
Abstract
Linear discriminant analysis (LDA) is a well-known supervised method that can perform dimensionality reduction and feature extraction effectively. However, traditional LDA-based methods need to be turned into the trace ratio form to compute the closed-form solution, in which the within-class scatter matrix should be nonsingular. In this article, we design a new model named generalized robust linear discriminant analysis (GRLDA) method to tackle this disadvantage and improve the robustness. GRLDA uses \({L}_{\mathrm{2,1}}\)-norm on both loss functions to reduce the influence of outliers and on regularization term to obtain joint sparsity simultaneously. The intrinsic graph and the penalty graph are constructed to characterize the intraclass similarity and interclass separability, respectively. A novel optimization method is proposed to solve the proposed model, in which a quadratic problem on the Stiefel manifold is involved to avoid the inverse computation on a singular matrix. We also analyze the computational complexity rigorously. Finally, the experimental results on face, object, and medical images exhibit the superiority of GRLDA.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
With the development of pattern recognition, dimensionality reduction (DR) algorithms have become more and more accessible [1]. Generally speaking, DR algorithms can reduce model’s computational complexity and run time, alleviating the impact of noisy information [2, 3] and redundant features [4, 5]. As one of the hottest topics in pattern recognition recently, researchers have paid greater attention to DR algorithms. DR algorithms can be used in many practical applications, such as human gait recognition and object identification [6], which aim to find an optimal projection matrix to maintain the most important features [7, 8], and [9].
DR algorithms are classified as linear DR algorithms [10] and non-linear DR algorithms [11] based on whether the mapping functions are linear or nonlinear. The most typical linear DR algorithms include principal component analysis (PCA) and locality preserving projection (LPP). The core idea of PCA is to obtain a set of orthogonal bases and the variance among the reduced data needs to be maximized [12] and the reconstruction error needs to be minimized [13]. In LPP [14], we first assign larger weights to the data points at closer distances. The projection matrix is obtained by minimizing the sum of products between the distances among point pairs and their corresponding weights. Non-linear DR algorithms include locally linear embedding (LLE) [15], isomap [16], and laplacian eigenmaps (LE) [17]. LLE tries to keep the linear relationship between samples in the neighborhood, while the purpose of Isomap is to keep the distance between near-neighbor samples different. And LE is aimed to construct relationships between data from a local approximation perspective.
LDA [13] is a well-known method in the supervised DR field. However, traditional LDA-based algorithms have many disadvantages. For example, on the one hand, LDA is required to be changed to trace ratio form and then utilizes the generalized eigenvalue decomposition (GEVD) method to obtain the closed-form solution [18]. This may result in errors between the optimal solution and the estimated solution since the trace ratio problem is not a convex optimization problem [19]. To solve the trace ratio problem, trace ratio linear discriminant analysis (TRLDA) [20] and ratio sum linear discriminant analysis (RSLDA) [21] were proposed, which effectively overcome this problem. The TRLDA method is a novel formulation of LDA, which can be turned into a quadratic problem with regard to the Stiefel manifold [20], but RSLDA is dedicated to maximizing the ratio of the between-class scatter to the within-class scatter in each dimension [21], so it could avoid selecting features with small variance. On the other hand, LDA aims to preserve the global Euclidean structure and does not preserve the local geometric features of the original high-dimensional data. However, locality is considered to be a more important characteristic than global structure and affects the performance of databases in the real-world applications [22]. As such, a large body of research has been done on various LDA algorithms that concentrate on locality relationships. Marginal Fisher Analysis (MFA) [23], which seeks to learn a more discriminating projection given neighbor information, is one of the most often used algorithms.
However, the above algorithms share a common drawback, i.e., Frobenius norm is used as the basic metric might enlarge the effect of outliers in certain senses. Therefore, some scholars proposed alternative approaches using \({L}_{1}\)-norm to replace the Frobenius norm. Some classical algorithms, such as R1-PCA [24] and LDA-R1 [25], were proposed to improve the robustness. Pang et al. proposed \({L}_{1}\)-norm tensor analysis [26], which can enhance the robustness of the model for tensor feature extraction. Recently, sparse learning has become more and more popular [23,24,25]. One of the most well-known methods, Sparse Principal Component Analysis [27], transforms PCA into a regression-type optimization problem and exerts a quadratic and a lasso regularization terms. Lai et al. proposed a novel sparse method called sparse bilinear discriminant analysis (SBDA [6]) to obtain the sparse subspace for gait recognition. However, Nie et al. point out that \({L}_{1}\)-norm enlarges the gaps among data points and degrades the subsequent classification performance [28]. He pointed out that \(\mathrm{L}\) -norm integrates the advantage for distance measurement of \({L}_{2}\) -norm and sparsity for enhancing the robustness of \({L}_{1}\) -norm [28].
Although the aforementioned algorithms, such as new formulation of TRLDA and RSLDA, are able to release trace ratio problem, they are still sensitive to outliers. Despite the fact that the effect of outliers can be suppressed by R1-PCA and LDA-R1, they cannot guarantee joint sparsity. Nie et al. [29] first pointed out that the mean value calculated by \({L}_{2}\) -norm is not optimal, and they proposed a novel robust PCA with an optimal re-weighted mean. Then, Zhao et al. [30] proposed a robust LDA measured by \({L}_{\mathrm{2,1}}\) -norm which can alleviate the influence of outliers. Even though extensive algorithms based on \({L}_{\mathrm{2,1}}\) -norm are proposed on different occasions, they do not use the local information of the original data effectively. Lai et al. [31] proposed a rotational invariant framework using \({L}_{\mathrm{2,1}}\) -norm as the basic metric, including rotational invariant LDA (RILDA) and rotational invariant MFA (RIMFA) which use \({L}_{\mathrm{2,1}}\) -norm as the measurement on scatter matrices to reduce the impact of outliers. Then, in [32], locally joint sparse marginal embedding (LJSME) was proposed by Mo et al. which can break through the small sample size (SSS) problem and enhance the ability to preserve the locality relationships with the joint sparsity simultaneously. Lin et al. [33] proposed the generalized robust multiview discriminant analysis (GRMDA) method for addressing the SSS problem of LDA in multiple-view scenarios. Drawing inspiration from the robust discriminative ability of LDA and the benefits of feature extraction with \({L}_{2,p}\) -norm regularization, Li et al. [34] proposed STR-LDA for classification tasks. Singular value decomposition served as inspiration for the development of JSOLDA [35], a brand-new subspace learning technique that addresses the challenge of obtaining orthogonal sparse solutions in OLDA. However, the last three methods are essentially the trace ratio optimization problem [19], and finally, eigenvalue decomposition is used to obtain the optimal solution. Therefore, to improve the performance of LDA-based methods for classification, a more robust and effective method is essential.
In this article, we propose a new LDA algorithm called generalized robust linear discriminant analysis (GRLDA) for feature extraction. This method is capable of releasing the SSS problem in the LDA-based methods and meanwhile ensuring locality preservation in a robust and effective form to obtain discriminant projections. Moreover, it can also guarantee the joint sparsity of the projection matrix. The main contributions or novelty of GRLDA are highlighted as follows.
-
1)
Unlike the trace ratio problem, a new robust LDA in the form of trace and square root of trace is proposed, which can be converted into a convex optimization problem so as to obtain the local optimal solution. We prove the equivalence of our proposed method and the trace ratio method. Furthermore, it is possible to circumvent the drawback that the trace ratio problem can only have an approximate solution.
-
2)
Several robust factors are integrated into the proposed GRLDA. Firstly, we construct two weighted graphs, the intrinsic graph and the penalty graph. But different from MFA, two scatter matrices are measured by \({L}_{\mathrm{2,1}}\)-norm so as to preserve the locality relationship with higher reconstruction ability and enhance the robustness to outliers. Meanwhile, we impose the \({L}_{\mathrm{2,1}}\)-norm-based regularization term to ensure that the learned projections are jointly sparse and thus improve the performance of feature selection.
-
3)
To calculate the best answer to the corresponding optimization problem, we design an iterative method. Additionally, the computational complexity is examined. Numerous tests have shown that the suggested GRLDA can outperform most algorithms and that the designed method has a rapid convergence speed.
The remainder of this paper is briefly outlined as follows. In Section 2, we first present some notations and then we will discuss our motivation and the objective function, meanwhile its optimal solution is also shown. The computational complexity is also presented. In Section 3, a series of experiments have been conducted. Finally, we draw a conclusion for this article in Section 6.
2 The proposed method (GRLDA)
In this section, some notations and definitions will be given and then the motivation and the objective function of the model are presented. We will also show how to compute the optimal solution using an iterative algorithm.
2.1 Notations and definitions
Let \(||A|{|}_{P}\) and tr(A) represent \({L}_{P}\) -norm and the trace of the matrix A, respectively. Given a sample matrix \(X=[{x}_{1},{x}_{2},...,{x}_{N}]\in {R}^{d\times N}\) including all the training samples \({\{{x}_{i}\}}_{i=1}^{N}\in {R}^{d}\) in its columns, where N is the number of samples and d is the original dimension. Let \(U\in {R}^{d\times m}\) denote the projection matrix, where m is the subspace dimension.
Given any matrix \(Q=[{q}_{ij}]\in {R}^{m\times n}\), the Frobenius norm of the matrix Q is denoted as:
the \({L}_{\mathrm{2,1}}\) -norm of the matrix Q is denoted as:
Many theoretical analyses and experiments have shown that imposing \({L}_{\mathrm{2,1}}\) -norm as the basic metric on the objective function can ensure joint sparsity. And for any given rotational matrix A,\(||QA|{|}_{\mathrm{2,1}}=||Q|{|}_{\mathrm{2,1}}\). In [36], Nie et al. pointed out that this characteristic is rotational invariant.
2.2 Motivation and objective function
Numerous techniques have been developed to mitigate the adverse impact of traditional LDA on outliers. However, there are still many drawbacks. Firstly, they cannot preserve the local structure of data [37]. However, this characteristic makes differences in reconstructing the locality relationship in a low-dimensional space. Secondly, those extensions of LDA that keep the locality relationships are required to be transformed into another form and then adopt GEVD so that the within-class scatter matrix is required to be non-singular. Therefore, we cannot obtain the closed-form solution if the sample size is very small. Moreover, the GEVD of between-class scatter matrix and within-class scatter matrix can only approximate the true value. Last but not least, despite the fact that some algorithms take the SSS and trace ratio problems into account, they do not consider joint sparsity [38]. Therefore, in this paper, we propose a generalized robust linear discriminant analysis (GRLDA) for feature extraction and dimensionality reduction. This approach addresses the joint sparsity utilizing \({L}_{\mathrm{2,1}}\) -norm as the basic metric on the regularization term as well as the primary component to increase the robustness. It also inherits the property of RIMFA in addition to taking into account the benefits of TRLDA.
The local within-class and local between-class scatter using \({L}_{\mathrm{2,1}}\) -norm as the basic metric can be computed as follows:
where \({W}_{ij}^{w}\) and \({W}_{ij}^{b}\) are defined the same as MFA [23] and the new sample matrix \({X}_{Gw}\) and \({X}_{Gb}\) are defined as:
and the two diagonal matrices are defined as:
We denote \({S}_{Gw}={X}_{Gw}^{T}{D}_{Gw}{X}_{Gw}\) and \({S}_{Gw}={X}_{Gb}^{T}{D}_{Gb}{X}_{Gb}\), and according to the definition of \({L}_{\mathrm{2,1}}\) -norm, a diagonal matrix D with the i-th diagonal element is defined as:
where \({u}^{i}\) denotes the i-th row of the matrix U.
RIMFA aims to learn the projection matrix U by maximizing the interclass separability and minimizing the intraclass compactness simultaneously. The objective function of RIMFA is as follows:
The optimal U of RIMFA could be obtained by the eigenvalue decomposition of the matrix \({S}_{Gw}^{-1}{S}_{Gb}\). However, when the number of training samples is very small, the inversion of within-class scatter matrix does not exist. The most commonly used method is to add a regularization term to the within-class scatter matrix. Therefore, the eigenvalue decomposition of \({S}_{Gw}\) and \({S}_{Gb}\) can only approximate the true value. Since the optimal solution of RIMFA cannot be obtained directly, it is natural to construct a novel function with respect to U and a learnable variable s, which is equivalent to the problem (10):
We can know that the Eq. (11) is equivalent to the Eq. (10) from the following theorem.
Theorem 1
The optimization problem in (11) is equivalent to the trace ratio problem (10).
Proof
The optimal solution of s can be obtained by taking the derivative of (11) with respect to s and setting it to be 0, we get.
Substitute the optimal s into the problem (11), we get
which completes the proof. □
With the above preparations and ensuring the joint sparsity of the projection matrix, the objective function of GRLDA is finally defined as follows:
2.3 The optimization
In problem (14), there are 2 iterative variables, i.e., projection matrix U, balance parameter s. In this paper, we firstly fix U to iterate s, then fix s to compute U.
-
1)
Fix \(U\) to update s
We can easily get the updated s by setting the derivative with respect to (w.r.t.) s to 0, then we have:
$$s=\frac{\sqrt{tr({U}^{T}{S}_{Gb}U)}}{tr({U}^{T}{S}_{Gw}U)}$$(15) -
2)
Fix s to update U
For updating the matrix U, it is worthwhile for us to introduce a theorem proposed by Nie [29], which is a solution to the maximization problem as follows:
$$\underset{m\in \Omega }{\mathrm{max}}{\sum }_{i}{f}_{i}({h}_{i}(m))$$(16)where \({f}_{i}({h}_{i}(m))\le 0\) is required to be an arbitrary convex function w.r.t.\({h}_{i}(m)\) under the arbitrary constraint of \(m\in \Omega\). Before introducing the theorem, we firstly give the following lemma.
Lemma1 [39]
Assume m is a matrix, vector or scalar, f(m) is a scalar output function while h(m) is arbitrary whether it is a matrix, vector or scalar. Then we can get the following equality:
which is also called Chain-Rule.
The Lagrange function of the problem (16) is given as follows:
Take the derivative of the Eq. (18) and use the lemma 1, we have the following derivation:
For simplicity, we suppose:
Namely, (20) is the Lagrange function of the following optimization problem [20]:
With the aforementioned preparations, we present the following theorem to compute the problem (14).
Theorem 2:
The solution to the optimization problem (16) can be obtained by the following iterative procedure [20].
-
1)
Initialize m that satisfies \(m\in \Omega\);
-
2)
Compute \({G}_{i}={{f}^{\prime}}_{i}({h}_{i}(m))\), where \({{f}^{\prime}}_{i}({h}_{i}(m))\) is an arbitrary super gradient of the function \({f}_{i}(m)\) at the point \({h}_{i}(m)\);
-
3)
Obtain the optimal \(m*\) of the problem (21);
-
4)
Update \(m\leftarrow m*\).
-
5)
Repeat 2) – 4) until convergence.
The proof of the theorem 2 is in the appendix. According to the theorem 2, we are required to convert the problem (14) into a convex function w.r.t.\(U\) as follows:
Where \(a\),\(\widetilde{D}=\alpha (\gamma I-D)\), \(\beta\) and \(\gamma\) need to be large enough to make \({\widetilde{S}}_{Gw}\) and \(\widetilde{D}\) be positive semi-definite (PSD). From (22), we can obviously know the first and third term are convex terms. It is necessary for us to prove the second term is a convex term but firstly we need to introduce Lemma 2.
Lemma 2 [21]
If \(f(s)\) is a linear output function, and \(F(s)\) is a convex function, then \(F(f(s))\) is still convex.
Proof
If \(f(s)\) is a linear output function, and \(F(s)\) is a convex function, then according to the definition of convex function, we have:
which proves that \(F(f(s))\) is still a convex function. □
We can easily know that \({S}_{Gb}\) is a PSD matrix so a corresponding matrix \(P\in {R}^{n\times d}\) can be found which satisfies \({S}_{Gb}={P}^{T}P\), then we get:
where \(R=PU\in {R}^{n\times m}\). It is easy to know that \(||\cdot |{|}_{F}^{2}\) is a convex function, and in each iteration, P is a constant matrix, so R(U) is a linear function w.r.t. U. According to the lemma 2, we can conclude that the second term of problem (22) is convex.
For simplicity, we denote \({\widetilde{S}}_{Gb}=s{S}_{Gb}U/\sqrt{tr({U}^{T}{S}_{Gb}U)}\), so the objective function can be rewritten as:
where\({f}_{i}({u}_{i})={u}_{i}^{T}{\widetilde{S}}_{Gw}{u}_{i}+2{u}_{i}^{T}{({\widetilde{S}}_{Gb})}_{i}+{u}_{i}^{T}\widetilde{D}{u}_{i}\),\({h}_{i}({u}_{i})={u}_{i}\),\({u}_{i}\) denotes the \(i\mathrm{-th}\) column of the matrix U. It is easy to know that \({f}_{i}({u}_{i})\) is a convex function. According to the theorem 1, the convex optimization problem (25) can be rewritten as:
where a and \(C=\left[c_1,c_2,...,c_m\right]\) . The optimal U* can be gained by the following method [21].
Firstly, we adopt the Singular Value Decomposition on C, and we get \(\widetilde{U}\in {R}^{d\times d}\) and \(V\in {R}^{m\times m}\) which satisfy \(C=\widetilde{U}\Sigma {V}^{T}\). Then we will have:
where \(Z={V}^{T}{U}^{T}\widetilde{U}\in {R}^{m\times d}\). We can easily know that \(Z{Z}^{T}={I}_{m}\in {R}^{m\times m}\),\({\sigma }_{ii}\) and \({\mathrm{z}}_{ii}\) are diagonal elements of Σ and \(Z\), so \({z}_{ii},(i=\mathrm{1,2},3,...,m)\) is no more than 1. That means that the function \(tr(\Sigma Z)\) can be maximized when all of the diagonal elements of Z are equal to 1. According to \(Z={V}^{T}{U}^{T}\widetilde{U}\in {R}^{m\times d}\), the optimal U can be obtained by \({U}^{*}=\widetilde{U}{Z}^{T}{V}^{T}=\widetilde{U}[{I}_{m};{0}_{(d-m)\times m}]{V}^{T}\). The optimal \({U}^{*}\) of problem (22) can be obtained via Algorithm 1. The whole algorithm flow is shown in Table 1

For solving the problem (22)
.
2.4 Computational complexity
From the proposed GRLDA algorithm, we can know that the outer loop is to update s, \(D_{Gw}\) , DGb, and the inner loop is to update the projection matrix U. The inner loop consists of three parts: computing the matrix C, adopting the full SVD of C, updating the projection matrix U. The computational complexity of both computing the matrix \(C\in {R}^{d\times m}\) and performing the full SVD on the matrix C is \(O(m{d}^{2})\) . The outer loop consists of computing s,\({\widetilde{S}}_{Gw}\) , \({\widetilde{S}}_{Gw}\) and updating \({D}_{Gw}\),\({D}_{Gb}\),\(D\), whose complexities are \(O(m{d}^{2})\) at most. Therefore, the total computational complexity of the proposed algorithm is \(O({T}_{1}{T}_{2}m{d}^{2})\), where \({T}_{1}\) and \({T}_{2}\) are the number of outer loop and inner loop iterations. Extensive experiments demonstrate that \({T}_{1}\) is no more than 3 on lots of databases.
3 Experiments
In this section, we compare the proposed GRLDA with some state-of-the-art algorithms including classical dimensionality reduction algorithms and some recent algorithms to illustrate the performance on some well-known databases. The classical dimensionality reduction methods include principle component analysis (PCA) [40], linear discriminant analysis (LDA) [10] and marginal fisher analysis (MFA) [23]. The recent methods include \({L}_{\mathrm{2,1}}\)-norm-based algorithms (i.e. rotational invariant LDA and MFA (RILDA, RIMFA) [31], the \({L}_{\mathrm{2,1}}\)-norm regularized locally joint sparse marginal embedding (LJSME) [32]), trace and square root of trace [18] based algorithms (i.e. trace ratio LDA (TRLDA) [20], ratio sum LDA (RSLDA) [21], sparse trace ratio LDA (STR-LDA) [34]) and jointly sparse orthogonal LDA (JSOLDA) [35]. The original data must be pre-processed because the dimensionality of each image is extremely high and there are very few training samples [41]. As a result, the scatter matrices may contain null space. In order to mitigate the effects of null space and preserve the primary energy, we employ PCA to minimize the dimensionality. Every image had its dimensionality lowered to 200. Next, the primary feature on the COIL-20, FERET, ORL, Extended Yale B, AR, Yale, BreastMNIST, and PneumoniaMNIST databases is extracted using GRLDA. Lastly, additional categorization is performed using the closest neighbor classifier (NN).
3.1 Explorations on Parameter Setting
In the experiment of GRLDA, we first try to find the optimal range of the parameter value from which we can obtain the best performance. We explore the recognition rate with the variable \(\alpha\) variously from \([{10}^{-9},{10}^{-8},...,{10}^{8},{10}^{9}]\) on 5 databases. The recognition rates versus the variable \(\alpha\) are illustrated in Fig. 1a. From the graph shown in Fig. 1a, it can be found that the best parameter area is \([{10}^{2},...,{10}^{9}]\). The potential reason lies in the fact that when the parameter α is larger, the projection obtained through the proposed GRLDA exhibits a greater number of rows with all zeros, which indicates the learned projection matrix is more jointly sparse, ultimately enabling the proposed GRLDA to achieve adaptive feature selection. The recognition rates do not decline significantly like other methods (i.e. LJSME, JSOLDA) when the parameter \(\alpha\) falls within other ranges, so we can conclude that our model is very stable even though the range of parameter \(\alpha\) is very small. For simplicity, we set \(\alpha \in [{10}^{2},{10}^{9}]\) in experiments for each database.

a The recognition rates versus the variation of parameter \(\alpha\) of GRLDA on different databases. The recognition rates versus the subspace dimension of different algorithms on b COIL-20 dataset, on c FERET dataset, on d ORL dataset
3.2 Experiments on COIL-20 Database
The COIL-20 object image database contains a total of 1440 images of 20 different objects, where the image size is \(128\times 128\). The 10 images of the first object with the different pose are shown in Fig. 2a. We randomly select the t(t = 5, 10, 15, 20) images as gallery set [32], and the rest of images are used as probe set [32]. We conduct the experiment to test the performance of GRLDA under the circumstances where images are rotated with 360 degrees. The experiment is conducted a total of 10 times.

The samples of COIL-20 images in (a), FERET images in (b), ORL images in (c), Yale images in (d), Extended Yale B images in (e), AR original images in (f), AR images with block size 10*10 in (g), BreastMNIST images in (h), PneumoniaMNIST images in (i)
The average recognition rates of the feature extraction algorithms (i.e., the proposed GRLDA and PCA, LDA, MFA, RILDA, RIMFA, LJSME, TRLDA, RSLDA, STR-LDA, GSOLDA) when selecting 200 projections are shown in Table 2 and the recognition rates versus subspace dimension using above algorithms are illustrated in Fig. 1b when the training samples are 10. Table 2 illustrates that GRLDA outperforms other algorithms when the number of training samples are 10, 15 and 20. Even though when the number of training samples are 5, the recognition of RSLDA is slightly more than GRLDA but GRLDA also performs very well and obtains the second place. Figure 1b indicates that the proposed GRLDA performs better than other methods at a low dimension and maintains a relatively stable value. Despite the fact that the recognition rate of GRLDA decreases slightly as the subspace dimension rises, it still performs better than other methods.
3.3 A. Experiments on FERET Database
The FERET dataset contains 200 people and every person has 7 images. It is a well-known dataset to test the robustness of many classical methods. Based on the eye area, the original image of each face is automatically cut [42]. The cropped image size is \(40\times 40\). The sample images of the first person are illustrated in Fig. 2b.
In this experiment, we randomly use \(L(L=\mathrm{3,4},5)\) images of each individual as gallery set [32], and we use the remained images as probe set [32]. Table 3 illustrates the recognition rates of different algorithms. Table 3 indicates that the proposed GRLDA fully displays its robustness to outliers against some classical methods such as LDA, MFA etc. Despite the fact that GRLDA is slightly less than RILDA when the training samples are 5, it becomes evident that GRLDA's superiority increases as the number of training samples decreases. We select 6 training samples for example, Fig. 1c depicts the trends of the recognition rates versus the subspace dimension. The figure indicates that GRLDA and STR-LDA are equally effective when the training samples are small and they can both obtain a high recognition rate. Nevertheless, as the dimension rises, GRLDA performs better than STR-LDA and they reach the corresponding peak when the subspace dimension is at 110 and 70, respectively.
3.4 Experiments on ORL Database
The ORL dataset contains 400 images of 40 individuals, where the image size is 56 × 46. In the experiment, we randomly select l(l = 3, 4, 5) images as gallery set [32], and the rest of images are used as probe set [32]. Meanwhile, according to Fig. 1a, we set the parameter \(\alpha\) to be\({10}^{3}\). Table 4 illustrates the average recognition rates of different algorithms. Figure 1d shows that the recognition rates versus the subspace dimension when the training samples are 3. It is obviously that GRLDA performs better than other methods again (Tables 5, 6, 7 and 8).
3.5 Experiments on Extended Yale B Database
The Extended Yale B database is a high-dimensional dataset used for face recognition research. It contains 2414 frontal-facial images with dimensions of 192 × 168 pixels. The dataset includes images of 39 individuals, with an average of about 64 images per person. The images were taken under diverse lighting circumstances and with a range of facial expressions. Figure 2e displays the 10 photos of the initial individual. Like the FERET dataset, the Extended Yale B dataset includes images of faces taken in challenging conditions, leading to the presence of outliers. Table 9 presents the test results of GRLDA and other cutting-edge approaches, with training samples of 5, 10, 15, and 20, respectively. Experimental results demonstrate that our proposed GRLDA approach achieves a recognition rate of approximately 90% on this high-dimensional dataset when the training samples are 20. This performance is notably superior to the present state-of-the-art method STR-LDA. Therefore, our proposed GRLDA is also capable to effectively handle high-dimensional datasets.
3.6 Experiments on AR Database
The AR dataset consists of 3120 images of 120 different individuals, where each image size is \(50\times 40.\) In this experiment, we use a subsection of AR dataset, namely the first 20 images are selected to verify the performance of GRLDA in the case when images are varying with different illustration, expressions and occlusions [43]. We randomly select \(t(t=\mathrm{3,4},5)\) images as gallery set [32], and the rest of images are used as probe set [32].
3.6.1 Robustness Evaluation
To test the robustness of the proposed GRLDA, we randomly add a block noise to each image. The sample images are shown in Fig. 2f and g respectively. Table 10 lists the highest recognition rates, the dimensions, and the standard deviations of different algorithms with different block size. Figure 3a shows that when the training samples are 5, the recognition rates versus the subspace dimension of the original images, and images with block size \(15\times 15,\) \(10\times 10,\) \(5\times 5,\) respectively. Results in Table 10 illustrates the stronger robustness of the proposed GRLDA to the corruption of image than other methods.

a The recognition rates versus the subspace dimension by GRLDA with different block size. b The recognition rates versus the subspace dimension by different methods on the Yale dataset
3.6.2 Face Reconstruction and Learned Projections
In this subsection, we further conduct a series of experiments to explore the reconstructed face images and the projection visualization of the proposed GRLDA and some state-of-the-art methods, i.e., LDA, MFA, RSLDA. We take two kinds of experiments into account. On the one hand, we use the first 5 original images of each individual to train and obtain the learned projections of LDA, MFA, RSLDA, GRLDA. Figure 4a illustrates one original image of the first person. The reconstructed images by LDA, MFA, RSLDA, GRLDA are shown in Fig. 4b-e. In each method, we use the first 50 projections to reconstruct the face image. To explore the learned subspace, we also show the first learned projection of LDA, MFA, RSLDA and GRLDA, respectively in Fig. 4f-i. On the other hand, we use the first 5 images corrupted by the block size \(15\times 15\) to obtain the projection matrix and conduct the same operation as above mentioned. The results are illustrated in Fig. 5 and some conclusions can be drawn from Figs. 4 and 5:

Original images in (a), reconstructed images by LDA (b), MFA (c), RSLDA (d), GRLDA (e); the first projection obtained by LDA (f), MFA (g), RSLDA (h), GRLDA (i)

Images with random block size 15*15 in (a), reconstructed images by LDA (b), MFA (c), RSLDA (d), GRLDA (e); the first projection obtained by LDA (f), MFA (g), RSLDA (h), GRLDA (i)
From Fig. 4h, we know that RSLDA performs well in selecting the most discriminative feature in the original space. However, it cannot effectively avoid the impact of outliers, which is obviously highlighted in Fig. 5h. From Fig. 4b to 4e, it is obvious to see that the reconstructing ability of LDA is the least but GRLDA not only has a relatively good reconstructing ability, but also can find discriminative projections for feature extraction and selection. As we know that GRLDA can reduce the impact of outliers by the \({L}_{\mathrm{2,1}}\)-norm as the basic measurement and the regularized term, and both Fig. 5e and i indicate this theoretical explanation since the images are less influenced by noised block.
3.7 Experiments on Yale Database
The Yale dataset involves a total of 15 people, each with 11 face images, with size of \(100\times 80.\) This dataset contains variations in illumination, facial expression and with or without glasses [43], Fig. 2d shows the sample images of the first person. In this experiment, we randomly choose t(t = 5, 6, 7) images of each individual as gallery set [32], and the rest of images are used as probe set [32]. And the corresponding parameter \(\alpha\) is set in \({10}^{3}\) according to Fig. 1a.
The average recognition rates of different algorithms are shown in Table 5. When the first 6 images of each people were used as gallery set, the testing recognition rates versus the subspace dimension are illustrated in Fig. 3b. Both of them indicates that the proposed GRLDA is robust to small samples and can reach a high recognition in a very low dimension and maintain a good stability.
3.8 Experiments on MedMNIST Database
The MedMNIST dataset comprises a vast collection of standardized biomedical images, consisting of 708,069 2D medical images across 12 different categories and 9,998 3D medical images spanning 6 different types. The dimensions of 2D images are 28 × 28, while the dimensions of 3D images are 28 × 28 × 28. Additionally, the background information of the images is eliminated, making them very suitable for testing machine learning methods. This dataset is utilized for lightweight image classification tasks, encompassing binary classification, multi-classification, ordinary regression, and multi-category tasks. For this study, we specifically chose two datasets, namely BreastMNIST and PneumoniaMNIST, to evaluate the performance of our approach. The sample images of the two subdatasets are shown in Fig. 2h and i. Table 6 provides a more comprehensive overview of the two subdatasets. The experimental results presented in Tables 7 and 8 clearly indicate that GRLDA achieves the highest level of classification accuracy among all the methods tested on breast cancers and pneumonia test datasets. Furthermore, GRLDA also attains the second-highest accuracy on the PneumoniaMNIST validation set.
3.9 Convergence Study
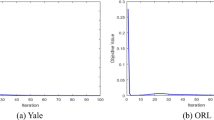
It is interesting and necessary for us to explore how fast GRLDA converges. Figure 6 depicts the objective function value of the proposed GRLDA versus the number of iteration times on different databases. It clearly indicates that the proposed GRLDA can converge within 3 iterations.

Convergence curves of GRLDA on (a) Yale, (b) FERET, (c) COIL-20, (d) AR, (e) ORL, (f) PIE
3.10 Experimental Results and Discussions
The experimental results in terms of the recognition accuracy of the proposed GRLDA and the classical algorithms (i.e., PCA, LDA and MFA), and some methods based on rotational invariant \({L}_{\mathrm{2,1}}\)-norm (i.e., RILDA and RIMFA [31], LJSME [32]) and other new methods (i.e. TRLDA [20], RSLDA [21], STR-LDA [34], and GSOLDA [35]) are listed in tables and figures above, we can draw some interesting conclusions:
-
1.
In most cases, the proposed GRLDA and GSOLDA [35] outperform other algorithms. The main reason is that the loss functions of the two algorithms are based on \({L}_{\mathrm{2,1}}\)-norm so that they are more robust to outliers than methods using \({L}_{2}\)-norm as the basic metric. However, GRLDA not only computes the intraclass and interclass scatter matrices using \({L}_{\mathrm{2,1}}\)-norm, but also defines a new formulation measured by trace and square root of trace, which can obtain the local optimal solution.
-
2.
The performances of rotational invariant algorithms and some classical algorithms approach GRLDA when the training samples are big. However, when the quantity of training samples falls, their performances significantly deteriorate. Furthermore, when the training samples change, GRLDA can retain greater stability. The possible explanation is that, in order to avoid computing the inverse of the intraclass (or interclass) scatter matrix and to obtain the optimal solution, the optimization problem is converted into a quadratic problem on the Stiefel manifold and singular value decomposition is used.
-
3.
Based on the performance statistics of various approaches as the subspace dimension increases, it can be observed that LDA, MFA, and RSLDA are susceptible to variations in the subspace dimension in some datasets. However, in the majority of databases, the suggested GRLDA can successfully overcome this drawback and reach the peak at a very low dimension.
-
4.
In most cases, the proposed GRLDA outperforms RSLDA, which is aimed to maximize the separability of the data point in each dimension of the subspace so that it can obtain the features with more discriminative ability. Figure 4h indicates that. However, when we compare Fig. 4d and e, we can observe that the reconstructing ability of GRLDA is better than RSLDA. The potential reason is that GRLDA preserves the local geometric structure, which is helpful to learn discriminative information and reconstruction ability simultaneously.
4 Conclusion
In this paper, we propose a more robust linear discriminant analysis method incorporating multiple factors and using \({L}_{\mathrm{2,1}}\)-norm as the basic metric on both loss function and regularization term. GRLDA tends to preserve the local geometric structures in the learned subspace with joint sparsity to obtain more discriminative features. Two sub problems can be broken down into an iterative approach that is designed to compute the optimal answer. The ideal solution can be found simply in the first section. The suggested goal function is transformed into a quadratic problem on the Stiefel manifold in the second section, and the best solution is found by applying SVD. This technique effectively avoids computing the inverse of a singular matrix so that the number of samples can be very small. Moreover, we rigorously analyze the computational complexity. Extensive experiments on face, object, and medical databases indicate that the speed of the convergence is very fast and the performance of the proposed GRLDA is superior to most state-of-the-art algorithms.
Data availability
The datasets analyzed during the current study are available in the following databases.
(1) COIL20 database (http://www.cs.columbia.edu/CAVE/software/softlib/coil-20.php),
(2) FERET database (http://www.nist.gov/itl/iad/ig/colorferet.cfm),
(3) ORL database (http://www.uk.research.att.com/facedatabase.html),
(4) AR database (http://www2.ece.ohio-state.edu/~aleix/ARdatabase.html).
(5) MedMNIST database (https://medmnist.com/).
(6) Extended Yale B Database (https://www.kaggle.com/datasets/tbourton/extyalebcroppedpng).
References
Tao D, Tang X, Li X (2006) Direct kernel biased discriminant analysis: a new content based image retrieval relevance feedback algorithm. IEEE Trans Multimed 8(4):716–727
Passalis N, Tefas A (2018) Dimensionality reduction using similarity-induced embeddings. IEEE Trans Neural Netw Learn Syst 29(8):3429–3441
Vashishtha G, Kumar R (2023) Unsupervised learning model of sparse filtering enhanced using wasserstein distance for intelligent fault diagnosis. J Vib Eng Technol 11(7):2985–3002
Lou Q, Deng Z, Choi K-S, Shen H, Wang J, Wang S (2021) Robust multi-label relief feature selection based on fuzzy margin co-optimization, IEEE Trans Emerg Topics Comput Intell, early access
Vashishtha G, Chauhan S, Kumar A, KumarAn R (2022) Ameliorated African Vulture Optimization Algorithm to Diagnose the Rolling Bearing Defects. Meas Sci Technol 33(7):075013
Lai Z, Xu Y, Jin Z, Zhang D (2014) Human gait recognition via sparse discriminant projection learning. IEEE Trans Circuits Syst Video Technol 24(10):1651–1662
Yang L, Song S, Gong Y (2019) Nonparametric dimension reduction via maximizing pairwise separation probability. IEEE Trans Neural Netw Learn Syst 30(10):3205–3210
Bhadra T, Maulik U (2022) Unsupervised Feature Selection Using Iterative Shrinking and Expansion Algorithm. IEEE Trans Emerg Topics Comput Intell 5(5):1453–1462
Vashishtha G, Kumar R (2022) Feature Selection Based on Gaussian Ant Lion Optimizer for Fault Identification in Centrifugal Pump, Recent Advances in Machines and Mechanisms: Select Proceedings of the iNaCoMM 2021. Singapore: Springer Nature Singapore. 295–310
Cunningham JP, Ghahramani Z (2015) Linear dimensionality reduction: Survey, insights, and generalizations. J Mach Learn Research 16(1):2859–2900
Sumithra V, Surendran S (2015) A review of various linear and non linear dimensionality reduction techniques. Int J Comput Sci Inf Technol 6(3):2354–2360
Kwak N (2008) Principal component analysis based on L1-norm maximization. IEEE Trans Pattern Anal Mach Intell 30(9):1672–1680
Martinez AM, Kak AC (2001) PCA versus LDA. IEEE Trans Pattern Anal Mach Intell 23(2):228–233
He X (2004) Locality preserving projections. Proc Adv Neural Inf Process Syst 16(1):186–197
Roweis ST, Saul LK (2000) Nonlinear dimensionality reduction by locally linear embedding, science, 2000, vol. 290, no. 5500, pp. 2323–2326
Balasubramanian M, Schwartz EL (2002) The isomap algorithm and topological stability. Science 295(5552):7–7
Belkin M, Niyogi P (2003) Laplacian eigenmaps for dimensionality reduction and data representation. Neural Comput 15(6):1373–1396
Wen J, Fang X, Cui J, Fei L, Yan K, Chen Y, Xu Y (2018) Robust sparse linear discriminant analysis. IEEE Trans Circuits Syst Video Technol 29(2):390–403
Wang H, Yan S, Xu D, Tang X, Huang T (2007) Trace ratio vs. ratio trace for dimensionality reduction, in Proc IEEE Comput Soc Conf Comput Vision Pattern Recognit, pp. 1–8
Wang J, Wang L, Nie F, Li X (2021) A novel formulation of trace ratio linear discriminant analysis, IEEE Trans Neural Netw Learn Syst, pp. 1–11
Wang J, Wang H, Nie F, Li X (2022) Ratio sum vs. sum ratio for linear discriminant analysis. IEEE Trans Pattern Anal Mach Intell 44(12):10171–10185
Pang Y, Yuan Y (2010) Outlier-resisting graph embedding. Neurocomputing 73(4–6):968–974
Yan S, Xu D, Zhang B, Zhang H-J, Yang Q, Lin S (2006) Graph embedding and extensions: a general framework for dimensionality reduction. IEEE Trans Pattern Anal Mach Intell 29(1):40–51
Ding C, Zhou D, He X, Zha H (2006) R1-PCA: Rotational invariant L1-norm principal component analysis for robust subspace factorization, Proc 23rd Int Conf Mach Learn: 281–288
Li X, Hu W, Wang H, Zhang Z (2010) Linear discriminant analysis using rotational invariant L1-norm. Neurocomputing 73(13–15):2571–2579
Pang Y, Li X, Yuan Y (2010) Robust tensor analysis with L1-norm. IEEE Trans Circuits Syst Video Technol 20(2):172–178
Zou H, Hastie T, Tibshirani R (2004) Sparse principal component analysis. J Comput Graph Stat 15(2):265–286
Nie F, Wang Z, Wang R, Wang Z, Li X (2019) Towards robust discriminative projections learning via non-greedy L2,1-norm minmax. IEEE Trans Pattern Anal Mach Intell 43(6):2086–2100
Nie F, Yuan J, Huang H (2014) Optimal mean robust principal component analysis, Int Conf Mach Learn, PMLR
Zhao H, Wang Z, Nie F (2019) A new formulation of linear discriminant analysis for robust dimensionality reduction. IEEE Trans Knowl Data Eng 31(4):629–640
Lai Z, Xu Y, Yang J, Shen L, Zhang D (2016) Rotational invariant dimensionality reduction algorithms. IEEE Trans Cybern 47(11):3733–3746
Mo D, Lai Z, Wong WK (2019) Locally joint sparse marginal embedding for feature extraction. IEEE Trans Multimed 21(12):3038–3052
Lin Y, Lai Z, Zhou J, Wen J, Kong H (2023) Multiview Jointly Sparse Discriminant Common Subspace Learning. Pattern Recognit 138:109342
Li Z, Nie F, Wu D, Wang Z, Li X (2023) Sparse Trace Ratio LDA for Supervised Feature Selection, IEEE Trans Cybern, early access. https://doi.org/10.1109/TCYB.2023.3264907
Mo D, Lai Z, Zhou J, Hu Q (2023) Scatter matrix decomposition for jointly sparse learning. Pattern Recognit 140:109485
Nie F, Huang H, Cai X, Ding C (2010) Efficient and robust feature selection via joint L2,1-norms minimization, Proc Adv Neural Inf Process Syst, pp. 1813–1821
Wong WK, Zhao HT (2012) Supervised optimal locality preserving projection. Pattern Recognit 45(1):186–197
Yang Y, Shen HT, Ma Z, Huang Z, Zhou X (2011) L2,1-norm regularized discriminative feature selection for unsupervised, IJCAI Int Joint Conf Artif Intell
Nie F, Wu D, Wang R, Li X (2007) Truncated robust principle component analysis with a general optimization framework. IEEE Trans Pattern Anal Mach Intell 40(1):339–342
Turk M, Pentland A (1991) Eigenfaces for recognition. J Cogn Neurosci 3(1):71–86
Ye J, Xiong T, Madigan D (2006) Computational and theoretical analysis of null space and orthogonal linear discriminant analysis J Machine Learn Res, vol. 7, no. 7
Mo D, Lai Z, Wang X, Wong WK (2019) Jointly sparse locality regression for image feature extraction. IEEE Trans Multimed 22(11):2873–2888
Lai Z, Mo D, Wen J, Shen L, Wong WK (2018) Generalized robust regression for jointly sparse subspace learning. IEEE Trans Circuits Syst Video Technol 29(3):756–772
Wang K, He R, Wang L, Wang W, Tan T (2015) Joint feature selection and subspace learning for cross-modal retrieval. IEEE Trans Pattern Anal Mach Intell 38(10):2010–2023
Huang J, Li G, Huang Q, Wu X (2017) Joint feature selection and classification for multilabel learning. IEEE Trans Cybern 47(3):876–889
Shi X, Yang Y, Guo Z, Lai Z (2014) Face recognition by sparse discriminant analysis via joint L2,1-normminimization. Pattern Recognit 47:2447–2453
Author information
Authors and Affiliations
Contributions
All authors contributed to the study conception and design. Material preparation, data collection and analysis were performed by Yufei Zhu, Zhihui Lai, Can Gao, and Heng Kong. The first draft of the manuscript was written by Yufei Zhu and Zhihui Lai, and all authors commented on previous versions of the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
This work was supported in part by the Natural Science Foundation of China under Grant 62272319, and in part by the Natural Science Foundation of Guangdong Province (Grant 2023A1515010677, 2024A1515011637) and Science and Technology Planning Project of Shenzhen Municipality under Grant JCYJ20210324094413037 and JCYJ20220818095803007.
Ethical and informed consent for data used
I confirm that I have obtained informed consent from all participants whose data I used in my research.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix
First, we introduce a lemma as follows:
Lemma 3
Assuming that f(x) is a convex function of x where x can be a scalar, vector or matrix variable, then we obtain:
where f'(x2) is the super-gradient of f(x) at x2.
Proof of the theorem 2
It is easy to know that \({\mathrm{f}}_{\mathrm{i}}({\mathrm{h}}_{\mathrm{i}}(\mathrm{m}))\) is an arbitrary convex function w.r.t. \({\mathrm{h}}_{\mathrm{i}}(\mathrm{m})\) under the arbitrary constraint of \(\mathrm{m}\in\Omega\). We assume that \({\mathrm{f}}_{\mathrm{i}}({\mathrm{h}}_{\mathrm{i}}(\mathrm{m}))\le0\). In the t-th iteration, we denote \({\mathrm{G}}_{\mathrm{i}}^{\mathrm{t}}={{\mathrm{f}}{\prime}}_{\mathrm{i}}({\mathrm{h}}_{\mathrm{i}}({\mathrm{m}}^{\mathrm{t}-1}))\). For each i, according to the lemma 3, we have:
According to (21), the following can be derived:
Summing (29) and (30), we have:
Summing (31) and \({\mathrm{f}}_{\mathrm{i}}({\mathrm{h}}_{\mathrm{i}}(\mathrm{m}))\le 0\), the value of the objective function (16) will monotonically increase until convergence.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Zhu, Y., Lai, Z., Gao, C. et al. Generalized robust linear discriminant analysis for jointly sparse learning. Appl Intell 54, 9508–9523 (2024). https://doi.org/10.1007/s10489-024-05632-6
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-024-05632-6