
Abstract
The present study provides an insight into a systematic evaluation of probability distributions using some statistical measures along with a few relevant catchment and flow properties to select a basin-scale model for flood frequency analysis (FFA) of Mahanadi river basin, India. A comprehensive analysis identified generalized extreme value (GEV), Pearson type 3, generalized Pareto, and Gumbel as the best-fit candidates for FFA of the watershed. GEV was selected as the basin-scale model based on a descriptive statistical ranking method followed by its test for predictive ability through bootstrap sampling. The distribution parameters were correlated with a few hydrological and physiographic characteristics of the watershed through regression analysis. The predictive capability of the regressed equations was assessed by comparing the observed mean annual flood (MAF) with the anticipated MAF derived from the expected value of GEV density function. Various return period quantiles were estimated using the parameters obtained from these equations and compared with the observed values, which confirmed the robustness of the physically based GEV model over the entire watershed. Flood flow values estimated at the gauging sites considering the site-wise best distribution and the basin-scale standard model were compared. The marginal difference of error between them further supported the application of a standard model for the entire basin despite site-wise different models.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
1 Introduction
Flood is one of the pervasive natural disasters, where every year, numerous catastrophic river floods, urban floods, and other flash flood events affect the fragile ecosystem along with human lives and other properties all over the world. Such situations demand an accurate prediction of flood flow values at various frequencies, which is a prerequisite for the effective planning and design of hydraulic structures, risk analysis, and management of resources (Stedinger et al. 1993). A comprehensive understanding of the probabilistic behavior of extreme events can be better analyzed by flood frequency study, which has been widely researched in hydrology but still has certain limitations regarding the sampling of random events and choice of an appropriate probability distribution. Out of the two types of sampling approaches such as annual maximum series (AMS) and partial duration series (PDS), AMS consists of the maximum flow value of each year, i.e., annual flood value and PDS involves all the discharge above a particular threshold. Application of PDS in flood frequency analysis is much constrained due to the complexity involved in the selection of thresholds and also, the independence criteria of exceedances. Therefore, in most of the circumstances, the statistical method of flood frequency analysis is applied, which involves fitting theoretical distributions directly to the observed AMS to estimate higher return period quantiles. Accuracy of such approaches depends upon various factors such as the length of available data, presence of outliers, selection of the best-fit distribution, etc. (Saghafian et al. 2014).
Mesbahzadeh et al. (2019) analyzed the frequency of flooding in the Loot river basin using annual peak discharge coupled with the method of maximum L moments. They found the log Pearson type III (LP III) distribution to have higher correlation statistics for the entire watershed. Calenda et al. (2009) proposed a sample quantile criterion for the selection of optimum distribution for flood frequency analysis and applied the same to the AMS observed at Ripetta gauge of the river Tiber in Rome. Drissia et al. (2019) compared the at-site and regional frequency analysis using the annual peak discharge of 43 stations spread over the state of Kerala, India. The best-fit model for both the cases was found to be completely different and no single distribution agreed to all the sites in case of at-site analysis. Bhat et al. (2019) performed a flood frequency analysis of River Jhelum in Kashmir, where LP III distribution gave relatively better estimates of various return period values. Langat et al. (2019) analyzed certain methods to select the best-fit distribution to model the maximum, minimum, and mean stream flows of the Tana river basin. Rizwan et al. (2018) carried out a flood frequency study on four rivers in Pakistan to select the best-fit distribution for the right-tailed flood events using Monte Carlo simulation of synthetic data series along with various goodness of fit and statistical criteria. The results confirmed GP and Weibull as the most suitable distribution model for the entire study area. Cassalho et al. (2018) researched on flood frequency study coupled with multi-parameter distributions using 106 AMS for the Rio Grande do Sul State—Brazil. They observed that Kappa and Wakeby had better performance than two-parameter distributions, and other shorter series were best described by GEV distribution. Farooq et al. (2018) carried out flood frequency analysis using four commonly used distributions such as generalized extreme value (GEV), Log Pearson 3 (LP 3), Gumbel, and Normal at four different gauging locations of river Swat. Based on goodness of fit tests, GEV and LP 3 were selected as the top two models for the study area. Similarly, Kamal et al. (2017) researched on the upper Ganga region using the statistical approach of fitting distributions to the AMS observed at two gauging sites to decide the best-fit model applying various goodness of fit criteria. Benameur et al. (2017) applied a complete flood frequency analysis using excellent statistical tools, and some modern techniques in Abiod watershed, Algeria. Generalized Pareto distribution coupled with the maximum likelihood parameter estimation method was found to be robust for the entire basin. Heidarpour et al. (2017) analyzed the effect of unexpected massive floods on at-site frequency study by identifying them with statistical outlier tests and standard probability plots. Chen et al. (2017) used generalized gamma distribution for frequency analysis along with the principle of maximum entropy theory for the estimation of its parameters. Comparison of T year design flood with other distributions concluded the superiority of the proposed model. Guru and Jha (2015) carried out frequency analysis by fitting 14 different probability distributions to the AMS and PDS observed at two gauging sites of Tel basin located in the Mahanadi river system. They identified generalized Pareto distribution was the best candidate for the annual peak flow values in the study area. Rahman et al. (2013) investigated the suitability of fifteen probability distributions to an Australian annual maximum data set and identified three distributions that must be considered in the frequency analysis of the study area as generalized extreme value, log Pearson 3, and generalized Pareto. Haddad and Rahman (2011) applied various model selection criteria to identify the best-fit model for the annual flood data obtained from Tasmania, Australia, where the two-parameter distributions performed better than the three-parameter ones. Lognormal, coupled with Bayesian Markov chain Monte Carlo method of parameter estimation, was identified as the best model for the entire area. Laio et al. (2009) analyzed different model selection criteria used in flood frequency study through a numerical simulation to reduce uncertainty in the estimation of the design flood. Laio et al. (2009) compared the well-known information criterion such as the akaike information criterion (AIC) and Bayesian information criterion (BIC). They proposed another method based on Anderson–Darling Test statistics (ADC) for flood frequency model selection. The numerical simulation and data analysis from 1000 catchments of the UK confirmed all three approaches produced comparable results, and AIC or BIC should be combined with ADC for better results. Kidson and Richards (2005) conducted a detailed study of flood frequency analysis and its assumptions. Karim and Chowdhury (1995) compared four probability distributions to be applied in Bangladesh based on root-mean-square error, probability plot correlation coefficient, and L moment ratio diagram, and GEV represented the observed AMS more precisely. Haktanir and Horlacher (1993) evaluated the performance of nine probability distributions applying them to 11 gauging sites in the Rhine basin in Germany and two streams in Scotland. GEV and three-parameter lognormal distribution gave accurate results for higher return periods. Vogel et al. (1993) studied the suitability of flood frequency models by L moment diagram in the Southwestern USA, which revealed the better performance GEV, LP 3 and lognormal distribution for the study area. Some of the other significant research in this field includes (McCollum and Beighley 2019; Pandey et al. 2018; Alam et al. 2016; Aziz et al. 2014; Ishak et al. 2011; Taylor et al. 2011; Merz and Blöschl 2005; Ouarda et al. 2001; Kuczera 1999; Bobée and Rasmussen 1995; Haktanir 1992; Cunnane 1988; Eagleson 1972).
The detailed literature survey indicates that the at-site analysis of a complete watershed always leads to the choice of multiple probability distributions based on specific model selection criteria. In the present study, an attempt is made to propose a generalized basin-scale model for site-wise frequency analysis of an entire watershed applying a systematic approach. The performance of this method is evaluated using the annual maximum series of twenty gauging sites located in the Mahanadi river basin, India. After a preliminary analysis of AMS at those sites, eight commonly used probability distributions are fitted to them. Based on some suitable model selection methods such as goodness of fit tests, information criteria, and other statistical measures, the top three models at each site are finalized using the statistical ranking method adopted by Olofintoye et al. (2009). The top distributions satisfying the maximum number of stations are identified, which must be a part of any FFA of the study area. Such descriptive statistical outcomes are coupled with the test for its predictive ability through the bootstrap technique. Also, a physically based regression analysis is performed to establish relationships between the distribution parameters and a few essential catchments and flow properties. These regressed equations are applied to all the sites to estimate model parameters and, thereby, various return period quantiles. Both numerical and graphical comparison of the anticipated flood quantile values with the observed ones suggest a basin-scale parent distribution for the entire watershed.
Overall, the two primary objectives of this study are; identifying the best-fit distributions which should be considered as a minimum while performing any flood frequency analysis in the study area, and thereby, selecting a generalized basin-scale model based on a detailed statistical examination and also, regression analysis of distribution parameters with watershed and flow properties.
2 Description of the watershed
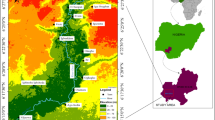
The Mahanadi river is one of the major rivers in east-central India with origin lying near Pharasiya village of Raipur, Chhattisgarh. A significant portion of the stream flows in the state of Chhattisgarh, Odisha, and some part in Jharkhand, and finally, it joins the Bay of Bengal through some channels near Paradeep, Odisha. The Mahanadi river basin extends mainly over two states, i.e., Chhattisgarh and Odisha, having a total drainage area of 141,589 km2 which lies within the geographical coordinates of 19°08′–23°32′ N latitude and 80°28′–86°43′ E longitude (Fig. 1). Because of its large size, a lot of geographical and climatic variation is observed over the entire watershed. The basin experiences more than 90% of total rainfall during monsoon season, i.e., from June to October, with an average rainfall of 1438.1 mm. The deltaic region formed by the river is often affected by disastrous flood events due to heavy rain in the upper part of the watershed, along with the effect of cyclonic storms and inadequate drainage system. The basin has witnessed serious flood problems in the year of 2003, 2008, 2011 and 2013, causing severe loss to human lives and materials. This basin is expected to be one of the worst affected river basins in India in terms of the increased intensity of floods, where the last decade has already seen five significant flood events (Jena et al. 2014). Central Water Commission (CWC) has placed 46 observational sites in Mahanadi Basin, out of which discharge is measured at 21 sites. Hirakud reservoir is situated nearly at the center of the watershed draining an area of 83,000 km2 into it. The location of all the 21 sites along with the Hirakud dam is shown in Fig. 1b. Out of these, seventeen sites lie on the upstream of the Hirakud dam, hence do not carry regulated flow from the reservoir. The remaining three sites also do not have regulated flow because of their locations concerning the main channel in the downstream of the reservoir except for Tikarapara (Kar et al. 2012). Therefore, daily discharge data of these 20 gauging locations lying on the non-regulated part of the catchment were downloaded from Indian-WRIS official Web site, and the extracted annual maximum series were used for flood frequency analysis of the study area.


a Location of Mahanadi river basin in India (source: South Asia Network on Dams, Rivers and People); b digital elevation model of the basin along with the geographical location of gauging sites and Hirakud dam; c catchment area; and d total length of AMS (the 18 sites finalized after the preliminary analysis is shown in c and d)
3 Methodology
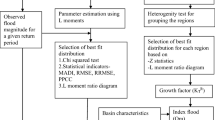
Flood frequency analysis was carried out using annual maximum series (AMS) to identify the best-fit probability distribution at each site along with the selection of a regionalized basin-scale model for the entire study area following the methodology presented in the flow chart (Fig. 2). The detailed theoretical background of this methodology is described later in this chapter.

The methodology implemented for the selection of basin-scale parent distribution
3.1 Choice of candidate probability distributions
The annual maximum series at each site were fitted to eight commonly used probability distributions such as Gumbel, Normal, Logistic, generalized extreme value (GEV), generalized logistic (GL), generalized Pareto (GPA), log Pearson 3 (LP 3) and Pearson Type III (PE 3) because of their enormous hydrological applications in frequency analysis all over the world (Drissia et al. 2019; Ghorbani et al. 2010; Rao and Hamed 2000; Karim and Chowdhury 1995; Cunnane 1988). The expressions for cumulative distribution function (CDF) of each distribution along with their L moment equations are illustrated in Table 1.
The two-parameter distributions have an advantage of the ease in the fitting. At the same time, the inclusion of shape parameters in the three-parameter models helps to consider the effect of skewness involved in most of the hydrologic series used in frequency analysis (Kidson and Richards 2005). LP 3 and PT 3 from the Gamma family are two commonly applied models in frequency analysis of hydrological processes such as discharge, rainfall, etc. (Bobee and Ashkar 1991). GPA and GL distribution have an excellent capability to model annual flood peak values used in frequency analysis (Zakaria et al. 2012; Oztekin 2005). GEV distribution and its particular case, i.e., Gumbel from the extreme distribution family, have been widely used in the frequency analysis of hydrological events. Several significant research carried out on FFA of Indian river basins have previously applied these distribution models such as (Kumar et al. 1999a, b, 2003, 2006; Kumar and Chatterjee 2005; Bhuyan et al. 2010; Kar et al. 2012; Basu and Srinivas 2016; Kumar 2019; Pandey et al. 2018)
The parameters of these models can be estimated by applying numerous available methods such as the method of moments, maximum like-hood, L moment, probability weighted moments, the principle of maximum entropy theory, etc. (Rao and Hamed 2000; Hosking and Wallis 1997). In the present study, the method of L moment is applied to estimate parameters of all the distributions because more accurate or less unbiased inferences can be made by using this method (Hosking 1990). Also, the statistical analysis and bootstrap sampling become computationally more effective by using the L-moment method. The expressions of the first three L moments for a sorted sample of length n (such as x1 ≤ x2 ≤ x3 ≤ x4 ≤ ……. ≤ xn−1 ≤ xn) are given below.
L moment ratios can be defined as, tr = λr/λ2, r = 3, 4, etc. For example, if r = 3, t3 = λ3/λ2, known as L skewness, which lies within a range of (− 1, 1) that makes it easier to interpret than conventional skewness, which can take arbitrarily large values. These L moments and L moment ratios are beneficial for summarizing any probability distributions which is described in many pieces of literature such as (Hosking 1990; Hosking and Wallis 1997; Sankarasubramanian and Srinivasan 1999; Bezak et al. 2014).
3.2 Model selection criteria
The accuracy of flood frequency analysis is mostly subjective to the choice of probability distributions along with appropriate model selection criteria for their evaluation (Kidson and Richards 2005). In the present study, two goodness of fit (GOF) tests such as Anderson–Darling (AD) and Kolmogorov–Smirnov test (KS); two information-based criteria such as modified Akaike Information Criterion (AICC) and Schwarz Bayesian Criterion (BIC) and a few statistical measures of error between the observed and predicted flood quantiles such as root-mean-square error (RMSE), relative root-mean-square error (RRMSE), maximum absolute error (MAE), correlation coefficient (CC) and the modified Anderson–Darling statistics (ADC) were applied to assess the performance of the probability distributions at any site. Details of these test statistics are illustrated in Table 2.
Both the GOF test statistics, KS, and AD, consider the empirical and predicted cumulative distribution functions to assess the degree of fitness of a model. However, AD gives more weightage to the right tail of the distributions, which has a vital significance in the frequency analysis of extreme events. The combination of ADC with information-based criteria such as AICC or BIC provides a useful tactic in flood frequency analysis (Laio et al. 2009). All the three statistics give similar results while recognizing the parent distribution; however, ADC has a better performance with increasing skewness coefficient (Laio et al. 2009). A combination of these criteria, along with the statistical measures mentioned in Table 2, evaluates the degree of fitting of probability distributions to the observed AMS over the entire sample length as well as in the higher quantile region. The results obtained by applying these performance indicators were subjected to a statistical ranking method proposed by Olofintoye et al. (2009). Each distribution was allotted a rank between 1 and 8 based on the value of these test statistics, such as rank one was given to the distribution with the lowest RMSE, RRMSE, MAE, AICC, BIC, KS, AD or the highest value of CC. The ranks assigned from each of these nine test statistics were summed up, and the distribution having the minimum total rank was selected as the best-fit model at a particular gauging site.
3.3 Basin-scale model
At-site flood frequency analysis over a particular catchment always results in a mixture of site-specific probability distribution models. In the present study, an attempt was made to propose a single standard model for an entire catchment, which gives optimal fitting to the maximum percentage of sites based on both statistical and physically based analysis of annual peak flow values.
3.3.1 Statistical analysis
The statistical indicators described in the previous section assessed the degree of fitting of each distribution model to the AMS. It helped to identify the top models satisfying the maximum percentage of sites, which must be a part of any FFA of the study area. Among these models, the top one having an optimal fitting at more number of sites was selected as the standard model for the entire watershed based on a descriptive statistical analysis of AMS. This result is mostly affected by the choice of model selection criteria illustrated in Table 2, which considers all most all aspects of statistically examining an AMS. The predictive ability of a model should be evaluated as it mostly influences the accuracy of peak flow estimation. The present study applied the bootstrapping method to analyze the predictive capacity of the best model obtained from descriptive analysis at all the sites. Bootstrapping is a useful technique to generate several synthetic samples having the same length as the existing series and analyze the same to describe the nature of distribution even though the information about the parent distribution is lacking (Efron and Tibshirani 1994). So the statistics derived from these bootstrap samples accurately represent the order statistics of the underlying distribution (Vogel 1995). In the present study, one thousand bootstrap samples were generated, having the same size as the existing AMS at each site, and the best model obtained from the descriptive analysis was fitted to these samples. 5-, 20-, 50-, and 100-year return period values were estimated, and the respective 95% confidence intervals were plotted and analyzed to assess the sampling uncertainty.
3.3.2 Physically based analysis
Basic catchment properties are area (A), length of the basin (L), effective basin width (B), perimeter (P), and slope (S). Along with this, other flow properties of AMS like mean annual flood (Qmean) and skewness coefficient (Cs) were calculated by processing Cartosat-1 DEM of the watershed in the ArcGIS toolbox. Jena et al. (2016) analyzed the performance of Cartosat–1 DEM for flood modeling in data scare regions of Mahanadi river basin and observed a better performance of this model derived cross sections as compared to other available global DEMs. Swamee et al. (1995) developed a dimensionless model for mean annual flow (MAF) estimation in 93 catchments of India, where most of the forecasted values fell within ± 50% of the observed ones. The proposed model comprised of average rainfall (p) of duration (D) and recurrence interval (T), catchment area (A), slope (So), and forest cover fraction (Cf) as independent variables for the estimation of Qmean. Similar findings from other research such as (Garde and Kothyari 1990; Mckerchar 1991; Merz and Blöschl 2005; Griffiths and Mckerchar 2008, 2012) also suggest that the mean annual flow is correlated with other physical characteristics of a catchment. Hence, in the present study, model parameters are related to the mean annual flow since MAF in itself represents the combined effect of various other catchment properties. Therefore, as discussed, no attempts are made to develop explicit relationships between the model parameters and all other pertinent catchment characteristics.
Regression analysis (RA) was performed to relate the parameters of top models with various hydrological and physiographic properties considered in the study. The equations thus developed were applied to all the sites to estimate the parameters of the models. Before the assessment of a basin-scale distribution from this physically based analysis, the predictive ability of RA was evaluated by comparing the observed and anticipated mean annual flood (MAF) over the entire watershed. MAF is one of the vital hydrological parameters that represents an index of the potential magnitude of flood flows and hence used in flood frequency studies and also in the designing of many hydraulic structures. Here, MAF was calculated as the expected value of probability density function, as given below.
The expected value of a continuous random variable (x) defined by its probability density function ‘f’ is given as,
For example, the above expression of MAF for the GEV distribution model becomes,
where k, µ, and σ represent the shape, location, and scale parameter of GEV distribution, respectively. The anticipated values of MAF from the above expression were calculated using the distribution parameters obtained from the regressed equations and also, the conventional method of L moments. Return period quantiles of all the sites estimated using parameters from these equations were compared to the observed ones. The distribution showing a better fit over the entire catchment was considered as the standard model based on the physically based analysis.
Finally, a graphical, as well as an analytical comparison, was made between the results of FFA using site-wise best-fit distributions and the basin-scale model.
4 Results and discussion
4.1 Preliminary analysis of AMS
Annual maximum series at 20 gauging sites of the Mahanadi basin, India (Fig. 1), were initially subjected to the preliminary investigation, i.e., check for the presence of trend and outlier in the series. The Cumulative sum or CUMSUM test (Mcgilchrist and Woodyer 1975) and Mann–Kendall test for trend analysis revealed the presence of a significant negative trend in the AMS of two sites at 5% significance level. After removing these two sites, AMS of the remaining 18 locations were tested for the existence of outlier applying Grubb’s outlier test at 10% significance level (Grubbs and Beck 1972). This data screening procedure finally led to 18 gauging sites with the total data length varying from 12 to 41 years, with an average of 31 years and 75th percentile of 38 years. Hence, the AMS in the present study satisfied the criteria of a minimum 10-year record length for flood frequency analysis in poorly monitored watersheds (Cassalho et al. 2018). Details of these gauging sites such as available data length, catchment area, mean annual flow, and skewness of observed annual peak values are listed in Table 3.
Manendragarh, located in the district of Chhattisgarh, had the minimum catchment area with the highest peak water level recorded in 1990. Basantpur possessed the largest drainage area, which leads to an average annual flow of 13,272 cumecs observed over the period from 1972–1973 to 2010–2011. The lowest and highest mean annual flow was recorded at Andhiyarkore and Basantpur, respectively. The AMS derived at all the sites were positively skewed except for Kurubhata. The highly positive skewness of the AMS signified the presence of a more massive right tail than the left part. The Cartosat-1 digital elevation model of the study area was processed in the Arc GIS toolbox to delineate the watershed along with the preparation of various maps, as shown in Fig. 1. The same was further examined to derive five essential physical characteristics such as catchment area, length, perimeter, effective basin width, and slope of the drainage region delineated at individual sites (Fig. 3). These properties were later used in the regression analysis of distribution parameters to identify a basin-scale model on a physical basis.


Physical characteristics of the drainage region at each gauging site, a catchment area (km2); b perimeter(km); c length (km) and effective basin width, and d slope (Note: sites are represented by their ID given in Table 3)
4.2 Site-wise FFA
Continuous probability distributions such as Gumbel, logistic, Normal, GEV, GL, GPA, Pearson type III, and LP 3 were fitted to the annual maximum series at all the gauging sites. At first, their degree of fitting was graphically assessed through quantile–quantile (Q–Q) plots. Q–Q plots of all AMS considered in the study indicated the better fitting of most of the three-parameter distributions as compared to the two-parameter models except the extreme value type I or Gumbel. Also, the right-tailed parts were overestimated or underestimated by the models at many sites. For illustration purpose, Q–Q plots of all the eight models at Andhiyarkore is shown in Fig. 4.

Q–Q plots of distribution models fitted to the AMS at Andhiyarkore
However, the choice of the best model cannot be solely based on graphical comparison due to insufficient information about the performance of models at higher quantile range. Therefore, a numerical assessment based on the statistical ranking method was applied using nine different model selection criteria (Table 2), as described in the methodology section, and the models were ranked according to these performance indicators. The final rank of distribution at any site was the sum of all the ranks. Rank of these distribution models and the total rank at Andhiyarkore (Site ID 1) is shown in Fig. 5 as an example.

Ranking of distribution models and their total rank at Andhiyarkore based on nine model selection criteria
A similar analysis was performed at all the sites to identify the top three models based on this statistical ranking scheme and listed in Table 4.
As evident from the result, no single distribution occupied the first rank at all the sites, and in many cases, two different distributions were found to have the same ranking. Mostly the tie of rank was between GEV and Extreme value type I or Gumbel distribution (Fig. 6). However, GEV satisfied the best fit at a maximum number of sites as compared to other three-parameter distributions. Also, it was one of the top three choices at all the locations of the watershed considered in this FFA except Kesinga. The two-parameter distributions showed a lack of fit to the AMS derived at most of the sites, which could be due to the absence of shape parameter that helps to account for the effect of skewness involved in the AMS. This outcome agreed well with the findings from the graphical comparison. Considering the best-fit distribution at each site GEV satisfied 44% of sites (i.e., 8 out of 18 sites) while PT 3 had the first rank at 28% of sites (i.e., 5 number of locations) and GPA and Gumbel each held the first position at 17% of sites. So based on this, GEV, PT 3, GPA, and Gumbel were finalized as the top models for the Mahanadi river basin, India, which must be taken into consideration as a minimum for practical application of FFA in the watershed.

Best-fit distribution model, a site-wise best model, and b the number of sites with the first rank of each model
4.3 Identification of basin-scale model
In the present study, a generalized basin-scale model for the entire watershed was proposed considering both statistical and physical aspects, as described in the methodology section.
4.3.1 Statistical analysis
The statistical approach includes the identification of a model which satisfies the maximum percentage of sites by analyzing the performance of various distributions based on a few statistical indicators. The site-wise analysis was performed initially, and it was observed that among the top distributions, i.e., GEV, PT 3, GPA and Gumbel, GEV showed the best fit at 44% of sites and also, it was one of the three top choices at 17 sites considered in the study. Therefore, GEV was selected as the basin-scale model based on descriptive statistical analysis. As compared to the other two distributions, GEV is derived from statistics of the extreme value theory, which gives it a more fundamental basis to be selected as the single model for the entire region. The predictive ability of GEV distribution was analyzed through a bootstrap sampling method in which one thousand samples with the same data length as the original series was generated. GEV distribution was fitted to those series to estimate various return period quantiles, and the respective 95% confidence interval (CI) of 5-, 20-, 50-, and 100-year flood flow values were plotted and analyzed for uncertainty, as shown in Fig. 7.

95% CI of 5-, 20-, 50-, and 100-year return period estimates from bootstrap sampling
As evident from the above plots, the GEV predicted return period values at all the sites of the study area lie within a 95% confidence interval of the AMS obtained from bootstrap sampling. The 5- and 20-year estimates have a relatively narrow confidence interval as compared to 50- and 100-year values, and this narrowed down CI of lower return period values signifies higher accuracy of prediction. Even though the limited data length of the AMS influenced the estimation of higher return period values, the predicted quantiles at all the sites found to lie within limits, which justified the predictive ability of GEV distribution as the standard basin-scale model for the entire watershed.
4.3.2 Physically based analysis
For the selection of a standard basin-scale model, a physically based analysis was also performed, which involved the comparison of flood flow quantiles predicted by fitting distribution models with parameters estimated from a few catchment and flow properties. A few essential physical characteristics of the catchment were derived with the help of the Arc GIS toolbox (Fig. 3) along with flow properties like the skewness coefficient and the mean annual flood at each site (Table 3). Regression analysis was performed between the parameters of the top distributions (dependent variables) and the catchment and flow properties (independent variables). As a prerequisite of this study, all the dependent and independent variables were first checked for the presence of outliers applying Grubb’s test since the outliers might affect the predictive capability of the models. The independence of those observations was tested by using Durbin–Watson statistics (Durbin and Watson 1951). The data were graphically analyzed for homoscedasticity by plotting standardized regression residuals against the predicted values to check the variance along the best-fit line. The normality of residuals was also verified using a normal probability plot and a histogram superimposed with the normality curve. After close examination of these variables, regression analysis was performed for each case, and the best-fit equations were derived as listed in Table 5.
Among the physical and flow characteristics of the watershed considered in the regression analysis, the skewness coefficient of the observed AMS had a better correlation with the shape parameter of all the distributions. Likewise, the mean annual flow (Qmean) and catchment area (A) possessed a fair degree of accuracy in predicting the location and scale parameter of the distributions. For the Pearson type 3 distribution, all three parameters had a better relationship with the skewness coefficient. The location and scale parameters of Gumbel were best expressed in terms of a linear relationship with the mean annual flood. Before analyzing the results in-depth, the robustness of the RA method was evaluated by comparing the observed MAF with the predicted values, as described in the methodology section. The anticipated and observed MAF at all the sites of the watershed using GEV distribution are compared as given in Fig. 8. As evident from the figure, for a few locations, the MAF calculated from both the methods showed a comparatively larger deviation from the observed MAF. Overall for the entire watershed, the correlation coefficient between the observed and estimated MAF using parameters from the RA method was slightly higher than the L moment method. The accuracy of the approach was also evaluated in terms of absolute percentage error averaged over the basin, i.e., mean absolute percentage error (MAPE). As evident, the Qmean estimated by considering the model parameters from the physically based regression analysis was nearly 12%, where for the L moment method, it was around 11%. The performance of the RA method was very close to the conventional way of L moments, which justified the predictive ability of the regression equations and hence, the aptness of this approach for the choice of a generalized basin-scale model for the study area.

Comparison of MAF obtained from the method of L moments and physically based regression analysis
The specific outcomes of regression analysis for GEV distribution are listed in Table 6 for illustration purposes. The linear regression indicates that the skewness coefficient of the AMS was statistically significant in predicting the shape parameter of the GEV model with F equals to 112.50 and p value less than 0.05. The R2 was 0.9494, i.e., the predictor ‘Cs’ explained the 94.94% variance of the dependent variable, i.e., shape parameter (k). Similarly, the scale and location parameters were well predicted by two variables Qmean and A, with a relatively higher value of R2, as given in Table 6.
The Durbin–Watson statistics for all three cases were higher than the standard upper limit proposed by (Savin and White 1977) based on sample size and number of terms, which concluded that there was no correlation between the observed values. Along with these statistical indicators, residual plots were analyzed for better assessment of the regression output and some underlying assumptions regarding homoscedasticity and normality. Four types of residual plots, such as the normal probability plot, the histogram of residuals, residual versus fit, and residual versus order for each parameter of the GEV model is shown above in Fig. 9.


Residual plots for all the three parameters of the GEV model, a shape parameter (k), b scale parameter (σ), and c location parameter (µ)
Since the length of samples for each case was less than 20, the bars in the histogram of residuals might not have sufficient data points to identify outliers or skewness in the data. So instead of relying upon histogram plot for small sample sizes, the normal probability plot was analyzed for the residuals. An approximate straight line of the normal probability plots for all the three cases indicated that the residuals were normally distributed. The graph between residual and their corresponding fitted values proved that the residuals were randomly distributed with a constant variance. The independence of residuals was also observed from the plots of the residuals versus the order. A similar analysis was performed to evaluate the best-fit regression equation for all the parameters of the top distribution models, as listed in Table 5. Out of all the physical characteristics of the basin, the catchment area was better at predicting the model parameters with a relatively higher degree of accuracy. The skewness coefficient of the AMS was statistically significant to describe the variance of shape parameter for all the three models. The location and scale parameter of PT 3 distribution also had the best-fit relationship with the skewness coefficient. The 95% prediction intervals (PI) of these models are shown in Fig. 10, along with R2 values. The regression equation obtained for the scale parameter of the PT 3 model possessed a small R2 indicating a relatively poor predictive ability.

95% Prediction interval of all the parameters, a PT 3 distribution, b GPA distribution, and c Gumbel distribution
The derived regression equations for the top models (Table 5) were applied to evaluate the distribution parameters at all the 18 sites of the watershed and thereby estimating flood quantiles of various return periods such as 5, 20, 50, and 100 years. The observed and model-predicted return period flow values were compared both graphically and analytically. Q–Q plots for 20 year return period estimates from all the four models are shown in Fig. 11 as an example. From the graphical analysis, GEV performed better among all the distributions over the entire catchment. The regression equations developed for extreme value type I or Gumbel distribution also had good accuracy in predicting the return period quantiles.

Scatter plot of 20-year return period quantiles using physically based parameter estimates
The performance of these models was also assessed by calculating the correlation coefficient (R2) and the averaged relative absolute error (RAE) of various return period estimates at all the gauging sites, as shown in Fig. 12. GEV predicted the flood peak values more accurately than other models with R2 lying in the range of 0.963–0.996 and mean RAE varying between 0.073 and 0.157. For higher return periods of 50 and 100 years, the accuracy of model prediction is relatively less, which might be due to the extrapolation of smaller available data series to calculate the observed quantiles. However, the performance of a physically based GEV model over the entire watershed was the best among the top models obtained from site-wise frequency analysis. The results obtained from this error evaluation were in agreement with the Q–Q plots.

Comparison of physically based models in terms of a correlation coefficient, and b mean relative absolute error
The result signifies the application of the GEV model as a single basin-scale model for the entire watershed, where the parameters were estimated considering the physical and flow characteristics of AMS. The finding of this physical approach matched well with the statistical analysis discussed in the previous section. Before suggesting GEV as the standard model for the study area, a comparison was made between the flood peak values predicted from site-wise best-fit models (Table 4) and the basin-scale GEV model. Predicted quantiles from both the cases were plotted against each other for T = 5, 20, 50, and 100 year return periods. As evident from the scatter plots, the basin-scale GEV model outputs were very close to the flood quantiles predicted from respective best-fit models at all the sites. Further analysis was made to calculate the correlation coefficient and mean relative absolute error between the observed and predicted peak flow values obtained from both the cases, as shown in Fig. 13e. As there is no significant difference between the two cases, instead of using different best-fit distribution model at each site of the study area, GEV can be applied as a basin-scale standard distribution for station wise frequency analysis of the entire watershed.

Comparison between the predicted flood quantiles from site-wise best-fit models and the basin-scale GEV model, scatter plot for a 5 year return period, b 20 year return period, c 50 year return period, d 100 year return period, and e correlation coefficient and mean RAE between observed and predicted quantiles for both the cases
5 Conclusions
The present study has a significant focus on a systematic evaluation of probability distributions for FFA considering the effect of catchment and flow characteristics along with some useful model selection criteria. The methodology was implemented to the AMS of twenty gauging sites situated in the Mahanadi river basin, India.
GEV yielded the best fit for 44% of sites. PT 3 had the first rank at five locations of the watershed, whereas GPA and Gumbel each performed better at three gauging sites considered in the present study. GEV, PT 3, GPA, and Gumbel distributions were selected as the ideal candidates for site-wise flood frequency analysis of the Mahanadi river basin based on a statstical ranking approach.
The descriptive statistical analysis proposed GEV as the basin-scale model for the watershed, and its predictive ability was tested through a bootstrap sampling procedure. The 95% confidence interval of bootstrapped samples for 5, 20, 50, and 100 year return period estimates justified the predictive capability of the GEV model at all the sites.
A physically based regression analysis was also performed where the parameters of the top models were correlated with a few relevant catchment and flow properties. Mean annual flow (Qmean), skewness coefficient of AMS (Cs), and catchment area (A) were more effective in predicting the model parameters.
The robustness of these regression equations was analyzed by comparing the observed and predicted mean annual flood flows obtained from the expected values of the GEV density function. The parameters estimated from RA performed close to the conventional method of L moments in predicting MAF.
The performance of these regression equations was evaluated in terms of F value and correlation coefficient, along with various residual plots, normal probability plot, and also 95% prediction interval.
5-, 20-, 50-, and 100-year return period quantiles were estimated using the parameters obtained from the regression equations of top models and compared with the observed values in terms of correlation coefficient and mean of relative absolute error. The results confirmed the performance of a physically based GEV model over the entire watershed was the best among the top models with R2 varying between 0.97 and 0.99.
Finally, the flood flow quantiles obtained using site-wise best-fit distributions, and the basin-scale GEV model was compared both graphically and statistically. Since there was a marginal difference between the two cases, instead of using different models at each site of the study area, GEV can be applied as a standard distribution for at-site frequency analysis of the entire watershed.
Similar studies can be carried out on different watersheds to compare the performance of various probability distributions employing both statistical and physically based regression analysis to propose a generalized basin-scale model.
Data availability
The daily discharge data of Mahanadi river basin used in this study are openly available to download from the official website of India WRIS, i.e., http://tamcnhp.com/wris/#/. The Cartosat-1 DEM of the watershed can be downloaded from the Indian Geo-Platform of ISRO, i.e., Bhuvan’s official website (https://bhuvan-app3.nrsc.gov.in/data/download/).
References
Alam J, Muzzammil M, Khan MK (2016) Regional flood frequency analysis: comparison of L-moment and conventional approaches for an Indian catchment. ISH J Hydraul Eng 22:247–253. https://doi.org/10.1080/09715010.2016.1177739
Anderson DA, Darling TW (1952) Asymptotic theory of certain “Goodness of Fit” criteria based on stochastic processes. Ann Math Stat 23:193–212
Aziz K, Rahman A, Fang G, Shrestha S (2014) Application of artificial neural networks in regional flood frequency analysis: a case study for Australia. Stoch Environ Res Risk Assess 28:541–554. https://doi.org/10.1007/s00477-013-0771-5
Basu B, Srinivas VV (2016) Regional flood frequency analysis using entropy-based clustering approach. J Hydrol Eng 21:04016020. https://doi.org/10.1061/(ASCE)HE.1943-5584.0001351
Benameur S, Benkhaled A, Meraghni D et al (2017) Complete flood frequency analysis in Abiod watershed, Biskra (Algeria). Nat Hazards 86:519–534. https://doi.org/10.1007/s11069-016-2703-4
Bezak N, Brilly M, Šraj M (2014) Comparison between the peaks-over-threshold method and the annual maximum method for flood frequency analysis. Hydrol Sci J 59:959–977. https://doi.org/10.1080/02626667.2013.831174
Bhat MS, Alam A, Ahmad B et al (2019) Flood frequency analysis of river Jhelum in Kashmir basin. Quat Int 507:288–294. https://doi.org/10.1016/j.quaint.2018.09.039
Bhuyan A, Borah M, Kumar R (2010) Regional flood frequency analysis of North-Bank of the River Brahmaputra by using LH-moments. Water Resour Manag 24:1779–1790. https://doi.org/10.1007/s11269-009-9524-0
Bobee B, Ashkar F (1991) The gamma family and derived distributions applied in hydrology. Water Resour Publications, Colorado
Bobée B, Rasmussen PF (1995) Recent advances in flood frequency analysis. Rev Geophys 33:1111–1116. https://doi.org/10.1029/95RG00287
Burnham KP, Anderson DR (2002) Model selection and multimodel inference: a practical information-theoretic approach. Springer, New York
Calenda G, Mancini CP, Volpi E (2009) Selection of the probabilistic model of extreme floods: the case of the River Tiber in Rome. J Hydrol 371:1–11. https://doi.org/10.1016/j.jhydrol.2009.03.010
Cassalho F, Beskow S, De MelloCR, De MouraMM et al (2018) At-site flood frequency analysis coupled with multiparameter probability distributions. Water Resour Manag 32:285–300. https://doi.org/10.1007/s11269-017-1810-7
Chen L, Singh VP, Xiong F (2017) An entropy-based generalized gamma distribution for flood frequency analysis. Entropy 19:239. https://doi.org/10.3390/e19060239
Cunnane C (1988) Methods and merits of regional flood frequency analysis. J Hydrol 100:269–290. https://doi.org/10.1016/0022-1694(88)90188-6
Drissia TK, Jothiprakash V, Anitha AB (2019) Flood frequency analysis using L moments: a comparison between at-site and regional approach. Water Resour Manag 33:1013–1037. https://doi.org/10.1007/s11269-018-2162-7
Durbin J, Watson GS (1951) Testing for serial correlation in least squares regression II. Biometrika 38:159–177
Eagleson PS (1972) Dynamics of flood frquency. Water Resour Res 8:878–898
Efron Bradley, Tibshirani RJ (1994) An introduction to the bootstrap. CRC Press, New York
Farooq M, Shafique M, Khattak MS (2018) Flood frequency analysis of river swat using Log Pearson type 3, generalized extreme value, normal, and Gumbel max distribution methods. Arab J Geosci 11(9):1. https://doi.org/10.1007/s12517-018-3553-z
Frank J, Massey J (1951) The Kolmogorov–Smirnov test for goodness of fit. J Am Stat As 46:68–78
Garde RJ, Kothyari UC (1990) Flood estimation in Indian catchments. J Hydrol 113:135–146
Ghorbani MA, Ruskeepää H, Singh VP, Sivakumar B (2010) Flood frequency analysis using mathematica. Turk J Eng Environ Sci 34:171–188. https://doi.org/10.3906/muh-1002-2
Griffiths GA, Mckerchar A (2008) Dependence of flood peak magnitude on catchment area. J Hydrol 47:123–131
Griffiths GA, Mckerchar A (2012) Estimation of mean annual flood in New Zealand. J Hydrol 51:111–120
Grubbs FE, Beck G (1972) Extension of sample sizes and percentage points for significance tests of outlying observations. Technometrics 14:847–854
Guru N, Jha R (2015) Flood frequency analysis of tel basin of Mahanadi river System, India using annual maximum and POT flood data. Aquat Procedia 4:427–434. https://doi.org/10.1016/j.aqpro.2015.02.057
Haddad K, Rahman A (2011) Selection of the best-fit flood frequency distribution and parameter estimation procedure: a case study for Tasmania in Australia. Stoch Environ Res Risk Assess 25:415–428. https://doi.org/10.1007/s00477-010-0412-1
Haktanir T (1992) Comparison of various flood frequency distributions using annual flood peaks data of rivers in Anatolia. J Hydrol 136:1–31. https://doi.org/10.1016/0022-1694(92)90002-D
Haktanir T, Horlacher HB (1993) Evaluation of various distributions for flood frequency analysis/evaluation de diverses distributions pour l’analyse des frequences des crues. Hydrol Sci J 38:15–32. https://doi.org/10.1080/02626669309492637
Heidarpour B, Saghafian B, Yazdi J, Azamathulla HM (2017) Effect of extraordinary large floods on at-site flood frequency. Water Resour Manag 31:4187–4205. https://doi.org/10.1007/s11269-017-1739-x
Hosking JRM (1990) L-moments: analysis and estimation of distributions using linear combinations of order statistics. J R Stat Soc B 52:105–124
Hosking JRM, Wallis JR (1997) Regional frequency analysis: an approach based on L-moments. Cambridge University Press, Cambridge
Hyndman RJ, Koehler AB (2006) Another look at measures of forecast accuracy. Int J Forecast 22:679–688
Ishak E, Haddad K, Zaman M, Rahman A (2011) Scaling property of regional floods in New South Wales Australia. Nat Hazards 58:1155–1167. https://doi.org/10.1007/s11069-011-9719-6
Jena PP, Chatterjee C, Pradhan G, Mishra A (2014) Are recent frequent high floods in Mahanadi basin in eastern India due to increase in extreme rainfalls? J Hydrol 517:847–862. https://doi.org/10.1016/j.jhydrol.2014.06.021
Jena PP, Panigrahi B, Chatterjee C (2016) Assessment of Cartosat-1 DEM for modeling floods in data scarce regions. Water Resour Manag 30:1293–1309. https://doi.org/10.1007/s11269-016-1226-9
Kamal V, Mukherjee S, Sen P, Sen R et al (2017) Flood frequency analysis of Ganga river at Haridwar and Garhmukteshwar. Appl Water Sci 7:1979–1986. https://doi.org/10.1007/s13201-016-0378-3
Kar AK, Goel NK, Lohani AK, Roy GP (2012) Application of clustering techniques using prioritized variables in regional flood frequency analysis—case study of Mahanadi Basin. J Hydrol Eng 17:213–223. https://doi.org/10.1061/(ASCE)HE.1943-5584.0000417
Karim AM, Chowdhury JU (1995) A comparison of four distributions used in flood frequency analysis in Bangladesh. Hydrol Sci J 40:55–66. https://doi.org/10.1080/02626669509491390
Kidson R, Richards KS (2005) Flood frequency analysis: assumptions and alternatives. Prog Phys Geog 3:392–410
Kuczera G (1999) Comprehensive at-site flood frequency analysis using Monte Carlo Bayesian inference. Water Resour Res 35:1551–1557
Kumar R (2019) Flood frequency analysis of the Rapti river basin using log pearson type-III and Gumbel Extreme Value-1 methods. J Geol Soc India 94:480–484. https://doi.org/10.1007/s12594-019-1344-0
Kumar R, Chatterjee C (2005) Regional flood frequency analysis using L-moments for North Brahmaputra Region of India. J Hydrol Eng 10:1–7
Kumar R, Singh RD, Seth SM (1999a) Regional flood formulas for seven subzones of zone 3 of India. J Hydrol Eng 4:240–244
Kumar R, Chatterjee C, Kumar S et al (1999b) Development of regional flood frequency relationship using L-moments for south Bihar/Jharkhand. NIH Roorkee, Roorkee
Kumar R, Chatterjee C, Kumar S et al (2003) Development of regional flood frequency relationships using L-moments for middle Ganga plains subzone 1(f) of India. Water Resour Manag 17:243–257. https://doi.org/10.1023/A:1024770124523
Kumar R, Sarkar A, Kumar S et al (2006) Prediction of floods of various return periods for gauged and ungauged catchments using L-moments based regional flood frequency analysis. In: Srinivasa KR (ed) Prediction in ungauged basins for sustainable watershed planning and management. Jain Brothers, New Delhi
Laio F, Di BaldassarreG, Montanari A (2009) Model selection techniques for the frequency analysis of hydrological extremes. Water Resour Res 45:1–11. https://doi.org/10.1029/2007WR006666
Langat PK, Kumar L, Koech R (2019) Identification of the most suitable probability distribution models for maximum, minimum and mean streamflow. Water 11:734. https://doi.org/10.3390/w11040734
McCollum J, Beighley E (2019) Flood frequency hydrology with limited data for the Weser River Basin, Germany. J Hydrol Eng 24:05019002. https://doi.org/10.1061/(ASCE)HE.1943-5584.0001713
Mcgilchrist ACA, Woodyer KD (1975) Note on a distribution-free CUSUM technique. Technometrics 17:321–325
Mckerchar A (1991) Regional flood frequency analysis for small New Zealand basins: 1. Mean annual flood estimation. J Hydrol 30:65–76
Merz R, Blöschl G (2005) Flood frequency regionalisation—spatial proximity vs. catchment attributes. J Hydrol 302:283–306. https://doi.org/10.1016/j.jhydrol.2004.07.018
Mesbahzadeh T, Soleimani Sardoo F, Kouhestani S (2019) Flood frequency analysis for the Iranian interior deserts using the method of L -moments: a case study in the Loot River Basin. Nat Resour Model 32:1–14. https://doi.org/10.1111/nrm.12208
Nguyen T, El OutayekS, Lim SH, Nguyen V (2017) A systematic approach to selecting the best probability models for annual maximum rainfalls—a case study using data in Ontario (Canada). J Hydrol 553:49–58. https://doi.org/10.1016/j.jhydrol.2017.07.052
Olofintoye OO, Sule BF, Salami A (2009) Best-fit probability distribution model for peak daily rainfall of selected cities in Nigeria. NY Sci J 2:1–12. https://doi.org/10.2174/138920312803582960
Ouarda TBMJ, Girard C, Cavadias GS, Bobée B (2001) Regional flood frequency estimation with canonical correlation analysis. J Hydrol 254:157–173. https://doi.org/10.1016/S0022-1694(01)00488-7
Oztekin T (2005) Comparison of parameter estimation methods for the three-parameter generalized Pareto distribution. Turk J Agric For 29:419–428
Pandey HK, Dwivedi S, Kumar K (2018) Flood frequency analysis of Betwa River, Madhya Pradesh India. J Geol Soc India 92:286–290. https://doi.org/10.1007/s12594-018-1007-6
Rahman AS, Rahman A, Zaman MA et al (2013) A study on selection of probability distributions for at-site flood frequency analysis in Australia. Nat Hazards 69:1803–1813. https://doi.org/10.1007/s11069-013-0775-y
Rao AR, Hamed KH (2000) Flood frequency analysis. CRC Press, USA
Rizwan M, Guo S, Xiong F, Yin J (2018) Evaluation of various probability distributions for deriving design flood featuring right-tail events. Water 10:1603. https://doi.org/10.3390/w10111603
Saghafian B, Golian S, Ghasemi A (2014) Flood frequency analysis based on simulated peak discharges. Nat Hazards 71:403–417. https://doi.org/10.1007/s11069-013-0925-2
Sankarasubramanian A, Srinivasan K (1999) Investigation and comparison of sampling properties of L-moments and conventional moments. J Hydrol 218:13–34. https://doi.org/10.1016/S0022-1694(99)00018-9
Savin NE, White KJ (1977) The Durbin–Watson test for serial correlation with extreme sample sizes or many regressors. Econometrica 45:1989–1996
Sinclair CD, Spurr BD, Ahmad MI (1990) Modified anderson darling test. Commun Stat Theory Methods 19:3677–3686. https://doi.org/10.1080/03610929008830405
Stedinger JR, Vogel RM, Foufoula-Georgiou E (1993) Frequency analysis of extreme events. In: Maidment DA (ed) Handbook of hydrology. McGraw-Hill, New York, pp 18.1–18.66
Swamee PK, Ojha CSP, Abbas A (1995) Mean annual flood estimation for Indian catchments. J Water Resour Plan Manag 121:403–407
Taylor M, Haddad K, Zaman M, Rahman A (2011) Regional flood modelling in Western Australia : application of regression based methods using ordinary least squares. In: 19th International Congress on modelling and simulation. Perth, Australia, pp 3803–3810
Vogel RM (1995) Recent advances and themes in hydrology. Rev Geophys 33:933
Vogel RM, Wilbert O, Thomas TA Jr (1993) Flood-flow frequency model selection in Southwestern United States. J Water Res Plan Manag 119:353–366
Yu FX, Naghavi B, Singh VP, Wang G (1994) MMO: an improved estimator for log-Pearson type-3 distribution. Stoch Hydrol Hydraul 8:219–231
Zakaria ZA, Shabri A, Ahmad UN et al (2012) Estimation of the generalized logistic distribution of extreme events using partial L-moments Estimation of the generalized logistic distribution of extreme events using partial L-moments. Hydrol Sci J 57:424–432. https://doi.org/10.1080/02626667.2012.658400
Acknowledgements
The authors acknowledge the Central Water Commission (CWC), India, that maintains and provides discharge data sets of Mahanadi Basin to scientific research, which can be easily downloaded from the Indian-WRIS official website. The authors express their gratitude to reviewers and the editors for their constructive reviews that helped in improving the quality of this manuscript. The first author of this article also wants to thank the Ministry of Human Resource Development (MHRD), India for providing fellowship for carrying out her doctoral research work.
Author information
Authors and Affiliations
Contributions
In this research work, data collection, analysis, and manuscript preparation were performed by SS under the proper guidance of CSPO. His intellectual suggestions and review helped in refining the article. Both the authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Swetapadma, S., Ojha, C.S.P. Selection of a basin-scale model for flood frequency analysis in Mahanadi river basin, India. Nat Hazards 102, 519–552 (2020). https://doi.org/10.1007/s11069-020-03936-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11069-020-03936-7