
Abstract
The rock porosity is considered a key petrophysical property for the rock due to its great impact on the hydrocarbon reserve estimation and petroleum economics. The conventional methods for determining the rock porosity either from the logging tools, lab measurements for the cored samples, or using empirical correlations from other parameters are costly, time-consuming, or did not provide the required level of accuracy. The new horizon for implementing machine learning techniques as a new approach for predicting the rock porosity overcomes all of the above drawbacks. Therefore, the objective of this research is to develop a new model based on an artificial neural network (ANN) for predicting rock porosity from only drilling parameters that include weight on bit, torque, standpipe pressure, drill string rotation speed, rate of penetration, and pump rate. The study used two data sets for building the model (3767 data points) and the second one for validating the developed ANN model (1676 data points). ANN model was built and optimized with deep sensitivity analysis for the ANN model parameters to achieve strong prediction results. ANN model showed a correlation coefficient (R) between the predicted and actual porosity values of 0.97 and 0.92 with average absolute percentage errors (AAPE) of 6.2 and 9.3% for training and testing, respectively. The model validation enhanced the high prediction performance as ANN achieved R of 0.95 and AAPE of 8.5%. The study provides new contributions as predicting the rock porosity for complex lithology formations (sandstone, shale, and carbonate), developing an ANN porosity model with a high level of accuracy, and a newly developed ANN-based equation for estimating the porosity from only the surface drilling data.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
The porosity as a rock property can be defined as the ratio between the void pore spaces in the rock to the total bulk volume for the rock, and hence, it represents the rock storage capacity for the petroleum fluids in the reservoir rock [1, 2]. The accurate estimation for this parameter is very critical as it has a great impact on petroleum reserve estimation, petroleum economics, and field development plans [3,4,5]. Many technical methods are followed for determining the rock porosity as using the downhole logging tools for determining the rock porosity and this technique is costly due to the cost of the logging operation and downhole tools; in addition, it might be affected by the hole conditions due to the mud contamination [6, 7]. The lab measurement is the direct way for determining the rock porosity and the most accurate approach [8, 9]; however, it takes much time and cost for coring the rock sample and lab testing and this technique will not provide a complete log for the rock porosity [10, 11].
A recent technique is introduced to the field applications of rock characterization and rock porosity measurement by employing the drilled cuttings; however, the technique required special cuttings size and advanced sample preparation [12].
Determining the rock porosity from the logs data approach was studied in the literature where the rock porosity was obtained based on the sonic log or rock density [13, 14]. Nuclear magnetic resonance measurement was introduced for determining the rock porosity [15]. However, such techniques required the logging data or lab measurements to determine the rock porosity values that required extra cost and time.
1.1 New Machine Learning Applications for Porosity Prediction
The applications of machine learning (ML) techniques provided huge contributions for dealing with petroleum data in different disciplines. ML tools such as artificial neural networks (ANNs), fuzzy logic (FL), expert systems, support vector machines (SVMs), functional networks (FN), and case-based reasoning provided high performance and accurate prediction results[16]. The implementation of such tools contributed to solving many technical problems such as estimation and optimization of drilling parameters [17,18,19,20,21], predicting and monitoring the drilling fluids properties [22,23,24,25,26,27], reservoir fluid properties [28,29,30,31,32,33], rock density[34], rock permeability estimation [35, 36], and rock strength and geomechanical properties [37,38,39,40,41].
The porosity prediction by employing artificial intelligence techniques was studied in the literature as shown in Table 1. The table shows the input parameters for predicting the rock porosity, rock formation type for the study, and the ML techniques that were employed to build the prediction model.
Studies among the literature investigated the rock porosity prediction using the well-logging data as density, neutron porosity, sonic time, resistivity log, gamma-ray (GR), and stratigraphic information [42,43,44]; however, these logs (input parameters) are not available for all wells and requires additional logging operations to acquire the log data. In addition, the drilling data were employed for predicting the formation porosity using drilling parameters as the rate of penetration (ROP), pump rate (Q), drill string rotating speed (RPM), standpipe pressure (SPP), torque (T), weight on bit (WOB), and mechanical specific energy [45, 46]; however, these studies are restricted to certain types of formations. As shown in Table 1, drilling data were employed but for carbonate formation during drilling horizontal well [45], and another study for sandstone and shale formations but with incorporating the mechanical specific energy as an additional input to the drilling data; furthermore, the model accuracy was low with a correlation coefficient between the predicted and actual porosity values was 0.6 [46].
The novel contributions for this research comprise generating the formation neutron porosity log from only the available surface drilling parameters for complex lithology drilled rocks with high accuracy using ANN model. The current study predicted the porosity using the collected drilling data during drilling complex lithology formations that have carbonate, sand, and shale formations. In addition, the study presented a newly developed ANN-based equation for easy estimation of the rock porosity from the drilling data. The obtained model from this study will help to save the operational cost and time to log or measure the rock porosity in the lab.
2 Methodology for Predicting the Rock Porosity
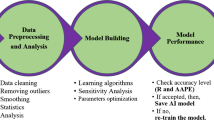
This research proposed an ANN prediction model for the rock porosity using the drilling data as inputs. The porosity profile was generated with a high accuracy using the developed ANN model for the whole drilled section that contains complex formation. Figure 1 represents the methodology flow to provide a robust porosity prediction model starting from the data gathering from the drilling sensors, followed by data preprocessing that includes data cleaning, removing the outliers, and data smoothing for removing the noise to provide the model input parameters with good quality. The next phase is to build and optimize the ANN model by training and optimizing processes with the trained algorithm. The model accuracy has to be determined to check the accuracy level of the model, and if the accuracy is low, then a retraining process should be performed to determine the optimum model parameters for high accuracy performance for the porosity prediction. Once the accepted accuracy is achieved, the model parameters will be saved and the results will be reported.

Methodology layout for building ANN model
2.1 Data Description and Statistics
The data in this study were collected during a drilling phase that covered the intermediate section for vertical wells. The drilled formations contain more than one rock type as sandstone, shale, and limestone that can be considered complex lithologies. The data covered 3767 readings for all the drilling parameters with the neutron porosity log after the data cleaning and preprocessing were used for building the machine learning model. Another data set of 1670 data points was collected from the same drilling phase that was employed for validating the developed model. The drilling parameters include the surface drilling parameters as the weight on bit (WOB) in klb, torque (T) in kft.lbf, standpipe pressure (SPP) in psi, drill string rotary speed (RPM) in min−1, drilling rate of penetration (ROP) in ft/h, and mudflow rate (Q) in gpm.
2.2 Data Statistics and Analysis
The collected data from the drilling sensors suffered from operational measurement and tool errors. And hence, the data should be preprocessed for removing the missing measurements, noise, and outliers by using a developed MATLAB code to ensure the data quality for developing the AI model. Statistical analysis for the cleaned data shows the minimum, maximum, mean, and standard deviation for each parameter as shown in Table 2.
From the data statistics, the drilling parameters and porosity indicated the wide range for the data that will enhance the prediction capabilities of the developed AI model. The statistics show that WOB ranged from 1.5 to 26.7 (klbf), T from 4.3 to 11.0 (kft.lbf), SPP from 2140 to 3076 psi, pipe speed from 77.9 to 162.5 (1/min), ROP from 26.1 to 119.6 (ft/h), flow rate ranged from 627 to 854 (gpm), and the target parameter from 0.055 to 0.429 that covered very tight rock class to high porous rock scale. Studying the porosity data range and frequency showed that the porosity values below 0.2 recorded 44% of the total recorded frequency, 49% of the total frequencies was recorded for the porosity values from 0.2 to 0.3, and only 8% from the total frequency was observed for the higher porosity values greater than 0.3. Hence, the porosity database covered a wide range of rock porosity data that enhances the capability of the prediction model.
The relationships between the drilling parameters (model inputs) and the rock porosity (model output) show a direct linear relationship between the porosity and drilling parameters as Q, RPM, WOB, ROP, and T with a correlation coefficient (R) of 0.299, 0.233, 0.151, 0.144, and 0.086, respectively. However, the porosity shows a very weak indirect relationship with SPP by R of −0.003. as represented in Fig. 2. However, it is worth mentioning that the relationship between the porosity and drilling parameters might reveal a nonlinear relationship.

Correlation coefficient of drilling data and rock porosity
2.3 Building and Evaluating the ANN Model
The artificial neural network tool was utilized for solving engineering problems by its processing algorithms based on interconnected artificial neurons that mimic the biological neural networks [47, 48]. Three layers represented the common architecture for ANN which are the input, hidden, and output layers [49]. Weights and biases are utilized in the ANN structure to link the layers and affect the network performance [50]. Different algorithms are used for model training and controlling neuron processing [51]. Many researchers studied extracting empirical correlations from the ANN architecture for easier applications in the petroleum industry [52, 53]. Many parameters were tested to check the impact on the ANN model accuracy as the hidden layer/s number, the neurons number, network, training, and transfer functions. Figure 3 shows the design of the developed ANN model in this study.

The structure of the ANN porosity model
The developed model was evaluated by determining two statistical parameters which are correlation coefficient (R) and average absolute percentage error (AAPE). R and AAPE are calculated as follows:
where N is the number of data points in the dataset, \({Y}_{i}\) is the actual output, \(\widehat{Y}\)i is the predicted output.
3 Results and Discussion
This section discusses the obtained results from building and optimizing the ANN model for the porosity prediction from the drilling data.
3.1 Model Training and Testing
The data were randomly distributed to training and testing sets by 70:30% as 2637 data points for training and 1130 points for the testing set from all the model data set of 3767 recordings. Optimizing the ANN model parameters was achieved by testing several runs for the model to obtain the optimum number of neurons, network function, training function, transfer function, and the drilling data as inputs. Figure 4 illustrates how the impact of changing the number of neurons in the hidden layer on the model results of the training and testing processes. Changing the neurons number from 15 to 30 showed that increasing the number of neurons caused increasing the model performance by increasing R and reducing AAPE for training and testing data sets. In addition, a sensitivity analysis was performed to check the impact of changing network function, training function, transfer function, and the drilling parameters as shown in Figs. 5, 6, 7, 8, respectively.

The impact of changing neurons number on ANN model results

The impact of changing network function on ANN model results

The impact of changing training function on ANN model results

The impact of changing transfer function on ANN model results

The impact of drilling parameters on ANN model results
The best model parameters were recorded for only one hidden layer with 30 neurons, function fitting neural network (fitnet) as a network function, Bayesian regularization backpropagation (trainbr) as a training function, hyperbolic tangent sigmoid transfer function (tansig) as a transfer function, and employing all the six drilling parameters. The optimized ANN model yielded a high correlation coefficient of 0.97 and 0.92 with a low AAPE of 6.2 and 9.3% for training and testing data sets, respectively, as shown in Fig. 9.

ANN model results. (a) training (b) testing
The obtained results showed a high degree of match between the actual and the predicted values for the porosity profile for the drilled section of different lithology formation types as presented in Fig. 10.

ANN porosity model results for the drilled section. (a) training (b) testing
3.2 Model Validation
In order to ensure the practical application for employing the developed model, a different data set from the same field that has the same penetrated rocks with complex lithology was utilized for validating the developed ANN model. A cleaned data set (1670 data points) was employed for validating the model, and the obtained results showed a strong prediction performance for the porosity log from the surface drilling parameters. The validation results showed R of 0.95 and AAPE of 8.5% for the ANN model as shown in Fig. 11.

ANN MODEL validation results
3.3 A Developed Empirical Correlation for Porosity Estimation
A new nonlinear relationship was extracted from the weights and biases of the developed ANN model. The ANN model equation is proposed to be used by non-AI users. To utilize the new ANN model equation, the input values should be normalized to be in the range between -1 and 1 as follows:
where \({X}_{{i}_{\mathrm{n}\mathrm{o}\mathrm{r}}}\) represents the normalized value for variable \(X\), \({X}_{i}\) is the value of variable \(X\), \(X_{{i{\text{min}}}}\) is the minimum value of variable \(X\), \(X_{{i{\text{max}}}}\) is the maximum value of variable \(X\).
The minimum and maximum values for all variables that are used for data normalization are presented in Table 3.
The proposed ANN equation that can be used for porosity prediction in the normalized form is presented in Eq. 4. The equation uses the weights and biases that are shown in Table 4.
where \({{\phi }_{n}}_{i}\) is the normalized porosity value, \(N\) is the number of neurons in the hidden layer, i.e., 30, \({w}_{{1}_{i}}\) is the weight associated with each feature between the input and the hidden layers, \({w}_{{2}_{i}}\) is the weight associated with each feature between the hidden and the output layers, \({b}_{{1}_{i}}\) is the bias associated with each neuron in the hidden layer, and \({b}_{2}\) is the bias of the output layer.
To convert the obtained normalized \(\phi\) to an actual \(\phi\) value, Eq. 5 can be used:
4 Conclusions
This study presented a novel approach for predicting the rock porosity from the drilling data during drilling complex lithology formations (sandstone, shale, and carbonate) using ANN. Two data sets were employed for building the ANN model (3763 data points) and the other set for validating the developed model (1670 points). The study findings can be withdrawn as follows:
-
ANN model was optimized as 30 neurons, fitnet as a network function, trainbr as a training function, tansig as a transfer function, and utilizing all the recorded drilling parameters.
-
The study results for the model showed R of 0.97 and 0.92 with AAPE of 6.2 and 9.3% for training and testing, respectively.
-
Validating the developed ANN model proved the strong prediction performance for the model with R of 0.95 with AAPE of 8.5%.
-
Furthermore, the study presented a newly developed empirical correlation for porosity estimation from the drilling parameters in real time.
The porosity estimation in real time using the developed ANN model will save cost and time for the porosity determination in reality by employing either the lab measurements or well logging operations.
Abbreviations
- ANN:
-
Artificial neural network
- RF:
-
Random forest
- SVM:
-
Support vector machines
- FL:
-
Fuzzy logic
- FN:
-
Functional networks
- R:
-
Correlation coefficient
- AAPE:
-
Average absolute percentage error
- ML:
-
Machine learning
- GR:
-
Gamma-ray
- WOB:
-
Weight on bit
- RPM:
-
Rotating speed in revolutions per minute
- ROP:
-
Rate of penetration
- Q:
-
Flow rate
- SPP:
-
Standpipe pressure
- T:
-
Torque
- Fitnet:
-
Function fitting neural network
- newff:
-
Create feedforward backpropagation network
- newpr:
-
Create pattern recognition network
- trainbr:
-
Bayesian regularization
- trainoss:
-
One-step secant backpropagation
- trainlm:
-
Levenberg–Marquardt backpropagation
- trainbfg:
-
BFGS quasi-Newton backpropagation
- traingdx:
-
Gradient descent with momentum and adaptive learning rule backpropagation
- tansig:
-
Hyperbolic tangent sigmoid transfer function
- logsig:
-
Log-sigmoid transfer function
- hardlims:
-
Hard-limit transfer function
- purelin:
-
Linear transfer function
- softmax:
-
Softmax transfer function
- tribas:
-
Triangular basis transfer function
- satlin:
-
Saturating linear transfer function
References
Tang, Y., Hou, C., He, Y., Wang, Y., Chen, Y., Rui, Z.: Review on Pore Structure Characterization and Microscopic Flow Mechanism of CO2 Flooding in Porous Media, https://onlinelibrary.wiley.com/doi/full/https://doi.org/10.1002/ente.202000787, (2021)
Zhong, H.; Yang, T.; Yin, H.; Lu, J.; Zhang, K.; Fu, C.: Role of Alkali type in chemical loss and ASP-flooding enhanced oil recovery in Sandstone formations. SPE Reserv. Eval. Eng. 23, 431–445 (2020). https://doi.org/10.2118/191545-PA
Olatunji, S.O.; Selamat, A.; Abdulraheem, A.: Modeling the permeability of carbonate reservoir using type-2 fuzzy logic systems. Comput. Ind. 62, 147–163 (2011). https://doi.org/10.1016/j.compind.2010.10.008
Adizua, O.F., Oruade, L.: Reservoir characterization of an offshore Niger delta “X” field using well log data. (2018)
Mahzari, P.; AlMesmari, A.; Sohrabi, M.: Co-history matching: a way forward for estimating representative saturation functions. Transp. Porous Media. 125, 483–501 (2018). https://doi.org/10.1007/s11242-018-1129-8
Bonnecaze, R.T., Sharma, M.M., Butler, J.E., Arboleda, G.: High resolution downhole measurements of porosity and fluid saturation while core drilling, https://doi.org/10.2118/77561-MS, (2002)
Kane, J.A., Jennings, J.W.: A method to normalize log data by calibration to large-scale data trends, https://doi.org/10.2118/96081-MS, (2005)
Andersen Brent Duncan Ryan McLin, M.A., Beeson, D., Harrison, D., Roberto Rojas, M., Zhang, L., Chaparro, C., Lobo, A., Charsky, A., Herron, M., Mawutor Ndinyah, J., Clopine, W.W., Hinton, W., Kumar, H., Spain, D.R., Samarasingha, U., Lake City, S., Smithson, T., Yabrudy, E.: Core truth in formation evaluation. (2013)
Patchett, J.G., Coalson, E.B.: SPWLA twenty-third the determination of porosity in sandstone and shaly sandstone part two effects of complex mineralogy and hydrocarbons. OnePetro (1982). http://onepetro.org/SPWLAALS/proceedings-abstract/SPWLA-1982/All-SPWLA-1982/SPWLA-1982-T/18474
Hook, J.R.: An introduction to porosity. Petrophysics 44(3), 205–212 (2003)
Gyllensten, A., Tilke, P., Al-Raisi, M., Allen, D.: Porosity Heterogeneity analysis using geostatistics. Presented at the October 10 (2004)
Kesserwan, H., Alshanqaiti, E., Jin, G., Nuic, I.: Porosity measurements on drill cuttings - comprehensive inputs to formation evaluation near real-time while drilling , https://doi.org/10.2118/188881-MS, (2017)
Wyllie, M.R.J.; Gregory, A.R.; Gardner, G.H.F.: An experimental investigation of factors affecting elastic wave velocities in porous media. Geophysics 23, 459–493 (1958). https://doi.org/10.1190/1.1438493
Gaymard, R., Poupon, A.: Response of neutron and formation density logs in hydrocarbon bearing formations. Log Anal. 9(5) (1968)
Timur, A.: Producible porosity and permeability of sandstone investigated through nuclear magnetic resonance principles. Log Anal. 10(1) (1969)
Mohaghegh, S.: Virtual-intelligence applications in petroleum engineering: part 1—artificial neural networks. J. Pet. Technol. 52, 64–73 (2000). https://doi.org/10.2118/58046-JPT
Gamal, H., Elkatatny, S., Abdulraheem, A.: Rock drillability intelligent prediction for a complex lithology using artificial neural network. Soc. Pet. Eng. - Abu Dhabi Int. Pet. Exhib. Conf. 2020, ADIP 2020. (2020)
Al-Abduljabbar, A.; Gamal, H.; Elkatatny, S.: Application of artificial neural network to predict the rate of penetration for S-shape well profile. Arab. J. Geosci. (2020). https://doi.org/10.1007/s12517-020-05821-w
Mahmoud, A.A., Elkatatny, S., Al-AbdulJabbar, A., Moussa, T., Gamal, H., Shehri, D. Al: Artificial neural networks model for prediction of the rate of penetration while horizontally drilling carbonate formations. In: 54th U.S. rock mechanics/geomechanics symposium (2020)
Ahmed, A.; Ali, A.; Elkatatny, S.; Abdulraheem, A.: New artificial neural networks model for predicting rate of penetration in deep shale formation. Sustainability (2019). https://doi.org/10.3390/su11226527
Hassan, A.; Al-Majed, A.; Mahmoud, M.; Elkatatny, S.; Abdulraheem, A.: Improved predictions in oil operations using artificial intelligent techniques. SPE Middle East Oil Gas Show Conf. (2019). https://doi.org/10.2118/194994-MS
Elzenary, M., Elkatatny, S., Abdelgawad, K.Z., Abdulraheem, A., Mahmoud, M., Al-Shehri, D.: New Technology to evaluate equivalent circulating density while drilling using artificial intelligence. SPE Kingdom Saudi Arab. Annu. Tech. Symp. Exhib. 14 (2018). https://doi.org/10.2118/192282-MS
Al-azani, K., Elkatatny, S., Abdulraheem, A., Mahmoud, M., Al-Shehri, D.: Real time prediction of the rheological properties of oil-based drilling fluids using artificial neural networks. SPE Kingdom Saudi Arab. Annu. Tech. Symp. Exhib. 17 (2018). https://doi.org/10.2118/192199-MS
Elkatatny, S.: Real-time prediction of the rheological properties of water-based drill-in fluid using artificial neural networks. Sustainability. 11, 5008 (2019). https://doi.org/10.3390/su11185008
Alsabaa, A., Gamal, H.A., Elkatatny, S.M., and Abdulraheem, A.: Real-time prediction of rheological properties of all-oil mud using artificial intelligence. Am. Rock Mech. Assoc. (2020). https://@@www.onepetro.org/conference-paper/ARMA-2020-1645
Alsabaa, A.; Gamal, H.; Elkatatny, S.; Abdulraheem, A.: Real-time prediction of rheological properties of invert emulsion mud using adaptive neuro-Fuzzy inference system. Sensors. 20, 1669 (2020). https://doi.org/10.3390/s20061669
Alsabaa, A.; Gamal, H.; Elkatatny, S.; Abdulraheem, A.: New correlations for better monitoring the all-oil mud rheology by employing artificial neural networks. Flow Meas. Instrum. (2021). https://doi.org/10.1016/j.flowmeasinst.2021.101914
Ahmadi, M.A.; Pournik, M.; Shadizadeh, S.R.; Ali, M.; Pournik, M.; Reza, S.: Toward connectionist model for predicting bubble point pressure of crude oils: Application of artificial intelligence. Petroleum. 1, 307–317 (2015)
Alakbari, F.S.; Elkatatny, S.; Baarimah, S.O.: Prediction of bubble point pressure using artificial intelligence AI techniques. Paper SPE-184208-MS presented at the SPE Middle East Artificial Lift Conference and Exhibition, Manama, Kingdom of Bahrain (2016). https://doi.org/10.2118/184208-MS
Wood, D.A.; Choubineh, A.: Transparent open-box learning network and artificial neural network predictions of bubble-point pressure compared. Petroleum (2018). https://doi.org/10.1016/j.petlm.2018.12.001
Mahdiani, M.R.; Norouzi, M.: A new heuristic model for estimating the oil formation volume factor. Petroleum. 4, 300–308 (2018)
Oloso, M.A.; Hassan, M.G.; Bader-El-Den, M.B.; Buick, J.M.: Hybrid functional networks for oil reservoir PVT characterisation. Expert Syst. Appl. 87, 363–369 (2017)
Elkatatny, S.; Moussa, T.; Abdulraheem, A.; Mahmoud, M.; Oil, P.; Volume, P.; Properties, T.: A self-adaptive artificial intelligence technique to predict oil pressure volume temperature properties. Energies 11, 3490 (2018). https://doi.org/10.3390/en11123490
Ahmed, A.; Elkatatny, S.; Gamal, H.; Abdulraheem, A.: Artificial intelligence models for real-time bulk density prediction of vertical complex lithology using the drilling parameters. Arab. J. Sci. Eng. (2021). https://doi.org/10.1007/s13369-021-05537-3
Khalifah, H.A.; Glover, P.W.J.; Lorinczi, P.: Permeability prediction and diagenesis in tight carbonates using machine learning techniques. Mar. Pet. Geol. (2020). https://doi.org/10.1016/j.marpetgeo.2019.104096
Shokooh Saljooghi, B.; Hezarkhani, A.: A new approach to improve permeability prediction of petroleum reservoirs using neural network adaptive wavelet (wavenet). J. Pet. Sci. Eng. 133, 851–861 (2015)
Alloush, R.M., Elkatatny, S., Mahmoud, M.A., Moussa, T.M., Ali, A.Z., Abdulraheem, A.: Estimation of geomechanical failure parameters from well logs using artificial intelligence techniques. SPE Kuwait Oil Gas Show Conf. 13 (2017). https://doi.org/10.2118/187625-MS
Tariq, Z., Elkatatny, S., Mahmoud, M., Ali, A.Z., Abdulraheem, A.: A new technique to develop rock strength correlation using artificial intelligence tools. SPE Reserv. Characterisation Simul. Conf. Exhib. 14 (2017). https://doi.org/10.2118/186062-MS
Elkatatny, S., Tariq, Z., Mahmoud, M., Abdulazeez, A., Mohamed, I.M.: Application of artificial intelligent techniques to determine sonic time from well logs. 50th U.S. Rock Mech. Symp. 11 (2016)
Tariq, Z., Elkatatny, S., Mahmoud, M., Abdulraheem, A., Fahd, K.: A new artificial intelligence based empirical correlation to predict sonic travel time. Int. Pet. Technol. Conf. 19 (2016). https://doi.org/10.2523/IPTC-19005-MS
Gowida, A.; Elkatatny, S.; Gamal, H.: Unconfined compressive strength (UCS) prediction in real-time while drilling using artificial intelligence tools. Neural Comput. Appl. (2021). https://doi.org/10.1007/s00521-020-05546-7
Elkatatny, S.; Tariq, Z.; Mahmoud, M.; Abdulraheem, A.: New insights into porosity determination using artificial intelligence techniques for carbonate reservoirs. Petroleum. 4, 408–418 (2018). https://doi.org/10.1016/j.petlm.2018.04.002
Ali, A.; Aïfa, T.; Baddari, K.: Prediction of natural fracture porosity from well log data by means of fuzzy ranking and an artificial neural network in Hassi Messaoud oil field, Algeria. . J. Pet. Sci. Eng. 115, 78–89 (2014). https://doi.org/10.1016/j.petrol.2014.01.011
Wood, D.A.: Predicting porosity, permeability and water saturation applying an optimized nearest-neighbour, machine-learning and data-mining network of well-log data. J. Pet. Sci. Eng. 184, 106587 (2020)
Al-Abduijabbar, A.; Al-Azani, K.; Elkatatny, S.: Estimation of reservoir porosity from drilling parameters using artificial neural networks. Petrophysics. 61, 318–329 (2020)
Kanfar, R., Shaikh, O., Yousefzadeh, M., Mukerji, T.: Real-time well log prediction from drilling data using deep learning, https://doi.org/10.2523/IPTC-19693-MS, (2020)
Bello, O.; Holzmann, J.; Yaqoob, T.; Teodoriu, C.: Application Of artificial intelligence methods in drilling system design and operations: a review of the state of the art. J. Artif. Intell. Soft Comput. Res. 5, 121–139 (2015). https://doi.org/10.1515/jaiscr-2015-0024
Abbas, A.K.; Rushdi, S.; Alsaba, M.; Al Dushaishi, M.F.: Drilling rate of penetration prediction of high-angled wells using artificial neural networks. J. Energy Resour. Technol. Trans. ASME. (2019). https://doi.org/10.1115/1.4043699
Cevik, A., Sezer, E.A., Cabalar, A.F., Gokceoglu, C.: Modeling of the uniaxial compressive strength of some clay-bearing rocks using neural network. In: Applied Soft Computing Journal. pp. 2587–2594. Elsevier (2011)
Lippmann, R.P.: An introduction to computing with neural nets. IEEE ASSP Mag. 4, 4–22 (1987). https://doi.org/10.1109/MASSP.1987.1165576
Graves, A.; Liwicki, M.; Fernández, S.; Bertolami, R.; Bunke, H.; Schmidhuber, J.: A novel connectionist system for unconstrained handwriting recognition. IEEE Trans. Pattern Anal. Mach. Intell. 31, 855–868 (2009). https://doi.org/10.1109/TPAMI.2008.137
Mahmoud, A.A., ElKatatny, S., Abdulraheem, A., Mahmoud, M., Ibrahim, M.O., Ali, A.: New technique to determine the total organic carbon based on well logs using artificial neural network (white box). In: Society of Petroleum Engineers - SPE Kingdom of Saudi Arabia Annual Technical Symposium and Exhibition 2017. pp. 1441–1452. Society of Petroleum Engineers (2017)
Moussa, T.; Elkatatny, S.; Mahmoud, M.; Abdulraheem, A.: Development of new permeability formulation from well log data using artificial intelligence approaches. J. Energy Resour. Technol. Trans. ASME. (2018). https://doi.org/10.1115/1.4039270
Acknowledgements
The authors wish to acknowledge King Fahd University of Petroleum and Minerals for permitting to publish this work.
Funding
This research received no external funding.
Author information
Authors and Affiliations
Contributions
The manuscript was written through the contributions of all authors [H.G., S.E.]. All authors have approved the final version of the manuscript.
Corresponding author
Ethics declarations
Conflicts of interest
The author declares no conflict of interest.
Rights and permissions
About this article

Cite this article
Gamal, H., Elkatatny, S. Prediction Model Based on an Artificial Neural Network for Rock Porosity. Arab J Sci Eng 47, 11211–11221 (2022). https://doi.org/10.1007/s13369-021-05912-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13369-021-05912-0