
Abstract
The expansion of fluctuating renewable energy sources leads to an increasing impact of weather-related uncertainties on future decentralized energy systems. Stochastic modeling techniques enable an adequate consideration of the uncertainties and provide support for both investment and operating decisions in such systems. In this paper, we consider a residential quarter using photovoltaic systems in combination with multistage air-water heat pumps and heat storage units for space heating and domestic hot water. We model the investment and operating problem of the quarter’s energy system as two-stage stochastic mixed-integer linear program and optimize the thermal storage units. In order to keep the resulting stochastic, large-scale program computationally feasible, the problem is decomposed in combination with a derivative-free optimization. The subproblems are solved in parallel on high-performance computing systems. Our approach is integrated in that it comprises three subsystems: generation of consistent ensembles of the required input data by a Markov process, transformation into sets of energy demand and supply profiles and the actual stochastic optimization. An analysis of the scalability and comparison with a state-of-the-art dual-decomposition method using Lagrange relaxation and a conic bundle algorithm shows a good performance of our approach for the considered problem type. A comparison of the effective gain of modeling the quarter as stochastic program with the resulting computational expenses justifies the approach. Moreover, our results show that heat storage units in such systems are generally larger when uncertainties are considered, i.e., stochastic optimization can help to avoid insufficient setup decisions. Furthermore, we find that the storage is more profitable for domestic hot water than for space heating.
Similar content being viewed by others


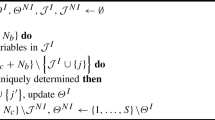
Avoid common mistakes on your manuscript.
1 Introduction
The provision of energy is continuously moving from a conventionally centralized toward a decentralized energy supply with a significant expansion of renewable energy sources. This fundamental, structural rearrangement of the energy system introduces an increased fluctuation and non-negligible uncertainties on the supply side. The resulting challenge is the actual technical and economical realization of the transition process. An additional challenge consists in the modeling of such energy systems taking into account their uncertainties to support a reliable, cost-efficient and technically feasible transition. These new problems call for tailored quantitative solutions to analyze and optimize energy systems (Hurink et al. 2016). In this context, energy systems with decentralized energy provision and load shift potentials of energy storage units are becoming increasingly important (Altmann et al. 2010; Kobayakawa and Kandpal 2016; Owens 2014; Yazdanie et al. 2016). Research needs include the development of approaches for determining the optimal dimensioning and usage of the decentralized energy system’s components, i.e., to support long-term investment and short-term operation decisions under uncertain conditions.
In this paper, we consider a residential quarter with photovoltaic (PV) generators and load flexibilities using heat pumps in combination with heat storage units. Our target is to support the investment and operation planning process of the quarter’s energy system. In order to meet the preferences of the quarter’s residents in terms of maximizing the share of self-generated electricity, the available roof area of the quarter is used completely resulting in a PV system of 240 kWp in this case study. The optimization of a 1-year period with the resolution of 15 minutes is based on real data for a new residential quarter located in Germany considering a total time horizon of 20 years. To ensure a consistent generation and handling of these input data and uncertainties, we present a module-based framework including three subsystems for (1) simulating consistent ensembles of the required input data by a stochastic process, (2) transforming these initial profiles into consistent sets of energy supply and demand profiles and (3) using the generated profiles in a two-stage stochastic programming optimization. In general, the framework serves as a modeling and optimizing concept for a wide variety of decentralized energy systems with various energy supply and demand components, all under consideration of uncertain conditions. Making use of stochastic programming (SP) instead of deterministic programming leads to the expected best solution with respect to the uncertainties.
Since renewable supply, such as PV generation, and energy demand essentially depend on fluctuating and uncertain meteorological data, a Markov process is used to generate profiles of the required meteorological parameters considering their stochastic nature. As mentioned above, our focus is not only on operation, but also on investment optimization. Therefore, our approach needs to take into account the short-term (intra-daily) and long-term (annual and seasonal) variations, since both can affect the optimal investment decision. The resulting meteorological profiles are transformed into PV and heat pump supply and electrical and thermal demand profiles for the subsequent optimization of the stochastic program. While the temperature- and solar-radiation-dependent PV supply and the temperature-dependent heat pump supply are transformed by physical models, the electrical and thermal demand is based on a typical day approach depending on day, season, temperature, cloudiness and building properties (VDI 4655 guideline 2008). Thereby, the so-called standard load or H0 profiles are employed to generate electrical demand profiles. The modeling of the heat storage units involves integer variables at the first stage. Since the employed heat pumps can only run stepwise, there are also integer variables at the second stage leading to a stochastic mixed-integer linear program (SMILP) with more than 100 million variables. To solve this problem with high computational intensity in reasonable time, the resulting large-scale SMILP is decomposed into subproblems. These subproblems are pooled by a scenario reduction technique of Growe-Kuska et al. (2003) and optimized in parallel on high-performance computing (HPC) systems. A commercial solver is used for the inner optimization of the subproblems. The entire problem is solved by a derivative-free optimization (DFO) algorithm that coordinates the optimization of the outer masterproblem on the HPC system. We also compare our results to the case where the heat pumps’ operation can be modeled by continuous variables at the second stage. Additionally, we contrast the gain of modeling the quarter as stochastic program to the resulting computational expenses. Finally, we show the scalability of the approach in comparison with a state-of-the-art dual decomposition method using Lagrangian relaxation and a conic bundle algorithm for solving such problem types.
The paper is structured as follows: Sect. 2 gives a literature review relevant to the developed approach which is described in Sect. 3. The focus of the paper is on the presentation of a real-world case study in Sect. 4. In this context, we demonstrate our approach for a residential quarter including about 70 households, a \(240\hbox {KW}_{\mathrm{p}}\) PV system and heat pumps in combination with heat storage units to cover the energy demand. At the end of Sect. 4, the computational expenses and the scalability of the approach are reflected upon. The approach itself is discussed separately in Sect. 5. The paper finishes with a conclusion and an outlook in Sect. 6.
2 Literature review
Numerous decentralized as well as centralized energy system models are designed for a specific system describing the interaction between energy suppliers, consumers and storage units [for a thorough overview, see, e.g., Connolly et al. (2010), Ventosa et al. (2005)]. Depending on the time horizon, the majority is based on time slices from 10 up to 35,040 slices per year, which already leads to large-scale problems when realistic energy systems are considered.Footnote 1 Here, the term ‘large scale’ does not refer to the geographic size of such a system, but to the number of decision variables which contours the complexity of the optimization model. According to Ventosa et al. (2005), large-scale problems have more than 10,000 variables with high computational expenses.
The economic profitability of energy systems generally depends on optimal energy management, i.e., on finding the optimal capacity of individual components at the first stage and, at the second stage, on their optimal operation over their lifetimes. Prevalently, energy systems are modeled deterministically to optimize the investment (Syed 2010; Vögele et al. 2009), the operation (Kanngießer 2014; Shang et al. 2017; Shirazi and Jadid 2017) or both (Beck et al. 2017; Evins et al. 2014; Kaschub et al. 2016; Lorenzi and Silva 2016) without uncertainty. However, the energy management and thus the economic profitability are subject to manifold uncertainties associated with the future development of energy prices, the electrical and thermal demand and the energy supply. In practice, the impact of uncertainties is often considered by using expected values. The impact is otherwise estimated by sensitivity or scenario analyses since the variation of parameters by such analyses does not increase the problem size. However, such analyses can only provide an estimation of the effect on the optimization results, but the complex impact cannot be captured entirely. Stochastic modeling techniques enable an adequate consideration of various uncertainties in the investment and operation planning processes, thus supporting the assessment of the system’s performance in both the short and long terms. There are several individual models of real energy systems that support optimal investment and operation, taking into account uncertainties with SP (e.g., Göbelt 2001; Kelman et al. 2001; Kovacevic and Paraschiv 2014; Möst and Keles 2010; Wallace and Fleten 2003). Most of them deal with continuous- or mixed-integer decision variables and linear objective functions and constraints. There is a lack of a general approach with a comprehensive modeling chain that generates the required energy profiles under consideration of their mutual dependencies. The arising large-scale SP with millions of mixed-integer variables needs an optimization framework finding an optimal solution with reasonable computational effort.
Two-stage SP enables an adequate consideration of different sources of uncertainties in the investment and operation planning processes of decentralized energy systems. Generally, uncertainties can be defined as information not exactly known (or neglected) at the time when the decision has to be made. There are manifold ways to classify uncertainties; they can be abstractly categorized as aleatory or epistemic (see, e.g., Bedford and Cooke 2001; French 1995; Goldstein 2012; Morgan and Henrion 1992; Mustajoki et al. 2006).Footnote 2 In our context, model results are subject to three different sources of uncertainties:
-
(Raw) Input data
-
Preparatory transformation of the (raw) input data
-
System modeling
Each optimization model requires input data fraught with aleatory uncertainties such as weather, prices, supply or demand. Additional aleatory or epistemic uncertainties are introduced by the process of transforming raw input data into data required for the optimization. Finally, uncertainties are induced by the model itself, mostly epistemically: the more it differs from the real system, the more uncertainty could be induced. The optimization results and the subsequent decision depend on all these sources of uncertainties. Stochastic modeling techniques can be used to account for the associated uncertainties of input and transformed data, resulting in a robust-sufficient solution that is expected to be optimal. In this paper, we consider uncertainty in raw input data and consistently model and propagate these uncertainties through the model chain to the stochastic program that is to be optimized. An optimization under uncertain model parameters has been initially considered about 60 years ago by Dantzig (1955) and by Beale (1955). Those parameter uncertainties are incorporated by their probability distributions through SP.Footnote 3 Since the economic profitability of an energy system depends predominantly, at the first stage, on the investment decision and, at the second stage, on its operation, the problem can be adequately formulated as a two-stage stochastic program with recourse (Dantzig and Infanger 2011; Kalvelagen 2003).
Two-stage stochastic linear programs without integer requirements are well studied (Schultz 2003). Then, the recourse function is a piecewise linear convex function. A number of algorithms have been developed for such programs (see Ruszczynski 1999). Most of these algorithms use an extension of the Benders decomposition introduced by Van Slyke and Wets (1969) known as the L-shaped method.Footnote 4 But for many cases, some decisions of the first and second stage can only be made on the basis of a stepwise selection. Then, the main challenge arises when integer variables are involved and the convexity is no longer present Schultz (2003) [for some major results in this area, see also Haneveld and Vlerk (1999)].
Birge and Louveaux (1997) have presented a branch-and-cut approach with the L-shaped method for the simplest form of two-stage SMILP: first-stage purely binary and second-stage continuous variables. For the most challenging class, with integer and continuous variables at both stages and uncertain parameters anywhere in the model, only few algorithms can be found in the literature. When integer variables are involved at the second stage, the L-shaped method (that requires convex subproblem value functions) cannot be applied directly. See Escudero et al. (2010) for a thorough review on this subject.
Carøe and Tind (1998) and Carøe and Schultz (1999) presented a generalized L-shaped method for models having integer variables at the second stage and either some continuous or some discrete first-stage variables. The dual-decomposition-based method focuses on using Lagrangian relaxation to obtain appropriate bounds. For a large number of mixed-integer variables at both stages, Nürnberg and Römisch (2002) have used stochastic dynamic programming techniques. Sherali and Fraticelli (2002), Sen and Sherali (2006) and Zhu (2006) have developed a branch-and-cut decomposition, modifying the L-shaped method by a relaxation in combination with a special convexification scheme called reformulation-linearization technique. Yuan and Sen (2009) and Sherali and Smith (2009) have enhanced this approach using Benders decomposition at the first stage and a stochastic branch-and-cut algorithm at the second. In addition, Alonso-Ayuso et al. (2003) have introduced a branch-and-fix coordination methodology. The main difference to the common branch-and-bound algorithm is that the search tree evaluates many subproblems. The decision to branch, prune or bound depends on all these subproblems at each step. This approach has been continuously upgraded to using the twin node family concept in combination with Benders decomposition and parallel processing for continuous and binary variables at both stages (Alonso-Ayuso et al. 2005; Escudero et al. 2007, 2010; Pagès-Bernaus et al. 2015).
Besides these exact algorithms for SMILP, there are also heuristic approaches: For instance, Till et al. (2007) propose a hybrid algorithm that is similar to our approach. It solves two-stage SMILP with integer and continuous variables at either stage. Based on stage decomposition, the second-stage scenario problems are solved by a MILP solver. An evolutionary algorithm performs the search of the first-stage variables. However, this procedure as well as exact algorithms is not practically applicable for extremely large-scale problems due the high computational expenses of each iteration step. The high number of variables and constraints of the stochastic program requires computing nodes with computational power that is not available to date. But even if the required computing resources were available, the program would not be feasible within reasonable time and accuracy, when integers are involved at the second stage. In contrast, we present a module-based approach where a well-performing DFO algorithm reliably finds a (locally) optimal solution of the first-stage variables in few steps. Furthermore, a necessary decomposition of the second stage is applied to achieve the required accuracy of the solutions within an acceptable period of time. Because of the extreme problem size, the decomposed second stage is computed in parallel.
3 The developed approach for two-stage stochastic, large-scale problems
In practice, an approach is needed for the economic optimization of decentralized energy systems under uncertainties, such as a residential quarter with storage units and its own PV energy provision. To support the investment and operation decisions, the problem is formulated as a stochastic program. In the context of a decentralized energy system, optimal decisions are achieved by an optimal balancing of its energy supply and demand with the objective of, for instance, maximal profits or minimal costs. Furthermore, the objective can depend on parameters such as prices, efficiencies and many others. Some of these cannot be used directly for the optimization, but have to be derived from raw data that are transformed into the required format. As the entire model chain is subject to the different uncertainties mentioned above, we propose a comprehensive approach, which is structured into three subsystems (see Fig. 1):
-
(a)
Input data subsystem (IDS)
-
(b)
Data transformation subsystem (DTS)
-
(c)
Economic optimization subsystem (EOS)

Conceptual structure of our comprehensive modeling approach (Bertsch et al. 2014)
For the energy system optimization, data of energy demand, supply and prices are needed which can be either acquired directly as input data at the IDS or transformed from raw input data at the DTS. The approach accounts for the associated uncertainties by generating consistent ensembles of raw input parameters (e.g., weather and prices) and transformed data (e.g., electrical and thermal supply or demand) considering their probabilistic properties. For instance, it includes the fundamental relationships between these input parameters and energy demand as well as supply. These profiles are used in the subsequent EOS.
3.1 Input data subsystem (IDS)
The main task of the IDS consists in generating input parameter profiles (e.g., meteorological profiles, such as global solar radiation and temperature) considering their fluctuating and stochastic nature as well as the interdependencies between them. Our ultimate target in this paper is the two-stage optimization of decentralized energy systems. On the one hand, this implies that our approach for simulating input profiles needs to take into account both the short-term fluctuations and uncertainties of the different load profiles and the long-term variations. For example, ‘good’ and ‘bad’ solar years may affect the choice of adequate dimensions for the components of a decentralized energy system. On the other hand, the decentralized energy system includes components on the supply and demand side. Therefore, our approach needs to be able to consider the interdependencies between the supply and demand profiles and the meteorological conditions, i.e., an independent stochastic simulation of the profiles would not be appropriate. For instance, the electricity generation from solar PV panels does not only depend on the global solar radiation but also on the temperature, which affects the panels’ efficiency. Moreover, the heat demand depends on the temperature as well as the cloudiness. We therefore need to simulate the meteorological conditions, such as the cloudiness, and its interdependencies with temperature and global solar radiation.
The stochastic characterization of solar radiation and other meteorological parameters has been studied intensely in the literature. The approaches can generally be divided into two categories: First, regression-based models draw random variables applying an estimate of the probability distribution functions of the observations (see Diagne et al. 2013 for an overview for instance). Second, Markov processes draw a random variable by applying a transition matrix which represents the probabilities of future states depending on past realizations. For instance, focusing on the long-term variations, Amato et al. (1986) model daily solar radiation using a Markov process. Ehnberg and Bollen (2005) simulate solar radiation on the basis of cloud observations available in 3-h intervals. Focussing on the short-term variations in a high temporal resolution, Morf (1998) proposes a Markov process aimed at simulating the dynamic behavior of solar radiation.
Overall, Markov processes have proven suitable to meet the above-mentioned requirements, e.g., to consider interdependencies between cloudiness, temperature and global solar radiation. While our approach is similar to the one by Ehnberg and Bollen (2005), we additionally include seasonal information in our Markov process, i.e., the corresponding transition probabilities may vary from month to month (see below). Moreover, we simulate temperature profiles, which are consistently compatible with the simulated radiation profiles.
In order to address the challenge of considering long-term as well as short-term variations, we suggest a two-step approach. In the first step, we start by modeling the daily cloudiness index \(\zeta \in \left\{ {0,\,\ldots ,8} \right\} \) as a Markov process in order to take the long-term variations into account. The cloudiness is considered in Oktas, describing how many eighths of the sky are covered by clouds, i.e., \(\zeta =0\) indicates a completely clear sky, while \(\zeta =8\) indicates a completely clouded sky (Jones 1992). The transition matrix \(\underline{\Theta }_\zeta ^{m} \) (where the index m indicates the month) is defined for the Markov process used for the simulation of the cloudiness \(\zeta \):
The transition probabilities \(\pi _{ij}^{\zeta ,m} \) in Eq. (1) are derived on the basis of publicly available weather data provided by Germany’s National Meteorological Service, which are available for a variety of locations across Germany for periods of often more than 50 years. A transition probability \(\pi _{ij}^{\zeta ,m} \) denotes the conditional probability that, in month m, the cloudiness \(\zeta _\delta \) on day \(\delta \) equals j, knowing that the cloudiness \(\zeta _{\delta -1} \) on day \(\delta -1\) was i:
The Markov process for the cloudiness based on the transition probabilities in (2) then takes the form
where \(\Xi \) is a uniformly distributed random variable in \(\left[ {0,1} \right] \). Let now \(\upxi \) be a realization of \(\Xi \). Then \(\upzeta _{\updelta }\) can be obtained by:
So basically, Eq. (4) is an operationalization of the Markov process. Higher (lower) transition probabilities \(\pi _{ij}^{\zeta ,m} \) (e.g., the probability of a clear sky on day \(\delta \), knowing that day \(\delta -1\) was clear would be rather high in June but low in December) would result in larger (smaller) intervals. With \(\upxi \) being a realization of a uniformly distributed random variable, this leads directly to a higher (lower) likelihood of the corresponding cloudiness on day \(\delta \).
An additional Markov process is used for modeling the daily global solar radiation on the basis of the cloudiness. The transition probabilities of the transition matrix \(\underline{\Theta }_\rho ^{m,\zeta } \) corresponding to the daily global solar radiation \(\rho _\delta \) on day \(\delta \) can be expressed as a function of the month m, the cloudiness \(\zeta _\delta \) on day \(\delta \) and the global solar radiation \(\rho _{\delta -1} \) on day \(\delta -1\):
The starting values of the Markov processes can be chosen arbitrarily since the influence is negligible in the long run. On the basis of the simulated daily cloudiness, the values for daily global solar radiation and average daily temperature are derived. Our analysis shows that deriving the transition probabilities on a monthly basis delivers more accurate results than using yearly transition probabilities. We validated our simulation approach by comparing the results to historical weather data published by Germany’s National Meteorological Service using short-term as well as long-term performance indicators. For the radiation supply time series, for instance, the validation included a comparison of the total annual radiation supply as well as a number of additional indicators on the basis of Schermeyer et al. (2015). Further details are provided in “Appendix A.”
In the second step, a stochastic process is used to generate profiles in 15-min resolution on the basis of the daily simulation results of step 1. This second step accounts for the short-term fluctuations. While, in general, the seasonal and daily variations of global solar radiation, for instance, can be described in a deterministic way, the stochastic short-term variations are related to the state of the atmosphere (e.g., the cloudiness). These short-term variations are simulated by an empirically determined, statistically varying term under the constraint that a given daily global solar radiation (determined in step 1) is achieved. The Markov process generates time series of the required input parameters (in our case solar radiation, temperature and cloudiness) for the following subsystems and is applied to obtain the desired number of scenarios \(\omega \in \left\{ 1,\ldots ,N\right\} \) that are the basis of the case study under uncertainty in Sect. 4.
3.2 Data transformation subsystem (DTS)
The DTS propagates the uncertainties of raw input data (sets of solar radiation, temperature and cloudiness profiles) and transforms the output of the IDS into data required for the subsequent optimization: energy supply and demand profiles of the decentralized energy system. A PV supply profile module provides the energy supply profiles of the PV system, taking into account the physical relationships. The main components of a PV system are solar modules which transform light into electrical energy through the photoelectric effect. Their electrical yield primarily depends on incident light, module efficiency and its orientation described by longitude, latitude, tilt and azimuth of the modules. A physical model on the basis of Ritzenhoff (2006) describes these dependencies. Thereby, the global solar radiation coming from the IDS is split into direct and diffuse solar radiation on the module and is used in conjunction with ambient temperature (also from the IDS) to determine accurate module efficiency.Footnote 5 In terms of the power generation from PV, the output of the DTS is a set of electrical energy supply profiles, which is consistent with the simulation results of the IDS. These profiles are subsequently used in the EOS. The thermal supply profiles of the heat pumps are transformed depending on their physical performance properties and the uncertain ambient temperature. Concerning the energy demand, we use a reference load profile approach. The generation of electrical demand profiles and heat demand profiles for space heating (SH) and domestic hot water (DHW) is based on the VDI guideline 4655 (2008) using parameters such as day, season, insulation, location, occupancy, temperature and cloudiness. Again, the latter two are taken from the sets of profiles generated by the IDS. Concerning the electricity demand profiles, the daily electricity demand is taken from the approach based on the VDI guideline 4655. As such, the daily demand depends on the uncertain temperature and cloudiness profiles. To achieve appropriate minute electricity demand profiles within each day, the so-called standard load or H0 profiles are scaled to match the daily electricity demand values. The main reason for using the H0 profiles here is that our analysis has shown a strong convergence of aggregate household load toward the H0 profile even for comparatively small numbers of households. (Further details are shown in “Appendix A.”) Figure 2 illustrates energy demand and supply profiles of a residential quarter with a PV system and energy requirement for electricity, SH and DHW. The electricity can also be taken from an external supplier, while heat demand is covered by heat pumps, heating elements and heat storage units within the quarter.

Illustrative energy demand and PV supply profiles of a residential quarter for a typical day
With respect to Fig. 2, the optimization task is to shift the ideal amount of energy demand for SH (dashed line) and DHW (dotted line) to times when a PV surplus is available by using heat pumps in combination with optimal heat storage capacities. In addition, minimization of storage losses and ramp-up losses of the heat pumps, as well as avoiding the use of the inefficient heating elements, will lower the energy costs.
3.3 Economic optimization subsystem (EOS)
Within the EOS, the problem is formulated as an SMILP by optimization modules tailored to the specific needs of the problem that allow for carrying out (locally) optimal economic decisions. Hereby the profiles of the DTS can be used as possible scenarios with the probability of occurrence \(\pi \). The stochastic program is decomposed into feasible and manageable subproblems by fixing inter- and intra-scenario-connected variables. In order to keep the computation time and costs acceptable, a scenario reduction technique is applied and the optimization of the remaining subproblems is executed in parallel on HPC systems, referred to as inner optimization. Within the masterproblem, which we refer to as outer optimization, the fixed, scenario-connected variables are optimized by a DFO algorithm.
3.3.1 Mathematical modeling of the optimization problem
Generally, finding economically optimal investment and operation decisions under uncertain parameters can be formulated as a two-stage stochastic program. Their analytical solution, however, is only possible for few simple cases. In order to solve the problem numerically, it can be formulated as one large linear program known as its deterministic equivalent (Dantzig and Infanger 2011; Ruszczyński and Świȩtanowski 1997):
At the first stage, the cost vector c, the matrix \(\underline{A}\) and the right-hand-side vector b are assumed to be known, while at the second stage, the price vector p, the matrices \(\underline{T}_{\omega } \) and \(\underline{W}_{\omega } \) and the right-hand-side vector \(h_\omega \) are uncertain. Hereby, each scenario \(\upomega \) is an element of the scenario set \(\varOmega =\left\{ 1,2,\ldots ,\,N\right\} \) occurring with probabilities \(\pi _1 ,\ldots ,\pi _N \), respectively.Footnote 6 Decision variables of the stochastic program such as \({\varvec{x}}\) (first stage) and \({\varvec{y}}\) (second stage) are highlighted in bold. In case of mixed integers, \({\varvec{x}}\) and \({\varvec{y}}\) are defined as Ahmed (2010):
where I,R,\(Z_1\) and \(Z_2\) are nonnegative integers with \(Z_1 \le I\) and \(Z_2 \le R\).
The scenarios have to be generated adequately depending on the probability distribution of the uncertain parameters. In the case of stochastic programs with integer recourse \((Z_2 >0)\), Schultz (1995) has also shown that, under mild conditions, discrete distributions can effectively approximate continuous ones to any given accuracy. Since the scenario generation in the IDS is based on a uniformly distributed random variable, each scenario has the same probability of occurrence \(\frac{1}{N}\) and (6) can be summarized to:
the so-called sample average approximation of the stochastic problem (Shapiro et al. 2009). By the law of large numbers, the approximated expectation converges pointwise to the exact value as \(N\rightarrow \infty \), assuming that each scenario is independent of other scenarios.
3.3.2 Decomposition and scenario reduction
The most common decomposition techniques for large-scale stochastic problems are the L-shaped method and the Lagrangian relaxation. The L-shaped method relaxes stage-connecting constraints to eliminate the ties between the stages, but it is not readily applicable when integers are involved at the second stage. Lagrangian relaxation removes the scenario-connecting, non-anticipativity constraints and tries to reestablish these by adding them to the objective function in combination with Lagrangian multipliers. Even if the application of Lagrangian relaxation could lead to a global optimum, it would conceivably take a lot of iterations and require accurate, very expensive solutions of the subproblems. That is why we decompose the problem not by relaxing these connections, but by fixing inter-scenario-connected variables. This decomposition approach is similar to Till et al. (2007) who fix the first-stage variables to optimize the scenarios separately. Therefore, Eq. (11) is written in its implicit form as a function of the first-stage decisions:
and for a given \({\varvec{x}}\), the evaluation of the implicit second-stage value function \(Q_\omega \left( {\varvec{x}} \right) \) requires the solution of N independent subproblems:
Inter-scenario-connected variables are linked by non-anticipativity constraints: the decisions have to be made at the first stage such as storage investments, without anticipating the actual realization at the second stage, and have thus to hold for all possible scenarios.Footnote 7
If necessary, the second stage itself can also be decomposed into M subproblems by fixing intra-scenario-connected variables. In energy systems, these are mostly the investments (first-stage decisions) and variables that are linked over time steps such as the storage level or losses (second-stage decisions). Then, the objective \(f\left( {\varphi =\left( {{\varvec{x}},{\varvec{y}}_{\varvec{\omega }_\mathbf{fix } } } \right) } \right) \) is to be minimized, where x presents the fixed first-stage variables and \(y_{\varvec{\omega }_\mathbf{\mathrm fix }}\) the fixed second-stage variables.
However, if this decomposition allows an extensive computation in parallel, the computational effort decisively depends on the number of scenarios. Hence, it is natural to reduce these scenarios so that the probability distributions of the uncertain conditions are still reasonably represented. A compact overview in scenario generation and reduction with references to further readings is given by Heitsch and Römisch (2011). According to the employed scenario generation and decomposition, a reduction based on moment-matching principles or on probability metrics is suitable.
Moment-matching aims at representing the probability distributions of the uncertain conditions by minimizing the difference between suitable moments of the original and the reduced scenario fan. Even if this heuristic methodology is accepted among practitioners, similar moments do not guarantee similarity of two distributions in general. It also lacks theoretical foundations, and it is unknown how matching moments relate to the approximation quality of the objective value (Kovacevic and Pichler 2015).
Scenario reduction techniques based on probability metrics minimize a certain distance measure between the original and the reduced scenario fan. Usually, as Dupačová et al. (2003) do, a family of the Kantorovich metric (also known as Wasserstein metric) is used as distance measure of two probability distributions. Reducing scenarios with minimal Kantorovich distance to the original program is generally an NP-hard optimization problem in itself (due to its combinatorial structure) that can be even more computationally expensive than the actual problem. Hence, there are conceptually heuristic forward selection and backward reduction algorithms. We have applied the backward reduction described by Growe-Kuska et al. (2003): The idea is to delete one scenario such that the Kantorovich distance of the original and the reduced scenario set \(D_k \left( {P^{\mathrm{all}};P^{\mathrm{red}}} \right) \) is minimal. The probability of occurrence of the deleted scenario is added to that with the minimal Kantorovich distance to the deleted one. This deletion process is repeated as long as a given relative accuracy \(\varepsilon _{\hbox {rel}} \le \frac{D_K }{D_{K,1} }\) holds, where \(D_{k,1} \) is the minimal possible Kantorovich distance of the original scenario set and only one scenario \(D_k \left( {P^{\hbox {all}};P^{1}} \right) \). This heuristic backward reduction algorithm shows close-to-optimal reductions within short runtimes for a high number of scenarios (Heitsch 2007), whereby there is no specific knowledge needed about the required data due to the dimension-independent reduction.
3.3.3 Inner parallel and outer derivative-free optimization
After the decomposition of the large-scale stochastic program into MxN mixed-integer subproblems and a scenario reduction, the remaining subproblems \(\mathrm{sp}_{mn} \) are solved by the standard MILP solver CPLEX (ver. 12.6.3) with a relative gap \(<1\% \). The inner optimization is executed in parallel using HPC nodes to reduce the computing time. The process is designed to solve the subproblems not only on one, but on computing nodes of different HPC systems. After the optimization of the subproblems, their solution is composed to calculate the minimal value of \(f\left( \varphi \right) \) for the fixed variables. An outer optimization performs the search of the fixed variables. Therefore, we propose a derivative-free optimization (DFO) due to integer requirements related to these variables. Figure 3 depicts the whole optimization process.

Parallel optimization process (POP) for large-scale, two-stage stochastic programs
In principle, there are global and local search algorithms that require only the availability of objective function values but no derivative information (Rios and Sahinidis 2013). A global solution would be preferable. Given the very expensive evaluation of all subproblems, a more important requirement is that only a few iterations are required to find an optimal solution. Also important is a reliable and robust solution process, especially a high tolerance to inaccuracy of the inner optimization solutions. Possible DFO algorithms are summarized in “Appendix B” in Table 5, which is based on the review of Rios and Sahinidis (2013) with regard to the mentioned requirements. Besides, the textbook of Conn et al. (2009) is incorporated, which is exclusively devoted to this topic and gives a detailed insight into the algorithms. We have deliberately chosen a hill-climbing algorithm because of its simplicity, flexibility and reliability. We are aware that this algorithm is outperformed by others in some cases but reasons for its choice include the fact that it robustly proceeds to the (local) optimum even without an exact solution of all subproblems. Hence, the computing time can be considerably reduced by setting lower relative gaps for the subproblems—the closer to the optimum, the more accuracy of the inner optimization is needed. Furthermore, with few fixed variables and a good starting point, then few iterations lead to the (locally) optimal solution. See Table 2 in Sect. 4.6 for a comparison of the hill-climbing algorithm with the DDSIP algorithm (dual decomposition in stochastic integer programming) by Carøe and Schultz (1999). In the following, the locally optimal solution of the hill-climbing algorithm that could be globally optimal is referred to just as optimal solution or optimum.
A hill-climbing algorithm is a local search algorithm that attempts to improve a given initial solution to a problem by incrementally altering its solution-dependent variables (Taborda and Zdravkovic 2012). In the optimization process, a steepest-ascent hill-climbing (SAHC) method attempts to minimize the objective function \(f\left( \varphi \right) \) by adjusting a single element of \(\varphi \) representing continuous and/or discrete value of the fixed inter- or intra-scenario-connected variable \(\varphi _k \). All components of \(\varphi \) are sequentially modified in the direction that improves the value of \(f\left( \varphi \right) \) at each iteration. The one leading to the greatest improvement is accepted (see, e.g., Forrest and Mitchell 1993). An initial procedure determines the ascending direction for each fixed variable \(\varphi _k \) that improves the objective value \(f\left( \varphi \right) \). Therefore, a certain step size \(s_k\) is separately added to each fixed variable \(\varphi _k \) and the minimal objective value of f is computed by the parallel optimization process (POP) as shown in Fig. 3. Then, the same step size \(s_k \) is subtracted from each fixed variable \(\varphi _k \) and the minimal objective value of f is computed. The improving ascending direction for each \(\varphi _k \) is memorized. The step with the best improvement is accepted, and the steepest-ascent search is repeated, only for the improving ascending direction. When there is no improvement, then the step size is halved and the process restarts with the initial procedure. The process continues until the relative change of \(f\left( \varphi \right) \) is smaller than a given stopping criterion \(a\in \mathbb {R}_+ \). The complete procedure can be found in “Appendix B.”
4 Application of the developed approach to a residential quarter
We demonstrate the described approach for a real-world case study: a residential quarter that is introduced in Sect. 4.1. Its mathematical model is described in the subsequent Sect. 4.2. The model is optimized on a Windows master machine and three different HPC slave systems: on a Windows-based cluster having 10 nodes with up to \(128\,\hbox {GB}\) RAM and 6 cores at maximal \(4.4\,\hbox {GHz}\) and two Linux-based clusters having 512 nodes each with up to \(128\,\hbox {GB}\) RAM and 40 cores at 2.4–2.6 GHz. The computational results are presented and discussed in Sects. 4.3 and 4.4. At the end of Sect. 4, the computational expenses and the scalability of the approach are reflected in Sects. 4.5 and 4.6, respectively.
4.1 Residential quarter
The focus is on a residential quarter including 70 households on \(7700\,\hbox {m}^{2}\) in multi-family or row houses that are clustered in several building groups \(g\in \left\{ {1,\ldots ,G} \right\} \).Footnote 8 Figure 4 shows the energy setup of the quarter that is optimized under uncertain conditions. On the energy supply side, the available roof area of the quarter is used completely in this case study leading to a PV system of \(240\hbox {kW}_{\mathrm{p}} \). There is also the possibility to obtain electricity that cannot be covered by own production from an external energy supplier at an assumed electricity price of  . If the PV supply exceeds the electricity demand of the quarter, the surplus can be fed into the external grid for a compensation of
. If the PV supply exceeds the electricity demand of the quarter, the surplus can be fed into the external grid for a compensation of  . On the energy demand side, there are the electrical and thermal consumption of each building group g. In this case study, the quarter consists of \(G=4\) building groups in total. The thermal consumption, i.e., demand for space heating (SH) and for domestic hot water (DHW), of one building group is covered by two air-water heat pumps in combination with heat storage units for each building group. Both heat storage units are hot water tanks, having their own electrical heating elements (with an efficiency \(\eta =95\% )\) to ensure thermal supply security in times of peak demand as well as adequate water disinfection. The heating system is separated into two cycles, because it allows the heat pump for SH to run at lower temperatures. As a result, a higher coefficient of performance (COP) and lower heat losses of the storage unit and, thus, lower energy costs are obtained. Because of the lower temperatures, underfloor heating systems are installed to exchange the required heat with a larger heat exchanger surface. SH storage units are implemented in a closed cycle, and their temperature can be assumed as thoroughly mixed and in the range from \(35\,^{\circ }\hbox {C}\) up to \(45\,^{\circ }\hbox {C}\). On the contrary, due to the fresh water requirements, the loop from the heat pump through DHW storage units is separated from the fresh water cycle by a heat exchanger in the tank. The temperature of the fresh water amounts to approximately \(10\,^{\circ }\hbox {C}\) and needs to be heated up to \(50\,^{\circ }\hbox {C}\).Footnote 9 The higher temperature difference results in a larger energy content for the same volume in comparison with the SH storage units.
. On the energy demand side, there are the electrical and thermal consumption of each building group g. In this case study, the quarter consists of \(G=4\) building groups in total. The thermal consumption, i.e., demand for space heating (SH) and for domestic hot water (DHW), of one building group is covered by two air-water heat pumps in combination with heat storage units for each building group. Both heat storage units are hot water tanks, having their own electrical heating elements (with an efficiency \(\eta =95\% )\) to ensure thermal supply security in times of peak demand as well as adequate water disinfection. The heating system is separated into two cycles, because it allows the heat pump for SH to run at lower temperatures. As a result, a higher coefficient of performance (COP) and lower heat losses of the storage unit and, thus, lower energy costs are obtained. Because of the lower temperatures, underfloor heating systems are installed to exchange the required heat with a larger heat exchanger surface. SH storage units are implemented in a closed cycle, and their temperature can be assumed as thoroughly mixed and in the range from \(35\,^{\circ }\hbox {C}\) up to \(45\,^{\circ }\hbox {C}\). On the contrary, due to the fresh water requirements, the loop from the heat pump through DHW storage units is separated from the fresh water cycle by a heat exchanger in the tank. The temperature of the fresh water amounts to approximately \(10\,^{\circ }\hbox {C}\) and needs to be heated up to \(50\,^{\circ }\hbox {C}\).Footnote 9 The higher temperature difference results in a larger energy content for the same volume in comparison with the SH storage units.

Energy setup of building group of the quarter
The concrete task is to determine optimal storage sizes for SH and DHW for each building group including their optimal operation that leads to minimal energy costs. In this case study, air-water heat pumps are used. Their maximal available heating power and their COP depend on the ambient air temperature. Further uncertain weather-dependent parameters are PV generation as well as thermal and electrical demand. Basically, there are two different operation technologies: one technology referred to as inverter heat pumps that can provide heating power at each level below or equal to their maximum heating power and the other technology referred to as on/off (non-inverter) heat pumps that can only run on certain performance levels. For this case study, heat pumps that can only run stepwise at idle, half or full load are to be installed. There are no inverter heat pumps available with the required heat power provision up to now. In the following, we show the results for both inverter and non-inverter heat pumps assuming the same investment needs. To determine the economically optimal sizes of the different components and their operation under these uncertain parameters, the energy setup (illustrated in Fig. 4) is modeled without (SMILP-1) or with integer requirements (SMILP-2) at the second stage depending on the employed heat pump technology.
Note that we do not consider any network (constraints) between the building groups in this case study, neither for heat nor for electricity. Concerning electricity, there actually is a network connecting the building groups, but this is designed from scratch so that the capacity of its components is chosen in such a way that internal network constraints are avoided. Therefore, we can assume a so-called copperplate in our analysis (i.e., omitting network constraints in the model). Concerning heat, a preliminary screening analysis has shown that the potential savings from economies of scale of yet larger heat pumps are outbalanced by the costs for creating and maintaining a local heat network. As a result, potential balancing effects of heat demand and supply between the building groups cannot be considered.
4.2 Mathematical model of the quarter
Corresponding to Eq. (6), the objective function of the deterministic equivalent for one possible scenario \(\omega \in \Omega =\left\{ {1,\ldots ,N} \right\} \) is to minimize the \(\mathrm{costs}_\omega \) over the capacity \({\varvec{x}}_{{\varvec{g,i}}}\) of each investment i of building group g, the used electricity from the grid \({\varvec{e}}_{\varvec{\omega } ,{\varvec{t}}}^{\mathbf{grid}} \) and the fed-in energy of the PV system \({\varvec{e}}_{\varvec{\omega } ,{\varvec{t}}}^{\mathbf{fi}} \) in scenario \(\omega \) at time t:
where the annual capital costs of each investment i of building group g are included by using the equivalent annual cost method: \({\varvec{x}}_{{\varvec{g,i}}} \) is multiplied by \(c_i^{\mathrm{var}} \) plus a fix amount \(c_i^{\hbox {fix}} \) (variable and fix capacity costs of component i), resulting in investments that are converted into an annuity per period T (Jones and Smith 1982). The integrated annuity factor ANF takes into account the lifetime of the investment and the possibility that the capital could be invested elsewhere at a certain interest rate. The equivalent annual cost is often used for investment decisions of energy systems (see, e.g., Hawkes and Leach 2005; Korpaas et al. 2003; Schicktanz et al. 2011; Silveira and Tuna 2003). In this case study, an interest rate of \(7\% \) and a technical lifetime of 20 years are assumed. The period T includes 1 year with a temporal resolution of 15 min. This resolution is required to adequately model the fluctuating energy demand and PV supply that determine the load shift potential of the quarter. More details on the energy demand and supply profiles used in our analysis are presented in “Appendix A” (see Fig. 8 for instance). Further components predefined in the presented case study are:
-
The installed PV capacity of the quarter: \(\mathop \sum \nolimits _{g=1}^4 {\varvec{x}}_{{\varvec{g,i}}=\mathbf{PV}} =240\),
-
The number of heat pumps for SH within a building group: \({\varvec{x}}_{{\varvec{g,i}}=\mathbf{HP}_{\mathbf{SH}}} =1\),
-
The number of heat pumps for DHW within a building group: \({\varvec{x}}_{{\varvec{g,i}}=\mathbf{HP}_{\mathbf{DHW}}} =1,\)
-
The number of heating elements for the SH storage unit: \({\varvec{x}}_{{\varvec{g,i}}=\mathbf{HE}_{\mathbf{SH}} } =4,\)
-
The number of heating elements for the DHW storage unit: \({\varvec{x}}_{{\varvec{g,i}}=\mathbf{HE}_{\mathbf{DHW}} } =4\).
The complete nomenclature is explained in Table 6 in “Appendix C.” Technically, the employed heating elements can provide heating power continuously below or equal to their maximum heating power \(\hat{d}^{\mathrm{he}}\). Similarly, the air-water heat pumps, if designed as inverter heat pumps, can provide heating power at each level below or equal to their maximum heating power \(\hat{d}_{\omega ,t}^{\mathrm{hp}} \). For this case study, the effectively used option is a heat pump that can only run at idle, half or full load. In this paper, the storage size for SH \({\varvec{x}}_{{\varvec{g,i}}=\mathbf{S}_{\mathbf{SH}} } \) and for DHW \({\varvec{x}}_{{\varvec{g,i}}=\mathbf{S}_{\mathbf{DHW}} } \) is optimized for both heat pump types. Because only discrete storage sizes are available as economically reasonable investments on the market, integer variables are used and multiplied by the smallest available storage size: \({\varvec{x}}_{{\varvec{g,i}}=\mathbf{S}_{\mathbf{SH}} } ={\varvec{z}}_{{\varvec{g,i}}=\mathbf{S}_{\mathbf{SH}} } \cdot 1.16\hbox {kWh}_{\mathrm{th}} \) and \({\varvec{x}}_{{\varvec{g,i}}=\mathbf{S}_{\mathbf{DHW}} } =z_{g,i=\mathbf{S}_{\mathbf{DHW}} } \cdot 4.65\hbox {kWh}_{\mathrm{th}} \).Footnote 10
An essential constraint of the system is that the electrical supply (\({\varvec{e}}_{\varvec{\omega } ,{\varvec{t}}}^{\mathbf{grid}} \) plus supplied PV energy \({\varvec{e}}_{\varvec{\omega } ,{\varvec{t}}}^{\mathbf{PV}} )\) and the electrical demand (used electricity of heat pumps \({\varvec{d}}_{\varvec{\omega } ,{\varvec{g,u,t}}}^{\mathbf{hp}} \) and heating elements \(d_{\omega ,g,u,t}^{\mathbf{he}}\) of building group g for use u plus electricity demand for electrical usage \(d_{\omega ,t}^{\hbox {ee}} \) and fed-in PV energy \({\varvec{e}}_{\varvec{\omega } ,{\varvec{t}}}^{\mathbf{fi}} \) in scenario \(\omega \) at time t) need to be balanced at all times:
The supplied PV energy depends on the size of the PV system: \({\varvec{e}}_{\varvec{\omega } ,{\varvec{t}}}^{\mathbf{pv}} =\mathop {\sum }\limits _{g=1}^4 {\varvec{x}}_{{\varvec{g,i}}=\mathbf{PV}} \cdot e_{\omega ,t}^{\mathrm{PV,kWp}} \). Analogously, the thermal supply of the heat pumps and heating elements plus the heat of the storages \({\varvec{s}}_{\varvec{\omega } ,{\varvec{g,u,t}}} \) need to be equal to the thermal demand \(d_{\omega ,g,u,t}^{\hbox {th}} \) in scenario \(\omega \) of building group g for use u at time t including the heat that is to be stored at \(t+1\):
In Eq. (16), storage heat losses \({\varvec{L}}_{\varvec{\omega } ,{\varvec{g,u,t}}} \) are integrated by a constant loss factor \(l_u^{\mathrm{hs}} \) dependent on the heat storage level:
The heat storage level is limited by a minimal storage level \(\check{s}_{g,u} \) and the maximal capacity:
The heat supply for each building group is limited by the number of heating elements \({\varvec{x}}_{{\varvec{g,i}}=\mathbf{HE}_{\varvec{u}}} \) and their maximal heating power \(\hat{d}^{he}\):
and the number of heat pumps \({\varvec{x}}_{{\varvec{g,i}}=\mathbf{HP}_{\varvec{u}}}\) and their maximum heating power values \(\hat{d}_t^{\mathrm{hp}} \):
Here, constraints (20–22) ensure that both heat pumps can be used to cover the demand for SH, but only one for DHW. This specific setup is reasoned by higher peak demands for space heating than for domestic hot water (up to ten times on winter days). When heat pumps can only run at idle, half or full load, then \(m=2\) (possible modes minus the idle mode) and the heating power level \({\varvec{z}}_{\varvec{\omega } ,{\varvec{g,u,t}}} \) is integer with \({\varvec{z}}_{\varvec{\omega } ,{\varvec{g,u}}=\mathbf{SH},t} \in \left\{ {0,1,2,3,4} \right\} \) and \({\varvec{z}}_{\varvec{\omega } ,{\varvec{g,u}}=\mathbf{DHW},t} \in \left\{ {0,1,2} \right\} \). In the case of inverter heat pumps, \({\varvec{z}}_{\varvec{\omega } ,{\varvec{g,u,t}}} \) is a continuous variable and \(m=1\).
Practically, positive load changes result in higher thermal and mechanical energy losses and reduce the COP of the heat pumps. Therefore, one further constraint is needed to differentiate between positive and negative load changes of the heat pumps achieved by positive auxiliary variables:
To take into account energy losses during positive ramp-up times, an additional term \(\mathbf pos _{\varvec{\omega } ,{\varvec{g,u,t}}} \cdot l_u^{\mathrm{hp}} \) is added to the right side of constraint (16), avoiding permanent load changes of the heat pumps. The loss factor \(l_u^{\mathrm{hp}} \) represents the ramp-up loss of the heat pumps and is defined as a \(5\% \) loss of the positive load change at time t. Additionally, the left side of constraint (16) can be relaxed by a further auxiliary variable \({\varvec{q}}_{\varvec{\omega } ,{\varvec{g,u,t}}} \), if heat supply below the demand is acceptable. Then this variable is multiplied by a compensation factor cf=10,000 and added as an economic penalty term to the objective function (14).
Variables that are connected by a constraint over two time steps are restricted to be equal at the first and last time step t:
Since the scenarios are generated by a Markov process with the same probability of occurrence for each scenario, the entire stochastic program can be expressed for a numerical optimization by adapting (14) analogously to (11):
This stochastic program is decomposed into a master and subproblem as in (12) and (13):
All presented variables need to be positive. The maximal storage capacity \({\varvec{x}}_{{\varvec{g,i}}=\mathbf{S}_{\varvec{u}}} \) is discrete in SMILP-1 and SMILP-2, but the heating power level of the heat pumps \({\varvec{z}}_{\varvec{\omega } ,{\varvec{g,u}}=\mathbf{SH},{\varvec{t}}} \) is integer only in SMILP-2.
The model dimension for one scenario is listed in Table 1 for one building group and the entire quarter. The integer variables of the SMILP-1 are the first-stage integer variables representing the discrete storage sizes for SH and DHW (in case of the quarter, one SH and one DHW storage for each of the four building groups). In addition, the SMILP-2 considers integer variables at the second stage, i.e., those related to the stepwise heat pump operation in each 15-min time step (35,040 integer variables per heat pump). For an appropriate consideration of the uncertainties, a problem with hundreds to thousands of such scenarios needs to be solved.
4.3 Computational results
As input for the storage optimization of the quarter located in Germany, 100 weather scenarios were generated by the Markov process representing the uncertain global solar radiation, temperature and cloudiness (see Sect. 3.1). These profiles are transformed into PV supply and energy demand profiles for electricity, SH and DHW for the described SMILP-1 and SMILP-2. Because of the extreme problem size of one scenario, the 1-year period T in Eq. (27) is also decomposed into periods of 2 weeks leading to 27 subproblems per scenario.Footnote 11 The resulting 2700 subproblems are solved in parallel by using POP. The fixed storage sizes of the first stage are optimized by the outer SAHC method. To save computing time, the 27 fixed storage levels per storage (of 35,040 storage levels per scenario) of the second stage are not optimized, but set to plausible levels. In the beginning of the SAHC, each subproblem is solved with low accuracy within a few minutes. Only for the last iterations, the computing time is limited to half an hour to achieve the accuracy that is required by the SAHC to find the optimum.Footnote 12 About 17 steps of the outer optimization are needed to find the optimal storage sizes. If the optimization was carried out sequentially on one computer, the computation would take up to 7 years. Due to the POP, the problem is solved in less than 1 week. Through the application of the scenario reduction, only \(1\,243\) subproblems need to be computed without changing the optimal storage sizes or notably influencing the optimal objective value. Thus, the problem can be computed in less than half a week. For a better illustration, only the results for building group 1 with 29 households are presented and discussed in the following and until the end of this paper.
Figure 5 shows the density function of minimal costs and optimal storage sizes of all scenarios for two program variants:
-
SMILP-1: with inverter heat pumps (no integers at second stage)
-
SMILP-2: with heat pumps that can run at idle, half or full load (integers at second stage)
The optimal SH and DHW storage size of each independent scenario is plotted on the lateral wide axis versus the minimal costs on the lateral depth axis. The vertical height axis represents the occurrence frequency for the optimal storage size with class intervals of \(1.16\hbox {kWh}_{\mathrm{th}} \) for SH and \(4.65\hbox {kWh}_{\mathrm{th}} \) for DHW and their according minimal costs with class intervals of  . Note that the abscissa is differently scaled for the SH and DHW storage size (where 1.16 and \(4.65\hbox {kWh}_{\mathrm{th}} \) are equivalent to the smallest possible water tank of 100L for SH and DHW, respectively).
. Note that the abscissa is differently scaled for the SH and DHW storage size (where 1.16 and \(4.65\hbox {kWh}_{\mathrm{th}} \) are equivalent to the smallest possible water tank of 100L for SH and DHW, respectively).

Density function of minimal costs and optimal storage size including the stochastic solution and the deterministic solution using expected values of the uncertain parameters of the SMILP-1 and SMILP-2 of building group 1
If each scenario is optimized separately and the heat pumps can run completely flexibly (Fig. 5, SMILP-1), i.e., all variables at the second stage are continuous, the optimal storage size for SH varies between 2.3 and 18.6 \(\hbox {kWh}_{\mathrm{th}} \) and for DHW between 60.4 and 69.7 \(\hbox {kWh}_{\mathrm{th}}\). The occurrence frequency peak is between 2.3 and 3.5 \(\hbox {kWh}_{\mathrm{th}} \) for SH and between 65.1 and 69.7 \(\hbox {kWh}_{\mathrm{th}} \) for DHW. The minimal costs amount to  for the SMILP-1. Thereof, about \(50\% \) can be attributed to the capital costs of the energy system’s components. The other \(50\% \) are variable energy costs. The boxes in Fig. 5 include the stochastic solution (in red) and the deterministic solution of the expected value problem (EV) (in black). The optimal solution of SMILP-1 is \(18.6\,\hbox {kWh}_{\mathrm{th}} \) for SH and \(65.1\,\hbox {kWh}_{\mathrm{th}} \) for DHW with expected minimal costs of
for the SMILP-1. Thereof, about \(50\% \) can be attributed to the capital costs of the energy system’s components. The other \(50\% \) are variable energy costs. The boxes in Fig. 5 include the stochastic solution (in red) and the deterministic solution of the expected value problem (EV) (in black). The optimal solution of SMILP-1 is \(18.6\,\hbox {kWh}_{\mathrm{th}} \) for SH and \(65.1\,\hbox {kWh}_{\mathrm{th}} \) for DHW with expected minimal costs of  . The solution of the EV is achieved by deterministically computing one scenario with expected values of the uncertain input parameters. Then, the optimal storage sizes are \(2.3\,\hbox {kWh}_{\mathrm{th}} \) and \(69.7\,\hbox {kWh}_{\mathrm{th}} \) for SH and DHW, respectively.
. The solution of the EV is achieved by deterministically computing one scenario with expected values of the uncertain input parameters. Then, the optimal storage sizes are \(2.3\,\hbox {kWh}_{\mathrm{th}} \) and \(69.7\,\hbox {kWh}_{\mathrm{th}} \) for SH and DHW, respectively.
Figure 5 analogously shows the results for mixed-integer variables at both stages in case of SMILP-2. The occurrence frequency peak is between 15.1 and 16.3 \(\hbox {kWh}_{\mathrm{th}} \) for SH and between 60.4 and 65.1 \(\hbox {kWh}_{\mathrm{th}}\) for DHW. The optimal solution is \(18.6\,\hbox {kWh}_{\mathrm{th}}\) for SH and \(69.7\hbox {kWh}_{\mathrm{th}}\) for DHW. The deterministic optimization using EV of the input data results in \(13.9\,\hbox {kWh}_{\mathrm{th}} \) for SH and \(65.1\,\hbox {kWh}_{\mathrm{th}}\) for DHW.

Characteristic values and measures of dispersion of scenarios for the optimal solution of SMILP-1 and SMILP-2 for building group 1, also shown as box-and-whisker plots where the whiskers represent the minimum and maximum values (*PV supply is illustratively calculated for building group 1 based on a subsystem of the entire system)
For the optimal investment solution of the SMILP-1 and SMILP-2, Fig. 6 shows variations of characteristic values of the 100 scenarios: minimum, 0.25 quantile, median, 0.75 quantile and maximum of the values are listed as measures of dispersion. In addition, the values are illustrated as box-and-whisker plots rotated through \(90\,^{\circ }\). These values indicate the variations that can be expected when the investment decision is made, i.e., when the first-stage variables are optimally set. The minimized costs for the calculated optimal storage sizes are 25,344 at a min and 27,501
at a min and 27,501 at a max.Footnote 13 The annual PV supply varies between 56,914 and 62,500 \(\hbox {kWh}_{\mathrm{el}} \). The electrical demand of the heating system, the heat pumps and heating elements amounts to 50,328–54,812 \(\hbox {kWh}_{\mathrm{el}}\) for SMILP-1 and is approximately \(1,300\hbox {kWh}_{\mathrm{el}} \) higher for SMILP-2.
at a max.Footnote 13 The annual PV supply varies between 56,914 and 62,500 \(\hbox {kWh}_{\mathrm{el}} \). The electrical demand of the heating system, the heat pumps and heating elements amounts to 50,328–54,812 \(\hbox {kWh}_{\mathrm{el}}\) for SMILP-1 and is approximately \(1,300\hbox {kWh}_{\mathrm{el}} \) higher for SMILP-2.
The higher demand results from different thermal storage and ramp-up losses of the heat pumps that are two and five times lower, respectively, when inverter heat pumps are used. Not listed in Fig. 6, the overall COP, which is related to the total thermal supply and total electrical demand of both heat pumps, is around 3.4 and only marginally better in SMILP-1. Further quantities of interest are the PV self-consumption rate of 53–58% and the actual autarky rate of 35–38%. With a marginally varying electricity demand of the households of around 40,000 \(\hbox {kWh}_{\mathrm{el}} \), the annually balanced autarky rate ranges between 60 and 70%.Footnote 14 The maximum electrical load of the external grid ranges between 38 and 54 \(\hbox {kW}_{\mathrm{el}} \) for the SMILP-1 and between 44 and 54 \(\hbox {kW}_{\mathrm{el}} \) for the SMILP-2.
4.4 Discussion of the results
The DHW storage size is larger than the SH storage size due to the non-simultaneity of PV generation and space heating demand. In winter, the complete PV supply is almost entirely used to cover the electrical demand. In summer, there is high PV supply, but a negligible need for SH. The energy demand for DHW, however, is more or less constant over the year. Consequently, the load flexibility provided by DHW storage units is also distributed more constantly over the year than the flexibility of SH storage units, i.e., DHW storage units provide a noteworthy load flexibility also in times of high PV supply. Hence, larger storage sizes for DHW enable a higher self-consumption of the PV system. Thus, they are more profitable than storage units for SH, because less energy is required from the external grid. The value of the SH storage unit is less in load shifting but rather in covering peak demands in winter, when the air-water heat pumps also supply low heat due to cold ambient temperatures of the air. The storage size of at least \(18.6\,\hbox {kWh}_{\mathrm{th}} \) is caused by scenarios with very cold winters. Implicitly, the optimal storage size depends on the capacities of the system’s components, i.e., the installed PV system and employed number and sizes of heat pumps. For example, a larger PV system makes a larger storage size more attractive, because more heat demand can be shifted to times when PV energy is supplied. A heating system with more heat pumps could cover peak demands with smaller SH storage sizes. The general result is that the usage of heat storage units in such a decentralized energy system with PV supply and energy demand of several households proves beneficial.
As mentioned above, the input assumption of a \(240\,\hbox {kW}_{\mathrm{p}}\) PV system is based on using the available roof area completely aimed at maximizing the amount of self-generated electricity which is in line with the residents’ preferences. However, we also carried out a sensitivity analysis, where we consider the installed PV capacity as an endogenous optimization variable. In this case, we find that the PV system leading to the minimum costs of the quarter’s energy system would be \(31\% \) smaller for SMILP-2 (\(35\%\) for SMILP-1). As a consequence, the optimal storage size for DHW decreases by \(13\% \) (\(27\% \) for SMILP-1). The SH storage remains unchanged to be capable of covering peak demands in cold winters. The smaller PV system in the sensitivity analysis would lead to a higher PV self-consumption rate of 65–70% (68–73% for SMILP-1) but, at the same time, to a lower autarky rate of 29–31% (26–30% for SMILP-1).
It might be expected that the storage size for SH is more sensitive to uncertain meteorological parameters than for DHW. However, when the scenarios are optimized separately, the variation of the storage sizes (in \(\hbox {kWh}_{\mathrm{th}} )\) is higher for the DHW storage unit than for the SH storage unit. The fact that the daily energy demand for DHW is more or less constant over the year and the demand for SH is mainly in winter indicates that the uncertainties on the supply side (i.e., PV generation) lead to this higher sensitivity in comparison with the uncertainties on the demand side (i.e., heat demand). However, in this case, it is not only the uncertain PV supply that influences the storage size. It is also the load shifting potential in general, which depends on the complex combination of time-dependent PV supply and electrical and thermal energy demand. Furthermore, storage losses and ramp-up losses of the heat pumps influence the profitability of load shifting. This influence is higher for discontinuous heat pump supply, resulting in an increased sensitivity to uncertainty and a higher variation of the DHW storage size in SMILP-2 in comparison with SMILP-1.
The optimal storage sizes differ notably from the results when using EV. If the investments were based on the results of the EV or even on the occurrence frequency peak, there would be scenarios that are very expensive or, if the heat constraint is not relaxed, even infeasible. In contrast, the optimal stochastic solution takes all scenarios into account and results in a storage size that is not optimal for a specific scenario, but feasible for all scenarios and cost minimal in expectation.
The variations of the costs are mainly driven by the PV supply and the thermal demand, both depending on uncertain, stochastic weather conditions: the higher the global solar radiation and temperatures of a year, the lower the minimal costs because of a higher PV supply and a lower thermal demand. The residual PV surplus of at least \(42\% \) up to \(47\% \) has to be fed into the external electricity grid. Similarly, the autarky rate indicates the part of the total energy demand that can be covered by the decentralized energy sources and how much energy is needed from an external supplier. In this residential quarter, an actual autarky rate of one-third is achieved. Thus, two-thirds need to be covered externally for the given residential quarter. Concerning the grid layout, it is important to know that the maximal electrical load from the external electricity grid is \(54\hbox {kW}_{\mathrm{el}} \), almost independent of the uncertainties or the used heat pump technology. The total electrical net consumption from the external grid amounts to \(60\,\hbox {GWh}_{\mathrm{el}} \)/a and varies by \(\pm 10\% \). Such model results are, inter alia, very useful to support contract design with external energy suppliers or distribution grid operators.
The quarter is modeled with integers at the second stage (SMILP-2) because the considered heat pumps can only run stepwise for technical reasons. If (continuous) inverter heat pumps with the required specifications were available on the market, these could be modeled without integers at the second stage (SMILP-1). In this case, the storage in the quarter would become more unattractive and would therefore be smaller in general, especially when each scenario is optimized separately (see also Fig. 5 in Sect. 4.3). The reason is that inverter heat pumps can provide heat exactly as needed. In SMILP-2, when the flexibility of the heat pumps is technically limited to stepwise supply, this lack of flexibility is compensated by the storages resulting in larger units. However, when only comparing the stochastic solutions of SMILP-1 and SMILP-2, the size of the SH storage is the same in both SMILP-1 and SMILP-2 to cover heating peak demand in cold winters. In contrast, the DHW storage is \(5\hbox {kWh}_{\mathrm{th}} \) larger in SMILP-2. In order to assess the value of modeling the program with integers at the second stage, we also solve SMILP-2 while fixing the storages to the optimal size of SMILP-1. A comparison of this result with the optimum of SMILP-2 shows that this value is below 1%. Thus, from a practical point of view, it would be sufficient to determine the optimal storage sizes by SMILP-1 which requires much less computing resources. However, we wish to emphasize that this conclusion is only true for the stochastic program. As discussed above, the value of modeling the program with integers at the second stage is higher for deterministic programs. Moreover, the gap between SMILP-1 and SMILP-2 depends on the temporal resolution. (It increases strongly for coarser resolutions, see Fig. 9 in “Appendix A.”)
In recent years, the long-term interest rate has continuously decreased in Germany.Footnote 15 The assumption of 7% for the case study is based on a survey of Schlesinger et al. (2010) about energy scenarios for the Energy Concept of the German Government. In order to assess the sensitivity of the results to the interest rate, the stochastic program is computed, in addition, with an interest rate of \(i=3\) and \(10\%\). The costs decrease by ca. \(10\% \) at \(i=3\% \) and increase by ca. \(20\% \) at \(i=10\% \). The SH storage units remain almost unchanged, because of the delimiting restriction to cover peak demands and the low load-shifting potential. Only the unbounded DHW storage units offer more flexibility of load shifting and increase when the interest is lower (by ca. \(20\% \) at \(i=3\% )\) or vice versa (decrease by ca. \(30\% \) at \(i=10\% )\). The general findings, however, remain unchanged.
4.5 Computational expenses
Using HPC systems can essentially reduce the computing time, but can lead to high overheads. Figure 7 illustrates the computational effort of the applied approach: the arising total computing costs and time as a function of the utilized computing nodes. For this purpose, the computing time of all subproblems and iterations is logged. These times are used ex post to virtually allocate the computation of one subproblem after the other to the next free node. In case of one computing node, all evaluations of the subproblems have to be solved in series. A price of  on-demand per full hour of the required node is assumed.Footnote 16 Thus, the total computing time without scenario reduction would amount to \(9240\,\hbox {h}\) with costs of
on-demand per full hour of the required node is assumed.Footnote 16 Thus, the total computing time without scenario reduction would amount to \(9240\,\hbox {h}\) with costs of  for SMILP-1 for one computing node. In case of SMILP-2, the mixed-integer subproblems take up to ten times more computing time than without integer requirements, causing higher computing time of 61,959 h and costs of
for SMILP-1 for one computing node. In case of SMILP-2, the mixed-integer subproblems take up to ten times more computing time than without integer requirements, causing higher computing time of 61,959 h and costs of  . Up to 100 nodes, the computing time can be constantly divided by the utilized number of nodes without increasing costs. Then, in case of SMILP-2, the costs increase because some nodes are in idle mode, while other nodes are still computing hard-to-solve mixed-integer subproblems. That is time decisive for the outer optimization. At about 6000 nodes, this effect compensates further time reduction achieved by the parallelization. In the case of SMILP-1, the continuous subproblems require nearly the same short computing time, resulting in continuously linear reduction per additional node without increasing costs.
. Up to 100 nodes, the computing time can be constantly divided by the utilized number of nodes without increasing costs. Then, in case of SMILP-2, the costs increase because some nodes are in idle mode, while other nodes are still computing hard-to-solve mixed-integer subproblems. That is time decisive for the outer optimization. At about 6000 nodes, this effect compensates further time reduction achieved by the parallelization. In the case of SMILP-1, the continuous subproblems require nearly the same short computing time, resulting in continuously linear reduction per additional node without increasing costs.
With regard to the employed HPC systems, 1034 physical nodes are in use. Because two subproblems are actually solved on one node in parallel, 2068 computing nodes are virtually available. Assuming exclusive access, the entire computation of SMILP-1 and SMILP-2 could be theoretically solved within 4.5 and \(47.8\,\hbox {h}\) at costs of  and
and  , respectively. Due to the job queuing system of the HPC systems, the computation was done within a week. If the scenario reduction is applied, cost and time can approximately be divided by two.
, respectively. Due to the job queuing system of the HPC systems, the computation was done within a week. If the scenario reduction is applied, cost and time can approximately be divided by two.

Computing time (continuous lines, left log-scaled vertical axis) and computation costs (dotted lines, right vertical axis) versus used number of computer nodes (log-scaled horizontal axis) of SMILP-1 (black color) and SMILP-2 (red color) (color figure online)
4.6 Scalability of the approach
To evaluate the scalability of the optimization approach, it is tested on problems with different complexity and size. In addition, the approach is benchmarked with the dual decomposition in stochastic integer programming (DDSIP). This exact decomposition algorithm was developed by Carøe and Schultz (1999), especially for two-stage SMILP, and has been continuously improved until today.Footnote 17 The main idea of the decomposition is the Lagrangian relaxation of the non-anticipativity constraints and a branch-and-bound algorithm to reestablish non-anticipativity. The mixed-integer subproblems in the branch-and-bound tree are solved by CPLEX. For the dual optimization, DDSIP uses ConicBundle provided by C. Helmberg.Footnote 18 The rationale behind comparing SAHC and DDSIP is that both need the solution of the second stage to proceed with either the steepest ascent of the fixed variables or the descent step of the dual problem. The inner optimization of the second stage is identical. Therefore, only the more challenging case is considered, when integers are involved at both stages: discrete storage sizes at the first stage and three heating power levels of the heat pumps (idle, half or full load) at the second stage, similar to SMILP-2.
Assuming that always enough nodes are available to compute all subproblems at the same time, only the outer iterations are time decisive for the computation. The optimization is done for problems with 1, 2 and 4 building groups to vary the number of first-stage variables. Since DDSIP computes the subproblems only sequentially at present, the scenarios are simplified to two-day subproblems and reduced to 1, 2, 5 or 10 scenarios. The results are summarized in Table 2. Note that we only compare the number of iterations of the outer optimization.
DDSIP outperforms the SAHC method if only 1 scenario is optimized since there is no first-stage variable that has to be equal to another scenario in this case. It appears that DDSIP can manage an increase in first-stage variables better than an increase in scenarios. The number of iterations slightly rises when more first-stage variables are added. But the number of iterations DDSIP needs to find a valid optimal solution increases strongly with the number of scenarios.Footnote 19
In contrast, the SAHC method always takes a similar number of iterations for few or many scenarios. Iterations only increase with more building groups because more first-stage variables have to be optimized. However, if the number of first-stage variables remains small, SAHC needs only few iterations. The search is always initialized at 8 for SH and DHW (equivalent to an 800-l water tank) with an initial step size of 4 which is a better starting set for some instances than for others. Note that the obtained locally optimal solutions are identical to the optimal solutions of the DDSIP. This analysis does not consider the fact that SAHC can deal with a lower accuracy of the inner optimization for most iterations, enabling a high potential in computing time reduction in the subproblems.
5 Discussion of the methodology
Commonly, when SP is applied to problems with uncertain data, the expected value of perfect information is presented. It gives an economic value for obtaining perfect information about the future, so it is a proxy for the value of accurate forecasts. The expected value of perfect information is calculated as the difference between minimal expected costs of the stochastic solution and the minimal expected costs possible in the best case. ‘In the best case’ means that perfect information about future scenarios would be available and the storage size could still be adapted for each occurring scenario. Mathematically, these minimal costs result from relaxing the non-anticipativity constraints. For SMILP-1 and SMILP-2, the difference is less than \(1\% \). Hence, the savings are marginal when the occurring scenario is known exactly and the storage size could be optimally adapted. Because each scenario is separately optimized by an exact branch-and-cut approach (of CPLEX) with relaxed non-anticipativity constraints, that information of the best case can be used as a better relative gap for the SMILP.
The advantage of modeling the problem as a stochastic program can be expressed by the value of stochastic solution: Thereby, the expected result of the EV solution is subtracted from the optimal solution of the SP (Birge 1982). The expected result of the EV solution is calculated by optimizing the stochastic program with storage sizes that are deterministically determined for one scenario with expected values of the uncertain input parameters. In both SMILP-1 and SMILP-2, the EV solution is not feasible for all scenarios with hard heat constraints. Thus, the value of stochastic solution is not quantifiable, but from a qualitative viewpoint, very valuable. If the decision was made on the basis of an optimization with expected values, not all scenarios in the future would be feasible. In this case study, the violation of heat constraints means there are time steps in the year with room temperatures below the target levels desired by the inhabitants. Therefore, compensation terms, as proposed in Sect. 4.2, are incorporated, resulting in a value of stochastic solution for SMILP-1 of  (\(174\% \) more than the optimal solution) and for SMILP-2 of
(\(174\% \) more than the optimal solution) and for SMILP-2 of  (\(14\% \) more than the optimal solution). Regarding the derived computational expenses of
(\(14\% \) more than the optimal solution). Regarding the derived computational expenses of  for SMILP-1 and
for SMILP-1 and  for SMILP-2, the application of the approach is advantageous. Due to the fact that computing costs rapidly decline, these advantages reflect a current status and will increase over time.
for SMILP-2, the application of the approach is advantageous. Due to the fact that computing costs rapidly decline, these advantages reflect a current status and will increase over time.
The high value of stochastic solution of SMILP-1 mainly results from high penalty costs due to a SH storage size that is dimensioned too small on the basis of EV to cover the thermal demand of several cold winter scenarios. Therefore, using the expected result of the EV solution might not reflect the performance of a deterministic modeling approach for this application. Intuitively, one would calculate with cold years to determine optimal storage sizes, in particular for SH. However, this inevitably leads to the question of the definition of a ‘cold year’: the year with the lowest average temperatures over the entire year (a), over the astronomical winter (b) or over the meteorological winter (c)? The deterministic optimization of definitions (a, b and c) instead of EV also results in too small SH storage sizes, i.e., not all peak heating demands can be covered, too.
Critically reviewing our approach, SP is only applicable when the uncertain parameters can be adequately represented by probability distributions. For the case study, a Markov process simulates the uncertain parameters based on historical data over more than 50 years. Occurrences or trends differing from historic data, e.g., the future climate development, might be taken into account by using model-derived forecasts or, if available, expert judgments. Besides the probability distributions, the number of scenarios and its reduction, which represent the distribution sufficiently well, are difficult to determine. Moreover, the optimal decision under uncertainties can depend on risk preferences of the decision maker (Pflug and Römisch 2007). Our results are purely based on economic considerations without accounting for such subjective criteria.
For reasons of computational feasibility, each scenario is decomposed into 27 subproblems by fixing the heat storage sizes and levels between the subproblems. The storage levels are not optimized in order to not increase the computational effort unnecessarily. For SH, they are set to zero reasoned by the fact that there is no SH demand in about 5 of 12 months. For the DHW storage unit, the level is set to \(50\% \) of the storage size, because a good estimation cannot be derived. Thus, the solution is not exactly optimal. However, the error is negligible in this case study (error is less than \(0.1\% )\). A stochastic dynamic programming technique could solve this problem but is not applied, because it disadvantageously results in a step-dependent optimization process, in which the independent optimization of all 2700 subproblems in parallel would not be possible any more. If this becomes critical, an outer optimization other than the SAHC method (e.g., a surrogate model approach) should be selected to remedy the problem.
The computational effort could also be reduced by a smaller temporal resolution of the problem. However, our analysis shows that a reduction in the temporal resolution has a crucial impact on the optimal solution. For example, time steps of 1 h instead of 15 min completely change the load-shifting potential and, in case of SMILP-2, even the stepwise flexibility of the heat pumps. The optimal storage sizes differ by more than \(50\% \). (Further findings are shown in “Appendix A,” Fig. 9.) On the contrary, a detailed modeling of the technical characteristics affecting the load-shifting potential could require resolutions below 15 min. In principle, the developed approach and model can deal with smaller time steps. But besides the problem of an increased computational effort, there are nearly no consistent data available in a higher temporal resolution. The time steps of 15 min in the case study should be sufficient, because the profiles of thermal supply and demand are smooth in comparison with the electrical profiles. Consequently, there is no balancing need below 15 min. If electrical storage units were used, their sizes would tend to be underestimated with 15-min time steps.
In terms of validating our approach and assessing its performance, we carried out the following comparisons. First, we solve SMILP-1 (integers for discrete storage sizes at the first stage but no integers at the second stage) for one building group as a closed program optimized by CPLEX on one computing node. For this problem, CPLEX finds an exact solution with a relative gap (to the relaxed problem) of \(0\% \) after 5 h. Exactly the same results of the objective function value and decision variables are achieved by our parallel optimization approach, but in less than half an hour. Second, we compare the performance for SMILP-2 (integers for discrete storage sizes at the first stage and for the heat pump operation at the second stage). For this problem, CPLEX does not find an exact solution. However, it finds a solution with a relative gap of \(15.3\% \) after three computing days on one computing node (requiring about \(0.5\hbox {TB}\) RAM). In contrast, our parallel optimization approach finds a solution with a relative gap of \(2\% \) within less than a half day.
The advantage of the outer SAHC approach as DFO is that it is robust against inaccuracy of the inner optimization and reliably proceeds to an optimal solution. Therefore, only few computations of the expensive inner optimization are required, given a good starting point and few fixed variables to optimize. The disadvantage is that the solution could only be locally optimal, if the solution space of the SMILP is non-convex. Even a more time-intensive evolutionary algorithm used by Till et al. (2007) as outer optimization can end in a local optimum. A global optimum can be guaranteed by either a complete enumeration or an exact algorithm such as the mentioned branch-and-bound approach used by DDSIP or the branch-and-fix coordination methodology. But these approaches appear to be prohibited by the problem size. For example, Pagès-Bernaus et al. (2015) apply their developed branch-and-fix coordination methodology to two real instances with 447, 771 variables (thereof 13, 338 binary) and 56, 700 variables (thereof 34, 479 binary). An application of one of these exact algorithms to the case study of this paper with more than 100 million variables would result in a non-performable computational effort that exceeds the current commonly available computing resources. The comparison with DDSIP corroborates this assertion.
6 Conclusion and outlook
This paper considers the optimization of the investment and operation planning process of a decentralized energy system, subject to different sources of uncertainties. The presented module-based, parallel computing approach accounts for the uncertainties by generating and transforming consistent ensembles of data required for the stochastic optimization problem. Thereby, mutual dependencies of the uncertain parameters are taken into account and propagated consistently through the complete model chain. Although the problem ends up in a large-scale two-stage stochastic mixed-integer program, the employed parallel optimization process and an outer derivative-free optimization find a local optimum reliably in a few steps. The solution quality can be assessed by the relative gap to the stochastic program without integer requirements or without non-anticipativity constraints. As a result of the parallelization, the computational feasibility is no longer constrained by the problem size, but rather by the available computer resources. The employed decomposition technique allows an extensive computation on high-performance computing systems in parallel.
The approach is applied to a residential quarter with 70 households using a PV system and heat pumps in combination with heat storage units for the energy supply in the quarter. Because of the complex impact of uncertain parameters on the solution, the investment decisions derived from the stochastic solution can be very different from the solution based on expected values of the input data or the occurrence frequency peak. Using two-stage stochastic programming leads to a solution that is expected to be optimal. This solution is much more reliable with respect to the parameter uncertainties than deterministic solutions which are not always feasible for all possible future scenarios. In general, heat storage units in such a quarter prove beneficial. The storage for domestic hot water is more profitable than for space heating as a result of the more constant provision of flexibility. A further finding is that the beneficial effect of the space heating storage is the fulfillment of all energy system restrictions, i.e., the covering of the heat demand, even in very cold winters. Therefore, the resulting capacity for space heating storage is generally larger than for the deterministic optimization, e.g., with expected values. This added value of stochastic solution amounts to 3700–45,500 , depending on the usage of inverter heat pumps or heat pumps that can only run stepwise.
, depending on the usage of inverter heat pumps or heat pumps that can only run stepwise.
These results are achieved by using high-performance computing which can be expensive and offset the savings in investments. In total, the problem was solved in parallel on more than 1000 computing nodes of different high-performance computing systems. Considering the computational expenses of less than  , the application of the approach is advantageous for this case study. A benchmark with an exact method of simplified stochastic programs shows a strong scalability with equivalent results for a number of test programs with different sizes. This holds especially for the optimization of few fixed first-stage and/or second-stage variables. Otherwise, our framework allows an adaptation (e.g., substitution of the outer SAHC optimization) to better cope with large numbers of fixed variables.
, the application of the approach is advantageous for this case study. A benchmark with an exact method of simplified stochastic programs shows a strong scalability with equivalent results for a number of test programs with different sizes. This holds especially for the optimization of few fixed first-stage and/or second-stage variables. Otherwise, our framework allows an adaptation (e.g., substitution of the outer SAHC optimization) to better cope with large numbers of fixed variables.
The general framework enables the easy exchange of the optimization module and, if necessary, modules that generate ensembles of the uncertain parameters or transfer these ensembles into energy supply and demand profiles. This allows the optimization and analysis of other setups (e.g., different tariffs, or additional technologies such as electrical storage units) and further uncertainties. Furthermore, risk preferences can be incorporated by adding an additional term to the objective function: instead of minimizing or maximizing an expected value, a combination of expectation and a measure of risk preference can be optimized. Prospectively, alternative outer optimization methods should be considered, in particular, when large numbers of variables need to be fixed and optimized or less computing power is available. This is important because, on a final note, the real-world case study shows that the approach using stochastic programming can be beneficial, even if the program is too large for determining a guaranteed global optimum.
Notes
For instance, see Jochem et al. (2015), who consider the operation of micro-combined heat and power units with a resolution of 15 min to model the physical system properties adequately.
Uncertainties are characterized as epistemic, if they could be reduced by gathering more data or by refining models. They are aleatory, if the modeler does not see the possibility of reducing them Kiureghian and Ditlevsen (2009).
At about the same time, the principle of robust optimization was introduced by Wald (1945) besides SP. It is an alternative approach to counteract uncertainties by minimizing the maximum risk, later termed as optimizing the worst case (Ben-Tal et al. 2009). Furthermore, fuzzy or parametric programming can be used as other opportunities to incorporate such uncertainties (see Zhou 1998; Verderame et al. 2010; Metaxiotis 2010).
The L-Shape is a specific application of the Benders decomposition to the stochastic program and gets the name from the block structure of the extensive form of the program. The main idea is to approximate the recourse function in the objective, i.e., a solution of all second-stage recourse linear programs.
The model also includes the albedo effect, averaged losses such as shadowing, module mismatching or cable and inverter losses for a certain PV system and the dependency of performance on low lighting and temperature for a certain module technology and manufacturer.
In usual practical applications, \(\underline{W}\) and \(p^\mathrm{T}\) do not depend on \(\omega \).
When the stage-variable formulation of Eqs. (6–9) is transformed into the scenario-variable formulation with the decision vectors \({\varvec{x}}_{\mathbf{1}} ,\cdots ,{\varvec{x}}_{\varvec{\omega }}\), then the non-anticipativity constraint \({\varvec{x}}_{\mathbf{1}}=\ldots ={\varvec{x}}_{\varvec{\omega }}\) emerges.
The corresponding project is aimed at developing energy-efficient, environmentally friendly residential quarters. A PV system in the quarter meets a large part of the energy demand that is reduced by modern passive house technology. Heat pumps in combination with storage units and intelligent load shifting within the quarter increase the cost-effective self-consumption of the PV system.
By using the density and heat capacity of water, the volume storage level is converted into an energy storage level required by the optimization model.
The converting factors of 1.16 and \(4.65\hbox {kWh}_{\mathrm{th}} \) correspond to a 100 l water tank. The factor is four times higher in the case of DHW due to the higher temperature difference in the storage.
The chosen period of 2 weeks results in problem sizes for an efficient utilization of the HPC systems with respect to computation requirements and total computing time.
Note that this local optimum is referred to just as optimum or optimal solution.
Note that these values are slightly higher than those of 100 separate (deterministic) optimizations of the storage sizes, in which the first-stage variables are still alterable.
The balanced autarky rate is the relation of the total PV supply to the total electrical demand of the quarter over 1 year. In contrast, the actual autarky rate is the relation of the total PV self-consumption to the total electrical demand of the quarter over 1 year.
See also long-term interest rates, European Central Bank (status June 2016, http://sdw.ecb.europa.eu/browseTable.do?node=bbn4864&SERIES_KEY=229.IRS.M.DE.L.L40.CI.0000.EUR.N.Z).
Because no costs could be derived from the used HPC clusters, they are based on Amazon EC2 instance types (https://aws.amazon.com/ec2/): 0.047
 on-demand per full hour of the required node (status June 2016).
on-demand per full hour of the required node (status June 2016).The Linux version can be downloaded from https://www.uni-due.de/~hn215go/ddsip.shtml.
For the computation, the default configurations of DDSIP with ConicBundle are used. Compared to common-used subgradient methods, ConicBundle does not require adjusting the size or number of iteration steps when minimizing the sum of convex functions that arise from Lagrangian relaxation. It supports finding optimal dual multipliers by generating primal optimal solutions and by addition and deletion of dual variables without loss of quality in the used cutting models (for details, see Märkert and Gollmer 2016).
An integration of progressive hedging could reduce the DDSIP iterations: a penalty term, usually a weighted quadratic deviation of the Lagrangian multipliers from their preceding average values, is added to f to accelerate the convergence (Rockafellar and Wets 1991). However, the convergence speed depends on the weight factor. The possibility of the process performing worse or unstably cannot be ruled out (Helgason and Wallace 1991).
 on-demand per full hour of the required node (status June 2016).
on-demand per full hour of the required node (status June 2016).References
Ahmed S (2010) Two-stage stochastic integer programming: a brief introduction. In: Cochran JJ, Cox LA, Keskinocak P, Kharoufeh JP, Smith JC (eds) Wiley encyclopedia of operations research and management science. Wiley, Hoboken
Alonso-Ayuso A, Escudero LF, Teresa Ortuño M (2003) BFC, a branch-and-fix coordination algorithmic framework for solving some types of stochastic pure and mixed 0–1 programs. Eur J Oper Res 151(3):503–519. https://doi.org/10.1016/S0377-2217(02)00628-8
Alonso-Ayuso A, Escudero LF, Garın A, Ortuño MT, Pérez G (2005) On the product selection and plant dimensioning problem under uncertainty. Omega 33(4):307–318. https://doi.org/10.1016/j.omega.2004.05.001
Altmann M, Brenninkmeijer A, Lanoix J-C, Ellison D, Crisan A, Hugyecz A, Koreneff G, Hänninen S (2010) Decentralized energy systems. Technical report European Parliament’s Committee (ITRE). http://www.europarl.europa.eu/document/activities/cont/201106/20110629ATT22897/20110629ATT22897EN.pdf. Zugegriffen 29 Sept 2016
Amato U, Andretta A, Bartoli B, Coluzzi B, Cuomo V, Fontana F, Serio C (1986) Markov processes and Fourier analysis as a tool to describe and simulate daily solar irradiance. Sol Energy 37(3):179–194. https://doi.org/10.1016/0038-092X(86)90075-7
Beale EML (1955) On minimizing a convex function subject to linear inequalities. J R Stat Soc B 17(2):173–184
Beck T, Kondziella H, Huard G, Bruckner T (2017) Optimal operation, configuration and sizing of generation and storage technologies for residential heat pump systems in the spotlight of self-consumption of photovoltaic electricity. Appl Energy 188:604–619. https://doi.org/10.1016/j.apenergy.2016.12.041
Bedford T, Cooke RM (2001) Probabilistic risk analysis. Foundations and methods. Cambridge University Press, Cambridge
Ben-Tal A, El Ghaoui L, Nemirovskiĭ AS (2009) Robust optimization. Princeton series in applied mathematics. Princeton University Press, Princeton
Bertsch V, Schwarz H, Fichtner W (2014) Layout optimisation of decentralised energy systems under uncertainty. In: Huisman D, Louwerse I, Wagelmans AP (Hrsg) Operations research proceedings 2013: selected papers of the international conference on operations research, OR2013, organized by the German Operations Research Society (GOR), the Dutch Society of Operations Research (NGB) and Erasmus University Rotterdam, Springer, Cham, S 29–35, 3–6 Sept 2013
Birge JR (1982) The value of the stochastic solution in stochastic linear programs with fixed recourse. Math Program 24(1):314–325. https://doi.org/10.1007/BF01585113
Birge JR, Louveaux F (1997) Introduction to stochastic programming. Springer series in operations research and financial engineering. Springer, New York
Carøe CC, Schultz R (1999) Dual decomposition in stochastic integer programming. Oper Res Lett 24(1–2):37–45. https://doi.org/10.1016/S0167-6377(98)00050-9
Carøe CC, Tind J (1998) L-shaped decomposition of two-stage stochastic programs with integer recourse. Math Program 83(1–3):451–464. https://doi.org/10.1007/BF02680570
Conn AR, Scheinberg K, Vicente LN (2009) Introduction to derivative-free optimization. Society for Industrial and Applied Mathematics, Philadelphia
Connolly D, Lund H, Mathiesen BV, Leahy M (2010) A review of computer tools for analysing the integration of renewable energy into various energy systems. Appl Energy 87(4):1059–1082. https://doi.org/10.1016/j.apenergy.2009.09.026
Dantzig GB (1955) Linear programming under uncertainty. Manag Sci 1:197–206
Dantzig GB, Infanger G (2011) A probabilistic lower bound for two-stage stochastic programs. In: Infanger G (Hrsg) Stochastic programming. The state of the art; in honor of George B. Dantzig, Bd 150. Springer, New York, NY, S 13–35
Diagne M, David M, Lauret P, Boland J, Schmutz N (2013) Review of solar irradiance forecasting methods and a proposition for small-scale insular grids. Renew Sustain Energy Rev 27:65–76. https://doi.org/10.1016/j.rser.2013.06.042
Dupačová J, Gröwe-Kuska N, Römisch W (2003) Scenario reduction in stochastic programming. Math Program 95(3):493–511. https://doi.org/10.1007/s10107-002-0331-0
Ehnberg JS, Bollen MH (2005) Simulation of global solar radiation based on cloud observations. ISES Solar World Congr 2003 78(2):157–162. https://doi.org/10.1016/j.solener.2004.08.016
Escudero LF, Garín A, Merino M, Pérez G (2007) A two-stage stochastic integer programming approach as a mixture of branch-and-fix coordination and benders decomposition schemes. Ann Oper Res 152(1):395–420. https://doi.org/10.1007/s10479-006-0138-0
Escudero LF, Garín MA, Merino M, Pérez G (2010) An exact algorithm for solving large-scale two-stage stochastic mixed-integer problems: some theoretical and experimental aspects. Eur J Oper Res 204(1):105–116. https://doi.org/10.1016/j.ejor.2009.09.027
Evins R, Orehounig K, Dorer V, Carmeliet J (2014) New formulations of the ‘energy hub’ model to address operational constraints. Energy 73:387–398. https://doi.org/10.1016/j.energy.2014.06.029
Forrest S, Mitchell M (1993) Relative building-block fitness and the building-block hypothesis, vol 2. Elsevier, Amsterdam, pp 109–126
French S (1995) Uncertainty and imprecision. Modelling and analysis. J Oper Res Soc 46(1):70. https://doi.org/10.2307/2583837
Göbelt M (2001) Entwicklung eines Modells für die Investitions- und Produktionsprogrammplanung von Energieversorgungsunternehmen im liberalisierten Markt [Development of a model for investment and production program planning of energy supply companies in liberalized markets]. Dissertation, Karlsruher Institut für Technologie
Goldstein M (2012) Bayes linear analysis for complex physical systems modeled by computer simulators. In: Dienstfrey AM, Boisvert RF (Hrsg) Uncertainty quantification in scientific computing. 10th IFIP WG 2.5 Working Conference, WoCoUQ 2011, Boulder, CO, USA, 1–4 Aug 2011, Revised selected papers, Bd 377. Springer, Berlin, S 78–94
Growe-Kuska N, Heitsch H, Romisch W (2003) Scenario reduction and scenario tree construction for power management problems. In: 2003 IEEE Bologna powertech conference proceedings, 23–26 June 2003. Faculty of Engineering, University of Bologna, Bologna, Italy. IEEE, Piscataway, NJ, S 152–158
Haneveld WK, van der Vlerk MH (1999) Stochastic integer programming: general models and algorithms. Ann Oper Res 85:39–57. https://doi.org/10.1023/A:1018930113099
Hawkes A, Leach M (2005) Impacts of temporal precision in optimisation modelling of micro-combined heat and power. Energy 30(10):1759–1779. https://doi.org/10.1016/j.energy.2004.11.012
Hayn M, Zander A, Fichtner W, Nickel S, Bertsch V (2018) The impact of electricity tariffs on residential demand side flexibility: Results of bottom-up load profile modeling, Energy Systems (Accepted)
Heitsch H (2007) Stabilität und Approximaton stochastischer Optimierungsprobleme [Stability and approximation of stochastic optimization problems]. Dissertation
Heitsch H, Römisch W (2011) Scenario tree generation for multi-stage stochastic programs. In: Bertocchi M, Consigli G, Dempster MAH (eds) Stochastic optimization methods in finance and energy. New financial products and energy market strategies, vol 163. Springer, New York, pp 313–341
Helgason T, Wallace SW (1991) Approximate scenario solutions in the progressive hedging algorithm. Ann Oper Res 31(1):425–444. https://doi.org/10.1007/BF02204861
Hurink J, Schultz R, Wozabal D (2016) Quantitative solutions for future energy systems and markets. OR Spectr 38(3):541–543. https://doi.org/10.1007/s00291-016-0449-8
Huyer W, Neumaier A (2008) SNOBFIT—stable noisy optimization by branch and fit. ACM Trans Math Softw 35(2):1–25. https://doi.org/10.1145/1377612.1377613
Jochem P, Schönfelder M, Fichtner W (2015) An efficient two-stage algorithm for decentralized scheduling of micro-CHP units. Eur J Oper Res 245(3):862–874. https://doi.org/10.1016/j.ejor.2015.04.016
Jones PA (1992) Cloud-cover distributions and correlations. J Appl Meteorol 31(7):732–741. https://doi.org/10.1175/1520-0450(1992) 031<0732:CCDAC>2.0.CO;2
Jones TW, Smith JD (1982) An historical perspective of net present value and equivalent annual cost. Account Hist J 9(1):103–110
Kalvelagen E (2003) Two-stage stochastic linear programming with GAMS. GAMS Corporation
Kanngießer A (2014) Entwicklung eines generischen Modells zur Einsatzoptimierung von Energiespeichern für die techno-ökonomische Bewertung stationärer Speicheranwendungen [Development of a generic model for operation optimization of energy storages for a techno-economic evaluation of stationary storage applications]. UMSICHT-Schriftenreihe, Bd. Nr. 69. Laufen, K M, Oberhausen, Rheinl
Kaschub T, Jochem P, Fichtner W (2016) Solar energy storage in German households. Profitability, load changes and flexibility. Energy Policy 98:520–532. https://doi.org/10.1016/j.enpol.2016.09.017
Kelman R, Barroso LAN, Pereira MV (2001) Market power assessment and mitigation in hydrothermal systems. IEEE Power Eng Rev 21(8):57. https://doi.org/10.1109/MPER.2001.4311542
Kiureghian AD, Ditlevsen O (2009) Aleatory or epistemic? Does it matter? Risk Accept Risk Commun 31(2):105–112. https://doi.org/10.1016/j.strusafe.2008.06.020
Kobayakawa T, Kandpal TC (2016) Optimal resource integration in a decentralized renewable energy system. Assessment of the existing system and simulation for its expansion. Energy Sustain Dev 34:20–29. https://doi.org/10.1016/j.esd.2016.06.006
Korpaas M, Holen AT, Hildrum R (2003) Operation and sizing of energy storage for wind power plants in a market system. Int J Electr Power Energy Syst 25(8):599–606. https://doi.org/10.1016/S0142-0615(03)00016-4
Kovacevic RM, Paraschiv F (2014) Medium-term planning for thermal electricity production. OR Spectr 36(3):723–759. https://doi.org/10.1007/s00291-013-0340-9
Kovacevic RM, Pichler A (2015) Tree approximation for discrete time stochastic processes. A process distance approach. Ann Oper Res 235(1):395–421. https://doi.org/10.1007/s10479-015-1994-2
Lorenzi G, Silva CAS (2016) Comparing demand response and battery storage to optimize self-consumption in PV systems. Appl Energy 180:524–535. https://doi.org/10.1016/j.apenergy.2016.07.103
Märkert A, Gollmer R (2016) User’s Guide to ddsip—AC package for the dual decomposition of two-stage stochastic programs with mixed-integer recourse. Department of Mathematics, University of Duisburg-Essen, Duisburg. https://github.com/RalfGollmer/ddsip/ddsip-man.pdf. Accessed 1 May 2016
Metaxiotis K (2010) Intelligent information systems and knowledge management for energy. Applications for decision support, usage, and environmental protection. Information Science Reference, Hershey PA
Morf H (1998) The stochastic two-state solar irradiance model (STSIM). Sol Energy 62(2):101–112. https://doi.org/10.1016/S0038-092X(98)00004-8
Morgan MG, Henrion M (1992) Uncertainty. A guide to dealing with uncertainty in quantitative risk and policy analysis. Cambridge University Press, Cambridge
Möst D, Keles D (2010) A survey of stochastic modelling approaches for liberalised electricity markets. Eur J Oper Res 207(2):543–556. https://doi.org/10.1016/j.ejor.2009.11.007
Mustajoki J, Hämäläinen RP, Lindstedt MR (2006) Using intervals for global sensitivity and worst-case analyses in multiattribute value trees. Eur J Oper Res 174(1):278–292. https://doi.org/10.1016/j.ejor.2005.02.070
Nürnberg R, Römisch W (2002) A two-stage planning model for power scheduling in a hydro-thermal system under uncertainty. Optim Eng 3(4):355–378. https://doi.org/10.1023/A:1021531823935
Owens B (2014) The rise of distributed power. General electric (ecomagination). https://www.ge.com/sites/default/files/2014%2002%20Rise%20of%20Distributed%20Power.pdf. Zugegriffen 30 Sept 2016
Pagès-Bernaus A, Pérez-Valdés G, Tomasgard A (2015) A parallelised distributed implementation of a branch and fix coordination algorithm. Eur J Oper Res 244(1):77–85. https://doi.org/10.1016/j.ejor.2015.01.004
Pflug GC, Römisch W (2007) Modeling, measuring and managing risk. World Scientific, Hackensack
Rios LM, Sahinidis NV (2013) Derivative-free optimization—a review of algorithms and comparison of software implementations. J Glob Optim 56(3):1247–1293. https://doi.org/10.1007/s10898-012-9951-y
Ritzenhoff P (2006) Erstellung eines Modells zur Simulation der Solarstrahlung auf beliebig orientierte Flächen und deren Trennung in Diffus-und Direktanteil. Forschungszentrum Jülich, Zentralbibliothek
Rockafellar RT, Wets RJ-B (1991) Scenarios and policy aggregation in optimization under uncertainty. Math OR 16(1):119–147. https://doi.org/10.1287/moor.16.1.119
Ruszczynski A (1999) Some advances in decomposition methods for stochastic linear programming. Ann Oper Res 85:153–172. https://doi.org/10.1023/A:1018965626303
Ruszczyński A, Świȩtanowski A (1997) Accelerating the regularized decomposition method for two stage stochastic linear problems. Eur J Oper Res 101(2):328–342. https://doi.org/10.1016/S0377-2217(96)00401-8
Schermeyer H, Bertsch V, Fichtner W (2015) Review and extension of suitability assessment indicators of weather model output for analyzing decentralized energy systems. Atmosphere 6(12):1871–1888. https://doi.org/10.3390/atmos6121835
Schicktanz MD, Wapler J, Henning H-M (2011) Primary energy and economic analysis of combined heating, cooling and power systems. Energy 36(1):575–585. https://doi.org/10.1016/j.energy.2010.002
Schlesinger M, Hofer P, Kemmler A, Kirchner A, Strassburg S, Lindenberger D, Lutz C (2010) Energieszenarien für ein Energiekonzept der Bundesregierung. Projekt Nr. 12/10 des Bundesministeriums für Wirtschaft und Technologie; Studie. Prognos, Basel, Köln, Osnabrück
Schultz R (1995) On structure and stability in stochastic programs with random technology matrix and complete integer recourse. Math Program 70(1–3):73–89. https://doi.org/10.1007/BF01585929
Schultz R (2003) Stochastic programming with integer variables. Math Program 97(1):285–309. https://doi.org/10.1007/s10107-003-0445-z
Sen S, Sherali HD (2006) Decomposition with branch-and-cut approaches for two-stage stochastic mixed-integer programming. Math Program 106(2):203–223. https://doi.org/10.1007/s10107-005-0592-5
Shang C, Srinivasan D, Reindl T (2017) Generation and storage scheduling of combined heat and power. Energy 124:693–705. https://doi.org/10.1016/j.energy.2017.02.038
Shapiro A, Dentcheva D, Ruszczynski AP (2009) Lectures on stochastic programming: modeling and theory, vol 9. MPS-SIAM Series on Optimization, SIAM, Philadelphia
Sherali HD, Fraticelli BM (2002) A modification of benders decomposition algorithm for discrete subproblems: an approach for stochastic programs with integer recourse. J Glob Optim 22(1/4):319–342. https://doi.org/10.1023/A:1013827731218
Sherali HD, Smith JC (2009) Two-stage stochastic hierarchical multiple risk problems. Models and algorithms. Math Program 120(2):403–427. https://doi.org/10.1007/s10107-008-0220-2
Shirazi E, Jadid S (2017) Cost reduction and peak shaving through domestic load shifting and DERs. Energy 124:146–159. https://doi.org/10.1016/j.energy.2017.01.148
Silveira JL, Tuna CE (2003) Thermoeconomic analysis method for optimization of combined heat and power systems. Part I. Prog Energy Combust Sci 29(6):479–485. https://doi.org/10.1016/S0360-1285(03)00041-8
Syed A (2010) Australian energy projections to 2029-30. ABARE, Canberra, A.C.T
Taborda D, Zdravkovic L (2012) Application of a hill-climbing technique to the formulation of a new cyclic nonlinear elastic constitutive model. Comput Geotech 43:80–91. https://doi.org/10.1016/j.compgeo.2012.02.001
Till J, Sand G, Urselmann M, Engell S (2007) A hybrid evolutionary algorithm for solving two-stage stochastic integer programs in chemical batch scheduling. Comput Chem Eng 31(5–6):630–647. https://doi.org/10.1016/j.compchemeng.2006.09.003
van Slyke RM, Wets R (1969) L-shaped linear programs with applications to optimal control and stochastic programming. SIAM J Appl Math 17(4):638–663. https://doi.org/10.1137/0117061
VDI 4655 guideline (2008) Reference load profiles of single-family and multi-family houses for the use of CHP systems. VDI Guideline 4655. Verein Deutscher Ingenieure (VDI), Düsseldorf
Ventosa M, Baıllo Á, Ramos A, Rivier M (2005) Electricity market modeling trends. Energy Policy 33(7):897–913. https://doi.org/10.1016/j.enpol.2003.10.013
Verderame PM, Elia JA, Li J, Floudas CA (2010) Planning and scheduling under uncertainty: a review across multiple sectors. Ind Eng Chem Res 49(9):3993–4017. https://doi.org/10.1021/ie902009k
Vögele S, Kuckshinrichs W, Markewitz P (2009) A hybrid IO energy model to analyze CO\(_{2}\) reduction policies: a case of Germany. In: Tukker A, Suh S (eds) Handbook of input-output economics in industrial ecology, vol 23. Springer, Dordrecht, pp 337–356
Wald A (1945) Statistical decision functions which minimize the maximum risk. Ann Math 46(2):265. https://doi.org/10.2307/1969022
Wallace SW, Fleten S-E (2003) Stochastic programming models in energy stochastic programming, vol 10. Elsevier, Amsterdam, pp 637–677
Yazdanie M, Densing M, Wokaun A (2016) The role of decentralized generation and storage technologies in future energy systems planning for a rural agglomeration in Switzerland. Energy Policy 96:432–445. https://doi.org/10.1016/j.enpol.2016.06.010
Yuan Y, Sen S (2009) Enhanced cut generation methods for decomposition-based branch and cut for two-stage stochastic mixed-integer programs. INFORMS J Comput 21(3):480–487. https://doi.org/10.1287/ijoc.1080.0300
Zhou M (1998) Fuzzy logic and optimization models for implementing QFD. Comput Ind Eng 35(1–2):237–240. https://doi.org/10.1016/S0360-8352(98)00073-4
Zhu X (2006) Discrete two-stage stochastic mixed-integer programs with applications to airline fleet assignment and workforce planning problems. Dissertation, Virginia Polytechnic Institute and State University
Acknowledgements
The authors acknowledge support by the state of Baden-Württemberg through bwHPC and the Germany Research Foundation (DFG) through Grant No INST 35/1134-1 FUGG. This research has been supported by KIC InnoEnergy. KIC InnoEnergy is a company supported by the European Institute of Innovation and Technology (EIT), and has the mission of delivering commercial products and services, new businesses, innovators and entrepreneurs in the field of sustainable energy through the integration of higher education, research, entrepreneurs and business companies. Valentin Bertsch acknowledges funding from the Energy Policy Research Centre of the Economic and Social Research Institute.
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix A: Further information on the energy supply and demand profiles
Concerning the supply side profiles, we provide details on the validation of the global solar radiation output of the developed Markov model (see Section 3.1) for illustrative purposes. Moreover, we present information about how the radiation profiles differ between the different scenarios. The other Markov model output parameters (temperature and cloudiness) have been validated accordingly. Note that historical measurement data over a longer horizon are only available in hourly resolution. For the validation, we therefore aggregate the model output from 15 min to hourly resolution. Let \(\rho _a =\left( {\rho _a^1 ,\,\ldots ,\rho _a^{8760} } \right) \) be an hourly series of global solar radiation in year a, where \(a\in \left\{ {1971,\,\ldots ,\,2011} \right\} \) for the historical data and \(a\in \left\{ {1,\,\ldots ,\,100} \right\} \) for the results of the Markov model. We now validate the Markov model on the basis of four indicators: (1) the total annual radiation supply in year a defined by \(\hbox {P}_a =\mathop {\sum }\nolimits _{h=1}^{8760} \rho _a^h \) as a long-term indicator and (2) the hourly volatility in year a defined by \(\mathrm{vola}_a =\sigma \left( {\rho _a } \right) /\mu \left( {\rho _a } \right) \) as a short-term indicator, where \(\sigma \left( {\rho _a } \right) \) and \(\mu \left( {\rho _a } \right) \) are the standard deviation and arithmetic mean of the global solar radiation in year a, respectively. In addition, we consider (3) the maximum amplitude of radiation supply \((\mathrm{MARS}_{a})\) in year a and (4) the maximum gradient of radiation supply \((\mathrm{MGRS}_a )\) in year a as defined by Schermeyer et al. (2015). In order to validate the performance of the Markov model in the long run, we compare the arithmetic means \(\mu \left( \cdot \right) \) of these four indicators over all available years (simulation results vs. historical data) as well as the 5 and \(95\% \) quantiles \(\mathrm{quant}_{5\% } \left( \cdot \right) \) and \(\mathrm{quant}_{95\% } \left( \cdot \right) \) over all available years to analyze the range of variation. Table 3 shows the relative deviation of these means and quantiles of the four indicators between the Markov model results and historical data. For instance, the values in the column \(\mu \left( \cdot \right) \) are calculated as \(\left( {\mu ^\mathrm{Mod}\left( \cdot \right) -\mu ^\mathrm{Hist}\left( \cdot \right) } \right) /\mu ^\mathrm{Hist}\left( \cdot \right) \), where the superscript Mod denotes the model results and the superscript Hist denotes historical data. The values in the other columns are calculated accordingly. Overall, this comparison shows satisfying results. At the same time, however, the table shows that there is room for further improvement of the Markov model in the future.
Figure 8 shows the importance of using 15-min profiles rather than hourly profiles on the supply side. The left diagram shows the variability of PV power output between the 100 considered scenarios in general for a day in June. It also shows that the spikes on the top only occur during short periods of time (15-min intervals rather than hours). This implies that the maximum amplitude of radiation supply is underestimated with hourly profiles. Moreover, when it comes to choosing the optimal sizes of the energy system’s components, the gradients of power output between time steps are very important. This is particularly relevant for storages which are at the core of our case study. The right diagram in Fig. 8 shows that the maximum positive and negative gradients are strongly underestimated when using an hourly resolution as opposed to a 15-min resolution.
Figure 9 shows the optimal storage size for SH and DHW under SMILP-1 and SMILP-2 for different temporal resolutions. When time steps of 60 min are used instead of 15 min, the optimal storage sizes differ by up to \(50\% \). The lower temporal resolution reduces the load-shifting potential and leads to smaller storage units for SMILP-1 (without integers at the second stage). In case of SMILP-2, the stepwise flexibility of the heat pumps is reduced when moving from a 15-min resolution to 60 or even 120 min. This makes the storage units more attractive. This effect outbalances the reduced load shift potential and results in larger storages for SMILP-2 for coarser temporal resolutions.

Variability of PV generation between scenarios (left) and range of maximum gradients (right) for an illustrative June day

Influence of the temporal resolution on the optimal storage size for space heating (SH) and domestic hot water (DHW)
Concerning the demand-side profiles, as described in Sect. 3.2, we use a standard load profile approach (based on so-called H0 profiles), to generate electricity demand time series for the 70 households of the quarter. Thereby, the total yearly electricity consumption (without the electricity demand of the heat pumps) is calculated according to VDI 4655, which takes the number of residents and the usable floor surface into account. Aiming for an ex post validation of the assumption that 70 households can be approximated by H0 profiles, we compare the H0 profiles to measured electricity demand profiles of households that have already moved into their dwellings in the quarter (see Table 4). The comparison is based on 40 households since we only include households where measurement data are available for an entire year and the remaining households have moved in at a later date. Table 4 shows the (linear) correlation coefficient between the H0 profiles and the measured profiles, the mean absolute percentage error (MAPE), the root-mean-square percentage error (RMSPE) and the relative difference of the demand volatility \(\Delta \left( \mathrm{vola_a } \right) \), where \(\Delta \left( \mathrm{vola_a } \right) =\left( \mathrm{vola_a \left( {H0} \right) -\mathrm{vola}_a \left( \mathrm{measured\,profiles} \right) } \right) /\mathrm{vola}_a \left( \mathrm{measured\,profiles} \right) \). The correlation coefficient between the 40 households and the H0 profiles already amounts to \(78\% \). For larger numbers of households, Hayn et al. (2018) show that the correlation coefficient between 100 households and the H0 profile increases to \(90\% \). We therefore expect the correlation coefficient of the entire quarter to be between 78 and \(90\% \). In terms of the load volatility, we find that there is only a \(-7\% \) difference between our 40 households and the H0 profiles, which we expect to further decrease for 70 households (similar to the effect described for the correlation).
Appendix B: Overview of derivative-free optimization approaches
As described in Sect. 3.3, a derivative-free optimization (DFO) is used for the outer optimization of the fixed mixed-integer variables. Table 5 summarizes DFO methods with regard to the mentioned requirements. DFO refers to problems when information on the derivatives of f is unavailable, unreliable or impractical to obtain. This definition includes any algorithm applied to these problems, even if the algorithm involves the computation of derivatives for functions other than f (Rios and Sahinidis 2013). Not included are commonly known algorithms such as branch-and-bound, cutting plane or Lagrangian relaxation, albeit specific variants could be considered as DFO according to this definition. However, the economic optimization subsystem introduced in Sect. 3.3, particularly the approach to parallelization, would need to be substantially changed to apply such algorithms.
The main task is to determine optimal storage sizes of the residential quarter. Therefore, the problem is decomposed by fixing storage sizes and storage levels. Since the non-optimization of the storage levels leads to a negligible error, only few fixed integer variables need to be optimized, i.e., 8 storage sizes of the quarter. To this purpose, SAHC is sufficient for the outer optimization. The advantages of the implementation are its simplicity, flexibility and reliability. Furthermore, it robustly proceeds to the (local) optimum even with inaccurate solutions of the subproblems. The complete SAHC procedure is presented in the following:
Procedure of the steepest-ascent hill-climbing (SAHC) method: | |
|---|---|
Step 0: | (Initialization) compute \(f\left( \varphi \right) \) for an initial \(\varphi \) (e.g., \(\varphi =0\)) by using POP and set step size \(s_k \) for each fixed variable \(\varphi _k \) of vector \(\varphi \). If \(\varphi _k \in \mathbb {Z}\), then \(s_k \in \mathbb {Z}\). Let \(e_k \in \mathbb {R}_+^{I+R-v} \) be the k-th unit vector, where I is the number of fixed first-stage variables and \(R-v\) is the number of fixed second-stage variables. |
Step 1: | Add \(s_k \) to \(\varphi _k \) and compute \(f\left( {\varphi +s_k e_k } \right) \) and subtract \(s_k \) from \(\varphi _k \) and compute \(f\left( {\varphi -s_k e_k } \right) \) by using POP sequentially for each fixation \(1\le k\le I+R-v\). Note if \(f\left( {\varphi +s_k e_k } \right) >f\left( {\varphi -s_k e_k } \right) \), then \(step_k^*=+s_k e_k ,\) else \(step_k^*=-s_k e_k \). |
Step 2: | Select \(\varphi ^{*}\in \left\{ {\varphi \pm s_k e_k |\forall 1\le k\le I+R-v} \right\} \) with \(f\left( \varphi \right) =\mathop {\hbox {min}}\limits _k \left\{ {f\left( {\varphi \pm s_k e_k } \right) } \right\} \). |
Step 3: | Define \(\Delta f\left( \varphi \right) _{rel} =\left( {f\left( \varphi \right) -f\left( {\varphi ^{*}} \right) } \right) /f\left( \varphi \right) \). |
Step 4: | If \(\Delta f\left( \varphi \right) _{rel} \quad \le \quad 0\), then \(s_k =\frac{s_k }{2}\); if \(\varphi _k \in \mathbb {Z}\) and \(\frac{s_k }{2}<1,\) then go to step 6; if \(\varphi _k \in \mathbb {Z}\) and \(\frac{s_k }{2}\notin \mathbb {Z}\), then round \(\frac{s_k }{2}\) to the larger integer; go to step 1. Otherwise continue. |
Step 5: | If \(\Delta f\left( \varphi \right) _{rel}>\) stopping criterion \(a\in \mathbb {R}_+ \), then accept \(f\left( \varphi \right) =f\left( {\varphi ^{*}} \right) \) and \(\varphi =\varphi ^{*}\), compute \(f\left( {\varphi +step_k^*} \right) \) by using POP sequentially for each fixation \(1\le k\le I+R-v\) and go to step 2. Otherwise continue. |
Step 6: | (End) Stop. The local optimal solution value is \(f\left( {\varphi ^{*}} \right) \) with the vector \(\varphi ^{*}\). |
Appendix C: Further information about the mathematical model of the quarter
Table 6 lists the complete nomenclature of the residential quarter modeled as a two-stage stochastic mixed-integer program.
Rights and permissions
About this article

Cite this article
Schwarz, H., Bertsch, V. & Fichtner, W. Two-stage stochastic, large-scale optimization of a decentralized energy system: a case study focusing on solar PV, heat pumps and storage in a residential quarter. OR Spectrum 40, 265–310 (2018). https://doi.org/10.1007/s00291-017-0500-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00291-017-0500-4