
Abstract
Pythagorean fuzzy set, initially extended by Yager from intuitionistic fuzzy set, is capable of modeling information with more uncertainties in the process of multi-criteria decision making (MCDM), thus can be used on wider range of conditions. The fuzzy decision analysis of this paper is mainly built upon two expressions in Pythagorean fuzzy environment, named Pythagorean fuzzy number (PFN) and interval-valued Pythagorean fuzzy number (IVPFN), respectively. We initiate a novel axiomatic definition of Pythagorean fuzzy distance measurement, including PFNs and IVPFNs. After that, corresponding theorems are put forward and then proved. Based on the defined distance measurements, the closeness indexes are developed for both expressions, inspired by the idea of technique for order preference by similarity to ideal solution (TOPSIS) approach. After these basic definitions have been established, the hierarchical decision approach is presented to handle MCDM problems under Pythagorean fuzzy environment. To address hierarchical decision issues, the closeness index-based score function is defined to calculate the score of each permutation for the optimal alternative. To determine criterion weights, a new method based on the proposed similarity measure and aggregation operator of PFNs and IVPFNs is presented according to Pythagorean fuzzy information from decision matrix, rather than being provided in advance by decision makers, which can effectively reduce human subjectivity. An experimental case is then conducted to demonstrate the applicability and flexibility of the proposed decision approach. Finally, extension forms of Pythagorean fuzzy decision approach for heterogeneous information are briefly introduced to show its potentials on further applications in other processing fields with information uncertainties.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
As a generalization of fuzzy sets (FSs) [66], intuitionistic fuzzy sets (IFSs) defined by Atanassov [2] fully describe the objective world from three aspects of support, opposition and neutrality, respectively, and thus have been widely studied and applied by researchers [10, 13]. Although IFSs can express human’s subjective opinions from a certain perspective, as Yager puts forward, in the real decision-making process, there may be cases where the sum of the supporters and the opponents of a decision-maker is greater than one. For example, to assess whether an employee is qualified for a job, bosses indicate that their support for membership of ’Yes’ is 0.8 and the support against membership is 0.5. Obviously, these two values have a sum greater than one, they are not allowable for intuitionistic membership grades. To address this issue, Yager et al. [62, 64] studied the complement operations of FSs, interval-valued fuzzy sets (IVFSs) and IFSs, and then Pythagorean fuzzy sets (PFSs) were proposed that allow the sum of membership and non-membership to exceed one and the sum of squares to not exceed one. The two membership values in the above example are allowable as Pythagorean membership grades since 0.82 + 0.52 ≤ 1. As an extension of IFSs, it enables decision-makers to make decisions without modifying the provided information to meet the constraints of IFSs in such situations [52, 58, 68]. It can be seen from this case that PFSs can express more uncertain information than IFSs, which imply that PFSs are more advantageous than IFSs in fuzzy and imprecise modeling [3, 27, 53].
A considerable number of studies have reported decision-making models and methods within the PFSs environment, of which the most commonly employed is the aggregation operator [1, 37, 40, 60]. Moreover, many other corresponding studies [4, 5, 7, 46, 67] have been conducted on decision making process, for example, Pythagorean fuzzy multi-granulation rough set is developed in [69] and a general algorithm is given for decision making problems [12, 55, 57]. IVPFNs is an effective tool to model the uncertain and imprecise information based on some novel score functions [9, 17, 18] and aggregation operators [26, 31]. In addtion, hesitant Pythagorean fuzzy sets (HPFSs) [30] are also developed for decision-making by some aggregation operators [16, 39, 51, 71] in hesitant situations. The real application needs efficient to handle uncertainty [11, 59]. Due to the increasing maturity of PFS, it has been extended to various forms, such as IVPFSs and HPFSs, which have made outstanding contributions to solve MCDM problems . In order to further improve the theory and explore more applications, scholars conducted a more in-depth study on their information measures and properties.
Information measure plays an important role in uncertainty information processing [70]. Because of the advantages in expressing and dealing with uncertain information, Pythagorean membership grades have been widely employed and studied, so its information measures and properties have received widespread attention. The basic Pythagorean fuzzy information measures are introduced by Peng et al. [45]. The distance measures of PFSs were defined in [65, 73, 74], and based on which the corresponding decision methods were put forward to solve MCDM problems. In addition, property analysis has been studied in Pythagorean fuzzy environment, such as the properties of continuous Pythagorean fuzzy information [19, 42], the properties of some operations [43, 44]. In summary, to deal with uncertainty efficiently [6, 25, 56], the purpose of developing the information measures and exploring the properties of Pythagorean fuzzy information are to improve its performance in real MCDM problems.
We have covered the beginning of Pythagorean membership grades, its advantages in representing and processing uncertain information, and its wide variety of extended forms that are applied widespreadly in MCDM field. In what follows, the Pythagorean fuzzy information measures and properties analysis are illustrated in great detail. In view of the practicality and effectiveness of Pythagorean membership grades in the field of MCDM and in order to solve the limitations and shortcomings in previous studies, in this paper, we attempt to construct a hierarchical MCDM framework and develop novel decision approach to solve it in the Pythagorean fuzzy environment. Firstly, aiming at the irrationality in the existing distance measures, such as [74] and [48], we proposed a novel distance measure for PFNs and IVPFNs, whose reasonableness and superiority can be seen from the comparative analysis in Section 2. Based on this distance measure, we define a new closeness index for PFNs and IVPFNs and compare it with the one in [72]. The advantages of the proposed closeness index can be demonstrated by the experimental results. A crucial issue in dealing with MCDM problems is how to determine the criterion weight. In the current work, weight is mostly given by experts in advance, such as [9, 46] and [73]. This way will undoubtedly lead to more subjectivity, which would reduce the credibility and convincingness of the decision results. To eliminate this effect, we propose a new similarity measure-based method to determine the criterion weight in this paper, which can effectively reduce human’s subjective factors and improve the accuracy of the decision results. Another key issue is how to aggregate the Pythagorean fuzzy values between different criteria. In response to this problem, a new aggregation operator is presented in this paper to fuse the corresponding evaluation information of different criteria. Based on the above preparation, a score function is defined to determine the optimal selection. To illustrate the superiority of the proposed decision method, we apply it in a risk assessment example and conduct an in-depth analysis of the decision results. Finally, we extend the proposed decision approach to other areas of uncertain information modeling. To sum up, this article has the following contributions: (1) A novel distance measure is introduced for PFNs and IVPFNs; (2) An improved closeness index is developed for PFNs and IVPFNs; (3) An aggregation operator is proposed for PFNs and IVPFNs; (4) A new method of weight generation is presented; (5) A novel score function is defined for hierarchical MCDM process; (6) The proposed decision approach is extended for heterogeneous information.
The rest of this paper is organized as follows. The related work of PFNs and IVPFNs is completed in Section 2 and 3. First, the basic concepts of them are reviewed briefly. Second, distance measures of them are defined. Then, the closeness indexes of them are developed based on defined distance measures. Last, aggregation operators for PFNs and IVPFNs are presented. The decision approach for MCDM under Pythagorean fuzzy environment is proposed in Section 4. In Section 5, an application is conducted using the proposed decision approach in risk assessment. Section 6 extends the proposed decision approach to other fields for heterogeneous information. The conclusion and future study of this article are given in Section 7.
2 Pythagorean fuzzy number
Many methods and models are used to handle uncertainty, such as Z numbers [24, 47], belief structure [20, 63], D numbers [75] and evidence theory [29, 49]. In this section, the general definition of Pythagorean fuzzy numbers (PFNs) and some basic operations on them are introduced firstly, then, the distance between two PFNs is defined and proved to satisfy all the axioms for distance. Drawing on the ideas of TOPSIS, a closeness index is developed as a measure of PFN’s magnitude based on the defined distance. Next, a novel Pythagorean fuzzy weighted averaging aggregation operator is proposed for PFNs.
Definition 1
Let X be a fixed set, then a PFS in X is defined as
where μP : X → [0,1] represents the membership degree and νP : X → [0,1] is the non-membership degree of the element x ∈ X to P, and it holds that 0 ≤ (μP(x))2 + (νP(x))2 ≤ 1, in addition, \(\pi _{P}(x) = \sqrt {1 - {\mu ^{2}_{P}}(x) - {\nu ^{2}_{P}}(x)}\) is named the degree of indeterminacy, and a PFN is defined by Zhang and Xu [74] as P(μP(x), νP(x)) denoted by β = P(μβ, νβ) for convenience.
The difference and relationship between IFSs and PFSs are shown in the Fig. 1, it is obvious that a PFS can express more fuzzy information than an IFS because it has more space than IFS. It is note that an IFN must be a PFN, but a PFN will degenerate into an IFN only if μβ + νβ ≤ 1. The distance measure between two PFNs is given as following definition.

Definition 2
Let \(\beta _{i} = P(\mu _{\beta _{i}}, \nu _{\beta _{i}})(i = 1, 2)\) be two PFNs, the distance between β1 and β2 is defined as:
Theorem 1
Let\(\beta _{i} = P(\mu _{\beta _{i}}, \nu _{\beta _{i}})(i = 1, 2)\)betwo PFNs, then 0 ≤ d(β1, β2) ≤ 1.
Proof of Theorem 1 is given in Appendix A.
Theorem 2
Let\(\beta _{i} = P(\mu _{\beta _{i}}, \nu _{\beta _{i}})(i = 1, 2)\)betwo PFNs, thend(β1, β2) = 0 if and only ifβ1 = β2.
Theorem 3
Let\(\beta _{i} = P(\mu _{\beta _{i}}, \nu _{\beta _{i}})(i = 1, 2)\)betwo PFNs, thend(β1, β2) = d(β2, β1).
Theorem 4
Let\(\beta _{i} = P(\mu _{\beta _{i}}, \nu _{\beta _{i}})(i = 1, 2, 3)\)bethree PFNs. Ifβ1 ≤ β2 ≤ β3,thend(β1, β2) ≤ d(β1, β3) andd(β2, β3) ≤ d(β1, β3).
Proof of Theorem 4 is given in Appendix B.
Remark 1
In this part, the new proposed distance measure between PFNs will be compared with some existing classical methods, the process will be conducted by some examples which are constructed to illustrate the advantages of the presented measure.
Currently, the more commonly employed distance measure in the field of PFNs is developed by Zhang and Xu in [74], which is defined as:
of which related parameters are the same as Definition 2.
Below a special example will be given to show that in some cases Zhang and Xu’s method fails to measure PFSs’ distance, but the new proposed measure can obtain the reasonable results.
Example 1
Let’s assume two PFNs: β1 = ξ+ = P(1,0) (defined in Remark 2), β2 = P(μ, ν). The distance measure can be calculated as \(d(\beta _{1}, \beta _{2}) = \frac {1}{\sqrt 2}\sqrt {(1-\mu )^{2} + \nu ^{2}}\) and dZ&X(β1, β2) = 1 − μ2 using our proposed method and Zhang and Xu’s method, respectively, based on Definition 2 and (3). The trend of the two distance measure with the changes of μ and ν is shown in Fig. 2. What has been defined as the fact that β1 = ξ+ is the biggest PFN based on Definition 2, therefore, when μ takes a constant, the distance between β1 and β2 should change in the same direction as μ, and so does ν. The results obtained by the proposed distance measure follow this rule as shown in Fig. 2b, but Zhang and Xu’s method do not. It can be seen from Fig. 2a that when μ takes a fixed value, the distance does not change with the change of ν, but a fixed value. A special case is given that when μ = 0, the distance between β1 and β2 is always 1, and such a result is obviously a violation of the facts. Therefore, such a conclusion can be drawn from this example that Zhang and Xu’s method fails to measure the distance of PFNs accurately in some specific cases, but the proposed measure works.

The comparison between the proposed distance measure and Zhang and Xu’s method
Also prominent studies in the distance measure of PFNs are done by Peng et al., who defined multiple distance measures for PFNs in [45]. In this example, these distance measures will be compared with the proposed method with some special cases to highlight the advantages of our approach.
Example 2
Let’s assume two PFNs: β1 = ξ+ = P(1,0), β2 = P(0, ν). Authors proposed 12 methods to measure the distance between PFNs in [45], the specific definitions are omitted here. The distance between β1 and β2 is calculated using method D2, D3, D4, D5, D7, D9, D11 defined by Peng et al. and our method and the results are shown in Fig. 3. (D1 is the same as Zhang and Xu’s method, D5 and D6, D7 and D8, D9 and D10 are the same for single element in PFNs, respectively.) What is the fact the distance between β1 and β2 should increase gradually as the value of ν varies from 0 to 1. It can be found from Fig. 3D4, D5, D7 and D9 fail to measure the distance between β1 and β2, but D2, D3, D11 and our method work.

Comparison between the proposed distance measure and the methods of Peng et al.
The distance measure D2, D3, D11 are effective in Example 2, the next example is designed to illustrate D2 will fail to measure the distance accurately in some cases.
Example 3
Let’s assume two PFNs: β1 = P(0,0), β2 = P(x, x). We have D2(β1, β2) = 0 based on the definition of D2 in [45]. Apparently this result does not reflect the distance between β1 and β2 correctly, the reasonable distance can be obtained based on the proposed method as d(β1, β2) = x, which can reveal the fact that the distance increases with increasing x value.
The following counterexample is constructed to negative the generality of method D11.
Example 4
Let’s assume two PFNs: β1 = P(0,1), β2 = P(0, ν). It is easy to get D11(β1, β2) = 1, which is counterintuitive obviously. The reasonable result can be measured using the proposed method as \(d(\beta _{1}, \beta _{2}) = \frac {1}{\sqrt 2}(1-\nu )\).
Some analyses of the above examples reveal that the existing distance measures of PFNs would fail under certain conditions and the proposed method yields reasonable results. Note that D3 is a combination of D1 and D2, but D1 and D2 do not hold in some cases, so we consider D3 is not reliable either.
Remark 2
According to [62], the order relationship between two PFNs β1 and β2 satisfies β1 ≥ β2 if and only if \(\mu _{\beta _{1}} \geq \mu _{\beta _{2}}\) and \(\nu _{\beta _{1}} \leq \nu _{\beta _{2}}\). So it is natural to obtain the biggest PFN ξ+ = P(1,0) and the smallest PFN ξ− = P(0,1).
Score functions are important to rank alternatives in MCDM, lots of useful score functions have been proposed, such as the gained and lost dominance score (GLDS) method [54] and Score-HeDLiSF method [34]. Motivated by the idea of TOPSIS [22], Zhang [72, 74] considered ξ+ = P(1,0) and ξ− = P(0,1) as the positive ideal PFN and the negative ideal PFN respectively and defined the closeness index of PFN as:
Then a new ranking method for PFNs is proposed based on the closeness index ∂(β) as:
Definition 3
Let \(\beta _{i} = P(\mu _{\beta _{i}}, \nu _{\beta _{i}})(i = 1, 2)\) be two PFNs, ∂(β1) and ∂(β2) are the closeness indexes of β1 and β2, then
- (1)
If ∂(β1) < ∂(β2), then β1 ≺∂β2;
- (2)
If ∂(β1) > ∂(β2), then β1 ≻∂β2;
- (3)
If ∂(β1) = ∂(β2), then β1 ∼∂β2.
Example 5
Let \(\beta _{1} = P(\sqrt {5}/3, 2/3)\) and β2 = P(2/3, \(\sqrt {11}/6)\) are two PFNs, according to (4), we have
Obviously, ∂(β1) = ∂(β2), that is, β1 ∼∂β2 based on Definition 3, so this is an ambiguous ranking result with the fact that β1 and β2 are two different PFNs. That is to say the closeness index proposed by Zhang fails to rank the order of PFNs in some cases. A novel concept of closeness index for PFNs is presented in this paper based on the new proposed distance measure for solving the above shortcomings.
Definition 4
Let β = P(μβ, νβ) be a PFN, ξ+ = P(1,0) be the positive ideal PFN and ξ− = P(0,1) be the negative ideal PFN, then the closeness index of β is defined as follows:
It is obvious if β = ξ−, then R(β) = 0; if β = ξ+, then R(β) = 1. And the following theorems can be obtained.
Theorem 5
For any PFNβ = P(μβ, νβ),the closenessR(β) ∈ [0,1].
Theorem 6
For two PFNs\(\beta _{i} = P(\mu _{\beta _{i}}, \nu _{\beta _{i}})(i=1,2)\),ifβ1 ≤ β2,thenR(β1) ≤R(β2).
Proof of Theorem 6 is given in Appendix C.
A novel ranking method for PFSs can be developed based on the new definition of closeness index R(β).
Definition 5
Let \(\beta _{i} = P(\mu _{\beta _{i}}, \nu _{\beta _{i}})(i = 1, 2)\) be two PFNs, R(β1) and R(β2) are the closeness indexes of β1 and β2, then
- (1)
If R(β1) < R(β2), then β1 ≺Rβ2;
- (2)
If R(β1) > R(β2), then β1 ≻Rβ2;
- (3)
If R(β1) = R(β2), then β1 ∼Rβ2.
Example 6
Let PFN β = P(μ, ν), μ ∈ [1,0] and ν ∈ [0,1]. When β changes from ξ+ to ξ−, the trend of the closeness index is shown in Fig. 4. It is obvious that the closeness index will get the maximum value 1 when β = ξ+, and the minimum value 0 will be obtained when β = ξ−. Therefore, the overall trend in Fig. 4 is consistent with this fact. In particular, the closeness index is given when μ2 + ν2 = 1 which denoted by the curly braces. This example can partly illustrate the rationality of the proposed closeness index.

The trend of closeness index when β from ξ+ to ξ−
Example 7
(Continued Example 5) Let \(\beta _{1} = P(\sqrt {5}/3, 2/3)\) and \(\beta _{2} = P(2/3, \sqrt {11}/6)\), according to Definition 4, we have
So, we have R(β1) ≤R(β2), that is, β1 ≺Rβ2 based on Definition 5. The conclusion can be drawn from the comparison results of Example 5 and Example 7 that the novel proposed closeness index R(β) is more reasonable than Zhang’s method.
The general approach in dealing with multi-criterion decision-making problems is to aggregate the decision values under different criteria , and it is also the same in Pythagorean fuzzy environment. To solve MCDM problems more effectively in Pythagorean fuzzy environment, the Pythagorean fuzzy weighted averaging aggregation operator (Yager’s operator) is developed by Yager [62] to aggregate multiple PFNs as follows:
Definition 6
Let \(\beta _{j} = P(\mu _{\beta _{j}}, \nu _{\beta _{j}})(j = 1, 2, \ldots , n)\) be a group of PFSs, Yager’s operator is defined as:
where wi is the weight of βi, and it holds that wi ≥ 0(i = 1,2,…, n) and \({\sum }_{i = 1}^{n}w_{i} = 1\).
Example 8
Let β1 = P(0.9,0.3), β2 = P(0.5,0.6), and β3 = P(0.7,0.4) be three PFNs, and the weight vector is w = (0.3,0.2,0.5)T, the aggregated result can be calculated based on Definition 6 as:
In order to aggregate PFNs more effective for dealing with MCDM problems, a new Pythagorean fuzzy weighted aggregation (PFWA) operator are proposed as follows:
Definition 7
Let \(\beta _{i} = P(\mu _{\beta _{i}}, \nu _{\beta _{i}})(i = 1, 2, \ldots , n)\) be a group of PFNs, according to the definition of PFNs, we have \(\mu _{\beta _{i}}^{2} + \nu _{\beta _{i}}^{2} + \pi _{\beta _{i}}^{2} = 1\), so naturally, \(\dot {\beta _{i}} = I(\mu _{\beta _{i}}^{2}, \nu _{\beta _{i}}^{2}, \pi _{\beta _{i}}^{2})\) is an IFS, which will be weighted by w as \(\dot {\beta }^{w} = I(\mu _{\dot {\beta }}, \nu _{\dot {\beta }}, \pi _{\dot {\beta }})\) that is still an IFS, where \(\mu _{\dot {\beta }}={\sum }_{i=1}^{n}w_{i}\mu _{\beta _{i}}^{2}\), \(\nu _{\dot {\beta }}={\sum }_{i=1}^{n}w_{i}\nu _{\beta _{i}}^{2}\), and \(\pi _{\dot {\beta }} = 1 - {\sum }_{i=1}^{n}w_{i}(\mu _{\beta _{i}}^{2}+\nu _{\beta _{i}}^{2})\). Then the aggregation operator of \(\dot {\beta }\) can be defined as:
So the new PFWA operator for PFNs is defined as follows:
where wi is the weight of βi, and it holds that wi ≥ 0(i = 1,2,…, n) and \({\sum }_{i = 1}^{n}w_{i} = 1\). In addition, it satisfies \(\hat {\mu }^{2} + \hat {\nu }^{2} \leq 1\), and \(\hat {\pi } = \sqrt {\frac {2\pi ^{2}_{\dot {\beta }}-\pi _{\dot {\beta }}-2\mu _{\dot {\beta }}\nu _{\dot {\beta }}}{1-(\mu _{\dot {\beta }}\nu _{\dot {\beta }})^{2}}}\).
Example 9
(Continued Example 8) Let β1 = P(0.9,0.3), β2 = P(0.5,0.6), and β3 = P(0.7,0.4) be three PFNs, the weight vector w = (0.3,0.2,0.5)T, the aggregated result can be calculated based on (8) as:
Firstly,
Then,
Remark 3
According to Definition 7, the operational laws of two PFNs: \(\beta _{1}=P(\mu _{\beta _{1}}, \nu _{\beta _{1}})\), \(\beta _{2}=P(\mu _{\beta _{2}}, \nu _{\beta _{2}})\) can be defined naturally (when the number of PFNs degenerates into 2) as follows:
where β1 and β2 are equal weights, denoted as \(w_{\beta _{1}}=w_{\beta _{2}}=\frac {1}{2}\).
3 Interval-valued Pythagorean fuzzy number
In the current section, the basic concept and related definitions are introduced of IVPFNs firstly, then the novel distance measure between two IVPNSs is developed and the closeness index for IVPNSs is proposed based on the new distance measure. Next, the interval-valued Pythagorean fuzzy weighted aggregation operator are defined for aggregating IVPNSs.
Definition 8
Let a set X be fixed, an IVPFS \(\widetilde {P}\) in X is defined by:
where \(\widetilde {\mu }_{\widetilde {P}}(x), \widetilde {\nu }_{\widetilde {P}}(x) \in [0, 1]\) are interval values, \(\widetilde {\mu }^{L}_{\widetilde {P}}(x)\) and \(\widetilde {\mu }^{U}_{\widetilde {P}}(x)\) are , respectively, the lower and upper limits of \(\widetilde {\mu }_{\widetilde {P}}(x)\); similarly, \(\widetilde {\nu }^{L}_{\widetilde {P}}(x)\) and \(\widetilde {\nu }^{U}_{\widetilde {P}}(x)\) are , respectively, the lower and upper limits of \(\widetilde {\nu }_{\widetilde {P}}(x)\), and with \((\widetilde {\mu }^{U}_{\widetilde {P}}(x))^{2} + (\widetilde {\nu }^{U}_{\widetilde {P}}(x))^{2} \leq 1\).
An IVPFN is defined by Zhang [72] as \(\tilde {P}(\tilde {\mu }_{\tilde {P}}(x), \tilde {\nu }_{\tilde {P}}(x))\) denoted by \(\tilde {\beta } = \tilde {P}([\tilde {\mu }^{L}_{\tilde {\beta }}, \tilde {\mu }^{U}_{\tilde {\beta }}], [\tilde {\nu }^{L}_{\tilde {\beta }}, \tilde {\nu }^{U}_{\tilde {\beta }}]) \) for convenience. Apparently, an IVPFN will degenerate into a PFN if \(\tilde {\mu }^{L}_{\tilde {P}}(x) = \tilde {\mu }^{U}_{\tilde {P}}(x)\) and \(\tilde {\nu }^{L}_{\tilde {P}}(x) = \tilde {\nu }^{U}_{\tilde {P}}(x)\). In addition, an IVPFN will degenerate into an interval-valued intuitionistic fuzzy number (IVIFN) if \(\tilde {\mu }^{U}_{\tilde {P}}(x) + \tilde {\nu }^{U}_{\tilde {P}}(x) \leq 1\). The comparison of spaces between IVIFN and IVPFN is shown in Fig. 5, it is obvious that a IVPFS can express more uncertain information than an IVIFS because it has more space than IVIFS.

Comparison of spaces between IVIFN and IVPFN
Remark 4
IVPFN is an effective tool to deal with MCDM problems because it can express more uncertainty and fuzziness, mainly in the following two aspects: 1) it can express more extensive information than PFN, for example, IVPFN \(\widetilde {\beta } = \widetilde {P}([0.4, 0.6], [0.2, 0.3])\) means decision maker considers the alternative meets the criterion of 0.4 − 0.6, while the non-criterion is 0.2 − 0.3, however, PFNs can only express this degree using a certain real number. 2) IVPFNs can express more information than IVIFNs, as already mentioned in Definition 4, for example, IVPFN \(\widetilde {\beta } = \widetilde {P}([0.7, 0.8], [0.4, 0.6])\), it represents the greatest degree of trust and mistrust the alternative can meet the criterion as 0.8 and 0.6, respectively. However, it is obvious that 0.82 + 0.62 ≥ 1, so IVIFNs will fail to express the information precisely in this case.
Distance function is very important in data process [8]. To employ IVPFNs more effectively, a new distance measure between different IVPFNs is proposed as below.
Definition 9
Let \(\widetilde {\beta }_{i} = \widetilde {P}([\widetilde {\mu }^{L}_{\widetilde {\beta }_{i}}, \widetilde {\mu }^{U}_{\widetilde {\beta }_{i}}] , [\widetilde {\nu }^{L}_{\widetilde {\beta }_{i}}, \widetilde {\nu }^{U}_{\widetilde {\beta }_{i}}])(i = 1, 2)\) be two IVPFNs, the distance measure between \(\widetilde {\beta }_{1}\) and \(\widetilde {\beta }_{2}\) is defined as follows:
Theorem 7
Let \(\widetilde {\beta }_{i} = \widetilde {P}([\widetilde {\mu }^{L}_{\widetilde {\beta }_{i}}, \widetilde {\mu }^{U}_{\widetilde {\beta }_{i}}] , [\widetilde {\nu }^{L}_{\widetilde {\beta }_{i}}, \widetilde {\nu }^{U}_{\widetilde {\beta }_{i}}])(i = 1, 2)\) be two IVPFNs, then \(0 \leq d(\widetilde {\beta }_{1}, \widetilde {\beta }_{2}) \leq 1\) .
Proof of Theorem 7 is given in Appendix D.
Theorem 8
Let \(\widetilde {\beta }_{i} = \widetilde {P}([\widetilde {\mu }^{L}_{\widetilde {\beta }_{i}}, \widetilde {\mu }^{U}_{\widetilde {\beta }_{i}}] , [\widetilde {\nu }^{L}_{\widetilde {\beta }_{i}}, \widetilde {\nu }^{U}_{\widetilde {\beta }_{i}}])(i = 1, 2)\) be two IVPFNs, then \(d(\widetilde {\beta }_{1}, \widetilde {\beta }_{2}) = 0\) if and only if \(\widetilde {\beta }_{1} = \widetilde {\beta }_{2}\) .
Theorem 9
Let \(\widetilde {\beta }_{i} = \widetilde {P}([\widetilde {\mu }^{L}_{\widetilde {\beta }_{i}}, \widetilde {\mu }^{U}_{\widetilde {\beta }_{i}}] , [\widetilde {\nu }^{L}_{\widetilde {\beta }_{i}}, \widetilde {\nu }^{U}_{\widetilde {\beta }_{i}}])(i = 1, 2)\) be two IVPFNs, then \(d(\widetilde {\beta }_{1}, \widetilde {\beta }_{2}) = d(\widetilde {\beta }_{2}, \widetilde {\beta }_{1})\) .
Theorem 10
Let \(\widetilde {\beta }_{i} = \widetilde {P}([\widetilde {\mu }^{L}_{\widetilde {\beta }_{i}}, \widetilde {\mu }^{U}_{\widetilde {\beta }_{i}}] , [\widetilde {\nu }^{L}_{\widetilde {\beta }_{i}}, \widetilde {\nu }^{U}_{\widetilde {\beta }_{i}}])(i = 1, 2)\) be three IVPFNs. If \(\widetilde {\beta }_{1} \leq \widetilde {\beta }_{2} \leq \widetilde {\beta }_{3}\) , then \(d(\widetilde {\beta }_{1}, \widetilde {\beta }_{2}) \leq d(\widetilde {\beta }_{1}, \widetilde {\beta }_{3})\) and \(d(\widetilde {\beta }_{2}, \widetilde {\beta }_{3}) \leq d(\widetilde {\beta }_{1}, \widetilde {\beta }_{3})\) .
As noted, Theorems 8, 9 and 10 are natural to be proved, so the proofs are omitted here.
Remark 5
According to [72], the order relationship between two IVPFNs \(\tilde {\beta }_{1}\) and \(\tilde {\beta }_{2}\) satisfies \(\tilde {\beta }_{1} \geq \tilde {\beta }_{2}\) if and only if \(\tilde {\mu }^{L}_{\tilde {\beta }_{1}} \geq \tilde {\mu }^{L}_{\tilde {\beta }_{2}}\), \(\tilde {\mu }^{U}_{\tilde {\beta }_{1}} \geq \tilde {\mu }^{U}_{\tilde {\beta }_{2}}\), \(\tilde {\nu }^{L}_{\tilde {\beta }_{1}} \leq \tilde {\nu }^{L}_{\tilde {\beta }_{2}}\) and \(\tilde {\nu }^{U}_{\tilde {\beta }_{1}} \leq \tilde {\nu }^{U}_{\tilde {\beta }_{2}}\). So it is natural to obtain the biggest IVPFN \(\tilde {\xi }^{+} = \tilde {P}([1, 1], [0, 0])\) and the smallest IVPFN \(\tilde {\xi }^{-} = \tilde {P}([0, 0], [1, 1])\).
A novel concept of closeness index for IVPFNs is presented in this paper based on the new distance measure in Definition 9 as follows.
Definition 10
Let \(\widetilde {\beta } = \widetilde {P}([\widetilde {\mu }^{L}_{\widetilde {\beta }}, \widetilde {\mu }^{U}_{\widetilde {\beta }}] , [\widetilde {\nu }^{L}_{\widetilde {\beta }}, \widetilde {\nu }^{U}_{\widetilde {\beta }}])\) be an IVPFN, \(\widetilde {\xi }^{+} = \widetilde {P}([1,1], [0,0])\) be the positive ideal IVPFN and \(\widetilde {\xi }^{-} = \widetilde {P}([0,0], [1,1])\) be the negative ideal IVPFN, then the closeness index of \(\widetilde {\beta }\) is defined as follows:
It is obvious if \(\widetilde {\beta }=\widetilde {\xi }^{-}\), then \({\boldsymbol {\Re }}(\widetilde {\beta }) = 0\); if \(\widetilde {\beta }=\widetilde {\xi }^{+}\), then \({\boldsymbol {\Re }}(\widetilde {\beta }) = 1\). And the following theorems can be obtained.
Theorem 11
For any IVPFN \(\widetilde {\beta } = \widetilde {P}([\widetilde {\mu }^{L}_{\widetilde {\beta }}, \widetilde {\mu }^{U}_{\widetilde {\beta }}] , [\widetilde {\nu }^{L}_{\widetilde {\beta }}, \widetilde {\nu }^{U}_{\widetilde {\beta }}])\) , the closeness index \({\boldsymbol {\Re }}(\widetilde {\beta })\in [0,1]\) .
Theorem 12
For two IVPFNs \(\widetilde {\beta }_{i} = \widetilde {P}([\widetilde {\mu }^{L}_{\widetilde {\beta }_{i}}, \widetilde {\mu }^{U}_{\widetilde {\beta }_{i}}] ,[\widetilde {\nu }^{L}_{\widetilde {\beta }_{i}},\) \( \widetilde {\nu }^{U}_{\widetilde {\beta }_{i}}])(i = 1, 2)\) , if \(\widetilde {\beta }_{1} \leq \widetilde {\beta }_{2}\) , then \({\boldsymbol {\Re }}(\widetilde {\beta }_{1}) \leq {\boldsymbol {\Re }}(\widetilde {\beta }_{2})\) .
Proof of Theorem 12 is given in Appendix E.
Then a new ranking method for IVPFNs is proposed based on the closeness index \({\boldsymbol {\Re }}(\tilde {\beta })\) as:
Definition 11
Let \(\widetilde {\beta }_{i} = \widetilde {P}([\widetilde {\mu }^{L}_{\widetilde {\beta }_{i}}, \widetilde {\mu }^{U}_{\widetilde {\beta }_{i}}] , [\widetilde {\nu }^{L}_{\widetilde {\beta }_{i}}, \widetilde {\nu }^{U}_{\widetilde {\beta }_{i}}])(i = 1, 2)\) be two IVPFNs, \({\boldsymbol {\Re }}(\tilde {\beta }_{1})\) and \({\boldsymbol {\Re }}(\tilde {\beta }_{2})\) are the closeness index of \(\tilde {\beta }_{1}\) and \(\tilde {\beta }_{2}\), then
- (1)
If \({\boldsymbol {\Re }}(\tilde {\beta }_{1}) < {\boldsymbol {\Re }}(\tilde {\beta }_{2})\), then \(\tilde {\beta }_{1} \prec _{{\boldsymbol {\Re }}} \tilde {\beta }_{2}\);
- (2)
If \({\boldsymbol {\Re }}(\tilde {\beta }_{1}) > {\boldsymbol {\Re }}(\tilde {\beta }_{2})\), then \(\tilde {\beta }_{1} \succ _{{\boldsymbol {\Re }}} \tilde {\beta }_{2}\);
- (3)
If \({\boldsymbol {\Re }}(\tilde {\beta }_{1}) = {\boldsymbol {\Re }}(\tilde {\beta }_{2})\), then \(\tilde {\beta }_{1} \sim _{{\boldsymbol {\Re }}} \tilde {\beta }_{2}\).
To select the best alternative in MCDM problems, the preference information of decision makers need to be aggregated by some proper aggregation operators [21], and IVPFNs naturally suit this situation. A new aggregation operator for IVPFNs is proposed in this paper denoted as IVPFWA operator. Firstly, a method is developed to convert IVPFNs to PFNs based on the C-OWA operator introduced by Yager [61] to aggregate the elements on a continuous interval as follows:
Definition 12
A C-OWA operator is a mapping f : Ω → R defined on a function Q as:
where Q is called the basic unit interval monotonic (BUM) function, and Q : [0,1] → [0,1] is monotonic with Q(0) = 0 and Q(1) = 1. Ω denotes the collection of all closed intervals [28].
In addition, Yager [61] pointed out that if \(\lambda = {{\int }_{0}^{1}}Q(y)dy\) is the attitudinal character of Q, λ ∈ [0,1], then the representation can be obtained as: fQ([βL, βU]) = (1 − λ)βL + λβU. λ can be considered as a representation of decision makers’ attitudes, and optimistic tendency is denoted by 0.5 < λ ≤ 1, neutral is λ = 0.5, and 0 ≤ λ < 0.5 means the pessimistic attitude.
To obtain the best alternative, some data aggregation and processing methods were proposed for decision makers to aggregate their preference information [15, 50]. Zhou et al. [76] proposed the continuous interval-valued intuitionistic fuzzy ordered weighted averaging (C-IVIFOWA) operator based on C-OWA operator, which was improved by Lin et al. [36] by modifying some of the flaws. The improved C-IVIFOWA operator GQ is shown as follows:
Motivated by the definition of Lin et al., we develop the operator to aggregate IVPFNs into PFNs as follows.
Definition 13
Let \(\widetilde {\beta } = \widetilde {P}([\widetilde {\mu }^{L}_{\widetilde {\beta }}, \widetilde {\mu }^{U}_{\widetilde {\beta }}] , [\widetilde {\nu }^{L}_{\widetilde {\beta }}, \widetilde {\nu }^{U}_{\widetilde {\beta }}])\) be an IVPFN, a continuous interval-valued Pythagorean fuzzy weighted averaging (C-IVPFWA) operator is a mapping G : ⋈ →▹ defined on a function Q as:
where ⋈ and ▹ are the collection of IVPFNs and PFNs, respectively. \(\tilde {G}_{Q}\) is also called \(\tilde {G}_{\lambda }\) for convenience.
Since \(\widetilde {\mu }^{L}_{\widetilde {\beta }}, \widetilde {\mu }^{U}_{\widetilde {\beta }} , \widetilde {\nu }^{L}_{\widetilde {\beta }}, \widetilde {\nu }^{U}_{\widetilde {\beta }} \in [0,1]\), we have \(0 \leq (1-\lambda )\tilde {\mu }^{L}_{\tilde {\beta }}+\lambda \tilde {\mu }^{U}_{\tilde {\beta }} \leq \tilde {\mu }^{U}_{\tilde {\beta }} \leq 1\), and \(0 \leq \lambda \tilde {\nu }^{L}_{\tilde {\beta }}+(1-\lambda )\tilde {\nu }^{U}_{\tilde {\beta }} \leq \tilde {\nu }^{U}_{\tilde {\beta }} \leq 1\), then \(((1-\lambda )\tilde {\mu }^{L}_{\tilde {\beta }}+\lambda \tilde {\mu }^{U}_{\tilde {\beta }})^{2} + (\lambda \tilde {\nu }^{L}_{\tilde {\beta }}+(1-\lambda )\tilde {\nu }^{U}_{\tilde {\beta }})^{2} \leq (\mu ^{L}_{\tilde {\beta }})^{2} + (\nu ^{L}_{\tilde {\beta }})^{2} \leq 1\). So, \(\tilde {G}_{Q}(\tilde {\beta })\) is a PFN.
It is easy to defined the IVPFWA operator based on Definition 13 and 7 to aggregate multiple IVPFNs as follows.
Definition 14
Let \(\widetilde {\beta }_{i} = \widetilde {P}([\widetilde {\mu }^{L}_{\widetilde {\beta }_{i}}, \widetilde {\mu }^{U}_{\widetilde {\beta }_{i}}] , [\widetilde {\nu }^{L}_{\widetilde {\beta }_{i}}, \widetilde {\nu }^{U}_{\widetilde {\beta }_{i}}])(i = 1, 2,\) …, n) be n IVPFNs. At first, we represent \(\widetilde {\beta }_{i}\) as a PFN using C-IVPFWA proposed in Definition 13 as:
⊧ means ’Abbreviated as’, the IVPFWA operator can be defined as follows:
where \(\tilde {\mu }_{\dot {\beta }}={\sum }_{i=1}^{n}w_{i}\tilde {\mu }_{\tilde {\beta }_{i}}^{2}\), \(\tilde {\nu }_{\dot {\beta }}={\sum }_{i=1}^{n}w_{i}\tilde {\nu }_{\tilde {\beta }_{i}}^{2}\), and \(\tilde {\pi }_{\dot {\beta }} = 1 - {\sum }_{i=1}^{n}w_{i}(\tilde {\mu }_{\tilde {\beta }_{i}}^{2}+\tilde {\nu }_{\tilde {\beta }_{i}}^{2})\), and wi indicates the importance degree of \(\tilde {\beta }_{i}\), satisfying wi ≥ 0(i = 1,2,…, n) and \({\sum }_{i = 1}^{n}w_{i} = 1\).
Example 10
Let \(\tilde {\beta }_{1} = P([0.6, 0.8],[0.4, 0.5])\), \(\tilde {\beta }_{2} = P([0.6, 0.7],[0.4, 0.6])\) and \(\tilde {\beta }_{3} = P([0.7, 0.8],[0.4, 0.5])\) be three IVPFNs, and the weight vector w = (0.3,0.2,0.5)T. Assume that decision maker select the BUM function Q(y) = y2, so the attitudinal character \(\lambda ={{\int }_{0}^{1}}Q(y)dy = \frac {1}{3}\). These three IVPFNs will first be aggregated into three PFNs, respectively, based on (15).
Next, the aggregation results of \(\tilde {\beta }_{1}\), \(\tilde {\beta }_{2}\) and \(\tilde {\beta }_{3}\) are calculated by (17) as:
Remark 6
According to Definition 14, the operational laws of two IVPFNs \(\widetilde {\beta }_{1} = \widetilde {P}([\widetilde {\mu }^{L}_{\widetilde {\beta }_{1}}, \widetilde {\mu }^{U}_{\widetilde {\beta }_{1}}] , [\widetilde {\nu }^{L}_{\widetilde {\beta }_{1}}, \widetilde {\nu }^{U}_{\widetilde {\beta }_{1}}])\) and \(\widetilde {\beta }_{2} = \widetilde {P}([\widetilde {\mu }^{L}_{\widetilde {\beta }_{2}}, \widetilde {\mu }^{U}_{\widetilde {\beta }_{2}}] , [\widetilde {\nu }^{L}_{\widetilde {\beta }_{2}}, \widetilde {\nu }^{U}_{\widetilde {\beta }_{2}}])\) can be defined naturally (when the number of IVPFNs degenerates into 2) as follows:
where \(\tilde {G}_{Q}(\tilde {\beta }_{1}) = ((1-\lambda )\tilde {\mu }^{L}_{\tilde {\beta }_{1}}+\lambda \tilde {\mu }^{U}_{\tilde {\beta }_{1}}, \lambda \tilde {\nu }^{L}_{\tilde {\beta }_{1}}+(1-\lambda )\tilde {\nu }^{U}_{\tilde {\beta }_{1}}) \models (\tilde {\mu }_{\tilde {\beta }_{1}}, \tilde {\nu }_{\tilde {\beta }_{1}})\) and \(\tilde {G}_{Q}(\tilde {\beta }_{2}) = ((1-\lambda )\tilde {\mu }^{L}_{\tilde {\beta }_{2}}+\lambda \tilde {\mu }^{U}_{\tilde {\beta }_{2}}, \lambda \tilde {\nu }^{L}_{\tilde {\beta }_{2}}+(1-\lambda )\tilde {\nu }^{U}_{\tilde {\beta }_{2}}) \models (\tilde {\mu }_{\tilde {\beta }_{2}}, \tilde {\nu }_{\tilde {\beta }_{2}})\).
4 Pythagorean fuzzy approach for MCDM analysis
Decision making under uncertainty is inevitable in real world [14, 35, 77], some significant ranking techniques are developed from multiple perspectives, such as hesitant fuzzy [33, 41] and probabilistic linguistic [23, 32] environments. In this section, a hierarchical Pythagorean fuzzy decision approach is proposed to solve MCDM problems based on the defined closeness indexes and aggregation operators of PFNs and IVPFNs. To deal with the Pythagorean fuzzy MCDM problems more factual and reasonable, a method of weight determination is developed based on the defined distance measure of PFNs and IVPFNs. In addition, some special cases of the proposed approach are also discussed.
4.1 Problem description of Pythagorean fuzzy decision
Pythagorean fuzzy MCDM problems can be described as having n (n ≥ 2) main criteria {C1, C2,…, Cn} and m (m ≥ 2) alternatives {A1, A2,…, Am}. There are ti sub-criteria {Ci(1), Ci(2),…, Ci(t(i))} under each main criterion Ci(i ∈ 1,2,…, n), where ti represents the number of sub-criteria under i th main criterion. The hierarchical framework of Pythagorean fuzzy MCDM problem with two-layer criteria structure is shown in Fig. 6.

The hierarchical framework of MCDM problem
The preference information from the decision-maker will be represented by PFNs or VIPFNs. As noted, we defined the subset CI as the expression criteria whose assessment information are denoted by PFNs, simultaneously, CII is the representation criteria whose Pythagorean fuzzy information are indicated by IVPFNs. It satisfies CI ∪ CII = C and CI ∩ CII = ϕ, and if Cj(t) ∈ CI, then xij(t) means a PFN which denoted as \(\beta _{ij(t)} = P(\mu _{\beta _{ij(t)}}, \nu _{\beta _{ij(t)}})\); if Cj(t) ∈ CII, then xij(t) means an IVPFN which denoted as \(\tilde {\beta }_{ij(t)} = P([\tilde {\mu }_{\tilde {\beta }_{ij(t)}}^{L}, \tilde {\mu }_{\tilde {\beta }_{ij(t)}}^{U}], [\tilde {\nu }_{\tilde {\beta }_{ij(t)}}^{L}, \tilde {\nu }_{\tilde {\beta }_{ij(t)}}^{U}])\). xij(t) expresses the Pythagorean fuzzy value of t th sub-criterion under i th main criterion for alternative Aj, then the decision matrix of Pythagorean fuzzy MCDM problems can be represented as Table 1.
Remark 7
In practical decision-making process, if the crisp values can be employed for decision-maker to determine the degree to which an alternative meets a certain criterion, PFNs would be used to express the assessment information of decision-maker at this time; however, if it is difficult for decision-maker to give the degree to which an alternative can meet a certain criterion based on the crisp values, in which case IVPFNs would be applied to express an assessment interval. This flexible way to represent assessment information is also a great advantage of the proposed decision approach.
The Pythagorean fuzzy decision approach is proposed in the following section.
4.2 Pythagorean fuzzy decision approach
Firstly, according to the decision matrix given in Table 1, for each alternative Aj, its closeness index of t th sub-criterion under i th main criterion Rij(t) will be calculated based on (5) and (12). There exist m alternatives in Pythagorean fuzzy MCDM problems based on the above description, so naturally there are m! possible ranking results for these m alternatives. The γ th permutation £γ is denoted as:
where Aξ and Aζ ∈ {A1, A2,…, Am}, and Aξ ranked higher than Aζ.
With respect to a permutation £γ, we consider its rationality depends on how well the alternatives’ position in this permutation matches their dominance relation. In other words, if the alternatives in £γ are ranked exactly as their performance, then £γ will be a perfect permutation, and vice versa. So how do we determine whether a permutation is reasonable? We define a score function F(£γ) as the representation of the rationality of a permutation £γ. The core idea of function F is that if Aζ is superior to Aξ, then we think their ranking is consistent with their performance, in which case it is a contribution to the permutation £γ and vice versa is a rejection. Especially, if they have the same score, their order has no effect on permutation £γ. The performance of a couple of alternatives (Aξ, Aζ) can be calculated as the concordance/discordance index based on the defined closeness index under the Pythagorean fuzzy environment. So, the concordance/discordance index \(\hbar ^{\gamma }_{\xi \zeta i(t)}\) for the couple of alternatives (Aξ, Aζ) of γ th permutation under t th sub-criterion of i th main criterion can be denoted as:
(I) When C ∈ CI,
where \(\beta _{ji(t)} = P(\mu _{\beta _{ji(t)}}, \nu _{\beta _{ji(t)}})\) is the Pythagorean fuzzy expression of t th sub-criterion under i th main criterion for alternative Aj.
The obvious conclusion can be drawn from (20) that:
- (i)
IF R(βξi(t)) > R(βζi(t)), that is, \(\hbar ^{\gamma }_{\xi \zeta i(t)} > 0\), which means the order Aξ ≻ Aζ is consistent with their factual performance, i.e., this order can make a contribution to the permutation £γi(t), denoted as \(F(\pounds _{\gamma i(t)}) = F(\pounds _{\gamma i(t)}) + |\hbar ^{\gamma }_{\xi \zeta i(t)}|\), where £γi(t) means γ th permutation of t th sub-criterion under i th main criterion.
- (ii)
IF R(βξi(t)) < R(βζi(t)), that is, \(\hbar ^{\gamma }_{\xi \zeta i(t)} < 0\), which means the order Aξ ≻ Aζ is inconsistent with their factual performance, i.e., this order can make a rejection to the permutation £γi(t), denoted as \(F(\pounds _{\gamma i(t)}) = F(\pounds _{\gamma i(t)}) - |\hbar ^{\gamma }_{\xi \zeta i(t)}|\).
- (iii)
IF R(βξi(t)) = R(βζi(t)), that is, \(\hbar ^{\gamma }_{\xi \zeta i(t)} = 0\), which means Aξ and Aζ have the same factual performance, i.e., this order has no effect on the permutation £γi(t), so F(£γi(t)) remains the same value.
According to the above analyses, as the rationality of the permutation £γ of t th sub-criterion under i th main criterion, the score function F(£γi(t)) (C ∈ CI) can be summarize as:
(II) When C ∈ CII,
where \(\\phantom{\dot {i}\!}widetilde{\beta }_{ji(t)} = \widetilde {P}([\widetilde {\mu }^{L}_{\widetilde {\beta }_{ji(t)}}, \widetilde {\mu }^{U}_{\widetilde {\beta }_{ji(t)}}] , [\widetilde {\nu }^{L}_{\widetilde {\beta }_{ji(t)}}, \widetilde {\nu }^{U}_{\widetilde {\beta }_{ji(t)}}])\) is the interval-valued Pythagorean fuzzy expression of t th sub-criterion under i th main criterion for alternative Aj.
The obvious conclusion can be drawn from (22) that:
- (i)
IF \({\boldsymbol {\Re }}(\tilde {\beta }_{\xi i(t)}) > {\boldsymbol {\Re }}(\tilde {\beta }_{\zeta i(t)})\), that is, \(\tilde {\hbar }^{\gamma }_{\xi \zeta i(t)} > 0\), which means the order Aξ ≻ Aζ is consistent with their factual performance, i.e., this order can make a contribution to the permutation £γi(t), denoted as F(£γi(t)) = \(F(\pounds _{\gamma i(t)}) + |\tilde {\hbar }^{\gamma }_{\xi \zeta i(t)}|\).
- (ii)
IF \({\boldsymbol {\Re }}(\tilde {\beta }_{\xi i(t)}) < {\boldsymbol {\Re }}(\tilde {\beta }_{\zeta i(t)})\), that is, \(\tilde {\hbar }^{\gamma }_{\xi \zeta i(t)} < 0\), which means the order Aξ ≻ Aζ is inconsistent with their factual performance, i.e., this order can make a rejection to the permutation £γi(t), denoted as F(£γi(t)) = \(F(\pounds _{\gamma i(t)}) - |\tilde {\hbar }^{\gamma }_{\xi \zeta i(t)}|\).
- (iii)
IF \({\boldsymbol {\Re }}(\tilde {\beta }_{\xi i(t)}) = {\boldsymbol {\Re }}(\tilde {\beta }_{\zeta i(t)})\), that is, \(\tilde {\hbar }^{\gamma }_{\xi \zeta i(t)} = 0\), which means Aξ and Aζ have the same factual performance, i.e., this order has no effect on the permutation £γi(t), so F(£γi(t)) remains the same value.
According to the above analyses, as the rationality of the permutation £γ of t th sub-criterion under i th main criterion, the score function F(£γi(t)) (C ∈ CII) can be summarize as:
The new decision matrix of Pythagorean fuzzy MCDM problems can be expressed as Table 2.
Remark 8
With respect to F(£γi(t)) (γ = 1,2,…, m!), its initial value is 0, and there will be m(m − 1)/2 comparisons for m alternatives in the permutation £γ. The final score of the γ th permutation of tth sub-criterion under ith main criterion should be the sum of all the m(m − 1)/2 operations.
There is no doubt that the determination of criterion weights is an important task in MCDM problems, in some work weights are given by experts in advance [9, 46, 73], which will introduce more subjectivity in the decision-making process. In order to minimize inevitable subjectivity, in this paper, a novel weighting approach is proposed based on the new defined similarity measure in Pythagorean fuzzy environment. Next we first introduce the similarity measure between two PFNs or IVPFNs, which is driven by the distance measure based on Definition 2 and 9.
Definition 15
Let \(\beta _{i} = P(\mu _{\beta _{i}}, \nu _{\beta _{i}})(i = 1, 2)\) be two PFNs, the similarity between β1 and β2 is defined as:
where d(⋅) is the distance measure between PFNs, and (β2)c is the complement operation of PFN β2 defined in [7, 62].
Definition 16
Let \(\widetilde {\beta }_{i} = \widetilde {P}([\widetilde {\mu }^{L}_{\widetilde {\beta }_{i}}, \widetilde {\mu }^{U}_{\widetilde {\beta }_{i}}] , [\widetilde {\nu }^{L}_{\widetilde {\beta }_{i}}, \widetilde {\nu }^{U}_{\widetilde {\beta }_{i}}])(i = 1, 2)\) be two IVPFNs, the similarity measure between \(\widetilde {\beta }_{1}\) and \(\widetilde {\beta }_{2}\) is defined as follows:
where d(⋅) is the distance measure between IVPFNs and \((\widetilde {\beta }_{2})^{c}\) is the complement operation of IVPFN \(\widetilde {\beta }_{2}\) defined in [72].
It is easy to prove the defined similarity measures of PFNs and IVPFNs satisfy the relevant axioms, so the proof process is omitted here.
Suppose the number of criteria is n, and each criterion is expressed under Pythagorean fuzzy environment by a PFN or an IVPFN. The similarity measure of each couple of PFNs and IVPFNs can be obtained based on Definition 15 and 16, then the similarity measure matrix (SMM) can be constructed which provides us the agreement between different Pythagorean fuzzy expressions as:
The support degree of criterion Ci is defined as:
The credibility degree of criterion Ci can be defined as:
It is noted that the credibility degree is actually the weight of the criterion which denotes its relative importance in all criteria and satisfies obviously that \({\sum }_{i=1}^{n}Crd(C_{i}) = 1\). The following example illustrates how to determine the weight based on the above proposed method.
Example 11
Consider a MCDM problem with four criteria {C1, C2, C3, C4}, and the performance of alternative Aj under each criterion are expressed by PFNs as: βj1 = P(0.5,0.3), βj2 = P(0.6,0.7), βj3 = P(0.7,0.4), βj4 = P(0.8,0.3). Then the similarity measure matrix can be obtained based on Definition 15 and 16 as:
Then the support degree of each criterion can be calculated based on (26) as: Sup(C1) = 1.7571, Sup(C2) = 1.2681, Sup(C3) = 1.8358, Sup(C4) = 1.8564. Then the credibility degree of each criterion can be obtained based on (27) as: Crd(C1) = 0.2616, Crd(C2) = 0.1888, Crd(C3) = 0.2732, Crd(C4) = 0.2764, that is, the weight of each criterion is W1 = 0.2616, W2 = 0.1888, W3 = 0.2732, W4 = 0.2764.
After defining the method to determine weights, let’s discuss how to implement the aggregation of sub-criteria under each main criterion in the hierarchical framework of MCDM problem. For alternative Aj, the weights of sub-criteria under each main criterion Ci can be calculated based on (27) as \(w^{j}_{i(*)}\). Then the overall weights of sub-criteria under each main criterion can be obtained by calculating the average as \(w_{i(*)} = {\sum }_{j=1}^{m}w^{j}_{i(*)}/m\). Then the Pythagorean fuzzy expresses of sub-criteria can be aggregated into their corresponding main criterion based on Definition 7 and 14. For alternative Aj under main criterion Ci, the aggregation result of sub-criteria can be denoted as \(\beta _{ji} = PFWA(\beta _{ji(1)}, \ldots , \beta _{ji(t_{i})})\) and \(\widetilde {\beta }_{ji} = IVPFWA(\tilde {\beta }_{ji(1)}, \ldots , \tilde {\beta }_{ji(t_{i})})\). The following example is conducted to illustrate how to aggregate sub-criteria into a main criterion based on the obtained weights.
Example 12
(Continued Example 11) Consider a MCDM problem with four criteria {C1, C2, C3, C4}, and the performance of alternative Aj under each criterion are expressed by PFNs as: βj1 = P(0.5,0.3), βj2 = P(0.6,0.7), βj3 = P(0.7,0.4), βj4 = P(0.8,0.3). According to Exam ple 11, the weights of the four criteria is W1 = 0.2616, W2 = 0.1888, W3 = 0.2732, W4 = 0.2764. Now they can be aggregated into a PFN based on Definition 7 as: βi = PFWA(βj1, βj2, βj3, βj4) = P(0.7940,0.4525).
The MCDM framework after weighted aggregation is shown in Table 3.
So far the score F(£γi(t)) of permutation £γ and weight of t th sub-criterion of i th main criterion have been obtained, next, the score of permutation £γ of each main criterion will be calculated by aggregating all of the sub-criteria and denoted as \(F(\pounds _{\gamma i}) = {\sum }_{t=1}^{t_{i}}F(\pounds _{\gamma i(t)})\cdot w_{t(i)}\).
To obtain the final score of permutation £γ, the weights of all the main criteria need to be calculated based on the aggregated decision matrix shown in Table 3 as wi. Then the final score of permutation £γ can be obtained as \(F(\pounds _{\gamma }) = {\sum }_{i=1}^{n}F(\pounds _{\gamma i})\cdot w_{i}\). Finally, the optimal alternative should be the one with the highest score denoted as \(\pounds _{*} = \max _{\gamma =1}^{m!}\{F(\pounds _{\gamma })\}\).
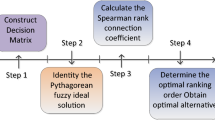
Here we have finished the description of the MCDM problems under Pythagorean fuzzy environment and introduced the decision-making approach based on the developed closeness index and aggregation operator. To make the readers clearly understand the approach above which is highly summarized as the following steps.
Step 1. According to the description of Pythagorean fuzzy decision problem, the hierarchical framework of MCDM problem can be determined and the Pythagorean fuzzy decision matrix can be obtained.
Step 2. List the possible m! permutations of the m alternatives, and calculate the score of each permutation based on the score function ((21) and (23)).
Step 3. Calculate the weights of all the sub-criteria under each main criterion based on (27), then aggregate all sub-criteria under each main criterion based on the obtained weights and Definition 7 and 14.
Step 4. Calculate the score of permutation of each main criterion by aggregating the scores of all the sub-criteria.
Step 5. Calculate the weights of all main criteria based on (27).
Step 6. Obtain the final score of each permutation based on the data of Step 4 and weights of Step 5.
Step 7. Select the permutation which has the highest score as the final decision-making result.
4.3 Some special cases of the proposed approach
The decision approach under Pythagorean fuzzy environment is developed for the framework of two-level criteria MCDM problems. In practice, there may exist some special cases in this framework, for example, the decision-making framework is a single-level structure, the expression of decision matrix are given by PFNs only, weights of criteria are given by decision makers in advance, ect. In these special cases, special consideration should be given to decision-making issues. Some of the differences in the decision-making process and the issues that need to be addressed are listed below.
- Case 1: :
-
When the framework of MCDM problems degenerate into a single criterion layer structure, the decision-making process becomes simpler. Specifically, the overall decision process needs only one weighting operation, in this way, the aggregation process developed in Definition 7 and 14 is omitted, only need to calculate the weights of all the criteria based on (27), and then to aggregate the score of each criterion to complete the decision-making activities.
- Case 2: :
-
In a special case, the decision matrix given by decision-making experts is only expressed by PFNs. The decision-making process is still simplified in this case, for example, calculating the closeness index, computing the score of permutation and aggregating the Pythagorean fuzzy expression are all available under the definition of PFNs, thus greatly saving the algorithm’s time and space overhead.
- Case 3: :
-
In the process of decision-making, if the weights of the criteria are given by decision-makers, the step of calculating the weights is omitted in this case, accordingly, the aggregation process of PFNs and IVPFNs is unnecessary and the decision-making process becomes more concise.
5 Application of Pythagorean fuzzy decision approach in risk assessment
In this section, the process of risk assessment of strategic emerging industries is demonstrated based on the above decision approach under Pythagorean fuzzy environment, which is conducted to illustrate the applicability and effectiveness of the proposed Pythagorean fuzzy decision approach.
5.1 Description of the risk assessment problem
Strategic emerging industries are based on major technological breakthroughs and major development needs. They are industries that have a leading role in promoting overall and long-term economic and social development, which ensures the sustained economic growth in China. They have the following characteristics: intensive knowledge and technology, less consumption of material resources, great potential for growth and good overall efficiency. Thus, how to select the appropriate leading company in strategic emerging industries is significant to nurture and develop strategic emerging industries. Strategic emerging industries are composed of seven parts, they have been the key target and direction of the national industry development, among which the new energy industry has been vigorously supported and promoted by the central government of China. There are three leading companies (Jinko A1, Trina Solar A2 and ReneSola A3) of a new energy industry are considered by government [38], so the proposed MCDM approach will be applied to select the best one from the perspective of risk of the technique innovation. The hierarchy of assessment criteria is a two-level structure with main criteria and sub-criteria given by experts and shown in the Table 4. This risk assessment issue is conducted in Pythagorean fuzzy environment, the values under each criterion of the alternatives will be represented by PFNs or IVPFNs, and the data in this case come from [72], which is illustrated in Table 5.
5.2 Decision process
In Step 1 and 2, there will be 6 (= 3!) possible permutations of three alternatives, and they are:
Then the score of each permutation under each sub-criterion will be calculated based on the score function F, and the results are shown in Table 6. In Step 3, the weights of all the sub-criteria of each criterion will be determined based on the weighting method proposed in Section 4.2. Firstly, for each alternative, the weights of each sub-criterion are computed, then the final weights are determined by averaging all alternatives, and the results are shown in Table 7. The next operation is to aggregate all of the sub-criteria under each main criterion, and the aggregation results are shown in Table 8. In Step 4, the score of each permutation under all the main criteria will be obtained based on the weights calculated in Step 3, and the results are shown in Table 9. In Step 5, the weights of all the main criteria will be calculated based on the aggregation results of Table 8, and the results are shown on the last line of Table 9. In Step 6, the final score of each permutation will be obtained by calculating the weighting values of the four main criteria base on Table 9, and the final results are shown in Table 10. In the last step, apparently, the conclusion can be drawn from Table 10 that the optimal permutation is £3 : A2 ≻ A3 ≻ A1, so the best leading company is Trina Solar A2 from the results of risk assessment. It is obvious the proposed Pythagorean fuzzy decision approach provide business or government with an effective way to handle hierarchical MCDM problems, such as risk assessment in Pythagorean fuzzy environment.
5.3 Discussion and analysis
The ranking of alternatives can be obtained using the above Pythagorean fuzzy decision approach, so that the best goal can be selected naturally. As noted, to determine the weights of main criteria, all sub-criteria under each main criterion are aggregated in Step 3. In the decision-making method presented above, the purpose of this operation is simply to obtain weights of main criteria, but after this operation, if we aggregate all of the main criteria to obtain the corresponding Pythagorean fuzzy representation of each alternative, then the closeness index of each alternative can be calculated based on (5) and (12), which can also be considered as a measure to make decisions. Based on this consideration, the aggregation results of all the main criteria and corresponding closeness indexes of all the alternatives are calculated and shown in Table 11, where the ranking of all the alternatives is easy to be obtained that A2 ≻ A1 ≻ A3 based on the values of closeness indexes. The decision process of the proposed approach in Section 4.2 for permutation £3 is given in Fig. 7a, and the process using the weighted aggregation method to get the final closeness index for alternative A2 is shown in Fig. 7b. By comparison, we can find that the weighted aggregation method mainly provides the weights for criteria of each layer for the decision approach proposed in this paper, while the weighted aggregation method itself can also work as a decision method. Consider the Case 3 mentioned in Section 4.3, when the weights of criteria are given by the decision-makers, the approach we proposed can also work independently of the weighted aggregation method, and at this time, they are two independent decision algorithm. A lot of work has been tried by scholars to deal with MCDM problems under Pythagorean fuzzy environment. In what follows, we will compare our approach with some other existing methods from the aspects of application environment, type of criteria weights, type of problem, main idea, etc., separately. As Table 12 shows, the following conclusions can be easily obtained:
- (i)
The proposed approach can be applied synchronously in the PFN and IVPFN decision environment, while other methods can not work except [72], for example, method [40] can only be used with PFNs data, method [18] can only work on IVPFNs data and method [30] can only act on HPFNs data.
- (ii)
With regard to the expression and determination of criterion weights, except for the approach we proposed, the weights of other methods all come from the decision-maker, which undoubtedly increases the subjectivity of decision-making process. Our approach determines the weights according to the decision matrix, doing so can effectively weaken the subjective factors of human decision-making and make the result of decision-making more accurately.
- (iii)
The proposed approach and method [72] can effectively deal with hierarchical MCDM problems, which can not be done by method [18, 40] and [30]. From the view of main idea and contribution, our work is more prominent than other papers, mainly in the following aspects: our paper proposed the distance measure between different PFNs and IVPFNs, and based on this we define the closeness indexes of PFNs and VIPFNs. In addition, the weighted aggregation operators of PFNs and IVPFNs are developed, which ensure the efficient and accurate implementation of Pythagorean fuzzy decision-making.

The comparison of the decision process between the proposed Pythagorean fuzzy decision approach and weighted aggregation method
6 Extension of the proposed decision approach for other uncertain information
In the previous sections, the Pythagorean fuzzy approach for MCDM problems has been introduced based on PFNs and IVPFNs expression of decision information. Consider that the decision matrix may be represented by other uncertain information, in order to adapt our approach to a broader uncertain environment, the proposed approach is extended further to handle other uncertain information, including fuzzy numbers (FNs), triangular fuzzy numbers (TFNs),
intuitionistic fuzzy numbers (IFNs), hesitation fuzzy numbers (HFNs), interval numbers (INs) and interval valued fuzzy numbers (IVFNs).
As aforementioned, we define six subsets Cψ(ψ = 1,2, 3,4,5,6) as the expression of criteria whose assessment information are denoted by FNs, TFNs, IFNs, HFNs, INs, IVFNs, respectively, which can be denoted as:
When Ci(t) ∈ C1, xij(t) = F(μij(t)) will be expressed by FNs;
When Ci(t) ∈ C2, \(x_{ij(t)}= T(a^{L}_{ij(t)}, a^{M}_{ij(t)}, a^{U}_{ij(t)})\) will be expressed by TFNs;
When Ci(t) ∈ C3, xij(t) = I(μij(t), νij(t)) will be expressed by IFNs;
When Ci(t) ∈ C4, \(x_{ij(t)}= H(h^{1}_{ij(t)}, h^{1}_{ij(t)}, ..., h^{\#x_{ij(t)}}_{ij(t)})\) will be expressed by HFNs;
When Ci(t) ∈ C5, \(x_{ij(t)}= \tilde {a}[a^{-}_{ij(t)}, a^{+}_{ij(t)}]\) will be expressed by INs;
When Ci(t) ∈ C6, \(x_{ij(t)} = \tilde {I}([\mu ^{L}_{ij(t)}, \mu ^{U}_{ij(t)}],[\nu ^{L}_{ij(t)},\)\( \nu ^{U}_{ij(t)}])\) will be expressed by IVFNs.
The main reason why the proposed Pythagorean fuzzy decision approach is effective is that the closeness indexes of PFNs and IVPFNs are defined, which play a crucial role in the final ranking of the alternatives. Therefore, as an extension of the proposed decision approach, we first define the closeness index of different assessment information for MCDM problems, and note that all the expressions of uncertain information are assumed to be normalized. The closeness indexes of FNs, TFNs, IFNs, HFNs, INs and IVFNs are defined, separately, as follows:
Definition 17
Consider a normalized decision matrix \(\mathbb {M} = (x_{ij(t)})_{m \times n \times t_{j}}\) expressed by uncertain information, if Cj(t) ∈ C1, then xij(t) = F(μij(t)) is a FN, whose closeness index can be defined as:
Definition 18
Consider a normalized decision matrix \(\mathbb {M} = (x_{ij(t)})_{m \times n \times t_{j}}\) expressed by uncertain information, if Cj(t) ∈ C2, then \(x_{ij(t)}= T(a^{L}_{ij(t)}, a^{M}_{ij(t)}, a^{U}_{ij(t)})\) is a TFN, whose closeness index can be defined as:
Definition 19
Consider a normalized decision matrix \(\mathbb {M} = (x_{ij(t)})_{m \times n \times t_{j}}\) expressed by uncertain information, if Cj(t) ∈ C3, then xij(t) = I(μij(t), νij(t)) is an IFN, whose closeness index can be defined as:
where πij(t) = 1 − μij(t) − νij(t).
Definition 20
Consider a normalized decision matrix \(\mathbb {M} = (x_{ij(t)})_{m \times n \times t_{j}}\) expressed by uncertain information, if Cj(t) ∈ C4, then \(x_{ij(t)}= H(h^{1}_{ij(t)}, h^{1}_{ij(t)}, ..., h^{\#x_{ij(t)}}_{ij(t)})\) is a HFN, whose closeness index can be defined as:
where #xij(t) is the number of the elements in xij(t).
Definition 21
Consider a normalized decision matrix \(\mathbb {M} = (x_{ij(t)})_{m \times n \times t_{j}}\) expressed by uncertain information, if Cj(t) ∈ C5, then \(x_{ij(t)}= \tilde {a}[a^{-}_{ij(t)}, a^{+}_{ij(t)}]\) is an IN, whose closeness index can be defined as:
Definition 22
Consider a normalized decision matrix \(\mathbb {M} = (x_{ij(t)})_{m \times n \times t_{j}}\) expressed by uncertain information, if Cj(t) ∈ C6, then \(x_{ij(t)}= \tilde {I}([\mu ^{L}_{ij(t)}, \mu ^{U}_{ij(t)}], [\nu ^{L}_{ij(t)}, \nu ^{U}_{ij(t)}])\) is an IVFN, whose closeness index can be defined as:
where \(\pi ^{L}_{ij(t)} = \sqrt {1-(\mu ^{L}_{ij(t)})^{2}-(\nu ^{L}_{ij(t)})^{2}}\) and \(\pi ^{U}_{ij(t)} = \sqrt {1-(\mu ^{U}_{ij(t)})^{2}-(\nu ^{U}_{ij(t)})^{2}}\).
It is noted that the distance measures used in Definition 17–22 are normalized Euclidean distance.
There will be m! possible ranking results for m alternatives in MCDM problems to be dealt with. The concordance/discordance index \(\check {\hbar }^{\gamma }_{\xi \zeta j(t)}\) for a couple of alternatives (Aξ, Aζ) of γ th permutation under t th sub-criterion of i th main criterion can be denoted as (29).
According to the aforementioned analyses, as the rationality of the permutation £γ of t th sub-criterion under i th main criterion, the score function F(£γi(t)) (C ∈ Cψ, ψ = 1,2,3,4,5,6) can be summarize as:
When the score function F(£γi(t)) is obtained, the other decision processes are similar to the Section 4.2, and the specific details are omitted here.
As noted, the weights of criteria in above MCDM problems may be derived from decision makers, or determined using a method similar to the one in Section 4.2. In addition, the weights may be expressed in crisp numbers or in the same form as assessment information, and of course, they can also be represented in a mixed way. Because this is beyond the scope of this paper, there is not too much illustration here.
7 Conclusion and further study
In this paper, we proposed a novel approach for hierarchical multi-criteria decision-making problems from Pythagorean fuzzy perspective. Within the framework of hierarchical MCDM approach, the distance measures are initially defined for PFNs and IVPFNs and some basic theorems are developed and proved to satisfy the corresponding axioms. Based on the defined distance measures, the closeness indexes are presented for PFNs and IVPFNs as the measure of their magnitude motivated by TOPSIS idea. Afterward, the score function is defined to calculate the score, denoted as the rationality, of each permutation for the optimal objective. With respect to criterion weights, taking into account the weights given by decision makers in advance would increase the uncertainty of the decision process, a novel weight determination method is presented, which employs Pythagorean fuzzy data from decision matrix. Furthermore, in the process of dealing with hierarchical MCDM problem, the fusion of different criteria would be conducted to obtain the upper level goal, so the new weighted aggregation operators, called PFWA and IVPFWA are developed for PFNs and IVPFNs, respectively. And finally, the optimal permutation will be determined as the one with the highest score according to the score function. In order to demonstrate the effectiveness and superiority of the proposed decision approach, an experiment about risk assessment is conducted under Pythagorean fuzzy environment. As illustrated in Section 2, the novel distance measure is superior to other existing methods, which determines that the developed closeness index is better than others, which undoubtedly can increase the accuracy of the decision results. In addition, the new presented criterion weight determination method can reduce human’s subjectivity to a certain extent and also laid the foundation for the reliability of decision making. The final extension of the proposed decision approach for heterogeneous information also provides a reference for its further application in other fields, which greatly enriches its flexibility and extensibility. What’s more, as depicted in the comparison analysis of Section 5.3, the proposed approach have different degrees of advantage over other methods in several aspects, such as the usage environment, the type of criterion weights and the problems that can be solved.
Admittedly, there still remain some issues to be addressed in future research, in what follows we summary several noticeable aspects. First, the number of permutations increases tremendously with the number of alternatives, which specifically means that m alternatives correspond to m! permutations, this will increase the computational complexity of the decision approach; Second, the presented aggregation operators for PFNs and IVPFNs does not preserve the property that the membership value in the aggregated result is between all the source Pythagorean fuzzy representation. For example, assume two PFNs: P1 = (0.5,0.1) and P2 = (0.6,0.2), the result can be denoted as P1 ⊕ P2 = (0.7138,0.1863) using the proposed aggregation operator for PFNs. Obviously 0.7138 > 0.5 and 0.7138 > 0.6, it can be seen that the belief of the aggregated PFNs moves closer to a certain element, which may also be seen as a breakthrough, because it can help decision makers employ multi-source information better; Third, the BUM function is needed based on the aforementioned conversion method from the continuous IVPFNs to PFNs, but there is no specific discussion on how to determine this function in this paper, which may effect the final decision results. Although there are some drawbacks at present, the proposed Pythagorean fuzzy decision approach is still an useful tool for hierarchical MCDM problem.
In future studies, the issues in the current version listed above will be improved firstly, mainly including the reduction of the approach’s computational complexity, the further explanation of the aggregation operators’ properties, and the sensitivity analysis of the BUM function. Another significant topic is to explore the relationship between these two methods, which are mentioned and discussed in Section 5.3. As it describes, in addition to the decision approach proposed in this paper, the weighted aggregation method itself can also work as a decision method, and the decision results based on these two methods for the case of risk assessment are consistent, then whether this is a coincidence, or there is a certain quantitative relationship between them, which will be further studied in the following work. Additionally, in future research, the decision-making ideas of this paper will be extended to solve more MCDM problems in Pythagorean fuzzy linguistic environment and type-2 Pythagorean fuzzy environment.
References
Ali Khan MS, Abdullah S, Ali A (2019) Multiattribute group decision-making based on pythagorean fuzzy einstein prioritized aggregation operators. Int J Intell Syst 34(5):1001–1033
Atanassov KT (1986) Intuitionistic fuzzy sets. Fuzzy Sets Syst 20(1):87–96
Biswas SK, Devi D, Chakraborty M (2018) A hybrid case based reasoning model for classification in internet of things (IoT) environment. J Organ End User Comput (JOEUC) 30(4):104–122
Chen TY (2018) An outranking approach using a risk attitudinal assignment model involving pythagorean fuzzy information and its application to financial decision making. Appl Soft Comput 71:460–487
Chen TY (2019) Multiple criteria decision analysis under complex uncertainty: a pearson-like correlation-based pythagorean fuzzy compromise approach. Int J Intell Syst 34(1):114–151
Cui H, Liu Q, Zhang J, Kang B (2019) An improved deng entropy and its application in pattern recognition. IEEE Access 7:18,284–18,292
Dick S, Yager RR, Yazdanbakhsh O (2016) On pythagorean and complex fuzzy set operations. IEEE Trans Fuzzy Syst 24(5):1009–1021
Dong Y, Zhang J, Li Z, Hu Y, Deng Y (2019) Combination of evidential sensor reports with distance function and belief entropy in fault diagnosis. Int J Comput Commun Control 14(3):329–343
Du Y, Hou F, Zafar W, Yu Q, Zhai Y (2017) A novel method for multiattribute decision making with interval-valued pythagorean fuzzy linguistic information. Int J Intell Syst 32(10):1085–1112
Fei L (2019) On interval-valued fuzzy decision-making using soft likelihood functions. Int J Intell Syst 34 (7):1631–1652
Fei L, Deng Y (2019) A new divergence measure for basic probability assignment and its applications in extremely uncertain environments. Int J Intell Syst 34(4):584–600
Fei L, Deng Y, Hu Y (2019) DS-VIKOR: a new multi-criteria decision-making method for supplier selection. Int J Fuzzy Syst 21(1):157–175
Fei L, Wang H, Chen L, Deng Y (2019) A new vector valued similarity measure for intuitionistic fuzzy sets based on owa operators. Iranian J Fuzzy Syst 16(3):113–126
Gao X, Deng Y (2019) The generalization negation of probability distribution and its application in target recognition based on sensor fusion. Int J Distrib Sens Netw 15(5), https://doi.org/10.1177/1550147719849,381
Gao X, Deng Y (2019) The negation of basic probability assignment. IEEE Access 7(1), https://doi.org/10.1109/ACCESS.2019.2901,932
Garg H (2017) Generalized pythagorean fuzzy geometric aggregation operators using einstein t-norm and t-conorm for multicriteria decision-making process. Int J Intell Syst 32(6):597–630
Garg H (2017) A new improved score function of an interval-valued pythagorean fuzzy set based topsis method. Int J Uncertain Quantif 7(5)
Garg H (2018) New exponential operational laws and their aggregation operators for interval-valued pythagorean fuzzy multicriteria decision-making. Int J Intell Syst 33(3):653–683
Gou X, Xu Z, Ren P (2016) The properties of continuous pythagorean fuzzy information. Int J Intell Syst 31(5):401–424
Han Y, Deng Y (2019) A novel matrix game with payoffs of Maxitive Belief Structure. Int J Intell Syst 34 (4):690–706
Han Y, Deng Y, Cao Z, Lin CT (2019) An interval-valued pythagorean prioritized operator based game theoretical framework with its applications in multicriteria group decision making. Neural Comput Applic. https://doi.org/10.1007/s00521-019-04014-1
Hwang C, Yoon K (1981) Multiple attribute decision making methods and applications: a state-of-the-art survey. Springer, Berlin
Jiang L, Liao H (2019) Mixed fuzzy least absolute regression analysis with quantitative and probabilistic linguistic information. Fuzzy Sets Syst. https://doi.org/10.1016/j.fss.2019.03.004. http://www.sciencedirect.com/science/article/pii/S0165011419301691
Kang B, Deng Y, Hewage K, Sadiq R (2019) A method of measuring uncertainty for Z-number. IEEE Trans Fuzzy Syst 27(4):731–738
Kang B, Zhang P, Gao Z, Chhipi-Shrestha G, Hewage K, Sadiq R (2019) Environmental assessment under uncertainty using dempster–shafer theory and z-numbers. J Ambient Intell Humaniz Comput pp. Published online, https://doi.org/10.1007/s12,652--019--01,228--y
Khan MSA, Abdullah S (2018) Interval-valued pythagorean fuzzy gra method for multiple-attribute decision making with incomplete weight information. Int J Intell Syst 33(8):1689–1716
Khan MSA, Abdullah S, Ali A, Amin F, Hussain F (2019) Pythagorean hesitant fuzzy choquet integral aggregation operators and their application to multi-attribute decision-making. Soft Comput 23(1):251–267
Li Y, Deng Y (2018) Generalized ordered propositions fusion based on belief entropy. Int J Comput Commun Control 13(5):792–807
Li Y, Deng Y (2019) TDBF: two dimension belief function. Int J Intell Syst 34. https://doi.org/10.1002/int.22,135
Liang D, Xu Z (2017) The new extension of topsis method for multiple criteria decision making with hesitant pythagorean fuzzy sets. Appl Soft Comput 60:167–179
Liang W, Zhang X, Liu M (2015) The maximizing deviation method based on interval-valued pythagorean fuzzy weighted aggregating operator for multiple criteria group decision analysis. Discret Dyn Nat Soc 2015
Liao H, Jiang L, Lev B, Fujita H (2019) Novel operations of pltss based on the disparity degrees of linguistic terms and their use in designing the probabilistic linguistic electre iii method. Appl Soft Comput 80:450–464
Liao H, Mi X, Yu Q, Luo L (2019) Hospital performance evaluation by a hesitant fuzzy linguistic best worst method with inconsistency repairing. J Clean Prod 232:657–671
Liao H, Qin R, Gao C, Wu X, Hafezalkotob A, Herrera F (2019) Score-hedlisf: a score function of hesitant fuzzy linguistic term set based on hesitant degrees and linguistic scale functions: an application to unbalanced hesitant fuzzy linguistic multimoora. Inform Fusion 48:39–54
Liao H, Wu X (2019) Dnma: a double normalization-based multiple aggregation method for multi-expert multi-criteria decision making. Omega. https://doi.org/10.1016/j.omega.2019.04.001. http://www.sciencedirect.com/science/article/pii/S0305048318302287
Lin J, Zhang Q (2017) Note on continuous interval-valued intuitionistic fuzzy aggregation operator. App Math Model 43(Supplement C):670–677
Liu C, Tang G, Liu P (2017) An approach to multicriteria group decision-making with unknown weight information based on pythagorean fuzzy uncertain linguistic aggregation operators. Math Probl Eng
Liu T, Deng Y, Chan F (2018) Evidential supplier selection based on dematel and game theory. Int J Fuzzy Syst 20(4):1321–1333
Lu M, Wei G, Alsaadi FE, Hayat T, Alsaedi A (2017) Hesitant pythagorean fuzzy hamacher aggregation operators and their application to multiple attribute decision making. J Intell Fuzzy Syst 33(2):1105–1117
Ma Z, Xu Z (2016) Symmetric pythagorean fuzzy weighted geometric/averaging operators and their application in multicriteria decision-making problems. Int J Intell Syst 31(12):1198– 1219
Mi X, Liao H (2019) An integrated approach to multiple criteria decision making based on the average solution and normalized weights of criteria deduced by the hesitant fuzzy best worst method. Comput Ind Eng 133:83–94
Peng X, Yang Y (2015) Some results for pythagorean fuzzy sets. Int J Intell Syst 30(11):1133–1160
Peng X, Yang Y (2016) Fundamental properties of interval-valued pythagorean fuzzy aggregation operators. Int J Intell Syst 31(5):444–487
Peng X, Yuan H (2016) Fundamental properties of pythagorean fuzzy aggregation operators. Fundamenta Informaticae 147(4): 415–446
Peng X, Yuan H, Yang Y (2017) Pythagorean fuzzy information measures and their applications. Int J Intell Syst 32(10):991– 1029
Ren P, Xu Z, Gou X (2016) Pythagorean fuzzy todim approach to multi-criteria decision making. Appl Soft Comput 42:246–259
Singh P, Agrawal R (2018) A customer centric best connected channel model for heterogeneous and IoT networks. J Organ End User Comput (JOEUC) 30(4):32–50
Song Y, Deng Y (2019) A new method to measure the divergence in evidential sensor data fusion. Int J Distrib Sens Netw 15(4), https://doi.org/10.1177/1550147719841,295
Sun R, Deng Y (2019) A new method to identify incomplete frame of discernment in evidence theory. IEEE Access 7(1):15,547–15,555
Sun R, Deng Y (2019) A new method to determine generalized basic probability assignment in the open world. IEEE Access 7(1):52,827–52,835
Wei G, Lu M, Tang X, Wei Y (2018) Pythagorean hesitant fuzzy hamacher aggregation operators and their application to multiple attribute decision making. Int J Intell Syst 33(6):1197–1233
Wei G, Wei Y (2018) Similarity measures of pythagorean fuzzy sets based on the cosine function and their applications. Int J Intell Syst 33(3):634–652
Wu SJ, Wei GW (2017) Pythagorean fuzzy hamacher aggregation operators and their application to multiple attribute decision making. Int J Knowledge-based Int Eng Syst 21(3):189–201
Wu X, Liao H (2019) A consensus-based probabilistic linguistic gained and lost dominance score method. Eur J Oper Res 272(3):1017–1027
Xiao F (2018) A hybrid fuzzy soft sets decision making method in medical diagnosis. IEEE Access 6:25,300–25,312
Xiao F (2019) Multi-sensor data fusion based on the belief divergence measure of evidences and the belief entropy. Inform Fusion 46(2019):23–32
Xiao F (2019) A multiple criteria decision-making method based on D numbers and belief entropy. Int J Fuzzy Syst. https://doi.org/10.1007/s40,815--019--00,620--2
Xiao F, Ding W (2019) Divergence measure of pythagorean fuzzy sets and its application in medical diagnosis. Appl Soft Comput 79:254–267
Xu H, Deng Y (2019) Dependent evidence combination based on DEMATEL method 34(7):1555–1571
Xu Q, Yu K, Zeng S, Liu J (2017) Pythagorean fuzzy induced generalized owa operator and its application to multi-attribute group decision making. Int J Innov Comput Inform Control 13(5):1527–1536
Yager RR (2004) Owa aggregation over a continuous interval argument with applications to decision making. IEEE Trans Syst Man Cybern B Cybern 34(5):1952–1963
Yager RR (2014) Pythagorean membership grades in multicriteria decision making. IEEE Trans Fuzzy Syst 22(4):958–965
Yager RR (2019) Generalized dempster–shafer structures. IEEE Trans Fuzzy Syst 27(3):428–435
Yager RR, Abbasov AM (2013) Pythagorean membership grades, complex numbers, and decision making. Int J Intell Syst 28(5):436–452
Yang Y, Ding H, Chen ZS, Li YL (2016) A note on extension of topsis to multiple criteria decision making with pythagorean fuzzy sets. Int J Intell Syst 31(1):68–72
Zadeh LA (1996) Fuzzy sets. In: Fuzzy sets, fuzzy logic, and fuzzy systems: selected papers by lotfi a zadeh, pp. 394–432. World Scientific
Zeng S (2017) Pythagorean fuzzy multiattribute group decision making with probabilistic information and owa approach. Int J Intell Syst 32(11):1136–1150
Zeng S, Chen J, Li X (2016) A hybrid method for pythagorean fuzzy multiple-criteria decision making. Int J Inf Technol Decis Mak 15(02):403–422
Zhang C, Li D, Ren R (2016) Pythagorean fuzzy multigranulation rough set over two universes and its applications in merger and acquisition. Int J Intell Syst 31(9):921–943
Zhang H, Deng Y (2018) Engine fault diagnosis based on sensor data fusion considering information quality and evidence theory. Adv Mech Eng 10(11):1687814018809,184
Zhang R, Wang J, Zhu X, Xia M, Yu M (2017) Some generalized pythagorean fuzzy bonferroni mean aggregation operators with their application to multiattribute group decision-making. Complexity 2017
Zhang X (2016) Multicriteria pythagorean fuzzy decision analysis: a hierarchical qualiflex approach with the closeness index-based ranking methods. Inf Sci 330:104–124
Zhang X (2016) A novel approach based on similarity measure for pythagorean fuzzy multiple criteria group decision making. Int J Intell Syst 31(6):593–611
Zhang X, Xu Z (2014) Extension of topsis to multiple criteria decision making with pythagorean fuzzy sets. Int J Intell Syst 29(12):1061–1078
Zhao J, Deng Y (2019) Performer selection in human reliability analysis: D numbers approach. Int J Comput Commun Control 14(3):437–452
Zhou L, Tao Z, Chen H, Liu J (2014) Continuous interval-valued intuitionistic fuzzy aggregation operators and their applications to group decision making. Appl Math Model 38(7):2190–2205
Zhou X, Hu Y, Deng Y, Chan FTS, Ishizaka A (2018) A DEMATEL-based completion method for incomplete pairwise comparison matrix in AHP. Ann Oper Res 271(2):1045–1066
Acknowledgments
The authors greatly appreciate the reviews’ valuable comments and the editor’s encouragement. The work is partially supported by National Natural Science Foundation of China (Grant Nos. 61573290, 61503237).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A: Proof of Theorem 1
Proof
Let
A coordinate system is established and shown in Fig. 8, which takes μ as the vertical axis with ν as the horizontal axis. According to the constraints, we know that \(P(\mu _{\beta _{1}} ,\nu _{\beta _{1}})\) and \(P(\mu _{\beta _{2}} ,\nu _{\beta _{2}})\) are the two points of the shaded part in the coordinate system. Based on (41), dTemp(β1, β2) is the distance between point β1 and β2. The maximum and minimum values between them are 0 and \(\sqrt {2}\), respectively. That is, \(d_{Temp}(A, B) \in [0, \sqrt {2}]\). Based on (2), we have 0 ≤ d(β1, β2) ≤ 1. □

The coordinate system for μ and ν
Appendix B: Proof of Theorem 4
Proof
As β1 ≤ β2 ≤ β3, we have \(\mu _{\beta _{1}} \leq \mu _{\beta _{2}} \leq \mu _{\beta _{3}}\) and \(\nu _{\beta _{1}} \geq \nu _{\beta _{2}} \geq \nu _{\beta _{3}}\) based on the Definition in [62]. As shown in Fig. 8, we take arbitrary values \(\mu _{\beta _{1}}\), \(\mu _{\beta _{2}}\), \(\mu _{\beta _{3}}\) and \(\nu _{\beta _{1}}\), \(\nu _{\beta _{2}}\), \(\nu _{\beta _{3}}\) on the coordinate axis. Their intersection points β1, β2 and β3 form a triangle. Obviously, ∠β1β2β3 is always an obtuse angle, so β1β2 < β1β3 and β2β3 < β1β3. That is, dTemp(β1, β2) ≤ dTemp(β1, β3) and dTemp(β2, β3) ≤ dTemp(β1, β3). So d(β1, β2) ≤ d(β1, β3) and d(β2, β3) ≤ d(β1, β3). □
Appendix C: Proof of Theorem 6
Proof
According to Definition 4, we have
Since
Since β1 ≤ β2, we have \(0\leq \mu _{\beta _{1}}\leq \mu _{\beta _{2}} \leq 1\) and \(1 \geq \nu _{\beta _{1}} \geq \nu _{\beta _{2}} \geq 0\) according to Definition in [62]. So, \(\mu _{\beta _{1}}+\mu _{\beta _{2}} \geq 0\), \(\mu _{\beta _{1}}-\mu _{\beta _{2}} \leq 0\), \(\nu _{\beta _{1}}+\nu _{\beta _{2}}-2 \leq 0\), \(\nu _{\beta _{1}}-\nu _{\beta _{2}} \geq 0\); that is, \((\mu _{\beta _{1}}+\mu _{\beta _{2}})(\mu _{\beta _{1}}-\mu _{\beta _{2}}) \leq 0\) and \((\nu _{\beta _{1}}+\nu _{\beta _{2}}-2)(\nu _{\beta _{1}}-\nu _{\beta _{2}}) \leq 0\), so \((\mu _{\beta _{1}}^{2}+(\nu _{\beta _{1}}-1)^{2})-(\mu _{\beta _{2}}^{2}+(\nu _{\beta _{2}}-1)^{2}) \leq 0\), then \((\mu _{\beta _{1}}^{2}+(\nu _{\beta _{1}}-1)^{2}) \leq (\mu _{\beta _{2}}^{2}+(\nu _{\beta _{2}}-1)^{2})\), then \(\sqrt {\mu _{\beta _{1}}^{2}+(\nu _{\beta _{1}}-1)^{2}} \leq \sqrt {\mu _{\beta _{2}}^{2}+(\nu _{\beta _{2}}-1)^{2}}\). Similarly, we have \(\sqrt {(\mu _{\beta _{2}}-1)^{2}+\nu _{\beta _{2}}^{2}} \leq \sqrt {(\mu _{\beta _{1}}-1)^{2}+\nu _{\beta _{1}}^{2}}\). So, in (37), we have
and
So, R(β1) −R(β2) ≤ 0, that is, R(β1) ≤R(β2). □
Appendix D: Proof of Theorem 7
Proof
Let
According to the proof of Theorem 1, it is easy to have \(d_{Temp}^{L}(\beta _{1}, \beta _{2}) \in [0, \sqrt 2]\) and \(d_{Temp}^{U}(\beta _{1}, \beta _{2}) \in [0, \sqrt 2]\), that is, \(0 \leq d(\widetilde {\beta }_{1}, \widetilde {\beta }_{2}) \leq 1\) based on (11). □
Appendix E: Proof of Theorem 12
Proof
According to (39) and corresponding definition in [72], we have
so,
so,
and,
so, \({\boldsymbol {\Re }}(\widetilde {\beta }_{1}) - {\boldsymbol {\Re }}(\widetilde {\beta }_{2}) \leq 0\), that is \({\boldsymbol {\Re }}(\widetilde {\beta }_{1}) \leq {\boldsymbol {\Re }}(\widetilde {\beta }_{2})\). □
Rights and permissions
About this article

Cite this article
Fei, L., Deng, Y. Multi-criteria decision making in Pythagorean fuzzy environment. Appl Intell 50, 537–561 (2020). https://doi.org/10.1007/s10489-019-01532-2
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-019-01532-2