
Abstract
The issue of global climate change has attracted worldwide attention. Many scientific studies have shown that in daily life and industrial production, greenhouse gases such as carbon dioxide are an important cause of climate warming and have an important impact on human survival and development. To effectively control the emission of greenhouse gases such as carbon dioxide, a "low carbon economy" composed of "low energy consumption", "low pollution" and "low emission" has emerged and has gradually become a new economic form. Given the problem that the low-carbon supply chain network computing speed is not fast enough and the cost is high, The purpose of this paper was to explore the use of big data technology to design and optimize a low-carbon supply chain network in China in the context of a low-carbon economy, to seek the optimal balance. In this paper, through the study of the calculation example, the improved genetic algorithm proposed in this paper had obvious advantages in all aspects. For example, its operation speed was fast, which only took 23.15 s. At the same time, it had good convergence and strong stability, which can avoid local optimum. At the same time, it could be found that a good supply chain network could not only reduce carbon emissions, but also reduce costs and bring better benefits to enterprises. Thus, the need to continuously improve the supply chain network is necessary.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
With the fast and booming global economy, the commercial circulation industry has developed rapidly. However, due to the wide variety of commodities on a global scale, large amounts of greenhouse gases are produced during the production process, transportation, storage, and distribution, resulting in the deterioration of the global climate and ecological environment. Under this circumstance, the "low-carbon economy" has become the consensus of countries around the world, and a series of low-carbon concepts such as low-carbon consumption and low-carbon society have been put forward one after another. However, the low-carbon economy is characterized by low pollution, low energy consumption, and low emissions, and its fundamental goal is to solve the problems of global temperature rise and climate warming. The essence of a low-carbon economy is to promote energy efficiency, energy saving, and renewable energy, and to reduce emissions of greenhouse gases, as well as develop low-carbon products to maintain the world's ecological balance. This is a new way of economic development in the energy era from high carbon to low carbon. Under this general trend, a new model of low-carbon economic development—a low-carbon supply chain came into being. Low-carbon supply chain refers to the integration of low-carbon, environmental protection, and other ideas into each link of the supply chain, such as raw material supply, product production, product distribution, product recycling/remanufacturing, and waste disposal. While considering the economic benefits, it is necessary to consider the ecological benefits it produces. Therefore, an optimization model was constructed through the big data algorithm, which further improved the research on related issues in the field of supply chain network planning.
With the development of informatization, the market environment is also constantly changing, and competition between companies has transformed into competition between supply chains. Therefore, the requirements for the supply chain are getting higher and higher, and many scholars across the country have studied this. In order to assess the impact of climate change on livestock production and evaluate response strategies, Muhammad U and other scholars used multi-group analysis (MGA) in the partial least squares path model (PLS-PM) to compare adaptors and non-adapters of climate change adaptation strategies. However, the results show that the adverse effects of climate change will have a serious impact on the livestock supply chain network (Muhammad et al., 2023). Ma S and other scholars established differential game models of four different LTSC network structures to explore the optimization of low-carbon tourism supply chain networks with vertical and horizontal cooperation. The results show that horizontal or vertical cooperation among LTSC network members is not always beneficial to the entire LTSC. network performance (Ma et al., 2023). Shen L and other scholars constructed a low-carbon e-commerce supply chain (LCE-SC) game decision-making model to discuss the impact of commissions and carbon trading on the optimal decision-making of LCE-SC. The results show that the implementation of carbon trading is conducive to regional sustainable development and controlling the intensity of environmental governance is conducive to improving carbon productivity (Shen et al., 2021). Scholars such as Zou F have explored the impact of retailers' low-carbon investment on the supply chain under carbon tax and carbon trading policies, providing a reference for future scholars to study low-carbon supply chain networks (Zou et al., 2020). According to the above-mentioned scholars, although the performance of designing and optimizing China's low-carbon supply chain network has been improved to a certain extent, the computing speed is not ideal.
With the development of science and technology, big data and related technologies have also been fully developed. Related algorithms have also increased and are gradually applied to all walks of life. Ren Y and other scholars optimized the supply chain network based on the genetic algorithm of fuzzy stochastic low-carbon comprehensive forward and reverse logistics network design. The results show that the fuzzy stochastic programming model has strong practicability and short computing speed (Ren et al., 2020). To minimize costs, scholars such as Zhang T use the multi-objective ant colony algorithm based on chaotic particles to optimize the sustainable supply chain network (Zhang et al., 2023). Scholars such as Wang Y summarized the application of digital technologies such as big data algorithms in green supply chains, providing a reference for future scholars (Goodarzian et al., 2021; Wang et al., 2023). It can be seen that it is feasible to optimize the low-carbon supply chain network by combining big data algorithms.
The ecological environment is the base of human existence and growth, which is now being continuously destroyed. Everyone should take care to protect their home. In terms of supply chain, it can be optimized to reduce carbon emissions, to protect the environment. In this paper, the supply chain network was optimized based on the genetic algorithm. Compared with others, the improved genetic algorithm optimization result was slightly better. In terms of operation speed, it only took 23.15 s.
The main contributions of this article are as follows:
-
To solve the problem of low-carbon supply chain network calculation speed not being fast enough and high cost: introducing big data technology to design low-carbon supply chain network can find potential carbon emission hotspots and optimization space, thereby guiding supply Design and operation of chain networks to reduce carbon emissions.
-
Application of improved genetic algorithm: The improved genetic algorithm is used to optimize the low-carbon supply chain network, which can find optimal solutions in a large-scale search space, avoid falling into local optimal situations, and reduce transportation costs.
-
Excellent performance: After a large number of experiments, the performance of the low-carbon supply chain network optimized using the improved genetic algorithm is better than the simulated annealing algorithm and the particle swarm algorithm, highlighting its advantages and reducing transportation costs while reducing computing time.
-
The framework of this article is specifically developed as follows: Sect. 1 introduces the background and significance, related work, and the contribution of this article; Sect. 2 elaborates on the low-carbon multi-level supply chain network model; Sect. 3 introduces the improved genetic model under the big data algorithm Algorithms optimize supply chain networks. Section 4 introduces the implementation details and experimental results and analysis; Sect. 5 outlines the conclusion of the article.
2 Low-carbon multi-level supply chain network model
2.1 Overview of supply chain network and supply chain management
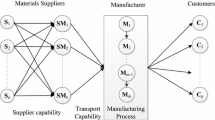
In a complete supply chain, the procurement of raw materials starts from the factory. After processing in the factory, the final product is obtained. The finished product is then transported to the warehouse, and then the finished product is sold to the customer by the retailer (Ye & Wang, 2019). A supply chain is a functional network system that connects suppliers, manufacturers, distributors, retailers, and end consumers (Hammou et al., 2018). It can be seen that the supply chain involves the whole process from procurement to final sales. Information, products, and funds flow between these various stages. The supply chain network diagram is shown in Fig. 1.

Supply chain network
In supply chain management, not only a single link but also the influence of each link should be considered comprehensively to maximize the benefits of the system. Supply chain management refers to the effective integration of suppliers, manufacturers, distribution centers, and retailers in the supply chain. It enables the control of product, information, and capital flows, which minimizes the total cost of the system and ensures a certain level of service.
2.2 Overview of green supply chain
2.2.1 Definition and content of green supply chain management
The green supply chain, also known as the supply chain with environmental awareness, aims to promote the development of the production chain under the premise of fully considering environmental factors (Cui et al., 2018). At present, some scholars have defined the concept of a green supply chain as "through cooperation with upstream manufacturers and exchanges with various links in the enterprise. In product design, material selection, product manufacturing, sales, recycling, and other links, the maximum environmental protection benefits are achieved, and the environmental performance and economic benefits of the enterprise are improved, thereby achieving the sustainable development of the enterprise and the supply chain."
2.2.2 Significance of green supply chain management
The implementation of the green supply chain can bring the following benefits to the company (Minjie et al., 2023; Najia et al., 2023):
-
1.
Integrate the environmental effects of supply chain activities into every part of the supply chain and adopt appropriate environmental protection strategies to achieve sustainable development.
-
2.
Through clean production and waste recycling, they can improve the utilization rate of resources and make enterprises gain greater economic benefits.
-
3.
By cooperating with upstream and downstream enterprises in the supply chain, they can provide consumers with green and environmentally friendly products and win their favor.
-
4.
It is beneficial to enhance the social image of the enterprise itself.
The importance of this study lies in the successful implementation of low-carbon optimization of the supply chain network through the introduction of an improved genetic algorithm, which provides a practical solution for sustainable development and the construction of a low-carbon society. The optimized network structure not only achieved significant economic benefits but also significantly reduced the adverse impact on the environment, emphasizing the key role of the supply chain network in sustainable development. This research not only expands the boundaries of supply chain network optimization in theory but also provides innovative application practices for the industry and provides strong support for future green supply chain management.
2.2.3 Network design of green supply chain
The green supply chain network design is to integrate environmental factors such as reverse logistics and carbon emissions into the supply chain network design, to achieve a balance between economic and environmental benefits (Smith & Powell, 2019). In addition to the supply chain cost and responsiveness that traditional supply chain models need to consider, green supply chain design considerations should also minimize the environmental impact of the entire supply chain. So, the decisions that need to be made in the design of green supply chain networks include not only those involved in traditional supply chain networks but also decisions related to the environment.
2.3 Low-carbon economy and low-carbon supply chain management
2.3.1 Low carbon economy
In the context of global warming, especially after the Copenhagen Summit, the low-carbon economy has received widespread attention. Low-carbon economy refers to the replacement of traditional fossil energy with clean energy such as wind energy, solar energy, and nuclear energy to achieve the purpose of energy saving, emission reduction, emission reduction, and pollution reduction.
2.3.2 Low-carbon supply chain management
The low-carbon supply chain is a further development of the green supply chain. Many scholars have given various definitions of a green supply chain, and some studies call it a closed-loop supply chain or sustainable supply chain; some define it as an environmentally ethical supply chain, an integrated supply chain, or a socially responsible supply chain. No matter how it is named, its prominent focus is also "environment" (Manogaran et al., 2018). Suppliers, manufacturers, and customers should share responsibility for the environmental impact of the production and use of products. The reverse supply chain and the forward supply chain form a closed-loop supply chain for recycled materials, which are then reused and remanufactured into new materials or other products. A green supply chain is a dual-purpose structure that includes reducing costs and reducing manufacturing waste. It is a fact that many manufacturing companies have taken supply chain management as their core competitiveness.
With the increasing emphasis on carbon emissions and the rise of carbon trading markets around the world, green supply chain management has gradually increased the requirements for low-carbon demand, and the concept of low-carbon supply chain management has emerged as the times require (Tsao et al., 2021). The main way to reduce carbon emissions within the supply chain is by reducing carbon emissions within the manufacturing process. Based on optimizing the production operation and decision-making methods of enterprises, carbon reduction methods such as adjustment of supply chain structure or improvement of logistics network design are gradually being valued by enterprises. Low-carbon supply chain management involves multiple links such as raw material suppliers, manufacturers, distributors, and final consumers. The management content involves product design, procurement methods, marketing channels, transportation and distribution channels, consumption and recycling, etc. Enterprises in the supply chain are required to fully consider low-carbon management issues while pursuing their business goals, to minimize environmental pollution at all stages of the supply chain (Alguliyev et al., 2019). It allows enterprises to obtain maximum profits and reduce environmental burdens while saving resources. Enterprises are required to raise their awareness of social responsibility without compromising their interests. Therefore, the low-carbon supply chain has further developed the requirements of green supply chain management, all of which are to reduce resource consumption and achieve the purpose of protecting the environment.
2.4 Network type
There are six types of products based on the paths they take through the supply chain network:
-
1.
The inventory of this product is the responsibility of the manufacturer, and it is shipped directly from the manufacturer to the customer. Under this sales model, the inventory of the product belongs only to the manufacturer, not to the distributor. Instead, it is shipped directly from the production plant to the customer, and the dealer's job is to collect and ship the customer's order, as can be seen in Fig. 2:
-
2.
The sale of the product is the responsibility of the manufacturer and the 3PL company. In this mode, the dealer receives the order from the customer, and the manufacturer is then notified of the order. The 3PL company then purchases parts from multiple manufacturers and assembles them into a product, as well as delivers them to customers, as shown in Fig. 3:
-
3.
The distribution center is responsible for inventory and sales, and the 3 PL company is responsible for distribution. In this model, the dealer receives the order from the customer and sends it to the manufacturer, and then the product is sent to the dealer. The distributor then sells the product to the customer, which is ultimately transported by the 3 PL company designated by the manufacturer, as can be seen in Fig. 4:
-
4.
The distribution center completes the sales and distribution of goods. In this type of situation, the distributor accepts the customer's order and sends it to the manufacturer. The product is then distributed to distributors or retailers and the finished product is finally delivered to consumers through distributors or retailers, as can be seen in Fig. 5:
-
5.
The manufacturer is responsible for sales, and the customer takes the goods by himself. In this mode, the sales center receives orders from network or telephone users. The order is then sent to the manufacturer, who delivers the product to the delivery location and then notifies the customer to pick it up at the delivery location, as can be seen in Fig. 6:
-
6.
Distributors are responsible for product sales, and customers pick them up. In this case, the distributor receives the order from the customer. The order is then sent to the manufacturer, who is then notified to pick it up at the retailer, as can be seen in Fig. 7:

Manufacturer-held, direct product delivery to customer model

Manufacturer is responsible for product sales, 3PL companies package and deliver model

Distributor sales, 3PL company delivery model

Distributors are responsible for product sales and distribution model

Manufacturer responsible for product sales, customer pick-up modelB

Distributor responsible for product sales, customer pick-up model
2.5 Supply chain network optimization model
Assuming that the supply chain network has a product manufacturing plant, x alternative distribution centers, and y independent distribution points, in the alternative locations of the x distribution centers, a distribution center is selectively set up to complete the distribution within the region. A typical single source and multiple transfer point logistics network is formed to reduce the overall cost of the system (Li et al., 2018).
2.5.1 Model assumptions
-
1.
The location of the manufacturer and the seller has been determined, and the manufacturer has sufficient supply capacity.
-
2.
A distribution center can supply multiple distribution points. However, each distribution point is limited to one distribution center, which has a limited capacity.
-
3.
The order turnover time between the distribution center and producer is fixed. The ordering distribution center can replenish the inventory for the distribution point in time, and the distribution center holds the safety stock. The distribution point holds only circulating inventory and does not take into account the cost of distribution point inventory.
-
4.
The distribution center uses the (o, O) inventory strategy of continuous inspection. When the inventory drops to p, the sales center gives the order quantity as [(O–o) + average lead-time demand].
-
5.
The probability distribution of the demand of distribution points is known and satisfies the normal distribution, and the demand of each distribution point is not related.
-
6.
Transportation cost increases as the volume of transportation increases, and transportation cost as the distance of transportation increases.
2.5.2 Related cost evaluation
In the supply chain network, facility cost, inventory cost, and transportation cost account for a very large proportion of the system cost, so they must be considered comprehensively in supply chain network optimization (Zokaee et al., 2017). The overall cost for the supply chain network is examined from a cost perspective, mainly including: the fixed cost of distribution center \({G}_{W}\), distribution cost from production point to distribution center \({G}_{T}\), distribution point cost of distribution center \({G}_{t}\), order cost of distribution center \({G}_{O}\), the inventory cost of the distribution center \({G}_{H}\), and the out-of-stock cost of the distribution center \({G}_{S}\).
1. Distribution center fixed cost
It mainly refers to the cost required for the operation of the distribution center, including the related costs of establishing and operating the distribution center. Fixed fees are generally proportional to the size (capacity) of the distribution center, but not linearly.
The daily fixed cost of a distribution center is shown in the following formula:
Among them, P is the set of alternative distribution centers, \(\text{p}\in \text{P},\text{P}=\left\{\text{1,2},\cdots ,\text{x}\right\}\) and \({f}_{p}\) are the daily fixed costs for the construction and operation of the distribution center i, and \({B}_{p}\) refers to whether to establish a distribution center at the alternative point p. \({B}_{p}\)=1 means establishing a distribution center, and \({B}_{p}\)=0 means not establishing a distribution center.
2. Distribution center inventory-related costs
Since distribution point demand is random, the distribution center has a buffer of safety stocks. Under the continuous inventory management strategy, there is a shortage of order lead time in the distribution center (Sabegh et al., 2017). The demand distribution of the distribution center can also be expressed by the demand distribution of the distribution points it provides. The daily demand of distribution points is random, and the demand among distribution points is independent of each other and obeys a normal distribution \(N\left( {\vartheta_{q} ,\delta_{q}^{2} } \right)\).
It can be seen that the daily demand of the distribution center also obeys the normal distribution \(N\left( {\vartheta_{wp} ,\delta_{wp}^{2} } \right)\); the demand of the distribution center in the lead time \({L}_{p}\) also obeys the normal distribution \(N\left( {L_{p} \vartheta_{wp} ,L_{p} \delta_{wp}^{2} } \right)\). Among them:
Among them, Q is the set of distribution points that need service,\(\text{q}\in \text{Q},\text{Q}=\left\{\text{1,2},\cdots ,\text{y}\right\}\) and \({\vartheta }_{q}\) are the mathematical expectations of the daily demand of the distribution point q, and \({\delta }_{q}\) is the standard deviation of the daily demand of the distribution point q. According to the assumption, the distribution center in this model adopts the (o, O) inventory strategy of continuous inspection. When the inventory drops to o, the distribution center issues an order with an order quantity of [(O–o) + average lead-time demand]. The main parameters of inventory include reorder point and maximum inventory.
(1) Safety stock and reorder points
Service level refers to the expected probability of out-of-stocks for each order lead time. According to the given service level, the corresponding safety stock can be calculated, and then the reorder point can be calculated from the safety stock (Yang et al., 2018). During the supply process, when the market demand is greater than the reorder time o, there is a shortage problem. Thus, the following formula can be derived:
Among them, \(\uprho\) is the service level, that is, the supply level of the replenishment cycle, which refers to the probability that there would be no shortage of goods within an order lead time.
The distribution function of the normal distribution is denoted as \(F\left( {c,\vartheta ,\delta } \right)\), which represents the probability that a random variable obeying a normal distribution with a parameter of \(\vartheta ,\delta^{2}\) is less than or equal to c. When \(\vartheta = 0,\delta = 1\), that is, when the random variable is a standard normal distribution, the distribution function is recorded as \(\upphi \left(\text{c}\right)\), then there are:
According to the above analysis, the service level of distribution center p without out-of-stock probability can be obtained:
From the formula, the reorder point of distribution center p can be obtained:
Among them, \({\rho }_{p}\) is the target service level provided by the distribution center p. According to the definition of the reorder point, it is the sum of the average demand and safety stock of the order lead time, so the reorder point of the distribution center p has the following formula:
\(o{o}_{p}\) is the safety stock. According to the definition of safety stock under the condition of uncertain demand and fixed lead time, the safety stock of distribution center p can be obtained:
\({\text{k}}_{\text{p}}\) is the safety stock factor. From Formulas 7–9, the safety stock coefficient of distribution center p can be obtained under the condition that the service level is satisfied:
Therefore, the safety stock coefficient \({k}_{p}\), reorder point \({o}_{p}\) and safety stock \({oo}_{p}\) of each distribution center can be obtained.
(2) Average inventory holding cost
When calculating the inventory cost of the inventory, the inventory cost of the inventory should be determined first. Commonly used is the cost of the unit product, which is expressed as the sum of the purchase price of the unit product and the purchase cost of the unit product (Devi & Sabrigiriraj, 2019). In general, once this percentage is determined, it is usually viewed as a constant, that is, the holdings per unit of inventory are fixed.
The order quantity of distribution center P is [+ average lead-time demand], namely:
According to the definition of average inventory, the average inventory of distribution center p can be known:
The daily average inventory carrying cost for the distribution center is obtained by multiplying the storage cost per unit of product by the average inventory:
Among them, \({h}_{p}\) refers to the daily storage cost of the product in the distribution center p.
(3) Ordering cost
Subscription fees consist of two main areas: The first is the fixed cost required for ordering. The other is the cost of the product itself related to the order quantity, which is a variable cost, mainly including the price of the product, transportation costs, etc. The ordering cost for this model is a fixed ordering cost related to the number of orders.
The expected value of the number of orders in the distribution center p-day is \(\frac{{\vartheta }_{wp}}{{N}_{p}}\). The expected value of the daily order cost of the distribution center is equal to the product of the cost per order and the expected number of daily orders:
(4) Out of stock cost
Out-of-stock cost refers to the loss of sales and the expected loss of customers due to out-of-stock.
The average out-of-stock quantity in the order cycle of distribution center p is as follows:
It can be obtained by the formula:
Among them, \(f\left({x}_{p}\right)\) is the probability density function of the demand of the sales center in the lead period. \(x_{p} \sim N\left( {L_{p} \vartheta_{wp} , L_{p} \delta_{wp}^{2} } \right)\) and \(\phi \left( \cdot \right)\) are the probability distribution functions of the standard normal distribution. d is the probability density function of the standard normal distribution.
The expected service level of the distribution center p is measured by the probability of not being out of stock, namely:
Therefore, the daily out-of-stock cost at the distribution center is:
(5) Shipping cost
The expected value of the daily transport cost per day from the manufacturing plant to the distribution center is:
The expected value of the daily transport cost per day from the distribution center to the distribution point is as follows:
(6) Total system cost.
To sum up, the total daily system cost of the supply chain network is the sum of the above-mentioned costs, namely:
It can be obtained by derivation:
2.5.3 Model Establishment
According to the above comprehensive analysis of the total cost of the supply chain network, Formula 22 is substituted into Formula 21, and the following inventory control-based supply chain network optimization model (Distribution-networkLocationInventoryModel, DLIM) can be established.
3 Supply chain network optimization under big data algorithm
3.1 Overview of big data algorithms
Big data algorithms require more powerful decision-making capabilities to analyze massive, high-rate, and diverse data to obtain its potential value. That is, under certain conditions, through a large amount of data as input, an algorithm that meets the requirements is generated under certain time constraints.
3.1.1 Big data evaluation methods
Big data algorithm is an important topic in big data at present, which requires a lot of data analysis to obtain more intelligent, in-depth, and useful information. The rapid development of big data technology determines its status and value in big data applications.
3.1.2 Application of big data evaluation algorithms
Today, as the era of big data comes, big data analysis methods are increasingly used by the public in various fields. Currently, the most well-known is the application of big data analysis methods in the trade industry. With the wide application and rapid development of big data analysis methods in business, finance, medical care, transportation, and other industries, data analysis algorithms are also commonly used when optimizing the supply chain. Therefore, this time, a genetic algorithm would be used to optimize the low-carbon multi-level supply chain.
3.2 Network optimization based on genetic algorithm
3.2.1 Overview of genetic algorithms
Genetic Algorithm (GA) is a global optimal adaptive probabilistic search algorithm based on genetics and evolution. The method first starts from the initial population with potential solution sets. The genetic operator is used to select the degree of adaptation of individuals in the problem area, and the genetic operator is used to combine crossover and mutation of the population, to form a population with a new solution set and enable the group to better adapt to the new environment.
3.2.2 Characteristics of genetic algorithms
The genetic algorithm is a robust search algorithm. The method has the following advantages over other optimization algorithms:
-
1.
The code of the decision variable is used as the object of the operation.
-
2.
The target function is used directly as information for the search.
-
3.
More than one search point at a time in an information search is used.
-
4.
The probabilistic search technique is used.
3.2.3 Improved genetic algorithm to solve the model
As the basic genetic algorithm for heuristic search, the principle of its optimal solution is not very mature. In practical applications, problems such as slow convergence, poor stability, and precociousness are often encountered. This paper proposes a simplified coding algorithm to reduce chromosome storage space. In addition, an improved method of adaptive probability and mutation probability based on self-adaptation is also presented in this paper, which can improve the individual diversity in the population to a certain extent, thus effectively preventing the problem of premature maturity of the genetic algorithm. Results show that the approach not only ensures population diversity but also can effectively improve the performance of the genetic algorithm and can well resolve early conversion and late search lag.
In the probability of crossbreeding, the probability of mating is too high if the generation of new individuals would be accelerated, and individuals with high fitness would have a higher probability of being destroyed; if the probability of crossover is too low, it would be difficult to generate new individuals and the algorithm would stall. In the mutation probability, if the value of the variable is too high, the method would become a pure random search; if the chance of genetic mutation is low, it is difficult to create new genes. Among them, the crossover probability \({P}_{r}\) and the mutation probability \({P}_{v}\) are adaptively adjusted according to the following formula.
In the formula, \({f}_{max}\) and \({f}_{avg}\) respectively represent the maximum fitness value in the population and the average fitness value of each generation of the population, \({f}^{\prime}\) represents the larger fitness value of the two individuals to be crossed, and \(f\) represents the fitness value of the individual to be mutated. \({c}_{1},{c}_{2},{c}_{3},{c}_{4}\) takes the value in the interval (0, 1). Among them, the crossover probability \({P}_{r}\) and the mutation probability \({P}_{v}\) are adjusted with the change of the fitness value, as shown in Fig. 8.

Adaptive crossover probability and variability probability
The algorithm makes the average fitness and maximum fitness value of the group have a linear relationship with the degree of individual fitness. With the increase in fitness, the probability of crossover and mutation also decreases; the probability of crossover and variation is almost zero when the fitness is close to the maximum fitness. However, this method has a major drawback, that is, its performance is not ideal in the early stages of evolution.
Based on the adaptive genetic algorithm, the adaptive crossover probability and mutation probability are improved. The improved crossover probability \({P}_{r}\) and mutation probability \({P}_{v}\) are adaptively adjusted according to the following formula.
In the formula, \({P}_{r1}>{P}_{r2}>{P}_{r3}\) \(\text{takes a value in the interval }(0, 1).\)
According to the above, the changes in crossover probability and variability probability can be obtained, as shown in Fig. 9.

Improved adaptive crossover probability and variability probability
The improved crossover and mutation probabilities have the following characteristics:
-
1.
In the case where the individual's fitness value is lower than the average fitness, the approach is more probable to fall into the partial optimum. At this time, by increasing the probability of crossover and variation, the mutation ability of the disadvantaged group is enhanced, to diversify the individuals in the group.
-
2.
In the case of above-average individual fitness, the convergence speed is accelerated.
-
3.
On this basis, it is ensured that the optimal individual still has a certain crossover probability and mutation probability in the evolution process, thus achieving the ultimate goal of the genetic algorithm.
This method can not only automatically change the probability of crossover according to fitness, but also make the probability of crossover and variability of individuals with the greatest fitness in the population not 0. Therefore, the crossover probability and variability probability of better-performing individuals in the population also increases, so that they would not fall into a state of near-stagnation, and the algorithm jumps out of the optimal solution. By comparing with the fitness of the current population, the genetic structure of excellent individuals can be effectively maintained, and the variation ability of inferior individuals can be improved, to achieve the purpose of jumping out of the local optimum and overcome the defects of premature maturity.
Driving the successful implementation of low-carbon supply chains requires a broader and comprehensive approach, in which policy plays a key role. In addition to optimization measures within the supply chain, governments and stakeholders can promote the development of low-carbon supply chains through the following ways. First, formulate clear regulations and industry standards to regulate enterprises’ carbon emissions in the supply chain and encourage the adoption of low-carbon technologies and clean energy. Second, provide incentives, such as tax incentives, subsidies, and reward mechanisms, to encourage companies to adopt low-carbon production methods and green supply chain management practices. Third, establish a mechanism for collecting and disclosing carbon emissions data to increase the transparency of companies’ carbon footprints in their supply chains and encourage them to take more proactive measures to reduce emissions. Fourth, invest in low-carbon technology and innovation, provide technical support and R&D funds for enterprises, and promote cleaner production and energy efficiency improvements in the supply chain. Fifth, provide training and education programs to enhance employees’ understanding of low-carbon supply chain management and promote the in-depth implementation of the concept of sustainable development in enterprises. Sixth, promote collaboration between different government departments to form policy integration and ensure that the development of low-carbon supply chains is not restricted by one-sided policies. Through these comprehensive policy measures, enterprises can be promoted at a broader level to realize the low-carbon transformation of the supply chain, and the entire society can be promoted in a more sustainable direction.
4 Data evaluation
After the supply chain network model design is completed, the data is summarized and tested. The entire network consists of 1 manufacturing plant, 4 alternative distribution centers (x = 4), and 12 distribution points (y = 12). The freight from the manufacturer to the distribution center is 0.11 yuan per ton, and the freight from the distribution center to the dealer is 0.3 yuan per ton. The relevant data will be introduced one by one below. First, the daily demand of each distribution point is shown in Fig. 10:

Daily demand at each distribution point
Second, the relevant data of each distribution center is shown in Table 1:
Finally, the distance from each distribution point to each distribution center is shown in Table 2:
According to the above data, an improved genetic algorithm is used to complete the optimization scheme. The genetic parameters used are as follows: the population size is 50, and the termination algebra is 300. The selection operator is 0.1, and the crossover probability \({P}_{r1}\), \({P}_{r2}\), \({and P}_{r3}\) are 0.9, 0.75, and 0.5, respectively. The mutation probability of \({P}_{v1}\), \({P}_{v2}\) and \({P}_{v3}\) is taken as 0.1, 0.05 and 0.01, respectively. After calculation, the best individual appears in the 48th generation, and the optimal objective function value is 19,398.77, that is, the minimum total cost of the supply chain network in this model is 19,398.77 yuan. Among them, the cost and proportion of each part are shown in Fig. 11a, b.

Costs consumed and percentage of each type of project
As can be seen from the figure, the total transportation cost accounts for about half of the total system cost. The fixed costs of building and operating distribution centers also represent a significant percentage of the total system costs, with inventory costs not accounting for a very high percentage of the total system costs.
At the same time, through calculation and analysis, the distribution relationship of the optimal network can be obtained, as shown in Table 3.
By the table's data, it can be seen that the distribution center is established in the alternative distribution center 2, 3, and 4, and the distribution center 2 can supply the distribution points 1, 2, 5, and 11. Distribution center 3 supplies distribution points 3, 7, 9, and 10, and distribution center 2 supplies distribution points 4, 6, 8, and 12. This not only reduces costs but also reduces transportation distances, thereby reducing carbon emissions and protecting the environment.
At the same time, the simulation experiment is carried out, and the improved genetic algorithm and the basic genetic algorithm are repeated 20 times for comparison and analysis. By calculating problems of different scales, the operation results of the improved genetic algorithm and the basic genetic algorithm are compared as shown in Fig. 12. Figure 12a is the running time, and Fig. 12b is the evolutionary algebra:

Comparison of operation results before and after algorithm improvement
Comparing with two optimization algorithms, it can be found that under the same parameter setting conditions, the improved genetic algorithm has fast operation speed, good convergence, and strong stability, and its advantages are more obvious when calculating large-scale problems. Through example analysis, it is demonstrated that the algorithm of the supply chain network optimization models based on inventory control put forward in the paper has a good optimization effect.
To verify the validity of the algorithm, the improved genetic algorithm is compared with the simulated annealing algorithm and the particle swarm algorithm, and the operation results are shown in Table 4.
The performance shows that the improved genetic algorithm outperforms the optimization results of other algorithms; in terms of operation speed, it only needs 23.15 s, which is much lower than the time required by other algorithms; meanwhile, the best results show that the improved genetic algorithm can better avoid local optimization. To sum up, improved genetic algorithms for network design of low-carbon multi-level supply chains can achieve better optimization results, and can greatly save the computing time.
5 Conclusions
In the current context of limited global resources and deteriorating environmental problems, achieving low-carbon optimization of supply chain networks has become the key to promoting sustainable development. This paper successfully optimizes the supply chain network by introducing an improved genetic algorithm. The determination of the optimal network structure minimizes the total cost and achieves the optimization goals of reducing carbon emissions, reducing costs, and shortening transportation distances. This optimization result provides strong support for the construction of a low-carbon society in the supply chain field.
In the current research context, supply chain network optimization and low-carbon society construction are hot research topics. Many scholars and researchers have achieved remarkable results in this field. Some studies have explored the environmentally friendly design of supply chain networks and proposed a method based on life cycle analysis to minimize environmental impact. Some also paid attention to the carbon footprint management of the supply chain, emphasizing the criticality of achieving low-carbon goals through supply chain network optimization. These literature results further verify the effectiveness of the improved genetic algorithm used in this article in supply chain network optimization.
Future research can be further expanded in the following aspects: as the complexity of the model increases, more supply chain network variables will be considered, such as multi-level supply chains, multiple product types, etc., to be closer to actual business scenarios. Research on multi-algorithm combinations further studies the combination of multiple optimization algorithms to adapt to different problems and environments and improve optimization effects. The expansion of empirical cases applies the algorithm to a wider range of actual supply chain cases to verify its versatility in different industries and environments. At the same time, since some variables of the supply chain network may be fuzzy, such as the fuzziness of customer needs and the fuzziness of branch factory production capabilities, fuzzy mathematical methods can be considered to handle and solve the optimization problem of the supply chain network. A combination of multiple optimization algorithms can be considered to solve the model to further improve the efficiency of model solving.
Data availability
The datasets used and/or analysed during the current study available from the corresponding author on reasonable request.
References
Alguliyev, R. M., Aliguliyev, R. M., & Abdullayeva, F. J. (2019). Privacy-preserving deep learning algorithm for big personal data analysis—ScienceDirect. Journal of Industrial Information Integration, 15, 1–14.
Cui, Z., Cao, Y., & Cai, X. (2018). Optimal LEACH protocol with modified bat algorithm for big data sensing systems in Internet of Things. Journal of Parallel and Distributed Computing, 132, 217–229.
Devi, S. G., & Sabrigiriraj, M. (2019). A hybridmulti-objective firefly and simulated annealing based algorithm for big data classification. Concurrency Practice & Experience, 31(14), e49851–e498512.
Goodarzian, F., Kumar, V., & Abraham, A. (2021). Hybrid meta-heuristic algorithms for a supply chain network considering different carbon emission regulations using big data characteristics. Soft Computing, 25, 7527–7557. https://doi.org/10.1007/s00500-021-05711-7
Hammou, B. A., Lahcen, A. A., & Mouline, S. (2018). APRA: An approximate parallel recommendation algorithm for Big Data. Knowledge-Based Systems, 157, 10–19.
Li, F., Triggs, C. M., & Dumitrescu, B. (2018). The matching pursuit algorithm revisited: A variant for big data and new stopping rules. Signal Processing, 155, 170–181.
Ma, S., He, Y., & Gu, R. (2023). Low-carbon tourism supply chain network optimisation with vertical and horizontal cooperations. International Journal of Production Research, 61(18), 6251–6270. https://doi.org/10.1080/00207543.2022.2063087
Manogaran, G., Lopez, D., & Chilamkurti, N. (2018). In-mapper combiner based map-reduce algorithm for big data processing of IoT based climate data. Future Generation Computer Systems, 86, 433–445.
Minjie, P., Xin, Z., Kangjuan, L., et al. (2023). Internet development and carbon emission-reduction in the era of digitalization: Where will resource-based cities go? Resources Policy, 81, 105. https://doi.org/10.1016/j.resourpol.2023.103345
Muhammad, U., Asghar, A., Joanna, R., et al. (2023). Climate change and livestock herders wellbeing in Pakistan: Does nexus of risk perception, adaptation and their drivers matter? Heliyon, 9(6), 16983–16997.
Najia, S., Magdalena, R., Muhammad, U., et al. (2023). Environmental technology, economic complexity, renewable electricity, environmental taxes and CO2 emissions: Implications for low-carbon future in G-10 bloc. Heliyon, 9(6), 16457–16473. https://doi.org/10.1016/j.heliyon.2023.e16457
Ren, Y., Wang, C., Li, B., Yu, C., & Zhang, S. (2020). A genetic algorithm for fuzzy random and low-carbon integrated forward/reverse logistics network design. Neural Computing and Applications, 32, 2005–2025. https://doi.org/10.1007/s00521-019-04340-4
Sabegh, M. H. Z., Mohammadi, M., & Naderi, B. (2017). Multi-objective optimization considering quality concepts in a green healthcare supply chain for natural disaster response: neural network approaches. International Journal of System Assurance Engineering & Management, 8, 1–15.
Shen, L., Wang, X., Liu, Q., Wang, Y., Lv, L., & Tang, R. (2021). Carbon trading mechanism, low-carbon e-commerce supply chain and sustainable development. Mathematics, 9(15), 1717–1742. https://doi.org/10.3390/math9151717
Smith, A. J., & Powell, K. M. (2019). Fault detection on big data: A novel algorithm for clustering big data to detect and diagnose faults - sciencedirect. IFAC-PapersOnLine, 52(10), 328–333.
Tsao, Y. C., Setiawati, M., & Vu, T. L. (2021). Designing a supply chain network under a dynamic discounting-based credit payment program. RAIRO - Operations Research, 55(4), 2545–2565.
Wang, Y., Yang, Y., Qin, Z., Yang, Y., & Li, J. (2023). A literature review on the application of digital technology in achieving green supply chain management. Sustainability, 15(11), 8564–8581. https://doi.org/10.3390/su15118564
Yang, W., Wang, G., & Choo, K. (2018). HEPart: A balanced hypergraph partitioning algorithm for big data applications. Future Generation Computer Systems, 83, 250–268.
Ye, Y., & Wang, J. (2019). Research on low carbon logistics network optimization considering segmented Carbon Tax[J]. Paper Asia, 2(3), 26–31.
Zhang, T., Xie, W., Wei, M., & Xie, X. (2023). Multi-objective sustainable supply chain network optimization based on chaotic particle—Ant colony algorithm. PLoS ONE, 18(7), e0278814. https://doi.org/10.1371/journal.pone.0278814
Zokaee, S., Jabbarzadeh, A., & Fahimnia, B. (2017). Robust supply chain network design: An optimization model with real world application. Annals of Operations Research, 257(1–2), 15–44.
Zou, F., Zhou, Y., & Yuan, C. (2020). The impact of retailers’ low-carbon investment on the supply chain under carbon tax and carbon trading policies. Sustainability, 12(9), 3597–3623. https://doi.org/10.3390/su12093597
Funding
The authors received no specific funding for this study.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Yu, F., Zhou, Y. & Xu, Y. Evaluation on network optimization model of low-carbon multi-level supply chain based on big data algorithm evaluation. Environ Dev Sustain (2024). https://doi.org/10.1007/s10668-024-05087-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10668-024-05087-2