
Abstract
Condition diagnosis of bearings is one of the most common plant maintenance activities in manufacturing industries. It is essential to detect bearing faults early to avoid unexpected breakdown of plant due to undetected faulty bearings. Many meta-heuristics techniques for condition diagnosis of single bearing systems have been developed. The techniques, however, are not effectively applicable for multiple bearing systems. In this paper, a new hybrid technique of genetic algorithms (GAs) with adaptive operator probabilities (AGAs) and back propagation neural networks (BPNNs), called AGAs–BPNNs, is proposed specifically for condition diagnosis of multiple bearing systems. In this technique, AGAs are integrated with BPNNs to attain better initial weights for the BPNNs and hence reduce their learning time. We tested the proposed technique on a two bearing systems, and used ten extracted features from the system’s vibration signals data as input and sixteen bearing condition classes as target output. The experimental results show that the AGAs–BPNNs technique obtains much higher classification accuracy in shorter CPU time and number of iterations compared with the standard BPNNs, and the hybrid of standard GAs and BPNNs.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
A bearing is a device that allows restrained relative motion between two moving parts. Bearings are used to reduce friction on rotating shaft by providing smooth metals ball or roller and a smooth inner and outer metal surface for the balls to roll against. They are widely used in many applications, and different application has different kind of bearing used. For instance, the angular-contact ball bearings are used for automobile wheels, the cylindrical roller bearings are used for aircraft gas turbine engine, and needle roller bearings are used for car follower assembly [1].
In all these applications, the common issues are how to extend bearing life in machines, how to reduce friction energy losses and wear, and how to minimize maintenance expenses and downtime of machinery due to frequent bearing failures [2]. Appropriate bearing maintenance requires good bearing condition diagnosis to prevent overall machine failure since bearing is one of machine parts which has high percentage of defect compared with other components [3]. Therefore, an early and effective fault or condition diagnosis of bearing is essential.
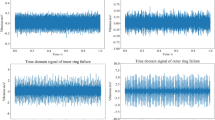
Earliness and effectiveness of fault diagnosis and assessment can be achieved by good condition monitoring. Condition monitoring is represented by vibration signals that are captured by accelerometers. These accelerometers record condition of the bearing system continuously. Vibration signals data are commonly used for bearing fault diagnosis since the information regarding the bearing condition is contained in the vibration signal [4]. Vibration signals show difference characteristic if a problem in the system exists. As can be seen in Fig. 1, the vibration signals of normal bearing are different from faulty bearing. In the faulty bearing vibration signals, the amplitude of the signals, for instance, are much higher than in the normal bearing. However, in a multiple bearing systems when, for instance, one of the bearings in the system has problems and the others are normal, the vibration signals that transpired from this condition may not give a representation that visually distinct from the condition when all the bearings are normal. Therefore, it is important to have a technique which is able to accurately diagnose the system condition based on the continuously monitored vibration signals.

Vibration signal data from normal bearing and inner race fault bearing
Many researchers have proposed techniques for bearing condition diagnosis. Su and Li [5], for instance, proposed a technique to detect fault of bearing by analyzing the frequency characteristic of bearing vibration signals. Another researcher applied discrete wavelet transform (DWT) to vibration signals to predict the occurrence of spilling in ball bearings [6]. Statistical analysis of sound vibration signal was also used by Heng and Nor [7] for monitoring the rolling element bearing condition. Other fault diagnosis techniques were developed based on empirical mode decomposition (EMD) and Hilbert Spectrum [8], and Laplace wavelet enveloped power spectrum [9].
Individual meta-heuristic techniques such as the genetic algorithms (GAs) and neural networks (NNs) have also been used for condition diagnosis [10–12]. However, individual meta-heuristic techniques suffer from their own drawbacks, which can be overcome by forming a hybrid approach combining the advantages of each technique [12]. Hence, researchers have recently started to propose hybrid techniques of meta-heuristic to improve the performance of condition diagnosis. Tang et al. [13] applied NN and niche GA to diagnose five fault types in a gear. Wulandhari et al. [14] improved the condition diagnosis work in specific type of fault for multiple bearing using hybrid GAs–BPNN approach. In order to extend our previous work in condition diagnosis of multiple bearing and specific classes of fault, we improve the classification accuracy and shorten the CPU time by modifying the hybrid meta-heuristic technique.
This paper proposes a new hybrid technique of GAs with adaptive operator probabilities (AGAs) and back propagation neural networks (BPNNs), called AGAs–BPNNs. In this hybrid, AGAs are applied to obtain the best initial weights for the learning process in BPNNs. In this technique, we used ten features extracted from vibration signals data of bearing system as inputs to diagnose the condition. Those features are standard deviation, skewness, kurtosis, the maximum peak value, absolute mean value, root mean square value, crest factor, shape factor, impulse factor and clearance factor [15]. These features are effective and practical in condition diagnosis due to their relative sensitivity to early faults, and robustness to various loads and speeds [16]. These features are used as the input of AGAs–BPNNs, whereas the target outputs are sixteen conditions of the bearing system. In the result and analysis section, we will show the comparison of performance of standard BPNN, hybrid GAs–BPNNs and hybrid AGAs–BPNNs. Detail steps for condition diagnosis of the bearing system are presented in the next section.
2 Bearing vibration data
In this research, the vibration signals data used were obtained from the Case Western Reserve University Bearing Data Center [17]. The vibration signals data were captured from a two bearing systems, which consists of drive end bearing (DE) and fan end bearing (FE), with various combinations of the bearing conditions. The specifications of the bearing are given in Table 1 below:
For the purpose of capturing the vibration signals data, three accelerometers were attached on the bearings and the baseline (BA) as shown in Fig. 2.

Bearing and accelerometer structure
Bearing vibration data were collected under seven different conditions: (1) FE and DE normal, (2) FE normal and DE inner race fault (DE-IRF), (3) FE normal and DE ball fault (DE-BF), (4) FE normal and DE outer race fault (DE-ORF), (5) FE inner race fault (FE-IRF) and DE normal, (6) FE ball fault (FE-BF) and DE normal and (7) FE outer race fault (FE-ORF) and DE normal. The example of the data captured is presented in Table 2.
From the Table 2, we can see that each condition has three streams of data as captured by the three accelerometers. Based on the available data, generally only seven condition classes of bearing can be specified as the output of the diagnosis. In this paper, we expanded the condition classes from seven to sixteen classes by combining and mixing the available data. The FE-IRF and DE-IRF class, for instance, its BA data were set or obtained from the average of BA accelerometer in FE-IRF and DE-IRF condition, the FE data were obtained from FE accelerometer in FE-IRF condition, and the DE data were obtained from DE accelerometer in DE-IRF condition. The expansion of condition classes was done to obtain more specific condition diagnosis for each bearing so that any action to each bearing can be specifically carried out. The advantage of this expansion is that, here, we can identify the condition of DE and FE bearing simultaneously. In these seven class cases, we can only identify the condition of either one. The sixteen classes of the bearing conditions are presented in Table 3.
The classes of multiple bearing conditions are influenced by ten features extracted from the data. The values of the features lie within the interval which is the lower and upper bound of the data extraction. The interval of the features values are presented in Table 4.
From the values that are presented in Table 4, we can see that some lower bound and upper bound of each condition has nearly similar values; therefore, it is difficult to identify the condition of the multiple bearing manually. Based on this fact, we propose AGAs–BPNNs as one of the techniques to identify the condition from multiple bearing and compare the performance of this technique with standard BPNNs and GAs–BPNNs technique.
3 Proposed technique
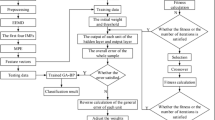
This paper proposed an AGAs technique in GAs to obtain better initial weights for BPNNs training. The adaptive technique is applied to maintain the diversity of the population by varying the probabilities of crossover (\( p_{\text{c}} \)) and mutation (\( p_{\text{m}} \)), see for examples [18–22]. The scheme of AGAs–BPNNs is given in Fig. 3 below.

The scheme of the proposed hybrid AGAs–BPNNs Algorithm
The algorithm for the proposed AGAs–BPNNs is as follows:
-
1.
Let (I k ,T k ) be the kth input and target pair of the problem to be solved by BPNN, with k = 1, 2,…, N in and N in is the number of paired data.
-
2.
Let N pop, N chro, p c0, p m0 and N iter be the number of populations, number of chromosomes, initial crossover probability, initial mutation probability and the maximum number of iterations, respectively. Initialize p c0, p m0, R pc and R pm where R pc are random vector of numbers which generated in range [0, 1] with size 1 × N chro /2 and R pm are random vector of numbers which generated in range [0, 1] with size 1 × N chro. Set i = 0.
-
3.
Determine the BPNN architecture in terms of the number of input neuron, hidden layer, hidden neuron and output neuron, and the activation functions.
-
4.
Generate an initial population of chromosomes Q 0. Each chromosome contains genes which correspond to BPNN random weights, and the number of genes in a chromosome is equal to the number of BPNN weights.
-
5.
Calculate the fitness value \( F\left( {i,j} \right) \) of the jth chromosome in population Q i using
$$ F\left( {i,j} \right) = \frac{1}{E(i,j)}\quad \, j = 1, \, 2, \ldots ,N_{\text{chro}} $$(1)where \( E(i,j) \) is mean square error (MSE) of the jth chromosome in the population Q i . It is calculated based on the selected BPPN architecture as follows:
$$ E(i,j) = \frac{1}{2}\sum\limits_{k = 1}^{{N_{\text{in}} }} {\left( {T_{kj} - O_{kj}^{i} } \right)^{2} } $$(2)where \( T_{kj} \) target of the kth input in the jth chromosome, \( O_{kj}^{i} \) output of the kth input in the jth chromosome of the population Q i based on the selected BPNN architecture
-
6.
Generate the mating pool by selecting the best chromosomes using roulette selection methods.
-
7.
Select parent pairs of population Q i , say \( \left( {\phi_{1s}^{i} ,\phi_{2s}^{i} } \right), \) from the mating pool for crossover mechanism where s = 1, 2, …, S; and \( S = \left\lfloor {\frac{{N_{\text{chro}} }}{2}} \right\rfloor . \)
-
8.
Calculate the crossover probability of the sth parents pairs in the population Q i [20].
$$ p_{\text{c}} (i,\phi_{1s}^{i} ,\phi_{2s}^{i} ) = \left\{ {\begin{array}{*{20}l} {p_{{{\text{c}}0}} \frac{{\left( {F_{\hbox{max} } (i) - F^{'} (i,s)} \right)}}{{\left( {F_{\hbox{max} } (i) - \overline{F} (i)} \right)}}} & {{\text{if }}F^{'} (i,s) > \overline{F} (i)} \\ {p_{{{\text{c}}0}} } & {\text{ otherwise}} \\ \end{array} } \right. $$(3)where
$$ F^{'} (i,s) = \left\{ {\begin{array}{*{20}c} {F(\phi_{1s}^{i} )} & {{\text{if }}F(\phi_{1s}^{i} ) > F(\phi_{2s}^{i} )} \\ {F(\phi_{2s}^{i} )} & {\text{otherwise}} \\ \end{array} } \right. $$\( F(\phi_{1s}^{i} ),\,F(\phi_{2s}^{i} ) \): Fitness value of parents 1 and 2, respectively\( F_{\rm max} (i) \): Maximum fitness value of the population Q i \( \overline{F} (i) \): Average fitness value of the population Q i
-
9.
Calculate mutation probability of the jth chromosome in the population Q i [20]
$$ p_{\text{m}} (i,j) = \left\{ {\begin{array}{*{20}l} {p_{{{\text{m}}0}} \frac{{\left( {F_{\hbox{max} } (i) - F(i,j)} \right)}}{{\left( {F_{\hbox{max} } (i) - \overline{F} (i)} \right)}}} & {{\text{if }}F(i,j) > \overline{F} (i)} \\ {p_{{{\text{m}}0}} } & {\text{otherwise}} \\ \end{array} } \right. $$(4)where \( F(i,j) \) is the fitness value of the jth chromosome in the population Q i
-
10.
Set i = i + 1
Generate Q i by applying crossover and mutation mechanism based on the following rules:
-
(a)
for s = 1:S
if \( p_{\text{c}} (i,\phi_{1s}^{i} ,\phi_{2s}^{i} ) > R_{\text{pc}} (s) \) do crossover between \( \phi_{1s}^{i} \) and \( \phi_{2s}^{i} \). Otherwise, copy \( \phi_{1s}^{i} \) and \( \phi_{2s}^{i} \) as offsprings.
-
(b)
for j = 1: N chro
if \( p_{m} (i,j) > R_{pm} (j) \) do mutation of the jth chromosome. Otherwise, the jth chromosome is kept unchanged.
-
(a)
-
11.
If Q i converge or i is equal to N iter, then the best chromosome is obtained and used as the initial weights for BPNN learning. Else, go to step 5
4 Result and analysis
In this section, we discuss the result of experiment from AGAs–BPNNs technique. We compared the hybrid AGAs–BPNNs performance with the individual BPPNs and hybrid GAs–BPNNs in terms of classification accuracy and CPU time. The accuracy of classification is defined as follows:
The experiment is executed using a computer with Intel Core 2 Quad processor Q8200, 2.33 GHz and 1.96 GHz and RAM 3.46 GB. The 240 samples of time series data are used in BPNNs, GAs–BPNNs and AGAs–BPNNs. These samples are split randomly into three sets: 80 % for training, 10 % for validation and 10 % for testing. BPNNs training uses 30 neurons for input which is composed based on ten features extracted from the vibration signal data of three accelerometers.
In GAs–BPNNs and AGAs–BPNNs techniques, we used BPNNs with the topology: 30 neurons of input, 30 neurons of each hidden layer and 16 neurons of output layer. In this experiment, we set GAs features as follows: 100 chromosomes of each population, each chromosome contains 1,426, 2,356 and 3,286 genes, respectively according to the number of hidden layer. Initial crossover probability is 0.6, and initial mutation probability is 0.01.
For BPNNs, we used three topologies as follows: (1) 30 neurons of input, 30 neurons of the first hidden layer and 16 neurons of output layers, (2) 30 neurons of input, 30 neurons of the first hidden layer, 30 neurons of the second hidden layer and 16 neurons of output layer and (3) 30 neurons of input, 30 neurons of the first hidden layer, 30 neurons of the second hidden layer, 30 neurons of the third hidden layers and 16 neurons of output layer. We refer m-l 1-l 2-l 3-n as BPNNs with m neurons input, l 1 neurons in the first hidden layers, l 2 neurons in the second hidden layers, l 3 neurons in the third hidden layers, and n neurons output.
We performed ten times experiments for each algorithm and record the average of their classification accuracy. Based on the experiment, we observed that the standard BPNNs require larger number of iteration and longer CPU time to achieve the classification accuracy at par with the accuracy obtained by AGAs–BPNNs. In BPNN 30-30-30-16 topology, for instance, the standard BPNNs at 10,000 iterations achieved 69.4, 69.4 and 67.5 % for training, validation and testing, respectively, in 396.8 s CPU time, meanwhile, AGAs–BPNNs is capable to achieve 77.4, 72.1 and 67.5 % for training, validation and testing at 5,000 iterations in 332.9 s CPU time. Generally, the performance comparisons between standard BPNNs, GAs–BPNNs and AGAs–BPNNs are given in Table 5.
As shown in Table 5, the classification accuracy of AGAs–BPNNs is higher than the standard BPNNs and GAs–BPNNs for training, validation and testing processes. The increment of the iteration influences to the increment of the accuracy in training, validation and testing. Figure 4 shows the increment of the accuracy of standard BPNNs, GAs–BPNNs and AGAs–BPNNs for topology 30-30-30-30-16, with respect to the number of iterations. Figure 4a describes the classification accuracy of training process. It is clearly shown that the accuracy obtained using AGAs–BPNNs accuracy is much higher than by GAs–BPNNs or BPNNs. In addition, the accuracies obtained during the validation and testing are also higher by AGAs–BPNNs than by the GAs–BPNN or BPNNs as shown in Fig. 4b, c, respectively.

The classification accuracy of training (a), validation (b) and testing (c) task from standard BPNN, GAs–BPNN and AGAs–BPNN for topology 30-30-30-30-16
5 Conclusion
In this paper, we introduced a new hybrid technique of AGAs in GAs and BPNNs, called AGAs–BPNNs, for condition diagnosis of multiple bearing systems. We exploited the strong capability in optimization of GAs, which here have been further improved by varying the mutation and crossover operators probabilities, for searching the best initial weights for BPNNs, and the strong capability in classification of BPNNs to classify or diagnose the condition of a multiple bearing system. The AGAs strengthen the BPNNs to achieve the higher classification accuracy in shorter CPU time compared with the standard BPNN or the hybrid GAs–BPNNs. Experimental results showed that the AGAs–BPNNs with 30-30-30-30-16 topology have the best performance to classify the condition of the tested multiple bearing systems. Within a shorter CPU time, it achieves 99.3, 91.7 and 92.4 % classification accuracies for the training, validation and testing, respectively. This achievement provides the benefits for condition diagnosis in the real case, since we require a precise and quick process to diagnose the condition of multiple bearing in order to avoid total breakdown.
References
Harris TA, Kotzalas MN (2007) Rolling bearing analysis: essential concepts of bearing technology, 5th edn. Taylor and Francis Group, London
Harnoy A (2003) Bearing design in machinery: engineering tribology and lubrication. Marcel Dekker Inc., New York
Rodriguez PVJ, Arkkio A (2008) Detection of stator winding fault in induction motor using fuzzy logic. Appl Soft Comput 8:1112–1120
Min X, Fanrang K, Fei H (2011) An approach for bearing fault diagnosis based on PCA and multiple classifier fusion. In: Information technology and artificial intelligence conference (ITAIC), 2011 6th IEEE joint international
Su YT, Lin SJ (1992) On initial fault detection of a tapered roller bearing: frequency domain analysis. J Sound Vib 155(1):75–84
Mori K et al (1996) Prediction of spalling on a ball bearing by applying the discrete wavelet transform to vibration signals. Wear 195:162–168
Heng RBW, Nor MJM (1998) Statistical analysis of sound and vibration signals for monitoring rolling element bearing condition. Appl Acoust 53(1–3):211–226
Yu D, Cheng J, Yang Y (2005) Application of EMD method and Hilbert spectrum to the fault diagnosis of roller bearings. Mech Syst Signal Process 19:259–270
Al-Raheem KF et al (2007) Rolling element bearing fault diagnosis using Laplace-wavelet envelope power spectrum. EURASIP J Adv Signal Process 2007:1–14
Wen F, Han Z (1995) Fault section estimation in power system using a genetic algorithm. Electr Power Syst Res 34:165–172
Rafiee J et al (2007) Intelligent condition monitoring of a gearbox using artificial neural network. Mech Syst Signal Process 21:1746–1754
Jayaswal P, Verma SN, Wadhwani AK (2010) Methodology and theory application of ANN, fuzzy logic and wavelet transform in machine fault diagnosis using vibration signal analysis. J Qual Maint Eng 16(2):190–213
Tang JL, Cai QR, Liu YJ (2010) Gear fault diagnosis with neural network based on niche genetic algorithm. In: International conference on machine vision and human-machine interface, pp 596–599
Wulandhari LA, Wibowo A, Desa MI (2011) Hybrid neural network-genetic algorithms approach for fault diagnosis of bearing system. In: The 1st international conference on industrial engineering and service science (IESS 2011). Solo, Indonesia
Li W et al (2003) Feature extraction and classification of gear faults using principal component analysis. J Qual Maint Eng 9(2):132–143
Lei Y, He Z, Zi Y (2009) Application of an intelligent classification method to mechanical fault diagnosis. Expert Syst Appl 36:9941–9948
Mak KL, Wong YS, Wang XX (2000) An adaptive genetic algorithm for manufacturing cell formation. Int J Adv Manuf Technol 16:491–497
Aihong J, Lizhe Y (2010) Fault diagnosis based on adaptive genetic algorithm and BP neural network. In: 2010 2nd international conference on computer engineering and technology vol 6, pp 427–430
Srinivas M, Patnaik LM (1994) Adaptive probabilities of crossover and mutation in genetic algorithms. IEEE Trans Syst Man Cybern 24(4):656–667
Blum S et al. (2001) Adaptive mutation strategies for evolutionary algorithms. In: The annual conference: EVEN at Weimarer Optimierungsund Stochastiktage 2.0
Snasel V, Kromer P, Platos J (2008) Benchmarking hybrid selection and adaptive genetic operators. In: Václav S (ed) Znalosti 2008, ISBN 978-80-227-2827-0. FIIT STU Bratislava, Ústav informatiky a softvérového inzinierstva, pp 224–233
Acknowledgments
The authors thank to Universiti Teknologi Malaysia (UTM) and Ministry of High Education (MOHE) for Fundamental Research Grant Scheme (FRGS) Vote No. R.J130000.7828.4F084 and Research University Grant (RUG) Vote No. Q.J. 130000.7128.00J96. We also thank to UTM’s Research Management Center (RMC) for supporting this research project. The first author sincerely thanks to UTM for awarding International Doctoral Fellowship (IDF).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Wulandhari, L.A., Wibowo, A. & Desa, M.I. Condition diagnosis of multiple bearings using adaptive operator probabilities in genetic algorithms and back propagation neural networks. Neural Comput & Applic 26, 57–65 (2015). https://doi.org/10.1007/s00521-014-1698-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-014-1698-6