
Abstract
In this paper, we introduce an inertial projection-type method with different updating strategies for solving quasi-variational inequalities with strongly monotone and Lipschitz continuous operators in real Hilbert spaces. Under standard assumptions, we establish different strong convergence results for the proposed algorithm. Primary numerical experiments demonstrate the potential applicability of our scheme compared with some related methods in the literature.
Similar content being viewed by others
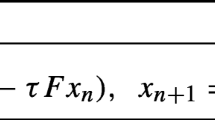

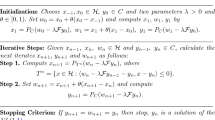
Avoid common mistakes on your manuscript.
1 Introduction
In this paper, we study the Quasi-Variational Inequality (QVI) problem, which generalizes the classical Variational Inequality (VI) problem of Fichera [1, 2] and Stampacchia [3] (see also Kinderlehrer and Stampacchia [4]). In a QVI, the associated feasible set of the problem is not fixed, but varies according to some explicit or implicit rule. For example, in many applications, the feasible set is defined as a “moving set,” i.e., there is a closed and convex set, also known as the core set, that is shifted by another single-valued mapping; see, for example, [5,6,7,8,9] and the references therein. In such a setting, the problem is often called “moving set” QVI.
There exist many techniques for solving QVIs; for example, very recently, Antipin et al. [5] presented gradient projection and extragradient methods for solving QVIs under the assumptions of strong monotonicity and Lipschitz continuity of the associated mappings. The main disadvantage of the extragradient method, with respect to the classical gradient projection algorithm, is that the number of orthogonal projections and mapping evaluations is doubled per each iteration. Moreover, while in the context of VIs, the extra projection and evaluation per iteration of the extragradient method guarantee convergence under weaker assumptions than strong monotonicity of the associated mapping, for QVIs, this is not the case and thus the extragradient does not have any advantage over the gradient projection method.
A more general gradient projection method, with strong convergence, for solving QVIs in real Hilbert spaces, is introduced by Mijajlović et al. in [10]. This method holds great potential since it works well on different practical applications. Other efficient solution methods for solving QVIs can be found in [11,12,13,14].
In the field of continuous optimization, inertial-type algorithms attracted much interest in recent years mainly due to their convergence properties. The idea is derived from the field of second-order dissipative dynamical systems [15, 16]. It is shown that such inertial terms speed up the convergence rate of the existing algorithms; see, e.g., the inertial proximal point algorithm [17,18,19,20,21], the inertial forward–backward splitting method [22,23,24], the inertial Douglas–Rachford splitting method [25, 26], the inertial ADMM [27, 28], and the inertial forward–backward–forward method [29].
Motivated by the above results, we wish to present a new inertial-type algorithm for solving QVIs with the following three major advantages.
- 1.
We consider general QVIs, in contrast to what is done; e.g., in [5] where only the “moving set” case, described above, is analyzed.
- 2.
Our new proposed scheme requires only one operator evaluation and one projection per each iteration, in contrast to other methods such as those provided in [5, 10], just to name a few.
- 3.
The convergence speed of our proposed method is better than other projection methods for solving QVIs; see e.g., [10].
The outline of the paper is as follows. In Sect. 2 we list some basic facts, concepts, and lemmas, which are needed for the rest of the paper. In Sect. 3 the new method with two different inertial and relaxation parameters is presented and analyzed. In Sect. 4, numerical examples illustrate the practical behavior of the proposed schemes and, finally, in Sect. 5 conclusion is given.
2 Preliminaries
Let \(\mathcal {H}\) be a real Hilbert space with inner product \(\langle \cdot ,\cdot \rangle \) and norm \(\Vert \cdot \Vert \). Let \(\mathcal {F}:\mathcal {H}\rightarrow \mathcal {H}\) be a nonlinear operator and \(K:\mathcal {H}\rightrightarrows \mathcal {H}\) be a set-valued mapping which, for any element \(u\in \mathcal {H}\), associates a closed and convex set \(K(u)\subset \mathcal {H}\). With the above data, we are concerned with the following Quasi-Variational Inequality (QVI), which consists of finding a point \(u^{*}\in \mathcal {H}\) such that \(u^{*}\in K(u^{*})\) and
Clearly, if \(K(u)\equiv K\) for all \(u\in \mathcal {H}\), then the problem reduces to the classical variational inequality; that is, finding a point \(u^{*}\in K\) such that
Definition 2.1
Let \(T:\mathcal {H}\rightarrow \mathcal {H}\) be a given mapping.
The mapping T is called L-Lipschitz continuous (\(L>0\)), if
$$\begin{aligned} \Vert F(x)-F(y)\Vert \le L \Vert x-y\Vert \quad \text { for all }\quad x,y\in \mathcal {H}. \end{aligned}$$(3)The mapping T is called \(\mu \)-strongly monotone (\(\mu >0\)), if
$$\begin{aligned} \langle T(x)-T(y),x-y\rangle \ge \mu \Vert x-y\Vert ^{2}\quad \text { for all }\quad x,y\in \mathcal {H}. \end{aligned}$$(4)The mapping T is called monotone, if
$$\begin{aligned} \langle F(x)-F(y),x-y\rangle \ge 0 \quad \text { for all }\quad x,y\in \mathcal {H}. \end{aligned}$$(5)
Let K be a nonempty, closed, and convex subset of \(\mathcal {H}\). For each point \(x\in \mathcal {H}\), there exists a unique nearest point in K, denoted by \(P_{K}(x)\), such that
The mapping \(P_{K}:\mathcal {H}\rightarrow K\) is called the metric projection of \(\mathcal {H}\) onto K and is characterized; see e.g., [30, Section 3], by the following two properties:
and
and if K is a hyper-plane, then (8) becomes an equality.
The following result, which is proved in [31], gives sufficient conditions for the existence of solutions of QVIs (1).
Lemma 2.1
Let \(\mathcal {F}:\mathcal {H}\rightarrow \mathcal {H}\) be L-Lipschitz continuous and \(\mu \)-strongly monotone on \(\mathcal {H}\), and \(K(\cdot )\) be a set-valued mapping with nonempty, closed, and convex values such that there exists \(\lambda \ge 0\) such that
Then the QVI (1) has a unique solution.
The next result is a fixed point formulation characterizing the solutions of the QVI (1).
Lemma 2.2
Let \(K(\cdot )\) be a set-valued mapping with nonempty, closed and convex values in \(\mathcal {H}\). Then \(x^* \in K(x^*)\) is a solution of the QVI (1) if and only if for any \(\gamma >0\) it holds that
A technical result, which is useful for our analysis, is given next; see [32].
Lemma 2.3
Let \(\{a_k\}\) be a sequence of nonnegative real numbers satisfying the following relation:
where
- (a)
\(\{\alpha _k\}\subset [0,1],\)\( \sum _{k=1}^{\infty } \alpha _k=\infty ;\)
- (b)
\(\limsup \sigma _k \le 0\);
- (c)
\(\gamma _k \ge 0 \ (n \ge 1),\)\( \sum _{k=1}^{\infty } \gamma _k <\infty .\)
Then, \(a_k\rightarrow 0\) as \(k\rightarrow \infty \).
3 Inertial Method
In this section, we introduce the inertial-type method and establish its strong convergence theorems.
Algorithm 3.1
Initialization: Select arbitrary starting points \(x^0,x^1 \in \mathcal {H}\).Iterative step: Given the iterates \(x^k\) and \(x^{k-1}\), compute the next iterate \(x^{k+1}\) as follows
Set \(k\leftarrow k+1\) and go to the Iterative step.
In Algorithm 3.1, \(\{\theta _k\}\) and \(\{\alpha _k\}\) are sequences that must satisfy different conditions, specified in the results below, to get convergence to solutions of the QVI.
Remark 3.1
-
1.
If \(\theta _k=0\) for all \(k\ge 1\), in Algorithm 3.1, then [10, Algorithm 1] is obtained. Thus, Algorithm 3.1 is actually [10, Algorithm 1] with an inertial extrapolation step \(y^k\).
-
2.
If both \(\theta _k=0\) and \(\alpha _k=1\), for all \(k\ge 1\) in Algorithm 3.1, we obtain the procedure [5, Eq. (5)] (also studied in [7, 33,34,35]).
We start the strong convergence analysis of Algorithm 3.1 with the special choice of parameters:
for some \(\eta \ge 3\) and \(\epsilon _k \in ]0,\infty [\).
We observe that in this case Algorithm 3.1 generates a sequence such that \(\sum _{k=1}^{\infty }\theta _k\Vert x^{k}-x^{k-1}\Vert <\infty ,\) because for every \(k\ge 1\) we get \(\theta _k\Vert x^{k}-x^{k-1}\Vert \le \epsilon _k\) when \(x^{k}\ne x^{k-1}\) and \(\theta _k\Vert x^{k}-x^{k-1}\Vert =0\) when \(x^{k}= x^{k-1}\).
Theorem 3.1
Consider the QVI (1) with \(\mathcal {F}\) being \(\mu \)-strongly monotone and L-Lipschitz continuous and assume there exists \(\lambda \ge 0\) such that (9) holds. Let \(\{x^k\}\) be any sequence generated by Algorithm 3.1 with the updating rule given by (11). Assume in addition that \(\gamma \ge 0\) satisfies
the sequence \(\{\alpha _k\}\subseteq ]0,1]\) is such that \(\sum _{k=1}^{\infty }\alpha _k=\infty \), and the sequence \(\{\epsilon _k\}\) satisfies \(\sum _{k=1}^{\infty }\epsilon _k<\infty \), then \(\{x^k\}\) converges strongly to the unique solution \(x^* \in K(x^*)\) of the QVI (1).
Proof
We know that
Now,
Using the fact that \(\mathcal {F}\) is \(\mu \)-strongly monotone and L-Lipschitz continuous, we obtain
Combining (13) and (14), we get
where \(\beta := \sqrt{1-2\mu \gamma +\gamma ^2L^2}+\lambda \). Now,
Plugging (16) into (15), we get
Observe that by (12), we have \(0<\beta <1\). Since \(\sum _{k=1}^{\infty }\theta _k\Vert x^{k}-x^{k-1} \Vert < \infty \), using Lemma 2.3, we get that \(x^k\rightarrow x^*, k\rightarrow \infty \), and the proof is complete. \(\square \)
Remark 3.2
Inequality (condition) (12) can always be satisfied by setting \(\gamma \) sufficiently close to the ratio \(\frac{\mu }{L^2}\).
Moreover, Theorem 3.1 still holds if in (11) the term \(\frac{k-1}{k+\eta -1}\) is replaced with some constant in [0, 1[. The idea of using it with \(\eta \ge 3\) derives from the recent inertial extrapolated step introduced in [19, 36].
Next we present the complexity bound of Algorithm 3.1 with the updating rule (11).
Theorem 3.2
Consider the QVI (1) with the same assumptions as in Theorem 3.1. Let \(\{x^k\}\) be any sequence generated by Algorithm 3.1 with the updating rule (11) and let \(x^* \in K(x^*)\) be the unique solution of the QVI (1). Let \(\alpha _k = \alpha \) and \(\epsilon _k = \epsilon \) be constant. Then, given \(\rho \in ]0,\alpha (1-\beta )[\), for any
assuming \(\bar{k} \ge 0\), it holds that
Proof
From the proof of Theorem 3.1, for any \(k\ge 1\), we get
because \((1-\alpha (1-\beta )) \ge 0\). Without the loss of generality, assume that for every \(k < \bar{k}\) we get
Concatenating (19) and (20), we obtain, for every \(k < \bar{k}\),
Therefore, by the definition of \(\bar{k}\), it holds that
For any \(k > \bar{k}\), there are two possibilities. If
then, by (19) and recalling that \((1-\alpha (1-\beta )) \le 1\), we obtain that \(x^k\) satisfies (18). Otherwise, if
then
and the desired result holds. \(\square \)
Remark 3.3
We observe that, in contradiction with the assumptions of Theorem 3.1, in Theorem 3.2 the summability of \(\{\epsilon _k\}\) is not required. However if one wants a good bound in (18) then a small value of \(\epsilon \) must be set; but in this case, small values of \(\theta _k\) are allowed.
Now, we present another convergence theorem for Algorithm 3.1 under different conditions on the inertial terms.
Theorem 3.3
Consider the QVI (1) with \(\mathcal {F}\) being \(\mu \)-strongly monotone and L-Lipschitz continuous and assume there exists \(\lambda \ge 0\) such that (9) holds. Let \(\{x^k\}\) be any sequence generated by Algorithm 3.1 with \(\gamma \ge 0\) satisfying (12), and \(\{\alpha _k\}\) and \(\{\theta _k\}\) satisfying the following conditions for some \(\epsilon \in ]0,1[\):
- 1.
\(0<\frac{1}{2(1-\beta )}\le \alpha _k < \frac{1}{1+\epsilon }\), with \(\beta := \sqrt{1-2\mu \gamma +\gamma ^2L^2}+\lambda \), and \(\sum _{k=1}^{\infty }\alpha _k=\infty \);
- 2.
\(0\le \theta _k\le \theta _{k+1}\le \theta<\frac{\sqrt{1+8\epsilon }-1-2\epsilon }{2(1-\epsilon )}<1\).
Then \(\{x^k\}\) converges strongly to the unique solution \(x^* \in K(x^*)\) of the QVI (1).
Proof
Define \(T(y^k):=P_{K(y^k)}(y^k-\gamma \mathcal {F}(y^k))\). Then for the unique solution \(x^*\) of (1), we obtain
Since \(\mathcal {F}\) is \(\mu \)-strongly monotone and \(L-\)Lipschitz continuous, we get
Combining (22) and (23), we get
From the definition of Algorithm 3.1, we get
Now,
Observe that
and so
Combining (27) with (25) yields
Now,
Using (26) and (29) with (28), we get
where \(\rho _k:=\frac{(1-\alpha _k)}{\alpha _k}(1- \theta _k)\) and \(\sigma _k:=\theta _k(1+\theta _k)-\frac{(1-\alpha _k)}{\alpha _k}(\theta _k^2-\theta _k)\).
Let \(\Gamma _k:=\Vert x^k-x^*\Vert ^2-\theta _k\Vert x^{k-1}-x^*\Vert ^2+\sigma _k\Vert x^{k}-x^{k-1}\Vert ^2\). Then we obtain from (30) that
Since \(0 \le \theta _k \le \theta _{k+1} <\theta \), we have
Combining (31) and (32), we get
where \(\delta :=-(1-\epsilon )\theta ^2-(1+2\epsilon )\theta +\epsilon \). Therefore, \(\Gamma _{k+1}\le \Gamma _k\). Hence \(\{\Gamma _k\}\) is nonincreasing. Furthermore,
Therefore,
and it can also be seen that
Note that
By (33), we have
and so by (34) and (35), we get
This shows that
and hence also,
From the above, we deduce that \(\lim _{k \rightarrow \infty } \Vert x^{k+1}-x^{k}\Vert =0\). Following the same arguments derived (17) from the proof of Theorem 3.1, we obtain
Since \(2\alpha _k(1-\beta )\ge 1\), it implies that
Observe that
since \(\{x^k\}\) is bounded and \(\lim _{n \rightarrow \infty } \Vert x^{k+1}-x^{k}\Vert =0\). Applying Lemma 2.3 to (38), we get that \(x^k\rightarrow x^*, k\rightarrow \infty \) and the desired result is obtained. \(\square \)
We discuss some relationships between the sets of assumptions of \(\{\theta _k\}\) given in Theorems 3.1 and 3.3 in the following remark.
Remark 3.4
-
1.
One can see from the choices of \(\{\theta _k\}\) in Theorem 3.1 (see (11)) and Theorem 3.3 that the two choices of \(\{\theta _k\}\) are independent of each other. For example, when \(x^k=x^{k-1}\), one can see from (11) that
$$\begin{aligned}&\theta _k \le \theta _{k+1} ~~\mathrm{but}~~\theta _{k+1} \nleqslant \frac{\sqrt{1+8\epsilon }-1-2\epsilon }{2(1-\epsilon )} \end{aligned}$$for all \(k\ge 1\) and \(\epsilon \in ]0,1[\). This negates the second assumption in Theorem 3.3.
-
2.
Also, from the proof of Theorem 3.3, we can see that \(\sum _{k=1}^{\infty } \theta _{k}\Vert x^{k+1}-x^{k}\Vert ^2 < \infty \), while in Theorem 3.1, we have \(\sum _{k=1}^{\infty } \theta _{k}\Vert x^{k+1}-x^{k}\Vert < \infty \).
4 Numerical Experiments
In this section, we compare the performances of our proposed scheme (Algorithm 3.1) with those of Algorithms 1 and 2 proposed in [10], and the extragradient method studied in [5].
We choose to use the test problem library QVILIB taken from [37]; the feasible map K is assumed to be given by \(K(x):=\{z \in \mathbb {R}^n \, : \, g(z,x) \le 0 \}\). We implemented Algorithm 3.1 in MATLAB/Octave. We implemented the projection over a convex set as the solution of a convex program. We considered the following performance measures for optimality and feasibility:
A point \(x^*\) is considered as a solution of the QVI if opt\((x^*) \le \)1e-3 and feas\((x^*) \le \)1e-3. As a nonlinear programming solver, we used the built-in function sqp with maxiter = 1000. All the experiments were carried out on an Intel Core i7-4702MQ CPU @ 2.20GHz x 8 with Ubuntu 14.04 LTS 64-bit and using GNU Octave version 3.8.1.
In Table 1 the results of Algorithm 3.1 with \(\gamma = 0.5\) and constant sequences \(\{\alpha _k=\alpha \}\) and \(\{\theta _k=\theta \}\) are presented. Different values for \(\alpha \) and \(\theta \) are considered, and we also report in Table 1 the number of iterations the algorithm requires to reach the stopping criterion. A failure is reported whenever the algorithm does not converge within 5000 iterations. We remark that when \(\alpha =1\) and \(\theta =0\) we obtain the classical gradient projection algorithm, and, more in general, when \(\theta = 0\) [10, Algorithm 1] is obtained.
It can be seen in Table 1 that small values of \(\alpha \) increase the robustness of the algorithm. Specifically, we observe only 5 successes when \(\alpha =1\), 20 successes when \(\alpha =0.2\), and 22-24 successes when \(\alpha = 0.05\). On the other hand, these results also show that the inertial step can significantly improve the performances of the projected gradient method. In Table 1, we report the performance measure iter./success that gives the average number of iterations needed to get a run successfully solved. These results clearly show that the algorithm with the inertial parameter \(\theta = 0.75\) outperforms the case with \(\alpha = 0\); i.e., Algorithm 1 in [10].
In Table 2, we compare our algorithm’s performances with \(\theta = 0.75\) and [10, Algorithm 2]. Recall that [10, Algorithm 2] requires an additional projection onto a closed and convex set per each iteration compared to Algorithm 3.1; i.e., one additional convex program needs to be solved at each iteration. Following this reasoning, we report in Table 2 the time in seconds needed for the algorithms to reach the stopping criterion. The number of iterations of [10, Algorithm 2] is however reported in brackets. Hence, clearly, the performance of Algorithm 3.1 is much better than [10, Algorithm 2].
We also tested the extragradient method proposed in [5] on the same benchmark problems, but we do not report these results here since this algorithm does not work well with the stepsizes considered for the other methods, and it is really slow with smaller stepsizes.
The experiments made here clearly show how the usage of \(\alpha \) makes Algorithm 3.1 robust, while the inertial parameter \(\theta \) can be used to speed up the method. Relying on these considerations, we tested Algorithm 3.1 with diminishing sequences \(\{\alpha _k\}\) and \(\{\theta _k\}\). Specifically, we set \(\alpha _0 = 0.5\), \(\theta _0 = 1\), and \(\alpha _{k+1} = 0.99 \alpha _k\), \(\theta _{k+1} = 0.99 \theta _k\) for \(k \ge 0\). Performances of this version of the algorithm can be found in Table 3. Comparing these performances with those reported in Tables 1 and 2 indicates that this variant is the fastest one at solving all the test problems.
We also report in Table 3 the performances of Algorithm 3.1 with the updating rule from (11). For this algorithm we set \(\theta _k = \bar{\theta }_k\), \(\eta = 3\), and \(\{\epsilon _k\}\) such that \(\epsilon _0 = 1\) and \(\epsilon _{k+1} = 0.99 \epsilon _k\).
5 Conclusions
In this paper, we propose a generalized gradient-type method with an inertial extrapolation step for solving QVIs in real Hilbert spaces and obtained strong convergence results with different updating rules. Throughout this paper, we do not assume that the set-valued mapping \(K(\cdot )\) is of the form \(K(u)=K+m(u)\) for all \(u\in \mathcal {H}\), as is commonly assumed in most published papers in this subject area. Our numerical experiments show that our suggested method outperforms most of the recently proposed gradient-type methods for solving QVIs in real Hilbert spaces when \(\mathcal {F}\) is strongly monotone and Lipschitz continuous.
References
Fichera, G.: Sul problema elastostatico di Signorini con ambigue condizioni al contorno (English translation: “On Signorini’s elastostatic problem with ambiguous boundary conditions”). Atti Accad. Naz. Lincei VIII. Ser. Rend. Cl. Sci. Fis. Mat. Nat. 34, 138–142 (1963)
Fichera, G.: Problemi elastostatici con vincoli unilaterali: il problema di Signorini con ambigue condizioni al contorno (English translation: “Elastostatic problems with unilateral constraints: the Signorini’s problem with ambiguous boundary conditions”). Atti Accad. Naz. Lincei Mem. Cl. Sci. Fis. Mat. Nat., Sez. I VIII. Ser. 7, 91–140 (1964)
Stampacchia, G.: Formes bilineaires coercitives sur les ensembles convexes. Acad. Sci Paris 258, 4413–4416 (1964)
Kinderlehrer, D., Stampacchia, G.: An Introduction to Variational Inequalities and Their Applications. Academic Press, New York (1980)
Antipin, A.S., Jaćimović, M., Mijajlovi, N.: Extragradient method for solving quasivariational inequalities. Optimization 67, 103–112 (2018)
Mosco, U.: Implicit variational problems and quasi variational inequalities. Lecture Notes in Mathathematics, vol. 543. Springer, Berlin (1976)
Noor, M.A.: An iterative scheme for a class of quasi variational inequalities. J. Math. Anal. Appl. 110, 463–468 (1985)
Noor, M.A.: Quasi variational inequalities. Appl. Math. Lett. 1, 367–370 (1988)
Noor, M.A., Noor, K.I., Khan, A.G.: Some iterative schemes for solving extended general quasi variational inequalities. Appl. Math. Inf. Sci. 7, 917–925 (2013)
Mijajlović, N., Jaćimović, M., Noor, M.A.: Gradient-type projection methods for quasi-variational inequalities. Optim. Lett. 13, 1885–1896 (2019)
Aussel, D., Sagratella, S.: Sufficient conditions to compute any solution of a quasivariational inequality via a variational inequality. Math. Methods Oper. Res. 85, 3–18 (2017)
Facchinei, F., Kanzow, C., Karl, S., Sagratella, S.: The semismooth Newton method for the solution of quasi-variational inequalities. Comput. Optim. Appl. 62, 85–109 (2015)
Facchinei, F., Kanzow, C., Sagratella, S.: Solving quasi-variational inequalities via their KKT conditions. Math. Program. 144, 369–412 (2014)
Latorre, V., Sagratella, S.: A canonical duality approach for the solution of affine quasi-variational inequalities. J. Global Optim. 64, 433–449 (2016)
Attouch, H., Goudon, X., Redont, P.: The heavy ball with friction. I. The continuous dynamical system. Commun. Contemp. Math. 2, 1–34 (2000)
Attouch, H., Czarnecki, M.O.: Asymptotic control and stabilization of nonlinear oscillators with non-isolated equilibria. J. Diff. Equ. 179, 278–310 (2002)
Alvarez, F.: Weak convergence of a relaxed and inertial hybrid projection-proximal point algorithm for maximal monotone operators in Hilbert space. SIAM J. Optim. 14, 773–782 (2003)
Alvarez, F., Attouch, H.: An inertial proximal method for maximal monotone operators via discretization of a nonlinear oscillator with damping. Set-Valued Anal. 9, 3–11 (2001)
Beck, A., Teboulle, M.: A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM J. Imaging Sci. 2, 183–202 (2009)
Maingé, P.E.: Regularized and inertial algorithms for common fixed points of nonlinear operators. J. Math. Anal. Appl. 344, 876–887 (2008)
Polyak, B.T.: Some methods of speeding up the convergence of iterative methods. Zh. Vychisl. Mat. Mat. Fiz. 4, 791–803 (1964)
Attouch, H., Peypouquet, J., Redont, P.: A dynamical approach to an inertial forward-backward algorithm for convex minimization. SIAM J. Optim. 24, 232–256 (2014)
Lorenz, D.A., Pock, T.: An inertial forward-backward algorithm for monotone inclusions. J. Math. Imaging Vis. 51, 311–325 (2015)
Ochs, P., Brox, T., Pock, T.: iPiasco: inertial proximal algorithm for strongly convex optimization. J. Math. Imaging Vis. 53, 171–181 (2015)
Boţ, R.I., Csetnek, E.R., Hendrich, C.: Inertial Douglas–Rachford splitting for monotone inclusion. Appl. Math. Comput. 256, 472–487 (2015)
Shehu, Y.: Convergence rate analysis of inertial Krasnoselskii–Mann-type iteration with applications. Numer. Funct. Anal. Optim. 39, 1077–1091 (2018)
Boţ, R.I., Csetnek, E.R.: An inertial alternating direction method of multipliers. Minimax Theory Appl. 1, 29–49 (2016)
Chen, C., Chan, R.H., Ma, S., Yang, J.: Inertial proximal ADMM for linearly constrained separable convex optimization. SIAM J. Imaging Sci. 8, 2239–2267 (2015)
Boţ, R.I., Csetnek, E.R.: An inertial forward-backward-forward primal-dual splitting algorithm for solving monotone inclusion problems. Numer. Algorithms 71, 519–540 (2016)
Goebel, K., Reich, S.: Uniform Convexity, Hyperbolic Geometry and Non-Expansive Mappings. Marcel Dekker Inc, New York (1984)
Noor, M.A., Oettli, W.: On general nonlinear complementarity problems and quasi equilibria. Matematiche (Catania) 49, 313–331 (1994)
Xu, H.K.: Iterative algorithms for nonlinear operators. J. Lond. Math. Soc. 66, 240–256 (2002)
Ryazantseva, I.P.: First-order methods for certain quasi-variational inequalities in a Hilbert space. Comput. Math. Math. Phys. 47, 183–190 (2007)
Antipin, A.S., Jaćimović, M., Mijajlovi, N.: A second-order iterative method for solving quasi-variational inequalities. Comput. Math. Math. Phys. 53, 258–264 (2013)
Nesterov, Y., Scrimali, L.: Solving strongly monotone variational and quasi-variational inequalities. Discrete Contin. Dyn. Syst. 31, 1383–1396 (2011)
Attouch, H., Peypouquet, J.: The rate of convergence of Nesterov’s accelerated forward-backward method is actually faster than \(1/k^2\). SIAM J. Optim. 26, 1824–1834 (2016)
Facchinei, F., Kanzow, C., Sagratella, S.: QVILIB: a library of quasi-variational inequality test problems. Pac. J. Optim. 9, 225–250 (2013)
Acknowledgements
We are grateful to the anonymous referees and editor whose insightful comments helped to considerably improve an earlier version of this paper. The research of the first author is supported by an ERC Grant from the Institute of Science and Technology (IST).
Author information
Authors and Affiliations
Corresponding author
Additional information
Radu Ioan Boţ.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Shehu, Y., Gibali, A. & Sagratella, S. Inertial Projection-Type Methods for Solving Quasi-Variational Inequalities in Real Hilbert Spaces. J Optim Theory Appl 184, 877–894 (2020). https://doi.org/10.1007/s10957-019-01616-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10957-019-01616-6