
Abstract
Sensitivity analysis of a model can identify key variables affecting the performance of the model. Uncertainty analysis is an essential indicator of the precision of the model. In this study, the sensitivity and uncertainty of the Long-Term Hydrologic Impact Assessment-Low Impact Development 2.1 (L-THIA-LID 2.1) model in estimating runoff and water quality were analyzed in an urbanized watershed in central Indiana, USA, using Sobol′‘s global sensitivity analysis method and the bootstrap method, respectively. When estimating runoff volume and pollutant loads for the case in which no best management practices (BMPs) and no low impact development (LID) practices were implemented, CN (Curve Number) was the most sensitive variable and the most important variable when calibrating the model before implementing practices. When predicting water quantity and quality with varying levels of BMPs and LID practices implemented, Ratio_r (Practice outflow runoff volume/inflow runoff volume) was the most sensitive variable and therefore the most important variable to calibrate the model with practices implemented. The output uncertainty bounds before implementing BMPs and LID practices were relatively large, while the uncertainty ranges of model outputs with practices implemented were relatively small. The limited observed data in the same study area and results from other urban watersheds in scientific literature were either well within or close to the uncertainty ranges determined in this study, indicating the L-THIA-LID 2.1 model has good precision.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Computer based mathematical hydrologic/water quality models, from the simplest to the most complex, are based on simplified mathematical descriptions of natural watershed processes. In hydrologic and water quality simulation, the physical processes are complex and involve high costs for measuring model variables (inputs and parameters) which vary at spatial and temporal scales. As a result, to properly simulate hydrology and water quality at the watershed scale, model variables must be specified for each application of the model (Duan et al. 2003; Gitau et al. 2016). Model calibration, which adjusts model parameters to match simulated results with observed data within a certain accuracy level, is commonly used to estimate model parameters (Abbott et al. 1986). Before the calibration process, sensitivity analysis is often conducted.
Sensitivity analysis of a model is a useful screening tool developed to find the main parameters affecting performance of the model by estimating which contribute the most to output variability (Muleta and Nicklow 2005; Kanakoudis et al. 2011; Castaño et al. 2013; D’Agostino et al. 2014; Sharifi and Dinpashoh 2014; Andersson et al. 2015; Debnath et al. 2015; Machado et al. 2016; Valdez et al. 2016). Sensitivity analysis methods can be divided into two groups: local sensitivity analysis and global sensitivity analysis. Local sensitivity analysis, or one at a time sensitivity analysis, estimates sensitivity by varying each variable in a certain range while keeping other variables at their nominal values (Holvoet et al. 2005); although it is easy to conduct, local sensitivity analysis has limitations due to assumptions of no interactions between variables, and local sensitivity analysis can capture model response with respect to only one variable at a time (Helton 1993; Muleta and Nicklow 2005). In comparison to local sensitivity analysis, global sensitivity analysis is more reliable because of computing integrated sensitivity over the entire range of variables; the impacts of variable interactions on model outputs can also be investigated. Sobol′‘s global sensitivity analysis method (Sobol′ 1993) is a popular variance decomposition based method that can characterize single variable and multivariable interactions (Sobol′ 1993; Sobol′ 2001; Tang et al. 2006; Tang et al. 2007; Cibin et al. 2010).
The calibrated model will have minimized propagation of variable uncertainties into the uncertainties of model outputs (Migliaccio and Chaubey 2008). However, uncertainty remains because of the complicated stochastic features of environmental processes, quantity/quality of input data, and parameter evaluation (Tsakiris and Spiliotis 2004; Muleta and Nicklow 2005; Gaur and Simonovic 2015; Narsimlu et al. 2015; Theodossiou and Fotopoulou 2015). Uncertainty analysis, which estimates overall uncertainty of the model results, is a vital indicator of the precision of a model. The bootstrap method, which is suitable for both simple and complicated models (Tang et al. 2006; Tang et al. 2007; Hanel et al. 2013; Sreekanth and Datta 2014; Kumar et al. 2015; Zhang et al. 2015), is able to estimate confidence intervals for model outputs with the lowest time consumption. Uncertainty analysis methods are discussed separately; however, they can also be employed to estimate parameter sensitivity.
The L-THIA-LID 2.1 model (Liu 2015; Liu et al. 2015a, b; Liu et al. 2016a, b), which was newly enhanced based on previous L-THIA models (e.g. Harbor 1994; Engel et al. 2003; Tang et al. 2005; Muthukrishnan et al. 2006; Wilson and Weng 2010; Ahiablame 2012; Ahiablame et al. 2012; Ahiablame et al. 2013; Wright et al. 2016), is an easy to use tool that aims to estimate the impacts of BMPs and LID practices on runoff and water quality at watershed scales. Although studies analyzed the sensitivity of the L-THIA model (Wilson and Weng 2010) and uncertainty of the L-THIA-LID model in estimating runoff (Ahiablame 2012), studies about sensitivity analysis and uncertainty analysis of the newly enhanced L-THIA-LID 2.1 model in estimating both runoff and water quality have not been reported. This paper was the first study to analyze the sensitivity and uncertainty of the newly enhanced L-THIA-LID 2.1 model, which would help model users and future researchers understand the precision of the model and the key variables affecting performance of the model.
The objectives of this study were to 1) use Sobol′‘s global sensitivity analysis method to analyze sensitivity of the L-THIA-LID 2.1 model in estimating runoff and water quality without and with BMPs and LID practices implemented; and 2) use the bootstrap method to analyze the output uncertainty of L-THIA-LID 2.1 model in predicting water quantity and quality without and with BMPs and LID practices implemented.
2 Materials and Methods
2.1 Study Area
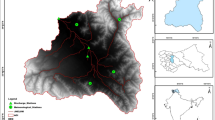
The study area is Crooked Creek Watershed in central Indiana, USA (Fig. 1). The total area of the watershed is 5129 ha, and the watershed is highly urbanized with over 88 % of its area covered by urban land uses (including residential, industrial, and commercial areas), which makes it suitable to model the impacts of BMPs and LID practices. Stormwater runoff flows to the outlet of watershed with no interaction of municipal sewer systems.

Location of Crooked Creek Watershed in Central Indiana, USA
2.2 Input Data
Daily precipitation data (from 1993 to 2010) for two stations (USC124249 and USC129557) were obtained from the National Climatic Data Center (http://www.ncdc.noaa.gov). Hydrologic soil group (HSG) data were obtained from Soil Survey Geographic (SSURGO) database. All hydrologic soil groups of high density residential, commercial, and industrial areas were assumed to be D because of construction impacts (Lim et al. 2006). Land use classes in the National Land Cover Dataset (NLCD) 2001 (http://www.mrlc.gov/nlcd2001.php) were obtained and reclassified by the method described in Liu et al. (2015b) using ArcGIS.
The GIS data for street centerlines, imperviousness, streams, lakes, and building footprints were downloaded from the IndianaMap Layer Gallery (http://maps.indiana.edu/layerGallery.html). Digital elevation model (DEM) data were obtained from the National Map (http://nationalmap.gov/). Based on methods described in Liu et al. (2015b), these data were combined to quantify surfaces of streets, sidewalks, parking lots, driveways, roof tops, patios, streams, and lakes; and also estimate imperviousness of the area, drainage area, and drainage slope.
2.3 Variables and Outputs for L-THIA-LID 2.1 Model
2.3.1 Ranges and Probability Density Function of Variables
The ranges, probability density function (pdf), notes, default values of variables and variables needed for each simulation in L-THIA-LID 2.1 are shown in Table 1. The inputs and parameters (together called variables) of the L-THIA-LID 2.1 model included curve number (CN), precipitation (P), event mean concentration (EMC), ratio of outflow runoff volume to inflow runoff volume (Ratio_r), irreducible concentration (IC), and ratio of outflow pollutant concentration to inflow pollutant concentration (Ratio_C).
The ranges of variables were defined as percent changes from default values. Previous studies suggested that parameters and input data ranges had more impact on results than actual probability distribution functions (pdfs), and uniform distribution would be sufficient for exploratory studies (Helton 1993; Haan et al. 1998; Muleta and Nicklow 2005). Therefore, the pdfs of the percent changes were assumed to be uniform distributions.
An upper limit of 2 % changes from default CN values was used to keep the biggest CN lower than 100; and a lower limit of −20 % changes from default CN values was adapted to keep the lowest CN of urban land uses reasonable. The lower and higher limits of changes (−10 % to 10 %) from measured P values were 25th and 75th percentiles of percent differences between the annual rainfalls of the two rainfall gauge stations near Crooked Creek Watershed (USC00129557 and USC00124249) used in the study. The annual rainfall data, instead of daily rainfall data, were compared because the L-THIA-LID 2.1 model estimates long-term annual results of runoff volume and pollutant loads. The lower and higher limits of percent changes from default EMC values were 25th and 75th percentiles of the percent differences between minimum and median, maximum and median values, respectively, using data from Baird et al. (1996). For Ratio_r, IC, and Ratio_c, based on data from the International Stormwater BMP database (www.bmpdatabase.org), the lower limits were median values of percent differences between 25th percentile and median values from the database; and higher limits were median values of percent differences between 75th percentile and median values from the database.
2.3.2 Outputs from L-THIA-LID 2.1 Model
Before implementing BMPs and LID practices, the outputs of the model tested included the runoff volume (m3/ha/yr), and loads of Total Nitrogen (TN) (kg/ha/yr), Total Kjeldahl Nitrogen (TKN) (kg/ha/yr), Nitrate + Nitrite (NOx) (kg/ha/yr), Total Phosphorus (TP) (kg/ha/yr), Dissolved Phosphorus (DP) (kg/ha/yr), Total Suspended Solids (TSS) (kg/ha/yr), Total Dissolved Solids (TDS) (kg/ha/yr), Total Lead (Pb) (g/ha/yr), Total Copper (Cu) (g/ha/yr), Total Zinc (Zn) (g/ha/yr), Total Cadmium (Cd) (g/ha/yr), Total Chromium (Cr) (g/ha/yr), Total Nickel (Ni) (g/ha/yr), Fecal Coliform (FC) (colonies/ha/yr), Fecal Streptococcus (FS) (colonies/ha/yr), Escherichia coli (E.coli) (MPN/ha/yr), Biochemical Oxygen Demand (BOD) (kg/ha/yr), Chemical Oxygen Demand (COD) (kg/ha/yr), and Oil and Grease (O&G) (kg/ha/yr).
After implementing BMPs and LID practices, the outputs of the model were cumulative runoff/pollutant value (CRPV) as shown in the following equations.
\( pollutant- CRPV=\frac{1}{19}\Big(\frac{TSS}{TS{S}^{\mathit{\hbox{'}}}}+\frac{TDS}{TD{S}^{\mathit{\hbox{'}}}}+\frac{TP}{T{P}^{\mathit{\hbox{'}}}}+\frac{DP}{D{P}^{\mathit{\hbox{'}}}}+\frac{TN}{T{N}^{\mathit{\hbox{'}}}}+\frac{TKN}{TK{N}^{\mathit{\hbox{'}}}}+\frac{N{O}_x}{N{O_x}^{\mathit{\hbox{'}}}} \) \( +\frac{Cd}{C{d}^{\hbox{'}}}+\frac{Cr}{C{r}^{\hbox{'}}}+\frac{Cu}{C{u}^{\hbox{'}}}+\frac{Pb}{P{b}^{\hbox{'}}}+\frac{Ni}{N{i}^{\hbox{'}}}+\frac{Zn}{Z{n}^{\hbox{'}}}+\frac{FC}{F{C}^{\hbox{'}}}+\frac{FS}{F{S}^{\hbox{'}}} \)
Where, runoffand pollutant names are runoff volume and pollutant loads after implementing BMPs and LID practices. Runoff 'and pollutant names '(with right single quotation mark) are runoff volume and pollutant loads before implementing BMPs and LID practices.
2.4 Sobol′‘S Sensitivity Analysis Method
Model sensitivity was analyzed using a variance-based technique named Sobol′‘s global sensitivity analysis method (Sobol′ 1993). Although Sobol′‘s method requires a large number of model evaluations, it is the most accurate method in characterizing single variable and multivariable interactions (Tang et al. 2006). The Monte Carlo method was combined with Sobol′‘s method to conduct sensitivity analysis (Sobol′ 1993; Sobol′ 2001; Hall et al. 2005). In this study, the number of samples for Monte Carlo approximation was set to be 2000 based on literature recommendations (Tang et al. 2007).
2.5 Uncertainty Analysis with Bootstrap Method
After sensitivity analysis, the uncertainties of the model outputs were analyzed with the bootstrap method. The bootstrap method (Efron 1979; Efron and Tibshirani 1993) is a nonparametric estimation technique using a random mechanism to create bootstrap samples by direct resampling with replacement from empirical distribution functions of data. The bootstrap technique can be applied with minimum assumptions and with unknown sample distributions (Efron 1979; Efron and Tibshirani 1993). In this study, 2000 was used as the resample dimension based on previous literature (Tang et al. 2006).
2.6 Simulation Scenarios
With BMPs and LID practices implemented, two groups of practices, including lower level implementation and higher level implementation, were applied in suitable areas of the watershed with randomly assigned implementation levels. Suitable areas of the watershed for implementing each practice were identified by considering drainage area, drainage slope, imperviousness, hydrologic soil group, road buffer, stream buffer, and building buffer (Liu et al. 2015a, 2015b). Random implementation levels were assigned to each practice from a group of preset values. The specific location of each practice did not matter in this study, because the implementation level of each practice was based on percentages of suitable areas. The lower level implementation of practices included 19 % green roof, 19 % rain barrel/cistern, 6 % green roof with rain barrel/cistern, 25 % bioretention system, 25 % porous pavement, 25 % permeable patio, 25 % grass strip, 12.5 % grassed swale, 12.5 % wetland channel, 18 % retention pond, 4 % detention basin, and 4 % wetland basin. The higher level implementation of practices included 37.5 % green roof, 37.5 % rain barrel/cistern, 12.5 % green roof with rain barrel/cistern, 50 % bioretention system, 50 % porous pavement, 50 % permeable patio, 50 % grass strip, 25 % grassed swale, 25 % wetland channel, 35 % retention pond, 7.5 % detention basin, and 7.5 % wetland basin. The percentages mentioned above are percent implementation of each BMP/LID practice in areas where they are suitable to be implemented.
Sobol′‘s global sensitivity analysis method was used for estimating sensitivity of the L-THIA-LID 2.1 model. Total order Sobol′‘s sensitivity indices for estimating runoff volume and pollutant loads without implementing BMPs/LID practices and for estimating runoff volume and pollutant loads with different levels of BMPs/LID practices implemented were estimated and compared.
The bootstrap method was used to analyze the output uncertainty of the L-THIA-LID 2.1 model in predicting water quantity and quality without and with BMPs and LID practices implemented. The 95 % confidence intervals and confidence interval widths of the model outputs were estimated and compared with results observed and from literature. Distributions of samples for uncertainty analysis were also studied.
3 Results and Discussion
3.1 Sensitivity Analysis
The total order Sobol′‘s sensitivity indices for estimating runoff volume and pollutant loads without and with BMPs/LID practices implemented are shown in Table 2. Note that the total order Sobol′‘s sensitivity indices measure contributions of both single variables and variable interactions to the L-THIA-LID 2.1 model output.
Table 2 shows that when estimating runoff volume without implementing practices, the model output was more sensitive to the variations in the CN parameter than the variations in the P input within the prescribed ranges. Table 2 shows that when estimating pollutant loads without implementing practices, CN was the most sensitive variable, and EMC was more sensitive than P. The findings were in accordance with the results of Wilson and Weng (2010) for the L-THIA model, which showed CN was the most sensitive variable estimating runoff volume and pollutant loads. This was expected because CN is the main factor for estimating runoff volume from a HRU. P was not as sensitive in this study when estimating runoff volume and pollutant loads before implementing practices, which may be because the range (or uncertainty) of P was smaller than other variables due to using uncertainty of annual rainfall values. Pollutant load is the product of runoff volume and EMC, making EMC a sensitive variable when estimating pollutant loads. These indicate that when estimating runoff volume and pollutant loads for the case in which no practices were implemented, CN was the most sensitive variable and the most important variable when calibrating the model before implementing practices.
Table 2 indicates that when estimating runoff volume with different levels of practices implemented, Ratio_r was the most sensitive variable, and CN was more sensitive than P. When estimating pollutant loads with different levels of practices implemented (Table 2), Ratio_r was the most sensitive variable. Other variables with less impact on estimating pollutant loads with practices implemented were EMC, IC, CN, Ratio_c, and P. High sensitivity of Ratio_r was expected because a high level of BMPs/LID practice implementation was simulated in this study, and Ratio_r indicates the performances of practices represented by the percent runoff volume reduction method. Ratio_r would strongly affect pollutant load estimation since pollutant loads were estimated using runoff volume and pollutant concentrations; the change of Ratio_r would affect runoff volume after implementing BMPs/LID practices, and therefore, would impact pollutant loads. IC was sensitive because it is the lowest pollutant concentration of effluent for practices due to the treatment abilities of the practices. When estimating pollutant loads with practices implemented, EMC was more sensitive than CN because EMC represents the original pollutant concentrations before treated by BMPs/LID practices, which is closely related to IC. P and Ratio_c were not as sensitive as other variables which may be because of the smaller ranges (or uncertainties) of P and Ratio_c in this study. These results indicate that when predicting water quantity and quality with varying practices implemented, Ratio_r was the most sensitive variable. Thus, when calibrating the model with practices implemented, Ratio_r would be the most important variable.
The first order Sobol′‘s sensitivity indices, which indicate the influence of single variables to the L-THIA-LID 2.1 model output, were also calculated; the results show the same sensitivity rankings comparing to results of total order Sobol′‘s sensitivity indices.
The first order and total order Sobol′‘s sensitivity indices were computed when the ranges changing from default variables in Table 1 were set to similar values (−10 % to 2 % for CN and −10 % to 10 % for all of the other variables); results show that when estimating pollutant loads without implementing practices, P was more sensitive than EMC; results indicate that when estimating pollutant loads with practices, the sensitivity rankings of EMC and Ratio_c in Table 2 switched due to using similar ranges changing from default variables. All other sensitivity rankings were the same as using original ranges in Table 1 for variables.
3.2 Uncertainty Analysis
Results of uncertainty analysis with 2.5 % threshold values, 97.5 % threshold values, width of 95 % confidence interval (CI), and results observed or from literature are shown in Table 3. Distributions of samples for uncertainty analysis of the L-THIA-LID 2.1 model are shown in Fig. 2. Figures 2(a) to (t) are results before implementing BMPs/LID practices. Figures 2(u) and (v) are results after implementing lower level of BMPs/LID practices. Figures 2(w) and (x) are results after implementing higher level of BMPs/LID practices.



Distributions of samples for uncertainty analysis. (a) to (t) are results before implementing BMPs/LID practices. (u) and (v) are results after implementing lower level of BMPs/LID practices. (w) and (x) are results after implementing higher level of BMPs/LID practices
Before implementing practices, the average observed runoff volume from the study area was 2000 m3/ha/yr., which was included in the uncertainty ranges of 462 to 2183 m3/ha/yr. simulated by the L-THIA-LID 2.1 model; TP loads of 0.20 to 1.80 kg/ha/yr. were found in other studies for urban areas, which fell within the uncertainty range of 0.19 to 1.81 kg/ha/yr.; O&G loads of 1.80 to 6.43 kg/ha/yr. were reported in other studies, which fell well within the uncertainty ranges of 0.73 to 6.44 kg/ha/yr. in this study.
Before implementing practices, TN loads of 1.70 to 10.00 kg/ha/yr. were reported for other urban watersheds, while uncertainty bounds of 0.58 to 4.98 kg/ha/yr. were found in this study; TKN and NOx loads of 2.40–6.00 kg/ha/yr. and 0.83–3.90 kg/ha/yr., respectively were found in other urban watersheds, while uncertainty ranges of 0.50–4.74 kg/ha/yr. and 0.17–1.60 kg/ha/yr., respectively, were found in this study; TSS loads of 65 to 570 kg/ha/yr. were found in previous studies, while uncertainty bounds of 17 to 149 kg/ha/yr. were found in this study. Loads of Pb, Cu, Zn and Cr were found to be 2.0–30.0, 18.0–120.0, 17.0–360.0 and 9.8–20.0 g/ha/yr., respectively, in urban areas of other studies, while uncertainty ranges of 3.3 to 29.3, 4.7 to 40.1, 34.4 to 349.9 and 1.2 to 12.0 g/ha/yr., respectively, were found in this study; 4.20E + 10 colonies/ha/yr. of FC was found, which was slightly lower than the uncertainty bounds of 4.95E + 10 to 4.38E + 11 colonies/ha/yr.; 59.0 kg/ha/yr. of BOD was found, which was slightly above the uncertainty range of 6.4 to 57.0 kg/ha/yr. No studies were found to directly compare other uncertainty results in Table 3.
Table 3 shows that uncertainty bounds before implementing practices were relatively large. Because of intensively simplifying natural processes, simple models, such as L-THIA-LID 2.1, are likely to generate more uncertain outputs compared to complex models (Patil and Deng 2010). The ranges of variables used in Table 1 to estimate output uncertainty were relatively large, which could be one reason for the relatively large output uncertainty bounds before implementing practices in Table 3. Figures 2(a) to (t) show that before implementing practices, most model outputs were smaller than mean values. This could be caused by the −20 % to 2 % change of CN from default values used in the uncertainty analysis, which increased the number of smaller CN values. The increased number of small CN values decreased the predicted runoff volume and in turn decreased the predicted pollutant load values. Therefore, the skewness of the pre-set bounds of the variables was likely the reason for the skewness of output distributions. This could be another reason why uncertainty bounds before implementing practices were relatively large.
The effectiveness of BMPs and LID practices was evaluated using model output after implementing practices, and the uncertainty ranges of model outputs were relatively small as shown in Table 3. Figures 2(u) to (x) showed that after implementing practices, the distributions of outputs were more symmetric compared to results before implementing practices. Figure 2 shows that relative predictions (outputs after implementing BMPs/LID practices) changed the output distribution to a more symmetric shape compared to that of estimating absolute results (outputs before implementing practices). Others found that uncertainty of model outputs estimating absolute results were found to be relatively large due to limitations of data availability and the model itself; that is to say, models are more accurate when comparing relative predictions instead of estimating absolute results (Benaman and Shoemaker 2004). In this case, the more symmetric distribution shape would present less uncertainty and more accurate results. The output uncertainty ranges of implementing higher levels of practices were greater than those of implementing lower level practices; this was due to more uncertainties of simulating additional practices in the model.
It should be noted that this work was conducted in a watershed with limited water quality data, and only the output uncertainty of runoff volume was compared to observed data from the same study area; all other output uncertainties in this study were compared to results of other study areas. Without a substantial budget, it is not feasible to acquire watershed scale runoff volume and water quality data before and after implementing BMPs and LID practices. Additional insight into L-THIA-LID 2.1 model behavior could be obtained by analyzing model uncertainty using watersheds with more water quality data.
4 Conclusions
The sensitivity and uncertainty of the L-THIA-LID 2.1 model in estimating hydrology and water quality were analyzed in an urbanized watershed in central Indiana, USA using Sobol′‘s global sensitivity analysis method and bootstrap method, respectively. When estimating runoff volume without implementing BMPs and LID practices, CN was more sensitive than P. When computing pollutant loads without implementing practices, the sensitivities were in the descending order of CN, EMC, and P. When predicting runoff volume with different levels of practices implemented, the sensitivities were in the descending order of Ratio_r, CN and P. When modeling nonpoint source pollutant loads with different levels of practices implemented, the sensitivities were in the descending order of Ratio_r, EMC, IC, CN, Ratio_c, and P. Therefore, when estimating runoff volume and pollutant loads for the case in which no practices were implemented, CN was the most sensitive variable and the most important variable when calibrating the model before implementing practices. When predicting water quantity and quality with practices implemented, Ratio_r was the most sensitive variable and thus would be the most important variable when calibrating the model for such conditions.
The relatively large output uncertainty bounds before implementing BMPs and LID practices may be due to simplifying natural processes by the simple model, large ranges (or uncertainty) for variables, and unsymmetrical changes (−20 % to 2 %) of CNs from default values. The uncertainty ranges of model outputs after implementing practices were relatively small, due to comparing relative predictions instead of absolute values. Before implementing practices, average observed runoff volume was well covered in the uncertainty ranges simulated by the L-THIA-LID 2.1 model. TP and O&G loads from other urban watersheds fell well within the uncertainty ranges in this study; TN, TKN, NOx, TSS, Pb, Cu, Zn, Cr, FC, and BOD loads from other study areas were similar to the uncertainty bounds found in this study. This indicates good precision of the model.
5 Appendix
References
Abbott MB, Bathurst JC, Cunge JA, O'Connell PE, Rasmussen J (1986) An introduction to the European Hydrological System—Systeme Hydrologique Europeen,“SHE”, 2: Structure of a physically-based, distributed modelling system. J Hydrol 87(1):61–77
Ahiablame, LM (2012) Development of methods for modeling and evaluation of low impact development practices at the watershed scale. Doctoral dissertation, PURDUE UNIVERSITY, West Lafayette, IN, USA
Ahiablame LM, Engel BA, Chaubey I (2012) Representation and evaluation of low impact development practices with L-THIA-LID: An example for site planning. Environ Pollut 1(2):p 1
Ahiablame LM, Engel BA, Chaubey I (2013) Effectiveness of low impact development practices in two urbanized watersheds: Retrofitting with rain barrel/cistern and porous pavement. J Environ Manage 119:151–161
Andersson JCM, Pechlivanidis IG, Gustafsson D, Donnelly C, Arheimer B (2015) Key factors for improving large-scale hydrological model performance. European Water 49:77–88
Baird, C, Jennings, M, Ockerman, D, Dybala, T (1996) Characterization of nonpoint sources and loadings to the Corpus Christi bay national estuary program study area; Corpus christi national estuary program, Corpus Christi, TX
Beaulac MN, Reckhow KH (1982) An examination of land use-nutrient export relationships1. J Am Water Resour As 18(6):1013–1024
Bedan ES, Clausen JC (2009) Stormwater runoff quality and quantity from traditional and low impact development watersheds. J Am Water Resour As 45:998–1008. doi:10.1111/j.1752–1688.2009.00342.x
Benaman J, Shoemaker CA (2004) Methodology for analyzing ranges of uncertain model parameters and their impact on total maximum daily load process. J Environ Eng 130(6):648–656
Castaño S, Sanz D, Gómez-Alday JJ (2013) Sensitivity of a Groundwater Flow Model to Both Climatic Variations and Management Scenarios in a Semi-arid Region of SE Spain. Water Resour Manag 27(7):2089–2101
Cibin R, Sudheer KP, Chaubey I (2010) Sensitivity and identifiability of stream flow generation parameters of the SWAT model. Hydrol Process 24(9):1133–1148
CWP and CSN (Center for Watershed Protection and Chesapeake Stormwater Network) (2008) Technical memorandum: the runoff reduction method. Ellicott City, MD. www.chesapeakestormwater.net
D’Agostino DR, Scardigno A, Lamaddalena N, El Chami D (2014) Sensitivity analysis of coupled hydro-economic models: quantifying climate change uncertainty for decision-making. Water Resour Manag 28(12):4303–4318
Debnath S, Adamala S, Raghuwanshi NS (2015) Sensitivity analysis of FAO-56 Penman-Monteith method for different agro-ecological regions of India. Environmental Processes 2(4):689–704
Dietz ME, Clausen JC (2008) Stormwater runoff and export changes with development in a traditional and low impact subdivision. J Environ Manage 87(4):560–566
Duan Q, Gupta HV, Sorooshian S, Rousseau AN, Turcotte R (2003) Calibration of watershed models. Am Geophys Union 6:1–345
Efron B (1979) Bootstrap methods: another look at the jackknife. The annals of. Statistics 7:1–26
Efron, B, Tibshirani, RJ (1993) An introduction to the Bootstrap, Chapman & Hall, New York
Ellis JB, Mitchell G (2006) Urban diffuse pollution: key data information approaches for the Water Framework Directive. Water Environ J 20(1):19–26
Engel BA, Choi JY, Harbor J, Pandey S (2003) Web-based DSS for hydrologic impact evaluation of small watershed land use changes. Comput Electron Agr 39(3):241–249
Gaur A, Simonovic SP (2015) Towards reducing climate change impact assessment process uncertainty. Environ Process 2(2):275–290
GC and WWE (Geosyntec Consultants and Wright Water Engineers) (2011) International Stormwater Best Management Practices (BMP) Database Technical Summary: Volume Reduction, 27. www.bmpdatabase.org (accessed November, 2012)
Gitau MW, Chen J, Ma Z (2016) Water Quality Indices as Tools for Decision Making and Management. Water Resour Manag 30(8):2591–2610
Haan CT, Storm DE, Al-Issa T, Prabhu S, Sabbagh GJ, Edwards DR (1998) Effect of parameter distributions on uncertainty analysis of hydrologic models. Transactions of the ASAE 41(1):65–70
Hall, JW, Tarantola, S, Bates, PD, Horritt, MS (2005) Distributed sensitivity analysis of flood inundation model calibration. J Hydraul Eng 131(2):117–126
Hanel M, Mrkvičková M, Máca P, Vizina A, Pech P (2013) Evaluation of simple statistical downscaling methods for monthly regional climate model simulations with respect to the estimated changes in runoff in the Czech Republic. Water Resour Manag 27(15):5261–5279
Harbor JM (1994) A practical method for estimating the impact of land-use change on surface runoff, groundwater recharge and wetland hydrology. J Am Plann Assoc 60(1):95–108
Helton JC (1993) Uncertainty and sensitivity analysis techniques for use in performance assessment for radioactive waste disposal. Reliab Eng Syst Safe 42(2):327–367
Holvoet K, van Griensven A, Seuntjens P, Vanrolleghem PA (2005) Sensitivity analysis for hydrology and pesticide supply towards the river in SWAT. Physics and Chemistry of the Earth, Parts A/B/C 30(8):518–526
Kanakoudis V, Tsitsifli S, Samaras P, Zouboulis A, Demetriou G (2011) Developing appropriate performance indicators for urban water distribution systems evaluation at Mediterranean countries. Water utility. Journal 1:31–40
Kumar S, Tiwari MK, Chatterjee C, Mishra A (2015) Reservoir inflow forecasting using ensemble models based on neural networks, wavelet analysis and bootstrap method. Water Resour Manag 29(13):4863–4883
Li H, Davis AP (2009) Water quality improvement through reductions of pollutant loads using bioretention. J Environ Eng 135(8):567–576
Lim KJ, Engel BA, Muthukrishnan S, Harbor J (2006) Effects of initial abstraction and urbanization on estimated runoff using CN technology1. J Am Water Resour As 42(3):629–643
Liu, Y (2015) Improvement of simulating BMPs and LID practices in L-THIA-LID model. Doctoral dissertation, Purdue University, West Lafayette, IN, USA
Liu Y, Ahiablame LM, Bralts VF, Engel BA (2015a) Enhancing a rainfall-runoff model to assess the impacts of BMPs and LID practices on storm runoff. J Environ Manage 147:12–23. doi:10.1016/j.jenvman.2014.09.005
Liu Y, Bralts VF, Engel BA (2015b) Evaluating the effectiveness of management practices on hydrology and water quality at watershed scale with a rainfall-runoff model. Sci Total Environ 511:298–308. doi:10.1016/j.scitotenv.2014.12.077
Liu Y, Cibin R, Bralts VF, Chaubey I, Bowling LC, Engel BA (2016a) Optimal selection and placement of BMPs and LID practices with a rainfall-runoff model. Environ Modell Softw 80:281–296
Liu Y, Theller LO, Pijanowski BC, Engel BA (2016b) Optimal selection and placement of green infrastructure to reduce impacts of land use change and climate change on hydrology and water quality: An application to the Trail Creek Watershed, Indiana. Sci Total Environ 553:149–163
Machado AR, Wendland E, Krause P (2016) Hydrologic simulation for water balance improvement in an outcrop area of the Guarani Aquifer system. Environ Process 3(1):19–38
Migliaccio KW, Chaubey I (2008) Spatial distributions and stochastic parameter influences on SWAT flow and sediment predictions. J Hydrol Eng 13(4):258–269
Muleta MK, Nicklow JW (2005) Sensitivity and uncertainty analysis coupled with automatic calibration for a distributed watershed model. J Hydrol 306(1):127–145
Muthukrishnan S, Harbor J, Lim KJ, Engel BA (2006) Calibration of a simple rainfall-runoff model for long-term hydrological impact evaluation. Urisa-Washington Dc 18(2):35
Narsimlu B, Gosain AK, Chahar BR, Singh SK, Srivastava PK (2015) SWAT model calibration and uncertainty analysis for streamflow prediction in the Kunwari River Basin, India, using sequential uncertainty fitting. Environ Process 2(1):79–95
NRCS (Natural Resources Conservation Services) (1986) Urban hydrology for small watersheds. Technical Release 55, USDA Natural Resources Conservation Services
Patil A, Deng Z (2010) Analysis of uncertainty propagation through model parameters and structure. Water Sci Technol 62(6)):1230–1239
Reinelt LE, Horner RR (1995) Pollutant removal from stormwater runoff by palustrine wetlands based on comprehensive budgets. Ecol Eng 4(2):77–97
Sample, DJ, Heaney, JP, Wright, LT, Koustas, R (2001) Geographic information systems, decision support systems, and urban storm-water management. J Water Res Pl 127(3):155–161
Sharifi A, Dinpashoh Y (2014) Sensitivity analysis of the Penman-Monteith reference crop evapotranspiration to climatic variables in Iran. Water Resour Manag 28(15):5465–5476
Sinclair Knight Merz Pty. Ltd (1999) Duck River stormwater management plan, Final, St Leonards, NSW
Sobol′ IM (1993) Sensitivity estimates for nonlinear mathematical models. Math Model Comput Exper 1(4):407–417
Sobol′ IM (2001) Global sensitivity indices for nonlinear mathematical models and their Monte Carlo estimates. Math Comput Simulat 55:271–280
Sreekanth J, Datta B (2014) Stochastic and robust multi-objective optimal management of pumping from coastal aquifers under parameter uncertainty. Water Resour Manag 28(7):2005–2019
Strecker, EW, Quigley, MM, Urbonas, B, Jones, J (2004) Analyses of the expanded EPA/ASCE International BMP Database and potential implications for BMP design. Proceedings of the World Water and Environmental Resources Congress 2004, Salt Lake City, Utah
Tang Z, Engel BA, Pijanowski BC, Lim KJ (2005) Forecasting land use change and its environmental impact at a watershed scale. J Environ Manage 76(1):35–45
Tang T, Reed P, Wagener T, Van Werkhoven K (2006) Comparing sensitivity analysis methods to advance lumped watershed model identification and evaluation. Hydrol Earth Syst Sci Discuss 3:3333–3395
Tang Y, Reed P, Van Werkhoven K, Wagener T (2007) Advancing the identification and evaluation of distributed rainfall-runoff models using global sensitivity analysis. Water Resour Res 43:W06415. doi:10.1029/2006WR005813
Theodossiou N, Fotopoulou E (2015) Delineating well-head protection areas under conditions of hydrogeological uncertainty. A case-study application in northern Greece. Environ Process 2(1):113–122
Tsakiris G, Spiliotis M (2004) Fuzzy linear programming for problems of water allocation under uncertainty. European Water 7(8):25–37
Valdez MC, Adler I, Barrett M, Ochoa R, Pérez A (2016) The Water-Energy-Carbon Nexus: Optimising Rainwater Harvesting in Mexico City. Environ Process 3(2):307–323
Weeks, CR (1982) Pollution in urban runoff. In: Hart, B.T. (Ed.), Water quality management monitoring programs and diffuse runoff Water Studies Centre, Chisholm Institute of Technology and Australian Society of Limnology, Melbourne, pp. 121–140.
Wilson C, Weng Q (2010) Assessing surface water quality and its relation with urban land cover changes in the Lake Calumet Area, Greater Chicago. Environ Manage 45(5):1096–1111
Wright, TJ, Liu, Y, Carroll, NJ, Ahiablame, LM, Engel, BA (2016) Retrofitting LID practices into existing neighborhoods: Is it worth it? Environ Manage 57(4):856–867
Zhang Q, Qi T, Singh VP, Chen YD, Xiao M (2015) Regional Frequency Analysis of Droughts in China: A Multivariate Perspective. Water Resour Manag 29(6):1767–1787
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Liu, Y., Chaubey, I., Bowling, L.C. et al. Sensitivity and Uncertainty Analysis of the L-THIA-LID 2.1 Model. Water Resour Manage 30, 4927–4949 (2016). https://doi.org/10.1007/s11269-016-1462-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11269-016-1462-z