{\varvec{I}}_{n_1}\), \({\varvec{x}}_{\mathrm{a}}(t-i)=\mathbf{1}_m/p_0\), \(\hat{{\varvec{w}}}(t-i)=\mathbf{1}_m/p_0\), \(i=1\), 2, \(\ldots \), \(\max [n_a,n_c]\), \(p_0=10^6\) and set a small positive number \(\varepsilon \).
-
2.
Collect the observation data \({\varvec{y}}(t)\) and \({\varvec{\varPhi }}_{\mathrm{s}}(t)\), and construct the information matrix \(\hat{{{{\phi }}}}_a(t)\) and the information vector \(\hat{{{{\phi }}}}_c(t)\) using (47), (48), and form \(\hat{{\varvec{\varPhi }}}(t)\) and \(\hat{{\varvec{\varPsi }}}(t)\) using (46) and (45).
-
3.
Compute the gain matrix \({\varvec{L}}(t)\) using (43) and compute the covariance matrix \({\varvec{P}}(t)\) using (44).
-
4.
Update the parameter estimation vector \(\hat{{\varvec{{\vartheta }}}}(t)\) using (42).
-
5.
Read \(\hat{{\varvec{{\theta }}}}_{\mathrm{s}}(t)\) from \(\hat{{\varvec{{\vartheta }}}}(t)\), and compute \({\varvec{x}}_{\mathrm{a}}(t)\) and \(\hat{{\varvec{w}}}(t)\) using (49), (50).
-
6.
Compare \(\hat{{\varvec{{\vartheta }}}}(t)\) with \(\hat{{\varvec{{\vartheta }}}}(t-1)\): if \(\Vert \hat{{\varvec{{\vartheta }}}}(t)-\hat{{\varvec{{\vartheta }}}}(t-1)\Vert <\varepsilon \), terminate recursive calculation procedure and obtain \(\hat{{\varvec{{\vartheta }}}}(t)\); otherwise, increase t by 1 and go to Step 2.
In the F-AM-RGLS algorithm in (20)–(40), the dimensions of the covariance matrices \({\varvec{P}}_1(t)\) and \({\varvec{P}}_2(t)\) are \((n+n_a) \times (n+n_a)\) and \((mn_c) \times (mn_c)\). In the AM-RGLS algorithm in (42)–(52), the dimension of the covariance matrix \({\varvec{P}}(t)\) in Eq. (44) is \(n_1 \times n_1\)\((n_1=n+n_1+m^2n_c)\). Here, we give the computational efficiencies of the two algorithms at each recursive step in Tables 1, 2, where flops represent the floating point operations. In order to compare the computational burden of the two algorithms, we do
where \(n_1=n+n_a+m^2n_c\), then
In general, when the orders \(m, n, n_a, n_c \geqslant 1\), it is obvious that the computational burden of the F-AM-RGLS algorithm in (20)–(40) is less than the AM-RGLS algorithm in (42)–(52), that is to say, \(N_1 \gg N_2\).
Remark 2
The system considered in this paper is disturbed by an autoregressive noise. In order to reduce the influence of the colored noise on the system, the F-AM-RGLS algorithm in (20)–(40) filters the input and output data by using the filter \({\varvec{C}}(z)\) and divides the original identification model (7) into a filtered identification model (13) and a noise identification model (3). Compared with the AM-RGLS algorithm in (42)–(52), the F-AM-RGLS algorithm gives more accurate estimates. Furthermore, the F-AM-RGLS algorithm also improves the computational efficiency.

The AM-RGLS and F-AM-RGLS estimation errors versus t with \(\sigma ^2=0.50^2\)

The AM-RGLS estimates \(\hat{\theta }_1(t)\), \(\hat{\theta }_5(t)\), \(\hat{\theta }_6(t)\), \(\hat{a}_2(t)\), \(\hat{c}_4(t)\) versus t (\(\sigma ^2=0.50^2\))
5 Example
Consider the following multivariate output-error autoregressive system:
In simulation, the inputs {\(u_1(t)\)} and {\(u_2(t)\)} are taken as two independent persistent excitation signal sequences with zero mean and unit variances, {\(v_1(t)\)} and {\(v_2(t)\)} are taken as two white noise sequences with zero mean and variances \(\sigma ^2_1\) for \(v_1(t)\) and \(\sigma ^2_2\) for \(v_2(t)\). Taking \(\sigma ^2_1=\sigma ^2_2=\sigma ^2=0.50^2\) and \(\sigma ^2_1=\sigma ^2_2=\sigma ^2=0.80^2\), respectively, we use them to generate the output vector \({\varvec{y}}(t)=[y_1(t),y_2(t)]^{\tiny \text{ T }}\). Applying the F-AM-RGLS algorithm in (20)–(40) and the AM-RGLS algorithm in (42)–(52) to estimate the parameters of this system, the parameter estimates and errors are shown in Tables 3, 4, 5, and 6. The parameter estimation errors \(\delta :=\Vert \hat{{\varvec{{\vartheta }}}}(t)-{\varvec{{\vartheta }}}\Vert /\Vert {\varvec{{\vartheta }}}\Vert \) versus t are shown in Figs. 2 and 5.

The F-AM-RGLS estimates \(\hat{\theta }_1(t)\), \(\hat{\theta }_5(t)\), \(\hat{\theta }_6(t)\), \(\hat{a}_2(t)\), \(\hat{c}_4(t)\) versus t (\(\sigma ^2=0.50^2\))

The AM-RGLS and F-AM-RGLS estimation errors versus t with \(\sigma ^2=0.80^2\)

The AM-RGLS estimates \(\hat{\theta }_1(t)\), \(\hat{\theta }_5(t)\), \(\hat{\theta }_6(t)\), \(\hat{a}_2(t)\), \(\hat{c}_4(t)\) versus t (\(\sigma ^2=0.80^2\))

The F-AM-RGLS estimates \(\hat{\theta }_1(t)\), \(\hat{\theta }_5(t)\), \(\hat{\theta }_6(t)\), \(\hat{a}_2(t)\), \(\hat{c}_4(t)\) versus t (\(\sigma ^2=0.80^2\))
From Tables 3, 4, 5, and 6 and Figs. 2, 3, 4, 5, 6, and 7, we can draw the following conclusions.
-
1.
The parameter estimation errors of the AM-RGLS algorithm and the F-AM-RGLS algorithm become smaller with the data length t increasing—see the estimation errors of the last columns in Tables 3, 4, 5, and 6.
-
2.
Under the same noise level, the F-AM-RGLS algorithm can give more accurate parameter estimates than the AM-RGLS algorithm—see Tables 3, 4, 5, and 6 and Figs. 2 and 5.
-
3.
A lower noise level results in smaller parameter estimation errors—see Tables 3, 4, 5, and 6 and Figs. 2 and 5.
6 Conclusions
In this paper, we employ the data filtering technique to propose an F-AM-RGLS algorithm for M-OEAR systems by adopting the auxiliary model identification idea. Compared with the AM-RGLS algorithm, the F-AM-RGLS algorithm can improve the parameter estimation accuracy and reduce the computational burden. The proposed approaches in the paper can combine other mathematical tools [25,26,27,28,29,30] and statistical strategies [13, 48,49,50,51,52] to study the performances of some parameter estimation algorithms and can be applied to other multivariable systems with different structures and disturbance noises and other literature [15, 23, 36, 47, 58, 59].
References
A. Al-Smadi, A least-squares-based algorithm for identification of non-Gaussian ARMA models. Circuits Syst. Signal Process. 26(5), 715–731 (2007)
Y. Cao, L.C. Ma, S. Xiao et al., Standard analysis for transfer delay in CTCS-3. Chin. J. Electron. 26(5), 1057–1063 (2017)
H.B. Chen, Y.S. Xiao et al., Hierarchical gradient parameter estimation algorithm for Hammerstein nonlinear systems using the key term separation principle. Appl. Math. Comput. 247, 1202–1210 (2014)
J.L. Ding, Recursive and iterative least squares parameter estimation algorithms for multiple-input-output-error systems with autoregressive noise. Circuits, Syst. Signal Process. 37(5), 1884–1906 (2018)
F. Ding, H.B. Chen, L. Xu, J.Y. Dai, Q.S. Li, T. Hayat, A hierarchical least squares identification algorithm for Hammerstein nonlinear systems using the key term separation. J. Franklin Inst. 355(8), 3737–3752 (2018)
F. Ding, D.D. Meng, J.Y. Dai, Q.S. Li, A. Alsaedi, T. Hayat, Least squares based iterative parameter identification for stochastic dynamical systems with ARMA noise using the model equivalence. Int. J. Control Autom. Syst. 16(2), 630–639 (2018)
F. Ding, F.F. Wang, L. Xu et al., Decomposition based least squares iterative identification algorithm for multivariate pseudo-linear ARMA systems using the data filtering. J. Franklin Inst. 354(3), 1321–1339 (2017)
F. Ding, L. Xu, F.E. Alsaadi, T. Hayat, Iterative parameter identification for pseudo-linear systems with ARMA noise using the filtering technique. IET Control Theory Appl. 12(7), 892–899 (2018)
F. Ding, L. Xu, Q.M. Zhu, Performance analysis of the generalised projection identification for time-varying systems. IET Control Theory Appl. 10(18), 2506–2514 (2016)
M. Gan, C.L.P. Chen, G.Y. Chen, L. Chen, On some separated algorithms for separable nonlinear squares problems. IEEE Trans. Cybern. (2018). https://doi.org/10.1109/TCYB.2017.2751558
M. Gan, H.X. Li, H. Peng, A variable projection approach for efficient estimation of RBF-ARX model. IEEE Trans. Cybern. 45(3), 462–471 (2015)
H.J. Gao, X.W. Li, J.B. Qiu, Finite frequency \(H_{\infty }\) deconvolution with application to approximated bandlimited signal recovery. IEEE Trans. Autom. Control 63(1), 203–210 (2018)
H.L. Gao, C.C. Yin, The perturbed sparre Andersen model with a threshold dividend strategy. J. Comput. Appl. Math. 220(1–2), 394–408 (2008)
W. Greblicki, M. Pawlak, Hammerstein system identification with the nearest neighbor algorithm. IEEE Trans. Inf. Theory 63(8), 4746–4757 (2017)
P.C. Gong, W.Q. Wang, F.C. Li, H. Cheung, Sparsity-aware transmit beamspace design for FDA-MIMO radar. Signal Process. 144, 99–103 (2018)
P. Li, R. Dargaville, Y. Cao et al., Storage aided system property enhancing and hybrid robust smoothing for large-scale PV systems. IEEE Trans. Smart Grid 8(6), 2871–2879 (2017)
X.W. Li, J. Lam, H.J. Gao et al., \(H_{\infty }\) and \(H_2\) filtering for linear systems with uncertain Markov transitions. Automatica 67, 252–266 (2016)
P. Li, R.X. Li, Y. Cao, G. Xie, Multi-objective sizing optimization for island microgrids using triangular aggregation model and Levy-Harmony algorithm. IEEE Trans. Ind. Inform. (2018). https://doi.org/10.1109/TII.2017.2778079
M.H. Li, X.M. Liu, Auxiliary model based least squares iterative algorithms for parameter estimation of bilinear systems using interval-varying measurements. IEEE Access 6, 21518–21529 (2018)
M.H. Li, X.M. Liu, The least squares based iterative algorithms for parameter estimation of a bilinear system with autoregressive noise using the data filtering technique. Signal Process. 147, 23–34 (2018)
M.H. Li, X.M. Liu et al., The maximum likelihood least squares based iterative estimation algorithm for bilinear systems with autoregressive moving average noise. J. Franklin Inst. 354(12), 4861–4881 (2017)
J.H. Li, W. Zheng, J.P. Gu, L. Hua, A recursive identification algorithm for Wiener nonlinear systems with linear state-space subsystem. Circuits Syst. Signal Process. 37(6), 2374–2393 (2018)
Y. Li, W.H. Zhang, X.K. Liu, H-index for discrete-time stochastic systems with Markovian jump and multiplicative noise. Automatica 90, 286–293 (2018)
Y. Lin, W. Zhang, Necessary/sufficient conditions for pareto optimum in cooperative difference game. Optim. Control, Appl. Methods 39(2), 1043–1060 (2018)
F. Liu, Continuity and approximate differentiability of multisublinear fractional maximal functions. Math. Inequal. Appl. 21(1), 25–40 (2018)
F. Liu, On the Triebel–Lizorkin space boundedness of Marcinkiewicz integrals along compound surfaces. Math. Inequal. Appl. 20(2), 515–535 (2017)
F. Liu, H.X. Wu, Singular integrals related to homogeneous mappings in triebel–lizorkin spaces. J. Math. Inequal. 11(4), 1075–1097 (2017)
F. Liu, H.X. Wu, Regularity of discrete multisublinear fractional maximal functions. Sci. China–Math. 60(8), 1461–1476 (2017)
F. Liu, H.X. Wu, On the regularity of maximal operators supported by submanifolds. J. Math. Anal. Appl. 453(1), 144–158 (2017)
F. Liu, Q.Y. Xue, K. Yabuta, Rough maximal singular integral and maximal operators supported by subvarieties on Triebel–Lizorkin spaces. Nonlinear Anal. 171, 41–72 (2018)
Q.Y. Liu, F. Ding, The data filtering based generalized stochastic gradient parameter estimation algorithms for multivariate output-error autoregressive systems using the auxiliary model. Multidimens. Syst. Signal Process. https://doi.org/10.1007/s11045-017-0529-1
L. Ljung, System Identification: Theory for the User, 2nd edn. (Prentice Hall, Englewood Cliffs, NJ, 1999)
P. Ma, F. Ding, Q.M. Zhu, Decomposition-based recursive least squares identification methods for multivariate pseudolinear systems using the multi-innovation. Int. J. Syst. Sci. 49(5), 920–928 (2018)
Y.W. Mao, F. Ding, A novel parameter separation based identification algorithm for Hammerstein systems. Appl. Math. Lett. 60, 21–27 (2016)
B.Q. Mu, E.W. Bai, W.X. Zheng et al., A globally consistent nonlinear least squares estimator for identification of nonlinear rational systems. Automatica 77, 322–335 (2017)
Z.H. Rao, C.Y. Zeng, M.H. Wu et al., Research on a handwritten character recognition algorithm based on an extended nonlinear kernel residual network. KSII Trans. Int. Inf. Syst. 12(1), 413–435 (2018)
Y.J. Wang, F. Ding, A filtering based multi-innovation gradient estimation algorithm and performance analysis for nonlinear dynamical systems. IMA J. Appl. Math. 82(6), 1171–1191 (2017)
Y.J. Wang, F. Ding, L. Xu, Some new results of designing an IIR filter with colored noise for signal processing. Dig. Signal Process. 72, 44–58 (2018)
D.Q. Wang, L. Mao et al., Recasted models based hierarchical extended stochastic gradient method for MIMO nonlinear systems. IET Control Theory Appl. 11(4), 476–485 (2017)
D.Q. Wang, Z. Zhang, J.Y. Yuan, Maximum likelihood estimation method for dual-rate Hammerstein systems. Int. J. Control Autom. Syst. 15(2), 698–705 (2017)
L. Xu, The parameter estimation algorithms based on the dynamical response measurement data. Adv. Mech. Eng. 9(11), 1–12 (2017). https://doi.org/10.1177/1687814017730003
L. Xu, F. Ding, Iterative parameter estimation for signal models based on measured data. Circuits Syst. Signal Process. 37(7), 3046–3069 (2018)
L. Xu, F. Ding, Parameter estimation algorithms for dynamical response signals based on the multi-innovation theory and the hierarchical principle. IET Signal Process. 11(2), 228–237 (2017)
L. Xu, F. Ding, Parameter estimation for control systems based on impulse responses. Int. J. Control Autom. Syst. 15(6), 2471–2479 (2017)
L. Xu, F. Ding, Recursive least squares and multi-innovation stochastic gradient parameter estimation methods for signal modeling. Circuits Syst. Signal Process. 36(4), 1735–1753 (2017)
L. Xu, F. Ding, Y. Gu, A. Alsaedi, T. Hayat, A multi-innovation state and parameter estimation algorithm for a state space system with d-step state-delay. Signal Process. 140, 97–103 (2017)
G.H. Xu, Y. Shekofteh, A. Akgul, C.B. Li, S. Panahi, A new chaotic system with a self-excited attractor: entropy measurement, signal encryption, and parameter estimation. Entropy 20(2), 86 (2018). https://doi.org/10.3390/e20020086
C.C. Yin, C.W. Wang, The perturbed compound Poisson risk process with investment and debit interest. Methodol. Comput. Appl. Probab. 12(3), 391–413 (2010)
C.C. Yin, Y.Z. Wen, Exit problems for jump processes with applications to dividend problems. J. Comput. Appl. Math. 245, 30–52 (2013)
C.C. Yin, Y.Z. Wen, Optimal dividend problem with a terminal value for spectrally positive Levy processes. Insur. Math. Econ. 53(3), 769–773 (2013)
C.C. Yin, K.C. Yuen, Optimality of the threshold dividend strategy for the compound Poisson model. Stat. Probab. Lett. 81(12), 1841–1846 (2011)
C.C. Yin, J.S. Zhao, Nonexponential asymptotics for the solutions of renewal equations, with applications. J. Appl. Probab. 43(3), 815–824 (2006)
Y.Z. Zhang, Y. Cao, Y.H. Wen, L. Liang, F. Zou, Optimization of information interaction protocols in cooperative vehicle-infrastructure systems. Chin. J. Electron. 27(2), 439–444 (2018)
X. Zhang, F. Ding, A. Alsaadi, T. Hayat, Recursive parameter identification of the dynamical models for bilinear state space systems. Nonlinear Dyn. 89(4), 2415–2429 (2017)
W. Zhang, X. Lin, B.S. Chen, LaSalle-type theorem and its applications to infinite horizon optimal control of discrete-time nonlinear stochastic systems. IEEE Trans. Automatic Control 62(1), 250–261 (2017)
E. Zhang, R. Pintelon, Identification of multivariable dynamic errors-in-variables system with arbitrary inputs. Automatica 82, 69–78 (2017)
X. Zhang, L. Xu et al., Combined state and parameter estimation for a bilinear state space system with moving average noise. J. Franklin Inst. 355(6), 3079–3103 (2018)
N. Zhao, R. Liu, Y. Chen, M. Wu, Y. Jiang, W. Xiong, C. Liu, Contract design for relay incentive mechanism under dual asymmetric information in cooperative networks. Wireless Netw. (2018). https://doi.org/10.1007/s11276-017-1518-x
D.Q. Zhu, X. Cao, B. Sun, C.M. Luo, Biologically inspired self-organizing map applied to task assignment and path planning of an AUV system. IEEE Trans. Cognit. Dev. Syst. 10(2), 304–313 (2018)
Acknowledgements
This work was supported by the National Natural Science Foundation of China (No. 61273194) and the 111 Project (B12018).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Liu, Q., Ding, F. Auxiliary Model-Based Recursive Generalized Least Squares Algorithm for Multivariate Output-Error Autoregressive Systems Using the Data Filtering. Circuits Syst Signal Process 38, 590–610 (2019). https://doi.org/10.1007/s00034-018-0871-z
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00034-018-0871-z