
Abstract
A novel observer-based control policy based on an interval type-3 fuzzy logic system is developed to tackle the main limitations of fuzzy-based controllers in sense of approximation of uncertainties and analyzing nonlinear complex systems without detailed dynamics model information. For this purpose, a novel scheme is proposed that includes online optimized tuning rules, a simple type reduction method, and adaptive mechanisms. Also, an adaptive compensator is implemented to enhance the robust performance of the closed-loop system and reduce the effect of approximation errors. For the stability analysis, appropriate Lyapunov functions and Barbalat’s lemma are employed. By both simulations and experimentally implementation, it is shown that the suggested approach results in a more accurate approximation of unknown models and complicated nonlinearities, and good resistance against uncertainties and parameter variations.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
The dynamical model of a substantial number of practical systems such as power, transportation, robotic, and aerospace systems is affected by unknown uncertainties and external disturbances. In view of these undesirable and unpredictable variations, some studies have been carried out to investigate the stability and robust performance analysis of systems over the past few years. Among them, the concept of sliding mode (SM) control that enforces the system states onto a sliding surface by a discontinuous control law and stays on it during the whole succeeding time is a useful strategy that has been proposed [1, 2]. For instance, a higher-order SM observer-based control scheme was suggested for nonlinear systems with unknown inputs [3]. The method was then developed and combined with interval observer in [4] to analyze linear parameter-varying systems composed of strongly observable subsystems. For bounded and derivative bounded uncertainties and to mitigate chattering phenomena, an adaptive high-order SM control policy has been used in [5]. Moreover, a dynamic SM algorithm, incorporating a disturbance observer, was suggested to investigate a mismatched disturbance in [6]. For linear and Lipschitz nonlinear systems, polytopic type and norm bounded uncertainties have been extensively discussed in the research works [7]. It is worth mentioning that the parametric uncertainty has been addressed recently to overcome the computational burden and conservatism of analyzing uncertain systems subject to Lipschitz nonlinearities [8,9,10].
However, the aforementioned results require exact model information for the control problem. Note that the considered uncertainties are bounded and we have access to the information of the upper bounds or belong to specific intervals. With the restrictions imposed on the robust stability analysis, a great number of physical systems with unknown and complex dynamics or unknown parameter variations cannot be fully addressed. Learning mechanisms and neuro-fuzzy-based controllers were employed to deal with unknown dynamics [11].
For a Takagi-Sugeno (TS) fuzzy model-based system, the boundary/regional information of the membership functions was used and the framework of multidimensional fuzzy summation has been achieved in [12, 13]. Moreover, a distributed compensator and constraints on the membership functions have been considered to reduce the conservativeness of the stabilization conditions for a TS fuzzy control system [14, 15]. The event-triggered scheme for TS fuzzy systems is developed in [16,17,18].
Another learning-based control involves the interval type-2 fuzzy logic system (IT2FLS) which has been implemented via type-2 fuzzy (T2F) sets [19]. Moreover, the Lyapunov stability analysis has been employed as an stability analysis tool for T2F-based control policies [20]. Optimization algorithms such as genetic and ant colony have been extended to design an optimal T2F controller [21]. By selecting the bee colony optimization technique, a T2F control approach was proposed in [22]. This concept with the backtracking search algorithm is implemented for the control traffic signal issues [23]. Moreover, utilizing a non-singleton T2F-based and invasive weed optimization algorithm, unknown dynamics were approximated in [24] to synchronize fractional-order chaotic systems. A T2F PI control method was designed to enhance the robust performance of a system and reduce computational complexities in [25]. Solving an iterative optimization algorithm and employing the SM control approach result in an T2F controller [26]. Moreover, a self-triggered mechanism was developed for applying an T2F control method [27]. A predictive T2F controller was proposed to regulate the glucose level in type-1 diabetes subject to completely unknown dynamics [28]. The tracking control problem was investigated via an IT2 fuzzy [29]. An T2F set was also used for nonlinear networked systems to design a fuzzy filter [30]. An observer-based T2F strategy was employed in [31] to study chaotic systems. For AC-microgrids, the frequency regulation problem was analyzed via a T2FLS with adaptive optimization rules [32]. A T2FLS incorporating a restricted Boltzmann machine has been extended for fractional-order multi-agent systems [33]. Such strategies have been combined with square-root-cubature Kalman filter to reduce the voltage oscillation of active/reactive power regulation problem [34]. Note that T2F-based control law has been developed to reduce the effect of noisy measurement [35].
Recently, the concept of an interval type-3 fuzzy logic system (IT3FLS) has been suggested for the efficiency and accuracy improvement of previous fuzzy control results. From the approximation ability perspective, an IT3FLS is able to approximate more complex nonlinearities and uncertainties of nonlinear systems compared to the other learning approaches. Furthermore, compared to the T1FLS and T2FLS in which the memberships are crisp value and type-1 fuzzy set, in an IT3FLS the membership has been defined as an T2F set [36]. While reducing the approximation and tracking error signals, IT3FLS-based strategies provide more degrees of freedom in designing a robust controller for unknown systems. Inspired by this concept, an accurate approximation of unknown micro-electro-mechanical system gyroscopes models was employed for the control synthesis strategy in [37]. Considering an adaptive IT3FLS, the robust stabilization of the 5G telecom power system has been analyzed [38]. Recently, an adaptive fuzzy kernel size was employed for optimizing rule and antecedent parameters in [39].
In this work, an improved nonlinear observer-based control scheme is designed to study the robust stabilization of nonlinear systems via developing a novel IT3FLS. The suggested learning scheme outperforms conventional robust control policies and neuro-fuzzy control policies demanding the known information about the system models, the structure of uncertainties, and upper bounds of external disturbances. As a consequence, the learning-based control method with fast tuning parameters proposed in this paper enables us to analyze general types of uncertainties, unknown models, and external disturbances while reconstructing unmeasurable states through a novel learning observer. Therefore, the stability and robustness of a wide and general class of complex nonlinear systems can be studied via the method of this paper. In the novel learning IT3FLS, new membership functions and online optimized tuning rules are designed. Furthermore, applying a novel adaptive compensator to the system boosts the robustness of the closed-loop system and weakens the effects of approximation error signals. The stability of the closed-loop system is then ensured via the Lyapunov tool and Barbalat’s lemma. The suggested method is tested on different cases to highlight an excellent robust performance.
The remaining is organized as follows. In Sect. 2, the problem is described. In Sect. 3, the suggested FLS is explained. The observer scheme is designed in Sect. 4. The stability is studied in Sect. 5. The implementation and computer simulations are investigated in Sects. 6–7. Finally, the conclusions are given in Sect. 8.
2 System representation
Consider a nonlinear system as follows:
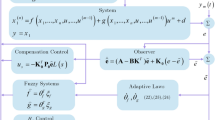
where \( {\varvec{x}} = {\left[ {{x_1},{x_2}, ... ,{x_n}} \right] ^T} = {\left[ {{x_1},{{\dot{x}}_1} ,... ,x_1^{(n - 1)}} \right] ^T}\) expresses state vector. In addition, nonlinear vector-valued functions a(.) and b(.) are unknown but bounded, \(u,y \in \mathbb {{\mathbb {R}}}\) denote the control signal and output of the system. For the unknown exogenous disturbance \( \delta (t) \), it is supposed that there exists an upper bound. The suggested control diagram is depicted in Fig. 1. To study the tracking control problem by defining reference signal, the following tracking errors are considered
where the estimations of \({\varvec{x}} \) and \( {\varvec{e}} \) are expressed as \( {\hat{\varvec{x}}} \) and \( \hat{{\varvec{e}}}\). Moreover, one can rewrite the system dynamic as:
in which
Assumption 1
It is supposed that \(0< b({\varvec{x}}) < \infty \); therefore, (3) is controllable in region \({U_c} \subset {{\mathbb {R}}^n}\), designated as certain controllability [40, 41], also \(0< b({\varvec{x}}) < \infty \) represents a fixed control direction.
In the case of known system functions \( a ({\varvec{x}})\) and \(b({\varvec{x}}) \) and when disturbance \(\delta (t) = 0\), the control law \({u^ * }\) is applied as follows to the system:
Note that we design \({{\mathcal {K}}_c} = {\left[ {{k_{c1}},{k_{c2}},...,{k_{cn}}} \right] ^T} \in {{\mathbb {R}}^n}\) such that \({s^n} + {k_{cn}}{s^{n - 1}} + \cdots + {k_{c1}}\) is Hurwitz stable [42]. However, the controller (5) cannot be applied to the system. Based on the following procedure, the improved nonlinear robust control policy is designed.
-
A novel adaptive IT3FLS is utilized for approximating unknown dynamic and nonlinear terms.
-
Based on the approximation information of a novel IT3FLS, an observer is designed to improve the robust stabilization.
-
The adaptive compensator is implemented to diminish the undesirable effects of the approximation error signals.

Diagram of the suggested controller
3 Type-3 FLS
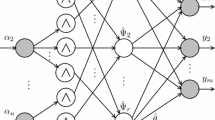
This section is allocated for the structure of IT3FLSs (see Fig. 2) explained as:

Type-3 FLS
-
The inputs are \(x _1,...,x _n\).
-
Consider \({{\tilde{\varphi }}_i^j}\) as the \(j-th\) fuzzy set (FS) for \(x _i\), the memberships at secondary levels \({ {{\underline{\sigma }}_i}}\) and \({ {{{\bar{\sigma }} }_i}}\) are obtained as [43]:
$$\begin{aligned} {{\bar{\xi } }_{{\tilde{\varphi }}_{i\,\,| {{{\bar{\sigma }} }_i}}^j}} = \left\{ {\begin{array}{*{20}{c}} {1 - {{\left( {\frac{{\left| {x _i - {C_{{\tilde{\varphi }}_i^j}}} \right| }}{{{{{\underline{\vartheta }} }_{{\tilde{\varphi }}_i^j}}}}} \right) }^{{{{\bar{\sigma }} }_i}}}\, \hbox {if} \,{C_{{\tilde{\varphi }}_i^j}} - {{{\underline{\vartheta }} }_{{\tilde{\varphi }}_i^j}}< x _i \le {C_{{\tilde{\varphi }}_i^j}}}\\ {1 - {{\left( {\frac{{\left| {x _i - {C_{{\tilde{\varphi }}_i^j}}} \right| }}{{{{{\bar{\vartheta }}}_{{\tilde{\varphi }}_i^j}}}}} \right) }^{{{{\bar{\sigma }} }_i}}}\, \hbox {if} \,{C_{{\tilde{\varphi }}_i^j}} < x _i \le {C_{{\tilde{\varphi }}_i^j}} + {{{\bar{\vartheta }}}_{{\tilde{\varphi }}_i^j}}}\\ {0\,\,\,\,\,\,\,\,\,\,\,\,\,\,\, \hbox {if} \,x _i > {C_{{\tilde{\varphi }}_i^j}} + {{{\bar{\vartheta }}}_{{\tilde{\varphi }}_i^j}}\,or\,x _i \le {C_{{\tilde{\varphi }}_i^j}} - {{{\underline{\vartheta }} }_{{\tilde{\varphi }}_i^j}}} \end{array}} \right. \end{aligned}$$(6)$$\begin{aligned} {{\bar{\xi } }_{{\tilde{\varphi }}_{i\,\,| {{{\underline{\sigma }} }_i}}^j}} = \left\{ {\begin{array}{*{20}{c}} {1 - {{\left( {\frac{{\left| {x _i - {C_{{\tilde{\varphi }}_i^j}}} \right| }}{{{{{\underline{\vartheta }} }_{{\tilde{\varphi }}_i^j}}}}} \right) }^{{{{\underline{\sigma }} }_i}}}\, \hbox {if} \,{C_{{\tilde{\varphi }}_i^j}} - {{{\underline{\vartheta }} }_{{\tilde{\varphi }}_i^j}}< x _i \le {C_{{\tilde{\varphi }}_i^j}}}\\ {1 - {{\left( {\frac{{\left| {x _i - {C_{{\tilde{\varphi }}_i^j}}} \right| }}{{{{{\bar{\vartheta }}}_{{\tilde{\varphi }}_i^j}}}}} \right) }^{{{{\underline{\sigma }} }_i}}}\, \hbox {if} \,{C_{{\tilde{\varphi }}_i^j}} < x _i \le {C_{{\tilde{\varphi }}_i^j}} + {{{\bar{\vartheta }}}_{{\tilde{\varphi }}_i^j}}}\\ {0\,\,\,\,\,\,\,\,\,\,\,\,\,\,\, \hbox {if} \,x _i > {C_{{\tilde{\varphi }}_i^j}} + {{{\bar{\vartheta }}}_{{\tilde{\varphi }}_i^j}}\,or\,x _i \le {C_{{\tilde{\varphi }}_i^j}} - {{{\underline{\vartheta }} }_{{\tilde{\varphi }}_i^j}}} \end{array}} \right. \end{aligned}$$(7)$$\begin{aligned} {\underline{\xi } _{{\tilde{\varphi }}_{i\,\,| {{{\bar{\sigma }} }_i}}^j}} = \left\{ {\begin{array}{*{20}{c}} {1 - {{\left( {\frac{{\left| {x _i - {C_{{\tilde{\varphi }}_i^j}}} \right| }}{{{{{\underline{\vartheta }} }_{{\tilde{\varphi }}_i^j}}}}} \right) }^{\frac{1}{{{{{\bar{\sigma }} }_i}}}}}\, \hbox {if} \, {C_{{\tilde{\varphi }}_i^j}} - {{{\underline{\vartheta }} }_{{\tilde{\varphi }}_i^j}}< x _i \le {C_{{\tilde{\varphi }}_i^j}}}\\ {1 - {{\left( {\frac{{\left| {x _i - {C_{{\tilde{\varphi }}_i^j}}} \right| }}{{{{{\bar{\vartheta }}}_{{\tilde{\varphi }}_i^j}}}}} \right) }^{\frac{1}{{{{{\bar{\sigma }} }_i}}}}}\, \hbox {if} \, {C_{{\tilde{\varphi }}_i^j}} < x _i \le {C_{{\tilde{\varphi }}_i^j}} + {{{\bar{\vartheta }}}_{{\tilde{\varphi }}_i^j}}}\\ {0\,\,\,\,\,\,\,\,\,\,\,\,\,\,\, \hbox {if} \,x _i > {C_{{\tilde{\varphi }}_i^j}} + {{{\bar{\vartheta }}}_{{\tilde{\varphi }}_i^j}}\,or\,x _i \le {C_{{\tilde{\varphi }}_i^j}} - {{{\underline{\vartheta }} }_{{\tilde{\varphi }}_i^j}}} \end{array}} \right. \end{aligned}$$(8)$$\begin{aligned} {\underline{\xi } _{{\tilde{\varphi }}_{i\,\,| {{{\underline{\sigma }} }_i}}^j}} = \left\{ {\begin{array}{*{20}{c}} {1 - {{\left( {\frac{{\left| {x _i - {C_{{\tilde{\varphi }}_i^j}}} \right| }}{{{{{\underline{\vartheta }} }_{{\tilde{\varphi }}_i^j}}}}} \right) }^{\frac{1}{{{{{\underline{\sigma }} }_i}}}}}\, \hbox {if} \,{C_{{\tilde{\varphi }}_i^j}} - {{{\underline{\vartheta }} }_{{\tilde{\varphi }}_i^j}}< x _i \le {C_{{\tilde{\varphi }}_i^j}}}\\ {1 - {{\left( {\frac{{\left| {x _i - {C_{{\tilde{\varphi }}_i^j}}} \right| }}{{{{{\bar{\vartheta }}}_{{\tilde{\varphi }}_i^j}}}}} \right) }^{\frac{1}{{{{{\underline{\sigma }} }_i}}}}}\, \hbox {if} \,{C_{{\tilde{\varphi }}_i^j}} < x _i\le {C_{{\tilde{\varphi }}_i^j}} + {{{\bar{\vartheta }}}_{{\tilde{\varphi }}_i^j}}}\\ {0\,\,\,\,\,\,\,\,\,\,\,\,\,\,\, \hbox {if} \,x _i > {C_{{\tilde{\varphi }}_i^j}} + {{{\bar{\vartheta }}}_{{\tilde{\varphi }}_i^j}}\,\,or\,\,x _i \le {C_{{\tilde{\varphi }}_i^j}} - {{{\underline{\vartheta }} }_{{\tilde{\varphi }}_i^j}}} \end{array}} \right. \end{aligned}$$(9)where \({{\bar{\xi } }_{{\tilde{\varphi }}_{i\, \, | {{{\bar{\sigma }} }_i}}^j}}\)/\({{\bar{\xi } }_{{\tilde{\varphi }}_{i\, \, | {{\underline{\sigma }}_i}}^j}}\) and \({\underline{\xi } _{{\tilde{\varphi }}_{i\, \, | {{{\bar{\sigma }} }_i}}^j}}\)/\({\underline{\xi } _{\tilde{\varphi }_{i\, \, | {{{\underline{\sigma }} }_i}}^j}}\) denote the upper/lower memberships for \({{\tilde{\varphi }}_i^j}\) at \({ {{{\underline{\sigma }} }_i}}\) and \({ {{{\bar{\sigma }} }_i}}\). \({{C_{{\tilde{\varphi }}_i^j}}}\) denote the center of \({{C_{\tilde{\varphi }_i^j}}}\) and \({{{{\underline{\vartheta }} }_{\tilde{\varphi }_i^j}}}\) and \({{{{\bar{\vartheta }}}_{{\tilde{\varphi }}_i^j}}}\) are the distances of \({{C_{{\tilde{\varphi }}_i^j}}}\) to the start/end points of \({{\tilde{\varphi }}_i^j}\) (see Fig. 3).
-
The rule firings are obtained as:
$$\begin{aligned} {\bar{\Phi }} _{{{{\bar{\sigma }} }_i}}^l = \prod \nolimits _{j = 1}^n {{{\bar{\xi }}_{{\tilde{\varphi }} _{j\, \, \, \, \, \, \, \, |\, \, {{\bar{\sigma }}_i}}^{{p_j}}}}} \end{aligned}$$(10)$$\begin{aligned} {\bar{\Phi }} _{{{{\underline{\sigma }} }_i}}^l = \prod \nolimits _{j = 1}^n {{{{\bar{\xi }} }_{{\tilde{\varphi }} _{j\, \, \, \, \, \, \, \, |\, \, {{{\underline{\sigma }} }_i}}^{{p_j}}}}} \end{aligned}$$(11)$$\begin{aligned} {\underline{\Phi }} _{{{{\bar{\sigma }} }_i}}^l = \prod \nolimits _{j = 1}^n {{{{\underline{\xi }} }_{{\tilde{\varphi }} _{j\, \, \, \, \, \, \, \, |\, \, {{{\bar{\sigma }} }_i}}^{{p_j}}}}} \end{aligned}$$(12)$$\begin{aligned} {\underline{\Phi }} _{{{{\underline{\sigma }} }_i}}^l = \prod \nolimits _{j = 1}^n {{{{\underline{\xi }} }_{{\tilde{\varphi }} _{j\, \, \, \, \, \, \, \, |\, \, {{{\underline{\sigma }} }_i}}^{{p_j}}}}} \end{aligned}$$(13)where \(l-th\) rule is:
$$\begin{aligned} \begin{array}{l} l - th\,Rule:\\ if\,{x _1}\,is\,\,{\tilde{\varphi }}_{1\,\,\,\, }^{{p_1}}\,and\,{x _2}\,is\,\,{\tilde{\varphi }}_2^{{p_2}}\,and\, \cdots \,\,{x _n}\,\,is\,\,{\tilde{\varphi }}_n^{{p_n}}\\ \,\,\,\,Then\,\,\mu \in \left[ {{{{\underline{\theta }} }_l},{{{\bar{\theta }} }_l}} \right] ,l = 1,...,M \end{array} \end{aligned}$$(14)where \({\tilde{\varphi }}_i^{{p_j}}\) is the \({{p_j}}-th\) FS for \(x _i\) and \({{{\underline{\theta }} }_l}\) and \({{\bar{\theta }} }_l\) are consequent trainable parameters.
-
The output is written as:
$$\begin{aligned} \mu = \frac{{\sum \nolimits _{i = 1}^{{n_\sigma }} {\left( {{{{\underline{\sigma }} }_i}{{{\underline{\mu }} }_i} + {{{\bar{\sigma }} }_i}{{{\bar{\mu }}}_i}} \right) } }}{{\sum \nolimits _{i = 1}^{{n_\sigma }} {\left( {{{{\underline{\sigma }} }_i} + {{{\bar{\sigma }} }_i}} \right) } }} \end{aligned}$$(15)where
$$\begin{aligned} {{{\bar{\mu }}}_i} = \frac{{\sum \nolimits _{l = 1}^{n_r} {\left( {{\bar{\Phi }} _{ {{{\bar{\sigma }} }_i}}^l{{{\bar{\theta }} }_l} + {\underline{\Phi }} _{ {{{\bar{\sigma }} }_i}}^l{{{\underline{\theta }} }_l}} \right) } }}{{\sum \nolimits _{l = 1}^{n_r} {\left( {{\bar{\Phi }} _{{{{\bar{\sigma }} }_i}}^l + {\underline{\Phi }} _{ {{{\bar{\sigma }} }_i}}^l} \right) } }} \end{aligned}$$(16)$$\begin{aligned} {{\underline{\mu }} _i} = \frac{{\sum \nolimits _{l = 1}^{n_r} {\left( {{\bar{\Phi }} _{ {{{\underline{\sigma }} }_i}}^l{{{\bar{\theta }} }_l} + {\underline{\Phi }} _{ {{{\underline{\sigma }} }_i}}^l{{{\underline{\theta }} }_l}} \right) } }}{{\sum \nolimits _{l = 1}^{n_r} {\left( {{\bar{\Phi }} _{ {{{\underline{\sigma }} }_i}}^l + {\underline{\Phi }} _{{{{\underline{\sigma }} }_i}}^l} \right) } }} \end{aligned}$$(17)The output (15) is rewritten as:
$$\begin{aligned} {\hat{y}}\left( {x|\theta } \right) = {\theta ^T}\zeta \end{aligned}$$(18)where
$$\begin{aligned} {\zeta ^T} = \left[ {{{{\underline{\zeta }} }_1},...,{{{\underline{\zeta }} }_{{n_r}}},{{{\bar{\zeta }} }_1},...,{{{\bar{\zeta }} }_{{n_r}}}} \right] \end{aligned}$$(19)$$\begin{aligned} {\theta ^T} = \left[ {{{{\underline{\theta }} }_1},...,{{{\underline{\theta }} }_{{n_r}}},{{{\bar{\theta }} }_1},...,{{{\bar{\theta }} }_{{n_r}}}} \right] \end{aligned}$$(20)$$\begin{aligned} \begin{array}{l} {{\underline{\zeta }} _l} = \frac{{\sum \nolimits _{i = 1}^{{n_\sigma }} {{{{\underline{\sigma }} }_i}{\underline{\Phi }} _{{{{\underline{\sigma }} }_i}}^l} }}{{\sum \nolimits _{i = 1}^{{n_\sigma }} {\left( {{{{\underline{\sigma }} }_i} + {{{\bar{\sigma }} }_i}} \right) } \sum \nolimits _{l = 1}^{{n_r}} {\left( {{\bar{\Phi }} _{{{{\underline{\sigma }} }_i}}^l + {\underline{\Phi }} _{{{{\underline{\sigma }} }_i}}^l} \right) } }} + \\ \,\,\,\,\,\,\,\frac{{\sum \nolimits _{i = 1}^{{n_\sigma }} {{{{\bar{\sigma }} }_i}{\underline{\Phi }} _{{{{\bar{\sigma }} }_i}}^l} }}{{\sum \nolimits _{i = 1}^{{n_\sigma }} {\left( {{{{\underline{\sigma }} }_i} + {{{\bar{\sigma }} }_i}} \right) } \sum \nolimits _{l = 1}^{{n_r}} {\left( {{\bar{\Phi }} _{{{{\bar{\sigma }} }_i}}^l + {\underline{\Phi }} _{{{{\bar{\sigma }} }_i}}^l} \right) } }} \end{array} \end{aligned}$$(21)$$\begin{aligned} \begin{array}{l} {{{\bar{\zeta }} }_l} = \frac{{\sum \nolimits _{i = 1}^{{n_\sigma }} {{{{\underline{\sigma }} }_i}{\bar{\Phi }} _{{{{\underline{\sigma }} }_i}}^l} }}{{\sum \limits _{i = 1}^{{n_\sigma }} {\left( {{{{\underline{\sigma }} }_i} + {{{\bar{\sigma }} }_i}} \right) } \sum \nolimits _{l = 1}^{{n_r}} {\left( {{\bar{\Phi }} _{{{{\underline{\sigma }} }_i}}^l + {\underline{\Phi }} _{{{{\underline{\sigma }} }_i}}^l} \right) } }} + \\ \,\,\,\,\,\,\,\frac{{\sum \nolimits _{i = 1}^{{n_\sigma }} {{{{\bar{\sigma }} }_i}{\bar{\Phi }} _{{{{\bar{\sigma }} }_i}}^l} }}{{\sum \nolimits _{i = 1}^{{n_\sigma }} {\left( {{{{\underline{\sigma }} }_i} + {{{\bar{\sigma }} }_i}} \right) } \sum \nolimits _{l = 1}^{{n_r}} {\left( {{\bar{\Phi }} _{{{{\bar{\sigma }} }_i}}^l + {\underline{\Phi }} _{{{{\bar{\sigma }} }_i}}^l} \right) } }} \end{array} \end{aligned}$$(22)

Type-3 FS
4 Observer-based control policy
To tackle the complexities of the problem, the control signal (5) is modified and rewritten as follows:
where \( {\hat{\varvec{x}}} /{\hat{a}} ( {\hat{\varvec{x}}}) / {\hat{b}} ( {\hat{\varvec{x}}}) / \hat{{\varvec{e}}} \) denote the estimates of \( {{\varvec{x}}} / a ( {{\varvec{x}}}) / b ( {{\varvec{x}}}) / {{\varvec{e}}} \). Furthermore, a small positive constant \(\varepsilon \) in the term \(\varepsilon \mathrm{sign}\left( {{\hat{b}} \left( {\hat{\varvec{x}}} \right) } \right) \) in (23) provides us the ability to solve the singularity of the control signal u and \(\mathrm{sign}\left( {{\hat{b}} \left( {\hat{\varvec{x}}} \right) } \right) \) denotes a signum function described as follows:
The adaptation law \({u_s}\) is designed to diminish the undesirable effects of the errors and disturbances preserving the robustness of the suggested control method. Through adding and subtracting the term \(\left( {{\hat{b}} ( {\hat{\varvec{x}}}) + \varepsilon \mathrm{sign}\left( {{\hat{b}} \left( {\hat{\varvec{x}}} \right) } \right) } \right) u \), Eq. (3) will be written as follows:
Moreover, employing (23) for (25) results in
where \({{\varvec{e}}_1} = y - r = {x_1} - r\). Regarding (26), to estimate the vector \({\varvec{e}} \), the observer is utilized in the form of the following
where the gains \( {\mathcal {L}}_0 = {\left[ {{l_{o1}},{l_{o2}},...,{l_{on}}} \right] ^T} \in {{\mathbb {R}}^n}\) is designed to make the characteristic polynomial \(\Xi - {\mathcal {L}}_0 {\Psi ^T} \) Hurwitz. By subtracting Eq. (27) from (26), the estimation error dynamic \(\dot{{\tilde{\varvec{{e}}}}}\) is acquired as follows:
5 Stability analysis
This section deals with the stability analysis and convergence of the error signals via the Lyapunov tools and Barbalat’s approach. To analyze the stability, adding and subtracting \({\hat{a}}^* ( {\hat{\varvec{x}}}) \) and \( {\hat{b}}^* ( {\hat{\varvec{x}}}) u\) in (28) leads to
From (18), \(\left[ {\hat{a}}^* ( {\hat{\varvec{x}}}) - {\hat{a}}( {\hat{\varvec{x}}}) \right] \) and \( \left[ {\hat{b}}^* ( {\hat{\varvec{x}}}) - {\hat{b}}( {\hat{\varvec{x}}}) \right] \) are expressed as:
The approximation errors \({J_a}\) and \({J_b}\) are defined as:
Note that \(a ( {{\varvec{x}}}) \) and \(b ( {{\varvec{x}}})\) are bounded which leads to the boundedness of \({J_a} \) and \({J_b}\) in (31) with the upper bounds \({{\bar{J}}_a}\) and \({{\bar{J}}_b}\). Now, regarding (30) and (31), one has
Select the Lyapunov function as:
where \( \hat{{\bar{J}}}_a/ \hat{{\bar{J}}}_b / \hat{{\bar{\delta }}} \), are estimations of \( {{\bar{J}}}_a/ {{\bar{J}}}_b / {{\bar{\delta }}} \) which are the upper bounds of \( J_a / J_b / \delta \). Moreover, defining \({\tilde{\theta }} _a^{} = \theta _a^ * - \theta _a^{}\,and\,{\tilde{\theta }} _b^{} = \theta _b^ * - \theta _b^{}\), \({\gamma _{{{\hat{{\bar{J}}}}_a}}}\), \({\gamma _{{{\hat{\bar{J}}}_b}}}\), \({\gamma _a}\) and \({\gamma _b}\) are the adaptation rate of \({{\hat{{\bar{J}}}}_a}\), \({{\hat{{\bar{J}}}}_b}\) , \(\theta _a^{}\) and \(\theta _b^{}\), respectively. \({{\mathcal {P}}_c}, {{\mathcal {P}}_o} \in {\mathbb {R}}^{n \times n}\) are positive definite matrices satisfying the following

where \({\Xi _c} = \Xi - \Pi {\mathcal {K}}_c^T \), \({\Xi _o} = \Xi - {\mathcal {L}}_o^{}{\Psi ^T}\), and \({Q_c}/{Q_o}\) are the arbitrary \(n \times n\) positive definite matrices. Utilizing (32), the time derivative of V is in the form of the following

Considering the terms \({\tilde{\theta }} _a^T\zeta _a^{}{ {\tilde{{\varvec{e}}}} ^T}{{\mathcal {P}}_o}\Pi - \frac{1}{{{\gamma _a}}}{\tilde{\theta }} _a^T{\dot{\theta }} _a^{}\) and \({\tilde{\theta }} _b^T\zeta _b^{}{ {\tilde{{\varvec{e}}}} ^T}{{\mathcal {P}}_o} \Pi u - \frac{1}{{{\gamma _b}}}{\tilde{\theta }} _b^T{\dot{\theta }} _b^{}\), the adaptation laws of \(\theta _a^{}/ \theta _b^{}\) can be obtained as follows:
Note that \({\tilde{{\varvec{e}}} ^T }{{\mathcal {P}}_o}\Pi \) is scalar. Regarding (34), (36), and \(\dot{V}(t)\), and after some calculations, it can be deduced that
According to (37), the adaptation laws of \({{\hat{\bar{J}}}_a}\), \({{\hat{{\bar{J}}}}_b}\) and \(\hat{{\bar{\delta }}}\) can be defined as:
Using adaptation laws (38), Eq. (37) can be rewritten as follows:
Considering (39), the compensator \(\,{u_s}\) is designed as

From (39) and (40), and considering:
and
one achieves that
To prove \(\mathop {\lim }\limits _{t \rightarrow \infty } \, {\hat{{\varvec{e}}} } = 0\) and \(\mathop {\lim }\limits _{t \rightarrow \infty } \,\tilde{{\varvec{e}}} = 0\), one has to demonstrate \({\hat{{\varvec{e}}} } \in {\ell _2}\, ,{\tilde{{\varvec{e}}} } \in {\ell _2}\) and the boundedness of \( \dot{{\hat{{\varvec{e}}} } } / \dot{{\tilde{{\varvec{e}}} } } \). Moreover, we have
Regarding the properties of the Lyapunov function, it is crystal clear that
Moreover, it is evident that
in which \({\lambda _{\min }}\left( {{ {{\mathcal {Q}}_c}}} \right) \) and \({\lambda _{\min }}\left( {{ {{\mathcal {Q}}_o}}} \right) \) denote the minimum eigenvalues of \({ {{\mathcal {Q}}_c}}\) and \({ {{\mathcal {Q}}_o}}\) respectively, then
Therefore, one can get that \( \hat{ {{\varvec{e}}} } \in {\ell _2}\,, \tilde{ {{\varvec{e}}} } \in {\ell _2}\). Moreover, regarding (27), (32), and assuming that the control signal and approximation errors \({J_a/J_b}\) are bounded, one has \( \dot{\hat{ {{\varvec{e}}} } } \in {\ell _\infty }\,, \dot{\tilde{ {{\varvec{e}}} }} \in {\ell _\infty }\). As a sequence, utilizing the Barbalat’s lemma results in
Remark 1
The IT3FLSs have a better ability to estimate the uncertainties. So, instead of considering upper bounds for uncertainties in a conservative approach, IT3FLSs by giving a better estimation efficiency, help in the reduction of conservatism.
6 Practical implementation
Example 1
In this section, the capability of the designed control strategy is experimentally scrutinized. The setup is depicted in Fig. 4. The robot has two conventional wheels with a diameter of 7 cm that are coupled to two high-precision motor steppers and two idle pins to keep it balanced. The robot contains eight sharp sensors on each of its four sides, as well as an MPU6050 angle acceleration sensor at its center of gravity. The motors are mounted on a 1.5 mm aluminum chassis that serves as the robot’s bottom plate. Two-phase stepper motors provide a step precision of 1.8 degrees per step. The surface of the chassis is lifted using four 7 cm spacers in order to install the PCB on it. The NRF24L01 radio transmitter module is used to communicate between the robot and the laptop. This module’s communication modulation is GFSK, and the chip’s communication frequency is 2.4 GHz. The objective is to design a control law to ensure that the robot follows the desired path.

Example 1: Experimental setup
The desired path is considered to be the first state of following chaotic system:
The path following performance is depicted in Fig. 5. It is perceptible that the robot tracks the prescribed chaotic path by implementing the suggested controller (23).

Example 1: The path-following response
One of the applications of the suggested approach is to design a secure path for patrol robots. As the robots follow the designed chaotic reference signal, the prediction of their path gets harder. In this way, the vertical coordinate represents displacement. In another way, the chaotic reference can be used for the speed of the robot. In other words, the robot moves in a straight line at a chaotic variable speed.
7 Computer simulations
Three computer simulations will be performed in this section to analyze the satisfaction of both observer and control objectives with unknown models/states, uncertainties, and external disturbances. The designing process is illustrated in detail for the first example. For the other examples, the process is similar. In all examples, the range of input space is normalized into − 1 and 1, and for each input, 3 MFs are considered. The centers of MFs are considered to be − 1, 0, and 1, to cover the input range.
Example 2
Based on the Euler-Lagrange equations, the flexible joint robot subject to unknown models is studied (see [44, 45] for more details)
The system dynamic is converted to the form of:
Utilizing a transformation results in
in which,
Now, (52) is expressed as:
The system parameters are declared as:
\(g = 9.80m/{s^2},\,\varrho = 2kg,\,\rho = 2N/m,\,I = 2Kg{m^2}\) and \(\aleph = 1m\). Moreover, \( \delta \) denotes white noise with the static characteristic (\( N \sim (0,0.1\)), affecting the performance of the system. To implement the suggested observer-based, one has the following
-
1.
The gains \({{\mathcal {K}}_c}\) and \({{\mathcal {L}}_o}\) should adjust the roots of \({s^4} + {k_{c4}}{s^3} + {k_{c3}}{s^2} + {k_{c2}}s + {k_{c1}}\) and \({s^4} + {l_{o1}}{s^3} + {l_{o2}}{s^2} + {l_{o3}}s + {l_{o4}}\) as \(-10\) and \(-20\), respectively.
-
2.
Solving (34), matrices \({{\mathcal {P}}_c}\) and \({{\mathcal {P}}_o}\) are selected as:
$$\begin{aligned} \begin{array}{l} \,{{\mathcal {Q}}_c} = {{\mathcal {Q}}_o} = {10^{ - 3}}\left[ {\begin{array}{*{20}{c}} 1&{}\quad 0&{}\quad 0&{}\quad 0\\ 0&{}\quad 1&{}\quad 0&{}\quad 0\\ 0&{}\quad 0&{}\quad 1&{}\quad 0\\ 0&{}\quad 0&{}\quad 0&{}\quad 1 \end{array}} \right] \\ \,{{\mathcal {P}}_c} = \left[ {\begin{array}{*{20}{c}} {{\mathrm{1}}{\mathrm{.3881}}}&{}\quad {{\mathrm{0}}{\mathrm{.6549}}}&{}\quad {{\mathrm{0}}{\mathrm{.0955}}}&{}\quad 0\\ {{\mathrm{0}}{\mathrm{.6549}}}&{}\quad {{\mathrm{0}}{\mathrm{.3297}}}&{}\quad {{\mathrm{0}}{\mathrm{.0542}}}&{}\quad {{\mathrm{0}}{\mathrm{.0003}}}\\ {{\mathrm{0}}{\mathrm{.0955}}}&{}\quad {{\mathrm{0}}{\mathrm{.0542}}}&{}\quad {{\mathrm{0}}{\mathrm{.0120}}}&{}\quad {{\mathrm{0}}{\mathrm{.0001}}}\\ 0&{}\quad {{\mathrm{0}}{\mathrm{.0003}}}&{}\quad {{\mathrm{0}}{\mathrm{.0001}}}&{}\quad {\mathrm{0}} \end{array}} \right] \\ {{\mathcal {P}}_o} = \left[ {\begin{array}{*{20}{c}} {{\mathrm{313}}{\mathrm{.5117}}}&{}\quad {{\mathrm{- 0}}{\mathrm{.0005}}}&{}\quad {{\mathrm{- 0}}{\mathrm{.5047}}}&{}\quad {{\mathrm{0}}{\mathrm{.0005}}}\\ {{\mathrm{- 0}}{\mathrm{.0005}}}&{}\quad {{\mathrm{0}}{\mathrm{.5047}}}&{}\quad {{\mathrm{- 0}}{\mathrm{.0005}}}&{}\quad {{\mathrm{- 0}}{\mathrm{.0040}}}\\ {{\mathrm{- 0}}{\mathrm{.5047}}}&{}\quad {{\mathrm{- 0}}{\mathrm{.0005}}}&{}\quad {{\mathrm{0}}{\mathrm{.0040}}}&{}\quad {{\mathrm{- 0}}{\mathrm{.0005}}}\\ {{\mathrm{0}}{\mathrm{.0005}}}&{}\quad {{\mathrm{- 0}}{\mathrm{.0040}}}&{}\quad {{\mathrm{- 0}}{\mathrm{.0005}}}&{}\quad {{\mathrm{0}}{\mathrm{.0001}}} \end{array}} \right] \end{array} \end{aligned}$$(55) -
3.
Given \(y = {z_1} = {x_1}\) and \({r}(s) = \frac{1}{s} \frac{{10}}{{s + 10}}\), solving (27) to obtain \({\hat{z}} = {\left[ {\begin{array}{*{20}{c}} {{{{\hat{z}}}_1}}&{{{{\hat{z}}}_2}}&{{{{\hat{z}}}_3}}&{{{{\hat{z}}}_4}} \end{array}} \right] ^T}\).
-
4.
The proposed IT3FLS \({\hat{a}}({\hat{z}})\) is implemented for the approximation of a(z) in (54). Note that 3 MFs are employed for inputs.
-
5.
The adaptation rates are \({\gamma _{{{\hat{{\bar{J}}}}_a}}} = 0.5,\,{\gamma _{\hat{{\bar{\delta }}}}} = 0.5,\,{\gamma _{{\theta _a}}} = 0.1\)
-
6.
Regarding (23), one can design
$$\begin{aligned} {u_s}&= - \tanh \left( \tilde{{\varvec{e}}}^T {\mathcal {P}}_o \Pi \right) \left\{ {{\hat{{\bar{J}}}}_a} + {\hat{{\bar{\delta }}}} +{\varepsilon \tanh \left( {{\hat{b}}(\widehat{\mathbf{x}})} \right) u}\right. \nonumber \\&\quad \left. + \frac{ \hat{{\varvec{e}}} ^T {\mathcal {P}}_c {\mathcal {L}}_o \tilde{{\varvec{e}}}_1 }{ \left| \tilde{{\varvec{e}}}^T {\mathcal {P}}_o \Pi \right| + 0.001 \,} \right\} \end{aligned}$$(56)

Example 2: The tracking response

Example 2: Control signal
Simulation results on a flexible joint robot are demonstrated in Figs. 6 and 7, while Fig. 6 portrays the tracking performance/errors. It is obvious that applying the suggested procedure results in stable tracking errors and robust stability of the closed-loop system. Furthermore, Fig. 7 verifies that the variation of the control signal is appropriate.
Example 3
The suggested IT3FLS-based control law is employed to control the two-link robot manipulator. The system dynamic is represented as [46]:
with
Moreover, it is easy to acquire that
where

Example 3: Tracking performance

Example 3: Control signals
Simulation parameters are \({m_1} = 1\,,\,{l_1} = 1,{m_e} = 2,{\delta _e} = {30^ \circ },\,\,{I_1} = 0.12,{l_{c1}} = 0.5,{I_e} = 0.25,{l_{ce}} = 0.6\) and \({r} = \sin (t)\). Utilizing the suggested method of this paper, \({a_1}\), \({a_2}\), \({b_1}\) and \({b_2}\) in (59) are estimated using the proposed IT3FLS \({{\hat{a}}_1}\), \({{\hat{a}}_2}\), \({{\hat{b}}_1}\) and \({{\hat{b}}_2}\). Note that functions \({{\hat{a}}_1}\) and \({{\hat{a}}_2}\) have five inputs. Moreover, one has the following:
The time evolutions of errors and the controller are sketched in Figs. 8 and 9, respectively. Regarding simulation analysis, it is vividly clear that the suggested IT3FLS control strategy is able to estimate and stabilize the state variables of unknown dynamics with significant performance and without chattering phenomenon.

Example 4: Tracking performance

Example 4: Controls signals
Example 4
The control law is implemented for the two inverted pendulums. The dynamics are as follows: (see [47] for detailed discussion)
with
For simulations, the parameters are \(M = m = 0.98\,0,\,\,l = 1.1,\,\,c = 0.50,\,\,w = 4,\,\,{w_1} = \,2,\,\,{w_1} = \,3,\,\,L = 2\), and \({r} = 0\).
From the proposed method, \({a_1}\) and \({a_2}\) in (62) are unknown and will be approximated via the proposed IT3FLS. \(\left( {{{{\hat{x}}}_{11}},{{{\hat{x}}}_{12}}} \right) \) and \(\left( {{{{\hat{x}}}_{21}},{{{\hat{x}}}_{22}}} \right) \) are selected for input of membership functions where \(\left[ {\begin{array}{*{20}{c}} { - 1}&0&1 \end{array}} \right] \) denote centers and upper/lower width are selected as 0.8/0.4. To design the control strategy, the parameters are:
The tracking trajectory is sketched in Fig. 10, while controllers are in Fig. 11. Comparing with the results of [47], the tunable parameters of this paper are less than that of [47] and the tracking errors are considerably less which confirm the superiority of the IT3FLS observer-based control policy of this paper.
Example 5
To have a comparison, Table 1 provides previous results of type-1/type-2 fuzzy-based strategies. In this regard, \(e_i = y_i - r\) \(i = 1,2\) and \({e_{ij}} = {x_{ij}} - {{\hat{x}}_{ij}},\,i,j = 1,2\) stand for the error signals. Note that T represents the final time and the sampling time specified by \(t_s=0.001\). It is obvious that utilizing IT3FLS leads to the better performance compared with employing type-2/type-1. Moreover, the number MFs is decreased which is another advantage of applying IT3FLS of this paper. Therefore, wide ranges of complexities and uncertainties can be studied via the suggested method of this paper.
8 Conclusion
Based on an online approximation of nonlinear functions via designing novel IT3FLS, an observer-based control law was developed to study uncertain nonlinear systems in this paper. The proposed method removed the restrictions of previous results of model-based control strategies and type-1/type-2 fuzzy-based control approaches and also improved the performance of a system and robustness against unknown dynamics, uncertainties, and unknown disturbances without detailed dynamics model information. Utilizing the proposed adaptive laws, approximation errors converged to zero and the upper bounds of exogenous disturbances were estimated online. Moreover, the stability of all error dynamics was guaranteed via using an appropriate Lyapunov function. Several simulations and a practical implementation have been provided to highlight the capabilities of our method in reducing computational burden, acquiring appropriate transient response, solving the robust tracking control problem, and ensuring robustness against unknown exogenous disturbances and uncertainties.
Data availability
There are no data associated with this paper.
Abbreviations
- IT3FLS:
-
Interval type-3 fuzzy logic system
- SM:
-
Sliding mode
- TS:
-
Takagi-Sugeno
- IT2FLS:
-
Interval type-2 fuzzy logic system
- T1FLS:
-
Type-1 fuzzy logic system
- T2F:
-
Type-2 fuzzy
- PI:
-
Proportional–Integral
- FS:
-
Fuzzy set
- MPU6050:
-
Angle acceleration sensor
- PCB:
-
Printed circuit board
- GFSK:
-
Gaussian frequency shift keying
- MF:
-
Membership function
References
Liu, X., Yu, H.: Continuous adaptive integral-type sliding mode control based on disturbance observer for pmsm drives. Nonlinear Dyn. 104(2), 1429–1441 (2021)
Li, T., Liu, X.: Non-cascade fast nonsingular terminal sliding mode control of permanent magnet synchronous motor based on disturbance observers. J. Electr. Eng. Technol. 17(2), 1061–1075 (2022)
Fridman, L., Shtessel, Y., Edwards, C., Yan, X.-G.: Higher-order sliding-mode observer for state estimation and input reconstruction in nonlinear systems. Int. J. Robust Nonlinear Control 18(4–5), 399–412 (2008)
Efimov, D., Fridman, L., Raïssi, T., Zolghadri, A., Seydou, R.: Interval estimation for lpv systems applying high order sliding mode techniques. Automatica 48(9), 2365–2371 (2012)
Edwards, C., Shtessel, Y.B.: Adaptive continuous higher order sliding mode control. Automatica 65, 183–190 (2016)
Yang, J., Li, S., Su, J., Yu, X.: Continuous nonsingular terminal sliding mode control for systems with mismatched disturbances. Automatica 49(7), 2287–2291 (2013)
da Silva, C., Campos, V., Nguyen, A.-T., Martínez Palhares, R.: Adaptive gain-scheduling control for continuous-time systems with polytopic uncertainties: an lmi-based approach. Automatica 133, 109856 (2021)
Taghieh, A., Shafiei, M.H.: Static output feedback control of switched nonlinear systems with time-varying delay and parametric uncertainties under asynchronous switching. Trans. Inst. Meas. Control. 43(5), 1156–1167 (2021)
Li, D., Ge, S.S., Lee, T.H.: Simultaneous arrival to origin convergence: sliding-mode control through the norm-normalized sign function. IEEE Trans. Autom. Control 67(4), 1966–1972 (2021)
Su, H., Zhang, W.: Observer-based adaptive neural quantized control for nonlinear systems with asymmetric fuzzy dead zones and unknown control directions. Nonlinear Dyn. 1–14 (2022)
Meng, Q., Ma, Q., Zhou, G.: Adaptive output feedback control for stochastic uncertain nonlinear time-delay systems. IEEE Trans. Circ. Syst. II Express Briefs
Zhang, X., Huang, W.: Robust \({H_\infty }\) adaptive output feedback sliding mode control for interval type-2 fuzzy fractional-order systems with actuator faults. Nonlinear Dyn. 104(1), 537–550 (2021)
Zhang, X., Jin, K.: State and output feedback controller design of takagi-sugeno fuzzy singular fractional order systems. Int. J. Control Autom. Syst. 19(6), 2260–2268 (2021)
Zhao, T., Zou, X., Dian, S.: Fixed-time observer-based adaptive fuzzy tracking control for mecanum-wheel mobile robots with guaranteed transient performance. Nonlinear Dyn. 107(1), 921–937 (2022)
Guo, B., Dian, S., Zhao, T.: Event-driven-observer-based fuzzy fault-tolerant control for nonlinear system with actuator fault. Nonlinear Dyn. 1–15 (2022)
Yan, S., Gu, Z., Park, J.H., Xie, X.: Adaptive memory-event-triggered static output control of TS fuzzy wind turbine systems. IEEE Trans. Fuzzy Syst
Yan, S., Shen, M., Nguang, S.K., Zhang, G., Zhang, L.: A distributed delay method for event-triggered control of T-S fuzzy networked systems with transmission delay. IEEE Trans. Fuzzy Syst. 27(10), 1963–1973 (2019)
Hao, R.-B., Lu, Z.-Q., Ding, H., Chen, L.-Q.: A nonlinear vibration isolator supported on a flexible plate: analysis and experiment. Nonlinear Dyn. 108(2), 941–958 (2022)
Zhang, Z., Niu, Y.: Sliding mode control of interval type-2 ts fuzzy systems with redundant channels. Nonlinear Dyn. 1–15 (2022)
Mohammadzadeh, A., Kaynak, O., Teshnehlab, M.: Two-mode indirect adaptive control approach for the synchronization of uncertain chaotic systems by the use of a hierarchical interval type-2 fuzzy neural network. IEEE Trans. Fuzzy Syst. 22(5), 1301–1312 (2014)
Castillo, O., Melin, P.: A review on the design and optimization of interval type-2 fuzzy controllers. Appl. Soft Comput. 12(4), 1267–1278 (2012)
Castillo, O., Amador-Angulo, L.: A generalized type-2 fuzzy logic approach for dynamic parameter adaptation in bee colony optimization applied to fuzzy controller design. Inf. Sci. 460–461, 476–496 (2018)
Khooban, M.H., Vafamand, N., Liaghat, A., Dragicevic, T.: An optimal general type-2 fuzzy controller for urban traffic network. ISA Trans. 66, 335–343 (2017)
Mohammadzadeh, A., Ghaemi, S., Kaynak, O., Khanmohammadi, S.: Robust \({H_\infty }\)-based synchronization of the fractional-order chaotic systems by using new self-evolving nonsingleton type-2 fuzzy neural networks. IEEE Trans. Fuzzy Syst. 24(6), 1544–1554 (2016)
Kumbasar, T., Hagras, H.: A self-tuning zslices-based general type-2 fuzzy pi controller. IEEE Trans. Fuzzy Syst. 23(4), 991–1013 (2015)
Yang, Y., Niu, Y., Reza Karimi, H.: Dynamic learning control design for interval type-2 fuzzy singularly perturbed systems: a component-based event-triggering protocol. Int. J. Robust Nonlinear Control 32(5), 2518–2535 (2022)
Yang, Y., Niu, Y., Li, J.: Local-boundary-information-dependent control design for interval type-2 fuzzy systems under self-triggered scheme. Inf. Sci. 596, 137–152 (2022)
Mohammadzadeh, A., Kumbasar, T.: A new fractional-order general type-2 fuzzy predictive control system and its application for glucose level regulation. Appl. Soft Comput. 91, 106241 (2020)
Amirkhani, A., Shirzadeh, M., Kumbasar, T., Mashadi, B.: A framework for designing cognitive trajectory controllers using genetically evolved interval type-2 fuzzy cognitive maps. Int. J. Intell. Syst. 37(1), 305–335 (2022)
Li, H., Wu, C., Wu, L., Lam, H.-K., Gao, Y.: Filtering of interval type-2 fuzzy systems with intermittent measurements. IEEE Trans. Cybern. 46(3), 668–678 (2016)
Sabzalian, M.H., Mohammadzadeh, A., Rathinasamy, S., Zhang, W.: A developed observer-based type-2 fuzzy control for chaotic systems. Int. J. Syst. Sci. 1–20 (2021)
Mohammadzadeh, A., Sabzalian, M.H., Ahmadian, A., Nabipour, N.: A dynamic general type-2 fuzzy system with optimized secondary membership for online frequency regulation. ISA Trans. 112, 150–160 (2021)
Mohammadzadeh, A., Kaynak, O.: A novel general type-2 fuzzy controller for fractional-order multi-agent systems under unknown time-varying topology. J. Franklin Inst. 356(10), 5151–5171 (2019)
Moghadam, H.M., Mohammadzadeh, A., Vafaie, R.H., Tavoosi, J., Khooban, M.-H.: A type-2 fuzzy control for active/reactive power control and energy storage management. Trans. Inst. Meas. Control. 44(5), 1014–1028 (2022)
Mohammadzadeh, A., Kaynak, O.: A novel fractional-order fuzzy control method based on immersion and invariance approach. Appl. Soft Comput. 88, 106043 (2020)
Mohammadzadeh, A., Sabzalian, M.H., Zhang, W.: An interval type-3 fuzzy system and a new online fractional-order learning algorithm: theory and practice. IEEE Trans. Fuzzy Syst. 28(9), 1940–1950 (2020)
Mohammadzadeh, A., Vafaie, R.H.: A deep learned fuzzy control for inertial sensing: micro electro mechanical systems. Appl. Soft Comput. 109, 107597 (2021)
Gheisarnejad, M., Mohammadzadeh, A., Farsizadeh, H., Khooban, M.-H.: Stabilization of 5g telecom converter-based deep type-3 fuzzy machine learning control for telecom applications. IEEE Trans. Circ. Syst. II Express Briefs 1–1 (2021)
Qasem, S.N., Ahmadian, A., Mohammadzadeh, A., Rathinasamy, S., Pahlevanzadeh, B.: A type-3 logic fuzzy system: optimized by a correntropy based kalman filter with adaptive fuzzy kernel size. Inf. Sci. 572, 424–443 (2021)
Boulkroune, A., M’saad, M.: On the design of observer-based fuzzy adaptive controller for nonlinear systems with unknown control gain sign. Fuzzy Sets Syst. 201, 71–85 (2012)
Lin, T.-C., Wang, C.-H., Liu, H.-L.: Observer-based indirect adaptive fuzzy-neural tracking control for nonlinear siso systems using vss and h-infinity approaches. Fuzzy Sets Syst. 143(2), 211–232 (2004)
Rovithakis, G.A., Christodoulou, M.A.: Direct adaptive regulation of unknown nonlinear dynamical systems via dynamic neural networks. Syst. Man Cybern. IEEE Trans. 25(12), 1578–1594 (1995)
Qasem, S.N., Ahmadian, A., Mohammadzadeh, A., Rathinasamy, S., Pahlevanzadeh, B.: A type-3 logic fuzzy system: optimized by a correntropy based kalman filter with adaptive fuzzy kernel size. Inf. Sci. 572, 424–443 (2021)
Krikochoritis, T., Tzafestas, S.: Control of flexible joint robots using neural networks. IMA J. Math. Control. Inf. 18(2), 269–280 (2001)
Meng, Q., Lai, X., Yan, Z., Su, C.-Y., Wu, M.: Motion planning and adaptive neural tracking control of an uncertain two-link rigid-flexible manipulator with vibration amplitude constraint. IEEE Trans. Neural Netw. Learn. Syst
Hung, L.-C., Chung, H.-Y., Chung-Li, T.-Y.: Hybrid neural sliding mode controller design for a robotic manipulator. J. Grey Syst. 17(2), 183–200 (2005)
Liu, Y.-J., Wang, W., Tong, S.-C., Liu, Y.-S.: Robust adaptive tracking control for nonlinear systems based on bounds of fuzzy approximation parameters. Syst. Man Cybern. Part A Syst. Hum. IEEE Trans. 40(1), 170–184 (2010)
Acknowledgements
This research is financially supported by the Ministry of Science and Technology of China (Grant No. 2019YFE0112400) and the Department of Science and Technology of Shandong Province (Grant No. 2021CXGC011204).
Funding
This research is financially supported by the Ministry of Science and Technology of China (Grant No.2019YFE0112400) and the Department of Science and Technology of Shandong Province (Grant No. 2021CXGC011204).
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Taghieh, A., Mohammadzadeh, A., Zhang, C. et al. A novel adaptive interval type-3 neuro-fuzzy robust controller for nonlinear complex dynamical systems with inherent uncertainties. Nonlinear Dyn 111, 411–425 (2023). https://doi.org/10.1007/s11071-022-07867-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11071-022-07867-9