
Abstract
Although the diffusion sign-error (DSE-LMS) algorithm is robust against impulsive noise, it has a slow convergence rate due to the application of the sign operation. Therefore, this study proposes a robust variable step-size DSE-LMS algorithm to solve the conflict between fast convergence rate and low misadjustment in impulsive noise environments. The step size is obtained by minimizing the l1-norm of the noiseless intermediate posterior error at each node, resulting in improved tracking capability of the proposed algorithm. Furthermore, the mean-square performance is analyzed based on the principle of energy conservation. The simulation results demonstrate that the proposed algorithm distinctly outperforms the existing algorithms in terms of both steady-state error and convergence rate in impulsive noise environments.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Recently, distributed adaptive networks have received considerable attention owing to their wide range of applications in the fields of environmental monitoring and spectrum sensing [3, 6, 9,10,11, 18, 21]. The distributed estimation algorithms are important for distributed adaptive networks. To this end, the diffusion least-mean-square (DLMS) algorithm has been widely studied because of its simplicity and easy implementation [4, 13,14,15, 29]. Adaptive filtering algorithms based on the mean-square error (MSE) criterion may suffer from severely degraded convergence performance, or even divergence problems when the measurement noise contains impulsive interference [5, 7, 8, 22, 25]. Similarly, distributed estimation algorithms based on the MSE criterion may also suffer from degraded performance when the network suffers from thunder or large pulse electromagnetic interference.
By combining the sign function and the DLMS algorithm, a diffusion sign-error (DSE-LMS) algorithm was developed to ameliorate the robustness against impulsive interference [16]. Similar to other conventional algorithms, although the DSE-LMS algorithm has low computational complexity and is robust against impulsive noise, the application of the sign operation degrades its performance (fast convergence rate and low steady-state error). The contradiction between the fast convergence rate and low steady-state mean-square deviation (MSD) can be solved by using a variable step-size scheme.
Inspired by earlier work [12], a robust variable step-size diffusion sign-error (RVSSDSE-LMS) algorithm is developed herein. As the step size is derived by minimizing the intermediate noiseless posterior error, the proposed algorithm has a fast convergence rate and good tracking capability. Then, the mean-square performance and computational complexity are analyzed. The simulation results demonstrate that the proposed algorithm achieves a fast convergence rate, low steady-state error, and good tracking capability in impulsive noise environments. Owing to the advantages of distributed networks and the variable step-size scheme, the proposed algorithm can be applied to adaptive echo cancellation, active noise control, etc.
2 Diffusion Sign-Error Algorithm
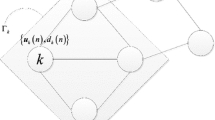
As shown in Fig. 1, each node k obtains an observed output signal dk(i) and a regression vector uk(i) at time i in the distributed network. The distributed algorithms are used to estimate the unknown M × 1 weight vector wo; the linear model can be expressed as:
where uk(i) = [uk(i),uk(i − 1),…,uk(i − M+1)]T, vk(i) is the background noise with variance \( \sigma_{v,k}^{2} \) at agent k.

Distributed network topology
Each node k has a set Γk, which includes itself and the nodes that connect with node k. In the set, each node can exchange information with its neighboring nodes. The weight update formula of the DSE-LMS algorithm can be rewritten as [16]:
and
where \( \varvec{\varphi }_{k} \left( i \right) \) is the intermediate weight estimate for wo at agent k and μk is the fixed step-size at agent k. al,k is the combination weight, which satisfies \( \sum\nolimits_{{l \in \varGamma_{k} }} {a_{l,k} } = 1 \);\( a_{l,k} = 0 \) if \( l \notin \varGamma_{k} \). The error signal at agent k is defined as follows:
3 Proposed Algorithm
The variable step-size is generally influenced by the error signal that should be minimized as soon as possible [17]. To solve the conflict between the fast convergence rate and the low steady-state error, a variable step-size of the adaptation step is proposed by minimizing the noiseless intermediate posterior error as follows.
Defining the noiseless intermediate priori error and posterior error, respectively,
Applying Eqs. (5) and (6) in (2) yields
Then, the proposed variable step-size is derived by solving the following minimization problem:
Since the optimization problem is irrelevant to the measurement noise, the step-size constraint [12] can be neglected. As can be seen from Eq. (8), the optimal step-size cannot be obtained by taking its deviation because the equation is the l1-norm with respect to μk. The optimal solution can be obtained by making Eq. (8) equal to 0, and the optimal step-size is derived as:
\( e_{a,k} \left( i \right) \) can be obtained by using the shrinkage denoising method [1, 2, 17, 19, 30]:
However, when the measurement noise vk(i) contains impulsive noise, the estimation results of the shrinkage method cause bias. In order to maintain the accuracy of the estimation method, the selection of threshold parameter t is [20, 27]:
where \( \theta_{k} \left( i \right) \) is selected as \( \theta_{k} \left( i \right) = \sigma_{e,k} \left( i \right) \); ξ is a positive value. \( \sigma_{e,k} \left( i \right) \) is calculated by:
and
where L is the extent of the estimation window.
As can be seen from (9), since \( e_{a,k} \left( i \right){ = }e_{k} \left( i \right) - \nu_{k} \left( i \right) \), the optimal step-size is influenced by the error signal and the noise signal at each node. As the noiseless intermediate posterior error is large in the transient state, \( e_{k} \left( i \right) > > \nu_{k} \left( i \right) \), μk tends to be large. When the proposed algorithm begins to converge to the steady state, \( e_{k} \left( i \right) \approx \nu_{k} \left( i \right) \) and \( e_{a,k} \left( i \right) \approx 0 \), thus making μk(i) close to 0. In addition, when the system suddenly changes, \( e_{a,k} \left( i \right) \) immediately becomes large, and the proposed algorithm achieves good tracking capability. As a result, the step size can be controlled optimally.
The proposed algorithm is summarized in Table 1.
4 Performance Analysis
4.1 Convergence Analysis
Taking the mean-square expectation on both sides of Eq. (7), the following is obtained:
Assuming that the noise-free prior error signal ea,k(i) is a zero-mean Gaussian process for a long filter [23, 24, 26], and using the Price theorem [28] in the second part of Eq. (12) will yield
Substituting Eq. (13) into Eq. (12) yields
To obtain maximum gradient attenuation, the following equation should satisfy:
That is
Therefore, the bound of step size is given as follows:
4.2 Computational Complexity
Table 2 compares the computational complexity of the DLMS, DSE-LMS, and the proposed algorithms in terms of additions, multiplications, and comparisons. The length of the filter is M and τk is the number of neighbors at node k. Owing to the computation of the optimal step-size, the proposed algorithm only requires 2 M + 1 more multiplications, 1 more addition, and τk more comparisons than the DSE-LMS algorithm. In other words, the proposed algorithm has a significant performance improvement than the DSE-LMS algorithm at the cost of litter computational complexity.
5 Simulation Results
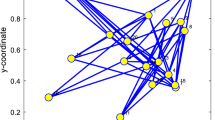
The performance of the proposed variable step-size algorithm is tested in system identification. The unknown parameter vector is randomly generated with length M. A network with N = 20 nodes is shown in Fig. 2. The network MSD is defined as \( NMSD\left( i \right) = \left( {1/N} \right)\mathop \sum \limits_{k = 1}^{N} \varvec{w}_{o} - \varvec{w}_{k} \left( i \right)^{2} \). The NMSD curves are obtained by the overall average of 50 independent trials. The uniform weighting rule is used for combination weights. The variance of the background Gaussian noise \( \varepsilon_{k} \left( n \right) \) is assumed to be known. The impulsive noise \( \vartheta_{k} \left( i \right) = b\left( i \right) \in \left( i \right) \) with the incidence of p is added to the output, and the variance is \( \sigma_{\varepsilon ,k}^{2} = \kappa \sigma_{\varepsilon ,k}^{2} \). The measurement noise vk(i) = \( \varepsilon_{k} \left( i \right) \) + \( \vartheta_{k} \left( i \right) \). The variances of the input signal and Gaussian noise \( \varepsilon_{k} \left( i \right) \) are depicted in Fig. 3.

Topology of the simulated diffusion adaptive network consisting of 20 agents

Powers of the input vectors and background Gaussian noises at each agent
In the first experiment, the performance of the proposed algorithm and other cited algorithms is compared, as shown in Figs. 4 and 5. Figure 3 shows the variances of the input signal and background Gaussian noise at node k. Figures 4 and 5 show the comparison of the network MSD of the proposed algorithm and the DLMS algorithm with the step size μ = 0.003; the two step-sizes of the DSE-LMS algorithm are 0.001 and 0.002. The forgetting factor of the proposed algorithm is chosen as \( \alpha = 1 - {1 \mathord{\left/ {\vphantom {1 {KM}}} \right. \kern-0pt} {KM}} \) with K = 3. The length of the unknown parameter vector M = 64 and L is chosen as 5. ξ is chosen as 1.53. The amplitudes of impulsive noise are 100 and 1000. To verify the robustness against impulsive noise, impulsive noise with p = 0.1 and p = 0.01 is added at all agents.

NMSD curves of the proposed algorithm compared with DLMS and DSE-LMS algorithms for \( \kappa { = }100 \). ap = 0.01, bp = 0.1

NMSD curves of the proposed algorithm compared with DLMS and DSE-LMS algorithms for \( \kappa { = }1000 \). ap = 0.01, bp = 0.1
As the proposed robust variable step-size algorithm is derived by minimizing the intermediate noiseless posterior error, it possesses a large step-size and a small step-size at the transient stage and the steady-state stage, respectively, as shown in Figs. 4 and 5. Thus, the proposed algorithm has a fast initial convergence rate and reduced steady-state NMSD compared to the DSE-LMS algorithm in impulsive noise environments.
Figure 6 shows the comparison of the tracking performance of the proposed algorithm and the conventional DLMS and DSE-LMS algorithms in the scenario of a sudden environment, where the coefficients of the impulse response transform during the iterations. The simulation conditions are the same as shown in Fig. 4. The entries of the impulse response are abruptly multiplied by –1 at iteration 1500. As shown in Fig. 6, when the system undergoes change, the intermediate posterior error becomes large and the step size at each agent becomes large to maintain the tracking capability of the proposed algorithm. Thus, the proposed RVSSDSE-LMS algorithm has good tracking capability.

NMSD curves of the proposed algorithm compared with DLMS and DSE-LMS algorithms for \( \kappa { = }1000 \). ap = 0.01, bp = 0.1
6 Conclusion
This study has proposed an RVSSDSE-LMS algorithm to improve the performance of the DSE-LMS algorithm for distributed estimation over adaptive networks. The robust variable step-size is achieved by minimizing the l1-norm of the noiseless intermediate posterior error. The proposed RVSSDSE-LMS algorithm uses the optimal step-size mechanism to solve the conflict between the fast convergence rate and low steady-state MSD. Simultaneously, the proposed algorithm can maintain tracking capability when the system mutates. The simulation results show that the RVSSDSE-LMS algorithm outperforms the DSE-LMS and DLMS algorithms in terms of both steady-state error and convergence rate in system identification.
References
M.Z.A. Bhotto, A. Antoniou, A family of shrinkage adaptive-filtering algorithms. IEEE Trans. Signal Process. 61(7), 1689–1697 (2013)
M.Z.A. Bhotto, M.O. Ahmad, M.N.S. Swamy, Robust shrinkage affine-projection sign adaptive-filtering algorithms for impulsive noise environments. IEEE Trans. Signal Process. 62(13), 3349–3359 (2014)
N. Bogdanović, J. Plata-Chaves, K. Berberidis, Distributed incremental-based LMS for node-specific adaptive parameter estimation. IEEE Trans. Signal Process. 62(20), 5382–5397 (2014)
F.S. Cattivelli, A.H. Sayed, Diffusion LMS strategies for distributed estimation. IEEE Trans. Signal Process. 58(3), 1035–1048 (2010)
F.S. Cattivelli, A.H. Sayed, Diffusion strategies for distributed Kalman filtering and smoothing. IEEE Trans. Autom. Control 55(9), 2069–2084 (2010)
F.S. Cattivelli, A.H. Sayed, Modeling bird flight formations using diffusion adaptation. IEEE Trans. Signal Process. 59(5), 2038–2051 (2011)
F.S. Cattivelli, C.G. Lopes, A.H. Sayed, Diffusion recursive least squares for distributed estimation over adaptive networks. IEEE Trans. Signal Process. 56(5), 1865–1877 (2008)
J. Chen, A.H. Sayed, On the learning behavior of adaptive networks–Part I: transient analysis. IEEE Trans. Inf. Theory 61(6), 3487–3517 (2015)
J. Chen, C. Richard, A.H. Sayed, Multitask diffusion LMS over networks. IEEE Trans. Signal Process. 62(16), 4129–4144 (2014)
D. Estrin, L. Girod, G. Pottie, M. Srivastava, Instrumenting the world with wireless sensor networks, in Proceedings of IEEE International Conference Acoustics, Speech, Signal Processing (ICASSP), 2001, vol. 4, pp. 2033C2036
T. Gross, H. Sayama, Adaptive networks (Springer, Berlin, 2009), pp. 1–8
J.H. Kim, J.H. Chang, S.W. Nam, Sign subband adaptive filter with l1-norm minimisation-based variable step-size. Electro. Lett. 49(21), 1325–1326 (2013)
L. Li, J. Chambers, C. Lopes, A.H. Sayed, Distributed estimation over an adaptive incremental network based on the affine projection algorithm. IEEE Trans. Signal Process. 58(1), 151–164 (2009)
C.G. Lopes, A.H. Sayed, Incremental adaptive strategies over distributed networks. IEEE Trans. Signal Process. 55(8), 4064–4077 (2007)
C.G. Lopes, A.H. Sayed, Diffusion least-mean squares over adaptive networks: formulation and performance analysis. IEEE Trans. Signal Process. 56(7), 3122–3136 (2008)
J. Ni, J. Chen, X. Chen, Diffusion sign-error LMS algorithm: formulation and stochastic behavior analysis. Signal Process. 128, 142–149 (2016)
C. Paleologu, J. Benesty, S. Ciochina, A robust variable forgetting factor recursive least-squares algorithm for system identification. IEEE Signal Process. Lett. 15, 597–600 (2008)
A.H. Sayed, S.Y. Tu, J. Chen, X. Zhao, Z. Towfic, Diffusion strategies for adaptation and learning over networks. IEEE Signal Process. Mag. 30(3), 155–171 (2013)
P. Wen, J. Zhang, Robust variable step-size sign subband adaptive filter algorithm against impulsive noise. Signal Process. 139, 110–115 (2017)
P. Wen, J. Zhang, A novel variable step-size normalized subband adaptive filter based on mixed error cost function. Signal Process. 138, 48–52 (2017)
P. Wen, J. Zhang, Variable step-size diffusion normalized sign-error algorithm. Circuits Syst Signal Process. 37(11), 4993–5004 (2018)
P. Wen, J. Zhang, Widely linear complex-valued diffusion subband adaptive filter algorithm. IEEE Trans. Signal Inf. Process. Over Netw. 5(2), 248–257 (2019)
P. Wen, S. Zhang, J. Zhang, A novel subband adaptive filter algorithm against impulsive noise and it’s performance analysis. Signal Process. 127, 282–287 (2016)
P. Wen, J. Zhang, S. Zhang et al., Augmented complex-valued normalized subband adaptive filter: algorithm derivation and analysis. J. Frankl. Inst. 356(3), 1604–1622 (2019)
S. Zhang, J. Zhang, New steady-state analysis results of variable step-size LMS algorithm with different noise distributions. IEEE Signal Process. Lett. 21(6), 653–657 (2014)
S. Zhang, W.X. Zheng, Mean-square analysis of multi-sampled multiband-structured subband filtering algorithm. IEEE Trans. Circuits Syst. I Regul. Pap. 66(3), 1051–1062 (2019)
S. Zhang, J. Zhang, H. Han, Robust shrinkage normalized sign algorithm in an impulsive noise environment. IEEE Trans. Circuits Syst. II Express Briefs 64(1), 91–95 (2017)
S. Zhang, W.X. Zheng, J. Zhang, H. Han, A family of robust M-shaped error weighted LMS algorithms: performance analysis and echo cancelation application. IEEE Access 5, 14716–14727 (2017)
X. Zhao, A.H. Sayed, Performance limits for distributed estimation over LMS adaptive networks. IEEE Trans. Signal Process. 60(10), 5107–5124 (2012)
H. Zhao, Z. Zheng, Bias-compensated affine-projection-like algorithms with noisy input. Electron. Lett. 52(9), 712–714 (2016)
Acknowledgements
This work was supported by the Fund for the National Nature Science Foundation of China (Grant: 61671392).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Wen, P., Zhang, J. Robust Variable Step-Size Diffusion Sign-Error Algorithm Over Adaptive Networks. Circuits Syst Signal Process 39, 3007–3018 (2020). https://doi.org/10.1007/s00034-019-01297-6
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00034-019-01297-6