
Abstract
In this paper, we propose an efficient and robust two-grid preconditioner for the linear elasticity equation with high contrasts. To tackle the challenges imposed by multiple scales and high-contrast, a coarse space (to form the coarse preconditioner) is constructed via a carefully designed spectral problem within the framework of the GMsFEM (Generalized Multiscale Finite Element Method). The dimension of coarse space can be adaptively controlled by a predefined eigenvalue tolerance. We also consider linear elasticity problems with stochastic coefficients and an efficient preconditioner with parameter-independent multiscale basis is proposed. The logarithm of Young’s modulus is decomposed using a truncated Karhunen–Lo\(\grave{e}\)ve expansion, and some sample parameters are used to generate the multiscale basis. Numerical results of both 2D and 3D examples demonstrate that our proposed preconditioner is robust with respect to the contrast of the material and highly efficient for large-scale elasticity problems.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Many materials and processes in nature and engineering are highly heterogeneous with features varying at a wide range of length scales. For example, subsurface flow in heterogeneous porous media, heat conduction in composite materials, and seismic metamaterial may have high-contrast properties, e.g., the Young’s modulus of foamed plate is about \(1.6\times 10^5\)Pa, while for steel it is about \(2.07\times 10^{11}\)Pa [39]. For models with multiple scale and high contrast, many model reduction techniques such as upscaling [18, 32, 35] and multiscale methods [5,6,7, 10, 11, 14, 36] are proposed to alleviate the computational burden. The upscaled solutions or the multiscale solutions are obtained with less computational cost at the compromise of accuracy. However, in some cases where small features are important information, it is necessary to solve the fine-scale problem. For example, in topology optimization [1, 38], the resolution of designs depends heavily on the discretization of the design domain, and fine discretization, which can representing small design features, is required. However, fine discretization also leads to large system of linear equations especially for large 3D problems where direct solve is either impossible or prohibitively expensive. Therefore, efficient iterative solution algorithms and scalable implementations are necessary. The number of iterations of iterative methods, e.g. domain decomposition methods, usually depends on the contrast in the media that is contained in each coarse-grid block. In many cases, it is impossible to separate the high- and low-stiffness regions into different coarse-grid blocks, and the high-contrast will result in a great number of iterations required by domain decomposition solvers.
It is well-known that appropriate preconditioning techniques usually yield fast convergence speed. Therefore, to solve large sparse linear systems efficiently, the key ingredient is the construction of powerful preconditioners with cheap computational cost. In this paper, we aim to design an effective and robust(independent of the contrast) two-grid preconditioner to get the fine-scale solution iteratively, for linear elasticity problems with high contrast. There is a vast literature on the topic of preconditioners for elliptic problems based on multigrid procedure or domain decomposition method [2, 9, 13, 13, 19,20,21, 27, 28, 37]. We mention a few here that aim at problems with multiple scale and high contrast. In [2], a two-level mortar domain decomposition preconditioner for heterogeneous elliptic problems with polynomial coarse space is developed, which is not very sensitive to the high contrast of the medium. In [37], the authors introduce a two-grid preconditioner for heterogeneous elliptic problems by using a multiscale coarse space constructed from GMsFEM, whose convergence performance is independent of the high-contrast.
The focus here is to design a two-grid multiscale preconditioners for linear elasticity problems with high contrast. The classical multigrid or multi-level domain decomposition preconditioners [16, 23,24,25, 29] fail to yield satisfactory results for high-contrast problems. It is shown in [5, 7, 8, 16, 26], the condition number of estimates for the traditional domain decomposition case depend on the contrast if the high stiffness regions are not aligned with the coarse grid decomposition. In [4], the authors utilize the linear MsFEM basis for the construction of robust coarse spaces in the context of two-level overlapping domain decomposition preconditioners, and their numerical experiments show uniform convergence rates independent of the contrast in Young’s modulus within the heterogeneous material, under the assumption that the material jumps are isolated, that is they occur only in the interior of the coarse grid elements. In [38], a robust multiscale preconditioner based on two-level domain decomposition techniques is proposed, where carefully designed local eigenvalue problems are used to form the coarse space. For large scale problems, two-level method relies heavily on the parallelization to have good performance, however, in some practical applications such as parameter estimation, one needs to solve a large number of elasticity problems with similar media properties simultaneously. Thus a huge number of CPU cores may needed to perform parallelization to handle multi-parameter inputs and apply local preconditioners for fast simulations. In this work, we use more efficient multigrid techniques, two-grid in particular, instead of Schwarz method to accelerate the iterative steps.
Our two-grid preconditioner consists of two major components: a smoother and a coarse level preconditioner. Jacobi iteration is used as smoother. The coarse preconditioner needs to offer a good approximation to the kernel of the elasticity operator. Moreover, it should contain all the eigenmodes corresponding to the eigenvalues related to the contrast. In view of this, the Generalized Multiscale Finite Element Method (GMsFEM) [15] is used, where carefully designed spectral problems are solved locally to ensure the desired performance. The GMsFEM provides a systematic way to construct coarse space that can capture the major complicated features of the material. The main steps of GMsFEM can be summarized as: a rich snapshot space is constructed first, e.g., all possible fine-grid functions or harmonic extensions; next an enriched multiscale space is obtained from the snapshot space by selecting the eigenvectors of carefully designed local spectral problems corresponding to small eigenvalues. The dimension of the coarse space can be controlled by a pre-defined eigenvalue tolerance. We compare the efficiency and robustness of two-grid preconditioners that use standard polynomial space and classical multiscale space with our proposed preconditioner. The online stage of our two-grid preconditioner has impressive performance even if no parallelization is adopted and thus suitable for multi-parameter problems. Several 2D and 3D numerical experiments are presented, which demonstrate that the proposed preconditioner has smaller condition number and need much less iterations, thus fast convergence speed.
We also adapt the proposed two-grid multiscale preconditioner to linear elasticity problems with parameterized inputs. It is often impossible to know the exact material properties, therefore physical parameters are introduced into the models. To solve the parameterized equations in a rapid and reliable way, some research based on the reduce basis method [30, 33] has been done. However, to our best knowledge, there is few existing work dealing with parameterized linear elasticity problems with high contrasts. To this end, we aim to extend the two-grid multiscale preconditioner to linear elasticity problems with parameterized inputs. The major challenge comes from the construction of multiscale coarse space since the multiscale basis functions usually depend on the parameters, which adversely affects the computation efficiency. In order to get parameter-independent multiscale basis functions, we first construct snapshot space based on a set of samples in the parameter space. Then the mean of the parameter is used in local spectral problems to form the multiscale basis functions. In this way, we do not need to recompute multiscale basis functions for a given new parameter, which can greatly improve computational efficiency, especially in situations where many queries or real-time response are required, such as engineering optimization and adaptive design or parameter estimation. Both 2D and 3D numerical experiments are carried out to show fast convergence independent of the contrast in Young’s modulus within the heterogeneous material.
The rest of the paper is organized as follows. In Sect. 2 we introduce some preliminaries, including the mathematical formulation of linear elasticity problems, weak form and grids discretization. In Sect. 3, the construction of adaptive multiscale coarse space for both parameter-dependent and parameter-independent cases following the GMsFEM is discussed. Section 4 is devoted to describing the two-grid preconditioner method using the multiscale coarse space. In Sect. 5, we present some representative 2D and 3D numerical examples or both parameter-dependent and parameter-independent cases to demonstrate that our proposed preconditioners are efficient and their convergence is independent of the contrast. Finally, we draw a conclusion in the last section.
2 Preliminaries
In this paper, we design a two-grid multiscale preconditioner for the following steady state elasticity equation [12, 34] in heterogeneous material
or with physical parameters
Here \(\sigma _{ij}(u;{\hat{\mu }})=c_{ijkl}(x; {\hat{\mu }}) \epsilon _{kl}(u)\) (throughout this paper summation over repeated indices means Einstein Summation)represent stresses, \(c_{ijkl}(x;{\hat{\mu }})\) is the elastic tensor, which contains multiscale scales and high-contrast, and \({\hat{\mu }}\in \Omega \subset {\mathbb {R}}^{p}\) is the parameter. Let \(D\subset {\mathbb {R}}^{d}\) (d= 2 or 3) be a bounded domain representing the elastic body of interest, and let \( {u} = (u_1,\ldots , u_d)\) be the displacement field. The strain tensor \( {\epsilon }( {u}) = (\epsilon _{ij}( {u}))_{1\le i,j \le d}\) is defined by
where \(\displaystyle \nabla {u} = (\frac{\partial u_i}{\partial x_j})_{1\le i,j \le d}\). In the component form, we have
In this paper, we assume the material is isotropic. Thus, the stress tensor \( {\sigma }( {u}) = (\sigma _{ij}( {u}))_{1\le i,j \le d}\) is related to the strain tensor \( {\epsilon }( {u})\) in the following way
where \(\lambda >0\) and \(\mu >0\) are the Lamé constants: \(\lambda =\frac{\nu E(x; {\hat{\mu }} )}{(1+\nu )(1-2\nu )}\), \(\mu =\frac{ E(x; {\hat{\mu }})}{2(1+\nu )}\), here E is the Young’s modulus and \(\nu \) is the Poisson ratio. We assume that \(\lambda \) and \(\mu \) have highly heterogeneous spatial variations with high contrasts introduced by Young’s modulus E. Given a forcing term \( {f} = (f_1,\ldots ,f_d)\), the displacement field u satisfies the following
For simplicity, we will consider the homogeneous Dirichlet boundary condition \( {u} = {0}\) on \(\partial D\).
To derive the weak formulation of problem (2)(can be similarly done for problem (1)), we introduce the following functional space
Multiplying (2) with a test function \(v\in V\), integrating over D, using the divergence theorem and applying the boundary condition, we get the following weak formulation in compact notation:
where
and
Let \(\mathcal {T}^h\) be a fine-grid discretization of D which will be introduced later in this section, and \(V^h\subset V\) be a finite element space defined on the fine grid \(\mathcal {T}^h\). The fine-grid solution \( {u}_h\) can be obtained as
Let \(\psi _1,\ldots ,\psi _n\) be a basis for \(V^h\). We assume \(u_h=\sum _{i=1}^{n}u_{i}\psi _i, u_h=(u_1,\ldots ,u_n)^T\). Then we can write the above system in matrix form:
where \(A_h\in R^{n\times n}\) is a symmetric positive definite matrix with
and
Next we introduce the notions of coarse and fine grids which are used to construct the multiscale basis functions. Let \(\mathcal {T}^H\) be a usual conforming partition of the domain D where \(H>0\). We call \(\mathcal {T}^H\) the coarse grid and H the coarse mesh size. Elements of \(\mathcal {T}^H\) are called coarse grid blocks. The set of all coarse grid nodes is denoted by \(\mathcal {S}^H\). We also use \(N_S\) to denote the number of coarse grid nodes, N to denote the number of coarse grid blocks. In addition, we let \(\mathcal {T}^h\) be a conforming refinement of the partition \(\mathcal {T}^H\). We call \(\mathcal {T}^h\) the fine grid and \(h>0\) is the fine mesh size. We remark that the use of the conforming refinement is only to simplify the discussion of the methodology and is not a restriction of the method. For an internal coarse node i, define its coarse neighborhood as the union of the coarse blocks that sharing the coarse node i. See Fig. 1 in 2D for illustration.

Fine grid \(\mathcal {T}^h\) , denoted by gray lines, and coarse grid \(\mathcal {T}^H\) , denoted by black lines. A coarse node i and its coarse neighborhood \(\omega _{i}\) (in orange), consisting of coarse blocks \(K_i^1, K_i^2, K_i^3, K_i^4\) (Color figure online)
3 Construction of Multiscale Space
In this section, we discuss the construction of multiscale space, for parameter independent and parameter dependent cases respectively. The appropriate choice of the coarse space plays a key role in developing effective two-grid preconditioners. Here we follow the idea of GMsFEM [11, 15], which provides a systematic way to construct an enriched coarse space that can capture the major complicated features of the material. The computational procedure can be split into two steps: the construction of snapshot space and generation of a low-dimensional offline space from the snapshot space by solving local spectral problems. We note that all the basis functions are constructed locally.
3.1 Parameter Independent Case
We begin with the construction of local snapshot spaces. Let \(\omega _i\) be a coarse neighborhood, \(i=1,2,\ldots , N_S\). The local snapshot space for \(\omega _i\) is chosen as
where \(V^h(\omega _i)\) is the restriction of the conforming space \(V^h\) onto \(\omega _i\). Therefore, \(V^{i,\text {snap}}\) contains all possible fine scale functions defined on \(\omega _i\). There are other methods for forming local snapshot spaces, for example, harmonic extensions. More details can be found in [11]. We write
where \(M^{i,\text {snap}}\) is the number of basis functions in \(V^{i,\text {snap}}\).
Next, to get the local offline spaces \(V^{i,\text {off}}\), we perform a dimension reduction on the above snapshot spaces via spectral decomposition. Specifically, we seek the subspace \(V^{i,\text {off}}\) such that for each \(\psi \in V^{i,\text {snap}}\), there exists \(\psi _0 \in V^{i,\text {off}}\), such that
for some given error tolerance \(\delta \), where \(a_{i}^{\text {off}}(\cdot , \cdot )\) and \(s_{i}^{\text {off}}(\cdot , \cdot )\) are auxiliary bilinear forms. In computations, problem (10) involves solving an eigenvalue problem and selecting basis functions according to some smallest eigenvalues. To formulate the eigenvalue problem according to (10), we first need a partition of unity function \(\chi _i\) for the coarse neighborhood \(\omega _i\). One choice of a partition of unity function is the coarse grid hat functions \(\Phi _i\), that is, the piecewise bi-linear function on the coarse grid having value 1 at the coarse vertex \( {x}_i\) and value 0 at all other coarse vertices. The other choice is the multiscale partition of unity function, which is defined in the following way. Let \(K_j\) be a coarse grid block having the vertex \( {x}_i\). Then we consider
Then we define the multiscale partition of unity as \( {\chi _i} = ( {\zeta }_i)_1\). The values of \( {\chi _i }\) on other coarse grid blocks are defined similarly.
We define the eigenvalue problem as (see [11]): find \((\xi ,u)\in {\mathbb {R}}\times V^{i,\text {snap}}\) such that
with
where \(\xi \) denotes the eigenvalue and
We let \((\phi _l, \xi _l)\) , \(l=1,2,\ldots , M^{i,\text {snap}}\) be the eigenfunctions and the corresponding eigenvalues of (12). According to the analysis for the elliptic equation [15] and for the acoustic wave equation [22], it is adequate to choose only a few of the eigenfunctions as the basis functions. The criterion for choosing eigenfunctions is to select those representing most of the energy in the eigenfunctions. That is, the sum of the inverse of the selected eigenvalues \(\sum _{i=1}^{L_i} \xi _i^{-1}\) should be a large portion of the sum of the inverse of all the eigenvalues \(\sum _{i=1}^{M^{i,\text {snap}}} \xi _i^{-1}.\) Assume that
According to a pre-defined eigenvalue tolerance, the first \(L_i\) eigenfunctions will be selected to construct the local offline space. In specific, we define an offline basis function as
where \(\phi _{lk}\) is the k-th component of the eigen-vector \(\phi _l\). The local offline space is then defined as
Next, we define the global offline space as
\(V^{\text {off}}\) is the space that will be used in the coarse preconditioner.
3.2 Parameter Dependent Case
For this case, different from the parameter-independent case, we first construct local snapshot spaces by solving local spectral problems for a set of sample parameters. For each coarse neighborhood \(\omega _i, \) \(i=1,2,\ldots , N_S\), we select a set of random parameters \(\{{\hat{\mu }}_1, \ldots , {\hat{\mu }}_{k_i}\}\), and denote \(\Lambda _i=\{{\hat{\mu }}_1, \ldots , {\hat{\mu }}_{k_i}\}.\) For each \({\hat{\mu }}_j \in \Lambda _i, j=1, \ldots , k_i,\) we solve a spectral problem to get the snapshot basis functions. Then combine all these basis functions and remove their dependency to form the local snapshot space \(V^{i,\text {snap}}\). Specifically, we solve the following spectral problem in \(V^h(\omega _i)\) with homogeneous Neumann boundary conditions: find \((\xi ^{\text {snap}},u)\in {\mathbb {R}}\times V^h(\omega _i)\) such that
with
where \(\xi ^{\text {snap}}\) denotes the eigenvalue and
Notice that the eigenfunctions are represented on the fine grid by the basis functions in \(V^h\), i.e., the functions in \(V^h(\omega _i).\) We write
where \(M^{i}\) is the number of basis functions in \(V^h(\omega _i) \).
We let \((\phi _l^j, \xi _l^j)\) , \(l=1,2,\ldots , M^{i}\) be the eigenfunctions and the corresponding eigenvalues of (15). Assume the eigenvalues are arranged in the following descending order
According to a pre-defined eigenvalue tolerance, the first \(l_i^{\text {snap}}\) eigenfunctions will be selected to construct the local snapshot basis functions \( {\psi }^{i,\text {snap}}_{j, l}, l=1,2,\ldots , l_i^{\text {snap}}\). Using the eigenfunctions, we define an snapshot function as
where \(\phi _{lk}^j\) is the k-th component of the eigen-vector \(\phi _l^j\). After solving a spectral problem for each \({\hat{\mu }}_j \in \Lambda _i, j=1, \ldots , k_i,\) we put all the snapshot functions together:
These functions are not necessarily linearly-independent, therefore, we apply principal orthogonal decomposition (POD) to eliminate their dependency. After this procedure, and using a single index, we define the local snapshot space as
The global snapshot space is further defined as
Next, we describe the formation of the offline space. At the offline stage, we perform a dimension reduction in the snapshot space by using an auxiliary spectral problem, whose bilinear forms are independent of the parameter. Therefore, there is no need to reconstruct the offline space for each \({\hat{\mu }}\) value. Specifically, we solve the following spectral problem with homogeneous Neumann boundary conditions: find \((\xi ^{\text {off}},u)\in {\mathbb {R}}\times V^{i,\text {snap}}\) such that
with
where \(\xi ^{\text {off}}\) denotes the eigenvalue, \(\bar{{\hat{\mu }}}\) is the average of the parameter \({\hat{\mu }}\), and
The rest derivation of the offline space \(V^{\text {off}}\) is the same as in the last section, therefore we omit the details here. We note that, for any \({\hat{\mu }}\) in the online stage, the online space is fixed, chosen as \(V^{\text {off}}\). Next, we present the two-grid preconditioner using the multiscale space to design the coarse preconditioner.
4 Construction of a Two-Grid Preconditioner
In this section, we address the construction of an effective and robust two-grid preconditioner by utilizing the GMsFEM coarse space. The preconditioned conjugate gradient(PCG) method is used to solve iteratively the fine-scale linear system Eq. (8).
The two-grid preconditioner consists of two parts, i.e., a smoother and a coarse preconditioner to exchange global information. For the smoother, we use Jacobi iteration which is easy to implement and efficient. The construction of coarse preconditioner is done in the following standard way: we first project the residual from the last step onto the coarse space, then a coarse problem with the residual as source is solved whose solution is projected back to the fine-grid. In matrix form, suppose y is the input of the preconditioner, the coarse preconditioner M can also be written as:
where \(R_H^T:V^{\text {off}}\rightarrow V^h \) is the standard interpolation from the coarse space to the fine space, \(R_H\) is the restriction operator from the fine space to the coarse space, y is the residual from the last step and \(A_H=R_HA_hR_H^T.\)
The implementation of the two-grid preconditioner involves some Jacobi iterations and solving a coarse problem in each l-th PCG iteration. Specifically, the following three steps are performed:
- Step 1:
-
Do \(n_1\) times pre-Jacobi smoothing iterations:
$$\begin{aligned} x=x+\alpha D^{-1}(F_h-A_hx), \end{aligned}$$where \(D=\text {diag}(a_{11}, a_{22}, \ldots , a_{nn}), a_{11}, a_{22}, \ldots , a_{nn}\) are elements on the diagonal of matrix \(A_h\) and \(\alpha \) is a fixed parameter.
- Step 2:
-
Do one coarse correction :
$$\begin{aligned} x=x+M(F_h-A_hx), \end{aligned}$$ - Step 3:
-
Do \(n_2\) times post-Jacobi smoothing iterations:
$$\begin{aligned} x=x+\alpha D^{-1}(F_h-A_hx), \end{aligned}$$
We perform LU decomposition to solve the coarse problem since its size is in general small, iterative scheme can also be applied [17]. Our main goal is to reduce the number of iterations in the PCG iterative procedure. The appropriate choice of the coarse space plays a key role in developing effective two-grid preconditioner. Here the multiscale space following the GMsFEM is applied as the coarse space, while using usual coarse space such as standard polynomials space usually fails to provide satisfactory performance for highly heterogeneous material. The condition number of the resulting preconditioned matrix with adaptive spectral coarse space and the number PCG iterations are both independent of the contrast. The computational efficiency of the preconditioner depends on the dimension of the coarse space, and the parameters \(\alpha , n_1, n_2\).
5 Numerical Results
In this section, we present some representative numerical experiments to demonstrate the performance of our proposed preconditioner for both deterministic and parameter-dependent cases.
5.1 Deterministic Case
For the deterministic case, we report two 2D examples and one 3D example. The Young’s modulus E(x) for the three examples are presented in Fig. 2. In all simulations reported below, we define \(D = [0,1]^d, d=2,3\), \(f=1\) and the Poisson ratio is 0.2. We discretize D into \(16\times 16\) equal sized coarse grid blocks, and each coarse block is further divided into \(16\times 16\) fine grid blocks. For the 3D model, we consider two set discretizations: one is \(64\times 64 \times 64\) fine-grid elements with \(8\times 8 \times 8\) equal sized coarse grid blocks, the other is \(128\times 128 \times 128\) fine grid blocks with \(16\times 16 \times 16\) coarse grid blocks. All numerical experiments are carried out on a workstation with Intel Xeon E5-2687W v4 (48 cores).

Test models: the Young’s modulus E(x)
The coarse preconditioner plays vital role for the success of the two-grid preconditioner, using usual coarse space such as MsFEM usually fails for highly heterogeneous media. To compare the performance of a number of preconditioners with different coarse space, we implement two-grid preconditioners with the following coarse spaces: \(Q_1\) polynomial space; multiscale basis functions with linear boundary conditions(MsFEM); multiscale basis functions based on GMsFEM with tolerance 0.25, denote as GMsFEM(0.25), and multiscale basis functions based on GMsFEM with tolerance 0.5, denote as GMsFEM(0.5). The comparison of these methods is done in terms of the number of PCG iterations until convergence, condition number of the resulting preconditioned matrix, and CPU time for computation. One goal here is to study the performance of two-grid preconditioners with different coarse spaces, therefore we fix the number of smoothing steps here. 10 pre-Jacobi and 10 post-Jacobi smoothing iterations are applied. We note that other smoothers like Gauss Seidel iteration can be used as well. The preconditioned system is solved using PCG with a tolerance of \(10^{-7}\), and the initial guess is GMsFEM solution with the adaptive coarse space.
Our main goal is to test the robustness of our method (robustness refers to the sensitivity of the convergence performance to the ratio of highest to the lowest stiffness of the material). For example 1 in Fig. 2a, the Young modulus \(E=1\) GPa in the blue region, and the values of E are varied within red regions to test the robustness of our method. A number of shot channels, isolated inclusions and a long channel are observed in this example. We test different orders of the contrast in numerical experiments: \(10^4, 10^6, 10^8,\) , The corresponding results are shown in Table 1, in which “dim” is the dimension of coarse matrix \(A_H\), “iter” is the number of PCG iterations until the pre-defined relative residual threshold is reached, “cond” represents the condition number of the resulting preconditioned matrix. The same notations are used in the rest of the tables. The dimension of the algebraic system we aim to solve is 130, 050. We can see that for the coarse space based on GMsFEM(last two columns), the number of iterations until convergence of the PCG stay almost the same, and the condition number remain bounded as the contrast increases. On the contrary, when \(Q_1\) space or the standard multiscale space are used, both the number of iterations increase as the contrast increases, the condition number is linearly dependent on the contrast. The tolerance for selecting multiscale basis functions in the offline stage is set as 0.25 and 0.5, corresponding results are given in the last two columns. The dimension of the coarse space is slightly larger than the former case, while convergence performances are almost the same. Figure 3 displays the solution of model 1 with our preconditioner, we can see the distortion of the displacement field caused by the high contrast of the material properties.
The second example is also in 2D. We consider the Young’s modulus depicted in Fig. 2b. Both vertical and horizontal channels and isolated inclusions are included in this example. We set \(E=1\) GPa in the blue region, and vary the values of E within red regions to test the robustness of our method. As in the last example, we test two-grid preconditioners with several coarse spaces. We also test different orders for the contrast in the numerical experiments: \(10^4, 10^6, 10^8,\) corresponding results are shown in Table 2. We observe similar results: for the coarse space based on GMsFEM(last two columns), the number of iterations until convergence of the PCG stay almost the same, and the condition number remain bounded as the contrast increases. On the contrary, when \(Q_1\) space or the standard multiscale space are used, the number of iterations and condition numbers increase linearly as the contrast increases. Figure 4 shows the displacement field obtained with our preconditioner.

Solution for model 1
Finally, we test a 3D example with the Young modulus depicted in Fig. 2c. As in previous examples, \(E=1\) GPa in the blank region, and the values of E are varied within red regions. We consider two set discretizations. One is \(64\times 64 \times 64\) fine-grid elements with \(8\times 8 \times 8\) equal sized coarse grid blocks. The dimension of the corresponding fine-scale algebraic system we need to solve is 750, 141. Numerical results for this case are shown in Table 3. In the table, “\(T_\text {setup}(s)\)” is the CPU time for computing the multiscale basis functions, assembling the coarse matrix \(A_H\) and perform the LU decomposition to the coarse matrix, and “\(T_\text {solve}(s)\)” is the CPU time for PCG iterations. We observe that the dimension of the coarse space based on GMsFEM is about three times of the other two coarse spaces, and it takes more setup time for preconditioners with GMsFEM coarse space, about ten times in this case, since the computation of multiscale basis functions following GMsFEM is more complicated. However, as contrast increases from \(10^4\) to \(10^8\), the CPU time for PCG iterations increases significantly for the first two coarse spaces, e.g., for MsFEM coarse space, solving is 157.6 s when the contrast is \(10^4\) and solving time increases to 3027.6 s with contrast equals \(10^8\). On the contrary, the number of iterations, condition number and CPU time for PCG iterations stay almost the same (and small) for GMsFEM coarse space as contrast increases. Figure 5 exhibits the displacement field obtained with our preconditioner, again we can observe the discontinuity due to the heterogeneous material.
The other partition for the 3D example is \(128\times 128 \times 128\) fine grid blocks with \(16\times 16 \times 16\) coarse grid blocks. The dimension of the corresponding fine-scale algebraic system we need to solve is 6, 145, 149. Numerical results for this case are shown in Table 4. Compared with the last partition, the number of coarse and fine grid blocks both increase by eight times, and the dimension of coarse spaces increase approximately by six times e.g., in the last row of Table 3, the dimension for GMsFEM(0.5) is 6,672, while in the last row of Table 4, the dimension for GMsFEM(0.5) is 36,275. As more coarse blocks are used, more local problems are solved to construct multiscale basis functions, therefore the CPU time for computing the multiscale basis functions and assembling the coarse matrix “\(T_\text {setup}(s)\)” increases. The same convergence performance is observed as in the last example, that two-grid preconditioners with GMsFEM coarse space converge independent of the contrast of the material.

Solution for model 2
5.2 Parameter-Dependent Case
In this section, we present both 2D and 3D numerical examples to demonstrate the performance of the proposed two-grid preconditioner for solving the parameterized linear elasticity problems with high contrasts.
We consider a logarithmic random field for the Young’s modulus, \(Y=\text {ln}( E(\mathbf{x} ;{\hat{\mu }}))\). Assume Y is a second-order Gaussian random field, characterized by a two point (for 2D) symmetric and positive-definite covariance function \(C_Y\):
or a three point (for 3D) covariance function \(C_Y\):
where \((x_i, y_i), i=1,\ldots , d\) is the spatial coordinate of a point, \(\sigma _Y^2\) and \(l_i\) denote the variance of the stochastic field Y and correlation length in the ith spatial dimension, respectively.

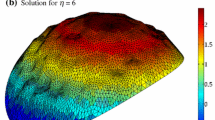
Solution for model 3
Using the truncated Karhunen-Lo\(\grave{e}\)ve expansion (KLE) [31], the random field Y can be numerically generated as:
where \(\xi _i({\hat{\mu }})\) are mutually uncorrelated random variables with unit variance and zero mean, \(\lambda _i\) and \(e_i\) are the eigenvalues and eigenfunctions of the covariance function \(C_Y\), respectively. Then, the KL expansion is truncated after \(N_K\) terms, i.e.,
For the covariance functions defined in (22) and (23), their eigenvalues decay at a rate asymptotic to \(O(1/N_k^2)\) and \(O(1/N_k^3)\), respectively [3, 40], therefore it is reasonable to do the truncation. In all the following examples, we use 100 terms in the KL expansion, i.e., \(N_K=100\). For simplicity, 10 random parameter samples are used to form snapshots, and contrast is set as \(10^6\). The tolerance for selecting multiscale basis functions in the offline stage is 0.25. To test that the multiscale basis functions are independent of a given parameter, we randomly select 1024 parameter samples from the parameter space, and for every parameter, we solve Eq. (8) by using the proposed two-grid preconditioner with the coarse space fixed as \(V^{\text {off}}\) in Sect. 3.2.

Condition number and number of iterations for 1024 parameter samples for different variance and correlation lengths, 2D example with \(E_1\)

Condition number and number of iterations for 1024 parameter samples for different variance and correlation lengths, 2D example with \(E_2\)

Condition number and number of iterations for 1024 parameter samples for different variance and correlation lengths, 3D example with \(E_3\)
For 2D examples, the domain D is partitioned into \(64\times 64\) fine-grid elements with \(8\times 8\) coarse-grid blocks, and we consider the following six different parameter settings for the covariance function \((\sigma _Y^2, l_x,l_y)=\): 1:(1, 0.5, 0.5), 2:(2, 0.5, 0.5), 3:(1, 0.05, 0.05),4:(2, 0.05, 0.05), 5:(1, 0.01, 0.01), 6:(2, 0.01, 0.01). In the first 2D example, the expectation \(E[Y(\mathbf{x} )]\) in Eq. (25) is depicted as \(E_1\) in Fig. 2a. Figure 6 presents the condition number and number of iterations until convergence versus 1024 randomly chosen parameter samples, corresponding to the above defined six different parameter settings for the covariance function. For example, in Fig. 6a, the variance \(\sigma _Y^2=1\), correlation lengths \(l_x=0.5\) and \(l_y=0.5\); in Fig. 6b, correlation lengths are fixed as \(l_x=0.5\) and \(l_y=0.5\), and we increase the variance \(\sigma _Y^2\) to 2. Similarly, in the second row in Fig. 6, correlation lengths are fixed as \(l_x=0.05\) and \(l_y=0.05\), and we vary the variance from 1 to 2. In general, the performance of the two-grid preconditioner for each Young’s modulus realization depends on the perturbation from the mean Young’s modulus, therefore depends on the variance \(\sigma _Y^2\) which affects the magnitude of the perturbations from the mean Young’s modulus field. We observe in every row of Fig. 6, more perturbations in the blue and red line can be seen in the right figure than the left figure, as the variance for the right figure is bigger than the left figure. It also can be seen that for each of the 1024 randomly chosen parameter samples, the condition number is bounded, and the number of iterations is less than 35. We note that for a given new parameter, despite multiscale basis is reused, the proposed preconditioner is robust and efficient.
In the second 2D example, \(E[Y(\mathbf{x} )]\) in Eq. (25) is depicted as \(E_2\) in Fig. 2b. Figure 7 presents the condition number and number of iterations until convergence versus1024 randomly chosen parameter samples corresponding to the above defined six different parameters settings for the covariance function. Similar results can be observed as the last example.
For the 3D example, \(E[Y(\mathbf{x} )]\) in Eq. (25) is depicted as \(E_3\) in Fig. 2c. \(64\times 64\times 64\) fine grid with \(8\times 8\times 8\) coarse grid is used. We also consider six different parameters settings for the covariance function \((\sigma _Y^2, l_x,l_y,l_z):\)= 1:(1, 0.5, 0.5, 0.5),2:(2, 0.5, 0.5, 0.5),3:\((1,0.05,0.05,0.05)\), 4:(2, 0.05, 0.05, 0.05),5:(1, 0.01, 0.01, 0.01),6:(2, 0.01, 0.01, 0.01).The condition number and number of iterations until convergence versus 1024 randomly chosen parameter samples corresponding to the above defined six different parameters settings for the covariance function are shown in Fig. 8. It also can be seen that for each of the 1024 randomly chosen parameter samples, the preconditioner is effective, with condition number bounded and the number of iterations being less than 25.
6 Conclusions
In this paper, we propose a two-grid preconditioner for linear elasticity problems with high contrasts. As the coarse-level preconditioner plays key role in designing effective and robust two-grid preconditioners, an enriched coarse multiscale space constructed from the GMsFEM is used. The multiscale space consists of basis functions that can capture the multiscale feature of the material. Efficient Jacobi iterative technique is used as the smoother. Several 2D and 3D numerical experiments are presented to show that our preconditioner is robust in terms of contrast. By comparing to other preconditioners that incorporate \(Q_1\) and the standard MsFEM space in coarse preconditioner, we demonstrate that our preconditioner is more efficient and robust. Moreover, we adapt the proposed two-grid multiscale preconditioner to linear elasticity problems with parameterized inputs. The preconditioner reuses the multiscale basis functions, therefore we do not need to recompute multiscale basis functions for a given new parameter, yielding a very efficient algorithm, which is admired in those contexts requiring many queries, such as engineering optimization and adaptive design. Numerical experiments show that the proposed preconditioner can yield fast convergence independent of the contrast.
Data availibility
Enquiries about data availability should be directed to the authors.
References
Andreassen, E., Clausen, A., Schevenels, M., Lazarov, B.S., Sigmund, O.: Efficient topology optimization in matlab using 88 lines of code. Struct. Multidiscip. Opt. 43(1), 1–16 (2011)
Arbogast, T., Xiao, H.: Two-level mortar domain decomposition preconditioners for heterogeneous elliptic problems. Comput. Method. Appl. Mech. Eng. 292, 221–242 (2015)
Mary, F., Wheeler, B., Tim Wildey, B., Ivan, Y.A.: A multiscale preconditioner for stochastic mortar mixed finite elements. Comput. Methods Appl. Mech. Eng. 200, 1251–1262 (2011)
Buck, M., Iliev, O., Andr, Heiko: Multiscale finite element coarse spaces for the application to linear elasticity. Cent. Eur. J. Math. 11(4), 680–701 (2013)
Buck, M., Iliev, O., Andra, Heiko: Multiscale Coarsening for Linear Elasticity by Energy Minimization. Springer, New York (2013)
Buck, M., Iliev, Oleg, Andra, H.: Multiscale finite element coarse spaces for the application to linear elasticity. Cent. Eur. J. Math. 11(4), 680–701 (2013)
Buck, M., Iliev, Oleg, Andra, H.: Multiscale finite elements for linear elasticity: oscillatory boundary conditions. Lect. Notes Comput. Sci. Eng. 98, 237–245 (2014)
Buck, M., Iliev, O., Andra, H.: Domain decomposition preconditioners for multiscale problems in linear elasticity. Numer. Linear Algeb. Appl. 25(5), e2171 (2018)
Calvo, J.G., Widlund, Olof B.: An adaptive choice of primal constraints for BDDC domain decomposition algorithms. Electron. Trans. Numer. Anal. 45, 524–544 (2016)
Chung, E., Efendiev, Y., Lee, C.: Mixed generalized multiscale finite element methods and applications. Multiscale Model. Simul. 13(1), 338–366 (2015)
Chung, E.T., Efendiev, Y., Fu, Shubin: Generalized multiscale finite element method for elasticity equations. GEM-Int. J. Geomath. 5(2), 225–254 (2014)
Dean, W.R., Muskhelishvili, N.I., Radok, J.R.M.: Some basic problems of the mathematical theory of elasticity. Math. Gaz. 39(330), 352 (1955)
Dolean, V., Nataf, F., Scheichl, R., Spillane, N.: Analysis of a two-level Schwarz method with coarse spaces based on local dirichlet-to-neumann maps. Comput. Methods Appl. Math. 12(4), 391–414 (2012)
Efendiev, Y., Ginting, V., Hou, T., Ewing, R.: Accurate multiscale finite element methods for two-phase flow simulations. J. Comput. Phys. 220(1), 155–174 (2006)
Efendiev, Y., Galvis, J., Hou, Thomas Y.: Generalized multiscale finite element methods (GMsFEM). J. Comput. Phys. 251, 116–135 (2013)
Efendiev, Y., Galvis, J., Lazarov, R., Willems, Joerg: Robust domain decomposition preconditioners for abstract symmetric positive definite bilinear forms. ESAIM Math. Model. Numer. Anal. 46(5), 1175–1199 (2012)
Efendiev, Y., Galvis, J., Vassilevski, P.S.: Spectral element agglomerate algebraic multigrid methods for elliptic problems with high-contrast coefficients. In: Domain Decomposition Methods in Science and Engineering XIX, pp. 407–414. Springer, (2011)
Ewing, R., Iliev, O., Lazarov, R., Rybak, I., Willems, Joerg: A simplified method for upscaling composite materials with high contrast of the conductivity. SIAM J. Sci. Comput. 31(4), 2568–2586 (2009)
Galvis, J., Efendiev, Yalchin: Domain decomposition preconditioners for multiscale flows in high-contrast media. Multiscale Model. Simul. 8(4), 1461–1483 (2010)
Galvis, J., Efendiev, Yalchin: Domain decomposition preconditioners for multiscale flows in high contrast media: reduced dimension coarse spaces. Multiscale Model. Simul. 8(5), 1621–1644 (2010)
Gander, M.J., Loneland, A.: Shem: an optimal coarse space for ras and its multiscale approximation. In: Domain decomposition methods in science and engineering XXIII, pp. 313–321. Springer, (2017)
Gibson, R.L., Jr., Gao, K., Chung, E., Efendiev, Y.: Multiscale modeling of acoustic wave propagation in 2D media. Geophysics 79(2), T61–T75 (2014)
Griebel, M., Oeltz, D., Schweitzer, Alexander: An algebraic multigrid method for linear elasticity. SIAM J. Sci. Comput. 25(2), 385–407 (2003)
Gustafsson, I., Lindskog, G.: On parallel solution of linear elasticity problems. Part I: theory. Numer. Linear Algebra Appl. 5(2), 123–139 (1998)
Gustafsson, I., Lindskog, G.: On parallel solution of linear elasticity problems. Part II: methods and some computer experiments. Numer. Linear Algebra Appl. 9(3), 205–221 (2002)
Alexandersen, J., Lazarov, B.S.: Topology optimisation of manufacturable microstructural details without length scale separation using a spectral coarse basis preconditioner. Comput. Methods Appl. Mech. Eng. 290, 156–182 (2015)
Kim, H.H., Chung, E., Wang, Junxian: BDDC and FETI-DP algorithms with a change of basis formulation on adaptive primal constraints. Electron. Trans. Numer. Anal. 49, 64–80 (2018)
Klawonn, A., Radtke, P., Rheinbach, O.: FETI-DP methods with an adaptive coarse space. SIAM J. Numer. Anal. 53(1), 297–320 (2015)
Lazarov, B.S.: Topology optimization using multiscale finite element method for high-contrast media. In: International Conference on Large-Scale Scientific Computing, (2013)
Liu, G. R., Zaw, K., Wang, Y. Y., Deng, B.: A novel reduced-basis method with upper and lower bounds for real-time computation of linear elasticity problems. Comput. Methods Appl. Mech. Eng. 198(2), 269–279 (2008)
Lo\(\grave{e}\)ve. M.: Probability theory(4th ed). Springer Berlin Heidelberg, (1977)
Margenov, S., Vutov, Yavor: Parallel MIC(0) Preconditioning for Numerical Upscaling of Anisotropic Linear Elastic Materials. Springer, Berlin Heidelberg (2010)
Milani, R., Quarteroni, A., Rozza, Gianluigi: Reduced basis method for linear elasticity problems with many parameters. Comput. Methods Appl. Mech. Eng. 197(51–52), 4812–4829 (2008)
Muskhelishvili, N.I.: Some Basic Problems of the Mathematical Theory of Elasticity. PhD thesis, Springer Netherlands, (2009
Wu, X., Efendiev, Y., Hou, T.Y.: Analysis of upscaling absolute permeability. Discret. Contin. Dyn. Syst. Ser. B 2(2), 185–204 (2002)
Yang, Y., Chung, E.T., Shubin, Fu.: An enriched multiscale mortar space for high contrast flow problems. Commun. Comput. Phys. 23, 476–499 (2018)
Yang, Y., Fu, S., Chung, Eric T.: A two-grid preconditioner with an adaptive coarse space for flow simulations in highly heterogeneous media. J. Comput. Phys. 39(1), 1–13 (2019)
Zambrano, M., Serrano, S., Lazarov, B.S., Galvis, J.: Fast multiscale contrast independent preconditioners for linear elastic topology optimization problems. J. Comput. Appl. Math. 389, 113366 (2021)
Zeng, Y., Yang, X., Deng, K., Peng, P., Yang, H., Muzamil, M., Qiujiao, Du.: A broadband seismic metamaterial plate with simple structure and easy realization. J. Appl. Phys. 125(22), 224901 (2019)
Zhang, D., Lu, Z.: An efficient, high-order perturbation approach for flow in random porous media via Karhunen Lo\(\grave{e}\)ve and polynomial expansions. J. Comput. Phys. 194(2), 773–794 (2004)
Funding
Yanfang Yang’s work is supported by the National Natural Science Foundation of China (Grant No. 11901129), Basic Research Project of Guangzhou, and Introduction of talent research start-up fund at Guangzhou University. The datasets generated during and/or analysed during the current study are available from the corresponding author on reasonable request.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
There is no conflicts of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Yang, Y., Fu, S. & Chung, E.T. An Adaptive Generalized Multiscale Finite Element Method Based Two-Grid Preconditioner for Large Scale High-Contrast Linear Elasticity Problems. J Sci Comput 92, 21 (2022). https://doi.org/10.1007/s10915-022-01869-w
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10915-022-01869-w