
Abstract
In this study, triethylene glycol (TEG) regeneration process, which is a critical step in natural gas (NG) dehydration, was investigated. Machine learning (ML) approach was used to develop robust models that could assess the impacts of operative variables on TEG regeneration. A supervised multilayer feed-forward neural network was employed to develop the models, and the k-fold cross-validation technique was used during the training phase. The impacts of TEG flowrate, pressure of distillation column, and temperature of reboiler on energy consumption and TEG purity were investigated. The optimal conditions for TEG regeneration was found using a genetic algorithm (GA) based on the developed models. The R2 values of test dataset were 0.9998 and 0.9989 for TEG purity and reboiler duty, respectively, demonstrating the reliability of optimally tuned models. Overall, this study sheds light on the factors that affect TEG regeneration and provides a useful framework for optimizing the NG dehydration process.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Natural gas (NG) production has been rising steadily for decades, and it is anticipated that this trend will continue as more environmentally friendly and cleaner energy sources are sought after (Karimi and Abdi 2009). NG is a clean and efficient energy source that has received a great deal of attention recently to address a variety of problems, including climate change and global warming (Zhang et al. 2021). Compared to coal and oil, NG is considered to be the cleanest fossil fuel (Xu et al. 2022). Up until 2030, the demand for NG is expected to increase by 3% annually (Arya et al. 2022). The US department of energy predicts that between 2015 and 2035, gas demand would rise by around 31% (Alnoush and Castier 2019). As of 31st December 2022, the world NG reserves is 202,179 billion cubic meter (BCM). 40% of these reserves are located in Middle East, 33% in Russia and central Asia, 8% in Africa, 8% in North America, and 11% in other areas (Eni World Energy Review 2022). Accordingly, it is obvious that the main NG reservoirs are usually far from consumption places. Therefore, NG transportation receives high importance.
NG transportation can be performed in the gaseous phase by pipeline or in the liquid phase as liquefied natural gas (LNG). In this aspect, NG dehydration is of important especially for distribution of NG. Hydrate formation due to the presence of water and hydrocarbons in NG is the main reason for pipeline plugging (Tagliabue et al. 2009). The different methods for NG dehydration process include absorption by triethylene glycol (TEG), adsorption by solid desiccants, and condensation (Netusil and Ditl 2011). By injecting the stripping gas or stripping solvent into the TEG regeneration column, the performance of TEG regeneration is improved.
Developing a mathematical model is an essential tool for investigation the effects of operational factors on process performance as well as optimization (Moghaddam and Sargolzaei 2015; Rezaei Behbahani et al. 2023). But in many cases, there is a lack of knowledge about the process or the relationship between operating parameters and responses is too complex to find. Therefore, a robust and reliable mathematical model will not be available. The design of experiment (DoE) approach is a potent tool for examining how operative factors affect the efficiency of a process and developing a statistical model. In different processes response surface methodology (RSM), a subset of DoE, has been applied (Ravald et al. 2023; Aslanzadeh et al. 2023; Hedayati Moghaddam et al. 2013; Kanakasabai et al. 2023; Hedayati Moghaddam 2022a; Tian 2023; Zeynali et al. 2017; Alara et al. 2023; Masoudi et al. 2018). In the previous work, the NG dehydration using TEG was investigated and modelled by statistical approach (Hedayati Moghaddam 2022b). Machine learning (ML) algorithms serve as robust tools to find out the input–output relationship where they are complicated and difficult to investigate. There are several examples where ML techniques were used to model and simulate the input–output relations (Hedayati Moghaddam et al. 2017; Singh et al. 2023; Mahmoudian et al. 2022; Bakhtom et al. 2023; Moghaddam et al. 2012; Salam et al. 2022; Rashidi and Moghaddam 2021; Vaziri et al. 2020).
Ghiasi et al. (2015) developed two intelligent approaches; a least squares support vector machine (LSSVM) algorithm and a multilayer perceptron (MLP) neural network to predict the ideal stripping gas flow rate in NG dehydration systems. According to the statistical analysis, the values generated from the predictive tools (such as MLP, LSSVM, and empirical equations) and the actual data were found to be well matched, and the average absolute relative deviation percent (AARD%) was shown to be less than 0.01%. Additionally, Ghiasi et al. (2014) developed an intelligent model based on the conventional feed-forward back-propagation neural network for precise TEG purity prediction based on reboiler operating conditions. By using several statistical factors, the ability of the provided neural-based model to estimate the TEG purity was assessed. The proposed smart technique was found to replicate the reported data in literature with an average AARD% of roughly 0.30%. In another later study, Ahmadi et al. (2015) investigated the potential of LSSVM modelling algorithms to predict the moisture content of NG dried by calcium chloride dehydrator units. The optimal LSSVM model parameters were found using genetic algorithms (GA) as population-based stochastic search techniques. According to the findings, the GA-LSSVM was able to accurately capture the complicated nonlinear relationship between the input and output variables. The GA-LSSVM model produced mean absolute error (MAE) and coefficient of determination (R2) values of 2.7898 and 0.9986, respectively.
In addition to MLP and LSSVM, many other ML algorithms have been used for conducting NG dehydration research. Okoro et al. (2022a) investigated the performance of a supersonic separator during the dehydration of NG using a decision tree ML model to examine the effects of design and operating parameters (inlet and outlet pressures, nozzle length, throat diameter, and pressure loss ratio) on the shock wave location. The model's findings indicated that the nozzle length and pressure loss ratio are the major factors affecting the shock location. Dew point depression was shown to be most significantly impacted by the former. With a mean average percentage error (MAPE) of 5.98 as opposed to 15.44 for the 1-D model, the ML model outperformed the 1-D iterative approach when accuracy was compared. In another study, Okoro et al. (2022b) developed three ML models, including the gradient boosted decision tree (GBDT), support vector regression (SVR), and radial basis function-neural network (RBF-NN) for predicting the compressibility factor (z-factor) of NG mixtures with a range of Pseudo-reduced pressure (Ppr) and temperature (Tpr) of 0–30 and 0.92–3.0, respectively. According to the findings, the GBDT model performed better than the other used ML models and published correlations. The root-mean-square error (RMSE) and R2 score for the proposed models were highly acceptable, coming in at 0.01033 and 0.99962, respectively.
Similarly, Ren et al. (2023) used GDBT for developing a process parameter online prediction approach for monitoring the quality of petrochemical equipment and machinery. The mapping model was created using an efficient Gaussian process (GP), and the online approach for predicting NG water dew points for the TEG dehydration unit was also examined. It was concluded that the research findings can be used to improve the safety of NG dehydration stations by enabling prompt monitoring of the water dew point and other important process parameters. Furthermore, Wu et al. (2023) used four ML models, including MLR, random forest (RF), M5 Rule (M5R), and support vector machine (SVM), to assess the hydrate formation temperature (HFT) of NG in the presence of amino acids. The purpose of the study was to capture the relationship between the structural properties of amino acids and the strength of their hydrate inhibition and choose the best type and concentration to use. The four models R2 scores were 0.9328, 0.9793, 0.9795, and 0.9980 after parameter optimization using the trial-and-error method. Since the RMSE of the SVM prediction of HFT was 83%, 76%, and 69% lower than those of the MLR, RF, and M5R, respectively, it outperformed other models.
In the present work, the aim is to develop an artificial intelligence (AI)-based model to investigate the effects of operating factors on the performance of TEG regeneration process in NG dehydration. The procedure used in this work is presented in Fig. 1. At first, the data obtained from Aspen-Hysys simulation from the previous work (Hedayati Moghaddam 2022b) and the data of performed simulation of the present work are gathered. Then, the data are evaluated to remove the anomalous items from the dataset. Before starting the model development phase, the data must be shuffled to create a randomized dataset. In the next step, the randomized data are split into the two separated sections (seen and unseen dataset). The unseen dataset is termed as test dataset. On the other hand, the seen dataset is used to develop and validate the model. After determining the structure of the model and training the network by tuning the hyperparameters, the test dataset is fed into the model to test the model outputs. Finally, the tested model is used to find the optimum condition in companion with GA.

Implemented procedure in developing the optimum model and subsequent optimization
Methodology and procedure
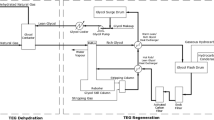
Water absorption process & TEG regeneration
In NG dehydration facility, wet NG after passing a flash drum enters into a contact column. TEG and wet NG flow counter currently in a tray or packed column. Lean TEG and wet NG flows downward and upward, respectively. Exiting from the base of the contact column, the enriched TEG that is termed weak or rich TEG enters a heat exchanger where exchanges of heat with water vapor flow out from the TEG regeneration column. Next, the heated weak TEG passes a flash drum to remove a portion of absorbed water. Then the TEG after passing a heat exchanger enters into a distillation column where water is completely separated from it. Due to prevent degradation of TEG, the reboiler temperature value should be set to less than 205 °C. Generally, one of the main disadvantages of separation based on the difference in boiling temperature (distillation process) is the possibility of thermal degradation. More details about the process can be found in previous work (Hedayati Moghaddam 2022b).
Data gathering
The source data used for AI model development were obtained from the previous work (Hedayati Moghaddam 2022b), where the effects of flowrate of TEG, pressure of distillation column, and temperature of reboiler as input factors on the reboiler duty of distillation column and TEG purity as responses were investigated using a statistical approach (central composite design). Note, more information about the way of design layout, simulation, data gathering, and statistical analysis was presented in previous work. In this study, to develop the robust models, several excess runs have been conducted to increase the size of data. The operative ranges of the input factors are shown in Table 1.
Data assessment
In Table 2, the specifications of the dataset are shown. Since data with unusual variance leads to incorrect model terms, before feeding data into the model development phase, data clarification should be performed. In Fig. 2, the values of reboiler duty and recovered TEG purity for performed simulations have been presented. In this case, there is no null or missed data. Further, unusual variance was not observed. So, there is no outlier. Accordingly, there is no need to remove any line of the dataset.

Values of reboiler duty and TEG purity
Note, the existence of correlation between operative parameters is not of interest. So, this issue should be checked. In Fig. 3, the correlation between operative parameters have been shown graphically. The closer the correlation coefficient between two parameters is to one or minus one, it means that there is a higher correlation between these two parameters. It is obvious that there is no considerable correlation between the operative parameters.

Correlations between parameters for a TEG purity and b reboiler duty
Before developing the regression models, data normalization should be performed. In this study, only operative parameters were normalized. The normalized value (yn) is calculated according to the following equation:
where ymax. and ymin. are highest and lowest values of operative parameter. So, the normalized input factors range from 0.05 to 0.95.
Model development
ML has several subsets including regression, data classification, data clustering etc. Note, in regression problems, the response is a continuous parameter, while in classification problems, the response is discrete. A precise model based on multi-layer feed forward neural network (MLFFNN) was created using a single hidden layer. Note, there is no feedback from outputs of neurons toward their own inputs or the inputs of other neurons.
In training process, the weights and biases are set in a way to reduce the average of the squared differences, also known as mean squared error (MSE). The definition of MSE can be expressed in the following manner:
Note, yf, y, and n are the forecasted value, target value, and size of dataset, respectively.
To check the performance of trained models, determination coefficient (R2) of test dataset is used. R2 is calculated as follows:
where \(\overline{y }\) is the mean value of targets.
The average relative error (ARE) is an index to evaluate the preciseness of model and is calculated as follow:
After building any machine learning model, a portion of the data termed the training dataset is fed into the model to train the model. Subsequently, the other portion of the data termed testing dataset is used to test the model accuracy. If the predicted output on the test dataset and the target response match well, this implies that the constructed model has the capability to forecast the results with a satisfactory level of precision. Usually, the accuracy of model on the given data (training dataset) is high. However, this is not enough since the model accuracy should be examined over unseen data (test dataset). If the model output matches well with the goal on the training dataset while weak prediction ability is observed on test dataset, this means that over-fitting is happening. On the other hand, if the developed model has not been trained well so this model will have poor prediction ability even on training dataset. This situation is called under-fitting.
In this work to assess the model prediction ability during the training process, a cross-validation technique is used. In Fig. 4, k-fold cross-validation technique is presented. The size of seen data is 40 × 5. Therefore, this dataset includes three features (operative parameters) and two responses. The values of each row is related to one run. In each iteration, 4 rows are selected as validation dataset. Accordingly, in this work, k is equal to 10. For training the network, Levenberg–Marquardt (LM) procedure is used.

Schematic of K-fold cross-validation technique
Results and discussion
Tuning hyper parameters
As previously stated in the earlier section, reboiler duty and TEG purity were modelled in terms of input factors. The value of R2 corresponded to validation dataset is an index to adjust the hyper parameters of the best-performing model. In this work, MLFFNN with a single hidden layer was chosen to continue as a platform for developing the models. The values of validation R2 and validation ARE regarding the quantity of neurons in the hidden layer for reboiler duty and TEG purity are shown in Fig. 5. As presented in Fig. 5a, the highest possible value of validation R2 of TEG purity and reboiler duty is 0.9993 and 0.9984, respectively. These values corresponded to 5 and 4 neurons in hidden layer, respectively. It is clear that for networks that have over 10 neurons in the hidden layer, a substantial reduction in the magnitude of validation R2 is observed. According to Fig. 5b, the minimum values of validation ARE of TEG purity and reboiler duty are observed when the hidden layer consists of 3 and 11 neurons, respectively.

Validation-R2 and Validation-ARE values versus number of neurons in the hidden layer
After selecting the structure of the optimum models for TEG purity and reboiler duty, the model training was repeated 10 times to ensure the predictive ability of the models by comparing the validation-R2 values of each run. In Fig. 6, the R2 values of each run for TEG purity and reboiler duty have been shown. The average values of R2 of these 10 runs were 0.9969 and 0.9981 for TEG purity and reboiler duty, respectively. These results confirm that the optimally tuned models are reliable.

Validation-R2 values for optimum structure versus run number
Figure 7 illustrates the values of errors (predicted—Hysys values) for responses. As shown in Fig. 7a, the absolute value of positive and negative error mean is about 1 × 10–4 that is acceptable.

Error values of predicted TEG purity and reboiler duty
In previous section, robust model were built, trained, and validated. In this section, an unseen (test) dataset with 10 rows is fed into the optimum tuned network to test the model accuracy. Figure 8 depicts a comparison between data generated by Hysys simulator and AI model. It is evident that the prediction of the AI-based model is reliable and R2 value is vicinity 1 that implies good agreement between the data generated by Hysys and AI model. It is found that R2 value of validation dataset is similar to the test dataset ones. So, the developed models can predict the process performance with high precision.

Comparison of Hysys and predicted data of test dataset for a TEG purity and b reboiler duty
So, in the left portion of this paper, these two optimum models are used to examine the impact of operational variables on the performance of process and process optimization.
TEG flowrate-pressure interaction
The effects of TEG flowrate and column pressure are demonstrated in Fig. 9 while the reboiler temperature was fixed at 170.5 °C. In this situation, the maximum and minimum amounts of TEG purity are 95.14% and 88.82%, respectively. Further, the minimum and maximum values of reboiler duty are 53.92 and 58.47 kW, respectively. According to Fig. 9a, an increase in column pressure results in a decrease in TEG purity. The phenomenon can be attributed to the fact that an increase in column pressure raises the bubble point of the mixture, leading to lower TEG purity. According to Fig. 9c, for column pressure of 40–70 kpa, the purity of TEG remains largely unaffected by an increase in the flowrate of TEG. For column pressure of 85 kpa, an increase in TEG flowrate from 2.8 to 2.9 kg mol/h causes a mild increase in TEG purity, and for higher values of TEG flowrate, no change is observed.

The purity of TEG and reboiler duty versus pressure and TEG flowrate while the temperature of reboiler remains constant at 170.5 °C
From Fig. 9b, it is clear that if the pressure inside the column increases, it will result in a reduction of the duty required for the reboiler. By increasing the column pressure, the rate of upward stream (vapor flowrate) decreases and leads to a lower reboiler duty. Figure 9d reveals that if the flowrate of TEG increases, it will lead to a corresponding increase in the duty required for the reboiler. The reason for these observations is that, in fact, with the increase in TEG flowrate, the flowrate of column feed increases and leads to more reboiler duty.
Reboiler temperature–pressure interaction
Figure 10 represents the impacts of reboiler temperature and pressure of column on TEG regeneration performance and energy consumption while the TEG flowrate was fixed at 2.95 kg mol/h. At this value of TEG flowrate, the highest and lowest purity values are 97.52% and 71.79.14%, respectively. And, the highest and lowest values of reboiler duty are 68.79 and 27.48 kW, respectively. Figure 10a shows that an increase in reboiler temperature at any pressure leads to higher TEG purity. The reason for this is that as the reboiler temperature increases, the flowrate of vapor phase rises which causes higher purity of TEG, subsequently. Figure 10c presents the changes in TEG purity versus column pressure for different reboiler temperature. It is clear that these changes are more severe for lower reboiler temperatures. According to Fig. 10b, when the reboiler temperature increases, there is a corresponding increase energy consumption. Figure 10d shows that for reboiler temperature higher than 190 °C, the changes in column pressure have no considerable effect on reboiler duty. However, for lower temperatures, the trend is descending. This means that, for temperatures less than 190 °C by increasing the column pressure, the reboiler duty decreases.

TEG Purity and reboiler duty versus pressure and reboiler temperature while the TEG flowrate remains constant at 2.9 kg mol/h
Optimization
Based on AI model, GA was used to find the approachable minimum and maximum values of responses. Table 3 represents the values of predicted minimum and maximum values based on AI model and Hysys simulation are shown and compared. The values of ARE show good agreement between the minimum and maximum TEG purity and reboiler duty obtained by AI model and Hysys simulation. According to the material of this table, the maximum achievable TEG purity is 97.52% based on AI model and 97.64% based on Hysys simulation. This value of TEG purity is achieved when TEG flowrate, reboiler temperature, and column pressure are 2.86 kg mol/h, 205 °C, and 40 kpa, respectively. Since this condition leads to a considerable amount of energy consumption, this condition may be applied if the energy consumption is not of importance.
Conclusion
Among all types of energy resources, natural gas (NG) is considered to be highly environmentally friendly that receive high attention due to its advantage over other fossil fuels. The performance of the distillation column in the process of regenerating the triethylene glycol (TEG) was modelled based on machine learning (ML) techniques. The energy consumption of the distillation column and TEG purity was modelled using a feed forward-based neural network with single hidden layer. The major findings of this study were:
-
The values of R2 of the test dataset were 0.9998 and 0.9989 for TEG purity and reboiler duty, respectively. These results confirm that the optimally tuned models are reliable.
-
The effects of TEG flowrate and column pressure on TEG purity and Reboiler duty were investigated while the reboiler temperature was fixed at 170.5 °C. Accordingly, the lowest and highest values of TEG purity were 88.82% and 95.14%, respectively. Further, the lowest and highest values of reboiler duty were 53.92 and 58.47 kW, respectively.
-
Further, the impacts of temperature of reboiler and pressure of column on TEG purity and reboiler duty were investigated while the TEG flowrate was fixed at 2.95 kg mol/h. At this value of TEG flowrate, the maximum and minimum values of TEG purity were 97.52% and 71.79%, respectively. Also, the maximum and minimum values of reboiler duty were 68.79 and 27.48 kW, respectively.
-
Based on AI model, the maximum achievable TEG purity was 97.52% which corresponds to a TEG flowrate, a reboiler temperature, and a column pressure of 2.86 kg mol/h, 205 °C, and 40 kpa, respectively.
References
Ahmadi MA, Lee M, Bahadori A (2015) Prediction of a solid desiccant dehydrator performance using least squares support vector machines algorithm. J Taiwan Inst Chem Eng 50:115–122
Alara OR, Abdurahman NH, Ali HA (2023) Optimization of microwave-enhanced extraction parameters to recover phenolic compounds and antioxidants from Corchorus olitorius leaves. Chem Pap 77:4217–4233
Alnoush W, Castier M (2019) Shortcut modeling of natural gas supersonic separation. J Nat Gas Sci Eng 65:284–300
Arya AK, Jain R, Yadav S, Bisht S, Gautam S (2022) Recent trends in gas pipeline optimization. Mater Today Proc 57:1455–1461
Aslanzadeh F, Konoz E, Niazi A, Bakhsh AF, Ezabadi A (2023) Simple and rapid synthesis of magnetic kiwifruit for the removal of sitagliptin and fampridine residues from aqueous media using HPLC method: optimization via central composite experimental design. Chem Pap 77:5097–5114
Bakhtom A, Ghasemzade Bariki S, Movahedirad S, Sobati MA (2023) Machine learning-guided prediction and optimization of precipitation efficiency in the Bayer process. Chem Pap 77:2509–2524
Eni World Energy Review (2022) www.eni.it
Ghiasi MM, Bahadori A, Zendehboudi S (2014) Estimation of triethylene glycol (TEG) purity in natural gas dehydration units using fuzzy neural network. J Nat Gas Sci Eng 17:26–32
Ghiasi MM, Bahadori A, Zendehboudi S, Chatzis I (2015) Rigorous models to optimise stripping gas rate in natural gas dehydration units. Fuel 140:421–428
Hedayati Moghaddam A (2022a) Simulation and optimization of separation section in methanol to olefin (MTO) process based on statistical approach. Chem Pap 76:4787–4794
Hedayati Moghaddam A (2022b) Investigation of natural gas dehydration process using triethylene glycol (TEG) based on statistical approach. Chem Pap 77(3):1433–1443
Hedayati Moghaddam A, Shayegan J, Sargolzaei J, Bahadori T (2013) Response surface methodology for modeling and optimizing the treatment of synthetic starchy wastewater using hydrophilic PES membrane. Desalin Water Treat 51:7036–7047
Hedayati Moghaddam A, Hazrati H, Sargolzaei J, Shayegan J (2017) Assessing and simulation of membrane technology for modifying starchy wastewater treatment. Appl Water Sci 7:2753–2765
Kanakasabai P, Sivamani S, Thirumavalavan K (2023) Box-Behnken design and analysis for liquid–liquid extraction of methyl red dye from its aqueous solution with benzene. Chem Pap. https://doi.org/10.1007/s11696-023-03013-w
Karimi A, Abdi MA (2009) Selective dehydration of high-pressure natural gas using supersonic nozzles. Chem Eng Process 48:560–568
Mahmoudian F, Moghaddam AH, Davachi SM (2022) Genetic-based multi-objective optimization of alkylation process by a hybrid model of statistical and artificial intelligence approaches. Can J Chem Eng 100:90–102
Masoudi SMA, Hedayati Moghaddam A, Sargolzaei J, Darroudi A, Zeynali V (2018) Investigation and optimization of the SND–SBR system for organic matter and ammonium nitrogen removal using the central composite design. Environ Prog Sustain Energy 37:1638–1646
Moghaddam AH, Sargolzaei J (2015) Biofilm development on normal and modified surface in a hybrid SBR-based bioreactor. J Taiwan Inst Chem Eng 49:165–171
Moghaddam AH, Sargolzaei J, Asl MH, Derakhshanfard F (2012) Effect of different parameters on WEPS production and thermal behavior prediction using artificial neural network (ANN). Polym-Plast Technol Eng 51:480–486
Netusil M, Ditl P (2011) Comparison of three methods for natural gas dehydration. J Nat Gas Chem 20:471–476
Okoro EE, Igbinedion U, Aimikhe V, Sanni SE, Agwu OE (2022a) Evaluation of influential parameters for supersonic dehydration of natural gas: machine learning approach. Pet Res 7:372–383
Okoro EE, Ikeora E, Sanni SE, Aimihke VJ, Ogali OI (2022b) Adoption of machine learning in estimating compressibility factor for natural gas mixtures under high temperature and pressure applications. Flow Meas Instrum 88:102257
Rashidi S, Moghaddam AH (2021) Investigation and optimization of anaerobic system for treatment of seafood processing wastewater. Chem Pap 75:4649–4660
Ravald H, Moghaddam AH, Jaikishan S, Lavainne M, Wiedmer SK (2023) Effect of liposome composition on β-blocker interactions studied by capillary electrokinetic chromatography. J Separation Sci 46(18):2300414
Ren H, Yin A, Dai Z, Liu X, Tan Z, Zhang B (2023) Parameter screening and optimized gaussian process for water dew point prediction of natural gas dehydration unit. Process Saf Environ Prot 170:259–266
Rezaei Behbahani M, Azizi S, Azizi Z, Peyghambarzadeh SM, Ghanavati B (2023) Experimental and modeling study of molecular diffusion of carbon dioxide in light oil. Chem Pap 77:4355–4368
Salam KK, Oke EO, Ude CJ, Yahaya U (2022) Zeolite-Y-based catalyst synthesis from Nigerian Elefun Metakaolin: computer-aided batch simulation, comparative predictive response surface and neuro-fuzzy modelling with optimization. Chem Pap 76:1213–1224
Singh R, Anand A, Ganeshpurkar A, Ghosh P, Chaurasia T, Singh RB, Kumar D, Singh SK, Kumar A (2023) Machine learning-based screening of in-house database to identify BACE-1 inhibitors. Chem Pap 77(11):6849–6858
Tagliabue M, Farrusseng D, Valencia S, Aguado S, Ravon U, Rizzo C, Corma A, Mirodatos C (2009) Natural gas treating by selective adsorption: Material science and chemical engineering interplay. Chem Eng J 155:553–566
Tian C (2023) Optimization of ferrous iron removal conditions by freezing from industrial titanyl sulfate solution for high purity TiO2 preparation. Chem Pap 77:4235–4244
Vaziri H, Hedayati Moghaddam A, Mirmohammadi SA (2020) Optimization of distillation column in phenol production process for increasing the isopropyl benzene concentration using response surface methodology and radial basis function (RBF) coupled with leave-one-out validation method. Chem Pap 74:3311–3324
Wu G, Coulon F, Feng J-C, Yang Z, Jiang Y, Zhang R (2023) Machine learning models for fast selection of amino acids as green thermodynamic inhibitors for natural gas hydrate. J Mol Liq 370:120952
Xu S, Wang J, Sun H, Huang L, Xu N, Liang Y (2022) Life cycle assessment of carbon emission from natural gas pipelines. Chem Eng Res Des 185:267–280
Zeynali V, Sargolzaei J, Hedayati Moghaddam A, Ali Masoudi SM (2017) Implication of statistical design approach methodology for optimization of COD removal, effluent quality, and biosludge settling properties in aerobic bioreactors. Environ Prog Sustain Energy 36:1428–1438
Zhang R-H, Chen S-N, Hu S-Y, Zhao Y-L, Zhang B-N, Wang R-H (2021) Numerical simulation and laboratory experiments of CO2 sequestration and being as cushion gas in underground natural gas storage reservoirs. J Nat Gas Sci Eng 85:103714
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
On behalf of all authors, the corresponding author states that there is no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Moghaddam, A.H., Sadeq, A.M. Development of supervised machine learning model for prediction of TEG regeneration performance in natural gas dehydration. Chem. Pap. 78, 587–597 (2024). https://doi.org/10.1007/s11696-023-03113-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11696-023-03113-7