
Abstract
An automatic breast cancer detection and classification system plays an essential role in medical imaging applications. But accurate disease identification is one of the complicated processes due to the existence of noisy contents and irrelevant structure of the original images. In conventional works, various medical image processing techniques have been developed for accurately classifying the types of breast cancer. Still, it confronts difficulties due to the aspects of increased complexity in computations, error values, false positives, and misclassification outputs. Hence, this research work proposes to develop an optimization-based classification system for the breast cancer identification system. Here, the Gaussian filtering and Adaptive Histogram Equalization (AHE) techniques are utilized for preprocessing the original mammogram images by eliminating the noisy contents and enhancing the contrast of an image. Then, the Markov Random Adaptive Segmentation (MRAS) technique is employed for detecting the boundary region based on the random value selection. To make the classifying procedure easier, the set of features is optimally extracted from the segmented region with the help of a Genetic Algorithm (GA). In which, the global best fitness value is estimated by using the crossover, mutation, and selection operations. Finally, the Convolutional Neural Network (CNN) classification technique is utilized for categorizing the image as to whether normal or abnormal with its type. The entire performance analysis of the suggested model is validated and compared using multiple measures during the evaluation. In the proposed method GA performs feature selection and prunes unnecessary features. The major goal is to improve the classification performance while reducing the number of features used. The proposed system GA-CNN provides improved performance results with a reduced error rate.The suggested GA-CNN increases accuracy (98.5), sensitivity (99.38), and specificity values (98.4) as compared to the existing technique by effectively identifying the classed label.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Recently, the breast cancer identification and classification system has gained significant attention in many applications. According to the World Health Report, breast cancer is considered the second most common cause of death in women [1,2,3,4]. Hence, it is essential to predict the disease at an earlier stage to provide appropriate treatment at that time. There are different types of imaging modalities used for detecting and accurately spotting the tumor affected region. Among the other imaging techniques, mammogram images are highly utilized by medical experts for accurate detection and treatment at an earlier stage. For detecting breast cancers from mammogram, various medical image processing approaches have been used in the existing works [5]. The general tumor detection system includes the working modules of image preprocessing, segmentation, optimization, and label prediction [6]. The most commonly used preprocessing techniques are mean, median, adaptive median, Gaussian, and hybrid filtering approaches. Similarly that, pattern extraction techniques are also mainly used for extracting from the preprocessed image [7, 8], which includes the feature types of texture patterns, binary patterns, shape, and density patterns. The major goal of utilizing optimization techniques, in this case is to find the best features for predicting the classified label with increased accuracy and reduced error values [9].
Also, it supports obtaining an improved classification performance [10] with reduced training and testing time. Conventionally, there are various kinds of optimization techniques used for computing the best fitness value to enhance the classification accuracy. Because the reduced number of features can minimize the required amount of time for training the models. The recently used feature selection techniques are Genetic Algorithm (GA), Greedy Optimization (GO), Grasshopper Optimization (GO), Artificial Bee Colony (ABC) optimization, and other bio-inspired optimization techniques [11,12,13,14,15].Similarly, there are various kinds of segmentation approaches used for segmenting the tumor affected regions based on the threshold value. Image segmentation is one of the vital processes used for enhancing detection accuracy and reducing the misclassification results oftumor classification systems[16]. At last, machine learning [17] or deep learning classification [18] algorithms are employed to produce the label as normal or tumor affected. It [2, 19, 20] includes the types of Support Vector Machine (SVM), Random Forest (RF), Decision Tree (DT), Fuzzy Logic (FL), Ensemble Learning (EL), Gradient Boost (GB), Neural Network (NN), and Naïve Bayesian (NB). Similarly, the deep learning models [20,21,22] are categorized into the types of Convolutional Neural Network (CNN), Deep Neural Network (DNN), Deep Belief Network (DBN), Long Short-Term Memory (LSTM), and Recurrent Neural Network (RNN). The major contributions of the proposed work are as follows:
-
To accurately classify breast cancer from the given mammogram image set, an enhanced Convolutional Neural Network (CNN) based classification technique is deployed.
-
To obtain the patterns from the input image by applying an efficient feature extraction mechanism.
-
To optimally select the best features from the extracted output based on the global fitness function, the meta-heuristic Genetic Algorithm (GA) has been utilized, which also helps to reduce the misclassification rate with increased detection performance outcomes.
-
To evaluate the detection performance of the suggested model, various evaluation metrics have been utilized during the analysis. Also, the obtained output values are compared with other recent detection methodologies.
Results of GA-CNN classification are also compared with existing classification methods such as Sparse AutoEncoder (SAE), Deep Belief Network (DBN), CNN and Decision Tree (DT)-CNN. The existing deep learning technique AHEE-CDLS-CNN is compared with a proposed deep learning technique GA-CNN. The goal is to contrast the result of theexisting deep learning technique with the GA-CNN technique and analyze the impact of reduced feature set selection on the classification accuracy and error rate of the proposed model. It is observed that GA-CNN shows considerable improvement in classification accuracy and reduced error rate with the optimal feature set.
In complex data models, the existing system AHEE-CDLS-CNN is costly to train the data set and consumes significant computing time when the number of variables is high. Optimal feature set selection is the process of picking the most relevant subset of features. The most effective feature set selection strategy eliminates irrelevant data, potentially improving system performance. The system’s computing cost is lowered as a result of the optimal feature set selection technique, resulting in greater computational efficiency. The suggested method aims to find the best feature set with the best-fitted value while consuming the minimum possible time for both training and testing models. in addition to increasing classification accuracy while lowering complexity. This work also gave a brief description of the DL-based breast cancer classification system using the GA-CNN technique to diagnose mammography images. The use of DL approaches in clinical analysis has a lot of promise for improving the diagnostic capability of present CAD systems. When compared to calcifications, masses are more difficult to detect and categorize when the density of the breast varies. Traditional machine learning approaches rely on constrained procedures that are restricted to certain dataset density categories. Although the GA-CNN approaches show promise in the diagnosis of breast cancer.
The other sections of this paper are categorized into the followings: Sect. 2 presents a comprehensive review of the conventional medical image processing techniques with their advantages and disadvantages. The working flow of the research method is illustrated with its flow and algorithm explanations in Sect. 3. The performance and comparative analysis of both conventional and proposed tumor detection methodologies are validated by using various measures in Sect. 4. Section 5 discusses a study’s findings. Finally, the overall paper is summarized with the future scope in Sect. 6.
2 Related Works
This unit examines some of the existing research works associatedwith the breast cancer detection and classification framework. Also, it covers the benefits and drawbacks of each technique based on its features and characteristics.
Chowdhary et al. [23] implemented the Fuzzy C-Means (FCM) clustering and incorporated the Support Vector Machine (SVM) classification mechanism for accurately detecting breast cancer from the mammograms. Here, the Otsu based thresholding technique was deployed for accurately segmenting cancer affected regions. The stages involved in this system were preprocessing, background segmentation, clustering, and classification. In order to enhance segmentation accuracy, this work extracted a set of features like shape, circularity, gradient, mean, and standard deviation from the segmented region. Still, this work is limited by the key challenges of increased testing and training duration for the models and high misclassification results. Oliveira et al. [24] suggested a lightweight deep learning model for accurately predicting breast cancer with increased accuracy. Here, the data augmentation has been performed initially to enhance the robustness based on affine transformations. Consequently, image segmentation and classification processes have been performed for training the models by fine tuning the parameters.
Khoulqi et al. [25] suggested the CAD model for using mammograms to diagnose breast cancer at an earlier stage. The median filtering technique has been at first to enhance the quality of input images with increased contrast. Then, the watershed and thresholding-based segmentation methodologies were applied to segment the tumor affected regions from the preprocessed results, which ensures the increased accuracy of classification. Moreover, three different classification approaches such as k-nearest neighbor, SVM, and C4.5 techniques have been applied to predicting the classified output label. Also, the performance of these classification techniques was analyzed and compared based on the increased detection accuracy. The major disadvantages of this work were inefficient classification, reduced performance outcomes, and does not have the ability to handle large dimensional data. Antari et al. [26] suggested an enhanced regional deep learning model, named the Full resolution CNN (FrCN) algorithm for classifying breast cancer from mammograms, which comprises the working steps of mass detection, segmentation, and classification. Here, the YOLO framework has been deployed for mass detection, and FrCN model was utilized for segmenting the mass regions. Finally, the CNN architecture was deployed for accurately classifying breast cancer. Jouni et al. [27] employed an Artificial Neural Network (ANN) for the detection and classification of breast cancer disease at an early stage. This method intends to find the most suitable optimal solution for reducing the classification error with a reduced number of blocks. The advantages of using this mechanism were as follows: reduced error rate, minimal computational complexity, and abetter optimal solution used for classification. However, it requires reducing the dimensionality of features by increasing the efficiency and reducing the time consumption of the classification system.
Muduli et al. [28] implemented a Moth Flame Optimization based Ensemble Learning Machine (MFO-ELM) technique for designing an automated breast cancer detection and classification system. It mainly intends to obtain the set of features from the given mammogram images by using the wavelet transformation technique. The working stages involved in this classification were ROI extraction, wavelet transformation-based feature extraction, feature reduction using PCA with LDA, and classification based on MFO-ELM. Yet, this work limits the issues of high complexity in algorithm design, increased effort for training and testing data, and reduced accuracy. Wang et al. [20] deployed an Extreme Learning Machine (ELM) based CNN methodology for accurately detecting breast cancer based on the set of features. The major stages involved in this work were image preprocessing, mass detection, feature extraction, and classification. Here, an adaptive mass region detection mechanism was employed to extract the ROI from the breast image, which helps to exactly spot the abnormal region. In addition to that, the ELM based training was performed to estimate the output vector for the random weights and bias function. Increased accuracy, excellent detection efficiency, and reduced design complexity were the main benefits of this effort.
In the paper [29], the Naïve Bayes (NB) classification approach was utilized for detecting breast cancer from mammograms with increased performance results. The main factor of this work was to categorize the benign and malignant tumors based on the weight attributes calculation of the NB classifier. Here, different types of feature vectors have been extracted from the input image to improve the detection accuracy.
Khuriwal and Mishs [30] utilized an enhanced deep learning model for detecting breast cancer from pathological images. Here, ROI has been extracted initially from the input image, and the preprocessing was performed on the filtered image to remove the noise that exists in the input image. As a consequence, the CNN model was used to extract the features from the preprocessed outcome. which helps to detect the cancer affected region with increased accuracy. Thawkar et al. [31] looked at effective techniques for mass classification and extraction of features in digital mammograms. The genetic ensemble method combined with tenfold cross-validation was used to choose the subsets of significant aspects. AdaBoost, RF, and single DT classifiers were trained and tested on the most significant feature subset that had the best classification accuracy. The results of the suggested strategy demonstrate how much more effective ensemble classifiers are than single classifiers.
Though the literature has supplied sufficient information on existing models for breast cancer diagnosis, we believe that a less complex feature selection method is required to improve accuracy and diagnostic efficiency for the proposed work. To overcome this challenge, the GA-CNN technique assisted with a breast cancer diagnosis is proposed in this study. With a reduced image feature set, the GA-CNN technique was used to identify the masses as malignant or benign. The automated detection of breast cancer is still a challenge. The proposed breast CAD technique in which genetic algorithms are utilized to extract relevant and significant features and CNN is employed to increase breast cancer detection accuracy.The deep learning approach outperformed the general approaches in a variety of applications [32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70]. This highlights the power of the deep learning method in encouraging breast cancer research.
3 Materials and Methods
A clear description of the working approach, including its suitable flow and algorithmic phases, is offered here.This work mainly objects to working with medical images by using advanced segmentation and classification mechanisms. The main intention of this paper is to accurately predict breast cancer from the given mammogram image dataset with increased detection efficiency and reduced time consumption.
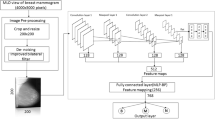
Typically, different types of medical image segmentation and classification techniques have been utilized for segmenting and classifying the breast cancer affected region from the given input. Still, it is limited by the problems of increased complexity in algorithm design, reduced level of accuracy, and high misclassification results. Therefore, the proposed research intends to create a hybrid methodology for breast cancer detection and classification that is both efficient and effective. The proposed breast cancer detection system’s overall flow is shown in Fig. 1 and it comprises the following modules:
-
1.
Data collection
-
2.
Preprocessing and contrast enhancement
-
3.
Segmentation
-
4.
Feature mapping
-
5.
CNN based Classification

The proposed breast cancer detection system’s overall flow
Also, the overall steps involved in the research methodology are illustrated as follows:
Step 1 Get the input mammogram image from the given Dataset;
Step 2 Apply filtering technique for noise removal;
Step 3 Increase the enchantment by using adaptive histogram equalization;
Step 4 Segment the image based on color dense level;
Step 5 Extract the features from the segmented image with respect to the higher dense tissue;
Step 6 Apply Genetic Algorithm (GA) for optimally selecting the set of features;
Step 7 The CNN based classification approach is applied to predict the classified label;
The active or pertinent features for the classification of breast cancer are chosen using an optimal feature selection genetic algorithm and the CNN classifier was used to predict masses. The method of selecting the optimal feature set from enormous data sets reduces computational complexity, increases algorithm performance, and allows for the evaluation of correct and effective outcomes.
3.1 Image Preprocessing and Contrast Enhancement
After getting the input image from the given dataset, the preprocessing is executed for noise elimination and contrast enhancement. Conventionally, various filtering approaches such as mean filter, median filter, adaptive median, and other hybrid filters are used for preprocessing the medical image data. Among the other filtering models, the Gaussian filtering technique is most suitable for medical imaging applications. Also, it provides the following advantages:
-
Simple implementation
-
Effective in noise removal
-
Increased ability to handle both the salt and pepper noise
-
Symmetric in nature
The overall detection efficiency of the classification technique highly depends on the quality of the input image. So, image enhancement is one of the most importantpartsof any medical imaging application system. In this work, both the Gaussian filtering and Adaptive Histogram Equalization (AHE) techniques are utilized for noise removal and quality enhancement. Moreover, the main benefit of using this technique is to efficiently extract breast masses with high contrast and quality. The steps involved in the AHE are illustrated as follows:
Step 1 Obtain the input gray image;
Step 2 Split the image into 3 \(\times\) 3 local matrices;
Step 3 Calculate the brightness of each local matrix;
Step 4 Enhance the local matrix by using the nearest local matrix;
3.2 Markov Random Adaptive Segmentation (MRAS)
In this stage, the preprocessed image has been obtained as the input for segmentation to accurately detect the tumor affected region. For this purpose, the Markov Random Adaptive Segmentation (MRAS) methodology has been utilized in this work, which segments the tumor region by selecting the random value of each group. Normally, segmentation is mainly used to make the image analysis part easier. In the existing detection methodologies, various segmentation approaches have been used to improve the performance of medical imaging applications. But, it limits the problems over segmentation, difficulties in handling textures, and complex ROI extraction. Toaddress these issues, this research model intends to implement the random value-based image segmentation method, which efficiently extracts the ROI with high accuracy. After obtaining the contrast enhanced image as the input, the random value of each group has been selected. Then, the nearest value is computed for each group of pixels, and its mean value is also estimated correspondingly. This estimate has been repeated until reaches the closest point of each group. If there is any change in the random value, the above processes have been repeated. Consequently, the Highest Brightness Pixel (HBP) group is selected and its region is extracted from the gray scale image. Moreover, the segmented region is utilized for further processes like optimization and classification. The detailed processes involved in this algorithm are illustrated as follows:
Step 1 Obtain the preprocessed image as input (Enhanced image, number group);
Step 2 Select the random value of each group;
Step 3 Estimate the nearest value of each group by using the following model:
Step 4 Compute the group mean value for each group;
Step 5 Repeat Step 3 until identifying the closet point of each group separately;
Step 6 If there is any change in the random value, repeat from step 4; else, finish;
Step 7 Select the Highest Brightness Pixel (HBP) group;
Step 8 Extract the area of HBP.
Step 9 Filter and extract the HBP values in Gray image;
The MRAS is used to enhance the images visual quality and separate a digital image into several sectors or pixels. It is essential to develop a mathematical model to isolate the area of interest rather than using complicated procedures, however, MRAS can reduce the complexity of handling operations while also making them less difficult.
3.3 GA Based Optimization
Typically, feature optimization is considered as the primary module of the medical imaging system, because it supports improving the overall detection performance.A large number of features can degrade the classifier’s performance by requiring more time to train and test the models.As a result, this work aims to make use of the meta-heuristic optimization technique, named Genetic Algorithm (GA) for identifying features ideally based on fitness value. It includes the processes of crossover, mutation, and selection operations, which automatically determine the relative importance across different features for providing the optimal set of values. In this work, the key reason for employing this strategy is to obtain the reduced set of features with the best fittest value. The processes involved in this technique are illustrated as follows:
Step 1 Optimize the neural network for the training of features using a Genetic algorithm
Step 2 It reduces the features from 37,636 to 1000.
Step 3 Get the position of a selected feature.
Step 4 Use this position to test the time.
The advantages of using this technique are listed below: increased optimization results, high detection rate andreducedeffort for training and testing the system.To locate a better quality subset, many search techniques are applied. In the proposed work GA is used to find a better subset of features and a higher quality of the extracted subset of features. The components of a genetic algorithm are the population size, the number of generations, and the crossover and mutation probabilities. By creating a list of features as the initial population, the search point is established. The chromosomes are employed as a filter of features in the genetic algorithm.
Feature maps are used to visualize the spatial characteristics of input patterns. A feature map reduces the false positives and helps to make the classification process easier. A highly informative image such as mammography includes larger input features. Each training image was separated into segments when the segmentation process was finished. The comparative standard is based on color and shape. Additionally, each segment also retrieved a different set of features. In the feature mapping process, each filter is 3 × 3 and the input image is 256 × 256. There are 7 conventional layers and 7 pooling layers, resulting in a final image size of 228 × 228 which flattens the image as 51,984. The feature length was minimized using GA optimization which handles feature selection.
3.4 Classification
After selecting the best combination of features,the normal and abnormal images are categorized by using the CNN based deep learning model. When compared to the machine learning models, the deep learning techniques have been extensively used in recent days due to their increased accuracy, reduced complexity, and improved detection efficiency. Typically, the mammogram images contain more gray value areas, which decreases the accuracy of the classifier. So, it is highly important to enhance the efficiency of these images by separating the mammary area from the given mammogram images, which is represented as the ROI. Here, the mass region is detected by sequentially scanning all rows of the image. Consequently, the sub-region partitioning is performed to separate the non-overlapping sub-regions. After that, the deep, morphological, density and texture features are extracted from the sub-regions, which help to improve the accuracy and detection efficiency of classification. The deep features are more useful for extracting the most important characteristics of images. The morphological features are considered as essential indicators for medical experts to differentiate the tissues of benign and malignant masses. Similarly, the texture and density features are also more important, which aids in the detection of breast cancer in its early stages. The density feature is extracted by computing the correlation between the benign and malignant portions.
At last, the CNN technique utilizes these feature vectors for predicting the classified label into seven different classes, which include:
-
1.
CALC–Calcification
-
2.
CIRC–Well-defined/circumscribed masses
-
3.
SPIC–Speculated masses
-
4.
MISC–Other, ill-defined masses
-
5.
ARCH–Architectural distortion
-
6.
ASYM–Asymmetry
-
7.
NORM–Normal
The CNN technique comprises the layers of convolution, maximum pooling, and fully connected. When compared to the other classification models, the CNN technique has the benefits of better generalization performance, not sensitivity, and high learning speed. Thus, this research work utilizes the CNN based classification model for accurately classifying breast cancer from mammogram images.
Step 1 Let’s consider, the input size of CNN is 254 \(\times\) 254;
Step 2 Define the kernel size as 3;
Step 3 The first convolution layer is filtered as a 254 \(\times\) 254 input image with a 3 \(\times\) 3 Layer;
Step 4 The output of convolution layer is 250X250
where, KV indicates the tth Kernel and BAt,lis the bias of tth layer;
Step 5 The convolution layer connected with the max pooling layer and, its convoluting operation is continued to the 15th layer;
Step 6 The classified output is predicted as follows: CALC, CIRC, SPIC, MISC, ARCH, ASYM, and NORM;
In this system, the output layer is 7, the hidden layer is 20, the size of the hidden layer is 10, and the input layer is 37,636.
The data on breast cancer were mapped, normalized, and encoded. The initial population was chosen at random. A random binary encoded vector is used as a feature selector with the GA, and a 0 bit indicates that the feature is not included. The suggested GA-CNN methodology which includes reduced set of features with the best fittest value has the advantage of reducing complexity and the predicted outcome precisely identifies cancer rather than any anomalies in the breast.
4 Results
The results and a comparative analysis of the conventional and proposed research methodologies are validated by using various measures. It includes the parameters of sensitivity, specificity, accuracy, precision, recall, and similarity coefficients. Among the other measures, sensitivity, specificity, and accuracy are increasingly utilized in many medical imaging applications for assessing the overall detection efficiency of the methodologies. The sensitivity is defined by the ratio of the actual number of true positives and the sum of the actual true positives and false negatives. Similarly, to that, the specificity is defined by the proportion of actual true negatives to the total number of true negatives and false positives, which are computed as shown below:
Consequently, the accuracy of the classifier is entirely based on the measures of sensitivity and specificity as shown below:
where, TP—True Positive, TN—True Negative, FP—False Positive, FN—False Negative. Figure 2 and Table 1 compare the existing and proposed tumor detection methodologies based on accuracy, sensitivity, and specificity. During this evaluation, the techniques such as DT-CNN, CNN, DBN, and SAE have been for validation.The key benefit of DT CNN method is high accuracy in determining whether the projected malignancy is malignant or benign.Deep belief networks (DBNs) are an excellent alternative, but the method for fine-tuning network weights and biases, as well as the number of hidden layers and neurons, make them difficult to implement [71].The Sparse AutoEncoder (SAE) is an automated approach [72] that uses a classifier to accomplish error-free breast cancer prediction by learning image features from the mammogram.The results reveal that the proposed method GA-CNN outcomes outperform the other methods currently in use in terms of accuracy, sensitivity, and specificity.

Accuracy, sensitivity, and specificity analysis
Table 2 presents the overall performance evaluation and comparison of both convention and proposed tumor detection methodologies. It compares quantitatively Accuracy, Sensitivity, Specificity, Precision, and F1 score. GA-CNN received an F1 score of 0.9952. GA-CNN has a higher F1 score over the existing model. In addition, GA-CNN outperformed the existing model in terms of Accuracy, Sensitivity, Specificity and Precision. The GA-CNN shows the best results with optimal feature selection. These results also indicate that the GA-CNN technique provides improved performance results by accurately detecting the tumor region from the given mammogram images.
The standard deviation and the mean are typically employed in clinical and experimental investigations to illustrate the properties of sample data and to explain the findings of statistical analysis.Training Statistics against feature selection listed in Table 3.When constructing a predictive model, the process of feature selection involves lowering the number of input variables. In some circumstances, reducing the number of input variables might enhance the efficiency of the model while also lowering the computing cost of modeling. The total performance of the training, applying the GA-selected optimal feature is better compared to training using all the features, as shown in Table 3.If the irrelevant features are removed from the data set, GA-CNN performs much better. For finding the optimal features for classification tasks, the GA-CNNis a suitable choice.
Figure 3 presents the comparative analysis of existing and proposed deep learning based classification techniques used for breast cancer detection. In the proposed system, the AHE based contrast enhancement is performed to improve the quality of the original mammograms.The overall performance and detection efficiency of the medical image processing technique are extremely dependent on the excellence of an image.

Sensitivity, specificity, and accuracy analysis of existing and proposed deep learning models
Due to the rising amount of high dimensional data, feature selection has evolved into a crucial phase in the data processing process for developing a machine learning model.The GA is extended to CNN in the suggested way to identify its finest features. GA feature optimization indicates that the metrics’ discernible improvement is adequate to demonstrate the method’s viability. The accuracy of the findings is significantly improved for the GA-based model trained on the optimized feature selection.When compared to the existingmethod, the proposed GA-CNN provides increased accuracy (98.5), sensitivity (99.38) and specificity values (98.4) by accurately categorizing the classified label.
Figure 4 compares the similarity coefficients of both existing and proposed methods based on the exact measures of precision, F1—score, MCC and kappa. As the parameters proceed nearer to their maximum value, it shows the classification performs better. Figure 5 shows the error values of existing and proposed techniques with respect to the measures of FPR and overall error rate. Error rates must be established in order to assess performance, decide whether change is required, gauge the success of interventions, and provide transparency. A lower error rate in the proposed technique produces results that are more exact and accurate.

Similarity coefficients of existing and proposed techniques

Error analysis
Figure 6 quantitatively compares the statistics between GA selected feature set and the feature set selected by the standard techniques. To estimate the training with all features and GA determined optimal feature set, the statistical validation metrics Mean and Standard Deviation are utilized.The success of our approach was proven by a comparison of the results of feature selection using a genetic algorithm and traditional procedures. From these evaluations, it is evident that the proposed GA-CNN technique provides enhanced performance outcomes with reduced error rates through proper segmentation and classification processes.

Training statistics against feature selection
When implementing the technique in a real-time application, computational complexity is a crucial factor. The computational complexity of the suggested and existing tumor identification approaches such as the Hybrid of K-means Gaussian Mixture Model, K-means, Gaussian mixture Model and Growth region hand selection method is compared in Table 4 based on the input size of the breast mammogram images. According to Table 4’s findings, the suggested model offers an excellent time consumption result.
5 Discussion
According to the obtained results, it is concluded that the proposed GA incorporated with the CNN technique excels the other techniques with better measures. Because the best selection of features helps to obtain improved detection accuracy by efficiently training the samples during classification. In this system, the image over segmentation problem is avoided by implementing MRAS segmentation technique, which accurately detects the object boundary based on the random value selection. Moreover, the proper segmentation with optimal feature selection processes could efficiently progress the overall classification efficiency of the proposed system with reduced false positives and error values. This shows the overall effectiveness of the proposed breast cancer detection and classification technique over the other techniques.
6 Conclusion
This paper developed an improved optimization-based classification technique for accurately detecting breast cancer from mammogram images. The main objective of this work is to design an effective breast cancer detection system with reduced computational complexity, over-segmentation, and false positives. For this purpose, a set of image processing techniques have been implemented in this work, which helps to improve the overall classification performance of the detection system. At first, the Gaussian filtering and AHE techniques are utilized for noise removal and quality enhancement. Moreover, the main benefit of using this technique is to efficiently extract the breast masses with high contrast and quality. Then, the MRAS methodology has been utilized for segmenting the tumor region by selecting the random value of each group. Consequently, the GA based optimization technique is utilized for effectivelyextracting the features depending on the best fitness value. It includes the processes of crossover, mutation, and selection operations, which automatically determine the relative importance across different features for providing the optimal set of values. Finally, the CNN based deep learning classification technique is used to determine whether the given image is normal orthe tumoris influenced by its type. Like any adaptive process, genetic algorithms require feedback. The feedback for feature selection appears to only occur when you assess the trained model using those features. This seems like an expensive fitness function. The performance of the proposed technique is validated by using various evaluation metrics. Then, the obtained results are compared with some of the existing techniques for proving the betterment of the proposed system. Based on this evaluation, it is evident that the GA-CNN outperforms the other techniques with increased performance outcomes.
7 Future Work
Automated segmentation of mammogram images is a challenging task.Future research will optimize self-segmentation for better performance in systems for diagnosing breast cancer. In future work, we propose to incorporate the efficient deep U-Net segmentation method to enhance segmentation efficiency.
Data Availability
Data sharing not applicable to this article as no datasets were generated or analyzed during the current study.
References
Agnes SA, Anitha J, Pandian SIA, Peter JD (2020) Classification of mammogram images using multiscale all convolutional neural network (MA-CNN). J Med Syst 44(1):1–9. https://doi.org/10.1007/s10916-019-1494-z
Khan S, Islam N, Jan Z, Din IU, Rodrigues JJC (2019) A novel deep learning based framework for the detection and classification of breast cancer using transfer learning. Pattern Recogn Lett 125:1–6. https://doi.org/10.1016/j.patrec.2019.03.022
Gardezi SJS, Elazab A, Lei B, Wang T (2019) Breast cancer detection and diagnosis using mammographic data: systematic review. J Med Internet Res 21(7):e14464. https://doi.org/10.2196/14464
Gecer B, Aksoy S, Mercan E, Shapiro LG, Weaver DL, Elmore JG (2018) Detection and classification of cancer in whole slide breast histopathology images using deep convolutional networks. Pattern Recogn 84:345–356. https://doi.org/10.1016/j.patcog.2018.07.022
Hekal AA, Elnakib A, Moustafa HED (2021) Automated early breast cancer detection and classification system. Signal, Image Video Process 15:1–9. https://doi.org/10.1007/s11760-021-01882-w
Saber A, Sakr M, Abo-Seida OM, Keshk A, Chen H (2021) A novel deep-learning model for automatic detection and classification of breast cancer using the transfer-learning technique. IEEE Access 9:71194–71209. https://doi.org/10.1109/ACCESS.2021.3079204
Shen L, Margolies LR, Rothstein JH, Fluder E, McBride R, Sieh W (2019) Deep learning to improve breast cancer detection on screening mammography. Sci Rep 9(1):1–12. https://doi.org/10.1038/s41598-019-48995-4
Ragab DA, Sharkas M, Marshall S, Ren J (2019) Breast cancer detection using deep convolutional neural networks and support vector machines. PeerJ 7:e6201. https://doi.org/10.7717/peerj.6201
Assegie TA (2021) An optimized K-Nearest neighbor based breast cancer detection. J Robot Control (JRC) 2(3):115–118. https://doi.org/10.18196/jrc.2363
Cao Z, Duan L, Yang G, Yue T, Chen Q (2019) An experimental study on breast lesion detection and classification from ultrasound images using deep learning architectures. BMC Med Imag 19(1):1–9. https://doi.org/10.1186/s12880-019-0349-x
Patil RS, Biradar N (2021) Automated mammogram breast cancer detection using the optimized combination of convolutional and recurrent neural network. Evol Intel 14(4):1459–1474. https://doi.org/10.1007/s12065-020-00403-x
Punitha S, Amuthan A, Joseph KS (2018) Benign and malignant breast cancer segmentation using optimized region growing technique. Futur Comput Inf J 3(2):348–358. https://doi.org/10.1016/j.fcij.2018.10.005
Cherif W (2018) Optimization of K-NN algorithm by clustering and reliability coefficients: application to breast-cancer diagnosis. Procedia Comput Sci 127:293–299. https://doi.org/10.1016/j.procs.2018.01.125
Alzubaidi L, Al-Shamma O, Fadhel MA, Farhan L, Zhang J, Duan Y (2020) Optimizing the performance of breast cancer classification by employing the same domain transfer learning from hybrid deep convolutional neural network model. Electronics 9(3):445. https://doi.org/10.3390/electronics9030445
Wang H, Zheng B, Yoon SW, Ko HS (2018) A support vector machine-based ensemble algorithm for breast cancer diagnosis. Eur J Oper Res 267(2):687–699. https://doi.org/10.1016/j.ejor.2017.12.001
Melekoodappattu JG, Subbian PS, Queen MF (2021) Detection and classification of breast cancer from digital mammograms using hybrid extreme learning machine classifier. Int J Imag Syst Technol 31(2):909–920. https://doi.org/10.1002/ima.22484
Meenalochini G, Ramkumar S (2021) Survey of machine learning algorithms for breast cancer detection using mammogram images. Mater Today Proc 37:2738–2743. https://doi.org/10.1016/j.matpr.2020.08.543
Krithiga R, Geetha P (2021) Breast cancer detection, segmentation and classification on histopathology images analysis: a systematic review. Arch Comput Methods Eng 28(4):2607–2619. https://doi.org/10.1007/s11831-020-09470-w
Poloju N, Rajaram A (2022) Data mining techniques for patients healthcare analysis during Covid-19 pandemic conditions. J Environ Prot Ecol 23(5):2105–2112
Wang Z, Li M, Wang H, Jiang H, Yao Y, Zhang H, Xin J (2019) Breast cancer detection using extreme learning machine based on feature fusion with CNN deep features. IEEE Access 7:105146–105158. https://doi.org/10.1109/ACCESS.2019.2892795
Charan S, Khan MJ, Khurshid K (2018) Breast cancer detection in mammograms using convolutional neural network. In: International conference on computing, mathematics and engineering technologies (iCoMET), pp1–5. https://doi.org/10.1109/ICOMET.2018.8346384
Ramesh S, Sasikala S, Gomathi S, Geetha V, Anbumani V (2022) Segmentation and classification of breast cancer using novel deep learning architecture. Neural Comput Appl 34:1–13. https://doi.org/10.1007/s00521-022-07230-4
Chowdhary CL, Mittal M, Pattanaik P, Marszalek Z (2020) An efficient segmentation and classification system in medical images using intuitionist possibilistic fuzzy C-mean clustering and fuzzy SVM algorithm. Sensors 20(14):3903. https://doi.org/10.3390/s20143903
Oliveira HS, Teixeira JF, Oliveira HP (2019) Lightweight deep learning pipeline for detection, segmentation and classification of breast cancer anomalies. In: International conference on image analysis and processing, pp 707–715. https://doi.org/10.1007/978-3-030-30645-8_64
Khoulqi I, Idrissi N (2019) Breast cancer image segmentation and classification. In: Proceedings of the 4th international conference on smart city applications, pp 1–9. https://doi.org/10.1145/3368756.3369039
Al-Antari MA, Al-Masni MA, Choi MT, Han SM, Kim TS (2018) A fully integrated computer-aided diagnosis system for digital X-ray mammograms via deep learning detection, segmentation, and classification. Int J Med Inf 117:44–54. https://doi.org/10.1016/j.ijmedinf.2018.06.003
Jouni H, Issa M, Harb A, Jacquemod G, Leduc Y (2016) Neural Network architecture for breast cancer detection and classification. In: IEEE international multidisciplinary conference on engineering technology (IMCET), pp 37–41. https://doi.org/10.1109/IMCET.2016.7777423
Muduli D, Dash R, Majhi B (2020) Automated breast cancer detection in digital mammograms: a moth flame optimization based ELM approach. Biomed Signal Process Control 59:101912. https://doi.org/10.1016/j.bspc.2020.101912
Kalaivani K, Kshirsagarr PR, Sirisha Devi J, Bandela SR, Colak I, Nageswara Rao J, Rajaram A (2023) Prediction of biomedical signals using deep learning techniques. J Intell Fuzzy Syst (Preprint) 1–14
Khuriwal N, Mishra N (2018) Breast cancer detection from histopathological images using deep learning. In: 3rd international conference and workshops on recent advances and innovations in engineering (ICRAIE). IEEE, pp 1–4. https://doi.org/10.1109/ICRAIE.2018.8710426
Thawkar S, Ingolikar R (2020) Classification of masses in digital mammograms using the genetic ensemble method. J Intell Syst 29(1):831–845. https://doi.org/10.1515/jisys-2018-0091
Sannasi Chakravarthy SR, Rajaguru H (2022) Automatic detection and classification of mammograms using improved extreme learning machine with deep learning. IRBM 43(1):49–61. https://doi.org/10.1016/j.irbm.2020.12.004
Tiryaki VM, Kaplanoglu V (2022) Deep learning-based multi-label tissue segmentation and density assessment from mammograms. IRBM 43(6):538–548. https://doi.org/10.1016/j.irbm.2022.05.004
Lu SY, Wang SH, Zhang YD (2023) BCDNet: an optimized deep network for ultrasound breast cancer detection. IRBM 44(4):100774. https://doi.org/10.1016/j.irbm.2023.100774
Sannasi Chakravarthy SR, Bharanidharan N, Rajaguru H (2023) Deep learning-based metaheuristic weighted K-nearest neighbor algorithm for the severity classification of breast cancer. IRBM 44(3):100749. https://doi.org/10.1016/j.irbm.2022.100749
Liu T, Huang J, Liao T, Pu R, Liu S, Peng Y (2022) A hybrid deep learning model for predicting molecular subtypes of human breast cancer using multimodal data. IRBM 43(1):62–74. https://doi.org/10.1016/j.irbm.2020.12.002
Kaushal C, Bhat S, Koundal D, Singla A (2019) Recent trends in computer assisted diagnosis (CAD) system for breast cancer diagnosis using histopathological images. IRBM 40(4):211–227. https://doi.org/10.1016/j.irbm.2019.06.001
Desbordes P, Petitjean C, Ruan S (2016) Segmentation of lymphoma tumor in PET images using cellular automata: a preliminary study. IRBM 37(1):3–10. https://doi.org/10.1016/j.irbm.2015.11.001
Sung PC, Hsu CC, Lee CL, Chiu YSP, Chen HL (2015) Formulating grip strength and key pinch strength prediction models for Taiwanese: a comparison between stepwise regression and artificial neural networks. J Ambient Intell Humaniz Comput 6:37–46. https://doi.org/10.1007/s12652-014-0245-8
Alqudah AM, Qazan S, Al-Ebbini L, Alquran H, Qasmieh IA (2021) ECG heartbeat arrhythmias classification: a comparison study between different types of spectrum representation and convolutional neural networks architectures. J Ambient Intell Humaniz Comput. https://doi.org/10.1007/s12652-021-03247-0
Wu JMT, Tsai MH, Xiao SH, Liaw YP (2020) A deep neural network electrocardiogram analysis framework for left ventricular hypertrophy prediction. J Ambient Intell Humaniz Comput. https://doi.org/10.1007/s12652-020-01826-1
Mohammed AAQ, Lv J, Islam MS, Sang Y (2022) Multi-model ensemble gesture recognition network for high-accuracy dynamic hand gesture recognition. J Ambient Intell Humaniz Comput. https://doi.org/10.1007/s12652-021-03546-6
Kumar Y, Koul A, Singla R, Ijaz MF (2022) Artificial intelligence in disease diagnosis: a systematic literature review, synthesizing framework and future research agenda. J Ambient Intell Humaniz Comput. https://doi.org/10.1007/s12652-021-03612-z
Saha A, Rajak S, Saha J, Chowdhury C (2022) A survey of machine learning and meta-heuristics approaches for sensor-based human activity recognition systems. J Ambient Intell Humaniz Comput. https://doi.org/10.1007/s12652-022-03870-5
Shi N, Wang Y (2020) Symmetry in computer-aided music composition system with social network analysis and artificial neural network methods. J Ambient Intell Humaniz Comput. https://doi.org/10.1007/s12652-020-02436-7
Chang H, Zhao D, Wu CH, Li L, Si N, He R (2020) Visualization of spatial matching features during deep person re-identification. J Ambient Intell Humaniz Comput. https://doi.org/10.1007/s12652-020-01754-0
Kumar KH, Srinivas K (2021) Preliminary performance study of a brief review on machine learning techniques for analogy based software effort estimation. J Ambient Intell Humaniz Comput. https://doi.org/10.1007/s12652-021-03427-y
Musa N, Gital AY, Aljojo N, Chiroma H, Adewole KS, Mojeed HA, Faruk N, Abdulkarim A, Emmanuel I, Folawiyo YY, Ogunmodede JA (2022) A systematic review and meta-data analysis on the applications of deep learning in electrocardiogram. J Ambient Intell Humaniz Comput. https://doi.org/10.1007/s12652-022-03868-z
El Rahman SA (2021) Predicting breast cancer survivability based on machine learning and features selection algorithms: a comparative study. J Ambient Intell Humaniz Comput 12(8):8585–8623. https://doi.org/10.1007/s12652-020-02590-y
Lee S, Park D (2022) Abnormal beat detection from unreconstructed compressed signals based on linear approximation in ECG signals suitable for embedded IoT devices. J Ambient Intell Humaniz Comput 13(10):4705–4717. https://doi.org/10.1007/s12652-021-03578-y
Thakur M, Dhanalakshmi S, Kuresan H, Senthil R, Narayanamoorthi R, Lai KW (2023) Automated restricted Boltzmann machine classifier for early diagnosis of Parkinson’s disease using digitized spiral drawings. J Ambient Intell Humaniz Comput 14(1):175–189. https://doi.org/10.1007/s12652-022-04361-3
Fakhfakh M, Chaari L, Fakhfakh N (2020) Bayesian curved lane estimation for autonomous driving. J Ambient Intell Humaniz Comput 11:4133–4143. https://doi.org/10.1007/s12652-020-01688-7
Gupta V (2023) Application of chaos theory for arrhythmia detection in pathological databases. Int J Med Eng Inf 15(2):191–202. https://doi.org/10.1504/IJMEI.2023.129353
Zhao Q (2021) Social emotion classification of Japanese text information based on SVM and KNN. J Ambient Intell Humaniz Comput. https://doi.org/10.1007/s12652-021-03034-x
Fasil OK, Rajesh R (2022) Epileptic seizure classification using shifting sample difference of EEG signals. J Ambient Intell Humaniz Comput. https://doi.org/10.1007/s12652-022-03737-9
Gupta V, Mittal M, Mittal V, Diwania S, Saxena NK (2023) ECG signal analysis based on the spectrogram and spider monkey optimisation technique. J Inst Eng (India) Series B 104(1):153–164. https://doi.org/10.1007/s40031-022-00831-6
Sénéchal P, Perroud H, Kedziorek MA, Bourg AC, Gloaguen E (2005) Non destructive geophysical monitoring of water content and fluid conductivity anomalies in the near surface at the border of an agricultural. Subsurf Sens Technol Appl 6:167–192. https://doi.org/10.1007/s11220-005-0005-0
Mukherjee A, Kundu PK, Das A (2021) Transmission line fault location using PCA-based best-fit curve analysis. J Inst Eng (India) Series B 102:339–350. https://doi.org/10.1007/s40031-020-00515-z
Gupta V (2023) Wavelet transform and vector machines as emerging tools for computational medicine. J Ambient Intell Humaniz Comput 14(4):4595–4605. https://doi.org/10.1007/s12652-023-04582-0
Liu J, Zhang Y, Li C (2019) ANFIS-based signal reconstruction for nonlinear multifunctional sensor. J Inst Eng (India) Series B 100:397–404. https://doi.org/10.1007/s40031-019-00403-1
Behera S, Tripathy RK, Mohanty S (2013) Least square support vector machine modelling of breakdown voltage of solid insulating materials in the presence of voids. J Inst Eng (India) Series B 94:21–27. https://doi.org/10.1007/s40031-013-0039-y
Singh C, Saini JS (2015) Accurate and fast algorithm for the plotting of contours using eight node quadrilateral meshes. J Inst Eng (Indi): Series B 96:311–325. https://doi.org/10.1007/s40031-014-0151-7
Kaur J, Khehra BS (2022) Fuzzy logic and hybrid based approaches for the risk of heart disease detection: state-of-the-art review. J Inst Eng (India) Series B 103(2):681–697. https://doi.org/10.1007/s40031-021-00644-z
Gupta V, Mittal M, Mittal V, Gupta A (2023) Adaptive autoregressive modeling based ECG signal analysis for health monitoring. In: Optimization methods for engineering problems, pp 1–15, Apple Academic Press, New Jersey
Abbasi AR, Mahmoudi MR (2021) Application of statistical control charts to discriminate transformer winding defects. Electric Power Syst Res 191:106890. https://doi.org/10.1016/j.epsr.2020.106890
Abbasi AR, Mahmoudi MR, Arefi MM (2021) Transformer winding faults detection based on time series analysis. IEEE Trans Instrum Meas 70:1–10. https://doi.org/10.1109/TIM.2021.3076835
Haghbin H, Mahmoudi MR, Shishebor Z (2015) Large sample inference on the ratio of two independent binomial proportions. J Math Ext 5(1):87–95
Pan JJ, Mahmoudi MR, Baleanu D, Maleki M (2019) On comparing and classifying several independent linear and non-linear regression models with symmetric errors. Symmetry 11(6):820. https://doi.org/10.3390/sym11060820
Mahmoudi MR, Behboodian J, Maleki M (2017) Large sample inference about the ratio of means in two independent populations. J Stat Theor Appl 16(3):366–374. https://doi.org/10.2991/jsta.2017.16.3.8
Mahmoudi MR, Nematollahi AR, Soltani AR (2015) On the detection and estimation of the simple harmonizable processes. Iran J Sci Technol (Sci) 39(2):239–242
Ronoud S, Asadi S (2019) An evolutionary deep belief network extreme learning-based for breast cancer diagnosis. Soft Comput 23:13139–13159. https://doi.org/10.1007/s00500-019-03856-0
Selvathi D, AarthyPoornila A (2017) Performance analysis of various classifiers on deep learning network for breast cancer detection. In: International conference on signal processing and communication (ICSPC), pp359–363. https://doi.org/10.1109/CSPC.2017.8305869
Acknowledgements
There is no acknowledgement involved in this work.
Funding
No funding is involved in this work.
Author information
Authors and Affiliations
Contributions
All authors are contributed equally to this work.
Corresponding author
Ethics declarations
Conflict of interest
Conflict of Interest is not applicable in this work.
Ethical Approval and Consent to Participate
No participation of humans takes place in this implementation process.
Human and Animal Rights
No violation of Human and Animal Rights is involved.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Meenalochini, G., Ramkumar, S. A Deep Learning Based Breast Cancer Classification System Using Mammograms. J. Electr. Eng. Technol. 19, 2637–2650 (2024). https://doi.org/10.1007/s42835-023-01747-x
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s42835-023-01747-x