
Abstract
Multi-objective optimization of complex engineering systems is a challenging problem. The design goals can exhibit dynamic and nonlinear behaviour with respect to the system’s parameters. Additionally, modern engineering is driven by simulation-based design which can be computationally expensive due to the complexity of the system under study. Bayesian optimization (BO) is a popular technique to tackle this kind of problem. In multi-objective BO, a data-driven surrogate model is created for each design objective. However, not all of the objectives may be expensive to compute. We develop an approach that can deal with a mix of expensive and cheap-to-evaluate objective functions. As a result, the proposed technique offers lower complexity than standard multi-objective BO methods and performs significantly better when the cheap objective function is difficult to approximate. In particular, we extend the popular hypervolume-based Expected Improvement (EI) and Probability of Improvement (POI) in bi-objective settings. The proposed methods are validated on multiple benchmark functions and two real-world engineering design optimization problems, showing that it performs better than its non-cheap counterparts. Furthermore, it performs competitively or better compared to other optimization methods.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
In real-world problems, the optimization goals mostly consist of multiple conflicting objectives. Thus, optimizing all the objectives simultaneously leads to multiple solutions that are mathematically equal. The solution for such a problem can be presented in the form of a Pareto set.
One of the techniques to attain the Pareto set is using weighted sum of the objectives [1,2,3], which can be optimized by standard single objective optimization algorithms. However, there are many ways to define the weighted sum function and to determine the proper coefficients, relying on experts opinion is fundamental [4]. Another alternative is using approaches based on Multi-objective Evolutionary Algorithms (MOEAs) [5,6,7], but the number of required function evaluations often is very high. This represents a clear limitation when optimizing engineering systems, whose performance are typically analyzed via computationally expensive and time-consuming simulations.
In this framework, surrogate-based optimization is a popular approach [8]: the idea is to approximate the desired design objective using a data-driven surrogate model. Several models are commonly used, including but not limited to Gaussian processes [9,10,11], Neural networks [12, 13], Polynomial chaos expansion [14, 15], and Tree-structured Parzen estimator [16] . Such model is built based on a limited number of (expensive) simulations and is cheap-to-evaluate. Examples include optimization of electronic circuits performance [17,18,19], the shape of airplane components [20,21,22], and the strength of adhesive joints [23].
A popular technique for surrogate-based optimization is Bayesian Optimization (BO) based on a Gaussian Process (GP) as surrogate model. The technique [24] proposes fast and efficient hypervolume-based BO for multi-objective problems. However, the technique [24] implicitly assumes that all of the objectives can be evaluated with the same computational cost.
This condition does not always hold in multi-objective optimization problems. Typically, some objectives are cheap to compute. For example, the footprint of electrical devices [25] and time of gluing in the adhesive bonding case [26]. Many multi-objective BO techniques [27,28,29] do not take into account the objectives with very cheap computational cost. In practice, cheap objectives are often modeled with the same surrogate model cost as the expensive ones. This can be an unnecessary burden to the optimization process.
In this work, we extend the standard hypervolume-based acquisition functions to deal with cheap-to-evaluate functions. More specifically, we focus on the bi-objective case, which can be easily extended later on. Instead of modeling the cheap function with a GP, we directly integrate it in the hypervolume-based acquisition functions. We derive the formula analytically resulting in two hypervolume-based acquisition functions: Cheap Hypervolume Expected Improvement (CHVEI) and Cheap Hypervolume Probability of Improvement (CHVPOI).
For evaluating its performance, we consider four analytical benchmark functions [30], and two realistic design problems in microwave engineering. We show that the proposed method performs better than state-of-the-art approaches. Since the cheap objective is computed directly, the inaccuracies introduced by modeling are eliminated.
This paper is organized as follows: Sect. 2 introduces the GP probabilistic model and BO. Section 3 presents the hypervolume-based bi-objective BO. Our extension to the hypervolume-based acquisition function is described in Sect. 4. Then, Sect. 5 presents relevant experimental results on benchmark functions and realistic design problems. Finally, conclusions are drawn in Sect. 6.
2 Bayesian optimization
2.1 Optimization procedure
In global optimization, the goal is to find an optimizer \({\varvec{x}}^*\) of an unknown objective function \(f({\varvec{x}})\), which can be mathematically described as:
where \({\mathcal {X}} \in {\mathbb {R}}^{d}\) is the design space. The unknown objective function \(f({\varvec{x}})\) typically does not have gradient information and is very expensive to evaluate, for example in terms of time or economic cost. Thus, a data-efficient algorithm to find \({\varvec{x}}^*\) is desired.
BO is a global optimization method that aims to minimize the number of function evaluations needed to estimate the global optimum of a function. It relies on two elements: a model of the objective function and a sequential sampling strategy. The idea is to iteratively refine the model until the solution to the optimization problem can be found. The sampling strategy relies on the model to estimate which data point should be acquired next. In order to do so, the sampling strategy relies on a function called acquisition function. The acquisition function balances the trade-off between exploration and exploitation, based on the surrogate model. Usually, the acquisition function has an analytical form that can be computed easily [10].
Before running the BO routine, we first need to generate initial points to train the model. In this paper, the Latin Hypercube Design (LHD) [31] is used. Then, the acquisition function is optimized based on the trained model. After a new point is selected, it is evaluated on the true objective function and the result is used to update the surrogate model. These steps are repeated until a suitable stopping criterion is met. The flowchart of BO is shown in Fig. 1.

General flowchart of Bayesian optimization. The two key components are the surrogate model and the acquisition function. The query point from the previous iteration is added to the surrogate model. Thus, the samples in the dataset are increased sequentially
2.2 Gaussian processes
The most common choice for the surrogate model for BO is a GP. It is analytically tractable and provides a predictive distribution given new input data. In a more formal definition, GP defines a prior over functions \(f({\varvec{x}})\sim GP(m({\varvec{x}}),k({\varvec{x}}, \varvec{x'}))\).
GP is fully specified by its mean function \(m({\varvec{x}})\) and positive semi-definite covariance function \(k({\varvec{x}}, \varvec{x'})\). Following previous work [24], we assume a zero mean function and train the GP on a set of data by maximizing the likelihood using the L-BFGS algorithm. The predictive distribution with a zero mean function of new data \(X_{\star }= [{\varvec{x}}_{\star 1},\ldots ,{\varvec{x}}_{\star N}]\) can be calculated using:
where \({\mathcal {D}}_{n}\) is the observed data, \(\mu \left( X_{\star }\right)\) is the predictive mean, and \(\sigma ^{2}\left( X_{\star }\right)\) is the predictive variance, and \(K_{\mathrm {xx}} = k({\varvec{x}}_{i},{\varvec{x}}_{j})\), \(K_{\star \mathrm {x}} = k({\varvec{x}}_{\star i},{\varvec{x}}_{j})\), \(K_{\star \star }=k({\varvec{x}}_{\star i},{\varvec{x}}_{\star j})\). For the covariance function, the Matérn 5/2 kernel [32] is used and defined as:
This kernel is chosen as it does not put strong smoothness assumptions on the target function compared to the other kernels [33]. Thus, it is more suitable for real-world cases such as the engineering design problems.
3 Multi-objective Bayesian optimization
3.1 Pareto optimality
In real life optimization problem, typically there are multiple conflicting objectives. This leads to solutions that cannot be improved in any of the objectives without sacrificing at least one of other objectives. These solutions are called Pareto optimal solutions, represented as a Pareto set [34].
For minimization problems with m objectives, the notation \({\varvec{x}}_{b} \succ {\varvec{x}}_{a}\) means that \({\varvec{x}}_{b}\) dominates \({\varvec{x}}_{a}\) if, and only if \(f_{j}\left( {\varvec{x}}_{b}\right) \le f_{j}\left( {\varvec{x}}_{a}\right) , \forall j \in \{1, . ., m\}\) and \(\exists j \in \{1, . ., m\}\) such that \(f_{j}\left( {\varvec{x}}_{b}\right) <f_{j}\left( {\varvec{x}}_{a}\right)\). In other words, \({\varvec{x}}_{b}\) is not worse than \({\varvec{x}}_{a}\) in all objectives and better in at least one objective. The Pareto set can then be defined by:
where m is the number of the objectives. Mathematically, the points inside the resulting Pareto set are equal. Also we denotes the Pareto front, the Pareto optimal solutions in output space as \({\mathcal {P}}\). In practice, after the optimal Pareto set is obtained, the decision makers can choose which point to use based on their preference.
3.2 Multi-objective hypervolume-based acquisition function
In multi-objective optimization problems, instead of calculating the improvement towards a single maximum, we want to get the improvement over the Pareto set \({\varvec{P}}\). For the hypervolume-based acquisition function, this improvement can be calculated using the hypervolume indicator \({\mathcal {H}}({\mathcal {P}})\). This indicator denotes the volume of the dominated region, bounded by a reference point r which needs to be dominated by all points in \({\mathcal {P}}\) [35]. The contribution of new points \({\varvec{y}}\) to \({\mathcal {P}}\) can be estimated by using the exclusive hypervolume (also called hypervolume contribution) \({\mathcal {H}}_{exc}\) as:
Using \({\mathcal {H}}_{exc}\), we can define the improvement function for the hypervolume-based multi-objective case as:
Next, we will build the acquisition function for multi-objective settings upon this improvement function. In order to make the formula simpler, given the predictive distribution defined in Eqs. (2) and (3), the probability density function \(\phi _{j}\) and cumulative density function \(\varPhi _{j}\) are compactly defined as:
Then, the hypervolume-based multi-objective POI (HVPOI) [24] is defined as follows:
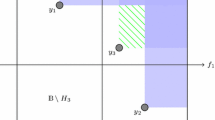
where \(\mu ({\varvec{x}})\) is a GP prediction at \({\varvec{x}}\) and A is the non-dominated region, see Fig. 2. m is the number of objectives, \({\varvec{y}}\) is the objective vector inside region A.
Furthermore, we can define the hypervolume-based EI (HVEI) [24] as:
Note that these acquisition functions are intractable. To mitigate this problem, Couckuyt et al. [24] suggests calculating the hypervolume from the set of disjoint cells built from the lower and upper bound of the Pareto front. This approach is more computationally efficient compared to the uniform grid search [36].
However, these multi-objective acquisition functions implicitly assume that the models of all objectives must be computed, regardless of the computational cost of evaluating each objective. A problem might arise using this assumption: If we have a cheap but complex objective function, the GP might introduce inaccuracies as well as a waste of computational resources.
4 Cheap-expensive hypervolume-based acquisition function
Without loss of generality, let us consider problems where two objective functions can be defined, where one is expensive \(f_1\) and the other is cheap \(f_2\). Our extended approach models \(f_1\) into a GP and uses it to predict new data \(\varvec{x^*}\) and estimate the corresponding mean \(\mu _1\) and variance \(\sigma ^{2}_{1}\) in the acquisition function calculation. Next, \({\varvec{y}} :=(y_1,y_2)\) is used to compute the improvement function \(I({\varvec{y}}, {\mathcal {P}})\), where \(y_1\) and \(y_2\) are potential observation and observation of \(f_1\) and \(f_2\), respectively. Here, \({\mathcal {P}} = \{(p_{1}^{1},p_{2}^{1}),(p_{1}^{2},p_{2}^{2}),\ldots ,(p_{1}^{M},p_{2}^{M})\}\), where \(p_{1}^{m}\) denotes the expensive dimension sorted in ascending order. Then it follows that \(p_{2}^{m}\), the cheap dimension, is sorted in descending order. Next, the Cheap Hypervolume EI (CHVEI) is defined as follows:

Illustration of the non-dominated region and the way the cheap objective function evaluation \(y_2\) is incorporated into the hypervolume-based acquisition function. \(P_i\) are the points in the Pareto set. The blue dotted curve illustrates the prediction of the expensive objective \(y_1\). The orange dot is the reference point, used as the bound to calculate the hypervolume
Using \({\mathcal {P}}\) we define horizontal and vertical cells as shown in Fig. 2. Based on these cells, we can derive the closed form of the CHVEI as follows:
where m is the cell of interest, k is the cell improvement relative to m, l is lower bound, u is upper bound and \(z^+=\max (z,0)\). Then, we can calculate the closed form solution of CHVEI. For cells of interest (\(m = k\)), the integrals on Eq. 13 are the definition of the single-objective EI [37] defined as:
while the integral for cells on the right of the cells of interest (\(l^{k}_{1} \ge u^{m}_{1}\)) are calculated by:
and 0 for cells in the left (\(u^{k}_{1}<l^{m}_{1}\)).
It is important to mention that the cheap objective is directly incorporated in the acquisition function, thus avoiding the inaccuracies due to modeling the cheap objective with a surrogate model. This is favorable especially when the cheap objective function has a complex dynamic behaviour in the design space. Additionally, it leads to a reduced computational complexity of the overall algorithm. The proposed BO approach based on CHVEI is summarized in Algorithm 1.

A similar approach can be used to define the cheap version of bi-objective POI as follows:
Now, a BO routine based on CHVPOI can be defined as for the CHVEI: the only difference with the approach described in Algorithm 1 is that Eq. (16) is used instead of \(\mathrm {CHVEI}(x)\).
5 Result and discussion
The proposed BO approach is implemented using the GPFlowOpt library [38] in python. For the initial data, 21 points are arranged using a Latin-Hypercube Design [31]. The acquisition function is optimized using the best solution of Monte Carlo sampling, further fine-tuned by a gradient-based optimizer. We consider four variants of the well known DTLZ benchmark functions [30] and two real-life electrical device design optimization problems to validate the proposed method.
In all experiments, the CHVEI and CHVPOI acquisition functions are compared with the standard HVEI and HVPOI, as well as random sampling. Additionally, we also compare against the MOEA algorithms SMS-EMOA [39] and NSGA-II [40]. We used hypervolume indicator metrics to assess the quality of the Pareto set per iteration, where the computational budget is fixed to 100 function evaluations for all methods except the MOEA, that uses a budget of 250 function evaluations instead. This choice guarantees a fair comparison, since MOEA needs more evaluations compared to approaches based on BO. Finally, when optimizing electrical devices we inspect the quality of the Pareto set by checking the design layout and its corresponding responses visually.
5.1 DTLZ benchmark functions
We consider four variants of the DTLZ functions: DTLZ1, DTLZ2, DTLZ5, and DTLZ7, as indicated in Table 1. DTLZ2 and DTLZ5 have a smooth set of Pareto solution, while DTLZ1 and DTLZ7 have a disjoint Pareto set.
The final hypervolume indicator is shown in Table 2. Overall results show that CHVPOI always performs better than the other methods, even compared to the MOEAs with 250 function evaluations budget.
Figure 3 shows the hypervolume indicator evolution with respect to the function evaluations number: the CHVEI and CHVPOI achieve a better hypervolume indicator in less iterations compared with their standard counterpart HVEI and HVPOI, respectively. Additionally, CHVEI and CHVPOI offer the best performance compared with all other methods for DTLZ1 and DTLZ7, while standard HVPOI is better than CHVEI in iteration 100 for the functions DTLZ2 and DTLZ5, that have a smooth Pareto solution. This is because EI based methods are less exploitative compared to the POI based methods.

Evolution of hypervolume indicator for the DTLZ benchmark functions. (a) and (d) are less smooth functions, DTLZ1 and DTLZ7 respectively. While (b) DTLZ2 and (c) DTLZ5 are smoother functions
Furthermore, we randomly sample 1 million points for all the benchmark functions to approximate the true Pareto set of the functions. Next, we calculate the distance of the sampled-based Pareto set and the Pareto set obtained via BO-based approaches and MOEAs. This metric is used to measure the convergence of the results with respect to approximate ”true” Pareto set: the lower the value, the more accurate the approximation. It is defined as:
\({\hat{P}}\) is a vector of Pareto front obtained by the algorithm, P is an approximation of true Pareto front obtained, for instance, by random sampling.
The convergence measure in Table 3 shows that CHVPOI is better in most cases except on DTLZ7. As we see in Fig. 3d, the hypervolume indicator does not improve much after iteration 10, indicating that the method is finding the extrema faster, which results in a less uniform Pareto set. This is prevalent in hypervolume-based improvement functions: since hypervolume is a product, it samples less in regions where at least one objective has a very small improvement.
5.2 Microstrip low-pass filter
Our first engineering problem is the design of a two-port low-pass stepped impedance microstrip filter device [41]. The simulator for the device is implemented in the MATLAB RF Toolbox (Mathworks Inc., Natick, MA, USA). The corresponding layout is presented in Fig. 4.

Top-view of microstrip low-pass filter. We use 1 widths \(w_{1}=w_{3}=w_{5}\) and 3 different lengths \(l_1\), \(l_3\), \(l_5\) as design parameters
The filter is a cascade of 6 microstrip lines, each specified by width and length, where by design \(w1 = w3 = w5\) and \(w2 = w4 = w6\). The cross-section view of each microstrip is depicted in Fig. 5.

The cross-section view of each microstrip. For \(w_n = w_1 = w_3 = w_5\), the values changes within the optimization iterations, while for \(w_n = w_2 = w_4 = w_6\) the values are fixed at 0.428 mm
Our target design is a filter with a 3 dB cut-off frequency at 2.55 GHz. To achieve this, we define the design goals as follows:
where \(\left| S_{21} \right|\) is the magnitude of the element \(S_{21}\) of the scattering matrix, and freq is the frequency. Visually, the target response is illustrated in Fig. 6. We also want to optimize the cost to produce the device, by minimizing the footprint of the filter. Hence, the target design and the area of the filter are used as our expensive and cheap objective, respectively.

Example of the desired response for the microstrip low-pass filter
In the optimization problem formulation, the chosen design parameters are the length and the width of the first, third and fifth microstrips, indicated as \(l_1\), \(l_3\), \(l_5\), \(w_1\), \(w_3\), \(w_5\), (see Fig. 4). Note that, these microstrips have the same width by design [41]: the width of all three microstrips is one single design parameter indicated as \(w_{1,3,5}\). The other geometrical and electrical characteristics of the filter are chosen according to Table 4.
To achieve our optimization goals, we formulate our objectives as follows:
In the first objective defined in Eq. (20), we want a response that assumes values as high as possible until \(f_{\text {pass}}\), and as low as possible for frequencies above \(f_{stop}\). This ensures that our device has a low-pass filter behavior, as shown in Fig. 6. The second cheap objective expressed in Eq. (21) represents the \(\log\) of sum of the three microstrips’s area, this means that the goal is to minimize the footprint of the filter. The \(\log\) term is to ensure numerical stability of the second objective. We solve this problem with our proposed methods. The hypervolume per iteration of all methods is shown in Fig. 7.

Hypervolume indicator evolution for low-pass filter case. The hypervolume is calculated using (1, 0) as the reference point
Comparison of the hypervolume indicator of all methods for a predefined computational budget is presented in Table 5. CHVPOI performs better compared to the other benchmark methods, while CHVEI performs worse in terms of hypervolume indicator compared to HVEI. To check this unexpected behavior, we evaluate the quality of the pareto set by using the same convergence measure adopted for the DTLZ functions. In particular, the Pareto set is approximated via 50000 evaluations on random points in the design space and the distance metric defined in Eq. (17) is computed for CHVEI and HVEI. The result show that CHVEI gives a better convergence measure (0.0127 ± 0.0009) than the HVEI (0.0468 ± 0.0027). This means that the CHVEI yields a Pareto front that is spread more evenly along the approximated true front than the HVEI. The full convergence measure results are described in Table 5.
5.3 Tapped-line filter
The second engineering example is a tapped-line filter [42, 43], implemented in the Advanced Design System simulator (Keysight EEsof EDA). The full layout of this device is shown in Fig. 8.

The design requirements for this filter are described in Eq. (22) and (23), as:
where \(\left| S_{21} \right|\) is the magnitude of the element \(S_{21}\) of the scattering matrix, and freq is the frequency. The requirements in Eqs. (22) and (23) lead to the to response depicted in Fig. 9: the desired filter response is lower than \({-20}\,\hbox {dB}\) in the low and high frequency parts (called stopbands) and higher than \({-3}\,\hbox {dB}\) in the mid part (passband of the filter).

The design requirements shown above are used as the first optimization goal. For the second cheap objective, the footprint of the device is used. We formulate these objectives as follows:
where \(fs_1 = {4}\,\hbox {GHz}\), \(fp_1 = {4.75}\,\hbox {GHz}\), \(fp_2 = {2.25}\,\hbox {GHz}\) and \(fs_2 = {6}\,\hbox {GHz}\). Equation (24) ensures that the filter’s response follows the design requirements. To balance the value, we put a higher weight for the response in the passband. Equation (25) represents the footprint of the device.
The variables for the optimization are the displacement \(L_1\) (mm) and the spacing g (mm) between the two conductors. Additionally, the dielectric constant \(\epsilon\) (mil), and height h (mm) of the substrate are also considered as design parameters. The corresponding design space is shown in Table 6.

Evolution of hypervolume for tapped-line filter case. (20, 20) is used as the reference point to calculate the hypervolume
Using these settings, we run the optimization with our proposed methods and other benchmark methods. The results in Fig. 10 show that CHVEI and CHVPOI get a higher hypervolume indicator faster than the other methods. Additionally, in Table 7 we can see that our methods have higher hypervolume indicator compared to the MOEAs: SMSEMOA and NSGA2b, even with a lower function evaluation budget.
6 Conclusion
We proposed the Cheap Hypervolume Expected Improvement (CHVEI) and Cheap Hypervolume Probability of Improvement (CHVPOI) which can directly exploit cheap-to-evaluate objective functions. The direct evaluation can speed up the optimization process and removes possible inaccuracies introduced by surrogate modeling. To evaluate the performance of the proposed method, we apply our algorithm to multiple benchmark functions and two engineering design problems. We evaluate the performance of the CHVEI and CHVPOI by measuring the hypervolume indicator and convergence measure at each iteration. It is shown that in the engineering design problems our proposed methods outperform the standard hypervolume-based methods, random sampling, and Genetic algorithm-based methods. In future works we will extend the algorithm for \(n>2\) objectives, and consider the case of noisy objective functions.
References
Knowles J (2006) ParEGO: a hybrid algorithm with on-line landscape approximation for expensive multiobjective optimization problems. IEEE Trans Evol Comput 10(1):50–66. https://doi.org/10.1109/TEVC.2005.851274 (ISSN 1089778X.)
Knowles J, Corne D, Reynolds A (2010) Noisy multiobjective optimization on a budget of 250 evaluations. Lecture notes in computer science (including subseries lecture notes in artificial intelligence and lecture notes in bioinformatics, vol 5467. Springer, Berlin, pp 36–50. https://doi.org/10.1007/978-3-642-01020-0_8 (ISSN 03029743ISSN 03029743)
Davins-Valldaura J, Moussaoui S, Pita-Gil G, Plestan F (2017) ParEGO extensions for multi-objective optimization of expensive evaluation functions. J Global Optim 67(1–2):79–96. https://doi.org/10.1007/s10898-016-0419-3 (ISSN 15732916.)
Astudillo R, Frazier P (2017) Multi-attribute Bayesian optimization under utility uncertainty. In: 31st Conference on Neural Information Processing Systems (NIPS 2017), p 5
Coello CCA, Brambila SG, Gamboa JF, Tapia MGC, Gómez RH (2020) Evolutionary multiobjective optimization: open research areas and some challenges lying ahead. Complex Intell Syst 6(2):221–236. https://doi.org/10.1007/s40747-019-0113-4 (ISSN 2199-4536)
Ray T, Tai K, Seow KC (2001) Multiobjective design optimization by an evolutionary algorithm. Eng Optim 33(4):399–424. https://doi.org/10.1080/03052150108940926 (ISSN 0305215X)
Zhou Q, Wu J, Xue T, Jin P (2021) A two-stage adaptive multi-fidelity surrogate model-assisted multi-objective genetic algorithm for computationally expensive problems. Eng Comput 37(1):623–639. https://doi.org/10.1007/s00366-019-00844-8 (ISSN 14355663)
Shao W, Deng H, Ma Y, Wei Z (2012) Extended Gaussian Kriging for computer experiments in engineering design. Engi Comput 28(2):161–178. https://doi.org/10.1007/s00366-011-0229-7 (ISSN 01770667)
Rasmussen CE, Williams CKI (2018) Gaussian processes for machine learning. The MIT Press, London. https://doi.org/10.7551/mitpress/3206.001.0001
Shahriari B, Swersky K, Wang Z, Adams RP, De Freitas N (2015) Taking the human out of the loop: a review of Bayesian optimization. Proc IEEE 104(1):148–756 (ISSN 15582256)
He Y, Sun J, Song P, Wang X (2021) Variable-fidelity hypervolume-based expected improvement criteria for multi-objective efficient global optimization of expensive functions. Eng Comput. https://doi.org/10.1007/s00366-021-01404-9 (ISSN 14355663)
Sun G, Wang S (2019) A review of the artificial neural network surrogate modeling in aerodynamic design. Proc Inst Mech Eng Part G 233(16):5863–5872. https://doi.org/10.1177/0954410019864485 (ISSN 20413025)
Shahriari M, Pardo D, Moser B, Sobieczky F (2020) A deep neural network as surrogate model for forward simulation of borehole resistivity measurement. Proced Manuf 42:235–238. https://doi.org/10.1016/j.promfg.2020.02.075 (ISSN 23519789)
Bhattacharyya B (2021) Uncertainty quantification and reliability analysis by an adaptive sparse Bayesian inference based PCE model. Eng Comput. https://doi.org/10.1007/s00366-021-01291-0 (ISSN 14355663)
Zhou Y, Lu Z, Cheng K, Shi Y (2019) An expanded sparse Bayesian learning method for polynomial chaos expansion. Mech Syst Signal Process 128:153–171. https://doi.org/10.1016/j.ymssp.2019.03.032 (ISSN 10961216)
Bergstra J, Bardenet R, Bengio Y , Kégl B (2011) Algorithms for hyper-parameter optimization. In: Advances in Neural Information Processing Systems 24: 25th Annual Conference on Neural Information Processing Systems 2011, NIPS 2011, pp 1–9
František M (2017) Bayesian approach to design optimization of electromagnetic systems under uncertainty. IEEE CEFC Bienn Conf Electromagn Field Comput 15:5090. https://doi.org/10.1109/CEFC.2016.7816315
Knudde N, Couckuyt I, Spina D, Lukasik K, Barmuta P, Schreurs D, Dhaene T (2018) Data-efficient Bayesian optimization with constraints for power amplifier design. IEEE MTT-S Int Conf Numer Electromagn Multiphys Model Optim. https://doi.org/10.1109/NEMO.2018.8503107
Passos F, Ye Y, Spina D, Roca E, Castro-Lopez R, Dhaene T, Fernández FV (2017) Parametric macromodeling of integrated inductors for RF circuit design. Microw Opt Technol Lett 59(5):1207–1212. https://doi.org/10.1002/mop.30498
Conlan-Smith C, Ramos-García N, Sigmund O, Andreasen CS (2020) Aerodynamic shape optimization of aircraft wings using panel methods. AIAA J 58(9):3765–3776. https://doi.org/10.2514/1.J058979 (ISSN 00011452)
Zuhal LR, Palar PS, Shimoyama K (2019) A comparative study of multi-objective expected improvement for aerodynamic design. Aerosp Sci Technol 91(May):548–560. https://doi.org/10.1016/j.ast.2019.05.044 (ISSN 12709638)
Jim TM, Faza GA, Palar PS, Shimoyama K (2020) Bayesian methods for multi-objective optimization of a supersonic wing planform. Proc Genet Evolut Comput Conf Companion. https://doi.org/10.1145/3377929.3398122 (ISBN 9781450371278)
da Silva LFM, Lopes MJCQ (2009) Joint strength optimization by the mixed-adhesive technique. Int J Adhes Adhes 29(5):509–514. https://doi.org/10.1016/j.ijadhadh.2008.09.009 (ISSN 01437496)
Couckuyt I, Deschrijver D, Dhaene T (2014) Fast calculation of multiobjective probability of improvement and expected improvement criteria for Pareto optimization. J Global Optim 60(3):575–594. https://doi.org/10.1007/s10898-013-0118-2 (ISSN 1573-2916)
Sachid AB, Paliwal P, Joshi S, Shojaei M, Sharma D, Rao V (2016) Circuit optimization at 22nm technology node. Proc IEEE Int Conf VLSI Des 25:322–327. https://doi.org/10.1109/VLSID.2012.91 (ISSN 10639667)
Sánchez CA, Basler R, Zogg M, Ermanni P (2012) Multistep heating to optimizethe curing process of a paste adhesive. In: ECCM 2012-Composites at Venice, Proceedings of the 15th European Conference on Composite Materials. (ISBN 9788888785332)
Couckuyt I, Deschrijver D, Dhaene T (2012) Towards efficient multiobjective optimization: multiobjective statistical criterions. IEEE Congr Evolut Comput. https://doi.org/10.1109/CEC.2012.6256586
Belakaria S, Deshwal A, Doppa JR (2019) Max-value entropy search for multi-objective Bayesian optimization. Advances in neural information processing systems. Springer, Berlin, p 32 (ISSN 10495258)
Daulton S, Balandat M, Bakshy E (2020) Differentiable expected hypervolume improvement for parallel multi-objective bayesian optimization. Advances in Neural Information Processing Systems. 33, pp 1–30 (ISSN 23318422)
Deb K, Thiele L, Laumanns M, Zitzler E (2005) Scalable test problems for evolutionary multiobjective optimization. Wiley, New Jersey. https://doi.org/10.1007/1-84628-137-7_6
Viana FAC, Venter G, Balabanov V (2010) An algorithm for fast optimal Latin hypercube design of experiments. Int J Numer Methods Eng. https://doi.org/10.1002/nme.2750 (ISSN 00295981)
Minasny B, McBratney AB (2005) The Matérn function as a general model for soil variograms. Geoderma 128(3–4 SPEC. ISS):192–207. https://doi.org/10.1016/j.geoderma.2005.04.003 (ISSN 00167061)
Snoek J, Larochelle Adams RP (2012) Practical Bayesian optimization of machine learning algorithms. Adv Neural Inf Process Syst 4:2951–2959 (ISSN 10495258)
Zitzler E, Thiele L, Laumanns M, Fonseca CM, Da Fonseca VG (2003) Performance assessment of multiobjective optimizers: an analysis and review in IEEE Transactions on Evolutionary Computation, vol 7, no 2. pp 117–132, April 2003. doi: https://doi.org/10.1109/TEVC.2003.810758. (ISSN 1089778X)
Zhang Q, Liu W, Tsang E, Virginas B (2010) Expensive multiobjective optimization by MOEA/D with gaussian process model. IEEE Trans Evol Comput 14(3):456–474. https://doi.org/10.1109/TEVC.2009.2033671 (ISSN 1089778X)
Emmerich MTM, Deutz AH, Klinkenberg JW (2011) Hypervolume-based expected improvement: monotonicity properties and exact computation. IEEE Congr Evolut Comput. https://doi.org/10.1109/CEC.2011.5949880
Jones DR, Schonlau M, Welch WJ (1998) Efficient global optimization of expensive black-box functions. J Glob Optim 13:455–492
Knudde N, Van Der Herten J, Dhaene T, Couckuyt I (2017) GPflowOpt: a Bayesian optimization library using tensorflow. arXiv preprint arXiv:1711.03845. ISSN 23318422
Beume N, Naujoks B, Emmerich M (2007) SMS-EMOA: multiobjective selection based on dominated hypervolume. Eur J Oper Res 181(3):1653–1669. https://doi.org/10.1016/j.ejor.2006.08.008 (ISSN 03772217)
Durillo JJ, Nebro AJ, Luna F, Alba E (2010) On the effect of the steady-state selection scheme in multi-objective genetic algorithms. Lecture notes in computer science (including subseries lecture notes in artificial intelligence and lecture notes in bioinformatics, vol 5467. Springer, Berlin, pp 183–197. https://doi.org/10.1007/978-3-642-01020-0_18 (ISSN 03029743)
Qing J, Knudde N, Couckuyt I, Spina D, Dhaene T (2020) Bayesian active learning for electromagnetic structure design. Eur Conf Anten Propag. https://doi.org/10.23919/EuCAP48036.2020.9136051
Manchec A, Quendo C, Favennec JF, Rius E, Person C (2006) Synthesis of capacitive-coupled dual-behavior resonator (ccdbr) filters. IEEE Trans Microw Theory Tech 54(6):2346–2355. https://doi.org/10.1109/TMTT.2006.875271 (ISSN 15579670)
Koziel S, Cheng QS, Bandler JW (2008) Space mapping. IEEE Microw Mag 9(6):105–122. https://doi.org/10.1109/MMM.2008.929554 (ISSN 15273342.)
Acknowledgements
This work has been supported by the Flemish Government under the ”Onderzoeksprogramma Artificiële Intelligentie (AI) Vlaanderen” and the ”Fonds Wetenschappelijk Onderzoek (FWO)” programmes.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Loka, N., Couckuyt, I., Garbuglia, F. et al. Bi-objective Bayesian optimization of engineering problems with cheap and expensive cost functions. Engineering with Computers 39, 1923–1933 (2023). https://doi.org/10.1007/s00366-021-01573-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00366-021-01573-7