
Abstract
Landslides lead to a great threat to human life and property safety. The delineation of landslide-prone areas achieved by landslide susceptibility assessment plays an important role in landslide management strategy. Selecting an appropriate mapping unit is vital for landslide susceptibility assessment. This paper compares the slope unit and grid cell as mapping unit for landslide susceptibility assessment. Grid cells can be easily obtained and their matrix format is convenient for calculation. A slope unit is considered as the watershed defined by ridge lines and valley lines based on hydrological theory and slope units are more associated with the actual geological environment. Using 70% landslide events as the training data and the remaining landslide events for verification, landslide susceptibility maps based on slope units and grid cells were obtained respectively using a modified information value model. ROC curve was utilized to evaluate the landslide susceptibility maps by calculating the training accuracy and predictive accuracy. The training accuracies of the grid cell-based susceptibility assessment result and slope unit-based susceptibility assessment result were 80.9 and 83.2%, and the prediction accuracies were 80.3 and 82.6%, respectively. Therefore, landslide susceptibility mapping based on slope units performed better than grid cell-based method.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Landslides pose a serious threat to human properties and lives (Kirschbaum et al. 2015; Hölbling et al. 2015). Landslide susceptibility assessment is able to ensure landslide-prone zones, thus it is vital for landslides prevention work (Eeckhaut et al. 2009a).
The accuracy of landslide susceptibility assessment is affected by mapping unit, prediction method, type of landslides, resolution of data and so on (Haacke et al. 2015; Kreuzer et al. 2017). Selecting suitable mapping unit is vital for the following analyses and modeling (Zhuang et al. 2016). The mapping units are regarded as the sampling units in landslide susceptibility zonation (Erener and Düzgün 2012; Rotigliano et al. 2012). After determining mapping units, the value of every landslide influence factor can be allotted to each unit.
The popular mapping units in landslide susceptibility assessment include grid cells, unique-condition units, slope units, etc. (Meijerink 1988; Chung and Fabbri 1995; Erener and Düzgün 2012). Grid cells are regular square cells with the given size (Cama et al. 2016). It can be stored in a matrix form which is convenient for the calculation. However, the grid cells are not related closely to geological environments (Guzzetti et al. 1999). Unique-condition units can be obtained by overlaying different landslide influential classification maps, thus every unit is determined by the combination of different properties (Chiessi et al. 2016). The size of units depends on the number of influence factors, while the total number of units depends on classified criteria of landslide influence factors. But some studies indicate that the disadvantage of the unique-condition units is that the classified criteria of influence factors is subjective (Carrara and Guzzetti 1995). Slope units are the watershed area defined by drainage lines (valley lines) and water divide lines (ridge lines), which are the basic topographical units of geological hazard occurrence (Wang et al. 2017). Slope units based on drainage and divide lines are more related to geological environment (Guzzetti et al. 1999). Although the identification of sub-basin boundaries is difficult, the hydrological tools of geographical information systems (GIS) can solve this problem (Erener and Düzgün 2012). This paper selects grid cells and slope units as mapping units for landslide susceptibility assessment.
A variety of models have been used for landslide susceptibility zonation (Parise and Jibson 2000; Lee 2004; Yesilnacar and Topal 2005; Fell et al. 2008), for instance, artificial neural network model (Zare et al. 2013; Garcíarodríguez and Malpica 2010), support vector machine (Pradhan 2013; Tham 2008), logistic regression model (Raja et al. 2017; Pradhan 2010) and analytic hierarchy process (Komac 2006; Myronidis et al. 2016). Information value model is a popular method (Che et al. 2012; Sharma et al. 2015). However, information value model does not take into consideration the different importance of different landslide influence factors but just assigns equal weight to every landslide influence factor. In this study, we utilizes a modified information value model proposed by Ba et al. (2017) for landslide susceptibility mapping which obtains the relative weights of different classes of every landslide influence factor through calculating information values of landslide influence factors and determines which landslide susceptibility rank each mapping unit belongs to using gray clustering analysis (Ba et al. 2017). Eight landslide influence factors are utilized in the model for evaluating landslide susceptibility.
The grid cell-based landslide susceptibility assessment result and the slope unit-based landslide susceptibility assessment result are finally compared by the receiver operating characteristics curve.
Methodology
Mapping units
Mapping unit is the minimum significative spatial unit which is obtained by subdividing the land surface into homogeneous areas. This paper selects the grid cells and slope units as mapping units to assess landslide susceptibility.
Grid cells
Grid cell is a popular mapping unit for susceptibility assessment since it can be obtained easily. The grid cells are generated through dividing the area into regular squares of a given size. Its matrix form is convenient for data processing and calculating. However, grid cells are not associated with geological environments, which is an important shortcoming of this mapping unit (Chiessi et al. 2016). Selection of the appropriate grid cell size for susceptibility mapping is vital. Trigila et al. (2015) used the most frequent landslide area to determine the correct size of the grid cell. The most frequent landslide area can be obtained by the use of frequency–area statistics. Moreover, in order to determine the correct size of grid cells, comparison of the slope gradient, obtained from DEM (digital elevation model) with different resolution, should also be considered.
Slope units
Slope units are generated according to hydrological theory. Slope units are thought as the watershed defined by the ridge lines and valley lines (Xie et al. 2004; Jia et al. 2015) (Fig. 1). Using the ArcGIS hydrology tools, these lines can be extracted to generate slope units. The slope units are closely related to actual geological environments, which is a main shortcoming for grid cells as mapping units (Chiessi et al. 2016).

The generation of slope units
The slope units are generated through following steps (Fig. 1). Firstly, Reverse DEM can be generated by subtracting the elevation value from the highest elevation value in each unit (Xie et al. 2004). Secondly, the DEM and Reverse DEM are filled to remove small imperfections in the data, which can be achieved by the Fill tool of ArcGIS. Thirdly, the flow direction is calculated by the eight direction method which can be obtained using the Flow Direction tool of ArcGIS. Fourthly, the flow accumulation can be obtained using the flow direction data. This step can be achieved by the Flow Accumulation tool of ArcGIS. In the next step, the stream network is obtained by selecting the flow accumulation of every cell above a certain threshold. Generally, 1% of the maximum flow accumulation is defined as the threshold (Erener and Düzgün 2012). Then the watershed of DEM or Reverse DEM is obtained and this step can be achieved by the Watershed tool of ArcGIS (Erener and Düzgün 2012). Finally, the watershed raster map from DEM and the watershed raster map from Reverse DEM are converted to the vector format. Then the watershed polygons from DEM and Reverse DEM are dissolved. After amending the unreasonable polygons, the slope units are generated.
Then for the continuous landslide influence factors including slope gradient, aspect, NDVI and MAP, the mean value of every landslide influence factor within every slope unit was assigned to this unit. As to the categorized landslide influence factors including distance to tectonic features, lithology, distance to stream network and distance to roads, the predominant value of every landslide influence factor within every slope unit was assigned to the corresponding unit.
Modified information value model
The modified information value model combined information value model with gray clustering. This method utilizes information value to calculate the weight of every landslide influence factor and utilizes gray clustering to determine which landslide susceptibility rank each mapping unit belongs to. The procedures are as follows.
-
Step 1
The information values were calculated to represent the likelihood of landslide occurrence. A larger information value indicates a higher likelihood of landsliding. Each landslide influence factor was classified into five classes using Jenks natural breaks optimization, except for aspect which was classified into nine classes (Chen et al. 2013; Xu et al. 2013). Jenks natural breaks optimization is a commonly-used data classification method which is achieved by diminishing the difference within every class and magnifying the variance among different classes. After classifying the landslide influence factors using ArcGIS Reclassify tools, the information value of each landslide influence factor can be calculated using Eq. (1) (Yan 1988; Yin and Yan 1988; Chen et al. 2016).
I(i) represents the information value; i(i = 1, 2, …, n) indicates the ith landslide influence factor; j(j = 1, 2, …, m) represents the jth class of the landslide influence factor; S indicates the total area of all mapping units; A indicates the total area of all landslide events; Sij indicates the total area of those mapping units having the distribution of jth class of ith landslide influence factor; Ai indicates the total area of those landslide events having the distribution of jth class of ith landslide influence factor.
-
Step 2
The value of the ith(i = 1, 2, …, n) influence factor in the pth(p = 1, 2, …, t) mapping unit which is represented by xpi should be standardized to remove the effect of dimension by the use of the min-max normalization method as follows. xM and xmindicates the maximum xpi and the minimum xpi. ypi is the standardized xpi (Wei and Feng 2004; Xie et al. 2014):
-
Step 3
According to the information value of the jth(j = 1,2, …, m) class of the ith(i = 1,2, …, n) landslide influence factor, the landslide susceptibility of the ith landslide influence factor was classified into five ranks, including very low, low, medium, high and very high susceptibility. The class of a landslide influence factor with a larger information value should be assigned to a higher rank of landslide susceptibility.
-
Step 4
Then the clustering weight ηi(i = 1, 2, …, n),representing the ith landslide influence factor’s effect on landsliding, can be determined as follows:
where λi indicates the sum of the positive information values of the ith factor, and \( \sum \limits_{i=1}^n{\lambda}_i \)represents the sum of the positive information value of all factors (Ba et al. 2017).
-
Step 5
Then the whitening weight functions of every landslide influence factor can be derived. It can be used to describe the degree every mapping unit belonged to a landslide susceptibility rank. The gray whitening weight function of the ith influence factor for the kth rank which is expressed as \( {f}_i^k\left(\cdotp \right)\left(i=1,2,\dots, n;k=1,2,\dots, s\right) \) can be determined through following equations (Li et al. 2014; Xie et al. 2014).
-
➀ The lower whitenization weight function (Fig. 2a) \( \left[-,-,{y}_i^k(3),{y}_i^k(4)\right] \)

Whitenization weight functions
-
➁ The moderate whitenization weight function (Fig. 2b) \( \left[y(1),{y}_i^k(2),-,{y}_i^k(4)\right] \)
-
➂ The upper whitenization weight function (Fig. 2c) \( \left[{y}_i^k(1),{y}_i^k(2),-,-\right] \)
-
Step 6
The clustering coefficient of every mapping unit in every susceptibility rank can be determined by Eq. (7):
where\( {\sigma}_p^k \) indicates the clustering coefficient of the pth unit in the kth rank.
-
Step 7
Finally, for every mapping unit, the maximum of\( {\sigma}_p^k\left(k=1,2,..,s\right) \)can be identified, then the k value of the maximum of\( {\sigma}_p^k \)can be expressed as k∗.According to the maximum membership principle, the ith mapping unit belongs to the susceptibility rank k∗.
Receiver operating characteristics curve
Receiver Operating Characteristics Curve (ROC curve) is one of the most commonly used validation method which can be used to validate the landslide susceptibility assessment results (Conforti et al. 2013; Günther et al. 2014). The horizontal axis (1-specificity) indicated the proportion of the mapping units without landslide occurrence which were correctly predicted. The vertical axis (Sensitivity) indicated the proportion of mapping units having landslide occurrence which were correctly predicted (Wang et al. 2015). The area under the ROC curve (AUC) value is able to quantitatively measure these prediction results (Chalkias et al. 2014). The ranges of AUC value is 0.5–1. A larger AUC value means higher model accuracy (Lee and Park 2016).
Study region and dataset
General situations of study region
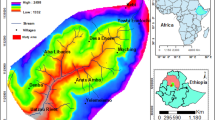
Chongqing, as the study region in this paper, is situated in southwestern China. It is seated between 105°11′E-110°11′E and 28°10′N-32°13′N. Chongqing is located in the transition zone between Middle-Lower Yangtze plains and Qinghai-Tibet Plateau which approximately occupies 82402km2. This region has an East-West-width of 470 km and a North-South-length of 450 km. The highest altitude was 2797 m. The climate belongs to subtropical monsoonal climate that has abundant and concentrated rainfall between late spring and early fall. This area has abundant precipitation whose mean annual precipitation reaches 1000–1400 mm. It has a distinct topographical relief and a series of tectonic folds and faults. The terrain tilts from the north and south to the Yangtze valley. Daba Mountain and Wuling Mountain are situated in southeast. Chongqing is a mountainous region with mountains and hills taking up 76% of the total area. Chongqing developed a complete set of emergence stratum with large thickness and wide distribution, and only upper Tertiary system was absent. The emergence stratum mainly were the sandstone, mudstone and shale in Middle Jurassic and Lower Jurassic and the loose deposit of Quaternary. The red clastic rock-based Jurassic stratum had a wide distribution. The Carbonatite-based lower Paleozoic erathem was mainly distributed in the southeast of Chongqing. The typical Karst landforms such as Stone Forest, Karst cave, Karst gorges and other landscape are distributed in this area. Yangtze River and Jialing River flow through this region. Recently, enhancive engineering constructions such as the development of Three Gorges Reservoir, also contributed to landslide occurrences.
Landslide inventory data
In this paper, landslide events before 2014 were collected from CIGMR (Chongqing Institute of Geology & Mineral Resources). As shown in Fig. 3, there were 8435 landslide events which were recorded as point features with the attribute of landslide area. All landslide events affected a total area of 194,442,814 m2. The largest and the smallest landslide area was 3,080,000 m2 and 3 m2, respectively. The most frequent landslide area was equal to 12,000 m2, obtained by Frequency tool of ArcGIS. The main types of the landslide events were debris flows, translational slides and rotational slides. A major triggering factor of these landslide events was rainfall. Xiao (1995) pointed out that the threshold of precipitation for landslide occurrence was 150 mm/day in Chongqing. Other factors such as earthquake, human activities and groundwater activity also contributed to the landslide occurrence.

The location of Chongqing and the distribution of landslide events. Points indicate landslide events this paper used
Landslide influence factors
A variety of factors make a contribution to the landslide occurrence. This paper selects eight landslide influence factors including slope, aspect, rainfall, the distance to tectonic features, lithology, the distance to roads, the distance to rivers and vegetation for landslide susceptibility assessment.
Slope gradient has a close relation with landsliding. In theory landslides easily happen on steep slopes (Shit et al. 2016). However, Eeckhaut et al. (2009b) indicate that the likelihood of landslide occurrence is larger on the moderate slope gradient, since steep slopes are lacking in material basis for landslide occurrences. Aspect indirectly affects the landslides occurrence through affecting soil, rock, water, and vegetation (Pourghasemi et al. 2012). Rainfall mainly contributes to the landslides, since it increases the weight of slopes and decreases the shearing strength of the sliding layer. The mean annual precipitation is utilized to represent the rainfall. Tectonic conditions are also related to landslides. As is known to all, landslides are apt to happen near tectonic features as it causes the development of fractures and the broken rock (Su et al. 2010). Thus the distance to tectonic features is selected as an influence factor. Landslide occurrence also has a strong connection with lithologies (Kouli et al. 2009). Different lithologies or rock types have different composition and structure. Compared with the weaker rocks, the stronger rocks give more resistance to the driving force, and hence are less prone to landslides (Kanungo et al. 2006). Road construction easily contributes to slope instability. Thus landslides tend to happen near the road network. The distance to roads is utilized in calculations. Streams negatively affect slope stability through eroding the slopes and absorbing the material at the bottom (Bhatt et al. 2013). Therefore, the distance to stream networks is selected as the corresponding index. Vegetation cover is also related to the landslide occurrence which can reduce the influence of rainfall through holding the soil (Lundgren 1978). This paper thus utilizes NDVI (normalized difference vegetation index) in calculations. Generally speaking, a smaller NDVI value indicates a larger likelihood of landslide occurrence (Wang et al. 2014).
The elevation, slope and aspect were derived from the stereoscopic data collected from ASTER GDEM with a resolution of 30 m (Fig. 4). From the elevation data, the stream network was obtained by the use of ArcGIS hydrology tools. The tectonic features and lithologies were obtained through digitizing the Chongqing geological map with a scale of 1:500,000. The roads in this region were extracted from the national electronic map with a scale of 1:25,000 in vector format. CIGMR also provided daily precipitation from 2005 to 2014 and the geographical coordinates of 1003 rainfall observation stations. The mean annual precipitation of every rainfall observation station was extracted by dividing the sum of the daily precipitations from 2005 to 2014 by the number of years. Then the mean annual precipitation of the whole region can be obtained through IDW (Inverse Distance Weighted) interpolation. The NDVI raster map was obtained from Landsat images with a resolution of 30 m. The derived data are shown in Fig. 5.

The digital elevation model (DEM) of Chongqing

Landslide influence factor dataset
Results and discussion
The landslide events were randomly split into two parts: 70% (5905) of the landslide events as model training data and residual 30% (2530) of all landslide events as validation data. Using both grid cells and slope units as the mapping units, the modified information value model was constructed to generate landslide susceptibility maps. Then the assessment results by using the two different mapping units are compared.
Grid cell-based susceptibility assessment
The most frequent landslide area is equal to 12,000 m2, obtained by the frequency-area statistics. The 10 × 10 m DEM maintain these morphological elements. Based on the above two reasons, the 10 × 10 m grid cell is the most appropriate in the study area. In this region, there are altogether 825,682,626 grid cells. The value of every landslide influence factor is allotted to every grid cell. Then the information values of landslide influence factors were obtained by Eq. (1) (Table 1).
According to the information values of slope gradient, landslides frequently happened in the range of 10°-35°. Landslides were more likely to occur between 10° and 20° which had the maximum information value (0.494). With respect to aspect, landslides more easily happened in northwest direction aspect as the maximum information value (0.387) was found in this range. Landslides were less likely to occur in the flat area as the minimum information value (−0.226) was found in the area. As to the distance to stream network, the maximum of information value was 0.441 in the range of <1000 m. Thus landslides tend to occur in the area with the distance to stream network less than 1000 m. Information values decreased along with the increasing of the distance to stream network. Therefore, the closer the distance, the higher likelihood of landsliding. As for the distance to tectonic features, information values were positive in the range of 0–1800 m and information values of other classes were negative. Hence the possibility of landslide occurrence was higher at the interval of<1800 m than any other classes. On the whole, the likelihood of landsliding increased as the distance to tectonic features decreased. With regard to rainfall, landslides were most likely to occur in the range of 1100–1200 mm/year as this range had the largest information value (0.247). The information value in the interval of 1200–1250 mm/year was 0.216, next only to the class 1100–1200 mm/year. It is generally thought that landslides should be most likely to occur in the area with the highest precipitation, but the results were inconsistent with it. This may be because sudden rainstorms also contributed to landsliding (Rampone and Valente 2012). With regard to the distance to roads, the maximum (0.619) of information values was founded in the range of 0–200 m. Thus landslides more easily happened around roads. As to NDVI, the maximum (0.663) and minimum (−0.781) of information value was found in the <0.55 class and in the >0.85 class, respectively. The larger the NDVI, the smaller the likelihood of landsliding. As for lithology, the results indicated that the areas with clastic rocks had the highest information value (0.955), and the information value of the areas with shales was the smallest (−3.351). Therefore, landslides occurred predominantly in the weaker rocks area because these rocks are easily saturated and then soften quickly, resulting in slope failures.
According to Table 1, a smaller information value represents a lower susceptibility rank. The landslide susceptibility ranks for each factor based on grid cells was shown in Table 2. It can be seen that the classes with the largest information value including slope gradient larger than 10° and smaller than 20°, distance to tectonic features smaller than 600 m, the areas with clastic rocks, reserviors and sandstones, distance to roads smaller than 200 m, MAP larger than 1100 mm and smaller than 1200 mm, distance to stream network smaller than 1000 m, northwest aspect direction and NDVI smaller than 0.5 were in the very high rank. According to the susceptibility ranks, whitenization weight functions of influence factors were generated.
Clustering weights reflects the effect of landslide influence factors on landsliding. The clustering weight of the lithology was the largest (0.250), while the clustering weight of distance to faults was the smallest (0.046). The clustering weight (0.181) of NDVI was the second largest, while the clustering weight (0.079) of aspect was the second smallest. The weights of slope, MAP, distance to stream network and distance to roads were 0.081, 0.081, 0.113 and 0.170, respectively. After that the clustering coefficient of every grid cell for every landslide susceptibility rank was calculated and then the clustering vector of every grid cell was constructed. Subsequently, the susceptibility rank each grid cell belonged to was ensured. Therefore the grid cell-based susceptibility map was created (Fig. 6).

Grid cell-based landslide susceptibility zonation
As shown in Fig. 6, high and very high susceptible zones were mainly distributed along tectonic features, roads and stream network. Moreover, low susceptible zones were mainly located far away from tectonic features, roads and stream network that were located in the west and north. High susceptible zones which covered 9.28%. Very high susceptible zones accounted for 10.33%.
Slope unit-based susceptibility assessment
Using the DEM data and the largest elevation value of this region, Reverse DEM was generated. After that the DEM and Reverse DEM were applied for generating slope units through these steps including fill, extraction of flow direction, calculation of flow accumulation, generation of stream network, generation of watershed, combination of the watersheds derived from DEM and Reverse DEM. There were altogether 34,453 slope units (Fig. 7).

The generated slope units
According to the classifications of landslide influence factors which were the same with the experiment based on grid cells, the information values of each landslide influence factor based on slope units was calculated (Table 3). In this table, the total area of the landslide events present in the aspect class of NW was 0, thus the information value of this class was assigned the smallest information value of aspect. Thus the information value of the northwest direction of aspect was equal to the information value of the flat class.
We can see from Table 3 that landslides easily happened in the slope gradient range of 10°–20° which has the maximum information value (0.485). The information value between 10° and 20° was second largest (0.042). Therefore, landslides extensively happened in the regions with medium slope gradient. As to aspect, the maximum (0.337) was distributed in the southwest aspect. In addition, the minimum (−0.381) was distributed in the flat regions and northwest aspect. Consequently, landslides were more likely to occur in the southwest direction aspect and were less likely to occur in the flat areas and northwest direction aspect. With regard to the distance to stream network, information values decreased along with the increasing of distance to stream network. Thus the smaller distance to stream network was, the higher likelihood of landsliding. With regard to distance to tectonic features, landslides were prone to occur in the areas at the interval of <600 m as a result of the largest information value (0.523). The likelihood of landsliding increased with the decrease of the buffer distance to tectonic features. As for MAP, the maximum (0.296) information value was found in the range of 1100–1200 mm/year, thus landslides were most likely to occur in this range. The likelihood of landslide occurrence at the interval of 1200–1250 mm/year was the second largest. With regard to the distance to roads, the maximum (0.360) of information value was found in the areas with the buffer distance to roads less than 200 m. Information values decreased along with the increasing of distance to road. Hence landslides more easily happened around roads. As for NDVI, the larger NDVI value was, the smaller information value was. Landslides were most likely to occur when the NDVI value was less than 0.5. With respect to lithology, the information value in the areas with clastic rocks was 1.047, next only to the areas with sandstones (0.131). Therefore, landslides occurred predominantly in the weaker rocks area because these rocks are easily saturated and then soften quickly, resulting in slope failures.
From Tables 1 and 3, it can be seen that the information values based on slope units are similar to the information values based on grid cells, except for aspect. The maximum information value of each influence factor was found in the same classes for grid cell-based and slope unit-based model, including slope gradient 10°–20°, distance to tectonic features <600 m, the areas with sandstones and clastic rocks, distance to roads <200 m, MAP 1100–1200 mm, distance to stream network <1000 m and NDVI <0.55. The information values of aspect based on grid cells are different from the results based on slope units. The maximum information value of aspect is in the northwest direction aspect the grid cell-based model, while the maximum value is found in the southwest and west direction aspect for the slope unit-based model. This difference may be principally because there are some grid cells whose aspects were greatly different from the aspects of neighboring cells.
Using the information values in Table 3, the susceptibility rank of every influence landslide factor based on slope units was generated (Table 4). The susceptibility rank increased along with the increasing of the information value. Hence the slope 10–20°, the southwest direction aspect, the distance to stream network <1000 m, the areas with sandstones and clastic rocks, the distance to tectonic <600 m, MAP 1100–1200 mm, the distance to roads <200 m and NDVI smaller than 0.5 were in very high susceptibility rank. Then the whitenization weight function of every landslide influence factor was determined.
The clustering weights based on slope units, reflecting the effect of landslide influence factors on landsliding, were subsequently determined. Lithology had the highest clustering weight (0.189), while the clustering weight (0.079) of NDVI was the minimum. The weight of slope was the second smallest (0.083). The weight of distance to stream network was the second largest (0.174). The weights of slope, aspect, the distance to tectonic features and the distance to roads were 0.083, 0.149, 0.111 and 0.130. Then clustering coefficients were obtained according to Eq. (7). According to the maximum membership principle, the maximum clustering coefficient within every clustering vector was obtained and then the susceptibility rank for every unit was ultimately confirmed (Fig. 8).

Slope unit-based landslide susceptibility zonation
As indicated in Fig. 8, very low and low susceptible zones were mainly located in the west and north area. Very high and high susceptible zones were situated along tectonic features, rivers and roads. On the whole, the grid cell-based susceptibility zonation was similar to the slope unit-based susceptibility zonation. High and very high susceptible zones occupied 19.30 and 3.18%, respectively.
Validation
This paper applies ROC curve for validating the susceptibility assessment results based on grid cells and slope units. The model training accuracy and prediction accuracy were measured by the success rate and prediction rate, respectively. The success rate (Fig. 9a) can be derived though making a comparison between the 70% landslide events (training data) and the susceptibility zonation results. The AUC values of the grid cell-based and slope unit-based results were 0.809 and 0.832, respectively. Therefore, the model training accuracies of the grid cell-based and slope unit-based results were 80.9 and 83.2%, respectively. The prediction rate (Fig. 9b) can be derived though making a comparison between the residual landslide events and the susceptibility zonation results. The AUC values of the grid cell-based and slope unit-based results were 0.803 and 0.826. Therefore, the prediction accuracies of the grid cell-based and slope unit-based results were 80.3 and 82.6%, respectively. As a result, the slope unit-based model outperformed the grid cell-based model in landslide susceptibility assessment due to higher training accuracy and prediction accuracy. Grid cells can be easily obtained in GIS but do not have a close relationship with geological environments. In contrast, slope units are the basic units of landslide occurrence (Wang et al. 2017). A slope unit is defined as the watershed delimited by ridge lines and valley lines. Therefore, slope units are more related to geological environments, which make the evaluation results more conformable to reality (Wang et al. 2017).

ROC curves for grid cell-based and slope unit-based susceptibility assessment results
Conclusions
This paper mainly analyzed the influence of using different mapping units in a landslide susceptibility assessment model. The modified information value model was adopted to assess landslide susceptibility and slope units and grid cells were used as mapping units, respectively. Eight landslide influence factors, including slope gradient, aspect, MAP, distance to roads, distance to stream network, distance to tectonic features, lithology and NDVI, were utilized to construct the model.
The landslide susceptibility assessment results indicated that landslide-prone zones were mainly located around tectonic features, rivers and roads. ROC curve was used to evaluate the accuracy of the two models based on grid cells and slope units. Through calculating the training accuracy and prediction accuracy, slope unit-based model performed better in landslide susceptibility assessment than grid cell-based model. Although grid cells can be easily obtained in GIS and it is convenient for calculation, they are not related closely to geological environment. Slope unit is the basic unit of the landslide occurrence, and it is derived from the DEM data. Therefore,the slope units are more related to geological environment, which make the evaluation results accurate.
Nevertheless, the classifications of landslide influence factors were based on previous studies and might be not suitable for our study region. Therefore, further studies should propose an objective influence factor classification method for landslide susceptibility assessment. And because of the lack of other data, this paper just used eight landslide influence factors. Other factors such as earthquakes and land use change should be considered in the future studies. For the slope unit-based model, the same likelihood of landslide occurrence was allotted to a whole unit (Huabin et al. 2005). Thus it is difficult to determine within which part of the slope landslides tend to occur. This problem should be considered in the future studies. Moreover, the following studies should consider the seed cells which reflect the real effect of parameter maps over the distribution of landslides (Suzen and Doyuran 2004a; Suzen and Doyuran 2004b).
References
Ba Q, Chen Y, Deng S, Wu Q, Yang J, Zhang J (2017) An improved information value model based on gray clustering for landslide susceptibility mapping. ISPRS Int J Geo-Inf 6(1):1–20. https://doi.org/10.3390/ijgi6010018
Bhatt BP, Awasthi KD, Heyojoo BP, Silwal T, Kafle G (2013) Using geographic information system and analytical hierarchy process in landslide hazard zonation. Appl Ecol Env Res 1(2):14–22. https://doi.org/10.12691/aees-1-2-1
Cama M, Conoscenti C, Lombardo L, Rotigliano E (2016) Exploring relationships between grid cell size and accuracy for debris-flow susceptibility models: a test in the Giampilieri catchment (Sicily, Italy). Environ Earth Sci 75(3):1–21. https://doi.org/10.1007/s12665-015-5047-6
Carrara A, Guzzetti F (1995) Geographical information systems in assessing natural hazards. Springer, Dordrecht. https://doi.org/10.1007/978-94-015-8404-3
Chalkias C, Ferentinou M, Polykretis C (2014) GIS-based landslide susceptibility mapping on the Peloponnese peninsula, Greece. Geosciences 4(3):176–190. https://doi.org/10.3390/geosciences4030176
Che VB, Kervyn M, Suh CE, Fontijn K, Ernst GGJ, Marmol MAD (2012) Landslide susceptibility assessment in Limbe (SW Cameroon): a field calibrated seed cell and information value method. Catena 92(1):83–98. https://doi.org/10.1016/j.catena.2011.11.014
Chen J, Yang ST, Li HW, Zhang B, Lv JR (2013) Research on geographical environment unit division based on the method of natural breaks (Jenks). Int Arch Photogramm Remote Sens Spat Inf Sci XL-4/W3(4):47–50. https://doi.org/10.5194/isprsarchives-XL-4-W3-47-2013
Chen T, Niu R, Jia X (2016) A comparison of information value and logistic regression models in landslide susceptibility mapping by using GIS. Environ Earth Sci 75(10):1–16. https://doi.org/10.1007/s12665-016-5317-y
Chiessi V, Toti S, Vitale V (2016) Landslide susceptibility assessment using conditional analysis and rare events logistics regression: a case-study in the Antrodoco area (Rieti, Italy). Journal of Geoscience and Environment Protection 4(12):1–21. https://doi.org/10.4236/gep.2016.412001
Chung CF, Fabbri AG (1995) Multivariate regression analysis for landslide hazard zonation. Advances in Natural & Technological Hazards Research 5:107–133. https://doi.org/10.1007/978-94-015-8404-3
Conforti M, Pascale S, Robustelli G, Sdao F (2013) Evaluation of prediction capability of the artificial neural networks for mapping landslide susceptibility in the Turbolo river catchment (northern Calabria, Italy). Catena 1:236–250. https://doi.org/10.1016/j.catena.2013.08.006.Onlinefirst
Eeckhaut MVD, Moeyersons J, Nyssen J, Abraha A, Poesen J, Haile M (2009a) Spatial patterns of old, deep-seated landslides: a case-study in the northern Ethiopian highlands. Geomorphology 105(3–4):239–252. https://doi.org/10.1016/j.geomorph.2008.09.027
Eeckhaut MVD, Reichenbach P, Guzzetti F, Rossi M, Poesen J (2009b) Combined landslide inventory and susceptibility assessment based on different mapping units: an example from the Flemish Ardennes, Belgium. Nat Hazards Earth Syst Sci 9(2):507–521. https://doi.org/10.5194/nhess-9-507-2009
Erener A, Düzgün HSB (2012) Landslide susceptibility assessment: what are the effects of mapping unit and mapping method? Environ Earth Sci 66(3):1–19. https://doi.org/10.1007/s12665-011-1297-0
Fell R, Corominas J, Bonnard C, Cascini L, Leroi E, Savage WZ (2008) Guidelines for landslide susceptibility, hazard and risk zoning for land use planning. Eng Geol 102(3–4):85–98. https://doi.org/10.1016/j.enggeo.2008.03.022
Garcíarodríguez MJ, Malpica JA (2010) Assessment of earthquake-triggered landslide susceptibility in El Salvador based on an artificial neural network model. Nat Hazards Earth Syst Sci 10(6):1307–1315. https://doi.org/10.5194/nhess-10-1307-2010
Günther A, Eeckhaut MVD, Malet JP, Reichenbach P, Hervás J (2014) Climate-physiographically differentiated pan-European landslide susceptibility assessment using spatial multi-criteria evaluation and transnational landslide information. Geomorphology 224(2):69–85. https://doi.org/10.1016/j.geomorph.2014.07.011
Guzzetti F, Carrara A, Cardinali M, Reichenbach P (1999) Landslide hazard evaluation: a review of current techniques and their application in a multi-scale study central Italy. Geomorphology 31(1-4):181–216. https://doi.org/10.1016/S0169-555X(99)00078-1
Haacke EM, Liu S, Buch S, Zheng W, Wu D, Ye Y (2015) Quantitative susceptibility mapping: current status and future directions. Magn Reson Imaging 33(1):1–25. https://doi.org/10.1016/j.mri.2014.09.004
Hölbling D, Friedl B, Eisank C (2015) An object-based approach for semi-automated landslide change detection and attribution of changes to landslide classes in northern Taiwan. Earth Sci Inform 8(2):327–335. https://doi.org/10.1007/s12145-015-0217-3
Huabin W, Gangjun Weiya LX, Gonghui W (2005) GIS-based landslide hazard assessment: an overview. Prog Phys Geogr 29(4):548–567. https://doi.org/10.1191/0309133305pp462ra
Jia N, Mitani Y, Xie M, Tong J, Yang Z (2015) GIS deterministic model-based 3d large-scale artificial slope stability analysis along a highway using a new slope unit division method. Nat Hazards 76(2):873–890. https://doi.org/10.1007/s11069-014-1524-6
Kanungo DP, Arora MK, Sarkar S, Gupta RP (2006) A comparative study of conventional, ANN black box, fuzzy and combined neural and fuzzy weighting procedures for landslide susceptibility zonation in Darjeeling Himalayas. Eng Geol 85(3–4):347–366. https://doi.org/10.1016/j.enggeo.2006.03.004
Kirschbaum DB, Stanley T, Simmons J (2015) A dynamic landslide hazard assessment system for central America and Hispaniola. Nat Hazards Earth Syst Sci 3(4):2847–2882. https://doi.org/10.5194/nhessd-3-2847-2015
Komac M (2006) A landslide susceptibility model using the analytical hierarchy process method and multivariate statistics in Perialpine Slovenia. Geomorphology 74(1–4):17–28. https://doi.org/10.1016/j.geomorph.2005.07.005
Kouli M, Loupasakis C, Soupios P, Vallianatos F (2009) Landslide hazard zonation in high risk areas of Rethymno prefecture, Crete Island, Greece. Nat Hazards 52(3):599–621. https://doi.org/10.1007/s11069-009-9403-2
Kreuzer MT, Wilde M, Terhorst B, Damm B (2017) A landslide inventory system as a base for automated process and risk analyses. Earth Sci Inform 10(4):1–9. https://doi.org/10.1007/s12145-017-0307-5
Lee S (2004) Application of likelihood ratio and logistic regression models to landslide susceptibility mapping using GIS. Environ Manag 34(2):223–232. https://doi.org/10.1007/s00267-003-0077-3
Lee JH, Park HJ (2016) Assessment of shallow landslide susceptibility using the transient infiltration flow model and GIS-based probabilistic approach. Landslides 13(5):885–903. https://doi.org/10.1007/s10346-015-0646-6
Li C, Wu S, Zhu Z (2014) The assessment of submarine slope instability in Baiyun sag using gray clustering method. Nat Hazards 74(2):1179–1190. https://doi.org/10.1007/s11069-014-1241-1
Lundgren L (1978) Studies of soil and vegetation development on fresh landslide scars in the Mgeta Valley, western Uluguru Mountains, Tanzania. Geogr Ann 60(3/4):91–127. https://doi.org/10.2307/520435
Meijerink AMJ (1988) Data acquisition and data capture through terrain mapping units. Int Comput J 1:23–44
Myronidis D, Papageorgiou C, Theophanous S (2016) Landslide susceptibility mapping based on landslide history and analytic hierarchy process (AHP). Nat Hazards 81(1):254–263. https://doi.org/10.1007/s11069-015-2075-1
Parise M, Jibson RW (2000) A seismic landslide susceptibility rating of geologic units based on analysis of characteristics of landslides triggered by the 17 January, 1994 Northridge, California earthquake. Eng Geol 58(3):251–270. https://doi.org/10.1016/S0013-7952(00)00038-7
Pourghasemi HR, Pradhan B, Gokceoglu C (2012) Application of fuzzy logic and analytical hierarchy process (AHP) to landslide susceptibility mapping at Haraz watershed, Iran. Nat Hazards 63(2):1–32. https://doi.org/10.1007/s11069-012-0217-2
Pradhan B (2010) Remote sensing and GIS-based landslide hazard analysis and cross-validation using multivariate logistic regression model on three test areas in Malaysia. Adv Space Res 45(10):1244–1256. https://doi.org/10.1016/j.asr.2010.01.006
Pradhan B (2013) A comparative study on the predictive ability of the decision tree, support vector machine and neuro-fuzzy models in landslide susceptibility mapping using GIS. Comput Geosci 51(2):350–365. https://doi.org/10.1016/j.cageo.2012.08.023
Raja NB, Çiçek I, Türkoğlu N, Aydin O, Kawasaki A (2017) Landslide susceptibility mapping of the sera river basin using logistic regression model. Nat Hazards 85(3):1–24. https://doi.org/10.1007/s11069-016-2591-7
Rampone S, Valente A (2012) Neural network aided evaluation of landslide susceptibility in southern Italy. Int J Mod Phys C 23(23):98–108. https://doi.org/10.1142/S0129183112500027
Rotigliano E, Cappadonia C, Conoscenti C, Costanzo D, Agnesi V (2012) Slope units-based flow susceptibility model: using validation tests to select controlling factors. Nat Hazards 61(1):143–153. https://doi.org/10.1007/s11069-011-9846-0
Sharma LP, Patel N, Ghose MK, Debnath P (2015) Development and application of Shannon’s entropy integrated information value model for landslide susceptibility assessment and zonation in Sikkim Himalayas in India. Nat Hazards 75(2):1555–1576. https://doi.org/10.1007/s11069-014-1378-y
Shit PK, Bhunia GS, Maiti R (2016) Potential landslide susceptibility mapping using weighted overlay model (WOM). Model Earth Syst Environ 2(1):21. https://doi.org/10.1007/s40808-016-0078-x
Su F, Cui P, Zhang J, Xiang L (2010) Susceptibility assessment of landslides caused by the Wenchuan earthquake using a logistic regression model. J Mt Sci 7(3):234–245. https://doi.org/10.1007/s11629-010-2015-1
Suzen ML, Doyuran V (2004a) Data driven bivariate landslide susceptibility assessment using geographical information systems: a method and application to Asarsuyu catchment, Turkey. Eng Geol 71(3–4):303–321. https://doi.org/10.1016/S0013-7952(03)00143-1
Suzen ML, Doyuran V (2004b) A comparison of the GIS based landslide susceptibility assessment methods: multivariate versus bivariate. Environ Geol 45(5):665–679. https://doi.org/10.1007/s00254-003-0917-8
Tham LG (2008) Landslide susceptibility mapping based on support vector machine: a case study on natural slopes of Hong Kong, China. Geomorphology 101(4):572–582. https://doi.org/10.1016/j.geomorph.2008.02.011
Trigila A, Iadanza C, Esposito C, Scarascia MG (2015) Comparison of logistic regression and random forests techniques for shallow landslide susceptibility assessment in Giampilieri (NE Sicily, Italy). Geomorphology 249:119–136. https://doi.org/10.1016/j.geomorph.2015.06.001
Wang M, Liu M, Yang S, Shi P (2014) Incorporating triggering and environmental factors in the analysis of earthquake-induced landslide hazards. Int J Disaster Risk Sci 5(2):125–135. https://doi.org/10.1007/s13753-014-0020-7
Wang Q, Wang D, Huang Y, Wang Z, Zhang L, Guo Q (2015) Landslide susceptibility mapping based on selected optimal combination of landslide predisposing factors in a large catchment. Sustainability 7(12):16653–16669. https://doi.org/10.3390/su71215839
Wang F, Xu P, Wang C, Wang N, Jiang N (2017) Application of a GIS-based slope unit method for landslide susceptibility mapping along the Longzi River, southeastern Tibetan plateau, China. ISPRS Int J Geo-Inf 6(6):172. https://doi.org/10.3390/ijgi6060172
Wei G, Feng XT (2004) Study on displacement predication of landslide based on grey system and evolutionary neural network. Rock Soil Mech 25(4):275–275
Xiao L (1995) Relative analysis between strong rainfall process and geological hazards Chongqing City. Chin J Geol Hazard Control 6:39–42
Xie M, Esaki T, Zhou G (2004) GIS-based probabilistic mapping of landslide hazard using a three-dimensional deterministic model. Nat Hazards 33(2):265–282. https://doi.org/10.1023/B:NHAZ.0000037036.01850.0d
Xie N, Xin J, Liu S (2014) China’s regional meteorological disaster loss analysis and evaluation based on grey cluster model. Nat Hazards 71(2):1067–1089. https://doi.org/10.1007/s11069-013-0662-6
Xu W, Yu W, Jing S (2013) Debris flow susceptibility assessment by GIS and information value model in a large-scale region, Sichuan Province (China). Nat Hazards 65(3):1379–1392. https://doi.org/10.1007/s11069-012-0414-z
Yan TZ (1988) Recent advances of quantitative prognoses of landslide in China. In: Proceedings of the 5th international symposium on landslides, Lausanne, Switzerland, pp 10–15
Yesilnacar E, Topal T (2005) Landslide susceptibility mapping: a comparison of logistic regression and neural networks methods in a medium scale study, Hendek region (Turkey). Eng Geol 79(3–4):251–266. https://doi.org/10.1016/j.enggeo.2005.02.002
Yin KL, Yan TZ (1988) Statistical prediction models for slope instability of metamorphosed rocks. In: Proceedings of the 5th international symposium on landslides, Lausanne, Switzerland, pp 10–15
Zare M, Pourghasemi HR, Vafakhah M, Pradhan B (2013) Landslide susceptibility mapping at VAZ watershed (Iran) using an artificial neural network model: a comparison between multilayer perceptron (MLP) and radial basic function (RBF) algorithms. Arab J Geosci 6(8):2873–2888. https://doi.org/10.1007/s12517-012-0610-x
Zhuang J, Peng J, Xu Y, Xu Q, Zhu X, Li W (2016) Assessment and mapping of slope stability based on slope units: a case study in Yan’an, China. J Earth Syst Sci 125(7):1–12. https://doi.org/10.1007/s12040-016-0741-7
Acknowledgments
The research is supported by National Science and Technology Major Project of the Ministry of Science and Technology of China (project No. 2017YFB0503704) and National Nature Science Foundation of China (project No. 41671380) and is funded by the Foundation of Key Laboratory for Geo-Environmental Monitoring of Coastal Zone of the National Administration of Surveying, Mapping and Geoinformation.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by: H. A. Babaie
Rights and permissions
About this article

Cite this article
Ba, Q., Chen, Y., Deng, S. et al. A comparison of slope units and grid cells as mapping units for landslide susceptibility assessment. Earth Sci Inform 11, 373–388 (2018). https://doi.org/10.1007/s12145-018-0335-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12145-018-0335-9