
Abstract
SS 201 had been reported as a good substitute for SS304 without any significant compromise in performance. However, modeling EBW process using an efficient tool like adaptive neuro-fuzzy inference system (ANFIS) and use of multi-objective optimization to optimize its performance are not reported yet. Thus, the present study employed ANFIS models tuned by genetic algorithm, particle swarm optimization, gray wolf optimizer, and bonobo optimizer (BO) to predict weld attributes during EBW of SS201 as a function of input process parameters. Among the developed models, ANFIS tuned by BO was seen to yield the best prediction accuracy. In multi-objective optimization (MOO), the two conflicting goals were to minimize secondary dendritic arm spacing and maximize Vicker’s hardness number simultaneously. In MOO, some interesting facts were observed, such as the fixed input parameter of power (P) as 3200-W and squeezed experimental range for the welding speed (S).
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Cost reduction without compromising quality has always been a primary concern of the industry and research areas. Industries and R&D laboratories usually prefer the use of cheaper material without compromising the quality. Sometimes, the performance of a more affordable material is found to be more or less comparable to that of an expensive one. Therefore, the cheaper material is used, and consequently, it minimizes the overall cost. AISI 304 stainless steel is extensively employed in numerous industries for its well-known properties. At the same time, this material is also expensive. However, literature suggested AISI 201 material to be a cheap substitute of AISI 304 due to the presence of less percentage of nickel in it compared to the other one [1, 2]. Even then, the differences in the mechanical properties and other related performances of SS201 are reported to be comparable to SS304. There are different applications of SS 201 grade, such as constructing structural members, formed stuffs, railway car roofing and siding and others. Among various metal joining processes, fusion welding is one of the most widely used techniques adopted by various industries and researchers. Moreover, high-energy welding methods, like laser beam welding (LBW), electron beam welding (EBW) and plasma arc welding (PAW), have also become popular nowadays. EBW process is inherited with several advantages, such as joining similar and dissimilar metals, high depth-to-width aspect ratio, less contamination due to the absence of air and others. Due to these benefits, EBW is observed to get more attention from the researchers and industries.
Although SS201 is a cheaper alternative to SS304, literature shows that only a few studies were carried out about the EBW of SS201. Moreover, input–output modeling of the same using adaptive neuro-fuzzy inference system (ANFIS) is missing in the literature. Conducting a vast number of real experiments are not always possible due to time and resource constraints. For this reason, the prediction of precise input–output behaviors of the EBW process has become a difficult task for the researchers. In this connection, different statistical regression methods may be of some use. However, the accuracy of the regression models might not always be good [3]. Experimental data are generally associated with some fuzziness and errors, such as instrumental error, operator error, environmental error and theoretical error due to approximations. ANFIS is such a tool, which can efficiently handle the uncertainty and fuzziness present in the experimental data. It can offer accurate input–output relationships using the experimental data. Here, it is essential to note that for developing a trained ANFIS model, a sufficient amount of input–output data are required. However, it is difficult to generate such a big data set through real experiments. Therefore, it is a general custom by the research community to obtain regression equations from the experimental data and then create the desired amount of artificial data using those regression equations. As statistical regression techniques cannot model the uncertainty and fuzziness of the data set, this generated data set is also found to be equipped with inaccuracies again. Now, the combined data set of real-experiment and artificially generated ones is used to train an ANFIS. The trained ANFIS is used to predict the outputs for some known input scenarios. As relatively less literature is available on the joining of SS201 plates using the electron beam welding process, authors are motivated to carry out the present investigation. Also, the modeling of weld geometries, hardness, etc., using ANFIS has not been reported yet. A trained ANFIS can help to predict outputs of several input scenarios accurately. Apart from these, there are a few outputs, which are found to be conflicting in nature. Therefore, it is not possible to determine the input parameters for optimizing these outputs simultaneously. A multi-objective evolutionary algorithm (MOEA) is considered an efficient technique to solve this issue. MOEA can offer a set of Pareto-optimal solutions with different weights put on the outputs. These are likely to help in selecting suitable input parameters to minimize the welding defects, associated cost and improve the overall joint quality.
Several metaheuristic algorithms are available in the literature. Genetic algorithm (GA) [4] and particle swarm optimization (PSO) [5] are the two popular optimization techniques, which had been used for solving a variety of optimization problems for the last two decades. Use of ANFIS optimized by GA and PSO for input–output modeling of friction stir welding [6], prediction of buckling damage of steel columns under axial compression [7] and prediction of accurate stress-intensity factor [8] is some of the recent applications of GA and PSO in tuning ANFIS efficiently. Gray wolf optimizer (GWO) [9] and bonobo optimizer (BO) [10] are the two newly developed optimization techniques in comparison with GA and PSO. However, these are also found to be very efficient in solving optimization problems for different applications, like prediction of compressive strength of concrete [11], parameter optimization of laser beam welding [12] and electron beam fabrication [13], determination of optimal preventive maintenance interval of crankshaft balancing machine [14] and others.
Some studies were carried out on the welding of SS201. Chuaiphan and Srijaroenpramong [1] observed improvements in weld characteristics using higher welding speed during GTAW of SS201. Wichan and Loeshpahn [15] investigated the role of different filler alloys on the nature of corrosion during the welding of SS201 and low carbon steel. Similarly, Chandra-Ambhorn et al. [16] observed changes in joint quality due to the presence of nitrogen during dissimilar welding of SS304 and SS201. Gholami et al. [17] used different filler materials during the joining of 4130 low alloy steel and SS201 utilizing gas tungsten arc welding to study the microstructure and mechanical properties of the dissimilar weld.
Several researchers used primary, secondary or higher-order dendrite arm spacing (DAS) to investigate the microstructural changes. DAS was also utilized to obtain cooling rates during welding [18, 19]. Neural network-based modeling of EBW had been reported in the literature using various nature-inspired algorithms [3, 20]. Das et al. [21] developed an input–output relationship using multi-objective optimization and neuro-fuzzy system during EBW of SS304. The approach predicted weld attributes accurately. Jaypuria and Pratihar [22] employed ANFIS to determine the penetration in EBW of copper plates. A new noncontact method using a special crucible assisted pyrometers was proposed by Zakharenko et al. [23] to obtain the thermal cycle in the melt pool. It prevented the use of expensive thermocouples, such as TPR-2085, TBP 2085 and was observed to minimize the errors and various associated uncertainties [23]. Yu et al. [24] proposed an efficient experimental method during casting of GTD-222 Ni-based superalloy to obtain the optimum process parameters through controlled cooling rates. They further correlated the temperature gradient, cooling rate and microstructure and predicted the casting process’s microstructure from cooling rate information. Additionally, they also developed simulations, which could successfully reproduce the overall casting process and save overall associated cost and time.
ANN was tuned through a non-dominated sorting genetic algorithm (NSGA-II) and differential evolution (DE) algorithm to carry out multi-objective optimizations (MOO) of process parameters. The goal was to achieve the best weld qualities in friction stir welding (FSW) joining process, where ANN-DE-MOO was observed to perform the best [25]. Chen et al. [26] carried out multi-objective optimization during micro-resistance spot welding of ultra-thin Ti–1Al–1Mn foils. They examined the effects of input parameters on the tensile-shear force, failure energy, etc., where the role of welding current was observed to be the most significant. Multi-objective optimization was carried out by Kitayama et al. [27] to obtain optimized weld line reduction and productivity using a Pareto front during plastic injection molding. They utilized conformal cooling channels to enhance the heating and cooling performances experimentally. Numerical and experimental results were also validated for the proposed approach. Multi-objective optimization using a neuro-based NSGA-II technique was developed to optimize the pulsed gas metal arc welding process of low carbon steel, where both the joint strength and transverse shrinkage were observed to be significantly improved through simulation and experimental results [28].
Relatively less literature is observed on the joining of SS201 materials [1]. Additionally, the literature on EBW of SS201 plates is found to be significantly less. Furthermore, its modeling through ANFIS tuned by metaheuristic has not yet been reported. Therefore, an attempt was made to model the input–output relationship of the EBW process for SS201 material in this study. To serve this purpose, ANFIS models tuned by several efficient optimization techniques, namely GA, PSO, GWO and BO had been developed and applied for predicting several responses of the EBW process. These optimization algorithms were chosen, as these were found to perform efficiently according to the literature. Thus, the present investigation’s novelty lies with the experimental study of weld geometries, Vickers hardness and SDAS. Detailed modeling using ANFIS tuned by several optimizers follows this. Next, an analysis of the said process using multi-objective evolutionary algorithms was also carried out.
The remaining part of the manuscript has been organized as follows: Sect. 2 describes the setup details of different experiments and regression analysis of EBW process. Section 3 provides a brief discussion of several soft computing tools and techniques used in this study. The EBW process modeling using ANFIS and results obtained using three different models are discussed in Sect. 4. Moreover, multi-objective optimization of the said process was carried out and the obtained results are analyzed in the same section. Finally, Sect. 5 provides some concluding remarks on the present study.
2 Experimental Setup and Regression Analysis
Electron beam welding (EBW) of 20 mm thick SS201 plates of thickness was conducted on an EBW machine, designed and developed by Bhabha Atomic Research Center (BARC), Mumbai at IIT Kharagpur, India (refer to Fig. 1). Electra Maxicut wire-EDM and Supertech double disk polishing machine were used to cut and polish the samples, respectively. Omnitech MVH-auto and ZEISS EVO 18 research scanning electron microscope (SEM) were employed to measure Vickers hardness number (VHN) and secondary dendritic arm spacing (SDAS), respectively.

The input parameters considered for the EBW process of this study were as follows: power (P) varying from 3200 to 5600 W and welding speed (S) ranging from 600 to 1800 mm/min (refer to Table 1). Responses of the process were the depth of penetration (DP) in mm, bead width (BW) in mm, secondary dendritic arm spacing (SDAS) in µm and Vicker’s hardness number (VHN).
There were 17 experimental data with input–output scenarios (refer to Appendix A). Among these data, the first 12 data were used for training and the rest were applied for testing purposes. However, these 12 numbers of data were insufficient to train an ANFIS. Therefore, using nonlinear regression analysis, equations for the four responses were determined with a 95% confidence level. These are given in Table 2 with their \( R^{2} \) values, which are nothing but the correlation coefficients of the nonlinear equations. \( R^{2} \) indicates the strength of a regression model to predict with high accuracy. From the \( R^{2} \) values, it was found that the derived equations were capable of predicting responses accurately, as these were observed to be more than 80%.
Table 3 gives the results of the analysis of variance, where DF, SS and MS represent the degrees of freedom, sum of the squares and mean squared error, respectively. Regression SS is the sum of square of the difference of the predicted output by the regression model and mean of the data set. For DP, regression SS and total SS are found to be equal to 126.958 and 134.685, respectively. This indicates that the regression model can explain \( \left( {\frac{126.958}{134.685} \approx } \right)94.3\% \) of all the variability in the dataset. Similarly, for BW, SDAS and VHN, these values were measured to be almost equal to 84%, 92% and 88%, respectively. Residual SS is nothing but the sum of squared values of differences between predicted and actual data points. The lower the residual SS, the better is the regression model. From the ANOVA test, residual SS is found to be low in most of the cases. Therefore, these regression models were capable enough for making the predictions. F was used to test the null hypothesis that the independent variable’s slope was kept equal to zero. Large F values and low \( p \) values indicate that relationships between dependent and independent variables are significant in these regression models. Therefore, from ANOVA tests, it is evident that the regression models could predict outputs accurately.
Using these regression equations for the responses, a total of 988 input–output scenarios were generated within the specified ranges of the input parameters, as mentioned in Table 1. Therefore, a total of 1000 (= 988 + 12) input–output data were applied to train each of the developed ANFIS models.
3 Brief Descriptions of Different Soft Computing Tools Used
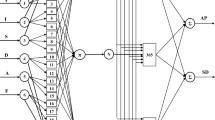
As discussed earlier, input–output relationships of the EBW process of SS201 were determined using an efficient tool, namely the adaptive neuro-fuzzy inference system (ANFIS) [31]. ANFIS is a neuro-fuzzy system designed based on the fuzzy reasoning tool of Takagi and Sugeno’s type. It consists of six layers. Layers 1 and 2 are the input layer and fuzzification layer, respectively. Layer 3 determines the firing strengths of the rules. The normalized firing strength values are calculated in layer 4. Layer 5 determines the product of the normalized firing strength and output for each rule. Layer 6 calculates the output of the network by summing up the product values determined in Layer 5 (refer to Fig. 2). As ANFIS utilizes both the principles of neural network (NN) and fuzzy reasoning tool, it is equipped with the advantages of both the models in a single structure. Moreover, the fuzzy reasoning used in ANFIS is Takagi and Sugeno’s type, which predicts the outputs more accurately.

Structure of an ANFIS
To use an ANFIS optimally, an optimization algorithm is used to tune it. In this study, ANFIS models were tuned by four different efficient metaheuristics, namely genetic algorithm (GA), particle swarm optimization (PSO), gray wolf optimizer (GWO) and bonobo optimizer (BO). Moreover, supervised learning with the batch mode of training had been used to train the ANFIS models. Brief descriptions of the optimization algorithms used in this study are given below.
3.1 Genetic Algorithm (GA)
GA [4] is one of the most popular metaheuristic techniques applied to solve various optimization problems. It is a population-based searching method. This has mainly three evolutionary operators, namely selection, crossover and mutation. It follows the principle of ‘survival of the fittest’. In each generation, children solutions are created from the parent solutions. The good offspring, according to their fitness values, is given preferences in selecting the population for the next generation. In this way, the searching mechanism of GA tries to find better solutions in each generation, and finally, it reaches the globally optimum solution. The algorithm stops, when the predefined condition, like the number of generations reaches the maximum number of generations, is satisfied. A flowchart of a GA is given in Fig. 3.

Flowchart of a standard genetic algorithm (GA)
3.2 Particle Swarm Optimization (PSO)
PSO [5] is also another population-based approach, where the concepts of global best and personal best are used. It was developed by mimicking the swarm behavior of birds flying together or a group of animals traveling jointly. It is an efficient technique for optimization, and it had been used to solve several linear and nonlinear optimization functions. Let say, jth variable of the \( i \)th particle at tth iteration is denoted as \( x_{ij} \left( t \right) \). The modified velocity (\( v_{ij} \left( {t + 1} \right) \)) and position (\( x_{ij} \left( {t + 1} \right) \)) of the \( x_{ij} \) are calculated as follows:
where \( w \) is the inertia weight; \( C_{1} \) and \( C_{2} \) are two positive numbers termed as cognitive and social parameters, respectively; \( r_{1} \) and \( r_{2} \) are two random numbers created in the range of (0, 1); \( p_{ij} \) and \( p_{gj} \) are the jth dimensions of the personal best of ith particle and global best solution, respectively. The performance of PSO depends on the selected values of \( w \), \( C_{1} \) and \( C_{2} \). Therefore, it is recommended to carry out a parametric study to ensure the good performance of this algorithm.
3.3 Gray Wolf Optimizer (GWO)
GWO [9] is a new optimization technique compared to GA and PSO. It was inspired by the hierarchical leadership and hunting strategy adopted by the community of gray wolves. It identifies the three best wolves, commonly named as alpha (\( \alpha \)), beta (\( \beta \)) and delta (\( \delta \)) in terms of their fitness values. The rest of the wolves (\( \omega \)) are found to follow these three wolves. Three steps of hunting, such as finding the prey, surrounding the prey and attacking the same are artificially modeled in GWO. It had been applied to solve several benchmark functions and real-world optimization problems. A simple flowchart of GWO is provided in Fig. 4.

A flowchart of GWO
3.4 Bonobo Optimizer (BO)
BO [32] is one of the most recently proposed metaheuristic techniques available in the literature. It imitates the natural behavior of the bonobos. A unique fission–fusion social strategy is observed in bonobo society. Moreover, bonobos are seen to adopt four kinds of mating schemes in a variety of situations for maintaining a good balance in the society. These natural behaviors of bonobos are mathematically modeled to construct an optimization algorithm, which can direct the search process efficiently for a variety of objective functions with different attributes. Moreover, the algorithm was designed nicely to keep a good balance between diversification and intensification. A detailed flowchart of BO is given in Fig. 5.

A flowchart of BO
Apart from modeling, the EBW process of SS201 was also analyzed using multi-objective optimization (MOO) tools and several interesting facts were revealed. Multi-objective evolutionary algorithms (MOEAs), namely Pareto envelope-based selection algorithm-II (PESA-II), SPEA-II, NSGA-II were used for this analysis. Short descriptions of these MOEAs are also provided below.
3.5 PESA-II
Pareto envelope-based selection algorithm-II was developed by Corne et al. [33]. PESA-II uses the concept of assigning fitness values to the hyper-boxes defined in objective space, instead of determining fitness strength for each solution. The defined hyper-boxes should contain at least one solution of the Pareto front. During the selection process, the hyper-boxes are chosen according to their assigned fitness values and calculated selection probabilities. Then, the individual is selected from the selected hyper-box, at random. This selection method was seen to be more efficient in finding diversified Pareto front compared to individual-based selection methods. Except for this selection mechanism, PESA-II used the basic framework of PESA [34].
3.6 SPEA-II [35]
SPEA-II was the improved version of SPEA [36]. In SPEA-II, weaknesses of the SPEA were removed and a more powerful MOEA was proposed. The significant differences between SPEA-II and its preceding version were as follows:
-
A better way of fitness assignment method was developed in SPEA-II, where the information regarding the number of solutions dominated by an individual and the number of solutions, which dominate that individual was considered.
-
A method for estimating the nearest neighborhood density was introduced in SPEA-II. This method guides the algorithm for more precise searching.
-
A novel archive trimming method was proposed in SPEA-II. It helps in preserving the boundary solutions in Pareto front.
SPEA-II was applied to solve several test problems and its performance was found to be superior compared to other popular MOEAs.
3.7 NSGA-II [37]
Non-dominated sorting genetic algorithm (NSGA-II) was the improved version of NSGA. In this enhanced version, the concept of crowding distance method was proposed for maintaining a proper diversity and spread of the Pareto front. A schematic representation of crowding distance calculation for the ith solution of Pareto front is shown in Fig. 6. No extra parameter was considered in this algorithm. Moreover, it was found to be a faster algorithm with less computation complexity compared to the NSGA.

A schematic representation of crowding distance calculation
4 Results and Discussion
As discussed earlier, an attempt was made to model the input–output relationships to predict the the EBW process’s responses. Moreover, multi-objective optimization was also implemented to derive some exciting facts about the EBW process. These are discussed, in detail, as follows:
4.1 Input–Output Modeling Using ANFIS
Input–output relationships for EBW of SS201 were modeled using ANFIS. Moreover, ANFIS models were tuned using four efficient optimization techniques, namely genetic algorithm (GA), particle swarm optimization (PSO), gray wolf optimizer (GWO) and bonobo optimizer (BO) for obtaining optimal performances of the models. Source codes for GA and PSO were obtained from: https://yarpiz.com/category/metaheuristics [38]; whereas MATLAB code for GWO was available at: http://www.alimirjalili.com/GWO.html [39]. In addition, the source code of BO used in this study was downloaded from: https://sites.google.com/site/softcomputinglaboratory/Home [40]. In ANFIS models, each input was expressed using Gaussian membership functions, which has two parameters: mean (\( m \)) and standard deviation (\( \sigma \)). Moreover, for each model, the training data set was clustered using the fuzzy clustering method (FCM). The number of clusters for the training data set was decided using a parametric study. Here, the number of clusters was varied in the range of 2–10 and that number of clusters, which yielded the minimum training error, was selected. Prediction error was calculated in terms of root mean square error (RMSE) using Eq. (3) as follows:
where \( T_{i} \) and \( O_{i} \) are the target and predicted outputs of the ith scenario, respectively; \( R \) is the total number of training scenarios. In the parametric study, the numbers of clusters chosen for ANFIS models tuned by GA, PSO, GWO and BO were found to be equal to 4, 5, 6 and 9, respectively. Depending upon the number of clusters, the number of variables or coefficients of the ANFIS models was determined. In this study, the Gaussian type of membership function with two unknown coefficients was used. In the data set, there were two inputs and four outputs. Therefore, an ANFIS with four clusters of the dataset, was found to have 64 (\( = 2 \times \left( {2 \times 4} \right) + 4 \times \left( {3 \times 4} \right) \)) unknown coefficients. Similarly, for five, six and nine clusters, ANFIS models were seen to have unknown coefficients equal to 80, 96 and 144, respectively. In Fig. 7, input membership functions are depicted for GA–ANFIS and PSO–ANFIS models. An optimization algorithm’s task was to find optimal values of these coefficients for the best performance of an ANFIS model (i.e., minimize RMSE value). The number of coefficients or variables was denoted by \( d \). Besides, the algorithm-specific parameters of the optimization techniques were also determined using the parametric study described in [41], and the selected parameters are given in Table 4.

Input membership function distributions of the models: a and b GA–ANFIS; c and d PSO–ANFIS
Each ANFIS model was trained for a maximum of 30,000 iterations. In Table 5, the obtained RMSE values for four outputs during the training of the ANFIS models have been reported. Moreover, the average RMSE value of the outputs was also calculated for each of the models and these are given in Table 5 (best obtained values are marked in bold).
After the training was over, the trained models were used to predict five experimental test cases’ outputs. The predicted outputs were shown in Fig. 8. Moreover, the yielded RMSE values of the outputs are reported in Table 6. In addition, average RMSE values were also calculated for all the models. In Table 7, the average absolute deviation in predictions for the test cases is provided. These average absolute deviation in predictions is nothing but the average absolute difference between the actual and predicted outputs for the test scenarios. The best results are written in bold in both the Tables 6 and 7.

Predictions of test cases using different ANFIS models for the responses: a depth of penetration (DP), b bead width (BW), c secondary dendritic arm spacing (SDAS) and d Vickers hardness number
4.1.1 Discussion on Input–Output Modeling Using ANFIS
For the training cases, it is evident that the ANFIS model tuned by BO was able to predict more accurately compared to the other three models tuned by GA, PSO and GWO, for all four outputs (refer to Table 5). The ANFIS optimized by PSO was found to be the overall second-best performer followed by the model tuned by GA. However, the ANFIS optimized by GWO was observed to perform the worst, in this case. Overall, all the obtained average RMSE values were small (maximum of 1.6442 for GWO). Therefore, it can be said that all the ANFIS models were well trained to predict the training outputs.
From the test results, it was seen that BO–ANFIS was able to predict most precisely for the outputs, like SDAS and VHN. However, in the case of DP and BW, GWO–ANFIS and PSO–ANFIS were the best performers, respectively. BO–ANFIS was found to be the third-best and second-best predictor for the outputs DP and BW (as per Table 6), respectively. The maximum average RMSE was observed to be equal to 3.1345 for GA. Therefore, it can be said that all the ANFIS models were able to predict the test cases with a low deviation in prediction. Overall, BO–ANFIS and PSO–ANFIS were found to be the best and second-best performer in both the training and test cases of this study.
BO was the most recently developed optimization algorithm among the four metaheuristic techniques used in this study. BO was designed to be equipped with the self-adaptive parameters to handle objective functions with several attributes efficiently. EBW of SS 201 is undoubtedly a nonlinear process. Moreover, modeling the same has become a difficult task, as the experimental data set involves uncertainty and fuzziness. Therefore, finding out the optimal coefficients of an ANFIS by an optimization algorithm are very difficult task, due to the nonlinear nature of the objective function. As BO is an intelligent and adaptive algorithm to tackle such nonlinearity more effectively, the BO–ANFIS was seen to have the better performance compared to the other three models in this experiment. Along with BO–ANFIS, PSO–ANFIS was also performed well in this study. PSO is an efficient optimization algorithm, which has the powerful global and local search capabilities [41]. Moreover, PSO’s velocity updating mechanism makes the search process efficient to reach near the globally optimum solutions (refer to Eq. (1)). Due to the application of globally best and personal best solutions, the new solutions are modified, so that the search process can focus on maintaining population diversity and exploitation of the algorithm. Thus, PSO becomes a robust optimization algorithm to solve complicated objective functions too. However, GA and GWO were found to be poor performer, in this study. This might have occurred due to the nature of the objective functions, for which these two optimization algorithms could not find the optimal solutions during their search process. BO–ANFIS and PSO–ANFIS will be implemented to model similar kind of processes in future studies.
4.2 Multi-objective Optimization of EBW process
For multi-objective optimization, two objectives, such as secondary dendritic arm spacing (SDAS) in µm and Vicker’s hardness number (VHN) were chosen. These were found to be conflicting in nature. There were two design variables in the problem, namely power (P in Watt) and welding speed (S in mm/min). This optimization problem is mathematically expressed as follows:
where
and
This optimization problem was solved using three multi-objective evolutionary algorithms (MOEAs), such as SPEA-II, PESA-II and NSGA-II. Brief descriptions of these algorithms are given in Sect. 3. Source codes of these algorithms were downloaded from [38]. Each MOEA was run for a maximum of 200 generations with a population size equal to 200. Other parameters were set through some trials and errors, and those were reported in Table 8.
The obtained Pareto fronts using the MOEAs are shown in Fig. 9. From the figure, it is clear that NSGA-II could yield a better Pareto front compared to the other two MOEAs in terms of both uniformity and spread.

Pareto front correlating SDAS and (1/VHN) using three MOEAs, such as NSGA-II, PESA-II and SPEA-II
Now, it is known that a Pareto front is nothing but the set of non-dominated optimal solutions. Therefore, the extreme points and a few in-between solutions from the Pareto front are provided in Table 9. A user for obtaining the less SDAS and high VHN may consider these suggested in-between points as the good solutions. In addition, these algorithm suggested solutions were also validated through real experiments. It was found that the MOEA suggested solutions were in good agreement with the results of real experiments. Another interesting fact is to be noted here. All the points lying on the Pareto front were found to have the value of input parameter P equal to 3200 W. Originally, in real experiments, P was varied from 3200 to 5600 W. However, after carrying out the analysis using MOEA, it had been seen that by varying S in the range of (1285.11, 1690.04 mm/min) and keeping P fixed at 3200 W, significant changes in the outputs could be achieved. This deciphered knowledge about the effective ranges of the input parameters of the EBW process must benefit the user in efficiently managing and stabilizing the process outputs. This is undoubtedly a phenomenal achievement regarding the EBW process of SS201.
4.2.1 Discussion on Multi-objective Optimization Results
It was already mentioned that the input parameters P and S were varied in the ranges of (3200, 5600 W) and (600, 1800 mm/min), respectively, in real experiments. However, it was observed from Table 9 that the Pareto front suggested the use of the lowest power and higher welding speed values from the predefined ranges of input parameters to obtain high VHN and low SDAS. This is so, because for both low power and high welding speed, the net heat input decreases, resulting into a relatively higher cooling rate. This speeds up the solidification process, resulting into the restricted grain growth and smaller SDAS values [7]. As a result, the fusion zone’s hardness values increase for SS201 material and these become close to that of the base metal, thus, improving the joint strength.
However, it is also observed that the Pareto front ignored the welding speed, lying in the range of 1690–1800 mm/min. This happens so, because the observed changes in hardness and SDAS values at the welding speed set above 1690 mm/min are negligible. Hence, increasing the welding speed above 1690 mm/min seemed to be unnecessary.
Among the three multi-objective evolutionary algorithms (MOEAs), NSGA-II was the best performer to generate the best possible Pareto-optimal front for the problem. NSGA-II uses the concept of non-dominating sorting and crowding distance approach. It has no other parameter except the parameters for the GA. The crowding distance approach is a very efficient method to maintain both population diversity and uniformity in the Pareto-optimal front. This is a simple but potent approach. Thus, NSGA-II could yield the better Pareto-optimal front for a variety of multi-objective problems and it showed the best performance in this study. On the other hand, PEAS-II and SPEA-II are not equipped with such efficient operator like crowding distance approach. Therefore, these algorithms showed the poor performance, in this study.
5 Conclusions
In this paper, modeling of electron beam welding (EBW) of SS201 material, a cheaper alternative to SS304 without affecting the weld quality, was done. From this study, the conclusions are drawn as follows:
-
Among the developed four different adaptive neuro-fuzzy inference systems (ANFIS), BO–ANFIS, a hybrid ensemble of recently proposed bonobo optimizer (BO) and ANFIS, was found to perform the best in both the training and test cases. As an intelligent and adaptive optimization algorithm, BO was observed to tune the ANFIS model in a better way.
-
Apart from BO, particle swarm optimization (PSO) was also seen to perform well, and it was the second-best performer among the used algorithms, followed by GA and GWO.
-
Overall, all four ANFIS models were found to be of capable of predicting the responses accurately. These models can be used efficiently to predict the responses for some new input–output scenarios. Thus, it may save the experimental time and cost for the EBW process.
-
In multi-objective optimization, among the three obtained Pareto fronts (PFs) using SPEA-II, PESA-II and NSGA-II, that by utilizing NSGA-II was observed to have the best uniformity and spread.
-
A few reasonable solutions from the obtained PF had been suggested to achieve both the objectives in good proportionality. Moreover, these recommended solutions were verified through real experiments, and the obtained results were found to have good matching with the suggested ones.
-
From the solutions lying in PF, it was observed that input parameter P was kept fixed at the value of 3200 W. From this observation, it is concluded that the practical value for P to get the variations in the outputs is 3200 W, for this experiment. Therefore, the fundamental analysis can be done again considering P as constant and this may be included in the scope for future study.
-
The effective range of welding speed (S) was found to be squeezed from (600, 1800 mm/min) to (1285.11, 1690 mm/min) in the Pareto-optimal front data set. It showed that the effective range for the input parameter S was shorter than that of the original range considered during the real experiments. These were some of the crucial observations on the EBW of SS201.
References
Chuaiphan, W.; Srijaroenpramong, L.: Effect of welding speed on microstructures, mechanical properties and corrosion behavior of GTA-welded AISI 201 stainless steel sheets. J. Mater. Process. Technol. 214(2), 402–408 (2014). https://doi.org/10.1016/j.jmatprotec.2013.09.025
Properties and composition of type 201 stainless steel. https://www.thebalance.com/type-201-stainless-steel-2340260. Accessed on 23 Feb 2019
Das, D.; Pal, A.R.; Das, A.K.; Pratihar, D.K.; Roy, G.G.: Nature-inspired optimization algorithm-tuned feed-forward and recurrent neural networks using CFD-based phenomenological model-generated data to model the EBW process. Arab. J. Sci. Eng. (2019). https://doi.org/10.1007/s13369-019-04142-9
Goldberg, D.E.: Genetic Algorithms in Search Optimization and Machine Learning. Addison-Wesley Longman Publishing Co., Inc., Boston (1989)
Eberhart, R.; Kennedy, J: A new optimizer using particle swarm theory. In: Proceedings of the Sixth International Symposium on Micro Machine and Human Science (MHS’95), 1995, pp. 39–43. IEEE
Jaypuria, S.; Ranjan Mahapatra, T.; Jaypuria, O.: Metaheuristic tuned ANFIS model for input–output modeling of friction stir welding. Mater. Today Proc. 18, 3922–3930 (2019). https://doi.org/10.1016/j.matpr.2019.07.332
Le, L.M.; Ly, H.-B.; Pham, B.T.; Le, V.M.; Pham, T.A.; Nguyen, D.-H.; Tran, X.-T.; Le, T.-T.: Hybrid artificial intelligence approaches for predicting buckling damage of steel columns under axial compression. Materials 12(10), 1670 (2019)
Ben Seghier, M.E.A.; Carvalho, H.; Keshtegar, B.; Correia, J.A.; Berto, F.: Novel hybridized adaptive neuro-fuzzy inference system models based particle swarm optimization and genetic algorithms for accurate prediction of stress intensity factor. Fatigue Fract. Eng. Mater. Struct. 43(11), 2653–2667 (2020)
Mirjalili, S.; Mirjalili, S.M.; Lewis, A.: Grey wolf optimizer. Adv. Eng. Softw. 69, 46–61 (2014). https://doi.org/10.1016/j.advengsoft.2013.12.007
Das, A.K.; Pratihar, D.K.: A new bonobo optimizer (BO) for real-parameter optimization. In: 2019 IEEE Region 10 Symposium (TENSYMP), 7–9 June 2019, pp 108–113. https://doi.org/10.1109/tensymp46218.2019.8971108
Golafshani, E.M.; Behnood, A.; Arashpour, M.: Predicting the compressive strength of normal and high-performance concretes using ANN and ANFIS hybridized with grey wolf optimizer. Constr. Build. Mater. 232, 117266 (2020). https://doi.org/10.1016/j.conbuildmat.2019.117266
Datta, S.; Raza, M.S.; Das, A.K.; Saha, P.; Pratihar, D.K.: Experimental investigations and parametric optimization of laser beam welding of NiTinol sheets by metaheuristic techniques and desirability function analysis. Opt. Laser Technol. 124, 105982 (2020). https://doi.org/10.1016/j.optlastec.2019.105982
Jaypuria, S.; Das, A.K.; Pratihar, D.K.: Swarm-intelligence-based computation for parametric optimization of electron beam fabrication. In: Advances in Computational Methods in Manufacturing, pp. 153–163. Springer. https://doi.org/10.1007/978-981-32-9072-3_14 (2019)
Das, A.K.; Pratihar, D.K.: Optimal preventive maintenance interval for a Crankshaft balancing machine under reliability constraint using bonobo optimizer. In: IFToMM World Congress on Mechanism and Machine Science, 2019, pp. 1659–1668. Springer. https://doi.org/10.1007/978-3-030-20131-9_164
Wichan, C.; Loeshpahn, S.: Effect of filler alloy on microstructure, mechanical and corrosion behaviour of dissimilar weldment between AISI 201 stainless steel and low carbon steel sheets produced by a gas tungsten arc welding. In: Advanced Materials Research, 2012, pp. 808–816. Trans Tech Publ
Chandra-Ambhorn, S.; Chauiphan, W.; Sukwattana, N.C.; Pudkhunthod, N.; Komkham, S.: Plasma arc welding between AISI 304 and AISI 201 stainless steels using a technique of mixing nitrogen in shielding gas. In: Advanced Materials Research, 2012, pp. 1464–1468. Trans Tech Publ
Gholami, M.; Mostaan, H.; Sonboli, A.: Development of dissimilar GTA 4130/201 SS weld joint and investigation on the effect of filler metals in order to obtain improved mechanical properties and microstructural features. IUT-JWSTI 4(2), 1–12 (2019)
Das, D.; Pratihar, D.K.; Roy, G.G.: Cooling rate predictions and its correlation with grain characteristics during electron beam welding of stainless steel. Int. J. Adv. Manuf. Technol. 97(5), 2241–2254 (2018). https://doi.org/10.1007/s00170-018-2095-6
Kou, S.: Welding Metallurgy, 2nd edn. Wiley, New Jersey (2003)
Das, D.; Pratihar, D.K.; Roy, G.G.; Pal, A.R.: Phenomenological model-based study on electron beam welding process, and input–output modeling using neural networks trained by back-propagation algorithm, genetic algorithms, particle swarm optimization algorithm and bat algorithm. Appl. Intell. 48(9), 2698–2718 (2018). https://doi.org/10.1007/s10489-017-1101-2
Das, A.K.; Das, D.; Pratihar, D.K.: Multi-objective optimization and cluster-wise regression analysis to establish input–output relationships of a process. In: Mandal, J.K., Mukhopadhyay, S., Dutta, P. (eds.) Multi-Objective Optimization: Evolutionary to Hybrid Framework, pp. 299–318. Springer, Singapore (2018). https://doi.org/10.1007/978-981-13-1471-1_14
Jaypuria, S.; Pratihar, D.K.: Fuzzy inference system-based neuro-fuzzy modeling of electron-beam welding. In: Narayanan, R.G., Joshi, S.N., Dixit, U.S. (eds.) Advances in Computational Methods in Manufacturing, pp. 839–850. Springer, Singapore (2019)
Zakharenko, V.A.; Veprikova, Y.R.: Fiber-optical method of pyrometric measurement of melts temperature. J. Phys: Conf. Ser. 944, 012126 (2018). https://doi.org/10.1088/1742-6596/944/1/012126
Yu, J.; Wang, D.; Li, D.; Tang, D.; Zhu, G.; Dong, A.; Shu, D.; Peng, Y.: Physical simulation of investment casting for GTD-222 Ni-based superalloy processed by controlled cooling rates. Int. J. Adv. Manuf. Technol. 105(7), 3531–3542 (2019). https://doi.org/10.1007/s00170-019-04616-y
Alkayem, N.F.; Parida, B.; Pal, S.: Optimization of friction stir welding process using NSGA-II and DEMO. Neural Comput. Appl. 31(2), 947–956 (2019). https://doi.org/10.1007/s00521-017-3059-8
Chen, F.; Wang, Y.; Sun, S.; Ma, Z.; Huang, X.: Multi-objective optimization of mechanical quality and stability during micro resistance spot welding. Int. J. Adv. Manuf. Technol. 101(5), 1903–1913 (2019). https://doi.org/10.1007/s00170-018-3055-x
Kitayama, S.; Ishizuki, R.; Takano, M.; Kubo, Y.; Aiba, S.: Optimization of mold temperature profile and process parameters for weld line reduction and short cycle time in rapid heat cycle molding. Int. J. Adv. Manuf. Technol. 103(5), 1735–1744 (2019). https://doi.org/10.1007/s00170-019-03685-3
Pal, K.; Pal, S.K.: Multi-objective optimization of pulsed gas metal arc welding process using neuro NSGA-II. J. Inst. Eng. India Ser. C 100(3), 501–510 (2019). https://doi.org/10.1007/s40032-018-0466-2
Das, D.; Pratihar, D.K.; Roy, G.G.: Electron beam melting of steel plates: temperature measurement using thermocouples and prediction through finite element analysis. In: Mandal, D.K., Syan, C.S. (eds.) CAD/CAM, Robotics and Factories of the Future, pp. 579–588. Springer, New Delhi (2016)
Das, D.; Pratihar, D.K.; Roy, G.G.: Effects of space charge on weld geometry and cooling rate during electron beam welding of stainless steel. Optik 206, 163722 (2019). https://doi.org/10.1016/j.ijleo.2019.163722
Jang, J.R.: ANFIS: adaptive-network-based fuzzy inference system. IEEE Trans. Syst. Man Cybern. 23(3), 665–685 (1993). https://doi.org/10.1109/21.256541
Das, A.K.; Pratihar, D.K.: A new bonobo optimizer (BO) for real-parameter optimization. In: Paper Presented at the The IEEE Region 10 Symposium (TENSYMP 2019) (published in CD rom version). Kolkata, India (2019)
Corne, D.W.; Jerram, N.R.; Knowles, J.D.: Oates MJ PESA-II: region-based selection in evolutionary multiobjective optimization. In: Proceedings of the 3rd Annual Conference on Genetic and Evolutionary Computation (GECCO), pp. 283–290. Morgan Kaufmann Publishers Inc (2001)
Corne, D.W.; Knowles, J.D.; Oates, M.J.: The Pareto envelope-based selection algorithm for multiobjective optimization. In: Schoenauer, M., Deb, K., Rudolph, G. et al. (eds) Parallel Problem Solving from Nature PPSN VI, pp. 839–848. Berlin, Heidelberg (2000)
Zitzler, E.; Laumanns, M.; Thiele, L.: SPEA2: Improving the strength Pareto evolutionary algorithm. In: Technical Report 103, Computer Engineering and Communication Networks Lab (TIK), Swiss Federal Institute of Technology (ETH) Zurich (2001)
Zitzler, E.; Thiele, L.: An evolutionary algorithm for multiobjective optimization: the strength pareto approach. In: Technical Report 43, Computer Engineering and Networks Laboratory (TIK), Swiss Federal Institute of Technology (ETH) Zurich, Gloriastrasse 35, CH-8092 Zurich, Switzerland (1998)
Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T.: A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 6(2), 182–197 (2002). https://doi.org/10.1109/4235.996017
Heris, S.M.K.: https://yarpiz.com/ Accessed on 01 Dec 2019
Mirjalili, S. http://www.alimirjalili.com/GWO.html. Accessed 01 Dec 2019
https://sites.google.com/site/softcomputinglaboratory/Home. Accessed 01 Dec 2019
Pratihar, D.K.: Soft Computing: Fundamentals and Applications. Alpha Science International Ltd, Oxford (2013)
Author information
Authors and Affiliations
Corresponding author
Appendix
Rights and permissions
About this article

Cite this article
Das, A.K., Das, D., Jaypuria, S. et al. Input–Output Modeling and Multi-objective Optimization of Weld Attributes in EBW. Arab J Sci Eng 46, 4087–4101 (2021). https://doi.org/10.1007/s13369-020-05248-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13369-020-05248-1