
Abstract
In this paper, we present the \(\hbox {L}^2\)-norm stability analysis and error estimate for the explicit single-step time-marching discontinuous Galerkin (DG) methods with stage-dependent numerical flux parameters, when solving a linear constant-coefficient hyperbolic equation in one dimension. Two well-known examples of this method include the Runge–Kutta DG method with the downwind treatment for the negative time marching coefficients, as well as the Lax–Wendroff DG method with arbitrary numerical flux parameters to deal with the auxiliary variables. The stability analysis framework is an extension and an application of the matrix transferring process based on the temporal differences of stage solutions, and a new concept, named as the averaged numerical flux parameter, is proposed to reveal the essential upwind mechanism in the fully discrete status. Distinguished from the traditional analysis, we have to present a novel way to obtain the optimal error estimate in both space and time. The main tool is a series of space–time approximation functions for a given spatial function, which preserve the local structure of the fully discrete schemes and the balance of exact evolution under the control of the partial differential equation. Finally some numerical experiments are given to validate the theoretical results proposed in this paper.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
In this paper we would like to present the \(\hbox {L}^2\)-norm stability analysis and error estimate for the explicit single-step time-marching discontinuous Galerkin (ESTDG) methods in a more general application of numerical fluxes. Two well-known examples include the RKDG method and the LWDG method to solve hyperbolic equations, which respectively employ the Runge–Kutta time marching [5,6,7,8,9], and the Lax–Wendroff time marching [13, 23] to solve the semidiscrete discontinuous Galerkin (DG) method. Many applications have shown that these methods are good at solving nonlinear conservation laws, due to good stability, high order accuracy and the ability for capturing shocks sharply. For more details, we refer to the review papers [10, 15, 20, 21] and the references therein.
Besides the time marching algorithms, the major concepts in these methods are the numerical fluxes used in the DG spatial discretization. We remark that, in numerical applications, nonlinear limiters are also used to improve the numerical performance when shocks appear. However, in this paper we do not consider the limiters and only pay attention to the interaction between the numerical fluxes and the time discretization. In most numerical experiments, numerical fluxes are often taken as the same type or with the same parameter at every element boundaries and time stages. However, the numerical fluxes are allowed to be changed and this strategy has been actually applied in many numerical simulations. A famous example is the downwind treatment in high order RKDG methods to deal with the negative time-marching coefficients [7, 10], in order to ensure the total variation diminishing in the means (TVDM) property (coupled with a suitable limiter) under the strong-stability-preserving (SSP) framework [11] such that a good numerical performance might be obtained nearby the shock. This downwind treatment is necessary because the Runge–Kutta algorithm for nonlinear problems must have negative time-marching coefficients to achieve fifth or higher orders of time accuracy, as well as in the fourth order with only four stages [12, 17]. We would like to mention that the downwind treatment is also used in many high order numerical methods (for instance, the TVD, ENO and WENO schemes) with the Runge–Kutta algorithms [12, 16, 18, 22] and the multistep algorithms [19]. Another example is the LWDG method, where the DG discretization for those high order Lax–Wendroff expansion is often different to that for the first order (convection) term; see the second example in Sect. 2.2.
To accurately understand the numerical effects of the above treatments, we need to carry out the corresponding theoretical analysis for the ESTDG method with stage-dependent numerical flux functions. However, as far as the authors know, till now there is not any discussion on this topic, even for a simple model equation. To fill in this gap, we would like in this paper to carry out the \(\hbox {L}^2\)-norm stability analysis and establish optimal error estimates of the ESTDG method in a unified framework, for the linear constant-coefficient hyperbolic equation in one dimension
equipped with the initial condition \(U(x,0)=U_0(x)\) and the periodic boundary condition. We think that the deep research on this topic provides a starting point to push ahead theoretical studies on the fully discrete DG method that is really used in the practical simulation of nonlinear conservation laws. For simplicity, we further assume that \(\beta \) is a positive constant, and that the numerical flux parameter involved in the numerical flux only changes at different stage time and does not change with respect to the space position; see Sect. 2.2. Different from the special case that numerical flux parameters are the same in the RKDG methods, we have to spend extra effort and propose a new strategy to carefully handle the analysis difficulties resulted from the perturbation of the numerical flux parameters in the ESTDG methods.
There are two major difficulties to carry out the \(\hbox {L}^2\)-norm stability analysis. On one hand, it is well known [2] that the DG method coupled with the forward Euler time-marching is unstable for any fixed CFL number if the polynomial space is not piecewise constant. That is to say, the \(\hbox {L}^2\)-norm stability of ESTDG methods can not be derived under the so-called SSP framework. We have to set up a facilitating energy equation to carry out energy analysis. However, this is difficult for the high order in time fully discrete DG methods. Recently this trouble is systematically settled by the technique of matrix transferring process based on temporal differences of stage solutions, which can automatically achieve the expected energy equation step by step. This technique has been successfully applied for the RKDG methods when numerical flux parameters are the same; see the references [1, 26,27,28,29,30]. Similar works on this issue can be found in the framework to analyze the stability of the explicit RK methods to solve an ODEs with semi-negative linear operator [24]. On the other hand, in this paper we have to overcome the new difficulty resulting from the stage-dependent numerical flux parameters. As a main highlight of this paper, we make an application and/or an extension of the matrix transferring process and put forward an important quantity, named as the averaged numerical flux parameter. This quantity reveals the overall upwind effect in every step time-marching, so it should be greater than one half from the viewpoint of practice. Further, by deep discussions on two detailed examples we find out that, via adjusting the numerical flux parameters (even though the averaged numerical flux are not enlarged), we have a chance to improve the stability performance of the ESTDG method, for example, from the strong stability to the monotonicity stability. For more detailed concepts and statements, see Sect. 3.
Unfortunately, for the ESTDG method with stage-dependent numerical flux parameters, the optimal error estimate becomes very difficult, although the suboptimal error estimate is trivial by traditional treatments. When numerical flux parameters are the same, this purpose has been achieved for the RKDG methods [27, 31, 32] by virtue of the above stability analysis and the generalized Gauss–Radau (GGR) projection with a fixed parameter. However, this proof strategy does not work well for the general case that numerical flux parameters are changed at different occurrence. The main reason is that the element boundary errors at different stages can not be simultaneously eliminated by a fixed GGR projection. To overcome this difficulty, we propose in this paper a new analysis tool, named as a series of space–time approximation functions for any given spatial function. They preserve not only the local structure of the fully discrete scheme, but also the local balance of exact evolution under the rule of the considered partial differential equation (PDE). Hence, they are able to provide a group of good reference functions belonging to the finite element space, such that the error accumulation in time of the fully discrete scheme is elaborately scattered over every gap, at the time level \(t^n\), between the head function (the first one in the series) of \(U(x,t^n)\) and the tail function (the last one in the series) of \(U(x,t^{n}-\tau )\). Here U(x, t) is the exact solution and \(\tau \) is the time step. With the help of the results and the stability conclusions for the nonhomogeneous problem (as a trivial extension of those in Sect. 3.2), the difficulty to obtaining the optimal error estimate is shifted to how to prove the optimal estimate for a series of space–time approximation functions. From our point of view, this analysis line is specifically designed for the fully discrete scheme and is remarkably distinguished to the traditional analysis line, which is often pushed ahead from a semi-discrete scheme in either time or space to the fully discrete scheme.
Because each one in a series of space–time approximation functions cannot be regarded as a traditional projection of the given function, we encounter serious difficulties in proving the optimal approximation property; see Lemma 4.1. Fortunately, this aim can be accomplished by the aid of those techniques and concepts proposed in the matrix transferring process, for instance, the temporal differences of stage solutions and the evolution identity. Here we would like to mention that the averaged numerical flux parameter still plays an important role in this analysis process. With this special quantity, the \(\hbox {L}^2\)-norms of the specially-defined error function sequences (see (4.25) for details) can be mainly bounded by each other in the forward and reverse directions, respectively; see Lemmas 4.2 and 4.3. In this entire process, the GGR projection and the flux lifting function (see Sect. 4.2) are fully utilized.
It is worthy to emphasize that the averaged numerical flux parameter makes significant contributions throughout the theoretical analysis of this paper. To prove Lemma 3.7, we have to make a deep investigation on the matrix transferring process and make more efforts to establish the subtle relationship among the one-step time marching and the multistep one. This procedure involves many manipulations of matrices, such as the matrix description of matrix transferring process and the Kronecker products of matrices. By tedious and rigorous calculations, we discover the important role of the hidden zero restriction related to the averaged numerical flux parameter, which is stated in Lemma 3.5 with \(m=1\) or the equivalent identity (7.28). This zero restriction helps us to prove that the concerned submatrix in the multistep spatial matrix is close to a symmetric positive definite (SPD) matrix congruent to the Hilbert matrix such that the distance is reciprocal to the multistep number; see the appendix. Another application of this zero restriction is the proof of Lemma 4.3, where the coefficient in front of the jump term of the head function is successfully eliminated; see Sect. 4.2.2.
The rest of paper is organized as follows. In Sect. 2 we describe the ESTDG method with stage-dependent numerical flux parameters and then present two well-known examples that will be analyzed and numerically tested in this paper. In Sect. 3 we present a framework to derive energy equation and carry out the \(\hbox {L}^2\)-norm stability analysis, where the averaged numerical flux parameter is proposed. Section 4 is devoted to obtaining the optimal error estimate in \(\hbox {L}^2\)-norm, where a series of space–time approximation functions are proposed and analyzed. Some numerical experiments are given in Sect. 5 to verify the theoretical results. The concluding remarks and some technical proofs are respectively presented in Sect. 6 and the appendix.
2 The ESTDG Method
In this section we present the detailed definition of the ESTDG methods to solve (1.1) and then show two well-known examples including the RKDG method and the LWDG method.
2.1 The Semidiscrete DG Method
Let J be any positive integer and \(0=x_{1/2}<x_{3/2}<\cdots <x_{J+1/2}=1\) be a quasi-uniform partition of the spatial interval I. Each element \(I_j=(x_{j-1/2},x_{j+1/2})\) has the length \(h_j=x_{j+1/2}-x_{j-1/2}\) for \(j=1,2,\ldots , J\). Denote \(h=\max _{1\le j\le J} h_j\). Then we define the discontinuous finite element space by
where \(\mathcal {P}^k(I_j)\) is the polynomial space in \(I_j\) of degree at most \(k\ge 0\). As usual we denote by \(v^{+}\) and \(v^{-}\) the limits of v from two sides.
In this paper, \(I_h\) denotes the partition and \(\varGamma _{\!h}\) the element boundaries. The inner product in \(L^2(I_h)\) and \(L^2(\varGamma _{\!h})\) are respectively denoted by \(({\cdot },{\cdot })_{I_h}\) and \(\langle {\cdot },{\cdot }\rangle _{\varGamma _{\!h}}\). The associated norms are \(\Vert \cdot \Vert _{L^2(I)}=\Vert \cdot \Vert _{L^2(I_h)}\) and \(\Vert \cdot \Vert _{L^2(\varGamma _{\!h})}\), respectively. For any \(v\in V_h\) there hold the inverse inequalities [4, 15]:
where \(\mu >0\) is the inverse constant independent of v and h.
The semidiscrete DG method for the model Eq. (1.1) is defined as follows: find a map \(u(t):[0,T]\rightarrow V_h\) such that it satisfies
with a well-defined initial solution \(u(0)\in V_h\). Here \(\mathcal {H}^{\theta }(u,v)\) is the so-called spatial DG discretization, defined in the form
with the weighted average and the jump at element boundary
In this paper, \(\theta \) is called the numerical flux parameter. It is often assumed to be independent of time and greater than 1/2 in order to provide the upwind mechanism and the \(\hbox {L}^2\)-norm stability.
The following properties [29] for the spatial DG discretization (2.4) will be used. Let u and v be any piecewise smooth functions. A simple application of integration by parts yields the approximating skew-symmetric property
which implies the nonpositive property (if \(\theta >1/2\))
to explicitly show the numerical viscosity in the spatial discretization. Moreover, we also have the weak boundedness property (with the parameter \(\theta \))
where the bounding constant \(C>0\) depends on \(\theta \) and the inverse constant \(\mu \).
2.2 The Fully Discrete ESTDG Methods
Let \(N>0\) be any positive integer and \(\{t^n=n\tau :0\le n\le N\}\) be a uniform partition of the time interval [0, T], where \(\tau =T/N\) is the time step. In this paper we would like to seek the numerical solution at every time level \(t^n\), denoted by \(u^n\in V_h\), by employing an explicit single-step time-marching algorithm to solve the semidiscrete DG method (2.3).
Suppose that \(u^n\) has been obtained at the current time level, we are able to seek \(u^{n+1}\) at the next time level through s intermediate (or generalized stage) solutions. The detailed procedure is often described in the Shu–Osher form as follows:
-
1.
Let \(u^{n,0}=u^n\).
-
2.
For \(\ell =0,1,\ldots ,s-1\), successively find the generalized stage solution \(u^{n,\ell +1}\in V_h\) through the variational formula
$$\begin{aligned} \Big ({u^{n,\ell +1}},{v}\Big )_{I_h} = \sum _{0\le \kappa \le \ell }\Big [ c_{\ell \kappa }\Big ({u^{n,\kappa }},{v}\Big )_{I_h} +\tau d_{\ell \kappa }\mathcal {H}^{\theta _{\ell \kappa }}(u^{n,\kappa },v) \Big ], \quad \forall \,v\in V_h. \end{aligned}$$(2.6)Here the time-marching coefficients, \(c_{\ell \kappa }\) and \(d_{\ell \kappa }\), are inherited from the r-th order explicit single-step algorithm. In this paper we demand \(d_{\ell \ell }\ne 0\) and \(c_{\ell \kappa }\ge 0\) for any \(\ell \) and \(\kappa \). Note that \(s\ge r\) in general.
-
3.
Let \(u^{n+1}=u^{n,s}\).
The initial solution \(u^0\in V_h\) can be set as any approximation of \(U_0\). In this paper we define it by the local \(\hbox {L}^2\)-projection \(\mathbb {P}_h\), namely
Till now we have completed the definition of the considered fully discrete method, which is named as the ESTDG(s, r, k) method in this paper for convenience.
We remark again that the numerical flux parameters in (2.6) are allowed to be changed at every time stage. In this paper we mainly consider two well-known examples and investigate their stability and accuracy order in the \(\hbox {L}^2\)-norm.
Example 2.1
The first example is the RKDG(4, 4, k) method with the downwind treatment [22] to deal with the negative time-marching coefficients in
where \(\ell \) and \(\kappa \) are taken from the set \(\{0,1,2,3\}\) in the natural order.
To be more general than [22], we would like in this paper to take the numerical flux parameters under the following rule: \(\theta _{\ell \kappa }>1/2\) if \(d_{\ell \kappa }\ge 0\) and \(\theta _{\ell \kappa }<1/2\) otherwise.
Example 2.2
The second one is the LWDG(r, k) method, which adopts the rth order Lax–Wendroff time marching to solve (2.3). This method has been proposed and analyzed in [13, 23] for \(r=2,3\), with some special numerical flux parameters.
For example, the second order LWDG method [23] is given in the form
where p is an auxiliary variable to approximate \(\partial _t U=-\beta \partial _x U\). As for the numerical flux parameters, the authors only take \(\theta _{00}=\theta _{10}=1\) and \(\theta _{11}\) to be either 0 or 1. Obviously, this method can be written as an ESTDG method by defining the so-called stage solution \(u^{n,1}=-\tau p^n\).
Actually, every LWDG(r, k) method can be written as an ESTDG(r, r, k) method with the contributory (or nonzero) parameters
by similar treatments for all auxiliary variables. In this paper we would like to investigate the LWDG method in a general case and remove the technical limitations that some numerical flux parameters must be the same [23], for example, \(\theta _{00}=\theta _{r-1,0}\).
To end this section we give a remark on the condition
which is often true for the RKDG method as a condition to ensure the consistency of the Runge–Kutta algorithm. However, (2.10) shows that the LWDG method does not satisfy this condition. Hence, in this paper we would like to discard this unessential condition for the ESTDG method and directly employ those results given in [26, 29], provided that this condition is not applied in the proofs.
3 Stability Analysis
In this section we devote to analyzing the \(\hbox {L}^2\)-norm stability for the ESTDG methods with stage-dependent numerical flux parameters. The presented analysis framework can be looked upon as an application and/or an extension of the technique of the matrix transferring process [27, 29] when numerical flux parameters are the same.
3.1 The Matrix Transferring Process
In order to accurately understand the stability performance, we have to investigate the scheme when combining several time steps together in the time-marching. For this purpose, we introduce the generalized notations for stage solutions, as those in [27, 29]. Namely, for any nonnegative integers n, i and j, we denote
Remark that this notational rule has been used in the scheme’s description.
In this paper we use an integer \(m\ge 1\) to represent the multistep number. It is evident for the ESTDG(s, r, k) method that every m-steps marching with time step \(\tau \) can be regarded as one-step marching of an ESTDG(ms, r, k) method with time step \(m\tau \). Namely, for \(0\le \ell \le ms-1\), there holds the following variation formula: for any \(v\in V_h\),
Let \(\ell '=\ell \pmod s\) and \(\kappa '=\kappa \pmod s\). The contributory (or nonzero) parameters in (3.2) only emerge for those \(\ell \) and \(\kappa \) satisfying \(\ell -\ell '=\kappa -\kappa '\), such that
Here \(\ell '\) and \(\kappa '\) are both taken from \(\{0,1,\ldots , s-1\}\).
3.1.1 Temporal Differences of Stage Solutions and Evolution Identity
For \(1\le i\le ms\), we would like to define the ith order temporal difference of stage solutions in the form
where \(\sigma _{ij}(m)\) are the undetermined combination coefficients independent of stage solutions. For convenience, we also denote \(\mathbb {D}_0(m)u^n=u^n\) and \(\sigma _{00}(m)=1\) throughout this paper.
Remark 3.1
The above concepts and notations originate from the error estimates [31, 32] and have been systematically studied in [27, 29], for the RKDG methods with the same numerical flux parameters.
The combination coefficients in (3.4) can be inductively defined along the same way as in [27, 29]. Assuming, for a certain integer \(i\ge 0\), the temporal differences of stage solutions up to the ith order have been well defined, we would like to define the next one in the form
where the combination coefficients \(\phi _{i\ell }(m)\) will be determined by the following procedure.
Since the above linear combination does not involve any terms about spatial discretization, we can easily define the combination coefficients by the special case that all the numerical flux parameters are the same. Hence we introduce an arbitrary fixed constant, denoted by \(\vartheta \) in this paper. Due to (3.2) and (3.5), after a changing of summation orders we yield
where the two terms on the right hand side show the kernel construct and the perturbation effect, respectively. They read
We call (3.7b) the perturbation term, since \(\varPsi _i(v)=0\) if \(\theta _{\ell \kappa }\equiv \vartheta \).
We want to define (3.5) to ensure a nice structure among the temporal differences of stage solutions, similar as that in [27, 29] for the RKDG method with the same numerical flux parameters. The process is described as follows. Since every diagonal entry \(d_{\kappa \kappa }(m)\) is nonzero, the triangular system of linear equations
uniquely determines \(\phi _{i\ell }(m)\) for \(0\le \ell \le i\). Substituting this into (3.7a), we can achieve the same expression as that in [27, 29]
At this moment, by comparing with the coefficients in the front of \(u^{n,\kappa }\), on both sides of (3.5), we are able to inductively define
with the supplemental notation \(\phi _{i,-1}(m)=0\), and
By these data we complete the definition of \(\mathbb {D}_{i+1}(m)u^n\).
Remark 3.2
In [26, 27, 29] for the RKDG method, it seems that we have demanded
Actually, this condition does not take effect in any analysis therein. In this paper we would like to completely abandon this condition for the ESTDG method, since it does not hold for the LWDG method; see Sect. 3.2.2.
After all temporal differences of stage solutions have been well defined, due to (3.10b), the inversion manipulation yields the linear equivalence of two function sequences \(\{u^{n,0},u^{n,1},\ldots ,u^{n,ms}\}\) and \(\{\mathbb {D}_0(m)u^n,\mathbb {D}_1(m)u^n,\) \(\ldots ,\mathbb {D}_{ms}(m)u^n\}\). Specially, there holds the evolution identity
Remark 3.3
In [27, 29], the left hand side of (3.11) was written as \(\alpha _0(m)u^{n+m}\), where \(\alpha _{0}(m)>0\) is introduced only for scaling. In this paper we always take \(\alpha _{0}(m)=1\) for convenience.
Note that the above manipulations only depend on the time-marching coefficients, \(c_{\ell \kappa }\) and \(d_{\ell \kappa }\), and they are totally independent on the numerical flux parameters. Hence all \(\sigma _{ij}(m)\) and \(\alpha _{i}(m)\) are the same as those when numerical flux parameters are the same; refer to [26, 27, 29] for more detailed conclusions.
The following lemma [26, Lemma 2.2] will be frequently used in this paper. It can be easily proved by the fact that the used single-step time-marching algorithm has the rth order in time.
Lemma 3.1
For any \(m\ge 1\), there holds \(\alpha _{\ell }(m)=1/\ell !\) for \(0\le \ell \le r\).
3.1.2 Relationship Among Temporal Differences of Stage Solutions
In what follows we continue to discuss (3.6) and set up the relationship among temporal differences of stage solutions. A simple manipulation yields
so the perturbation term (3.7b) can be written in the form
To express the right hand side in terms of temporal differences of stage solutions, we would like to introduce a series of numbers \(q_{i\ell }(m;\vartheta )\), for \(0\le \ell \le i\), by the triangular system of linear equations: for \(\kappa =0,1,\ldots ,i\),
The existence and uniqueness are trivial since every diagonal entry \(\sigma _{\kappa \kappa }(m)\) is nonzero, due to (3.10b). By substituting (3.13) into the previous identity and changing the summary order, we can deduce
where the definition of temporal differences of stage solutions, like (3.4), is used at the last step.
Substituting (3.9) and (3.14) into (3.6), we eventually achieve the relationship among the temporal differences of stage solutions: for any \(v\in V_h\), there holds
It is worthy to mention that the right hand side is independent of the choice of \(\vartheta \), hence its value can be set arbitrarily.
At the end of this subsection, we present the kernel relationship that will be extensively used in the matrix transferring process. For convenience of notations, we would like to denote a series of quantities independent of the choice of \(\vartheta \), namely
Throughout this paper \(\delta _{i\ell }\) is a standard Kronecker symbol, being 1 if \(i=\ell \) and otherwise 0. The independence is easily verified, because (3.16) satisfies the triangular system of linear equations that is independent of \(\vartheta \),
We will see later two kinds of fundamental members in the matrix transferring process. One is the joint of two \(L^2(I_h)\)-inner products terms (named as the temporal information terms)
and the other is the \(L^2(\varGamma _{\!h})\)-inner product term (the essential ingredient of the spatial information)
The kernel relationship is stated in the following lemma.
Lemma 3.2
For \(0\le i,j\le ms-1\), there holds
Proof
This lemma follows from (3.15), (3.16) and an application of (2.5a). \(\square \)
Remark 3.4
Suppose all numerical flux parameters are the same, say, \(\theta _{\ell \kappa }\equiv \theta \). Taking the fixed parameter \(\vartheta =\theta \), it is easy to see \(q_{\ell \kappa }(m;\theta )=0\) due to (3.13) and hence \(\tilde{q}_{\ell \kappa }(m)=\theta \delta _{\ell \kappa }\) due to (3.16). Then we have
from the above lemma. This result is the same as that in [29].
3.1.3 Derivation of Energy Equations
Along the same line as that in the previous works [26, 27, 29], we would like to carry out the matrix transferring process to automatically achieve a perfect energy equation for the considered ESTDG method, through a sequence of energy equations
Here \(\ell \ge 0\) stands for the sequence number, and
respectively contain all temporal information and all spatial information. For convenience, we abbreviate two formulas in (3.19) by two symmetric matrices
Remark 3.5
It is worthy to mention that (3.19b) is different to that in [26, 27, 29] for the RKDG methods. Actually, the modification in this paper originates from the application of the approximating skew-symmetric property (2.5a); see Lemma 3.2.
As a purpose of matrix transferring process, we expect to dig out the contribution of the spatial discretization as much as possible, by successively transforming the lower order temporal information into the spatial information. To show that, in what follows we give a more detailed description on the matrix transferring process.
The initial energy equation is easily derived by squaring and integrating the evolution identity (3.11). It deduces the initial matrices with
with \(\alpha _0(m)\equiv 1\) as stated in Remark 3.3. Remark that this energy equation does not reflect any contribution of the spatial discretization.
The matrix transferring process is carried out step by step. By induction, for \(\ell \ge 1\), the \(\ell \)th step matrix transform starts from two obtained matrices

where \(\mathbb {O}\) remarks the zero block and \(\star \) remarks the transformed (nonzero) region. Here and below the notation (m) is dropped for convenience if there is no confusion.
The next action depends on the leading element \(a_{\ell -1,\ell -1}^{(\ell -1)}(m)\). If it is equal to zero, we carry out the following manipulations. In this step, we would like to use Lemma 3.2 to eliminate every entry at the \((\ell -1)\)th row and column of \(\mathbb {A}^{(\ell -1)}\). This process generates two new matrices \(\mathbb {A}^{(\ell )}\) and \(\mathbb {B}^{(\ell )}\).
More specifically, for the temporal matrix \(\mathbb {A}^{(\ell )}\), the entries at the lower triangular region are given by the following formulas
Since \(\mathbb {A}^{(\ell )}\) is demanded to be symmetric, the upper triangular entry is easily filled in. To understand the above formula in (3.22), we give some comments.
-
The difference between the second and the third line results from whether the basic elimination (with respect to one entry) along the row and column is superimposed on the same position.
-
The third line is used to eliminate \(a_{i+1,\ell -1}^{(\ell -1)}\) by applying Lemma 3.2 to the joint term \(a_{i+1,\ell -1}^{(\ell -1)}\mathcal {J}(i, \ell -1)\), with the help of the neighbor entry \(a_{i,\ell }^{(\ell -1)}\).
Remark that the order of the left-top zero block is enlarged now.
The above elimination is accompanied by the changing of the spatial matrix. For stage-dependent numerical flux parameters, each basic elimination affects many entries of the spatial matrix. For example, the basic elimination on \(a_{i+1,\ell -1}^{(\ell -1)}\) (corresponding to the third line in (3.22)) has influence on those entries of the spatial matrix at both the left half-line and the top half-line starting from the position \((i,\ell -1)\). As a result, it is not easy to present short and unified formulas for calculating each entry of the new spatial matrix \(\mathbb {B}^{(\ell )}\). However, the manipulation process can be conveniently expressed in the pseudo-code and summarized as Algorithm 1.
Algorithm 1. Generate the spatial matrix \(\mathbb {B}^{(\ell )}=\{b_{ij}^{(\ell )}\}\) for the given \(\ell \). | |
|---|---|
Step 1. Initialization: set \(g_{ij}=0\) for any \(0\le i,j\le ms\); | |
Step 2. Modification: for \(\kappa =\ell -1,\ldots , ms-1\), do | |
if \(\kappa =\ell -1\) then let \(\nu =1/2\); otherwise, \(\nu =1\); | |
compute \(g_{\kappa ,\ell -1} \leftarrow g_{\kappa ,\ell -1}-\nu a_{\kappa +1,\ell -1}^{(\ell -1)}\); | |
compute \(g_{i,\ell -1} \leftarrow g_{i,\ell -1}+\nu a_{\kappa +1,\ell -1}^{(\ell -1)}\tilde{q}_{\kappa ,i}\) for \(i=0,\ldots ,\kappa \); | |
compute \(g_{\kappa ,j} \leftarrow g_{\kappa ,j}+\nu a_{\kappa +1,\ell -1}^{(\ell -1)}\tilde{q}_{\ell -1,j}\) for \(j=0,\ldots , \ell -1\); | |
Step 3. Generation: define \(b_{ij}^{(\ell )}=b_{ij}^{(\ell -1)}+g_{ij}+g_{ji}\) for \(0\le i,j\le ms\). |
Remark 3.6
Recalling Remark 3.4 for the same numerical flux parameters, it is easy to see that the two sub-loops in Step 2 really execute only for \(i=\kappa \) and \(j=\ell -1\), respectively. Note that \(\tilde{q}_{\kappa ,\kappa }=\tilde{q}_{\ell -1,\ell -1}=\vartheta =\theta \) in this case.
Otherwise, if \(a_{\ell -1,\ell -1}^{(\ell -1)}(m)\ne 0\), we stop the entire transform process and name this entry as the central objective of temporal matrix. At the same time, we output the termination index of time marching
together with the ultimate temporal matrix and the ultimate spatial matrix, respectively denoted by
Motivated by [26, 27, 29], it is important for the ultimate spatial matrix to find the largest order of the SPD sequential principal submatrix, i.e.,
This quantity is also named as the contribution index of spatial discretization. If the set in (3.24) is empty, we define \(\rho (m)=0\) as a supplement.
Till now we have completed the description of the matrix transferring process. The stability performance of the ESTDG method will be determined by three important quantities: two indices \(\zeta (m)\) and \(\rho (m)\), as well as the sign of central objective. See Sect. 3.2 for details.
3.1.4 Discussion on Three Important Quantities
Since the ultimate temporal matrix \(\mathbb {A}(m)\) solely depends on the time-marching coefficients, we have the same conclusions as those in [26] for the RKDG method with the same numerical flux parameters. Below we list some conclusions that will be used in this paper.
Lemma 3.3
The termination index \(\zeta (m)\ge 1\) is independent of m, and hence we denote it by \(\zeta \) throughout this paper.
Lemma 3.4
For any \(m\ge 1\), the central objective \(a_{\zeta \zeta }(m)\) keeps the same sign.
The ultimate spatial matrix \(\mathbb {B}(m)\) depends on not only the time-marching coefficients but also the numerical flux parameters. Hence, for the time-dependent numerical flux parameters, the property of \(\rho (m)\) becomes a little complex and the corresponding analysis turns out to be much more difficult.
We begin with the assumption that \(\rho (m)\) is always positive, in view of the practical application. This is equivalent to \(b_{00}(m)>0\) for any \(m\ge 1\). When all numerical flux parameters are taken to be \(\theta >1/2\), we have found out in [26] for the RKDG method that
As an extension of this conclusion, we would like to propose an important concept for the ESTDG method with stage-dependent numerical flux parameters.
Definition 3.1
For the ESTDG method, the averaged numerical flux parameter every m-steps marching is defined by
Especially, \(\varTheta =\varTheta (1)\) is called the averaged numerical flux parameter.
To well understand the above definition, we need to make more detailed discussions on (3.26). From Algorithm 1, it is easy to see that
which is determined at the first step of the matrix transferring process. Noticing (3.21) and Lemma 3.1, we have \(a_{10}^{(0)}(m)=\alpha _0(m)\alpha _1(m)=1\) and \(a_{\ell +1,0}^{(0)}(m)=\alpha _{\ell +1}(m)\). Then it follows from (3.26) that
As a direct application of this formula, we can easily find out the hidden zero restriction that will be used to analyze the performance of \(\rho (m)\) as m goes to infinity and used to obtain the optimal error estimate. This important conclusion is stated in the following lemma.
Lemma 3.5
There holds for any \(m\ge 1\) that
Proof
We can prove this lemma by (3.16) and taking \(\vartheta = \varTheta (m)\) in (3.27). \(\square \)
Similar as (3.25) for the fixed numerical flux parameters, we have the following lemma for variant numerical flux parameters. The proof is put aside in the appendix, since it shares many materials in the proof of the next lemma.
Lemma 3.6
\(\varTheta (m)\) is independent of m, namely \(\varTheta (m)=\varTheta \).
From our point of view, \(\varTheta \) is an essential quantity to accurately describe the upwind attribute for the fully discrete method. Owing to Lemma 3.6, the assumption that \(\rho (m)\ge 1\) holds forever is equivalent to demand
which means the upwind mechanism at least in the average sense. Actually, this demand plays a critical role in the whole analysis of this paper.
Lemma 3.7
If \(\varTheta >1/2\), then there is an \(m_{\star }\ge 1\) such that \(\rho (m)=\zeta \) for \(m\ge m_{\star }\).
The proof line of this lemma is the same as that in [26] for the RKDG method with the same numerical flux parameters. However, the stage-dependent numerical flux parameters cause serious analysis difficulties such that the proof process involves many matrix manipulation and looks much lengthy and technical. We would like to postpone the proof of this lemma to the appendix and only present the key points in the proof.
-
1.
Algorithm 1 is not convenient to carry out the analysis, and we have to set up a matrix description for the ultimate spatial matrix \(\mathbb {B}(m)\). In this process, many tricks are used to get some convenient and unified formulas, especially for the \(\zeta \)th order sequential principle submatrix of \(\mathbb {B}(m)\), which is denoted by \(\tilde{\mathbb {B}}(m)\) for convenience of statement.
-
2.
Roughly speaking, in order to prove Lemma 3.7, we would like to split \(\tilde{\mathbb {B}}(m)\) into two symmetrical matrices for any given parameter \(\vartheta \). Although this matrix is independent of \(\vartheta \), finding a good separation with a suitable choice of \(\vartheta \) is important for the theoretical analysis.
-
One matrix is just the same as that for the special case that all numerical flux parameters are taken to be \(\vartheta \). Provided \(\vartheta >1/2\), we can prove similarly as in [26] that this matrix tends to a special SPD matrix as m goes to infinity.
-
The other matrix results from the perturbation of stage-dependent numerical flux parameters with respect to the fixed \(\vartheta \). As a trivial purpose, we expect that this perturbation matrix tends to zero as m goes to infinity. In general, this purpose is not easily accomplished for arbitrary choice of \(\vartheta \). However, this aim is fortunately addressed with the help of a special choice \(\vartheta =\varTheta \), owing to the hidden zero restriction (3.28) in Lemma 3.5.
-
-
3.
In order to achieve the second goal in the previous item, we need to reveal the relationship of the perturbation matrix with regard to the multistep number m. To do that, a large number of matrix manipulations (including Kronecker products of matrix) are executed. This simplification process is long and technical.
To end this subsection, we would like to show how to ensure \(\varTheta >1/2\) by adjusting the numerical flux parameters. This purpose can be implemented by the following two propositions, whose proofs will be given in the appendix.
Proposition 3.1
\(\varTheta \) is a weighted average of the numerical flux parameters. Moreover, it increases with respect to \(\theta _{\ell \kappa }\) if \(d_{\ell \kappa }>0\) and decreases otherwise.
For the RKDG method, the averaged numerical flux parameter often depends on all numerical flux parameters. For example, the RKDG(4, 4, k) method (2.8) has
However, it is not true for the LWDG method.
Proposition 3.2
For the LWDG(r, k) method we always have \(\varTheta =\theta _{r-1,0}\).
Proposition 3.2 gives a theoretical support to the upwind requirement \(\theta _{r-1,0}>1/2\) for the LWDG method, which has been implicitly stressed in [13, 23]. This is to say, only the first order term in the Lax–Wendroff expansion demands the DG discretization with upwind numerical flux, and the other term can be arbitrarily discretized.
3.2 Energy Analysis and Stability Conclusions
The matrix transferring process yields the final energy Eq. (3.18) for any \(m\ge 1\), with the termination index \(\ell =\zeta \), the sign of the central objective, and the contribution index \(\rho (m)\). Based on these informations, we are able to easily carry out the energy analysis and conclude the \(\hbox {L}^2\)-norm stability performance along the same line as that in [29].
It is worthy pointing out that the stage-dependent numerical flux parameters do not cause any essential analysis difficulty in this subsection. To shorten the length of this paper, we only present the key steps and conclusions and point out the main modifications in this process.
The increment every m steps is still bounded in the form
where
Here \(\varepsilon _{\star }(m)\) is the smallest eigenvalue of the SPD submatrix \(\{b_{ij}(m)\}_{0\le i,j<\rho (m)}\), and C(m) means the generic constant independent of n, h and \(\tau \).
All terms in \(\mathcal {S}_{\textrm{hot}}\) can be well controlled by the inverse inequality to the jump term of temporal differences
and the relationship among temporal differences of stage solutions
where \(\lambda =\tau \beta /h\) is the CFL number. The inequality (3.31b) can be easily obtained by taking \(v=\mathbb {D}_{i+1}(m)u^n\) in (3.15) and using (2.5c). The last summation on the right hand side of (3.31b) originates from the perturbation of numerical flux parameters, and thus we inevitably encounter some terms involved the jumps of lower order temporal differences in the estimating process to \(\mathcal {S}_{\textrm{hot}}\). This is the only analysis difference when numerical flux parameters are stage-dependent. It is worthy pointing out that we can further diminish the jump norms for those temporal differences of order not less than \(\rho (m)\) in (3.31b) if \(i\ge \rho (m)\), by an inductive application of two inequalities in (3.31). Namely, we have for \( i\ge \rho (m)\) that
By these treatments, together with some applications of Cauchy–Schwartz inequality, we can easily bound \(\mathcal {S}_{\textrm{hot}}\) in the form
As long as \(\lambda \) is small enough, the last term in this inequality can be controlled with the help of \(\mathcal {S}_{\textrm{bry}}\). Since the obtaining inequality is almost the same as that in the previous works [29], the stability results can be similarly stated if the polynomials degree k is not specified.
Along the same line as for (3.32) we can similarly have
Note that \(\Vert \mathbb {D}_{\zeta }(m)u^n\Vert _{L^2(I)}^2\) can be bounded by either (3.33) or (3.32), since \(\zeta \ge \rho (m)\) due to their definitions. Summing up the above discussions into (3.30), we have the rough estimate
Together with Lemma 3.7 for sufficient large m, we can easily obtain the weak stability, as stated in the next theorem. This conclusion does not consider the effect of the sign of the central objective.
Theorem 3.1
The ESTDG method (2.6) has the weak(\(2\zeta \)) stability at least. Namely, for sufficiently small h there holds
under a severe temporal–spatial condition \(\tau \le Mh^{\frac{2\zeta }{2\zeta -1}}\). Here M is any given positive constant, and the bounding constant \(C=C(T,M)\) is independent of n, h and \(\tau \).
As usual, we pay more attention on the stability under suitable CFL conditions. To this end, we introduce an important quantity
which is not larger than \(m_{\star }\) due to Lemma 3.7. Actually, we have proved in [26, Proposition 3.5] that \(n_\star = m_\star \) holds for many RKDG method with the same numerical flux parameters. Although we can not prove this conclusion for any ESTDG method with stage-dependent numerical flux parameters, numerical experiments proposed in this paper indicate that this statement might be true.
Note that the negativity of the central objective plays a pivotal role in the next theorem.
Theorem 3.2
If the central objective is negative, the ESTDG method (2.6) has the strong(\(n_\star \)) stability for any \(k\ge 0\), namely, there exists a maximal CFL number \(\lambda _{\max }\) such that
holds under the CFL condition \(\lambda \le \lambda _{\max }\). Furthermore, if \(n_\star =1\) is allowed, there holds the monotonicity stability in the sense that
Remark 3.7
Actually, the strong stability is obtained by the monotonicity stability for the corresponding ESTDG(ms, r, k) method (3.2), where the multistep number m goes through \(n_{\star }, n_{\star }+1, \ldots , 2n_{\star }-1\). Detailed discussions can be found in [27, 29].
Along the same line as that in [29], we can similarly obtain a nice control among the temporal differences of stage solutions. For instance, the first term on the right hand side of (3.31b) can be replaced by \(C\Vert (m\tau \beta \partial _x)\mathbb {D}_i(m)u^n\Vert _{L^2(I)}\), which helps us to enhance the stability performance for piecewise polynomials of lower degree. Detailed discussions are referred to [29]. The related conclusions are stated in the next theorem.
Theorem 3.3
The ESTDG method (2.6) can have a better stability performance for lower degree k:
-
the strong(\(n_\star \)) stability for \(k<\zeta \), if the central objective is positive.
-
the monotonicity stability for \(k<\rho (1)\) no matter whether the central objective is positive or negative.
From the last two theorems we are happy to find out an opportunity to enlarge the contribution index \(\rho (m)\) and get better stability performance, by means of suitably adjusting the numerical flux parameters. If so, the quantity \(n_{\star }\) may become smaller, even to 1 so that the strong stability is improved to the monotonicity stability. In the next subsections we will give some detailed discussions on two examples given in Sect. 2.2.
3.2.1 The RKDG Method
Consider the RKDG(4, 4, k) method proposed in Example 2.1, and take the numerical flux parameters
where \(\varepsilon , y\) and z are positive constants. Three negative entries in the right matrix correspond to the so-called downwind treatment.
Below we take \(z=1\) and focus on the effect of y. We begin the stability analysis with \(m=1\). The temporal differences of stage solutions are defined as
and the numerical flux parameters lead to
The matrix transferring process gives two matrices. The first one is the ultimate temporal matrix
where \(\mathbb {O}_3\) is the third order zero matrix. This matrix implies that the termination index of time marching is \(\zeta =3\) and the central objective satisfies \(a_{\zeta \zeta }(1)=-1/72<0\). The second one is the ultimate spatial matrix
of which the first three leading principle determinants are
The first quantity indicates that the averaged numerical flux parameter indeed satisfies Proposition 3.1. Now we can claim the following stability results:
-
For \(y>125/54\), these three quantities are all positive and hence \(\rho (1)=3=\zeta \). Now we can claim the monotonicity stability for \(k\ge 0\) by Theorem 3.2.
-
For \(y<125/54\), the stability performance becomes a little weaker. In this case, only the first two quantities in (3.39) are positive, and thus \(\rho (1)=2\) becomes smaller. A series of matrix transferring process for multisteps time-marching yields \(\rho (2)=\rho (3)=3=\zeta \), as we have predicted in Lemma 3.7. By Theorems 3.2 and 3.3 we can claim the strong(2) stability for any \(k\ge 0\) and the monotonicity stability only for \(k\le 1\). The sharpness of this statement will be shown in the numerical experiments.
Remark 3.8
Consider the same RKDG method with \(y=1\), and focus on the effect of z. The matrix transferring process derives that \(\rho (1)=\zeta =3\) (i.e., the monotonicity stability) hold only for \(z<(2\sqrt{598}-37)/27\approx 0.441\). If we increase z out of the above region, although \(\varTheta = \varepsilon (67/54 + z/3) + 1/2\) becomes larger, the stability performance is weakened to the strong stability.
From this numerical example (or the LWDG method), we can see that sometimes the stability performance may be not improved by enlarging the averaged numerical flux parameter. This contradicts the commonly accepted concept that the greater numerical viscosity provides the better stability. Hence it seems to show that this quantity should not be simply understood as the numerical viscosity coefficients for the ESTDG methods of stage-dependent numerical flux parameters.
3.2.2 The LWDG Method
We now turn to the LWDG(r, k) method for \(r\le 5\); see Example 2.2. For simplicity, all involved numerical flux parameters are taken to be \(1/2\pm \varepsilon \), where \(\varepsilon \) is a positive constant. Due to Proposition 3.2, we must set \(\theta _{r-1,0}=1/2+\varepsilon \) to ensure \(\varTheta >1/2\) for all cases.
Let us take the second order (\(r=2\)) LWDG method as an example. By the matrix transferring process we can obtain
and get \(\zeta =2\) and \(a_{\zeta \zeta }(1)=1/4\). Due to Theorem 3.1, we claim that this method at least has the weak(4) stability for \(k\ge 0\).
Due to Theorem 3.3, we can get the strong stability and/or monotonicity stability for lower degree k. For different combination of \(\theta _{00}\) and \(\theta _{11}\), we may achieve different values of \(n_\star \) by calculating the contribution index of spatial discretization as m increases. The detailed conclusions are listed as follows.
-
Let \(\theta _{00}=\theta _{11}=1/2+\varepsilon \). We get \(\rho (1)=2=\zeta \), since
$$\begin{aligned} \{{\tilde{q}}_{ij}(1)\}_{0\le i,j\le 1} = \begin{pmatrix} 1/2+\varepsilon \\ &{}1/2+\varepsilon \\ \end{pmatrix}, \quad \{b_{ij}(1)\}_{0\le i,j\le 1} = \varepsilon \begin{pmatrix} 2&{}1\\ 1&{}1 \end{pmatrix}. \end{aligned}$$This concludes the monotonicity stability for \(k\le 1\).
-
Let \(\theta _{00}=1/2+\varepsilon \) and \(\theta _{11}=1/2-\varepsilon \). Let \(m=1\) and we get
$$\begin{aligned} \begin{aligned} \{{\tilde{q}}_{ij}(1)\}_{0\le i,j\le 1} = \begin{pmatrix} 1/2+\varepsilon \\ &{}1/2-\varepsilon \\ \end{pmatrix}, \quad \{b_{ij}(1)\}_{0\le i,j\le 1} = \varepsilon \begin{pmatrix} 2&{}0\\ 0&{}-1 \end{pmatrix}, \end{aligned} \end{aligned}$$which implies \(\rho (1)=1\) and hence the monotonicity stability for \(k=0\).
By carrying out the matrix transferring process for increasing multistep number, we can have \(\rho (3)=\rho (4)=\rho (5)=2=\zeta \) and then conclude the strong(3) stability for \(k\le 1\).
-
The other cases can be studied similarly.
The stability results for the LWDG(2, k) method are gathered in Table 1, where ± stands for \(1/2\pm \varepsilon \) here and below.
For \(r=3\) or \(r=4\), we are able to similarly find \(\zeta =r-1\) and that the central objective is negative. Hence we can claim the strong stability for \(k\ge 0\), due to Theorem 3.2. The detailed results are collected in Tables 2 and 3.
For \(r=5\), we can get \(\zeta =3\) and the positive central objective, which implies the strong stability for \(k\le 2\) due to Theorem 3.3 and the weak(6) stability for \(k\ge 3\) due to Theorem 3.1. The detailed results are collected in Table 4.
Remark 3.9
In the above four tables, the first row gives the numerical flux parameters to have the monotonicity stability for some k. If \(r\ne 4\), it is acceptable to take \(\theta _{\ell \kappa }\equiv 1/2+\varepsilon \) for any \(\ell \) and \(\kappa \). Otherwise, for \(r=4\), we have to take all \(\theta _{\ell \kappa }\equiv 1/2+\varepsilon \) except \(\theta _{22}=1/2-\varepsilon \).
Remark 3.10
Associated with the second row in Table 1 with \(\varepsilon =1/2\), we get the LWDG(2, 1) method with \(\theta _{00}=\theta _{10}=1\) and \(\theta _{11}=0\). This LWDG scheme has been proved in [23] to have the stability result (\(u^{n,1}=-\tau p^n\))
This result can not yield the strong(3) stability \(\Vert u^n\Vert _{L^2(I)}\le \Vert u^0\Vert _{L^2(I)}\) for \(n\ge 3\), as claimed in this paper.
So does for the LWDG(3,k) method [23] when the numerical flux parameters are taken from the second row of Table 2 with \(\varepsilon =1/2\).
4 Optimal Error Estimate
In this section we are devoted to obtaining the optimal \(\hbox {L}^2\)-norm error estimate for the ESTDG method with the stage-dependent numerical flux parameters. This result is stated in the following theorem.
Theorem 4.1
For the ESTDG(s, r, k) method (2.6) with the averaged numerical flux parameter \(\varTheta >1/2\), we have the optimal error estimate
under the same type of temporal–spatial condition to ensure the \(\hbox {L}^2\)-norm stability, as stated in Theorems 3.1 through 3.3. Here \(\natural =\max (k+1,r)\) and the bounding constant \(C>0\) is independent of \(h, \tau \) and \(U_0\).
This theorem has been proved for the RKDG method with the same numerical flux parameters, where the fourth order in time scheme is taken as an example [27]. Besides the stability analysis, the major techniques to prove this theorem are the standard GGR projection with a fixed parameter and the good definition of the reference functions which are related to the local time marching of the exact solutions. However, this strategy does not work well for the ESTDG method with stage-dependent numerical flux parameters, because the GGR projection with any fixed parameter can not simultaneously eliminate the projection error at boundary endpoints for all time stages. We have to find a new approach to prove this theorem.
4.1 Proof of Theorem 4.1
To address the difficulties resulted from the stage-dependent numerical flux parameters, we would like in this paper to propose a new tool, named as a series of space–time approximation functions for any given spatial function. They will be used to set up a group of good reference functions and delicately define the stage errors for the fully discrete scheme. Different to the traditional analysis technique, they depend on not only the numerical method but also the considered PDE.
Definition 4.1
Let \(W(x)\in L^2(I)\) be a given periodic function. Associated with the ESTDG(s, r, k) method of the time step \(\tau >0\) and the finite element space \(V_h\), a series of space–time approximation functions, denoted by
are defined by the following conditions:
-
Matching the local structure of the fully discrete numerical scheme, namely
$$\begin{aligned} \Big ({W_h^{\ell +1}},{v}\Big )_{I_h} = \sum _{0\le \kappa \le \ell } \Big [ c_{\ell \kappa } \Big ({W_h^{\kappa }},{v}\Big )_{I_h} +\tau d_{\ell \kappa } \mathcal {H}^{\theta _{\ell \kappa }} \big (W_h^{\kappa },v\big ) \Big ], \quad \forall \,v\in V_h, \end{aligned}$$(4.3a)holds for \(0\le \ell \le s-1\);
-
Preserving the balance of exact evolution under the control of PDE (1.1), namely
$$\begin{aligned} \Big ({W_h^{s}-W_h^{0}},{v}\Big )_{I_h}=\Big ({W(x-\tau \beta )-W(x)},{v}\Big )_{I_h}, \quad \forall \,v\in V_h^{\star }. \end{aligned}$$(4.3b)Here \(V_h^{\star }=\Big \{v\in V_h:({v},{1})_{I_h}=0\Big \}\) is an orthogonal complementary space.
-
Conserving the overall mean for the head function \(W_h^{0}\), namely
$$\begin{aligned} \Big ({W_h^{0}},{1}\Big )_{I_h}=\Big ({W(x)},{1}\Big )_{I_h}. \end{aligned}$$(4.3c)
Remark 4.1
The head function is the most important one in the definition. For convenience of statement, \(W_h^{s}\) is called the tail function.
In what follows we give some comments to this definition. First of all, we point out that condition (4.3a) can be well understood by making full use of those concepts proposed in the matrix transferring process, for instance, the temporal differences of stage solutions and the evolution identity. That is to say, there holds
where \(\alpha _\ell =\alpha _\ell (1)\) and \(\sigma _{\ell \kappa }=\sigma _{\ell \kappa }(1)\) have been defined in (3.11) and (3.4), respectively. Analogously, there also holds for \(0\le \ell \le s-1\) that
for any \(v\in V_h\), where \(q_{\ell ,\kappa }(\vartheta )=q_{\ell ,\kappa }(1;\vartheta )\) has been defined in (3.13).
As for the second condition (4.3b), we point out that it can be extended to the whole finite element space, i.e.,
This conclusion holds owing to the following facts:
-
Since \(\mathcal {H}^{\vartheta }(\mathbb {D}_{\ell }W_h,1)=0\), by taking \(v=1\) in (4.5) we can inductively derive that
$$\begin{aligned} \Big ({\mathbb {D}_{\ell }W_h},{1}\Big )_{I_h}=0,\quad \ell \ge 1. \end{aligned}$$(4.7)Together with (4.4), this equality yields \(({W_h^{s}-W_h^{0}},{1})_{I_h}=0\).
-
Since W(x) is periodic, it is easy to see \(({W(x-\tau \beta )-W(x)},{1})_{I_h}=0\).
In other words, condition (4.3c) is only used to ensure the uniqueness if the space–time approximation functions are made up of (4.3a) and (4.6).
It is worthy to emphasize that any space–time approximation function given in Definition 4.1 is not a projection of W(x), even when the numerical flux parameters are the same. An example is given below. Let \(I_h\) be a uniform mesh with the mesh size h, and consider the function \(W(x)\in V_h\), which in each cell is defined by
Associated with the classical second order RKDG method (refer to [29] for details) with \(\theta _{\ell \kappa }\equiv 1\), we can yield (with \(\lambda =\vert \beta \vert \tau /h\))
which are all not equal to W. This distinct property will cause many difficulties in obtaining the next lemma with respect to the approximation property.
Lemma 4.1
For sufficiently small \(\lambda =\vert \beta \vert \tau /h\), a series of space–time approximation functions (4.2) are well defined, and further, if \(W(x)\in H^{\max (k+1,r+1)}(I)\), the head function \(W_h^{0}\) satisfies the optimal error estimate
where the bounding constant \(C>0\) is independent of \(h,\tau \) and W. Note that the notation \(\natural =\max (k+1,r)\) has been given in Theorem 4.1.
For ease of reading and understanding, we postpone the lengthy and technical proof of this lemma to the next subsection and come back to prove Theorem 4.1 now. For any \(n\ge 0\), we utilize Definition 4.1 to define a series of space–time approximation functions with respect to \(U^n(x)=U(x,t^n)\), namely
It is worthy to emphasize that \(\chi ^{n+1,0}\ne \chi ^{n,s}\) in general, and the accumulation of these gaps at all time level forms the main error of the ESTDG method.
The reference functions are then defined by those functions in (4.9) except \(\ell =s\). As a result, for any \(n\ge 0\) we denote the stage errors in the finite element space by
As used in the definition of the ESTDG method, we would like to give a supplementary notation
Every function \(\chi ^{n,\ell }\) in (4.9) satisfies the variation form (4.3a) with \(W_h^{\ell }=\chi ^{n,\ell }\). Subtracting them from the fully discrete method with the same n and \(\ell \), we can obtain a series of error equations as following: for \(\ell =0,1,\ldots ,s-1\), there holds
for any \(v\in V_h\), where the source term \(F^{n,\ell }\) is equal to zero except the last one
These error equations have the same form as the nonhomogeneous ESTDG method. Along the similar analysis line as in Sect. 3, we can get
under the same type of temporal–spatial condition as stated in Theorems 3.1 through 3.3. where the bounding constant \(C>0\) is independent of h and \(\tau \), but may depend on the final time T.
Below we estimate each term on the right hand side of (4.12). It follows from the initial setting that \(\xi ^0=\mathbb {P}_hU_0-\mathbb {Q}_{h,\tau }^{0}U_0\). By using the triangle inequality, we have
where the well-known approximation property of \(\mathbb {P}_h\) (\(\hbox {L}^2\) projection) and Lemma 4.1 are used separately. Since the time step is uniform, definition (4.3) implies that
It follows from (4.6) that \(({\chi ^{n,s}-\chi ^{n,0}},{v})_{I_h}=({U^{n+1}-U^n},{v})_{I_h}\). Hence (4.11) implies
which, together with Lemma 4.1 again, yields
Since \(U(x,t)=U_0(x-\beta t)\) and \(U^{n+1}-U^n=\int _{t^n}^{t^{n+1}}U_t(x,t')\textrm{d} t'\), we can obtain from the above inequality that
Since \(\natural =\max (k+1,r)\), now we yield \( \Vert \xi ^N\Vert _{L^2(I)} \le C(h^{k+1}+\tau ^r)\Vert U_0\Vert _{H^{\natural +1}(I)}\) by substituting (4.13) and (4.15) into (4.12). It follows from Lemma 4.1 that
Since \(u^N-U^N=\xi ^N-(U^N-\chi ^{N,0})\), the above two inequalities and the triangle inequality complete the proof of Theorem 4.1.
Remark 4.2
Due to (4.13), the initial solution is admitted to be any function satisfying \(\Vert U_0-u^0\Vert _{L^2(I)}\le C\Vert U_0\Vert _{H^{\natural }(I)}h^{k+1}\).
Remark 4.3
In this paper the proof of inequality (4.15) strongly depends on the property (4.14), which only holds for the uniform time step. Till now we have not found a good way to rigorously prove this inequality for nonuniform time step size. How to address this difficulty is left for our further work.
4.2 Proof of Lemma 4.1
In this subsection we want to prove Lemma 4.1. Since the total number of the restrictions proposed by Definition 4.1 is equal to the unknowns’ degrees of freedom, it is sufficient and necessary to prove the uniqueness and existence by verifying that there is only one trivial solution \(W_h^{0}=\cdots =W_h^{s}=0\) for \(W=0\). The proof line of this topic is almost the same as that for the optimal estimate, so we would like to solely present the proof of (4.8) in this subsection.
In the next analysis, we will use the GGR projection and the flux lifting function for any given parameter \(\vartheta \ne 1/2\). For convenience, we first give the definitions for \(k\ge 1\) and then a remark for \(k=0\) later on.
Definition 4.2
Let w be a periodic function belonging to \(H^1(I_j)\) for \(j=1,2,\ldots , J\). The GGR projection, denoted by \(\mathbb {G}_{\vartheta }w\), is defined as the unique function in \(V_h\) such that for \(j=1,2,\ldots , J\),
Definition 4.3
Let \(w^{\textrm{b}}\) be a single-valued periodic function defined on all element endpoints. The flux lifting function, denoted by \(\mathbb {L}_{\vartheta }w^{\textrm{b}}\), is defined as the unique function in \(V_h\) such that for \(j=1,2,\ldots , J\),
It has been proved in [3, Lemma 3.2] that the GGR projection is well-defined and the projection error \(\mathbb {G}_{\vartheta }^\perp w=w-\mathbb {G}_{\vartheta }w\) satisfies
where \(\aleph \ge 1\) is the smoothness requirement. Actually, the proof therein has implicitly used \(\mathbb {G}_{\vartheta }w=\mathbb {P}_hw +\mathbb {L}_{\vartheta }\{\!\!\{w-\mathbb {P}_hw\}\!\!\}^\vartheta \) and has shown that the flux lifting function is well-defined and satisfies
Furthermore, a direct application of Definitions 4.2 and 4.3 yields for any \(v\in V_h\),
as well as the property on the overall mean
Remark 4.4
The above two definitions can be extended to \(k=0\) with some minor modifications. The process is divided into two steps:
-
Define two piecewise constant functions by the second condition in (4.16) and (4.17), respectively.
-
Respectively subtract a constant to get two modified functions such that (4.21) holds.
It is easy to verify that the conclusions from (4.18) to (4.20) also hold.
Since \(r\le s\), we would like to adopt the cutting-off technique [26, 27] and define a series of functions
By this treatment, the smoothness assumption can be well controlled and we can get rid of the effect of the stage number.
Since \(W(x)\in H^{r+1}(I)\), we know every \(\partial _{\ell }W\in H^2(I)\) and hence is continuous everywhere by an application of the Sobolev embedding theorem. Using integration by parts, after some manipulations we can get the consistency property
Furthermore, the approximation property (4.18) with \(\aleph =\max (k+1-\ell ,1)\) and the definition (4.22) show
no matter whether \(k+1\ge r\) or not. Here and below we assume \(\lambda \le 1\) without losing generality, since it is small enough.
For \(0\le \ell \le s\), we define a series of error function in the finite element space
which leads to the decomposition \(\mathbb {D}_{\ell }W_h-\partial _{\ell }W=\varXi _{\ell }^{\vartheta }-\mathbb {G}_{\vartheta }^\perp (\partial _{\ell }W)\) as usual. Due to the triangle inequality and (4.24), it is sufficient to obtain (4.8) by proving
with a special choice \(\vartheta =\varTheta \).
To do that, we have to set up two relationships among \(\Vert \varXi _{\ell }^{\vartheta }\Vert _{L^2(I)}\) for \(\ell =0,1,\ldots ,s\), in the forward and reverse direction, respectively. For ease of reading, we would like to only state them in the following two lemmas and put aside their proofs in the next two small subsections.
Lemma 4.2
For any \(\vartheta \ne \frac{1}{2}\), there exists a bounding constant \(C=C(\vartheta )>0\) such that for \(0\le \ell \le s-1\) there holds
Lemma 4.3
For \(\vartheta =\varTheta \), there exists a bounding constant \(C>0\) such that
Till now (4.26) is implied by collecting Lemmas 4.2 and 4.3 if \(\lambda \) is small enough. This completes the proof of Lemma 4.1 and ends this subsection.
4.2.1 Proof of Lemma 4.2
We can prove this lemma by (4.5), which is equivalent to condition (4.3a). By adding and subtracting some terms involving \(\mathbb {G}_{\vartheta }(\partial _{i}W)\) three times, we have
where
In what follows we estimate the above terms one by one.
Using (2.5c) for the first term, and using the Cauchy–Schwartz inequality and the inverse inequality (2.2) for the second term, we have
Due to (4.20) and (4.23), it follows from definition (4.22) that
Using (4.24) for the first case and (4.22) for the second case, respectively, an application of Cauchy–Schwartz inequality yields a unified inequality
Since \([\![\partial _{\kappa }W]\!]=0\) and \(\lambda \le 1\), we can use (4.24) and (2.2) to get
Summing up the above three conclusions and taking \(v=\varXi _{\ell +1}^{\vartheta }\in V_h\), we finally obtain
for \(0\le \ell \le s-1\). This completes the proof of Lemma 4.2.
4.2.2 Proof of Lemma 4.3
We can prove this lemma by (4.6), which is mainly related to condition (4.3b). Substitute (4.4) into the left hand side (LHS) of this condition and expand each term by the relationship (4.5). By changing the summation orders for those terms involving \(q_{\kappa ,\ell }(\vartheta )\), we can easily get
where the second identity in (4.20) is used at the last step, and
Next we consider the right hand side (RHS) of condition (4.6). An application of the Taylor expansion up to rth order derivative yields
with the truncation function
It is easy to see that \(({\widetilde{W}},{1})_{I_h}=0\) and
By integration by part for the definition of \(\widetilde{W}(x)\), say,
the derivative order of \(W(\cdot )\) is dropped to be \(r-1\). With this new formula and noticing the relationship of integration and the norm in Hilbert space, we are able to get
Substituting (4.34) into RHS and using the consistency property (4.23) for every \(\partial _\ell W\) and \({\widetilde{W}}\), we can obtain from the first identity in (4.20) that
where Lemma 3.1 has been used. Here the upper bound of summation index is raised from \(r-1\) to \(s-1\), since \(\partial _\ell W=0\) for \(\ell \ge r\), due to (4.22).
Due to (4.32) and (4.37), it follows from condition (4.6) that
satisfies the variational form \(\mathcal {H}^{\vartheta }(\varrho ^{\vartheta },v)=0\) for any \(v\in V_h\). By successively taking \(v=\varrho ^{\vartheta }\) and \(v=\partial _x\varrho ^{\vartheta }\) here, we can see that \(\varrho ^{\vartheta }\) must be a constant. This concludes
since the overall mean is equal to zero. In fact, it is trivial to verify \(({\varrho ^{\vartheta }},{1})_{I_h}=0\) as following:
-
By (4.21), we have \(({\mathbb {L}_{\vartheta }[\![\mathbb {D}_{\ell }W_h]\!]},{1})_{I_h}=0\) for \(\ell \ge 0\) and \(({\mathbb {G}_{\vartheta }\widetilde{W}},{1})_{I_h}=({\widetilde{W}},{1})_{I_h}=0\).
-
Furthermore, we also have \(({\varXi _{\ell }^{\vartheta }},{1})_{I_h}=0\) for different cases:
-
For \(\ell =0\), condition (4.3c) implies \(({W_h^{0}},{1})_{I_h}=({W},{1})_{I_h}=({\mathbb {G}_{\vartheta }W},{1})_{I_h}\);
-
Otherwise, for \(\ell \ge 1\), the periodicity means \(({\mathbb {G}_{\vartheta }(\partial _{\ell }W)},{1})_{I_h}=({\partial _{\ell }W},{1})_{I_h}=0\), and (4.7) shows \(({\mathbb {D}_{\ell }W_h},{1})_{I_h}=0\).
-
Lemma 3.5 with \(m=1\) implies the main property
Thanks to this property, we can get rid of the trouble term \(\mathbb {L}_{\vartheta }[\![\mathbb {D}_{0}W_h]\!]\) in (4.38). At this moment it follows from (4.39) and \(\alpha _1\ne 0\) (due to Lemma 3.1) that
Here and below \(\vartheta \) is fixed to be \(\varTheta \).
Due to the continuity of \(\partial _\ell W\), as mentioned after its definition, we have \([\![\mathbb {D}_{\ell }W_h]\!]=[\![\mathbb {D}_{\ell }W_h-\partial _{\ell }W]\!]= [\![\varXi _{\ell }^{\vartheta }]\!]-[\![\mathbb {G}_{\vartheta }^\perp \partial _{\ell }W]\!]\). Then it follows from (4.19) and the triangle inequality that
Together with (2.2) and (4.24) for each term, this deduces
By the triangle inequality and (4.18), we have
The two terms on the right hand side are bounded by (4.35) and (4.36), respectively. Since \(\lambda \le 1\), we can get the unified inequality
Substituting (4.42) and (4.43) into (4.41) completes the proof of Lemma 4.3.
5 Numerical Experiments
In this section we present some numerical experiments to verify the proposed theoretical results. Let \(\beta =1\) in (1.1) for all tests. All schemes are taken from the two examples given in Sect. 3.
5.1 Verification on Stability Results
Take the uniform meshes with \(J=64\), as an example. With standard orthogonal basis functions of the discontinuous finite element space, the ESTDG method can be written into \(\widetilde{\varvec{u}}^{n+1}=\mathbb {K}\widetilde{\varvec{u}}^{n}\), where \(\widetilde{\varvec{u}}^{n}\) is the solution vector made up of the expansion coefficients of \(u^n\). The spectral norm \(\Vert \mathbb {K}^m\Vert _2\) describes the \(\hbox {L}^2\)-norm amplification every m step time marching [29].
5.1.1 The RKDG Method
Consider the RKDG(4, 4, k) method with the numerical flux parameters (3.38), where \(\varepsilon =0.25,0.50,0.75\) and \(z=1\). For \(y=3\) and \(y=1\), we respectively plot in Figs. 1 and 2 the quantity
for different CFL number \(\lambda \) in the logarithmic coordinates, with \(k=1,2,3\) from left to right.
-
For \(y=3\), this quantity is always close to \(10^{-16}\) and thus implies the monotonicity stability.
-
For \(y=1\), the data points increase along the line of slope 5 only for \(k\ge 2\) and \(m=1\). These numerical results show the strong(2) stability at least and the monotonicity stability for \(k\le 1\).
These observation verify what we have stated in Sect. 3.2.1.

The \(\hbox {L}^2\)-norm amplification of the RKDG(4, 4, k) solutions every m-step: \(k=1,2,3\) from left to right. Here \(\varepsilon =0.25,0.50,0.75\), \(z=1\) and \(y=3\)

The \(\hbox {L}^2\)-norm amplification of the RKDG(4, 4, k) solutions every m-step: \(k=1,2,3\) from left to right. Here \(\varepsilon =0.25,0.50,0.75\), \(z=1\) and \(y=1\)
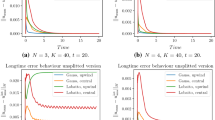
To show the difference between the strong stability and the monotonicity stability, we take \(k=3\) as an example and plot in Fig. 3 the \(\hbox {L}^2\)-norm evolution at the first twelve steps, where \(\lambda =0.02\) and \(\varepsilon =0.50\). The initial solution is taken as the first unit singular vector of \(\mathbb {K}\). For \(y=1\), we can see in the left picture that the \(\hbox {L}^2\)-norm overshoots at the first step and decreases every two and three steps. But for \(y=3\), the monotonicity stability is clearly observed in the right picture. This sharply verifies our theoretical results given in Sect. 3.2.1.

The \(\hbox {L}^2\)-norm evolution for the RKDG(4, 4, 3) method. Left: \(y=1\); Right: \(y=3\). Here \(z=1\), \(\lambda =0.02\) and \(\varepsilon =0.50\)
5.1.2 The LWDG Method
Consider the LWDG(2, k) method. As an example, the numerical flux parameters are defined as \(\theta _{00}=\theta _{10}=1/2+\varepsilon \) and \(\theta _{11}=1/2-\varepsilon \), with \(\varepsilon =0.25,0.50,0.75\). We plot in Fig. 4 some pictures about the quantity (5.1) for \(k=0,1,2\) and \(m=1,2,3,4,5\).
-
If \(k=0\), this quantity is close to \(10^{-16}\) and shows the monotonicity stability.
-
If \(k=1\), the data points increase along the line of slope 3 for \(m\le 2\) and are close to \(10^{-16}\) for \(m\ge 3\). This verifies the strong(3) stability for \(k=1\).
-
If \(k=2\), the data points increase with slope 3 (odd) for \(m\le 2\) and with slope 4 (even) for \(m\ge 3\). This shows the weak(4) stability.
The above observations well support the results listed in Table 1.

The \(\hbox {L}^2\)-norm amplification of the LWDG(2, k) solution every m-step: \(\theta _{00}=\theta _{10}=1/2+\varepsilon \) and \(\theta _{11}=1/2-\varepsilon \). Here \(k=0,1,2\) from left to right and \(\varepsilon =0.25,0.50,0.75\)
In Fig. 5, the left picture plots the \(\hbox {L}^2\)-norm evolution of the LWDG(2, 1) solution at the previous twelve steps, where \(\lambda =0.02\) and \(\varepsilon =0.50\). The initial solution vector is taken as the first unit singular vector of \(\mathbb {K}^2\). We can see that the monotonicity decreasing is lost at the first two steps and conclude that the scheme can not have the strong(2) stability. As a comparison, we also plot in the right picture for the LWDG(2,1) method with \(\theta _{11}=1/2+\varepsilon \) and the others are kept the same. We can see the monotonicity stability for this case, as we have predicted in theory.

The \(\hbox {L}^2\)-norm evolution for the LWDG(2, 1) method. Left: \(\theta _{11}=0\); Right: \(\theta _{11}=1\). Here \(\lambda =0.02\) and \(\theta _{00}=\theta _{10}=1\)
5.2 Verification on the Error Estimate
In this subsection we investigate the numerical accuracy of the ESTDG method with two initial solutions. Since the numerical results are almost the same, we only present the experiment data for the RKDG(4,4,k) method on nonuniform mesh, which is constructed by perturbing the uniform mesh nodes randomly by at most 10%. Take the final time \(T=1\), and the time step \(\tau =0.05h_{\min }\) in what follows, where \(h_{\min }\) is the minimal length.
First we take a sufficiently smooth initial solution, for example,
In Tables 5 and 6, we give the error and convergence order in the \(\hbox {L}^2\)-norm for \(y=3\) and \(y=1\) respectively. We can clearly observe the optimal convergence order, which supports the result in Theorem 4.1.
Next we investigate the smoothness requirement proposed in this paper. To do that, we take \(k=3\) and the initial solution
and \(\epsilon \) is a positive integer. This function belongs to \(H^{\epsilon +1}(I)\), but not \(H^{\epsilon +2}(I)\). In Table 7, the optimal convergence order is clearly observed when \(\epsilon =r\), but not \(\epsilon =r-1\). This indicates that the regularity requirement in Theorem 4.1 appears to be sharp.
5.3 Discussions on \(\varTheta =1/2\)
In this subsection we give some discussions on the stability performance and the convergence order when \(\varTheta =1/2\). As an example, we consider the standard RKDG(3, 3, k) method [32] with numerical flux parameters \(\theta _{00},\theta _{11}\) and \(\theta _{22}\), for which the average numerical flux parameter is
In Table 8 we give three examples that the related schemes convergent with different convergence orders. In this test, we take the final time \(T=\pi \), and the regular nonuniform mesh [14]
The time step is set as \(\tau = 0.1h_{\min }\). Different to the same numerical flux parameter, the last parameter triplet \((\theta _{00},\theta _{11},\theta _{22})=(1,0,0.5)\) gives the optimal order even when the mesh is nonuniform for \(k=1\) and \(k=2\).
For the above three schemes, the stability under the CFL condition is implied by the convergence. However, the stability conclusion is inconclusive when \(\varTheta =1/2\). Below we give an example that the RKDG(3, 3, 2) scheme with \((\theta _{00},\theta _{11},\theta _{22})=(1,1,0.25)\) seems to be linearly unstable. To this end we take the uniform mesh with \(J=64\), and take the initial solution as the local \(\hbox {L}^2\) projection of \(\sqrt{2}\sin (8\pi x)\). Even with a very small CFL number, \(\lambda =0.001\), one can clearly observe in Fig. 6 that the \(\hbox {L}^2\)-norm of numerical solution exponentially increases, which indicates a possible instability.

The \(\hbox {L}^2\)-norm evolution of numerical solution of the RKDG(3, 3, 2) method with \((\theta _{00},\theta _{11},\theta _{22})=(1,1,0.25)\). Here \(\lambda =0.001\) and \(J=64\)
6 Conclusion
In this paper we have presented the \(\hbox {L}^2\)-norm stability analysis and optimal error estimate for the ESTDG method, which adopts the explicit single-step time-marching and the spatial DG discretization with stage-dependent numerical flux parameters. By a unified analysis framework, we successfully address many difficulties in theoretical analysis and then set up the detailed \(\hbox {L}^2\)-norm stability stability results for the RKDG method with downwind treatments and the LWDG method with different numerical flux parameters for the auxiliary variables. The main technique used in this paper is the matrix transferring process based on temporal differences of stage solutions, in order to achieve a good energy equation with some important indices to carry out the energy analysis. Motivated by the studies for the RKDG methods with the same numerical flux parameters, the averaged numerical flux parameter is proposed in this paper to measure the upwind effect in the fully discrete ESTDG method. In order to obtain the optimal error estimate for the ESTDG method with stage-dependent numerical flux parameters, we put forward a new proof framework by proposing a series of space–time approximation functions for any given spatial function. During this procedure, many techniques proposed in the matrix transferring process, together with the averaged numerical flux parameter, still play essential roles to establish the corresponding approximation property. In future work, we will extend the above works to variable-coefficient linear hyperbolic problems and nonlinear conservation laws in one and/or multidimensional cases.
Data Availability
The datasets generated during the current study are available from the corresponding author upon reasonable request.
References
Ai, J., Xu, Y., Shu, C.W., Zhang, Q.: \({\rm L}^2\) error estimate to smooth solutions of high order Runge–Kutta discontinuous Galerkin method for scalar nonlinear conservation laws with and without sonic points. SIAM J. Numer. Anal. 60(4), 1741–1773 (2022). https://doi.org/10.1137/21M1435495
Chavent, G., Cockburn, B.: The local projection \(P^0P^1\)-discontinuous-Galerkin finite element method for scalar conservation laws. RAIRO Modél. Math. Anal. Numér. 23(4), 565–592 (1989). https://doi.org/10.1051/m2an/1989230405651
Cheng, Y., Meng, X., Zhang, Q.: Application of generalized Gauss–Radau projections for the local discontinuous Galerkin method for linear convection–diffusion equations. Math. Comp. 86(305), 1233–1267 (2017). https://doi.org/10.1090/mcom/3141
Ciarlet, P.G.: The finite element method for elliptic problems. In: Studies in Mathematics and its Applications, vol. 4. North-Holland Publishing Co., New York (1978)
Cockburn, B., Hou, S., Shu, C.W.: The Runge–Kutta local projection discontinuous Galerkin finite element method for conservation laws. IV. The multidimensional case. Math. Comput. 54(190), 545–581 (1990). https://doi.org/10.2307/2008501
Cockburn, B., Lin, S.Y., Shu, C.W.: TVB Runge–Kutta local projection discontinuous Galerkin finite element method for conservation laws. III. One-dimensional systems. J. Comput. Phys. 84(1), 90–113 (1989). https://doi.org/10.1016/0021-9991(89)90183-6
Cockburn, B., Shu, C.W.: TVB Runge–Kutta local projection discontinuous Galerkin finite element method for conservation laws. II. General framework. Math. Comput. 52(186), 411–435 (1989). https://doi.org/10.2307/2008474
Cockburn, B., Shu, C.W.: The Runge–Kutta local projection \(P^1\)-discontinuous-Galerkin finite element method for scalar conservation laws. RAIRO Modél. Math. Anal. Numér. 25(3), 337–361 (1991). https://doi.org/10.1051/m2an/1991250303371
Cockburn, B., Shu, C.W.: The Runge–Kutta discontinuous Galerkin method for conservation laws. V. Multidimensional systems. J. Comput. Phys. 141(2), 199–224 (1998). https://doi.org/10.1006/jcph.1998.5892
Cockburn, B., Shu, C.W.: Runge–Kutta discontinuous Galerkin methods for convection-dominated problems. J. Sci. Comput. 16(3), 173–261 (2001). https://doi.org/10.1023/A:1012873910884
Gottlieb, S., Ruuth, S.J.: Optimal strong-stability-preserving time-stepping schemes with fast downwind spatial discretizations. J. Sci. Comput. 27(1–3), 289–303 (2006). https://doi.org/10.1007/s10915-005-9054-8
Gottlieb, S., Shu, C.W.: Total variation diminishing Runge–Kutta schemes. Math. Comput. 67(221), 73–85 (1998). https://doi.org/10.1090/S0025-5718-98-00913-2
Guo, W., Qiu, J., Qiu, J.: A new Lax–Wendroff discontinuous Galerkin method with superconvergence. J. Sci. Comput. 65(1), 299–326 (2015). https://doi.org/10.1007/s10915-014-9968-0
Liu, Y., Shu, C.W., Zhang, M.: Sub-optimal convergence of discontinuous Galerkin methods with central fluxes for linear hyperbolic equations with even degree polynomial approximations. J. Comput. Math. 39(4), 518–537 (2021). https://doi.org/10.4208/jcm.2002-m2019-0305
Qiu, J., Zhang, Q.: Stability, error estimate and limiters of discontinuous Galerkin methods. In: Handbook of Numerical Methods for Hyperbolic Problems, Handbook of Numerical Analysis, vol. 17, pp. 147–171. Elsevier, Amsterdam (2016). https://doi.org/10.1016/bs.hna.2016.06.001
Ruuth, S.J.: Global optimization of explicit strong-stability-preserving Runge–Kutta methods. Math. Comput. 75(253), 183–207 (2006). https://doi.org/10.1090/S0025-5718-05-01772-2
Ruuth, S.J., Spiteri, R.J.: Two barriers on strong-stability-preserving time discretization methods. J. Sci. Comput. 17(1–4), 211–220 (2002). https://doi.org/10.1023/A:1015156832269
Ruuth, S.J., Spiteri, R.J.: High-order strong-stability-preserving Runge–Kutta methods with downwind-biased spatial discretizations. SIAM J. Numer. Anal. 42(3), 974–996 (2004). https://doi.org/10.1137/S0036142902419284
Shu, C.W.: Total-variation-diminishing time discretizations. SIAM J. Sci. Stat. Comput. 9(6), 1073–1084 (1988). https://doi.org/10.1137/0909073
Shu, C.W.: Discontinuous Galerkin methods: general approach and stability. In: Numerical Solutions of Partial Differential Equations, Adv. Courses Math. CRM Barcelona, pp. 149–201. Birkhäuser, Basel (2009)
Shu, C.W.: Discontinuous Galerkin methods for time-dependent convection dominated problems: basics, recent developments and comparison with other methods. In: Building Bridges: Connections and Challenges in Modern Approaches to Numerical Partial Differential Equations, Lecture Notes in Computer Science Engineering, vol. 114, pp. 369–397. Springer, New York (2016)
Shu, C.W., Osher, S.: Efficient implementation of essentially nonoscillatory shock-capturing schemes. J. Comput. Phys. 77(2), 439–471 (1988). https://doi.org/10.1016/0021-9991(88)90177-5
Sun, Z., Shu, C.W.: Stability analysis and error estimates of Lax–Wendroff discontinuous Galerkin methods for linear conservation laws. ESAIM Math. Model. Numer. Anal. 51(3), 1063–1087 (2017). https://doi.org/10.1051/m2an/2016049
Sun, Z., Shu, C.W.: Strong stability of explicit Runge–Kutta time discretizations. SIAM J. Numer. Anal. 57(3), 1158–1182 (2019). https://doi.org/10.1137/18M122892X
Van Loan, C.F.: The ubiquitous Kronecker product. J. Comput. Appl. Math. 123(1–2), 85–100 (2000). https://doi.org/10.1016/S0377-0427(00)00393-9
Xu, Y., Meng, X., Shu, C.W., Zhang, Q.: Superconvergence analysis of the Runge–Kutta discontinuous Galerkin methods for a linear hyperbolic equation. J. Sci. Comput. 84, 23 (2020). https://doi.org/10.1007/s10915-020-01274-1
Xu, Y., Shu, C.W., Zhang, Q.: Error estimate of the fourth-order Runge–Kutta discontinuous Galerkin methods for linear hyperbolic equations. SIAM J. Numer. Anal. 58(5), 2885–2914 (2020). https://doi.org/10.1137/19M1280077
Xu, Y., Zhang, Q.: Superconvergence analysis of the Runge–Kutta discontinuous Galerkin method with upwind-biased numerical flux for two dimensional linear hyperbolic equation. Commun. Appl. Math. Comput. 4, 319–352 (2022). https://doi.org/10.1007/s42967-020-00116-z
Xu, Y., Zhang, Q., Shu, C.W., Wang, H.: The \(\text{ L}^2\)-norm stability analysis of Runge–Kutta discontinuous Galerkin methods for linear hyperbolic equations. SIAM J. Numer. Anal. 57(4), 1574–1601 (2019). https://doi.org/10.1137/18M1230700
Xu, Y., Zhao, D., Zhang, Q.: Local error estimates for Runge–Kutta discontinuous Galerkin methods with upwind-biased numerical fluxes for a linear hyperbolic equation in one-dimension with discontinuous initial data. J. Sci. Comput. 91, 11 (2022). https://doi.org/10.1007/s10915-022-01793-z
Zhang, Q., Shu, C.W.: Error estimates to smooth solutions of Runge–Kutta discontinuous Galerkin methods for scalar conservation laws. SIAM J. Numer. Anal. 42(2), 641–666 (2004). https://doi.org/10.1137/S0036142902404182
Zhang, Q., Shu, C.W.: Stability analysis and a priori error estimates of the third order explicit Runge–Kutta discontinuous Galerkin method for scalar conservation laws. SIAM J. Numer. Anal. 48(3), 1038–1063 (2010). https://doi.org/10.1137/090771363
Funding
Yuan Xu is supported by NSFC Grant 12301513, Natural Science Foundation of Jiangsu Province Grant BK20230374 and Natural Science Foundation of Jiangsu Higher Education Institutions of China Grant 23KJB110019. Chi-Wang Shu is supported by NSF grant DMS-2309249. Qiang Zhang is supported by NSFC Grant 12071214.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors have no relevant financial or non-financial interests to disclose.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
In this section we give some supplemental materials for those conclusions unproved in Sect. 3. This process involves many notations and manipulations of matrices.
To do that, we give some elemental notations here. Associated with the multistep number m and the stage number s, we introduce some column vectors and square matrices of size ms, whose component is either 0 or 1. More specifically, we denote \(\varvec{1}(m,s)=(1,1,\ldots ,1)^\top \) and let \(\varvec{e}_i(m,s)\), for \(0\le i\le ms-1\), be the unit vector which has 1 at the i-th position. Let \(\underline{\varvec{I}}(m,s)\) be the identity matrix and \(\underline{\varvec{E}}(m,s)\) be the shifting matrix which has 1 at the lower second diagonal line. Then we define
which has 1 at the strictly lower region. For simplicity of notations, we would like to denote, for example
This notation rule will be used throughout the entire section.
1.1 Matrix Description of the Ultimate Spatial Matrix
In this subsection we devote to presenting a matrix description of how to get the ultimate spatial matrix. To do that, we define the ms order matrices
related to the description of the ESTDG method, and
related to the definition of temporal differences of stage solutions. Here all indices i and j are taken from 0 to \(ms-1\), and \(\vartheta \) is the parameter as mentioned in subsection 3.1.1. We would like to remark that all data in the above matrices are set to be zero, if they are not clearly stated or defined.
1.1.1 Elemental Formula
The ultimate spatial matrix is obtained by running Algorithm 1 for \(\ell =1,2,\ldots ,\zeta \), where the crucial calculation is the increment accumulation in Step 2.
To do that, we define a lower triangle matrix \(\underline{\varvec{A}}^\star (m)=\{a_{ij}^\star (m)\}_{0\le i,j\le ms-1}\), whose entries are all defined to be zero except
Since \(\{\tilde{q}_{ij}(m)\}_{0\le i,j\le ms-1}\) is a lower triangle matrix, all summation ranges in Step 2 can be enlarged to \(\{0,1,\ldots ,ms-1\}\). Gathering up the related operation till the matrix transferring process stops, we can obtain a unified description for the increment procedure at any fixed position. More specifically, the integrated calculation at every \((i',j')\) position reads (dropping (m) here for convenience)
where \(i',j'\) and \(\kappa '\) go through \(\{0,1,\ldots ,ms-1\}\). As a result, the total increment at Step 2 of Algorithm 1 can be expressed in the matrix form
where the definition (3.16), i.e., \(\tilde{q}_{ij}(m)=q_{ij}(m;\vartheta )+\vartheta \delta _{ij}\) is used.
From Step 3 of Algorithm 1, we have the ultimate spatial matrix (below the last row and column is dropped, since they are always zero)
with the symmetric matrix
The entry at the lower triangular zone is defined as
as the same as in the ultimate spatial matrix in [26] for the RKDG methods with a fixed numerical flux parameter.
To investigate the property of the second term in (7.3), we just need to study the perturbation matrix
Taking into account on definition of the contribution index, we only pay attention on those left-top entries in (7.6). In what follows we try to deduce a convenient and unified formula for
The formula of every \(b_{i\ell }^{\star }(m)\) has been given in [26], but is variant according to the size relationship of i and \(\ell \). In this paper we have to rebuild an equivalent and unified formula, as stated in the next lemma.
Lemma 7.1
For \(0\le i\le \zeta -1\), there holds
Here and below we define \(\alpha _{i'}(m)=0\) if \(i'>ms\) for simplicity.
We put aside the proof of this lemma in Sect. 7.1.3. Substituting (7.8) into (7.7) deduces for any \(0\le i,j\le \zeta -1\) that
In what follows we would like to set up a useful formula of \(\pi _{\kappa ,j}(m;\vartheta )\) by those data to define the ESTDG method.
1.1.2 Formula of \(\pi _{\kappa ,j}(m;\vartheta )\)
Due to (3.13) and (3.8), we can respectively obtain
This implies \(\underline{\varvec{Q}}(m;\vartheta ) =\underline{\varvec{\varSigma }}(m)\underline{\varvec{D}}(m)^{-1}\underline{\varvec{W}}(m;\vartheta )\underline{\varvec{\varSigma }}(m)^{-1}\). With the short notation
it follows from (7.9) and \(q_{\ell ,j}(m;\vartheta )=\varvec{e}_{\ell }^{\top }(m)\underline{\varvec{Q}}(m;\vartheta )\varvec{e}_j(m)\) that
Below we are going to express three terms in (7.12). To that end, we start this work from the calculation of \(\underline{\varvec{\varSigma }}(m)^{-1}\).
By denoting (here and below we omit (m) for the matrix entry)
the definition procedure of the temporal differences of stage solutions can be written into the matrix form

Recalling the definition of the evolution identity, the matrix inversion on both sides of the above identity yields

where we have used (7.10) to get \(\underline{\varvec{\varPhi }}(m)^{-1}=\underline{\varvec{D}}(m)\underline{\varvec{\varSigma }}(m)^{-1}\). Comparing with the matrices entries on both sides, we can achieve the following equalities for every column in the matrix \(\underline{\varvec{\varSigma }}(m)^{-1}\),
and for every evolution coefficient in (3.11),
Then, an induction process for (7.13) yields that
and the matrix identity
For any \(\kappa \ge 0\), substituting (7.14b) into (7.11) yields
where (7.16) is used at the last step. Substituting (7.17) and (7.15) into (7.12), we finally have
In order to investigate the relationship between this quantity and the multistep number, we would like to make some (right) Kronecker product of matrices [25] to simplify each term in (7.18). For example, we will use
which implies
Due to the definition (3.3), we derive
where \(\underline{\varvec{W}}(\vartheta )=\underline{\varvec{W}}(1;\vartheta )\). Based on these identities, by some lengthy and tedious matrices manipulations, we can get the following important conclusions
In this process, we have used the following simple conclusions
and an important identity as a corollary of (7.14a) and \(\alpha _0(m)=1\),
For ease of reading, we present the verifications of (7.22) in Sect. 7.1.4.
With the help of (7.21), substituting (7.22c) and (7.22d) into (7.18) yields the final simplification expression
If needed, we can use (7.22b) to further deal with \(\underline{\varvec{K}}(m)\).
1.1.3 Proof of Lemma 7.1
To end this subsection, we need to prove the skipped Lemma 7.1. Since all related manipulation does not depend on the spatial discretization, the results given in [26, Lemma 3.1] still hold. Hence, for \(0\le j'\le \zeta \) and \(j'< i'\le ms\) we have
and for \(1\le i'\le \zeta \) we have
Based on the formulas in (7.26), we can prove this lemma by simple discussions for different cases of \(\ell \).
If \(\ell >i\), since \(\mathbb {B}^{\star }(m)\) is symmetric, it follows from (7.5) that
This proves (7.8) by using (7.26a) with \(i'=\ell +1\) and \(j'=i\).
Otherwise, if \(\ell \le i\), we similarly have from (7.26a) that
To show it can be written in (7.8), we just need to show \(\varUpsilon =0\), with
Here we have respectively used the replacements of index \(\kappa '=\ell -\kappa \) and \(\kappa '=\ell +1+\kappa \) in two summations of the first equality. The verification is easy as follows.
-
If \(\ell +i+1\) is odd, the replacement \(\kappa '=i+\ell +1-\kappa \) implies \(\varUpsilon =(-1)^{i+\ell +1}\varUpsilon \) and hence \(\varUpsilon =0\).
-
Otherwise, if \(\ell +i+1\) is even, denoted by 2L, a simple replacement of summation index again reduces
$$\begin{aligned} (-1)^{\ell -L}\varUpsilon = \sum _{-L\le \kappa \le L} (-1)^\kappa \alpha _{L+\kappa }(m)\alpha _{L-\kappa }(m) =a_{L,L}^{(L)}(m), \end{aligned}$$where the last step uses (7.26b). Since \(L<\zeta \), it follows \(a_{L,L}^{(L)}(m)=0\) from the definition of \(\zeta \). This implies \(\varUpsilon =0\) also.
Till now we sum up the above conclusions and complete the proof of this lemma.
1.1.4 Verifications of (7.22)
To verify the first identity (7.22a), we start from the definition of \(\underline{\varvec{S}}(m)\). Substituting the identities (7.19), (7.21) and (7.20), we have
Expanding the right-hand side and using the definition of \(\underline{\varvec{S}}\), after some manipulations we have
Since \((\hat{\underline{\varvec{E}}})^m\) is a zero matrix, the inverse of the first matrix is expressed by
Using (7.24), we have for any \(i\ge 1\) that
Summing up the above identities, we have
where we have used the definition (7.1) of \(\hat{\underline{\varvec{L}}}\) at the second step. This completes the verification of (7.22a).
We start the verification of (7.22b) from the definition (7.13b) of \(\underline{\varvec{K}}(m)\). Substituting the identities (7.20), (7.22a) and (7.21), we have
Expanding the right-hand side, using (7.24) and the first identity in (7.23), we achieve
where at the last step we have used the definitions of \(\varvec{q}\) and \(\varvec{p}^\top \) in (7.13a) and (7.14b). This completes the verification of (7.22b).
The third identity (7.22c) is verified along the same line. Starting from the definition of \(\varvec{p}(m)^{\top }\) in (7.14b), and substituting the identities (7.19), (7.22a) and (7.21), we have
Expanding the above expression and using (7.24), we have
where at the last step we have used the second identity in (7.23) and the definition of \(\varvec{p}^\top \) in (7.14b). This proves (7.22c).
The fourth identity (7.22d) is verified similarly. To save the length of this paper, we omit the detailed procedure.
1.2 Some Proofs
In this subsection we would like to prove Lemmas 3.6 and 3.7, as well as Propositions 3.1 and 3.2.
1.2.1 Proof of Lemma 3.6
Recalling the definition of \(\pi _{\kappa ,j}(m;\vartheta )\), given in (7.9), it follows from (3.16) and (3.27) that \(\varTheta (m)=\vartheta +\pi _{00}(m;\vartheta )\). Substituting (7.25) implies that
where the simple fact \(\hat{\varvec{1}}^\top \hat{\underline{\varvec{I}}}\hat{\varvec{1}}=m\) is used. This completes the proof of Lemma 3.6.
Remark 7.1
Taking \(m=1\) and \(\vartheta =\varTheta \) in (7.27), we use Lemma 3.6 to get
This is just the conclusion in Lemma 3.5 with \(m=1\). As an essence property of the averaged numerical flux parameter, it plays an important role in the proof of Lemma 3.7.
1.2.2 Proof of Lemma 3.7
For convenience of notations, in what follows we use a generic notation C to denote a positive constant independent of m. Recalling the proof of [26, Proposition 3.3], we have for \(0\le i,j\le \zeta -1\) that
where \(\{\frac{2}{i!j!(i+j+1)}\}_{0\le i,j\le \zeta -1}\) forms a symmetric positive definite matrix congruent to an Hilbert matrix. Since \(\varTheta >1/2\), it follows from (7.3) and (7.6) with \(\vartheta =\varTheta \) that we can prove this lemma by showing that \(z_{ij}(m;\varTheta )\) for \(0\le i,j\le \zeta -1\) all tends to zero as m goes to infinity. By (7.9), it is sufficient to prove
since [26, inequality (3.16)] shows that \(\alpha _{i-\kappa }(m)\) is bounded independent of m.
Denote \(\pi _{\kappa ,j}=\pi _{\kappa ,j}(m;\varTheta )\) and \(\underline{\varvec{W}}=\underline{\varvec{W}}(\varTheta )\) for simplicity. Below we are going to prove (7.30) for different cases of \(\kappa \) and j, where (7.28) plays an important role to well control the accumulation and growth as m goes to infinity.
-
If \(\kappa =j=0\), we have \( \pi _{0,0}= (\hat{\varvec{1}}^{\top }\hat{\underline{\varvec{I}}}\hat{\varvec{1}})\otimes (\varvec{p}^{\top }\underline{\varvec{D}}^{-1}\underline{\varvec{W}}\varvec{q})=0\), due to (7.28).
-
If \(\kappa >0\) and \(j>0\), we have
$$\begin{aligned} \pi _{\kappa ,j} = \frac{1}{m} \Big (\hat{\varvec{1}}^{\top }\otimes \varvec{p}^{\top }\Big ) [\underline{\varvec{K}}(m)]^{\kappa -1} \varvec{\varPi }_{\kappa ,j}(m) [\underline{\varvec{K}}(m)]^{j-1} \Big (\hat{\varvec{1}}\otimes \varvec{q}\Big ), \end{aligned}$$(7.31)where \( \varvec{\varPi }_{\kappa ,j}(m) = \underline{\varvec{K}}(m) \Big (\hat{\underline{\varvec{I}}}\otimes \underline{\varvec{D}}^{-1}\underline{\varvec{W}}\Big ) \underline{\varvec{K}}(m)\). Substituting (7.22b) into this formula and then using (7.28) to eliminate the term involving \(\hat{\underline{\varvec{L}}}^2\). After some manipulations we yield
$$\begin{aligned} \begin{aligned} \varvec{\varPi }_{\kappa ,j}(m) =&\; \frac{1}{m^2}\hat{\underline{\varvec{L}}}\otimes [ \varvec{q}\varvec{p}^{\top }\underline{\varvec{D}}^{-1}\underline{\varvec{W}}\underline{\varvec{E}}\underline{\varvec{S}}^{-1}\underline{\varvec{D}}+ \underline{\varvec{E}}\underline{\varvec{S}}^{-1}\underline{\varvec{W}}\varvec{q}\varvec{p}^{\top } ]\\&\; +\frac{1}{m^2}\hat{\underline{\varvec{I}}}\otimes \underline{\varvec{E}}\underline{\varvec{S}}^{-1}\underline{\varvec{W}}\underline{\varvec{E}}\underline{\varvec{S}}^{-1}\underline{\varvec{D}}. \end{aligned} \end{aligned}$$The row norms for all matrices (including the row vectors and column vectors) do not depend on m, except that \(\Vert \hat{\underline{\varvec{L}}}\Vert _\infty =m-1\). Hence we have
$$\begin{aligned} \Vert \varvec{\varPi }_{\kappa ,j}(m)\Vert _{\infty }\le \frac{C}{m}. \end{aligned}$$Noticing \(\Vert \frac{1}{m} (\hat{\varvec{1}}^{\top }\otimes \varvec{p}^{\top })\Vert _{\infty }\le C\) and \(\Vert \underline{\varvec{K}}(m)\Vert _{\infty }\le C\), we get from (7.31) what we want to prove.
-
If \(\kappa =0\) and \(j>0\), we have \( \pi _{0,j}=\frac{1}{m} \varvec{\varPi }_{0,j}(m)[\underline{\varvec{K}}(m)]^{j-1}(\hat{\varvec{1}}\otimes \varvec{q})\) with
$$\begin{aligned} \varvec{\varPi }_{0,j}(m)= \Big (\hat{\varvec{1}}^{\top }\otimes \varvec{p}^{\top }\Big ) \Big (\hat{\underline{\varvec{I}}}\otimes \underline{\varvec{D}}^{-1}\underline{\varvec{W}}\Big )\underline{\varvec{K}}(m) = \frac{1}{m}\hat{\varvec{1}}^{\top }\otimes \varvec{p}^{\top } \underline{\varvec{D}}^{-1}\underline{\varvec{W}}\underline{\varvec{E}}\underline{\varvec{S}}^{-1}\underline{\varvec{D}}, \end{aligned}$$by some manipulations with the help of (7.22b) and (7.28). The remaining proof follows the same line as above, hence is omitted.
-
If \(\kappa >0\) and \(j=0\), we have \(\pi _{\kappa ,0}= \frac{1}{m}(\hat{\varvec{1}}^{\top }\otimes \varvec{p}^{\top }) [\underline{\varvec{K}}(m)]^{\kappa -1}\varvec{\varPi }_{\kappa ,0}(m)\), where
$$\begin{aligned} \varvec{\varPi }_{\kappa ,0}(m) = \underline{\varvec{K}}(m) (\hat{\underline{\varvec{I}}}\otimes \underline{\varvec{D}}^{-1}\underline{\varvec{W}}) (\hat{\varvec{1}}\otimes \varvec{q}) = \hat{\varvec{1}}\otimes \underline{\varvec{E}}\underline{\varvec{S}}^{-1}\underline{\varvec{W}}\varvec{q}, \end{aligned}$$with the help of (7.22b) and (7.28). Then we can prove (7.31) as above.
Summing up the above conclusions, we verify (7.30) and then prove this lemma.
1.2.3 Proof of Propositions 3.1 and 3.2
Taking \(\vartheta =0\) in (7.27) and substituting the definition of \(\varvec{p}^{\top }\) and \(\varvec{q}\), we have
This identity will be used to prove these propositions.
Since we have assumed \(c_{\ell \kappa }\ge 0\) for any \(\ell \) and \(\kappa \) in this paper, all entries of \(\underline{\varvec{S}}^{-1}\) are non-negative due to the simple fact
Hence we can conclude from (7.32) that \(\varTheta \) is a non-negative linear combination of the entries of \(\underline{\varvec{W}}(0)=\{d_{\ell \kappa }\theta _{\ell \kappa }\}_{0\le \ell ,\kappa \le s-1}\). As a trivial conclusion for special case that all numerical flux parameters are the same, it is easy to conclude that \(\varTheta \) is a weighted average of \(\theta _{\ell \kappa }\). This proves Proposition 3.1.
Remark 7.2
This is the only place that the condition \(c_{\ell \kappa }\ge 0\) is used in this paper.
For the LWDG method with the time marching coefficients (2.10), we have \(\underline{\varvec{S}}=\underline{\varvec{I}}\) and then get from (7.32) that
since \(\underline{\varvec{I}}+\underline{\varvec{E}}\underline{\varvec{S}}^{-1}\underline{\varvec{C}}=\underline{\varvec{I}}+\underline{\varvec{E}}\underline{\varvec{C}}=\underline{\varvec{I}}\). This completes the proof of Proposition 3.2.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Xu, Y., Shu, CW. & Zhang, Q. Stability Analysis and Error Estimate of the Explicit Single-Step Time-Marching Discontinuous Galerkin Methods with Stage-Dependent Numerical Flux Parameters for a Linear Hyperbolic Equation in One Dimension. J Sci Comput 100, 64 (2024). https://doi.org/10.1007/s10915-024-02621-2
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10915-024-02621-2
Keywords
- Discontinuous Galerkin method
- Explicit single step time marching
- Stage-dependent numerical flux parameters
- Hyperbolic equation
- Stability analysis and error estimate