
Abstract
Unconfined compressive strength (UCS) is a major mechanical parameter of the rock which has an essential role in developing geomechanical models. It can be estimated directly by lab testing of retrieved core samples or from well log data. These methods are very expensive and require huge efforts and time. Therefore, there is a need to develop a new technique for predicting UCS values in real-time. In this study, three artificial intelligence (AI) models were developed using artificial intelligence tools; artificial neural networks (ANN), adaptive neuro-fuzzy inference system (ANFIS), and support vector machine (SVM) to predict UCS of the downhole formations while drilling based on real-time recording of the drilling mechanical parameters. These parameters include rate of penetration (ROP), mud pumping rate (GPM), stand-pipe pressure (SPP), rotary speed in revolution per minute (RPM), torque (T), and weight on bit (WOB). A dataset of 1771 points from a Middle Eastern field was used to build the developed models: for training and testing processes. A new UCS correlation was developed based on the optimized AI model. Another set of data (2175 data points unseen by the model) was used to validate the model and the developed UCS correlation. The developed ANN-model outperformed the ANFIS- and SVM-models with a correlation coefficient (R-value) of 0.99 and an average absolute percentage error (AAPE) of 3.48% between the predicted and actual UCS values. The new UCS correlation outperformed the available correlations for UCS prediction and it was able to predict the UCS with AAPE of 4.2% compared to the actual UCS values.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Unconfined compressive strength (UCS) is an essential mechanical rock-parameter for building geomechanical models. It defines the maximum compressive stress limit that the rock can endure without failure when uniaxial loading is applied under confinement conditions [1]. Rock mechanics is generally theoretical and applied science that describes the mechanical behavior of the rock when different stresses are applied. Rock failure is one of the petroleum-related features of rock mechanics which is the reason behind many downhole problems such as solids production and wellbore instability issues [2]. The availability of UCS data of the downhole formations has a high degree of importance in optimizing the drilling operation performance, bit hydraulics, determining the proper mud weight while drilling, and avoiding wellbore instability issues [3].
Rock mechanical properties can be determined directly using experimental tests conducted on retrieved core samples representing the actual stress-state conditions and mechanical properties of the rocks downhole. UCS can be estimated in the laboratory using different tests such as uniaxial compressive strength test, triaxial compressive strength test, scratch test, Schmidt hammer test, and point load test. These laboratory measurements are considered the most accurate and reliable method for determining such properties [4]. However, since retrieving core samples representing the sections of interest is very costly and requires a lot of time, core-testing data cannot yield a continuous profile of UCS along the drilled wellbore [5]. Besides, representative core samples are not always available and their number is often restricted. Therefore, indirect methods were developed to fill the missing gaps using derived correlations between the rock mechanical properties and petrophysical well-log data.
Many studies in the literature have reported different correlations (Table 1) to predict UCS of different lithologies using logging data based on nonlinear regression techniques [6,7,8,9,10,11]. Most of these models are based on sonic transit time (Δt) and formation porosity (Ø) for estimating UCS. Moreover, the application of artificial intelligence tools has been introduced to correlate core-testing UCS data with different well-log data such as bulk density and sonic log data [12,13,14]. However, such well-log data are not always available while drilling the wellbore, as they are often obtained using a wireline logging technique which is usually performed after drilling the wellbore to avoid the harsh drilling environment [15]. Besides, the acquisition of logging data while drilling is a costly process and has several operational limitations and requires many corrections as well. This created the main motivation behind this study which is developing a new technique through which UCS values can be estimated in real-time other than using the well-log data. Additionally, the substantial value of obtaining the UCS data during drilling addresses the increasing need for such data in real-time. This is because it is very crucial to optimize the drilling operation, reduce the non-productive time (NPT), prevent the collapse of downhole formations, and, hence, avoid many wellbore instability problems by choosing the proper mud weight.
Therefore, the main objective of this paper is to introduce a novel technique for predicting the UCS values of the downhole formations while drilling. This involved developing new models using different AI tools to predict UCS depending on the mechanical drilling parameters instead of well log data. These mechanical drilling parameters are usually available while drilling; include rate of penetration (ROP), mud pumping rate (GPM), stand-pipe pressure (SPP), drillstring rotating-speed (RPM), drilling torque (T), and weight on bit (WOB). Unlike the logging data, such drilling data are always available during the drilling operation at a low cost. Accordingly, the developed AI-based models would help estimate UCS of the downhole formations while drilling in a time- and cost-effective way.
2 Materials and methods
In this study, new AI models were developed to estimate UCS values of the downhole formations while drilling using three AI tools: the artificial neural network (ANN), adaptive neuro-fuzzy inference system (ANFIS), and support vector machine (SVM). The developed models used the mechanical drilling parameters as feeding inputs to predict the output; formations’ UCS-values.
2.1 Data description
A dataset of 1771 data points was collected representing a vertical section (Well A) within a field in the Eastern province of Saudi Arabia (Middle East Region). The obtained dataset included mechanical drilling data and the corresponding UCS values of the drilled formations. These drilling parameters (ROP, GPM, SPP, RPM, T, and WOB) are normally recorded at the surface while drilling using accurate real-time sensors to monitor the drilling performance. The corresponding UCS data were extracted from the geomechanical model of the area under study: The aforementioned model was developed based on actual core samples lab-testing data.
2.2 Dataset statistical analysis
The dataset used was statistically analyzed to describe its ranges and distributions before the model development. Table 2 lists different statistical parameters for the inputs (ROP, GPM, SPP, RPM, T, and WOB) and the output parameter (UCS). The ranges of the input and output parameters are ROP from 35.18 to 108.34 ft/hr, GPM from 645.30 to 854.01 gallon-per-minute, SPP from 2140 to 3076 psi, RPM from 77.94 to 162.53 revolution-per-minute, T from 4.29 to 10.68 kft.Ib, WOB from 1.54 to 25.48 kIb, and UCS from 1030.02 to 17378.06 psi. The dataset used was found to cover wide ranges with satisfactory distribution as inferred from the statistical analysis. This would boost the prediction performance of the proposed model to describe the phenomena more efficiently.
2.3 Data processing and filtration
The prediction accuracy of the AI-based models is significantly affected by the quality of the data used while developing the model. Therefore, the data were pre-processed and filtered using statistical analysis and engineering sense based on the literature. A specially designed MATLAB program was used to remove unreasonable values like zeros and negative values in addition to any missing points. Then, outliers were removed using box and whisker plot, in which the top whisker represents the upper limit of the data and the bottom whisker represents the lower limit of the data [16]. Any value beyond these limits was considered an outlier then removed. These limits were determined using the statistical parameters listed in Table 2.
2.4 Study of input(s)/output relationship strength
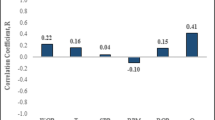
To identify the strength of the relationship between the output (UCS) and the input parameters, the Pearson correlation coefficient (R) with a mathematical formula expressed in Eq. 8 was used to identify how strongly two parameters are linearly related to each other [17]. Its value ranges from − 1 to +1. A strong direct linear-relation is indicated with an R-value of +1. On the contrary, the R-value of − 1 shows a strong inverse linear-relation between these two variables. While the R-value of zero indicates no linear relationship exists between the two study variables. Figure 1 shows the relative importance between the output parameter (UCS) and the input parameters individually in terms of R-value. UCS had R-values of 0.15, 0.14, 0.12, 0.07, 0.02 and -0.18 with ROP, SPP, T, WOB, GPM, and RPM, respectively.
where; R represents the correlation coefficient between the two variables x and y.

Relationship strength between the output (UCS) and the input parameters in terms of correlation coefficient (R)
2.5 Application of artificial intelligence tools
2.5.1 Artificial neural network (ANN)
ANN is an artificial intelligence tool which has recently got a remarkable reputation for modeling complex engineering phenomenon and complicated problems in a significant efficient way. Recently, ANN has been used in many applications in petroleum engineering fields. Many studies in the literature introduced the application of ANN in the area of formation evaluation and rock characterization [18,19,20,21,22,23,24]. A typical neural network consists of three types of layers; input layer, hidden layer, and output layer [25]. These layers are connected by a set of weights and biases which are tuned during the optimization process of the network to control the prediction performance of the network [26]. The connection between the network components mimics that of the biological neural system in handling and processing the data [27]. The network is usually trained with different learning algorithms to optimize the network and to control the processing of the neurons [28]. These neurons are considered the elementary elements from which any neural network is constructed [29].
2.5.1.1 Neural network application to predict UCS
In this study, a new model was developed using the obtained dataset to predict UCS while drilling using ANN. A specially designed MATLAB program was used to feed the network with the input parameters to estimate UCS. Figure 2 shows a schematic diagram for the developed network architecture. The model development passes through three main stages; these are the training process, the testing process, and the validation process. First, the obtained dataset was randomly stratified into two sets; training and testing set for building the model. Splitting the data was in the way that the testing set was within the same range as the training set. During the training process, the network was trained with the data to tune its parameters to achieve the highest possible accuracy. Then, the results were evaluated and compared to the actual output (UCS) values based on two main evaluating factors; these were correlation coefficient (R), and average absolute percentage error (AAPE). The formulas used for estimating these factors (R and AAPE) are stated in Eqs. 8 and 9. Thereafter, the developed network was tested and cross-validated using hidden testing set to check the performance of the developed network while using unseen data.
where; n is the number of the data points used.

The typical schematic architecture of the developed network
2.5.1.2 ANN-model optimization
The accuracy of the prediction process depends mainly on the tuning process of the network parameters. These parameters include:
-
Data splitting ratio
-
Number of hidden layers
-
Number of neurons in each hidden layer
-
Network function
-
Type of transfer functions
-
Type of training algorithm
-
Learning rate
The developed network was trained using the stochastic gradient descent optimization algorithm which is considered the most popular optimization algorithm in AI applications. It depends on updating the network parameters iteratively in the gradient direction of the objective function. Through every update, the algorithm helps the model gradually converge to reach the optimal value of the objective function. It involves taking random values of the model hyperparameters and adjusting them iteratively based on the available options to reduce the loss function eventually. Through each iteration, the model is guided to update the model hyperparameters to reduce the error of the next iteration using the backpropagation technique.
The developed MATLAB code was designed to generate different combinations of the aforementioned parameters with their available options listed in Table 3. The network was run with several trials and each trial included using one of the generated combinations of ANN parameters. During each trial, the results were tested, and the prediction performance was evaluated based on the comparison between the actual UCS values and the predicted ones, indicated from the evaluating factors (R, and AAPE). The target of the optimization process was to identify the ANN parameters’ combination which would result in the highest prediction accuracy. This would be inferred from the highest R-value between the predicated and actual UCS values accompanied by the lowest AAPE between them. The optimized network parameters were:
-
Data splitting ratio: 70/30 ratio for training and testing respectively
-
Number of hidden layers: single hidden layer
-
Number of neurons in each hidden layer: 30 neurons
-
Network function: fitnet
-
Type of transfer functions: tan-sigmoidal function (tansig)
-
Type of training algorithm: Bayesian Regularization backpropagation (trainbr)
-
Learning rate: 0.12
The proposed model was developed by training the network with 70% of the dataset (1240 points) while 30% of the data (531 points) was used for testing the performance of the model. The results of the prediction process showed that the predicted UCS values significantly matched with the actual values. This obvious match is indicated from the high R-value which reached 0.99 between the predicted and actual UCS values for both the training and testing processes as shown in the cross-plots (Fig. 3a and b). These cross-plots inferred that the predicted UCS is so close to the actual ones as the plotted data considerably coincide with the forty-five-line with a correlation novalety coefficient exceeded 0.99 between the actual and predicted UCS values. This confirms the high accuracy of the prediction of The UCS values using the developed ANN-model.

Crossplots between the predicted and actual UCS values for a training process, and b testing process, using the developed ANN-model. This shows how the predicted values were so close to the actual ones
2.5.2 Adaptive neuro-fuzzy inference system (ANFIS)
Fuzzy Logic (FL) systems are structured based on fuzzy techniques that resemble human reasoning during information processing. Its technique emulates the way of human decision making involving all intermediate possibilities. Adaptive fuzzy systems depend on the automatic online synthesis and tuning of fuzzy controller parameters using online data to continually “learn” the fuzzy controller. Recently, different adaptive fuzzy systems are used to simulate complex, and nonlinear systems; adaptive neuro-fuzzy inference system (ANFIS), Event-triggered adaptive fuzzy systems, etc. [30,31,32]. From the functionality perspective, there are almost no constraints on the node functions of the ANFIS network except piecewise differentiability. While from the structure perspective, the only limitation of network configuration is that it should be a feedforward network. According to these minimal restrictions, ANFIS applications are immediate and immense in various areas [33].
Additionally, many studies in the literature introduced ANFIS as a reliable predictive tool with several applications in the petroleum industry [34,35,36,37]. Therefore, ANFIS was selected in this study to build the predictive model of UCS. ANFIS is an integrated supervised learning algorithm for processing data that combines the concepts of neural networks and fuzzy logic utilizing a fuzzy inference system [38, 39]. Such a combination between neural networks and fuzzy logic provides an advantage of easy translation of the final system into a set of if–then rules, and the fuzzy system can be viewed as a neural network structure with knowledge distributed throughout connection strengths. It follows Takagi–Sugeno inference system which employs conventional Boolean logic (i.e., zeros and ones) while analyzing the systems using a set of fuzzy IF–THEN rules [33].
ANFIS uses a hybrid learning algorithm to identify parameters of Sugeno-type fuzzy inference systems. This learning algorithm uses the least-squares method and the backpropagation gradient descent method for training membership function parameters of the Fuzzy Inference System (FIS) to imitate a certain training dataset. The learning algorithm works in two main steps. First, in the forward phase, consequent parameters identify the least-squares estimate. In the backward phase, the error signals represented by the derivatives of the squared error concerning each node output, propagate in the backward direction into the input layer. During the second step, the parameters are updated by the gradient descent algorithm. A combination of the gradient descent algorithm and a least-squares algorithm is used as an effective tool for investigating the optimal parameters with much faster convergence. This is because it helps reduce the search space dimensions used by the backpropagation method [40].
2.5.2.1 ANFIS application to predict UCS
The same filtered dataset was used to build the ANFIS-model. Data were split randomly using MATLAB for selecting the best partitioning ratio that resulted in the highest prediction accuracy. Two different algorithms were tested while building the model; these are Grid partitioning; genfis-1, and subtractive clustering; genfis-2. No reasonable results were observed when genfis-1 type was applied, however, subtractive clustering type (Sugeno-Fis type) yielded much better results with accepted accuracy. The developed ANFIS-model was optimized by testing different cluster radii and evaluating the prediction accuracy in terms of R-value and AAPE as listed in Table 4. The optimized ANFIS-model of Sugeno-Fis type with a clustering radius of 0.3 and splitting ratio of 70/30 for training and testing, respectively, resulted in acceptable prediction accuracy with an R-value exceeds 0.97 between the actual and predicted UCS values compared to the other tested options. Figure 4a and b shows a high-degree matching between the predicted UCS values using the optimized ANFIS-model and the corresponding actual ones with AAPE of 7.85% for the testing process.

Cross-plots between the predicted and actual UCS values for a training process, and b testing process, using the developed ANFIS-model
2.5.3 Support vector machine (SVM)
SVM is one of the AI tools that can handle highly complex problems for both regression and classification purposes. It provides a larger space for training the data features in hyperplanes by transforming the data into space with a higher degree of dimensions [41]. SVM uses a statistical learning algorithm for solving quadratic-programming problems by minimizing generalization errors to reach the optimized solution [42]. SVM has been introduced as an effective predicting and classifier tool in the oil and gas industry through many studies in the literature [43,44,45].
2.5.3.1 SVM application to predict UCS
Another model was developed using the same dataset using SVM to predict UCS of the drilled formations from the drilling parameters (ROP, SPP, GPM, ROP, T, and RPM). Splitting the data into a 70/30 ratio for training and testing the model, respectively, the model was tested using two kernel functions; polynomial and Gaussian functions, with different tuning parameters; kernel option, epsilon, lambda, verbose, and C-value). Thereafter, the model performance was evaluated in terms of R-value and AAPE between the predicted and actual UCS-values. The SVM-model with the optimized parameters listed in Table 5, yielded to predicting the UCS values with an R-value of 0.94 and AAPE of 6.5% when they are compared with the actual values during the testing process. The results show that the predicted UCS values using the SVM model agreed in a satisfactory degree with the actual ones as shown in the cross-plots; Fig. 5a and b.

Cross-plots between the predicted and actual UCS values for a training process, and b testing process, using the developed SVM-model
The results of the testing process of the three developed models, listed in Table 6, show that the ANN-model is more accurate with AAPE of 3% between actual and predicted UCS values, and outperforms the two other models when tested using an unseen dataset. This observation is also confirmed by the significant match between the actual and predicted UCS values from the ANN model when a continuous profile therebetween is plotted along with the section understudy for both the training and testing processes (see Fig. 6a and b). Thus, it is more recommended to use the ANN-model as a robust tool for predicting the UCS of the downhole formations from the drilling mechanical parameters while drilling.

Predicted UCS versus actual UCS for a training process, and b testing process, using the developed ANN-model
3 New correlation development for estimating UCS
The ANN-model was converted from a black-box into a white-box model by extracting an empirical correlation that mimics the developed network. The derived correlation includes the weights and biases that control the connections between input/hidden layers and hidden/output layers as described in Eq. 10. Table 7 lists the weights and biases of the developed correlation.
where, UCSn is the normalized UCS value, N is the number of neurons in the hidden layer, w1 is the weights between input/hidden layers, w2 is the weights between hidden/output layers, b1 is the biases associated with the hidden layer, and b2 is the bias associated with the output layer.
To use the developed correlation, the input parameters should be normalized between − 1 and +1 as shown in Eq. 11.
where Y is the normalized input value, X is the input parameter value, Xmin is the minimum value of the input dataset, and Xmax is the maximum value of the input.
Thereafter, the normalized value of the output (UCSn) can be calculated using Eq. 10 with the weights and biases listed in Table 7. Finally, UCSn should be de-normalized to get the UCS value using Eq. 12.
4 Model validation
4.1 Phase # 1
To evaluate the performance of the developed ANN-based correlation, it was tested using the validation dataset. This dataset included 2175 points comprising drilling parameters and the corresponding UCS values of formation interval of 2175 ft. These data were collected from another well (Well B) from the same field under study. It should be noted that the validation dataset was not used while training and testing the model. The results showed an obvious agreement between the predicted and actual UCS values indicated from the R-value which exceeded 0.98 and AAPE of 4.2%. Figure 7 shows the predicted UCS values versus the actual ones along with the depth interval. The results of the validation process demonstrated the high accuracy of the developed ANN model in estimating the UCS values of the drilled formations while drilling.

Predicted UCS versus actual UCS for the validation process using data from Well B
4.2 Phase # 2
In this phase, the developed correlation was validated by comparing its performance with previously published correlations. A dataset of 2175 points from Well B was used for testing the developed ANN-correlation against some of the previously published correlations listed in Table 1. The results confirmed the robustness of the developed ANN-based correlation for predicting the UCS values with high accuracy in terms of the lowest AAPE (4.16%) between the predicted and measured UCS values, compared to the published correlations as shown in Fig. 8. Additionally, the results of the ANN-based correlation were plotted in a cross plot versus those obtained from Eq. 1 (see Fig. 9) which resulted in the lowest AAPE (24.71%) among the other published correlations. Figure 9 shows the significant deviation of Eq. 1 results from the forty-five line which indicates that its results are far from the actual UCS values. On the other hand, the results of the developed ANN-based correlation significantly coincided with the forty-five line to confirm the high accuracy of its prediction process.

Comparison of the prediction accuracy of the developed ANN-based correlation against the preciously published correlations in terms of AAPE, %

UCS prediction using the developed ANN-based correlation versus the published correlations
5 Conclusions
This study presents a novel technique for predicting UCS values of the downhole formations while drilling in a time-and cost-effective way. This involved developing new AI-based models to predict UCS based on the low-cost mechanical drilling parameters other than using the high-cost well-log data. Besides, the usual availability of the mechanical data during the drilling operation makes it possible to predict the UCS values on a real-time basis using the developed correlations. In this study, three different AI tools (ANN, ANFIS, and SVM) were applied to develop the proposed models using the mechanical drilling parameters (WOB, T, ROP, SPP, RPM, and GPM) as inputs for these models. The models were developed using 1771 actual data from a Middle Eastern field to be optimized. The ANN-model outperformed ANFIS- and SVM-models with a considerable match between the predicated and actual UCS values inferred from the high R-value of 0.99 and AAPE of 3.48%. An empirical correlation was then extracted to convert the model into a white-box model. The results of the validation process of the ANN-based correlation confirmed its robustness to predict the UCS values of the drilled formations while drilling with high accuracy. This was indicated from the significant match between the predicted UCS values and the actual ones with R-value exceeded 0.98 and AAPE of 4.2%.
The performance of the developed models is guaranteed whenever they are applied using a dataset within the same range of the data used for training the AI model. For other fields with different data ranges and geologic features, it is recommended to update the models with these data to update the network weights to guarantee a viable prediction process with high accuracy.
Abbreviations
- AAPE:
-
Average absolute percentage error
- AI:
-
Artificial Intelligence
- ANN:
-
Artificial neural network
- ANFIS:
-
Adaptive network-based fuzzy interference system
- SVM:
-
Support vector machine
- R:
-
Correlation coefficient
- R2 :
-
Coefficient of determination
- ROP:
-
Rate of penetration
- WOB:
-
Weight on bit
- RPM:
-
Rotating speed in revolution per minute
- GPM:
-
Gallon per minute
- SPP:
-
Standpipe pressure
- T:
-
Torque
- Fitnet Function:
-
Fitting neural network
- Newdtdnn:
-
Create distributed time delay neural network
- newnarx:
-
Create feedforward backpropagation network with feedback from output to input
- newelm:
-
Create Elman backpropagation network
- newfftd:
-
Create feedforward input-delay backpropagation network
- newff:
-
Create feedforward backpropagation network
- newlrn:
-
Layer-Recurrent Network
- tansig:
-
Hyperbolic tangent sigmoid transfer function
- logsig:
-
Log-sigmoid transfer function
- hardlims:
-
Hard-limit transfer function
- trainbr:
-
Bayesian regularization
- purelin:
-
Linear transfer function
- softmax:
-
Softmax transfer function
- tribas:
-
Triangular basis transfer function
- trainlm:
-
Levenberg–Marquardt backpropagation
- trainbfg:
-
BFGS quasi-Newton backpropagation
- traingdx:
-
Gradient descent with momentum and adaptive learning rule backpropagation
- trainoss:
-
One step secant backpropagation
References
Chau KT, Wong RHC (1996) Uniaxial compressive strength and point load strength of rocks. Int J Rock Mech Min Sci Geomech Abstracts 33(2):183–188. https://doi.org/10.1016/0148-9062(95)00056-9
Fjar E, Holt RM, Raaen AM, Horsrud P (2008) Petroleum related rock mechanics. Elsevier, Amsterdam
Shi X, Meng Y, Li G, Li J, Tao Z, Wei S (2015) Confined compressive strength model of rock for drilling optimization. Petroleum 1(1):40–45.
Liu H (2017) Rock mechanics. In: Principles and applications of well logging. Springer, Berlin, Heidelberg. pp. 237–269. https://doi.org/10.1007/978-3-662-54977-3
Abdulraheem A, Ahmed M, Vantala A, Parvez T (2009) Prediction of rock mechanical parameters for hydrocarbon reservoirs using different artificial intelligence techniques. In: SPE Saudi Arabia section technical symposium. Society of Petroleum Engineers., https://doi.org/10.2118/126094-MS
Militzer H, Stoll R (1973) Einige Beitrageder geophysics zur primadatenerfassung im Bergbau. Neue Bergbautechnik, pp 21–25
Golubev AA, Rabinovich G (1976) Resultaty primeneia appartury akusticeskogo karotasa dlja predeleina proconstych svoistv gornych porod na mestorosdeniaach tverdych isjopaemych. Prikl. Geofiz. Moskva 73:109–116
Chang C (2004) Empirical rock strength logging in boreholes penetrating sedimentary formations. J. Eng. Geol. 7(3):174–183
Mostofi M, Rahimzadeh H, Shahbazi K (2011) The development of a new sonic correlation for UCS estimation from drilling data. Pet Sci Technol 29(7):728–734. https://doi.org/10.1080/10916460903452025
Nabaei M, Shahbazi K (2012) A new approach for predrilling the unconfined rock compressive strength prediction. Pet Sci Technol 30(4):350–359. https://doi.org/10.1080/10916461003752546
Amani A, Shahbazi K (2013) Prediction of rock strength using drilling data and sonic logs. Int J Comput Appl 81(2):5–10. https://doi.org/10.5120/13982-1986
Asadi A (2017) Application of artificial neural networks in prediction of uniaxial compressive strength of rocks using well logs and drilling data. Proc Eng 191:279–286
Tariq Z, Abdulraheem A, Mahmoud M, Elkatatny S, Ali AZ, Al-Shehri D, Belayneh MW (2019) A new look into the prediction of static Young’s modulus and unconfined compressive strength of carbonate using artificial intelligence tools. Pet Geosci 25(4):389–399
Hassanvand M, Moradi S, Fattahi M, Zargar G, Kamari M (2018) Estimation of rock uniaxial compressive strength for an Iranian carbonate oil reservoir: Modeling vs artificial neural network application. Pet Res 3(4):336–345. https://doi.org/10.1016/j.ptlrs.2018.08.004
Amani A, Shahbazi K (2013) Prediction of rock strength using drilling data and sonic logs. Int J Comput Appl 81(2):7–10
Jackson CE, Heysse DR (1994) Improving formation evaluation by resolving differences between lwd and wireline log data. In: SPE annual technical conference and exhibition. Society of Petroleum Engineers
Dawson R (2011) How significant is a boxplot outlier? J Stat Educ 19
Zhou H, Deng Z, Xia Y, Fu M (2016) A new sampling method in particle filter based on Pearson correlation coefficient. Neurocomputing 216:208–215. https://doi.org/10.1016/j.neucom.2016.07.036
Tariq Z, Elkatatny S, Mahmoud M, Ali AZ, Abdulraheem A (2017) A new technique to develop rock strength correlation using artificial intelligence tools. In SPE reservoir characterization and simulation conference and exhibition; Society of Petroleum Engineers: Calgary, AB, Canada. https://doi.org/10.2118/186062-MS
Elkatatny S, Tariq Z, Mahmoud M, Abdulraheem A, Mohamed I (2018) An integrated approach for estimating static Young’s modulus using artificial intelligence tools. Neural Comput Appl. https://doi.org/10.1007/s00521-018-3344-1
Gowida A, Moussa T, Elkatatny S, Ali A (2019) A hybrid artificial intelligence model to predict the elastic behavior of sandstone rocks. Sustainability 11(19):5283
Anifowose FA, Labadin J, Abdulraheem A (2017) Ensemble machine learning: An untapped modeling paradigm for petroleum reservoir characterization. J PetSci Eng 151:480–487. https://doi.org/10.3390/su11195283
Jamshidi E, Arabjamaloei R, Hashemi A, Ekramzadeh MA, Amani M (2013) Real-time Estimation of Elastic Properties of Formation Rocks Based on Drilling Data by Using an Artificial Neural Network. Energy Sources, Part A: Recovery, Utilization, and Environmental Effects 35(4):337–351
Zorlu K, Gokceoglu C, Ocakoglu F, Nefeslioglu HA, Acikalin SJEG (2008) Prediction of uniaxial compressive strength of sandstones using petrography-based models. Eng Geol 96(3–4):141–158
Cevik A, Sezer EA, Cabalar AF, Gokceoglu C (2011) Modeling of the uniaxial compressive strength of some clay-bearing rocks using neural network. Appl Soft Comput 11:2587–2594. https://doi.org/10.1016/j.asoc.2010.10.008
Lippman RP, Lippman RP (1987) An intrduction to computing with neural nets. In: Mag A (ed.) IEEE ASSP Magazine. IEEE. pp. 4–22, https://doi.org/10.1109/MASSP.1987.1165576
Hinton GE, Osindero S, Teh Y-W (2006) A Fast Learning Algorithm for Deep Belief Nets. Neural Comput 18:1527–1554. https://doi.org/10.1162/neco.2006.18.7.1527
Graves A, Liwicki M, Fernandez S, Bertolami R, Bunke H, Schmidhuber J (2009) A Novel Connectionist System for Unconstrained Handwriting Recognition. IEEE Trans Pattern Anal Mach Intell 31:855–868. https://doi.org/10.1109/TPAMI.2008.137
Nakamoto P (2017) Neural Networks and Deep Learning: Deep Learning Explained to Your Granny a Visual Introduction for Beginners Who Want to Make Their Own Deep Learning Neural Network (Machine Learning); CreateSpace Independent Publishing Platform: Scotts Valley. CA, USA
Jang JS, Sun CT (1995) Neuro-fuzzy modeling and control. Proc IEEE 83(3):378–406
Wang T, Ma M, Jianbin Q, Gao H (2020) Event-triggered adaptive fuzzy tracking control for pure-feedback stochastic nonlinear systems with multiple constraints. IEEE Trans Fuzzy Syst. https://doi.org/10.1109/TSMC.2020.3013744
Qiu J, Ma M, Wang T (2020) Event-triggered adaptive fuzzy fault-tolerant control for stochastic nonlinear systems via command filtering. IEEE Trans Syst Man Cybern Syst 2:1493–1499. https://doi.org/10.1109/FUZZY.1996.552396
Jang JS (1996) Input selection for ANFIS learning. In: Proceedings of IEEE 5th international fuzzy systems (Vol. 2, pp. 1493—1499). https://doi.org/10.1109/fuzzy.1996.552396
Aghli Ghasem, Moussavi-Harami Reza, Mortazavi Saiedollah, Mohammadian Roohangiz (2019) Evaluation of new method for estimation of fracture parameters using conventional petrophysical logs and ANFIS in the carbonate heterogeneous reservoirs. J Petrol Sci Eng 172:1092–1102
Gowida A, Elkatatny S, Al-Afnan S, Abdulraheem A (2020) New computational artificial intelligence models for generating synthetic formation bulk density logs while drilling. Sustainability 12(2):686. https://doi.org/10.3390/su12020686
Ja’fari A, Kadkhodaie-Ilkhchi A, Sharghi Y, Ghaedi M (2014) Integration of adaptive neuro-fuzzy inference system, neural networks and geostatistical methods for fracture density modeling. Oil & Gas Science and Technology-Revue d’IFP Energies nouvelles 69(7):1143–1154. https://doi.org/10.2516/ogst/2012055
Anifowose FA, Labadin J, Abdulraheem A (2013) Prediction of petroleum reservoir properties using different versions of adaptive neuro-fuzzy inference system hybrid models. Int. J. Comput. Inf. Syst. Ind. Manage. Appl 5:413–426
Vilela LRM, Oluyemi G, Petrovski A (2019) A fuzzy inference system applied to value of information assessment for oil and gas industry. Decision Making: Applications in Management and Engineering 2(2):1–18
Stojcic M, Stjepanovic A, Stjepanovic Djordje (2019) ANFIS model for the prediction of generated electricity of photovoltaic modules. Decision Making: Applications in Management and Engineering 2(1):35–48
Walia N, Singh H, Sharma A (2015) ANFIS: Adaptive neuro-fuzzy inference system-a survey. Int J Comput Appl 123(13):515–535
Xuegong Z (2000) Statistical learning theory and support vector machines. Acta Automatica Sinica 26(1):32–42
Xuegong Z (2000) Introduction to statistical learning theory and support vector machines. Acta Automatica Sinica 26(1):32–42
Gholami R, Shahraki AR, Jamali Paghaleh M (2012) Prediction of hydrocarbon reservoirs permeability using support vector machine. Math Probl Eng. https://doi.org/10.1155/2012/670723
Rostami H, Khaksar Manshad A (2014) A new support vector machine and artificial neural networks for prediction of stuck pipe in drilling of oil fields. J Energy Technol 136(2):67. https://doi.org/10.1115/1.4026917
Zhong YH, Li R (2009) Application of principal component analysis and least square support vector machine to lithology identification. Well Logging Technol 33(5):425–429
Funding
This research received no external funding.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The author declares no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Gowida, A., Elkatatny, S. & Gamal, H. Unconfined compressive strength (UCS) prediction in real-time while drilling using artificial intelligence tools. Neural Comput & Applic 33, 8043–8054 (2021). https://doi.org/10.1007/s00521-020-05546-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-020-05546-7