
Abstract
In this paper, the improved wavelet transform domain least mean squares (IWTDLMS) adaptive algorithm is established. The IWTDLMS algorithm has a faster convergence speed than the conventional WTDLMS for colored input signals. Since the performances of WTDLMS and IWTDLMS are degraded in impulsive noise interference, the IWTDLMS sign algorithm (IWTDLMS-SA) is proposed. In comparison with IWTDLMS, the IWTDLMS-SA has lower computational complexity. In order to improve the performance of IWTDLMS-SA, the variable step-size IWTDLMS-SA (VSS-IWTDLMS-SA) is introduced. The VSS-IWTDLMS-SA is derived by minimizing the \(\ell _1\)-norm of the a posteriori error vector. To increase the tracking ability of the VSS-IWTDLMS-SA, the modified VSS-IWTDLMS-SA (MVSS-IWTDLMS-SA)is presented. The simulation results demonstrate that the proposed algorithms have a faster convergence rate and lower misadjustment than the conventional WTDLMS. The robustness feature of the IWTDLMS-SA, VSS-IWTDLMS-SA, and MVSS-IWTDLMS-SA against impulsive noises is also verified through several experiments in a system identification setup.
Similar content being viewed by others
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Adaptive filters play a significant role in signal processing fields such as system identification, channel equalization, network and acoustic echo cancellation, and active noise control [8, 9, 21]. The least mean square (LMS) and normalized LMS (NLMS) algorithms are the most popular adaptive filter algorithms due to their simplicity and ease of realization. However, the LMS algorithm has slow convergence in highly correlated signals [14]. To overcome the slow convergence in highly correlated signals, the affine projection algorithm (APA) has been proposed. In the APA, the convergence rate and the computational complexity increase along with increasing the recent input vectors in adaptation [13, 14].
The variable step-size APA (VSS-APA) is derived by minimizing the MSD to improve the convergence rate in the APA [17]; however, the APA and the VSS-APA are unstable against the impulsive noise interference. When the \(\ell _2\)-norm minimization is used for adaptive algorithms in impulsive noise interference, their performances are deteriorated. To address this problem, the sign algorithm was introduced based on the \(\ell _1\)-norm minimization. In comparison with conventional adaptive algorithms, the sign algorithms utilize the error signal sign in filter coefficients adaptation. The sign algorithms not only reduce the computation cost, but also improve the stability in impulsive noise interference [7, 15, 20, 27]. In another class of sign adaptive algorithm, the sign operation is applied into the input signal regressors. The computational complexity can be significantly reduced by this approach [2, 3].
In the case of APA, various sign algorithms have been proposed. The affine projection sign algorithm (APSA) was proposed to utilize the benefits of the affine projection and the sign algorithm [16]. Additionally, the variable step-size APSA (VSS-APSA) was introduced to decrease the mean square deviation (MSD) in APSA [18]. To increase the tracking ability, the VSS-SA and VSS-APSA with reset methods were also introduced in [24, 25]. Furthermore, by minimizing the \(\ell _1\)-norm, the VSS-APA-SA was proposed in [10]. The results in [10] show that the performance of the presented algorithm is better than other APSA algorithms in [18, 25] and [24].
It should be noted that the transform domain filters such as the discrete Fourier transform (DFT), the discrete cosine transform (DCT) and the wavelet transform (WT) improve the convergence performance of the LMS-type algorithms by prewhitening the input signal. In the case of WT, different WT domain LMS (WTDLMS) algorithms were proposed [1, 4, 5, 22]. In recent studies, the WTDLMS with dynamic subband coefficients update (WTDLMS-DU) was introduced [1]. In comparison with WTDLMS, the WTDLMS-DU has a faster convergence speed and lower computational complexity.
In the current research, we extend the affine projection approach to WTDLMS algorithm to improve the performance of the WTDLMS. The improved WTDLMS (IWTDLMS) has a faster convergence speed than WTDLMS, especially for colored input signal. Since the performances of the WTDLMS and IWTDLMS are degraded in impulsive noise interference, the IWTDLMS sign adaptive algorithm (IWTDLMS-SA) is introduced based on \(\ell _1\)-norm minimization. In the following, the variable step-size IWTDLMS-SA (VSS-IWTDLMS-SA) is established to improve the performance of IWTDLMS-SA. In this algorithm, the variable step size is obtained by minimizing a posteriori error vector. Also, the modified VSS-IWTDLMS-SA is proposed which has a better tracking capability than VSS-IWTDLMS-SA. Table 1 compares the features of other studies and the proposed algorithms.
What we propose in this paper can be summarized as follows:
-
1.
The establishment of the IWTDLMS: This algorithm utilizes the strategy of APA to speed up the convergence rate of WTDLMS.
-
2.
The establishment of the IWTDLMS-SA: To improve the convergence speed of IWTDLMS against impulsive interference, the IWTDLMS-SA is proposed.
-
3.
The establishment of the VSS-IWTDLMS-SA: The VSS approach is extended to IWTDLMS-SA in order to achieve a fast convergence speed and low steady-state error.
-
4.
The establishment of the MVSS-IWTDLMS-SA: To increase the tracking ability of VSS-IWTDLMS-SA, the MVSS-IWTDLMS-SA is introduced.
This paper is organized as follows. Section 2 presents the data model and background on NLMS and APA. In Sect. 3, the IWTDLMS algorithm is introduced. Section 4 presents the IWTDLMS-SA, VSS-IWTDLMS-SA and the MVSS-IWTDLMS-SA. The computational complexity of the proposed algorithms is studied in Sect. 5. Section 6 introduces the convergence conditions for the proposed algorithms. Finally, before concluding the paper, the usefulness of the proposed algorithms is demonstrated by presenting several experimental results. Table 2 summarizes the notations and abbreviations which are used in the paper.

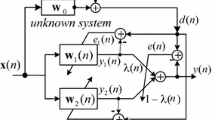
Structure of the WTDLMS algorithm
2 Data Model and Background on APA
Consider a linear data model for d(n) as
where \({\mathbf {w}}_t\) is an unknown M-dimensional vector that we expect to estimate, v(n) is the measurement noise with variance \(\sigma _{v}^2\), and \({\mathbf {x}}(n) =[x(n),x(n-1),\ldots ,x(n-M+1)]^T\) denotes an M-dimensional input (regressor) vector. It is assumed that v(n) is zero mean, white, Gaussian, and independent of \({{\mathbf {x}}}(n)\). The update equation for NLMS algorithm is given by
where \({\mathbf {w}}(n)\) is \(M \times 1\) weight coefficients of adaptive filter, \(\mu \) is the step size, and \(e(n)=d(n)-{\mathbf {w}}^T(n){\mathbf {x}}(n)\). To improve the performance of NLMS, the APA was proposed. By defining the input signal matrix and desired signal vector as
where K is the number of recent regressors, the update equation for APA is obtained by
where \({\mathbf {e}}(n)={\mathbf {d}}(n)-{\mathbf {X}}^T(n){\mathbf {w}}(n)\).
3 The IWTDLMS Adaptive Algorithm
Figure 1 shows the structure of the WTDLMS algorithm [4]. In this figure, the \(M \times M\) matrix \(\mathbf {T}\) is an orthogonal matrix derived from a uniform N-band filter bank with filters denoted by \(h_0, h_1,\ldots , h_{N-1}\) following the procedure given in [4, 19, 23]. In matrix form, the orthogonal WT can be expressed as \({\mathbf {z}}(n)={\mathbf {T}}{\mathbf {x}}(n)\). This vector is represented as \({\mathbf {z}}(n)=[{\mathbf {z}}_{h_0}^T(n),{\mathbf {z}}_{h_1}^T(n),\ldots ,{\mathbf {z}}_{h_{N-1}}^T(n)]^T\) where \({\mathbf {z}}_{h_i}(n)\)’s are output vectors of an N-band filter bank. By splitting the wavelet transform domain adaptive filter coefficients at time n, \({\mathbf {g}}(n)\), into N subfilters, each having \(\frac{M}{N}\) coefficients, \({\mathbf {g}}(n)=[{\mathbf {g}}_{h_0}^T(n),{\mathbf {g}}_{h_1}^T(n),\ldots ,{\mathbf {g}}_{h_{N-1}}^T(n)]^T\), the output signal can be stated as
and the error signal is obtained by \(e(n)=d(n)-y(n)\). The update equation for each subfilter in WTDLMS is given by
where \(\mu \) is the step size and \(\sigma ^2_{h_i}(n)\) can be computed iteratively by
with the smoothing factor \(\alpha \) (\(0\ll \alpha <1\)). The new improved WTDLMS (IWTDLMS) scheme is proposed based on the following cost function
subject to
where
and
In comparison with WTDLMS, the IWTDLMS applies K input vector and the desired signal for the establishment of the update equation. It means that K constraints are used based on (10) to achieve the IWTDLMS algorithm. This strategy improves the convergence speed of the proposed algorithm. The IWTDLMS algorithm is obtained from the solution of the following constraint minimization problem:
which can be represented as
where
and \({\varvec{\varLambda }}=[\lambda _{1},\lambda _{2},\ldots ,\lambda _{K}]\) is the Lagrange multipliers vector with length K. Using \(\frac{\partial {\mathbf {J}}(n)}{\partial {\mathbf {g}}_{h_i}(n+1)}=0\) and \(\frac{\partial {\mathbf {J}}(n)}{\partial {\varvec{\varLambda }}}=0\), we get
where
and \({\mathbf {e}}(n)=[e(n),e(n-1),\ldots ,e(n-K+1)]^{T}\), which is expressed as
Substituting (17) into (16), the update equation for IWTDLMS is given by
which can be reformulated as
To take care of the possibility that \([{\mathbf {Z}}^{T}(n){\mathbf {Z}}(n)]\) may be close to singular, it is replaced by \([\epsilon {\mathbf {I}}+{\mathbf {Z}}^{T}(n){\mathbf {Z}}(n)]\), where \(\epsilon \) is the regularization parameter. Also, the parameter \(\mu \) controls the convergence rate in IWTDLMS. Note that for \(K=1\), the conventional WTDLMS is established. Tables 3 and 4 summarize all the notations and the IWTDLMS algorithm.
4 The IWTDLMS Sign Adaptive Algorithms
This section presents two IWTDLMS sign adaptive algorithms. In the first algorithm, the sign approach extended to IWTDLMS and IWTDLMS-SA is established. In the second algorithm, the variable step-size IWTDLMS-SA (VSS-IWTDLMS-SA) is proposed which has better performance than IWTDLMS-SA. Finally, to increase the tracking capability, the modified VSS-IWTDLMS-SA is introduced.
4.1 The IWTDLMS Sign Adaptive Algorithms
The IWTDLMS-SA minimizes the following cost function:
subject to
where \({\mathbf {e}}_{p}(n)\) is a posteriori error vector defined as
Therefore, the cost function is obtained as
This equation can be expressed as
Equation (25) can be rewritten as
Taking the derivative of (26) with respect to the tap-weight vector \(\partial {\mathbf {g}}_{h_i}(n+1)\), we have
where \({\mathbf {e}}_{p}(n)=[e_{p}(n),e_{p}(n-1),\ldots ,e_{p}(n-K+1)]^{T}\) and the elements of \({\mathbf {e}}_{p}(n)\) for \(0 \le m \le K-1\) are given by
By combining (28) and (27), we get
where \(\mathrm {sgn}[{\mathbf {e}}_{p}(n)]=[\mathrm {sgn}(e_{p}(n)),\mathrm {sgn}(e_{p}(n-1)),\ldots ,\mathrm {sgn}(e_{p}(n-K+1))]^{T}\). Setting \(\frac{\partial {\mathbf {J}}(n)}{\partial {\mathbf {g}}_{h_i}(n+1)}=0\), we obtain
From (30), we can get
Therefore,
Finally, we have
and then
From the above analyses, the update equation for IWTDLMS-SA is established as
which can be represented as
As the a posteriori error vector \({\mathbf {e}}_{p}(n)\) depends on \({\mathbf {g}}(n+1)\) which is not accessible, it is reasonable to approximate it with the a priori error vector \({\mathbf {e}}(n)\). Therefore, the update equation of IWTDLMS-SA becomes
Table 5 summarizes the relations of IWTDLMS-SA.
4.2 IWTDLMS-SA with Variable Step Size
By substituting (37) into (23) and using the variable step size \(\mu (n)\), we have
which can be written as
where
The IWTDLMS-SA minimizes the following cost function:

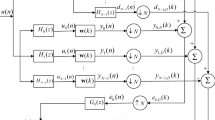
The diagram of the MVSS-IWTDLMS-SA
subject to
In (41), \(f[\mu (n)]\) is a function of \(\mu (n)\). In practice, the lower bound \(\mu _{L}\) in (42) should be selected to be a small positive constant to force the step size to be positive and the upper bound \(\mu _U\) in (42) should be selected to be smaller than one in order to guarantee the convergence of the introduced algorithm [10]. Since the objective function (41) is a piecewise linear convex one, the minimum of (41) is obtained by
where
and \({\mathbf {r}}(n)=[r_{1}(n),r_{2}(n),\ldots ,r_{K}(n)]^T\) and \(\epsilon \) is a small positive constant introduced to avoid dividing by zero. If \(\mu _{\mathrm{sol}}(n)>\mu _U\), then \(\mu _{\mathrm{sol}}(n)=\mu _U\), and if \(\mu _{\mathrm{sol}}(n)<\mu _L\) then \(\mu _{\mathrm{sol}}(n)=\mu _L\). If several consecutive impulsive noises occur, they add to the filter output. In this situation, \(\mu _{\mathrm{sol}}(n)\) may increase and the performance of VSS-IWTDLMS-SA is degraded. To avoid such possibility, the proposed step size is designed to decrease monotonically by adopting the following time-average scheme:
Therefore, the update equation of VSS-IWTDLMS-SA is given by
Table 6 describes the relations of VSS-IWTDLMS-SA. To improve the tracking capability of VSS-IWTDLMS-SA, the modified VSS-IWTDLMS-SA is proposed. If the filter coefficients of the unknown system are constant during the iterations, then \(\mu (n)\) begins from \(\mu _U\) and goes to \(\mu _L\). Thus, if the filter coefficients of the unknown system change at the middle of the iterations, then \(\mu (n)\) needs to be reset and start from \(\mu _U\) to have a good tracking of the filter coefficients of the unknown system. But the parameter \(\mu (n)\) in Eq. (45) cannot increase during the iterations due to the \(\mathrm {min} \{\mu _{\mathrm{sol}}(n),\mu (n-1)\}\). The parameter \(\mu _{\mathrm{sol}}(n)\) increases to high values in two situations (when the strong interference takes place at iteration n and when the weight vector of the unknown system changes). The effect of the changing of the unknown system on \(\mu _{\mathrm{sol}}(n)\) is very high during the iterations. Therefore, we propose the following relation for detecting this iteration as
Table 7 presents the MVSS-IWTDLMS-SA. Also, Fig. 2 describes the diagram of MVSS-IWTDLMS-SA. The dotted line box in this diagram shows the process of updating the equation in the proposed algorithm.
5 Computational Complexity
Table 8 shows the number of multiplications for each term in MVSS-IWTDLMS-SA at every adaptation. We can calculate the computational complexity of other algorithms through this strategy. Table 9 describes the computational complexity of the IWTDLMS, IWTDLMS-SA, VSS-IWTDLMS-SA, and MVSS-IWTDLMS-SA. The number of multiplications has been calculated for each algorithm at every adaptation. In this table, M is the number of filter coefficients and K is the number of recent regressors. In comparison with IWTDLMS, the IWTDLMS-SA needs \(M^2+M(K+2)+1\) multiplications which is lower than IWTDLMS. The VSS-IWTDLMS-SA needs \(M^2+M(2K+1)+K^2+2K+3\) multiplications. This algorithm has also lower computational complexity than IWTDLMS. But the performance of VSS-IWTDLMS-SA is significantly better than that of IWTDLMS.
6 Convergence Analysis
To study the convergence analysis of the proposed methods, the weight error vector is defined as \(\tilde{\mathbf {g}}(n)={\mathbf {g}}^\circ -{\mathbf {g}}(n)\), where \({\mathbf {w}}^\circ \) is an unknown system vector of the filter coefficients and \({\mathbf {g}}^\circ = {\mathbf {T}}{\mathbf {w}}^\circ \). By taking the squared Euclidean norm and then expectation from both sides of (37), we have
where
By defining the noise-free vector, \({\mathbf {e}_a}(n)={\mathbf {e}}(n)-{\nu (n)}={\mathbf {Z}}^T(n)\tilde{\mathbf {g}}(n)\), the numerator of (49) becomes
In (49), \(\varDelta \) can be approximated as [24]:
If \(\varDelta <0\), (48) is stable. Therefore, from (51), the range of \(\mu \) is given by
This range guarantees the convergence of the IWTDLMS-SA, VSS-IWTDLMS-SA, and MVSS-IWTDLMS-SA.
7 Simulation Results
We demonstrate the performance of the proposed algorithms by several computer simulations in a system identification and acoustic echo cancellation (AEC) scenarios. For the system identification, two unknown systems (\({\mathbf {w}}_t\)) have been used. The first unknown impulse response is randomly selected with 16 taps (\(M=16\)), and the second one is the car echo path with \(M=256\) (Fig. 3). The input signal is an AR(1) signal generated by passing a zero-mean white Gaussian noise through a first-order system \(H(z)=\frac{1}{1-0.9z^{-1}}\). In AEC, the input signal is real speech (Fig. 3) and the unknown system is the car echo path. An additive white Gaussian noise with variance \(\sigma ^2_v=10^{-3}\) is added to the system output, setting the signal-to-noise ratio (\(\mathrm {SNR}\)) to 30 dB. The Haar wavelet transform (HWT) is used in all simulations which leads to the reduction in computational complexity due to the elements (+1 and -1) in HWT. In all simulations, we show the normalized mean square deviation (NMSD) which is evaluated by ensemble averaging over 30 independent trials.
Figure 4a compares the NMSD learning curves of WTDLMS and IWTDLMS algorithms with \(M = 16\). The value of the step size is set to 0.3, and different values for K are chosen. As we can see, by increasing the parameter K, the convergence speed and the steady-state NMSD values increase. Figure 4b presents the NMSD learning curves of WTDLMS and IWTDLMS algorithms with \(M = 256\). Again, the IWTDLMS has a higher convergence speed than WTDLMS algorithm. As we can see, for large values of M, the convergence speed of IWTDLMS is significantly higher than that of WTDLMS.
In the simulations, a strong interference signal is also added to the system output with a signal-to-interference (SIR) of -30 dB. The Bernoulli–Gaussian (BG) distribution is used for modeling the interference signal, which is generated as the product of a Bernoulli process and a Gaussian process, w(n)b(n), where b(n) is a white Gaussian random sequence with zero mean and variance \(\sigma ^2_b\) and w(n) is a Bernoulli process with the probability mass function given as \(P(w)=1-P_r\) for \(w=0\), and \(P(w)=P_r\) for \(w=1\). The average power of a BG process is \(P_r.\sigma ^2_b\). Keeping the average power constant, a BG process is spikier when it is smaller. It reduces to a Gaussian process when \(P_r=1\) [16].

The impulse response of the car echo path and real speech input signal

a The NMSD learning curves of WTDLMS and IWTDLMS (\(M = 16\)), b the NMSD learning curves of WTDLMS and IWTDLMS (\(M = 256\)), input: colored Gaussian AR(1)

a The NMSD learning curves of WTDLMS, IWTDLMS, IWTDLMS-SA, and VSS-IWTDLMS-SA (\(M=16\), \(\mu =0.01\)), input: colored Gaussian AR(1) with impulsive noise. b The NMSD learning curves of WTDLMS, IWTDLMS, IWTDLMS-SA, and VSS-IWTDLMS-SA (\(M=256\)), input: colored Gaussian AR(1) with impulsive noise

a The tracking performance of WTDLMS, IWTDLMS, IWTDLMS-SA, VSS-IWTDLMS-SA, and MVSS-IWTDLMS-SA (\(M=16\)), input: colored Gaussian AR(1) with impulsive noise. b Variation of the step size in VSS-IWTDLMS-SA and MVSS-IWTDLMS-SA

a The NMSD learning curves of DCT-LMS, VSS-TDlMS, VSS-APA-SA, WTDLMS, and IWTDLMS (\(M=256\)), input: real speech signal. b The tracking performance of DCT-LMS, VSS-TDlMS, VSS-APA-SA, WTDLMS, IWTDLMS, and MVSS-IWTDLMS-SA (\(M=256\)), input: real speech signal

a The ERLE of DCT-LMS, VSS-TDlMS, VSS-APA-SA, WTDLMS, and IWTDLMS (\(M=256\)), input: real speech signal. b The ERLE tracking performance of DCT-LMS, VSS-TDlMS, VSS-APA-SA, WTDLMS, IWTDLMS, and MVSS-IWTDLMS-SA (\(M=256\)), input: real speech signal
Figure 5a shows the NMSD learning curves of WTDLMS, IWTDLMS, IWTDLMS-SA, and VSS-IWTDLMS-SA when the impulsive noise is added to the system output. The parameter M is set to 16, and the value of the step size is set to 0.01. The results show that the IWTDLMS-SA and VSS-IWTDLMS-SA have better performance than IWTDLMS and conventional WTDLMS. In Fig. 5b, we present the results for \(M=256\). The step size is set to 0.01. We observe that the IWTDLMS-SA and VSS-IWTDLMS-SA have better performance than other algorithms in impulsive noise interference environments.
In Fig. 6a, the impulsive noise is added to the system output. The results show that the proposed MVSS-IWTDLMS-SA and IWTDLMS-SA have better performance than other algorithms in this environment. It is important to note that the tracking ability of VSS-IWTDLMS-SA is weaker than other algorithms. Figure 6b describes the variation of the defined step sizes (\(\mu (n),\mu _{\mathrm{sol}}(n),\bar{\mu }_{\mathrm{sol}}(n)\)) in VSS-IWTDLMS-SA and MVSS-IWTDLMS-SA. In VSS-IWTDLMS-SA, the step size does not change when the impulse response of the unknown system changes. But in MVSS-IWTDLMS-SA, the step size changes when the impulse response of the unknown system changes.
Figure 7a and 7b shows the performance of the proposed algorithms for real speech input signal. Figure 7a compares the NMSD learning curves of WTDLMS and IWTDLMS with those of the proposed algorithms in [6, 11, 12, 26] and [10]. The parameters in these algorithms are set according to Table 10. The results show that the IWTDLMS has better performance than other algorithms. The tracking capability of the proposed algorithm for real speed input is justified in Fig. 7b. Due to the good tracking performance of MVSS-IWTDLMS-SA, we added the learning curve of this algorithm in Fig. 7b. We observe that the tracking performance of MVSS-IWTDLMS-SA is better than other algorithms.
Also, to measure the effectiveness of the proposed algorithms, we compute the echo return loss enhancement (ERLE). The ERLE is obtained by evaluating the difference between the powers of the echo and the error signal. The segmental ERLE curves for the measured speech and echo signals are shown in Fig. 8. Figure 8a illustrates the ERLE of the simulated algorithm in Fig. 7a. As can be seen, a good performance is observed for IWTDLMS. Figure 8b compares the ERLE of the simulated algorithms in Fig. 7b. This figure shows that the MVSS-IWTDLMS-SA performs well for tracking situation.
8 Conclusion
In this paper, the IWTDLMS adaptive algorithm was established. The IWTDLMS had better convergence speed than conventional WTDLMS in highly colored input signals. The IWTDLMS-SA was introduced which is useful for impulsive noise interference. To improve the performance of IWTDLMS-SA, the VSS-IWTDLMS-SA was proposed. Finally, the MVSS-IWTDLMS-SA was established which had better tracking capability in comparison with other algorithms. We demonstrated the good performance of the proposed algorithms through different simulation results.
References
M.S.E. Abadi, H. Mesgarani, S.M. Khademiyan, The wavelet transform-domain LMS adaptive filter employing dynamic selection of subband-coefficients. Digit. Signal Process. A Rev. J. 69, 94–105 (2017)
M.S.E. Abadi, M.S. Shafiee, Diffusion normalized subband adaptive algorithm for distributed estimation employing signed regressor of input signal. Digit. Signal Process. 70, 73–83 (2017)
M.S.E. Abadi, M.S. Shafiee, M. Zalaghi, A low computational complexity normalized subband adaptive filter algorithm employing signed regressor of input signal. EURASIP J. Adv. Signal Process. 21(1), 1–23 (2018)
S. Attallah, The wavelet transform-domain lms algorithm: a more practical approach. IEEE Trans. Circuits Syst. II Analog Digit. Signal Process. 47(3), 209–213 (2000)
S. Attallah, The Wavelet Transform-Domain LMS Adaptive Filter With Partial Subband-Coefficient Updating. IEEE Trans. Circuits Syst. II Express Br. 53(1), 8–12 (2006)
R.C. Bilcu, P. Kuosmanen, K. Egiazarian, A transform domain LMS adaptive filter with variable step-size. IEEE Signal Process. Lett. 9(2), 51–53 (2002)
J. Chambers, A. Avlonitis, A robust mixed-norm adaptive filter algorithm. IEEE Signal Process. Lett. 4(2), 46–48 (1997)
B. Farhang-Boroujeny, Adaptive Filters: Theory and Applications (Wiley, New York, 2013)
S.S. Haykin, Adaptive Filter Theory, 5th edn. (Pearson Education India, India, 2013)
J.H. Kim, J.H. Chang, S.W. Nam, Affine projection sign algorithm with \(\ell _1\) minimization-based variable step-size. Signal Process. 105, 376–380 (2014)
D.I. Kim, P.D. Wilde, Performance analysis of the DCT-LMS adaptive filtering algorithm. Signal Process. 80(8), 1629–1654 (2000)
K. Mayyas, A transform domain LMS algorithm with an adaptive step size equation, Proceedings of the Fourth IEEE International Symposium on Signal Processing and Information Technology, pp. 229–232, (2004)
K. Ozeki, T. Umeda, An adaptive filtering algorithm using an orthogonal projection to an affine subspace and its properties. Electron. Commun. in Japan (Part I Commun.) 67(5), 19–27 (1984)
A.H. Sayed, Adaptive Filters (Wiley, New York, 2011)
T. Shao, Y.R. Zheng, A new variable step-size fractional lower-order moment algorithm for non-Gaussian interference environments, 2009 IEEE International Symposium on Circuits and Systems, pp. 2065–2068, (2009)
T. Shao, Y.R. Zheng, J. Benesty, An affine projection sign algorithm robust against impulsive interferences. IEEE Signal Process. Lett. 17(4), 327–330 (2010)
H.C. Shin, A.H. Sayed, W.J. Song, Variable step-size NLMS and affine projection algorithms. IEEE Signal Process. Lett. 11(2), 132–135 (2004)
J. Shin, J. Yoo, P. Park, Variable step-size affine projection sign algorithm. Electron. Lett. 48(9), 483–485 (2012)
D. Sundararajan, Discrete Wavelet Transform: A Signal Processing Approach (Wiley, New York, 2016)
L.R. Vega, H. Rey, J. Benesty, S. Tressens, A new robust variable step-size NLMS algorithm. IEEE Trans. Signal Process. 56(5), 1878–1893 (2008)
B. Widrow, D. Stearns, Adaptive Signal Processing (Prentice Hall Inc, NJ, 1985)
W.W. Wu, Y.S. Wang, J.C. Zhang, An adaptive filter based on wavelet transform and affine projection algorithm, 2010 International Conference on Wavelet Analysis and Pattern Recognition, pp. 392–397, (2010)
S.K. Yadav, R. Sinha, P.K. Bora, Electrocardiogram signal denoising using non-local wavelet transform domain filtering. IET Signal Process. 9(1), 88–96 (2015)
J. Yoo, J. Shin, P. Park, Variable step-size affine projection sign algorithm. IEEE Trans. Circuits Syst. II: Express Br. 61(4), 274–278 (2014)
J. Yoo, J. Shin, P. Park, Variable step-size sign algorithm against impulsive noises. IET Signal Process. 9(6), 506–510 (2015)
S. Zhao, D.L. Jones, S. Khoo, Z. Man, New variable step-sizes minimizing mean-square deviation for the LMS-type algorithms. Circuits Syst. Signal Process. 33(7), 2251–2265 (2014)
Y.R. Zheng, T. Shao, A variable step-size lmp algorithm for heavy-tailed interference suppression in phased array radar, 2009 IEEE Aerospace Conference, pp. 1–6, (2009)
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Abadi, M.S.E., Mesgarani, H. & Khademiyan, S.M. Two Improved Wavelet Transform Domain LMS Sign Adaptive Filter Algorithms Against Impulsive Interferences. Circuits Syst Signal Process 40, 958–979 (2021). https://doi.org/10.1007/s00034-020-01508-5
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00034-020-01508-5