
Abstract
In this paper, we systematically study the integrability and data-driven solutions of the nonlocal mKdV equation. The infinite conservation laws of the nonlocal mKdV equation and the corresponding infinite conservation quantities are given through Riccti equation. The data-driven solutions of the zero boundary for the nonlocal mKdV equation are studied by using the multilayer physical information neural network algorithm, which include kink soliton, complex soliton, bright-bright soliton and the interaction between soliton and kink-type. For the data-driven solutions with nonzero boundary, we study kink, dark, anti-dark and rational solution. By means of image simulation, the relevant dynamic behavior and error analysis of these solutions are given. In addition, we discuss the inverse problem of the integrable nonlocal mKdV equation by applying the physics-informed neural network algorithm to discover the parameters of the nonlinear terms of the equation.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
In recent years, due to the wide application of nonlocal equations in various aspects, it has attracted the attention of many scholars [1,2,3]. The most classical nonlocal equation was the nonlocal nonlinear Schrödinger(NNLS) equation proposed by Ablowitz and Musslimani in 2013 [2]. And the most important parity-time(PT) symmetry in nonlocal equations was introduced into AKNS system for the first time. Later, many scholars have studied this equation at various levels [4,5,6,7,8]. Then, many other nonlocal equations were proposed and studied, such as nonlocal Davey-Stewartson equation [9], nonlocal derivative nonlinear Schrödinger equation [10], nonlocal Hirota [11, 12], nonlocal KdV [13] and so on. Recently, a nonlocal modified KdV(mKdV) was proposed
which also called reverse-space-time mKdV equation. In physical applications, the nonlocal mKdV has shifted parity and delayed time reversal symmetry, which is related to Alice Bob system [14]. In fact, the nonlocal mKdV equation has been widely discussed by scholars. For example, the inverse scattering transform of the nonlocal mKdV equation was given in Ref. [15, 16]. The soliton solution of the nonlocal mKdV equation was solved through Darboux transformation [17]. The Dbar dressing method for the nonlocal mKdV equation was shown in Ref. [18]. The long-time asymptotic behavior of the nonlocal mKdV equation with decaying initial data was studied by using Deift-Zhou steepest descent method [19].
Conservation law is universal in applied mathematics [20]. It reflects a phenomenon that some physical quantities do not change with time. In soliton theory, conservation law plays an important role in discussing the integrability of soliton equations. The existence of infinitely many conservation laws is closely related to the existence of soliton equations. In fact, most nonlinear development equations with soliton solutions have infinitely many conservation laws. Therefore, for a soliton system, finding its infinite conservation laws has important practical and theoretical significance for proving the integrability of the system. Since Miura, Gardner and Kruskal discovered that the KdV equation has an infinite conservation laws [21], a series of methods have been developed to construct the (1 + 1)-dimensional integrable system, some of which are no longer in use due to their limitations. For instance, through the scattering problem and the gradual expansion of the scattering quantity \(a(\lambda )\) can yield an endless number of conserved quantities [22], but it cannot be used to build the conservation rule, hence, this method is currently of little use in application areas. In the study of infinite conservation laws, Wadati et al. have made considerable contributions. Generally speaking, the infinite conservation law of a continuous system can be obtained through the following ways: Lax pair, Bäcklund transform, formal solution of eigenfunction and trace identity, etc. [23,24,25,26]. Although there are many ways to obtain infinite conservation laws, the final result is the same. This variety of methods and the consistency of results can be seen as an external manifestation of integrability.
In fact, there are many ways to investigate the integrability of a partial differential equation, such as Liuville integrable, Painlevé test, inverse scattering integrable, Lax integrable, Hirota bilinear, solvable potential and quantum inverse scattering integrable. Among them, the Painlevé test is a method proposed by Weiss, Tabor and Carnevale [27]. Many nonlinear partial differential equations can be verified by this method, and the scope of application is very wide. A large number of subsequent scholars have done a lot of work in this area to verify the effectiveness of the method [28, 29]. Especially, Wazwaz has extended this method to higher-dimensional equations and has also obtained good results [30, 31]. Then, a more important goal is to accurately solve the nonlinear partial differential equations. These solutions have very important practical significance in nonlinear physical systems such as nonlinear optics, biophysics, plasmas, cold atoms and Bose-Einstein condensate systems, and they are usually called nonlinear waves. According to physical properties and dynamic characteristics, solitary wave, lump, breather and rogue wave are four kinds of common nonlinear waves. Solitary waves have stability and particle properties, and all integrable equations have soliton solutions that reflect the general nonlinear phenomena in nature. The most classical soliton solutions, including bright soliton solutions, dark soliton solutions, kink solutions, and anti-kink solutions, have been widely studied for their dynamic behavior and numerical simulation solutions [32,33,34]. Compared with the solitary wave solution, the lump solution is a special type of rational function solution, which has localization in all directions of space [35]. Breather and rogue waves are two kinds of typical nonlinear structures with obvious instability localized on the plane wave background [36, 37]. In real life, there are a large number of nonlinear waves interacting with each other. It is of great significance to study the mechanism of their occurrence and the physical parameters controlled by the main interaction. In the process of interaction, there will be many local excited state phenomena. Therefore, it is very important to discuss the inelastic interaction between solitary waves of nonlinear partial differential equations and other nonlinear waves in the physical background, which can provide a theoretical tool for studying the relevant dynamic behavior.
Machine learning is the mainstream method to solve many AI problems at this stage. As an independent direction, it is developing at a high speed. As a form of machine learning, deep learning trains models with multiple hidden layers between input and output. In general, deep learning means using deep neural networks. Deep neural network has the advantages of fast computing speed and high accuracy and has been widely used in natural language processing [42], face recognition [38], speech recognition [41] and other fields [39, 40]. Recently, a new physical information neural network (PINN) is proposed by the mathematical physics system based on the multilayer network of deep learning mode, which is proved to be suitable for dealing with forward problems and highly ill inverse problems. The approximate solution of the control equation and the parameters of the control equation are found from the training data [43]. And the numerical findings demonstrate that high-dimensional network tasks can be successfully completed using the PINN approach with fewer data sets. This training neural network is a supervised learning task to solve some nonlinear partial differential equations that follow the laws of physics. Then, the PINN method is used to generate data-driven solutions to reveal the dynamic behavior of nonlinear partial differential equations under physical constraints, which has attracted wide attention from many scholars. Chen’s team has built many data-driven solutions of nonlinear partial differential equations using the PINN approach during the last two years, including soliton solutions [44, 45], breather solutions [46], rational solution [47], rogue wave [46, 48], higher-order breather waves [49]and rogue periodic wave [50]. In particular, Lin and Chen add the properties of integrable systems such as conserved quantities and Miura transform to the training network and propose a two-stage PINN method and find new local wave solutions [51, 52]. In addition, other scholars also obtained some important results of data-driven solutions for nonlinear partial differential equations using PINN method [53,54,55,56,57]. In particular, Dai’s team extended PINN to non-integrable equations and used PINN to predict multipolar soliton solutions of the saturated nonlinear fractional Schrödinger equation [58]. As far as we know, the application of PINN to nonlocal equations has been rarely studied.
In this paper, we will derive the Ricatti equation from the x part of the Lax pair for the nonlocal mKdV equation and construct the conservation law using the compatibility condition. The infinite conservation laws and infinite conserved quantities are obtained from the solution of Ricatti equation. Besides, we add the nonlocal term to the classical PINN to simulate the data-driven solutions of the nonlocal mKdV equation under zero boundary and nonzero boundary conditions and give the error analysis. At the same time, we use the PINN of the nonlocal term to discover the parameter of the nonlocal mKdV.
The structure of this paper is as follows. In Sect. 2, we mainly study the integrability of the nonlocal mKdV equation and obtain its infinite conservation laws by using the Riccti equation. In Sect. 3, the composition of PINN is introduced. Then, we use PINN to study the data-driven solutions under zero boundary conditions and give its dynamic behavior in Sect. 4. In Sect. 5, we learn the data-driven solutions of the nonzero boundary of the nonlocal mKdV equation and its dynamic behavior. In Sect. 6, the inverse problem is learned based on PINN, which mainly studies the nonlinear coefficients for the nonlocal mKdV equation, while adding different noises to the network. The conclusion is given in Sect. 7.
2 Conservation laws for the nonlocal mKdV equation
The nonlocal mKdV Eq. (1) has the following Lax pair
where \(\varPhi \) is the matrix eigenfunction, \(\lambda \) is the spectral parameter and
For the solution of Lax pair Eq. (2) written in the form of vector \(\varPhi =(\phi _1,\phi _2)^T\), the following function is introduced
we can put it into Eq. (2) and get
The derivatives of x and t of the above two equations are as follows
In addition, combining the Lax pair equation, we can get the Riccti equation and conservation law equation about \(\varGamma \)
where
The function \(\varGamma \) is expanded in the following series
and collects the coefficient of the same power of \(\lambda \) to obtain the following formula
Thus, we can write several conservation laws for the nonlocal mKdV equation as
At the same time, the corresponding conserved quantities can also be obtained as
The above proves the integrability of the nonlocal mKdV equation. Next, we will apply PINN to the integrable nonlinear equation to obtain its data-driven solutions.
3 The PINN deep learning method
In this part, we will introduce the PINN deep learning method for partial differential equation. Generally, the (1+1)-dimensional nonlinear partial differential equation has the following form
where u is a function of x and t, \({\mathcal {N}}[\cdot ]\) is a nonlinear differential operator in space, which generally contains high-order dispersion terms and nonlinear terms. Then, the following equation can be defined by the left part of Eq. (5)
and a deep neural network is used to approximate u. Here, without losing generality, we first consider a neural network with depth H, which is composed of an input layer, \(H-1\) hidden layers and an output layer. And the \(h^{th}\) hidden layer is composed of \(N_h\) neurons, and then, the output \({\textbf{x}}^{h-1}\) of the previous layer after the action of the activation function \(\sigma \) is taken as the input of the next hidden layer. This process is formed through the following radiation transformation
where \({\textbf{w}}^h\in {\mathbb {R}}^{N_h\times N_{h-1}}\) and \({\textbf{b}}^h\in {\mathbb {R}}^{N_h}\) are the weights and deviations of the \(h^{th}\) layer. Usually, we initialize the bias term to zero, the weight is initialized by Xavier initialization, and the activation function is selected as tanh function. After layer upon layer operation, a neural network can be obtained as
where the operator \(``\circ ''\) is the composition operator, and \(\varTheta =\left\{ {\textbf{w}}^h, {\textbf{b}}^h\right\} _{h=1}^H\) represents the parameters that can be learned in the network. The core of the neural network is to constantly update the weights and deviations so that the solution u of the partial differential equation satisfies Eq. (6) and minimizes f. And the neural network f and the network representing u have the same parameters, and these shared parameters can be learned by minimizing the mean square error loss
where
\(\{x_{u}^{i}, t_{u}^{i}, u^{i}\}_{i=1}^{N_{u}}\) is the sampled initial and boundary value training data of u(x, t). Similarly, the collocation points for f(x, t) are marked by \(\{x_{f}^{j}, t_{f}^{j}\}_{j=1}^{N_{f}}\). The loss function (7) contains the losses of initial boundary value data and the losses of networks (5) at a finite set of collocation points.
Further, if the solution of the partial differential equation is complex, we can write the solution of the final form as \(u=p+iq\). Thus, Eq. (7) can be divided into two equations with real part and imaginary part, as follows
Then, the physics-informed neural networks \(f_{p}(x, t)\) and \(f_{q}(x, t)\) can be defined as
where p(x, t; w, b), q(x, t; w, b) are the latent function of the deep neural network with the weight parameter w and bias parameter b, which can be used to approximate the exact complex-valued solution u(x, t) of objective equations. This form is reasonable, and in Ref. [59], the network \(f_{p}(x, t), f_{q}(x, t)\) can be found under the automatic differentiation mechanism.
Similarly, there is also a loss function in this network, and its form is more complex. We can set it to the following form
where
and
where \(\{x_{p}^{i}, t_{p}^{i}, p^{i}\}_{i=1}^{N_{p}}\) and \(\{x_{q}^{i}, t_{q}^{i}, q^{i}\}_{i=1}^{N_{q}}\) are the sampled initial and boundary value training data of u(x, t). Similarly, the collocation points for \(f_{p}(x, t)\) and \(f_{q}(x, t)\) are marked by \(\{x_{f}^{j}, t_{f}^{j}\}_{j=1}^{N_{f_p}}\) and \(\{x_{f}^{j}, t_{f}^{j}\}_{j=1}^{N_{f_q}}\).
For the loss function (14), the first two terms try to make the learned solution close to the exact solution when approaching the initial value and boundary value data, and the last two terms make the hidden functions p and q meet Eqs. (12) and (13).
4 Soliton solutions of the nonlocal mKdV equation under zero boundary condition
In this part, we mainly use the neural network method to obtain the simulation solution of the nonlocal mKdV equation under the zero boundary condition, as well as its dynamic behavior and error analysis. We consider the nonlocal mKdV equation with Dirichlet boundary conditions, which is given by the following formula:
where \(x_{0}, x_{1}\) represent the boundary of x, and \(t_{0}, t_{1}\) represent the start and end times of time t. The \(u_{0}(x)\) defines the initial condition.
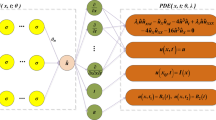
In order to better understand the PINN method, we give the flow diagram of the nonlocal mKdV equation according to Sect. 3. It can be seen from Fig. 1 that compared with the classical network diagram of the local equation, the nonlocal term is added to the NN part, which makes more functions output and more complex training. Then, the relevant physical information is supplemented, and the loss function is evaluated by NN and the residual of the control equation given in combination with the relevant physical information. Then, the weight w and the deviation b are continuously updated to minimize the loss function to less than a certain tolerance \(\varepsilon \) until the specified maximum number of iterations is reached.

(Color online) The PINN scheme solving the nonlocal mKdV equation, where \({\tilde{u}}=u(-x,-t), {\tilde{p}}=p(-x,-t)\) and \({\tilde{q}}=q(-x,-t)\)
Next, we will use PINN to simulate the 1-soliton and 2-soliton solutions of the nonlocal mKdV equation, including kink solution, complex solution and their interactions. At the same time, the simulated solutions are compared with the accurate solutions.
4.1 1-soliton solution
In Ref. [17], the method of Darboux transformation is used to obtain the kink solution form of the nonlocal mKdV:
when \(\nu =-1\), a kink solution is generated,
which is a real solution. Therefore, according to Eq. (6), the PINN f(x, t) can be constructed as
where we choose [-4,4] as the boundary of x and t, so we can give the initial and boundary information as follows:
To get a better simulation effect, we divide x into 512 points in the interval and 200 points in the time interval. That is to say, the interval is divided into \(512\times 200\) points. \(N_u=100\) points are randomly selected in the initial boundary data set, and the internal \(N_f=10000\) points are sampled by the Latin hypercube sampling method [60]. Here, we construct a feedforward neural network with six layers and 40 neurons in each hidden layer. By adjusting all the learnable parameters of the neural network and the loss function, we successfully learn the 1-soliton solution u(x, t). The relative \({\mathbb {L}}_2\) error of the final PINN model is \(2.583821{\textrm{e}}-04\) in about 84.7319 s, and the number of iterations is 346.

(Color online) The 1-soliton solution u(x, t) for the nonlocal mKdV equation: a The density plot and the error density diagram; b The wave propagation plot at three different times; c The three-dimensional plot; d The loss curve figure
Figure 2a and b shows the density plots of the exact solution and the learning solution, the error density plots and three wave propagation plots at different times, respectively. We can find that the error between the learning solution and the accurate solution is very small. Figure 2c and d displays the three-dimensional motion and loss curves, respectively. As shown in Fig. 2d, the loss curve is relatively smooth, which implies that the integrable deep learning method is very effective and stable.
In addition, the complex soliton solution of the nonlocal mKdV equation was given by the Hirota direct method in Ref. [61], which can be expressed as
In this case, we set \(u=p+iq\), then the construction of PINN needs to divide the real part and the imaginary part of the equation reference Eqs.(12) and (13),
noindent Let \([x_{0}, x_{1}]\) and \([t_{0}, t_{1}]\) in Eq.(17) be \([-5, 5]\) and \([-\frac{1}{100}, \frac{1}{100}]\), respectively. We select the complex soliton solution at \(t=-\frac{1}{100}\) as the initial condition
With the help of LHS, \(N_u=100\) collocation points and \(N_f=5000\) collocation points are randomly selected at the boundary and inside, respectively, to obtain training data and put them into a network with six hidden layers and 40 neurons. Finally, we successfully learned the complex soliton solution, and the training solution and accurate solution achieved a \({\mathbb {L}}_{2}\) error of 5.639394e\(-\)04. The whole training process take 743.5638 s, with 10,414 iterations. In Fig. 3, we not only give the density and error diagrams of the exact solution and the training solution, but also show the differences between the two solutions at different time stages. It can be seen from Fig. 3b that they are very consistent. In addition, we also give the three-dimensional graph of the training solution and the loss function graph in the iteration process in graphs (c) and (d).

(Color online) The complex soliton solution u(x, t) for the nonlocal mKdV equation: a The density plot and the error density diagram; b The wave propagation plot at three different times; c The three-dimensional plot; d The loss curve figure
4.2 2-soliton solution
In this subsection, we mainly simulate two soliton solutions, including bright-bright soliton and soliton kink interaction solutions. As shown in Ref. [61], the general formula of the 2-soliton solution is
where
When \(k=\frac{1}{2},l=1,a_1=a_2=b_1=b_2=1\), Eq. (25) can be reduced to
which is a non-singular 2-soliton solution. Let \([x_{0}, x_{1}]\) and \([t_{0}, t_{1}]\) in Eq. (17) be \([-15, 15]\), the corresponding initial condition is given by
We select the same configuration points as the 1-soliton solution and use the LHS method to obtain training data sets, then we input these training data sets into the depth network of nine hidden layers, each of which has 40 neurons. We have successfully learned the 2-soliton solution. Compared with the exact solution, its \({\mathbb {L}}_2\)-norm error is 5.937731e\(-\)02. The whole training time is 162.7119 s, and the number of iterations is 1715. What needs to be noted here is not that more configuration points or more training network layers will lead to better results. Through experiments, we choose deeper network layers, and the results will be worse. The \({\mathbb {L}}_2\)-norm error will become 2.027299e\(-\)01. The training time is 155.5235 s, and the number of iterations is 1402. The training results are shown in Fig. 4, including the density diagram, error dynamics diagram, propagation diagram at different times, three-dimensional diagram and loss curve diagram of learning 2-soliton solution and accurate 2-soliton solution. It can be seen that the results are quite satisfactory.

(Color online) The 2-soliton solution u(x, t) for the nonlocal mKdV equation: a The density plot and the error density diagram; b The wave propagation plot at three different times; c The three-dimensional plot; d The loss curve figure
When \(k=0,l=2,a_1=a_2=b_1=b_2=-1\), Eq. (25) can be reduced to
which represents interaction of soliton and kink-type wave. The Dirichlet boundary x and t of Eq. (28) are [-10,10] and [-15,15], respectively. The initial training condition is
Select the same configuration points as above to obtain training data, and put them into a six-layer neural network with each 40 neurons. The solution of soliton kink interaction is well learned. Under the condition of training duration of 373.2689 s and iteration number of 7028, we get that the error of \({\mathbb {L}}_2\)-norm between the exact solution and the training solution is 1.452126e\(-\)02. In Fig. 5a, b, the density graph, error graph and time evolution graph of the training and exact solution at t=\(-\)10.05, t=0, t=10.05 are specifically given. In Fig. 5c, d, we use the training data to give the three-dimensional graph and the iterative degree graph.

(Color online) Solution of the interaction between soliton and kink-type waves u(x, t) for the nonlocal mKdV equation: a The density plot and the error density diagram; b The wave propagation plot at three different times; c The three-dimensional plot; d The loss curve figure
5 Data-driven solutions of the nonlocal mKdV equation with nonzero boundary
This part mainly studies the solutions of the nonlocal mKdV equation under nonzero boundary, including kink solution, dark solution, anti-dark solution and rational solution.
5.1 Data-driven solitary wave solution
The kink solution of the nonlocal mKdV with nonzero boundary has been obtained by inverse scattering method in Ref. [16], which is expressed as
In order to distinguish between the training initial boundary and the nonzero boundary conditions satisfied by the equation, we use \({\tilde{u}}_0\) to represent the nonzero boundary conditions satisfied by the equation. The neural network is constructed by Eq. (6), and its training initial condition is
At this time, we select the region of x and t as \([-10,10]\) and divide 512 points and 200 points in the region of x and t, respectively. \(N_u=1000\) and \(N_f=10,000\) points are randomly selected as training data at the boundary and inside, respectively. We numerically predict the kink soliton solution with proper parameters \({\tilde{u}}_0=1, \theta _1=\theta _2=0\) under a six hidden layer deep PINN with the 40 neurons per layer. The training results show that its \({\mathbb {L}}_2\) error is 5.162946e\(-\)04 compared with the exact solution, the training time is merely 23.7374 s, and the number of iterations is only 350, the final result is shown in Fig. 6. Once again, it shows the power of the deep integrable system.

(Color online) The kink soliton solution u(x, t) for the nonlocal mKdV equation under nonzero boundary: a The density plot and the error density diagram; b The wave propagation plot at three different times; c The three-dimensional plot; d The loss curve figure

(Color online) The dark soliton solution u(x, t) for the nonlocal mKdV equation: a The density plot and the error density diagram; b The wave propagation plot at three different times; c The three-dimensional plot; d The loss curve figure

(Color online) The anti-dark soliton solution u(x, t) for nonlocal mKdV equation: a The density plot and the error density diagram; b The wave propagation plot at three different times; c The three-dimensional plot; d The loss curve figure
The dark and anti-dark soliton solutions of the nonlocal mKdV were also given in Ref. [16], and the overall expression is
where
it is a dark soliton solution as \({\tilde{u}}_0=1,w=\frac{3}{2}, \theta _1=\pi , \theta _2=\theta =0,\) and it is an anti-dark soliton solution as \({\tilde{u}}_0=1,w=\frac{3}{2}, \theta _1=\theta =0,\theta _2=\pi \). For the dark soliton solution, let the interval of x and t be [-1,1], and the corresponding initial condition is
For the anti-dark soliton solution, let the intervals of x and t be [-4,4] and [-2,2], respectively, and its initial condition becomes
By performing the same data collection and training procedures as kink soliton solution, through training, we can get that the \({\mathbb {L}}_2\)-norm error between the learning solution and the accurate solution is 2.459108e\(-\)02 for the dark soliton solution, the whole learning process takes about 261.6747 s and iterates 4618. For the anti-dark soliton solution, the \({\mathbb {L}}_2\)-norm error between the learning solution and the exact solution is 3.244125e\(-\)04, and the whole learning process takes about 24.5986 s, with 345 iterations. The construction of this neural network is easier to learn the anti-dark soliton solution, takes less time, and the training result is more ideal. The learning results are shown in Figs. 7 and 8, respectively.

(Color online) The rational soliton solution u(x, t) for the nonlocal mKdV equation: a The density plot and the error density diagram; b The wave propagation plot at three different times; c The three-dimensional plot; d The loss curve figure

(Color online) Parameter discovery of the nonlocal mKdV equation: a Iteration diagram of different internal configuration points; b Iterative graph of different neurons in each layer with the same neural network depth; c Iterative graph under different noise conditions; d The variation of loss function with the different noise
5.2 Data-driven rational solution
In this section, we use the PINN method to construct the rational soliton solution of Eq. (1). The form of its solution was given in Ref. [16]
If the boundary regions of x and t are [\(-\)0.5,0.5] and [\(-\)0.3,0.3], then the corresponding initial condition is
in order to learn rational soliton solution better and more accurately, \(N_u=100\) configuration points are selected at the boundary and \(N_f=5000\) configuration points are selected internally for training. The training results are compared with the accurate solution to achieve a relative \({\mathbb {L}}_2\) error of 1.164655e\(-\)02 in about 477.8897 s, and the number of iterations is 2848. In Fig. 9, we give the specific training results, including the density graph, error graph and time evolution graph of the exact solution and the training solution. The 3D stereoscopic map is generated from the training results. The training error map is not very stable, and there will be some burrs in the middle, but this will not affect the final training results.
6 The PINN algorithm for the data-driven parameter discovery
In this section, we focus on data-driven discovery of the nonlocal mKdV equation through PINN algorithm. It is well known that linear equations have good properties, while most equations in real life are nonlinear. It is precisely because of the existence of these nonlinear terms that more physical properties are stimulated and widely used in various fields, such as physics, mechanics, and life sciences. Therefore, it is necessary to learn the specific forms of nonlinear terms. For nonlocal nonlinear partial differential mKdV equation, we mainly study the coefficient a of the following nonlinear terms
Theoretically, parameter can be found by using any known nonlocal mKdV solution. Here, we choose to use the complex solution to do parameter discovery, and choose Eqs. (22) and (23) as the physical information neural network of the nonlocal mKdV equation. The Latin hypercube is still used for sampling. With the help of the exact soliton solutions of a=6 and \((x, t)\in [-5, 5]\times [-\frac{1}{100}, \frac{1}{100}]\), the training data set is generated by randomly selecting \(N_u=200\) as the initial boundary data and \(N_f=50000\) as the configuration point. According to the training data set obtained, the data-driven parameter a can be found by using the PINN.
When the hidden layer of PINN is determined, we give the data-driven parameter a under different neurons of each layer and show the results in Table 1. From the table, it can be found that, when no noise is added to the system, the precision of PINN learning unknown parameters becomes higher and higher as the number of neurons increases. When we add different noises, the results of parameter discovery will oscillate with the increase in the number of neurons. When the number of hidden layers and neurons is fixed, the number of internal configuration points also affects the discovery of parameter. In Table 2, we list the results of parameter learning under different internal configuration points and different noises. It can be seen from the table that the more internal configuration points are given, the better the learning results will be. However, when the internal configuration points are determined, different noises are added to the neural network, and the results are also oscillatory. In general, the more configuration points, the greater the noise added to the neural network, and the result of parameter discovery is the closest to the ideal result.
In Fig. 10a and b, we show the iterative changes of unknown parameters in the process of inverse problem under different internal configuration points and different number of neurons. When other conditions are determined, the more internal configuration points or the more neurons in each layer, the faster the convergence of unknown parameters. In Fig. 10c and d, the changes of unknown parameters and loss functions with iteration are analyzed when different noises are used in the inverse problem. The iteration of unknown parameters under different noises is described in Fig. 10c. The convergence without noise is faster than that with noise, but the final learning result is better when the noise is \(0.5\%\). Figure 10d describes the change of loss functions of different noises with the increase in iteration times. The results show that the convergence effect is the best when \(0.5\%\) noise is added to the PINN. When \(0.1\%\) noise is added to the network, the convergence effect is the worst. This shows that adding proper noise into the network is beneficial to improving the training results.
7 Conclusion
In this paper, we first give the infinite conservation laws of the nonlocal mKdV equation by using Riccti-type equation, which shows the integrability of the nonlocal mKdV equation. Then, the components of PINN are introduced, and two forms of loss functions for nonlinear equation solutions are given. After that, the nonlocal term is added to the PINN deep learning to reconstruct the zero boundary solutions of the nonlocal mKdV equation, including kink solution, complex soliton solution, bright-bright soliton and bright-kink interaction solutions. For nonzero boundary, we use PINN to numerically simulate kink solution, dark soliton solution, anti-dark soliton solution and rational solution. At the same time, the error of each learning solution under \({\mathbb {L}}_2\) norm is given. The results show that the error between the exact solution and the predictive solution generated by the PINN deep learning method is very small, which verifies the effectiveness and stability of the integrable deep learning method. For a given region, PINN can quickly and accurately learn the corresponding solution by using less data and network layers, which shows the power of integrable deep learning. Finally, the problem of data-driven parameter discovery is solved. The coefficients of nonlinear terms for the nonlocal mKdV equation are learned through PINN. In the process of inverse problem processing, we add noise to the network. Using the control variable method, when the training data and network depth are determined, we compare the parameter discovery of different neurons in each hidden layer under different noise conditions and present the results in the form of a table. Under the condition of determining the network depth and neurons, we compare the learning results of parameters given different training datas and noises. The results show that the more internal configuration points are given, the more accurate the learning results are. In addition, the discovery of parameters is also closely related to noise. The addition of different noises has a great influence on the learning results, which indicates that noise has a strong sensitivity.
Here, we only verify the integrability of the nonlocal mKdV equation and numerically simulate various solutions for the nonlocal mKdV through PINN, without applying the integrability to PINN. Whether adding some properties of integrability to the PINN for nonlocal partial differential equations will have better results is a question we need to consider further. Just as the conservation laws were added to the PINN of the local equation in Ref. [51, 62], whether there is less error for the nonlocal equation under the \({\mathbb {L}}_2\)-norm is a question to be investigated. In addition, other neural networks can also predict the solutions of nonlinear partial differential equations. For example, Zhang has predicted and analyzed the dynamic behavior of bright soliton solutions, dark soliton solutions and rouge wave solutions of the (3+1)-dimensional Jimbo-Miwa equation, p-gBKP equation and other nonlinear partial differential equations through bilinear residual network and bilinear neural network [35, 37, 63,64,65], whether these neural network models are suitable for nonlocal equations is also the direction we need to consider in the future.
Data Availability
All data generated or analyzed during this study are included in this published article.
References
Nixon, S., Ge, L., Yang, J.: Stability analysis for solitons in \(PT\)-symmetric optical lattices. Phys. Rev. A 85(2), 023822 (2012)
Ablowitz, M.J., Musslimani, Z.H.: Integrable nonlocal nonlinear Schrödinger equation. Phys. Rev. Lett. 110(6), 064105 (2013)
Bender, C.M., Brody, D.C., Jones, H.F.: Complex extension of quantum mechanics. Phys. Rev. Lett. 89, 270401 (2002)
Ablowitz, M.J., Musslimani, Z.H.: Inverse scattering transform for the integrable nonlocal nonlinear Schrödinger equation. Nonlinearity 29, 915–946 (2016)
Feng, B.F., Luo, X.D., Ablowitz, M.J., Musslimani, Z.H.: General soliton solution to a nonlocal nonlinear Schrödinger equation with zero and nonzero boundary conditions. Nonlinearity 31(12), 5385 (2018)
Wang, M.M., Chen, Y.: Dynamic behaviors of general N-solitons for the nonlocal generalized nonlinear Schrödinger equation. Nonlinear Dyn. 104(3), 2621–2638 (2021)
Rybalko, Y., Shepelsky, D.: Long-time asymptotics for the integrable nonlocal nonlinear Schrödinger equation. J. Math. Phys. 60(3), 031504 (2019)
Li, G., Yang, Y., Fan, E.: Long time asymptotic behavior for the nonlocal nonlinear Schrödinger equation with weighted Sobolev initial data. arXiv preprint arXiv:2110.05907 (2021)
Rao, J.G., Cheng, Y., He, J.S.: Rational and semi-rational solutions of the nonlocal Davey-Stewartson equations. Stud. Appl. Math. 139(4), 568–598 (2017)
Zhou, Z.X.: Darboux transformations and global solutions for a nonlocal derivative nonlinear Schrödinger equation. Commun. Nonlinear Sci. Numer. Simul. 62, 480–488 (2018)
Cen, J., Correa, F., Fring, A.: Integrable nonlocal Hirota equations. J. Math. Phys. 60(8), 081508 (2019)
Zhu, J., Chen, Y.: Long time asymptotic analysis for a nonlocal Hirota equation via the Dbar steepest descent method. arXiv preprint arXiv:2206.08634, (2022)
Gürses, M., Pekcan, A.: Nonlocal KdV equations. Phys. Lett. A 384(35), 126894 (2020)
Lou, S.Y., Huang, F.: Alice-Bob physics: coherent solutions of nonlocal KdV systems. Sci. Rep. 7(1), 1–11 (2017)
Ji, J.L., Zhu, Z.N.: Soliton solutions of an integrable nonlocal modified Korteweg-de Vries equation through inverse scattering transform. J. Math. Anal. Appl. 453, 973–984 (2017)
Zhang, G., Yan, Z.: Inverse scattering transforms and soliton solutions of focusing and defocusing nonlocal mKdV equations with non-zero boundary conditions. Physica D 402, 132170 (2020)
Ji, J.L., Zhu, Z.N.: On a nonlocal modified Korteweg-de Vries equation: integrability, Darboux transformation and soliton solutions. Commun. Nonlinear Sci. Numer. Simul. 42, 699–708 (2017)
Luo, J., Fan, E.: \({\bar{\partial }}\)-dressing method for the nonlocal mKdV equation. J. Geom. Phys. 177, 104550 (2022)
He, F.J., Fan, E.G., Xu, J.: Long-time asymptotics for the nonlocal mKdV equation. Commun. Theor. Phys. 71, 475–488 (2019)
Hydon, P.E.: Conservation laws of partial difference equations with two independent variables. J. Phys. A Math. Gen. 34(48), 10347 (2001)
Miura, R.M., Gardner, C.S., Kruskal, M.D.: Korteweg-de vries equation and generalizations .II. Existence of conservation laws and constants of motion. J. Math. Phys. 9(8), 1204–1209 (1968)
Ablowitz, M.J., Ladik, J.F.: Nonlinear differential-difference equations and Fourier analysis. J. Math. Phys. 17(6), 1011–1018 (1976)
Wadati, M., Sanuki, H., Konno, K.: Relationships among inverse method, Bäcklund transformation and an infinite number of conservation laws. Prog. Theoret. Phys. 53(2), 419–436 (1975)
Shabat, A., Zakharov, V.: Exact theory of two-dimensional self-focusing and one-dimensional self-modulation of waves in nonlinear media. Sov. Phys. JETP 34(1), 62 (1972)
Konno, K., Sanuki, H., Ichikawa, Y.H.: Conservation laws of nonlinear-evolution equations. Prog. Theoret. Phys. 52(3), 886–889 (1974)
Tsuchida, T., Wadati, M.: The coupled modified Korteweg-de Vries equations. J. Phys. Soc. Jpn. 67(4), 1175–1187 (1998)
Weiss, J., Tabor, M., Carnevale, G.: The Painlevé property for partial differential equations. J. Math. Phys. 24(3), 522–526 (1983)
Lou, S., Wu, Q.: Painlevé integrability of two sets of nonlinear evolution equations with nonlinear dispersions. Phys. Lett. A 262(4–5), 344–349 (1999)
Lü, X., Peng, M.: Painlevé-integrability and explicit solutions of the general two-coupled nonlinear Schrödinger system in the optical fiber communications. Nonlinear Dyn. 73(1), 405–410 (2013)
Wazwaz, A.M.: New (3+ 1)-dimensional Painlevé integrable fifth-order equation with third-order temporal dispersion. Nonlinear Dyn. 106(1), 891–897 (2021)
Wazwaz, A.M.: Painlevé integrability and lump solutions for two extended (3+ 1)-and (2+ 1)-dimensional Kadomtsev-Petviashvili equations. Nonlinear Dyn. (2022). https://doi.org/10.1007/s11071-022-08074-2
Wazwaz, A.M., El-Tantawy, S.A.: Bright and dark optical solitons for (3+ 1)-dimensional hyperbolic nonlinear Schrödinger equation using a variety of distinct schemes. Optik 270, 170043 (2022)
Kaur, L., Wazwaz, A.M.: Optical soliton solutions of variable coefficient Biswas-Milovic (BM) model comprising Kerr law and damping effect. Optik 266, 169617 (2022)
Zhang, R.F., Bilige, S., Liu, J.G., Li, M.: Bright-dark solitons and interaction phenomenon for p-gBKP equation by using bilinear neural network method. Phys. Scr. 96(2), 025224 (2020)
Zhang, R.F., Li, M.C., Albishari, M., Zheng, F.C., Lan, Z.Z.: Generalized lump solutions, classical lump solutions and rogue waves of the (2+ 1)-dimensional Caudrey-Dodd-Gibbon-Kotera-Sawada-like equation. Appl. Math. Comput. 403, 126201 (2021)
Dudley, J.M., Dias, F., Erkintalo, M., Genty, G.: Instabilities, breathers and rogue waves in optics. Nat. Photonics 8(10), 755–764 (2014)
Zhang, R.F., Li, M.C., Gan, J.Y., Li, Q., Lan, Z.Z.: Novel trial functions and rogue waves of generalized breaking soliton equation via bilinear neural network method. Chaos Solit. Fract. 154, 111692 (2022)
Sun, X.D., Wu, P.C., Hoi, S.C.H.: Face detection using deep learning: an improved faster RCNN approach. Neurocomputing 299, 42–50 (2018)
Alipanahi, B., Delong, A., Weirauch, M.T., Frey, B.J.: Predicting the sequence specificities of DMA-and RNA-binding proteins by deep learning. Nat. Biotechnol. 33(8), 831–838 (2015)
Shao, Z.F., Wang, L.G., Wang, Z.Y., Du, W., Wu, W.J.: Saliency-aware convolution neural network for ship detection in surveillance video. IEEE Trans. Circ. Syst. Video Technol. 30, 781–94 (2020)
Nassif, A.B., Shahin, I., Attili, I., Azzeh, M., Shaalan, K.: Speech recognition using deep neural networks: a systematic review. IEEE Access 7, 19143–19165 (2019)
Collobert, R., Weston, J., Bottou, G., Karlen, M., Kavukcuoglu, K., Kuksa, P.: Natural language processing (almost) from scratch. J. Mach. Learn. Res. 12, 2493–537 (2011)
Raissi, M., Perdikaris, P., Karniadakis, G.E.: Physics-informed neural networks: a deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. J. Comput. Phys. 378, 686–707 (2019)
Li, J., Chen, Y.: Solving second-order nonlinear evolution partial differential equations using deep learning. Commun. Theor. Phys. 72, 105005 (2020)
Peng, W.Q., Chen, Y.: N-double poles solutions for nonlocal Hirota equation with nonzero boundary conditions using Riemann-Hilbert method and PINN algorithm. Physica D 435, 133274 (2022)
Pu, J.C., Li, J., Chen, Y.: Soliton, breather and rogue wave solutions for solving the nonlinear Schrödinger equation using a deep learning method with physical constraints. Chin. Phys. B 30(6), 060202 (2021)
Pu, J.C., Li, J., Chen, Y.: Solving localized wave solutions of the derivative nonlinear Schrödinger equation using an improved PINN method. Nonlinear Dyn. 105(2), 1–17 (2021)
Pu, J.C., Chen, Y.: Data-driven vector localized waves and parameters discovery for Manakov system using deep learning approach. Chaos Solit. Fract. 160, 112182 (2022)
Miao, Z.W., Chen, Y.: Physics-informed neural networks method in high-dimensional integrable systems. Mod. Phys. Lett. B 36(01), 2150531 (2022)
Peng, W.Q., Pu, J.C., Chen, Y.: PINN deep learning for the Chen-Lee-Liu equation: rogue wave on the periodic background. Commun. Nonlinear Sci. Numer. Simul. 105, 106067 (2022)
Lin, S., Chen, Y.: A two stage physics-informed neural network method based on conserved quantities and applications in localized wave solutions. J. Comput. Phys. 457, 111053 (2022)
Lin, S., Chen, Y.: Physics-informed neural network methods based on Miura transformations and discovery of new localized wave solutions. arXiv preprint arXiv:2211.15526, (2022)
Wang, L., Yan, Z.: Data-driven rogue waves and parameter discovery in the defocusing nonlinear Schrödinger equation with a potential using the PINN deep learning. Phys. Lett. A 404, 127408 (2021)
Fang, Y., Wu, G.Z., Wang, Y.Y., Dai, C.Q.: Data-driven femtosecond optical soliton excitations and parameters discovery of the high-order NLSE using the PINN. Nonlinear Dyn. 105(1), 603–616 (2021)
Mo, Y., Ling, L., Zeng, D.: Data-driven vector soliton solutions of coupled nonlinear Schrödinger equation using a deep learning algorithm. Phys. Lett. A 421, 127739 (2022)
Li, J., Li, B.: Mix-training physics-informed neural networks for the rogue waves of nonlinear Schrödinger equation. Chaos Solit. Fract. 164, 112712 (2022)
Wen, X.K., Wu, G.Z., Liu, W., Dai, C.Q.: Dynamics of diverse data-driven solitons for the three-component coupled nonlinear Schrodinger model by the MPS-PINN method. Nonlinear Dyn. 109(4), 3041–3050 (2022)
Bo, W.B., Wang, R.R., Fang, Y., Wang, Y.Y., Dai, C.Q.: Prediction and dynamical evolution of multipole soliton families in fractional Schrödinger equation with the PT-symmetric potential and saturable nonlinearity. Nonlinear Dyn. 111(2), 1577–1588 (2023)
Baydin, A.G., Pearlmutter, B.A., Radul, A.A., Siskind, J.M.: Automatic differentiation in machine learning: a survey. J. Mach. Learn. Res. 18, 1–43 (2018)
Stein, M.: Large sample properties of simulations using Latin hypercube sampling. Technometrics 29(2), 143–151 (1987)
Gürses, M., Pekcan, A.: Nonlocal modified KdV equations and their soliton solutions by Hirota method. Commun. Nonlinear Sci. Numer. Simul. 67, 427–448 (2019)
Fang, Y., Wu, G.Z., Wen, X.K., Dai, C.Q.: Predicting certain vector optical solitons via the conservation-law deep-learning method. Opt. Laser Technol. 155, 108428 (2022)
Zhang, R.F., Li, M.C., Yin, H.M.: Rogue wave solutions and the bright and dark solitons of the (3+ 1)-dimensional Jimbo-Miwa equation. Nonlinear Dyn. 103(1), 1071–1079 (2021)
Zhang, R.F., Bilige, S.: Bilinear neural network method to obtain the exact analytical solutions of nonlinear partial differential equations and its application to p-gBKP equation. Nonlinear Dyn. 95(4), 3041–3048 (2019)
Zhang, R.F., Li, M.C.: Bilinear residual network method for solving the exactly explicit solutions of nonlinear evolution equations. Nonlinear Dyn. 108(1), 521–531 (2022)
Funding
The project is supported by National Natural Science Foundation of China (No. 12175069 and No. 12235007) and Science and Technology Commission of Shanghai Municipality (No. 21JC1402500 and No. 22DZ2229014).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that there is no conflict of interests regarding the publication of this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The project is supported by National Natural Science Foundation of China (No. 12175069 and No. 12235007) and Science and Technology Commission of Shanghai Municipality (No. 21JC1402500 and No. 22DZ2229014).
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Zhu, J., Chen, Y. Data-driven solutions and parameter discovery of the nonlocal mKdV equation via deep learning method. Nonlinear Dyn 111, 8397–8417 (2023). https://doi.org/10.1007/s11071-023-08287-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11071-023-08287-z