
Abstract
Extreme flood events have detrimental effects on society, the economy and the environment. Widespread flooding across South East Queensland in 2011 and 2013 resulted in the loss of lives and significant cost to the economy. In this region, flood risk planning and the use of traditional flood frequency analysis (FFA) to estimate both the magnitude and frequency of the 1-in-100 year flood is severely limited by short gauging station records. On average, these records are 42 years in Eastern Australia and many have a poor representation of extreme flood events. The major aim of this study is to test the application of an alternative method to estimate flood frequency in the form of the Probabilistic Regional Envelope Curve (PREC) approach which integrates additional spatial information of extreme flood events. In order to better define and constrain a working definition of an extreme flood, an Australian Envelope Curve is also produced from available gauging station data. Results indicate that the PREC method shows significant changes to the larger recurrence intervals (≥100 years) in gauges with either too few, or too many, extreme flood events. A decision making process is provided to ascertain when this method is preferable for FFA.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Flooding is one of the most devastating hazards to life, the economy and infrastructure in many parts of the world. Average global flood-related costs are expected to increase nine-fold from US$6 billion in 2005 to US$52 billion by 2050 (Hallegatte et al. 2013). In Australia, floods are the most expensive natural hazard, costing an average of A$377 million per annum (Middelmann-Fernandes 2009). In the last few years, South East Queensland (SEQ) has experienced a number of rare flood events including the floods of 2011 and 2013. The damage left by the flood in 2011 cost the Australian economy an estimated A$30 billion (Australian Government online 2015). Better understanding of the frequency and magnitude of such ‘extreme’ flood events is needed to evaluate flood risk and guide future planning (Croke et al. 2013).
Currently in Australia, the 1-in-100 year flood is commonly used as the design flood in planning processes (Wenger et al. 2013) and is often invoked as the threshold discharge (Q) to describe a rare or extreme flood (e.g. Thompson and Croke 2013). It represents the average recurrence interval (ARI), expressed as a statistical estimate of the average period in years, between the occurrences of a flood of a given size. It is derived from the annual exceedance probability (AEP) such that an event with a 1 % AEP is equivalent to a 100-year ARI (ARI100) event. ARI or AEP are statistical benchmarks used for flood comparison (Middlemann et al. 2001; Engineers Australia 2015) however, for high magnitude and infrequent events they are highly dependent on record length and the nature or variability of events recorded. Other terminology and definitions used to describe extreme floods include ‘great floods’ by Levy and Hall (2005) for events with Q exceeding ARI100 in catchments greater than 200,000 km2. Erskine (1993) defined a catastrophic flood as having an event peak Q to mean annual flood peak Q ratio >10, but this is for post event evaluation and reliant on record length. For these definitions, the events are rare within the record (Enzel et al. 1993; Benito et al. 2004). To a broader extent, IPCC (2001) define an extreme event as an ‘event that is rare within its statistical reference distribution at a particular place and an extreme weather event that is as, or rarer, than the 90th percentile’.
An alternative method of determining an extreme flood is based on a graphical representation of flood magnitude plotted against catchment area and constructing an envelope curve (EC) above the highest plotting points (Creager 1939). Costa’s (1987) world EC has become a benchmark against which to compare all rainfall-runoff floods (e.g. Wohl et al. 1994; Nott and Price 1999; Oguchi et al. 2001; Ruin et al. 2008; Gaume et al. 2009; Croke et al. 2013). Various methods have been devised for interpolating the EC. For example, one method is to select the individual highest observed river stages or discharges (i.e. Floods of Record) and applying a least squares regression equation (e.g. Herschy 2002) across them. However, this method is highly dependent on available records, hence bias to flood records selected. Additionally, linear regression methods do not envelope all plotted flood records. Other studies have also indicated that different climatic regions may have different upper limits to flood magnitude (e.g. Gaume et al. 2009; Padi et al. 2011) hence the world EC may over predict the upper limit of flood magnitude in many locations. Regional Envelope Curves (REC) are constructed to capture national or regional climatic characteristics to estimate extreme flood magnitude (Enzel et al. 1993). This paper examines the application of an Australian EC for defining an extreme event which can be used to evaluate the distribution of flood events recorded at a gauge.
The AEP, and hence ARI, have traditionally been derived by flood frequency analysis (FFA) applied to a continuous set of systematic records of annual maximum discharge series. In ungauged and poorly gauged catchments, the Regional Flood Frequency Analysis (RFFA) is usually applied. This incorporates data from a set of stations with similar hydrological and climatic characteristics (homogenous regions). In Australia, design floods for engineering and planning purposes are typically based on flood records. These are typically derived from software such as TUFLOW (Syme and Apelt 1990), NLFIT (Kuczera 1994) and FLIKE (Kuczera 1999) which incorporate discharge records with various other input parameters including rainfall data and catchment characteristics. FLIKE, for example, performs a Bayesian-type FFA using gauge records and supports many commonly used flood distributions (Micevski et al. 2003). The key assumption of these analyses is that the set of systematic records captures a good spectrum of flood magnitudes. However, this assumption is rarely met in short gauging records, thus decreasing the likelihood of capturing extreme events.
Different probability distributions and parameter estimations method are used in FFA with the Log Pearson type III (PE3), Generalised Extreme Values (GEV) and the Generalised Pareto (GPA) Distributions most commonly used in Australia. Recently, Rahman et al. (2015) reviewed the Wakeby distribution that can take four or five parameters, more than most of the others which typically uses three or less. The use of more parameters can lead to a better fitting of the flood records but it is noted that it may not be applicable to stations with short record lengths (Rahman et al. 2015).
Alternatives to the use of gauge discharge records are rainfall-based techniques, such as Design Event Approach (DEA) which is commonly used in Australia (Mirfenderesk et al. 2013). This method translates the ARI for a given rainfall input to a similar ARI for a flood output by considering the probabilistic nature of rainfall depth but, no other model inputs, which can lead to bias in ARI derivation (Caballero and Rahman 2014). More recently, a Monte Carlo simulation method, known as the Joint Probability Approach (JPA), has been developed to address this shortcoming. The JPA allows for a design flood to be generated by a variety of hydrological inputs. This method has shown to be a theoretically superior method of design flood estimation than the DEA and appropriate for the ARI up to 100 years (Rahman et al. 2002). The use of rainfall-based techniques such as the DEA and JPA are useful if floods are predominately caused by heavy rain events as it is a direct translation of rainfall to flood discharge.
In contrast to event-based approaches, using either gauge records or rainfall records, another alternative method to estimate design flood recurrence intervals is the use of continuous simulation. Developed from a need for longer records, the continuous simulation method is noted by Boughton and Droop (2003) to be reliable for 2–10 years ARI events whereas the rainfall-runoff methods are more reliable for larger events.
Determining a comprehensive gauge record is problematic when (i) only relatively short gauging records are available, (ii) there remains a lack of extreme events within these records, and (iii) subtropical climates present high hydrological variability. It is widely accepted that short gauging station records are less likely to capture the full range of likely flood magnitudes. The effect of short records was evident at Spring Bluff gauge (#143219A) in SEQ which recorded the 2011 flood in the Lockyer Valley. It had a record length of 26 years prior to the 2011 flood. Using the annual flood series up to 2010, the ARI of the 2011 flood was 2000 years (Thompson and Croke 2013). Three more years of flood data (including the 2011 and 2013 floods) incorporated into the annual flood series results in an ARI of 55 years (Sargood et al. 2015). The question therefore is: how to determine whether records at a gauge or a homogenous region capture a wide enough distribution of events, including extreme events? These have a direct impact on accuracy of extrapolated and predicted extreme flood events.
A method to improve extreme flood information at-site is the Probabilistic Regional Envelope Curves (PRECs) (e.g. Castellarin et al. 2005, 2007; Guse et al. 2009, 2010b). The method uses homogenous regions to provide additional extreme Q information to the existing gauged record, but unlike the RFFA, the PREC method only incorporates the extreme events. The PREC method assigns an exceedance probability to the REC, where its inverse, i.e. recurrence interval, is derived with a paired PREC Q. Guse et al. (2010a) have developed a method to integrate PRECs into distribution functions to improve traditional FFA.
In this study, the PREC method is applied to data from a subtropical region of eastern Australia which has predominantly short gauging records (~30 years). The method is compared with the traditional FFA. An Australian REC developed using an objective statistical method is then used to provide a measure of robustness to the PREC method.
2 Study area
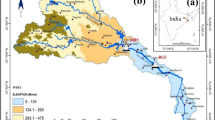
The Southeast corner of Queensland encompasses two Natural Resource Management (NRM) regions, namely South East Queensland Region and Wide Bay Burnett Region (SEQWBB). This region is bounded by the Great Dividing Range to the West and drains east to the Pacific Ocean (Fig. 1). This region is dominated by Paleozoic and Mesozoic-paleozoic age geology (Blewett et al. 2012) and is considered tectonically stable currently. The SEQWBB covers an area of almost 77,000 km2 with average daily temperatures ranging from 6 to 27 °C and mean annual rainfall ranging between 650 and 2850 mm (Bureau of Meteorology (BoM) Australia 2015). It is made up of 14 catchments (11 on mainland) (Table 1) and includes the major rivers of the Brisbane, Mary and Burnett which flow past major agricultural towns. The cities of Brisbane, Maryborough, and Bundaberg are situated at their respective river mouths (Fig. 1).

Area of study—a Distribution of gauging stations used for the Australian Envelope Curve. Southeast Queensland, Australia (orange outline). b The locations of major catchments (demarcated by black outlines) and their main rivers (blues) and the distribution of gauging stations used in this study
SEQWBB has a subtropical climate with no distinct dry season under the Köppen classification and it has a wet summer and a low winter rainfall seasonal rainfall classification (BoM Australia Online). Cyclones that develop over the warm waters off the North and Northeast coast of Queensland do occasionally move inland and southwards into this region and result in devastating storms. The East Coast Lows (ECLs) that bring about intense rainfall occasionally affect the southern part of the region (BoM 2015).
This is a region of high hydrological variability as characterised by the high Flash Flood Magnitude Index (FFMI), which is the log of Standard Deviation of the Annual Maximum Series (AMS), compared to the wet tropics and temperate regions of the east coast of Australia (Rustomji et al. 2009).
The region has a total of 269 closed and open gauging stations with on average 30 years of gauging records. One station has remained open for 106 years (Miva Station #138001A, Mary catchment) and four stations have just over 100 years of record when combining closed and open stations (Table 1).
3 Methods
This section describes the derivation of an Australian EC, the construction of the PRECs (Castellarin et al. 2005) and the integration of spatial extreme flood information (i.e. PREC flood quantiles) into an improved flood series for gauging stations under study (Guse et al. 2010a). A total of 91 gauging stations with at least 30 years of records (combined both closed and open stations) are investigated.
3.1 Australian envelope curve
A total of 2669 maximum Q records from open and closed gauging stations were compiled from six climate zones (Köppen classification) throughout Australia (Fig. 1a; Table 2). To create an objective and statistically robust EC, non-linear quantile regression analysis was conducted which uses log-transformed peak Q (m3 s−1) and catchment area (A km2) of all the gauging stations. An optimisation function produces the best-fit line of the 99.99th quantile and this was applied using the ‘quantreq’ R package v5.19 (Koenker 2015). The equation and the parameters of the exponential curve for the upper limit Q are,
where Q is log-transformed discharge, A is the log-transformed catchment area, and the model parameters are asymptote (Asym), mid-point (mid) and scale (scal). Asym is the asymptote value, mid is the inflection point of the curve, and scal is the scale parameter.
3.2 Derivation of an extreme event
The majority of gauging stations have short record lengths and potentially high uncertainty associated with large ARI events. The ARI100 Q estimates of the four stations (Table 1) with the longest record length (>100 years) were used to compare against the Australian EC to determine a suitable quantile to define an extreme event.
3.3 Construction of empirical probabilistic regional envelope curves (PRECs)
The PREC method (Fig. 2) was first developed by Castellarin et al. (2005), and later applied by Castellarin (2007) to Italian catchments and Guse et al. (2009) and Guse et al. (2010b) to catchments in Germany. It is based on the well-known index flood approach (Dalrymple 1960) which requires the identification of homogenous regions for sites, and the relationship between a given flood Q and the recurrence interval (i.e. the growth curve) can be produced (Castellarin et al. 2001). As such, a PREC can only be constructed if a region is considered homogenous. The mean AMS is used as the index flood in this approach. It attempts to substitute extreme flood information from the homogenous region into a site’s AMS records to produce estimated exceedance probabilities and the recurrence interval for a given flood Q.

Summary of PREC derivation and integration to flood series
3.3.1 Formulation of candidate sets of catchment descriptors
Homogenous regions are defined by sets of catchment descriptors which consist of hydroclimatic, geophysical and infiltration properties (Table 3). Individual contributing upstream catchment areas of respective gauging stations are first produced using hydrological datasets from the Australian Hydrological Geospatial Fabric (Geofabric). Geospatial hydrological data for the region was created and the catchment areas were subsequently generated with Geofabric’s Sample Toolset v1.5.0 for ArcGIS tools (BoM 2015).
Daily rainfall data from January 1889 to April 2015 of 215 rainfall stations was used for the hydro-climatic descriptors. Ordinary kriging was performed to interpolate each of these five hydro-climatic descriptors (Table 3) and the mean values of each catchment area are derived. Geophysical descriptors are derived from a 25 m DEM of the region. Landuse groupings was categorised as either arable or built-up areas. Arable land includes natural vegetation, agricultural and grazing land. Mining occupied <1.3 % of the region and therefore not included in the analysis.
The derived values of the descriptors for each of the stations’ catchment are used as predicator variables of homogenous regions standardised with Z-scores. All negative correlations to the index flood are converted to positive so the values can be combined and a positive correlation can be made with the index flood. Similar to Guse et al. (2010b) all possible subsets with up to three descriptors are first produced by summing up the values and a correlation analysis is performed and values of at least 0.6 between a subset and the unit index flood is the criteria to retain the subset. A total of six candidate subsets remained (Table 4). A check for multi-collinearity between the candidate subsets is done using the Variance Inflation Factor formula (Hirsch et al. 1992). All six subsets had values of less than two, which are well below the most common rule-of-thumb values of 10 (O’Brien 2007) and therefore are all included in the analysis.
3.3.2 Construct homogenous regions using the region of influence
The Region of Influence approach (Burn 1990) is used to construct the homogenous regions. Stations with similar physiographical characteristics based on their Euclidean Distance between the site of interest and each of the other sites are grouped together (pooling groups). Using the nsRFA package (Viglione, 2014) in R, homogenous groups are formed by pooling the nearest station (i.e. lowest Euclidean Distance) to the station of interest. The next nearest station is added until the limit of the homogeneity (in this case set at 2) is reached. Homogeneity limit is based on the Heterogeneity test (Hosking and Wallis 1993) and values greater than 2 are considered heterogeneous. The process is repeated for all gauging stations and each candidate subsets derived in previous step.
3.3.3 Deriving PREC slope and intercept
A linear regional EC is produced for each of the homogenous pooling groups. Maximum Q records of all the stations in each group are normalised and related to catchment area (A) in a double-log scale. The equation of the regional EC is defined as (Castellarin et al. 2005),
where slope b is the linear regression of the unit index flood against A, and the intercept a is achieved by a parallel upshift of the regression line to envelope all unit maximum Qs. Regional EC’s were derived for all groups with at least four stations to improve the representativeness of the linear regression using the pREC package (Castellarin et al. 2013) in R. Nine stations were removed as they did not form any homogenous regions with at least three other stations and they could not form at least one regional EC.
3.3.4 Estimating PREC recurrence interval
An exceedance probability, the inverse of the recurrence interval of the PREC, is assigned to each data pair of unit maximum Q and A. The overall sample years of the AMS of all stations in a given homogeneous region is used to estimate the recurrence interval (Castellarin et al. 2005). To overcome cross-correlation and overlap in flood information in the AMS of the stations, the number of effective sampling years of data is calculated. This is determined by first deriving a regional cross-correlation coefficient function (Eq. 3, Castellarin (2007)) where optimisation is achieved for each station pair (i,j) using the distances between catchment centroids (d) and correlation coefficients between the AMS (λ). The effective sampling year is then calculated using Eq. 4 (Castellarin 2007). The Hazen plotting position (Stedinger et al. 1993) is used to determine the recurrence interval T PREC (Eq. 5) following the methods of Castellarin (2007).
A recurrence interval (T PREC) is assigned to each PREC while each station in the homogeneous region will have a discharge (Q PREC) associated with the catchment size. For each station, PREC flood quantiles (paired values of T PREC and Q PREC) from all the PREC realisations are derived. However, flood quantiles that are more than three times larger from the same T PREC estimated by the index flood method are removed because they are deemed to have high performance error (Guse et al. 2010a) and as a result two stations were excluded.
3.4 Integration of PREC flood quantiles
PREC flood quantiles are integrated into a synthetic AMS of a gauging station based on the method proposed by Guse et al. (2010a) and outlined in Fig. 2. A suitable parent distribution is first selected and the lower (T l) and upper (T u) TPREC are determined from the range of T PREC derived in previous steps. Thereafter, a synthetic flood series is produced where the PREC flood quantiles are inserted.
3.4.1 Selecting a parent distribution for the flood series
A parent distribution for the flood series is required for curve fitting of individual stations. A L-moment ratio diagram is used to determine the most suitable parent distribution (Peel et al. 2001). This has shown to be an appropriate indication of a distribution that describes the regional data (Vogel and Wilson 1996). Distribution types evaluated here are: GEV, GPA, PE3, Generalised Normal (GNO) and Generalised Logistic (GLO). Once the appropriate distribution type is determined, the observed AMS of each station is fitted to the distribution.
3.4.2 Derive synthetic flood series
A synthetic AMS is derived for the incorporation of PREC flood quantiles as it was not possible to add a Q PREC directly to the AMS (Guse et al., 2010a). Each station’s synthetic flood series is generated with the three parent distribution parameters (ξ, α, κ). T u Random numbers between 0 to 1 (Psim) are generated for this set. The total number is determined at T u to provide a data series that extends over 1000 values and also this was the maximum of the TPREC for the region. This allows for the derivation of the synthetic flood series. The random generation of the P sim numbers are repeated until a difference of less than 1 % in the Q value of T u is achieved. This is to ensure consistency between the observed and simulated distribution (see Guse et al. 2010a).
In addition, a binomial function is calculated to estimate the number of T > T l floods that are expected to occur within T u years. The largest probability range of 4–5 floods are used as the number of floods that will be substituted from the synthetic flood series values. The substitution requires these 4–5 values to have exceedance probability (P E) greater than the (1 − \(\frac{1}{T}\)) for representations of T > T l years.
3.4.3 Integrating PREC into the simulated flood series
To integrate the PREC flood quantiles into the simulated series, 4–5 Q values of the synthetic series that are larger than the P E are replaced by the Q PREC values. Taking into account that a larger T PREC has a lower chance of occurring than a smaller T PREC, a binomial function is used to consider the mean occurrence of a specific Q PREC with a recurrence interval within T u years. A vector, V PREC, is generated with PREC Qs assigned the number of times that it has the largest probability of occurring (see Guse et al. 2010a). This leads to PREC Qs with higher T PREC assigned less often to the vector. The replacements of the Q PREC values are randomly chosen without replacement from this vector. In the case where there are less than 4–5 values in the vector, the removed values are randomly chosen and reinserted. This ensures that the new series has T u values again. Using L-moments, a new distribution can be fitted to the new flood series. The random process of selecting the PREC Qs implies that the upper-tail end of change can be significantly different depending on the randomly selected 4–5 values. As such, the process of random selection and substitution is repeated 100 times and the distribution parameter set that estimated the median Q for T = 1000 was used.
4 Results
4.1 Australian envelope curve
The updated world EC (Li et al. 2013) encapsulates the maximum recorded Q values for Australia (Fig. 3). The Australian EC displays an upper catchment area limit to its applicability based on the K index of Francou and Rodier (1967) which is used to assess if a flood is larger than others across different catchment areas. K values should increase with catchment size up until a maximum before it decreases. A sharp drop in K values occurs from 130,000 km2 and these relate to 15 gauging stations in two of Australia’s largest and driest basins: Murray Darling Basin (11 stations) and Lake Eyre basin (4).

Comparing the world envelope curve and climate-segregated maximum recorded discharges from Australia gauging stations
Separating the data set into different climatic regions based on the Köppen classification showed that the records from the temperate and equatorial region plot well below the Australian EC. Records from subtropical gauges showed a very similar curve to that of the Australian curve, as do the curves for tropical and grassland climatic regions. As such, the Australian EC is used to show the existing empirical limits of Q records for the area of study.
The non-linear quantile regression of the 99.99th quantile produced an Australian EC (Fig. 4) which encapsulates all the 2669 gauging stations’ maximum gauged Q. It is clear that using this method produces an EC that takes into consideration all available maximum records and provides a closer envelope fit than the world EC. However, there is still divergence between the largest catchment area and the Australian EC. The function for the Australian EC is,
where x is the catchment area, and the derived parameters are Asym = 4.825, mid = 0.749 and scal = 1.431.

A non-linear quantile regression derived envelope curve for Australia
4.2 Extreme floods
The estimated Qs of ARI100 of the four gauging stations with the longest (over 100 years) records were used to find the nearest Australia EC quantile. The nearest quantile values within 1 % error to the Q value of the respective ARI100’s estimated Qs are 96, 82, 91.5 and 90.1 respectively. As a result, the average value, i.e. the 90th percent quantile is used as the definition of an extreme Q event for this paper. The decision to use this quantile is further supported by IPCC definition of extreme events mentioned previously.
The 90th quantile nonlinear regression equation is,
Using the definition of the 90th quantile of the Australia EC as the minimum benchmark to define an extreme event (Fig. 5), 56 % of gauges have not captured an extreme event in their record period. For these stations, incorporation of additional flood records is critical for improving FFA.

Curve defining an extreme event based on the non-linear 90th quantile regression. Points above the curve indicate gauging stations that have recorded an extreme event
4.3 Homogenous regions for PREC
Defining homogenous regions is a prerequisite for expanding gauge flood records. Figure 6 shows the distribution of gauging stations and their homogeneity with other gauges in the region. Gauges with higher homogeneity have greater number of other gauges that can form homogenous regions and therefore have greater potential of improving flood records. Many of the gauges in the Burnett and Logan-Albert catchments have high homogeneity while in the Mary few gauges have comparatively similar physiographical characteristics.

Extent of homogeneity of physiographical characteristics between the gauges in the Region. HR represents the number of gauges in the region that are homogenous to a gauge
4.4 Integrating probabilistic regional envelope curves
The integration of PREC flood quantiles into gauge records first requires the derivation of the upper and lower limits of T PREC and the determination of the parent distribution function (Fig. 2). The range of T PREC derived from estimating the PREC recurrence interval is 243–1311 therefore T l and T u are determined as 243 and 1311 respectively for the integration of PREC flood quantiles.
4.5 Parent distribution
Based on an L-moment ratio diagram (Fig. 7), the GPA Distribution was selected as the most suitable distribution function to fit the flood series. This was also found as the most suitable distribution in other studies investigating Australia’s flood frequency analysis (Rahman et al. 2013; Rustomji et al. 2009).

L-moment ratio diagram of the Annual Maximum Series for the study region generalised extreme value (GEV), generalised logistic (GLO), generalised normal (GNO), generalised Pareto (GPA), Log Pearson type III (PE3) distributions
4.6 Flood frequency analysis supplemented by probabilistic regional envelope curve
Based on the pooled flood records from homogenous regions, PREC flood quantiles were generated for 80 gauging stations and integrated into FFA to produce new curves of flood peak Q regressed against ARI. Three general outcomes were observed based on comparison between the methods: (1) no change to the predicted ARI (<5 % difference for 42 % of stations, Fig. 8a), (2) a positive shift in ARI for a given Q (29 % of stations, Fig. 8b) and, (3) a negative shift ARI for a given Q (29 % of stations, Fig. 8c). A positive change in ARI indicates that for a given flood peak, for example 14,000 m3 s−1 (Fig. 8b) the FFA predicted ARI of 300 y shifts upwards to 500 years based on PREC prediction. Hence, the predicted probability of an occurrence of a 14,000 m3 s−1 peak magnitude flood has decreased or becomes less likely. A negative change in ARI indicates that for a given flood peak, for example 7000 m3 s−1 (Fig. 8c) the FFA predicted ARI of 1000 y shifts downwards to 600 y based on PREC prediction. Hence, the predicted probability of an occurrence of a 7000 m3 s−1 peak magnitude flood has increased or becomes more likely. Overall, the results show ~60 % of the stations have >5 % change in the estimated Q between the traditional FFA and the PREC method.

Representative PREC method plots illustrating the three possible results of integrating the PREC into the FFA to determine ARI: a no change in ARI (e.g., Helidon station), b positive shift in ARI (e.g., Eidsvold Station) and c negative shift in ARI (e.g., Stonelands Station)
The degree of difference in predicted flood magnitude between the methods for a given ARI increases with increasing ARI and the number of gauging stations that exhibit change also increases (Table 5). However, the maximum change in predicted flood magnitude asymptotes at 150 % of the Q predicted by FFA for ARI1000. In summary, stations with a positive shift in the ARI for a given Q will have a decrease in estimated Q for a given ARI.
4.6.1 Combining probabilistic regional envelope curves and the Australian envelope curve
The non-linear 99.99th and 90th quantile regression can be added to the PREC plots to provide context to the distribution of a station’s AMS and determine whether extreme events have been captured. The 99.99th and 90th quantiles are the Australian EC and the minimum discharge value that defines an extreme event for the given station respectively (Fig. 8). Stations with an existing record of extreme events (e.g. Fig. 8a, b), that is events recorded above 90th quantile, either have no change between traditional FFA and PREC or an increase in ARI indicating the event is less likely to happen. In both of these examples, the PREC curve intersects the Australian EC at ~ARI1000 interval. Gauging stations which have not recorded an extreme event (e.g. Fig. 8c) have decreases in ARI for a given Q based on the PREC. Similarly, the intercept with the Australian EC decreases towards ARI1000 for the PREC.
4.6.2 Spatial variability in prediction between methods
Figure 9 shows the relative deviation of change in estimated Q for ARI100. Stations with negative values are stations with positive shift in their ARIs but a lower Q estimated from the PREC method. Conversely, stations with positive values have a negative shift in their ARIs and a higher estimated Q. There is no distinct spatial trend for stations which either exhibited no change, a positive or negative shift in ARI for a given flood magnitude or a shift in ARI for a given flood magnitude. However, from North to South, there is a general transition from stations with positive to negative shifts in their ARIs estimation between the two methods. In addition, the majority of gauging stations in the Mary Catchment show a positive shift in the ARI based on the PREC method. 11 of the 15 stations showed the PREC method estimated Q for ARI100 to be lower than the FFA derived estimate and the remaining 4 have comparatively low positive relative deviations.

Percent difference in the flood magnitude for ARI100 between the FFA and PREC method
4.6.3 Effect of gauging station record length
The greatest variability in prediction between the two methods occurs in stations with the shortest record length (Fig. 10). As record length increases, differences in prediction between both methods decrease. The convergence in prediction between methods falls within 5 % (i.e. confidence interval for no change) at 60 years. This indicates that for gauging stations with ≥60 years of record, the more complex PREC method generally does not provide any additional information over the simpler FFA method. However, the majority of gauging stations have record lengths shorter than 60 years.

The percent difference between PREC method and FFA method in predicted flood magnitude for ARI100s. Horizontal dashed lines indicate ±5 % difference. Dotted lines represent the interpolated convergence in prediction between methods
4.7 Magnitude and frequency of annual maximum series data
The cumulative frequency distribution of grouped AMS stations from each of the three categories, namely (i) decrease in ARIs, (ii) increase in ARIs and, (iii) no change in ARIs, is shown in Fig. 11. They are summed to exhibit general trends in the frequency distribution of flood sizes and are separated using the 10th percent quantile of the Australian EC. All three groupings show a general decrease in the number of years of AMS data from low to high quantile. This is analogous to the return period of estimated Q values in a typical gauging station. Stations with decreased ARI (e.g. Fig. 8c) have a higher proportion of lower quantile AMS values and a lower proportion of higher quantile AMS values. The reverse is seen for stations with increasing ARI (e.g. Fig. 8b). ‘Stations with no change’ shows a smoother distribution/transition from low to high quantile.

Cumulative frequency distribution of AMS data for 3 possible outcome of the PREC FFA
In terms of extreme events, stations with negative change to the ARI100 Q estimation have about four times (1 % of total summed AMS against 4 %) more extreme events in the summed AMS data compared to stations with positive change. For individual station records, 74 % of the stations that exhibit a reduced ARI100 Q estimate have at least one extreme flood during the record period. Of these, 35 % have three to six AMS values (i.e. at least three extreme flood events) that fulfil the criteria of the extreme flood definition. In contrast, 80 % of gauging stations that exhibit an increased ARI100 typically have no extreme floods during the record period.
5 Discussion
The PREC method as applied in this study is one approach to determining FFA and seeks to provide better spatial information on extreme floods. This method informs users of the relative frequency of extreme flood events through the integration of extreme flood records from stations within a homogenous region. Additional information of extreme events can significantly adjust the magnitude of estimated discharge of floods with high return periods. The reluctance of planners to move away from the ARI100 as the design flood threshold (Babister and Retallick 2011) highlights the need to better understand and improve the upper end distribution of the ARI. The starting point for this is a clear and quantifiable estimate of what constitutes an extreme flood.
5.1 Application and evaluation of the Australian envelope curve
The 90th quantile of the EC provides an extreme flood definition that satisfies various definitions used in other literature. The non-linear quantile regression method to derive the EC provides a better estimate than previous methods using linear regression for Flood of Records (e.g. Herschy 2002) or a series of linear best-fit lines to envelope all maximum Qs (e.g. Costa 1987; Li et al. 2013). In addition, the quantile regression method allows for the ‘fit-for-purpose’ definition of an extreme flood event in this study.
The Australian EC produced in this study provides a first-order upper limit of flood magnitude based on contemporary gauging records. The Australian EC sits close to, but under the updated World EC of Li et al. (2013). This shows that while the Australian contemporary flood record has events that plot close to the World EC, there is still capacity for events significantly larger than recorded to date. Maximum flood peak Qs for catchments between 20 and 130,000 km2, lie close to the EC. However, for catchments outside this range, maximum peak flood Qs diverge from the world curve indicating that it may be over-estimating the upper limits of flood magnitude and what constitutes an extreme event. These gauges lie in the lower catchments which are in semi-arid to arid regions. Flood producing rain falls in the upper catchments and transmission losses through wide floodplains downstream limit flood magnitudes in the lower catchment (Knighton and Nanson 2001; Costelloe et al. 2006).
5.2 Application of the PREC method
With almost 60 and 74 % of the stations showing significant changes to the FFA estimate of ARI100 and ARI1000 respectively (Table 5), the use of the PREC method has relevance in planning and policy. As a result of the 2011 flood, the Queensland Government has allowed the use of different design flood thresholds. However, the 1-in-100 year flood remains the typical threshold used (Croke et al. 2013). As the degree of change in the estimated flood magnitude increases with the ARI, the uncertainty of higher ARIs increases and needs to be addressed. Flood risk in areas that are deemed outside the ARI100 flood inundation area will potentially be at risk by a 1-in-100 year flood. Conversely, using 1-in-100 year design flood in landuse planning and allocation will be affected when the FFA is overestimating the Q. The scale of these problems increases as the magnitude of the ARI used increases. Larger ARIs, ≥ARI1000 are used to evaluate the Population at Risk (PAR) component in the risk assessments of dam design and constructions (DEWS, Queensland 2012). Significant error in the FFA derived 1-in-1000 year flood can have devastating effects, especially if the estimated Q of the ARI is grossly underestimated. The dams will not have the necessary capacity to hold the water during extreme flood events of such magnitude. A less serious implication results if the ARI is overestimated. Resources used in the construction of the dam, as well as the ecological and economic costs lost in the construction of the dam can be deemed as unnecessary. As such there is great significance for reducing inaccuracy in extrapolating large return periods of which the PREC method has shown to be able to perform in ~74 % of the stations for ARI1000.
A decision flow chart (Fig. 12) is proposed to facilitate the process of using the PREC method for FFA. This flow chart is designed for users who are concerned with the ARI100 and beyond.

Decision tree for the application of PREC method for ARI100
The estimated ARI of the Australian EC from the traditional FFA can provide a first order decision if PREC method should be used. It is recommended to use the PREC method if the ARI is beyond an order of magnitude from the 1-in-1000 year return period. This is because stations with no significant change to the ARI tend to have the distribution curve intercepting the Australian EC at ~1000. In addition, stations with an increase (decrease) in ARI tend to have the distribution curve shift upwards (downwards) towards ARI1000. Significant deviation can be seen as poor extrapolation and prediction of the upper end distribution of the ARIs and the associated estimated discharge. Therefore, the use of the PREC method is recommended if a station’s FFA shows the distribution curve intercepting the Australian EC at an ARI that deviates significantly from the ARI1000.
A second order decision to recommend the use of the PREC method is if station’s record is less than <60 years. The additional extreme flood spatial information provided from homogenous stations increases when record length is less than 60 years. A further third stage decision can be made based on the frequency distribution of the number of extreme events recorded by the station. Based on the results, PREC is recommended if extreme events do not make up 1–4 % of the AMS data.
5.3 Evaluation of the PREC method
The derivation of homogenous regions is critical in the PREC method for the integration of extreme flood information. This method has been previously applied in Saxony, Germany (Guse et al. 2010b) but it differs in the degree of homogeneity of stations (Fig. 6). This highlights the physiographical complexity of the study area. The high hydrological variability of this region (Rustomji et al. 2009) partly explains this reduced homogeneity between stations. In terms of geophysical conditions, the elevation range of the contributing catchments is the only consistent predictive variable for forming pooling groups. Generally, stations on higher elevations have better homogeneity based on this predictor variable. The greater heterogeneity for stations on lower elevations is largely a function of the greater range of catchment area of these stations as this variable is normalised against catchment area. As a result of these, there are some stations that do not have sufficient or have relatively fewer stations in a homogenous region. One way to overcome this is to expand the area of study and incorporate more stations to provide more extreme Q information.
The consequence of short record lengths, specifically the frequency of extreme events is well illustrated in this study. For at-site FFA, gauges with short records “create a most unfavourable situation for obtaining accurate estimates of extreme quantiles” (Hosking et al. 1985, p.89). This is especially a problem when the return period of interest (e.g. 100 years) is beyond the available gauge record length (Adamowski and Feluch 1990). However, this does not necessarily mean that any stations with >60 years records have an accurate estimate of ARIs. Longer records can be made up of periods of enhanced, or reduced, extreme events and as a result distort the estimation of ARI. On the other hand, about a quarter of the stations exhibit less than 5 % change in the ARI100 prediction even though they have relatively shorter periods of records. One reason for this is that some of these stations, with their current records, have a fairly good magnitude and frequency distribution of floods. The lack of significant change can also be partly attributed to stations without any significantly larger magnitude flood events from other stations in the homogenous region. This is a limitation of all flood regionalisation methods, including the PREC method.
Contrary to the concern with the lack of extreme flood events in gauging records, some stations may have too many extreme events in their records. This is shown by the negative change in the ARI100’s estimated Q for about 30 % of the stations. The assumption here is that the regional spatial information of extreme flood events is a good indication of what the station may encounter. The Mary catchment has over 70 % of its stations showing a positive shift in the ARIs. Three of these stations (138110, 138111 and 138113) have the most number of floods (six) that fulfilled the definition of an extreme event. In addition, all have records of less than 60 years. This is an example where the relatively higher number of floods in a short record highlights the complex interplay between length of records and the frequency and magnitude distribution of flood records.
The PREC method, similar to traditional FFA, assumes climate stationarity. The issue of climate non-stationarity and the effects on data used for FFA has been subject to critical review recently (see Table 1 in Ishak et al. 2013). Recommendations include incorporating other flood characteristics such as flood volume and flood duration via multivariate analysis and accounting for climate non-stationarity in FFA. The assumption that flood volume, duration and flood peak belong to the same statistical distribution is a key limitation of the multivariate analysis (Vittal et al. 2015). Therefore, multivariate FFA and inclusion of climate models to account for non-stationarity increases the complexity and uncertainty of FFA beyond the uncertainty associated under climate non-stationarity (Serinaldi and Kilsby 2015). In Eastern Australia it has been shown AEP changes depending on El Niño Southern Oscillation (ENSO) and its modulation by the Interdecadal Pacific Oscillation (IPO) (Kiem and Verdon-Kidd 2013), however the temporal scale of climate cyclicity (decadal) is less than the scale or ‘horizon’ required for infrastructure and land use planning which is generally in the order of 100 years or more. Hence, while the AEP of an event will change from year-to-year based on ENSO-IPO phases, a longer term planning horizon of the life of the development is required. Furthermore, given the uncertainty of anthropogenic impacts on climate and consequently flood magnitude and/or frequency, it is imperative that FFA be sufficiently robust to accommodate known climate cyclicity due to ENSO and IPO by incorporating comprehensive gauge records into flood series analysis.
5.4 Further improvement for flood frequency analysis
The concept of flood frequency hydrology proposed by Merz and Blöschl (2008a, b) and subsequently quantified by Viglione et al. (2013) highlights the combined use of spatial, temporal and causal flood information. The PREC method presented here reflects the use of spatial flood information (i.e. extreme flood information from gauging stations of homogenous regions). The limitation due to a lack of extreme events, hence uncertainties in the upper limit of flood magnitudes, in such a regionalisation method can be addressed with the use of additional temporal flood information. In a region where historical records are limited to post-European settlement (early-mid 1800s) the potential of paleoflood data can be significant.
On average, gauge records in Eastern Australia are 42 years long (Rustomji et al. 2009). The length of available records is comparatively shorter than in Europe and North America where for example, cities in England such as York, and Nottingham have annual records starting from as early as the mid-19th century (Macdonald 2012; 2013). For example, in the Midwest United States, Villarini et al. (2011) used 196 gauging stations that have at least 75 years of records for flood frequency distribution analysis. The consequence of using short records is the high level of uncertainty associated with the Q estimates of design flood with larger return periods (Kjeldsen et al. 2014). This study shows that generally the PREC method adds information to FFA for records of 60 years or less, but the information is still only being drawn from a relatively short time period of similar climatic conditions. As reported above, recent meteorological and climate studies have highlighted decadal-scale cyclicity with ENSO (e.g. Power et al. 1999; Kiem and Franks 2001) and its modulation by IPO, of which there has been ≤2 alternating phases over the gauging record period (e.g. Kiem et al. 2003; Verdon et al. 2004; Micevski et al. 2006; Power et al. 2006). More recently, Vance et al. (2013) have developed a high resolution rainfall proxy for subtropical Australia and observed multi-decadal to centennial scale cycles. These studies provide plenty of warning that our short temporal gauge records may have only captured part of a limb in a longer term cyclical fluctuation (Gregory et al. 2008).
One well-established method to extend known flood magnitudes is the use of paleoflood slack water deposits (SWDs) (Baker 1987). SWDs are sediments deposited in low energy flow zones during extreme floods. Secondly, only more extreme floods can deposit sediment overtop of previous deposits. Finally, for Q estimation it is assumed that the channel capacity has not changed over time, nor has the channel bed degraded or aggraded, hence preferred sites are associated with bedrock or resistant boundary channels. The method has been applied widely in the Northern Hemisphere (e.g. Ely and Baker 1985; Webb et al. 2002; Benito et al. 2003; Thorndycraft et al. 2005; Huang et al. 2013). Few studies have applied the SWDs to reconstructing extreme floods in Australia and they are mostly limited to tropical Australia and restricted in bedrock settings (e.g. Wohl 1992a, b; Baker and Pickup 1987; Pickup et al. 1988; Gillieson et al. 1991). Although these studies found SWDs enveloped by the Australian EC (Fig. 13), they are deposited by Q estimates greater than the highest recorded from the nearest gauges. For example, Q estimates for 2 SWD sites found in the Herbert Gorge of 17, 000 m3 s−1 was higher than the single outlier value of 15, 335 m3 s−1 recorded in 1967 (Wohl 1992b). In temperate New South Wales (NSW), Saynor and Erskine (1993) identified SWDs in Fairlight Gorge that are 8 m higher than the highest recorded peak Q of 16, 600 m3 s−1 that yield a radiocarbon date of 3756 ± 72 years BP. These paleofloods occurred within the period of ‘modern’ ENSO establishment at ~4000 BP (Shulmeister and Lees 1995). Preliminary results of paleoflood reconstruction from two SWD sites in the study region (Fig. 13) show floods of greater stage height and magnitude occurring at 165 ± 20 and 600 ± 60 years within two km downstream of a gauging station (136207A) in the Burnett River catchment (Fig. 1b). The gauge has a 49 year record, with a peak Q of 7600 m3 s−1 recorded during an extreme event in 2013. The SWDs were sampled 0.9 m above the debris lines created during the 2013 event. The PREC method showed a positive shift of the ARI100 by 11 % from the traditional FFA for this station. The two paleofloods reconstructed from SWDs have estimated Qs ranging between 8500 and 9000 m3s−1. This data can be added to the systematic records and assessed with a non-systematic FFA (e.g. Peak Over Threshold method) and PREC. Currently, paleofloods are not integrated into FFA, however it is likely that such information will require further adjustments to existing ARI estimates.

Relation of the Australian envelope curve and the existing and new extreme paleoflood records in Australia
6 Conclusion
In recognition of the growing risk of increased flood frequency and magnitude with future climate change predictions, this project sought to explore the application of a non-traditional approach to estimating FFA in sub-tropical Australia. A starting point involved the construction of an Australian EC which provides robustness in the definition of an ‘extreme’ event and facilitated the assessment of the distribution of events recorded in gauging stations. Comparison between the PREC method and the traditional at-site FFA showed that the integration of spatial information can better estimate discharges of larger ARIs (≥100 years) in gauges that have no, relatively few, or an excess extreme discharge records in the AMS. For the region of SEQWBB, estimations of the frequency of extreme events can be improved. This has significant implications for existing flood mitigation approaches that may currently under- or over-predict flood magnitude for hazard planning. A decision making flow chart is provided to assess when the PREC method may be most useful.
With the use of homogenous spatial information, the PREC method considers a larger scale of Q variability, and partly addresses the concerns with limited temporal records. One key limitation of this method is the assumption that the homogenous regions capture a more representative distribution of frequency and magnitude of extreme events for the last 100 years. Gauges with >60 years of records generally showed no change between traditional at-site FFA and the PREC method in the estimation of the 100 year floods. However, non-stationarity in climate is assumed to be accounted for within the relatively short timescale of these systematic records. In line with recent concerns about climate non-stationarity, this assumption can be tested with the integration of multiple techniques that specifically target the temporal extension of flood records, such as SWDs from extreme paleofloods. Further research is advancing the application of SWDs to regional estimates of flood limits in SEQ.
References
Adamowski K, Feluch W (1990) Nonparametric flood-frequency analysis with historical information. J Hydraul Eng 116(8):1035–1047
Baker VR (1987) Paleoflood hydrology and extraordinary flood events. J Hydrol 96(1):79–99
Baker VR, Pickup G (1987) Flood geomorphology of the Katherine Gorge, Northern Territory, Australia. Geol Soc Am Bull 98(6):635–646
Babister M, Retallick M (2011) Brisbane River 2011 flood event—Flood frequency analysis. Final Report, WMA water, Submission to Queensland Flood Commission of Inquiry
Benito G, Lang M, Barriendos M, Llasat MC, Francés F, Ouarda T, Bobée B (2004) Use of systematic, palaeoflood and historical data for the improvement of flood risk estimation. Review of scientific methods. Nat Hazards 31(3):623–643
Benito G, Sánchez-Moya Y, Sopeña A (2003) Sedimentology of high-stage flood deposits of the Tagus River, Central Spain. Sediment Geol 157(1):107–132
Blewett RS, Kennett BLN, Huston DL (2012) Australia in time and space. In: Blewett RS (ed) Shaping a nation: a geology of Australia. Geoscience Australia and ANU E Press, Canberra, pp 47–117
Boughton W, Droop O (2003) Continuous simulation for design flood estimation—a review. Environ Model Softw 18(4):309–318
Burn DH (1990) Evaluation of regional flood frequency analysis with a region of influence approach. Water Resour Res 26(10):2257–2265
Caballero WL, Rahman A (2014) Development of regionalized joint probability approach to flood estimation: a case study for Eastern New South Wales, Australia. Hydrol Processes 28(13):4001–4010
Castellarin A (2007) Probabilistic envelope curves for design flood estimation at ungauged sites. Water Resour Res 43(4):W04406. doi:10.1029/2005WR004384
Castellarin A, Burn DH, Brath A (2001) Assessing the effectiveness of hydrological similarity measures for flood frequency analysis. J Hydrol 241(3):270–285
Castellarin A, Guse B, Pugliese A (2013) pREC: Probabilistic Regional Envelope Curve. R package version 1.0
Castellarin A, Vogel RM, Matalas NC (2005) Probabilistic behaviour of a regional envelope curve. Water Resour Res 41(6):W06018. doi:10.1029/2004WR003042
Castellarin A, Vogel RM, Matalas NC (2007) Multivariate probabilistic regional envelopes of extreme floods. J Hydrol 336(3–4):376–390
Costa JE (1987) A comparison of the largest rainfall-runoff floods in the United States with those of the People’s Republic of China and the world. J Hydrol 96(1):101–115
Costelloe JF, Grayson RB, McMahon TA (2006) Modelling streamflow in a large anastomosing river of the arid zone, Diamantina River, Australia. J Hydrol 323(1):138–153
Creager WP (1939) Possible and probable future floods. Civ Eng 9:668–670
Croke J, Reinfelds I, Thompson C, Roper E (2013) Macrochannels and their significance for flood-risk minimisation: examples from southeast Queensland and New South Wales, Australia. Stoch Env Res Risk Assess 28(1):99–112
Dalrymple T (1960) Flood frequency analyses. Water Supply Paper 1543-A. US Geol. Survey, Reston, VA
Ely LL, Baker VR (1985) Reconstructing paleoflood hydrology with slackwater deposits: Verde River, Arizona. Phys Geogr 6(2):103–126
Enzel Y, Ely LL, House PK, Baker VR, Webb RH (1993) Paleoflood evidence for a natural upper bound to flood magnitudes in the Colorado River Basin. Water Resour Res 29(7):2287–2297
Erskine W (1993) Erosion and deposition produced by a catastrophic flood on the Genoa River, Victoria. Aust J Soil Water Conserv 6(4):35–43
Francou J, Rodier, JA (1967) Essai de classification des crues maximales. In: Proceedings, Leningrad Symposium on Floods and their Computation, UNESCO
Gaume E, Bain V, Bernardara P et al (2009) A compilation of data on European flash floods. J Hydrol 367(1):70–78
Gillieson D, Smith DI, Greenaway M, Ellaway M (1991) Flood history of the limestone ranges in the Kimberley region, Western Australia. Appl Geogr 11(2):105–123
Gregory KJ, Benito G, Downs PW (2008) Applying fluvial geomorphology to river channel management: background for progress towards a palaeohydrology protocol. Geomorphology 98(1):153–172
Guse B, Castellarin A, Thieken AH, Merz B (2009) Effects of intersite dependence of nested catchment structures on probabilistic regional envelope curves. Hydrol Earth Syst Sci 13(9):1699–1712
Guse B, Hofherr T, Merz B (2010a) Introducing empirical and probabilistic regional envelope curves into a mixed bounded distribution function. Hydrol Earth Syst Sci 14(12):2465–2478
Guse B, Thieken AH, Castellarin A, Merz B (2010b) Deriving probabilistic regional envelope curves with two pooling methods. J Hydrol 380(1):14–26
Hallegatte S, Green C, Nicholls RJ, Corfee-Morlot J (2013) Future flood losses in major coastal cities. Nat Climate Change 3:802–806
Herschy RW (2002) The world’s maximum observed floods. Flow Meas Instrum 13(5):231–235
Hirsch RM, Helsel DR, Cohn TA, Gilroy EJ (1992) Statistical analysis of hydrological data. In: Maidment DA (ed) Handbook of hydrology. McGraw-Hill, New York, pp 17.1–17.55
Hosking JRM, Wallis JR, Wood EF (1985) An appraisal of the regional flood frequency procedure in the UK Flood Studies Report. Hydrol Sci J 30(1):85–109
Hosking J, Wallis J (1993) Some statistics useful in regional frequency analysis. Water Resour Res 29(2):271–281
Huang CC, Pang J, Zha X et al (2013) Extraordinary hydro-climatic events during the period AD 200–300 recorded by slackwater deposits in the upper Hanjiang River valley, China. Palaeogeogr Palaeoclimatol Palaeoecol 374:274–283
Ishak EH, Rahman A, Westra S, Sharma A, Kuczera G (2013) Evaluating the non-stationarity of Australian annual maximum flood. J Hydrol 494:134–145
Kiem AS, Franks SW (2001) On the identification of ENSO-induced rainfall and runoff variability: a comparison of methods and indices. Hydrol Sci J 46(5):715–727
Kiem AS, Franks SW, Kuczera G (2003) Multi-decadal variability of flood risk. Geophys Res Lett 30(2):1035. doi:10.1029/2002GL015992
Kiem AS, Verdon-Kidd DC (2013) The importance of understanding drivers of hydroclimatic variability for robust flood risk planning in the coastal zone. Aust J Water Resour 17(2):126
Kjeldsen TR, Macdonald N, Lang M et al (2014) Documentary evidence of past floods in Europe and their utility in flood frequency estimation. J Hydrol 517:963–973
Knighton AD, Nanson GC (2001) An event-based approach to the hydrology of arid zone rivers in the Channel Country of Australia. J Hydrol 254(1):102–123
Koenker R (2015) quantreg: Quantile Regression. R package version 5.11. http://CRAN.R-project.org/package=quantreg
Kuczera G (1994) NLFIT: A Bayesian nonlinear regression program suite. Department of Civil Engineering and Surveying, The University of Newcastle, Callaghan
Kuczera G (1999) Comprehensive at-site flood frequency analysis using Monte Carlo Bayesian Inference. Water Resour Res 35(5):1551–1558
Levy JK, Hall J (2005) Advances in flood risk management under uncertainty. Stoch Env Res Risk Assess 19(6):375–377
Li C, Wang G, Li R (2013) Maximum observed floods in China. Hydrol Sci J 58(3):728–735
Macdonald N (2012) Trends in flood seasonality of the River Ouse (Northern England) from archive and instrumental sources since AD 1600. Clim Change 110(3–4):901–923
Macdonald N (2013) Reassessing flood frequency for the River Trent through the inclusion of historical flood information since AD 1320. Hydrol Res 44(2):215–233
Merz R, Blöschl G (2008a) Flood frequency hydrology 1: temporal, spatial, and causal expansion of information. Water Resour Res 44:W08432. doi:10.1029/02007WR006744
Merz R, Blöschl G (2008b) Flood frequency hydrology 2: combining data evidence. Water Resour Res 44:W08433. doi:10.1029/02007WR006745
Micevski T, Franks SW, Kuczera G (2006) Multidecadal variability in coastal eastern Australian flood data. J Hydrol 327(1):219–225
Micevski T, Kiem AS, Franks SW, Kuczera G (2003) Multidecadal Variability in New South Wales Flood Data. In: Boyd MJ, Ball JE, Babister MK, Green, J (eds) 28th International Hydrology and Water Resources Symposium: About Water; Symposium Proceedings. Barton, ACT. Institution of Engineers, Australia, pp 1.173–1.179
Middlemann M, Harper B, Lacey R (2001) Chapter 9. In: Granger K, Hayne M (eds) Natural hazards and the risk they pose to South-East Queensland. Technical Report, Geoscience Australia, Commonwealth Government of Australia, Canberra
Middelmann-Fernandes MH (2009) Review of the Australian Flood Studies Database. Record 2009/034. Geoscience Australia, Canberra
Mirfenderesk H, Carroll D, Chong E, Rahman M, Kabir M, Van Doorn R, Vis S (2013) Comparison between design event and joint probability hydrological modelling. In: Flood Management Association National Conference, Tweed Heads, pp 1–9
Nott J, Price D (1999) Waterfalls, floods and climate change: evidence from tropical Australia. Earth Planet Sci Lett 171(2):267–276
O’Brien RM (2007) A caution regarding rules of thumb for variance inflation factors. Qual Quant 41(5):673–690
Oguchi T, Saito K, Kadomura H, Grossman M (2001) Fluvial geomorphology and paleohydrology in Japan. Geomorphology 39(1):3–19
Padi PT, Di Baldassarre G, Castellarin A (2011) Floodplain management in Africa: large scale analysis of flood data. Phys Chem Earth A/B/C 36(7):292–298
Peel MC, Wang QJ, Vogel RM, McMahon TA (2001) The utility of L-moment ratio diagrams for selecting a regional probability distribution. Hydrol Sci J 46(1):147–155
Pickup G, Allan G, Baker VR (1988) History, palaeochannels and palaeofloods of the Finke River, central Australia. In: Warner RF (ed) Fluvial geomorphology of Australia. Academic Press, Sydney, pp 177–200
Power S, Casey T, Folland C, Colman A, Mehta V (1999) Inter-decadal modulation of the impact of ENSO on Australia. Clim Dyn 15(5):319–324
Power S, Haylock M, Colman R, Wang X (2006) The predictability of interdecadal changes in ENSO activity and ENSO teleconnections. J Clim 19(19):4755–4771
Rahman AS, Rahman A, Zaman MA, Haddad K, Ahsan A, Imteaz M (2013) A study on selection of probability distributions for at-site flood frequency analysis in Australia. Nat Hazards 69(3):1803–1813
Rahman A, Weinmann PE, Hoang TMT, Laurenson EM (2002) Monte Carlo simulation of flood frequency curves from rainfall. J Hydrol 256(3):196–210
Rahman A, Zaman MA, Haddad K, El Adlouni S, Zhang C (2015) Applicability of Wakeby distribution in flood frequency analysis: a case study for eastern Australia. Hydrol Process 29(4):602–614
Ruin I, Creutin JD, Anquetin S, Lutoff C (2008) Human exposure to flash floods–Relation between flood parameters and human vulnerability during a storm of September 2002 in Southern France. J Hydrol 361(1):199–213
Rustomji P, Bennett N, Chiew F (2009) Flood variability east of Australia’s great dividing range. J Hydrol 374(3):196–208
Sargood MB, Cohen TJ, Thompson CJ, Croke J (2015) Hitting rock bottom: morphological responses of bedrock-confined streams to a catastrophic flood. Earth Surface Dynamics 3(2):265–279
Saynor MJ, Erskine WD (1993) Characteristics and implications of high-level slackwater deposits in the Fairlight Gorge, Nepean River, Australia. Mar Freshw Res 44(5):735–747
Shulmeister J, Lees BG (1995) Pollen evidence from tropical Australia for the onset of an ENSO-dominated climate at c. 4000 BP. Holocene 5(1):10–18
Serinaldi F, Kilsby CG (2015) Stationarity is undead: uncertainty dominates the distribution of extremes. Adv Water Resour 77:17–36
Stedinger JR, Vogel RM, Foufoula-Georgiou E (1993) Chapter 18: Frequency analysis of extreme events. In: Maidment DA (ed) Handbook of hydrology. McGraw-Hill, New York, pp 1–66
Syme WJ, Apelt CJ (1990) Linked two-dimensional/one-dimensional flow modelling using the shallow water equations. In: Conference on Hydraulics in Civil Engineering, 1990: Preprints of Papers (p 28). Institution of Engineers, Australia
Thorndycraft VR, Benito G, Rico M, Sopeña A, Sánchez-Moya Y, Casas A (2005) A long-term flood discharge record derived from slackwater flood deposits of the Llobregat River, NE Spain. J Hydrol 313(1):16–31
Thompson C, Croke J (2013) Geomorphic effects, flood power, and channel competence of a catastrophic flood in confined and unconfined reaches of the upper Lockyer valley, southeast Queensland, Australia. Geomorphology 197:156–169
Vance TR, van Ommen TD, Curran MA, Plummer CT, Moy AD (2013) A millennial proxy record of ENSO and eastern Australian rainfall from the Law Dome ice core, East Antarctica. J Clim 26(3):710–725
Vittal H, Singh J, Kumar P, Karmakar S (2015) A framework for multivariate data-based at-site flood frequency analysis: essentiality of the conjugal application of parametric and nonparametric approaches. J Hydrol 525:658–675
Verdon DC, Wyatt AM, Kiem AS, Franks SW (2004) Multidecadal variability of rainfall and streamflow: eastern Australia. Water Resour Res 40(10):W10201. doi:10.1029/2004WR003234
Viglione A (2014) nsRFA: Non-supervised regional frequency analysis. R package version 0.7-12. http://CRAN-R-project.org/package=nsRFA
Viglione A, Merz R, Salinas JL, Blöschl G (2013) Flood frequency hydrology: 3. A Bayesian analysis. Water Resour Res 49(2):675–692
Villarini G, Smith JA, Baeck ML, Krajewski WF (2011) Examining flood frequency distributions in the Midwest US 1. J Am Water Resour Assoc 47(3):447–463
Vogel RM, Wilson I (1996) Probability distribution of annual maximum, mean, and minimum streamflows in the United States. J Hydrol Eng 1(2):69–76
Wenger C, Hussey K, Pittock J (2013) Living with floods: key lessons from Australia and abroad. National Climate Change Adaptation Research Facility, Gold Coast, pp 1–267
Webb RH, Blainey JB, Hyndman DW (2002) Paleoflood hydrology of the Paria River, southern Utah and northern Arizona, USA. Water Science and Application 5:295–310
Wohl EE (1992a) Bedrock benches and boulder bars: floods in the Burdekin Gorge of Australia. Geol Soc Am Bull 104(6):770–778
Wohl EE (1992b) Gradient irregularity in the Herbert Gorge of northeastern Australia. Earth Surf Proc Land 17(1):69–84
Wohl EE, Fuertsch SJ, Baker VR (1994) Sedimentary records of late Holocene floods along the Fitzroy and Margaret Rivers, Western Australia. Aust J Earth Sci 41(3):273–280
Online
Australian Government (2015) Natural disasters in Australia http://www.australia.gov.au/about-australia/australian-story/natural-disasters. Accessed 1 Nov 2015
Bureau of Meteorology (2015) http://www.bom.gov.au. Accessed 1 June 2015
Department of Energy and Water Supply, State of Queensland (2012) Guidelines on Acceptable Flood Capacity for Water Dams https://www.dews.qld.gov.au/__data/assets/pdf_file/0003/78834/acceptable-flood-capacity-dams.pdf. Accessed 15 Nov 2015
Engineers Australia (2015) Position Paper on Flooding and Flood Mitigation. https://www.engineersaustralia.org.au/water-engineering/publications. Accessed 20 Oct 2015
IPCC (2001) Working Group I: The Scientific Basis—Glossary http://www.ipcc.ch/ipccreports/tar/wg1/518.htm. Accessed 22 Sep 2015
Acknowledgments
This research was funded by an Australian Research Council Linkage Award (LP120200093). DL is supported by a University of Queensland (UQ) International Postgraduate Award Scholarship. Dr. Simon Blomberg is thanked for his statistical inputs. Dr. Anthony Kiem is thanked for his constructive comments from an earlier draft. We are grateful for the constructive comments by the reviewers.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Lam, D., Thompson, C. & Croke, J. Improving at-site flood frequency analysis with additional spatial information: a probabilistic regional envelope curve approach. Stoch Environ Res Risk Assess 31, 2011–2031 (2017). https://doi.org/10.1007/s00477-016-1303-x
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00477-016-1303-x