
Abstract
In this study, we concentrate on multiple attribute decision-making (MADM) problems in the probabilistic linguistic preference information surroundings based on novel aggregation operators. Considering interrelationships among the multi-input arguments of probabilistic linguistic term sets (PLTSs), we extend dual Muirhead mean (DMM) operators to the probabilistic linguistic preference environment and develop a decision-making approach to deal with probabilistic linguistic MADM (PLMADM) problems. In specific, we define probabilistic linguistic dual Muirhead mean operators, i.e., probabilistic linguistic dual Muirhead mean (PLDMM) operator and probabilistic linguistic weighted dual Muirhead mean (PLWDMM) operator, and further investigate their corresponding propositions, theorems as well as properties. In the light of VIKOR method, a novel decision-making approach for PLMADM problems has been carefully explored. Finally, an application of hospitals selection can fruitfully demonstrate and signify the practicality and feasibility of the proposed decision-making approach.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Multiple attribute decision making (MADM) is one of meaningful and significant behaviors which selects optimal alternative from several candidates with respect to finite attributes according to evaluation information given by decision makers (DMs). It has been widely focused and largely applied in the various fields, such as the determination of importance ratings of customer requirements [1], assessment of the renewable energies [2], evaluation of water conservancy project [3], research and development (R&D) project selection [4], investment projects’ selection for company [5], selection of intelligent medical hospital [6] and so on. Since the complexity of decision making and fuzziness of human thinking, one of the challenges in MADM problems is to correctly depict DMs’ evaluation. As an extension of hesitant fuzzy sets (HFSs), hesitant fuzzy linguistic term sets (HFLSs) were introduced by Rodriguez et al. [7] to quantitatively express experts’ judgement with two or more linguistic terms in case of hesitancy when DMs evaluate in decision making. Although HFLSs are powerful, they merely consider different importances/occurance probabilities/preference degrees for all possible linguistic variables. To mitigate this issue, Pang et al. [8] proposed probabilistic linguistic term sets (PLTSs), which can simultaneously present the hesitancy and preference degree of DMs, to reflect evaluators’ opinions with several linguistic terms and corresponding probabilistic distributions. Then, scholars have turned to research MADM problems with probabilistic linguistic preference information called probabilistic linguistic MADM (PLMADM) problems [9,10,11,12,13,14,15,16].
In the PLMADM process, the aggregation of evaluation information is an essential step, and aggregation operators have been investigated increasingly. Most classical and popular aggregation operators are probabilistic linguistic arithmetic averaging (PLA) operator and probabilistic linguistic geometric (PLGeo) operator developed by Pang et al. [8]. A strict assumption of these two operators is that attributes are seemed as independent when using PLA or/and PLGeo operators. However, attributes in the real applications are interrelated but not independent. Some researchers then focus on aggregation operators which are able to capture the interrelationship among input arguments in PLMADM problems. Probabilistic linguistic geometric Bonferroni mean (PLGeoBM) operator [17] and probabilistic linguistic Heronian mean (PLHM) operator [18] have been gradually developed to consider interrelationship between arbitrary two input arguments. Besides, Liu and Li [19] designed probabilistic linguistic geometric Maclaurin symmetric mean (PLGeoMSM) operator to capture correlation among any three arguments. However, there may exist many situations in which multi-input arguments instead of three or two arguments interrelate with each other in PLMADM problems. Hence, it is urgent to introduce more feasible and general operators to capture interrelationships among any number of input arguments. Dual Muirhead mean (DMM) operator is just the suitable one which enables to consider the interrelationships of multi-input arguments by a parameter vector and is a generalization of some existing aggregation operators, such as averaging operator, geometric operator, geometric BM operator, geometric MSM operator, etc. At present, DMM operators have been populated and extended in the light of several fuzzy sets, such as hesitant fuzzy sets [20], Pythagorean fuzzy sets [21], interval-valued probabilistic hesitant fuzzy sets [22], q-rung orthopair fuzzy sets [23], T-spherical fuzzy sets [24], etc. With the strength of generalization and flexibility, therefore, DMM operators were improved in this paper to fuse probabilistic linguistic preference information.
The information aggregated through above operators usually was utilized to determine the final decision making for DMs with the aid of MADM approaches. VIKORFootnote 1 method, proposed by Opricovic [25], is one of effective ways to solve MADM problems especially with incompatible and noncommensurable information [26]. VIKOR mainly concentrates on ranking and selecting from a collection of candidates in the presence of conflicting criterion. It also maximizes the majority’s group utility as well as minimizes the individual regret for minority so as to offer DMs a compromised solution [27,28,29,30]. Owing to its features and superiority, we introduce VIKOR method based on PLTSs and design a powerful decision-making approach to address PLMADM problems.
Based on above analysis, it is necessary and valuable to investigate relative theory of PLTS since it can genuinely depict psychology of evaluators in MADM process. Besides, DMM operators offer a quite flexible function to aggregate evaluations and solve MADM problems more appropriately, and VIKOR method can address conflicts among attributes as well as give a compromised solution. Therefore, it is extremely worth processing PLMADM problems by extending DMM operators to the probabilistic linguistic environment and exploring a decision-making approach based on VIKOR method. The innovations of this paper are summarized as follows:
-
1.
DMM operators are introduced and improved in this paper to capture interrelationships among any number of multi-input arguments in PLMADM problems;
-
2.
We define two novel aggregation operators based on DMM operators, i.e., probabilistic linguistic DMM (PLDMM) operator and probabilistic linguistic weighted DMM (PLWDMM), and further investigate their corresponding propositions, theorems as well as properties;
-
3.
A powerful decision-making approach based on PLWDMM operator and VIKOR has been designed to address complex PLMADM problems.
The rest of the paper is organized as follows. Section 2 briefly reviews the relevant studies. Aggregation operators (i.e., PLDMM and PLWDMM), and their corresponding definitions, propositions, theorems as well as properties are developed in Sect. 3. A novel decision-making approach based on PLWDMM aggregation operator and VIKOR is designed to solve a complex PLMADM problem in Sect. 4. In Sect. 5, an illustrative example is provided to explain the validity and feasibility of the proposed decision-making method. Finally, Sect. 6 concludes the paper and elaborates on future studies.
2 Preliminaries
In this section, we briefly review some basic concepts, including probabilistic linguistic term sets (PLTSs), Muirhead mean (MM), and dual Muirhead mean (DMM).
2.1 Probabilistic Linguistic Term Sets (PLTSs)
Probabilistic linguistic term set (PLTS) is a kind of useful extension of hesitant fuzzy linguistic term set (HFLTS), which considers the multiple preference information and their corresponding occurrence probabilities simultaneously. In the following, we introduce some concepts of PLTSs, relative operation and comparison laws.
Definition 1
[8] Let \(S=\left\{ S_{t}|t=-\tau ,\dots ,-1,0,1,\dots ,\tau \right\}\) be a linguistic term set. Then, a PLTS is defined as
where \(L^{(k)} \left( P^{(k)} \right)\) is the linguistic term \(L^{(k)}\) associated with probability \(P^{(k)}\), \(r^{(k)}\) is the subscript of \(L^{(k)}\) and \(\#L(P)\) is the number of all linguistic terms in L(P).
To facilitate the information fusion as well as maintain the consistency, Gou and Xu [31] and Bai et al. [32] have developed the equivalent transformation functions of L(P) as follows.
Definition 2
[31, 32] Let \(S=\left\{ S_{t}|t=-\tau ,\dots ,-1,0,1,\right.\) \(\left. \dots ,\tau \right\}\) be a linguistic term set. L(P) is a PLTS. Then, equivalent transformation function of L(P) is given as
Definition 3
[31, 32] Let \(S=\left\{ S_{t}|t=-\tau ,\dots ,-1,0,1,\right.\) \(\left. \dots ,\tau \right\}\) be a linguistic term set. \(\lambda\) be a positive real number. L(P), \(L_{1}(P_{1})\) and \(L_{2}(P_{2})\) be three PLTSs, which satisfy the following operation laws:
-
(i)
\(\begin{aligned} \begin{aligned}&L_1(P_{1})\oplus L_2(P_{2})\\&=g^{-1}\left( \bigcup _{\eta _1^{(i)}\in g(L_1),\eta _2^{(j)}\in g(L_2)}\left\{ \left( \eta _1^{(i)}+\eta _2^{(j)}-\eta _1^{(i)}\eta _2^{(j)}\right) \left( P_1^{(i)}P_2^{(j)}\right) \right\} \right) ,\\&i=1,2,\dots ,\#L_1(P_{1}),j=1,2,\dots ,\#L_2(P_{2}); \end{aligned} \end{aligned}\)
-
(ii)
\(\begin{aligned} \begin{aligned}&L_1(P_{1})\otimes L_2(P_{2})\\ =\,&g^{-1}\left( \bigcup _{\eta _1^{(i)}\in g(L_1),\eta _2^{(j)}\in g(L_2)}\left\{ \left( \eta _1^{(i)}\eta _2^{(j)}\right) \left( P_1^{(i)}P_2^{(j)}\right) \right\} \right) ,\\&i=1,2,\dots ,\#L_1(P_{1}),j=1,2,\dots ,\#L_2(P_{2}); \end{aligned} \end{aligned}\)
-
(iii)
\(\begin{aligned} \begin{aligned} \lambda L(P)=\,&g^{-1}\left( \bigcup _{\eta ^{(k)}\in g(L)}\left\{ \left( 1-\left( 1-\eta ^{(k)}\right) ^\lambda \right) \left( P^{(k)}\right) \right\} \right) ,\\&k=1,2,\dots ,\#L(P); \end{aligned} \end{aligned}\)
-
(iv)
\(\begin{aligned} \begin{aligned} \left( L(P)\right) ^\lambda =\,&g^{-1}\left( \bigcup _{\eta ^{(k)}\in g(L)}\left\{ \left( \eta ^{(k)}\right) ^\lambda \left( P^{(k)}\right) \right\} \right) ,\\&k=1,2,\dots ,\#L(P). \end{aligned} \end{aligned}\)
For the PLTS, it cannot be compared when the numbers of linguistic terms are unequal. Pang et al. [8] has defined normalization of PLTSs as follows.
Definition 4
[8] Let \(L_1(P)=\left\{ L_1^{(k)}\left( P_1^{(k)}\right) \big |k=1,2,\dots ,\right.\) \(\left. \#L_1(P)\right\}\) and \(L_2(P)=\left\{ L_2^{(k)}\left( P_2^{(k)}\right) \big |k=1,\dots ,\#L_2(P)\right\}\) be arbitrary two PLTSs, \(\#L_1(P)\) and \(\#L_2(P)\) are their relative numbers of linguistic terms, separately. Generally, \(\#L_1(P)\ne \#L_2(P)\). Therefore, we add \(\#L_1(P)-\#L_2(P)\) linguistic terms to \(L_2(P)\) if \(\#L_1(P)>\#L_2(P)\) so as to unify the numbers of linguistic terms in \(L_1(P)\) and \(L_2(P)\). The added linguistic terms are the smallest ones in \(L_2(P)\) following by zero probabilities.
The score function and deviation degree have proposed by Pang et al. [8] to help DMs compare arbitrary two PLTSs.
Definition 5
[8] Let \(L(P)=\left\{ L^{(k)}\left( P^{(k)}\right) \big |k=1,2,\dots ,\right.\) \(\left. \#L(P)\right\}\) be a PLTS, and \(r^{(k)}\) be the subscript of linguistic term \(L^{(k)}\). Then, the score of L(P) is defined as
where \({\widetilde{\alpha }}=\left. {\sum _{k=1}^{\#L(P)}{r^{(k)}\left( P^{(k)}\right) }}\bigg /{\sum _{k=1}^{\#L(P)}P^{(k)}}\right.\), and the deviation degree of L (P) is
A preorder for PLTSs can be constructed through the score and deviation degree formulas. Let \(L_{1}(P_{1})\) and \(L_{2}(P_{2})\) are arbitrary two PLTSs, and the detailed comparison laws are denoted as follows [8]:
-
1.
if \(E(L_1(P_{1}))> E(L_2(P_{2}))\), then \(L_1(P_{1}) > L_2(P_{2})\);
-
2.
if \(E(L_1(P_{1}))< E(L_2(P_{2}))\), then \(L_1(P_{1}) < L_2(P_{2})\);
-
3.
if \(E(L_1(P_{1})) = E(L_2(P_{2}))\), then
-
a.
if \({\sigma \left( L_1(P_{1})\right) }> {\sigma \left( L_2(P_{2})\right) }\), then \(L_1(P_{1})< L_2(P_{2});\)
-
b.
if \({\sigma \left( L_1(P_{1})\right) }< {\sigma \left( L_2(P_{2})\right) }\), then \(L_1(P_{1})> L_2(P_{2});\)
-
c.
if \({\sigma \left( L_1(P_{1})\right) }={\sigma \left( L_2(P_{2})\right) }\), then \(L_1(P_{1})\sim L_2(P_{2}).\)
-
a.
Pang et al. [8] also designed Euclidean distance measure between any two PLTSs. The detailed definition is presented as follows.
Definition 6
[8] Let \(L_1(P)=\left\{ L_1^{(k)}\left( P_1^{(k)}\right) \big |k=1,2,\dots ,\right.\) \(\left. \#L_1(P)\right\}\) and \(L_2(P)=\left\{ L_2^{(k)}\left( P_2^{(k)}\right) \big |k=1,\dots ,\#L_2(P)\right\}\) be arbitrary two PLTSs, the Euclidean distance measure between \(L_1(P_1)\) and \(L_2(P_2)\) is described as:
where \(\#L_1(P_1)=\#L_2(P_2)\). \(r_1^{(k)}\) and \(r_2^{(k)}\) are separately subscripts of \(L_1^{(k)}\) and \(L_2^{(k)}\).
2.2 Muirhead Mean (MM)
Since the superiority of capturing the interrelationship among multi-input arguments, the MM operator is regarded as an available aggregation method. The definition of MM is presented as follows.
Definition 7
[33] Let \(a_{j} (j=1,2,\dots ,n)\) be a collection of real numbers, \(P=(p_1,p_2,\dots ,p_n)\in R^n\) be a parameter vector which denotes the risk appetite values, then MM is given as
where \(\vartheta (j)(j=1,2,\dots ,n)\) be any permutation of \((1,2,\dots ,n)\), and \(S_n\) is the set of all possible permutations of \((1,2,\dots ,n)\).
2.3 Dual Muirhead Mean (DMM)
Definition 8
[34, 35] Let \(a_{j} (j=1,2,\dots ,n)\) be a collection of real numbers, \(P=(p_1,p_2,\dots ,p_n)\in R^n\) be a parameter vector which denotes the risk appetite values, then DMM is given as
where \(\vartheta (j)(j=1,2,\dots ,n)\) be any permutation of \((1,2,\dots,n),\)
and \(S_n\) is the set of all possible permutations of \((1,2,\dots ,n)\).
3 Probabilistic Linguistic Dual Muirhead Mean Operators
We extend the traditional DMM operator to appropriate the probabilistic linguistic preference environment. Aggregation operators, i.e., PLDMM operator and PLWDMM operator, and their corresponding definitions, propositions, theorems as well as properties are explored detailedly as follows.
3.1 Probabilistic Linguistic Dual Muirhead Mean (PLDMM) Operator
Definition 9
Let \(L_i(P_i)\!=\!\{L_i^{(k)}P_i^{(k)}\big |k=1,2,\dots,\#L_i(P_i)\}\) \((i=1,2,\dots ,n)\) be n PLTSs, \(P=(p_1,p_2,\dots ,p_n)\) \(\in R^n\) be a parameter vector denoting the risk appetite values. Then, we define PLDMM operator as
where \(\vartheta (i)(i=1,2,\dots ,n)\) be any permutation of \((1,2,\dots ,n)\), and \(S_n\) is the set of all possible permutations of \((1,2,\dots ,n)\).
We can obtain some outcomes from Definition 9 by means of operation laws of PLTSs.
Proposition 1
Suppose \(L_i(P_i)=\{L_i^{(k)}P_i^{(k)}\big |k=1,2,\dots ,\) \(\#L_i(P_i)\}(i=1,2,\dots ,n)\) be n PLTSs, \(p_i(i=1,2,\dots ,n)\) is arbitrary nonnegative number, which denotes the risk appetite value. \(\vartheta (i)(i=1,2,\dots ,n)\) be any permutation of \((1,2,\dots ,n)\). Then we have
Proof
With the aid of operation law (iii) depicted in Definition 3, it is easy to demonstrate the Proposition 1 always holds. \(\square\)
Proposition 2
Suppose \(L_i(P_i)=\{L_i^{(k)}P_i^{(k)}\big |k=1,2,\dots ,\) \(\#L_i(P_i)\}(i=1,2,\dots ,n)\) be n PLTSs, \(p_i(i=1,2,\dots ,n)\) is an arbitrary nonnegative number, which denotes the risk appetite value. \(\vartheta (i)(i=1,2,\dots ,n)\) be any permutation of \((1,2,\dots ,n)\). Then we have
Proof
In the light of the result of Proposition 1 and the operation law (i) of Definition 3, we can compute
then we have
Hence, we complete the proof of Proposition 2. \(\square\)
Proposition 3
Suppose \(L_i(P_i)=\{L_i^{(k)}P_i^{(k)}\big |k=1,2,\dots ,\) \(\#L_i(P_i)\}(i=1,2,\dots ,n)\) be n PLTSs, \(p_i(i=1,2,\dots ,n)\) is an arbitrary nonnegative number, which denotes the risk appetite value. \(\vartheta (i)(i=1,2,\dots ,n)\) be any permutation of \((1,2,\dots ,n)\). Then we have
Proof
From the operation law (ii) in Definition 3 and Proposition 2, we can compute
and we get
Therefore, the statement of Proposition 3 holds. \(\square\)
Proposition 4
Suppose \(L_i(P_i)=\{L_i^{(k)}P_i^{(k)}\big |k=1,2,\dots ,\) \(\#L_i(P_i)\}(i=1,2,\dots ,n)\) be n PLTSs, \(p_i(i=1,2,\dots ,n)\) is an arbitrary nonnegative number, which denotes the risk appetite value. \(\vartheta (i)(i=1,2,\dots ,n)\) be any permutation of \((1,2,\dots ,n)\). Then we have
Proof
In accordance with the result of Proposition 3 and operation law (iv) in Definition 3, it is easy to prove Proposition 4 always holds. \(\square\)
Theorem 1
Suppose \(L_i(P_i)=\{L_i^{(k)}P_i^{(k)}\big |k=1,2,\dots ,\) \(\#L_i(P_i)\}(i=1,2,\dots ,n)\) be n PLTSs, \(p_i(i=1,2,\dots ,n)\) is an arbitrary nonnegative number, which denotes the risk appetite value. \(\vartheta (i)(i=1,2,\dots ,n)\) be any permutation of \((1,2,\dots ,n)\). Then, aggregated result by Definition 9 is shown as
Proof
According to the outcomes of Proposition 4, Definition 9 and operation law (iii) described in Definition 3, we have
\(\square\)
So, we complete the proof of Theorem 1.
Next, we begin to investigate properties of PLDMM operator and deduce four corollaries.
Corollary 1
(Monotonity). Let \(L(P)_a=\left\{ L_1(P_1)_a,\dots ,\right.\) \(\left. L_n(P_n)_a\right\}\) and \(L(P)_b=\left\{ L_1(P_1)_b,\dots ,L_n(P_n)_b\right\}\) be arbitrary two PLTSs, \(P=(p_1,p_2,\dots ,p_n)\in R^n\) be a parameter vector denoting the risk appetite values. For \(\eta _{\vartheta a(i)}^{(k)}\in g(L_{\vartheta a(i)})\), \(\eta _{\vartheta b(i)}^{(k)}\in g(L_{\vartheta b(i)})\), if \(\eta _{\vartheta a(i)}^{(k)}\leqslant \eta _{\vartheta b(i)}^{(k)}\) and \(P_{\vartheta a(i)}^{(k)}\leqslant P_{\vartheta b(i)}^{(k)}\), then we have
Corollary 2
(Idempotency). If \(L_i{P_i}=L(P)=\left\{ L^{(k)}\left( P^{(k)}\right)\right.\)
\(\big |L^{(k)}\in S, r^{(k)}\in t, P^{(k)}\ge 0, k=1,2,\dots ,\#L(P),\) \(\left. \sum _{k=1}^{\#L(P)}P^{(k)}\leqslant 1\right\}\) for all \(i=1,2,\dots ,n\), then we have
Corollary 3
(Commutativity). If \(L_i^{'}(P_i^{'})\) be any permutation of \(L_i(P)_i(i=1,2,\dots ,n)\), then we have the relationship:
Corollary 4
(Boundness). Let \(L(P)^{-}=min(L_1(P_1),\)
\(L_2(P_2),\dots ,L_n(P_n))\) and \(L(P)^{+}=max(L_1(P_1),L_2(P_2),\)
\(\dots ,L_n(P_n))\), then we have
In the following, we further explore five special cases of PLDMM operator in accordance with different values of parameter vector P.
Case 1
If parameter vector is \(P=(1,0,\dots ,0)\), then PLDMM operator will reduce to probabilistic linguistic geometric (PLGeo) operator, which is denoted as
Case 2
If parameter vector is \(P=(\lambda ,0,\dots ,0)\), then PLDMM operator will reduce to probabilistic linguistic generalized geometric (PLGGeo) operator, which is presented as
Case 3
If parameter vector is \(P=(1,1,0,\dots ,0)\), then PLDMM operator will reduce to probabilistic linguistic geometric Bonferroni mean (PLGeoBM) operator, which is displayed as
Case 4
If parameter vector is \(P=(\overbrace{1,1,\dots ,1}^{m},\overbrace{0,\dots ,0}^{n-m})\), then PLDMM operator will reduce to probabilistic linguistic geometric Maclaurin Symmetric mean (PLGeoMSM) operator, that is,
Case 5
If parameter vector is \(P=(1,1,\dots ,1)\) or \(P= (\frac{1}{n},\frac{1}{n},\dots ,\frac{1}{n})\), then PLDMM operator will reduce to probabilistic linguistic arithmetic averaging (PLA) operator, namely
3.2 Probabilistic Linguistic Weighted Dual Muirhead Mean (PLWDMM) Operator
With the consideration of importance of aggregated multi-input arguments, we further define PLWDMM operator in this section.
Definition 10
Let \(L_i{(P_i)}\!=\!\{L_i^{(k)}P_i^{(k)}\big |k=1,2,\dots,\#L_i(P_i)\}\) \((i=1,\dots ,n)\) be n PLTSs, \(P=(p_1,\dots ,p_n)\in R^n\) be a parameter vector denoting the risk appetite values. Suppose that \(\omega _i\) be the weight of input argument \(L_i(P_i)\) such that \(\omega _i\in [0,1]\) and \(\sum _{i=1}^{n}\omega _i=1\). Then, PLWDMM operator is described as
where \(\vartheta (i)(i=1,2,\dots ,n)\) be any permutation of \((1,2,\dots,n),\)
and \(S_n\) is the set of all possible permutations of \((1,2,\dots ,n)\).
Based on the Definition 10 and operation laws depicted in Definition 3, we can get the following propositions.
Proposition 5
Suppose \(L_i{(P_i)}\!=\!\{L_i^{(k)}P_i^{(k)}\big |k=1,2,\dots,\#L_i(P_i)\}\) \((i=1,2,\dots ,n)\) be n PLTSs, \(p_i (i=1,2,\dots ,n)\) is an arbitrary nonnegative number, which denotes the risk appetite value. \(\vartheta (i)(i=1,2,\dots ,n)\) be any permutation of \((1,2,\dots ,n)\). Then we have
Proof
In the light of the result of Proposition 1 and operation law (iv) in Definition 3, we have
So, the statement of Proposition 5 holds. \(\square\)
Proposition 6
Suppose \(L_i{(P_i)}\!=\!\{L_i^{(k)}P_i^{(k)}\big |k=1,2,\dots,\#L_i(P_i)\}\) \((i=1,2,\dots ,n)\) be n PLTSs, \(p_i (i=1,2,\dots ,n)\) is an arbitrary nonnegative number, which denotes the risk appetite value. \(\vartheta (i)(i=1,2,\dots ,n)\) be any permutation of \((1,2,\dots ,n)\). Then we have
Proof
According to outcome of Proposition 5 and operation law (i) in Definition 3, we have
and we can get
Hence, we finish the proof of Proposition 6. \(\square\)
Proposition 7
Suppose \(L_i{(P_i)}\!=\!\{L_i^{(k)}P_i^{(k)}\big |k=1,2,\dots,\#L_i(P_i)\}\) \((i=1,2,\dots ,n)\) be n PLTSs, \(p_i (i=1,2,\dots ,n)\) is an arbitrary nonnegative number, which denotes the risk appetite value. \(\vartheta (i)(i=1,2,\dots ,n)\) be any permutation of \((1,2,\dots ,n)\). Then we have
Proof
With the aid of result of Proposition 6 and operation law (ii) in Definition 3, we have
then
Therefore, Proposition 7 always holds. \(\square\)
Proposition 8
Suppose \(L_i{(P_i)}\!=\!\{L_i^{(k)}P_i^{(k)}\big |k=1,2,\dots,\#L_i(P_i)\}\) \((i=1,2,\dots ,n)\) be n PLTSs, \(p_i (i=1,2,\dots ,n)\) is an arbitrary nonnegative number, which denotes the risk appetite value. \(\vartheta (i)(i=1,2,\dots ,n)\) be any permutation of \((1,2,\dots ,n)\). Then we have
Proof
It is not difficult to demonstrate Proposition 8 through the outcome of Proposition 7 and operation law (iv) presented in Definition 3. \(\square\)
Theorem 2
Suppose \(L_i{(P_i)}\!=\!\{L_i^{(k)}P_i^{(k)}\big |k=1,2,\dots,\#L_i(P_i)\}\) \((i=1,2,\dots ,n)\) be n PLTSs, \(P=(p_1,\dots ,p_n)\in R^n\) be a parameter vector denoting the risk appetite values, \(\omega _i\) be the weight of input argument \(L_i(P_i)\) with \(\omega _i \in [0,1]\) and \(\sum _{i=1}^{n}\omega _i=1\). Then aggregated result by Definition 10 is shown as
Proof
Based on Theorem 1, Propositions 5–8 and operation laws of PLTSs described in Definition 3, we have
\(\square\)
Thus, we complete the proof of Theorem 2.
Likewise, we further explore desirable properties for PLWDMM operator and give four corollaries.
Corollary 5
(Monotonity). Let \(L(P)_a=\left\{ L_1(P_1)_a,\dots ,\right.\) \(\left. L_n(P_n)_a\right\}\) and \(L(P)_b=\left\{ L_1(P_1)_b,\dots ,L_n(P_n)_b\right\}\) be arbitrary two PLTSs, \(P=(p_1,p_2,\dots ,p_n)\in R^n\) be a parameter vector denoting the risk appetite values. For \(\eta _{\vartheta a(i)}^{(k)}\in g(L_{\vartheta a(i)})\), \(\eta _{\vartheta b(i)}^{(k)}\in g(L_{\vartheta b(i)})\), if \(\eta _{\vartheta a(i)}^{(k)}\leqslant \eta _{\vartheta b(i)}^{(k)}\) and \(P_{\vartheta a(i)}^{(k)}\leqslant P_{\vartheta b(i)}^{(k)}\), then we have
Corollary 6
(Idempotency). If \(L_i{P_i}\!=\!L(P)\!=\!\left\{ L^{(k)}\left( P^{(k)}\right) \right.\)
\(\big |L^{(k)}\in S, r^{(k)}\in t, P^{(k)}\ge 0, k=1,2,\dots ,\#L(P),\) \(\left. \sum _{k=1}^{\#L(P)}P^{(k)}\leqslant 1\right\}\) for all \(i=1,2,\dots ,n\), then we have
Corollary 7
(Commutativity). If \(L_i^{'}(P_i^{'})\) be any permutation of \(L_i(P)_i(i=1,2,\dots ,n)\), then we have the relationship:
Corollary 8
(Boundness). Let \(L(P)^{-}=min(L_1(P_1),\)
\(L_2(P_2),\dots ,L_n(P_n))\) and \(L(P)^{+}=max(L_1(P_1),L_2(P_2),\)
\(\dots ,L_n(P_n))\), then we have
If \(\omega =(\frac{1}{n},\frac{1}{n},\dots ,\frac{1}{n})\), then PLWDMM operator is reduced to PLDMM operator. Therefore, PLDMM operator is regarded as a special case of PLWDMM operator. According to Theorems 1 and 2, it is clear that PLWDMM operator being an effective extension of PLDMM operator is more appropriate to capture the interrelationship and importance of multi-input arguments in the PLMADM problems.
4 A Novel Decision-Making Approach to PLMADM Based on PLWDMM Operator and VIKOR
In this section, we investigate a novel method in accordance with PLWDMM aggregation operator and VIKOR to handle complicated PLMADM problems.
4.1 Problem Description
For a PLMADM problem, DMs are required to pick out the optimal or best alternative from several candidates with regard to finite attributes. Therefore, alternatives and attributes should be decided first. Let \(A=\left\{ a_1,\dots ,a_i,\dots ,a_m\right\}\) be a discrete collection of m alternatives, \(C=\left\{ c_1,\dots ,c_j,\dots ,c_n\right\}\) be a finite set of n attributes, and weight sector of attributes is given as \(\omega =\left( \omega _1,\dots ,\omega _j,\dots ,\omega _n\right) ^{T}\) such that \(\sum _{j=1}^{n}{\omega _j}=1\) and \(\omega _j \in [0,1]\). Suppose that \(DM=\left\{ dm_1,\dots ,dm_q,\dots ,dm_e\right\}\) be a set of DMs with relative weights \(\lambda =\left( \lambda _1,\dots ,\lambda _q,\dots ,\lambda _e\right) ^{T}\). Similarly, for \(q=1,2,\dots ,e\), \(\lambda _q\) satisfies \(\sum _{q=1}^{e}{\lambda _q}=1\) and \(\lambda _q \in [0,1]\). According to linguistic scale \(S=\left\{ S_{t}|t=-\tau ,\dots ,-1,0,1,\dots ,\tau \right\}\), each DM is invited to choose suitable linguistic terms in set S and display corresponding possible probability/preference degree when providing his/her evaluation information on each alternative with respect to attributes. Let \(D^{q}=\left( r_{ij}^{q}\right) _{m\times n}\) be alternatives–attributes probabilistic linguistic evaluation matrix given by decision maker \(dm_{q} (q=1,2,\dots ,e)\). The matrix \(D^{q}\) can be written as follows:
where for all \(i=1,2,\dots ,m; j=1,2,\dots ,n\), \(r_{ij}^{q}=L_{ij}^{q}\left( P_{ij}^{q}\right)\) presents probabilistic linguistic evaluation information provided by decision maker \(dm_{q}\) over alternative \(a_i\) about attribute \(c_j\).
4.2 Decision Procedures for PLMADM Based on PLWDMM Operator and VIKOR
DMs are invited one by one to offer their real evaluation on alternatives regarding to different attributes. Then e alternatives–attributes probabilistic linguistic evaluation matrices are successfully constructed. In the light of PLWDMM operator, collective result of alternative \(a_i\) with respect to attribute \(c_j\) is fused by means of formulas (22) and (27) for all \(i=1,2,\dots ,m; j=1,2,\dots ,n\). The outcome is denoted as
where \(\vartheta (q)(q=1,2,\dots ,e)\) be any permutation of \((1,2,\dots,e),\)
and \(S_e\) is the set of all possible permutations of \((1,2,\dots ,e)\).
Similarly, we can obtain other aggregated information. Then alternatives–attributes group evaluation matrix denoted as \(D=\left( r_{ij}\right) _{m\times n}\) is built and depicted as follows:
where for all \(i=1,2,\dots ,m; j=1,2,\dots ,n\), \(r_{ij}=L_{ij}\left( P_{ij}\right)\) presents group probabilistic linguistic evaluation information on alternative \(a_i\) regarding to attribute \(c_j\).
According to Definition 4, group evaluation matrix D can be normalized as \({\bar{D}}\), in which the numbers of linguistic terms in all evaluation information are identical.
Next, we further use VIKOR method to solve PLMA-DM problem described in Sect. 4.1. First of all, we need to find the positive ideal solutions and negative ideal solutions according to matrix \({\bar{D}}\). Let \(R^{+}\!=\!(r_1^{+},\dots,r_j^{+},\dots ,r_n^{+})\)
and \(R^{-}=(r_1^{-},\dots ,r_j^{-},\dots ,r_n^{-})\) be positive and negative ideal solutions, respectively. \(r_j^{+}\) and \(r_j^{-}\) separately denote the best and the worst solutions on attribute \(c_j\), which are computed by formulas (29) and (30):
where \(\left( {\bar{L}}_{j}^{(k)}\right) ^{+}=S_{\begin{array}{c} max\\ 1\leqslant i \leqslant m \end{array}\left\{ r_{ij}^{(k)}P_{ij}^{(k)}\right\} }\), \(\#{\bar{L}}_{ij}(P)\) presents number of linguistic terms in \({\bar{L}}_{ij}(P)\). For all \(i=1,\dots ,m;\) \(j=1,\dots ,n\), \(r_{ij}^{(k)}\) is the subscript of the linguistic term \({\bar{L}}_{ij}^{(k)}\) and \(P_{ij}^{(k)}\) be corresponding possible probability or preference degree of linguistic term \({\bar{L}}_{ij}^{(k)}\).
where \(\left( {\bar{L}}_{j}^{(k)}\right) ^{-}=S_{\begin{array}{c} min\\ 1\leqslant i \leqslant m \end{array}\left\{ r_{ij}^{(k)}P_{ij}^{(k)}\right\} }\), \(\#{\bar{L}}_{ij}(P)\) presents number of linguistic terms in \({\bar{L}}_{ij}(P)\). For all \(i=1,\dots ,m;\) \(j=1,\dots ,n\), \(r_{ij}^{(k)}\) is the subscript of the linguistic term \({\bar{L}}_{ij}^{(k)}\) and \(P_{ij}^{(k)}\) be corresponding possible probability or preference degree of linguistic term \({\bar{L}}_{ij}^{(k)}\).
For each alternative \(a_i\), we then compute group utility \(S_i\) and individual regret \(R_i\) based on the positive ideal solutions and negative ideal solutions.
The group utility \(S_i\) is given by
The individual regret \(R_i\) can be calculated by
where \(\omega _j\) be the weight of attribute \(c_j\), \(d\left( r_j^{+},r_{ij}\right)\) presents the distance between \(r_j^{+}\) and \(r_{ij}\). Distance measure of PLTSs is cited from [8] depicted in Definition 6.
Now, we calculate total utility \(Q_i\) for every alternative \(a_i\) by the following formula:
where \(S^{+}=\begin{array}{c} min\\ i \end{array}S_i\), \(S^{-}=\begin{array}{c} max\\ i \end{array}S_i\), \(R^{+}=\begin{array}{c} min\\ i \end{array}R_i\), \(R^{-}=\begin{array}{c} max\\ i \end{array}R_i\). Parameter \(\mu (\mu \in [0,1])\) denotes weight of maximum group utility, and \(1-\mu\) is the weight of individual regret. In general, \(\mu\) is equal to 0.5 [26, 29, 36].
According to values of \(S_i,R_i,Q_i\), three ranking results for all alternatives in ascending orders are obtained.
Assumed that \(A^{(1)},A^{(2)},\dots ,A^{(m)}\) be a increasing ranking based on values of \(Q_i(i=1,2,\dots ,m)\). \(A^{(1)}\) is a promising solution if satisfying the following two constraints:
-
(i)
Acceptable advantage: \(Q\left( A^{(2)}\right) -Q\left( A^{(1)}\right) \ge \frac{1}{m-1}\);
-
(ii)
Acceptable stability: alternative \(A^{(1)}\) also be in first position by \(S_i\) or/and \(R_i\).
However, these two conditions sometimes cannot be met simultaneously, then compromised solutions have been developed as follows:
If constraint (ii) is not satisfied, then \(A^{(1)}\) and \(A^{(2)}\) are regarded as compromised solutions. If constraint (i) is not met, then \(A^{(1)},A^{(2)},\dots ,A^{(M)}\) are considered as compromised solutions, in which value of M is obtained by \(Q\left( A^{(M)}\right) -Q\left( A^{(1)}\right) < \frac{1}{m-1}\) for maximum M.
4.3 The Algorithm for PLMADM Based on PLWDMM Operator and VIKOR
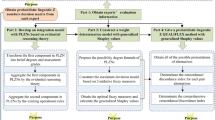
Based on the above-detailed decision procedures, we further summarize our proposed decision-making approach described in Fig. 1 and put forward a powerful algorithm for dealing with complex PLMADM problems through PLWDMM operator and VIKOR method. The algorithm for PLMADM is depicted as follows:

Framework of our proposed decision-making approach to PLMADM
-
Step 1:
Identify alternatives set \(A=\{a_1,\dots ,a_i,\dots ,a_m\}\), attributes set \(C=\{c_1,\dots ,c_j,\dots ,c_n\}\) and DMs set \(DM=\{dm_1,\dots ,dm_q,\dots ,dm_e\}\). Given that weight vectors of attributes and DMs are denoted as \(\omega =\left( \omega _1,\dots ,\omega _j,\dots ,\omega _n\right) ^{T}\) and \(\lambda =\left( \lambda _1,\dots ,\lambda _q,\dots ,\lambda _e\right) ^{T}\), respectively. Each evaluator is invited to choose linguistic term in set \(S=\left\{ S_{t}|t=-\tau ,\dots ,-1,0,1,\dots ,\tau \right\}\) and express relative possible probability/preference degree when evaluating each candidate with regard to attributes;
-
Step 2:
Construct e alternatives–attributes probabilistic linguistic evaluation matrices;
-
Step 3:
Fuse collective result of alternative \(a_i\) with respect to attribute \(c_j\) by means of formula (28), and obtain the alternatives–attributes group evaluation matrix \(D=\left( r_{ij}\right) _{m\times n} \left( i=1,2,\dots ,m;\right.\) \(\left. j=1,2,\dots ,n\right)\);
-
Step 4:
Acquire normalized group evaluation matrix \({\bar{D}}\) according to Definition 4;
-
Step 5:
Find the positive ideal solutions \(R^{+}=(r_1^{+},\dots ,r_j^{+},\) \(\dots ,r_n^{+})\) and negative ideal solutions \(R^{-}=(r_1^{-},\dots ,\) \(r_j^{-},\dots ,r_n^{-})\) with the aid of formulas (29) and (30);
-
Step 6:
Compute group utility \(S_i\) and individual regret \(R_i\) by formulas (31) and (32) for each alternative \(a_i\);
-
Step 7:
Calculate total utility \(Q_i\) for every alternative \(a_i\) in the light of formulas (6) and (33);
-
Step 8:
Obtain three ranking results for all candidates in ascending orders according to values of \(S_i,R_i,\) \(Q_i\);
-
Step 9:
Determine the compromised solution: assumed that \(A^{(1)},A^{(2)},\dots ,A^{(m)}\) be an increasing ranking based on values of \(Q_i (i=1,2,\dots ,m)\). If \(A^{(1)}\) meets constraints of acceptable advantage and acceptable stability, then \(A^{(1)}\) is a promising solution; If only constraint of acceptable advantage is satisfied, then \(A^{(1)}\) and \(A^{(2)}\) are regarded as compromised solutions. If only condition of acceptable stability is met, then \(A^{(1)},A^{(2)},\dots ,A^{(M)}\) are considered as compromised solutions, in which value of M is obtained by \(Q\left( A^{(M)}\right) -Q\left( A^{(1)}\right) <\frac{1}{m-1}\) for maximum M.
5 Illustrative Example
In the following, we further demonstrate the practicality and feasibility of the proposed decision-making approach by a practical example adapted from Liang et al. [17].
Owing to severe ceaselessly environment pollution in China and finite medical resources, some domestic hospitals have to be assessed to seek the optimal one, especially their personalized healthcare systems. Suppose that three DMs \(DM=\{dm_1,dm_2,dm_3\}\) with the weight vector \(\lambda =(0.3,0.3,0.4)^T\) are invited to evaluate four hospitals \(a_i (i=1,2,3,4)\) according to three attributes. They are (1) the environmental factor of medical and health service \((c_1)\); (2) personalized diagnosis and treatment optimization \((c_2)\); (3) social resource allocation optimization under the pattern of wisdom medical and health services \((c_3)\). The weights of attributes are given as \(\omega =(0.2,0.1,0.7)^T\). And the original decision matrices expressed in the form of PLTSs are integrated and presented in Table 1.
5.1 The Proposed Decision-Making Approach for the Example
According to the designed decision-making approach described in Sect. 4, we first aggregate the probabilistic linguistic evaluation information presented in Table 1. The collective result for every candidate \(a_i\) with respect to attribute \(c_j (i=1,2,3,4;j=1,2,3)\) can be acquired in the light of PLWDMM aggregation operator depicted in the formula (28) when parameter vector is given as \(P=(1,1,1)\). The obtained group evaluation matrix D is presented in Table 2. Based on Definition 4, we normalize group evaluation matrix D and get the normalized group evaluation matrix.
Based on the normalized group evaluation matrix as well as formulas (29) and (30), we then find the positive ideal solutions \(R^{+}=(\{S_3,S_{0.306},S_{0.1728},S_{0.0708}\},\) \(\{S_{1.005},S_{0.875},S_{0.2625},S_{0.213}\},\{S_3,S_{0.072},S_0,S_0\})\) and negative ideal solutions
\(R^{-}=(\{S_{0.36},S_0,S_0,S_0\},\{S_{0.03},\) \(S_0,S_0,S_0\},\{S_{0.012},S_0,S_{-0.114},S_{-0.116}\})\). We further calculate group utility \(S_i\), individual regret \(R_i\) and total utility \(Q_i\) for each alternative \(a_i (i=1,2,3,4)\) with the aid of formulas (31–33). The calculation and ranking results for all candidates are integrated and shown in Table 3.
From two constraints of VIKOR method and results shown in Table 3, it is clear that alternative \(a_2\) is the best in the ranking lists of S and R. However, \(Q(A^{(2)})-Q(A^{(1)})=0.14<1/(4-1)\approx 0.33\). It implies that constraint (i) is not met. We then deduce the following relationship: \(Q(A^{(3)})-Q(A^{(1)})=0.6>1/(4-1)\approx 0.33\). Hence, the alternative hospitals \(a_2\) and \(a_3\) are the compromised solutions.
5.2 The Effect of Risk Appetite Parameter on Ranking Result
In Sect. 5.1, we have taken the relationships parameter vector \(P=(1,1,1)\). Obviously, P can also take other values with different risk appetites. Generally, if DM is risk-seeking, then parameter vector is defined as \(P=(1,1,0,\dots ,0)\) or/and \(P=(\overbrace{1,\dots ,1}^{m},\overbrace{0,\dots ,0}^{n-m})\) in PLWDMM operator; on the contrary, if DM prefers to risk-averse, parameter vector is given as \(P=(1,0,\dots ,0)\) or \(P=(\lambda ,0,\dots ,0)\); if DM is risk-neutral, parameter vector is denoted as \(P=(1,1,\dots ,1)\) or \(P=(\frac{1}{n},\frac{1}{n},\dots ,\frac{1}{n})\). For discussing the effect of parameter vector P on the ranking list, several values of P are introduced to analyze the ranking results which are depicted in Table 4.
As shown in Table 4, we find that three kinds of ranking results are almost the same and are in accordance with the ranking \(a_2>a_3>a_4>a_1\) except the ranking result from Q derived when parameter vector is given as \(P=(2,0,0)\). When \(P=(2,0,0)\) presents the risk appetite values of DMs, we can compute \(Q(A^{(2)})-Q(A^{(1)})=0<0.33\) and \(Q(A^{(3)})-Q(A^{(1)})=1>0.33\). Based on the two constraints of VIKOR method, we deduce alternative hospitals \(a_2\) and \(a_3\) are the compromised solutions which are exactly consistent with the outcomes from other values of parameter vector P. Therefore, a meaningful conclusion is summarized as follows: the compromised solutions (i.e., \(a_2\) and \(a_3\)) determined by PLWDMM operator and VIKOR are totally unchanged in this example although the parameter vector P changes. This interesting phenomenon can also illustrate the proposed decision-making approach has wonderful robust property.
5.3 Further Discussions
To further signify the superiorities and strength of proposed decision-making approach in handling MADM problems under probabilistic linguistic preference environment, we further compare the proposed method with other existing approaches in this section.
5.3.1 Comparison with Method from Pang et al.
[8]
Based on the MADM with PLTSs, Pang et al. [8] fused evaluation information by PLWA operator and utilized TOPSIS method to deal with PLMADM problems. As mentioned in Sect. 3.1, PLDMM operator will become PLA operator as long as parameter vector is \(P=(1,1,\dots ,1)\) or \(P=(1/n,1/n,\dots ,1/n)\). To reduce the differences and enhance the comparability; therefore, PLWDMM operator with parameter vector \(P=(1,1,1)\) or \(P=(1/n,1/n,1/n)\) is used to compare the proposed approach and method from Pang et al. [8]. The decision results of these two techniques are presented in Table 5.
Table 5 shows that ranking results are remaining the same in spite of derived from different decision-making methods. It implies the outcome acquired by designed decision-making approach is reasonable and proposed technique is feasible. In the following, we analyze some characteristics of different aggregation operators which are listed in Table 6. According to the result of Table 6, we find that being a special case of PLWDMM, PLWA operator has two limitations when aggregating evaluations: (1) input arguments are regarded as independent when fusing information by PLWA operator; (2) PLWA operator does not consider interrelationships of input arguments in PLMADM problems. However, PLWDMM aggregation operator not only takes these interrelationships into account but also is a generalization of most existing operators (including PLWA operator). Hence, our proposed PLWDMM operator is more flexible and general than PLWA operator to fuse input arguments in PLMADM problems. Besides, though ideal solutions are involved both in TOPSIS technique and VIKOR method, VIKOR is more suitable to handle sophisticated MADM problems especially with conflicted attributes. Therefore, proposed approach is totally superior than method from Pang et al. [8] in dealing with PLMADM problems.
5.3.2 Comparison with Method from Liang et al.
[17]
Similarly, Liang et al. [17] proposed the PLWGeoBM operator to aggregate information and employed GRA to solve PLMADM problems. Since PLWDMM operator with parameter vector \(P=(1,1,0,\dots ,0)\) is equivalent to PLWGeoBM with parameters \(p=q=1\), we use PLWDMM operator with \(P=(1,1,0)\) and VIKOR to compare with method from Liang et al. [17]. And the decision results determined by proposed approach and method from Liang et al. [17] are shown in Table 7.
From results of Table 7, we know that ranking result from proposed approach is in accordance with the result from Liang et al. [17], which not only further demonstrates the rational of outcome obtained from proposed approach but also explains the available of designed decision-making approach. Although PLWGeoBM being a special case of PLWDMM operator involves the interrelationship of two input arguments according to the result of Table 6, it cannot capture these interrelationships among three or multiple input arguments and lacks of the ability to make decision-making approach flexible. On the contrary, PLWDMM operator can accurately analyze interrelationships of multi-input arguments and make the designed decision-making method flexible. In real situation, input arguments in PLMADM problems are interrelated even multiple; therefore, PLWDMM operator plays better at dealing with multi-input arguments in PLMADM problems. Compared with GRA, VIKOR can provide DMs with compromised solutions in the situation where criterion are conflicted. So, it also proves that proposed approach is better at addressing complex PLMADM problems than method in Liang et al. [17].
Based on above analysis, the desirable advantages of our proposed method are concluded as follows: (1) it not only contains probabilistic linguistic preference information, but also fully captures the interrelationships among multi-input arguments; (2) it is flexible with the aid of parameter vector and is fulfilled with robust property. (3) Our proposed method offers DMs an effective way to get compromised solutions under PLP environment. Thus, our proposed method is more appropriate to deal with complicated PLMADM problems.
6 Conclusion
With the consideration of interrelationships among multi-input arguments, we extend the traditional DMM operator into probabilistic linguistic preference surroundings. In this paper, we separately define PLDMM and PLWDMM aggregation operators which have the characteristics of generalization, flexibility and robust property. For sophisticated PLMADM problems, we investigate a new extension of the VIKOR method and design a corresponding decision-making approach in the light of PLWDMM operator. Introduction of DMM operator not only contributes to expand the application of PLTSs and propose relative aggregation operators but also conduces to develop a novel technique based on improved PLWDMM operator and VIKOR method to solve PLMADM problems. Our designed decision-making approach can also be powerful in addressing other operational research problems, such as supplier selection, performance evaluation for enterprises, assessment of project quality, etc. Future work will further focus on exploring new generalized operators and decision-making methods to handle complex PLMADM problems.
Notes
VlseKriterijumska Optimizacija I Kompromisno Resenje (VIKOR) means multi-criteria optimization and compromise solution, in Serbian.
References
Li, Y.L., Du, Y.F., Chin, K.S.: Determining the importance ratings of customer requirements in quality function deployment based on interval linguistic information. Int. J. Prod. Res. 56(14), 4692–4708 (2018)
Liang, D.C., Darko, A.P., Xu, Z.S., Wang, M.W.: Aggregation of dual hesitant fuzzy heterogenous related information with extended Bonferroni mean and its application to MULTIMOORA. Comput. Ind. Eng. 135, 156–176 (2019)
He, Y., Xu, Z.S.: Multi-attribute decision making methods based on reference ideal theory with probabilistic hesitant information. Expert Syst. Appl. 118, 459–469 (2019)
Liang, D.C., Xu, Z.S., Liu, D., Wu, Y.: Method for three-way decisions using ideal TOPSIS solutions at Pythagorean fuzzy information. Inf. Sci. 435, 282–295 (2018)
Liu, P.D., Teng, F.: Some Muirhead mean operators for probabilistic linguistic term sets and their applications to multiple attribute decision-making. Appl. Soft Comput. 68, 396–431 (2018)
Zhai, Y.L., Xu, Z.S., Liao, H.C.: Measures of probabilistic interval-valued intuitionistic hesitant fuzzy sets and the application in reducing excessive medical examinations. IEEE Trans. Fuzzy Syst. 26(3), 1651–1670 (2017)
Rodriguez, R.M., Martinez, L., Herrera, F.: Hesitant fuzzy linguistic term sets for decision making. IEEE Trans. Fuzzy Syst. 20(1), 109–119 (2011)
Pang, Q., Wang, H., Xu, Z.S.: Probabilistic linguistic term sets in multi-attribute group decision making. Inf. Sci. 369, 128–143 (2016)
Liao, H.C., Jiang, L.S., Xu, Z.S., Xu, J.P., Herrera, F.: A linear programming method for multiple criteria decision making with probabilistic linguistic information. Inf. Sci. 415, 341–355 (2017)
Lin, M.W., Xu, Z.S., Zhai, Y.L., Yao, Z.Q.: Multi-attribute group decision-making under probabilistic uncertain linguistic environment. J. Oper. Res. Soc. 69(2), 157–170 (2018)
Liao, H.C., Mi, X.M., Xu, Z.S.: A survey of decision-making methods with probabilistic linguistic information: bibliometrics, preliminaries, methodologies, applications and future directions. Fuzzy Optim. Decis. Ma. 19(1), 81–134 (2020)
Gao, J., Xu, Z.S., Ren, P.J., Liao, H.C.: An emergency decision making method based on the multiplicative consistency of probabilistic linguistic preference relations. Int. J. Mach. Learn. Cyb. 10(7), 1613–1629 (2019)
Liao, H.C., Jiang, L.S., Lev, B., Fujita, H.: Novel operations of PLTSs based on the disparity degrees of linguistic terms and their use in designing the probabilistic linguistic ELECTRE III method. Appl. Soft Comput. 80, 450–464 (2019)
Liu, P.D., Teng, F.: Probabilistic linguistic TODIM method for selecting products through online product reviews. Inf. Sci. 485, 441–455 (2019)
Krishankumar, R., Saranya, R., Nethra, R.P., Ravichandran, K.S., Kar, S.: A decision-making framework under probabilistic linguistic term set for multi-criteria group decision-making problem. J. Intell. Fuzzy Syst. 36(6), 1–13 (2019)
Zhang, X.L.: A novel probabilistic linguistic approach for large-scale group decision making with incomplete weight information. Int. J. Fuzzy Syst. 20(7), 2245–2256 (2018)
Liang, D.C., Kobina, A., Quan, W.: Grey relational analysis method for probabilistic linguistic multi-criteria group decision-making based on geometric Bonferroni mean. Int. J. Fuzzy Syst. 20(7), 2234–2244 (2018)
Xiao, F., Wang, J.Q.: Multistage decision support framework for sites selection of solar power plants with probabilistic linguistic information. J. Clean. Prod. 230, 1396–1409 (2019)
Liu, P.D., Li, Y.: Multi-attribute decision making method based on generalized maclaurin symmetric mean aggregation operators for probabilistic linguistic information. Comput. Ind. Eng. 131, 282–294 (2019)
Hong, Z.Y., Rong, Y., Qin, Y., Liu, Y.: Hesitant fuzzy dual Muirhead mean operators and its application to multiple attribute decision making. J. Intell. Fuzzy Syst. 35(2), 2161–2172 (2018)
Xu, Y., Shang, X.P., Wang, J.: Pythagorean fuzzy interaction Muirhead means with their application to multi-attribute group decision-making. Inf. 9(7), 157 (2018)
Krishankumar, R., Ravichandran, K.S., Ahmed, M.I., Kar, S., Peng, X.D.: Interval-valued probabilistic hesitant fuzzy set based muirhead mean for multi-attribute group decision-making. Mathematics 7(4), 342 (2019)
Wang, J., Zhang, R.T., Zhu, X.M., Zhou, Z., Shang, X.P., Li, W.Z.: Some q-rung orthopair fuzzy Muirhead means with their application to multi-attribute group decision making. J. Intell. Fuzzy Syst. 36(2), 1599–1614 (2019)
Liu, P.D., Khan, Q., Mahmood, T., Hassan, N.: T-spherical fuzzy power Muirhead mean operator based on novel operational laws and their application in multi-attribute group decision making. IEEE Access 7, 22613–22632 (2019)
Opricovic, S.: Multicriteria optimization of civil engineering systems. Faculty of Civil Engineering, Belgrade 2(1), 5–21 (1998)
Rani, P., Mishra, A.R., Pardasani, K.R., Mardani, A., Liao, H.C., Streimikiene, D.: A novel VIKOR approach based on entropy and divergence measures of Pythagorean fuzzy sets to evaluate renewable energy technologies in India. J. Clean. Prod. 238, 117936 (2019)
Opricovic, S., Tzeng, G.H.: Compromise solution by MCDM methods: A comparative analysis of VIKOR and TOPSIS. Eur. J. Oper. Res. 156(2), 445–455 (2004)
Opricovic, S., Tzeng, G.H.: Extended VIKOR method in comparison with outranking methods. Eur. J. Oper. Res. 178(2), 514–529 (2007)
Ding, X.F., Liu, H.C.: An extended prospect theory-VIKOR approach for emergency decision making with 2-dimension uncertain linguistic information. Soft Comput. 23(22), 12139–12150 (2019)
Bai, C.G., Sarkis, J.: Integrating and extending data and decision tools for Sustainable third-party reverse logistics provider selection. Comput. Oper. Res. 110, 188–207 (2019)
Gou, X.J., Xu, Z.S.: Novel basic operational laws for linguistic terms, hesitant fuzzy linguistic term sets and probabilistic linguistic term sets. Inf. Sci. 372, 407–427 (2016)
Bai, C.Z., Zhang, R., Qian, L.X., Wu, Y.N.: Comparisons of probabilistic linguistic term sets for multi-criteria decision making. Knowl.-based Syst 119, 284–291 (2017)
Muirhead, R.F.: Some methods applicable to identities and inequalities of symmetric algebraic functions of n letters. Proceedings of the Edinburgh Mathematical Society 21, 144–162 (1902)
Qin, J.D., Liu, X.W.: 2-tuple linguistic Muirhead mean operators for multiple attribute group decision making and its application to supplier selection. Kybernetes 45(1), 2–29 (2016)
Liu, P.D., Li, D.F.: Some Muirhead mean operators for intuitionistic fuzzy numbers and their applications to group decision making. PloS one 12(1), e0168767 (2017)
Jing, S.W., Niu, Z.W., Chang, P.C.: The application of VIKOR for the tool selection in lean management. J. Intell. Manuf. 30(8), 2901–2912 (2019)
Acknowledgements
This work is supported by the National Natural Science Foundation of China (Nos. 61876157, 71571148), and the Yanghua Scholar Plan (Part A) of SWJTU.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Du, Y., Liu, D. A Novel Approach for Probabilistic Linguistic Multiple Attribute Decision Making Based on Dual Muirhead Mean Operators and VIKOR. Int. J. Fuzzy Syst. 23, 243–261 (2021). https://doi.org/10.1007/s40815-020-00897-8
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40815-020-00897-8