
Abstract
In this paper we consider polynomial conic optimization problems, where the feasible set is defined by constraints in the form of given polynomial vectors belonging to given nonempty closed convex cones, and we assume that all the feasible solutions are non-negative. This family of problems captures in particular polynomial optimization problems (POPs), polynomial semi-definite polynomial optimization problems (PSDPs) and polynomial second-order cone-optimization problems (PSOCPs). We propose a new general hierarchy of linear conic optimization relaxations inspired by an extension of Pólya’s Positivstellensatz for homogeneous polynomials being positive over a basic semi-algebraic cone contained in the non-negative orthant, introduced in Dickinson and Povh (J Glob Optim 61(4):615–625, 2015). We prove that based on some classic assumptions, these relaxations converge monotonically to the optimal value of the original problem. Adding a redundant polynomial positive semi-definite constraint to the original problem drastically improves the bounds produced by our method. We provide an extensive list of numerical examples that clearly indicate the advantages and disadvantages of our hierarchy. In particular, in comparison to the classic approach of sum-of-squares, our new method provides reasonable bounds on the optimal value for POPs, and strong bounds for PSDPs and PSOCPs, even outperforming the sum-of-squares approach in these latter two cases.
Similar content being viewed by others
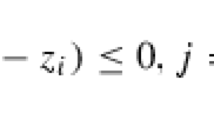


Avoid common mistakes on your manuscript.
1 Introduction
Polynomial optimization problems (POPs) are those for which we want to optimize a polynomial objective function over a feasible set defined by a set of polynomial inequalities (we call such a feasible set a basic semi-algebraic set). Several NP-hard problems can be formulated in this way. We provide a short list of some examples of such problems: (i) optimizing a homogeneous quadratic polynomial over the non-negative orthant, which is equivalent to testing the matrix copositivity [7, 32]; (ii) 0–1 linear optimization problems [48, 49, 55]; (iii) quadratic optimization problems including, for example, the Quadratic assignment problem, the Graph partitioning problem and the MAX-CUT problem [9, 27, 40,41,42, 45, 46]. Polynomial optimization is also a strong tool in control, see [10]. A good overview of the possible applications of polynomial optimization can also be found in [2].
Polynomial optimization problems attract a lot of attention in theoretical and applied mathematics. Real algebraic geometry and semi-algebraic geometry are sub-fields in algebra that are strongly related to polynomial optimization problems. Since these problems are, in general, very difficult, it is a natural choice to look for tractable relaxations. These relaxations are often based on some variant of a “Positivstellensatz” for given semi-algebraic sets [43, 44, 47]. Many researchers have proposed hierarchies of such relaxations that are based on moment and sums-of-squares (SOS) approximations of the original problem, and give semi-definite optimization/programming (SDP) problems. Lasserre [21] proposed a hierarchy of semi-definite optimization problems that, under certain conditions, converge with their optimal values to the optimal value of the original polynomial optimization problem, see also [38, 50]. We refer the reader to a 2010 book by Lasserre [22] and a 2008 chapter by Laurent [26] for beautiful and comprehensive overviews of the results from this area.
In polynomial optimization we have inequality constraints, and a natural extension to this is to consider other conic constraints, giving us, for example, polynomial semi-definite optimization (PSDP) and polynomial second-order cone optimization (PSOCP). The feasible set in the first case is primarily defined by the constraint that a given matrix polynomial (i.e., a matrix whose entries are polynomials) is positive semi-definite. In the second case the feasible set is primarily determined by the constraint that a given polynomial vector must belong to the second-order cone.
In the papers [13,14,15, 19] the authors considered how to extend the SOS approach to obtain good relaxations for PSDP problems, see also [10, 18]. The hierarchy of relaxations, which contain SOS polynomials and matrix SOS polynomials, is recaptured in Sect. 4.2.
The PSOCPs can be simply rewritten as classic POPs and later approached using tools from this area. The authors of the paper [20] proposed a general lift-and-project and reformulation-linearization technique that can also be efficiently applied to this family of problems.
If the feasible set for a POP is contained in the non-negative orthant then the existing approaches still work and the sign constraints can be modelled explicitly, i.e., by adding constraints \(x_i\ge 0\) to the set of polynomial constraints. The same idea works for PSDP and PSOCP. In [8, Theorem 2.4] a new Positivstellensatz was presented that is tailored for the non-negativity case and can be used to develop new, linear, conic optimization approximation hierarchies for POPs over the non-negative semi-algebraic sets.
The main contributions of this paper are:
-
Based on [8, Theorem 2.4], we propose a new hierarchy of linear conic optimization relaxations that can be uniformly applied to general polynomial conic optimization problems (over the non-negative orthant), including the special cases listed above.
-
We prove that under conditions closely related to the compactness of the feasible set and non-redundancy in its description, the optimal values of the proposed hierarchy are monotonic and asymptotically convergent to the optimal value of the original problem.
-
Numerical evaluations are considered for POPs, and it is found that in these examples, our method performs poorly in comparison with the classic SOS method. However, by adding an additional (redundant) positive semi-definite constraint to the original problem, our new method then performs reasonably well in comparison to the classic SOS approach.
-
We also provide numerical evaluations for PSDPs and PSOCPs, which demonstrate that in these examples our new method performs very well in comparison to the classic SOS approach. This performance is further improved by adding a (redundant) positive semi-definite constraint to the original problem, which implies SOS-like semi-definite programming constraints in our hierarchy. The enhanced hierarchy often outperforms the classic SOS approach also on POP problems.
Our work is also inline with recent results from Ahmadi and Majumdar [1] and Lasserre et al. [24], who developed new approximation hierarchies that would overcome the complexity drawbacks of the existing SOS hierarchies. New linear optimization/programming (LP) and second-order cone (SOC) hierarchies are presented in [1]. In [24] the authors proposed an LP-SDP hierarchy, but with only one SDP constraint with which they can control the dimension. They also provided proof of convergence for the hierarchy and numerical results, which together with the numerical results from [30] show that these approaches have a strong potential. A sparse version of this hierarchy is provided in [53] and can solve much larger problem instances. Another provably convergent hierarchy, called the mismatch hierarchy, is proposed in [16], which solves complex polynomial optimization problems with several thousand variables and constraints arising in electrical engineering.
Throughout the paper we will use \(\mathbb {N}\) to denote the set of non-negative integers \(\{0,1,2,\ldots \}\) and use \(\mathbb {R}_+\) to denote the set of non-negative real numbers.
2 Polynomial conic optimization
We define a polynomial conic optimization problem to be one with the following form
where
- i:
-
\(f:\mathbb {R}^n\rightarrow \mathbb {R}\) is a polynomial of degree \(d_0\ge 1\),
- ii:
-
For \(i=1,\ldots ,p\), we have that \(\mathbf {g}_i:\mathbb {R}^n\rightarrow \mathbb {R}^{m_i}\) is a polynomial vector of degree \(d_i\ge 1\), i.e., \(d_i\) is the maximum degree of the polynomials \(\big (\mathbf {g}_i(\mathbf {x})\big )_j\) for \(j\in \{1,\ldots ,m_i\}\),
- iii:
-
For \(i=1,\ldots ,p\), we have that \(\mathcal {K}_i^*\subseteq \mathbb {R}^{m_i}\) is a nonempty closed convex cone.
For \(i=1,\ldots ,p\) we will in fact consider the cone \(\mathcal {K}_i^*\) to be the dual cone to a nonempty convex cone \(\mathcal {K}_i\), i.e., \(\mathcal {K}_i^*= \{\mathbf {u}\in \mathbb {R}^{m_i}\mid \langle \mathbf {u},\mathbf {w}\rangle \ge 0 \text { for all } \mathbf {w}\in \mathcal {K}_i\}\) where \(\langle \mathbf {u},\mathbf {w}\rangle := \mathbf {u}^\mathsf {T}\mathbf {w}= \sum _{j=1}^{m_i} u_jw_j\). For a nonempty closed convex cone \(\mathcal {K}_i^*\) in Euclidean space, there always exists such a cone \(\mathcal {K}_i\), for example, the dual cone to \(\mathcal {K}_i^*\). For the theory in this paper, the cones \(\mathcal {K}_i\) need not be closed, whereas dual cones in Euclidean space are always closed, and it is for this reason that we have denoted our cones in this unusual manner (i.e., the dual cone being in the problem). Note that the sets \(\mathcal {K}_i\) and \(\mathcal {K}_i^*\) are convex cones in Euclidean space, i.e.,
and likewise for \(\mathcal {K}_i^*\). They should not be confused with polynomial cones, which are often discussed in relation to polynomial optimization.
Problems such as (1) include as special cases (i) POPs over the non-negative orthant (for \(m_i=1\) and \(\mathcal {K}_i=\mathcal {K}_i^*=\mathbb {R}_+\) for all i), (ii) PSDPs over the non-negative orthant (for \(\mathcal {K}_i^*\) being linearly isomorphic to a positive semi-definite cone for all i) and (iii) PSOCPs over the non-negative orthant (here we take \(\mathcal {K}_i^*\) to be linearly isomorphic to a second-order cone for all i). This will be discussed further in Sect. 4, where examples of such problems will also be looked at.
Note that polynomial equality constraints can be included through the cones \(\mathcal {K}_i=\mathbb {R}\), \(\mathcal {K}_i^*=\{0\}\). Also note that if we have a polynomial conic optimization problem, similar to the form (1), with a compact feasible set but without the sign constraint \(\mathbf {x}\in \mathbb {R}_+^n\), then through a change of coordinates we can move the feasible set into the non-negative orthant and can then add the (redundant) sign constraint (see Example 4.3). For the main results in this paper we need a compactness-like assumption (Assumption 2.2), therefore having \(\mathbf {x}\in \mathbb {R}_+^n\) explicitly in the problem is not very restrictive.
For ease of notation, throughout the paper we will let \(\mathcal {F}\) be the feasible set of (1), i.e.
We will make the following two assumptions about the problem (1):
Assumption 2.1
For all i we assume that \(\mathcal {K}_i\) has a nonempty interior.
Assumption 2.2
We assume that one of the constraints in the problem (1) is of the form \(R-\mathbf {a}^\mathsf {T}\mathbf {x}\in \mathbb {R}_+\), where \(\mathbf {a}\in \mathbb {R}^n\) is a vector with all entries being strictly positive.
These assumptions guarantee asymptotic convergence of the hierarchy of lower bounds introduced in the following section. Without these assumptions we would still have valid lower bounds, but we would not be able to guarantee their convergence.
The first assumption is equivalent to having \(\mathcal {K}_i^*\cap (-\mathcal {K}_i^*)=\{\varvec{0}\}\) for all i, see, e.g., [3, Theorem 2.3]. Within the conic optimization literature, this property is referred to as \(\mathcal {K}_i^*\) being pointed; however, we shall avoid this term due to the confusion with alternative meanings of the term pointed. If we have a cone \(\mathcal {K}_i^*\) such that \(\mathcal {K}_i^*\cap (-\mathcal {K}_i^*)\ne \{\varvec{0}\}\) then it is possible to project this constraint into a smaller subspace with the cone having the required property in this subspaceFootnote 1. We thus see that for simple cones Assumption 2.1 is relatively mild. However, it should be noted that for cones with a complicated definition it might be more difficult to ensure that this holds.
Also note that if the feasible set of problem (1) is bounded, then we can always add a redundant constraint to the problem of the form required in Assumption 2.2. This assumption holding means that provided \(\mathcal {F}\ne \emptyset \) then \(\mathcal {F}\) is compact and the optimal solution to problem (1) is obtained. Further discussion of these assumptions will be provided in Sect. 3.3.
3 Approximation
3.1 New hierarchy
For an optimization problem (P), we let \({{\,\mathrm{val}\,}}(P)\) denote its optimal value. From the definition of the infimum, we have that \({{\,\mathrm{val}\,}}\)(1) is equal to the optimal value of the following problem:
Letting \(D=\max _i\{d_i \mid i=0,\ldots ,p\}\) and \(\mathbf {e}\) be the all ones vector, we now introduce the following problems for \(r\in \mathbb {N}:=\{0,1,2,\ldots \}\):
The “\(\ge _c\)” means that we are comparing the coefficients of the polynomials, for example, \(a x_1^3 + bx_1x_2 \ge _c c x_1^3 + dx_2^2\) iff \(a\ge c\) and \(b\ge 0\) and \(0 \ge d\) (see also Example 3.1 below). This should not be confused with the NP-hard problem of checking whether one polynomial is greater than or equal to another for all \(\mathbf {x}\). It is, however, a simple sufficient condition for one polynomial being greater than or equal to another for all \(\mathbf {x}\in \mathbb {R}_+^n\). In Sect. 3.2 we will see that
and in Sect. 3.4 we will see that if Assumptions 2.1 and 2.2 hold then we have
Written out explicitly, the problem \(({4}_{r})\) is a linear conic optimization problem over the cones \(\mathcal {K}_i\). Therefore, if we can optimize over combinations of these cones then we can solve \(({4}_{r})\). The problem \(({4}_{r})\) is in fact a linear conic optimization problem with
-
\(\left( {\begin{array}{c}n+D-d_i+r\\ n\end{array}}\right) \) cone constraints of being in \(\mathcal {K}_i\), for \(i\in \{1,\ldots ,p\}\),
-
\(\left( {\begin{array}{c}n+D+r\\ n\end{array}}\right) \) inequality constraints,
-
\(1+\sum _{i=1}^p m_i \left( {\begin{array}{c}n+D-d_i+r\\ n\end{array}}\right) \) variables.
This compares favourably with other standard approximation hierarchies for polynomial optimization. One of the advantages of our new approach is that although as r increases, the number of cones we have to optimize over increases dramatically, the cones themselves remain the same. This is in contrast to the sum-of-squares approach for polynomial matrix problems, as will be discussed in Sect. 4.
Another advantage of our new approach is that we are not dependent on the form of \(\mathcal {K}_i\), we only require that it is a convex cone that we can optimize over. This increases the range of possible future applications.
Before discussing the theory behind this new approach, we will first consider an illustrative example. This example is purposely picked to be a simple example for which the convergence of our method is slow. In Sect. 4 we will consider more representative examples, which fully demonstrate the strength of our new method.
Example 3.1
Let us consider the following polynomial optimization problem:
Trivially, \(x=1\) is the only feasible point for this problem and thus the optimal value is equal to 1. This problem is in the form required with
The rth level of our new hierarchy is given by
We have
Therefore, the rth level of the hierarchy is equivalent to the following, where after the vertical line we show which monomial term this constraint corresponds to:

By first eliminating the \(\mathbf {y}\) variable, this problem can be solved analytically to give an optimal value of \(1-(1+2^{r+1})^{-1}\), which tends towards 1, the optimal value of the original problem, as r tends to infinity.
3.2 Monotonically increasing lower bounds
In this subsection we will prove the inequality relations from (5).
Proposition 3.2
We have \({{\,\mathrm{val}\,}}({4}_{r})\le {{\,\mathrm{val}\,}}\)(3)\(={{\,\mathrm{val}\,}}\)(1) for all \(r\in \mathbb {N}\).
Proof
From the definition of the infimum it is trivial to see that \({{\,\mathrm{val}\,}}\)(3)\(={{\,\mathrm{val}\,}}\)(1). It is also trivial to see that if \((\lambda ,\mathbf {y})\) is feasible for \(({4}_{r})\) then \(\lambda \) is feasible for (3). \(\square \)
Proposition 3.3
We have \({{\,\mathrm{val}\,}}({4}_{r})\le {{\,\mathrm{val}\,}}({4}_{r+1})\) for all \(r\in \mathbb {N}\).
Proof
We will show that if \((\lambda ,\mathbf {y})\in \mathbb {R}\times \left( \mathcal {K}_i^{\left| \{\varvec{\alpha }\in \mathbb {N}^n\mid \mathbf {e}^\mathsf {T}\varvec{\alpha }\le D-d_i+r\}\right| }\right) _{i\in \{1,\ldots ,p\}}\) is feasible for \(({4}_{r})\) then there exists \({\widetilde{\mathbf {y}}}\in \left( \mathcal {K}_i^{\left| \{\varvec{\alpha }\in \mathbb {N}^n\mid \mathbf {e}^\mathsf {T}\varvec{\alpha }\le D-d_i+r+1\}\right| }\right) _{i\in \{1,\ldots ,p\}}\) such that \((\lambda ,{\widetilde{\mathbf {y}}})\) is feasible for \(({4}_{r+1})\).
Such a \({\widetilde{\mathbf {y}}}\) is constructed by letting
where \(\mathbf {e}_j\in \mathbb {R}^n\) is the unit vector with the jth entry equal to one and all the other entries equal to zero, with membership of \(\mathcal {K}_i\) following from this being a convex cone.
This construction implies that
Having \((\lambda ,\mathbf {y})\) feasible for \(({4}_{r})\), and \((1+\mathbf {e}^\mathsf {T}\mathbf {x})\) with all the coefficients non-negative, this implies that
\(\square \)
3.3 Analysis of the assumptions
Before we look at the convergence of our new approximation hierarchy, we will first need to analyse the assumptions we made about problem (1). We will show that Assumptions 2.1 and 2.2 imply two properties, introduced below. The presence of these properties simplifies the workings in Sect. 3.4. We could have in fact assumed that these properties are held in place of Assumptions 2.1 and 2.2. This would have had the advantage of encapsulating a larger class of problems. However, we chose not to do this as these properties are somewhat more complicated than Assumptions 2.1 , 2.2.
Before defining these properties, we first need to introduce some new notation. For \(i\in \{1,\ldots ,p\}\) and \(\mathbf {w}\in \mathbb {R}^{m_i}\) we define the polynomial \(g_{i,\mathbf {w}}(\mathbf {x}):=_c \langle \mathbf {w}, \mathbf {g}_i(\mathbf {x}) \rangle \), and note that \({{\,\mathrm{deg}\,}}(g_{i,\mathbf {w}})\le d_i\). The first property is then as follows:
Proposition 3.4
For all \(i\in \{1,\ldots ,p\}\) there exists \(\varvec{\gamma }\in \mathcal {K}_i\) such that \({{\,\mathrm{deg}\,}}(g_{i,\varvec{\gamma }})=d_i\).
An intuitive justification for Property 3.4 is that it ensures that none of the highest-degree terms are trivially redundant. If Property 3.4 does not hold for some i then we can remove all the degree \(d_i\) terms from \(\mathbf {g}_i\) without affecting the feasible set \(\mathcal {F}\).
For \(i\in \{1,\ldots ,p\}\), we now let \(\widetilde{\mathbf {g}_i}(\mathbf {x})\) be the highest-order homogeneous part of \(\mathbf {g}_i(\mathbf {x})\), i.e., the homogeneous polynomial vector \(\mathbf {g}_i(\mathbf {x})\) with all the terms of degree strictly less than \(d_i\) removed (and similarly for \(\widetilde{f}\)). For example, if
We also let \({\widetilde{\mathcal {F}}}=\{\mathbf {x}\in \mathbb {R}_+^n \mid \widetilde{\mathbf {g}_i}(\mathbf {x})\in \mathcal {K}_i^*\text { for } i=1,\ldots ,p \}\). The second property is then as follows:
Proposition 3.5
We have \(\widetilde{f}(\mathbf {x})>0\) for all \(\mathbf {x}\in {\widetilde{\mathcal {F}}}\setminus \{\varvec{0}\}\).
An intuitive justification for Property 3.5 is that it ensures that the problem is well behaved at infinity.
From the following two results it immediately follows that Assumptions 2.1 and 2.2 imply Properties 3.4 and 3.5, respectively.
Proposition 3.6
For \(i\in \{1,\ldots ,p\}\) let \(\widehat{\mathcal {K}_i} = \{\mathbf {w}\in \mathcal {K}_i \mid {{\,\mathrm{deg}\,}}(g_{i,\mathbf {w}})=d_i \}\), where \(\mathcal {K}_i\subseteq \mathbb {R}^{m_i}\), \(g_{i,\mathbf {w}}\in \mathbb {R}[\mathbf {x}]\) and \(d_i\in {\mathbb {N}}\) are as given earlier in the paper. Now, consider the following statements:
-
i
\({{\,\mathrm{int}\,}}\mathcal {K}_i\ne \emptyset \);
-
ii
\(\widehat{\mathcal {K}_i}\ne \emptyset \);
-
iii
\(\widehat{\mathcal {K}_i}\) is a dense subset of \(\mathcal {K}_i\);
-
iv
\(\widehat{\mathcal {K}_i}^*=\mathcal {K}_i^*\).
We then have
Proof
We begin by noting that \({{\,\mathrm{deg}\,}}(g_{i,\mathbf {w}})\le d_i\) for all \(\mathbf {w}\in \mathbb {R}^{m_i}\) and \(\widehat{\mathcal {K}_i}\subseteq \mathcal {K}_i\). We split the remainder of the proof into the following parts:
- \((i)\Rightarrow (ii)\)::
-
Consider an arbitrary \(\mathbf {w}\in {{\,\mathrm{int}\,}}\mathcal {K}_i\). If \(\mathbf {w}\in \widehat{\mathcal {K}_i}\) then we are done, and from now on in this part of the proof we will assume that \(\mathbf {w}\notin \widehat{\mathcal {K}_i}\), i.e. \({{\,\mathrm{deg}\,}}(g_{i,\mathbf {w}})<d_i\).
There exists \(j\in \{1,\ldots ,m_i\}\) such that \(d_i={{\,\mathrm{deg}\,}}((\mathbf {g}_i(\mathbf {x}))_j)={{\,\mathrm{deg}\,}}(g_{i,\mathbf {e}_j})\), where \(\mathbf {e}_j\in \mathbb {R}^{m_i}\) is the unit vector with the jth entry equal to one and all the other entries equal to zero. For all \(\varepsilon \ne 0\) we then have \({{\,\mathrm{deg}\,}}(g_{i,\mathbf {w}+\varepsilon \mathbf {e}_j}) = {{\,\mathrm{deg}\,}}(g_{i,\mathbf {w}}+\varepsilon g_{i,\mathbf {e}_j}) = d_i.\) The proof of this part is then completed by noting that as \(\mathbf {w}\in {{\,\mathrm{int}\,}}\mathcal {K}_i\) there exists \(\varepsilon \ne 0\) such that \(\mathbf {w}+\varepsilon \mathbf {e}_j\in \mathcal {K}_i\).
- \((ii)\Rightarrow (iii)\)::
-
Suppose that \(\exists \varvec{\gamma }\in \widehat{\mathcal {K}_i}\) and consider an arbitrary \(\mathbf {w}\in \mathcal {K}_i\setminus \widehat{\mathcal {K}_i}\). Then \({{\,\mathrm{deg}\,}}(g_{i,\varvec{\gamma }})=d_i>{{\,\mathrm{deg}\,}}(g_{i,\mathbf {w}})\), and thus for all \(\varepsilon \ne 0\) we have
$$\begin{aligned} {{\,\mathrm{deg}\,}}(g_{i,\mathbf {w}+\varepsilon \varvec{\gamma }}) = {{\,\mathrm{deg}\,}}(g_{i,\mathbf {w}}+\varepsilon g_{i,\varvec{\gamma }}) = d_i. \end{aligned}$$The proof of this part is then completed by noting that as \(\mathcal {K}_i\) is a convex cone we have \(\mathbf {w}+\varepsilon \varvec{\gamma }\in \mathcal {K}_i\) for all \(\varepsilon >0\).
- \((ii)\Leftarrow (iii)\)::
-
This trivially follows from the fact that \(\mathcal {K}_i\ne \emptyset \).
- \((iii) \Rightarrow (iv)\)::
-
If \(\widehat{\mathcal {K}_i}\) is a dense subset of \(\mathcal {K}_i\) then \({{\,\mathrm{cl}\,}}\widehat{\mathcal {K}_i}={{\,\mathrm{cl}\,}}\mathcal {K}_i\) and from a well-known result for sets in Euclidean space we have \(\mathcal {K}_i^*= ({{\,\mathrm{cl}\,}}\mathcal {K}_i)^*= ({{\,\mathrm{cl}\,}}\widehat{\mathcal {K}_i})^*= \widehat{\mathcal {K}_i}^*\), e.g., [3, Theorem 2.1].
\(\square \)
Proposition 3.7
If Assumption 2.2 holds for the problem (1) then \({\widetilde{\mathcal {F}}}=\{\varvec{0}\}\).
Proof
First, note that \(\varvec{0}\in {\widetilde{\mathcal {F}}}\) follows from \(\widetilde{\mathbf {g}_i}(\mathbf {x})\) being homogeneous and \(\mathcal {K}_i^*\) being a nonempty closed cone for all i. We then complete the proof by noting that if Assumption 2.2 holds for the problem (1) then
\(\square \)
3.4 Asymptotic convergence
In this subsection we look at the theory behind how our new hierarchy converges. In Sect. 4 we will then look at some numerical examples to see how it performs in practice.
In order to prove the convergence we need to begin by considering the following Positivstellensatz:
Theorem 3.8
[8, Theorems 2.4 and 4.1] Consider the homogeneous polynomials \(f_i:\mathbb {R}^{n+1}\rightarrow \mathbb {R}\) for \(i\in \{0\}\cup \mathcal {I}\) such that \(f_0(\mathbf {x})>0\) for all \(\mathbf {x}\in \mathbb {R}_+^{n+1}\setminus \{\varvec{0}\}:\, f_i(\mathbf {x})\ge 0 \,\forall i\in \mathcal {I}\). Then for some \(R\in \mathbb {N}{}\) there exists a subset \(\mathcal {J}\subseteq \mathcal {I}\) of finite cardinality and homogeneous polynomials \(q_j:\mathbb {R}^{n+1}\rightarrow \mathbb {R}\) for \(j\in \mathcal {J}\), with all of their coefficients non-negative and \({{\,\mathrm{deg}\,}}(q_j)+{{\,\mathrm{deg}\,}}(f_j)=R+{{\,\mathrm{deg}\,}}(f_0)\), such that \((\mathbf {e}^\mathsf {T}\mathbf {x})^R f_0(\mathbf {x}) \ge _c \sum _{j\in \mathcal {J}} f_j(\mathbf {x})q_j(\mathbf {x})\).
The restriction on the degrees was not in the original theorems, but can be added as all of the polynomials are homogeneous. There are no limitations on the set \(\mathcal {I}\), it could in fact index uncountably many polynomials \(f_i\).
Before we can use this Positivstellensatz, we first need to adapt it to apply for nonhomogeneous polynomials. In order to do this we use the notation from Property 3.5, i.e., \(\widetilde{g}(\mathbf {x})\) is the polynomial \(g(\mathbf {x})\) with all terms of degree strictly less than \({{\,\mathrm{deg}\,}}(g)\) removed. We then obtain the following Positivstellensatz:
Theorem 3.9
Consider polynomials \(f_i:\mathbb {R}^n\rightarrow \mathbb {R}\) for \(i\in \{0\}\cup \mathcal {I}\) such that
-
i
\(f_0(\mathbf {x})>0\) for all \(\mathbf {x}\in \mathbb {R}_+^n:\, f_i(\mathbf {x})\ge 0 \,\forall i\in \mathcal {I}\), and
-
ii
\(\widetilde{f_0}(\mathbf {x})>0\) for all \(\mathbf {x}\in \mathbb {R}_+^n\setminus \{\varvec{0}\}:\, \widetilde{f_i}(\mathbf {x})\ge 0 \,\forall i\in \mathcal {I}\).
Then for some \(R\in \mathbb {N}{}\) there exists a subset \(\mathcal {J}\subseteq \mathcal {I}\) of finite cardinality and polynomials \(q_j:\mathbb {R}^n\rightarrow \mathbb {R}\) for \(j\in \mathcal {J}\), with all of their coefficients non-negative and \({{\,\mathrm{deg}\,}}(q_j)+{{\,\mathrm{deg}\,}}(f_j)\le R+{{\,\mathrm{deg}\,}}(f_0)\), such that \((1+\mathbf {e}^\mathsf {T}\mathbf {x})^R f_0(\mathbf {x}) \ge _c \sum _{j\in \mathcal {J}} f_j(\mathbf {x})q_j(\mathbf {x})\).
Proof
For a polynomial \(g:\mathbb {R}^n\rightarrow \mathbb {R}\) of degree d, we define \(g^H(\mathbf {x},x_{n+1}):\mathbb {R}^{n+1}\rightarrow \mathbb {R}\) to be the unique homogeneous polynomial of degree d such that \(g(\mathbf {x})=g^H(\mathbf {x},1)\). We then have \(\widetilde{g}(\mathbf {x})=g^H(\mathbf {x},0)\), e.g., for \(g(x_1,x_2)=x_1x_2^2+x_1\) we have
Using this notation, for \(f_0\) given in the theorem we have
-
i
\(f_0^H(\mathbf {x},1)>0\) for all \(\mathbf {x}\in \mathbb {R}_+^n:\, f_i^H(\mathbf {x},1)\ge 0 \,\forall i\in \mathcal {I}\), and
-
ii
\(f_0^H(\mathbf {x},0)>0\) for all \(\mathbf {x}\in \mathbb {R}_+^n\setminus \{\varvec{0}\}:\, f_i^H(\mathbf {x},0)\ge 0 \,\forall i\in \mathcal {I}\).
As all the polynomials are homogeneous, this is equivalent to
From Theorem 3.8 we find that for some \(R\in \mathbb {N}{}\) there exists a subset \(\mathcal {J}\subseteq \mathcal {I}\) of finite cardinality and homogeneous polynomials \(q_j:(\mathbb {R}^n\times \mathbb {R})\rightarrow \mathbb {R}\) for \(j\in \mathcal {J}\), with all of their coefficients non-negative and \({{\,\mathrm{deg}\,}}(q_j)+{{\,\mathrm{deg}\,}}(f_j)=R+{{\,\mathrm{deg}\,}}(f_0)\), such that \((\mathbf {e}^\mathsf {T}\mathbf {x}+x_{n+1})^R f_0^H(\mathbf {x},x_{n+1}) \ge _c \sum _{j\in \mathcal {J}} f_j^H(\mathbf {x},x_{n+1})q_j(\mathbf {x},x_{n+1})\). Letting \(x_{n+1}=1\), we then obtain the required result. \(\square \)
We are now ready to apply this result for our case:
Theorem 3.10
Let \(\mathcal {F}\) be as given in (2) with Properties 3.4 and 3.5 holding, and consider a polynomial f of degree \(d_0\) and \(\lambda \in \mathbb {R}\) such that \(f(\mathbf {x})-\lambda >0\) for all \(\mathbf {x}\in \mathcal {F}\). Then there exists \(r\in \mathbb {N}\) and \(\mathbf {y}_{i,\varvec{\alpha }}\in \mathcal {K}_i\) for \(i=1,\ldots ,p\), \(\varvec{\alpha }\in \mathbb {N}^n: \mathbf {e}^\mathsf {T}\varvec{\alpha }\le D-d_i+r\) such that
Proof
In order to apply Theorem 3.9 we let \(f_0(\mathbf {x})=f(\mathbf {x})-\lambda \) and \(f_i\in \mathbb {R}[\mathbf {x}]\) for i in some set \(\mathcal {I}\) be such that
where \(\widehat{\mathcal {K}_i}\) is as given in Proposition 3.6 and recall from this proposition that Property 3.4 implies that \(\widehat{\mathcal {K}_i}^*=\mathcal {K}_i^*\). We then have
This, in addition to Property 3.5 holding, implies that the requirements of \(f_0\) for Theorem 3.9 hold, and thus for some \(R\in \mathbb {N}\) there exists a finite set
and polynomials \(q_{i,\mathbf {w}}:\mathbb {R}^n\rightarrow \mathbb {R}\) for \((i,\mathbf {w})\in \mathcal {J}\), with non-negative coefficients and \({{\,\mathrm{deg}\,}}(q_{i,\mathbf {w}})+d_i\le R+d_0\), such that
We can write \(q_{i,\mathbf {w}}\) in the form
where \(q_{i,\mathbf {w},\varvec{\alpha }}\) are non-negative scalars for all \(i,\mathbf {w},\varvec{\alpha }\). Using this notation we have
Now letting \(r=\max \{0,R+d_0-D\}\) and considering Proposition 3.3 we obtain the required result. \(\square \)
Remark 3.11
Suppose that the polynomial f and the polynomial vectors \(\mathbf {g}_i\) are in fact homogeneous, i.e., \((\mathbf {g}_i(\mathbf {x}))_j\) is a homogeneous polynomial of degree \(d_i\) for all \(j=1,\ldots ,m_i\). Then from Theorem 3.8 (using the techniques from Theorem 3.10), we find that if \(f(\mathbf {x})>0\) for all \(\mathbf {x}\in \mathcal {F}\setminus \{\varvec{0}\}\), then there exist \(r\in \mathbb {N}\) and \(\mathbf {y}_{i,\varvec{\alpha }}\in \mathcal {K}_i\) for \(i=1,\ldots ,p\), \(\varvec{\alpha }\in \mathbb {N}:\mathbf {e}^\mathsf {T}\varvec{\alpha }= D-d_i+r\) such that
3.5 Enhancing the convergence
The main characteristic of our hierarchy, the conic linearity, has an affect on the tightness of the bounds it provides. The bounds improve if we increase r, but sometimes we would like to improve these bounds already for the beginning members of the hierarchy. One way to make such improvements and stay tractable is to add to the original problem the redundant constraint
and then apply our hierarchy, where \(\mathcal {PSD}^{n+1}\) denotes the set of positive semi-definite matrices of the order \(n+1\). This gives us (extra) positive semi-definite variables in the hierarchy, but these positive semi-definite variables would be limited to having the order \(n+1\), unlike in the classic SOS approach, where the order of the positive semi-definite constraints quickly grows to an intractable level. This approach is closely related to that taken by Peña, Vera and Zuluaga [39], which has been demonstrated to be very effective, and it was its effectiveness in this paper that provided the inspiration for us to consider it. It is also aligned with a recent hierarchy of Lasserre et al. [24], where each member of the hierarchy is an SDP with a bounded size and some linear constraints. Considered on the dual side, this approach is closely related to considering truncated moment matrices, but with subtle differences caused by the multiplication with \(\mathbf {x}^{\varvec{\alpha }}\) [see problem (12)].
We tested this approach on several examples in Sect. 4, and the numerical results show that it improves the bounds significantly.
Another approach to improve our hierarchy would be to add optimality conditions to the original problem, similar to was previously done for Lasserre’s hierarchy [6, 34, 37]. If the cones \(\mathcal {K}_i^*\) from (1) are semi-algebraic, then we can write out the polynomial inequalities for the cones explicitly, and then apply the SOS or linear optimization approach from this subsection. However, this could result in a lot of terms with a very high degree, and thus large semi-definite or linear optimization instances. We have not tested this approach.
3.6 Further discussion on convergence
One advantage of the moment and sums-of-squares-based hierarchies is the occurrence of a finite convergence [11, 12, 25, 35]. Recently Nie has provided in [33, 36] an extensive and clear study of the convergence of Lasserre’s hierarchy. He showed that under some generic assumptions, the so-called flat truncation is a necessary and sufficient condition for finite convergence. A similar property also holds for non-commutative polynomials [4, 17].
We do not yet have results of this type for our hierarchy - neither for the original nor for the enhanced version. Actually, we hope that this paper will motivate other researchers to pursue this direction.
We know that for our new hierarchy (without enhancement) we would not generally expect to get finite convergence, and in Example 3.1 we saw an example with an asymptotic but not finite convergenceFootnote 2. If \(\mathcal {K}_1,\ldots ,\mathcal {K}_m\) are all polyhedral cones, then the optimization problems in our hierarchy would all be linear ones and thus we cannot expect them to encapsulate the nonlinearity in the problem. However, after adding (8) the resulting hierarchy converges in practice much better and we believe a variant of Nie’s results can be obtained.
While the convergence results for Lasserre’s hierarchy are beautiful results, they are limited by the fact that in practice the finite convergence can be at a level of the hierarchy that is intractable. The main advantage of our new hierarchy is that much higher levels of the hierarchy remain tractable, as will be seen in Sect. 4.
4 Applications of the new hierarchy
In this section we will consider generalized classes of polynomial conic optimization problems from the literature, and consider how the application of our new approach to these problems compares with previous approaches. In particular we consider:
-
POP over the non-negative orthant, where we found that our hierarchy in its standard form performs poorly compared to state-of-the-art methods, but performs comparatively well when we added the redundant SDP constraint (8) to the original problem before applying our hierarchy.
-
PSDP over the non-negative orthant, where we found that our hierarchy (in its standard form) performs comparatively well in comparison to state-of-the-art methods, and performs even better when adding the redundant SDP constraint (8) to the original problem.
-
PSOCP over the non-negative orthant, where we found that our hierarchy outperforms state-of-the-art methods in its standard form.
For all the examples in this section, for ease of implementation we used YALMIP [28] within MATLAB [29], which can handle polynomials directly. This converted the optimization problems from our hierarchy (and state-of-the-art hierarchies) into LP, SOC and SDP optimization problems, which were then in almost all cases solved by SeDuMi [52]. We also used MOSEK [31] to compute the values for (11) in Table 2 and the SOS bounds in Table 9.
Although using YALMIP made the implementations easier, it meant that most of the computation times were spent in constructing the problems, rather than in solving them. These total computation times can be reduced through better, more direct implementations, and thus are not representative measures of the performance. For this reason no computation times have been included. Instead, we consider whether the optimization problems can be solved, or if there are memory problems, along with comparing the size of these problems.
All the computations were carried out on a laptop with two 2.30-GHz CPU cores and 4.0 GB of RAM. The code for these examples is available from the authors on request.
4.1 Constrained polynomial optimization over the non-negative orthant
In this subsection we will apply our method to POPs over the non-negative orthant. We will see that our method performs poorly in comparison to the classic SOS approach. If, however, we add the constraint (8) to the original problem before applying our method then the performance is drastically improved, even occasionally outperforming the classic SOS approach. We are, however, of the opinion that the classic SOS approach is currently still superior to our new method for these problems and instead this subsection should be thought of as an illustration of how our new method works, in preparation for the subsequent subsections where we apply our (enhanced) method to the more complicated cases of PSDPs and PSOCPs.
A polynomial \(f:\mathbb {R}^n\rightarrow \mathbb {R}\) is defined to be a sum-of-squares (SOS) polynomial if there exists a polynomial vector \(\mathbf {h}:\mathbb {R}^n\rightarrow \mathbb {R}^q\) such that \(f(\mathbf {x})=_c \mathbf {h}(\mathbf {x})^\mathsf {T}\mathbf {h}(\mathbf {x})=_c \sum _{i=1}^q h_i(\mathbf {x})^2\), and we then trivially have that \(f(\mathbf {x})\ge 0\) for all \(\mathbf {x}\in \mathbb {R}^n\).
Letting \(\mathbf {v}_{d}(\mathbf {x}):\mathbb {R}^n\rightarrow \mathbb {R}^{\left( {\begin{array}{c}n+d\\ n\end{array}}\right) }\) be such that \(\mathbf {v}_{d}(\mathbf {x})=_c (\mathbf {x}^{\varvec{\alpha }})_{\varvec{\alpha }\in \mathbb {N},\; \mathbf {e}^\mathsf {T}\varvec{\alpha }\le d}\), it is well known that a polynomial \(f:\mathbb {R}^n\rightarrow \mathbb {R}\) of degree at most 2d is SOS if and only if there exists an order \(\left( {\begin{array}{c}n+d\\ n\end{array}}\right) \) positive semi-definite matrix A, denoted \(A\in \mathcal {PSD}^{\left( {\begin{array}{c}n+d\\ n\end{array}}\right) }\), such that \(f(\mathbf {x})=_c \mathbf {v}_{d}(\mathbf {x})^\mathsf {T}A \mathbf {v}_{d}(\mathbf {x})\), and there is a linear relationship between the elements of A and the coefficients of f. This allows us to optimize over the set of SOS polynomials using positive semi-definite optimization [22, 26].
Let us consider a constrained polynomial optimization problem over the non-negative orthant:
Note that this is a special instance of (1) with \(\mathcal {K}_i^*=\mathbb {R}_+\) for all i.
If the sign constraints \(x_i\ge 0\) are considered as the usual polynomial inequalities then (9) is a special instance of a classic constrained polynomial optimization problem, formulated in [22, problem (5.2)].
Due to the hardness of (9), several approximation hierarchies are proposed in the literature. Probably one of the most well-known and tight is the SOS hierarchy, which consists of the following approximation problems (for each \(r\in \mathbb {N}\)):
In practice this method provides very good approximations. If we know some constant N such that the feasible set for (9) is contained in the Euclidean ball centred at the origin with the radius N (note that this is essentially our Assumption 2.2) then we can add this ball constraint to the problem (9) and then the solutions of the dual problems (10) converge to the optimal value of (9), when \(r\rightarrow \infty \) (see [21, Theorem 4.2], [22, Theorem 5.6]). However, as r (and/or D) increase, the hierarchy members contain increasingly larger positive semi-definite constraints that are more and more difficult to handle. The problem from the hierarchy corresponding to fixed r has:
-
One positive semi-definite constraint of the order \(\left( {\begin{array}{c}n+\lfloor \tfrac{1}{2}(D+r) \rfloor \\ n\end{array}}\right) \),
-
n positive semi-definite constraints of the order \(\left( {\begin{array}{c}n+\lfloor \tfrac{1}{2}(D+r-1) \rfloor \\ n\end{array}}\right) \),
-
a positive semi-definite constraint of the order \(\left( {\begin{array}{c}n+\lfloor \tfrac{1}{2}(D+r-d_i) \rfloor \\ n\end{array}}\right) \) for each \(i\in \{1,\ldots ,p\}\),
-
\(\left( {\begin{array}{c}n+D+r\\ n\end{array}}\right) \) equality constraints,
-
\(1+\tfrac{1}{2} \left( {\begin{array}{c}n+\lfloor \tfrac{1}{2}(D+r) \rfloor \\ n\end{array}}\right) \left[ \left( {\begin{array}{c}n+\lfloor \tfrac{1}{2}(D+r) \rfloor \\ n\end{array}}\right) +1\right] +\tfrac{1}{2}n \left( {\begin{array}{c}n+\lfloor \tfrac{1}{2}(D+r-1) \rfloor \\ n\end{array}}\right) \left[ \left( {\begin{array}{c}n{+}\lfloor \tfrac{1}{2}(D+r-1) \rfloor \\ n\end{array}}\right) {+}1\right] + +\sum _{i=1}^p\tfrac{1}{2} \left( {\begin{array}{c}n+\lfloor \tfrac{1}{2}(D+r-d_i) \rfloor \\ n\end{array}}\right) \left[ \left( {\begin{array}{c}n+\lfloor \tfrac{1}{2}(D+r-d_i) \rfloor \\ n\end{array}}\right) +1\right] \) variables.
Our hierarchy from Sect. 3 applied to (9) can be simplified to
This hierarchy is usually weaker, but on the other hand contains problems that are easier to solve. It contains
-
\(\left( {\begin{array}{c}n+D+r\\ n\end{array}}\right) +\sum _{i=1}^p \left( {\begin{array}{c}n+D-d_i+r\\ n\end{array}}\right) \) inequality constraints,
-
\(1+\sum _{i=1}^p \left( {\begin{array}{c}n+D-d_i+r\\ n\end{array}}\right) \) variables.
By adding the redundant PSD constraint (8) to the original problem and then applying our hierarchy to give the following problem adds additional \(\left( {\begin{array}{c}n+D+r-2\\ n\end{array}}\right) \) PSD constraints of the order \(n+1\) and an additional \(\tfrac{1}{2}\left[ \left( {\begin{array}{c}n+D+r-2\\ n\end{array}}\right) \right] \left[ \left( {\begin{array}{c}n+D+r-2\\ n\end{array}}\right) +1\right] \) variables:
Remark 4.1
Suppose we have \(d_0=d_1=\cdots =d_p=2\). For \(r=0\) the SOS relaxation (10) is equivalent to the enhanced relaxation (12), since every feasible solution for the first problem yields a feasible solution with the same objective value for the second problem and vice versa.
In Table 1 we consider the explicit problem sizes that this would give for an instance with \(r=4~,n=d_0=8,~p=d_1=d_2=2\). As we see, the SOS problem, (10), is on the boundary or even beyond the reach of state-of-the-art SDP solvers that are based on the interior point methods, but are still solvable with some other SDP solvers, like SDPNAL [57], while our new LP approximation (11) is solvable with most LP solvers. The new SDP hierarchy (12) contains a lot of SDP variables of small size and is solvable with SDP solvers that enable parallelization, see ,e.g., [51, 56].
Example 4.2
In the paper [24], in particular instances C4_2, C4_4, C4_6, C6_2, C6_4, C6_6, C8_2, C8_4, C10_4, C20_2, the authors considered some polynomial optimization problems of the form (9) such that for all feasible points of this problem and all \(i\in \{1,\ldots ,m\}\) we have \(g_i(\mathbf {x})\le 1\).Footnote 3 For these problems the authors compared the standard SOS approach, a bounded SOS approach [23] and an LP approach based on Krivine-Stengle’s Positivstellensatz to compute the lower bounds on these problems.
For these instances we computed the lower bounds provided by our new LP hierarchy, (11), and SDP hierarchy, (12). The new LP hierarchy was computed for all r for which we did not get “out of memory” warnings, while the new SDP hierarchy was computed for \(r=1\). The results for this are in Table 2.
As we can see, our new LP approximation, (11), does not perform very well in comparison to the other methods, but our new SDP approximation, (12), does perform extremely well, always giving the tightest lower bound of all the approximations in the instances considered. It is even strictly better than all of the other bounds for instances C4_6 and C6_6.
In order to compare the sizes of these problems, in Table 3 we consider the size of the hierarchies for the case C6_6. For \(r=1\) we see that not only does our new SDP hierarchy, (12), provide a better lower bound than the (bounded) SOS approach, but the size of the problem, in terms of the order of the largest PSD constraints, is also significantly smaller.
4.2 Polynomial semi-definite optimization over the non-negative orthant
In this subsection we will apply our method to PSDPs over the non-negative orthant. We will see that our method performs very well on these problems, especially after adding the redundant constraint (8) to the original problem, but the method does not suffer as severely from memory problems as the classic SOS approach.
In [13,14,15, 19] the authors considered PSDPs, and how the SOS approach could be extended for positive semi-definite constraints using the concept of matrix SOS.
Let us consider a (scalar) polynomial f and the matrix polynomials \(G_i:\mathbb {R}^n\rightarrow \mathcal {S}^{m_i}\) (i.e., (\((G_i)_{k\ell }=(G_i)_{\ell k}\) is a polynomial for all \(k,\ell =1,\ldots ,m_i\)). We define
Following [13, 14] we define a PSDP over the non-negative orthant as
This is again a very hard problem, so tractable relaxations are very desirable. The standard SOS approach to (13) is based on using matrix SOS constraints.
A polynomial matrix \(G:\mathbb {R}^n\rightarrow \mathcal {S}^{m}\) is matrix SOS if there exists a matrix polynomial \(H:\mathbb {R}^n\rightarrow \mathbb {R}^{q\times m}\) such that \(G(\mathbf {x})=_c H(\mathbf {x})^\mathsf {T}H(\mathbf {x})\), and we then trivially have that \(G(\mathbf {x})\in \mathcal {PSD}^{m}\) for all \(\mathbf {x}\in \mathbb {R}^n\). Similar to the standard SOS case (see, e.g., [14, 19]), we have that \(G(\mathbf {x}):\mathbb {R}^n\rightarrow \mathcal {S}^{m}\) is a matrix SOS of degree at most 2d if and only if there exists \(A\in \mathcal {PSD}^{m \left( {\begin{array}{c}n+d\\ n\end{array}}\right) }\) such that
where “\(\otimes \)” denotes the Kronecker product and \(I_m\) denotes the identity matrix of the order m. Also, similar to before, there is a linear relationship between the elements of A and the coefficients of the elements of \(G(\mathbf {x})\), and thus we can optimize over the set of matrix SOS polynomials using positive semi-definite optimization. We can also construct the SOS relaxation hierarchy for (13) for each \(r\in \mathbb {N}\) [13, 14]:
where \(D=\max \{d_i:i=0,1,\ldots ,p\}\). Under some conditions related to the compactness of the feasibility set for (13), the optimal values of this hierarchy converge to the optimal value of (13) [13, Theorem 2.2].
Similar to before, the order of the PSD constraints in this problem grows very quickly with r. In fact for each \(i\in \{1,\ldots ,p\}\), the SOS constraint for \(A_i(\mathbf {x})\) is equivalent to a PSD constraint of the order \(m_i\left( {\begin{array}{c}n+\lfloor (D+r-d_i)/2\rfloor \\ n\end{array}}\right) \).
Alternatively, by taking \(\mathcal {K}_i = \mathcal {PSD}^{m_i} = \mathcal {K}_i^*\) for all i, we can apply our hierarchy from Sect. 3 to problem (13), both with and without the additional PSD constraint (8) in the original problem, to give the following problems, respectively:
Here, in comparison to the matrix SOS approach, we have many more SDP constraints, but the order of the positive semi-definite constraints is fixed.
In Table 4 we consider the sizes of these approximation problems for \(r=4\) with \(n=8\) variables and \(p=5\) matrix SDP constraints of the order 10 with degrees \(d_0=4\) and \(d_i=2,~i=1,\ldots ,5\).
The difference is significant. While the Matrix SOS problem is already out of reach for most of the SDP solvers, our new hierarchies are manageable by at least those SDP solvers that can explore parallelization, like [51, 56].
Example 4.3
Let us consider the example from [13, Sect. II E]:
This has the optimal solutions (0, 2) and \((0,-2)\) with the optimal value \(-4\).
As reported in [13, Table II], the SOS approximation hierarchy (14) applied to this problem reduces for \(r=0\) to semi-definite optimization problems with 2 PSD constraints of the orders 3 and 2, giving an optimal value of \(-4\), which is already the optimal value of the original problem.
We can transform the semi-definite constraint from (17) into two (scalar) polynomial constraints and apply the approach from Sect. 4.1. However, in [13, Table I] it is reported that only the 7th member of the hierarchy (10) yields the optimal value of \(-4\). This member of the hierarchy has 3 PSD constraints of the orders 36, 28 and 21.
To apply our hierarchy to this problem, we first need to translate its feasible set into the non-negative orthant. To do this we substitute \(x_1\) by \(x_1-2\) and \(x_2\) by \(x_2-2\) to give the following problem.
Note that the semi-definite constraint implies that \(4-(x_1-2)^2-(x_2-2)^2\ge 0\); therefore, \(x_1,x_2\ge 0\), i.e., after the substitution the sign constraint is redundant and we can add it without affecting the feasible region.
Our hierarchy (15) for this problem reduces for \(r=1\) to
The optimal value for this is also equal to \(-4\), i.e., the member of the hierarchy corresponding to \(r=1\) is already giving the optimal value of the original problem. Note that the problem from our hierarchy has only 3 PSD constraints, all being of the order 2.
Example 4.4
Let us consider the following family of PSDPs:
where
It is shown in Appendix A that for the problem (18) we have:
-
The optimal value is equal to \(n-1\);
-
The matrix SOS hierarchy, (14), for \(r\in \{0,1\}\) has an optimal value of zero;
-
Our new hierarchy, (15), for \(r\in \{0,1\}\) has an optimal value of zero;
-
Our new hierarchy, (16), for \(r=0\) has an optimal value of zero.
In Table 5 we report on the numerical results for higher levels of these hierarchies, and in Table 6 we compare how large these problems are for \(n=21\). From these results we see that, in terms of optimal values, our new hierarchies perform very competitively in comparison with the matrix SOS approach. Moreover, in Table 6, we see that the sizes of our hierarchies, in terms of the order of the largest PSD constraint, are much smaller than the matrix SOS approach. We also see that adding the redundant constraint (8) to the original problem before applying our hierarchy to give the problem (16), significantly improves the lower bound in comparison to the problem (15).
4.3 Polynomial second-order cone optimization over the non-negative orthant
In this subsection we will apply our method to PSOCPs over the non-negative orthant. We will see that our method performs very well on these problems, especially after adding the redundant constraint (8) to the original problem, convincingly outperforming the classic SOS approach.
Suppose that the cones \(\mathcal {K}_i^*\) in (1) are the second-order cones (SOC):
Note that \((z_1,\mathbf {z})\in \mathbb {R}\times \mathbb {R}^{m_i-1}\) belongs to \(\mathcal {SOC}^{m_i}\) iff \(z_1\ge 0\) and \(z_1^2-\sum _{i=2}^{m_i}z_i^2\ge 0\).
For \(\mathbf {g}:\mathbb {R}^n\rightarrow \mathbb {R}^{m_i}\) being a polynomial vector of degree d, we call \(\mathbf {g}(\mathbf {x})\in \mathcal {SOC}^{m_i}\) a polynomial second-order cone constraint (PSOC). It can be transformed into two polynomial inequalities, one of the order d and one of the order 2d. Therefore, we can handle PSOCPs as classic polynomial optimization problems and use approaches from Sect. 4.1.
Since SOCs are tractable, i.e., we can solve linear conic optimization problems over these cones numerically efficiently, it is a natural idea to approximate PSOCPs also using the new hierarchy from Sect. 3 directly. We demonstrate this with the following two examples.
Example 4.5
Let us consider the following simple PSOC optimization problem:
Its minimum, obtained by Mathematica [54], is attained at \(\mathbf {x}^*=(1.6180, 0)^\mathsf {T}\) and is equal to 2.6180. Our hierarchy reduces for fixed r to
The optimal values of (20) for \(r\in \{0,\ldots ,5\}\) are reported in the second row of Table 7.
We can replace the PSOC constraint \(\mathbf {g}(\mathbf {x})\in \mathcal {SOC}^{3}\) by two equivalent polynomial constraints:
and apply the SOS hierarchy (10). The lower bounds provided by the SOS hierarchy are shown in the fourth row of Table 7. We can see that in this example our hierarchy outperforms the SOS hierarchy. This is especially apparent when we consider the sizes of the problems in Table 8. We also consider adding the redundant PSD constraint (8) to the original problem and then applying our hierarchy, and when doing this the \(r=1\) member of the hierarchy gives the exact optimal value (within numerical errors) using a very small optimisation problem, as is also shown in Tables 7 and 8.
Example 4.6
We have also evaluated our hierarchy on seven randomly generated polynomial second-order cone-optimization problems in three variables. Each such problem has two polynomial SOC constraints of degree two and dimension four. More precisely, for \(i=1,2\) we generated polynomials \(g^i_1(\mathbf {x}),\ldots ,g^i_4(\mathbf {x})\), which have all possible monomials in three variables of the degree two with coefficients generated randomly from \([-0.3,\,0.7]\) following the uniform distribution. We then replaced \(g^i_1\) with \({\tilde{g}}^i_1 = \sum _{k=1}^4g^i_k\) and set the PSOC \(\mathbf {g}^i=(\tilde{g}^i_1,g^i_2,g^i_3,g^i_4)^\mathsf {T}\in \mathcal {SOC}^{4}\). When we have generated both PSOCs, we set the objective function \(f(\mathbf {x}) = \tilde{g}^1_1(\mathbf {x})+\tilde{g}^2_1(\mathbf {x})+h(\mathbf {x})\), where h is polynomials of the degree two with random uniform coefficients from \([-0.5,\,0.5]\).
For each random polynomial second-order cone optimization problem we computed the optimum value using Mathematica [54] and the optimal values of the first three members of our hierarchy (with and without adding the additional SDP constraint (8) to the original problem) and of the standard SOS hierarchy. Recall that the SOS hierarchy is applied after reformulating each polynomial SOC constraint into two polynomial inequalities, as described at the beginning of this subsection. The results are in Table 9.
As we can see, for these examples our new hierarchy [without (8)] provides better bounds through solving smaller optimization problems in comparison to the standard SOS method. If we add (8) to the original problem, then the hierarchy is even better.
5 Conclusion
In this paper we considered polynomial conic optimization over the non-negative orthant. We proposed a hierarchy of relaxations that are in the form of conic linear optimization problems. We demonstrated that when the feasible set is contained in the non-negative orthant we can successfully apply the proposed hierarchy to constrained polynomial optimization problems (POPs), polynomial semi-definite optimization problems (PSDPs) and polynomial second-order cone-optimization problems (PSOCPs). We proved that the hierarchy is monotonic and gives bounds that converge asymptotically to the optimum value of the original problem, if some classic assumptions are satisfied. Through the addition of a redundant PSD constraint in the original problem, the proposed hierarchy performs reasonably well for POPs, in comparison to the classic SOS approach, and outperforms the classic SOS approach for PSDPs and PSOCPs, while also being cheaper to compute. The preliminary numerical evaluation confirms that this hierarchy deserves a deeper theoretical/numerical study and efficient code development. In particular, it would be of interest to consider the dual problems of our hierarchy, investigating whether similar results to that for the SOS/moment hierarchies hold with regards to the flat extension conditions [5], flat truncations [33] and extracting optimal solutions [12, Sect. 2].
Notes
Considering the linear space \(\mathcal {L}_i=\mathcal {K}_i^*\cap (-\mathcal {K}_i^*)=\mathcal {K}_i^\perp \), we have that \(\mathcal {L}_i^\perp \cap \mathcal {K}_i^*=(\mathcal {L}_i+\mathcal {K}_i)^*\) is a closed convex cone with \((\mathcal {L}_i^\perp \cap \mathcal {K}_i^*)\cap (-(\mathcal {L}_i^\perp \cap \mathcal {K}_i^*))=\{\varvec{0}\}\) and \(\mathbf {g}\in \mathcal {K}_i^*\Leftrightarrow \mathrm {Proj}_{\mathcal {L}_i^\perp }(\mathbf {g})\in \mathcal {L}_i^\perp \cap \mathcal {K}_i^*\).
This example does not in fact satisfy Assumption 2.2, but we can add the extra redundant constraint “\(3-2x\in \mathbb {R}_+\)” to the original problem to satisfy this assumption without changing the optimal values in our hierarchy.
Note that for compact optimization problems we can always normalize the constraints so that this inequality holds; however, doing this involves computing a good upper bound of \(g_i\) on the feasibility set, which is itself a demanding task.
References
Ahmadi, A. A., Majumdar, A.: DSOS and SDSOS optimization: LP and SOCP-based alternatives to sum of squares optimization. In: 2014 48th Annual Conference on Information Sciences and Systems (CISS), IEEE, pp. 1–5. Princeton, NJ (2014)
Ahmadi, A.A., Majumdar, A.: Some applications of polynomial optimization in operations research and real-time decision making. Optim. Lett. 10(4), 709–729 (2016)
Berman, A.: Cones, Matrices and Mathematical Programming. Lecture Notes in Economics and Mathematical Systems, vol. 79. Springer (1973)
Burgdorf, S., Klep, I., Povh, J.: Optimization of Polynomials in Non-commuting Variables. Springer, Berlin (2016)
Curto, R.E., Fialkow, L.A.: Truncated k-moment problems in several variables. J. Oper. Theory 54, 189–226 (2005)
Demmel, J., Nie, J., Powers, V.: Representations of positive polynomials on noncompact semialgebraic sets via KKT ideals. J. Pure Appl. Algebra 209(1), 189–200 (2007)
Dickinson, P.J.C.: The Copositive Cone, the Completely Positive Cone and their Generalisations. Ph.D. thesis, University of Groningen, Groningen, The Netherlands (2013)
Dickinson, P.J.C., Povh, J.: On an extension of Pólya’s Positivstellensatz. J. Glob. Optim. 61(4), 615–625 (2015)
Goemans, M.X., Williamson, D.P.: Improved approximation algorithms for maximum cut and satisfiability problems using semidefinite programming. J. Assoc. Comput. Mach. 42(6), 1115–1145 (1995)
Henrion, D., Garulli, A.: Positive Polynomials in Control, vol. 312. Springer, Berlin (2005)
Henrion, D., Lasserre, J.-B.: Gloptipoly: global optimization over polynomials with matlab and sedumi. ACM Trans. Math. Softw. 29(2), 165–194 (2003)
Henrion, D., Lasserre, J.-B.: Detecting Global Optimality and Extracting Solutions in GloptiPoly. Lecture Notes in Control and Information Science, vol. 312, pp. 293–310. Springer, Berlin (2005)
Henrion, D., Lasserre, J.-B.: Convergent relaxations of polynomial matrix inequalities and static output feedback. IEEE Trans. Autom. Control 51(2), 192–202 (2006)
Hol, C.W., Scherer, C.W.: Sum of squares relaxations for polynomial semidefinite programming. In: Proceedings of Symposium on Mathematical Theory of Networks and Systems (MTNS), Leuven, Belgium, (2004)
Hol, C.W.J., Scherer, C.W.: A sum-of-squares approach to fixed-order \(H_\infty \)-synthesis. In: Positive Polynomials in Control. Lecture Notes in Control and Information Science, vol. 312, pp. 45–71. Springer, Berlin (2005)
Josz, C., Molzahn, D.K.: Moment/sum-of-squares hierarchy for complex polynomial optimization (2015). arXiv preprint arXiv:1508.02068
Klep, I., Povh, J.: Constrained trace-optimization of polynomials in freely noncommuting variables. J. Glob. Optim. 64(2), 325–348 (2016)
Klep, I., Schweighofer, M.: Pure states, positive matrix polynomials and sums of hermitian squares. Indiana Univ. Math. J. 59(3), 857–874 (2010)
Kojima, M.: Sums of squares relaxations of polynomial semidefinite programs. Department of Mathematical and computing Sciences, Tokyo Institute of Technology, Meguro, Tokyo (2003)
Kojima, M., Kim, S., Waki, H.: A general framework for convex relaxation of polynomial optimization problems over cones. J. Oper. Res. Soc. Jpn. 46(2), 125–144 (2003)
Lasserre, J.B.: Global optimization with polynomials and the problem of moments. SIAM J. Optim. 11(3), 796–817 (2001)
Lasserre, J.B.: Moments, Positive Polynomials and their Applications, vol. 1. Imperial College Press, London (2010). Imperial College Press Optimization Series
Lasserre, J.B.: A lagrangian relaxation view of linear and semidefinite hierarchies. SIAM J. Optim. 23(3), 1742–1756 (2013)
Lasserre, J.B., Toh, K.-C., Yang, S.: A bounded degree SOS hierarchy for polynomial optimization. EURO J. Comput. Optim. 5, 1–31 (2015)
Laurent, M.: Semidefinite representations for finite varieties. Math. Program. 109(1), 1–26 (2007)
Laurent, M.: Sums of Squares, Moment Matrices and Optimization Over Polynomials, The IMA Volumes in Mathematics and its Applications, vol. 149, pp. 157–270. Springer, Berlin (2009)
Laurent, M., Rendl, F.: Semidefinite programming and integer programming. In: Aardal, G.N.K., Weismantel, R. (eds.) Discrete Optimization, Handbooks in Operations Research and Management Science, vol 12, pp 393–514. Elsevier, New York (2005)
Löfberg, J.: YALMIP : A toolbox for modeling and optimization in matlab. In: In Proceedings of the CACSD Conference, Taipei, Taiwan (2004)
Matlab version (r2012a), : The MathWorks. Natick, MA, USA (2012)
Marandi, A., Dahl, J., de Klerk, E.: A numerical evaluation of the bounded degree sum-of-squares hierarchy of Lasserre, Toh, and Yang on the pooling problem. Ann. Oper. Res. 265(1), 67–92 (2018)
MOSEK ApS. The MOSEK optimization toolbox for MATLAB manual. Version 7.1 (Revision 28) (2015)
Murty, K.G., Kabadi, S.N.: Some NP-complete problems in quadratic and nonlinear programming. Math. Program. 39(2), 117–129 (1987)
Nie, J.: Certifying convergence of Lasserre’s hierarchy via flat truncation. Math. Program. 142(12), 485–510 (2013)
Nie, J.: An exact jacobian SDP relaxation for polynomial optimization. Math. Program. 137(12), 225–255 (2013)
Nie, J.: Polynomial optimization with real varieties. SIAM J. Optim. 23(3), 1634–1646 (2013)
Nie, J.: Optimality conditions and finite convergence of Lasserre’s hierarchy. Math. Program. 146(12), 97–121 (2014)
Nie, J., Demmel, J., Sturmfels, B.: Minimizing polynomials via sum of squares over the gradient ideal. Math. Program. 106(3), 587–606 (2006)
Parrilo, P.A.: Structured semidefinite programs and semialgebraic geometry methods in robustness and optimization. Ph.D. thesis, California Institute of Technology, Pasadena, California, (2000)
Peña, J., Vera, J., Zuluaga, L.F.: Computing the stability number of a graph via linear and semidefinite programming. SIAM J. Optim. 18(1), 87–105 (2008)
Povh, J.: Contribution of copositive formulations to the graph partitioning problem. Optim. A J. Math. Program. Oper. Res. 62, 1–13 (2011)
Povh, J., Rendl, F.: A copositive programming approach to graph partitioning. SIAM J. Optim. 18(1), 223–241 (2007)
Povh, J., Rendl, F.: Copositive and semidefinite relaxations of the quadratic assignment problem. Discrete Optim. 6(3), 231–241 (2009)
Putinar, M.: Positive polynomials on compact semi-algebraic sets. Indiana Univ. Math. J. 42(3), 969–984 (1993)
Putinar, M., Vasilescu, F.-H.: Positive polynomials on semi-algebraic sets. Compt. Rendus de l’Académie des Sci.—Ser. I—Math. 328(7), 585–589 (1999)
Rendl, F., Rinaldi, G., Wiegele, A.: Solving max-cut to optimality by intersecting semidefinite and polyhedral relaxations. Math. Program. 121(2, Ser. A), 307–335 (2010)
Sahni, S., Gonzalez, T.: \(P\)-complete approximation problems. J. Assoc. Comput. Mach. 23(3), 555–565 (1976)
Schmüdgen, K.: The \(K\)-moment problem for compact semi-algebraic sets. Math. Ann. 289(2), 203–206 (1991)
Schrijver, A.: Theory of Linear and Integer Programming. Wiley, Hoboken (1999)
Schrijver, A.: Combinatorial Optimization. Springer, Berlin (2003)
Schweighofer, M.: Optimization of polynomials on compact semialgebraic sets. SIAM J. Optim. 15(3), 805–825 (2005)
Simionica, M., Povh, J.: A parallel implementation of the boundary point method. In: SOR ’17 Proceedings, Bled, Slovenia, pp. 114–119 (2017)
Sturm, J.: Using SeDuMi 1.02, a MATLAB toolbox for optimization over symmetric cones. Optim. Methods Softw. 11–12, 625–653 (1999). Version 1.05 http://fewcal.kub.nl/sturm
Weisser, T., Lasserre, J.-B., Toh, K.-C.: Sparse-BSOS: a bounded degree SOS hierarchy for large scale polynomial optimization with sparsity. Math. Program. Comput. 10, 1–32 (2017)
Wolfram Research, Inc., Mathematica, Version 11.3, Champaign, IL (2018). http://support.wolfram.com/kb/472
Wolsey, L.: Integer Programming. A Wiley-Interscience Publication. Wiley, Hoboken (1998)
Yamashita, M., Fujisawa, K., Kojima, M.: SDPARA: semidefinite programming algorithm parallel version. Parallel Comput. 29(8), 1053–1067 (2003)
Zhao, X.-Y., Sun, D., Toh, K.-C.: A newton-cg augmented lagrangian method for semidefinite programming. SIAM J. Optim. 20(4), 1737–1765 (2010)
Acknowledgements
The research for this paper was started while P.J.C. Dickinson was at the Johann Bernoulli Institute for Mathematics and Computer Science, University of Groningen, The Netherlands. It was then continued while this author was at the Department of Statistics and Operations Research, University of Vienna, Austria, and then again after he joined the Department of Applied Mathematics, University of Twente, The Netherlands. This author would like to gratefully acknowledge support from The Netherlands Organisation for Scientific Research (NWO) through Grant No. 613.009.021. The second author started this research when he was affiliated to the Faculty of Information Studies in Novo Mesto, Slovenia, and continued the work after moving to the University of Ljubljana, Slovenia. He wishes to thank the Slovenian Research Agency for support via the program P1-0383 and projects J1-8132, N1-0057, N1-0071. Both authors would also like to the thank the anonymous referees for their useful comments with regards to this paper.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix: Proofs of Example 4.4
Appendix: Proofs of Example 4.4
Lemma A.1
We have \({{\,\mathrm{val}\,}}\)(18)\(=n-1\).
Proof
If we consider \(\mathbf {x}=2\mathbf {e}_1\) then we have \(G(2\mathbf {e}_1)=\mathrm {Diag}(0,1,\ldots ,1)\in \mathcal {PSD}^{n}\) and thus \({{\,\mathrm{val}\,}}\)(18) \(\le \mathrm {trace}~G(2\mathbf {e}_1) = n-1\). Now assume for the sake of contradiction that \({{\,\mathrm{val}\,}}\)(18)\(< n-1\). This is possible only if there exists \(\mathbf {x}\in \mathbb {R}_+^n\) such that at least two of the on-diagonal entries of \(G(\mathbf {x})\) are strictly less than one (otherwise, we have \(n-1\) diagonal entries that are at least 1, and the remaining is nonnegative, hence \(\mathrm {trace}~G(\mathbf {x})\ge n-1\)). Without loss of generality the first two on-diagonal entries of \(G(\mathbf {x})\) are strictly less than one, implying that \(x_1,x_2> \frac{4}{3}\). The positive semi-definiteness of G implies that the determinant of the submatrix of G corresponding of the first two rows and columns is non-negative, but
which is a contradiction. Hence, \({{\,\mathrm{val}\,}}\)(18)\(=n-1\). \(\square \)
Considering the approximation hierarchies discussed in this paper for problem (18), we have the following results:
Lemma A.2
The optimal value of our new hierarchy, (15) (without the additional constraint (8) in the original problem), for \(r\in \{0,1\}\) is equal to zero.
Proof
Our hierarchy, (15), for \(r=0\) and \(r=1\) reduces to the following respectively:
Considering \(\lambda =0\) and Y equal to the identity matrix gives us a feasible point of (21), and thus \({{\,\mathrm{val}\,}}\)(21)\(\ge 0\).
From Proposition 3.3 we have \({{\,\mathrm{val}\,}}\)(21)\(\le {{\,\mathrm{val}\,}}\)(22). We will now complete the proof by showing that \({{\,\mathrm{val}\,}}\)(22)\(\le 0\).
For an arbitrary feasible point of (22), we consider the following coefficient inequalities explicitly:

This implies that for all i we have \((Y_0)_{ii} \ge \tfrac{4}{3} (Y_i)_{ii} - \tfrac{1}{3} \ge \tfrac{4}{3}-\tfrac{1}{3} = 1,\) which in turn implies that \(\lambda \le n - \mathrm {trace}\, Y_0 \le n-n = 0\), and thus \({{\,\mathrm{val}\,}}\)(22)\(\le 0\). \(\square \)
Lemma A.3
The optimal value of both of our new hierarchy, (16) (with the additional constraint (8) in the original problem), and the Matrix SOS hierarchy, (14), are equal to zero for \(r=0\).
Proof
These problems both reduce to the following problem:
Considering \(\lambda =v=0\), \(\mathbf {w}=\varvec{0}\), \(Z=0\) and Y equal to the identity matrix gives us a feasible point of (23), and thus \({{\,\mathrm{val}\,}}\)(23)\(\ge 0\).
For an arbitrary feasible point of(23), we consider the following coefficient inequalities explicitly:

Considering the positive semi-definiteness constraints, we also have \(0 \le v\) and \(0\le z_{ii}\) for all i. Therefore, \(y_{ii} \ge 1 + \tfrac{4}{3}z_{ii} \ge 1\) for all i and \(\lambda \le n-\mathrm {trace}\, Y - v \le n - n-0 =0\), implying that \({{\,\mathrm{val}\,}}\)(23)\(\le 0\). \(\square \)
Lemma A.4
The optimal value of the Matrix SOS hierarchy, (14), is equal to zero for \(r=1\).
Proof
This problem reduces to the following problem:
For \(i,j\in \{1,\ldots ,n\}\) such that \(i=j\), considering the coefficient equalities for \(x_i^3\) and \(x_i^2x_j\) explicitly, for any feasible point to this problem we have \(0=(Z_i)_{ii}\) and \(0=2(Z_i)_{ij}+(Z_i)_{jj}\). As \(Z_i\in \mathcal {PSD}^{n}\), this implies that \(Z_i\) is equal to the zero matrix for all i. Therefore, this problem reduces to the problem (23), which we have already shown to have an optimal value equal to zero. \(\square \)
Rights and permissions
About this article

Cite this article
Dickinson, P.J.C., Povh, J. A new approximation hierarchy for polynomial conic optimization. Comput Optim Appl 73, 37–67 (2019). https://doi.org/10.1007/s10589-019-00066-0
Received:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10589-019-00066-0
Keywords
- Polynomial conic optimization
- Polynomial semi-definite programming
- Polynomial second-order cone programming
- Approximation hierarchy
- Linear programming
- Semi-definite programming