
Abstract
Multi-objective evolutionary algorithm (MOEA) is an efficient tool for solving different problems in engineering and various other fields. This chapter deals with an approach used to establish input–output relationships of a process utilizing the concepts of multi-objective optimization and cluster-wise regression analysis. At first, an initial Pareto-front is obtained for a given process using a multi-objective optimization technique. Then, these Pareto-optimal solutions are applied to train a neuro-fuzzy system (NFS). The training of the NFS is implemented using a meta-heuristic optimization algorithm. Now, for generating a modified Pareto-front, the trained NFS is used in MOEA for evaluating the objective function values. In this way, a new set of trade-off solutions is formed. These modified Pareto-optimal solutions are then clustered using a clustering algorithm. Cluster-wise regression analysis is then carried out to determine input–output relationships of the process. These relationships are found to be superior in terms of precision to that of the equations obtained using conventional statistical regression analysis on the experimental data. To validate the performance of the developed method, an engineering problem, related to the electron beam welding (EBW) of SS 304, is selected and its input–output relationships have been established.
Access provided by CONRICYT-eBooks. Download chapter PDF
Similar content being viewed by others

Keywords
- Multi-objective optimization
- NSGA-II
- Input–output relationships
- Clustering
- Regression analysis
- Neuro-fuzzy system
1 Introduction
We, human beings, have a natural tendency to know input–output relationships of a process. Goldberg (2002) claimed that a genetic algorithm (GA) is competent for yielding innovative solutions in a single-objective optimization (SOO) problem domain. An SOO is generally used for finding out a single optimal solution out of several possibilities. However, a multi-objective optimization (MOO) problem involves at least two conflicting objective functions and a Pareto-optimal front of solutions can be obtained for the same. This present chapter deals with an application of MOO.
For the last few decades, MOO had been applied for solving various research and industrial problems (Ahmadi et al. 2015, 2016; Aghbashlo et al. 2016; Jarraya et al. 2015; Khoshbin et al. 2016; Marinaki et al. 2015; Ahmadi and Mehrpooya 2015; Sadatsakkak et al. 2015). Making large data intelligent transportation system (Wang et al. 2016), fabrication and optimization of 3D structures in bone tissue engineering area (Asadi-Eydivand et al. 2016), portfolio optimization with functional constraints (Lwin et al. 2014), optimization of building design (Brownlee and Wright 2015), disaster relief operations (Zheng et al. 2015), etc. are some of the worth-mentioning examples, where MOO has been utilized successfully in the recent times. By using a multi-objective evolutionary algorithm (MOEA), a Pareto-front of solutions is obtained. These solutions are not generated randomly (Askar and Tiwari 2009) and they must satisfy mathematically Karush–Kuhn–Tucker (KKT) conditions (Miettinen et al. 1999). It is argued (Deb and Srinivasan 2008) that there is a high chance of finding some commonalities among these high-performing solutions of the Pareto-front. Nevertheless, it is also debated that this commonality may exist for either the whole Pareto-front or different subsets of the same. However, if the said commonalities are embedded in those optimal or near-optimal solution sets, then it is expected to obtain the design principles for that process after some numerical analysis of the solutions.
The said fact can have an immense effect in designing a product or process. If a designer does have this type of information a priori, then it will help him to do his job more efficiently. For example, let us take the case of metal cutting operation with the inputs, such as cutting speed, feed, and depth of cut, and take two conflicting outputs as minimizing the machining time and minimizing the surface roughness of the machined product. By using the MOEA, if it is found that one or more parameters are varying in a particular fashion within the Pareto-front or the objective functions are changing with the inputs in a certain manner, then this information can provide an extra advantage to the process designer to set the same in a more efficient way. Similar things are applicable to other processes as well.
This fact of obtaining various design principles has another significance for the manufacturing industries. Reduction of cost without compromising the safety and quality of the products has always been the primary concern of any industry. The scope of cost minimization through proper inventory and manpower management would be possible, if the facts discussed above are available. Moreover, similar prior information may assist the process designer to establish and stabilize the process of interest with ease.
To use an MOEA, input–output relationships are required to define the objective functions. In many instances, these equations are not obtained from the literature and we have to derive these using the statistical tools on the experimental data. Now, generation of a wide range of experimental data requires not only proper facilities, but also a sequence of several tedious steps, and it demands time, cost, and effort. Moreover, noticeable variations in output data of any experiments are likely to be observed for a given set of input parameters. This results in fuzziness and inaccuracy in the experimental dataset, as shown by Gil and Gil (1992). The inaccuracy of the data can be minimized through multiple repetitions of the experiments, thereby providing the upper and lower limits of variation in the developed dataset, for a given set of input parameters. However, it again becomes difficult due to time and resource constraints in most of the cases. Gil (1987) also argued that experimental data may suffer from the loss of information about the state or parameter space owing to the fuzziness in it. Therefore, the generated Pareto-optimal solutions using an MOEA may also be affected by the fuzziness and inaccuracy of the experimental data, and we may end up with largely inaccurate design principles for the analyzed process. Due to this issue, it is desirable to tackle inherent fuzziness of the experimental data to establish input–output relationships of the process more accurately.
2 Literature Survey
Evolutionary multi-objective optimization has been used to establish input–output relationships by several researchers. The existence of the resemblance among the Pareto-optimal front of solutions was highlighted by Deb (2003). He also suggested that these commonalities could be revealed through regression and manual plotting. Obayashi and Sasaki (2003) used the self-organizing map to view the higher dimensional objective space and design variable space on a lower dimensional map. They also used a clustering technique to make the clusters of decision parameters, which showed the role of the variables in improving the design and trade-offs. Taboada and Coit (2006) suggested applying k-means clustering technique on the Pareto-optimal solutions for ease of further analysis. Deb and Srinivasan (2008) used Benson’s method to obtain a modified Pareto-front from the initial one and after that, they used statistical regression analysis to get different design principles. This method had also been adopted and implemented by various researchers in their works (Deb et al. 2009; Deb and Jain 2003; Deb and Sindhya 2008). An analytical approach was suggested by Askar and Tiwari (2011) to get a Pareto-front for multi-objective optimization problem, and the obtained Pareto-optimal solutions were analyzed to derive several innovative commonality principles. Deb et al. (2014) proposed the method of automated innovization to decode several important relationships through the extensive use of an evolutionary algorithm. They used the word, innovization, which means the act of obtaining innovative solutions through optimization. In this case, they had not used regression tools to decipher the said principles. Later, a concept of higher level innovization was introduced by Bandaru et al. (2011) and Bandaru et al. (2015) in a generalized form. Also, a simulation-based innovization procedure was developed by Dudas et al. (2011). In this approach, they tried to evaluate the effect of variables on the performance of the process and they showed a method of getting in-depth knowledge about a process after these analyses.
Among all these stated approaches, no one adopted any method to model the inherent fuzziness of the Pareto-optimal solutions. As already discussed, if this work is not done, then there will be a high chance that we shall obtain imprecise design principle for the process of interest. Therefore, a method has been developed here to obtain different input–output relationships after modeling the fuzziness in the Pareto-optimal dataset. This method has been applied for an electron beam welding process on SS304 plates, and the obtained results clearly show the significance of this developed approach. The rest of the text has been arranged as follows:
The developed method has been described in Sect. 3, whereas Sect. 4 deals with the experimental data collection procedure. The results and discussion are provided in Sect. 5, and some concluding remarks are made in Sect. 6.
3 Developed Approach
In the proposed approach, an attempt has been made to establish the input–output relationships of a process through the extensive use of a multi-objective evolutionary algorithm (MOEA). The approach has been explained in the following steps:
-
Step 1: Develop initial Pareto-optimal front
In this step, an initial Pareto-front is obtained using an MOEA, where the input–output relationships are used to determine the fitness values of the objective functions. The obtained Pareto-front is subjected to some inherent fuzziness in it, which is going to be removed in further steps.
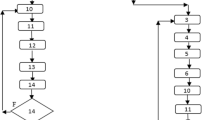
Several strategies for the MOEA are available in the literature, such as niched Pareto genetic algorithm (NPGA) (Horn et al. 1994), strength Pareto evolutionary algorithm (SPEA) (Zitzler and Thiele 1998), Pareto-archived evolution strategy (PAES) (Knowles and Corne 1999), non-dominated sorting genetic algorithm-II (NSGA-II) (Deb et al. 2002), multi-objective algorithm based on decomposition (MOEA/D) (Zhang and Li 2007), multiple populations for multiple objectives (MPMO) (Zhan et al. 2013), and others. In our study, NSGA-II has been used as the MOEA and its working principle is described in Fig. 1.

Flowchart of NSGA-II algorithm
-
Step 2: Train a neuro-fuzzy system
Using the initial Pareto-front of solutions, a neuro-fuzzy system (NFS) is trained. In NFS, a fuzzy logic controller (FLC) is expressed as the form of a neural network. During the training, an evolutionary optimization technique is used to tune the NFS. The initial Pareto-optimal solutions are clustered using a clustering algorithm, and the number of rules of the NFS is kept as the same with that of a total number of clusters obtained. The data obtained through experiments are subjected to inaccuracy and fuzziness. This may be due to various reasons, such as experimental inaccuracy, error due to the unskilled operator, instrumental inaccuracy, and others. To take care of this inherent fuzziness, NFS is an efficient tool (Mitra and Pal 1996), which works based on the principles of fuzzy sets. In NFS, the advantages of both fuzzy logic controller and neural network are clubbed together to design and remove the uncertainty and imprecision of a set of data. The NFS has been used successfully to solve a variety of problems related to several fields of research (Takagi and Hayashi 1991; Takagi et al. 1992; Keller et al. 1992; Berenji and Khedkar 1992; Jang 1993; Ishibuchi et al. 1994). Here, an NFS with Mamdani approach (Mamdani and Assilian 1975) is used to model fuzziness in the initial Pareto-optimal solutions. The said NFS has mainly five layers, namely, input layer, fuzzification layer, And operation layer, fuzzy inference layer, and defuzzification layer. Gaussian type of membership functions, which has been used in input and output layers of the NFS, can be expressed using Eq. (1):
where σ and m are the standard deviation and mean of the Gaussian distribution, respectively. During the training, the NFS is evolved with the help of a genetic algorithm, where the Gaussian parameters (σ and m) are used as the design variables and the objective is to minimize the root-mean-square error (RMSE) value (here, error is the amount of deviation in prediction).
-
Step 3: Obtain a modified Pareto-front
In this step, the trained NFS is used in another MOEA to evaluate the fitness values of the objective functions. As NFS is a strong tool to take care the fuzziness of the used data, there is every possibility to get a better quality of Pareto-front compared to that of the initial one. In this way, the imprecision of the initial Pareto-optimal solutions is removed using the NFS and a modified and better Pareto-front in terms of both the objective functions’ values is obtained.
-
Step 4: Clustering of the obtained modified Pareto-front
The modified Pareto-optimal dataset, obtained in Step 3, is clustered using a clustering algorithm. The purpose of carrying out this operation is to find that whether the design principles of the process are varying for the different clusters, or they are kept the same for the whole set of Pareto-front.
There are several techniques of clustering available in the literature. However, we have considered three popular clustering algorithms like fuzzy C-means clustering (FCM) (Bezdek 1973), entropy-based fuzzy clustering (EFC) (Yao et al. 2000), and density-based spatial clustering application with noise (DBSCAN) (Ester et al. 1996), in our study. In case of FCM, a data point may belong to several predefined numbers of clusters with different membership values. It is an iterative method, where the cluster centers and the membership values of the cluster members are going to be updated with the iterations. In every step of the algorithm, the focus is to reduce the dissimilarity measurement (which is evaluated in terms of Euclidean distance) of the cluster members. The members of the same cluster are likely to have the higher values of similarity, whereas the data points belonging to different clusters should be dissimilar in nature. The EFC algorithm works based on the entropy measures of the data points, which are calculated depending on the values of the distances (say Euclidean distances) among them. A data point is declared as a cluster center, if it is found with the minimum entropy value. The other points, which have the similarity measures with the cluster center greater than a user-defined value, will be put into the cluster. In case of DBSCAN, two user-specified parameters are used, such as neighborhood radius and minimum number of neighborhood points. The philosophy of this algorithm is that the density of the members lying within a cluster is higher than that of the outsider points. The details of these algorithms can be found out in (Pratihar 2007).
-
Step 5: Analysis of the modified Pareto-front
The obtained modified Pareto-optimal solutions are statistically analyzed cluster-wise to get several input–output relationships for the problem. Moreover, any relationship, which is common to all the clusters, has to be checked. The developed approach has been described through a flowchart, as shown in Fig. 2. Generally, the outputs of a natural process vary nonlinearly with the input parameters. Keeping this idea in mind, a nonlinear regression tool (using MINITAB 16.0 software (http://www.minitab.com)) has been used to determine various input–output relationships in power form.

Flowchart of the developed approach
4 Experimental Data Collection
To explain the proposed approach in more details, an engineering problem, namely, electron beam welding (EBW), has been selected and the developed approach has been implemented for the said process. The details of the experimental procedure, along with the setup information, have been provided in this section.
4.1 Experimental Setup and Procedure
Bead-on-plate welding was carried out on EBW facility, developed by Bhabha Atomic Research Centre (BARC), Mumbai, at IIT Kharagpur (refer to Fig. 3). The machine has a maximum power rating of 12 kW. The beam was kept stationary, while the table containing the workpiece, fixture, and other arrangements traveled in the horizontal plane at a predefined welding speed. A vacuum was provided in the work chamber and gun chamber with the help of vacuum pumps before the initiation of the welding process. The stream of highly accelerated electrons was made incident on 20-mm-thick AISI 304 stainless steel workpiece in the vacuum environment. The chemical composition of the used material can be found out in (Das et al. 2016). The EBW experiments had been carried out following a multilevel full-factorial design. This study aims to investigate the effects of beam power and welding speed on the depth of penetration and bead width of the weld.

Electron beam welding (EBW) setup, IIT Kharagpur, India
4.2 Data Collection
Two input parameters, namely, beam power (P in W) and welding speed (S in mm/min), were considered in this study. Considering four levels of the input parameters, the experiments had been carried out according to the multilevel full-factorial design with 24 = 16 combinations of design variables. For each combination of input variables, welding was carried out three times in order to ensure repeatability.
These samples were sectioned, polished, etched, and observed under the microscope in order to obtain the desired measurements. The average values of the bead width (BW in mm) and depth of penetration (DP in mm) were calculated and used in this study. The details of the experimental data used for developing the model and testing the same are shown in Appendices 1 and 2, respectively.
5 Results and Discussion
As like other natural processes, electron beam welding process has also nonlinear input–output relationships (Jha et al. 2014). These relationships were obtained from the experimental data using a nonlinear regression tool. After this, the developed approach was used to get the relationships among the responses and design variables, and other important information regarding the said process.
5.1 Obtaining Nonlinear Input–Output Relationships from the Experimental Data
Using the statistical software Minitab 16.0, a nonlinear regression analysis had been carried out to obtain the input–output relationships from the experimental data (refer to Appendix 1) collected within the upper and lower limits of the input variables, as provided in Table 1.
The following expression was obtained for depth of penetration:
The model was found to be capable of predicting accurate results because of a high value of regression coefficient of 0.97. A confidence level of 95% was considered. The other response, BW was also expressed in terms of the input parameters as follows:
The regression coefficient for this case was found to be 0.8.
5.2 Formulation of the Optimization Problem
The objective was to maximize the depth of penetration (DP), while keeping the bead width (BW) at a lower value. These said goals are contradictory to each other, as with the increase of DP, and output parameter BW increases. Therefore, this is an ideal problem for MOO and it can be expressed as follows:
5.3 Obtaining Initial Pareto-Front
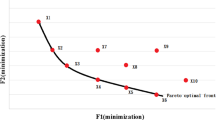
Using NSGA-II, an initial Pareto-front was obtained (refer to Fig. 4). In this case, Eqs. (2) and (3) were used to evaluate the numerical values for the outputs DP and BW, respectively. The user-defined parameters for the NSGA-II, such as probability of crossover \( (p_{c} ) \), probability of mutation \( (p_{m} ) \), population size (N), and maximum number of generations \( (G_{max} ) \), were selected through a detailed parametric study. This study had been carried out by varying parameters one at a time and keeping the others fixed. The sequence for varying the parameters was taken as follows: \( p_{c} ,p_{m} ,N \) and \( G_{max} \), as suggested in Pratihar (2007). The best parameters were chosen based on the maximum spread of the Pareto-front. The details of this parametric study have been provided in Table 2, where the selected parameters are written in bold.

Obtained initial Pareto-front of solutions
In NSGA-II, different genetic operators, such as tournament selection, arithmetic crossover, and Gaussian mutation, were used. Now, the initial Pareto-front of optimal solutions was obtained utilizing the selected parameters, as shown in Fig. 4.
5.4 Training of an NFS
Using the initial Pareto-front dataset, a neuro-fuzzy system (NFS) had been trained. The training dataset had been clustered using a clustering technique, namely, fuzzy C-means clustering and in this case, the level of cluster fuzziness was considered as 2.0. To obtain the best results, the said data set was clustered into 16 different clusters. Therefore, the total number of rules for the NFS became equal to the number of clusters made. The structure of the developed NFS has been shown in Fig. 5.

Structure of the neuro-fuzzy system
In the used NFS, a supervised learning with a batch mode of training method had been applied. In the input and output layers, the Gaussian type of membership functions had been used. So, the total number of unknown parameters of this model was found to be equal to (16 × 4 × 2 =) 128 (as there are two inputs and two outputs each in the model, and each Gaussian function has two unknown parameters, that is, σ and m). For the training purpose, 300 input data points of the initial Pareto-front had been used and a root-mean-square error (RMSE) was calculated each time. Here, the error is nothing but the deviation in prediction. This NFS was evolved using a genetic algorithm, where the objective was set to minimize the RMSE value and the design variables were those 128 numbers of unknown parameters of the model. Different genetic operators, such as roulette wheel selection, linear crossover, and random mutation, had been utilized in the GA, and to obtain the best results, the selected GA parameters were as follows: crossover probability \( (p_{c} = 0.9), \) mutation probability \( (p_{m} = 0.1), \) and population size \( (N = 60). \)
5.5 Obtaining Modified Pareto-Front
In this step, the trained NFS had been used in an NSGA-II for determining the fitness values of the objectives. It is important to note that Eqs. (2) and (3) were used previously in the NSGA-II for obtaining the initial Pareto-front of solutions. The parameters for this NSGA-II were kept the same as in that of the previous case described in Sect. 5.3. We could get a modified Pareto-front, as shown in Fig. 6, and the quality of this Pareto-front had been improved in terms of the objective function values compared to that of the initial one.

Initial and modified Pareto-front of solutions
5.6 Clustering of the Modified Pareto-Front Data Set
The obtained modified Pareto-optimal solutions were clustered using three different algorithms, namely, fuzzy C-means clustering (FCM), entropy-based fuzzy clustering (EFC), and density-based spatial clustering application with noise (DBSCAN). By using FCM algorithm with the level of cluster fuzziness kept equal to 1.25, two clusters were obtained, as shown in Fig. 7.

Clustering of the modified Pareto-front using FCM
In case of EFC, two distinct clusters (refer to Fig. 8) were obtained with the user-defined parameters like the constant of similarity \( (\alpha = 0.12) \) and threshold value of similarity \( (\beta = 0.9) \).

Clustering of the modified Pareto-front using EFC
In another case, where the clustering was done using DBSCAN algorithm, three distinct clusters were obtained, as shown in Fig. 9. In this algorithm, a point was considered to form a cluster, when a minimum of three other points were found to be present in a neighborhood radius of 0.032.

Clustering of the modified Pareto-front using DBSCAN
For the different clusters obtained using the said three clustering algorithms, the respective ranges of variation for the two outputs, such as DP and BW, are given in Table 3.
The clustered solutions were analyzed using nonlinear regression analysis. For this purpose, a Gauss–Newton approach was used with 95% confidence level for all intervals and the convergence tolerance was assumed to be equal to 0.00001. In Table 4, cluster-wise obtained different input–output relationships are provided.
The two extreme points on the modified Pareto-front correspond to the maximum and minimum values of the two outputs of the EBW process. One of these points shows the highest values of DP and BW with the input parameters as follows: \( P = 5600\,{\text{W}},S = 900\,{\text{mm}}/{ \hbox{min} } \). On the other hand, the other point provides the information regarding the lowest values of the outputs with an input variables setting as \( P = 4750.98\,{\text{W}},S = 1800\,{\text{mm}}/{ \hbox{min} } \). It is observed (refer to Fig. 10) that for increasing the depth of penetration (DP), beam power (P) has to be increased and welding speed (S) should be at its lower value. In other situation, where a user requires a lower value of bead width (BW), the input parameter, P, has to be decreased and S is needed to be increased. Moreover, both DP and BW are found to be proportional to the heat input, which is a unified effect of beam power and welding speed on the weld geometries. This trend is in accordance with the literature (Das et al. 2017; Kar et al. 2015). Therefore, a user may be recommended to choose input parameters setting to avail the high depth of penetration (7.01 mm) and low bead width (4.36 mm) as follows: \( P = 5548.8\,{\text{W}} \), \( S = 1096.46\,{\text{mm}}/{ \hbox{min} } \).

Variations of DP and BW with the inputs, P and S, in the modified Pareto-front
The obtained input–output relationships were used on some test data (refer to Appendix 2), and an average absolute percentage error (AAPE) was calculated for each of the cases of clustering techniques. These were compared to the results obtained using Eqs. (2) and (3). The comparison (refer to Table 5) clearly indicates the fact that the relationships derived by the developed approach could predict more accurately compared to the regression equations did. In addition, FCM algorithm could perform a slightly better compared to the other two algorithms of clustering.
Another interesting fact to observe here is that the range for the input variable power (P) had been squeezed from (3200, 5600 W) to (4750.98, 5600 W) in the modified Pareto-optimal dataset. This fact denotes that the effective range of the input parameter P for this process has been shortened and it is advisable to operate only in this squeezed range to get the best results. This information will surely help the designers to design and establish the process efficiently.
6 Conclusion
An approach was developed to obtain different input–output relationships of the EBW process by the extensive use of a multi-objective optimization technique and a neuro-fuzzy system. It is quite different from the approaches available, because it adopts a method to model the inherent fuzziness in the experimental data and at the end, it could generate more accurate input–output relationships for a process. The approach was applied for an EBW process, and the results obtained were superior to that of the other methods in terms of precision and accuracy. This happens due to the fact that in the developed approach, an NFS, which is capable of handling uncertainty and inaccuracy of the data, is used and the imprecision in the data is removed to come up with the more accurate relationships.
The solutions of the modified Pareto-front were clustered and analyzed to obtain input–output relationships cluster-wise. A comparison has also been made among the relationships obtained in different cases of clustering algorithms based on the results of the test cases. Another interesting fact has been found out that for an input parameter, the effective range to get the best results has been squeezed. This prior information may increase the opportunities to reduce the operating cost and make the process more stable. Moreover, some physical aspects of the process are derived after analyzing the modified Pareto-optimal dataset, and the conclusions are seen to be inline with those made by other researchers for the process. Therefore, the developed approach can be applied to any process for obtaining input–output relationships and other important facts of the same.
References
M. Aghbashlo, S. Hosseinpour, M. Tabatabaei, H. Younesi, G. Najafpour, On the exergetic optimization of continuous photobiological hydrogen production using hybrid ANFIS–NSGA-II (adaptive neuro-fuzzy inference system–non-dominated sorting genetic algorithm-II). Energy 96, 507–520 (2016)
M.H. Ahmadi, M. Mehrpooya, Thermo-economic modeling and optimization of an irreversible solar-driven heat engine. Energy Convers. Manag. 103, 616–622 (2015)
M.H. Ahmadi, M.A. Ahmadi, S.A. Sadatsakkak, Thermodynamic analysis and performance optimization of irreversible Carnot refrigerator by using multi-objective evolutionary algorithms (MOEAs). Renew. Sustain. Energy Rev. 51, 1055–1070 (2015)
M.H. Ahmadi, M.A. Ahmadi, A. Mellit, F. Pourfayaz, M. Feidt, Thermodynamic analysis and multi objective optimization of performance of solar dish Stirling engine by the centrality of entransy and entropy generation. Int. J. Electr. Power Energy Syst. 78, 88–95 (2016)
M. Asadi-Eydivand, M. Solati-Hashjin, A. Fathi, M. Padashi, N.A.A. Osman, Optimal design of a 3D-printed scaffold using intelligent evolutionary algorithms. Appl. Soft Comput. 39, 36–47 (2016)
S.S. Askar, A. Tiwari, Multi-objective optimisation problems: a symbolic algorithm for performance measurement of evolutionary computing techniques. in Proceedings of EMO 2009 (Springer, 2009), pp. 169–182
S. Askar, A. Tiwari, Finding innovative design principles for multiobjective optimization problems. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev 41(4), 554–559 (2011)
S. Bandaru, C.C. Tutum, K. Deb, J.H. Hattel, Higher-level innovization: a case study from friction stir welding process optimization. Evol. Comput. (CEC) 2011, 2782–2789 (2011)
S. Bandaru, T. Aslam, A.H. Ng, K. Deb, Generalized higher-level automated innovization with application to inventory management. Eur. J. Oper. Res. 243(2), 480–496 (2015)
J.C. Bezdek, Fuzzy mathematics in pattern classification. Ph.D. thesis, Applied Math. Center, Cornell University, 1973
H.R. Berenji, P. Khedkar, Learning and tuning fuzzy logic controllers through reinforcements. IEEE Trans. Neural Netw. 3(5), 724–740 (1992)
A.E. Brownlee, J.A. Wright, Constrained, mixed-integer and multi-objective optimisation of building designs by NSGA-II with fitness approximation. Appl. Soft Comput. 33, 114–126 (2015)
D. Das, D.K. Pratihar, G.G. Roy, Electron beam melting of steel plates: temperature measurement using thermocouples and prediction through finite element analysis. CAD/CAM, Robotics and Factories of the Future (Springer, 2016), pp. 579–588
D. Das, D.K. Pratihar, G.G. Roy, A.R. Pal, Phenomenological model-based study on electron beam welding process, an input-output modeling using neural networks trained by back-propagation algorithm, genetic algorithm, particle swarm optimization algorithm and bat algorithm. Appl. Intell. (2017). https://doi.org/10.1007/s10489-017-1101-2
K. Deb, Unveiling innovative design principles by means of multiple conflicting objectives. Eng. Optim. 35(5), 445–470 (2003)
K. Deb, S. Jain, Multi-speed gearbox design using multi-objective evolutionary algorithms. Trans. Am. Soc. Mech. Eng. J. Mech. Des. 125(3), 609–619 (2003)
K. Deb, A. Pratap, S. Agarwal, T. Meyarivan, A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 6(2), 182–197 (2002)
K. Deb, A. Srinivasan, Innovization: Discovery of innovative design principles through multiobjective evolutionary optimization. Multiobjective Problem Solving from Nature, pp. 243–262 (2008)
K. Deb, S. Gupta, D. Daum, J. Branke, A.K. Mall, D. Padmanabhan, Reliability-based optimization using evolutionary algorithms. IEEE Trans. Evol. Comput. 13(5), 1054–1074 (2009)
K. Deb, K. Sindhya, Deciphering innovative principles for optimal electric brushless DC permanent magnet motor design. in IEEE World Congress on Computational Intelligence Evolutionary Computation 2008, pp. 2283–2290 (2008)
K. Deb, S. Bandaru, D. Greiner, A. Gaspar-Cunha, C.C. Tutum, An integrated approach to automated innovization for discovering useful design principles: case studies from engineering. Appl. Soft Comput. 15, 42–56 (2014)
C. Dudas, M. Frantzén, A.H. Ng, A synergy of multi-objective optimization and data mining for the analysis of a flexible flow shop. Robot. Comput. Integr. Manuf. 27(4), 687–695 (2011)
M. Ester, H.-P. Kriegel, J. Sander, X. Xu, A density-based algorithm for discovering clusters in large spatial databases with noise. in Proceedings of KDD 1996, vol. 34, pp. 226–231 (1996)
M.A. Gil, Fuzziness and loss of information in statistical problems. IEEE Trans. Syst. Man Cybern. 17(6), 1016–1025 (1987)
M.A. Gil, P. Gil, Fuzziness in the experimental outcomes: comparing experiments and removing the loss of information. J. Stat. Plan. Inference 31(1), 93–111 (1992)
D.E. Goldberg, The Design of Innovation: Lessons from and for Competent Genetic Algorithms, vol. 7 (Springer Science & Business Media, 2002)
J. Horn, N. Nafpliotis, D.E. Goldberg, A niched Pareto genetic algorithm for multiobjective optimization. in IEEE World Congress on Computational Intelligence Evolutionary Computation 1994, pp. 82–87 (1994)
H. Ishibuchi, H. Tanaka, H. Okada, Interpolation of fuzzy if-then rules by neural networks. Int. J. Approx. Reason. 10(1), 3–27 (1994)
J.-S. Jang, ANFIS: adaptive-network-based fuzzy inference system. IEEE Trans. Syst. Man Cybern. 23(3), 665–685 (1993)
Y. Jarraya, S. Bouaziz, A.M. Alimi, A. Abraham, Evolutionary multi-objective optimization for evolving hierarchical fuzzy system. Evol. Comput. (CEC) 2015, 3163–3170 (2015)
M. Jha, D.K. Pratihar, A. Bapat, V. Dey, M. Ali, A. Bagchi, Modeling of input-output relationships for electron beam butt welding of dissimilar materials using neural networks. Int. J. Comput. Intell. Appl. 13(03), 1450016 (2014)
J. Kar, S. Mahanty, S.K. Roy, G. Roy, Estimation of average spot diameter and bead penetration using process model during electron beam welding of AISI 304 stainless steel. Trans. Indian Inst. Met. 68(5), 935–941 (2015)
J.M. Keller, R.R. Yager, H. Tahani, Neural network implementation of fuzzy logic. Fuzzy Sets Syst. 45(1), 1–12 (1992)
F. Khoshbin, H. Bonakdari, S.H. Ashraf Talesh, I. Ebtehaj, A.H. Zaji, H. Azimi, Adaptive neuro-fuzzy inference system multi-objective optimization using the genetic algorithm/singular value decomposition method for modelling the discharge coefficient in rectangular sharp-crested side weirs. Eng. Optim. 48(6), 933–948 (2016)
J. Knowles, D. Corne, The Pareto archived evolution strategy: a new baseline algorithm for Pareto multiobjective optimisation. CEC 99, 98–105 (1999)
K. Lwin, R. Qu, G. Kendall, A learning-guided multi-objective evolutionary algorithm for constrained portfolio optimization. Appl. Soft Comput. 24, 757–772 (2014)
E.H. Mamdani, S. Assilian, An experiment in linguistic synthesis with a fuzzy logic controller. Int. J. Man Mach. Stud. 7(1), 1–13 (1975)
M. Marinaki, Y. Marinakis, G.E. Stavroulakis, Fuzzy control optimized by a multi-objective differential evolution algorithm for vibration suppression of smart structures. Comput. Struct. 147, 126–137 (2015)
K. Miettinen, Nonlinear Multiobjective Optimization, vol. 12 (Springer Science & Business Media, 1999)
S. Mitra, S.K. Pal, Neuro-fuzzy expert systems: relevance, features and methodologies. IETE J. Res. 42(4–5), 335–347 (1996)
S. Obayashi, D. Sasaki, Visualization and data mining of Pareto solutions using self-organizing map. in Proceedings of EMO 2003 (Springer, 2003), pp. 796–809
D.K. Pratihar, Soft Computing (Alpha Science International, Ltd, 2007)
S.A. Sadatsakkak, M.H. Ahmadi, M.A. Ahmadi, Optimization performance and thermodynamic analysis of an irreversible nano scale Brayton cycle operating with Maxwell-Boltzmann gas. Energy Convers. Manag. 101, 592–605 (2015)
H.A. Taboada, D.W. Coit, Data mining techniques to facilitate the analysis of the Pareto-optimal set for multiple objective problems. in Proceedings 2006, Institute of Industrial and Systems Engineers (IISE) IIE Annual Conference, pp. 1–6 (2006)
H. Takagi, I. Hayashi, NN-driven fuzzy reasoning. Int. J. Approx. Reason. 5(3), 191–212 (1991)
H. Takagi, N. Suzuki, T. Koda, Y. Kojima, Neural networks designed on approximate reasoning architecture and their applications. IEEE Trans. Neural Netw. 3(5), 752–760 (1992)
C. Wang, X. Li, X. Zhou, A. Wang, N. Nedjah, Soft computing in big data intelligent transportation systems. Appl. Soft Comput. 38, 1099–1108 (2016)
J. Yao, M. Dash, S. Tan, H. Liu, Entropy-based fuzzy clustering and fuzzy modeling. Fuzzy Sets Syst. 113(3), 381–388 (2000)
Z.-H. Zhan, J. Li, J. Cao, J. Zhang, H.S.-H. Chung, Y.-H. Shi, Multiple populations for multiple objectives: a coevolutionary technique for solving multiobjective optimization problems. IEEE Trans. Cybern. 43(2), 445–463 (2013)
Q. Zhang, H. Li, MOEA/D: a multiobjective evolutionary algorithm based on decomposition. IEEE Trans. Evol. Comput. 11(6), 712–731 (2007)
Y.-J. Zheng, S.-Y. Chen, H.-F. Ling, Evolutionary optimization for disaster relief operations: a survey. Appl. Soft Comput. 27, 553–566 (2015)
E. Zitzler, L. Thiele, An evolutionary algorithm for multiobjective optimization: the strength Pareto approach (1998)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Appendices
Appendices
Appendix 1 collected experimental data
Sl. no. | Power (W) | Speed (mm/min) | Depth of penetration (mm) | Bead width (mm) |
|---|---|---|---|---|
1 | 3200 | 1800 | 2.73 | 4.82 |
2 | 3200 | 1500 | 3.27 | 5.36 |
3 | 4000 | 1800 | 3.43 | 4.46 |
4 | 3200 | 1200 | 4 | 3.4 |
5 | 4000 | 1500 | 4.13 | 4.4 |
6 | 4800 | 1800 | 3.41 | 5.54 |
7 | 5600 | 1800 | 4.55 | 3.4 |
8 | 4800 | 1500 | 4.5 | 3.5 |
9 | 4000 | 1200 | 4.6 | 4.7 |
10 | 3200 | 900 | 3.9 | 6.92 |
11 | 5600 | 1500 | 4.8 | 5.1 |
12 | 4800 | 1200 | 5.29 | 5.31 |
13 | 4000 | 900 | 5.69 | 4.99 |
14 | 5600 | 1200 | 5.8 | 5.5 |
15 | 4800 | 900 | 7.15 | 5 |
16 | 5600 | 900 | 8.2 | 5.6 |
Appendix 2 Experimental data collected for testing the performance of the developed approach
Sl. no. | Power (W) | Speed (mm/min) | Depth of penetration (mm) | Bead width (mm) |
|---|---|---|---|---|
1 | 4800 | 1650 | 4.37 | 3.38 |
2 | 4800 | 1325 | 5.03 | 3.87 |
3 | 5200 | 1650 | 4.39 | 3.86 |
4 | 5200 | 1325 | 5.27 | 4.51 |
5 | 5600 | 1000 | 7.91 | 5.28 |
Rights and permissions
Copyright information
© 2018 Springer Nature Singapore Pte Ltd.
About this chapter

Cite this chapter
Das, A.K., Das, D., Pratihar, D.K. (2018). Multi-Objective Optimization and Cluster-Wise Regression Analysis to Establish Input–Output Relationships of a Process. In: Mandal, J., Mukhopadhyay, S., Dutta, P. (eds) Multi-Objective Optimization. Springer, Singapore. https://doi.org/10.1007/978-981-13-1471-1_14
Download citation
DOI: https://doi.org/10.1007/978-981-13-1471-1_14
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-13-1470-4
Online ISBN: 978-981-13-1471-1
eBook Packages: Computer ScienceComputer Science (R0)