
Abstract
The sine cosine algorithm (SCA) is a metaheuristic algorithm that employs the characteristics of sine and cosine trigonometric functions. SCA’s deficiencies include a tendency to get trapped in local optima, exploration–exploitation imbalance, and poor accuracy, which limit its effectiveness in solving complex optimization problems. To address these limitations, a multi-trial vector-based sine cosine algorithm (MTV-SCA) is proposed in this study. In MTV-SCA, a sufficient number of search strategies incorporating three control parameters are adapted through a multi-trial vector (MTV) approach to achieve specific objectives during the search process. The major contribution of this study is employing four distinct search strategies, each adapted to preserve the equilibrium between exploration and exploitation and avoid premature convergence during optimization. The strategies utilize different sinusoidal and cosinusoidal parameters to improve the algorithm’s performance. The effectiveness of MTV-SCA was evaluated using benchmark functions of CEC 2018 and compared to state-of-the-art, well-established, CEC 2017 winner algorithms and recent optimization algorithms. The results demonstrate that the MTV-SCA outperforms the traditional SCA and other optimization algorithms in terms of convergence speed, accuracy, and the capability to avoid premature convergence. Moreover, the Friedman and Wilcoxon signed-rank tests were employed to statistically analyze the experimental results, validating that the MTV-SCA significantly surpasses other comparative algorithms. The real-world applicability of this algorithm is also demonstrated by optimizing six non-convex constrained optimization problems in engineering design. The experimental results indicate that MTV-SCA can effectively handle complex optimization challenges.
Similar content being viewed by others



Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Optimization is defined as the process of identifying the optimal solution among the feasible set of solutions that minimizes or maximizes a given problem. With the advancement of science and technology, optimization difficulties have gotten more complicated, and new optimization challenges have evolved, which must be solved using the most suitable optimization algorithms. There are two categories of algorithms for tackling optimization problems: deterministic and stochastic [1]. Deterministic algorithms, which are divided into gradient-based and non-gradient-based categories, perform well when addressing linear, convex, and uncomplicated optimization problems. However, these algorithms are ineffective in solving complex problems, objective functions that are not differentiable, nonlinear search spaces, and non-convex problems [2]. Nonetheless, the aforementioned traits represent the main characteristics of optimization problems encountered in practical applications. Owing to these characteristics and the inadequacy of deterministic algorithms to effectively address them, stochastic approaches, such as metaheuristic algorithms, have been developed [3, 4]. Effective solutions to optimization problems can be generated by metaheuristic algorithms in a reasonable time. The No-Free-Lunch (NFL) theorem [5], which states that no single optimization algorithm can perform equally well across all types of problems with varying levels of complexity, has motivated the development of new and novel optimization algorithms.
Metaheuristic algorithms’ prevalence and widespread usage are credited to their simple concepts, easy implementation, and efficiency in solving high-dimensional, non-linear, and non-convex problems. Moreover, the absence of a need for a derivation process makes metaheuristic algorithms particularly useful in situations where the objective function is not well-defined, or the problem is complex and challenging to solve using traditional optimization algorithms. Metaheuristic algorithms generate a set of random solutions in the search space and iteratively update and refine them based on the algorithm’s instructions. Once the iterative process is completed, the candidate solution exhibiting the highest degree of optimality is designated as the identified solution to the problem [6]. It is imperative to note that metaheuristic algorithms cannot provide an assurance that the solution obtained represents the globally optimal solution [7]. While the identified solution may constitute a local optimum, the existence of a superior global optimum cannot be definitively excluded. The performance of metaheuristic algorithms can vary greatly depending on the specific problem they are applied to and the process used to seek and update potential solutions. Numerous optimization algorithms have been designed and developed to overcome this challenge and enhance metaheuristic algorithms’ effectiveness.
Due to the rapid expansion of computational intelligence tools, non-deterministic algorithms have made remarkable strides in solving optimization issues in the past decades. As an alternative, metaheuristic algorithms were utilized to tackle optimization issues by mimicking biological, physical, or social phenomena. There are several metaheuristic algorithms suggested, including genetic algorithm (GA) [8], differential evolution (DE) [9], particle swarm optimization (PSO) [10], grey wolf optimizer (GWO) [11], whale optimization algorithm (WOA) [12], salp swarm algorithm (SSA) [13], orca predation algorithm (OPA) [14], special forces algorithm (SFA) [15], and Greylag goose optimization (GGO) [16]. In many situations where traditional algorithmic approaches are unable to solve the problem, these algorithms have demonstrated remarkable success, such as in feature selection [17], multi-modal medical image registration [18], and engineering problems [19].
The sine cosine algorithm (SCA) [20] is derived from a mathematical model based on the trigonometric characteristics of sine and cosine curves. Using either the sine- or cosine-based equation, each solution in the current population is updated. To retain the algorithm’s stochastic nature, random parameters have been incorporated into its equations to maintain a balance between the search stages. The simplicity and efficacy of the SCA have garnered significant attention from a variety of disciplines. It has been utilized to address a number of optimization problems, such as power system damping controllers [21], global optimization [22], hydrothermal-solar-wind scheduling [23], sequential clustering [24], network reconfiguration [25], support vector regression parameter optimization [26], and community detection [27]. Despite concerns about its novelty, SCA updates the population using a straightforward updating rule with a simple structure and minimal parameters. However, SCA is known to suffer from issues such as low diversity, slow convergence speed, stagnation in local optima, and low solution accuracy [28,29,30].
While nature-inspired algorithms like the sine cosine algorithm (SCA) have demonstrated effectiveness in specific applications, they often struggle with complex optimization problems due to inherent limitations such as poor solution accuracy, local optima trapping, slow convergence speed, and stagnation in local optima. Therefore, the need for a new algorithm or improvements to existing ones stems from the evolving landscape of optimization problems, where novel challenges require more robust and efficient solutions. However, based on the No-Free-Lunch (NFL) theorem, new metaheuristic algorithms and their improvements almost suffer from the same inherited weaknesses. Thus, to obtain optimal performance at various phases of the search process, adding multi-movement strategies to the SCA is beneficial to increase its potential and effectiveness. This study aims to improve SCA by integrating a satisfactory number of search strategies and adapting them through a multi-trial vector (MTV) approach [31]. Although the SCA is simple in implementation, it possesses certain flaws of poor solution accuracy, a tendency to become trapped in local optima, a lack of exploitation, slow convergence speed, and stagnation in local optimum, notably in tackling complex optimization problems [32, 33]. By integrating multiple search strategies through approaches like the multi-trial vector (MTV), the improved algorithm aims to achieve better exploration and exploitation of the search space, leading to improved solution quality and convergence rates.
This study presents a new variant of SCA named multi-trial vector-based sine cosine algorithm (MTV-SCA). The proposed MTV-SCA enhances the original SCA by addressing its inherent limitations through a solid theoretical foundation integrating multiple search strategies and adaptive parameter adjustments. The theoretical framework of MTV-SCA is rooted in the diversification and intensification of the search process, achieved by employing four distinct trial vector producers (TVPs), each designed to achieve a particular objective and their cooperation throughout the search process. S1-TVP focuses on balancing exploration and exploitation to prevent local optima trapping, S2-TVP emphasizes extensive exploration, S3-TVP targets rapid convergence for unimodal problems, and S4-TVP aims to maintain an equilibrium between exploration and exploitation to mitigate premature convergence. Furthermore, the algorithm dynamically adjusts control parameters using a combination of sinusoidal and cosinusoidal functions, specifically through Chebyshev, Sinusoidal, and sin-cos coefficients. These coefficients modulate the search step sizes and directions, enabling efficient navigation of the search space. The Chebyshev coefficient is used to investigate the search space more efficiently by taking larger steps in regions with flat fitness landscapes and smaller steps in rugged areas. The Sinusoidal coefficient prevents premature convergence by adjusting the search radius, and the sin-cos coefficient maintains a balance between exploration and exploitation by dynamically varying the control parameters.
To validate the efficacy of the proposed MTV-SCA, a comprehensive set of experiments was conducted utilizing test functions introduced in the CEC 2018 [34]. This benchmark suite provided a rigorous framework for evaluating the performance of the algorithm across a diverse array of optimization challenges. The gained results were compared to state-of-the-art, well-established, CEC 2017 winner algorithms and recently proposed nature-inspired metaheuristic algorithms, including krill herd (KH) [35], grey wolf optimizer (GWO) [11], moth-flame optimization (MFO) [36], whale optimization algorithm (WOA) [12], sine–cosine algorithm (SCA) [20], salp swarm algorithm (SSA) [13], henry gas solubility optimization (HGSO) [37], fitness dependent optimizer (FDO) [38], chimp optimization algorithm (ChOA) [39], Archimedes optimization algorithm (AOA) [40], fox-inspired optimization (FOX) [41], particle swarm optimization (PSO) [10], gravitational search algorithm (GSA) [42], and adaptive differential evolution with optional external archive (JADE) [43], LSHADE-SPACMA [44] and LSHADE–cnEpSin [45]. Furthermore, the proposed algorithm was statistically analyzed using two non-parametric tests, Wilcoxon signed-rank and Friedman test [46]. Finally, the effectiveness of MTV-SCA in addressing real-world engineering challenges was evaluated by applying six distinct non-convex constrained optimization problems. Based on the comparison of the results, it was found that the MTV-SCA exhibited superior performance in the majority of test problems.
The following is a condensed overview of the paper’s contributions.
-
Integration of multiple search strategies: The study introduces MTV-SCA, which integrates multiple search strategies through the MTV approach. This integration allows the algorithm to utilize a diverse set of TVPs tailored to specific objectives, promoting their cooperation throughout the search process. The proposed algorithm improves the efficiency of SCA in addressing intricate optimization problems.
-
Four distinct search strategies: The MTV-SCA incorporates four distinct search strategies, namely S1-TVP, S2-TVP, S3-TVP, and S4-TVP, each designed to address specific aspects of optimization. S1-TVP is designed to establish an equilibrium between exploring the search space and exploiting promising regions; S2-TVP emphasizes facilitating an effective exploration process. S3-TVP aims to achieve a balance between exploration and exploitation for rotated problems, and S4-TVP is formulated to mitigate the tendency for premature convergence to suboptimal solutions. By integrating these strategies, MTV-SCA demonstrates its capability to address various optimization challenges across various domains effectively.
-
Sinusoidal and cosinusoidal function parameter adjustment: The algorithm utilizes a combination of sinusoidal and cosinusoidal functions to adjust the parameter values of the respective TVPs. This adjustment allows the algorithm to maintain a trade-off between exploiting previously discovered optimal solutions and exploring unexplored regions of the search space. The Chebyshev coefficient enables efficient exploration by adapting step sizes to the landscape’s ruggedness, the sinusoidal coefficient adjusts the search radius and direction to prevent premature convergence, and the sin-cos coefficient dynamically adjusts control parameters to balance exploration and exploitation.
-
Performance evaluation and comparison: MTV-SCA was extensively evaluated using 29 test functions and compared to state-of-the-art, well-established, CEC 2017 winner algorithms and recently proposed nature-inspired metaheuristic algorithms. The evaluation included statistical analysis using the Friedman and Wilcoxon signed-rank tests. The results demonstrated the superior performance of the MTV-SCA on the majority of test problems. Additionally, the algorithm’s effectiveness in solving real-world engineering problems was assessed, further confirming its capabilities.
The subsequent structure of this paper is as follows: Sect. 2 reviews related works, and Sect. 3 presents the mathematical formulation of SCA. The proposed MTV-SCA is introduced in Sect. 4. Section 5 outlines the performance evaluation of the MTV-SCA and its comparison with other optimization algorithms, while Sect. 6 elucidates the statistical analysis conducted. The real-world applicability of the MTV-SCA is investigated in Sect. 7 through its application to engineering design problems. Section 8 discusses the main reasons for the MTV-SCA’s success. Finally, Sect. 9 concludes the work and offers suggestions for future research.
2 Related work
Metaheuristic algorithms are a versatile set of problem-solving techniques that can tackle a wide range of optimization problems. These algorithms are used to find high-quality solutions to complex problems, for which exact or deterministic algorithms may be ineffective or inefficient [47]. Metaheuristic algorithms are a class of optimization algorithms inspired by natural processes, such as genetic mutation and evolution, swarm behavior, biological phenomena, and physical rules. These algorithms use a set of rules and operations to identify the most effective solution to an optimization problem, even when the problem is complex and poorly defined. Metaheuristic algorithms are utilized extensively in various fields due to their ability to find good solutions quickly and their flexibility in handling various optimization problems. As such, metaheuristic algorithms are likely to continue to play an increasingly important role in advancing these fields, and new applications and improvements to these algorithms are expected to emerge.
Various fields have benefited from metaheuristic algorithms, including engineering, health care and medicine, business, and management, as well as optimization and machine learning [48,49,50,51,52,53]. In engineering, metaheuristic algorithms have been employed in several applications, including the estimation of parameters in solar cell models [54], optimizing design parameters in engineering problems [55, 56], optimization of multi-objective problems [57], optimization of water resource management in environmental engineering [58], feature selection in wind speed forecasting systems [59], optimization of supply chain management [60], optimize the design of aircraft structures [61], parameter optimization of control systems in electrical engineering [62], optimization of production scheduling in industrial engineering [63], design optimization of structures in civil engineering [64], optimization of energy performance of building [65], optimization of energy systems in energy engineering [66, 67], optimization of community detection algorithms [68], workflow scheduling in fog computing [69], and parameter optimization of structural designs [70, 71].
Metaheuristic algorithms have found applications in diverse medical areas, such as medical imaging [72], drug discovery [73], and radiation therapy planning [74]. In medical imaging, the segmentation and registration of images are crucial for accurately diagnosing and treating diseases. The other uses of metaheuristic algorithms in this field are the prediction of drug efficacy and toxicity [75], identification of disease biomarkers from large-scale data [76], medical image segmentation [77], cancer classification [78], identification of features for disease diagnosis [79], optimization of surgical planning and execution [80], optimization of EEG signal processing for detecting brain disorders [81], radiation therapy planning to optimize the treatment plan by adjusting the radiation dose [82], and feature selection and classification [83].
In logistics and transportation, metaheuristics are employed for solving various optimization problems, such as vehicle routing [84], facility location [85], optimization of slot allocation in air traffic flow management [86], optimization of flight and crew scheduling for airlines [87], traffic flow forecasting [63], and optimization of warehouse layout and inventory management [88]. Other applications of metaheuristic algorithms include botnet detection in IoT [89], virtual machines allocation in cloud data centers [90], signal processing of fiber SPR sensors [91], global optimization [92, 93], anomaly-based intrusion detection systems in the internet of things [94], feature selection in data classification [95], and malware detection [96].
The sine cosine algorithm (SCA), which is grounded in the category of physics-based algorithms, has proven to be effective in tackling a diverse range of optimization issues. These include, but are not limited to, the optimization of engineering designs, data mining, machine learning, structural optimization, and power system optimization. However, there are also some limitations to using the SCA. One of the main challenges is that it can get trapped in local optima, which can prevent it from finding the global optimum. Additionally, it lacks a balance between exploration and exploitation, so it cannot effectively search for solutions in a large solution space and may quickly converge to the optimal local solution. Thus, some enhancements to its performance have been made during its proposal.
Some hybridized variants, designed to enhance SCA’s performance in solving optimization problems, are reviewed. The paper [97] proposes a hybrid PSO algorithm with sine cosine acceleration coefficients (H-PSO-SCAC) to overcome the limitations of particle swarm optimization in solving complex optimization tasks, such as premature convergence and exploration–exploitation balance. The proposed algorithm incorporates several improvements, including SCAC for controlling local search and convergence, opposition-based learning for initialization, a sine map for adjusting inertia weight, and a modified position updating strategy. The experimental results on seven unimodal and five multimodal benchmark functions demonstrate that H-PSO-SCAC outperforms comparative algorithms.
In [98], the authors introduce a hybrid optimization algorithm named PSOSCALF. This algorithm combines the strengths of PSO, SCA, and Levy flight techniques. The proposed algorithm is designed to improve the exploration ability of the PSO while also avoiding the problem of being stuck in local minima, leading to better outcomes for constrained engineering issues. This study used 23 benchmark functions, including unimodal, multimodal, and fixed-dimension multimodal functions, to evaluate the proposed PSOSCALF algorithm. The results illustrate that PSOSCALF surpasses other algorithms in finding the global minimum and provides better solutions for constrained engineering problems. A recent study presented a hybrid forecasting approach for wind speed prediction. As described in [99], the proposed algorithm utilized the multi-objective sine cosine algorithm (MOSCA) and a modified data decomposition technique to enhance the forecasting performance. Furthermore, a hybrid wavelet neural network model was developed by combining MOSCA to achieve high prediction accuracy and strong stability. The results showed that MOSCA outperformed other models through an experimental analysis of four typical multi-objective test functions and eight different wind speed datasets.
In [100], the authors address the problem of feature selection in large datasets with high dimensionality, which can be time-consuming and complex. The proposed improved version of the sine–cosine algorithm (ISCA) with an elitism strategy and the new best solution update mechanism is tested on ten benchmark datasets. The results show that it yields superior classification performance while utilizing fewer features compared to other algorithms used for comparison. With its multitude of constraints, the optimal power flow (OPF) is a challenging optimization problem. To tackle this issue, a modified sine–cosine algorithm (MSCA) has been suggested in [101]. MSCA has been developed to enhance SCA’s capacity to identify the global optimum while avoiding the issue of being stuck in local optima. This is achieved through the incorporation of Levy flights. The testing of the MSCA algorithm on several benchmark test systems demonstrates its effectiveness and potential as a powerful optimization method for the OPF problem. In [102], a new optimization algorithm named ASCA-PSO is introduced to improve pairwise local sequence alignment, a crucial task in the field of bioinformatics. The proposed algorithm combines SCA and PSO to improve the exploration abilities of SCA. The performance of ASCA-PSO is then evaluated on twenty benchmark functions of unimodal and multimodal functions, and the results demonstrate its superior accuracy and computational efficiency.
In [103], the SCA-PSO algorithm is proposed for optimization problems and object tracking to overcome the premature convergence limitation of SCA. The proposed algorithm combines the strengths of PSO and SCA, such as exploitation and exploration capabilities, respectively. The effectiveness of the algorithm is evaluated using 23 classical benchmark functions, CEC 2005, and CEC 2014 benchmark functions and compared with state-of-the-art metaheuristic algorithms. In addition, the proposed algorithm is applied to object tracking and compared with other trackers, demonstrating its robustness in challenging conditions. Another proposed enhanced variant of SCA is in [104], in which a population diversity-based local refinement strategy helps to maintain diversity at a high level, addressing the SCA’s struggle to find solutions for complex problems. The proposed algorithm is evaluated using twenty-nine test functions of the CEC 2017 benchmark suite, showing its effectiveness in controlling diversity.
The limitations of SCA, such as low diversity and premature convergence, have resulted in the development of modified versions of the algorithm. Two modified versions of SCA, named m-SCA [105] and RFSCA [106], are proposed in order to tackle the limitations of SCA, such as low diversity and premature convergence. The m-SCA algorithm uses a self-adaptive element to take advantage of search regions already explored by SCA’s search equations, which may be productive. Simultaneously, it generates a contrasting population by using opposite values predicated on a perturbation rate to overcome the local optima. The RFSCA algorithm integrates a Riesz fractional derivative mutation strategy that employs quasi-opposition learning to initialize the population, as well as a novel mutation methodology to update the optimal individual based on the Riesz fractional derivative’s approximate formula with second-order accuracy. The performance of both algorithms is assessed across various classical benchmark problems, CEC benchmark functions, and engineering optimization problems, with promising outcomes regarding exploration, exploitation, and solution quality.
The development of the ISCA algorithm was motivated by the need to tackle challenging global optimization problems arising in high-dimensional settings, as explained in [107]. To achieve this, ISCA relies on a position-updating equation that has been modified to incorporate both an inertia weight and a Gaussian-based strategy. This approach is designed to balance the opposing forces of exploration and exploitation, thereby optimizing the algorithm’s overall performance. The testing of ISCA on twenty-four high-dimensional benchmark functions, large-scale global optimization problems from the IEEE CEC2010 competition, and real-world engineering applications has yielded results demonstrating its superior performance compared to SCA. ISCA has exhibited faster convergence and better escape from local optima. Another alternative approach to address optimization challenges is SCA-OPI [108], which introduces orthogonal parallel information to enhance exploration while emphasizing exploitation. Further, the algorithm utilizes a strategy of opposition direction based on prior experience to maintain the ability for exploration. The evaluation of SCA-OPI on unconstrained optimization problems, including unimodal and multimodal benchmark functions, and constrained optimization, including quadratic and nonlinear functions, demonstrates its superiority in optimality and reliability compared to other algorithms.
To address the local optima issue of SCA, in [109], a multi-strategy enhanced SCA named MSCA was proposed. This memetic algorithm integrates various control mechanisms to explore the search space effectively, leading to better performance in finding optimal solutions for complex problems. To verify the performance of MTV-SCA, the CEC2014 benchmark problems, and 23 continuous benchmark functions were employed, including seven unimodal functions, six multimodal benchmark functions, and ten diverse fixed-dimension multimodal functions. Another SCA variant is the bare bones sine cosine algorithm (BBSCA) [110], which improves exploitation ability and maintains diversity well. BBSCA uses Gaussian search equations, exponential decrement strategies, and a greedy selection mechanism to generate new candidate individuals and make full use of previously searched information. The results of testing BBSCA on a classic set of 23 well-known benchmark functions, standard IEEE CEC 2014 and CEC 2017 benchmark test functions, and engineering optimization issues demonstrate that it outperforms other SCA variants and generates better solutions for real-life global optimization problems.
To address the issues of SCA, such as slow convergence and lack of robustness, in [32], a new algorithm, the dimension by dimension dynamic sine cosine algorithm (DDSCA), is proposed. DDSCA enhances the SCA update equation by integrating a dimensional and a greedy strategy to produce novel solutions. Furthermore, a dynamic control parameter is implemented to maintain exploration and exploitation. The algorithm’s performance is evaluated using 23 benchmark test functions, IEEE CEC 2010 large-scale functions, and engineering optimization problems. The results show that DDSCA outperforms comparative algorithms. In an effort to address the sluggish convergence and high computational complexity of SCA, an algorithm named chaotic sine cosine firefly (CSCF) [111] has been proposed. By incorporating the chaotic forms of both the SCA and firefly algorithms, the CSCF algorithm aims to enhance convergence speed and efficiency while minimizing computational complexity. This algorithm has been evaluated using twenty benchmark functions, with simulation results demonstrating its efficiency in addressing engineering design problems.
The Q-learning embedded sine cosine algorithm (QLESCA) [33] proposes a new variant of SCA that employs a Q-learning algorithm to regulate the parameters of SCA during runtime. QLESCA underwent evaluation using 23 continuous benchmark functions, 20 large-scale benchmark optimization functions, and three engineering problems, demonstrating superior performance compared to other optimization algorithms. The proposed algorithm addresses the limitations of conventional SCA by providing a balance between exploration and exploitation modes. In [22], MAMSCA is proposed, which divides the population into two halves, updates them using either sine or cosine strategies, and uses a modified mutualism phase to add further diversity to the population. The algorithm’s performance was evaluated using classical benchmark functions and IEEE CEC 2019 functions. EBSCA [112], on the other hand, presents a position-updated equation that highlights the positional information of the superior individual to direct the updating of fresh candidates, thereby enhancing the exploitation capability. Additionally, it introduces a new integrated approach that fuses the quantization orthogonal crossover strategy with SCA to augment the searching space’s utility efficiency. The efficacy of EBSCA was assessed on 13 classical benchmark functions, IEEE CEC 2015 problems, and four engineering problems that demonstrate significant improvements compared to other methods.
3 Sine cosine algorithm (SCA)
The sine cosine algorithm (SCA) is developed for global optimization and inspired by two functions, sine and cosine. As with other metaheuristic population-based algorithms, SCA generates candidate solutions randomly within the preset minimum and maximum boundaries of the problem. Then, an updated solution for the exploration and exploitation balance is calculated by applying two distinct mathematical expressions shown in Eq. (1),
where \({X}_{i}^{t}\) and \({P}_{i}^{t}\) in the tth iteration are the position of ith solution and the destination solution, and r1, r2, and r3 are randomly generated. The choice of an expression from Eq. (1) is determined by a random number r4, which follows a uniform distribution between 0 and 1.
Through the use of r1, r2, and r3, the SCA regulates how the algorithm is explored and used. Parameter r1 can be used to balance exploration and exploitation in both early and late stages of the SCA. Depending on this parameter, either the new solution will be directed toward the destination or outward from it. In order to identify the optimal solution in the latter stages of the algorithm, it first directs the search process to find solutions throughout the whole search space or to exploit the vicinity of the destination solution. When r1 is greater than 0, the distance between the destination solution and the solution will increase, while when r1 is smaller, the distance will decrease. The calculation of r1 is performed using Eq. (2),
where a is a constant value, t is the current iteration, and T is the number of maximum iterations. The value of the solution’s distance from the position of the target solution is represented by the random parameter r2. Generally, a greater value of r1 signifies increased exploration, given the greater distance between the current solution and the destination solution; conversely, a lesser value signifies exploitation, given the shorter distance. The parameter r3 is used to demonstrate how much the distance calculation is affected by the destination solution.
4 Proposed multi-trial vector-based sine cosine algorithm (MTV-SCA)
Despite the simplicity and versatile usage of SCA for solving optimization problems, its efficacy is constrained, posing significant challenges when applied to complex problems. SCA possesses weaknesses of poor solution accuracy, a slow convergence speed, a tendency to become trapped in local optima, a lack of exploitation, and an inability to sustain a balance between exploitation and exploration. These flaws stem from the SCA search strategy, which leads to weak performance while dealing with complex challenges. The best current solution is the only solution used in the canonical SCA’s position-updating equation to estimate the distance to the next searching area, providing the SCA with excellent exploration capability but limited exploitation. Furthermore, the SCA is not fully utilizing the information provided by the current solution’s position. This is while the performance of an algorithm depends on the search strategies and control parameters used to solve problems with a wide range of characteristics. In addition, to get optimal performance at various phases of the search process, it is beneficial to use a variety of alternative strategies in conjunction with various parameter values.
This paper introduces a multi-trial vector-based sine cosine algorithm (MTV-SCA), in which the single SCA’s search strategy is reinforced with a multi-trial vector (MTV) approach. It is advantageous to use the MTV approach in order to define a variety of different search strategies, each customized to achieve a distinct objective, as well as their cooperation throughout the search process. Further, various sinusoidal and cosinusoidal functions are supplied to adjust the parameters’ value of the corresponding search strategies. The purpose of utilizing the provided functions is to achieve a good equilibrium between exploiting previously discovered good solutions and discovering previously unvisited portions of the search space. Furthermore, in the proposed MTV-SCA, each trial vector producer (TVP) is assigned to apply to a specific portion of the population based on the winner-based distributing policy of the MTV approach. This approach ensures that the information is shared effectively among the solutions from different subpopulations, ultimately improving the algorithm’s performance during the population distributing phase.
Figure 1 shows the flowchart of MTV-SCA, which comprises four steps: initialization, distribution, multi-trial vector production, and population evaluation and update. Once N solutions have been initialized within the search space, the subpopulation size of each TVP is computed for every nIter iteration during the distribution step. Next, in the multi-trial vector production step, a candidate solution is generated for each solution by either SC-TVP or one of the strategies from Pool-TVP. In the Pool-TVP, we designed four new search strategies named S1-TVP, S2-TVP, S3-TVP, and S4-TVP in order to perform an effective search on the solutions of their subpopulations. To achieve a balanced exploration and exploitation and avoid getting trapped in local optima, S1-TVP was proposed. Additionally, S2-TVP effectively explores the search space, while S3-TVP sustains a state of equilibrium to search for new solutions with the refinement of current solutions. Moreover, S4-TVP is designed to balance the exploration and exploitation of the search space and prevent premature convergence. Moreover, each TVP utilizes a sinusoidal and cosinusoidal functions with the aim of maintaining a trade-off between exploiting previously obtained optimal solutions and discovering new unvisited areas of the search space. The Chebyshev function used in S1-TVP introduces a degree of randomness and variability in the search process, which can help the algorithm explore different regions of the search space more effectively. The Sinusoidal coefficient provides periodic adjustments to the search radius and direction, allowing the algorithm to search more thoroughly and avoid getting trapped in local optima. The sin-cos coefficient balances exploration and exploitation, helps to refine the solutions, and focuses the search on promising areas of the search space. Then, in the population evaluation and update step, the candidate solutions’ fitness is computed and compared to their prior values. As a final step, a candidate solution is replaced by the solution’s current position if its fitness is less than that of the solution. Other than that, a solution’s position and fitness value remain unchanged. Table 1 contains the parameter descriptions referenced in the subsequent section. Following is a detailed explanation of the proposed MTV-SCA.

The proposed MTV-SCA flowchart
Initialization: N solutions are initialized at random in a D-dimensional search space considering the lower (L) and upper (U) boundaries using Eq. (3),
where the value of the jth dimension of the ith solution is represented by xi,j. The minimum and maximum boundaries of the jth dimension are denoted by Lj and Uj, respectively, while rand is a random value uniformly distributed in the range of [0,1]. The population size and dimension size of the problem are represented by N and D, respectively. The N × D matrix, known as X, is used to keep the positions of the generated solutions. The fitness function, f(Xi(t)), is used to determine the fitness value of the solution Xi after the initialization of the population and at each iteration t.
Distribution: In order to determine the size of subpopulations SC-TVP and Pool-TVP, it is essential to consider the number of improved solutions after passing nIter iterations, a specified number of iterations. ImpRate is the ratio of improved solutions’ fitness to the total number of function evaluations in the preceding nIter iterations. The TVP ImpRate is determined by Eq. (4),
where the improved rates are denoted by ImpRateSC-TVP and ImpRatePool-TVP, the subpopulation size of SC-TVP and Pool-TVP are denoted by NSC-TVP and NPool-TVP, and the number of function evaluations carried out by each TVP in the preceding nIter iterations is denoted by NFEs, respectively.
The distribution rule that is stated in Eq. (5) is taken into consideration for distribution policy in the MTV-SCA; as a result, the TVP that has a higher ImpRate has a bigger subpopulation.
where N is the total number of solutions, the subpopulations’ size by considering the TVPs’ improved rate denoted by NSC-TVP and NPool-TVP, and the portion coefficient λ is considered 0.5. After the sizes of the subpopulations are calculated, subpopulations XSC and XPool are created.
Multi-trial vector production: Search strategies and parameter values have a significant influence in determining the efficiency of an algorithm when solving optimization problem. However, the nature of the problem, i.e. unimodality, multimodality, separability, and non-separability, imply that various search strategies and control parameter values are required for various optimization tasks. In addition, multiple search strategies with varied control parameters could be superior to a single search strategy with unique parameter values at various periods of development when addressing a particular problem. Motivated by these observations, we propose a collection of trial vector producers and control parameters for canonical SCA in which trial vector producers compete to generate a thriving population at each iteration. As the iteration progresses, the position of solution Xi is adjusted by the strategies SC-TVP and Pool-TVP, respectively. The SC-TVP enhances the capability to search for promising regions of the search space and find new solutions in a localized area. The Pool-TVP is employed when it comes to exploiting, escaping the local optima, and achieving a balance between exploitation and exploration.
A piece of preliminary information is presented first, followed by a comprehensive explanation of the proposed TVPs. In the proposed S1-TVP and S2-TVP, two transformation matrices, denoted as M and \(\overline{M}\) to generate candidate trial vectors for each subpopulation. Matrix M, having dimensions N × D, is created from a D × D lower triangular matrix with all elements are equal to one. This D × D matrix is replicated (N/D) times to form a square matrix. If there are any remaining rows in M, they are filled with the first rows of the square matrix. Then, a random permutation is applied to the rows of M. Following this, the \(\overline{M}\) matrix is obtained by replacing each element in M with its inverse value.
Sine cosine trial vector producer (SC-TVP): In each iteration t, a candidate solution is generated for the ith solution of the SC-TVP’s subpopulation XSCit by Eq. (6),
where CSCit+1 represents the generated candidate solution for XSCit, r1 is calculated by Eq. (2), r2, r3, and r4 are random numbers, and Pt is the position of the destination solution in tth iteration, respectively.
Pool trial vector producer (Pool-TVP): Pool-TVP is a collection of different trial vector producers S1-TVP, S2-TVP, S3-TVP, and S4-TVP with various sinusoidal and cosinusoidal functions as the search strategies’ control parameters. The suggested distribution policy for dividing XPool among four TVPs involves the random allocation of solutions in each iteration. The assignment of solutions to TVPs is determined by considering the size of XPool, resulting in the creation of subpopulations XS1, XS2, XS3, and XS4. The trial vector producers in a pool possess varied qualities to demonstrate varying performance characteristics at various phases of the search process while confronting a specific problem. Proposing S1-TVP aims to help the algorithm maintain a balance between exploration and exploitation, so avoiding being trapped in local optima. S1-TVP, has the fastest convergence speed and performs well for solving unimodal problems. On the other hand, S2-TVP is effective at exploring the search space and it shows a slow convergence speed and a higher ability for exploration. S3-TVP strikes a good balance between exploration and exploitation, has a higher convergence rate, and it is efficiently appropriate for solving rotated problems. S4-TVP is intended for balancing the exploration and exploitation of the search space and avoiding premature convergence.
S1-TVP: The aim of proposing S1-TVP is to enable the algorithm to maintain the balance between exploration and exploitation and avoid getting stuck in local optima. This reached by considering the population’s best solution and the scaled difference between two randomly chosen solutions. The strategy combines information from the current best’s position, the differentiate of randomly selected solutions, to produce a candidate solution and move it towards potentially better solutions. Also, the Chebyshev and the rand control parameters provide a balance between exploration and exploitation, which results in a more directed search towards the best regions of the search space.
For each solution \({XS1}_{i}^{t}\) belongs to the subpopulation of XS1, a trial vector \({VS1}_{i}^{t+1}\) is calculated by Eq. (7),
where Pt is the best solution so far, and \({X}_{r1}^{t}\), \({X}_{r2}^{t}\), \({X}_{r3}^{t}\) and \({X}_{r4}^{t}\) are randomly selected solutions from the current population X. Chebyshev, which is calculated by Eq. (8) [113], is a function that generates a sequence of values that oscillate between -1 and 1, and the oscillation frequency increases with the iteration number. The use of the Chebyshev function allows the algorithm to explore the search space more effectively by taking larger steps in regions where the fitness landscape is flat and smaller steps in regions where it is rugged.
The candidate trial vector of the ith solution \({XS1}_{i}^{t}\) is calculated by Eq. (9),
where Mi and \(\overline{M}\)i are corresponding values of the ith solution and \({CS1}_{i}^{t+1}\) is the candidate trial vector generated for the ith solution of S1-TVP subpopulation.
S2-TVP: The strategy involves selecting three individuals randomly from the population and creating a new trial vector by adding the scaled difference between two of the individuals to the third individual. This strategy has been shown to be effective at exploring the search space, which can be particularly useful when dealing with complex and high-dimensional optimization problems. The mutation strategy allows the algorithm to move away from the current population and explore new regions of the search space. Also, its ability to explore the search space efficiently leads to converging quickly, which means it can find good solutions in a shorter amount of time compared to other metaheuristic algorithms.
For each solution \({XS2}_{i}^{t}\) belongs to the subpopulation of XS2, a trial vector \({VS2}_{i}^{t+1}\) is calculated by Eq. (10),
rand is a randomly generated number, and \({X}_{r1}^{t}\), \({X}_{r2}^{t}\), and \({X}_{r3}^{t}\) are randomly selected solutions from the current population X. The candidate trial vector of the ith solution \({XS2}_{i}^{t}\) is calculated by Eq. (11),
where Mi and \(\overline{M}\)i are corresponding values of the ith solution and \({CS2}_{i}^{t+1}\) is the candidate trial vector generated for the ith solution of S2-TVP subpopulation.
S3-TVP: S3-TVP strikes a good balance between exploration and exploitation and has a higher convergence rate. It achieves these by using both the current and random solutions in the search process. This is because it uses a random solution in the mutation process, which helps to explore different regions of the search space. The current solution \({XS3}_{i}^{t}\) from the subpopulation of XS3 is moved in the direction of a random vector \({X}_{r1}^{t}\) before being disturbed by a scaled difference between two other randomly chosen solutions \({X}_{r2}^{t}\) and \({X}_{r3}^{t}\) from the current population. The candidate trial vector of the ith solution \({XS3}_{i}^{t}\) is calculated by Eq. (12),
where \({CS3}_{i}^{t+1}\) represents the candidate solution provided for the ith solution \({XS3}_{i}^{t}\), sinusoidal(t) is the coefficient which is used to adjust the search radius and direction of the algorithm calculated by Eq. (13), and \({X}_{r1}^{t}\), \({X}_{r2}^{t}\), and \({X}_{r3}^{t}\) are randomly selected solutions from the current population X.
The sinusoidal function [113] can help prevent premature convergence by allowing the algorithm to explore the search space more thoroughly. By periodically increasing the search radius and changing the search direction, the algorithm can avoid getting stuck in local optima and continue searching for the global optimum.
S4-TVP: The goal of balancing the exploration and exploitation of the search space and avoiding premature convergence is maintained by this strategy. It updates the position of \({XS4}_{i}^{t}\), based on its current position, two randomly chosen solutions, and a combination of sine and cosine functions depend on the current iteration number and the total number of iterations. The candidate trial vector of the ith solution \({XS4}_{i}^{t}\) is calculated by Eq. (14),
where t is the current iteration, MaxIter is the total number of iterations, and \({X}_{r1}^{t}\) and \({X}_{r2}^{t}\) are randomly selected solutions from the current population X. The role of cos(t/MaxIter) × sin(rand × (t/MaxIter)) is to provide a dynamic adjustment of the control parameters to balance exploration and exploitation and avoid premature convergence, thus improving the efficiency of the proposed TVP. The former part varies from 1 to − 1 as t approaches MaxIter, which allows the gradual reduction of the search radius, which helps to refine the solutions and focus the search on promising areas of the search space. The latter part presents a random element into the control parameter adjustment. The random value rand is uniformly distributed between 0 and 1, which generates a random angle for the sine function. This randomness helps to avoid getting trapped in local optima by exploring different areas of the search space.
Population evaluation and update: Following each optimization cycle, the objective function is computed for the current population of candidate solutions and compared to previous fitness values. The optimal candidate solutions are then retained for subsequent iterations as they prove to be the most effective. This process is important because it helps to ensure that the population of candidate solutions maintains diversity while also improving overall fitness. By selecting the best solutions for the next iteration, the algorithm is able to focus on exploring new areas of the search space while also exploiting promising regions that have already been identified.
4.1 The computational complexity of MTV-SCA
As shown in Algorithm 1, the MTV-SCA consists of four main steps: initialization, distribution, multi-trial vector production, and population evaluation and update. In the initialization step, all N solutions are distributed in the D-dimensional search space with a computational complexity O(ND). The while-loop (lines 6–19), which includes distribution, multi-trial vector production, and population evaluation and update, has a computational complexity of O(N + NSC-TVPD + NPool-TVPD). Given that N = NSC-TVP + NPool-TVP, then the computational complexity of the while-loop for each iteration is simplified to O(N + ND). The movement step for all iterations (T) has a complexity of O(T(N + ND)). Therefore, the overall computational complexity of the MTV-SCA is O(ND + TN + TND) or O(TND).

Multi-trial vector-based sine cosine algorithm (MTV-SCA)
5 Performance evaluation
In this section, we present a comprehensive experimental study and statistical analysis to evaluate the performance of the proposed MTV-SCA. The algorithm’s performance was evaluated through tests for exploration and exploitation, local optima avoidance, and convergence assessment. Various nature-inspired algorithms, including krill herd (KH) [35], grey wolf optimizer (GWO) [11], moth-flame optimization (MFO) [36], whale optimization algorithm (WOA) [12], sine cosine algorithm (SCA) [20], salp swarm algorithm (SSA) [13], henry gas solubility optimization (HGSO) [37], and Archimedes optimization algorithm (AOA) [40] were compared to the proposed algorithm under consideration to assess its performance. Additionally, we extend our comparative analysis to include three algorithms: fitness-dependent optimizer (FDO) [38], chimp optimization algorithm (ChOA) [39], and fox-inspired optimization (FOX) [41], presenting their performance in separate tables for clarity and comparison. The proposed MTV-SCA is also evaluated against state-of-the-art algorithms and well-established algorithms, including particle swarm optimization (PSO) [10], gravitational search algorithm (GSA) [42], adaptive differential evolution with optional external archive (JADE) [43], and the CEC 2017 winner algorithms LSHADE-SPACMA [44] and LSHADE-cnEpSin [45].
5.1 Benchmark test functions and experimental environment
The test functions utilized in the evaluation of the proposed MTV-SCA are from the CEC 2018 benchmark suite [34], comprising of (F1, F3), simple multimodal (F4–F10), hybrid (F11–F20), and composition functions (F21–F30). The purpose of the functions was to serve as an appropriate benchmark for evaluating the algorithm’s exploration, exploitation, convergence behavior, balance between exploration and exploitation, and local optima avoidance capabilities. The implementation of the MTV-SCA was carried out using Matlab R2018a, and tested on a computer with an Intel Core i7-3770 processor running at 3.4 GHz with 8.00 GB of RAM.
5.2 Experimental setup
For this study, all comparative algorithms were established utilizing the identical parameter values as recommended by their respective works, as outlined in Table 2. To evaluate each algorithm’s performance, 20 independent runs of the benchmark functions were executed with dimensions of 10, 30, and 50. The maximum number of iterations (MaxIter) was established based on the problem’s dimension (Dim) and set to (Dim × 10,000)/N, where N is 100. The results were reported based on the fitness error, f(Fbest) − f(X*), where f(Fbest) represents the minimum fitness value obtained, and f(X*) is the global optimum. The mean, standard deviation, and minimum of the error value were used to quantify algorithm performance. The detailed experimental results are presented in Tables 4, 5, 6, 7, 8, 9, where the best-obtained error values are bolded, and the overall results are compared. The ‘l/t/w’ displayed in the final three rows of each table signifies the number of losses (l), ties (t), and wins (w).
5.3 Sensitivity analysis
In this subsection, the analysis delves into the diverse values for the initial points of the Chebyshev and sinusoidal functions. The initial point is variable within the range of 0 to 1, and its selection plays a crucial role in shaping the fluctuation pattern of the functions. Specifically, we considered initial values spanning from 0.1 to 0.9. The sensitivity analysis of different values for these two parameters, as presented in Table 3, indicates that an initial value of 0.7 is optimal for both points.
5.4 Exploration and exploitation evaluation
An algorithm’s ability to solve unimodal functions is essential in optimization problems. Unimodal functions have a single optimum solution, which is generally easier to find than multimodal functions with multiple optimum solutions. A good optimization algorithm should quickly converge to the global optimum solution while avoiding getting trapped in local optima. In this regard, algorithms with a strong exploitation capability are preferred for solving unimodal functions. Exploitation refers to the process of fine-tuning the current best solution in the search space to converge toward the global optimum. Algorithms with strong exploitation capability achieve this by prioritizing the best candidate solutions in each iteration and using them to explore the search space more intensely. According to the results presented in Tables 4 and 6, the suggested MTV-SCA achieves significantly more precise results for unimodal functions of all dimensions than SCA. This is primarily due to the exploitative nature of the SC-TVP and the ability of S1-TVP to maintain the balance between exploration and exploitation, which is an essential factor in avoiding getting stuck in local optima, a common problem when optimizing unimodal functions. The MTV-SCA has been found to be more effective in employing the optimal solution when compared SCA and benchmark algorithms.
The ability of an algorithm to solve multimodal functions is crucial for successful optimization in real-world applications where the search space is often complex and non-convex. Multimodal functions have multiple local optima, which can trap the search process and hinder the algorithm from finding the global optimum. Therefore, a good multimodal optimization algorithm should possess the ability to explore different areas of the search space and avoid getting stuck in local optima while exploiting promising regions. According to the results presented in Tables 5 and 6, the suggested MTV-SCA achieves significantly more precise results for multimodal functions of all dimensions than SCA and comparative algorithms.
S2-TVP is effective at exploring the search space, which is essential when dealing with complex and high-dimensional optimization problems, such as multimodal functions. S3-TVP is designed to balance exploration and exploitation well, leading to a higher convergence rate. This characteristic is essential when optimizing multimodal functions since finding the global optimum often requires a balance between exploration and exploitation. Finally, S4-TVP aims to balance the exploration and exploitation of the search space and avoid premature convergence, another common issue when optimizing multimodal functions. In summary, the proposed MTV-SCA algorithm’s ability to maintain a balance between exploration and exploitation, combined with its ability to explore and converge effectively, makes it an effective algorithm for solving both unimodal and multimodal functions. In summary, the proposed MTV-SCA algorithm’s ability to maintain a balance between exploration and exploitation, combined with its ability to explore and converge effectively, makes it an effective algorithm for solving both unimodal and multimodal functions.
5.5 Assessing the effectiveness of local optima avoidance
The hybrid and composition functions of CEC 2018 are designed to be challenging optimization problems that combine multiple unimodal and multimodal functions. Hybrid functions combine different unimodal or multimodal functions in a way that makes the search space complex and difficult to explore, while composition functions are constructed by combining multiple functions in a nested way, where the output of one function serves as the input for the next. These functions pose a challenge to optimization algorithms due to their complex search landscape, which includes multiple local optima.
The gained results are shown in Tables 7, 8, 9. Using the proposed MTV-SCA for solving hybrid and composition functions indicates that it effectively explores the search space thoroughly to find promising regions and avoid getting stuck in local optima, while also exploiting the current best solution to refine its search. The S1-TVP strategy implemented in the algorithm helps avoid local optima and ensures that the algorithm explores the search space efficiently. The S2-TVP strategy is also useful in exploring complex and high-dimensional optimization problems, which is crucial for solving hybrid and composite functions. The S3-TVP strategy maintains a good balance between exploration and exploitation, which leads to a higher convergence rate for the algorithm. Additionally, the S4-TVP strategy helps balance the exploration and exploitation of the search space, reducing the likelihood of premature convergence. Overall, the combination of these strategies in the MTV-SCA helps in achieving better results when solving hybrid and composite functions by effectively exploiting, exploring, and maintaining a balance between them.
5.6 Comparison of MTV-SCA with state-of-the-art and well-established algorithms
In this experiment, the proposed MTV-SCA is compared to that of the state-of-the-art algorithm and well-established algorithms particle swarm optimization (PSO) [10], gravitational search algorithm (GSA) [42], and adaptive differential evolution with optional external archive (JADE) [43], and CEC 2017 winner algorithms LSHADE-SPACMA [44] and LSHADE–cnEpSin [45]. The experiments conducted here are based on a maximum population size of 428 and a minimum size of 4 for the LSHADE-SPACMA and LSHADE–cnEpSin. The maximum number of iterations and population size for the other algorithms are set according to their previously defined values. The results of the experiment, presented in terms of mean fitness error, are tabulated in Table 10. These algorithms were independently applied 20 times to the CEC 2018 test functions with a dimensionality of 10. Moreover, the Friedman test is utilized to illustrate the distinction in performance achieved by the proposed MTV-SCA compared to other algorithms.
5.7 Assessing convergence performance
The goal of this experiment is to evaluate the convergence behavior and speed of MTV-SCA against other comparative algorithms. Figure 2 shows the convergence curves for different functions. Each curve represents the mean of the best results from twenty runs of each algorithm. Convergence analysis is important in population-based metaheuristic algorithms because it helps assess the effectiveness and efficiency of the optimization process. In these algorithms, a population of candidate solutions is maintained and iteratively improved using various search strategies. The convergence analysis provides insight into how quickly the algorithm can find the optimal or near-optimal solution and how stable the optimization process is. It helps to determine whether the algorithm is progressing toward finding a good solution. If the algorithm is converging too slowly or not at all, it may indicate that the algorithm’s parameters need to be adjusted or that the algorithm is not well-suited for the specific optimization problem. On the other hand, if the algorithm converges too quickly, it may indicate that the algorithm has become trapped in a local minimum or is not exploring the search space thoroughly enough.

Convergence curves of selected functions
During the optimization process, the MTV-SCA exhibits three convergence behaviors. Firstly, the algorithm experiences early decreasing convergence, where a reasonably good but not necessarily optimal solution is found in the early iterations and then maintained for several iterations, with only minor changes. Secondly, the algorithm undergoes faster convergence in the first half of the iterations, where more significant improvements are made to the solution. Finally, the algorithm exhibits steady improvement in the later iterations, where smaller improvements are made to the solution until a stopping criterion is met. Overall, the combination of these convergence behaviors allows the MTV-SCA to strike a balance between exploration and exploitation throughout the optimization process. The algorithm achieves sufficient convergence, exploitation, and diversity by utilizing the differences between random and the best-obtained solutions. The MTV-SCA’s ability to maintain diversity throughout the optimization process is critical in dealing with complex optimization problems. Moreover, the results show that the MTV-SCA outperforms other comparative algorithms in terms of faster convergence and maintaining diversity in both multimodal and composition functions. Therefore, the MTV-SCA is a promising candidate for solving various optimization problems.
The proposed MTV-SCA surpasses other comparative algorithms in terms of faster convergence on multimodal and composition functions. The algorithm achieves this feat by combining the best solutions obtained in the proposed TVPs and the differences between random solutions, resulting in a suitable equilibrium between exploration and exploitation. The MTV-SCA sustains diversity during optimization by leveraging differences between random solutions. The convergence curves in Fig. 2 exhibit that the MTV-SCA outperforms other algorithms in both hybrid and composition functions. This suggests a balanced exploration and exploitation process in these functions. Additionally, the MTV-SCA effectively addresses challenges in complicated functions by maintaining essential diversity.
6 Statistical analysis
While the experimental findings compared the overall performance of MTV-SCA versus comparative algorithms, they did not assess the statistical significance of these comparisons. Then, two non-parametric tests, Friedman and Wilcoxon signed-rank, are conducted to prove the statistical superiority of the MTV-SCA.
6.1 Friedman test
The Friedman test [46] was used to show that the proposed MTV-SCA is statistically superior to other algorithms. The Friedman test is a non-parametric test that ranks all algorithms according to their performance based on their obtained fitness values. The test does not assume any specific distribution of data which makes it a suitable test for comparing the performance of metaheuristic algorithms while often having unpredictable search behavior and producing diverse outcomes across different problems. Another reason for using the Friedman test is that it takes into account the rank ordering of the algorithms’ performances across multiple problems. This is important because the ranking of algorithms can vary significantly across different problems. By considering the rank ordering rather than the absolute values of the performance metrics, the Friedman test can detect significant differences between algorithms that may not be apparent through other statistical tests. The Friedman test was conducted using Eq. (15) to rank the algorithms based on their fitness values.
where k, n, and Rj are the number of algorithms, case tests, and the mean rank of the jth algorithm, respectively. The evaluation process involves assigning numerical scores to each algorithm/problem combination, with a score of 1 indicating the best-gained result and a score of k indicating the worst-gained result. These scores are then averaged across all problems to produce a comprehensive rating for the algorithm. Algorithms that receive lower scores are deemed superior.
Table 11 presents the results of the Friedman rank test, conducted with a 95% confidence level. The results confirm that the MTV-SCA surpasses other algorithms in a statistically significant manner with regards to dimensions 10, 30, and 50. The non-parametric test has further confirmed the importance of the findings, as indicated by the p-value acquired.
6.2 Wilcoxon signed-rank test
The Wilcoxon signed-rank test is employed to show the difference between the performance gained by the proposed MTV-SCA and other algorithms. In Table 12, these pair-wise statistical test results are demonstrated with a significance value of α = 0.05. The R+ column denotes the sum of ranks in which the MTV-SCA outperforms its competitor, while R− represents the sum of ranks for the functions that the MTV-SCA performs worse than the competitor algorithm. The significant difference between each pair of algorithms is denoted by the p-value column and considered when the p-value < α. The p-value results prove that the proposed MTV-SCA’s superiority is statistically significant compared to the competitor algorithms.
7 Exploring the suitability of MTV-SCA in solving constrained problems
Design optimization problems are prevalent in real-world engineering applications, and solving them effectively can significantly improve design quality and efficiency. Metaheuristic algorithms have become increasingly popular in recent years for addressing such optimization problems due to their ability to find high-quality solutions in complex, multimodal search spaces, even in the presence of constraints. Compared to traditional optimization algorithms, metaheuristic algorithms can achieve better results in less time and can handle problems with high levels of complexity and uncertainty.
This section contains six non-convex constrained engineering problems used to investigate MTV-SCA’s capability to solve real-world engineering problems. Pressure vessel [114], three-bar truss [115], welded beam [116], tension/compression spring [117], speed reducer [118], and gas transmission compressor design problem [119] have all been solved using MTV-SCA and other comparative algorithms. As MTV-SCA is intended to be used for optimization purposes, it should be able to handle the equality and inequality constraints included in these engineering design problems. In this paper, the death penalty function [1] is used to handle constraints, which is one of the most straightforward multi-constraint problem-solving procedures among the many constraint-handling methods. The death penalty function assigns a high fitness value to solutions that violate one or more constraints, thus eliminating infeasible solutions. Each algorithm was run 30 times with the maximum number of iterations and population size (N) set to (D × 104)/N and 20, respectively. The results of these engineering design problems are presented in Tables 13, 14, 15, 16, 17, 18 and demonstrate that MTV-SCA outperformed other methods in addressing real-world mechanical engineering challenges.
-
Pressure vessel design problem
The major aim of this problem, represented in Fig. 3, is optimizing the cost of material, forming, and welding a vessel. The problem has four variables Ts, Th, R, and L. The mathematical representation of this problem is provided in Eq. (16).
$$\text{Consider }\overrightarrow{x}=\left[{x}_{1}{x}_{2}{x}_{3}{x}_{4}\right]=[{T}_{s}{ T}_{h} R L]$$(16)$$\text{minimize }f\left(\overrightarrow{x}\right)=0.6224{x}_{1}{x}_{3}{x}_{4}+1.7781{x}_{2}{x}_{3}^{2}+3.1661{x}_{1}^{2}{x}_{4}+19.84{x}_{1}^{2}{x}_{3}$$$$\text{subject to }{g}_{1}\left(\overrightarrow{x}\right)=-{x}_{1}+0.0193{x}_{3}\le 0,{g}_{2}\left(\overrightarrow{x}\right)=-{x}_{2}+0.00954{x}_{3}\le 0$$$${g}_{3}\left(\overrightarrow{x}\right)=-{\pi {x}_{3}^{2}x}_{4}-\frac{4}{3}\pi {x}_{3}^{3}+\text{1,296,000}\le 0, {g}_{4}\left(\overrightarrow{x}\right)={x}_{4}-240\le 0$$where \(0\le {x}_{i}\le 100\text{ for }i=1, 2\) and \(10\le {x}_{i}\le 200\text{ for }i=3, 4\)
Fig. 3 
Design of pressure vessel
-
Welded beam problem
Determining the minimum cost to fabricate a welded beam is the subject of this design problem. It has four design factors that need to be optimized as shown in Fig. 4 and four restrictions that should be considered. Equation (17) is the mathematical representation of this problem.
$${\text{Consider }}\vec{x} = \left[ {x_{1} x_{2} x_{3} x_{4} } \right] = \left[ {h{ }l{ }t{ }b} \right]$$(17)$$\text{minimize }f\left(\overrightarrow{x}\right)=1.10471{x}_{1}^{2}{x}_{2}+0.04811{x}_{3}{x}_{4}\times (14.0+{x}_{2})$$$$\text{subject to }{g}_{1}\left(\overrightarrow{x}\right)=\uptau \left(\overrightarrow{x}\right)-{\tau }_{max}\le 0,{g}_{2}\left(\overrightarrow{x}\right)=\upsigma \left(\overrightarrow{x}\right)-{\sigma }_{max}\le 0,$$$${g}_{3}\left(\overrightarrow{x}\right)=\updelta \left(\overrightarrow{x}\right)-{\delta }_{max}\le 0$$$${g}_{4}\left(\overrightarrow{x}\right)={x}_{1}-{x}_{4}\le 0,{g}_{5}\left(\overrightarrow{x}\right)=\text{P}-{P}_{\text{c}}\left(\overrightarrow{x}\right)\le 0, {g}_{6}\left(\overrightarrow{x}\right)=0.125-{x}_{1}\le 0$$$${g}_{7}\left(\overrightarrow{x}\right)=1.10471{x}_{1}^{2}+0.04811{x}_{3}{x}_{4}\times \left(14.0+{x}_{2}\right)-0.5\le 0$$where \(0.1\le {x}_{i}\le 2\text{ for }i=1, 2\) and \(0.1\le {x}_{i}\le 10\text{ for }i=3, 4\)
Fig. 4 
Design of welded beam
-
Tension/compression spring design problem
The major goal of this design problem is to reduce the weight of the tension/compression spring. This problem has three design factors, as shown in Fig. 5. Equation (18) is the mathematical representation of this problem.
$$\text{Consider }\overrightarrow{x}=\left[{x}_{1}{x}_{2}{x}_{3}\right]=[d D N]$$(18)$$\text{minimize }f\left(\overrightarrow{x}\right)=({x}_{3}+2){{x}_{2}x}_{1}^{2}$$$$\text{subject to }{g}_{1}\left(\overrightarrow{x}\right)=1-\frac{{x}_{2}^{3}{x}_{3}}{71785{x}_{1}^{2}}\le 0,{g}_{2}\left(\overrightarrow{x}\right)=\frac{{4x}_{2}^{2}-{x}_{1}{x}_{2}}{12566({x}_{2}{x}_{1}^{3}-{x}_{1}^{4})}+\frac{1}{5108{x}_{1}^{2}}\le 0$$$${g}_{3}\left(\overrightarrow{x}\right)=1-\frac{140.45{x}_{1}}{{x}_{2}^{2}{x}_{3}}\le 0,{g}_{4}\left(\overrightarrow{x}\right)=\frac{{x}_{1+}{x}_{2}}{1.5}-1\le 0$$where \(0.05\le {x}_{1}\le 2.00\), \(0.25\le {x}_{2}\le 1.30\),\(2.00\le {x}_{3}\le 15.0\)
Fig. 5 
Design of tension/compression spring
-
Three-bar truss problem
This issue’s purpose is to manufacture a truss with the least weight while still adhering to three limitations. Regarding Fig. 6, two design variables, x1 and x2, should be chosen while considering limits on stress, deflection, and buckling. Equation (19) is the mathematical representation of this problem.
$$\text{Consider }\overrightarrow{x}=\left[{x}_{1}{x}_{2}\right]$$(19)$$\text{minimize }f\left(\overrightarrow{x}\right)=\left(2\sqrt{2}{x}_{1}+{x}_{2}\right)\times l$$$$\text{subject to }{g}_{1}\left(\overrightarrow{x}\right)=\frac{\sqrt{2}{x}_{1}+{x}_{2}}{\sqrt{2}{x}_{1}^{2}+2{x}_{1}{x}_{2}}\text{P}-\upsigma \le 0,{g}_{2}\left(\overrightarrow{x}\right)=\frac{{x}_{2}}{\sqrt{2}{x}_{1}^{2}+2{x}_{1}{x}_{2}}\text{P}-\upsigma \le 0$$$${g}_{3}\left(\overrightarrow{x}\right)=\frac{1}{\sqrt{2}{x}_{2}+{x}_{1}}\text{P}-\upsigma \le 0$$where \(0\le {x}_{1}, {x}_{2}\le 1\), \(l=100 \, cm, P=2 \, kN/c{m}^{2}\), \(\sigma =2 \, kN/c{m}^{2}\).
Fig. 6 
Design of three-bar truss
-
Speed reducer design problem
Taking into consideration the bending stress of the gear teeth, the surface stress, the transverse deflections, and the stresses in the shafts, the goal of this restricted optimization issue is to minimize the weight of the speed reducer. This problem has seven variables, as shown in Fig. 7. The mathematical representation of this problem shown in Eq. (20).
$$\text{Consider }\overrightarrow{x}=\left[{x}_{1}{x}_{2}{x}_{3}{x}_{4}{x}_{5}{x}_{6}{x}_{7}\right]=[b m p {l}_{1} {l}_{2} {d}_{1} {d}_{2}]$$(20)$$\text{minimize }f\left(\overrightarrow{x}\right)=0.7854{x}_{1}{x}_{2}^{2}\left(3.3333{x}_{3}^{2}+14.9334{x}_{3}-43.0934\right)-1.508{x}_{1}\left({x}_{6}^{2}+{x}_{7}^{2}\right)+7.4777\left({x}_{6}^{3}+{x}_{7}^{3}\right)+0.7854\left({x}_{4}{x}_{6}^{2}+{{x}_{5}x}_{7}^{2}\right)$$\(\text{subject to }{g}_{1}\left(\overrightarrow{x}\right)=\frac{27}{{{x}_{1}x}_{2}^{2}{x}_{3}}-1\le 0\),\({g}_{2}\left(\overrightarrow{x}\right)=\frac{397.5}{{{x}_{1}x}_{2}^{2}{x}_{3}^{2}}-1\le 0,\) \({g}_{3}\left(\overrightarrow{x}\right)=\frac{1.93{x}_{4}^{3}}{{{x}_{2}x}_{6}^{4}{x}_{3}}-1\le 0\)
$${g}_{4}\left(\overrightarrow{x}\right)=\frac{1.93{x}_{5}^{3}}{{{x}_{2}x}_{7}^{4}{x}_{3}}-1\le 0,{g}_{5}\left(\overrightarrow{x}\right)=\frac{{\left[{\left(745({x}_{4}/{x}_{2}{x}_{3})\right)}^{2}+16.9\times {10}^{6}\right]}^{1/2}}{110{x}_{6}^{3}}-1\le 0$$$${g}_{6}\left(\overrightarrow{x}\right)=\frac{{\left[{\left(745({x}_{5}/{x}_{2}{x}_{3})\right)}^{2}+157.5\times {10}^{6}\right]}^{1/2}}{85{x}_{7}^{3}}-1\le 0$$$${g}_{7}\left(\overrightarrow{x}\right)=\frac{{x}_{2}{x}_{3}}{40}-1\le 0,{g}_{8}\left(\overrightarrow{x}\right)=\frac{{5x}_{2}}{{x}_{1}}-1\le 0, {g}_{9}\left(\overrightarrow{x}\right)=\frac{{x}_{1}}{{12x}_{2}}-1\le 0$$$${g}_{10}\left(\overrightarrow{x}\right)=\frac{1.5{x}_{6}+1.9}{{x}_{4}}-1\le 0,{g}_{11}\left(\overrightarrow{x}\right)=\frac{1.1{x}_{7}+1.9}{{x}_{5}}-1\le 0$$where \(2.6\le {x}_{1}\le 3.6, 0.7\le {x}_{2}\le 0.8, 17\le {x}_{3}\le 28, 7.3\le {x}_{4}\le 8.3,\)
Fig. 7 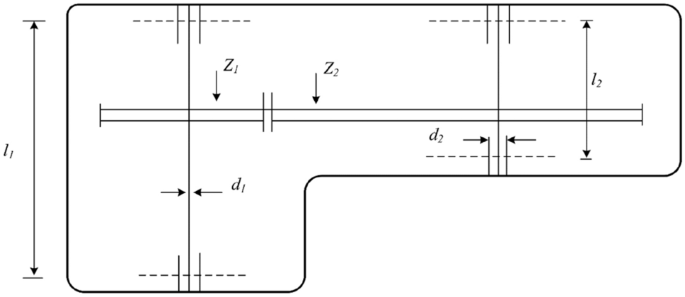
Design of speed reducer
$$7.3\le {x}_{5}\le 8.3, 2.9\le {x}_{6}\le 3.9, 5.0\le {x}_{7}\le 5.5$$ -
Gas transmission compressor design problem
The design of gas transmission compressors aims to minimize the daily cost of gas pipeline transmission systems. This problem, depicted in Fig. 8, involves optimizing four decision variables: x1 for the distance between compressor stations, x2 representing the compression ratio from inlet pressure to the compressor, x3 as the internal pipe diameter in inches, and x4. The total annual cost of the transmission system and its operation is defined by Eq. (21).
Fig. 8 
Design of gas transmission compressor
$$\text{Consider }\overrightarrow{x}=\left[{x}_{1}{x}_{2}{x}_{3}{x}_{4}\right]$$(21)$$\text{minimize }f\left(\overrightarrow{x}\right)=8.61\times {10}^{5}{x}_{1}^{1/2}{x}_{2}{x}_{3}^{-2/3}{x}_{4}^{-1/2}+3.69\times {10}^{4}{x}_{3}+7.72\times {10}^{8}{x}_{1}^{-1}{x}_{2}^{0.219}-765.43\times {10}^{6}{x}_{1}^{-1}$$$$\text{subject to }{x}_{4}{x}_{2}^{-2}+{x}_{2}^{-2}-1\le 0$$$$\text{with bounds }20\le {x}_{1}\le 50, 1\le {x}_{2}\le 10, 20\le {x}_{3}\le \text{50,0.1}\le {x}_{4}\le 60$$






8 Discussion
The proposal of an enhanced variant of metaheuristic algorithms holds significant importance in advancing optimization techniques and addressing the challenges posed by complex real-world problems. The main objective of this study is to enhance the effectiveness of the sine cosine algorithm (SCA) in solving complex optimization problems by integrating multiple search strategies through the multi-trial vector (MTV) approach. The SCA has been found to exhibit limitations in solution accuracy, local optima trapping, exploitation, convergence speed, and stagnation in local optima when confronted with complex optimization problems. The multi-trial vector-based sine cosine algorithm (MTV-SCA) introduced in this study integrates the MTV approach with the single SCA search strategy, aiming to enhance the algorithm’s effectiveness in solving complex optimization problems. MTV-SCA incorporates four distinct search strategies, namely S1-TVP, S2-TVP, S3-TVP, and S4-TVP, along with three control parameters: Chebyshev, sinusoidal, and sin-cos. S1-TVP aims to balance exploration and exploitation, preventing the algorithm from becoming trapped in local optima. It exhibits the fastest convergence speed and performs well on unimodal problems. In contrast, S2-TVP is effective in exploring the search space but has a slower convergence speed and a notable ability for exploration. S3-TVP balances exploration and exploitation and has a higher convergence rate, making it suitable for solving rotated problems. Finally, S4-TVP is designed to balance exploration and exploitation to avoid premature convergence.
The algorithm utilizes a combination of sinusoidal and cosinusoidal functions to adjust the parameter values of the respective TVPs. This adjustment aims to maintain a trade-off between exploiting previously discovered optimal solutions and exploring unexplored regions of the search space. The Chebyshev coefficient enables more efficient exploration by taking larger steps in flat fitness landscapes and smaller steps in rugged regions. The sinusoidal coefficient adjusts the search radius and direction to prevent premature convergence and continue searching for the global optimum. The sin-cos coefficient dynamically adjusts the control parameters, progressively decreasing the search radius and introducing randomness to balance exploration and exploitation. The incorporation of these coefficients improves the algorithm’s ability to explore the search space, mitigate premature convergence, and refine solutions during the search process.
The proposed MTV-SCA algorithm was evaluated using 29 benchmark test functions from the CEC 2018 special session focused on real-parameter optimization problems. Its performance was compared to several state-of-the-art, well-established, CEC 2017 winner algorithms and recently proposed nature-inspired metaheuristic algorithms. The algorithm’s effectiveness was assessed through statistical analysis using the Friedman test and Wilcoxon signed-rank test. Additionally, the MTV-SCA’s capability to solve real-world engineering problems was evaluated in six different cases. The results revealed that the MTV-SCA variant demonstrated superior performance on the majority of test problems. The experimental evaluation, statistical analysis, and solutions obtained for engineering design problems led to the following conclusions:
-
In the evaluation of unimodal functions with dimensions 10, 30, and 50, the MTV-SCA demonstrated notably improved accuracy compared to the SCA algorithm. This improvement can be attributed to two key factors: the exploitative nature of the SC-TVP strategy and the ability of the S1-TVP strategy to maintain a balance between exploration and exploitation. By leveraging the exploitative nature of SC-TVP and effectively managing the exploration–exploitation trade-off with S1-TVP, the MTV-SCA algorithm was able to avoid local optima and effectively utilize the optimal solution.
-
The MTV-SCA demonstrates its effectiveness in exploring the search space for complex and high-dimensional optimization problems through S2-TVP. The MTV-SCA algorithm is able to converge more quickly by effectively balancing exploration of the solution space and exploitation of promising regions, achieved through the S3-TVP. Additionally, S4-TVP prevents premature convergence, a common issue in multimodal function optimization. Overall, the MTV-SCA’s strength lies in maintaining an adept balance between exploring new areas and intensively exploiting already-discovered good regions, along with its capabilities for thorough exploration and rapid convergence, making it a powerful solution for tackling multimodal optimization problems.
-
The evaluation of the MTV-SCA on hybrid and composite functions showcased its effectiveness in thoroughly exploring the search space, avoiding local optima, and refining the search using the current best solution. The S1-TVP strategy played a crucial role in preventing local optima and ensuring efficient exploration. S2-TVP proved beneficial for exploring complex and high-dimensional optimization problems essential for solving hybrid and composite functions. S3-TVP achieved a balance between exploration and exploitation, resulting in a higher convergence rate. Lastly, the S4-TVP strategy helped maintain a balance between exploration and exploitation, minimizing premature convergence
-
The MTV-SCA has demonstrated its efficacy in solving real-world engineering design problems.
9 Conclusions and future work
This study tackles the challenges stochastic algorithms face when dealing with complex problems. It introduces the multi-trial vector-based sine cosine algorithm (MTV-SCA) to improve the traditional sine cosine algorithm (SCA). The SCA often struggles with issues like unbalanced exploration and exploitation, which can lead to premature convergence. The study adapts the multi-trial vector (MTV) approach to overcome these limitations, integrating four trial vector producers to replace the SCA’s search strategy to handle various problem types with differing characteristics.
Through experimental validation using the CEC 2018 test suite, the study demonstrates the superior performance of MTV-SCA compared to existing optimization algorithms in terms of exploration, exploitation, avoidance of local optima, and convergence speed. Statistical tests such as the Friedman and Wilcoxon signed-rank tests confirm the statistical significance of MTV-SCA’s performance, validating its ability to effectively maintain a balanced exploration–exploitation trade-off. Furthermore, the practical applicability of MTV-SCA is showcased through its successful resolution of six engineering design problems, consistently surpassing alternative algorithms in terms of effectiveness and efficiency.
While the proposed algorithm exhibits strengths, it also has specific limitations. The MTV-SCA is introduced to excel in single-objective and continuous optimization problems. However, it is essential to note a significant gap in its capability regarding multi-objective and discrete problems. One particular aspect that may require adjustments is the winner-based distribution policy, which is fine-tuned for the four TVPs utilized in this study. Adapting this policy to handle new trial vectors across diverse problems will be important for maintaining optimal performance. Additionally, it’s worth noting that the performance evaluation of MTV-SCA has not yet encompassed assessments for large-scale global optimization (LSGO) problems. This limitation could potentially affect its effectiveness as problem dimensionality increases.
In future studies, there are various potential directions to explore using the proposed MTV-SCA for enhancing continuous single-objective optimization. Adapting MTV-SCA to tackle binary and multi-objective challenges could extend its utility to address discrete and many-objective optimization problems, broadening its applicability across different domains. Additionally, investigating the use of MTV-SCA in feature selection, clustering, community detection, and scheduling could be advantageous. Lastly, another promising direction for future research would be proposing an aggregate MTV-SCA version. This version would incorporate the search strategies of other algorithms, allowing the trial vector producers of MTV-SCA to benefit from the strengths and diversities of other optimization approaches. Combining the best aspects of different algorithms, the aggregate MTV-SCA could achieve enhanced performance and robustness in solving optimization problems.
Data availability
The experimental data used to support the findings of this study are included within the article.
References
Talbi, E.G.: Metaheuristics: From Design to Implementation. Wiley, Oxford (2009)
Yang, X.-S.: Engineering Optimization: An Introduction with Metaheuristic Applications. Wiley, Oxford (2010)
Yang, X.-S.: Mathematical analysis of nature-inspired algorithms, Nature-inspired algorithms and applied optimization, pp. 1–25. Springer, Berlin (2018)
Halim, A.H., Ismail, I., Das, S.: Performance assessment of the metaheuristic optimization algorithms: an exhaustive review. Artif. Intell. Rev. 54, 2323–2409 (2021)
Wolpert, D.H., Macready, W.G.: No free lunch theorems for optimization. IEEE Trans. Evol. Comput. 1, 67–82 (1997)
Boussaïd, I., Lepagnot, J., Siarry, P.: A survey on optimization metaheuristics. Inf. Sci. 237, 82–117 (2013)
Yang, X.-S.: Nature-Inspired Metaheuristic Algorithms. Luniver Press, Bristol (2010)
Goldberg, D.E., Holland, J.H.: Genetic Algorithms and Machine Learning, pp. 95–99 (1988)
Storn, R., Price, K.: Differential evolution–a simple and efficient heuristic for global optimization over continuous spaces. J. Global Optim. 11, 341–359 (1997)
Eberhart, R., Kennedy, J.: A new optimizer using particle swarm theory, in MHS’95. In: Proceedings of the Sixth International Symposium on Micro Machine and Human Science, Nagoya, Japan, pp. 39–43 (1995)
Mirjalili, S., Mirjalili, S.M., Lewis, A.: Grey wolf optimizer. Adv. Eng. Softw. 69, 46–61 (2014)
Mirjalili, S., Lewis, A.: The whale optimization algorithm. Adv. Eng. Softw. 95, 51–67 (2016)
Mirjalili, S., Gandomi, A.H., Mirjalili, S.Z., Saremi, S., Faris, H., Mirjalili, S.M.: Salp Swarm Algorithm: a bio-inspired optimizer for engineering design problems. Adv. Eng. Softw. 114, 163–191 (2017)
Jiang, Y., Wu, Q., Zhu, S., Zhang, L.: Orca predation algorithm: a novel bio-inspired algorithm for global optimization problems. Expert Syst. Appl. 188, 116026 (2022)
Zhang, W., Pan, K., Li, S., Wang, Y.: Special Forces Algorithm: a novel meta-heuristic method for global optimization. Math. Comput. Simul 213, 394–417 (2023)
El-kenawy, E.-S.M., Khodadadi, N., Mirjalili, S., Abdelhamid, A.A., Eid, M.M., Ibrahim, A.: Greylag goose optimization: nature-inspired optimization algorithm. Expert Syst. Appl. 238, 122147 (2024)
Manohar, K., Logashanmugam, E.: Hybrid deep learning with optimal feature selection for speech emotion recognition using improved meta-heuristic algorithm. Knowl.-Based Syst. 246, 108659 (2022)
Gui, P., He, F., Ling, B.W.-K., Zhang, D.: United equilibrium optimizer for solving multimodal image registration. Knowl.-Based Syst. 233, 107552 (2021)
Nadimi-Shahraki, M.H., Taghian, S., Mirjalili, S.: An improved grey wolf optimizer for solving engineering problems. Expert Syst. Appl. 166, 113917 (2021)
Mirjalili, S.: SCA: a sine cosine algorithm for solving optimization problems. Knowl.-Based Syst. 96, 120–133 (2016)
Eslami, M., Neshat, M., Khalid, S.A.: A novel hybrid sine cosine algorithm and pattern search for optimal coordination of power system damping controllers. Sustainability 14, 541 (2022)
Saha, A.K.: Multi-population-based adaptive sine cosine algorithm with modified mutualism strategy for global optimization. Knowl.-Based Syst. 251, 109326 (2022)
Dasgupta, K., Roy, P.K., Mukherjee, V.: Solution of short term integrated hydrothermal-solar-wind scheduling using sine cosine algorithm. Energ. Strat. Rev. 40, 100824 (2022)
Kuo, R., Setiawan, M.R., Nguyen, T.P.Q.: Sequential clustering and classification using deep learning technique and multi-objective sine-cosine algorithm. Comput. Ind. Eng. 173, 108695 (2022)
Raut, U., Mishra, S.: An improved sine–cosine algorithm for simultaneous network reconfiguration and DG allocation in power distribution systems. Appl. Soft Comput. 92, 106293 (2020)
Li, S., Fang, H., Liu, X.: Parameter optimization of support vector regression based on sine cosine algorithm. Expert Syst. Appl. 91, 63–77 (2018)
Nadimi-Shahraki, M.H., Moeini, E., Taghian, S., Mirjalili, S.: DMFO-CD: a discrete moth-flame optimization algorithm for community detection. Algorithms 14, 314 (2021)
Zhou, W., Wang, P., Heidari, A.A., Zhao, X., Chen, H.: Spiral Gaussian mutation sine cosine algorithm: framework and comprehensive performance optimization. Expert Syst. Appl. 209, 118372 (2022)
Chen, H., Heidari, A.A., Zhao, X., Zhang, L., Chen, H.: Advanced orthogonal learning-driven multi-swarm sine cosine optimization: framework and case studies. Expert Syst. Appl. 144, 113113 (2020)
Abualigah, L., Dulaimi, A.J.: A novel feature selection method for data mining tasks using hybrid sine cosine algorithm and genetic algorithm. Clust. Comput. 24, 2161–2176 (2021)
Nadimi-Shahraki, M.H., Taghian, S., Mirjalili, S., Faris, H.: MTDE: an effective multi-trial vector-based differential evolution algorithm and its applications for engineering design problems. Appl. Soft Comput. 97, 106761 (2020)
Li, Y., Zhao, Y., Liu, J.: Dimension by dimension dynamic sine cosine algorithm for global optimization problems. Appl. Soft Comput. 98, 106933 (2021)
Hamad, Q.S., Samma, H., Suandi, S.A., Mohamad-Saleh, J.: Q-learning embedded sine cosine algorithm (QLESCA). Expert Syst. Appl. 193, 116417 (2022)
Awad, N., Ali, M., Liang, J., Qu, B., Suganthan, P.: Problem Definitions and Evaluation Criteria for the CEC 2017 Special Session and Competition on Single Objective Real-Parameter Numerical Optimization. Nanyang Technological University, Jordan University of Science and Technology and Zhengzhou University, Singapore and Zhenzhou, China, Tech. Rep, vol. 201611 (2016)
Gandomi, A.H., Alavi, A.H.: Krill herd: a new bio-inspired optimization algorithm. Commun. Nonlinear Sci. Numer. Simul. 17, 4831–4845 (2012)
Mirjalili, S.: Moth-flame optimization algorithm: a novel nature-inspired heuristic paradigm. Knowl.-Based Syst. 89, 228–249 (2015)
Hashim, F.A., Houssein, E.H., Mabrouk, M.S., Al-Atabany, W., Mirjalili, S.: Henry gas solubility optimization: a novel physics-based algorithm. Futur. Gener. Comput. Syst. 101, 646–667 (2019)
Abdullah, J.M., Ahmed, T.: Fitness dependent optimizer: inspired by the bee swarming reproductive process. IEEE Access 7, 43473–43486 (2019)
Khishe, M., Mosavi, M.R.: Chimp optimization algorithm. Expert Syst. Appl. 149, 113338 (2020)
Hashim, F.A., Hussain, K., Houssein, E.H., Mabrouk, M.S., Al-Atabany, W.: Archimedes optimization algorithm: a new metaheuristic algorithm for solving optimization problems. Appl. Intell. 51, 1531–1551 (2021)
Mohammed, H., Rashid, T.: FOX: a FOX-inspired optimization algorithm. Appl. Intell. 53, 1030–1050 (2023)
Rashedi, E., Nezamabadi-Pour, H., Saryazdi, S.: GSA: a gravitational search algorithm. Inf. Sci. 179, 2232–2248 (2009)
Zhang, J., Sanderson, A.C.: JADE: adaptive differential evolution with optional external archive. IEEE Trans. Evol. Comput. 13, 945–958 (2009)
Mohamed, A.W., Hadi, A.A., Fattouh, A.M., Jambi, K.M.: LSHADE with semi-parameter adaptation hybrid with CMA-ES for solving CEC 2017 benchmark problems. In: 2017 IEEE Congress on evolutionary computation (CEC), pp. 145–152 (2017)
Awad, N.H., Ali, M.Z., Suganthan, P.N.: Ensemble sinusoidal differential covariance matrix adaptation with Euclidean neighborhood for solving CEC2017 benchmark problems. In: 2017 IEEE congress on evolutionary computation (CEC), pp. 372–379 (2017)
Derrac, J., García, S., Molina, D., Herrera, F.: A practical tutorial on the use of nonparametric statistical tests as a methodology for comparing evolutionary and swarm intelligence algorithms. Swarm Evol. Comput. 1, 3–18 (2011)
Nadimi-Shahraki, M.H., Taghian, S., Mirjalili, S., Ewees, A.A., Abualigah, L., Abd Elaziz, M.: Mtv-mfo: multi-trial vector-based moth-flame optimization algorithm. Symmetry 13, 2388 (2021)
Xu, Y., Zhong, R., Zhang, C., Yu, J.: Multiplayer battle game-inspired optimizer for complex optimization problems. Clust. Comput., 1–25 (2024)
Gu, Q., Li, S., Gong, W., Ning, B., Hu, C., Liao, Z.: L-SHADE with parameter decomposition for photovoltaic modules parameter identification under different temperature and irradiance. Appl. Soft Comput. 143, 110386 (2023)
Zhu, M., Guan, X., Li, Z., He, L., Wang, Z., Cai, K.: sEMG-based lower limb motion prediction using CNN-LSTM with improved PCA optimization algorithm. J. Bionic Eng. 20, 612–627 (2023)
Jain, R., Sharma, N.: A quantum inspired hybrid SSA–GWO algorithm for SLA based task scheduling to improve QoS parameter in cloud computing. Clust. Comput. 26, 3587–3610 (2023)
Nijaguna, G., Babu, J.A., Parameshachari, B., de Prado, R.P., Frnda, J.: Quantum Fruit Fly algorithm and ResNet50-VGG16 for medical diagnosis. Appl. Soft Comput. 136, 110055 (2023)
Wang, X., Dong, X., Zhang, Y., Chen, H.: Crisscross Harris hawks optimizer for global tasks and feature selection. J. Bion. Eng. 20, 1153–1174 (2023)
Navarro, M.A., Oliva, D., Ramos-Michel, A., Haro, E.H.: An analysis on the performance of metaheuristic algorithms for the estimation of parameters in solar cell models. Energy Convers. Manage. 276, 116523 (2023)
Nadimi-Shahraki, M.H., Taghian, S., Zamani, H., Mirjalili, S., Elaziz, M.A.: MMKE: multi-trial vector-based monkey king evolution algorithm and its applications for engineering optimization problems. PLoS ONE 18, e0280006 (2023)
Cui, J., Liu, T., Zhu, M., Xu, Z.: Improved team learning-based grey wolf optimizer for optimization tasks and engineering problems. J. Supercomput. 79, 10864–10914 (2023)
Khodadadi, N., Mirjalili, S.Z., Mirjalili, S.M., Nadim-Shahraki, M.H., Mirjalili, S.: Multi-objective archived-based whale optimization algorithm. In: Handbook of Whale Optimization Algorithm, pp. 169–177. Elsevier, Oxford (2024)
Paryani, S., Neshat, A., Pourghasemi, H.R., Ntona, M.M., Kazakis, N.: A novel hybrid of support vector regression and metaheuristic algorithms for groundwater spring potential mapping. Sci. Total. Environ. 807, 151055 (2022)
El-Kenawy, E.-S.M., Mirjalili, S., Khodadadi, N., Abdelhamid, A.A., Eid, M.M., El-Said, M., et al.: Feature selection in wind speed forecasting systems based on meta-heuristic optimization. PLoS ONE 18, e0278491 (2023)
Rajabi-Kafshgar, A., Gholian-Jouybari, F., Seyedi, I., Hajiaghaei-Keshteli, M.: Utilizing hybrid metaheuristic approach to design an agricultural closed-loop supply chain network. Expert Syst. Appl. 217, 119504 (2023)
Kilimtzidis, S., Kotzakolios, A., Kostopoulos, V.: Efficient structural optimisation of composite materials aircraft wings. Compos. Struct. 303, 116268 (2023)
Nadimi-Shahraki, M.H., Taghian, S., Mirjalili, S., Abualigah, L., Abd Elaziz, M., Oliva, D.: EWOA-OPF: effective whale optimization algorithm to solve optimal power flow problem. Electronics 10, 2975 (2021)
Sa, A., Yv, R.R., Sadiq, A.S.: Traffic flow forecasting using natural selection based hybrid Bald Eagle Search—Grey Wolf optimization algorithm. PLoS ONE 17, e0275104 (2022)
Minh, H.-L., Khatir, S., Rao, R.V., Abdel Wahab, M., Cuong-Le, T.: A variable velocity strategy particle swarm optimization algorithm (VVS-PSO) for damage assessment in structures. Eng. Comput. 39, 1055–1084 (2023)
Zhou, G., Moayedi, H., Foong, L.K.: Teaching–learning-based metaheuristic scheme for modifying neural computing in appraising energy performance of building. Eng. Comput. 37, 3037–3048 (2021)
Nadimi-Shahraki, M.H., Taghian, S., Mirjalili, S., Zamani, H., Bahreininejad, A.: GGWO: gaze cues learning-based grey wolf optimizer and its applications for solving engineering problems. J. Comput. Sci. 61, 101636 (2022)
Suresh, V., Janik, P., Jasinski, M., Guerrero, J.M., Leonowicz, Z.: Microgrid energy management using metaheuristic optimization algorithms. Appl. Soft Comput. 134, 109981 (2023)
Nadimi-Shahraki, M.H., Moeini, E., Taghian, S., Mirjalili, S.: Discrete improved grey wolf optimizer for community detection. J. Bion. Eng. 20, 1–28 (2023)
Javaheri, D., Gorgin, S., Lee, J.-A., Masdari, M.: An improved discrete harris hawk optimization algorithm for efficient workflow scheduling in multi-fog computing. Sustain. Comput. Inform. Syst. 36, 100787 (2022)
Artar, M., Carbas, S.: Discrete sizing design of steel truss bridges through teaching-learning-based and biogeography-based optimization algorithms involving dynamic constraints. Structures 34, 3533–3547 (2021)
Nadimi-Shahraki, M.H., Farhanginasab, H., Taghian, S., Sadiq, A.S., Mirjalili, S.: Multi-trial vector-based whale optimization algorithm. J. Bion. Eng. 21, 1–31 (2024)
Fernandes, F.E., Jr., Yen, G.G.: Pruning of generative adversarial neural networks for medical imaging diagnostics with evolution strategy. Inf. Sci. 558, 91–102 (2021)
Masoudi-Sobhanzadeh, Y., Jafari, B., Parvizpour, S., Pourseif, M.M., Omidi, Y.: A novel multi-objective metaheuristic algorithm for protein-peptide docking and benchmarking on the LEADS-PEP dataset. Comput. Biol. Med. 138, 104896 (2021)
Fallahi, A., Mahnam, M., Niaki, S.T.A.: A discrete differential evolution with local search particle swarm optimization to direct angle and aperture optimization in IMRT treatment planning problem. Appl. Soft Comput. 131, 109798 (2022)
An, F., Sayed, B.T., Parra, R.M.R., Hamad, M.H., Sivaraman, R., Foumani, Z.Z., et al.: Machine learning model for prediction of drug solubility in supercritical solvent: modeling and experimental validation. J. Mol. Liq. 363, 119901 (2022)
Kundu, R., Chattopadhyay, S., Cuevas, E., Sarkar, R.: AltWOA: Altruistic Whale Optimization Algorithm for feature selection on microarray datasets. Comput. Biol. Med. 144, 105349 (2022)
Verma, H., Verma, D., Tiwari, P.K.: A population based hybrid FCM-PSO algorithm for clustering analysis and segmentation of brain image. Expert Syst. Appl. 167, 114121 (2021)
Meenachi, L., Ramakrishnan, S.: Metaheuristic search based feature selection methods for classification of cancer. Pattern Recogn. 119, 108079 (2021)
Nadimi-Shahraki, M.H., Banaie-Dezfouli, M., Zamani, H., Taghian, S., Mirjalili, S.: B-MFO: a binary moth-flame optimization for feature selection from medical datasets. Computers 10, 136 (2021)
Belkhamsa, M., Jarboui, B., Masmoudi, M.: Two metaheuristics for solving no-wait operating room surgery scheduling problem under various resource constraints. Comput. Ind. Eng. 126, 494–506 (2018)
Prabhakar, S.K., Rajaguru, H., Lee, S.-W.: A framework for schizophrenia EEG signal classification with nature inspired optimization algorithms. IEEE Access 8, 39875–39897 (2020)
Kalantzis, G., Shang, C., Lei, Y., Leventouri, T.: Investigations of a GPU-based levy-firefly algorithm for constrained optimization of radiation therapy treatment planning. Swarm Evol. Comput. 26, 191–201 (2016)
Nadimi-Shahraki, M.H., Taghian, S., Mirjalili, S., Abualigah, L.: Binary aquila optimizer for selecting effective features from medical data: a COVID-19 case study. Mathematics 10, 1929 (2022)
Rincon-Garcia, N., Waterson, B., Cherrett, T.J., Salazar-Arrieta, F.: A metaheuristic for the time-dependent vehicle routing problem considering driving hours regulations—an application in city logistics. Transp. Res. Part A Policy Pract. 137, 429–446 (2020)
Maia, M.R., Reula, M., Parreño-Torres, C., Vuppuluri, P.P., Plastino, A., Souza, U.S., et al.: Metaheuristic techniques for the capacitated facility location problem with customer incompatibilities. Soft. Comput. 27, 1–14 (2022)
Tian, J., Hao, X., Huang, J., Huang, J., Gen, M.: Solving slot allocation problem with multiple ATFM measures by using enhanced meta-heuristic algorithm. Comput. Ind. Eng. 160, 107602 (2021)
Ouyang, W., Zhu, X.: Meta-heuristic solver with parallel genetic algorithm framework in airline crew scheduling. Sustainability 15, 1506 (2023)
Hu, X., Chuang, Y.-F.: E-commerce warehouse layout optimization: systematic layout planning using a genetic algorithm. Electron. Comm. Res. 23, 1–18 (2022)
Hosseini, F., Gharehchopogh, F.S., Masdari, M.: MOAEOSCA: an enhanced multi-objective hybrid artificial ecosystem-based optimization with sine cosine algorithm for feature selection in botnet detection in IoT. Multimedia Tools Appl. 82, 13369–13399 (2023)
Hashemi, M., Javaheri, D., Sabbagh, P., Arandian, B., Abnoosian, K.: A multi-objective method for virtual machines allocation in cloud data centres using an improved grey wolf optimization algorithm. IET Commun. 15, 2342–2353 (2021)
Junfeng, D., Li-hui, F.: Application of dynamic baseline adjustment based on swarm intelligence optimization in the signal processing of fiber SPR sensor. Optik 273, 170470 (2023)
Hosseini, E., Sadiq, A.S., Ghafoor, K.Z., Rawat, D.B., Saif, M., Yang, X.: Volcano eruption algorithm for solving optimization problems. Neural Comput. Appl. 33, 2321–2337 (2021)
Aditya, N., Mahapatra, S.S.: Switching from exploration to exploitation in gravitational search algorithm based on diversity with Chaos. Inf. Sci. 635, 298–327 (2023)
Asgharzadeh, H., Ghaffari, A., Masdari, M., Gharehchopogh, F.S.: Anomaly-based intrusion detection system in the internet of things using a convolutional neural network and multi-objective enhanced capuchin search algorithm. J. Parallel Distrib. Comput. 175, 1–21 (2023)
Too, J., Sadiq, A.S., Mirjalili, S.M.: A conditional opposition-based particle swarm optimisation for feature selection. Connect. Sci. 34, 339–361 (2022)
Javaheri, D., Lalbakhsh, P., Hosseinzadeh, M.: A novel method for detecting future generations of targeted and metamorphic malware based on genetic algorithm. IEEE Access 9, 69951–69970 (2021)
Chen, K., Zhou, F., Yin, L., Wang, S., Wang, Y., Wan, F.: A hybrid particle swarm optimizer with sine cosine acceleration coefficients. Inf. Sci. 422, 218–241 (2018)
Chegini, S.N., Bagheri, A., Najafi, F.: PSOSCALF: a new hybrid PSO based on Sine Cosine Algorithm and Levy flight for solving optimization problems. Appl. Soft Comput. 73, 697–726 (2018)
Wang, J., Yang, W., Du, P., Niu, T.: A novel hybrid forecasting system of wind speed based on a newly developed multi-objective sine cosine algorithm. Energy Convers. Manage. 163, 134–150 (2018)
Sindhu, R., Ngadiran, R., Yacob, Y.M., Zahri, N.A.H., Hariharan, M.: Sine–cosine algorithm for feature selection with elitism strategy and new updating mechanism. Neural Comput. Appl. 28, 2947–2958 (2017)
Attia, A.-F., El Sehiemy, R.A., Hasanien, H.M.: Optimal power flow solution in power systems using a novel Sine-Cosine algorithm. Int. J. Electr. Power Energy Syst. 99, 331–343 (2018)
Issa, M., Hassanien, A.E., Oliva, D., Helmi, A., Ziedan, I., Alzohairy, A.: ASCA-PSO: adaptive sine cosine optimization algorithm integrated with particle swarm for pairwise local sequence alignment. Expert Syst. Appl. 99, 56–70 (2018)
Nenavath, H., Jatoth, R.K., Das, S.: A synergy of the sine-cosine algorithm and particle swarm optimizer for improved global optimization and object tracking. Swarm Evol. Comput. 43, 1–30 (2018)
Zhang, Z., Yu, Y., Zheng, S., Todo, Y., Gao, S.: Exploitation enhanced sine cosine algorithm with compromised population diversity for optimization. In: 2018 IEEE International Conference on Progress in Informatics and Computing (PIC), pp. 1–7 (2018)
Gupta, S., Deep, K.: A hybrid self-adaptive sine cosine algorithm with opposition based learning. Expert Syst. Appl. 119, 210–230 (2019)
Guo, W., Wang, Y., Zhao, F., Dai, F.: Riesz fractional derivative elite-guided sine cosine algorithm. Appl. Soft Comput. 81, 105481 (2019)
Long, W., Wu, T., Liang, X., Xu, S.: Solving high-dimensional global optimization problems using an improved sine cosine algorithm. Expert Syst. Appl. 123, 108–126 (2019)
Rizk-Allah, R.M.: An improved sine–cosine algorithm based on orthogonal parallel information for global optimization. Soft. Comput. 23, 7135–7161 (2019)
Chen, H., Wang, M., Zhao, X.: A multi-strategy enhanced sine cosine algorithm for global optimization and constrained practical engineering problems. Appl. Math. Comput. 369, 124872 (2020)
Li, N., Wang, L.: Bare-bones based sine cosine algorithm for global optimization. J. Comput. Sci. 47, 101219 (2020)
Hassan, B.A.: CSCF: a chaotic sine cosine firefly algorithm for practical application problems. Neural Comput. Appl. 33, 7011–7030 (2021)
Li, C., Liang, K., Chen, Y., Pan, M.: An exploitation-boosted sine cosine algorithm for global optimization. Eng. Appl. Artif. Intell. 117, 105620 (2023)
Saremi, S., Mirjalili, S., Lewis, A.: Biogeography-based optimisation with chaos. Neural Comput. Appl. 25, 1077–1097 (2014)
Kannan, B., Kramer, S.N.: An augmented Lagrange multiplier based method for mixed integer discrete continuous optimization and its applications to mechanical design. J. Mech. Des. 116, 405–411 (1994)
Nowacki, H.: Optimization in pre-contract ship design. In: Fujita, Y., Lind, K., Williams, T.J. (eds.) Computer Applications in the Automation of Shipyard Operation and Ship Design, vol. 2, pp. 327–338 (1974)
Coello, C.A.C.: Use of a self-adaptive penalty approach for engineering optimization problems. Comput. Ind. 41, 113–127 (2000)
Arora, J.S.: Introduction to Optimum Design. Elsevier, Oxford (2004)
Golinski, J.: An adaptive optimization system applied to machine synthesis. Mech. Mach. Theory 8, 419–436 (1973)
Beightler, C.S., Phillips, D.T., Dembo, R.S., Reklaitis, G., Woolsey, R.: Applied Geometric Programming. Wiley, New York (1976)
Funding
This research received no funding.
Author information
Authors and Affiliations
Contributions
Mohammad H. Nadimi-Shahraki: Conceptualization, Methodology, Software, Validation, Formal analysis, Investigation, Writing—Original Draft, Writing—Review and Editing, Supervision and Project administration; Shokooh Taghian: Conceptualization, Methodology, Software, Validation, Formal analysis, Investigation, Writing—Original Draft, Writing—Review and Editing; Danial Javaheri: Validation, Formal analysis, Writing—Review and Editing; Ali Safaa Sadiq: Validation, Formal analysis, Writing—Review and Editing; Nima Khodadadi: Validation, Formal analysis, Writing—Review and Editing; Seyedali Mirjalili: Formal analysis, Writing—Review and Editing, Supervision and Project administration.
Corresponding author
Ethics declarations
Conflict of interest
The authors have no competing interests to declare that are relevant to the content of this article.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Nadimi-Shahraki, M.H., Taghian, S., Javaheri, D. et al. MTV-SCA: multi-trial vector-based sine cosine algorithm. Cluster Comput (2024). https://doi.org/10.1007/s10586-024-04602-4
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10586-024-04602-4