
Abstract
In this study, an entropy-based grey wolf optimizer (IEGWO) algorithm is proposed for solving global optimization problems. This improvement is proposed to alleviate the lack of population diversity, the imbalance between exploitation and exploration, and the premature convergence of grey wolf optimizer algorithm and consists of three aspects: Firstly, we proposed an information entropy-based population generation strategy to optimize the distribution of initial grey wolf pack. Secondly, a modified dynamic position update equation based on information entropy is introduced to maintain the population diversity in the process of iteration, thus avoiding premature convergence. Thirdly, a nonlinear convergence strategy is proposed to balance the exploration and exploitation. The performance of the proposed IEGWO algorithm is assessed on the CEC2014 and CEC2017 test suites and compared with other meta-heuristic algorithms. Furthermore, two engineering design problems and one real-world problem are also solved using the IEGWO algorithm. The experimental and statistical results indicate that the IEGWO algorithm has better solution accuracy and robustness than the compared algorithms in solving global optimization problems.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Meta-heuristic algorithms play an important role in solving complex problems in different applications due to their simple structure and easy implementation (Manna et al. 2021; Kumar et al. 2021), such as chip design (Venkataraman et al. 2020), diseases diagnosis (Arjenaki et al. 2015), production inventory problem (Das et al. 2021; Manna and Bhunia 2022), feature selection (Hu et al. 2021), and path planning (Qu et al. 2020). Many nature-inspired algorithms have been proposed by simulating the swarm intelligence behavior of various biological systems in nature, such as particle swarm optimization (PSO) (Eberhart and Kennedy 1995), fruit fly optimization algorithm (FOA) (Wang et al. 2013), whale optimization algorithm (WOA) (Mirjalili and Lewis 2016), butterfly optimization algorithm (BOA) (Arora and Singh 2019), conscious neighborhood-based crow search algorithm (CCSA) (Zamani et al. 2019), sparrow search algorithm (SSA) (Xue and Shen 2020), slime mold algorithm (SMA) (Li et al. 2020), etc.
Grey wolf optimizer (GWO) (Mirjalili et al. 2014) is a relatively novel meta-heuristic inspired by the hunting behavior of grey wolf pack and is the only swarm intelligence algorithm based on leadership hierarchy (Luo and Zhao 2019). Due to its excellent optimization performance, GWO has been increasingly focused and successfully applied to many practical engineering problems. Zhang et al. (2016) used GWO to solve the unmanned combat aerial vehicle two-dimension path planning problem. Hadavandi et al. (2018) hybridized GWO and neural network to achieve the prediction of yarns tensile strength. Samuel et al. (2020) combined empirical method and GWO to optimize the extraction process of biodiesel from waste oil. Sundaramurthy and Jayavel (2020) hybridized GWO and PSO with C4.5 approach to realize the prediction of rheumatoid arthritis. Kalemci et al. (2020) designed a reinforced concrete cantilever retaining wall using GWO algorithm. Karasu and Saraç (2020) classified the power quality disturbances by combining GWO and k-Nearest Neighbor (KNN). Saxena et al. (2020) utilized GWO to solve the problem of harmonic estimation in power networks. Zareie et al. (2020) developed a GWO-based method to identify the influential users in viral marketing and achieved the best results so far. Naserbegi and Aghaie (2021) applied GWO to optimize the exergy of nuclear-solar dual proposed power plant.
However, the “no free lunch” theorem (Wolpert and Macready 1997) has logically demonstrated that no meta-heuristic can perfectly handle all optimization problems. For example, GWO is prone to get stuck at local optimum when dealing with complex multimodal problems (Long et al. 2018a). Therefore, several variants of GWO have been developed. Rodríguez et al. (2017) introduced a fuzzy operator in GWO algorithm to optimize the leadership hierarchy of grey wolves. Long et al. (2017) added a modulation index into GWO algorithm to balance the exploration and exploitation. Tawhid and Ali (2017) embedded genetic mutation operator in GWO to avoid premature convergence. Gupta and Deep (2020) optimized the search mechanism of GWO algorithm by applying crossover and greedy selection. Adhikary and Acharyya (2022) introduced random walk with student’s t distribution into GWO to balance the exploration and exploitation. Mohakud and Dash (2022) proposed a neighborhood based searching strategy that integrates individual haunting strategies and global haunting strategies to balance the exploration and exploitation of GWO.
The above researches indicate that increasing population diversity and balancing exploration and exploitation are an effective approach to improve the performance of GWO. For this purpose, this paper proposed a modified GWO called information entropy-based GWO (IEGWO). In the IEGWO, an initial population generation method based on information entropy is proposed to optimize the distribution of initial grey wolf pack, a dynamic position update mechanism based on information entropy is introduced to maintain the population diversity in the process of iteration, and a nonlinear convergence factor strategy is proposed to balance the exploration and exploitation. The proposed IEGWO algorithm is tested on 10 well-known benchmark functions to analyze the influence of information entropy and nonlinear strategy. The performance of IEGWO is tested and compared with other GWO variants on CEC2014 (Liang et al. 2013) and CEC2017 (Awad et al. 2016) problems. In this paper, the IEGWO is also applied to solve two engineering design problems and to optimize the model parameters in the field of hyperspectral imaging.
The rest of this paper is structured as follows. The next section introduces the original GWO. In Sect. 3 we present the proposed IEGWO in detail. In Sect. 4, the IEGWO is tested by 10 well-known benchmark functions, CEC2014 and CEC2017. In Sect. 5, results on two engineering optimization problems and one practical problem are presented. The last section concludes this paper and provides some ideas for future study.
2 Grey wolf optimizer
The GWO algorithm (Mirjalili et al. 2014) mimics the social leadership and hunting behavior of the grey wolf pack. In this algorithm, the wolves are divided into two parts, one is dominant wolf pack, and the other wolves are named as ω. The dominant wolf pack includes α, β and δ wolves, representing the optimal solution, suboptimal solution, and the third optimal solution, respectively.
To mimic the hunting behavior, the following motion equations are used:
where t represents the current iteration; \(\vec{X}_{P}\) and \(\vec{X}\) are the position vectors of the prey and a grey wolf, respectively; \(\vec{A}\) and \(\vec{C}\) denote the coefficient vectors, which can be calculated as follows:
where \(\vec{r}_{1}\) and \(\vec{r}_{2}\) denote random vectors between 0 and 1; \(\vec{a}\) is the convergence factor linearly decreased from 2 to 0 as follows:
where m indicates the maximum number of iterations.
Figure 1 shows the movement mechanism of GWO, where the red, yellow, purple and blue circles represent α, β, δ and ω wolves, respectively. In this process, the ω wolves move to the center of α, β and δ wolves by applying the following formulas:
where \(\vec{A}_{1}\), \(\vec{A}_{2}\) and \(\vec{A}_{3}\) are the same as \(\vec{A}\), \(\vec{C}_{1}\), \(\vec{C}_{2}\) and \(\vec{C}_{3}\) are the same as \(\vec{C}\). Figure 2 presents the pseudocode of GWO algorithm.

Evolution of position in GWO

Pseudocode of GWO algorithm
3 Information entropy-based grey wolf optimizer
The theorem of entropy was originally proposed by Shannon (1948) to describe the complexity of spatial energy distribution, which plays a fundamental and important role in the field of modern information theory. The formula of information entropy is as follows (Feng et al. 2022):
where n is the number of information records in a system and pi(x) is the probability of the ith record. For meta-heuristic algorithms, the information entropy can also be used to reflect the diversity of population. Inspired by this idea, the information entropy is introduced into GWO to increase the population diversity in the process of generating initial population and updating position. Besides, a nonlinear convergence factor \(\vec{a}\) is proposed to balance the exploration and exploitation.
3.1 Initial population generation based on information entropy
In the original GWO, the initial population is generated by random sampling. However, in practical application, it is inevitable that some grey wolves may be overly concentrated in a local area, resulting in a restricted search range. To optimize the distribution of initial population in the solution space, an information entropy-based sampling method was proposed. Suppose that there is a population with group size of N and dimension of D, the entropy Hj of the jth dimension can be defined by:
where ubj and lbj denote the upper and lower limits of the jth dimension, respectively. The value of Pik describes the similarity probability of the jth dimension between the ith and the kth individuals. The entropy value of the whole population H is defined by:
The process of generating initial population is as follows:
-
Step1: Set a critical value H0 for entropy (for example, H0 = 0.25).
-
Step2: Generate the first individual by random sampling method in the solution space.
-
Step3: Generate a new individual by random sampling. If the entropy value of the population H > H0, the new individual will be retained; otherwise, a new individual will be regenerated until H > H0.
-
Step4: Repeat Step 3 until enough individuals are generated.
3.2 Dynamic position update equation
In the original GWO algorithm, all the ω wolves constantly move to the center of α, β and δ wolves in the process of iteration. As a consequence, GWO is prone to fall into local optimum due to the over learning from the dominant wolf pack and the rapid reduction in population diversity. To maintain the population diversity during the process of updating position and weaken the influence of dominant wolf pack, we modified the position-updating equation as follows:
where Pωα, Pωβ and Pωδ are the same of Pik in Eq. (10). It can be seen from Eq. (12) that each w wolf updates its position according to its similarity to the dominant wolf pack to avoid over-concentration of wolves. It should be noted that the weights of w1, w2 and w3 are constantly changing in the process of iteration. Thus, it can bring more information and maintain the diversity of population.
3.3 Nonlinear convergence factor \(\vec{a}\)
From the original paper of GWO, the grey wolves attack toward prey when the value |A|< 1 and diverge from prey when the value |A|> 1. Therefore, the exploration and exploitation are balanced by the linear convergence factor \(\vec{a}\) using Eq. (5), and the ratio is 1:1. However, the real search process is highly complex, and the linear strategy is difficult to adapt to it. Based on the above consideration, we proposed a nonlinear convergence factor \(\vec{a}\) as follows:
where t denotes the current iteration, m indicates the maximum number of iterations and k is the nonlinear modulation parameter in [0, 1]. The iterative curves of convergence factor \(\vec{a}\) with different values of k are shown in Fig. 3.

Iterative curves of nonlinear convergence factor \(\vec{a}\) with different values of k
Compared with the original GWO algorithm, the value of \(\vec{a}\) is increased in the early stage to explore more unknown regions and then reduced to narrow the search range in the later stage. In other words, the modification is to enhance the global exploration in the early stage and the local exploitation in the later stage, and the parameter k is used to control the proportion of exploration and exploitation. The ratio of iterations used for exploration and exploitation with different values of k is shown in Table 1.
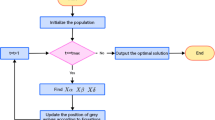
The pseudocode of the proposed IEGWO is presented in Fig. 4. The influence of parameter k to the performance of IEGWO will be discussed in the parameter setting experiment.

Pseudocode of IEGWO algorithm
4 Results and discussion
4.1 Comparison with GWO
4.1.1 Benchmark functions and parameter settings
In this section, the impact of information entropy and nonlinear convergence factor on the performance of IEGWO is analyzed by 10 well-known benchmark functions, including 5 unimodal benchmark functions and 5 multimodal benchmark functions. These functions are listed in Table 2, where fmin denotes the theoretical optimal value in search range. The 2-D versions of these functions are shown in Fig. 5.

2-D version of test functions
In all experiments, the maximum number of iterations, the population size, and the dimension of test functions were fixed as 500, 30, and 30, respectively. Each algorithm was executed 30 times independently. All programs were coded in MATLAB 2016b and ran on a computer with CPU of AMD Ryzen7 5800U (4.4 GHz) under Windows 10 system.
4.1.2 The impact of information entropy and nonlinear convergence factor
To investigate the impact of information entropy and nonlinear convergence factor, the GWO, IEGWO with original linear convergence factor (IEGWO-L), and IEGWO with different k values were executed on the 10 benchmark functions, and the results are shown in Table 3. The unimodal functions (F1–F5) can be used to evaluate the exploitation performance of algorithms, while the multimodal functions (F6–F10) are utilized to examine the exploration strength and the ability of avoiding local optimum of algorithms. As seen from Table 3, the optimization performance of IEGWO-L outperforms that of GWO on all benchmark functions. Although the improvement in solution accuracy is small on the unimodal functions, it is significant on the multimodal functions, which is because the increase in population diversity improves the ability of the algorithm to jump out of the local optimum. The reduction in standard deviation (Std Dev) indicates that the introduction of information entropy can effectively improve the robustness of GWO. With the increase in k, the performance of IEGWO is evidently improved, and when the value of k is greater than 0.75, the IEGWO outperforms GWO and IEGWO-L obviously. Therefore, for unimodal functions, more exploration helps to improve the optimization accuracy and robustness, while for multimodal functions, the optimization performance of IEGWO increases and then decreases as the proportion of exploration increases, and when the value of k is 0.875, the error of the objective function values reaches the lowest, indicating that the exploration and exploitation are well balanced.
4.1.3 Wilcoxon test
In order to statistically assess the performance of GWO and IEGWO, Wilcoxon test at a 5% significance is utilized. The results are recorded in Table 4, where the following rating criteria are applied.
-
1.
A—IEGWO has better performance and p-value ≤ 0.05.
-
2.
B—The performance of the two algorithms is comparable and p-value > 0.05.
-
3.
C—IEGWO has poor performance and p-value ≤ 0.05.
From Tables 1 and 4, it can be seen that when the exploration ratio is greater than 65.8%, the performance of IEGWO is significantly better than that of GWO. When the exploration ratio reaches 72.2%, all the ratings of IEGWO are A, indicating that more proportion of exploration can effectively improve the optimization performance of IEGWO. However, with the increasing proportion of exploration, the performance of IEGWO on multimodal functions decreases due to the scarcity of exploitation. Therefore, 0.875 is an appropriate value for the parameter k, which provides a good balance between exploitation and exploration.
4.1.4 Computational complexity and running time
The computational complexity is an important index to evaluate the running time of an optimization algorithm, which can be defined based on the structure of the algorithm (Gupta and Deep 2019). The major computational cost of GWO and IEGWO is in the while loop, both equal to O (N × D × T), where N is the population size, D is the dimension of the problem, and T is the maximum number of iterations. Figure 6 shows the total time consumed by GWO and IEGWO to run 30 times on each function. As shown in Fig. 6, the running time of IEGWO is approximately 6% longer than that of GWO, which is mainly due to the fact that some grey wolf individuals need to be regenerated to meet the critical value of information entropy in the process of generating initial population.

Running time of GWO and IEGWO
4.1.5 Convergence analysis
The convergence curves of GWO and IEGWO (k = 0.875) are shown in Fig. 7. Due to the expansion of the search range in the early stage, the error in objective function values of IEGWO is larger than that of GWO in some functions (F1–F4, F7). However, the expansion also increases the possibility of finding better solutions by exploring more unknown regions, so the error reduction rate of IEGWO is accelerated in the middle stage. In the late stage of optimization, IEGWO has higher solution accuracy due to the enhancement of local exploitation. From Fig. 7, it can be concluded that the proposed strategies effectively improve the performance of GWO.

Convergence curves of GWO and IEGWO
4.1.6 Comparison with other modified GWO algorithms
The previous section shows that IEGWO has better performance than GWO in terms of exploitation and exploration. In this section, the IEGWO is compared with E-GWO (Duarte et al. 2020), IGWO (Long et al. 2018a), EEGWO (Long et al. 2018b), and FH-GWO (Rodríguez et al. 2017) on 30 dimensional CEC2014 and CEC2017 problems based on the average error in objective function value. The parameter setting of the three algorithms is the same as reported in their original papers. The comparison is presented in Tables 5 and 6. For clarity, the best solutions are marked in boldface. Tables 5 and 6 show that the proposed IEGWO has the smallest error in 21 of the 30 functions on CEC 2014 and 18 of the 29 functions on CEC 2017. The outcomes obtained by applying the Wilcoxon test are also recorded in the same tables. Whether for the unimodal, multimodal, and hybrid benchmark problems, the IEGWO provides better results compared to other GWO variants in most of the tested functions. Therefore, it can be concluded that the performance of IEGWO is significantly better than that of the other modified GWO algorithms.
5 Real applications of IEGWO
The proposed IEGWO algorithm is applied to two classical engineering applications: tension/compression spring design and pressure vessel design, which are often used as constrained optimization benchmark problems (Mirjalili et al. 2014). Besides, the IEGWO is also employed to optimize the model parameters in the field of hyperspectral imaging.
5.1 Tension/compression spring design
The aim of the problem is to minimize the weight of a spring with constraints such as minimum deflection, shear stress, and surge frequency. The design variables include wire diameter d(x1), the mean coil diameter D(x2), and the number of active coils N(x3). The mathematical formulation of this problem is stated as follows:
The GA (Coello and Montes 2002), CPSO (He and Ling 2007), SMA (Li et al. 2020), FH-GWO (Rodríguez et al. 2017), IGWO (Long et al. 2018a), EEGWO (Long et al. 2018b), E-GWO (Duarte et al. 2020), and the proposed IEGWO are applied to solve this problem. The population size and maximum iterations of all algorithms are set to 20 and 1500. The results obtained by conducting 30 runs are shown in Table 7. In the same table, the outcomes of the statistical results obtained by using Wilcoxon test are also recorded. The table verified the better performance of IEGWO compared to other meta-heuristic algorithms.
5.2 Pressure vessel design
The goal of this problem is to minimize the cost including material, forming and welding of a vessel as shown in Fig. 8. The design variables include shell thickness Ts(x1), head thickness Th(x2), inner radius R(x3), and shell length L(x4). The mathematical formulation of this problem is as follows:

Pressure vessel design problem
The proposed IEGWO, GA (Coello and Montes 2002), CPSO (He and Ling 2007), SMA (Li et al. 2020), FH-GWO (Rodríguez et al. 2017), IGWO (Long et al. 2018a), EEGWO (Long et al. 2018b), and E-GWO (Duarte et al. 2020) are applied to solve this problem. The population size and maximum iterations of all algorithms are set to 20 and 2000. The results obtained by conducting 30 runs are shown in Table 8. In the same table, the outcomes of the statistical results obtained by using Wilcoxon test are also recorded. Except for SMA, the performance of IEGWO is significantly better than that of the other algorithms. However, the optimal solution found by IEGWO is better than the best known solution so far.
5.3 Optimization of model parameters in the field of hyperspectral imaging
In recent years, many researchers have applied hyperspectral imaging (HSI) technique in the nondestructive testing of food and agricultural products and developed various methods to improve the performance of models (Yao et al. 2022; Suktanarak and Teerachaichayut 2017). Among them, parameter optimization is a commonly used and effective way to improve the accuracy and robustness of the models.
Support vector regression (SVR) is a classical machine learning algorithm, which has been widely used to solve regression prediction problems (Xu et al. 2016). The performance of SVR is mainly influenced by three parameters, namely penalty factor (c), kernel parameter (g), and insensitive loss function parameter (ε). In this section, the SVR model is used to establish a prediction model for Haugh unit (HU) values of eggs based on HSI technique, and the proposed IEGWO is used to optimize the three parameters.
Figure 9 shows the reflectance spectral curves of 330 egg samples with different HU values in the wavelength range of 479–986 nm. The spectral reflectance is taken as the input of SVR and the HU value is taken as the output. As an example, the 330 egg samples are randomly divided into training set and test set according to the ratio of 3:1 to evaluate the performance of GA, PSO, GWO, and IEGWO.

Spectral curves of egg samples
In the process of parameter optimization, the fivefold cross-validation root mean square error (RMSECV) of training set is taken as the fitness function. The optimization range of parameters c, g, and ε are set to [10−4, 103], [10−4, 103] and [10−4, 100]. The population size and the maximum iteration are set to 20 and 50.
Figure 10 shows the optimal fitness curves of IEGWO-SVR, GWO-SVR, PSO-SVR and GA-SVR models for 30 runs. As shown in Fig. 9, the IEGWO-SVR model has higher accuracy and faster convergence speed than the other three models.

Optimal fitness curves of GA-SVR, PSO-SVR, GWO-SVR, and IEGWO-SVR models
6 Conclusion
This study proposes a modified version of GWO called information entropy-based GWO (IEGWO). In the IEGWO, an initial population generation method and a dynamic position update equation based on information entropy are proposed to maintain the population diversity. In addition, a nonlinear convergence strategy is applied to balance the exploration and exploitation. The IEGWO is tested on 10 well-known benchmark functions, CEC2014 and CEC2017, and compared with the other meta-heuristic algorithms. Two engineering design problems and one real-world parameter optimization problem in the field of hyperspectral imaging are also solved using IEGWO. The experimental results show that the IEGWO has better robustness and solution accuracy than the other compared algorithms.
Although the IEGWO is efficient, it also has some drawbacks that should be addressed. One is that the number of parameters is larger than the original GWO algorithm, and another is that the current study does not have automatic adjustment for the parameter k. In the future wok, we tend to study an adaptive parameter k to achieve the optimal optimization effect. In addition, we are going to investigate how to extend the IGWO algorithm to handle multi-objective optimization and combinatorial optimization problems.
Data availability
The data used to support the findings of this study are available from the corresponding author upon request.
References
Adhikary J, Acharyya S (2022) Randomized balanced grey wolf optimizer (RBGWO) for solving real life optimization problems. Appl Soft Comput 117:108429
Arjenaki HG, Nadimi-Shahraki MH, Nourafza N (2015) A low cost model for diagnosing coronary artery disease based on effective features. Int J Electron Commun Comput Eng 6(1):93–97
Arora S, Singh S (2019) Butterfly optimization algorithm: a novel approach for global optimization. Soft Comput 23(3):715–734
Awad NH, Ali MZ, Liang JJ, Qu BY, Suganthan PN (2016) Problem definitions and evaluation criteria for the CEC 2017 special session and competition on single objective real-parameter numerical optimization. Technical Report
Coello C, Montes EM (2002) Constraint-handling in genetic algorithms through the use of dominance-based tournament selection. Adv Eng Inform 16(3):193–203
Das SC, Manna AK, Rahman MS, Shaikh AA, Bhunia AK (2021) An inventory model for non-instantaneous deteriorating items with preservation technology and multiple credit periods-based trade credit financing via particle swarm optimization. Soft Comput 25(7):5365–5384
Duarte D, de Moura Oliveira PB et al (2020) Entropy based grey wolf optimizer. Springer International Publishing, Cham
Eberhart R, Kennedy J (1995) A new optimizer using particle swarm theory. In: MHS’95. Proceedings of the sixth international symposium on micro machine and human science
Feng H, Grifoll M, Yang Z, Zheng P (2022) Collision risk assessment for ships’routeing waters: an information entropy approach with automatic identification system (AIS) data. Ocean Coast Manag 224:106184
Gupta S, Deep K (2019) An opposition-based chaotic grey wolf optimizer for global optimisation tasks. J Exp Theor Artif Intell 31(5):751–779
Gupta S, Deep K (2020) A memory-based grey wolf optimizer for global optimization tasks. Appl Soft Comput 93:106367
Hadavandi E, Mostafay S, Soltani P (2018) A grey wolf optimizer-based neural network coupled with response surface method for modeling the strength of siro-spun yarn in spinning mills. Appl Soft Comput 72:1–13
He Q, Ling W (2007) An effective co-evolutionary particle swarm optimization for constrained engineering design problems. Eng Appl Artif Intell 20(1):89–99
Hu X, Zhang S, Li M, Deng JD (2021) Multimodal particle swarm optimization for feature selection. Appl Soft Comput 113:107887
Kalemci EN, Kizler SB, Dede T, Angn Z (2020) Design of reinforced concrete cantilever retaining wall using grey wolf optimization algorithm. Structures 23:245–253
Karasu S, Saraç Z (2020) Classification of power quality disturbances by 2D-Riesz Transform, multi-objective grey wolf optimizer and machine learning methods. Digit. Signal Process 101:102711
Kumar N, Manna AK, Shaikh AA, Bhunia AK (2021) Application of hybrid binary tournament-based quantum-behaved particle swarm optimization on an imperfect production inventory problem. Soft Comput 25(16):11245–11267
Li S, Chen H, Wang M, Heidari AA, Mirjalili S (2020) Slime mould algorithm: a new method for stochastic optimization. Future Gener Comput Syst 111:300–323
Liang J, Qu B, Suganthan, P (2013) Problem definitions and evaluation criteria for the CEC 2014 special session and competition on single objective real-parameter numerical optimization. In: Computational intelligence laboratory, Zhengzhou
Long W, Liang X, Cai S, Jiao J, Zhang W (2017) A modified augmented lagrangian with improved grey wolf optimization to constrained optimization problems. Neural Comput Appl 28(1):421–438
Long W, Jiao J, Liang X, Tang M (2018a) Inspired grey wolf optimizer for solving large-scale function optimization problems. Appl Math Model 60:112–126
Long W, Jiao J, Liang X, Tang M (2018b) An exploration-enhanced grey wolf optimizer to solve high-dimensional numerical optimization. Eng Appl Artif Intell 68:63–80
Luo K, Zhao Q (2019) A binary grey wolf optimizer for the multidimensional knapsack problem. Appl Soft Comput 83:105645
Manna AK, Bhunia AK (2022) Investigation of green production inventory problem with selling price and green level sensitive interval-valued demand via different metaheuristic algorithms. Soft Comput. https://doi.org/10.1007/s00500-022-06856-9
Manna AK, Akhtar M, Shaikh AA, Bhunia AK (2021) Optimization of a deteriorated two-warehouse inventory problem with all-unit discount and shortages via tournament differential evolution. Appl Soft Comput 107:107388
Mirjalili S, Lewis A (2016) The whale optimization algorithm. Adv Eng Softw 95:51–67
Mirjalili S, Mirjalili SM, Lewis A (2014) Grey wolf optimizer. Adv Eng Softw 69:46–61
Mohakud R, Dash R (2022) Skin cancer image segmentation utilizing a novel EN-GWO based hyper-parameter optimized FCEDN. J King Saud Univ Comput Inf Sci. https://doi.org/10.1016/j.jksuci.2021.12.018
Naserbegi A, Aghaie M (2021) Exergy optimization of nuclear-solar dual proposed power plant based on GWO algorithm. Prog Nucl Energy 140:103925
Qu C, Gai W, Zhong M, Zhang J (2020) A novel reinforcement learning based grey wolf optimizer algorithm for unmanned aerial vehicles (UAVs) path planning. Appl Soft Comput 89:106099
Rodríguez L, Castillo O, Soria J, Melin P, Valdez F, Gonzalez CI, Martinez GE, Soto J (2017) A fuzzy hierarchical operator in the grey wolf optimizer algorithm. Appl Soft Comput 57:315–328
Samuel OD, Okwu MO, Oyejide OJ, Taghinezhad E, Afzal A, Kaveh M (2020) Optimizing biodiesel production from abundant waste oils through empirical method and grey wolf optimizer. Fuel 281:118701
Saxena A, Kumar R, Mirjalili S (2020) A harmonic estimator design with evolutionary operators equipped grey wolf optimizer. Expert Syst Appl 145:113125
Shannon CE (1948) The mathematical theory of communication. Bell Syst Tech J 27(3):373–423
Suktanarak S, Teerachaichayut S (2017) Non-destructive quality assessment of hens’ eggs using hyperspectral images. J Food Eng 215:97–103
Sundaramurthy S, Jayavel P (2020) A hybrid grey wolf optimization and particle swarm optimization with C4.5 approach for prediction of rheumatoid arthritis. Appl Soft Comput 94:106500
Tawhid MA, Ali AF (2017) A hybrid grey wolf optimizer and genetic algorithm for minimizing potential energy function. Memet Comput 9(4):347–359
Venkataraman NL, Kumar R, Shakeel PM (2020) Ant lion optimized bufferless routing in the design of low power application specific network on chip. Circuits Syst Signal Process 39(2):961–976
Wang L, Zheng X, Wang S (2013) A novel binary fruit fly optimization algorithm for solving the multidimensional knapsack problem. Knowl-Based Syst 48:17–23
Wolpert D, Macready W (1997) No free lunch theorems for optimization. IEEE Trans Evol Comput 1(1):67–82
Xu J, Riccioli C, Sun D (2016) Development of an alternative technique for rapid and accurate determination of fish caloric density based on hyperspectral imaging. J Food Eng 190:185–194
Xue J, Shen B (2020) A novel swarm intelligence optimization approach: sparrow search algorithm. Syst Sci Control Eng 8(1):22–34
Yao K, Sun J, Chen C, Xu M, Zhou X, Cao Y, Tian Y (2022) Non-destructive detection of egg qualities based on hyperspectral imaging. J Food Eng 325:111024
Zamani H, Nadimi-Shahraki MH, Gandomi AH (2019) CCSA: conscious neighborhood-based crow search algorithm for solving global optimization problems. Appl Soft Comput 85:105583
Zareie A, Sheikhahmadi A, Jalili M (2020) Identification of influential users in social network using gray wolf optimization algorithm. Expert Syst Appl 142:112971
Zhang S, Zhou Y, Li Z, Pan W (2016) Grey wolf optimizer for unmanned combat aerial vehicle path planning. Adv Eng Softw 99:121–136
Acknowledgements
This work is partially supported by Postgraduate Research & Practice Innovation Program of Jiangsu Province (KYCX20_3033). Priority Academic Program Development of Jiangsu Higher Education Institutions (PAPD-2018-87). Six Talent Peaks Project in Jiangsu Province (ZBZZ-019).
Funding
The authors have not disclosed any funding.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The author declares that there is no conflict of interest in presenting this manuscript.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Yao, K., Sun, J., Chen, C. et al. An information entropy-based grey wolf optimizer. Soft Comput 27, 4669–4684 (2023). https://doi.org/10.1007/s00500-022-07593-9
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00500-022-07593-9