
Abstract
Pile foundations are often subjected to lateral pressures in addition to axial loads due to earthquakes, ground pressure, and wind pressures in various buildings. As a result, pile foundations have gotten more research than any other type of foundation. Furthermore, estimating the lateral load capacity of a pile (LLCP) accurately is a difficult undertaking, and there has been relatively little study in this field. To overcome these problems, in this study, the adaptive neuro-fuzzy inference system (ANFIS) was ustilized to construct forecasting models for the indirect assessment of LLCP embedded in clay in this work. The fuzzy c-means clustering technique (FCM) and the subtractive clustering method (SCM) were implemented as ANFIS models. The data from open-source literature were used to evaluate the two ANFIS models. In these models, pile length (L), pile diameter (D), undrained shear strength of soil (Su), and eccentricity of load (e) were used as the inputs, while the measured LLCP in clay was the output. To compare the performance of the estimating models, several statistical performance measures were used. The modeling results show that the relationships determined for estimating the LLCP in clay by ANFIS models (ANFIS-SCM and ANFIS-FCM) are accurate and close to the real value. It can also be concluded that the use of ANFIS models to predict the LLCP in clay is very efficient.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Deep foundations are utilized to avoid low-quality soils or to transfer enormous loads to the earth under the buildings. In recent decades, researchers have focused on the design and analysis of deep foundations under various loading situations (Rasouli and Fatahi 2021; Talal Alfach and Al Helwani 2021; Tan et al. 2021). The use of static equilibrium equations to construct axially loaded piles can be a useful strategy; however, solving nonlinear differential equations is the only way to design laterally loaded piles, according to several research contributions (Brinch-Hansen 1961; Broms 1964a, b; Matlock and Reese 1962; Muthukkumaran et al. 2008; Poulos and Davis 1980). Brinch-Hansen (1961) and Bromes (1964a, b) made the first efforts at predicting laterally loaded piles using earth pressure theories. Poulos and Davis (1980) utilized Winkler's soil model to create dynamic equations. Laterally laden piles, on the other hand, are difficult to construct and require the solution of differential equations. The analysis used by Poulos and Davis (1980) is not appropriate for complex soil behavior. Nonlinear PY curves were utilized by Matlock and Reese (1962) to forecast the lateral load capacity for piles. Muthukkumaran et al. (2008) suggested a new approach for drawing the PY curves in level ground subjected to a lateral load for piles. Slope's influence on PY curves was also investigated (Brown et al. 1994). However, due to changes in soil characteristics, these approaches were shown to have a high level of uncertainty in their predictions. As a result, several empirical approaches are used, such as Brinch-Hansen (1961) and Bromes (1964a, b). Begum and Muthukkumaran (2009) investigated the behavior of pile on sloping terrain under lateral load and presented correction factors for calculating their maximum bending moment and lateral load capacity. Muthukkumaran (2014) used a model to investigate the loading direction on laterally loaded pile and impact of slope ain soil.
Although previous efforts have been valuable, empirical models such as the ones discussed above are typically incapable of recognizing the complex patterns seen in datasets. These have been the primary drivers of interest in determining the relationship between output and input factors and proposing a more exact and certain solution. It is helpful to employ existing methods for this purpose, such as computational intelligence approaches, which can successfully simulate the performance of nonlinear and linear involved in data (Das et al. 2011; Mohammadi and Rahmannejad 2010; Muduli et al. 2013; Tarawneh and Imam 2014). For example, the ultimate LLCP estimated by an artificial neural network (ANN) outperformed the Hiley formula, Janbu formula, and Engineering News formula, according to Goh (1995, 1996). Later studies to forecast LLCP using ANN in clayey soils revealed that ANN had a stronger prediction power than previous empirical approaches (Chan et al. 1995; Elgamal et al. 2021; Kiefa 1998; Teh et al. 1997). Using another artificial intelligence method, support vector machine, Samui (2008) found a better forecast than ANN. In other research, Das and Basudhar (2006) applied the ANN model to predict the LLCP in clay. Also, Alkroosh and Nikraz (2013) used a artifitial intelligence model (gene expression programming) for forecasting the LLCP in clay.
In this study, the application of soft computing methods for data analysis named ANFIS model based on FCM and SCM to estimate LLCP in clay is demonstrated.
The advantages of fuzzy systems, which deal with explicit knowledge that can be explained and understood, and ANNs, which deal with implicit knowledge that can be learned, are combined in hybrid systems known as ANFIS. To satisfy particular standards and decrease expenses and design time, ANN learning is an excellent technique to change the expert's knowledge and automatically produce membership functions and extra fuzzy rules. When extrapolation beyond the boundaries of the training data is necessary, fuzzy logic increases an ANN's generalization potential by producing more dependable output. The learning process is data driven rather than knowledge based. Recently, the ANFIS method has been applied by several scientists all over the world in the study of rock/soil mechanics (Fattahi 2016a, 2017; Karimpouli and Fattahi 2018). The well–known research works are discussed in this study. Fattahi et al. (2013) used ANFIS approach to predict damaged zone around underground spaces. Jahed Armaghani et al. (2021) suggested an ANFIS model to estimat bearing capacity of the thin-walled foundations. After constructing the database, numerous models were created and suggested to estimate the carrying capacity of the aforementioned foundations in order to meet the study's goal. Also, based on an ANFIS and a grasshopper optimization method, Fattahi and Hasanipanah (2021) built a novel integrated intelligent model to approximate flyrock. A complete database was employed to achieve the study's goal, which was gathered from three quarry sites in Malaysia. Li et al. (2019) proposed a estimation model based on ANFIS to evaluate and predict curtain grouting efficiency. Geological variables (rock quality designation before grouting, Lugeon value, and fracture intensity), effective grouting operation variables, and tested interval depth are selected as inputs for estimation methods. The indicators for evaluating grouting efficiency (rock quality designation, Lugeon value value, and fracture filled rate after grouting) are chosen as outputs for efficiency evaluation. Fattahi (2016b) proposed using ANFIS to develop a model for prediction of a rock mass's deformation modulus. Grid partitioning, SCM, and FCM were used to implement three ANFIS models. Using field data from railway and road building sites in Korea, the estimating abilities afforded by three ANFIS models were demonstrated. The input parameters for these models were the elastic modulus of intact rock, uniaxial compressive strength of intact rock, depth, and rock mass rating. Babanouri and Fattahi (2020) trained an ANFIS approach combined with a teaching–learning-based optimization algorithm for prediction of the shear strength criteria of rock joints.
In this paper, in ANFIS–FCM and ANFIS–SCM models, length of the pile (L), the diameter of the pile (D), undrained shear strength (Su), and eccentricity of load (e) are used as input parameters while LLCP is the output. Data from open-source literature are used to show the estimating abilities of ANFIS models.
2 The methodology of ANFIS
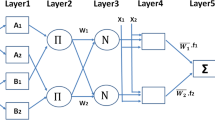
When extrapolation beyond the constraints of the training dataset is necessary, the ANFIS increases the generalization capacity of an ANN by producing more accurate output. Rather than being knowledge based, the learning process is data driven. Figure 1 depicts the ANFIS architecture with two inputs.

A typical ANFIS architecture for a two-inputs Sugeno model (after Jang 1993)
The ANFIS architecture is composed of five layers (Fig. 1), and the following is a quick overview of the concept.
Layer 1 The linguistic label membership grades are provided by each node i in this layer. For example, the ith node's node function is stated in Eq. (1).
where Ai is the linguistic label for this node, x is the input to node i, and \(\left\{ {\sigma_{i} ,V_{i} ,b_{i} } \right\}\) is the variable set that alters the membership function's shape.
Layer 2 Calculate the "firing strength" of rule (Eq. (2)).
Layer 3 As per Eq. (3), determine the ratio of the ith rule's firing strength to the aggregate of all the rule's firing strengths.
Layer 4 Each node i is a node that is stated as in Eq. (4),
\(\overline{W}_{i}\) is the output.
Layer 5 Compute the "overall output," as shown in Eq. (5).
Various identification procedures may be used to create different ANFIS models for a given dataset. The approaches used in this paper to determine the antecedent membership functions were SCM and FCM.
2.1 SCM
The SCM is an appealing solution to ANFIS network synthesis since it automatically calculates cluster location and cluster number. In SCM, each sample is seen as a potential cluster center of all data. This strategy makes computing time proportional to the size of the data while staying independent of the problem dimension (Chopra et al. 2006; Smuda et al. 2007). The SCM was used to find the cluster center. Using the number of subtractive centers, automated membership functions and rule bases, as well as the position of membership function inside dimensions, were constructed. Chiu (1994) proposed an SCM in which data points are assessed as cluster center candidates. The algorithm is the same as before:
-
Step 1: In a M–dimensional space, evaluate a collection of n data points \(\left\{ {X_{1} ,X_{2} ,X_{3} ,...,X_{n} } \right\}.\) Because each data point might be a candidate for a cluster center, a density measure at data point \(X_{i}\) is defined as follows:
$$ D_{i} = \sum\limits_{j = 1}^{n} {\exp } \left( { - \frac{{\left\| {x_{i} - x_{j} } \right\|^{2} }}{{\left( {\frac{{r_{a} }}{2}} \right)^{2} }}} \right) $$(6)A neighborhood is defined by the radius \(r_{a}\), and data points outside of this radius contribute only a little proportion to the density measure.
-
Step 2: After each data point's density value is computed, the dataset with the greatest density measure is chosen as the center of initial cluster. Let \(D_{c1}\) be the density measure and \(X_{c1} ,\) be the selected point. The density value at each dataset \(x_{i}\) is then changed to Eq. (7),
$$ D_{i} = D_{i} - D_{ci} \exp \left( { - \frac{{\left\| {x_{i} - x_{ci} } \right\|^{2} }}{{\left( {\frac{{r_{b} }}{2}} \right)^{2} }}} \right) \, $$(7)where \(r_{b}\) is a constant.
-
Step 3: Choose the next center of cluster \(X_{c2}\) and review all of the data point density estimates once again. This method is continued until there are a sufficient number of cluster centers.
2.2 FCM
The FCM is a data clustering approach that assigns any dataset to a cluster based on its membership grade. This algorithm was created by Bezdek (Bezdek 1973). The following are the steps of the FCM technique:
-
Step 1: Select the centers of cluster \(c_{i} ,\,\,i = 1,2,...,c,\)
-
Step 2: Using Eq. (8), calculate the membership matrix U
$$ \mu_{ij} = \frac{1}{{\sum\nolimits_{k = 1}^{c} {\left( {\frac{{d_{ij} }}{{d_{kj} }}} \right)^{2/m - 1} } }} \, $$(8)The fuzziness index is denoted by the letter m.
-
Step 3: Calculate the objective function using Eq. (9):
$$ J(U,c_{1} , \ldots ,c_{2} ) = \sum\limits_{i = 1}^{c} {J_{i} } = \sum\limits_{i = 1}^{c} \cdot \sum\limits_{j = 1}^{n} {\mu_{ij}^{m} } d_{ij}^{2} \, $$(9) -
step 4: Calculate new c fuzzy cluster centers according to Eq. (10).
$$ c_{i} = \frac{{\sum\nolimits_{j = 1}^{n} {\mu_{ij}^{m} x_{j} } }}{{\sum\nolimits_{j = 1}^{n} {\mu_{ij}^{m} } }} $$(10)go to step 2.
3 Data source and data structure
The major scope of this study is to apply the approaches described above to the problem of LLCP forecasting. The dataset used in this study to ascertain the link between the set of input and output variables was compiled from open-access literature (Rao and Suresh Kumar 1996). There were a total of 38 datasets gathered. The pile length (L), pile diameter (D), undrained shear strength of soil (Su), and eccentricity of load (e) and LLCP are all included in each dataset. A detailed explanation of the reasons for selecting these input parameters, can be found in Rao and Suresh Kumar (1996). Table 1 shows the partial dataset utilized in this investigation. Table 2 also includes descriptive statistics for all datasets.
4 Models performance evaluation
In order to remove any outliers, missing values, or inaccurate data, several preprocessing techniques are often utilized in data-driven system modeling methodologies before any computations. This procedure assures that the raw data obtained from the database is ideal for modeling. All data samples are normalized to fit the range [0, 1] using the following linear mapping function to optimize training and improve prediction accuracy.
where x represents the original value of the dataset, xM represents the mapped value, and xmin (xmax) denotes the min. (max.) raw input values, respectively.
The the Nash–Sutcliffe efficiency (NSE), squared correlation coefficient (R2), and mean square error (MSE) were chosen as the accuracy measures to test the ANFIS models' performance.
The following are the definitions of MSE, R2, and NSE:
where tk and \(\hat{t}_{k}\) are the measured and estimated values, respectively, and n is the sample size.
5 Indirect estimation of LLCP in clay using ANFIS models
The ANFIS models (ANFIS-FCM model and ANFIS-SCM model) were used to construct a forecasting models for indirect prediction of LLCP from existing dataset using the MATLAB software. A dataset comprising 38 data points was utilized in this study, with 30 data points (80%) used to create the model and the remaining data points (20%) used to evaluate the degree of reliability. The process of training the models now was done in 100 epochs. The MSE, NSE, and R2 values obtained for training datasets show the capacity to learn the structure of data samples, whereas the testing dataset results reflect the generalization capacity and resilience of the system modeling methodologies. Table 3 shows the ANFIS models' characterizations. The characterizations of the best models are established through trial and error in this work.
The fuzzy rules number achieved for the ANFIS-FCM and ANFIS-SCM models is 15 rules. In Figs. 2 and 3, the membership functions of the inputs for ANFIS models are presented.


Membership functions achieved using ANFIS–SCM


Membership functions achieved using ANFIS–FCM
A comparison of the performance of two models for training and testing datasets is shown in Table 4. Both the ANFIS–SCM and ANFIS–FCM models were capable of predicting the LLCP in clay, as demonstrated in this Table 4; however, the ANFIS–SCM performs better in training and testing datasets than the ANFIS–FCM.
Table 4 shows that the both ANFIS models performs well and could be used to estimate LLCP indirectly in clay. In addition, throughout the testing and training stages, correlations between estimated LLCP values and measured are provided in Figs. 4 and 5.

Correlations between measured and estimated LLCP values using ANFIS–SCM model: a training dataset, b testing dataset

Correlations between measured and estimated LLCP values using ANFIS–FCM model: a training dataset, b testing dataset
Figures 6 and 7 show a comparison of estimated LLCP values from ANFIS models vs observed values for datasets during the training and testing phases following modeling. The findings of the ANFIS–SCM in connection to real data are presented in Figs. 6 and 7. The ANFIS–SCM has a high level of precision, as shown in Figs. 6 and 7.

Comparison between estimated LLCP using ANFIS–SCM and measured for a training dataset, b testing dataset

Comparison between estimated LLCP using ANFIS–FCM and measured for a training dataset, b testing dataset
6 Discussions
As was already indicated, it appears that ANFIS is a more precise approach for predicting LLCP throughout the testing and training phases. This assertive remark still requires further endorsements. In reality, there is still one point in this area that has to be addressed: Can the performance of the models be altered by varying the training and testing data fractions? To demonstrate how the performance of the models may alter with varied quantities of training and testing data, several tries with various fractions of data would be necessary to answer this question (Fattahi and Bazdar 2017).
Table 5 shows that in virtually all cases, the MSE and R2 of the ANFIS models (for training/testing = 80/20) are lower than those of the other models, indicating that it would be a preferable choice for the prediction process.
7 Conclusion
The analysis for indirect LLCP estimate was examined in this study utilizing ANFIS-FCM and ANFIS-SCM models, and the following findings were reached:
-
D, L, e, and Su are incorporated in order to predict LLCP in clay.
-
The modeling results show that the relationships determined for estimating the LLCP in clay by ANFIS models (ANFIS-SCM and ANFIS-FCM) are accurate and close to the real value after a comparison of two ANFIS models utilizing 38 data samples and performance indices: NSE, MSE, and R2.
-
As a result, ANFIS models may be considered a robust system modeling methodology for forecasting LLCP in clay with a high degree of precision.
-
This study illustrates how the ANFIS approach may be used to simulate a wide range of mining and civil engineering problems.
Data availability
The dataset used in this study was compiled from open-access literature (Rao and Suresh Kumar 1996).
References
Alkroosh I, Nikraz H (2013) Evaluation of pile lateral capacity in clay applying evolutionary approach. Int J Geomate 4:462–465
Babanouri N, Fattahi H (2020) An ANFIS–TLBO criterion for shear failure of rock joints. Soft Comput 24:4759–4773. https://doi.org/10.1007/s00500-019-04230-w
Begum N, Muthukkumaran K (2009) Experimental investigation on single model pile in sloping ground under lateral load. Int J Geotech Eng 3:133–146
Bezdek JC (1973) Fuzzy mathematics in pattern classification. Cornell University, Ithaca
Brinch-Hansen J (1961) The ultimate resistance of rigid piles against transversal forces, Geoteknisk Instit, Bull
Broms BB (1964a) Lateral resistance of piles in cohesionless soils. J Soil Mech Found Div 90:123–156
Broms BB (1964b) Lateral resistance of piles in cohesive soils. J Soil Mech Found Div 90:27–63
Brown DA, Hidden SA, Zhang S (1994) Determination of py curves using inclinometer data. Geotech Test J 17:150–158
Chan W, Chow Y, Liu L (1995) Neural network: an alternative to pile driving formulas. Comput Geotech 17:135–156
Chiu SL (1994) Fuzzy model identification based on cluster estimation. J Intell Fuzzy Syst 2:267–278
Chopra S, Mitra R, Kumar V (2006) Reduction of fuzzy rules and membership functions and its application to fuzzy PI and PD type controllers. Int J Control Autom Syst 4:438
Das SK, Basudhar PK (2006) Undrained lateral load capacity of piles in clay using artificial neural network. Comput Geotech 33:454–459
Das SK, Biswal RK, Sivakugan N, Das B (2011) Classification of slopes and prediction of factor of safety using differential evolution neural networks. Environ Earth Sci 64:201–210
Elgamal A, Elnimr A, Ahmed Dif AE-SN, Gabr A (2021) Prediction of pile bearing capacity using artificial neural networks (Dept C). MEJ Mansoura Eng J 37:1–14
Fattahi H (2016a) Adaptive neuro fuzzy inference system based on fuzzy C–means clustering algorithm, a technique for estimation of TBM peneteration rate. Int J Optim Civ Eng 6:159–171
Fattahi H (2016b) Indirect estimation of deformation modulus of an in situ rock mass: an ANFIS model based on grid partitioning, fuzzy c-means clustering and subtractive clustering. Geosci J 20:681–690. https://doi.org/10.1007/s12303-015-0065-7
Fattahi H (2017) Applying soft computing methods to predict the uniaxial compressive strength of rocks from schmidt hammer rebound values. Comput Geosci 21:665–681
Fattahi H, Bazdar H (2017) Applying improved artificial neural network models to evaluate drilling rate index. Tunn Undergr Space Technol 70:114–124
Fattahi H, Hasanipanah M (2021) An integrated approach of ANFIS-grasshopper optimization algorithm to approximate flyrock distance in mine blasting. Eng Comput. https://doi.org/10.1007/s00366-020-01231-4
Fattahi H, Shojaee S, Farsangi ME (2013) Application of adaptive neuro-fuzzy inference system for the assessment of damaged zone around underground spaces. Int J Optim Civ Eng 3:673–693
Goh A (1995) Empirical design in geotechnics using neural networks. Geotechnique 45:709–714
Goh AT (1996) Pile driving records reanalyzed using neural networks. J Geotech Eng 122:492–495
Jahed Armaghani D, Harandizadeh H, Momeni E (2021) Load carrying capacity assessment of thin-walled foundations: an ANFIS–PNN model optimized by genetic algorithm. Eng Comput. https://doi.org/10.1007/s00366-021-01380-0
Jang JSR (1993) ANFIS: adaptive-network-based fuzzy inference system. IEEE Trans Syst Man Cybern 23:665–685
Karimpouli S, Fattahi H (2018) Estimation of P-and S-wave impedances using Bayesian inversion and adaptive neuro-fuzzy inference system from a carbonate reservoir in Iran. Neural Comput Appl 29:1059–1072
Kiefa MA (1998) General regression neural networks for driven piles in cohesionless soils. J Geotech Geoenviron Eng 124:1177–1185
Li X, Zhong D, Ren B, Fan G, Cui B (2019) Prediction of curtain grouting efficiency based on ANFIS. Bull Eng Geol Environ 78:281–309. https://doi.org/10.1007/s10064-017-1039-y
Matlock H, Reese LC (1962) Generalized solutions for laterally loaded piles. Trans Am Soc Civ Eng 127:1220–1248
Mohammadi H, Rahmannejad R (2010) The estimation of rock mass deformation modulus using regression and artificial neural networks analysis. Arab J Sci Eng 35:205
Muduli PK, Das MR, Samui P, Kumar Das S (2013) Uplift capacity of suction caisson in clay using artificial intelligence techniques. Mar Georesour Geotechnol 31:375–390
Muthukkumaran K (2014) Effect of slope and loading direction on laterally loaded piles in cohesionless soil. Int J Geomech 14:1–7
Muthukkumaran K, Sundaravadivelu R, Gandhi S (2008) Effect of slope on py curves due to surcharge load. Soils Found 48:353–361
Poulos HG, Davis EH (1980) Pile foundation analysis and design, vol Monograph
Rao K, Suresh Kumar V (1996) Measured and predicted response of laterally loaded piles. In: Proceedings of the sixth international conference and exhibition on piling and deep foundations, India, pp 1–16
Rasouli H, Fatahi B (2021) Geosynthetics reinforced interposed layer to protect structures on deep foundations against strike-slip fault rupture. Geotext Geomembr 49:722–736
Samui P (2008) Prediction of friction capacity of driven piles in clay using the support vector machine. Can Geotech J 45:288–295
Smuda J, Dold B, Friese K, Morgenstern P, Glaesser W (2007) Mineralogical and geochemical study of element mobility at the sulfide-rich excelsior waste rock dump from the polymetallic Zn–Pb–(Ag–Bi–Cu) deposit, Cerro De Pasco. Peru J Geochem Explor 92:97–110
Talal Alfach M, Al Helwani A (2021) Seismic interactions between adjacent and crossing bridges on deep foundations in nonlinear soil. Geomech Geoeng 16:163–181
Tan M, Cheng X, Vanapalli S (2021) Simple approaches for the design of shallow and deep foundations for unsaturated soils I: theoretical and experimental studies. Indian Geotech J 51:97–114
Tarawneh B, Imam R (2014) Regression versus artificial neural networks: predicting pile setup from empirical data. KSCE J Civ Eng 18:1018–1027
Teh C, Wong K, Goh A, Jaritngam S (1997) Prediction of pile capacity using neural networks. J Comput Civ Eng 11:129–138
Funding
The authors have not disclosed any funding.
Author information
Authors and Affiliations
Contributions
Conceptualization, methodology, software, validation, investigation, data curation, writing—review and editing, supervision: HF.
Corresponding author
Ethics declarations
Conflict of interests
The authors have not disclosed any conflict of interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Fattahi, H. Applying computational intelligence methods to evaluate lateral load capacity for a pile. Soft Comput 27, 8919–8929 (2023). https://doi.org/10.1007/s00500-022-07801-6
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00500-022-07801-6