
Abstract
Bilinear systems are a special class of nonlinear systems. Some systems can be described by using bilinear models. This paper considers the parameter identification problems of bilinear stochastic systems. The difficulty of identification is that the model structure of the bilinear systems includes the products of the states and inputs. To this point, this paper gives the input–output representation of the bilinear systems through eliminating the state variables in the model and derives a least squares algorithm and a multi-innovation stochastic gradient algorithm for identifying the parameters of bilinear systems based on the least squares principle and the multi-innovation identification theory. The simulation results indicate that the proposed algorithms are effective for identifying bilinear systems.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
The parameter identification of linear systems has been mature [31, 32], and many identification methods have been developed, e.g., the recursive identification methods [25] and the iterative identification methods [34, 44]. By comparison, there is a lot of research space for the parameter identification for bilinear stochastic systems. The identification of bilinear systems has been studied for a long history, at least more than four decades. Earlier work on identification for bilinear systems exists: Karanam et al. [26] utilized the Walsh functions for bilinear system identification; Fnaiech and Ljung [19] discussed recursive identification methods for bilinear systems. In respect of nonlinear system identification, the heuristic optimization techniques seem to be very helpful and have been used in system identification [3, 5], control engineering [6, 12, 30], parameter estimation [2, 4] and the Lorenz chaotic systems [1]. By means of the heuristic algorithms, Modares et al. [29] proposed an adaptive particle swarm optimization (PSO) algorithm to estimate the parameters of bilinear systems, increasing the convergence speed and accuracy compared with the basic PSO algorithm. Gibson et al. [20] developed a maximum-likelihood parameter estimation algorithm of bilinear systems. Inspired by the fixed point theory, Li et al. [27] presented an iterative algorithm to recursively identify bilinear models. Lopes dos Santos et al. [28] identified the Wiener–Hammerstein bilinear system using an iterative bilinear subspace identification algorithm.
In the field of nonlinear system identification, much work has been performed for decades [41]. A class of nonlinear systems can be described by a static nonlinearity followed by a linear subsystem. For such nonlinear systems, a decomposition-based Newton iterative identification method [14] and a hierarchical parameter estimation algorithm [33] were developed. Also, Chen et al. [9] presented a hierarchical gradient parameter estimation algorithm for Hammerstein nonlinear systems using the key term separation principle. Wang and Zhang [43] derived an improved least squares identification algorithm for multivariable Hammerstein systems.
The least squares (LS) methods are basic in system identification [18, 39]. For example, for a class of linear-in-parameter output error moving average systems, Wang and Tang proposed an auxiliary model-based recursive least squares (RLS) algorithm [42]; Hu [21] developed iterative and recursive LS algorithms to estimate the parameters of moving average systems; Cao et al. [7] have presented a novel two-dimensional RLS identification approach with soft constraint for batch processes, which can improve the identification performance by exploiting information not only from time direction within a batch but also along batches. Recently, Ding et al. [15] presented an auxiliary model-based least squares algorithm for a dual-rate state space system with time delay using the data filtering and a Kalman state filtering-based least squares iterative parameter estimation algorithm for observer canonical state space systems using decomposition [17].
Multi-innovation identification is an important branch of system identification [13]. The innovation is the valuable information which can improve parameter or state estimation accuracy. In this respect, Ding [13] proposed the innovation-based identification theory and methods, by expanding a scalar innovation to an innovation vector and then to an innovation matrix. Based on this theory, Hu et al. [22] suggested a multi-innovation generalized extended stochastic gradient algorithm for output nonlinear autoregressive moving average systems.
This paper focuses on the parameter identification problems of bilinear stochastic systems. It is organized as follows. Section 2 derives the identification model for bilinear systems. Sections 3 and 4 propose a RLS identification algorithm and a multi-innovation stochastic gradient (MISG) identification algorithm. Section 5 provides two simulation examples to prove the validity of the proposed algorithms. Finally, some concluding remarks are made in Sect. 6.
2 The Identification Model for Bilinear Systems
In this section, we describe a bilinear system and derive its identification model for parameter estimation. Let us define some notation. “\(A=:X\)” or “\(X:=A\)” represents “A is defined as X,” and \(z^{-1}\) stands for a unit forward shift operator with the following properties:
Assume that the bilinear systems under consideration have the following observability canonical form [11]:
where \(\varvec{x}(t):=[x_1(t), x_2(t), \cdots , x_n(t)]^{\tiny \text{ T }}\) is the n-dimensional state vector, \(u(t)\in {\mathbb R}\) and \(y(t)\in {\mathbb R}\) are the input and output of the system, respectively, and \(\varvec{A}\in {\mathbb R}^{n\times n}\), \(\varvec{B}\in {\mathbb R}^{n\times n}\), \(\varvec{f}\in {\mathbb R}^n\) and \(\varvec{h}\in {\mathbb R}^{1\times n}\) are constant matrices and vectors:

Define the following polynomials:
The coefficients \(c_i\) and \(d_i\) can be determined using \(a_i\), \(b_i\) and \(f_i\). Referring to the method in [11], eliminating the state vector \(\varvec{x}(t)\) in (1)–(2), we have the following input–output relation,
Since the practical systems are always interfered with various factors, e.g., stochastic noise, introducing a noise term \(v(t)\in {\mathbb R}\), we have
Define the parameter vector \({\varvec{\theta }}\) and the information vector \({\varvec{\varphi }}(t)\) as
where
Inserting A(z), B(z), C(z) and D(z) into (3) leads to
Equation (4) is the identification model of the bilinear system with white noise.
The objective of the paper is to develop new identification methods for estimating the parameters \(a_i\), \(b_i\), \(c_i\) and \(d_i\) or the parameter vectors \(\varvec{a}\), \(\varvec{b}\), \(\varvec{c}\) and \(\varvec{d}\), from the observation data \(\{u(t), y(t): t=1, 2, 3, \ldots \}\).
3 The Recursive Least Squares Identification Algorithm
In this part, aiming at the model in (4), we propose the RLS estimation algorithm so that online identification can be carried out. Using the data with \(t=1,2, \ldots , t\), we define
According to (4), define a quadratic criterion function
Minimizing the criterion function \(J({\varvec{\theta }})\) and letting the partial derivative of \(J({\varvec{\theta }})\) with regard to \({\varvec{\theta }}\) be zero, we obtain the least squares estimate of \({\varvec{\theta }}\):
where \(\hat{{\varvec{\theta }}}(t)\) is the estimate of \({\varvec{\theta }}\) at time t, \(\hat{{\varvec{\theta }}}(0)\) is a very small real vector. To derive the recursive least squares algorithm conveniently, define the covariance matrix \(\varvec{P}(t)\) as
Using the definition of \({\varvec{\varGamma }}_t\), it follows that
To avoid computing the matrix inversion of \(\varvec{P}(t)\), applying the matrix inverse lemma [18]
to (7) gives
Using (6) and from (5), we have
Combining (8) and (9), we can obtain the RLS algorithm for estimating the parameter vector \({\varvec{\theta }}\) in (4):
The computational amount of the RLS algorithm for bilinear systems is given in Table 1 and its has \((64n^2-8n-2)\) flops. The RLS algorithm is simple and can be implemented online.
4 The Multi-Innovation Stochastic Gradient Identification Algorithm
Based on the identification model in (4), we can acquire the stochastic gradient (SG) identification algorithm;
where the norm of a matrix \(\varvec{X}\) is defined by \(\Vert \varvec{X}\Vert ^2:=\hbox {tr}[\varvec{X}\varvec{X}^{\tiny \text{ T }}]\). It is well known that the SG algorithm has slow convergence rates, in order to improve the situation, expanding the scalar innovation e(t) to an innovation vector [40]:
Define the information matrix \({\varvec{\varPhi }}(p, t)\) and the stacked output vector \(\varvec{Y}(p, t)\) as
Then the innovation vector \(\varvec{E}(p, t)\) in (19) can be expressed as
We can obtain the MISG algorithm for bilinear systems:
In this algorithm, \(\varvec{E}(p,t)\in {\mathbb R}^p\) is an innovation vector (i.e., multi-innovation). When \(p=1\), the MISG algorithm reduces to the SG algorithm.
The advantage of the multi-innovation identification method is that it makes full use of the identification innovations and can raise the convergence speed to a certain degree, and the stationarity of data can improve identification accuracy. The computation amount of the MISG algorithm for bilinear systems is \((24pn-5p)\) flops as given in Table 2.

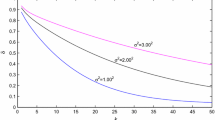
RLS parameter estimation errors \(\delta \) versus t
Equation (22) can be modified as
In order to track the time-varying parameters, we must introducing a forgetting factor \(\lambda \) in (22) and get
or
5 Examples
Example 1
Consider the following bilinear system:
The parameter vector to be estimated is given by
In simulation, we adopt an independent persistent excitation signal sequence with zero mean and unit variance as the input \(\{u(t)\}\), and a white noise sequence with zero mean and variance \(\sigma ^2=0.50^2\) as \(\{v(t)\}\). Applying the recursive least squares algorithm in (10)–(15) to compute the parameters estimates \(\hat{{\varvec{\theta }}}(t)\) of the system, the parameter estimates and the estimation errors are given in Table 3, the estimation errors \(\delta \) versus the data length t is shown in Fig. 1. The parameter estimation errors are computed by \(\delta :=\Vert \hat{{\varvec{\theta }}}(t)-{\varvec{\theta }}\Vert /\Vert {\varvec{\theta }}\Vert \).
From Table 3 and Fig. 1, we can see that the RLS parameter estimation errors become smaller with the increase of t.

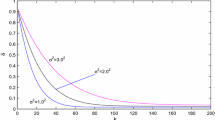
Parameter estimation errors \(\delta \) versus t
Example 2
Consider the system in Example 1 and the same simulation conditions. Applying the MISG algorithm to estimate the parameters of this system, the parameter estimates and their errors are shown in Tables 4, 5 and Fig. 2, where Table 4 lists the parameter estimates and errors given by the MISG algorithm when \(p=1\), i.e., the stochastic gradient algorithm.
From Table 5 and Fig. 2, it is observed that the MISG algorithm can identify the parameters of the bilinear system. Meanwhile, the estimation errors become smaller as the innovation length increases. These results show that the proposed algorithms work well for bilinear systems with white noise.
6 Conclusions
This paper derives the identification model of bilinear systems. On the basis of the obtained model, we present a RLS algorithm and an MISG algorithm for bilinear stochastic systems and give the state estimation algorithm. The simulation results indicate that for the multi-innovation identification algorithm, increasing the innovation length can enhance the parameter estimation accuracy, reducing the sensitivity of the algorithm to noise. The algorithms in this paper can be extended to study the identification problems of other bilinear systems, linear and nonlinear systems with colored noise [16, 33, 35], stochastic multivariable systems [36–38], uncertain chaotic delayed nonlinear systems [23] and hybrid switching–impulsive dynamical networks [24], and applied to other fields [8, 10].
When the uncertainty in parameters is small, the obtained parameter estimates are close to their true values. The estimates can be taken as the real parameters for controller design when the errors are tolerable.
References
A. Alfi, Particle swarm optimization algorithm with dynamic inertia weight for online parameter identification applied to Lorenz chaotic system. Int. Innov. Comput. Inf. Control 8(2), 1191–1203 (2012)
A. Alfi, PSO with adaptive mutation and inertia weight and its application in parameter estimation of dynamic systems. Acta Autom. Sin. 37(5), 541–549 (2011)
A. Alfi, M.M. Fateh, Identification of nonlinear systems using modified particle swarm optimization: a hydraulic suspension system. J. Veh. Syst. Dyn. 46(6), 871–887 (2011)
A. Alfi, M.M. Fateh, Intelligent identification and control using improved fuzzy particle swarm optimization. Expert Syst. Appl. 38(10), 12312–12317 (2011)
A. Alfi, H. Modares, System identification and control using adaptive particle swarm optimization. Appl. Math. Model. 35, 1210–1221 (2011)
A. Arab, A. Alfi, An adaptive gradient descent-based local search in memetic algorithm for solving engineering optimization problems. Inf. Sci. 299, 117–142 (2015)
Z.X. Cao, Y. Yang, J.Y. Lu, F.R. Gao, Constrained two dimensional recursive least squares model identification for batch processes. J. Process Control 24(6), 871–879 (2014)
X. Cao, D.Q. Zhu, S.X. Yang, Multi-AUV target search based on bioinspired neurodynamics model in 3-D underwater environments. IEEE Trans. Neural Netw. Learn. Syst. (2016). doi:10.1109/TNNLS.2015.2482501
H.B. Chen, Y.S. Xiao, Hierarchical gradient parameter estimation algorithm for Hammerstein nonlinear systems using the key term separation principle. Appl. Math. Comput. 247, 1202–1210 (2014)
Z.Z. Chu, D.Q. Zhu, S.X. Yang, Observer-based adaptive neural network trajectory tracking control for remotely operated Vehicle. IEEE Trans. Neural Netw. Learn. Syst. (2016). doi:10.1109/TNNLS.2016.2544786
H. Dai, N.K. Sinha, Robust recursive least-squares method with modified weights for bilinear system identification. IEE Proc. Part D 136(3), 122–126 (1989)
A. Darabi, A. Alfi, B. Kiumarsi, H. Modares, Employing adaptive PSO algorithm for parameter estimation of an exciter machine. J. Dyn. Syst-T ASME 134(1). doi:10.1115/1.4005371, (2012)
F. Ding, System Identification—New Theory and Methods (Science Press, Beijing, 2013)
F. Ding, K.P. Deng, X.M. Liu, Decomposition based Newton iterative identification method for a Hammerstein nonlinear FIR system with ARMA noise. Circuits Syst. Signal Process. 33(9), 2881–2893 (2014)
F. Ding, X.M. Liu, Y. Gu, An auxiliary model based least squares algorithm for a dual-rate state space system with time-delay using the data filtering. J. Franklin Inst. 353(2), 398–408 (2016)
F. Ding, X.M. Liu, M.M. Liu, The recursive least squares identification algorithm for a class of Wiener nonlinear systems. J. Franklin Inst. 353(7), 1518–1526 (2016)
F. Ding, X.M. Liu, X.Y. Ma, Kalman state filtering based least squares iterative parameter estimation for observer canonical state space systems using decomposition. J. Comput. Appl. Math. 301, 135–143 (2016)
F. Ding, X.H. Wang, Q.J. Chen, Y.S. Xiao, Recursive least squares parameter estimation for a class of output nonlinear systems based on the model decomposition. Circuits Syst. Signal Process. 35, (2016). doi:10.1007/s00034-015-0190-6
F. Fnaiech, L. Ljung, Recursive identification of bilinear systems. Int. J. Control 45(2), 453–470 (1987)
S. Gibson, A. Wills, B. Ninness, Maximum-likelihood parameter estimation of bilinear systems. IEEE Trans. Autom. Control 50(10), 1581–1596 (2005)
Y.B. Hu, Iterative and recursive least squares estimation algorithms for moving average systems. Simul. Model. Pract. Theory 34, 12–19 (2013)
Y.B. Hu, B.L. Liu, Q. Zhou, A multi-innovation generalized extended stochastic gradient algorithm for output nonlinear autoregressive moving average systems. Appl. Math. Comput. 247, 218–224 (2014)
Y. Ji, X.M. Liu, New criteria for the robust impulsive synchronization of uncertain chaotic delayed nonlinear systems. Nonlinear Dyn. 79(1), 1–9 (2015)
Y. Ji, X.M. Liu, Unified synchronization criteria for hybrid switching-impulsive dynamical networks. Circuits Syst. Signal Process. 34(5), 1499–1517 (2015)
S.X. Jing, T.H. Pan, Z.M. Li, Recursive bayesian algorithm with covariance resetting for identification of Box–Jenkins systems with non-uniformly sampled input data. Circuits Syst. Signal Process. 16, 1–14 (2015)
V.R. Karanam, P.A. Frick, R.R. Mohler, Bilinear system identification by Walsh functions. IEEE Trans. Autom. Control 23, 709–713 (1978)
G.Q. Li, C.Y. Wen, A.M. Zhang, Fixed point iteration in identifying bilinear models. Syst. Control Lett. 83, 28–37 (2015)
P. Lopes dos Santos, J.A. Ramos, J.L. Martins de Carvalho, Identification of a Benchmark Wiener–Hammerstein: a bilinear and Hammerstein–Bilinear model approach. Control Eng. Pract. 20, 1156–1164 (2012)
H. Modares, A. Alfi, M.N. Sistani, Parameter estimation of bilinear systems based on an adaptive particle swarm optimization. Eng. Appl. Artif. Intell. 23, 1105–1111 (2010)
Y. Mousavi, A. Alfi, A memetic algorithm applied to trajectory control by tuning of fractional order proportional–integral–derivative controllers. Appl. Soft. Comput. 36, 599–617 (2015)
B.Q. Mu, J. Guo, L.Y. Wang, G. Yin, L.J. Xu, W.X. Zheng, Identification of linear continuous-time systems under irregular and random output sampling. Automatica 60, 100–114 (2015)
J. Na, X.M. Ren, Y.Q. Xia, Adaptive parameter identification of linear SISO systems with unknown time-delay. Syst. Control Lett. 66, 43–50 (2014)
D.Q. Wang, Hierarchical parameter estimation for a class of MIMO Hammerstein systems based on the reframed models. Appl. Math. Lett. 57, 13–19 (2016)
D.Q. Wang, Least squares-based recursive and iterative estimation for output error moving average systems using data filtering. IET Control Theory Appl. 5(14), 1648–1657 (2011)
D.W. Wang, F. Ding, Parameter estimation algorithms for multivariable Hammerstein CARMA systems. Inf. Sci. 355, 237–248 (2016)
Y.J. Wang, F. Ding, Novel data filtering based parameter identification for multiple-input multiple-output systems using the auxiliary model. Automatica (2016). doi:10.1016/j.automatica.2016.05.024
Y.J. Wang, F. Ding, The filtering based iterative identification for multivariable systems. IET Control Theory Appl. 10(8), 894–902 (2016)
Y.J. Wang, F. Ding, The auxiliary model based hierarchical gradient algorithms and convergence analysis using the filtering technique. Signal Process. 128, 212–221 (2016)
Y.J. Wang, F. Ding, Recursive least squares algorithm and gradient algorithm for Hammerstein–Wiener systems using the data filtering. Nonlinear Dyn. 84(2), 1045–1053 (2016)
X.H. Wang, F. Ding, Modelling and multi-innovation parameter identification for Hammerstein nonlinear state space systems using the filtering technique. Math. Comput. Model. Dyn. Syst. 22(2), 113–140 (2016)
X.H. Wang, F. Ding, Recursive parameter and state estimation for an input nonlinear state space system using the hierarchical identification principle. Signal Process. 117, 208–218 (2015)
C. Wang, T. Tang, Recursive least squares estimation algorithm applied to a class of linear-in-parameters output error moving average systems. Appl. Math. Lett. 29, 36–41 (2014)
D.Q. Wang, W. Zhang, Improved least squares identification algorithm for multivariable Hammerstein systems. J. Franklin Inst. Eng. Appl. Math. 352(11), 5292–5370 (2015)
W.G. Zhang, Decomposition based least squares iterative estimation for output error moving average systems. Eng. Comput. 31(4), 709–725 (2014)
Acknowledgments
This work was supported by the National Natural Science Foundation of China (No. 61273194). The author is grateful to her Master Supervisor Professor Feng Ding and the main idea of this paper comes from him and his books “System Identification—New Theory and Methods, Science Press, Beijing, 2013,” “System Identification—Performances Analysis for Identification Methods, Science Press, Beijing, 2014” and “System Identification—Multi-Innovation Identification Theory and Methods, Science Press, Beijing, 2016.”
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Meng, D. Recursive Least Squares and Multi-innovation Gradient Estimation Algorithms for Bilinear Stochastic Systems. Circuits Syst Signal Process 36, 1052–1065 (2017). https://doi.org/10.1007/s00034-016-0337-0
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00034-016-0337-0