
Abstract
The service life of downstream dams, river hydraulics, waterworks construction, and reservoir management is significantly affected by the amount of sediment load (SL). This study combined models such as the artificial neural network (ANN) algorithm with the Firefly algorithm (FA) and Artificial Bee Colony (ABC) optimization techniques for the estimation of monthly SL values in the Çoruh River in Northeastern Turkey. The estimation of SL values was achieved using inputs of previous SL and streamflow values provided to the models. Various statistical metrics were used to evaluate the accuracy of the established hybrid and stand-alone models. The hybrid model is a novel approach for estimating sediment load based on various input variables. The results of the analysis determined that the ABC-ANN hybrid approach outperformed others in SL estimation. In this study, two combinations, M1 and M2, with different input variables, were used to assess the model's accuracy, and the best-performing model for monthly SL estimation was identified. Two scenarios, Q(t) and Q(t − 1), were coupled with the ABC-ANN algorithm, resulting in a highly effective hybrid approach with the best accuracy results (R2 = 0.90, RMSE = 1406.730, MAE = 769.545, MAPE = 5.861, MBE = − 251.090, Bias Factor = − 4.457, and KGE = 0.737) compared to other models. Furthermore, the utilization of FA and ABC optimization techniques facilitated the optimization of the ANN model parameters. The significant results demonstrated that the optimization and hybrid techniques provided the most effective outcomes in forecasting SL for both combination scenarios. As a result, the prediction outputs achieved higher accuracy than those of a stand-alone ANN model. The findings of this study can provide essential resources to various managers and policymakers for the management of water resources.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
This paper focuses on sediment estimation based on machine learning modeling and controlling the sediment conserved at proper sites because a lot of sediments move to other places in rivers. Sediment particles of different sizes and shapes are transported into rivers as bedload (Gomez 1991). Suspended fluids move the suspended particles in a river bed because of the turbulence of eddies. This causes the particles to be suspended, allowing the sediment particles to outweigh particle deposition (Parsons et al. 2015). Sediment accumulation poses a significant challenge to the management and preservation of water storage reservoirs, rivers, and lakes globally and on a watershed scale. More effective control of sediment and accurate estimation of SL can help in making policies for management and planning. Sedimentation leads to the siltation of reservoirs, reducing the availability of water resources for drinking, irrigation, and hydroenergy generation in hydraulic systems (Bashar et al., 2010; Ghernaout and Remini 2014). For instance, studies have found that the sedimentation rate is so rapid that over 65% of storage in some reservoirs was reduced by this single factor in Asia (Wisser et al. 2013). The need for increased sediment transport was established over three decades ago, and the loss of viable storage in Pakistan's Mangla and Tarbela reservoirs has been recorded as considerably high owing to inaccurate estimates and high variance in sediment yield (Khan and Tingsanchali 2009; Ackers et al. 2016). It is important to note that the accumulation of sediment in a river also results in a reduction of river cross-section. It modifies the river plan shape, reducing the riverine habitat available to marine life (Adnan et al., 2021). Sediment production and transport are inherently nonlinear processes that depend on many parameters and are difficult to calculate. The complexity of the physical processes of sediment production, flow rate, sediment source, sediment sources, catchment erosion, river bed slope and resistance, and type of sediment particles are some of the factors that regulate SL amounts (Faran Ali and de Boer 2008). Determination of SL values is valuable for developing solutions to problems related to reservoir and dam design. It also provides information about the transport of sediment and pollutants in rivers, lakes and reservoirs (Ciğizoğlu 2004). Moreover, due to sediment aggradation, the channel's lateral migration can lead to severe flooding during heavy rainfall, significantly reducing the channel capacity (Kisi 2005). Hydrological and environmental problems are complicated by sediment transport and river erosion (Kisi 2009). It is challenging to predict the sediment accumulation in a river either manually or with an automated sampling machine, as it is laborious, time-consuming, and costly (Melesse et al. 2011; Kisi and Shree 2012). Therefore, modeling water quality and sediment is difficult in computational hydrology (Kisi 2009).
Accurate sediment prediction is critical in the operation and design of hydraulic systems related to hydroelectric dams to keep rivers healthy for agriculture and human activities in general (Hassan et al., 2020; Gomez et al., 1991; Mohammadi et al. 2021). Researchers have focused on the further development of a global model for sediment discharge prediction using approaches such as artificial ML models and AI techniques (Kitsikoudis, et al. 2015; Choubin, et al. 2018; Kumar, et al. 2019; Banadkooki, et al. 2020; Harun, et al. 2021; Niazkar and Zakwan 2023; Fathabadi, et al. 2022; Latif, et al. 2023).
The modeling based on AI will tend to predict the SL in rivers more accurately. The AI-based models are generally utilized for SSL estimation since they help manage the complexity and issues of nonlinearity typically considered to be associated with SSL (Malik et al. 2017). AI-based models used for the prediction of SSL are radial basis function neural networks (Ghanbari-Adivi et al. 2022), classification and regression tree (CART), support vector machine (SVM) (Choubin et al. 2018), artificial neural networks (ANN) (Bisoyi et al. 2019a, b), genetic programming (Kisi et al. 2012a, b), M5 model tree (Adnan et al. 2021), multivariate adaptive regression spline (Shiri et al. 2022), dynamic evolving neural-fuzzy inference systems, wavelet-based artificial neural network (Sharghi et al. 2019). The investigation by Gupta et al. (2021) is an extensive one on AI-based models for the estimation of SSL. Similar investigations dealing with the prediction of suspended sediment in the USA were done by Melesse et al. (2011), in which the predictive ability of the ANN model in comparison with multiple linear regression (MLR) and ARIMA was done. This study showed that ANN outperforms MLR and ARIMA models. A random vector functional linkage (RVFL) model combined with a boundary-corrected maximum overlap discrete wavelet transform (MODWT) was used by Hazarika and Gupta (2022) in India, where the studied models were found to perform well for the estimation of the river SSL. Yilmaz et al. (2018) utilized both the ABC and MARS models and concluded that the MARS model exhibited superior predictive performance compared to the ABC model. Ghambari and Rahati (2018) developed an improved ABC metaheuristic model for the slow convergence issue. The authors Karaboga et al. (2020) examined the application of the ABC algorithm within the ML model. They agreed that the ABC algorithm was reasonably suited to a large variety of studies. Another algorithm improvement was that of Zeng et al. (2021), who proposed a modified version of the ABC algorithm with adaptive search tactics and randomized grouping mechanisms, which they indicated provided advantages for the application. Kaya et al. (2022) did a comprehensive work on the performance of ABC. They observed it to be very successful since it is employed more than in 100 works to solve combinatorial optimization problems. In the related study, the analysis by Choubin et al. (2018) was comparative, which showed that the SVM model was better than the ANN model in terms of predictive performance. In general, the SVM requires several operators for it to be optimally calibrated, making the model quite complicated and laborious in the calibration process. Several methods for predicting sediment yield have been reported to address the problems related to sediment issues (Kulsoontornrat and Ongsomwang 2021). Mathematical models have been developed based on performance indices to measure SL (Stone et al. 2021; Kang et al. 2021).
Furthermore, different optimization algorithms are employed to improve prediction accuracy in several disciplines. Kisi et al. (2012a, b) applied ANN with the algorithm to set the model of discharge and suspended sediment. They determined that ANN-ABC outperformed neural networks, neural differential evolution, neurofuzzy, and rating curve models. Le et al. (2019) used ANN-ABC to predict the heating load of structures, saving energy for city planning. The ABC-ANN model was applied to determine the appropriate computation factors for landslide susceptibility mapping on Penang Island, Malaysia, by Huqqani et al. (2023). The Firefly Algorithm (FA) is one of the popular optimization algorithms (Kayarvizhy et al. 2014). The FA algorithm, which draws inspiration from fireflies' blinking behavior, is a multimodal metaheuristic optimization technique as described in Yang's (2009) work. Yang (2010) integrated MLP and FA to estimate SL. A hybrid SVM-FA scheme was developed by Ghorbani et al. (2017) to estimate field capacity and the permanent wilting point of soils in northwestern Iran. They developed a hybrid model that integrates FA into MLP to estimate SL.
This paper focuses on the development of ML and hybrid models and their application to the SL datasets to predict future increases and decreases of SL in the study area. Many researchers have developed ML and hybrid models for other soil studies, but we have found that very few works have presented estimations of optimized and hybrid prediction modeling. Overall, the investigations observed in various papers indicate that hybrid modeling is essential for better accuracy in SL estimation on both global and national scales. Sediment plays a crucial role in water and land resource development planning because many areas depend on rainwater conservation, natural resources, ecosystems, and crop production development globally and nationally. In this study, we have developed ML and hybrid models based on different input combinations to select the most accurate model for the estimation of SL in the study area. The critical contribution of this study is the development of accurate models and the precise estimation of SL for any study area on a global scale. Such results are needed for the maintenance and control of the environmental system, water resources, and irrigation crop water requirements. By fine-tuning the neural network architecture and optimizing the model parameters, we could achieve better prediction performance, leveraging the special strengths of these nature-inspired optimization techniques.
The present paper aims to optimize neural network prediction modeling of SSL in Çoruh River using FA and ABC algorithms. The objectives are as follows: (1) To develop ML and hybrid modeling based on the different input variables; (2) To create the modeling into two scenarios with various input combinations to show the accuracy of ML compared with other variables and models; (3) The novel use of the FA and ABC algorithms to enhance the neural network prediction model specifically for SSL estimation is at the heart of our research's originality. (4) select the best model based on the various statistical indicators for monthly SL estimation for water resources. (5) The results of the investigation can be helpful to policy in water resources and agriculture purposes with sustainable development. This study.
Forecasting in the sediment science of hydrology globally aids in predicting natural disasters like floods and landslides, enabling preparedness. It helps control erosion, ensuring soil fertility and infrastructure stability. By managing sediment deposition, water resources are optimized for various uses. Ecological impacts of sediment transport on aquatic ecosystems can be assessed and mitigated. Sediment forecasting assists in adapting to climate change, informing infrastructure design and maintenance for resilience. Overall, it supports sustainable development by guiding land-use planning, watershed management, and policy decisions on a global scale, fostering environmental conservation and resource management.
This research highlights the connection of natural and stream flow variables in river basins and the suitability for Ml and hybrid modeling to observe these dynamics and inform data-driven method basin or watershed development, planning and conservation approach.
2 Material and methods
2.1 Study area and data
This particular study has been focused on the investigation of the Çoruh River basin, which has been selected as the study area. The Çoruh River rises in Bayburt Province in Turkey and flows into the Black Sea along its main bed for 431 km, the last 20 km of which is in Georgia (Sucu and Dinç 2008). The river basin is one of Turkey's most beautiful but significantly underdeveloped regions. The region's rural incomes are one-third of the national average. In recent decades, the lack of arable land has led to migration rates far above other regions. The high mountainous areas lying to the south of the Çoruh valley contribute to the formation of a mild climate by breaking the cold climate effect of Eastern Anatolia. The mild climatic conditions gradually harden as you move from Ispir to Pazaryolu. The temperature differences increase and in this respect, it becomes closer to the continental climate.
Table 1 presents summary of statistical parameters for the SL (Qs) and streamflow (Q) data used in the study. The basic statistics such as mean, maximum, minimum and standard deviation skewness and kurtosis coefficients are presented. Accordingly, it was observed that the mean and maximum flow and sediment load were observed in the first spring months and had a linear relationship with each other.
The Çoruh River has substantial hydroelectric potential, making it a valuable water resource (Kankal et al. 2014). It, which originates on the western side of Mescit Mountain, is the country's fastest-pouring river (Yilmaz et al. 2018). Aside from the comparatively high and unpredictable flow rates, the river transports a high quantity of sediment and deposits caused by erosion in the Turkish mountains. It accounts for approximately 10% of the overall sediment supply in the Black Sea (Berkun 2010).
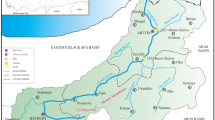
The SL and streamflow data of the Çoruh River, Ispir Bridge (Station No: E23A016) from February 1971 to September 2022 are used in the analysis. Figure 1 shows the study area. 70% (1971–2004) of data were trained to set the model, while 30% (2005–2022) of data was tested to verify the model. The data were provided by the General Directorate of State Hydraulic Works (DSI).

Çoruh River location map
2.2 Methods
2.2.1 Artificial neural network (ANN)
ANNs have been designed as parallel models of the biologically based distributed networks in the human brain's learning process. It has many applications in data analysis, adaptive control and pattern recognition (Zhang et al. 2002). ANNs are computation systems that simulate how information is addressed, learned, and processed in the human brain. ANNs are general artificial intelligence applications and can deal with complex topics according to both human and statistical standards. Furthermore, ANN often has the powerful capability to approximate unknown functions or forecast values in the future based on potentially noisy time series data. Analysis of the structure of an ANN involves some simple components working in parallel. To describe the function of the ANN with similarity to natural processing, the links between the elements are mainly considered.
A neural network typically has three layers: (a) an input layer, (b) an output layer, and (c) an intermediate or hidden layer (Schalkoff 1997).The input vectors are ∈ Rn and D = (X1, X2, …, Xn)T, the outputs of the output layer are Y ∈ Rm, Y = (Y1, Y2, …, Yn)T and the outputs of q neurons in the hidden layer are Z = (Z1, Z2, …, Zn)T. When assuming wij and yj as the threshold and weight between the input layer and the hidden layer, the outputs of each neuron in the hidden and output layers can be stated as follows. The threshold and weight between the hidden and output layers are assumed to be wjk and yk, respectively (Olatomiwa et al. 2015).
Here the transfer function f() is the rule for mapping the total input of the neuron to its output and is a way to introduce a non-linearity into the network design by an appropriate choice. Among the most common functions is the sigmoid function, which is monotonically increasing and varies between 0 and 1.
2.2.2 Artificial bee colony (ABC)
Karaboga (2005) describes the ABC algorithm as a method of solving optimization problems involving the simulation of bee colonies' foraging behavior. The bees' food sources in this simulation represent the solutions to the problems, and the amount of nectar present determines the quality of each solution. The ABC algorithm includes three types of bees: employed bees, onlooker bees, and scout bees. The employed bee forages around food sources and shares information; the onlooker bee chooses sources of good nutrients for further foraging based on the information acquired; and the scout bee, which is a transformed employed bee, forages randomly. In the colony of ABC, both employed bees and scout bees are equal in number, with the condition that there is only one scout bee at most. In order to achieve an optimal solution, the ABC method requires a multi-step process that includes an initial phase, followed by three successive stages of iteration until the terminal condition is met, as outlined in Wang et al. (2022).
-
(1)
Initiation phase.
Similar to other population-based optimization algorithms, ABC starts with the random production of a population of N solutions. xi = (xi1; xi2; …; xiD) be the ith solution produced in the following:
$$ x_{i,j} = x_{j}^{min} + rand\left( {0,1} \right)\left( {x_{j}^{max} - x_{j}^{min} } \right) $$(3)in which i = 1, 2, …, N, N is the number of employed bees. j = 1, 2;…;D, D refers to the dimension of the problem. xjmin is the lower and xjmax is the upper limit of dimension j.
-
(2)
Employed bee phase
Employed bees produce a new candidate solution νi based on the old solution xi = 1; 2;…; N,
$$_{i,j} = x_{i,j} + \varphi_{i,j} \left( {x_{i,j} - x_{k,j} } \right) $$(4)in which j and k are chosen from {1; 2,…, D} to {1,2,…,N} as random, respectively. i and k are different. \({\varphi }_{i,j}\) is a uniformly random number within [− 1,1]. Just one size of xi is modified to generate νi. If νi, j is outside previously defined boundaries, It is set to null based on Eq. (3). In addition, xi is associated with a counter indicating the number of successive failed upgrades. If νi performs better than xi, then xi will be substituted with νi and its counter will be changed to 0. In return, xi will be maintained, and its counter will be increased to 1.
-
(3)
Onlooker bee phase
Upon completion of the search, the employed bees communicate the solution details to the onlooker bees. Onlooker bees play a critical role in the process by evaluating the fitness values of the solutions and then identifying the optimal solutions for additional searches. Let fiti be the fitness value of solution xi, and the related selection probability pi is computed below:
$$ p_{i} = \frac{{fit_{i} }}{{\mathop \sum \nolimits_{m = 1}^{N} fit_{m} }} $$(5)Better solutions are more likely to be selected. Here, the roulette wheel selection method is used to select solutions by onlooker bees (Akay et al. 2021). When an onlooker bee chooses a better solution xi, it generates a novel nominated solution νi following Eq. (4). In the same way, the greedy selection is reused between νi and xi.
-
(4)
Scout bee phase
This stage regards the solution with the highest counter value. The solution is not recognized as hopeful when this value is larger than a previously defined value. At this time, the relevant employed bee abandons this solution and becomes a scout bee that looks for a new solution using Eq. (3). Once the new solution is generated, the relevant counter is set to null. The scout bee reverts to being an employed bee.
The flowchart of the ABC algorithm is shown in Fig. 2. After the initiation phase. Three steps follow each cycle of the search: placement of employed bees on food sources and calculation of nectar quantities; placement of scouts on food sources and calculation of nectar quantities; identification of scout bees and placement on randomly chosen food sources (Karaboga 2009).

The flowchart of the ABC algorithm (Karaman et al. 2023)
2.2.3 Firefly algorithm (FA)
The FA algorithm, first introduced by Yang (2010), is a nature-inspired optimization approach inspired by the flashing behavior of fireflies. With this technique, an optimization issue is set up as an operator, i.e., a firefly that blinks according to its value. Therefore, for each sunlit firefly it attracts accomplices with little attention to their gender, searching for the pursuit space more functional (Lukasik and Zak, 2009; Hemalatha et al. 2016; Al-shammari et al. 2016).
The fireflies are attracted to brightness. The whole swarm moves towards the sunniest firefly. The brightness of fireflies draws their attention (Kayarvizhy et al. 2014; Fateen et al. 2012; Sudheer et al. 2015). Furthermore, the brilliance depends on the concentration of the substance. The main issues in the development of FA are the formulation of the objective function and the variation in light intensity. The attraction (\(\alpha \)), the light intensity \(I\left(L\right)\), and the Cartesian distance between fireflies k and j explained as:
And the two fireflies can be distanced as below:
where \(I\left(L\right)\) is the concentration of light at a distance L. \({I}_{O}\) is the concentration of the initial light from the firefly. \(\gamma \) is the light absorption coefficient; \(\alpha \left(L\right)\) and \({\alpha }_{O}\) are the attractiveness at distances L and L = 0., respectively. Firefly j's next action is illustrated as below:
In Eq. (9), the first part denotes the level of attraction that exists between fireflies, while the second part is associated with the randomization parameters. The coefficient of randomization, which falls between 0 and 1, determines the degree of randomness. and εi is the vector of random numbers obtained from a Gaussian distribution. Figure 3 shows the flowchart of the FA (Meshram et al. 2022).

The flowchart of the FA algorithm (Meshram et al. 2022)
2.2.4 Performance criteria
In this study, seven statistical measures such as root mean squared error (RMSE), mean absolute error (MAE), mean absolute percentage error (MAPE), coefficient of determination (R2) and mean bias error, bias factor (BF), Kling Gupta efficiency (KGE) were used to evaluate model performance. The models' prediction accuracy was evaluated from various perspectives, thereby assessing its effectiveness. Evaluating the forecasting performance is done using a number of metrics. The computation of these metrics involved the utilization of the equations listed below..
Coefficient of Determination (\({R}^{2})\) | \(R^{2} = \frac{{\mathop \sum \nolimits_{i = 1}^{n} \left( {o_{i} - o_{mean} } \right)^{2} - \mathop \sum \nolimits_{i = 1}^{n} \left( {o_{i} - p_{i} } \right)^{2} }}{{\mathop \sum \nolimits_{i = 1}^{n} \left( {o_{i} - o_{mean} } \right)^{2} }}\) | (11) |
Bias Factor | \({\text{Bias Factor }} = \frac{1}{N}\mathop \sum \limits_{i = 1}^{n} \frac{{p_{i} }}{{o_{i} }}\) | (12) |
Mean Absolute Percentage Error (MAPE) | \(MAPE = \frac{1}{N}\mathop \sum \limits_{i = 1}^{n} \left| {\frac{{o_{i} - p_{i} }}{{o_{i} }}} \right|\) | (13) |
Mean Absolute Error (MAE) | \(MAE = \frac{1}{N}\mathop \sum \limits_{i = 1}^{n} \left| {\left( {p_{i} - o_{i} } \right)} \right|\) | (14) |
Root Mean Squared Error (RMSE) | \(RMSE = \sqrt {\frac{1}{N}\mathop \sum \limits_{i = 1}^{N} \left( {o_{i} - p_{i} } \right)^{2} }\) | (15) |
Mean Bias Error (MBE) | \(MBE = \frac{1}{N}\mathop \sum \limits_{i = 1}^{n} \left( {p_{i} - o_{i} } \right)\) | (16) |
Nash Sutcliffe model Efficiency (NSE) coefficient | \(NSE = 1 - \frac{{\mathop \sum \nolimits_{i = 1}^{n} \left( {o_{i} - p_{i} } \right)^{2} }}{{\mathop \sum \nolimits_{i = 1}^{n} \left( {o_{i} - o_{mean} } \right)^{2} }}\) | (17) |
Here, p is the predicted value and, o is the observed value, oi, and pi are the observed and predicted ith values. Error values close to 0 and R2 and Bias Factor values close to 1 mean that They have the most accurate possible prediction results.
A new criterion named Kling-Gupta efficiency (KGE) was introduced by Gupta et al. (2009). The NSE decomposition inspired the KGE. NSE is a metric used to measure a model's prediction accuracy based on observed data. This metric evaluates the residual variance of the model by comparing it with the variance of the measured data.
in which ED is the Euclidean distance of (α, β, r) to (1,1,1) and is calculated as below:
in which \(\beta ={m}_{y}/{m}_{\widetilde{y}}\) dimensionless measure of bias (β ∈ R). The KGE could have values between minus infinity and unity, in which unity means an excellent match to the measured data similar to R2 and NSE. Gupta et al. (2009) presented the benefits of KGE compared to the commonly applied NSE. This has encouraged the wide use of KGE in the field of hydrology to evaluate the quality of the agreement between relevant observations, \(\widetilde{y}\) and model simulations, y. There is a potentially relevant concern with the application of KGE is that the three components of Eq. (19), α, β and r, are the product-moment ratios, which exhibit very large bias for skewed data such as daily flow records (Lamontagne et al. 2020; Vogel and Fennessey 1993; Barber et al. 2019).
3 Results
The precise prediction of SSL in rivers is significant for managing water resources and other aspects of riverine systems. Table 2 presents the correlation coefficients between SL, stream flow, previous SL, and selected model combinations. Accordingly, the variables with the highest correlation coefficient are presented as inputs to the ML models. Thus, the aim is to improve the accuracy of the model prediction. The selected model combinations are shown in Table 3. To choose these combinations, a model was first used to evaluate the effect of stream flows on sediment prediction. Secondly, in-model M2 combinations were created to evaluate the effect of stream flows and past SL on SL prediction.
The trainlm function was utilized to establish the ANN model. Through the Levenberg–Marquardt optimization technique, the weight and bias values are updated by this function. Additionally, the ANN model has chosen a hidden layer size of 10 (Katipoğlu et al. 2023). The feedforward neural network and Hyperbolic tangent sigmoid (tansig) transfer function were employed when constructing the ABC-ANN model. Other parameters that were similar to the single ANN model were generally selected.
Certain parameters have been utilized to develop the FA-ANN model. They are outlined: Transfer functions: tansig and purelin, Maximum Number of Iterations: 100, Number of Fireflies (Swarm Size): 30, Light Absorption Coefficient: 1, Attraction Coefficient Base Value: 2, Mutation Coefficient: 0.2, alpha_damp = 0.98 (Mutation Coefficient Damping Ratio: 0.98), Uniform Mutation Range: delta = 0.05 * (VarMax–VarMin) (Mohammadi 2023).
The performance evaluation of sediment prediction models established in Table 4 was based on various statistical criteria. For this purpose, the statistics from the testing phase of both model combinations were compared, and the models with the highest R2 and KGE indices and the lowest error values were determined to have the most accurate sediment predictions. The ABC-ANN hybrid algorithm exhibits the highest prediction accuracy for both model combinations. Furthermore, when evaluating the performance of the model combinations, it was revealed that the M1 model combinations perform better in terms of lower error and higher termination coefficient than the M2 model combinations, indicating better SL prediction. Therefore, it can be inferred that using streamflow as input provides satisfactory levels of success in estimating SL. This finding is of significant value for decision-makers in water resource planning and water infrastructure construction.
3.1 ANN model results
In Fig. 4, time series graphs, error bars, and error distribution graphs were examined to evaluate the performance of the SL prediction combinations in the ANN model. Based on the observed close oscillation between the predicted and actual values in both model combinations, the spread of errors around the zero axis, and the normal distribution of errors, it can be inferred that quite satisfactory outcomes were achieved. However, it is worth noting that the prediction failed to capture the maximum and minimum values. Furthermore, it is noteworthy that the M1 combination exhibited significantly better performance than the M2 combination. Therefore, using streamflow values to predict SL values resulted in more effective outputs than using both streamflow and past SL values. This situation can be stated by the high correlation between the streamflow values used and sediment while having a weak correlation with past sediment values. In addition, the R-square value of both models is over 0.5, indicating that they are promising in SL prediction. However, advanced optimization techniques such as ABC and FA were employed to strengthen this result.

Comparison of ANN results with time series plot in sediment estimation: a M1, b M2 combination
Figure 5 displays scatter plots of various combinations of the ANN model. These graphs depict the relationship and accuracy between the predicted and actual values. Based on the scatter plot shown in Fig. 5a, it can be observed that the test prediction accuracy of the M1 model is slightly stronger than the prediction accuracy of the M2 model combination depicted in Fig. 5b. Additionally, the scatter plot of the M1 model exhibits a distribution of predicted values closer to the regression line, indicating higher accuracy than the M2 combination.

Scatter plots of ANN test outputs: a M1, b M2 combinations
3.2 FA-ANN model results
The evaluation of the performance of the SL prediction via the FA-ANN model involved examining time series graphs, error bars, and error distribution graphs in Fig. 6. The satisfactory outcomes can be inferred from the observed close propagation between the predicted and actual values in both model combinations, the even spread of errors around the zero axis, and the normal distribution of errors. However, it is essential to note that the prediction failed to capture the highest values.

Comparison of FA-ANN results with time series plot in sediment estimation: a M1 combination, b M2 combination
Figure 7 illustrates the spread of errors for the FA used to optimize the parameters of the ANN model. According to the graph, 100 iterations were applied, and the M1 combination reached low error values around the 10th iteration, while the M2 combination achieved optimal model performance at approximately the 30th iteration.

Propagation graph of errors for various model combinations of FA-ANN: a M1, b M2
The scatter diagrams obtained for the prediction of SL using the FA-ANN hybrid model are presented in Fig. 8. The graphs compare the correlation between the prediction and actual values alongside their distribution according to the regression line. As a result, the M1 model's SL prediction accuracy is near that of the M2 model combination.

Scatter plots of FA-ANN test outputs: a M1, b M2 combinations
3.3 ABC-ANN model results
The determination of the truth of the SL prediction with the ABC-ANN model required the inspection of time series graphs, error bars, and error distribution graphs shown in Fig. 9. The even spread of errors around the zero axis, the normal distribution of errors, and the observed close oscillation between the predicted and actual values in both model combinations all suggest satisfactory outcomes. Furthermore, it is worth noting that the M1 combination exhibited significantly superior performance compared to the M2 combination. Therefore, the utilization of streamflow data for predicting SL values has demonstrated greater efficacy when compared to the employment of streamflow data and prior SL values. The current state of affairs can be explained by the robust correlation between the streamflow values utilized and sediment, while the correlation with preceding sediment values is weak.

Comparison of ABC-ANN results with time series plot in sediment estimation: a M1 combination, b M2 combination
Figure 10 shows the scatter diagrams generated for the SL prediction of the ABC-ANN hybrid model. These graphs compare the relationship between the prediction and actual values and the distribution according to the regression line. Accordingly, it is seen that the accuracy of the SL prediction of the M1 model is slightly more robust than the prediction accuracy of the M2 model combination. In addition, the distribution of the predicted values and actual values of the M1 model combination is closer to the regression line. It can be inferred to be more accurate than the M2 combination.

Scatter plots of ABC-ANN test outputs: a M1, b M2 combinations
3.4 Comparison of all model results
Figure 11 presents the error Bullet charts for various ANN-based algorithms for the M1 combination. The model with the lowest error is considered to have the highest performance. Accordingly, based on all error statistics, the lowest error values were observed in the ABC-ANN hybrid algorithm. It can be inferred that the most accurate SL prediction results were achieved with the ABC-ANN hybrid approach. Additionally, in Fig. 11b, when evaluating the errors using the radar chart, it can be observed that the lowest error values were obtained from the ABC-ANN hybrid approach. In contrast, the highest error values were obtained from the single ANN. Therefore, the highest prediction accuracy was obtained with the hybrid ABC-ANN approach, while the lowest predictions were obtained with single ANN. It is also worth noting that both optimization techniques significantly improved the prediction performance of the ANN model.

Bullet Charts of established models a M1, b M2 combination
Figure 12 depicts polar plot graphs of RMSE, MAE, MAPE, and MBE values for the established models. According to these graphs, the algorithm with the lowest error exhibits the highest SL prediction outputs. In line with this, the ABC-ANN algorithm, which has the lowest error in both model combinations, demonstrates superior results. Secondly, FA-ANN shows the most accurate results, while single ANN exhibits the weakest results. Therefore, it has been proven that the bio-inspired optimization techniques used significantly improve the performance of the single ANN model.

Polar plots of established models a M1, b M2 combination
Figure 13 compares the relationship between SL prediction results and actual data ccording to violin plots. The violin plot method is implemented to comprehend the distribution and central tendency of two distinct data sets, compare various groups, and visually represent any outliers. The dataset's similarities and structure are evident in the variations between groups regarding the violins' shape and width. Accordingly, the ABC-ANN algorithm exhibits the closest structure and distribution to the real data in both model combinations. Hence, the ABC-ANN algorithm shows the highest prediction accuracy. In addition, the FA-ANN model's prediction of the SL value is quite close to the real data and draws attention. The ANN model shows significant deviations from the real data and it is inferred that the prediction accuracy is poor.

Violin plots of established models a M1, b M2 combination
4 Discussion
An essential problem in the engineering of water resources is the prediction of river SSL. Many researchers have optimized the parameters of the ANN model for SSL prediction with various metaheuristic optimization techniques. The results of the study conducted by Kisi et al. (2012a, b) support the superiority of the ABC-ANN model in obtaining optimal or near-optimal solutions by determining the optimal network architecture, learning parameters, and weight values to achieve ideal solutions. Additionally, the study aligns with the current work on SL prediction, highlighting the significance of current values as the most important parameter. Buyukyildiz and Kumcu (2017) predicted SSL using the ANFIS, ANN and SVM in Coruh River. They concluded that the ε-SVR model for the S4 combination, consisting of Qt, Qt − 1, and St − 1 data, outperformed other models in estimating SSL.
Yilmaz et al. (2018) used multivariate adaptive regression spline, teaching–learning-based optimization (TLBO), and ABC models to predict SSL in The Coruh River. They reported that the simultaneous observation of streamflow with SSL is one of the most influential parameters to apply when forming a reliable predictive model. MARS is the most accurate model for predicting SSL. Yilmaz et al. (2019) used the ANN models based on ABC and TLBO models to predict SSL in the Çoruh River Basin of Turkey. ANN-SSL models are connected with stream flow and previous SSL to make predictions. The analyses showed that the ANN-ABC and ANN-TLBO hybrid models are superior to the single ANN model. The combination of MLP with FA for modeling SSL in Lake Mahabad, Iran, was done by Meshram et al. (2022). It had been shown through the analysis that using the FA algorithm increases the prediction accuracy of the MLP model from R2:0.90 to R2:0.95. The hybrid FA-MLP technique may provide a pretty accurate and reasonable price estimation method for predicting SSL in rivers. Samantaray et al. (2022) utilized the combination of PSR and SVM with FA to predict SL and obtained WI values for the SVM, SVM-FA, and PSR-SVM-FA methods equal to 0.942, 0.955, and 0.966. Research evidence in favor of global optimization capabilities about ABC and FA optimization techniques and improved search efficiency in SL prediction to enhance the ANN model, therefore improving studies by Yilmaz et al. (2019), Meshram et al. (2022), and Samantaray et al. (2022). These methodologies will make the ANN model close to the actual solution in a very short period, thus increasing its competency to predict SL.
Figures 14 and 15 present heat maps and line plot graphs applied to evaluate the estimation performance of peak values in sediment estimation. Since the distribution of the data deviated significantly from normal, the peak values were chosen according to the 1000 (ton/day) reference level instead of the 3 standard deviation approach from the mean. According to the heatmap of the correlations of the peak values in Fig. 14, the model with the highest relationship with the peak values of the actual data in the M1 combination is ABC-ANN and the lowest model is ANN. In the M2 model combination, the model with the highest relationship with the peak values of the actual data is FFA-ANN and the lowest model is ANN. Accordingly, it has been determined that hybrid models capture peak values more accurately than the ANN model. The line plot in Fig. 15 represents the peak values for the combination of M1 and M2. Accordingly, in both model combinations, the ABC-ANN algorithm captures the peak values best, while the single ANN model captures the weakest. Accordingly, it has been revealed that the ANN model can predict peak values more realistically by parameter optimization.

Heatmap of peak values for M1 and M2 combination

Line plot of peak values for M1 and M2 combination
5 Conclusion
In this study, the ANN algorithm was combined with ABC and FA optimization approaches to estimate SSL in the Çoruh River in northern Turkey. Various combinations of input variables, including streamflow and past SL values, were tested for SL prediction. The selection of model combinations was based on correlation coefficients. According to the results, the ABC-ANN hybrid approaches established solely with streamflow values outperformed the models established with streamflow and SL values. The highest prediction accuracy was achieved using the input combinations of Q(t) and Q(t − 1), with the highest correlation with SL values. The superior SL prediction results were obtained with ABC-ANN with test statistics: R2: 0.905, RMSE:1406.730, MAE:769.545, MAPE:5.861, MBE: − 251.090, BF:4.457, KGE:0.737, followed by FA-ANN in the second place. In addition, it has been revealed that the peak values of the hybrid models exhibit better performance than the ANN model. Accordingly, in both model combinations, the ABC-ANN algorithm determines the peak values best, while the single ANN model detects the weakest. Therefore, it can be concluded that both FA and ABC optimization techniques significantly improved the performance of the ANN algorithm. As a result, It can be inferred that using streamflow as input provides satisfactory levels of success in estimating SL. This finding is of significant value for decision-makers in water resource planning and water infrastructure construction in terms of planning water structures and resources, reservoir optimization, formation of surface features, and environmental studies. In light of the outcomes, it is possible to incorporate other optimizing techniques such as bat, Greywolf, Wildhorse, Butterfly, and Ant Colony algorithms to enhance the single ANN model for SL estimation. Moreover, these techniques can be utilized to address other hydrological issues, which could be regarded as future research directions.
Data availability
No datasets were generated or analysed during the current study.
References
Achite M, Yaseen ZM, Heddam S, Malik A, Kisi O (2021) Advanced machine learning models development for suspended sediment prediction: comparative analysis study. Geocarto Int. https://doi.org/10.1080/10106049.2021.1933210
Ackers J, Hieatt M, Molyneux JD (2016) Mangla reservoir, Pakistan—approaching 50 years of service. Dams Reserv 26:68–83
Adnan RM, Parmar KS, Heddam S, Shahid S, Kisi O (2021) Suspended sediment modeling using a heuristic regression method hybridized with kmeans clustering. Sustainability 13(9):4648
Adnan RM, Yaseen ZM, Heddam S, Shahid S, Sadeghi-Niaraki A, Kisi O (2022) Predictability performance enhancement for suspended sediment in rivers: Inspection of newly developed hybrid adaptive neuro-fuzzy system model. Int J Sediment Res 37:383–398
Akay B, Karaboga D, Gorkemli B, Kaya E (2021) A survey on the artificial bee colony algorithm variants for binary, integer and mixed integer programming problems. Appl Soft Comput 106:107351
Al-Shammari ET, Mohammadi K, Keivani A, Ab Hamid SH, Akib S, Shamshirband S, Petković D (2016) Prediction of daily dewpoint temperature using a model combining the support vector machine with firefly algorithm. J Irrig Drain Eng 142(5):04016013
Banadkooki FB, Ehteram M, Ahmed AN, Teo FY, Ebrahimi M, Fai CM, El-Shafie A (2020) Suspended sediment load prediction using artificial neural network and ant lion optimization algorithm. Environ Sci Pollut Res 27:38094–38116
Barber C, Lamontagne J, Vogel RM (2019) Improved estimators of correlation and r2 for skewed hydrologic data. Hydrol Sci J 65(1):87–101. https://doi.org/10.1080/02626667.2019.1686639
Bashar KE, ElTahir EO, Fattah SA, Ali AS, Osman M (2010) Nile basin reservoir sedimentation prediction and mitigation. Nile Basin Capacity Building Network Cairo Egypt.
Berkun M (2010) Hydroelectric potential and environmental effects of multidam hydropower projects in Turkey. Energy Sustain Dev 14(4):320–329
Bisoyi N, Gupta H, Padhy NP, Chakrapani GJ (2019a) Prediction of daily sediment discharge using a back propagation neural network training algorithm: a case study of the Narmada river India. Int J Sed Res 34(2):125–135
Bisoyi N, Gupta H, Padhy NP, Chakrapani GJ (2019b) Prediction of daily sediment discharge using a back propagation neural network training algorithm: a case study of the Narmada River India. Int J Sediment Res 34(2):125–135
Buyukyildiz M, Kumcu SY (2017) An estimation of the suspended sediment load using adaptive network based fuzzy inference system, support vector machine and artificial neural network models. Water Resour Manage 31:1343–1359
Ch S, Sohani SK, Kumar D, Malik A, Chahar BR, Nema AK, Dhiman RC (2014) A support vector machine-firefly algorithm based forecasting model to determine malaria transmission. Neurocomputing 129:279–288
Chen XY, Chau KW (2016) A hybrid double feedforward neural network for suspended sediment load estimation. Water Resour Manag 30:2179–2194
Choubin B, Darabi H, Rahmati O, Sajedi-Hosseini F, Kløve B (2018) River suspended sediment modelling using the CART model: a comparative study of machine learning techniques. Sci Total Environ 615:272–281
Cigizoglu HK (2004) Estimation and forecasting of daily suspended sediment data by multi-layer perceptrons. Adv Water Resour 27(2):185–195
de Faran Ali K, Boer DH (2008) Factors controlling specific sediment yield in the upper Indus river basin, Northern Pakistan. Hydrol Process 22:3102–3114
Fateen S, Bonilla-Petriciolet A, Pandu Rangaiah G (2012) Evaluation of covariance matrix adaptation evolution strategy, shuffled complex evolution and firefly algorithms for phase stability. Phase Equilib Chem Equilib Probl 90(12):2051–2071
Fathabadi A, Seyedian SM, Malekian A (2022) Comparison of Bayesian, k-Nearest neighbor and Gaussian process regression methods for quantifying uncertainty of suspended sediment concentration prediction. Sci Total Environ 818:151760
Ghambari S, Rahati A (2018) An improved artificial bee colony algorithm and its application to reliability optimization problems. Appl Soft Comput 62:736–767. https://doi.org/10.1016/j.asoc.2017.10.040
Ghanbari-Adivi E, Ehteram M, Farrokhi A, Sheikh Khozani Z (2022) Combining radial basis function neural network models and inclusive multiple models for predicting suspended sediment loads. Water Resour Manag 36(11):4313–4342
Ghernaout R, Remini B (2014) Impact of suspended sediment load on the silting of SMBA reservoir (Algeria). Environ Earth Sci 72:915–929
Ghorbani MA, Shamshirband S, ZareHaghie D, Azania A, Bonakdarif H, Ebtehajf I (2017) Application of firefly algorithm-based support vector machines for prediction of field capacity and permanent wilting point. Soil till Res 172:32–38
Gomez B (1991) Bedload transport. Earth Sci Rev 31:89–132
Gupta HV, Kling H, Yilmaz KK, Martinez GF (2009) Decomposition of the mean squared error and nse performance criteria: implications for improving hydrological modelling. J Hydrol 377(1):80–91. https://doi.org/10.1016/j.jhydrol.2009.08.003
Gupta D, Hazarika BB, Berlin M, Sharma UM, Mishra K (2021) Artificial intelligence for suspended sediment load prediction: a review. Environ Earth Sci 80(9):1–39
Harun MA, Safari MJS, Gul E, Ghani AA (2021) Regression models for sediment transport in tropical rivers. Environ Sci Pollut Res 28:53097–53115
Hazarika BB, Gupta D (2022) MODWT—Random vector functional link for river-suspended sediment load prediction. Arab J Geosci 15(10):966
Hemalatha C, ValanRajkumar M, Vidhya Krishnan G (2016) Simulation and analysis of MPPT control with modified firefly algorithm for photovoltaic system. Int J Innov Stud Sci Eng Technol 2(11):48–52
Huqqani IA, Tay LT, Mohamad-Saleh J (2023) Spatial landslide susceptibility modelling using metaheuristic-based machine learning algorithms. Engineering with Computers 39(1):867–891
Hussan WU, Shahzad MK, Seidel F, Nestmann F (2020) Application of soft computing models with input vectors of snow cover area in addition to hydro-climatic data to predict the sediment loads. Water 12:1481
Kang W, Jang EK, Yang CY, Julien PY (2021) Geospatial analysis and model development for specific degradation in South Korea using model tree data mining. CATENA 200:105142
Kankal M, Bayram A, Uzlu E, Satilmiş U (2014) Assessment of hydropower and multi-dam power projects in Turkey. Renewable Energy 68:118–133
Karaboga N (2009) A new design method based on artificial bee colony algorithm for digital IIR filters. J Franklin Inst 346(4):328–348
Karaboğa D, Akay BA (2009) Comparative study of artificial bee colony algorithm. Appl Math Comput 214:108–132
Karaboga D, Akay B, Karaboga N (2020) (2020) A survey on the studies employing machine learning (ML) for enhancing artificial bee colony (ABC) optimization algorithm. Cogent Eng. https://doi.org/10.1080/23311916.2020.1855741
Karaboga D (2005) An idea based on honey bee swarm for numerical optimization, Technical report-tr06, Erciyes university, engineering faculty, Comput. Eng. Department 1–10.
Karaman A, Pacal I, Basturk A, Akay B, Nalbantoglu U, Coskun S, Karaboga D (2023) Robust real-time polyp detection system design based on YOLO algorithms by optimizing activation functions and hyper-parameters with artificial bee colony (ABC). Expert Syst Appl 221:119741
Katipoğlu OM, Keblouti M, Mohammadi B (2023) Application of novel artificial bee colony optimized ANN and data preprocessing techniques for monthly streamflow estimation. Environ Sci Pollut Res. https://doi.org/10.1007/s11356-023-28678-4
Kaya E, Gorkemli B, Akay B, Karaboga D (2022) A review on the studies employing artificial bee colony algorithm to solve combinatorial optimization problems. Eng Appl Artif Intell 115:105311. https://doi.org/10.1016/j.engappai.2022.105311
Kayarvizhy N, Kanmani S, Uthariaraj RV (2014) ANN models optimized using swarm intelligence algorithms. WSEAS Trans Comput 13(45):501–519
Khan NM, Tingsanchali T (2009) Optimization and simulation of reservoir operation with sediment evacuation: a case study of the Tarbela Dam Pakistan. Hydrol Process: Int J 23(5):730–747
Kişi Ö (2009) Wavelet regression model as an alternative to neural networks for monthly streamflow forecasting Hydrological. Process: Int J 23(25):3583–3597
Kisi O, Shiri J (2012) River suspended sediment estimation by climatic variables implication: comparative study among soft computing techniques. Comput Geosci 43:73–82
Kisi O, Dailr AH, Cimen M, Shiri J (2012a) Suspended sediment modeling using genetic programming and soft computing techniques. J Hydrol 450:48–58
Kisi O, Ozkan C, Akay B (2012b) Modeling discharge–sediment relationship using neural networks with artificial bee colony algorithm. J Hydrol 428:94–103. https://doi.org/10.1016/j.jhydrol.2012.01.026
Kisi O (2005) Suspended sediment estimation using neuro-fuzzy and neural network approaches/Estimation des matières en suspension par des approches neurofloues et à base de réseau de neurones. Hydrol Sci J. https://doi.org/10.1623/hysj.2005.50.4.683
Kitsikoudis V, Sidiropoulos E, Hrissanthou V (2015) Assessment of sediment transport approaches for sand-bed rivers by means of machine learning. Hydrol Sci J 60:1566–1586
Kulsoontornrat J, Ongsomwang S (2021) Suitable land-use and land-cover allocation scenarios to minimize sediment and nutrient loads into kwan phayao, upper ing watershed. Thailand Appl Sci 11(21):10430
Kumar A, Kumar P, Singh VK (2019) Evaluating diferent machine learning models for runof and suspended sediment simulation. Water Resour Manag 33:1217–1231
Lamontagne JR, Barber CA, Vogel RM (2020) Improved estimators of model performance efficiency for skewed hydrologic data. Water Resour Res 56(9):1–25. https://doi.org/10.1029/2020wr027101
Latif SD, Chong KL, Ahmed AN, Huang YF, Sherif M, El-Shafe A (2023) Sediment load prediction in Johor river: deep learning versus machine learning models. Appl Water Sci 13:79
Le LT, Nguyen H, Dou J, Zhou J (2019) A comparative study of PSO-ANN, GA-ANN, ICA-ANN, and ABC-ANN in estimating the heating load of buildings’ energy efficiency for smart city planning. Appl Sci 9(13):2630
Lukasik S, Zak S (2009) Firefly algorithm for continuous constrained optimization tasks. In: Łukasik S, Żak S (eds) Computational collective intelligence semantic web, social networks and multiagent systems. Springer, Berlin, pp 97–106s
Malik A, Kumar A, Piri J (2017) Daily suspended sediment concentration simulation using hydrological data of Pranhita River Basin, India. Comput Electron Agric 138:20–28
Melesse AM, Ahmad S, McClain ME, Wang X, Lim YH (2011) Suspended sediment load prediction of river systems: An artificial neural network approach. Agric Water Manag 98(5):855–866
Meshram SG, Meshram C, Pourhosseini FA, Hasan MA, Islam S (2022) A multi-layer perceptron (MLP)-Fire fly algorithm (FFA)-based model for sediment prediction. Soft Comput. https://doi.org/10.1007/s00500-021-06281-4
Mohammadi B (2023) Modeling various drought time scales via a merged artificial neural network with a firefly algorithm. Hydrology 10(3):58. https://doi.org/10.3390/hydrology10030058
Mohammadi B, Guan Y, Moazenzadeh R, Safari MJS (2021) Implementation of hybrid particle swarm optimization-differential evolution algorithms coupled with multi-layer perceptron for suspended sediment load estimation. CATENA 198:105024
Niazkar M, Zakwan M (2023) Developing ensemble models for estimating sediment loads for diferent times scales. Environ Dev Sustain. https://doi.org/10.1007/s10668-023-03263-4
Olatomiwa L, Mekhilef S, Shamshirband S, Mohammadi K, Petković D, Sudheer C (2015) A support vector machine–firefly algorithm-based model for global solar radiation prediction. Sol Energy 115:632–644
Parsons AJ, Cooper J, Wainwright J (2015) What is suspended sediment? Earth Surf Proc Land 40(10):1417–1420
Samantaray S, Sahoo A, Paul S, Ghose DK (2022) Prediction of bed-load sediment using newly developed support-vector machine techniques. J Irrig Drain Eng 148(10):04022034. https://doi.org/10.1061/(ASCE)IR.1943-4774.0001689
Schalkoff RJ (1997) Artificial neural networks. McGraw-Hill Higher Education.
Sharghi E, Nourani V, Najafi H, Gokcekus H (2019) Conjunction of a newly proposed emotional ANN (EANN) and wavelet transform for suspended sediment load modeling. Water Supply 19(6):1726–1734
Shiri N, Shiri J, Nourani V, Karimi S (2022) Coupling wavelet transform with multivariate adaptive regression spline for simulating suspended sediment load: independent testing approach. ISH J Hydraul Eng 28(sup1):356–365
Stone M, Krishnappan BG, Silins U, Emelko MB, Williams CH, Collins AL, Spencer SA (2021) A new framework for modelling fine sediment transport in rivers includes flocculation to inform reservoir management in wildfire impacted watersheds. Water 13(17):2319
Sucu, S., & Dinc, T. (2008). Coruh Havzası Projeleri, TMMOB 2. Su Politikaları Kongresi. 33–38
Tung TM, Yaseen ZM (2020) A survey on river water quality modelling using artificial intelligence models: 2000–2020. J Hydrol 585:124670
Vogel RM, Fennessey NM (1993) L-moment diagrams should replace productmoment diagrams. Water Resour Res 29(6):1745–1752. https://doi.org/10.1029/93WR00341
Vrugt JA, de Oliveira DY (2022) Confidence intervals of the Kling-Gupta efficiency. J Hydrol 612:127968
Wang Y, Jiao J, Liu J, Xiao R (2022) A labor division artificial bee colony algorithm based on behavioral development. Inf Sci 606:152–172
Wisser D, Frolking S, Hagen S, Bierkens MF (2013) Beyond peak reservoir storage? A global estimate of declining water storage capacity in large reservoirs. Water Resour Res 49(9):5732–5739
Yang XS (2009) Firefly algorithms for multimodal optimization. stochastic algorithms: foundations and applications, SAGA 2009. Lect Notes Comput Sci 5792:169–178
Yang XS (2010) Firefly algorithm, stochastic test functions and design optimization. Int J Bio-Inspired Comput 2(2):78–84
Yaseen ZM, El-Shafie A, Afan HA, Hameed M, Mohtar WHMW, Hussain A (2016) RBFNN versus FFNN for daily river flow forecasting at Johor River, Malaysia. Neural Comput Appl 27:1533–1542
Yilmaz B, Aras E, Nacar S, Kankal M (2018) Estimating suspended sediment load with multivariate adaptive regression spline, teaching-learning based optimization, and artificial bee colony models. Sci Total Environ 639:826–840
Yilmaz B, Aras E, Kankal M, Nacar S (2019) Prediction of suspended sediment loading by means of hybrid artificial intelligence approaches. Acta Geophys 67:1693–1705. https://doi.org/10.1007/s11600-019-00374-3
Zeng T, Wang W, Wang H, Cui Z, Wang F, Wang Y, Zhao J (2021) Artificial bee colony based on adaptive search strategy and random grouping mechanism. Expert Syst Appl 192:116332. https://doi.org/10.1016/j.eswa.2021.116332
Zhang Z, Klein P, Friedrich K (2002) Dynamic mechanical properties of PTFE based short carbon fibre reinforced composites: experiment and artificial neural network prediction. Compos Sci Technol 62(7–8):1001–1009
Acknowledgements
The author would like to express gratitude to the General Directorate of State Hydraulic Works for providing the data. Thanks to Grammarly Premium Software, which helps correct grammatical errors and spelling mistakes in article. Thanks are extended to the Editor and the anonymous reviewers for their valuable contributions to the content and development of this paper.
Funding
Open access funding provided by the Scientific and Technological Research Council of Türkiye (TÜBİTAK). No funding was received for the execution of this study.
Author information
Authors and Affiliations
Contributions
O. M. Katipoğlu contributed to the data analysis, findings, and conclusions. V. Kartal contributed to data collection, Introduction, and writing methods. C. B. Pande contributed to Discussion and editing paper. All authors have reviewed and approved the final manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no competing interests.
Ethical approval
The manuscript adheres to all ethical requirements. It has not been previously published in any journal.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Katipoğlu, O.M., Kartal, V. & Pande, C.B. Sediment load forecasting from a biomimetic optimization perspective: Firefly and Artificial Bee Colony algorithms empowered neural network modeling in Çoruh River. Stoch Environ Res Risk Assess (2024). https://doi.org/10.1007/s00477-024-02785-1
Accepted:
Published:
DOI: https://doi.org/10.1007/s00477-024-02785-1