
Abstract
Pile as a type of foundation is a structure which can transfer heavy structural loads into the ground. Determination and proper prediction of pile bearing capacity are considered as a very important issue in preliminary design of geotechnical structures. This study attempts to develop several intelligent techniques for prediction of pile bearing capacity in cohesionless soil. To show the effects of fuzzy inference system and imperialism competitive algorithm (ICA) on a pre-developed artificial neural network (ANN), two hybrid ANN models namely ICA-ANN and adoptive neuro-fuzzy inference system (ANFIS) were considered and developed to estimate pile bearing capacity. Then, results of these techniques were compared with those of ANN model and the best one among them was chosen according to the results of performance indices. Several parameters (i.e., internal friction angle of soil located in shaft and tip, effective vertical stress at pile toe, pile area, and pile length) were set as model inputs, while the output is the total driven pile bearing capacity. As a result of the developed models, coefficient of determination (R2) values of (0.895, 0.905), (0.945, 0.958), and (0.967, 0.975) were obtained for training and testing data sets of ANN, ICA-ANN, and ANFIS models, respectively. The results showed that both hybrid models are able to predict bearing capacity with high degree of accuracy; however, ANFIS receives more applicable based on used performance indices and it can be utilized for further researchers and engineers in practice.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
In general, it is too expensive and time consuming to carry out a parametric research on the response of pile (of both bored and driven types) in a static and dynamic load experiment in the field, and it might be confined by scaling impacts at the model scale [1, 2]. Furthermore, a number of field tests need to be carried out in each project. To decrease the cost of a project, it is important to reduce the number of tests needed [3,4,5]. Proposing some intelligent techniques, we can achieve this end. Artificial neural networks (ANN) have been applied very extensively to the solution of several complex problems; this has resulted in a great attention to these networks and their utilization in civil and geotechnical engineering [6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23]. Such popularity is because of its competency in the exploration of complex nonlinear relationships that may exist amongst various parameters.
Literature consists of many studies conducted on the use of the ANN-based models for the purpose of predicting some factors such as the pile settlements [24], the piles’ lateral load capacity, the bearing capacity of pile foundation [25], the effectiveness level of the pile groups that have been installed in regions with sandy soil [26], driven piles in soils that are not cohesive [27], the use of methods that are based on SPT to predict the toe bearing capacity of driven piles [28], and the base resistance of open-ended piles [29]. The design of driven piles in sand was studied by Randolph et al. [30] proposing a design approach that took well into consideration the impacts of confining stress on two elements of sand, i.e., its frictional characteristics and compressibility, which may result in an impact on the end-bearing capacity. At the final step, a comparison is made between the resultant design approach and the in situ data, and the impacts of the most important factors, e.g., the direction of loading, are discussed. Alawneh et al. [31] investigated the axial compressive capacity of driven pile in cohesionless sand. In this solution, post-driving residual stresses were also included. An innovative empirical formulae was applied to friction angle of the sand, average effective vertical stress, relative density, the recognized bearing capacity factor of the piles (Nq and β), as well as the deformability level of the soil when it is underneath the pile toe. A database was constructed containing a total of 28 axially compressive pile load tests. The predicted and measured compressive capacities of an independent database were compared to each other; the obtained results confirmed the accuracy and reliability of the proposed formula. Yang et al. [32] attempted to have a deep insight into how jacked and driven piles behave in sandy soils. They carried out a wide-ranging in situ study aiming at the exploration of the differences and similarities between the way the driven H-piles and jacked H-piles behave. The length of the instrumented piles was fixed between 32 and 55 m having a pile design bearing capacity of up to 3540 kN. Findings showed a correlation between the ultimate shaft friction and the value of mean standard penetration test (N). This suggested that the shaft friction capacity could be taken as 1.5 (N) over bar to 2 (N) over bar (kPa) in case of both driven and jacked H-piles. A research was conducted by Lee et al. [33] to investigate the combined load (i.e., lateral and vertical load) response of the driven pile models in sand. Numerous lateral load experiments were carried out on the pile simultaneously exposed to vertical loads. As shown by findings of combined load test, in cases where a vertical compression load (driven pile installed in sand) exists, the lateral capacity reduces. Consequently, where axial loads existed, a considerable increase (by 10, 36, and 39% for loose, medium dense, and dense sand, respectively) occurred in the bending moments at the pile head. Adopting the approach of MARS (multivariate adaptive regression spline), Samui [34] attempted to explore the ultimate capacity of the driven piles that were installed in sand. In the MARS approach, a variety of parameters are taken into account as input variables, including driven pile area (A), pile length (L), the angle of shear resistance of the soil that surrounds the shaft (φ shaft) and soil at the tip of the derived pile (φ tip), and effective vertical stress at the tip of the pile (σv). On the other hand, its output is the ultimate bearing capacity of the pile. A comparison was made between the results obtained from MARS and those of the other developed ANN-based models, e.g., GRNN (Generalized Regression Neural Network). At the final step, based on the proposed MARS, an equation was provided. The driven pile bearing capacity in clay was tested by Dzagov and Razvodovskii [35], reporting that, based on the properties of the surrounding soil and pile length, the driven piles can arrange for basic characteristics that can be recognized as both end-bearing and/or friction piles. Momeni et al. [18] made use of ANN to predict the shaft and tip resistances of concrete piles. They developed an ANN-based predictive model in a way to efficiently estimate the axial bearing capacity of the bored piles and their distribution. A total of 36 PDA (pile driving analyzer) tests were carried out on different concrete piles for the purpose of constructing the network. The researchers gathered the required data from a variety of project sites. The results obtained from PDA, soil investigation data, and pile geometrical features were applied to the process of constructing the ANN models. As confirmed by findings, ANN was able to predict the ultimate, shaft, and tip bearing resistances of the piles. The coefficients of determination (R2) equaled 0.941, 0.936, and 0.951 for testing data. This showed that the shaft, tip, and ultimate bearing capacities of piles that were predicted by the proposed ANN-based model well conformed those of in situ pile. In addition, sensitivity analysis indicated that length and area of the piles were dominant factors in the developed predicting model.
As mentioned earlier, ANN has been developed extensively for engineering and science fields. Although ANN as a prediction model benefits from various gradient-based learning approaches, two major problems may occur during learning process, i.e., getting trapped in local optima and slow convergence rate [36,37,38,39]. One efficient way of dealing with the mentioned problems is to design hybrid systems of ANN. In this study, two hybrid models, namely, imperialism competitive algorithm (ICA)-ANN and fuzzy inference system (FIS)-ANN or adoptive neuro-fuzzy inference system (ANFIS), were selected and applied to predict bearing capacity of the driven piles. Then, performance of these hybrid models was compared to performance prediction of ANN model and the best one among them was selected. In the following, after some explanations about implemented methods and the used data sets, modeling process of the developed predictive techniques is described. Then, performance prediction of these models is evaluated and compared, and the best model is selected accordingly for prediction of bearing capacity of the driven piles.
2 Methods
2.1 Artificial neural networks
Artificial neural networks refer to methods of parallel information processing capable of expressing the complex and nonlinear relationships using the number of input–output training patterns extracted from experimental data. Using its intrinsic capability, an ANN makes available a nonlinear mapping between inputs and outputs [40]. A neural network architecture that is known as the most popular one is feed-forward neural network wherein the signals or information will be propagated in only one direction; from input towards output [41, 42]. A three-layer feed-forward neural network that is well equipped with back propagation algorithm will be capable of approximating any nonlinear continuous function to an arbitrary accuracy [43]. Training the network is done through optimizing the weights for each node interconnection and bias terms until, at the output layer neurons, the output values are close as much as possible to actual outputs. To learn more about ANN structure and implementation, some other references [44,45,46] can be considered.
2.2 Imperialist competitive algorithm
One of the optimization algorithms is the imperialist competitive algorithm (ICA) developed by Atashpaz-Gargari and Lucas [47]; its performance is on the basis of a global search population technique. The initial step of this algorithm comprises a number of countries as random initial population. In the initial stage of this system, a random number of countries (Ncountry) are created. Then, the countries with the minimum costs or lowest mean-square error (MSE) or root-mean-square error (RMSE) are selected as the imperialists (Nimp) (the most powerful countries), while the rest of the countries are assigned as colonies (Ncol). After that, the colonies are distributed among the empires based on the initial power of the empires. In this system, more colonies are assigned to more powerful imperialists that actually stand for individuals with the minimum costs.
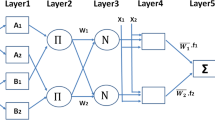
ICA, comparable to other optimization algorithms, involves three operators, i.e., assimilation, revolution, and competition. A colony may turn into imperialist through the assimilation operation. In the revolution operation, position of the countries is subjected to a number of sudden movements. Therefore, during the operations of assimilation and revolution, a colony has chance to get more stable. In the competition operation, the imperialists attempt to gain more colonies, and for all of the empires, it is attractive to take possession of other empires’ colonies. Such competition will cause weaker empires to lose power and stronger empires to gain more and more power. This process goes on until all of the weak empires are totally collapsed or the predefined termination criterion (e.g., RMSE, MSE, or maximum number of decades) is met. Remember that there is a similarity between the number of decades in ICA and the number of generations in genetic algorithm (GA). The ICA algorithm and its structure are shown in Fig. 1. To gain more information about ICA, refer to related studies in the literature [14, 48, 49].

ICA algorithm [50]
2.3 Hybrid algorithms
Literature consists of numerous studies attempting to enhance the performance quality of ANNs using the optimization algorithms such as ICA, particle swarm optimization (PSO), and GA [1, 51,52,53,54,55,56]. BP is known as an algorithm of local search learning; therefore, the optimum search process of ANN may fail to result in an efficient solution. As a result, the optimization algorithms are applicable to the adjustment of biases and weights of ANN in a way to enhance the quality of its performance. Concerning the local minimum in ANN systems, convergence is more probable, while optimization algorithms are capable of discovering a global minimum. Consequently, the hybrid systems (e.g., ICA-ANN) have the chance of using the search properties of ICA and ANN techniques. Within the search space, ICA can search for global minimum; ANN then uses it to find the best results of the whole system.
2.4 ANFIS
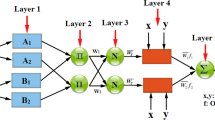
Jang [57] developed ANFIS as a soft computing technique incorporating fuzzy logic into neural networks. This technique has been extensively applied to engineering and earth sciences [58,59,60,61]. ANFIS is capable of simulating and analyzing the mapping relationships between input and output data by a hybrid learning in a way to properly identify the optimal distribution of membership function. As shown in Fig. 2, the base of this technique is the fuzzy “if-then” rules from the Takagi and Sugeno type [62]. This includes two different parts: a premise part and a consequent part. Figure 2 presents the equivalent ANFIS architecture from the Takagi and Sugeno type. In this inference system, it is consisted of five layers each of which contains a number of nodes described by the node function. The output signals released by the nodes existing within the preceding layers actually play the role of input signals in current layer. When the output is manipulated in current layer by the node function, the output serves as input signals for the next layer. In this study, square nodes, also called adaptive nodes, are adopted to show that the parameter sets in these nodes can be well adjusted. On the other hand, the circle nodes, also called fixed nodes, are used to confirm that the parameter sets are completely fixed within the system. Referring to Jang [57], you can find a detailed explanation on the ANFIS procedure.

Architecture of ANFIS [62]
3 Database
In artificial intelligent techniques, there is a need to prepare an appreciate database for a better model development and model evaluation. To predict bearing capacity of the driven piles, the data sets used by Mohanty et al. [63], which is based on in situ driven pile load tests from the installed location, were selected. Therefore, to design intelligent techniques, 59 data sets (see Table 1) were considered where according to Swingler [43], 80% of that (47 data sets) were used for training the systems and 20% of that (12 datasets) was used for testing the systems. In these data sets, angle of shear resistance of soil at the shaft (φ shaft) and at the tip (φ tip) of the pile, effective overburden pressure (σ′v) at the tip of the pile, length of pile (L), and cross-sectional area of pile (A) were set as input parameters to estimate bearing capacity of the piles. The following section is related to designing intelligent systems of this study namely, ANN, ICA-ANN, and ANFIS techniques.
4 Designing intelligent models
4.1 ANN
In the present paper, the normalization of all data sets was done using the following equation:
where X signifies the measured value, Xnorm denotes the normalized value of the measured parameter; Xmax and Xmin stand for the maximum and minimum values of the measured parameters in the data set, respectively. The range of the normalized data is between (0 and 1) using Eq. 1. Considering the normalized data sets, it is expected to get higher performance prediction.
There are many training algorithms for ANN systems. Among them, Levenberg–Marquardt (LM) was selected and utilized to train the ANN systems. Many researchers have highlighted the efficiency of the LM algorithm (among other training algorithms) in solving engineering problems [9, 15, 64,65,66]. The optimal network architecture needs to be identified to accomplish the premier ANN performance. According to Hornik et al. [40], in the network architecture, a single hidden layer is capable estimating any continuous function. As a result, in the present paper, only one hidden layer was employed. Remember that, in the ANN architecture, the most important task is to choose the number of nodes in the hidden layer [67]. Several researchers have proposed a number of relations for the purpose of determining the number of nodes in hidden layers, while Hornik et al. [40] stated that the maximum number of hidden node is ≤ 2 × Ni + 1 (Ni is number of input layers). Based on the number of input parameters, the number of nodes that need to be employed in the hidden layer will be varied from 1 to 11. The next step of the analysis needs to be involved in determining the optimum number of nodes in the hidden layer. Therefore, a parametric investigation was carried out on the optimum number of hidden nodes from 1 to 11. Several ANN models were designed and the best one among them was chosen according to R2 results. The best R2 results were obtained as 0.895 and 0.901 for model development and evaluation, respectively. These results were related to hidden node of 8. Therefore, an ANN structure of 5 × 8 × 1 is suggested for the prediction of bearing capacity of driven piles. More discussion regarding the selected ANN model will be given later.
4.2 ICA-ANN
When modeling the ICA-ANN, parallel to hybrid ANN models, the key factors on ICA (as mentioned earlier, they are Ncountry, Nimp, and Ndecade) need to be recognized and designed. Different values of Ncountry have been applied to the approximation of the problems related to geotechnical engineering. Ahmadi et al. [68], Marto et al. [69], and Hajihassani et al. [70] recommended the values of 40, 56, and 135, respectively, for Ncountry. Findings of the above-mentioned studies indicated that parametric research is required to achieve an appropriate value of Ncountry. As a result, a series of ICA-ANN analyses were carried out using different values of Ncountr in a range between 25 and 500, in which Ndecade was set to 200 and Nimp to 5. As indicated by findings, Ncountry = 300 is able to provide higher performance capacity of the ICA-ANN models compared to the other Ncountry. Thus, in modeling of bearing capacity of the driven piles, the value of 300 was chosen as optimum Ncountry.
The next stage of ICA-ANN involves obtaining the optimum Nimp with respect to another sensitivity analysis. To this end, Nimp was ranged between 5 and 65 to identify the best Nimp in modeling of bearing capacity of the driven piles. Results showed that Nimp = 10 outperformed the other values for the number of imperialists. Thus, optimum Nimp was set to 10. In the next stage of ICA-ANN modeling procedure, Ndecade needs to be determined. To explore how Ndecade affects the network performance, another parametric research required to be carried out. In this part, Ndecade was fixed at 500. The results obtained from the use of different numbers of Ndecade in the estimation of bearing capacity of the driven piles were based on RMSE. The results showed that no significant changes occurred to the network performance (RMSE) after setting Ndecade to 400. Therefore, the optimum Ndecade was fixed at 400 and results of this model were considered for the analysis of ICA-ANN model. R2 values of 0.945 and 0.958 were achieved for training and testing of ICA-ANN model. It should be noted that the suggested ANN architecture (5 × 8 × 1) was considered in ICA-ANN models, as well.
4.3 ANFIS
This study attempts to provide an insight into applying ANFIS to the prediction of bearing capacity of the driven piles. The data sets needed for modeling, similar to the previous parts, were grouped randomly into two separate subsets: 80% for training the model and the rest of the data set was dedicated to testing purposes. The numbers of fuzzy rules, in the present paper, were set by means of a trial/error method. To do this, several models with a variety of fuzzy rule combinations (e.g., 2, 3, etc.) were employed. The final results confirmed that the ANFIS structure with three MFs for each input meaningfully outperformed RMSE. In general, as suggested by the findings of the parametric research, the model is expected to do its best prediction task in case the ANFIS model is trained with 243 fuzzy roles. To each of the inputs, an MF of the type of Gaussian was applied. This type of MF is the most popular MF in the field of fuzzy systems, since it brings both flexibility and simplicity [61, 71,72,73]. The linguistic variables allocated to input parameters are low (L), medium (M), and high (H) in the fuzzy rules. In addition, the type of output membership function was selected linear. Therefore, based on the mentioned structure, five ANFIS models were constructed and their performance was evaluated based on system error. Finally, the best ANFIS model with R2 of 0.967 and 0.975 for training and testing data sets was found to predict bearing capacity of the driven piles. The MFs of the input, in the selected model, were adjusted after 9700 epochs by means of the hybrid optimization method that included BP for the parameters accompanied with the input MFs in addition to the estimation of least squares for those parameters that were accompanied with the output MFs. Remember that all ANFIS ANN and ICA-ANN models in this study were created by means of MATLAB software (version 7.14.0.739). To determine the RMSE values and do the statistical computations, we made use of the SPSS package (version 18.0).
5 Evaluation of the designed models
In this study, several intelligent techniques were selected, applied, and constructed for the purpose of prediction of pile bearing capacity based on established database comprising of 59 data sets. ANN together with two hybrid models, i.e., ICA-ANN and ANFIS, were designed in details considering the most effective parameters of these models. Then, based on the final structures of these models, many ANN, ANFIS, and ICA-ANN models were designed and the best models among them were selected according to only R2 results. To evaluate the built models, two more performance indices (RMSE and variance account for, VAF) were considered where their equations are shown as follows:
where y and y′ are the predicted and measured values, respectively, ỹ is the mean of the y values, and N is the total number of data. The predictive technique will be excellent if R2 = 1, VAF = 100, and RMSE = 0.
Table 2 shows the obtained results of performance indices for all the developed models. All results of VAF, RMSE, and R2 for both training and testing data sets showed that two hybrid models receive a better performance prediction compared to pre-developed ANN model. RMES results of (0.083, 0.055), (0.041, 0.033), and (0.056, 0.035) were obtained for ANN, ANFIS, and ICA-ANN models, respectively, which showed that, by developing ANFIS models, a significant decrease in system error can be found. Therefore, ANFIS compared to the other proposed models can provide a better performance capacity in predicting bearing capacity of driven piles.
Figure 3,4, and 5 present the predicted and measured values of pile bearing capacity and their coefficients of determination by developing ANN, ICA-ANN, and ANFIS predictive approaches, respectively. As a result, R2 values of (0.895, 0.905), (0.945, 0.958), and (0.967, 0.975) were obtained for ANN, ICA-ANN, and ANFIS predictive techniques, respectively which showed that a difference of 0.7 can be found between ANN and ANFIS models. In addition, Figs. 6, 7 show the comparison of RMSE and VAF results, respectively, for ANN, ICA-ANN, and ANFIS models. Based on these figures, the best model with the minimum RMSE and the maximum VAF is related to ANFIS model. In fact, this model with assistance/advantage of both ANN and FIS techniques can perform better for solving problem of pile bearing capacity, and it can be introduced as a comprehensive model in the mentioned field.

Training and testing data sets modeled by ANN

Training and testing data sets modeled by ICA-ANN

Training and testing data sets modeled by ANFIS

Comparison of the RMSE results

Comparison of the VAF results
6 Conclusions
In the present study, we apply three intelligent models (i.e., ANN, ANFIS, and ICA-ANN) to estimate the bearing capacity of driven piles. A database comprising a total of 59 datasets was provided. In each data set, φ shaft, φ tip, σ′v, L, and A were selected as inputs, while Q was set as the output of the system. All effecting parameters of each model were identified and applied for each model to receive higher performance capacity. Therefore, a series of parametric studies were conducted on the developed intelligent models by means of particular parameters of FIS, ICA, and ANN. As shown by the obtained results, both hybrid models were capable of significantly improving the performance prediction, though the ANFIS predictive model outperformed the ICA-ANN in terms of predicting the Q values. The obtained results of the developed models were as (0.895, 0.905), (0.945, 0.958), and (0.967, 0.975) for ANN, ICA-ANN, and ANFIS models, respectively, based on R2. In addition, ANFIS model receives highest results of VAF and lowest results of RMSE among all the developed models in estimating pile bearing capacity. VAF values of 96.585 and 97.510 were obtained for training and testing of ANFIS model, and they are higher than results of ANN and ICA-ANN. It can be concluded that the ANFIS model would be the proper alternative as it combines the advantages of the ANN and FIS techniques to demonstrate a high prediction capacity in solving a mentioned problem in geotechnics.
References
Moayedi H, Jahed Armaghani D (2017) Optimizing an ANN model with ICA for estimating bearing capacity of driven pile in cohesionless soil. Eng Comput. https://doi.org/10.1007/s00366-017-0545-7
Moayedi H, Nazir R, Mosallanezhad M (2015) Determination of reliable stress and strain distributions along bored piles. Soil Mech Found Eng 51:285–291
Momeni E, Nazir R, Armaghani D, Maizir H (2014) Prediction of pile bearing capacity using a hybrid genetic algorithm-based ANN. Measurement 57:122–131
Moayedi H, Hayati S (2018) Applicability of a CPT-based neural network solution in predicting load-settlement responses of bored pile. Int J Geomech 18:6018009
Moayedi H, Mosallanezhad M (2017) Uplift resistance of belled and multi-belled piles in loose sand. Measurement 109:346–353
Asadi A, Moayedi H, Huat BBK et al (2011) Prediction of zeta potential for tropical peat in the presence of different cations using artificial neural networks. Int J Electrochem Sci 6:1146–1158
Moayedi H, Rezaei A (2017) An artificial neural network approach for under-reamed piles subjected to uplift forces in dry sand. Neural Comput Appl:1–10
Hasanipanah M, Monjezi M, Shahnazar A et al (2015) Feasibility of indirect determination of blast induced ground vibration based on support vector machine. Meas J Int Meas Confed. https://doi.org/10.1016/j.measurement.2015.07.019
Hasanipanah M, Noorian-Bidgoli M, Jahed Armaghani D, Khamesi H (2016) Feasibility of PSO-ANN model for predicting surface settlement caused by tunneling. Eng Comput. https://doi.org/10.1007/s00366-016-0447-0
Armaghani D, Mohamad E, Hajihassani M (2016) Evaluation and prediction of flyrock resulting from blasting operations using empirical and computational methods. Eng Comput 32:109–121
Shams S, Monjezi M, Majd VJ, Armaghani DJ (2015) Application of fuzzy inference system for prediction of rock fragmentation induced by blasting. Arab J Geosci 8:10819–10832
Mosallanezhad M, Moayedi H (2017) Developing hybrid artificial neural network model for predicting uplift resistance of screw piles. Arab J Geosci 10:479
Koopialipoor M, Nikouei SS, Marto A et al (2018) Predicting tunnel boring machine performance through a new model based on the group method of data handling. Bull Eng Geol Environ 1–15
Khandelwal M, Mahdiyar A, Armaghani DJ et al (2017) An expert system based on hybrid ICA-ANN technique to estimate macerals contents of Indian coals. Environ Earth Sci 76:399. https://doi.org/10.1007/s12665-017-6726-2
Hasanipanah M, Shahnazar A, Bakhshandeh Amnieh H, Jahed Armaghani D (2017) Prediction of air-overpressure caused by mine blasting using a new hybrid PSO–SVR model. Eng Comput. https://doi.org/10.1007/s00366-016-0453-2
Safa M, Shariati M, Ibrahim Z et al (2016) Potential of adaptive neuro fuzzy inference system for evaluating the factors affecting steel-concrete composite beam’s shear strength. Steel Compos Struct 21:679–688
Mohammadhassani M, Nezamabadi-Pour H, Suhatril M, Shariati M (2013) Identification of a suitable ANN architecture in predicting strain in tie section of concrete deep beams. Struct Eng Mech 46:853–868
Momeni E, Nazir R, Armaghani DJ, Maizir H (2015) Application of artificial neural network for predicting shaft and tip resistances of concrete piles. Earth Sci Res J 19:85–93
Mohamad ET, Armaghani DJ, Momeni E et al (2016) Rock strength estimation: a PSO-based BP approach. Neural Comput Appl 1–12. https://doi.org/10.1007/s00521-016-2728-3
Hasanipanah M, Shahnazar A, Amnieh H (2017) Prediction of air-overpressure caused by mine blasting using a new hybrid PSO–SVR model. Eng Comput. https://doi.org/10.1007/s00366-016-0453-2
Armaghani DJ, Hasanipanah M, Mahdiyar A et al (2016) Airblast prediction through a hybrid genetic algorithm-ANN model. Neural Comput Appl. https://doi.org/10.1007/s00521-016-2598-8
Singh R, Vishal V, Singh TN, Ranjith PG (2013) A comparative study of generalized regression neural network approach and adaptive neuro-fuzzy inference systems for prediction of unconfined compressive strength of rocks. Neural Comput Appl 23:499–506
Khandelwal M, Singh TN (2013) Prediction of blast-induced ground vibration using artificial neural network. Int J Rock Mech Min Sci 46:1214–1222. https://doi.org/10.1016/j.ijrmms.2009.03.004
Armaghani DJ, Faradonbeh RS, Rezaei H et al (2016) Settlement prediction of the rock-socketed piles through a new technique based on gene expression programming. Neural Comput Appl. https://doi.org/10.1007/s00521-016-2618-8
Das SK, Basudhar PK (2006) Undrained lateral load capacity of piles in clay using artificial neural network. Comput Geotech 33:454–459
Hanna AM, Morcous G, Helmy M (2004) Efficiency of pile groups installed in cohesionless soil using artificial neural networks. Can Geotech J 41:1241–1249
Kiefa MAA (1998) General regression neural networks for driven piles in cohesionless soils. J Geotech Geoenvironmental Eng 124:1177–1185
Dung NT, Chung SG, Kim SR, Beak SH (2011) Applicability of the SPT-based methods for estimating toe bearing capacity of driven PHC piles in the thick deltaic deposits. KSCE J Civ Eng 15:1023–1031
Kumara JJ, Kikuchi Y, Kurashina T, Hyodo T (2016) Base resistance of open-ended piles evaluated by various design methods. Int J 11:2643–2650
Randolph MF, Dolwin R, Beck R (1994) Design of driven piles in sand. Geotechnique 44:427–448
Alawneh AS, Nusier O, Husein Malkawi AI, Al-Kateeb M (2001) Axial compressive capacity of driven piles in sand: a method including post-driving residual stresses. Can Geotech J 38:364–377
Yang J, Tham LG, Lee PKK, Chan ST, Yu F (2006) Behaviour of jacked and driven piles in sandy soil. Géotechnique 56(4):245–259
Lee J, Prezzi M, Salgado R (2011) Experimental investigation of the combined load response of model piles driven in sand. Geotech Test J 34(6):653–667
Samui P (2012) Determination of ultimate capacity of driven piles in cohesionless soil: a multivariate adaptive regression spline approach. Int J Numer Anal Methods Geomech 36:1434–1439
Dzagov AM, Razvodovskii DE (2013) Bearing capacity of driven piles supported on slightly compressible soils. Soil Mech Found Eng 50:187–193
Wang X, Tang Z, Tamura H et al (2004) An improved backpropagation algorithm to avoid the local minima problem. Neurocomputing 56:455–460
Hajihassani M, Jahed Armaghani D, Kalatehjari R (2017) Applications of particle swarm optimization in geotechnical engineering: a comprehensive review. Geotech Geol Eng. https://doi.org/10.1007/s10706-017-0356-z
Koopialipoor M, Armaghani DJ, Haghighi M, Ghaleini EN (2017) A neuro-genetic predictive model to approximate overbreak induced by drilling and blasting operation in tunnels. Bull Eng Geol Environ. https://doi.org/10.1007/s10064-017-1116-2
Koopialipoor M, Jahed Armaghani D, Hedayat A et al (2018) Applying various hybrid intelligent systems to evaluate and predict slope stability under static and dynamic conditions. Soft Comput. https://doi.org/10.1007/s00500-018-3253-3
Hornik K, Stinchcombe M, White H (1989) Multilayer feedforward networks are universal approximators. Neural Netw 2:359–366
Mohamad ET, Armaghani DJ, Hajihassani M et al (2013) A simulation approach to predict blasting-induced flyrock and size of thrown rocks. Electron J Geotech Eng 18(B):365–374
Saghatforoush A, Monjezi M, Faradonbeh RS, Armaghani DJ (2016) Combination of neural network and ant colony optimization algorithms for prediction and optimization of flyrock and back-break induced by blasting. Eng Comput 32:255–266
Swingler K (1996) Applying neural networks: a practical guide. Academic Press, New York
Khandelwal M, Singh TN (2009) Prediction of blast-induced ground vibration using artificial neural network. Int J Rock Mech Min Sci 46:1214–1222
Hecht-Nielsen R (1987) Kolmogorov’s mapping neural network existence theorem. In: Proceedings of 1st IEEE annual international conference on neural networks, San Diego, June 21–24. IEEE Press, Piscataway, NJ, pp III.11-111.14
Jahed Armaghani D, Hajihassani M, Yazdani Bejarbaneh B et al (2014) Indirect measure of shale shear strength parameters by means of rock index tests through an optimized artificial neural network. Meas J Int Meas Confed. https://doi.org/10.1016/j.measurement.2014.06.001
Atashpaz-Gargari E, Lucas C (2007) Imperialist competitive algorithm: an algorithm for optimization inspired by imperialistic competition. In: IEEE Congress on Evolutionary computation, 2007. CEC 2007, pp 4661–4667. https://doi.org/10.1007/s00366-018-0674-7
Jahed Armaghani D, Hasanipanah M, Tonnizam Mohamad E (2016) A combination of the ICA-ANN model to predict air-overpressure resulting from blasting. Eng Comput. https://doi.org/10.1007/s00366-015-0408-z
Taghavifar H, Mardani A, Taghavifar L (2013) A hybridized artificial neural network and imperialist competitive algorithm optimization approach for prediction of soil compaction in soil bin facility. Measurement 46:2288–2299
Mahdiyar A, Armaghani DJ, Marto A et al (2018) Rock tensile strength prediction using empirical and soft computing approaches. Bull Eng Geol Environ. https://doi.org/10.1007/s10064-018-1405-4
Jahed Armaghani D, Shoib RSNSBR, Faizi K, Rashid ASA (2017) Developing a hybrid PSO–ANN model for estimating the ultimate bearing capacity of rock-socketed piles. Neural Comput Appl. https://doi.org/10.1007/s00521-015-2072-z
Alavi NK, Abad SV, Yilmaz M, Jahed Armaghani D, Tugrul A (2016) Prediction of the durability of limestone aggregates using computational techniques. Neural Comput Appl. https://doi.org/10.1007/s00521-016-2456-8
Saemi M, Ahmadi M, Varjani A (2007) Design of neural networks using genetic algorithm for the permeability estimation of the reservoir. J Pet Sci Eng 59:97–105
Jahed Armaghani D, Hasanipanah M, Mahdiyar A et al (2016) Airblast prediction through a hybrid genetic algorithm-ANN model. Neural Comput Appl. https://doi.org/10.1007/s00521-016-2598-8
Ghaleini EN, Koopialipoor M, Momenzadeh M et al (2018) A combination of artificial bee colony and neural network for approximating the safety factor of retaining walls. Eng Comput. https://doi.org/10.1007/s00366-018-0625-3
Koopialipoor M, Jahed Armaghani D, Haghighi M, Ghaleini EN (2017) A neuro-genetic predictive model to approximate overbreak induced by drilling and blasting operation in tunnels. Bull Eng Geol Environ. https://doi.org/10.1007/s10064-017-1116-2
Jang J-S (1993) ANFIS: adaptive-network-based fuzzy inference system. IEEE Trans Syst Man Cybern 23:665–685
Armaghani D, Momeni E, Abad S (2015) Feasibility of ANFIS model for prediction of ground vibrations resulting from quarry blasting. Environ Earth Sci 74:2845–2860
Grima MA, Bruines PA, Verhoef PNW (2000) Modeling tunnel boring machine performance by neuro-fuzzy methods. Tunn Undergr Sp Technol 15:259–269
Shahnazar A, Nikafshan Rad H, Hasanipanah M et al (2017) A new developed approach for the prediction of ground vibration using a hybrid PSO-optimized ANFIS-based model. Environ Earth Sci. https://doi.org/10.1007/s12665-017-6864-6
Armaghani DJ, Hajihassani M, Sohaei H et al (2015) Neuro-fuzzy technique to predict air-overpressure induced by blasting. Arab J Geosci 8:10937–10950. https://doi.org/10.1007/s12517-015-1984-3
Jang R, Sun C, Mizutani E (1997) Neuro-fuzzy and soft computation. PrenticeHall, New Jersey, p 614
Mohanty R, Suman S, Das SK (2016) Prediction of vertical pile capacity of driven pile in cohesionless soil using artificial intelligence techniques. Int J Geotech Eng 12(2):209–216
Jiang W, Arslan CA, Tehrani MS et al (2018) Simulating the peak particle velocity in rock blasting projects using a neuro-fuzzy inference system. Eng Comput. https://doi.org/10.1007/s00366-018-0659-6
Monjezi M, Hasanipanah M, Khandelwal M (2013) Evaluation and prediction of blast-induced ground vibration at Shur River Dam, Iran, by artificial neural network. Neural Comput Appl 22:1637–1643
Hasanipanah M, Bakhshandeh Amnieh H, Khamesi H et al (2018) Prediction of an environmental issue of mine blasting: an imperialistic competitive algorithm-based fuzzy system. Int J Environ Sci Technol. https://doi.org/10.1007/s13762-017-1395-y
Sonmez H, Gokceoglu C, Nefeslioglu HA, Kayabasi A (2006) Estimation of rock modulus: for intact rocks with an artificial neural network and for rock masses with a new empirical equation. Int J Rock Mech Min Sci 43:224–235
Ahmadi MA, Ebadi M, Shokrollahi A, Majidi SMJ (2013) Evolving artificial neural network and imperialist competitive algorithm for prediction oil flow rate of the reservoir. Appl Soft Comput 13:1085–1098
Marto A, Hajihassani M, Jahed Armaghani D et al (2014) A novel approach for blast-induced flyrock prediction based on imperialist competitive algorithm and artificial neural network. Sci World J. https://doi.org/10.1155/2014/643715
Hajihassani M, Jahed Armaghani D, Marto A, Tonnizam Mohamad E (2015) Ground vibration prediction in quarry blasting through an artificial neural network optimized by imperialist competitive algorithm. Bull Eng Geol Environ. https://doi.org/10.1007/s10064-014-0657-x
Armaghani DJ, Momeni E, Abad SVANK, Khandelwal M (2015) Feasibility of ANFIS model for prediction of ground vibrations resulting from quarry blasting. Environ Earth Sci 74:2845–2860. https://doi.org/10.1007/s12665-015-4305-y
Jahed Armaghani D, Hajihassani M, Monjezi M et al (2015) Application of two intelligent systems in predicting environmental impacts of quarry blasting. Arab J Geosci. https://doi.org/10.1007/s12517-015-1908-2
Momeni E, Armaghani DJ, Fatemi SA, Nazir R (2018) Prediction of bearing capacity of thin-walled foundation: a simulation approach. Eng Comput 34:319–327
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Shaik, S., Krishna, K.S.R., Abbas, M. et al. Applying several soft computing techniques for prediction of bearing capacity of driven piles. Engineering with Computers 35, 1463–1474 (2019). https://doi.org/10.1007/s00366-018-0674-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00366-018-0674-7