
Abstract
This paper investigates the recursive parameter and state estimation algorithms for a special class of nonlinear systems (i.e., bilinear state space systems). A state observer-based stochastic gradient (O-SG) algorithm is presented for the bilinear state space systems by using the gradient search. In order to improve the parameter estimation accuracy and the convergence rate of the O-SG algorithm, a state observer-based multi-innovation stochastic gradient algorithm and a state observer-based recursive least squares identification algorithm are derived by means of the multi-innovation theory. Finally, a numerical example is provided to demonstrate the effectiveness of the proposed algorithms.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
System identification is the methodology of establishing mathematical models [1,2,3] and has wide applications in many areas such as linear system modeling [4, 5] and nonlinear system modeling [6,7,8,9]. The identification of linear systems has reached a high level of maturity [10], and nonlinear systems generally exist in industry areas, so their identification has received extensive attention. Bilinear systems are considered as a special class of nonlinear systems and are linear to the state and the control input, respectively, but not to them jointly. The bilinear system is a simple nonlinear extension of a linear system. So it is necessary to introduce some work about the identification of nonlinear systems such as Hammerstein systems. Many nonlinear parameter estimation methods [11,12,13] have been developed, such as the subspace methods [14, 15], the hierarchical methods [16, 17] and the key term separation methods [18]. For example, under the assumption of a white unobserved Gaussian input signal, errorless output observations and an invertible nonlinearity, Vanbeylen et al. [19] proposed a maximum likelihood estimator for Hammerstein systems with output measurements. Ase and Katayama [20] presented a subspace-based method to identify the Wiener–Hammerstein benchmark model by using the orthogonal projection subspace method and the separable least squares method.
The parameter identification [21,22,23] and the design of state observers [24,25,26] for bilinear systems have been carried out throughout the years both for continuous-time bilinear systems [27, 28] and for discrete-time bilinear systems [29, 30]. In the literature, Jan et al. [31] utilized the block pulse functions for the bilinear system identification in order to reduce the computation time. Dai et al. [32] proposed a robust recursive least squares method for bilinear systems identification. dos Santos et al. [33] presented a subspace state space identification algorithm for multi-input multi-output bilinear systems driven by white noise inputs by utilizing the Kalman filter idea.
State space systems can describe not only the system input and output characteristics but also the system internal structure characteristics, and play an important role in dynamical system state estimation [34, 35] and parameter estimation [36]. Many identification methods have been proposed for linear state space systems, but the identification of nonlinear state space systems is still difficult and has not been fully investigated. Schön et al. [37] derived an expectation maximization algorithm for the parameter estimation of nonlinear state space systems using a particle smoother. Marconato et al. [38] presented an identification method for nonlinear state space models on a benchmark problem based on the classical identification techniques and regression methods.
The least squares methods contain the recursive least squares algorithms [39,40,41] and the least squares-based iterative algorithms [42, 43]. In the literature, Arablouei et al. [44] studied an unbiased recursive least squares algorithm for errors-in-variables systems utilizing the dichotomous coordinate-descent iterations. Xu et al. [45] proposed the recursive least squares and multi-innovation stochastic gradient parameter estimation methods for signal modeling. Wan et al. [46] presented a novel method for the T-wave alternans assessment based on the least squares curve fitting technique. This paper addresses the identification issue for the bilinear state space systems with unmeasurable state variables. The basic idea is to transform a bilinear state space system into its observer canonical form and then to derive the recursive parameter estimation algorithms based on the multi-innovation theory and design the state observer to estimate the unknown states. The main contributions of this paper lie in the following.
-
By using the gradient search and the state observer, we overcome the difficulty that there exists both unmeasurable states and unknown parameters in the identification models, and propose the state observer-based gradient identification algorithms for bilinear state space systems.
-
By utilizing the current innovations and past innovations, this paper presents a state observer-based multi-innovation stochastic gradient (O-MISG) algorithm for bilinear state space systems to improve the parameter estimation accuracy and convergence rates.
To close this section, we give an outline of this paper. Section 2 derives the observer canonical state space model for bilinear systems. Section 3 introduces the identification model for the bilinear state space models. A state estimation-based recursive parameter identification algorithm is presented in Sect. 4. Section 5 provides an illustrative example for the results in this paper. Finally, some concluding remarks are given in Sect. 6.
2 The observer canonical state space model for bilinear systems
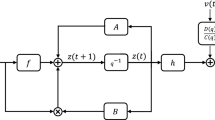
First of all, let us introduce some notation. “\(A=:X\)” or “\(X:=A\)” stands for “A is defined as X”; the symbol \(\varvec{I}\) (\(\varvec{I}_n\)) represents an identity matrix of appropriate size (\(n\times n\)); z denotes a unit forward shift operator like \(z\varvec{x}(t)=\varvec{x}(t+1)\) and \(z^{-1}\varvec{x}(t)=\varvec{x}(t-1)\); the superscript T symbolizes the vector/matrix transpose; \(\hat{\varvec{{\theta }}}(t)\) denotes the estimate of \(\varvec{{\theta }}\) at time t.
Consider the bilinear state space system described by
where \(\bar{\varvec{x}}(t):=[\bar{x}_1(t),\bar{x}_2(t),\ldots ,\bar{x}_n(t)]^{\tiny \text{ T }}\in {\mathbb {R}}^n\) is the state vector, \(u(t)\in {\mathbb {R}}\) and \(y(t)\in {\mathbb {R}}\) are the system input and output variables, \(v(t)\in {\mathbb {R}}\) is a random noise with zero mean and variance \(\sigma ^2\), and \(\bar{\varvec{A}}\in {\mathbb {R}}^{n\times n}\), \(\bar{\varvec{B}}\in {\mathbb {R}}^{n\times n}\), \(\bar{\varvec{f}}\in {\mathbb {R}}^n\) and \(\bar{\varvec{h}}\in {\mathbb {R}}^{1\times n}\) are the parameter matrices/vectors of the system.
Suppose that the system in (1) and (2) is controllable and observable. The bilinear system can be transformed into an observer canonical form under the non-singular linear transformation such as \(\bar{\varvec{x}}(t)=\varvec{T}_\mathrm{o}\varvec{x}(t)\), where \(\varvec{T}_\mathrm{o}\in {\mathbb {R}}^{n\times n}\) stands for the non-singular matrix. The transformation is as follows.
where
The transformation matrix is given by
where \(\varvec{l}_n\) is the nth column of \(\varvec{T}_\mathrm{ob}\).
where \(\varvec{T}_\mathrm{ob}\) is another non-singular matrix which transform the general system into its observability canonical form.
Proof
As \(\varvec{T}=[*,\ \varvec{l}_n]\), we have
and the nth column can be written as
Hence, we have
or
Therefore, we obtain
Suppose that the characteristic equation of \(\bar{\varvec{A}}\) can be represented as
According to the Cayley–Hamilton theorem, we have
or
Pre- and post-multiplying (8) by \(\varvec{T}^{-1}\) and \(\varvec{l}_n\) gives
By substituting the above equation into (7), the proof is finished. \(\square \)
The model in (1) and (2) contains \(2n^2+2n\) parameters, but the observer canonical form in (3) and (4) contains only \(n^2+2n\) parameters. The decrease in the parameters to be identified leads to the reduction in the identification computation because both the initial parameters and the transformed parameters describe the relationship between input and output of the same bilinear state space system.
It is pointed out that this paper does not consider the process noise in the state equation, because if adding the process noise, the problem is more complex and more difficult, more challenging and more interesting, the related work can be found in [15, 47] without considering the process noise. In the future work, we will investigate the case with process noise.
3 The identification model for the bilinear state space system
From (3) to (5), we have the following n equations:
which can be simplified as
Multiplying both sides of (10) by \(z^{-i}\) gives
Summing (12) for i from \(i=1\) to \(i=(n-1)\), we have
Then, multiplying both sides of (11) by \(z^{-n}\) gives
Substituting (14) into (13), we obtain
From (4), we have
Define the information vector \(\varvec{{\varphi }}(t)\) and the parameter vector \(\varvec{{\theta }}\) as
Substituting (15) into (16), we obtain the identification model of the bilinear state space system in (3) and (4):
4 The recursive state and parameter estimation algorithm
The recursive state and parameter estimation algorithm is composed of the state estimation and parameter identification.
4.1 The state estimation algorithm
Although the open-loop observer [26], closed-loop observer [48] and the Kalman filter [35] all can estimate the system states, in the state estimate-based parameter identification methods in this paper, we use the open-loop observer, which can also achieve good performance. From the simulation results, we can see that the estimated states are very close to the actual states of the system (see Figs. 3, 4, 7, 8), which show that the open-loop state observer we propose is valid. Compared with the closed-loop state observer, the open-loop state observer is simpler in structure and has less computation cost. So when the open-loop state observer can satisfy the estimation accuracy, we will give priority to the design of the open-loop state observer instead of the closed-loop state observer to reduce the computation cost. Of course, we may use the closed-loop observer like in Refs. [25] and [48]. Then we carry on the design of the open-loop observer.
If the parameter matrices/vector \(\varvec{A}\in {\mathbb {R}}^{n\times n}\), \(\varvec{B}\in {\mathbb {R}}^{n\times n}\) and \(\varvec{f}\in {\mathbb {R}}^n\) are known, we can apply the following state observer to generate the estimate \(\hat{\varvec{x}}(t)\) of the unknown state vector \(\varvec{x}(t)\):
When the parameter matrices/vector \(\varvec{A}\in {\mathbb {R}}^{n\times n}\), \(\varvec{B}\in {\mathbb {R}}^{n\times n}\) and \(\varvec{f}\in {\mathbb {R}}^n\) are unknown, we replace them with their estimated parameter matrices/vector \(\hat{\varvec{A}}(t)\), \(\hat{\varvec{B}}(t)\) and \(\hat{\varvec{f}}(t)\) in the following parameter estimation algorithms to compute the estimate \(\hat{\varvec{x}}(t)\) of the state vector \(\varvec{x}(t)\) and obtain
In (18) and (19), the initial state \(\hat{\varvec{x}}(1)\) is usually defined as a real vector with small entries, e.g., \(\hat{\varvec{x}}(1)=\mathbf{1}_n/p_0\), where \(\mathbf{1}_n:=[1,1,\ldots ,1]^{\tiny \text{ T }}\in {\mathbb {R}}^n\), and \(p_0\) is a large number, e.g., \(p_0=10^6\gg 1\).
4.2 The state observer-based multi-innovation stochastic gradient algorithm
Based on the identification model in (17), we propose the stochastic gradient (SG) algorithm as
where the norm of a matrix \(\varvec{X}\) is defined as \(\Vert \varvec{X}\Vert ^2:=\mathrm{tr}[\varvec{X}\varvec{X}^{\tiny \text{ T }}]\), 1 / r(t) represents the convergence factor or the step size, and \(e(t):=y(t)-\varvec{{\varphi }}^{\tiny \text{ T }}(t)\hat{\varvec{{\theta }}}(t-1)\) is defined as the scalar innovation. As is known to us, the SG algorithm has slow convergence rates. In order to overcome this weakness, we take advantage of the multi-innovation identification theory and expand the scalar innovation e(t) to an innovation vector (p represents the innovation length):
Define the stacked output vector \(\varvec{Y}(p,t)\) and the stacked information matrix \(\varvec{\varPhi }(p,t)\) as
Then the innovation vector \(\varvec{E}(p,t)\) can be expressed as
In the case of \(p=1\), we obtain \(\varvec{E}(1,t)=e(t)\), \(\varvec{\varPhi }(1,t)=\varvec{{\varphi }}(t)\), \(\varvec{Y}(1,t)=y(t)\). Equation (20) is equivalent to
Replacing the “1” in \(\varvec{\varPhi }(1,t)\) and \(\varvec{Y}(1,t)\) with p obtains
Because the information vector \(\varvec{{\varphi }}(t)\) contains the unmeasurable state vector \(\varvec{x}(t)\), the algorithm in (20) to (22) cannot be realized. The scheme here is to replace \(\varvec{x}(t)\) in \(\varvec{{\varphi }}(t)\) with its estimate \(\hat{\varvec{x}}(t)\) and to define
By using the estimate \(\hat{\varvec{{\varphi }}}(t)\) to replace \(\varvec{{\varphi }}(t)\) and using the estimate \(\hat{\varvec{\varPhi }}(t)\) to replace \({\varvec{\varPhi }}(t)\), the O-MISG algorithm can be derived as
When \(p=1\), the O-MISG algorithm reduces to the state observer-based stochastic gradient (O-SG) algorithm. Then we study the convergence of the O-SG algorithm by establishing a recursive relation about the parameter estimation error and by using the martingale convergence theorem.
In identification, the output is linear about the parameter space, the algorithms are not sensitive to the initial values and can achieve global minima, and the final parameter estimates do not depend on the initial values. We have the following theorem about the convergence of the proposed algorithms.
Theorem 1
For the system in (17) and the O-SG algorithm in (26) to (38) \((p=1)\), assume that \(\{v(t)\}\) is a white noise sequence with zero mean and variance \(\sigma ^2\), i.e.,
and \(r(t)\rightarrow \infty \), and there exist an integer N and a positive constant c independent of t such that the following strong excitation condition holds:
Then the parameter estimation error given by the O-SG algorithm converges to zero.
The proofs of Theorems1 and 2 in the sequel can be done in a similar way to those in [47, 48].
4.3 The state observer-based recursive least squares algorithm
In order to improve the convergence rate and parameter estimation accuracy of the SG algorithm, we define the output vector \(\varvec{Y}(t)\) and the information matrix \(\varvec{H}(t)\) as
Based on the identification model in (17), we define the criterion function as
According to the least squares principle, and minimizing \(J(\varvec{{\theta }})\), we can obtain the following recursive least squares algorithm:
In order to avoid computing the inversion of the covariance matrix \(\varvec{P}(t)\), applying the matrix inversion lemma
to (42) gives
Defining the gain vector \(\varvec{L}(t):=\varvec{P}(t)\varvec{{\varphi }}(t)\in {\mathbb {R}}^{n^2+2n}\), we obtain
Therefore, the recursive least squares algorithms in (41) and (42) can be equivalent to
Aimed at the unmeasurable state variables included in the information vector \(\varvec{{\varphi }}(t)\), we replace \(\varvec{{\varphi }}(t)\) with its estimates \(\hat{\varvec{{\varphi }}}(t)\) in the identification algorithm. Then, combined with the state observer, we can obtain the state observer-based recursive least squares (O-RLS) algorithm:
About the convergence of the parameter estimate \(\varvec{{\theta }}(t)\), we have the following theorem.
Theorem 2
Provided that the controllable and observable system in (1) and (2) is stable (i.e., \(\varvec{A}\) is stable), for the identification model in (17) and the state observer-based RLS parameter identification algorithm in (49) to (59), suppose that v(t) is a white noise sequence with zero mean and variance \(\sigma ^2\), i.e., \(\mathrm{E}[v(t)]=0\), \(\mathrm{E}[v^2(t)]=\sigma ^2\), \(\mathrm{E}[v(t)v(i)]=0(i\ne t)\), and that there exist positive constants \(\alpha \) and \(\beta \) such that the following persistent excitation conditions holds:
Then the parameter estimation error \(\Vert \hat{\varvec{{\theta }}}(t)-\varvec{{\theta }}\Vert \) converges to zero.

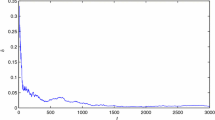
O-MISG parameter estimation errors \(\delta \) versus t (\(\sigma ^2=0.50^2\))

O-RLS parameter estimation errors \(\delta \) versus t (\(\sigma ^2=0.50^2\))

State \(x_1(t)\) and the estimated state \(\hat{x}_1(t)\) against t (\(p=8\), \(\sigma ^2=0.50^2\))

State \(x_2(t)\) and the estimated state \(\hat{x}_2(t)\) against t (\(p=8\), \(\sigma ^2=0.50^2\))
The identification method proposed in this paper can be extended to multi-input multi-output systems through expanding the single input to multiple inputs and the single output to multiple outputs.
5 Numerical example
Consider the following observer canonical bilinear state space system:

The parameter vector to be identified is
In simulation, the input \(\{u(t)\}\) is taken as an uncorrelated persistent excitation signal sequence with zero mean and unit variance, and \(\{v(t)\}\) as a white noise sequence with zero mean and variance \(\sigma ^2\). Take the data length \(L=5000\), and apply the O-MISG algorithm in (26) to (38) and the O-RLS algorithm in (49) to (59) to estimate the states and parameters of this bilinear system. The O-MISG parameter estimates and errors \(\delta =\Vert \hat{\varvec{{\theta }}}(t)-\varvec{{\theta }}\Vert /\Vert \varvec{{\theta }}\Vert \) with different innovation length p are shown in Table 1 and Fig. 1 with \(\sigma ^2=0.50^2\). The O-RLS parameter estimates and errors \(\sigma ^2=0.50^2\) are shown in Table 2 and Fig. 2. The states \(x_{i}(t)\) and their estimates \(\hat{x}_{i}(t)\) against t are shown in Figs. 3 and 4.
For comparison with the noise variance \(\sigma ^2=0.50^2\), Tables 3, 4 and Figs. 5, 6 give the O-MISG and O-RLS parameter estimates and the parameter estimation error curves with \(\sigma ^2=0.10^2\). The states \(x_{i}(t)\) and their estimates \(\hat{x}_{i}(t)\) against t are shown in Figs. 7 and 8.

O-MISG parameter estimation errors \(\delta \) versus t (\(\sigma ^2=0.10^2\))

O-RLS parameter estimation errors \(\delta \) versus t (\(\sigma ^2=0.10^2\))

State \(x_1(t)\) and the estimated state \(\hat{x}_1(t)\) against t (\(p=8\), \(\sigma ^2=0.10^2\))

State \(x_2(t)\) and the estimated state \(\hat{x}_2(t)\) against t (\(p=8\), \(\sigma ^2=0.10^2\))
From Tables 1, 2, 3, 4 and Figs. 1, 2, 3, 4, 5, 6, 7, 8, we can draw the following conclusions.
-
(1)
The O-RLS algorithm is superior to the O-SG algorithm in the parameter estimation accuracy and convergence rates.
-
(2)
The parameter estimation errors \(\delta \) of the O-MISG algorithm become smaller with the innovation length p increasing and converge to zero fast if the innovation length p is large enough, and the data length tends to infinity.
-
(3)
Under the same innovation length, a smaller noise variance leads to higher parameter estimation accuracy and a faster convergence rate.
-
(4)
The estimated states are very close to the actual states of the system.
6 Conclusions
This paper considers the parameter identification problems of bilinear state space systems using the multi-innovation theory and the least squares principle. The utilization of the non-singular linear transformation for general bilinear systems reduces the number of the parameters of the identification model, a state observer-based multi-innovation stochastic gradient algorithm and a state observer-based recursive least squares algorithm are derived for observer canonical bilinear state space systems. The convergence analysis indicates that the algorithms proposed are effective and the parameter estimates given by the proposed algorithms can converge to their true values. The numerical simulation results indicate that the designed state observer makes the estimated states close to the actual states of the systems. The O-MISG and O-RLS algorithm can give effective parameter estimates compared with the O-SG algorithm. The multi-innovation identification method can improve the parameter estimate accuracy and the convergence rates compared with the single-innovation identification methods. The proposed algorithms can realize the interactive estimation for unknown states and parameters for bilinear systems.
Although the algorithms in the paper are developed for single-input single-output systems with white noise disturbance, the methods can be extended to identify multiple-input multiple-output systems by expanding the single input to multiple inputs and the single output to multiple outputs. They can also be extended to study identification problems of other linear and nonlinear multivariable systems with colored noises and applied to other fields [49,50,51].
References
Xu, L.: A proportional differential control method for a time-delay system using the Taylor expansion approximation. Appl. Math. Comput. 236, 391–399 (2014)
Xu, L., Chen, L., Xiong, W.L.: Parameter estimation and controller design for dynamic systems from the step responses based on the Newton iteration. Nonlinear Dyn. 79(3), 2155–2163 (2015)
Xu, L.: Application of the Newton iteration algorithm to the parameter estimation for dynamical systems. J. Comput. Appl. Math. 288, 33–43 (2015)
Ding, F., Wang, F.F., Xu, L., Wu, M.H.: Decomposition based least squares iterative identification algorithm for multivariate pseudo-linear ARMA systems using the data filtering. J. Frankl. Inst. 354(3), 1321–1339 (2017)
Ding, F., Xu, L., Zhu, Q.M.: Performance analysis of the generalised projection identification for time-varying systems. IET Control Theory Appl. 10(18), 2506–2514 (2016)
Wang, D.Q., Zhang, W.: Improved least squares identification algorithm for multivariable Hammerstein systems. J. Frankl. Inst. 352(11), 5292–5307 (2015)
Wang, D.Q.: Hierarchical parameter estimation for a class of MIMO Hammerstein systems based on the reframed models. Appl. Math. Lett. 57, 13–19 (2016)
Mao, Y.W., Ding, F.: A novel parameter separation based identification algorithm for Hammerstein systems. Appl. Math. Lett. 60, 21–27 (2016)
Mao, Y.W., Ding, F.: Multi-innovation stochastic gradient identification for Hammerstein controlled autoregressive autoregressive systems based on the filtering technique. Nonlinear Dyn. 79(3), 1745–1755 (2015)
Xu, L.: The damping iterative parameter identification method for dynamical systems based on the sine signal measurement. Signal Process. 120, 660–667 (2016)
Wang, C.N., He, Y.J., Ma, J.: Parameters estimation, mixed synchronization, and antisynchronization in chaotic systems. Complexity 20(1), 64–73 (2014)
Ma, J., Zhang, A.H., Xia, Y.F.: Optimize design of adaptive synchronization controllers and parameter observers in different hyperchaotic systems. Appl. Math. Comput. 215(9), 3318–3326 (2010)
Wang, D.Q., Ding, F.: Parameter estimation algorithms for multivariable Hammerstein CARMA systems. Inf. Sci. 355, 237–248 (2016)
Van Overschee, P., De Moor, B.: Subspace Identification for Linear Systems: Theory, Implementation, Applications. Springer Science Business Media, New York (1996)
Wang, D.Q., Ding, F., Liu, X.M.: Least squares algorithm for an input nonlinear system with a dynamic subspace state space model. Nonlinear Dyn. 75(1–2), 49–61 (2014)
Xu, L., Ding, F.: The parameter estimation algorithms for dynamical response signals based on the multi-innovation theory and the hierarchical principle. IET Signal Process. 11(2), 228–237 (2017)
Wang, Y.J., Ding, F.: The auxiliary model based hierarchical gradient algorithms and convergence analysis using the filtering technique. Signal Process. 128, 212–221 (2016)
Vörös, J.: Identification of nonlinear cascade systems with output hysteresis based on the key term separation principle. Appl. Math. Model. 39(18), 5531–5539 (2015)
Vanbeylen, L., Pintelon, R., Schoukens, J.: Blind maximum likelihood identification of Hammerstein systems. Automatica 44(12), 3139–3146 (2008)
Ase, H., Katayama, T.: A subspace-based identification of Wiener–Hammerstein benchmark model. Control Eng. Pract. 44, 126–137 (2015)
Juang, J.N.: Applied System Identification. Prentice Hall, New Jersey (1994)
Juang, J.N., Phan, M., Horta, L.G.: Identification of observer/Kalman filter Markov parameters: theory and experiments. J. Guid. Control Dyn. 16(2), 320–329 (1993)
Ma, J., Li, F., Huang, L., et al.: Complete synchronization, phase synchronization and parameters estimation in a realistic chaotic system. Commun. Nonlinear Sci. Numer. Simul. 16(9), 3770–3785 (2011)
Hara, S., Furuta, K.: Minimal order state observers for bilinear systems. Int. J. Control 24(5), 705–718 (1976)
Phan, M.Q., Vicario, F., Longman, R.W.: Optimal bilinear observers for bilinear state-space models by interaction matrices. Int. J. Control 88(8), 1504–1522 (2015)
Ma, X.Y., Ding, F.: Recursive and iterative least squares parameter estimation algorithms for observability canonical state space systems. J. Franklin Inst. – Engineering. Appl. Math. 352(1), 248–258 (2015)
Juang, J.N.: Continuous-time bilinear system identification. Nonlinear Dyn. 39(1–2), 79–94 (2005)
Lee, C.H., Juang, J.N.: System identification for a general class of observable and reachable bilinear systems. J. Vib. Control 20(10), 1538–1551 (2013)
Hizir, N.B., Phan, M.Q., Betti, R.: Identification of discrete-time bilinear systems through equivalent linear models. Nonlinear Dyn. 69(4), 2065–2078 (2012)
Vicario, F., Phan, M.Q., Longman, R.W.: A linear-time-varying approach for exact identification of bilinear discrete-time systems by interaction matrices. Astronaut. Sci. 150, 1057–1076 (2014)
Jan, Y.G., Wong, K.M.: Bilinear system identification by block pulse functions. J. Frankl. Inst. 312(5), 349–359 (1981)
Dai, H., Sinha, N.K.: Robust recursive least-squares method with modified weights for bilinear system identification. IEEE Proc. D Control Theory Appl. 163(3), 122–126 (1989)
dos Santos, P.L., Ramos, J.A., de Carvalho, J.L.M.: Identification of bilinear systems with white noise inputs: an iterative deterministic–stochastic subspace approach. IEEE Trans. Control Syst. Techn. 17(5), 1145–1153 (2009)
Li, B.B.: State estimation with partially observed inputs: a unified Kalman filtering approach. Automatica 49(3), 816–820 (2013)
Pan, J., Yang, X.H., Cai, H.F., Mu, B.X.: Image noise smoothing using a modified Kalman filter. Neurocomputing 173, 1625–1629 (2016)
Vicario, F., Phan, M.Q., Betti, R.: Linear state representations for identification of bilinear discrete-time models by interaction matrices. Nonlinear Dyn. 77(4), 1561–1576 (2014)
Schön, T.B., Wills, A., Ninness, B.: System identification of nonlinear state-space models. Automatica 47(1), 39–49 (2011)
Marconato, A., Sjöberg, J., Suykens, J., Schoukens, J.: Identification of the Silverbox benchmark using nonlinear state-space models. IFAC Proc. 45(16), 632–637 (2012)
Ljung, L.: System Identification: Theory for the User. Englewood Cliffs, New Jersey (1987)
Söderström, T., Stoica, P.: System Identification. Prentice-Hall Inc, New Jersey (1988)
Xu, L., Ding, F., Gu, Y., Alsaedi, A., Hayat, T.: A multi-innovation state and parameter estimation algorithm for a state space system with d-step state-delay. Signal Process. 140, 97–103 (2017)
Wang, F.F., Liu, Y.J., Yang, E.: Least squares-based iterative identification methods for linear-in-parameters systems using the decomposition technique. Circuits Syst. Signal Process. 35(11), 3863–3881 (2015)
Wang, Y.J., Ding, F.: The filtering based iterative identification for multivariable systems. IET Control Theory Appl. 10(8), 894–902 (2016)
Arablouei, R., Doğancay, K., Adalı, T.: Unbiased recursive least-squares estimation utilizing dichotomous coordinate-descent iterations. IEEE Trans. Signal Process. 62(11), 2973–2983 (2014)
Xu, L., Ding, F.: Recursive least squares and multi-innovation stochastic gradient parameter estimation methods for signal modeling. Circuits Syst. Signal Process. 36(4), 1735–1753 (2017)
Wan, X.K., Li, Y., Xia, C., Wu, M.H., Liang, J., Wang, N.: A T-wave alternans assessment method based on least squares curve fitting technique. Measurement 86, 93–100 (2016)
Ding, F., Gu, Y.: Performance analysis of the auxiliary model-based stochastic gradient parameter estimation algorithm for state space systems with one-step state delay. Circuits Syst. Signal Process. 32(2), 585–599 (2013)
Ding, F.: State filtering and parameter estimation for state space systems with scarce measurements. Signal Process. 104, 369–380 (2014)
Feng, L., Wu, M.H., Li, Q.X., et al.: Array factor forming for image reconstruction of one-dimensional nonuniform aperture synthesis radiometers. IEEE Geosci. Remote Sens. Lett. 13(2), 237–241 (2016)
Wang, T.Z., Qi, J., Xu, H., et al.: Fault diagnosis method based on FFT-RPCA-SVM for cascaded-multilevel inverter. ISA Trans. 60, 156–163 (2016)
Wang, T.Z., Wu, H., Ni, M.Q., et al.: An adaptive confidence limit for periodic non-steady conditions fault detection. Mech. Syst. Signal Process. 72–73, 328–345 (2016)
Acknowledgements
This work was supported by the National Natural Science Foundation of China (No. 61273194) and the 111 Project (B12018).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Zhang, X., Ding, F., Alsaadi, F.E. et al. Recursive parameter identification of the dynamical models for bilinear state space systems. Nonlinear Dyn 89, 2415–2429 (2017). https://doi.org/10.1007/s11071-017-3594-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11071-017-3594-y