
Abstract
In civil engineering applications, piles, categorized as deep foundations, provide solid support for buildings by being pushed into the soil. The careful evaluation of the settling of foundations is crucial during the design phase due to their significant load-bearing capability. Therefore, the management and evaluation of settlement present a significant challenge within the piling design and construction domain. The novelty of this study could be combining the Adaptive Neuro-Fuzzy Inference System (ANFIS) with the Equilibrium Optimizer (EO), the Black Widow Optimization Algorithm (BWOA), and Particle Swarm Optimization (PSO), specific application to rock settlement prediction, use of local data, selection of key input parameters, and practical implications. The findings suggest that all ANFE, ANFB, and ANFP have significant promise in properly forecasting the pile settlement (SP). Uncertainty analysis depicts a better performance of the ANFE compared to ANFB by gaining 0.4916 lower than 0.7485 in the train part and 0.7099 smaller than 0.94 in the test part. It is important to note that deleting the UCS variable from the input category leads R2 to decrease and RRSE, MAE, and U95 to increase.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Rock-socketed piles use a combination of end bearing, shaft resistance, and a hybrid of these two systems to protect against imposed pressures. The use of piles in rock formations has been proposed as a potentially optimal arrangement in scenarios where an unsteady soil foundation overlays bedrock at a shallow depth (Sarkhani Benemaran et al. 2022a). Even if there is minimal pile displacement in these circumstances, the structural frame’s resistance may impact the extraordinary load-carrying capacity (Carrubba 1997). Requirements for socketed piles are rising since there is a rising requirement to improve piles’ structure and design efficiency. Both practical and mathematical methods impact the design of rock-socketed piles. A thorough modeling examination is, thus, planned. The findings show that both methods are suitable for building rock-based socketed piles (Ng et al. 2001).
The application of machine learning-based algorithms to estimate various properties in civil engineering was reported successfully recently (Sarkhani Benemaran et al. 2022b, 2024; Sarkhani Benemaran and Esmaeili-Falak 2023; Esmaeili-Falak and Sarkhani Benemaran 2024). Nevertheless, due to the intricate nature of the pile’s motion, no more dependable alternatives provide inaccurate estimates. Given the significance of pile settlement (\(SP\)) in pile architecture, a novel approach using soft computing techniques is presented to anticipate SP (Carrubba 1997).The precision of the input data plays a vital role in determining the effectiveness of estimating heaps. The following statements aim to reassess the relevant literature to determine the suitable input factors for predicting the progress of \(SP\). Based on an academic publication, several parameters have been identified as influential in the settling of the pile’s foundations, such as the magnitude of the applied force, the length of the pile, the modulus of shear of the soil, the width of the pile, and the angle at which the shear force becomes insignificant (Randolph and Wroth 1978).Within the framework of this specific geological creation, prior research has found that the unconfined compressive strength (\(UCS\)) of rocks acts a pivotal role in ascertaining the capacity of the pile, therefore influencing the \(SP\) (Tirant 1992). The information analysis approach was expanded to include the forecasting of foundation settling by including traditional penetration test findings. The present model was enhanced with around 1000 estimations from other articles, like ground data (Nejad et al. 2009). A neural network-based approach was developed to forecast the settlement of raft foundations on non-cohesive soils. The assessment or ground assessment included soil properties, footing measurements, and strengthening criteria (Soleimanbeigi and Hataf 2006). The evidence indicates that several important variables are critical in determining the settling of rock-socketed piles. These variables are the rock’s \(UCS\), the length-to-diameter ratio, the pile power, the proportion of the pile’s length in the soil to its length in the rock, and amount of \({N}_{SPT}\) (Shahin et al. 2002). Data mining techniques are expanded algorithms to address geotechnical issues that are discussed in many works (Momeni et al. 2015; Armaghani et al. 2016). To accurately forecast the depth of scouring around bridge piers (Najafzadeh and Barani 2011), as well as the formation of scour pile groups resulting from wave action (Najafzadeh and Azamathulla 2015), it is important to possess a comprehensive understanding of the cohesive properties of the soil (Najafzadeh et al. 2013). The genetic algorithm and genetic programming, also referred to as gene expression programming (\(GEP\)), are widely acknowledged as predictive approaches in the field such as liquefaction (Raja et al. 2023a). Through the use of approaches such as \(GEP\), it becomes feasible to create an innovative solution by building a linkage between the input variables and their related output. Several analytic methodologies, including multivariate adaptable regression spline (\(MARS\)), Gaussian method regression, and minimax probability machine regression, have been extensively and correctly used in prior research endeavors (Samui 2019; Le and Le 2021). The systematic application of \(GEP\) has facilitated the development of effective resolutions for several challenges encountered in geotechnical engineering (Dindarloo 2015). \(GEP\) was taken into consideration while trying to determine the axial ability of the piles (Alkroosh and Nikraz 2011). The authors proposed a unique description using the \(GEP\) technique to approximate the deformation moduli of soil (Mollahasani et al. 2011). Additional research was undertaken utilizing three different algorithms, namely the multilayer perceptron, supporting vector machine, and \(GEP\), to forecast the \(UCS\) of rock (Dindarloo 2015). The \(GEP\) approach is used to ascertain the deformation modulus of a stratified sedimentary rock creation (Alemdag et al. 2016).
A novel methodology has been devised to forecast \(SP\) using \(GEP\) in conjunction with multiple linear regression. To receive this data, a comprehensive study was performed on a substantial number of rock samples that were gathered from the project situated in Malaysia. Results suggest a strong probability of achieving success in the \(GEP\) analysis, as demonstrated by \({R}^{2}\) coefficients of 0.872 and 0.861 for the training and testing records, respectively. The root mean square error (\(RMSE\)) values were around 1.29 and 1.65 for the training and testing, respectively, further demonstrating the effectiveness of this method for forecasting \(SP\) (Armaghani et al. 2018). A model derived from a soft computing technique linked to swarming optimization was the goal of several investigations to anticipate \(SP\). The probability stage of the suggested hybrid algorithm’s performance in forecasting pile settlement was shown to have coefficients of determination that had been in the train 0.851 and test 0.079 (Armaghani et al. 2020).
Research uses an optimized Radial Basis Function Neural Network (RBFNN) to achieve its goals. This method is used to evaluate how well the chosen methods perform in the setting of this study. \(RBFNN\) have been proven to be useful in a variety of scientific and technological contexts in several types of research. An effective approach for rainfall predicting involves the use of a hybrid \(RBFNN\) that has been tuned using both Particle Swarm Optimization (PSO) and genetic algorithm techniques (Wu et al. 2015). The allocation of resources has been achieved using quantum PSO and \(RBF\) neural network techniques (Xu et al. 2016). The use of \(RBF\) neural networks in conjunction with the cuckoo search algorithm has been employed to accomplish the modeling of overhead crane systems (Zhu and Wang 2017). The computational analysis of a competitive swarm optimized \(RBF\) neural network has been important in enhancing the accuracy of short-term solar energy generation forecasts. Furthermore, optimizing the \(RBFNN\) using a sine–cosine method has successfully achieved sonar goal sorting.
Researchers in the study hoped to get an understanding of how to use \(SVR\) to predict pile settlement. They may improve the accuracy of the prediction with the addition of meta-heuristic approaches like the Arithmetic Optimization Algorithm (\(AOA\)) or the Grasshopper Optimization Algorithm (\(GOA\)). When compared to the \(SVR-GOA\mathrm{^{\prime}}s\) \(R\) value of 0.99, the \(SVR-AOA\mathrm{^{\prime}}s\) ratio of 0.994 is within a reasonable margin of error (Ge et al. 2023). To precisely calculate the vertical motions of piles under both dynamic and static loading conditions, researchers have turned to using Artificial Neural Networks (\(ANN\)). Using a \(RBFNN\), the Equilibrium Optimizer Algorithm (\(EOA\)), and the \(GOA\), the ideal number of neurons in the hidden layer was calculated. After running simulations, the \(RMSE\) error ratios for \(RBF-GOA\) (0.6312) and \(HRBF-EOA\) (0.5947) were found (Jiang 2022). To find the right number of neurons in hidden layers, this research suggests combining the Hybrid Radial Basis Function (\(HRBF\)) neural network method with the \(AOA\) and Biogeography-Based Optimization (\(BBO\)). The Klang Valley transportation network, including the Mass Rapid Transit system in Malaysia, was the primary subject of the research, emphasizing assessing the settling of piles and ground structures. For this study, we used the \(HRBF-AOA\) and \(HRBF-BBO\) scenarios. Throughout making predictions, the \(R\) values were 0.9825 for \(HRBF-AOA\) and 0.9724 \(HRBF-BBO\) (Zhang et al. 2022). Multivariate adaptive regression splines (\(MARS\)) were proposed as a method of forecasting pile settlement at varying degrees of interface. Results show that the order 3 \(MARS\) framework performs better than the others, with performance index (\(PI\)) levels of training (0.0541) and testing (0.0951) [49], utilizing the \(PI\) as a holistic evaluation of network efficiency (Zuo 2022).
1.1 The objective of this study
The novelty of your study lies in several aspects:
-
Integration of \(ANFIS\) with optimization algorithms: Combining the Adaptive Neuro-Fuzzy Inference System (\(ANFIS\)) with optimization algorithms like the Equilibrium Optimizer (\(EO\)), the Black Widow Optimization Algorithm (\(BWOA\)), and \(PSO\) is innovative. This integration can potentially improve the accuracy and efficiency of predicting pile settlement in rock formations compared to using \(ANFIS\) alone or other traditional methods.
-
Specific application to rock settlement prediction: This study focuses on predicting the settlement of piles in rocks, which is a critical issue in geotechnical engineering. While there are various methods for predicting pile settlement, applying \(ANFIS\) and optimization algorithms specifically to rock formations is relatively novel.
-
Use of local data: This study utilizes data from the Klang Valley Mass Rapid Transit (\(KVMRT\)) project in Kuala Lumpur, Malaysia. Using local data is important because geotechnical conditions can vary significantly from one location to another. Applying these methods to a specific regional project adds a practical and site-specific dimension to the research.
-
Selection of key input parameters: Your study identifies and uses five key input parameters, including the ratio of pile length in different layers, total length-to-diameter ratio, uniaxial compressive strength, standard penetration test results, and final bearing capacity. The selection of these parameters and their combination within the \(ANFIS\) framework represents a unique approach to solving the problem of pile settlement prediction in rocks.
-
Practical implications: The study’s findings can have practical implications for engineering and construction projects in regions with similar geological conditions to Kuala Lumpur. Accurate prediction of pile settlement is crucial for ensuring the stability and safety of structures, and this research could potentially contribute to more reliable foundation design practices.
2 Methodology
2.1 Dataset and pre-processing
Creating a suitable dataset with extremely efficient dependent variables is the first step in constructing a model for forecasting. The most influential factors on a model’s results should be described. The mentioned tests were conducted with a pile evaluation instrument developed by Pile Dynamic, Inc. The rate at which the pile undergoes distortion is governed by its dimension and length, as discussed earlier. This article utilized the dataset related to the Klang Valley Mass Rapid Transit (\(KVMRT\)) project in Malaysia, where the location and circumstances of the project are provided in Fig. 1 (Armaghani et al. 2020). So, the present research looks at the ratio of the length of the pile in the soil layer to the pile length in the stone layer (\({L}_{s}/{L}_{r}\)) and the ratio of total pile length to pile width (\({L}_{p}/D\)) to figure out how pile shape affects things. Moreover, the \(UCS\) was added as the system’s input for the purpose of forecasting pile collapse, owing to its considerable importance. The metric \({N}_{SPT}\) has been generally acknowledged as a significant factor in assessing the condition of the layer of soil. The input for the entire pile-bearing ability (\({Q}_{u}\)) was also supplied since the force placed on the pile directly affects sinking. To assess the settling of the pile (\(SP\)), five input factors were applied. According to the literature (Aghayari Hir et al. 2022; Bardhan et al. 2022; Raja et al. 2023b; Sarkhani Benemaran 2023), several ratios could be considered for dataset division into training and testing portions, such as 70/30, 80/20, 75/25, and 90/10. In the present study, the models were developed using all of these ratios, and the best ratio of 75% / 25% was selected for phases. Table 1 provides an overview of the inputs and outputs used in each model employed for this study, along with their corresponding intensities. Furthermore, Fig. 2 presents a visual representation of the bar chart and lognormal distribution of inputs and output.

Location of the \(KVMRT\) project

The lognormal distribution of parameters in the train and test phases
The Pearson correlation coefficient (Eq. 1) is used to assess the magnitude and degree of the linear connection between two discrete parameters. It measures how effectively a straight line can capture the connection between the two parameters. This statistic has a value that ranges from − 1 to 1. A complete positive linear connection is shown by a coefficient of + 1, which means that if one variable rises, the other rises correspondingly as well. A complete negative linear connection, as shown by a coefficient of − 1, means that when one variable rises, the other falls proportionately. There is no linear link between the two variables, as shown by a correlation coefficient of 0. The findings show that (Fig. 3), with minor exceptions, the majority of the variables show strong linear relationships. In addition to this, a 0.78 positive connection between \({L}_{s} / {L}_{r}\) and \({L}_{p} / D\) was found. In terms of negative values, \(UCS\) and \(SP\) were separated by -0.753.

The Pearson correlation analysis
2.2 Equilibrium optimizer (\({\varvec{E}}{\varvec{O}}\))
The unique meta-heuristic algorithm known as \(EO\) was introduced by Faramarzi et al. (Faramarzi et al. 2020) as a means to address optimization challenges. This method draws inspiration from the mass balancing mechanism used in control-level systems. \(EO\) has commendable efficacy in addressing evaluate optimization problems with dimensions of up to 200. \(EO\) includes three important facets: the process of initialization involves setting up the balance pool, which consists of four members and their average position. In addition, the updating method incorporates an exponential part and creation ratio. The fundamental principles of \(EO\) are presented in the following manner. During the initialization step, the locations of search agents, often referred to as particles, are randomly created inside the search space. This is typically represented as:
The initialization location of the \(i-th\) particle, denoted as \({X}_{i}^{initial}\), is determined by a random vector, \({r}_{ini}\), which is created from the interval (0,1). \({l}_{b}\) and \({u}_{b}\) respectively, signify the minimum and maximum values for the design parameter.
The balanced pool of evolutionary optimization (\(EO\)) comprises many agents of search that are in close proximity to the near-optimal answer. The balanced pool consists of five candidates, namely four elements with the highest fitness values and a fifth element determined by averaging the positions of the four best-performing elements. Potential choices inside the balance pool are first produced during the startup step and then adjusted after every repetition during the optimization stage.
The symbol \({X }_{eq,pool}\) denotes a balance pool, whereas \({X}_{eq(i)} (i = 1, 2, 3, 4)\) indicates the four potential candidates with the highest fitness values amid the elements. In addition, \({X }_{eq(ave)}\) refers to the average position of the four best-performing particles seen so far. In each cycle, the optimal particle to update the locations is selected randomly from the balanced pool with the same chance.
The optimization method involves updating the balance pool as well. During the update section, the \(EO\) framework adheres to two primary rules to follow: the focus updating rule, which is regulated by the exponential element (\(F\)), and the equilibrium state rule, which is governed by the creation ratio (\(G\)). The exponential element (\(F\)) has been officially defined as:
The variable \({a}_{1}\), as stated by Faramarzi et al. (Faramarzi et al. 2020), is set to a value of 2 to regulate the investigation capability. The variables \({r}_{1}\) and \({r}_{2}\) represent random vectors inside the interval (0,1), whereas t denotes the ratio of \(EO\) and can be mathematically written as:
where \(T\) is the current iteration and \({M}_{iter}\) represents the maximum number of iterations. The exploitation potential of \(EO\) may be regulated by adjusting the generation ratio (\(G\)), which is defined as:
Let \({X}_{eq}\) represent the candidate chosen from the balance pool as defined in Eq. (3).\(X(T)\) denotes the present location. The equation for \(GP\) may be expressed as \(GP = 0.5{r}_{d1}\), where \({r}_{d1}\) and \({r}_{d2}\) are randomly generated values between 0 and 1. In addition, \(u\) represents the unit vector. The updating method of search tools in \(EO\) is stated as follows:
The new location, denoted as \(X(T + 1)\), is determined by a random vector, \({r}_{3}\), which is uniformly distributed across the range \((0, 1)\). In addition, \(V\) denotes a unit. In Formula (8), the determination of the equilibrium concentration is mostly governed by the first term. At the same time, the second term predominantly influences searchability, while the third term primarily affects the exploitation ability. The procedure of \(EO\) algorithm is provided step by step in Algorithm. 1.

EO's steps Faramarzi et al. (2020)
2.3 Black widow optimization algorithm (\({\varvec{B}}{\varvec{W}}{\varvec{O}}{\varvec{A}}\))
Widows often inhabit forested areas as well as several other regions around the world. One special kind of widow spider is often referred to as the black widow, characterized by its distinctive behavioral patterns. The black widow spider often maintains a concealed presence during daylight hours, reserving its activity for the nighttime when it retreats to its web. The female black widow spider uses pheromones to attract the male counterpart by marking certain areas of her web during the mating process (El-Fergany 2018). By reducing the size of the web, the first male widower to enter the arena is able to steal attractive females from their male rivals. In this particular reproductive behavior, the female feeds the male partner in its entirety, afterward assuming the responsibility of carrying the eggs inside a specialized egg sac. Following the process of egg marking, the offspring partake in a period of sibling living together, during which they temporarily reside inside their mothers' web. This arrangement persists to the point when the offspring may even feed their moms. Consequently, the widows who had strength and physical fitness were more likely to succeed in this regular pattern. The duration of the life of the widow is considered to be a very effective approach for developing an optimal algorithm.
2.3.1 A novel black widow optimization algorithm
In a manner similar to previous evolutionary algorithms, the first phase of the innovative optimization process involves the establishment of an initial population of spiders, and each spider represents a potential solution. The primary objective of these female spiders, in conjunction with their male counterparts, is to ensure the successful reproduction and continuation of their lineage. During the mating period or subsequent to it, the female widow spider engages in cannibalistic behavior by consuming her male partner. Eventually, she transfers preserved sperm into her sperm storage organs and subsequently introduces them into the ovisacs. The gestation period for spiders is around 11 days. During a certain period ranging from a few days to a week, the offspring cohabit inside the maternal web, during which instances of sibling cannibalism have been seen. Finally, the little spiders traverse the air currents.
2.3.2 Initial population
In the context of an optimization problem involving \(N\) dimensions, a window is conceptualized as an array of dimensions (\(1\times {N}_{var}\)) that represents the solution to the optimization problem. The array is represented by the following notation:
Each of the parameter amounts (\({x}_{1}, {x}_{2} \dots {x}_{Nvar}\)) is represented as a floating-point number. The fitness an amount of a widow is determined by evaluating the fitness function, denoted as \(f\), at a widow consisting of parameters (\({x}_{1}, {x}_{2} \dots {x}_{Nvar}\)).
2.3.3 Generation
It is important to acknowledge that each couple is mutually separate, beginning the process of pairing to produce offspring simultaneously, akin to natural occurrences. Every couple has unique web compatibility. In nature, each successful couple produces more than 1,000 eggs, but only a few healthy spider lings survive. In the suggested process, it is necessary to renew an array called alpha if a widow array holding random numbers is present since this would result in the creation of children. In the equation that follows, the variables \({x}_{1}\) and \({x}_{2}\) are defined as parental entities, whereas the parameters \({y}_{1}\) and \({y}_{2}\) are chosen to represent children.
This process is repeated \({N}_{var}/2\) times, or until it is clear that the random integers being used are unique.
2.3.4 Cannibalism
Within this particular stage, there are two distinct forms of cannibalism. The first phenomenon under discussion is often referred to as sexual cannibalism when the female black widow spider consumes her male partner either during or during the mating process. The suggested method distinguishes between females and men based on their respective fitness scores. Sibling cannibalism is the second form, in which the stronger spider lings use their weaker siblings. Identify if spiderlings are strong or weak using the fitness amount.
2.3.5 Mutation
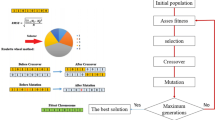
During this particular stage, the selection of \(Muttpop\) is conducted in a random manner, as seen in Fig. 4.

Mutation
2.3.6 Convergence
Like other methods of evolution, it is possible to consider three-stage scenarios: (\(A\)) a preset amount of rounds, (\(B\)) the requirement that the fitness and amount of the best solution remain unchanged for many iterations, and (\(C\)) the achievement of a certain degree of accuracy.
2.3.7 Parameter setting
One crucial aspect of the suggested algorithm is the identification of several factors to get improved outcomes. The factors in the study are the cannibalism rate (\(CR\)), procreation rate (\(PP\)), and mutation rate (\(PM\)). The procedure of \(BWO\) algorithm is provided step by step in Algorithm 2.

BWOA Hayyolalam and Kazem (2020)
2.4 Adaptive Neuro-Fuzzy Inference System (\({\varvec{A}}{\varvec{N}}{\varvec{F}}{\varvec{I}}{\varvec{S}}\))
As a well-known machine learning technique, the \(ANFIS\) algorithm has seen extensive use in the study and solution of challenging nonlinear problems (Jiang et al. 2019; Masoumi et al. 2020). The present approach effectively combines the neural network with the fuzzy conclusion system. The \(ANFIS\) utilizes the least squares and gradient descent algorithms to facilitate the learning process of the method. It is being discovered that \(ANFIS\) is a useful technique for use in solving forecast issues. This is an explanation of a five-tiered \(ANFIS\) (Shahnazar et al. 2017).
In the first layer, known as the fuzzification layer, every node is considered an adaptable input.
The symbols \(\mu {A}_{i}({x}_{1})\) and \(\mu {B}_{i-2}({x}_{2})\) represent Gaussian membership activities, whereas the quantity n represents the number of fuzzy sets for other input variables (Shahnazar et al. 2017). Using Eq. 14, each node in the second layer (the product layer) determines the efficacy of a given rule by means of its ability to trigger an event.
The normalizing procedure takes place inside the third layer, or the normalized layer, using Eq. 15 and the summing of the firing strength ratio of the \(i\) th condition to the firing strength of all the other rules (Shahnazar et al. 2017).
The defuzzification procedure is executed inside the fourth layer. Within this particular layer, every individual node has the ability to change in accordance with Eq. 16.
The symbol \({\overline{w} }_{i}\) shows the result of the third layer, whereas \(\left\{{k}_{1}^{i},{k}_{2}^{i},{k}_{0}^{i}\right\}\) indicates the variable ranges associated with the \({\overline{w} }_{i}\) node. The result of the fifth layer, namely the output layer, is generated by summing the result of the preceding layer according to Eq. (17).
\(ANFIS\) involves the use of three distinct simulations, namely fuzzy \(C-\) means clustering (\(FCM\)), subtractive clustering (\(SCM\)), and grid partitioning (\(GP\)). Since \(FCM\) has been shown to be the strongest simulation in the literature, it was selected for use in the \(ANFIS\) algorithm’s predictive capabilities. Nikafshan Rad et al. provide a thorough explanation of \(FCM\) (Rad et al. 2015). In relation to \(ANFIS\) concepts, a primary \(ANFIS\) design was generated employing the initial variables. The \(EO\), \(BWOA\), and \(PSO\) methodologies were then used to improve the \(ANFIS\) framework that had been built. The membership function parameters for the suggested network were improved by applying the \(EO\), \(BWOA,\) and \(PSO\) methods in this study. The \(RMSE\) metric was used as a fitness indicator to evaluate the accuracy of the optimization framework. In conclusion, a hybridized and optimized network consisting of \(ANFE\), \(ANFB\), and \(ANFP\) components were established, with the network parameters, including the quantity of fuzzy words and the maximum iteration count, being specified.
Here is a detailed explanation of the coupling process:
-
The initializing of the \(ANFIS\) model begins with random or predefined initial parameters. These parameters include membership function parameters, rule weights, and input/output scaling factors.
-
\(EO\), \(BWOA,\) and \(PSO\) are integrated into the parameter learning process of the \(ANFIS\) model.
-
During optimization, \(EO\), \(BWOA,\) and \(PSO\) interact with the \(ANFIS\) architecture to update the parameters, such as membership function parameters and rule weights, based on the fitness evaluations.
-
The optimization algorithms modify the parameters of the \(ANFIS\) model iteratively, gradually improving its performance on the training data.
-
The optimization process continues until a termination criterion is met, such as convergence of the objective function or reaching a maximum number of iterations.
-
Once optimization is complete, the performance of the coupled \(ANFIS\) model with \(EO\), \(BWOA,\) and \(PSO\) is evaluated using testing data.
2.5 Metrics
Seven efficiency indicators were used to compare and evaluate the performance of the hybrid ANFE, ANFB, and ANFP models. The indices are:
-
Coefficient of determination (\({R}^{2}\))
-
Root mean square error (\(RMSE\))
-
Normalized root mean square error (\(NRMSE\)
-
Root relative squared error (\(RRSE\))
-
Relative absolute error (\(RAE\))
-
Mean absolute error (\(MAE\))
Lesser values of RMSE, NRMSE, RRSE, MAE, and RAE show more accuracy. Furthermore, a higher \({R}^{2}\) number is a sign of better performance.
-
In addition, the \(OBJ\) metric was taken into account as a complete indication that RMSE, MAE, and R2 values were concurrently calculated for the training and testing phases.
$${{R}^{2}=\left(\frac{{\sum }_{d=1}^{D}\left({m}_{d}-\overline{m }\right)\left({z}_{d}-\overline{z }\right)}{\sqrt{\left[{\sum }_{d=1}^{D}{\left({m}_{P}-m\right)}^{2}\right]\left[{\sum }_{d=1}^{D}{\left({z}_{d}-\overline{z }\right)}^{2}\right]}}\right)}^{2}$$(18)$$RMSE=\sqrt{\frac{1}{D}{\sum }_{d=1}^{D}{\left({z}_{d}-{m}_{d}\right)}^{2}}$$(19)$$NRMSE=RMSE/\overline{z }$$(20)$$RRSE=\sqrt{\frac{\sum_{d=1}^{D}{({m}_{d}-{z}_{d})}^{2}}{\sum_{d=1}^{D}{({m}_{d}-\overline{m })}^{2}}}$$(21)$$RAE=\frac{\sum_{d=1}^{D}\left|{m}_{d}-{z}_{d}\right|}{\sum_{d=1}^{D}\left|{m}_{d}-\overline{m }\right|}$$(22)$$MAE=\frac{1}{D}\sum_{d=1}^{D}\left|{z}_{d}-{m}_{d}\right|$$(23)$$OBJ = \left[ {\frac{d}{D} \times \frac{{RMSE + MAE}}{{R^{2} + 1}}} \right]_{{train}} + \left[ {\frac{d}{D} \times \frac{{RMSE + MAE}}{{R^{2} + 1}}} \right]_{{test}}$$(24)
The variables \({m}_{d}\), \(\overline{m }\), \({z}_{d}\), and \(\overline{z }\) represent the observed values, the mean of the observed values, the simulated values, and the mean of the simulated values, respectively, in the given equations. Moreover, the variable \(D\) denotes the total number of datasets. Uncertainty analysis at 95% confidence level (\({U}_{95}\)) provided further information on scenario efficacy [63,64]. This inquiry compares the real and simulated outcomes, as shown by Eq. 25.
3 Findings and justifications
This research paper shows the findings of the \(ANFE\), \(ANFB\), and \(ANFP\) investigations. These analyses were performed to ascertain the \(SP\) of deep foundations when they are buried in rock. Figure 5 displays the measured and estimated quantities of the \(SP\) throughout the training and evaluation stages of the established \(ANFE\) and \(ANFB\) methodologies. Moreover, the chart presented exhibits an error percentage distribution along with a time series. Furthermore, the present study compared the results of the generated models with the most relevant literature sources to assess the reliability and effectiveness of these models considering order three \(MARS\) (\(MO3\)) (Zuo 2022), ant lion optimizer with multi-layered perceptron (\(ALO-MLP\)) (Hu 2022), ant lion optimizer with \(ANFIS\) (\(ALO-ANFIS\)) (Yu 2022), ant lion optimizer with \(RBF\) (\(ALO-RBFNN\)) (\(neuro-swarm system\)Armaghani et al. 2020; Gao and Jun-Wei 2022), and (\(GEP\)Armaghani et al. 2018).

The performance of systems (correlation, time series, and error histogram)
The findings suggest that all \(ANFE\), \(ANFB,\) and \(ANFP\) have significant promise in properly forecasting the \(SP\). The \(ANFE\) system demonstrated high levels of accuracy, with \({R}^{2}\) values of 0.9977 and 0.996 attained during the phases of training and testing. Similarly, the \(ANFB\) system exhibited strong performance, with \({R}^{2}\) values of 0.9946 and 0.993 in its training and evaluating stages, respectively. Moreover, the third rank belonged to \(ANFP\), getting the \({R}^{2}\) values of 0.9805 and 0.989 attained during the phases of training and testing. To achieve this purpose, it is crucial to do a thorough assessment of the behavior shown by different error-based metrics. By analyzing the divergent values of \(ANFE\) and \(ANFB\) in relation to these parameters, it becomes apparent that \(ANFE\) demonstrates an approximate 50% reduction when compared to \(ANFE\). The aforementioned decrease highlights the dependability of \(ANFE\) in predicting the stock price. Uncertainty analysis values by calculating \({U}_{95}\) as a precious index (the lower values, the more accuracy) depict a better performance of the \(ANFE\) compared to \(ANFB\) by gaining 0.4916 lower than 0.7485 in the train part and at 0.7099 smaller than 0.94 in the test. In addition, a comprehensive index was computed, referred to as the \(OBJ\), which encompasses the values of \(RMSE\), \(MAE\), and \({R}^{2}\) for both the training and test phases. In this context, lower values of these metrics indicate greater precision of the systems. The results show that the \(ANFE\) model received the lowest \(OBJ\) at 0.1649 compared to \(ANFB\) at 0.2444, and compared to \(ANFP\) at 0.2968, approving the applicability and reliability of the models.
A comprehensive comparison is performed to validate the reliability of the models with the literature \(MO3\) (\(ALO-MLPALO-ANFISALO-RBFNNneuro-swarm system\)Armaghani et al. 2020; Zuo 2022; Hu 2022; Yu 2022; Gao and Jun-Wei 2022), and (\(GEP\)Armaghani et al. 2018). After conducting a thorough analysis of Table 2, it becomes apparent that the \(ANFE\) proposed in this study exhibited a superior level of efficacy in comparison to previous investigations reported in the existing scholarly literature. This assessment considered comparable evaluation measures, including \({R}^{2}\), \(MAE\), and \(RMSE\). The findings of this research exhibit more robustness and precision compared to existing literature, as shown by the attainment of higher \({R}^{2}\) values and lower \(RMSE\) and \(MAE\) values. Regarding the \({R}^{2}\), a significant improvement can be observed when attaining values beyond 0.99, starting with beginning values below 0.844 (Armaghani et al. 2020). The ALO–RBFNN [53] has the lowest \(RMSE\) when compared to other developed models (Gao and Jun-Wei 2022). However, it is worth noting that the RMSE values for the ALO–RBFNN model are very high when compared to the \(ANFE\) model, with values of 0.1767 \(mm\) and 0.2535 \(mm\) seen in the train and test stages, respectively.
3.1 Sensitivity analysis
How inputs affect the simulation’s performance may be understood via the use of sensitivity analyses in mathematical models. To find the impact of removing each parameter, several models were created in the present investigation, each employing unique input elements. The generated models were compared with the results of the outperformed models, i.e., \(ANFE\). \(ANFE\) was used to calculate and compare the \({R}^{2}\), \(RRSE\), \(MAE\), and \({U}_{95}\) metrics evaluate the impact of various inputs (Table 3). The impact of variables that have been removed from the conclusion becomes increasingly obvious as measurement discrepancies widen. Based on the findings, it can be concluded that almost every input has a marginally detrimental effect on output as compared to \(ANFE\). It is important to note that deleting the \(UCS\) variable from the input category leads \({R}^{2}\) to decrease and \(RRSE\), \(MAE\), and \({U}_{95}\) to increase. In the training phase, the value of the \({R}^{2}\) showed a reduction from 0.9977 to 0.971. In this phase, \(RRSE\), \(MAE\), and \({U}_{95}\) depict the remarkable increment from 0.0491 to 0.173, 0.1269 to 0.4231, and from 0.4916 to 1.7326, respectively. This trend is valid for the testing phase. Removing \({L}_{s}/{L}_{r}\) has the lowest impact on the output by resulting in lower differences of the metrics with respect to the model with no removal. It is important to point out that the models were made using a set of data that came from tests. So, leaving out any number could make the programs less complete and reliable.
3.2 Limitations, suggestions, and practical usages
The accuracy of the predictive model heavily relies on the quality and quantity of data available. Future research could explore ways to obtain more comprehensive and high-quality data. The generalizability of the proposed approach to other geological conditions and foundation types may be limited. Future research could investigate the adaptability of this model to different scenarios. The choice of optimization algorithms and modeling techniques (\(ANFIS\), \(EO\), \(BWOA\), and \(PSO\)) can significantly affect the results. It is possible that the performance of these algorithms may vary for different datasets or applications. Future work could explore a wider range of optimization techniques to assess their robustness.
By providing more reliable predictive models, the study’s findings can directly contribute to enhancing the design process. Engineers can use these models to optimize pile configurations, sizes, and placement strategies, leading to more cost-effective and structurally sound foundations.
Unforeseen settlement can lead to delays, structural damage, and costly remediation efforts. By leveraging accurate predictive models, project stakeholders can anticipate potential settlement issues early in the design phase and implement preventive measures to minimize risks.
Understanding the anticipated settlement behavior of piles in rock formations allows construction planners to optimize project schedules and sequencing. By incorporating predictive models into construction planning software, project managers can better allocate resources, schedule activities, and mitigate potential conflicts between construction activities and ground settlement constraints.
4 Conclusion
To operationalize hybrid \(ANFIS\) designs, the study employed the results of \(PDA\) tests, together with the properties of both piles and soil. In relation to this matter, five elements, namely \({L}_{s}/{L}_{r}\), \({L}_{p}/D\), \(UCS\), \(N\), and \({Q}_{u}\), were selected as independent variables for the purpose of forecasting the pile settlement (\(SP\)) in rock formations. To improve the precision of the models, the primary essential parameters of the \(ANFIS\) were calculated by integrating the \(EO\), the \(BWOA\), and \(PSO\).
-
The findings suggest that all \(ANFE\), \(ANFB,\) and \(ANFP\) have significant promise in properly forecasting the \(SP\). The \(ANFE\) system demonstrated high levels of accuracy, with \({R}^{2}\) values of 0.9977 and 0.996 attained during the phases of training and testing. Similarly, the \(ANFB\) system exhibited strong performance, with \({R}^{2}\) values of 0.9946 and 0.993 in its training and evaluating stages, respectively. Moreover, the third rank belonged to \(ANFP\) getting the \({R}^{2}\) values of 0.9805 and 0.989 during the phases of training and testing, respectively.
-
By analyzing the divergent values of \(ANFE\) and \(ANFB\) in relation to error-based metrics, it becomes apparent that \(ANFE\) demonstrates an approximate 50% reduction when compared to \(ANFE\).
-
Uncertainty analysis depicts a better performance of the \(ANFE\) compared to \(ANFB\) by gaining 0.4916 lower than 0.7485 in the train part and at 0.7099 smaller than 0.94 in the test part.
-
The results show that the \(ANFE\) model received the lowest \(OBJ\) at 0.1649 compared to \(ANFB\) at 0.2444, and compared to \(ANFP\) at 0.2968, approving the applicability and reliability of the models.
-
The findings of this research exhibit more robustness and precision compared to existing literature, as shown by the attainment of higher \({R}^{2}\) values and lower \(RMSE\) and \(MAE\) values.
-
It Is important to note that deleting the \(UCS\) variable from the input category leads \({R}^{2}\) to decrease and \(RRSE\), \(MAE\), and \({U}_{95}\) to increase. In the training phase, the value of the \({R}^{2}\) showed a reduction from 0.9977 to 0.971. In this phase, \(RRSE\), \(MAE\), and \({U}_{95}\) depict the remarkable increment from 0.0491 to 0.173, 0.1269 to 0.4231, and from 0.4916 to 1.7326, respectively. This trend is valid for the testing phase.
-
The generalizability of the proposed approach to other geological conditions and foundation types may be limited. Future research could investigate the adaptability of this model to different scenarios. The choice of optimization algorithms and modeling techniques (\(ANFIS\), \(EO\), \(BWOA\), and \(PSO\)) can significantly affect the results. It is possible that the performance of these algorithms may vary for different datasets or applications. Future work could explore a wider range of optimization techniques to assess their robustness.
-
By providing more reliable predictive models, the study’s findings can directly contribute to enhancing the design process. Engineers can use these models to optimize pile configurations, sizes, and placement strategies, leading to more cost-effective and structurally sound foundations. Understanding the anticipated settlement behavior of piles in rock formations allows construction planners to optimize project schedules and sequencing. By incorporating predictive models into construction planning software, project managers can better allocate resources, schedule activities, and mitigate potential conflicts between construction activities and ground settlement constraints.
Data availability
The authors do not have permissions to share data.
References
Aghayari Hir M, Zaheri M, Rahimzadeh N (2022) Prediction of rural travel demand by spatial regression and artificial neural network methods (Tabriz County). J Transp Res 20(4):367–386
Alemdag S, Gurocak Z, Cevik A, Cabalar AF, Gokceoglu C (2016) Modeling deformation modulus of a stratified sedimentary rock mass using neural network, fuzzy inference and genetic programming. Eng Geol 203:70–82
Alkroosh I, Nikraz H (2011) Correlation of pile axial capacity and CPT data using gene expression programming. Geotech Geol Eng 29:725–748
Armaghani DJ, Amin MFM, Yagiz S, Faradonbeh RS, Abdullah RA (2016) Prediction of the uniaxial compressive strength of sandstone using various modeling techniques. Int J Rock Mech Min Sci 85:174–186
Armaghani DJ, Faradonbeh RS, Rezaei H, Rashid ASA, Amnieh HB (2018) Settlement prediction of the rock-socketed piles through a new technique based on gene expression programming. Neural Comput Appl 29:1115–1125
Armaghani DJ, Asteris PG, Fatemi SA, Hasanipanah M, Tarinejad R, Rashid ASA, Van Huynh V (2020) On the use of neuro-swarm system to forecast the pile settlement. Appl Sci 10:1904
Bardhan A, GuhaRay A, Gupta S, Pradhan B, Gokceoglu C (2022) A novel integrated approach of ELM and modified equilibrium optimizer for predicting soil compression index of subgrade layer of Dedicated Freight Corridor. Transp Geotech 32:100678
Carrubba P (1997) Skin friction on large-diameter piles socketed into rock. Can Geotech J 34:230–240
Dindarloo SR (2015) Prediction of blast-induced ground vibrations via genetic programming. Int J Min Sci Technol 25:1011–1015
El-Fergany AA (2018) Electrical characterisation of proton exchange membrane fuel cells stack using grasshopper optimiser. IET Renew Power Gener 12:9–17
Esmaeili-Falak M, Sarkhani Benemaran R (2024) Application of optimization-based regression analysis for evaluation of frost durability of recycled aggregate concrete. Struct Concr. https://doi.org/10.1002/suco.202300566
Faramarzi A, Heidarinejad M, Stephens B, Mirjalili S (2020) Equilibrium optimizer: a novel optimization algorithm. Knowl-Based Syst 191:105190. https://doi.org/10.1016/j.knosys.2019.105190
Gao H, Jun-Wei Z (2022) Estimation of pile settlement applying hybrid radial basis function network with BBO ALO, and GWO Optimization Algorithms. 淡江理工學刊 25:1183–1196
Ge Q, Li C, Yang F (2023) Support vector machine to predict the pile settlement using novel optimization algorithm. Geotech Geol Eng. https://doi.org/10.1007/s10706-023-02487-5
Hayyolalam V, Kazem AAP (2020) Black widow optimization algorithm: a novel meta-heuristic approach for solving engineering optimization problems. Eng Appl Artif Intell 87:103249
Hu J (2022) Estimation of pile settlement applying hybrid ALO-MLP and GOA-MLP approaches. 淡江理工學刊 25:1239–1255
Jiang R (2022) Using the integrated neural network of radial basis function (RBF) via optimization algorithms to estimate pile settlement range. J Intell Fuzzy Syst. https://doi.org/10.3233/JIFS-220741
Jiang W, Arslan CA, Soltani Tehrani M, Khorami M, Hasanipanah M (2019) Simulating the peak particle velocity in rock blasting projects using a neuro-fuzzy inference system. Eng Comput 35:1203–1211
Le T-T, Le MV (2021) Development of user-friendly kernel-based Gaussian process regression model for prediction of load-bearing capacity of square concrete-filled steel tubular members. Mater Struct 54:1–24
Masoumi F, Najjar-Ghabel S, Safarzadeh A, Sadaghat B (2020) Automatic calibration of the groundwater simulation model with high parameter dimensionality using sequential uncertainty fitting approach. Water Supply 20:3487–3501
Mollahasani A, Alavi AH, Gandomi AH (2011) Empirical modeling of plate load test moduli of soil via gene expression programming. Comput Geotech 38:281–286
Momeni E, Nazir R, Armaghani DJ, Maizir H (2015) Application of artificial neural network for predicting shaft and tip resistances of concrete piles. Earth Sci Res J 19:85–93
Najafzadeh M, Azamathulla HM (2015) Neuro-fuzzy GMDH to predict the scour pile groups due to waves. J Comput Civ Eng 29:4014068. https://doi.org/10.1061/(ASCE)CP.1943-5487.0000376
Najafzadeh M, Barani G-A (2011) Comparison of group method of data handling based genetic programming and back propagation systems to predict scour depth around bridge piers. Sci Iran 18:1207–1213. https://doi.org/10.1016/j.scient.2011.11.017
Najafzadeh M, Barani G-A, Azamathulla HM (2013) GMDH to predict scour depth around a pier in cohesive soils. Appl Ocean Res 40:35–41. https://doi.org/10.1016/j.apor.2012.12.004
Nejad FP, Jaksa MB, Kakhi M, McCabe BA (2009) Prediction of pile settlement using artificial neural networks based on standard penetration test data. Comput Geotech 36:1125–1133
Ng CWW, Yau TLY, Li JHM, Tang WH (2001) Side resistance of large diameter bored piles socketed into decomposed rocks. J Geotech Geoenviron Eng 127:642–657
Rad HN, Jalali Z, Jalalifar H (2015) Prediction of rock mass rating system based on continuous functions using Chaos–ANFIS model. Int J Rock Mech Min Sci 73:1–9
Raja MNA, Abdoun T, El-Sekelly W (2023a) Smart prediction of liquefaction-induced lateral spreading. J Rock Mech Geotech Eng. https://doi.org/10.1016/j.jrmge.2023.05.017
Raja MNA, Jaffar STA, Bardhan A, Shukla SK (2023b) Predicting and validating the load-settlement behavior of large-scale geosynthetic-reinforced soil abutments using hybrid intelligent modeling. J Rock Mech Geotech Eng 15:773–788
Randolph MF, Wroth CP (1978) Analysis of deformation of vertically loaded piles. J Geotech Eng Div 104:1465–1488
Samui P (2019) Determination of friction capacity of driven pile in clay using Gaussian process regression (GPR), and minimax probability machine regression (MPMR). Geotech Geol Eng 37:4643–4647
Sarkhani Benemaran R (2023) Application of extreme gradient boosting method for evaluating the properties of episodic failure of borehole breakout. Geoenergy Sci Eng 226:211837. https://doi.org/10.1016/j.geoen.2023.211837
Sarkhani Benemaran R, Esmaeili-Falak M (2023) Predicting the Young’s modulus of frozen sand using machine learning approaches: State-of-the-art review. Geomech Eng 34:507–527
Sarkhani Benemaran R, Esmaeili-Falak M, Katebi H (2022a) Physical and numerical modelling of pile-stabilised saturated layered slopes. Proc Inst Civ Eng Eng 175:523–538
Sarkhani Benemaran R, Esmaeili-Falak M, Javadi A (2022b) Predicting resilient modulus of flexible pavement foundation using extreme gradient boosting based optimised models. Int J Pavement Eng. https://doi.org/10.1080/10298436.2022.2095385
Sarkhani Benemaran R, Esmaeili-Falak M, Sadighi Kordlar M (2024) Improvement of recycled aggregate concrete using glass fiber and silica fume. Multiscale Multidiscip Model Exp Des. https://doi.org/10.1007/s41939-023-00313-2
Shahin MA, Maier HR, Jaksa MB (2002) Predicting settlement of shallow foundations using neural networks. J Geotech Geoenviron Eng 128:785–793
Shahnazar A, Nikafshan Rad H, Hasanipanah M, Tahir MM, Jahed Armaghani D, Ghoroqi M (2017) A new developed approach for the prediction of ground vibration using a hybrid PSO-optimized ANFIS-based model. Environ Earth Sci 76:1–17
Soleimanbeigi A, Hataf N (2006) Prediction of settlement of shallow foundations on reinforced soils using neural networks. Geosynth Int 13:161–170
Le Tirant P (1992) Design guides for offshore structures: Offshore pile design
Wu J, Long J, Liu M (2015) Evolving RBF neural networks for rainfall prediction using hybrid particle swarm optimization and genetic algorithm. Neurocomputing 148:136–142
Xu L, Qian F, Li Y, Li Q, Yang Y, Xu J (2016) Resource allocation based on quantum particle swarm optimization and RBF neural network for overlay cognitive OFDM system. Neurocomputing 173:1250–1256
Yu D (2022) Estimation of pile settlement socketed to rock applying hybrid ALO-ANFIS and GOA-ANFIS approaches. 淡江理工學刊 25:1131–1144
Zhang M, Du Q, Yang J, Liu S (2022) Modeling the pile settlement using the Integrated Radial Basis Function (RBF) neural network by Novel Optimization algorithms: HRBF-AOA and HRBF-BBO. J Intell Fuzzy Syst 43(6):7009–7022
Zhu X, Wang N (2017) Cuckoo search algorithm with membrane communication mechanism for modeling overhead crane systems using RBF neural networks. Appl Soft Comput 56:458–471
Zuo Q (2022) Settlement prediction of the piles socketed into rock using multivariate adaptive regression splines. J Appl Sci Eng 26:111–119
Author information
Authors and Affiliations
Contributions
All authors contributed to the study’s conception and design. Data collection, simulation and analysis were performed by “Xi CHEN, Liting ZHU and Lingfeng JI”. The first draft of the manuscript was written by “Xi CHEN” and all authors commented on previous versions of the manuscript. All authors have read and approved the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflict of interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Chen, X., Zhu, L. & Ji, L. Settlement estimation of the piles socketed into rock employing hybrid ANFIS systems. Multiscale and Multidiscip. Model. Exp. and Des. 7, 3375–3389 (2024). https://doi.org/10.1007/s41939-024-00410-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s41939-024-00410-w