
Abstract
To overcome the performance degradation of adaptive filtering algorithms in the presence of impulsive noise, a novel normalized sign algorithm (NSA) based on a convex combination strategy, called NSA-NSA, is proposed in this paper. The proposed algorithm is capable of solving the conflicting requirement of fast convergence rate and low steady-state error for an individual NSA filter. To further improve the robustness to impulsive noises, a mixing parameter updating formula based on a sign cost function is derived. Moreover, a tracking weight transfer scheme of coefficients from a fast NSA filter to a slow NSA filter is proposed to speed up the convergence rate. The convergence behavior and performance of the new algorithm are verified by theoretical analysis and simulation studies.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
In general, the performance of an adaptive filtering algorithm degrades when signals are contaminated by impulsive or heavy-tailed noise. To overcome this limitation, many algorithms were proposed, such as the sign algorithm (SA) [26], the signed regressor algorithm (SRA) [7], and the sign-sign algorithm (SSA) [9]. Although the SA has been successfully applied to system identification under impulsive noise, its convergence rate is slow [26]. As a variant of SA, the convergence behavior of the SRA is heavily dependent on the inputs, and there may exist some inputs for which the SRA is unstable while the least mean square (LMS) algorithm is stable [7]. Among the family of SA algorithms, the SSA has the lowest computational complexity and the most similar characteristic to SA [9]. In addition, the degradations of two algorithms depend significantly on the initial weights. Similar to the normalized least mean square (NLMS), the normalized versions of these sign algorithms can be easily derived, including the normalized SA (NSA) [10], the normalized SRA (NSRA) [11], and the normalized SSA (NSSA) [12]. The NSA can improve the robustness of the filter against impulsive noises. However, its convergence performance is still not good in general. Several variants have been proposed aiming at improving the convergence [5, 6, 8, 13, 14, 16, 27, 30, 32]. Particularly, in [14], a dual SA (DSA) with a variable step size (VSS) was proposed, but it has a local divergence problem especially when a large disparity occurs between two successive step sizes. In [8], attempt was made to obtain better stability and convergence performance by inserting another step size. Note that the above-mentioned efforts have all been made for a single adaptive filtering architecture.
On the other hand, to cope with impulsive noise, the family of mixed-norm algorithms were developed to combine the benefits of stochastic gradient adaptive filter algorithms [3, 4, 17, 24, 31]. Chambers et al. [4] introduced a robust mixed-norm (RMN) algorithm, where the cost function is a combination of the error norms that underlie the LMS and SA. Later, Papoulis et al. [17, 23] proposed a novel VSS RMN (NRMN) algorithm, which circumvents the drawback of slow convergence for RMN to some extent, by using time-varying learning rate.
The convex combination approach is another way to effectively balance the convergence rate and steady-state error. An adaptive approach using combination LMS (CLMS) was proposed in [1], utilizing two LMS filters with different step sizes to obtain fast convergence and small misadjustment. Nevertheless, when the signals are corrupted by impulsive noise, the algorithms in [1] and [15] usually fail to converge. To improve performance, an NLMS-NSA algorithm was developed where a combination scheme was used to switch between the NLMS and NSA algorithms [2]. Regrettably, in the initial stage of adaptation, the NLMS algorithm may cause large misadjustment especially when the noise becomes severe. Moreover, the adaptation rule of the mixing parameter of NLMS-NSA is unsuitable for impulsive noise, such that the algorithm fails to perform at a desirable level.
In this work, to address the above-mentioned problems, a NSA-NSA algorithm is proposed by using the convex combination approach. This novel algorithm achieves robust performance in impulsive noise environments by leveraging two independent NSA filters with a large and a small step sizes, respectively. To further enhance the robustness against impulsive noise, the mixing parameter is adjusted using a sign cost function. In addition, a tracking weight transfer of coefficients is proposed in order to obtain fast convergence speed during a transition period. Our main contributions are listed as follows: (1) propose a NSA-NSA that is well suited for system identification problems under impulsive noise; (2) modify an existing update scheme of the mixing parameter, and analyze its behavior; (3) propose a novel weight transfer scheme that is computationally simple yet can significantly improve the convergence rate.
The rest of this paper is organized as follows. In Sect. 2, we propose the NSA-NSA and develop a novel weight transfer scheme. In Sect. 3, simulation results in different impulsive noise environments are presented. Lastly, Sect. 4 concludes the paper.
2 Adaptive Combination of NSA Algorithms
2.1 The Proposed Algorithm
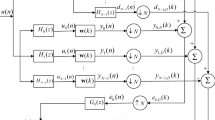
The diagram of adaptive combination scheme of two NSA filters is illustrated in Fig. 1, where \(\mathbf{x}(n)\) and y(n) are the filter input and output signals, respectively; d(n) is the desired signal; \(y_1 (n)\) and \(y_2 (n)\) are symbols of the two-component filters defined by weight vectors \(\mathbf{w}_1\) and \(\mathbf{w}_2\), respectively; v(n) is the impulsive noise; and \(\mathbf{w}_0\) is the weight vector of the unknown system. The overall error of the combined filter is given by \(e(n)=d(n)-y(n)\). To improve performance, both filters are combined with a scalar mixing parameter \(\lambda (n)\):
where \(\lambda (n)\in [0,1]\) is defined by a sigmoidal activation function with auxiliary parameter a(n)
A gradient descent adaptation of a(n) is given as
Note that \(\nu _a \) is the step size of the auxiliary parameter a(n). This adaptation rule is derived by the cost function \(J(n)=e(n)^{2}\) [1]. To improve the robustness against impulsive noise, the new cost function is defined as \(J_s (n)=|e(n)|\) based on the classical sign-error LMS algorithm [26]. Therefore, the updated scheme of a(n) is derived by minimizing the cost function \(J_s (n)\) as follows:
where \(\mu _a \) is the step size.

Diagram of the proposed algorithm
Using the chain rule, the gradient adaptation of \(J_s (n)\) can be calculated as follows:
where \(\rho _{a}\) is a positive constant, and the sign function \(\mathrm{sign}(\cdot )\) can be expressed as
At each iteration cycle, the weight update of NSA-NSA takes the form [10]
where \(\mathbf{w}_i(n)\) is the weight vectors with length \(M,\,\mu _i\) is the constant step size, \(\varepsilon _{i}>0\) is a regularization constant close to zero, and \(||\cdot ||_2\) represents the Euclidian norm. As a result, the combined filter is obtained by using the following convex combination scheme
2.2 Proposed Weight Transfer Scheme
Inspired by the instantaneous transfer scheme from [22], a tracking weight transfer scheme is proposed, as shown in Table 1. By using a sliding window approach, the proposed scheme involves few parameters and retains the robustness against impulsive noise with low cost. Like the instantaneous transfer scheme in [22], the parameter of proposed weight transfer scheme is not sensitive to the choice. This scheme can speed up the convergence property of the overall filter, especially during the period of convergence transition. Define \(N_0\) as the window length. If \(n-1\hbox { mod }N_0 \) is equal to zero, then implement the following operations. It is well known that the standard convex combination scheme needs to check whether \(a(n+1)=a^{+}\), so the only additional operation is the n mod \(N_0 \) operation. The judgment condition \(a(n+1)\ge a^{+}\) represents the condition when the fast filter (filter with large step size) switches to the slow filter (filter with small step size) at the transient stage. The operations \(\lambda (n+1)=0\) and \(\lambda (n+1)=1\) are the limitations for \(a(n+1)<-a^{+}\) and \(a(n+1)\ge a^{+}\), respectively. The operation \(\mathbf{w}_2 (n+1)=\mathbf{w}_1 (n+1)\) denotes the transfer of coefficients, which is only applied in the transient stage. By applying the weight transfer, the adaptation of \(\mathbf{w}_2 (n+1)\) is similar to that of the fast filter, which speeds up the convergence rate of \(\mu _2 \) NSA filter. Moreover, the cost of the proposed weight transfer scheme is smaller than that of the original combination, because only one filter is adapted.
Figures 2 and 3 display the comparison of excess means-square error (EMSE) obtained from NSA-NSA with the tracking weight transfer scheme and no-transfer scheme [the mixing parameter is adjusted according to (6)]. The same step size is chosen for this comparison. As can be seen, the overall performance of the filter bank is improved by the transfer scheme. It shows from these figures that the proposed weight transfer scheme exhibits faster convergence than no-transfer scheme. The proposed algorithm is summarized in Table 1.

Comparison of EMSE of NSA-NSA for Gaussian input in example 1

Comparison of EMSE of NSA-NSA for Gaussian input in example 2
2.3 Computational Complexity
The computational complexity of the basic CLMS [1], NLMS-NSA [2], and NSA-NSA algorithms is listed in Table 2. Since the basic CLMS combines two LMS algorithms, it requires \(4M+2\) multiplications for the adaptation of the component filters. The NLMS-NSA algorithm provides additional insensitivity to the input signal level by combining the NLMS and NSA, and it requires \(6M+1\) multiplications for the adaptation of the component filters. In contrast to the CLMS, the proposed algorithm uses NSA as the fast filter to replace the NLMS filter, which reduces the computational burden and the negative effect of impulsive noise. From (1) and (4), the basic CLMS and NLMS-NSA algorithms need six multiplications to compute the filter output and to update a(n). However, the proposed algorithm requires five multiplications to update a(n) [see (1) and (6), respectively]. According to (9), all the algorithms demand 2M multiplications to calculate the explicit weight vector. Moreover, due to using the slide window of tracking weight transfer scheme, the NSA-NSA can further reduce the computation operations. Consequently, these would lead to significant computational efficiency.
2.4 The Analysis of the Mixing Parameter
In this section, the convergence behavior of the mixing parameter is analyzed, and the range of \(\rho _a\) will be discussed. When the error term e(n) is expanded with a Taylor series [18–20], we have
where h.o.t. represents the higher-order terms of the remainder of the Taylor series expansion. According to \(e(n)=d(n)-y(n)\) and (3), \(\frac{\partial e(n)}{\partial a(n)}\) can be obtained as follows:
The mixing parameter correction \(\Delta a(n)\) can be calculated from (6)
Combining (10), (11), and (12), we can express (10) as
The NSA-NSA can converge if
Hence,
Solving the inequality with respect to \(\rho _a \) gives
2.5 Steady-State Performance of the Proposed Algorithm
To measure the steady-state performance, the EMSEs of the filters are expressed as [1]
where \(E\{\cdot \}\) denotes the expectation, \(J_{\mathrm{ex},i} (\infty )\) represents the individual EMSE of the ith filter, \(J_\mathrm{ex} (\infty )\) is the cross-EMSE of the combined filters, \(J_{\mathrm{ex},12} (\infty )\) is the steady-state correlation between the a priori errors of the elements of the combination, \(e_{a,i} (n)\), and \(e_a (n)\) are a priori error, respectively, defined by
where \(\varsigma _i (n)\) is the weight error vector of the individual filter, and \(\varsigma (n)\) is the weight error vector of the overall filter.
Additionally, for the modified combination (2), \(J_{\mathrm{ex},u} (\infty )\) is defined as
where
and \(\varepsilon \) is a small positive constant.
Taking expectations of both sides of (6) and using \(y_1 (n)-y_2 (n)=e_{a,2} (n)-e_{a,1} (n)\) yields:
According to the Price theorem [21, 25], we have
where \(\chi _{e,n} \) is the standard deviation of the error e(n), i.e., \(\chi _{e,n}^2 =E\{e^{2}(n)\}\), and \(\theta (n)\) can be defined as \(\theta (n)=[e_{a,2} (n)-e_{a,1} (n)]\lambda (n)[1-\lambda (n)]\). Therefore, (24) becomes
where \(\phi _a =\mu _a \sqrt{\frac{2}{\pi }}\frac{1}{\chi _{e,n} }\). Then, (26) can be rewritten as:
Assume \(\lambda (n)\) is independent of a prior error \(e_{a,i} (n)\) in the steady state, under this assumption, \(E\{a(n+1)\}\) is governed by
where \(\Delta J_i =J_{\mathrm{ex},i} (\infty )-J_{\mathrm{ex},12} (\infty ),\;\;i=1,2\). Suppose the NSA-NSA converges, the optimal mean combination weights under convex constraint are given by [1], which is discussed in the three situations as follows:
(1) If \(J_{\mathrm{ex},1} (\infty )\le J_{\mathrm{ex},12} (\infty )\le J_{\mathrm{ex},2} (\infty )\), we have \(\Delta J_1 \le 0\) and \(\Delta J_2 \ge 0\). Since a(n) and \(\lambda (n)\) are limited in the effective range, an assumption can be expressed as
where \(C=\lambda ^{\hbox {+}}(1-\lambda ^{\hbox {+}})^{2}(\Delta J_2 -\Delta J_1 )\) is a positive constant. In this case, we can conclude that
Therefore, (30) shows that the NSA-NSA algorithm performs as well as the component filters.
(2) If \(J_{\mathrm{ex},1} (\infty )\ge J_{\mathrm{ex},12} (\infty )\ge J_{\mathrm{ex},2} (\infty )\), we have \(\Delta J_1 \ge 0\) and \(\Delta J_2 \le 0\). Then, (28) can be rewritten as
for a positive constant\(C=\lambda ^{\hbox {+}}(1-\lambda ^{\hbox {+}})^{2}(\Delta J_1 -\Delta J_2 )\) and
From (32), the overall filter performs approximately equal to the better component filter.
3) If \(J_{\mathrm{ex},12} (\infty )<J_{\mathrm{ex},i} (\infty ),\;i=1,2\), we have \(\Delta J_1 >0\) and \(\Delta J_2 >0\).
Assume \(\lambda (n)\rightarrow 0\) when \(n\rightarrow \infty \), we obtain
where \(\bar{{\lambda }}(\infty )\) is given by
Consequently, it can be concluded from (34) that: if \(J_{\mathrm{ex},1} (\infty )<J_{\mathrm{ex},2} (\infty )\), then \(\lambda ^{+}\ge \bar{{\lambda }}(\infty )>0.5\); if \(J_{\mathrm{ex},1} (\infty )>J_{\mathrm{ex},2} (\infty )\), so \(0.5\ge \bar{{\lambda }}(\infty )>1-\lambda ^{+}\).
Consider the following formulas
and rearranging (35), we have
Then, we can rewrite (37) using (34) as
Since \(\bar{{\lambda }}(\infty )=\Delta J_2 /(\Delta J_1 +\Delta J_2 )\) and \(1-\bar{{\lambda }}(\infty )=\Delta J_1 /(\Delta J_1 +\Delta J_2 )\), yielding
Hence, we obtain
According to \(\bar{{\lambda }}(\infty )\in (1-\lambda ^{+},\lambda ^{+})\), the following bounds hold:
that is,
From the above three situations, it is clear that the proposed NSA-NSA filter performs equally or outperforms the best component filter.
3 Simulation Results
To evaluate the performance of the proposed algorithm, three examples of system (channel) identification were carried out. The results presented here were obtained from 200 independent Monte Carlo trials. The software of MATLAB 8.1 version (2013a) was used to simulate the proposed algorithm under the computer environment of AMD (R) A-10 CPU 2.10 GHz and 8 Gb memory. To measure the performance of the algorithms, EMSE using logarithmic scale (dB) was used, defined as:
The unknown system was a 10-tap FIR filter given by random. White Gaussian noise (WGN) with zero mean and unit variance was used as input. The system was corrupted by additive WGN and an impulsive noise sequence. The impulsive noise v(n) was generated from the Bernoulli–Gaussian (BG) distribution [4, 17, 23, 29]
where A(n) is a binary-independent and identically distributed (i.i.d.) Bernoulli process with \(p\{A(n)=1\}=c\) and \(p\{A(n)=0\}=1-c\), and c is the probability of occurrence for the impulsive interference I(n). The mean value of v(n) is zero, and its variance is given by
where \(\sigma _I^2 =\mathrm{var}\{I(n)\}\), and the parameter c is set as \(c=0.01\) [4, 17, 23].
3.1 Example 1
For the first example, the parameter \(\sigma _I^2 \) in (46) was fixed at \(\sigma _I^2 =10^{4}/12\), and the 10 dB SNR WGN [4, 17, 23]. The unknown system changes abruptly at \(n=\)10,000.
Figures 4 and 5 show the performances of the proposed algorithm with different sets of \(N_0 \) and \(\rho _a \). The filter values of the NSA were \(\mu _1 =0.05,\,\mu _2 =0.005\) (which satisfies the stability condition), \(\varepsilon _1 =\varepsilon _2 =0.0001\), and \(a^{+}=4\). Consider the stability of evolution of the mixing parameter and the convergence rate, the best choice is \(N_0 =2\). In addition, we can observe from Fig. 5 that the best choice is \(\rho _a =10\).

Choice of parameter \(N_0 \) in example 1

Choice of parameter \(\rho _a \) in example 1. (the mixing parameter a(n))
Figures 6 and 7 display the evolution of the mixing parameters \(\lambda (n)\) and a(n) in NSA-NSA. Run 1 used the no-transfer scheme [1], Run 2 and Run 3 represent the mixing parameters based on the tracking weight transfer scheme, according to (4) and (6), respectively. Results demonstrate that the proposed transfer scheme achieves faster convergence rate and improves the filter robustness in the presence of impulsive noise. Moreover, Figs. 6 and 7 show that adjusting the mixing parameter a(n) using (6) (Run3) results in better stability than other methods.

Evolution of the mixing parameter \(\lambda \,(n)\) of NSA-NSA

Evolution of the mixing parameter a(n) of NSA-NSA
To further show the performance advantage of the proposed method, Fig. 8 depicts the learning curves of the NLMS-NSA and the NSA-NSA algorithms. This figure verifies that the performance of the proposed algorithm is at least as good as the better component in the combination. Both algorithms have the same misadjustment, since the step size of the slow filters is the same. However, the fast filter of the NLMS-NSA is the NLMS, which results in large misadjustment in high background noise environments. Consequently, the NLMS-NSA suffers from higher misadjustment in the initial convergence stage. Figure 9 plots a comparison of NRMN [23], NSA [10], VSS-NSA [27], VSS-APSA [29], and the proposed algorithm. Clearly, the NSA has a trade-off between fast convergence rate and low EMSE, while the proposed algorithm shows a good balance between the steady-state error and convergence rate.

Comparison of EMSE of NLMS-NSA algorithm and NSA-NSA for Gaussian input when 1 % impulsive noises are added

Comparison of EMSE of NRMN, NSA, VSS-NSA, VSS-APSA algorithms, and NSA-NSA for Gaussian input when 1 % impulsive noises are added
3.2 Example 2
Next, we consider the case of \(\sigma _I^2 =10^{4}/20\) and SNR = 5 dB, which corresponds to case with the slightly impulsive case and highly Gaussian noises. The abrupt change appeared in the system at the \(n=\)10,000.
In this example, the step size of NSA-NSA filter was selected as \(\mu _1=0.05,\,\mu _2=0.008\), and \(\varepsilon _1=\varepsilon _2 =0.0001\). This selection of the parameters ensures good performance of the algorithm in terms of the convergence rate and steady-state misadjustment. Figure 10 displays the choice of \(N_0 \) in example 2. We can see that the proposed method is not sensitive to this selection, with the optimal value at \(N_0 =2\). Figure 11 shows the EMSE of NSA-NSA for different \(\rho _a \). The mixing parameter \(\rho _a =10\) for the proposed algorithm was selected to guarantee the stability.

Choice of parameter \(N_0 \) in example 2

Choice of parameter \(\rho _a \) in example 2. [the mixing parameter a(n)]
Figures 12 and 13 show the time evolution of the mixing coefficients, where Run 1 represents the no weight transfer scheme [1], and Run 2 and Run 3 represent the mixing parameters based on the tracking weight transfer scheme given by (4) and (6), respectively. Clearly, it can be observed from these figures that the best selection is Run 3. The robust performance in the presence of impulsive noise is also improved by using (9).

Evolution of the mixing parameter \(\lambda (n)\) of NSA-NSA

Evolution of the mixing parameter a(n) of NSA-NSA
Figure 14 plots a comparison of NLMS-NSA and the proposed algorithms. Again, we see that the EMSE of NSA-NSA is consistent with the theoretical analysis. Both algorithms achieve quite similar steady-state error, but the proposed algorithm has the smaller misadjustment in the initial stage of convergence. This is due to the fact that the NLMS algorithm is not well suited for impulsive noise environment. Figure 15 shows a comparison of the learning curves from NRMN [23], NSA [10], VSS-NSA [27], VSS-APSA [29], and NSA-NSA for high Gaussian noise and low impulsive noise environments. It is observed that the proposed algorithm achieves an improved performance in the presence of impulsive noise.

Comparison of EMSE of NLMS-NSA algorithm and NSA-NSA for Gaussian input when 1 % impulsive noises are added

Comparison of EMSE of NRMN, NSA, VSS-NSA, VSS-APSA algorithms, and NSA-NSA for Gaussian input when 1 % impulsive noises are added
3.3 Intersymbol Interference (ISI) Channel Identification Under Impulsive Noise Environment
In this section, we consider a real intersymbol interference (ISI) channel corrupted by impulsive noise, which occurs quite often in communication systems. Here, we model the ISI channel as
In practice, the channel information is unknown. To deal with such problem, the length of our filter was set to \(M=13\). Quadrature phase shift keyin (QPSK) was used as the input signal. A segment of 10,000 samples was used as the training data and another 10,000 as the test data. The ISI channel was corrupted by impulsive noise, as shown in Fig. 16. The performance of the proposed NSA-NSAFootnote 1 is demonstrated, in comparison with the NLMS-NSA.Footnote 2
Figure 17 shows the learning curves of the two algorithms in impulsive noise. Clearly, with impulsive noise, the performance of NSA-NSA is barely affected by large disturbances, while the performance of NLMS-NSA deteriorates significantly due to NLMS’s sensitivity to outliers.

Learning curves of NLMS-NSA and NSA-NSA in ISI channel identification (Testing stage)
4 Conclusions
A novel NSA-NSA was proposed to improve the performance of NSA for system identification under impulsive noise. The proposed adaptive convex scheme combines a fast and a slow NSA filter to achieve both fast convergence speed and low steady-state error. Moreover, a sign cost function scheme to adjust the mixing parameter was introduced to improve the robustness of the algorithm under impulsive noise. To further accelerate the initial convergence rate, a tracking weight transfer scheme was applied in the NSA-NSA. Simulation results demonstrated that the proposed algorithm has better performance than the existing algorithms in terms of convergence rate and steady-state error.
Notes
With QPSK input, the adaptation of a(n) of NSA-NSA is given as \(a(n+1)\hbox { }=a(n)+\rho _a \mathrm{conj}\{\mathrm{sign}\{e(n)\}\}[y_1 (n)-y_2 (n)]\lambda (n)[1-\lambda (n)]\), where \(\mathrm{conj}\{\cdot \}\) denotes conjugate operation.
Fig. 16 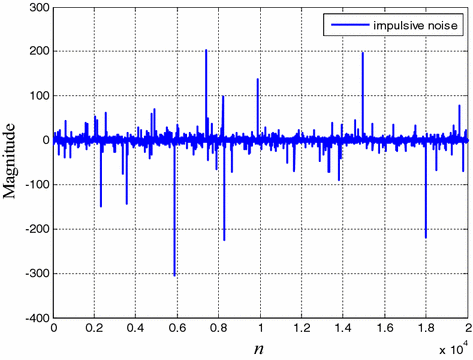
Impulsive noise in ISI channel
The derivation of VSS-NSA, VSS-APSA, and NRMN is different from the original literatures, when input signal is the complex number. For paper length optimization, and in order to focus on the simplicity of the proposed approach, we have decided to only compare to NLMS-NSA algorithm.

References
J. Arenas-García, A.R. Figueiras-Vidal, A.H. Sayed, Mean-square performance of a convex combination of two adaptive filters. IEEE Trans. Signal Process. 54(3), 1078–1090 (2006). doi:10.1109/TSP.2005.863126
J. Arenas-Garcia, A.R. Figueiras-Vidal, Adaptive combination of normalised filters for robust system identification. Electron. Lett. 41(15), 874–875 (2005). doi:10.1049/el:20051936
J.A. Chambers, O. Tanrikulu, A.G. Constantinides, Least mean mixed-norm adaptive filtering. Electron. Lett. 30(19), 1574–1575 (1994). doi:10.1049/el:19941060
J. Chambers, A. Avlonitis, A robust mixed-norm adaptive filter algorithm. IEEE Signal Process. Lett. 4(2), 46–48 (1997). doi:10.1109/97.554469
S.C. Douglas, A family of normalized LMS algorithms. IEEE Signal Process. Lett. 1(3), 49–51 (1994). doi:10.1109/97.295321
S. C. Douglas, Analysis and implementation of the max-NLMS adaptive filter, in Proceedings on 29th Asilomar Conference on Signals, Systems, and Computers, pp. 659–663 (1995)
E. Eweda, Analysis and design of signed regressor LMS algorithm for stationary and nonstationary adaptive filtering with correlated Gaussian data. IEEE Trans. Circuits Syst. 37(11), 1367–1374 (1990). doi:10.1109/31.62411
S.B. Jebara, H. Besbes, Variable step size filtered sign algorithm for acoustic echo cancellation. Electronics Lett. 39(12), 936–938 (2003). doi:10.1049/el:20030583
B. E. Jun, D. J. Park, Y. W. Kim, Convergence analysis of sign-sign LMS algorithm for adaptive filters with correlated Gaussian data, in IEEE International Conference on Acoustics, Speech, and Signal Processing, pp. 1380–1383 (1995)
S. Koike, Variable step size normalized sign algorithm for fast convergent adaptive filters with robustness against impulsive noise. NEC Res. Dev. 41(3), 278–288 (2000)
S. Koike, Analysis of adaptive filters using normalized sign regressor LMS algorithm. IEEE Trans. Signal Process. 47(10), 2710–2723 (1999). doi:10.1109/78.790653
S. Koike, Convergence analysis of adaptive filters using normalized sign-sign algorithm. IEICE Trans. Fundam. Electron. Commun. Comput. Sci. E88–A(11), 3218–3224 (2006)
R.H. Kwong, E.W. Johnston, A variable step size LMS algorithm. IEEE Trans. Signal Process. 40(7), 1633–1642 (1992). doi:10.1109/78.143435
C.P. Kwong, Dual sign algorithm for adaptive filtering. IEEE Trans. Commun. 34(12), 1272–1275 (1986). doi:10.1109/TCOM.1986.1096490
L. Lu, H. Zhao, A novel convex combination of LMS adaptive filter for system identification, in 2014 12th International Conference on Signal Processing (ICSP), Hangzhou, pp. 225–229 (2014)
V.J. Mathews, Z. Xie, A stochastic gradient adaptive filter with gradient adaptive step size. IEEE Trans. Signal Process. 41(6), 2075–2087 (1993). doi:10.1109/78.218137
D. P. Mandic, E. V. Papoulis, C. G. Boukis, A normalized mixed-norm adaptive filtering algorithm robust under impulsive noise interference, in IEEE International Conference on Acoustics, Speech, and Signal Processing, pp. 333–336 (2003)
D.P. Mandic, NNGD algorithm for neural adaptive filters. Electronics Lett. 36(9), 845–846 (2000). doi:10.1049/el:20000631
D.P. Mandic, J.A. Chambers, Toward the optimal learning rate for backpropagation. Neural Process. Lett. 11(1), 1–5 (2000). doi:10.1023/A:1009686825582
D.P. Mandic, A.I. Hanna, M. Razaz, A normalized gradient descent algorithm for nonlinear adaptive filters using a gradient adaptive step size. IEEE Signal Process. Lett. 8(11), 295–297 (2001). doi:10.1109/97.969448
V.J. Mathews, S.H. Cho, Improved convergence analysis of stochastic gradient adaptive filters using the sign algorithm. IEEE Trans. Acoust. Speech Signal Process. 35(4), 450–454 (1987). doi:10.1109/TASSP.1987.1165167
V. H. Nascimento, R. C. de Lamare, A low-complexity strategy for speeding up the convergence of convex combinations of adaptive filters, in IEEE International Conference on Acoustics, Speech and Signal Processing, pp 3553–3556 (2012)
E.V. Papoulis, T. Stathaki, A normalized robust mixed-norm adaptive algorithm for system identification. IEEE Signal Process. Lett. 11(1), 56–59 (2004). doi:10.1109/LSP.2003.819353
D.I. Pazaitis, A.G. Constantinides, LMS+F algorithm. Electronics Lett. 31(17), 1423–1424 (1995). doi:10.1049/el:19951026
R. Price, A useful theorem for nonlinear devices having Gaussian inputs. IRE Trans. Inform. Theory 4(2), 69–72 (1958). doi:10.1109/TIT.1958.1057444
A.H. Sayed, Fundamentals of Adaptive Filtering (Wiley IEEE Press, New York, 2003)
T. Shao, Y. R. Zheng, J. Benesty, A variable step-size normalized sign algorithm for acoustic echo cancelation, in IEEE International Conference on Acoustics, Speech, and Signal Processing, pp. 333–336 (2010)
T. Shao, Y.R. Zheng, J. Benesty, An affine projection sign algorithm robust against impulsive interferences. IEEE Signal Process. Lett. 17(4), 327–330 (2010). doi:10.1109/LSP.2010.2040203
J. Shin, J. Yoo, P. Park, Variable step-size affine projection sign algorithm. Electronics Lett. 48(9), 483–485 (2012). doi:10.1049/el.2012.0751
J. Soo, K.K. Pang, A multi step size (MSS) frequency domain adaptive filter. IEEE Trans. Signal Process. 39(1), 115–121 (1991). doi:10.1109/78.80770
O. Tanrikulu, J.A. Chambers, Convergence and steady-state properties of the least-mean mixed-norm (LMMN) adaptive algorithm. IEE Proc. Vis. Image Signal Process. 143, 137–142 (1996)
P. Yuvapoositanon, J. Chambers, An adaptive step-size code-constrained minimum output energy receiver for nonstationary CDMA channels, in IEEE International Conference on Acoustics, Speech, and Signal Processing, pp. 465–468 (2003)
Acknowledgments
The authors want to express their deep thanks to the anonymous reviewers for many valuable comments which greatly helped to improve the quality of this work. This work was supported in part by National Natural Science Foundation of China (Grants: 61271340, 61571374, 61134002, 61433011, U1234203), the Sichuan Provincial Youth Science and Technology Fund (Grant: 2012JQ0046), and the Fundamental Research Funds for the Central Universities (Grant: SWJTU12CX026).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Lu, L., Zhao, H., Li, K. et al. A Novel Normalized Sign Algorithm for System Identification Under Impulsive Noise Interference. Circuits Syst Signal Process 35, 3244–3265 (2016). https://doi.org/10.1007/s00034-015-0195-1
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00034-015-0195-1