
Abstract
This paper develops a groupwise dimension reduction-based adaptive-to-model test for partially linear single-index models. The test behaves as a local smoothing test would if the model were bivariate. The test statistic under the null hypothesis is asymptotically normally distributed. The test can detect local alternatives distinct from the null hypothesis at the rate that existing local smoothing tests can achieve when the regression model contains bivariate covariates. Therefore, the curse of dimensionality is largely alleviated. Numerical studies, including two real data examples, are conducted to examine the finite sample performance of the proposed test.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Consider the following partially linear single-index model (PLSIM):
where Y is the scale response, \(W=(X^{\top },Z^{\top })^{\top }\in {\mathbb {R}}^{p_1+p_2}\) is the \((p_1+p_2)-\)dimensional covariate, \(g(\cdot )\) an unknown smooth functions, \(\beta \) and \(\alpha \) are unknown vectors of parameters, and \(\epsilon \) is the error term such that \(E(\epsilon |X, Z)=0\). For identifiability, \(\alpha \) satisfies \(||\alpha ||=1\). Typically, model (1.1) is a reasonable compromise between fully parametric and fully nonparametric modelling. The literature on PLSIM estimation is enormous. For example, Carroll et al. (1997) first proposed a maximum quasi-likelihood method to estimate the generalised PLSIM, Xia and Härdle (2006) extended the minimum average variance estimation (MAVE) approach developed by Xia et al. (2002), Zhu and Xue (2006) proposed empirical-likelihood-based inference for the PLSIM, Wang et al. (2010) developed a two-step method to estimate the model, Liang et al. (2010) proposed the semi-parametrically efficient profile least-squares estimators of coefficients, and Lu et al. (2019) devised a method to consistently estimate the biased PLSIM. Zhao et al. (2020) considered PLSIMs of panel data with errors correlated in space and time and proposed a generalised F-type test method to check index parameters. It is not all so easy to determine whether a real data set corresponds to the given statistical formalisation. Therefore, it is crucial to perform a suitable and efficient model checking before further statistical analysis.
Many efforts have been devoted to checking parametric models since the 1980s. The two most popular methodologies in the literature are local and global smoothing methods. Local smoothing methods are sensitive to high-frequency/oscillating alternative models in low-dimensional cases. However, they suffer from slow convergence rates due to nonparametric estimation and thus are greatly affected by the curse of dimensionality. For examples of local smoothing methods based on nonparametric estimation, see Härdle and Mammen (1993), Zheng (1996), Fan and Li (1996), Dette (1999), Fan et al. (2001), Fan and Huang (2001), Koul and Ni (2004) and Van Keilegom et al. (2008).
Globally smoothing methods involve empirical process-based tests that are typically functions of the averages of weighted sums of residuals. These tests converge to their weak limits at the rate of \(n^{-1/2}\), which is the fastest possible rate at which they can detect local alternatives at the fastest possible rate of \(n^{-1/2}\). Thus, they have theoretical advantages over local smoothing tests. However, when the dimension is greater than 1, the intractability of the limiting null distributions requires a resampling approximation such as the wild bootstrap to determine critical values. Practical evidence shows that these type of tests are less sensitive to oscillating alternatives models. For examples of these methods, see Stute (1997), Stute et al. (1998), Zhu (2003), Khmaladze and Koul (2004), and Stute et al. (2008). González Manteiga and Crujeiras (2013) provided a comprehensive review of the studies in this domain.
A direct way to alleviate the curse of dimensionality is to project the high-dimensional covariates onto one-dimensional spaces. Escanciano (2006) and Lavergne and Patilea (2008, 2012) proposed tests based on projected covariates. Zhu (2003) and Stute et al. (2008) used residual processes to construct tests that can also be considered dimension reduction types. These tests typically require Monte Carlo approximations to determine critical values (e.g. Escanciano 2006; Lavergne and Patilea 2008), although some of them, such as that of Lavergne and Patilea (2012), are asymptotically distribution-free. All these tests use one-dimensional projections to overcome the curse of dimensionality. However, the computational of the test statistics is a serious burden. The computations become even more elaborate if we further need to use a re-sampling approximation such as the bootstrap to determine critical values. Recently, Guo et al. (2016) developed the innovative model-adaptive local smoothing methodology to test the specification of parametric single-index models, thus alleviating the dimensionality problem. Zhu et al. (2017), Tan et al. (2018), Tan and Zhu (2019), Zhu et al. (2021) and Zhu et al. (2022) extended this strategy to use other parametric dimension reduction models. Li et al. (2021) proposed an adaptive-to-model hybrid of tests for parametric regression models, which fully inherits the merits of nonparametric estimation-based tests and empirical process-based tests and while avoiding their shortcomings. However, few studies have considered model checking for PLSIMs based on dimension reduction. In this paper, we construct a groupwise dimension reduction-based adaptive-to-model test for PLSIMs, to mitigate the curse of dimensionality. First, the groupwise dimension reduction method ensures that the proposed test statistic is automatically adaptive to the underlying model under the respective null and alternative hypotheses. It can thus alleviate the dimensionality problem, and simultaneously achieve the omnibus property under the alternative hypothesis. Under the null hypothesis, in probability, the test statistic only involves the bivariate covariates \(\beta ^{\top }X\) and \(\alpha ^{\top }Z\). The null distribution of the proposed test statistic converges to the limiting null distribution at a faster rate \(O_p(nh)\), where h is being a bandwidth converging to zero at a certain rate. Moreover, by fully utilising the information of the low-dimensional null model, the proposed test can detect the local alternatives distinct from the null hypothesis at a faster rate \(O_p(n^{-1/2}h^{-1/2})\) than the convergence rate \(O_p(n^{-1/2}h^{-(p_{1}+p_{2})/4})\) of existing local smoothing tests for parametric models, where \(p_1+p_2\) is the dimension of the complete set (X, Z), for example, as in the tests developed by Fan and Li (1996). Therefore, when the dimensions of X and Z are large, the new test is superior to existing local smoothing tests in terms of significance level maintenance and power enhancement.
The rest of the paper is organised as follows. In Sect. 2, we construct the test statistic. Because growpwise sufficient dimension reduction techniques play a crucial role in the proposed test, we also review groupwise least-squares (GLS) estimation. Section 3 discusses some asymptotic properties of the new test. Section 4 includes simulation studies and the analyses for two real data sets. The regularity conditions and all of the proofs of the theoretical results are presented in the Appendix.
2 Model-adaptive test construction
2.1 Basic construction
As we often have no knowledge of the model structure under the alternative hypothesis, the general alternative hypothesis takes the following form:
where \(m(X,Z)=E(Y|X,Z)\) with \(m(\cdot ,\cdot )\) being an unknown smoothing function. For any \(p_1\times p_1\) orthogonal matrix \(B_1\) and \(p_2\times p_2\) orthogonal matrix \(B_2\), we have \(m(X,Z)=m(B_1B^{\top }_1X,B_2B^{\top }_2Z)\equiv : {\tilde{m}}(B^{\top }_1X,B^{\top }_2Z)\) with \({\tilde{m}}(\cdot ,\cdot )=m(B_1\cdot ,B_2\cdot )\) as the function m is unknown. Therefore, any purely nonparametric regression model (2.1) can be reformulated as the groupwise dimension reduction model:
where \(B_1\) is a \(p_1 \times q_1\) matrix with \(q_1\) orthogonal columns and \(B_2\) is a \(p_2 \times q_2\) matrix with \(q_1\) orthogonal columns, \(q_1\) and \(q_2\) are unknown numbers such that \(1 \le q_1 \le p_1\) and \(1 \le q_2 \le p_2\). For identifiability, we assume that the matrixes \(B_1\) and \(B_2\) satisfy \(B^{\top }_1B_1=I_{q_1}\) and \(B^{\top }_2B_2=I_{q_2}\). Based on this observation, we consider an alternative model (2.2) that covers more model structures and is widely used in the sufficient dimension reduction field. We reformulate the hypotheses as
The null and alternative models can then be unified. Under the null hypothesis, \(q_1=1\), \(q_2=1\), \(B_1=\beta /||\beta ||_2\) and \(B_2=\alpha \). \(||A||_2\) denotes the \(L_2\)-norm of a vector A throughout this paper. Under the alternative hypothesis, \(q_1\ge 1\) and \(q_2\ge 1\). Therefore, we can construct a test that is automatically adaptive to the null and alternative models by consistently estimating \(q_1\), \(q_2\), \(B_1\) and \(B_2\) under the null and the alternative models, respectively.
Let \(\epsilon =Y-\beta ^{\top }X-g(\alpha ^{\top }Z)\). Under the null hypothesis \(H_0\), \(B_1=\kappa \beta \) with \(\kappa =1/||\beta ||_2\), and \(B_2=\alpha \). Thus, we have
such that
where \(f(\cdot )\) denotes the density function of \((B^{\top }_1X,B^{\top }_2Z)\). Under the alternative hypothesis \(H_1\), as
we have
The above argument implies that we can construct a consistent test based on the left term in (2.3). The null hypothesis \(H_0\) is rejected for large values of the test statistic.
Let \(\{(x_1,z_1,y_1), \cdots , (x_n,z_n,y_n)\}\) denote independent and identically distributed (i.i.d.) samples. We estimate \(E(\epsilon |B^{\top }_1X,B^{\top }_2Z)\) using the kernel estimate:
where \(K_{h}=K(\cdot /h)/h^{{\hat{q}}_1+{\hat{q}}_2}\) with \(K(\cdot )\) being a \(({\hat{q}}_1+{\hat{q}}_2)\)-dimensional product kernel function with univariate kernel function \(k(\cdot )\) and h being a bandwidth, \(B_{1n}\) and \(B_{2n}\) are estimates of \(B_1\) and \(B_2\) with estimated structural dimensions \({\hat{q}}_1\) and \({\hat{q}}_2\), respectively, which we discuss in the next subsection. Here, \({\hat{\epsilon }}_i\) denotes the estimate of the residual term \(\epsilon _i\), and \({\hat{\epsilon }}_i = y_i-{\hat{\beta }}^{\top }_1x_i-{\hat{g}}({\hat{\alpha }}^{\top } z_i)\), where \({\hat{\beta }}^{\top }_1\), \({\hat{\alpha }}\) and \({\hat{g}}(\cdot )\) denote the estimators of \(\beta \), \(\theta \) and \(g(\cdot )\), respectively. More details are presented in the Appendix.
The density function \(f({B}^{\top }_{1n} x_i,{B}^{\top }_{2n} z_i)\) for \(i=1,2,...,n\), can be estimated by the following kernel form:
Therefore, a non-standardised test statistic is defined by
Remark 2.1
The nonparametric kernel-based test in Zheng (1996) can also be extended to check the PLSIM, and its test statistic can be defined as:
where \({\tilde{K}}_{h}={\tilde{K}}(\cdot /h,\cdot /h)/h^{p_1+p_2}\) with \({\tilde{K}}(\cdot )\) being a \((p_1+p_2)-\)dimensional kernel function. There are two differences between the formulae (2.4) and (2.5). First, we use \(K_h(\cdot )\) in \(S_n\) instead of \({\tilde{K}}_h(\cdot ,\cdot )\) in \(T_{ZH}\). We prove that under \(H_0\), \({\hat{q}}_1={\hat{q}}_2= 1\), \({B}_{1n}\rightarrow \beta /||\beta ||_2\) and \({B}_{2n}\rightarrow \alpha /||\alpha ||_2\) in probability, implying that our test reduces the dimension \(p_1+p_2\) to 2. Under the alternative hypothesis, we show that \(B_{1n}\) and \(B_{2n}\) are automatically consistently estimated. Second, it can be easily shown that for the test statistic \(S_{ZHn}\) to have a finite limiting distribution under the null hypothesis, the standardising constant must be \(nh^{(p_1+p_2)/2}\) to obtain \(nh^{(p_1+p_2)/2}S_{ZHn}\). We will see that the standardising form \(nhS_n\) has a finite limit under \(H_0\) and diverges to infinity much faster than the typical rate \(nh^{(p1+p2)/2}\) of the test in Zheng (1996) under \(H_1\). The results are presented in Sect. 3.
2.2 A review of groupwise least squares estimation
In general, matrices \(B_1\) and \(B_2\) are not identifiable. For any \(q_1 \times q_1\) orthogonal matrix \(C_1\) and \(q_2 \times q_2\) orthogonal matrix \(C_2\), as the \(\sigma \)-fields generated by the random variable \((B^{\top }_1X,B^{\top }_2Z)\) are equivalent to those generated by \(({\tilde{B}}^{\top }_1X,{\tilde{B}}^{\top }_2Z)\) with \({\tilde{B}}_1=B_1\times C_1\) and \({\tilde{B}}_2=B_2\times C_2\), we have
However, it is sufficient to identify the spaces spanned by \(B_1\) and \(B_2\) when we construct an adaptive-to-model test in Sect. 2.1. Groupwise dimension reduction (Li 2009) can be used to identify the subspaces spanned by the column vectors of matrices \(B_1\) and \(B_2\).
There are several groupwise dimension reduction approaches available in the literature. Li (2009) proposed a framework for grouped sufficient dimension reduction. Motivated by the MAVE method in Xia et al. (2002), Li et al. (2010) proposed an estimator to incorporate group information into dimension reduction. Guo et al. (2015) developed groupwise dimension reduction based on the “direct sum envelope". Zhou et al. (2016) discussed overlapped groupwise dimension reduction. Generally, these methods are computationally demanding because the resulting estimators need to be solved by an iterative procedure. This procedure involves iteratively estimating the nonparametric and the parametric component. Zhu et al. (2021) proposed a GLS estimation method for groupwise dimension reduction to avoid the iterative procedure. Thus, we recommend the GLS method in Zhu et al. (2021) to estimate \(B_1\) and \(B_2\).
According to Zhu et al. (2021), GLS estimation proceeds as follows:
-
1.
Consider some transformation functions of the response variable, \(f_1(Y),\ldots ,f_t(Y)\) satisfying \(E(f_k(Y))=0\), where t is a prespecified number, and the least-squares estimates of regressing \(f_k(Y)\) on \(W=(X^{\top },Z^{\top })^{\top }\) is
$$\begin{aligned} \beta _{k}=\arg \min _{\beta _k}E\{f_k(Y)-W^{\top }\beta _k\}^2, \end{aligned}$$for \(k=1,\cdots , t\). Then the target matrix M can be constructed as follows:
$$\begin{aligned} M=(M^{\top }_1, M^{\top }_2)^{\top }=\left( \frac{\beta _{1}}{1+||\beta _{1}||},\ldots , \frac{\beta _{t}}{1+||\beta _{t}||}\right) , \end{aligned}$$(2.6)where \(M_1\) and \(M_2\) are \(p_1\times t\) and \(p_2\times t\) matrixes, respectively.
-
2.
Then \(M_iM^{\top }_i\) is a \( p_i\times p_i\) positive semi-definite matrix satisfying \(\mathrm{{Span}}(M_iM^{\top }_i) =\mathrm{{Span}}(B_i)\), for \(i=1,2\).
-
3.
When the observations \(\{w_i, y_i\}_{i=1}^n\) are available, \(\beta _k\) can be estimated by the least squares estimates as:
$$\begin{aligned} \beta _{kn}=\arg \min _{\beta _k}\sum _{i=1}^n\left\{ f_k(y_i)-w^{\top }_i\beta _k\right\} ^2. \end{aligned}$$The target matrix M in (2.6) can be estimated by:
$$\begin{aligned} M_n=(M^{\top }_{1n}, M^{\top }_{2n})^{\top }=\left( \frac{\beta _{1n}}{1+||\beta _{1n}||},\ldots , \frac{\beta _{tn}}{1+||\beta _{tn}||}\right) . \end{aligned}$$When \(q_i\) is given, an estimate \( B_{in}\) of \(B_i\) consists of the eigenvectors associated with the \(q_i\) largest eigenvalues of \(M_iM^{\top }_i\), for \(i=1,2\). For more details, refer to Zhu et al. (2021).
2.3 Dimensionality estimation
As illustrated above, the two structure dimensions \(q_1\) and \(q_2\) are essential to estimating matrices \(B_1\) and \(B_2\). We adopt the thresholding double ridge ratio criterion proposed by Zhu et al. (2020). To address the special case \(q_i=p_i\), we define some artificial eigenvalues \({\hat{\lambda }}_{i(p_i+1)}={\hat{\lambda }}_{i(p_i+2)}=0\). Let
where \(c_{1n}\) and \(c_{2n}\) are the two ridges converging to 0, and \(0 \le {\hat{\lambda }}_{ip_i} \le \ldots \le {\hat{\lambda }}_{i1}\) are the eigenvalues of matrix \(M_{in}M^{\top }_{in}/t\). The dimension \(q_i\) can be estimated by:
where \(0<\tau <1\). Based on the rule of thumb in Zhu et al. (2020), we set \(\tau =0.5\) to avoid overestimation with a large \(\tau \) or underestimation with small \(\tau \). As the target matrix here differs from that in Zhu et al. (2020), we recommend the ridge values \(c_{1n}=0.4\log (n)/\sqrt{n}\) and \(c_{2n}=0.8\log (n)/\sqrt{n}\), based on some numerical studies.
The following proposition presents the consistency of the estimators \({\hat{q}}_k\), for \(k=1,2\).
Proposition 2.1
Under conditions A1 and A2 in the Appendix, assume that \(c_{1n} \rightarrow 0\), \(c_{2n} \rightarrow 0\) and \(c_{1n}c_{2n}n \rightarrow \infty \). Then we have
3 Asymptotic properties
3.1 Limiting null distribution
First, we provide some notation. Let
and
Next, we state the result for the null limiting distribution.
Theorem 3.1
Under \(H_0\) and the regularity conditions in the Appendix, we have
Furthermore, \({s^2}\) can be consistently estimated by \({\hat{s}}^2\).
From Theorem 3.1, we have the standardised test statistic \(T_n\):
3.2 Power study
To study how sensitive the new test statistic is against the alternative hypothesis, we consider the following sequence of local alternative models:
where the function \(f(\cdot ,\cdot )\) is continuous and differentiable and satisfies \(E[f^2(B^{\top }_1X,B^{\top }_2Z)] < \infty \), \(E(\eta |X,Z)=0\), and \(\beta \) and \(\theta \) are the linear combination of the columns of \(B_1\) and \(B_2\), respectively.
Lemma 3.1
Under the local alternative \(H_{1n}\) in (3.3) with \(C_n = n^{-1/2}h^{-1/2}\) and the same conditions in Proposition 2.1 except that \(C_n^2\log {n} \le c_n \rightarrow 0\), we have
Next, we state the results of the power performance of the test statistic.
Theorem 3.2
Under the regularity conditions in the Appendix, we have the following results.
-
(i)
Under \(H_{1n}\) with a fixed \(C_n >0\)
$$\begin{aligned} T_{n}/(n h) {\mathop {\longrightarrow }\limits ^{P}} {Constant} >0. \end{aligned}$$ -
(ii)
Under the sequence of local alternative hypotheses \(H_{1n}\) in (3.3), \(T_n\) has different asymptotic properties based on the rates of \(C_n\) as follows.
-
(a)
If \(q_1=q_2=1\) and \(C_n = n^{-1/2}h^{-1/2}\),
$$\begin{aligned} T_n {\mathop {\longrightarrow }\limits ^{d}} N(u, 1), \end{aligned}$$where
$$\begin{aligned} u=E\{f^2(B^{\top }_1X,B^{\top }_2Z)p_{B_1B_2}(B^{\top }_1X,B^{\top }_2Z)\}/s \end{aligned}$$with \(s^2\) defined by (3.1);
-
(b)
if \(q_1+q_2>2\), \(C_nn^{1/2} h^{1/2}\rightarrow c_0>0\) for some constant \(c_{0}\) or \(C_nn^{1/2} h^{1/2}\rightarrow \infty \) and \(C_nn^{1/2} h^{(q_1+q_2)/4}\rightarrow 0\), we have
$$\begin{aligned} T_n/h^{(q_1+q_2-2)/2} {\mathop {\longrightarrow }\limits ^{\mathrm {d}}} N(0,1); \end{aligned}$$ -
(c)
if \(q_1+q_2>2\) and, \(C_n=n^{-1/2} h^{-(q_1+q_2)/4}\), we have
$$\begin{aligned} T_n/h^{(q_1+q_2-2)/2} {\mathop {\longrightarrow }\limits ^{\mathrm {d}}} N(u,1); \end{aligned}$$ -
(d)
if \(q_1=q_2=1\) and \(C_n n^{1/2}h^{1/2} \rightarrow \infty \), or \(q_1+q_2>2\) and \(C_nn^{1/2} h^{(q_1+q_2)/4}\rightarrow \infty \), we have
$$\begin{aligned} T_n/(C^2_nnh){\mathop {\longrightarrow }\limits ^{\mathrm {P}}} {u} >0. \end{aligned}$$
-
(a)
4 Numerical studies
4.1 Simulations
In this subsection, we examine the finite-sample performance of the proposed test using several numerical examples. Each experiment is repeated 1000 times to compute the empirical sizes and powers at the significance level \(\alpha = 0.05\). The parametrical vectors \(\beta \) and \(\alpha \) are estimated using the MAVE method in Xia and Härdle (2006) (see the Appendix). In some applications, the asymptotic normal approximation does not work well in finite sample settings. Thus, re-sampling techniques are often used in finite samples. We apply the wild bootstrap algorithm adopted by Guo et al. (2016). Consider the bootstrap observations \(y_{i}^{*}={{\hat{\beta }}}^{T} x_i +g({\hat{\alpha }}^{T}z_i)+\epsilon _{i}^{*},\) where \(\epsilon _{i}^{*}={\hat{\epsilon }}_{i} \times U_{i}\). \(\left\{ U_{i}\right\} _{i=1}^{n}\) can be chosen to be i.i.d. Bernoulli variates with
Let \(T^*_n\) be the bootstrap version of \(T_n\), based on the bootstrap samples \(\{(x_1,z_1,y^*_1)\), \(\cdots , (x_n,z_n,y^*_n)\}\). The null hypothesis is rejected if \(T_n\) is larger than the corresponding quantile of the bootstrap distribution of \(T^*_n\).
For our test, we select the kernel function \(K(\cdot )\) to be Gaussian, and set the bandwidths as \(h_1=0.8n^{-1 /(1+4)}\) and \(h=0.8n^{-1 /\left( {\hat{q}}_{1}+{\hat{q}}_{2}+4\right) }\) with the estimated dimensions \({\hat{q}}_{1}\) and \({\hat{q}}_{2}\) of \(B_{1 n}^{\top } X\) and \(B_{2 n}^{\top } Z\), where \(h_1\) is used to estimate \(\beta \), \(\alpha \) and the function \(g(\cdot )\) and h is used to construct the test statistics.
As in Remark 2.1, we extend the test in Zheng (1996) to check the PLSIMs for comparison and write the test statistic as \(T^{ZH}_n\). For the test in Zheng (1996), we set the bandwidth as \(h=1.5 n^{-1 / (4+p_1+p_2)}\) and select the quartic kernel function \(K(u)=\frac{15}{16}\left( 1-u^{2}\right) ^{2}\), if \(|u| \le 1\) and 0, otherwise. We compare the results of these two test statistics computed from the 500 wild bootstrap samples.
The observations \(\left\{ x_i\right\} ^n_{i=1}\) and \(\left\{ z_i\right\} ^n_{i=1}\) are generated i.i.d. from multivariate normal distributions \(N(0_{p_1}, \Sigma _{1})\) and \(N(0_{p_2}, \Sigma _{2})\), respectively, and independent of the standard normal errors. Here, \(\Sigma _{1}=I_{p_1 \times p_1}\) and \(\Sigma _{2}=I_{p_2 \times p_2}\). The sample sizes are set as n = 200, 400 and the dimensions are \(p_{1} = p_{2} = 4, 8\).
Example 1
Consider the model
where \(\beta \) and \(\alpha \) are set using the following two cases:
-
Case 1: \(\beta =(\underbrace{1, \ldots , 1}_{p_{1} / 2}, 0, \ldots , 0)^{\top } / \sqrt{p_{1} / 2}\), and \(\alpha =(0, \ldots , 0, \underbrace{1, \ldots , 1}_{p_{2} / 2})^{\top } / \sqrt{p_{2} / 2}\);
-
Case 2: \(\beta =(\underbrace{1, \ldots , 1}_{p_{1}}) / \sqrt{p_{1}}\), and \(\alpha =(\underbrace{1, \ldots , 1}_{p_{2}}) / \sqrt{p_{2}}\).
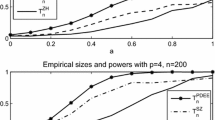
The error term \(\epsilon \) follows the standard normal distribution. In this example, \(a=0\) and \(a \ne 0\) correspond to the null and the alternative hypothesis, respectively. The results of the empirical sizes and powers are displayed in Table 1. From Table 1, we make the following observations:
First, the proposed \(T_n\) can control the empirical sizes well. \(T^{ZH}_n\) tends to be conservative, especially when \(p_1=p_2=4\), but when \(p_1 =p_2= 8\), the significance level can be better maintained. Second, the empirical powers of the proposed test \(T_n\) increase reasonably with larger a, and thus the test is significantly and uniformly more powerful than \(T^{ZH}_n\). \(T^{ZH}_n\) is invalid when detecting the alternative hypothesis with a large dimension \(p_1=p_2=8\). For \(p_1=p_2=4\) and \(p_1=p_2=8\), the dimensions of X and Z have less influence for \(T_n\) than they do for \(T^{ZH}_n\). \(T_n\) performs uniformly better than \(T^{ZH}_n\) in the above two cases.
Example 2
In this example, we examine the finite sample performance of the proposed method under the following model:
where all parameter values are set to be the same as those in Example 1. \(a = 0\) corresponds to the null hypothetical model. The empirical sizes and powers are presented in Table 2.
We observed that the power performances of \(T_n\) in Example 1 and Example 2 are similar by comparing Tables 1, 2 and 3. The proposed test can maintain the significance level as well as in the previous example, and its power performs significantly and uniformly better than that of the test in Zheng (1996).
Example 3
In this example, we examine the finite sample performance of the proposed method under the model:
where \(X_i\) and \(Z_i\) denote the \(i-\)th components of X and Z, respectively. All parameters values are the same as those used in Example 1. The related results are displayed in Table 3.
From Table 3, both tests still control the size well. When \(p_1=p_2=4\), the empirical powers of \(T_{n}\) increase faster than those of \(T^{ZH}_n\) as a increase. For \(T^{ZH}_n\), the empirical sizes and powers are close to the significance level \(\alpha =0.05\) when \(p_1=p_2=8\). \(T_{n}\) is significantly better than \(T^{ZH}_n\) at detecting the alternative hypothesis because dimension reduction mitigates the curse of dimensionality.
Example 4
To examine the stability of powers against the structure dimension, we consider a more complex model with higher structure dimensions \(q_1\) and \(q_2\):
where \(X_i\) and \(Z_i\) denote the \(i-\)th components of X and Z, respectively. All parameters values are the same as those used in Example 1. \(a = 0\) corresponds to the null hypothetical model. Under the alternative hypotheses, the structural dimensions \(q_1\) and \(q_2\) of the alternative models are equal to 4. The results are presented in Table 4.
We observe that the performances of empirical powers and sizes in Example 4 and Examples 1–3 are similar by comparing Table 4 and Tables 1, 2 and 3. The empirical sizes of the two tests are close to the significance level. However, the proposed test has significantly higher power than \(T_{n}^{ZH}\), especially when \(p_1=p_2=8\). We also find that the structural dimensions have a negligible effect on the empirical sizes and powers of our test.
4.2 Real data analysis
4.2.1 Body fat data
We now apply the proposed method to the analysis of the body fat data, which can be found at http://lib.stat.cmu.edu/datasets/bodyfat. Chen et al. (2016) analysed this dataset, which provides estimates of the percentage of body fat determined by underwater weighing and various body circumference measurements. The dataset contains 251 samples with 14 attributes. Consistent with Chen et al. (2016), we select the following 12 attributes: \(\mathrm height^4/weight^2\), age, and circumferences of 10 body parts, namely, neck, chest, abdomen, hip, thigh, knee, ankle, biceps, forearm, and wrist. We set the knee, ankle, and forearm circumferences as \(X=(X_1, X_2, X_3)\). The other predictors are set as \(Z=(Z_1,Z_2,\cdots ,Z_9)\). The response variable is the logarithm of the percentage of body fat (Y). We delete one observations in which the percentage of body fat is equal to 0.
The value of the test statistic is \(T_n=18.2261\) and the \(p-\)value is approximately 0. Therefore, there is enough evidence to reject the null hypothesis at the significance level \(\alpha = 0.05\). The residual plot of the PLSIM fitted against \({\hat{\beta }}^{\top }X\) and \({\hat{\alpha }}^{\top }Z\) in Fig. 1 shows a linear relationship between \({\hat{\beta }}^{\top }X\) and the residuals.

Plot of the residuals against the linear part and single-indexing direction in the body fat data
4.2.2 Auto MPG
This data set is obtained from the Machine Learning Repository at the University of California-Irvine (http://archive.ics.uci.edu/ml/datasets/Auto+MPG). Xia (2007) and Guo et al. (2016) analysed this data set. It has 406 samples and 8 attributes. The predictors are cylinders, engine displacement, horsepower, vehicle weight, time to accelerate from 0 to 60 mph, model year, and the origin of the car. Miles per gallon (Y) is the response variable. Consistent with Xia (2007), we set cylinders, engine displacement, horsepower, vehicle weight, time to accelerate from 0 to 60 mph, and model year as \(Z_1,Z_2,\cdots ,Z_6\). \(X_1=1\) if a car is from America, and 0 otherwise. \(X_2=1\) if a car is from Europe and 0 otherwise.
The value of the proposed test statistic is \(T_n= -1.1447\), and the p-value is 0.2523. Hence, the null hypothesis should be accepted at the significance level \(\alpha = 0.05\). We plot the residual plot against the single-indexing direction in Fig. 2, and the plot shows no pattern. Thus, it is reasonable to fit this dataset based on the PLSIM.

Plot of the residuals against the single-index direction in the Auto MPG data
References
Carroll R, Fan J, Gijbels I, Wand M (1997) Generalized partially linear single-index models. J Am Stat Assoc 92:477–489
Chen K, Lin J, Wang Z (2016) Least product relative error estimation. J Multivar Anal 144:91–98
Dette H (1999) A consistent test for the functional form of a regression based on a difference of variance estimates. Ann Stat 27:1012–1050
Escanciano JC (2006) A consistent diagnostic test for regression models using projections. Economet Theor 22:1030–1051
Fan JQ, Huang LS (2001) Goodness-of-fit tests for parametric regression models. J Am Stat Assoc 96:640–652
Fan Y, Li Q (1996) Consistent model specification tests: omitted variables and semiparametric functional forms. Econometrica 64:865–890
Fan J, Zhang C, Zhang J (2001) Generalized likelihood ratio statistics and Wilks phenomenon. Ann Stat 29:153–193
González Manteiga W, Crujeiras RM (2013) An updated review of goodness of fit tests for regression models. TEST 22:361–411
Guo Z, Li L, Lu W, Li B (2015) Groupwise dimension reduction via envelope method. J Am Stat Assoc 110:1515–1527
Guo X, Wang T, Zhu LX (2016) Model checking for generalized linear models: a dimension-reduction model-adaptive approach. J Roy Stat Soc B 78:1013–1035
Hall P, Li K (1993) On almost linearity of low dimensional projections from high dimensional data. Ann Stat 21:867–889
Härdle W, Mammen E (1993) Comparing nonparametric versus parametric regression fits. Ann Stat 21:1926–1947
Khmadladze EV, Koul HL (2004) Martingale transforms goodness-of-fit tests in regression models. Ann Stat 37:995–1034
Koul HL, Ni PP (2004) Minimum distance regression model checking. J Stat Plan Inference 119:109–141
Lavergne P, Patilea V (2008) Breaking the curse of dimensionality in nonparametric testing. J Econ 143:103–122
Lavergne P, Patilea V (2012) One for all and all for one: regression checks with many regressors. J Bus Econ Stat 30:41–52
Li LZ, Zhu XH, Zhu LX (2021) Adaptive-to-model hybrid of tests for regressions. J Am Stat Assoc 1–10
Li KC (1991) Sliced inverse regression for dimension reduction. J Am Stat Assoc 86:316–327
Li LX (2009) Exploiting predictor domain information in sufficient dimension reduction. Comput Stat Data Anal 94:603–613
Li LX, Li B, Zhu LX (2010) Groupwise dimension reduction. J Am Stat Assoc 105:1188–1201
Liang H, Liu X, Li RZ, Tsai CL (2010) Estimation and testing for partially linear single-index models. Ann Stat 38:3811–3836
Lu J, Zhu XH, Lin L, Zhu LX (2019) Estimation for biased partial linear single index models. Comput Stat Data Anal 139:1–13
Robinson PM (1988) Root-n-consistent semiparametric regression. Econometrica 56:931–954
Serfling RJ (1980) Approximation theorems of mathematical statistics. Wiley, New York
Stute W (1997) Nonparametric model checks for regression. Ann Stat 25:613–641
Stute W, Zhu LX (2005) Nonparametric checks for single-index models. Ann Stat 33:1048–1083
Stute W, Manteiga WG, Quindimil MP (1998) Bootstrap approximation in model checks for regression. J Am Stat Assoc 93:141–149
Stute W, Xu WL, Zhu LX (2008) Model diagnosis for parametric regression in high dimensional spaces. Biometrika 95:1–17
Tan FL, Zhu LX (2019) Adaptive-to-model checking for regressions with diverging number of predictors. Ann Stat 47:1960–1994
Tan FL, Zhu XH, Zhu LX (2018) A projection-based adaptive-to-model test for regressions. Stat Sin 28:157–188
Van Keilegom I, Gonzáles-Manteiga W, Sánchez Sellero C (2008) Goodness of fit tests in parametric regression based on the estimation of the error distribution. TEST 17:401–415
Wang JL, Xue LG, Zhu LX, Chong YS (2010) Estimation for a partial-linear single-index model. Ann Stat 38:246–274
Wu CF (1986) Jackknife, bootstrap and other resampling methods in regression analysis. Ann Stat 14:1261–1295
Wu Y, Li L (2011) Asymptotic properties of sufficient dimension reduction with a diverging number of predictors. Stat Sin 21:707–730
Xia YC (2007) A constructive approach to the estimation of dimension reduction directions. Ann Stat 35:2654–2690
Xia Y, Härdle W (2006) Semi-parametric estimation of partially linear single-index model. J Multivar Anal 97:1162–1184
Xia Y, Tong H, Li WK, Zhu LX (2002) An adaptive estimation of dimension reduction space. J Roy Stat Soc B 64(3):363–388
Zhao J, Zhao Y, Lin J, Miao Z, Khaled W (2020) Estimation and testing for panel data partially linear single-index models with errors correlated in space and time. Random Matrices Theory Appl 9:2150005
Zheng JX (1996) A consistent test of functional form via nonparametric estimation techniques. J Econ 75:263–289
Zhou JK, Wu JR, Zhu LX (2016) Overlapped groupwise dimension reduction. Sci China Math 59:2543–2560
Zhu XH, Zhang QM, Zhu LX, Zhang J, Yu LY (2022) Specification testing of regression models with mixed discrete and continuous predictors. J Bus Econ Stat 1–39 (just-accepted)
Zhu LX (2003) Model checking of dimension-reduction type for regression. Stat Sin 13:283–296
Zhu LX, Xue LG (2006) Empirical likelihood confidence regions in a partially linear single-index model. J Roy Stat Soc B 68:549–570
Zhu XH, Zhu LX (2018) Significance testing in nonparametric regression based on dimension reduction. Electron J Stat 12:1468–1506
Zhu XH, Guo X, Zhu LX (2017) An adaptive-to-model test for partially parametric single-index models. Stat Comput 27:1193–1204
Zhu XH, Guo X, Wang T, Zhu LX (2020) Dimensionality determination: a thresholding double ridge ratio criterion. Comput Stat Data Anal 146:106910
Zhu XH, Lu J, Zhang J, Zhu LX (2021) A groupwise dimension reduction adaptive-to-model test for conditional independence. Scand J Stat 48:549–576
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Thanks to the Editor, Associate Editor, and two anonymous referees for their constructive suggestions that significantly improved an early manuscript. Xuehu Zhu’s research was supported by the National Social Science Foundation of China (21BTJ048)
Appendix
Appendix
1.1 Brief review of the minimum average variance estimation of the PLSIM
As stated previously, the proposed test procedure needs to estimate the parameter vectors \(\beta \) and \(\alpha \) and the function g. Therefore, we briefly review the MAVE approach developed by Xia and Härdle (2006) to estimate the PLSIM. The basic algorithm is based on the minimum average variance:
subject to \(||\alpha ||=1\). A two-step iterative algorithm to estimate the PLSIM. Given \((\beta , \theta )\), we have:
Given \(\left( a_{j}, d_{j}\right) \), we have:
where \(z_{ij}=z_i-z_j\), \(w_{i j}\), for \(i,j=1,2,\cdots , n\), are some weights with \(\sum _{i=1}^nw_{i j}=1\), and \(G(\cdot )\) is another weight function that controls the contribution of \((X_j , Z_j , Y_j )\) to the estimation of \(\beta \) and \(\theta \). The function g can be estimated using the following kernel estimate:
where \(Q_{h_1}=K(\cdot /h_1)/h_1\) with \(Q(\cdot )\) being some univariate kernel function.
In our numerical studies, the MAVE method is implemented by using the first column vector of \(B_{1n}\) and \(B_{2n}\) as the initial estimators for \(\beta \) and \(\alpha \) and setting the maximum number of iterations to 100. More details can be found in Xia and Härdle (2006).
1.2 Regularity conditions
-
A1
Let \(W=(X,Z)\). Assume that \(E(W|B^\top W)\) is a linear function of \(B^{\top } W\) with the columns of \(B \in {\mathbb {R}}^{p \times q}\) being any basis of the central space \({\mathcal {S}}_{Y|W}\), where \(p=p_1+p_2\) and q denotes the dimension of \({\mathcal {S}}_{Y|W}\).
-
A2
\(f_i(Y)\)’s satisfy \(E[f_i(Y)]=0\) and \(E[f^2_i(Y)]<\infty \) for \(i=1,\cdots , t\) and the coverage condition holds, namely, the target matrix M defined in (2.6) is such that \(\mathrm{{Span}}(M) ={\mathcal {S}}_{Y|W}\). Additionally, the second moment of W exists.
-
A3
The density function \(p_{B_1,B_2}(\cdot ,\cdot )\) of \((B^{\top }_1X,B^{\top }_2Z)\) is continuous with a bounded first-order derivative and satisfies, on its support \({\mathbb {C}}_1\),
$$\begin{aligned} 0<\inf _{(B^{\top }_1 x,B^{\top }_2 z) \in {\mathbb {C}}_2} p_{B_1,B_2}(B^{\top }_1x,B^{\top }_2z)\le & {} \sup _{(B^{\top }_1 x,B^{\top }_2 z) \in {\mathbb {C}}_2} p_{B_1,B_2}(B^{\top }_1x,B^{\top }_2z)< \infty . \end{aligned}$$ -
A4
The function \(g(\cdot )\) is \(\eta -\)order partially differentiable for some positive integer \(\eta \), and the \(\eta \)th partially derivative of \(g(\cdot )\) is bounded.
-
A5
The kernel function \(Q(\cdot )\) is symmetric and second-order continuously differentiable, and satisfies
$$\begin{aligned} \int u^{i}Q(u)du= & {} \delta _{i0}, \ \ (i=0, 1,\ldots , \eta -1 ),\\ Q(u)= & {} O((1+|u|^{\eta +1+\gamma })^{-1}), \ \text{ some }\ \gamma >0, \end{aligned}$$where \(\delta _{ij}\) is the Kronecker delta with \(\eta \) given in Condition A4.
-
A6
The kernel function \(K(\cdot )\) is a bounded, symmetric kernel function. It is first order continuously differentiable and satisfies \(\int K(u)du = 1\).
-
A7
\(n \rightarrow \infty \), \(h_1 \rightarrow 0\), \(h \rightarrow 0\),
-
1)
under the null or local alternative hypotheses with \(C_n = n^{-{1}/{2}}h^{-{1}/{2}}\), \(nh_1\rightarrow \infty \), \(nh^{2}\rightarrow \infty \) and \(nh^{2\eta }_1h\rightarrow 0\);
-
2)
under the global alternative hypothesis, \(nh_1\rightarrow \infty \), \(nh^{q_1+q_2}\rightarrow \infty \) and \(nh^{2\eta }_1h^{(q_1+q_2)/2}\rightarrow 0\),
-
1)
where \(\eta \) is given in Condition A6.
Remark 5.1
Conditions A1 and A2 are necessary for obtaining consistent estimators of matrixes \(B_1\) and \(B_2\). The linearity condition A1 holds when W follows an elliptically contoured distribution, see Li (1991), and it is mild in high-dimensional scenarios (see Hall and Li 1993). The coverage condition \(\mathrm{{Span}}(M) ={{\mathcal {S}}}_{Y|W}\) in Condition A2 in the literature is widely adopted to overcome technical issues, see Wu and Li (2011). Conditions A3, A4, A5 and A6 are widely used in the literature for nonparametric estimation. The four conditions ensure that the test is well-behaved, see Fan and Li (1996) and Zheng (1996). It is worth pointing out that Condition A5 pertaining to the higher-order kernel plays a critical role in bias reduction, see Robinson (1988) and Fan and Li (1996). We use different bandwidths \(h_1\) and h to estimate the function \({\hat{g}}(\cdot )\) and construct the test statistic \(T_n\), because they involve the various covariates under the alternative hypothesis. This phenomenon has been discussed in several studies. For example Stute and Zhu (2005) stated that the optimal bandwidth for estimation should be different from that for test statistic construction. For more details on Conditions A3-A7 refer to Fan and Li (1996), Zhu and Zhu (2018) and Zhu et al. (2021).
1.3 The proofs of the theoretical results
Proof of Proposition 2.1
Employing the same justification procedure to that for Theorem 2.1 in Zhu et al. (2020), we can get the results. Then we omit the detail here.
Proof of Theorem 3.1
Define the events \(A_{1n} = \{T_n \le c\}\) for any constant c and \(A_{2n} = \{{\hat{q}}_1 = 1, {\hat{q}}_2 = 1\}\). Proposition 2.1 shows that under the null hypothesis, \(\lim _{n\rightarrow \infty }P(A_{2n}) = 1\), where P(A) denotes the probability that event A happens. Then we have \(\lim _{n\rightarrow \infty }P(A_{2n}) = \lim _{n\rightarrow \infty }P(A_{1n} \cap A_{2n})\). This result ensures that under the null hypothesis, in an asymptotic sense we only need to consider the properties of the test statistic on the event that \({\hat{q}}_1=1\) and \({\hat{q}}_2=1\).
For notation simplicity, define \(K_{B_{1n}B_{2n}ij} = K((B^{\top }_1x_i -B^{\top }_1x_j)/h, (B^{\top }_2z_i -B^{\top }_2z_j)/h)\), \(K^1_{B_{1}B_{2}ij}=\frac{\partial {K}(B^{\top }_{1}(x_i-x_j)/h,B^{\top }_{1}(z_i-z_j)/h)}{\partial (B^{\top }_{1}(x_i-x_j)/h)}\), \(K^1_{B_{1}B_{2}ij}=\frac{\partial {K}(B^{\top }_{1}(x_i-x_j)/h,B^{\top }_{1}(z_i-z_j)/h)}{\partial (B^{\top }_{2}(z_i-z_j)/h)}\), \(g_i = g(\theta ^{\top }z_i)\), \({\hat{g}}_i ={\hat{g}}({\hat{\theta }}^{\top }z_i)\), \(\epsilon _{i}=y_i-\beta ^{\top }_1x_j-g_i\), \({\hat{\epsilon }}_{i}=y_i-{\hat{\beta }}^{\top }_1x_j-{\hat{g}}_i\), \(p_i = p_{B_2}(B^{\top }_2z_i)\) and \({\hat{p}}_i = {\hat{p}}_{B_{2n}}(B^{\top }_{2n}z_i)\), \({\tilde{y}}_i=y_i-\beta ^{\top }x_i\). Throughout the proof of this theorem, \(E_i(\cdot )=E(\cdot |B^{\top }_1x_i, B^{\top }_2w_i)\).
Noted that \({\hat{\epsilon }}_i = y_i-{\hat{\beta }}^{\top }_1x_i-{\hat{g}}({\hat{\alpha }}^{\top } z_i)=\epsilon _{i}+ [\beta ^{\top }x_i- {\hat{\beta }}^{\top }x_i]+[g(\alpha ^{\top } z_i) -{\hat{g}}({\hat{\alpha }}^{\top } z_i)]\). We then decompose the term \(S_n\) as
We now prove that both the terms \(n hS_{n}\) and \(n hS_{1n}\) have the same limiting null distribution, \(n hS_{2n}=o_p(1)\), \(n hS_{3n}=o_p(1)\), \(n hS_{4n}=o_p(1)\), \(n hS_{5n}=o_p(1)\) and \(n hS_{6n}=o_p(1)\).
Consider the term \(S_{1n}\). The first order Taylor expansion for \(S_{1n}\) with respect to \(B_1\) and \(B_2\) yields
where \(S_{11n}\) and \(S_{12n}\) have the following forms:
with \({\tilde{B}}_1=\{{\tilde{B}}_{1ij}\}_{p_1\times q_1}\), \({\tilde{B}}_{1ij} \in [\min \{B_{1ij}, B_{1nij}\}, \max \{B_{1ij}, B_{1nij}\}]\), \(B_{1}=\{B_{1ij}\}_{p_1\times q_1}\) and \(B_{1n}=\{B_{1nij}\}_{p_1\times q_1}\). Due to the facts that \(||B_{1n}-B_1||=O_p(1/\sqrt{n})\) and the kernel function \(K(\cdot )\) has a continuous and bounded first-order derivative, we infer that replacing \({\tilde{B}}_1\) by \(B_1\) does not influence the convergence rates of \(S_{12n}\) and \(S_{13n}\). Similarly, we can infer that replacing \({\tilde{B}}_2\) by \(B_2\) does not influence the convergence rates of \(S_{12n}\) and \(S_{13n}\).
It is obvious that \(S_{11n}\) is an \(U-\)statistic with the kernel as:
where \(v_i=(x_i,z_i, y_i)\). Under null hypothesis, as \(E[H(v_i, v_j)|v_j]=0\), \(S_{11n}\) is a degenerate U-statistic. Under Conditions A3–A7, adapting the similar arguments as that for Lemma 3.3 in Zheng (1996), we can obtain
We now prove that the second term \(nhS_{12n}\) and \(nhS_{13n}\) tend to zero. As \(K(\cdot )\) is spherically symmetric, the term \(S_{12n}\) can be rewritten as an U-statistic with the kernel:
It is obvious that \(E[H(v_i,v_j)|v_i]=0\). Thus, the term \(S_{12n}\) is a degenerate \(U-\)statistic. Applying the arguments used for handling the term \(S_{11n}\), together with \(||B_{1n}-B_1||=O_p(1/\sqrt{n})\), it yields that \(nhS_{12n}=o_p(1)\). Similarly, we can get that \(nhS_{13n}=o_p(1)\).
Therefore, together with the results about \(S_{11n}\), \(S_{12n}\) and \(S_{13n}\), we have
Now we turn to prove that \(nhS_{2n}=o_p(1)\). Note that
Due to the fact \({\tilde{S}}_{2n}\) is a \(U-\)statistic, it is easy to conclude that \({\tilde{S}}_{2n}=O_p(1)\). Because \(\beta _1- {\hat{\beta }}_1=O_p(1/\sqrt{n})\) and \(h\rightarrow 0\), we get \(nhS_{2n}=O_p(h)=o_p(1)\).
Consider the term \(S_{3n}\) that can be written as:
Substituting the kernel estimators \({\hat{g}}_i\) and \({\hat{p}}_i\) into \({\tilde{S}}_{3n}\), we have
Due to the facts \(B_{1n}-B_1=O_p(1/\sqrt{n})\), \(B_{2n}-B_2=O_p(1/\sqrt{n})\) and \(\beta _n-\beta =O_p(1/\sqrt{n})\), adapting the similar statement for dealing with the term \(S_{1n}\), we can infer that replacing \(B_{1n}\), \(B_{2n}\) and \({\hat{\beta }}\) by \(B_{1}\), \(B_{2}\) and \(\beta \) respectively does not influence the convergence rates of \({\tilde{S}}_{3n}\), namely,
where
Following the similar idea of justifying Proposition A.1 in Fan and Li (1996), we will show \(nh{\tilde{S}}_{31n}=o_p(1)\) by proving that \(E({\tilde{S}}^2_{31n})=o(n^{-2}h^{-2}).\) However, it is difficult and tedious to directly calculate \(E({\tilde{S}}^2_{31n})\) since it contains eight summations. We first show \(E({\tilde{S}}_{31n})= o(n^{-1}h^{-1})\). Then we use this result and a symmetry argument to show \(E({\tilde{S}}^2_{31n})=o(n^{-2}h^{-2}).\)
Decompose \(E({\tilde{S}}_{31n})\) with two terms with two subsets of subscripts as:
-
\({\mathcal {A}}_1=\) {i, j, l, k are all different from each other};
-
\({\mathcal {A}}_2=\) {i, j, l, k take no more than three different values}.
Then \({\tilde{S}}_{31n}\) can be decomposed as \({\tilde{S}}_{31n} = {\tilde{S}}_{311n}+ {\tilde{S}}_{312n}\), where the summation indices of \({\tilde{S}}_{311n}\) and \({\tilde{S}}_{312n}\) are associated with \({\mathcal {A}}_1\) and \({\mathcal {A}}_2\), respectively.
Under the assumption that \(nh^{2{\eta }}_1h=o(1)\), by applying Lemma B.1, Lemmas 2 and 3 in Robinson (1988), we have
Next we consider subset \({\mathcal {A}}_2\). It can be divided into three groups: case (I) \(l=k\); case (II) \(l=j\); case (III) \(k=i\). Then \({\tilde{S}}_{312n}\) can be further decomposed as \({\tilde{S}}_{312n}= {\tilde{S}}_{3121n}+ {\tilde{S}}_{3122n}+ {\tilde{S}}_{3123n}\) associated with the above three sub-events. For \({\tilde{S}}_{3121n}\) with the sub-event (I),
By applying Lemma B.1, Lemmas 2 and 3 in Robinson (1988) and Fubini’s theorem, we have
The same argument can be applied to the terms \(E({\tilde{S}}_{3122n})\) and \(E({\tilde{S}}_{3123n})\) to obtain the upper bound \(o(n^{-1}h^{-1}).\) Hence, altogether we have \(E({\tilde{S}}_{31n})=E({\tilde{S}}_{311n}) + E({\tilde{S}}_{312n})=o(n^{-1}h^{-1})\).
Now we consider \(E({\tilde{S}}^2_{31n})\) by using the similar decomposition of \(E({\tilde{S}}_{31n})\) although it is much more complicated. Note that
where the summation indices of \(LA_1\), \(LA_2\) and \(LA_3\) respectively associated with three subsets of subscripts \({\mathcal {B}}_1\), \({\mathcal {B}}_2\) and \({\mathcal {B}}_3\) as:
-
\({\mathcal {B}}_1=\) {i, j, l, k are all different from \(i',j',l',k'\) };
-
\({\mathcal {B}}_2=\) {exactly one index from i, j, l, k equals one of subscripts \(i',j',l',k'\)};
-
\({\mathcal {B}}_3=\) {the eight summation indices \(i,j,l,k, i',j',l',k'\) take no more than six different values}.
With \({\mathcal {B}}_1\), the sums in \(LA_1\) with i, j, l, k and \(i',j',l',k'\) are independent of each others. Thus \(LA_1\) is equal to the square of \(E({\tilde{S}}_{21n})\). Hence we can obtain that \(LA_1=o(n^{-2}h^{-q_1})\). Next we consider \(LA_2\) with the subset \({\mathcal {B}}_2\). By symmetry, we only need to compute three cases: case (I) \(i=i'\); case (II) \(i=l'\); case (III) \(l=l'\), and \(LA_2\) can be further decomposed as \(LA_2= LA_{21}+ LA_{22}+ LA_{23}\) associated with the above three subsets.
Under case (I),
Via an application of the Fubini’s theorem and Lemma B.1, Lemmas 2 and 3 in Robinson (1988), we have
In case (II),
The application of Fubini’s theorem and Lemma B.1, Lemmas 2 and 3 in Robinson (1988) again yields
For case (III), the similar argument as above for case (II) can be used to justify \(LA_{23}=o(n^{-2}h^{-q_1})\). Altogether, we have \(LA_2=o(n^{-2}h^{-q_1})\).
Last, consider the sum \(LA_3 \) with the subset \({\mathcal {B}}_3\) in which the eight summation indices \(i,j,l,k, i',j',l',k'\) take no more than six different values. As it is easy to show that \(LA_3=o(n^{-2}h^{-2})\) by the similar arguments used above, we then omit the detail. Altogether, we conclude that \(E({\tilde{S}}^2_{31n})=o(n^{-2}h^{-2})\). The application of Chebyshiev’s inequality implies \({\tilde{S}}_{31n}=o_p(n^{-1}h^{-1})\).
Using the similar process as those for the term \({\tilde{S}}_{31n}\), under Conditions A3−A7 in Appendix, we can justify that the terms \({\tilde{S}}_{321n}\), \({\tilde{S}}_{322n}\) and \({\tilde{S}}_{323n}\) have the following converging rates:
To save the space, we omit some more detailed deductions. The Chebyshiev’s inequality yields that
As \(||B_{1n}-B_1||=O_p(n^{-1/2})\), together with the above convergence rates, we have \({\tilde{S}}_{32n}=o_p(n^{-1}h^{-1})\). Combining the convergence rates of \({\tilde{S}}_{31n}\) and \({\tilde{S}}_{32n}\), we conclude \({\tilde{S}}_{3n}=o_p(n^{-1}h^{-q_1/2})\).
Now we discuss the convergence rate of the term \(S_{5n}\). Note that
Substituting the kernel estimators \({\hat{g}}_j\) and \({\hat{p}}_j\) into \({\tilde{S}}_{5n}\), we have
Adopting the similar process for dealing with the term \(S_{1n}\) and \(S_{3n}\), we can infer that replacing \(B_{1n}\), \(B_{2n}\) and \({\hat{\beta }}\) by \(B_{1}\), \(B_{2}\) and \(\beta \) respectively does not influence the convergence rates of \({\tilde{S}}_{3n}\), namely,
where
As \(E[\epsilon _{i}|x_i,z_i]=0\), Fubini’s theorem and the properties of conditional expectation yield \(E({\tilde{S}}_{51n})=0\). We then consider the second order moment of \({\tilde{S}}_{51n}\) as:
Note that \(E[\epsilon _{i}\epsilon _{i'}|w_i, w_{i'}] \ne 0\) if and only if \(i = i'\). Fubini’s theorem and the Lemma B.1, Lemmas 2 and 3 in Robinson (1988) altogether yields:
The Chebyshiev’s inequality implies that \({\tilde{S}}_{51n}=o_p(n^{-1}h^{-1})\). Thus \(S_{5n}=o_p(n^{-1}h^{-1})\).
Using the similar statement to deal with the terms \(S_{1n}\), \(S_{2n}\) and \(S_{5n}\), we can conclude that \(S_{4n}=o_p(n^{-1}h^{-1})\) and \(S_{6n}=o_p(n^{-1}h^{-1})\).
To sum up, together with all the results about the terms \(S_{in}\) for \(i=1,\cdots ,6\), we conclude that
To complete the proof of this theorem, we justify the consistency of \(s^{2}_{n}\) to \(s^2\), where \(s^2_{n}\) is
Under the null hypothesis, since \(B_{1n}\), \(B_{2n}\) and \({\hat{g}}\) are uniformly consistent to \(B_1\), \(B_2\) and g, respectively, some elementary computations yield an asymptotic presentation:
It is clear that \( {\tilde{s}}^2_{n}\) is an \(U-\)statistic with kernel:
We can easily show that the condition of lemma 3.1 of Zheng (1996) is satisfied. Based on U-statistic theory, it is easy to justify \({\tilde{s}}^2_{n}= E({\tilde{s}}^2_{n})+o(1)\), where
The more details can be found in Fan and Li (1996) and Zheng (1996). \(\square \)
Proof of Theorem 3.2
Here we use the similar notations as those in Theorem 3.1 of the main body. Define \(K_{B_{1n}B_{2n}ij} = K((B^{\top }_1x_i -B^{\top }_1x_j)/h, (B^{\top }_2z_i -B^{\top }_2z_j)/h)\), \(g_i = g(\theta ^{\top }z_i)\), \({\hat{g}}_i ={\hat{g}}({\hat{\theta }}^{\top }z_i)\), \(\epsilon _{i}=y_i-\beta ^{\top }_1x_j-g_i\), \({\hat{\epsilon }}_{i}=y_i-{\hat{\beta }}^{\top }_1x_j-{\hat{g}}_i\), \(p_i = p_{B_2}(B^{\top }_2z_i)\) and \({\hat{p}}_i = {\hat{p}}_{B_{2n}}(B^{\top }_{2n}z_i)\), \({\tilde{y}}_i=y_i-\beta ^{\top }x_i\). Throughout the proof of this theorem, \(E_i(\cdot )=E(\cdot |B^{\top }_1x_i, B^{\top }_2z_i)\). Define the events \(A_{1n} = \{T_n \le c\}\) for any constant c and \(A_{2n} = \{{\hat{q}}_1 = q_1, {\hat{q}}_2 = q_2\}\). Proposition 2.1 and Lemma 3.1 purport that under the global and local alternative hypothesis, we have \(\lim _{n\rightarrow \infty }P(A_{2n}) = \lim _{n\rightarrow \infty }P(A_{1n} \cap A_{2n})\). This result ensures that under the global and local alternative hypotheses, in an asymptotic sense it is only needed to consider the events \({\hat{q}}_1=q_1\) and \({\hat{q}}_2=q_2\).
Proof of Part (I). Under Conditions A1 and A2 in Appendix, due to the facts \(||B_{1n}-B_1||=O_p(1/\sqrt{n})\) and \(||B_{2n}-B_2||=O_p(1/\sqrt{n})\), \({\hat{g}}\) is an uniformly consistent estimator of g, see Fan and Gijbels (1996). It is easy to prove that under the global alternative hypothesis, we have
where \(\epsilon _{i}=y_i-\beta ^{\top }_0x_i - g(\alpha ^{\top }_0z_i)\) with \((\beta _0, \alpha _0)=\arg \min _{\beta , \alpha } E[Y-\{\beta ^{\top } X+g(\alpha ^{\top } Z)\}]^{2}\). It is obvious that the term
is an \(U-\)statistic with the kernel \(\frac{1}{h^{q_1+q_2}}K_{B_{1}B_{2}ij} \epsilon _{i}\epsilon _{j}\).
Using the element properties of \(U-\)statistic and Fubini’s theorem, we have
where \(p_{B_1B_2}\) stands for the density function of \((B^{\top }_1X,B^{\top }_2Z)\).
Additionally, applying the same argument as that in the justification of Theorem 3.1, we can prove that in probability \(s^2_{n}\) converges to some positive value which may be different from \(s^2\) in Theorem 3.1. Thus, altogether, we have
Proof Part (II): As the description as the proof of Part (I) in this theorem, here it is also only needed to consider the events \({\hat{q}}_1=q_1\) and \({\hat{q}}_2=q_2\) in an asymptotic sense. Under the local alternative hypotheses \(H_{1n}\), using the similar statement as that used to justify Theorem 3.1, we can conclude that:
where
with \(\epsilon _{i}=y_i-\beta ^{\top }_0x_i + g(\alpha ^{\top }_0z_i)\). Let \(\varepsilon _i=y_i-\beta ^{\top }_0x_i - g(\alpha ^{\top }_0z_i)-C_n f(B^{\top }_1x_i,B^{\top }_2z_i)\). Then we have \(\epsilon _{i}=\varepsilon _i+C_n f(B^{\top }_1x_i,B^{\top }_2z_i)\) and \(E[\varepsilon _i|w_i]=0\). Furthermore, \(Q_{n}\) is decomposed as:
where \(Q_{1n}\), \(Q_{2n}\) and \(Q_{3n}\) have the following forms as:
Again following the similar argument to that in the justification of Theorem 3.1, we can easily obtain that \(nh^{\frac{q_1+q_2}{2}}Q_{1n}{\mathop {\longrightarrow }\limits ^{\mathrm {d}}} N(0,s^2)\) and thus \(Q_{1n}=O_p(n^{-1}h^{-\frac{q_1+q_2}{2}}).\)
Then we consider the term \(Q_{2n}\). In fact, \(Q_{2n}\) can be written as \(U-\)statistic with the kernel:
where \(t_i=(x_i, z_i, y_i)\). Since \(E[\varepsilon _j|x_i, z_i]=0\), then \(E[H(t_i,t_j)]=0\). To use the properties of a non-degenerate U-statistic (Serfling 1980), it is essential to prove \(E[H^2(t_i,t_j)] = o(n)\). Note that
By the application of Fubini’s theorem and the change of the original variables to be \(v_1=(B^{\top }_1x_2-B^{\top }_1x_1)/h\) and \(v_2=(B^{\top }_2z_2-B^{\top }_2z_1)/h\) yield
We now turn to discuss the conditional expectation of \(H_n(t_i, t_j)\). By Fubini’s theorem, it is easy to calculate \(r_n(t_i)=E\{H_n(t_i, t_j)|t_i\}\) to be
Let \({\tilde{Q}}_{2n}\) denote the “projection" of the statistic \(Q_{2n}\) as:
Central-limit theorem yields that \(\sqrt{n}Q_{21n}=O_p(1)\). As the functions \(g(\cdot ,\cdot )\) and \(p_{B_1B_2}(\cdot ,\cdot )\) satisfy the Lipschitz condition, we have \(E\{l^2_n(t_i)\}=O(h^2)\rightarrow 0\). Note that \(E\{l_n(t_i)\}=0\). We can conclude that \(\sqrt{n}Q_{22n}=o_p(1)\). Therefore, altogether, \(Q_{2n}=O_p(1/\sqrt{n})\). Under the local alternative hypothesis, \(C_nQ_{2n}=O_p(C_n/\sqrt{n})\).
Finally consider the term \(C^2_nQ_{3n}\). It is obvious that \(Q_{3n}\) is also an \(U-\)statistic with the kernel:
with \(t_i=(x_i,z_{i}, y_i)\). Using the element characteristic of \(U-\)statistic, we have
Again, we can derive that \(E\{H_n(t_i,t_j)\}=\mu _1+o(1)\) with
Therefore, we have \(Q_{3n}=\mu _1+o_p(1)\). The above equation implies \(C^2_nQ_{3n}=O_p(C^2_n)\). Altogether, we have
Additionally, following the similar arguments for proving Theorem 3.1, \(s^2_{n} {\mathop {\longrightarrow }\limits ^{\mathrm {p}}} s^2\). Therefore, we have the following conclusions.
If \(q_1=q_2=1\) and \(C_n = n^{-1/2}h^{-1/2}\), \(Q_{1n}\) and \(Q_{3n}\) are the leading terms of \(Q_n\), which yields that
where \(u=E\{f^2(B^{\top }_1X,B^{\top }_2Z)p_{B_1B_2}(B^{\top }_1X,B^{\top }_2Z)\}/s\).
If \(q_1=q_2=1\) and \(C_n n^{1/2}h^{1/2} \rightarrow \infty \), \(Q_{3n}\) is the leading term of \(Q_n\). This implies that
If \(q_1+q_2>2\), if \(C_nn^{1/2} h^{1/2}\rightarrow c_0>0\) for some constant \(c_{0}\) or \(C_nn^{1/2} h^{1/2}\rightarrow \infty \) and \(C_nn^{1/2} h^{(q_1+q_2)/4}\rightarrow 0\), \(Q_{1n}\) is the leading term of \(Q_n\), then we have
If \(q_1+q_2>2\), if \(C_n=n^{-1/2} h^{-(q_1+q_2)/4}\), \(Q_{1n}\) and \(Q_{3n}\) are the leading terms of \(Q_n\), thus, we have
If \(q_1+q_2>2\) and \(C_nn^{1/2} h^{(q_1+q_2)/4}\rightarrow \infty \), \(Q_{3n}\) is the leading term of \(Q_n\). This implies that
The proof is finished. \(\square \)
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Liu, J., Zhu, D., Yu, L. et al. Specification testing of partially linear single-index models: a groupwise dimension reduction-based adaptive-to-model approach. TEST 32, 232–262 (2023). https://doi.org/10.1007/s11749-022-00833-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11749-022-00833-y