
Abstract
In engineering design optimization, there are often multiple conflicting optimization objectives. Bayesian optimization (BO) is successfully applied in solving multi-objective optimization problems to reduce computational expense. However, the expensive expense associated with high-fidelity simulations has not been fully addressed. Combining the BO methods with the bi-fidelity surrogate model can further reduce expense by using the information of samples with different fidelities. In this paper, a bi-fidelity BO method for multi-objective optimization based on lower confidence bound function and the hierarchical Kriging model is proposed. In the proposed method, a novel bi-fidelity acquisition function is developed to guide the optimization process, in which a cost coefficient is adopted to balance the sampling cost and the information provided by the new sample. The proposed method quantifies the effect of samples with different fidelities for improving the quality of the Pareto set and fills the blank of the research domain in extending BO based on the lower confidence bound (LCB) function with bi-fidelity surrogate model for multi-objective optimization. Compared with the four state-of-the-art BO methods, the results show that the proposed method is able to obviously reduce the expense while obtaining high-quality Pareto solutions.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Simulation models have been widely used in engineering design optimization. However, obtaining the Pareto solutions of multi-objective optimization problems usually requires many evaluations of objective functions. The evaluation processes of objective functions rely on time-consuming simulation models, which increases the burden of the optimization tasks. To solve this problem, surrogate models, such as Kriging models (Jerome et al. 1989; Liu et al. 2018; Williams et al. 2021), radial basis function models (Sóbester et al. 2005; Zhou et al. 2017), support vector regression models (Shi et al. 2020), are commonly adopted to replace expensive simulations in engineering design optimization.
Bayesian optimization (Shahriari et al. 2016) is a typical surrogate-based optimization method, which is able to balance the exploitation and exploration by utilizing the uncertainty term of the surrogate model with an acquisition function (Jeong et al. 2005). Commonly used acquisition functions include the probability of improvement (PI) (Ruan et al. 2020), expected improvement (EI) (Jones 2001; Zhan et al. 2022), and lower confidence bound (LCB) (Srinivas et al. 2012; Zheng et al. 2016). In recent years, extending these single-objective BO methods to multi-objective optimization has also gained much attention. For example, Knowles (2006) proposed the ParEGO method, which extended the EI function to multi-objective optimization. Emmerich et al. (2011) combined the hypervolume improvement with the EI function, which clarifies the regions where the Pareto frontier can be improved by establishing the monotonicity properties. Zhan et al. (2017) expanded the EI function into a matrix form (EIM), where the elements of the matrix are the EI value corresponding to each objective. Shu et al. (2020) defined an acquisition function for multi-objective optimization problems, considering convergence and diversity of the Pareto frontier.
However, these methods only utilize the high-accuracy samples to build the surrogate model, which still expends much computational cost (Chen et al. 2016). A potential way to further reduce the expense is adopting the multi-fidelity (MF) surrogate model (Zhang et al. 2018a, b), constructed based on a few costly high-fidelity (HF) samples and plenty of cheap low-fidelity (LF) samples. There are three main MF surrogate modeling methods: the scaling function method (Choi et al. 2009; Li et al. 2017), the space mapping method (Leifsson et al. 2015), and the Co-Kriging method (Kennedy et al. 2000; Perdikaris et al. 2015; Singh et al. 2017). Moreover, several new MF modeling methods have been proposed in the past few years, such as the method proposed by Eweis-Labolle et al. (2022), which utilizes latent-map Gaussian processes and outperforms the space mapping method. With above MF surrogate models gaining much attention, several multi-fidelity BO methods have been developed. For example, Zhang et al. (2018a, b) proposed a multi-fidelity method with an extension of Co-Kriging model, hierarchical Kriging (HK) model (Han et al. 2012), which avoids the construction of cross covariance in Co-Kriging. Jiang et al. (2019) proposed a new method to obtain the new sample and fidelity level, extended BO based on the LCB function with MF surrogate model. However, very limited work is accomplished for multi-objective optimization with BO based on the MF surrogate model. He et al. (2022) introduced a novel method for multi-objective problems, combining the HK model and EIM method. The blank of the research domain in extending BO based on the LCB function with MF surrogate model for multi-objective optimization still needs to fill. The bi-fidelity (BF) surrogate model is the surrogate model with two different fidelities, which is the special case of the MF surrogate model and needs to be considered first.
In this paper, a bi-fidelity BO method for multi-objective optimization is proposed, which utilizes the advantages of the bi-fidelity surrogate model and BO framework to further reduce the expense. In the method, a novel acquisition function is developed, in which a cost coefficient considering a cost ratio between different fidelity levels is introduced to balance the sampling cost and information of the new sample. The proposed method is compared with four state-of-the-art BO methods using several numerical examples and two engineering design optimization problems. The results show that the proposed method presents prominent performance in computational cost, especially for solving high-dimension problems.
The remainder of the paper is organized as follows. In Sec. 2, the technical background of the multi-objective optimization, HK model, and Bayesian optimization are recalled. Sec. 3 introduces the proposed method in detail. In Sec. 4, the results of comparative study between the proposed method and other state-of-the-art methods are presented. Sec. 5 summarizes this paper with conclusions and future work provided.
2 Background
2.1 Multi-objective optimization
Multi-objective optimization exists multiple conflicting objectives to optimize, and the optimization problem can be formulated as follows:
where the dimension of objective functions \(\, F({\text{x}}) \,\) is \(\, M\), \({\text{x}} = (x_{1} ,x_{2} ,...,x_{N} )^{T}\) denotes N-dimension design variable vector with lower/upper bounds of \({\text{x}}_{lb}\) and \({\text{x}}_{ub}\), \({\text{g}} = (g_{1} ,g_{2} ,...,g_{q} )\) is the constrain vector that can be simple linear or nonlinear.
The multi-objective improvement functions are usually employed as acquisition functions in BO for multi-objective optimization. Euclidean distance improvement function (Keane 2006), maximin distance improvement function (Svenson et al. 2016), and hypervolume (HV) (Yang et al. 2019) improvement function are three state-of-the-art multi-objective improvement functions. The Euclidean distance improvement function can be expressed as follows:
where \(f_{i}^{j}\) is the jth Pareto solution of the ith objective, \(y_{i} ({\text{x}})\) is the prediction of the ith objective.
The maximin distance improvement function is expressed as follows:
Before the HV improvement function is introduced in detail, firstly the concept of the HV should be clarified. With a reference point dominated by the Pareto set, the HV of the dominated region can be measured as follows:
where \(p \prec y \prec R\) means the dominated region bounded by current Pareto \(p\) and the reference point, Volume (·) is the HV indicator.
The HV improvement is the difference of the HV indicator between the current Pareto set and Pareto set with the next sample. It can be formulated as follows:
where \(p \cup y\) represents the Pareto set obtained by the non-dominated-sort method after the new sample y added. \(I(y)\) is the HV improvement beyond the current Pareto set after adding a new sample \(\, y \,\). Figure 1 presents the 2D example of the HV improvement. The light gray area is the HV of current Pareto set and the dark gray area illustrates the \(I(y)\). A higher HV improvement means a better-quality improvement beyond the current Pareto set.

2-dimension example of the HV improvement
More information about these improvement functions can be consulted in Svenson’s work (2016).
2.2 Hierarchical kriging (HK) model
Kriging model (Williams et al. 2006) is an interpolative surrogate model, which originated from the geostatistics and was applied to fit expensive simulation (Jerome et al. 1989).
HK model is a MF surrogate model based on the Kriging model, which takes LF prediction as an overall trend of the MF model with the HF function adopted to be a correction. To build an HF surrogate model for expensive function, first we build a Kriging model with LF samples, which is adopted thereafter to assist the construction of the MF model. The LF Kriging model is expressed as follows:
where \(\beta_{0,l}\) is the mean term and \(Z_{l} ({\text{x}})\) is a random process with variance \(\sigma^{2}\) and zero mean. One of the most commonly used spatial correlation functions between the error term of two points \({\text{ x }}\) and \({\text{ x}}^{\prime}\), named the Gaussian correlation function, is given as follows:
where \(\sigma^{2}\) is the variance of the \(Z({\text{x}})\),\(\, d \,\) is the dimension of design variables, and \({\uptheta } = \left\{ {\theta_{1} ,\theta_{2} ,...,\theta_{d} } \right\}\) is a “roughness” parameter associated with dimension i.
The prediction of mean and mean-squared error (MSE) from LF model at any unobserved points can be formulated as follows:
respectively, where \(\beta_{0,l} = ({1}^{T} {\text{R}}_{l}^{ - 1} {1})^{ - 1} {1}^{T} {\text{R}}_{l}^{ - 1} f_{l} ({\text{x}})\), \(f_{l} ({\text{x}})\) is the LF response of samples \({\text{ x}}\),\({1}\) is a vector filled with 1, \({\text{R}}_{l}\) is the covariance matrix with \(R_{l,mn} = {\text{cov}} (Z({\text{x}}^{m} ),Z({\text{x}}^{n} ))\) as elements, and \({\text{r}}_{l}\) is a vector of correlation between the unobserved point and samples. Above hyperparameters \(\beta_{0,l}\), \(\sigma^{2}\), \(\theta_{i}\) are calculated by Maximum Likelihood Estimation (MLE).
Taking the predicted value of the LF model to construct the prior mean of the HF Kriging model, it will be built as follows:
where the \(\hat{y}_{l} ({\text{x}})\) is the prediction of the LF model scaled by a constant factor \(\beta_{0}\), \(Z({\text{x}})\) is a random process with zero mean and a covariance of \({\text{cov}} (Z({\text{x}}),Z({\text{x}}^{^{\prime}} ))\).
The prediction of mean value and mean-squared error (MSE) of HK model at the unobserved point can be formulated as follows:
respectively, where \(\beta_{0} = \left[ {f_{l} ({\text{x}})^{T} {\text{R}}^{ - 1} f_{l} ({\text{x}})} \right]^{ - 1} f_{l} ({\text{x}})^{T} {\text{R}}^{ - 1} f_{h} ({\text{x}})\) is a scaling factor, and \(f_{h} ({\text{x}})\) is the high-fidelity response of sample points \({\text{ x}}\).
More details about hierarchical Kriging model are introduced in Han’s work (2012).
2.3 Bayesian optimization based on the LCB function
Bayesian optimization is a type of the surrogate model-based method for expensive optimization problems. The BO method utilizes the uncertainty and prediction information from surrogate model to quantify the improvement or probability of improvement between new sample and current optimum, which can balance the exploitation and exploration. EI and LCB functions are commonly used acquisition functions (Tran et al. 2019). With the number of objectives increased, due to the complexity of the non-dominated region, a piecewise integral approach is often used to calculate the EI value, where the integral region is commonly resolved into some regular cells (Zhan et al. 2017). Hence, such improvement-based acquisition function as above multi-objective EI criteria becomes so complicated that the EI value is hard to be calculated. On the contrary, an outstanding advantage using LCB function is that it is no need to calculate such tedious piecewise integral like EI and PI function. This property economizes many computational resources from the calculation of high-dimension integrals.
Given the samples \(\left\{ {x_{1} ,x_{2} ,...,x_{N} } \right\}\) and their associated response \(\left\{ {f_{1} ,f_{2} ,...,f_{N} } \right\}\), LCB function is formulated as follows:
where \(\hat{f}({\text{x}})\) represents the prediction value of surrogate model, \(s({\text{x}})\) is the square root of uncertainty, \(k\) is a parameter balanced the exploitation and exploration. In multi-objective optimization, the form of LCB function will be a vector (Shu et al. 2020):
where M is the number of objectives, each objective is fitted by the surrogate model respectively, and \(s_{i} (x)\) is the square root of the posterior predictive variance. A larger value of the coefficient \(k_{i}\) represents that the algorithm is encouraged to search the solution in the uncertain region, conversely a small value encourages exploitation in the current optimum region.
More information about EI, PI, and other acquisition functions can be consulted in following reference papers (Jones et al. 1998) (Ruan et al. 2020; Shahriari et al. 2016).
3 Proposed method
In this section, a bi-fidelity BO method for multi-objective optimization is proposed. Firstly, the cost and HV improvement after adding a new sample with different fidelity are analyzed, then the new acquisition function is introduced in detail. Finally, the terminal condition and procedure of the method are presented.
3.1 Predicted HV improvement after adding a new sample with different fidelities
The LCB function utilizes the predicted mean and uncertainty to measure the worth of each point in the unobserved area. The HV improvement function is employed to quantify the predicted quality improvement after adding a new sample in the proposed method, as presented in Eqs. (4) and (5). The HV improvement function can be formulated as follows:
where the \(f_{LCB} (x)\) is the LCB function defined in Eq. (14). Figure 2 presents the Pareto set and predicted HV improvement after adding a new sample (\(I_{LCB} (x)\)) in 2D objective space. The red point in Fig. 2 represents the \(f_{LCB} ({\text{x}})\) at sample x.

2-dimension example of Pareto set and predicted HV improvement
Figure 3 presents the HV improvement while the surrogate model has two fidelity levels and the HV improvement functions are formulated, respectively, as follows:
where the \(I_{LCB}^{l} (x)\) and \(I_{LCB}^{h} (x)\) denote the HV improvement after adding HF and LF samples, respectively,\(f_{LCB}^{l} (x)\) and \(f_{LCB}^{h} (x)\) are expressed as follows:
respectively, where

the predicted HV improvement after adding HF and LF samples
\(s_{i}^{h} (x)\) is the error term arising from the lack of an HF sample in HK model, \(\beta_{0} s_{i}^{l} (x)\) is the error of the LF model prediction because of the lack of a LF sample (Zhang et al. 2018a, b).
The light gray area in Fig. 3 is the HV of the current Pareto frontier. The blue and dark gray areas represent the HV improvement after adding the LF sample (\(I_{LCB}^{l} (x)\)) and the HF sample (\(I_{LCB}^{h} (x)\)) beyond current Pareto set, respectively. It should be noted that the \(I_{LCB}^{h} (x)\) includes the blue area, which denotes the HV indicator of the region between \(f_{LCB}^{h} (x)\) and the Pareto set. In most circumstances, the \(I_{LCB}^{h} (x)\) is larger than the corresponding \(I_{LCB}^{l} (x)\) due to the discrepant uncertainty term so that there is a conflict between computational cost and HV improvement of the sample with different fidelity.
3.2 The proposed acquisition function
As illustrated in the following Fig. 4, the predicted HV improvement can be partitioned into two parts, one from the predicted mean and the other from the uncertainty region.

the predicted HV improvement of the predicted mean after adding new samples
The green region in Fig. 4 means the HV improvement of the predicted mean after adding a new sample (\(I_{LCB}^{\mu } (x)\)) and it is expressed as follows:
where \(\hat{f}_{i} (x)\) means the prediction mean of each objective. The blue and dark gray areas represent the HV improvement as the same as shown in Fig. 3, and they can be expressed as \(I_{LCB}^{l} (x)\) and \(I_{LCB}^{h} (x)\) calculated by Eqs. (16) and (17).
To balance the cost and improvement of a new sample with different fidelity, here a novel improvement function with different fidelity is introduced, which can be expressed as follows:
where \(t = 1\) and \(t = 2\) represent the improvement function with low fidelity and high fidelity, respectively, \(CR(t)\) is the cost coefficient that is formulated as follows:
where \(c \ge 1\), which is the ratio of cost between HF and LF simulations. With the cost coefficient applied, the HV improvement with LF sample is expanded proportionally by controlling the computational cost to the same level for different fidelities. Thus, the HV improvement with different fidelities can be reasonably compared and choose the most appropriate one. When the cost ratio \(c\) is larger than one, it is invidious to compare \(I_{LCB}^{l} (x)\) with corresponding \(I_{LCB}^{h} (x)\) after multiplying the cost coefficient \(CR(t)\) because the predicted mean with all fidelity levels has no discrepancy between each other in BF surrogate model. Hence, the effect of the cost coefficient on the HV improvement of the predicted mean should be eliminated.
As the cost coefficient \(CR(t)\) with HF level is equal to 1, the term where \(t = 2\) in Eq. (24) can be regarded as follows:
and the \(I(x,t)\) can be simplified as follows:
When the \(f_{LCB} ({\text{x}})\) locates in dominated region, all of terms in \(I(x,t)\) is equal to zero and it cannot estimate which fidelity level is more appropriate. On the other hand, the algorithm of optimizing the acquisition function, such as genetic algorithm (GA) (Jin 2011), adopts random sampling to obtain the initial population, whereas Pareto solutions usually only occupy a narrow region relative to the whole design space. Therefore, GA may not be able to acquire a solution located in the area of Pareto set during the searching process, which leads to the decline of search efficiency in optimization process. Figure 5 illustrates the situation that the LCB function locates in dominated region of Pareto frontier.

the LCB function located in dominated region
To address this issue, we refer to our previous work (Shu et al. 2020), a novel acquisition function is defined as follows:
where \(I(x,t)\) is Eq. (27), \(X_{i}\) (\(i = 1,2,...,q\)) denotes the current Pareto solution, \(\left\| {f_{LCB} (x) - f(X_{i} )} \right\|_{2}\) means the Euclidean distance between \(f_{LCB} (x)\) and the Pareto solution \(X_{i}\). The acquisition function makes an encouragement to help GA find the solution close to the Pareto frontier so that the optimization efficiency can be improved.
3.3 Procedure and termination condition
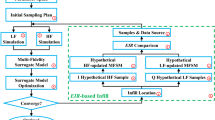
The proposed method, based on BF model and LCB function for multi-objective optimization (BF-MOLCB), follows a process as illustrated in Fig. 6. In the study, the Latin hypercube sampling (LHS) (Wang 2003) policy is applied to generate two initial sample sets for two fidelity levels. With the corresponding responses of initial samples evaluated, the current Pareto frontier can be obtained by the non-dominated sorting method (Deb et al. 2002).

the flowchart of the proposed method
The procedure of the BF-MOLCB is summarized in the flowchart as shown in Fig. 6, includes
-
Step 1 Generate two sample sets for LF and HF model by LHS.
-
Step 2 Evaluate the true responses of the corresponding samples.
-
Step 3 Construct the LF Kriging models for each objective utilizing the DACE toolbox (Lophaven et al. 2002).
-
Step 4 Construct the hierarchical Kriging model based on LF Kriging model and HF samples. The initial value of the hyperparameter \(\theta\) is set to be 1. The region of \(\theta\) is set to be \([10^{ - 6} ,10^{3} ]\).
-
Step 5 Obtain the current Pareto frontier by the non-dominated sorting method.
-
Step 6 Judge the termination criterion, if it is not satisfied, go to step 7. Otherwise, the method is stopped and output the solution.
-
Step 7 Maximize the proposed acquisition function to obtain a new sample, turn back to step 2.
A stop criterion is adopted to terminate the optimization process after the following two conditions are satisfied:
-
(1)
After the algorithm finds at least 20 solutions, thus, the Pareto set will provide enough choice to the decision maker; Or the computational expense gets the maximum budget, defined as 200 in this paper.
-
(2)
The discrepancy of the quality metrics in two adjacent iterations represents the variation of the current Pareto frontier. Hence, when the ratio of the difference and the current HV value is less than a specific value (e.g., 0.1% in this paper), the algorithm will be terminated, which is defined as follows:
$$HV_{T} = \frac{{HV_{i} - HV_{i - 1} }}{{HV_{i} }}$$(29)
where the \(HV_{i}\) means the HV value of the ith iteration (Shu et al. 2020).
4 Examples and results analysis
In this section, four numerical examples and an engineering design problem are adopted to test the efficiency and applicability of the proposed method. The formulations and true Pareto solutions of the four numerical examples (Shu et al. 2019) are summarized in Table 1. There are two single-fidelity BO methods (Sun et al. 2021; Zhan et al. 2017) only utilizing HF simulations and other two bi-fidelity BO methods (He et al. 2022) to compare with the proposed BF-MOLCB method: (1) Euclidean distance-based EIM method (EIMe), (2) Euclidean distance-based LCBM method (LCBMe), (3) Hypervolume-based VFEIM method (VFEIMh), and (4) VFEMHVI method.
4.1 Numerical examples
ZDT1, ZDT2, FON, and POL examples are solved by above methods and the results are compared in this part. The cost of the initial sample is set as 10*n (n is the dimension of design variable), where the cost of the bi-fidelity method is formulated by an equivalent calculation as follows:
where \(N_{l}\)/\(N_{h}\) denotes the number of LF/HF samples. For initial sampling, \(N_{l}\) and \(N_{h}\) are set as 5*n*CR and 5*n, respectively. The \(CR\) is the ratio of cost between LF and HF samples, which is set to be 4 in the following numerical test problems. To obtain the HV indicator, a reference point is set in each test function, as the shown in Table 2.
Firstly, a detailed comparison between these methods is demonstrated using the example ZDT1 (dimension \(n = 3\)). Each method is run 10 times, where the statistics of the HV indicator and computational expense (COST) are recorded. The comparison results of HV and COST using different methods are summarized in Table 3, including the mean, median value, and STDs of HV and COST from 10 runs. The best indicators are shown in bold in the Table. Figure 7 illustrates the box charts of the HV and COST obtained from different methods in ZDT1 problem.

the box chart of the HV and COST. a HV, b COST
As the HV indicators presented in Table 3, the LCBMe method, the VFEMHVI method, and proposed method have the most ideal Pareto frontier approximation quality according to the HV indicator. Meanwhile, the minimum mean and STD value of the COST demonstrate that the proposed method enables to have an ideal performance with lowest computational expense simultaneously, in which the COST means of the proposed method have 55.67%, 43.74%, 46.03%, and 28.13% decline over EIMe, LCBMe, VFEIMh, and VFEMHVI, respectively. Figure 7 illustrates the comparison over different methods intuitively. It can be seen that COST indicator of the proposed method has the most inconspicuous abnormal value in this box chart.
Table 4 presents the average computational expense required to obtain different number of Pareto solutions in ZDT1, further comparing the efficiency of finding Pareto solutions over these methods. As shown in Table 4, the proposed method always has the lowest value of the average computational expense. It is important to find enough Pareto solutions to provide adequate options for designers.
The quality of Pareto frontier is also a considerable metric in multi-objective optimization problems, which directly determines the information provided for designers. Hence, it is necessary to compare the quality of Pareto frontier from different methods. There are several figures illustrating the Pareto frontier with the lowest HV indicator over 10 runs, as shown in Fig. 8. In the ZDT1 problem, the most ideal Pareto frontier are still obtained by the VFEMHVI method and the proposed method, but the advantage is not evident enough, in which the difference of the HV means between the proposed method and VFEMHVI is lower than 0.01. Other methods also have nonnegligible competitiveness in this case.

Pareto frontier with the lowest HV indicator in 10 runs on ZDT1 problem
The comparisons of remaining examples are summarized in Tables 5 and 6. All these methods present satisfactory performance in obtaining the Pareto solutions on FON and ZDT2 problems with \(n = 3\) and the proposed method still has the lowest computational cost and ideal HV indicators. A very diverse phenomenon appears in POL problem. Even though the discrepancy of the cost among different methods is not significant enough, the cost of the proposed method is slightly higher than other single-fidelity methods and VFEIMh method. However, the proposed method has the highest HV indicator, which means it enables to obtain a Pareto set with better quality than other methods. Similar to Fig. 8, Fig. 9 illustrates the Pareto frontier with the lowest HV indicator in 10 runs on POL problem. It can be seen that the Pareto solutions obtained by the proposed method uniformly distribute on the true Pareto frontier, which is obviously better than VFEIMh and other single-fidelity methods. The VFEMHVI method has the same situation but its expense is 3.43% higher than the proposed method.

Pareto frontier with the lowest HV indicator in the 10 runs on POL problem

Parameterization of the torque arm (Shu et al. 2020)
Additionally, there are several high-dimension test problems (ZDT2 problem with dimension \(n = 68{,}\,10\)) for measuring the ability to solve the optimization problems under more complex cases. The proposed method reveals a prominent performance in these problems, as shown in Table 6. The “/” symbol denotes that the termination criterion cannot be satisfied when the computational expense reaches the maximum budget 200. For these high-dimension problems, the proposed method always has the lowest computational expense and ideal quality of Pareto frontiers. In the ZDT2 problem with \(n = 6\), single-fidelity methods sometimes fail to obtain 20 Pareto solutions before the maximum budget reached. The performance of the VFEMHVI and the proposed BF-MOLCB method has notable improvement, in which the COST means of the proposed method have 52.89%, 62.87%, 60.24%, and 34.70% decline over EIMe, LCBMe, VFEIMh, and VFEMHVI, respectively. The VFEMHVI method can obtain the largest HV indicator. The proposed method can also obtain an ideal Pareto frontier (difference of HV between the VFEMHVI and the proposed method is less than 0.01% of the whole HV), meanwhile the computational expense of the proposed method is much lower than the VFEMHVI. In the test problem with \(n = 8,10\), all single-fidelity methods cannot meet the termination criterion until the maximum budget 200 reached. The cost of the VFEIMh and VFEMHVI method is also unsatisfactory. Especially in ZDT2 with \(n = 10\), only the proposed method can still obtain a satisfactory Pareto frontier with controllable computational expense.
Comparing these test problems in terms of the dimensions, low-dimension problems (\(n = 2,3\)) have a smaller difference in the computational cost between these methods, whereas the corresponding discrepancy in high-dimension problems is much more noteworthy. Therefore, the bi-fidelity surrogate models have better performance than single-fidelity models in approximating the complex problems, which confirms the research significance of utilizing bi-fidelity models in BO to solve the multi-objective optimization problems.
4.2 Engineering case
In this section, two engineering examples, torque arm and honeycomb structure vibration isolator design optimization, are adopted to verify the performance of the proposed method. The torque arm is fixed at the left end. The load on the torque arm, \(P_{1} = 8.0kN\) and \(P_{2} = 4.0kN\), is exerted at the right end (Fig. 10).
Six design variables are applied for the torque in this example, including \(\alpha ,b_{1} ,D_{1} ,h,t_{1} ,t_{2}\), and \(t_{2}\). The optimization problem is expressed as follows:
where \(V\) is the total volume, \(\max \_d\) is the maximum displacement of the torque arm, and the Young’s modulus is 200 GPa and Poisson’s ratio is 0.3. In this example, the reference point is [1000;10] and the cost ratio between high- and low-fidelity samples is 4.
Each method is run 10 times, where the average of the HV indicator and computational expense is recorded, as the shown in Table 7. All of these methods can meet the termination condition; thereinto, the proposed method has the best performance in the quality of Pareto solutions due to the highest HV indicator. However, the cost of the proposed method is higher than other methods. The reason why this phenomenon appears is that the non-dominated solutions obtained by the single-fidelity methods and the VFEIMh method early on have satisfied the termination criterion, which leads the method cannot obtain an ideal Pareto set. There are some figures in Fig. 11 used to show the Pareto frontier with the lowest HV indicator in 10 runs on this torque arm problem. Obviously, the Pareto solutions obtained from proposed method distribute uniformly on the true Pareto frontier, distinctly better than other single-fidelity methods and VFEIMh.

Pareto frontier with the lowest HV indicator in 10 runs on the torque arm problem
To compare the proposed method with other methods more fairly, the same budget is adopted to compare the quality of the Pareto solution set, which is set 100 in this study. Each method works 10 times repeatedly, terminated when the cost of optimization process reaches 100, and summarizes the median, mean, and std value of the HV indicator. The results are shown in Table 8. It can be seen that the median and mean value of the HV indicator obtained by the proposed method are still better than other methods; meanwhile, the least std value reveals the stability of the proposed method. Even the HV indicators obtained by the single-fidelity methods and the VFEIMh method after 100 iterations are still less than the corresponding value when the proposed method has obtained 20 Pareto solutions (5488.2470 on average), whereas the proposed method only costs 35.93 on average to obtain 20 Pareto solutions in optimization process. The VFEMHVI method also has a good performance, which has slight discrepancy with the proposed method.
Figure 12 intuitionally presents the Pareto frontier of the lowest HV indicator with the same budget. The Pareto frontiers obtained by the single-fidelity methods are much better than before but still distributed unevenly. The diversity of the Pareto solutions is also worser than the proposed method obtained, in which a fixed area many non-dominated solutions intensively distributed. Compared with other two bi-fidelity method, the proposed method still has the best performance in the torque arm optimization problem.

Pareto frontier of the lowest HV indicator with the same budget
In the vibration isolator optimization problem, six design variables are applied, including \(\theta ,D,R_{f} ,L,t_{h}\), and \(t_{l}\) as shown in Fig. 13. The ratio of the natural frequency \(e\) and the Equivalent strain \(\varepsilon_{\max }\) are set as the goal of the multi-objective optimization problem to minimize. The nonlinear coefficient \(\xi\), the transverse-longitudinal stiffness ratio \(R_{k}\), the total height \(H\), and the dimensional coordination conditions \(T_{s}\) are set as the constraints, in which \(\xi\) and \(R_{k}\) should be evaluated by computationally expensive simulations while the \(H\) and \(T_{s}\) can be obtained by mathematical formulas. The optimization problem is expressed as follows:
where the parameters are shown in Tables 9, 10, and 11.

The vibration isolator and the geometry of a honeycomb cell (Qian et al. 2021)
The vibration isolator test problem is modeled and simulated using ANSYS 18.2, in which high- and low-fidelity levels are set via adjusting the dimension of the mesh division. The number of mesh division of the high-fidelity analysis model in the direction of inclined beam thickness \(t_{l}\) is set as 6, and the corresponding number in the low-fidelity analysis model is set as 2, as shown in Fig. 14. The cost coefficient is set as 3. The penalty function is used to handle the constraints which are obtained by mathematical formulas. For constraints which need time-consuming simulations to obtain, this paper addresses them based on the method proposed by Schonlau (1998), which was extended to solve multi-fidelity optimization problems in our previous work (Shu et al. 2021). The reference point is set as [10;0.2].

The mesh division for high- and low-fidelity finite element. a Fine mesh. b Coarse mesh (Qian et al. 2021)
Each method is run 10 times, where the average of the HV indicator and computational expense is recorded, as the shown in Table 12. All of these methods can meet the termination condition; thereinto, the proposed method has the best performance in the quality of Pareto solutions due to the highest HV indicator. With regard to the computational expense, there is only a small variation between these methods, in which the EIMe has the lowest cost and the VFEMHVI is the highest one. Other three methods are almost the same level. However, the proposed method has notable advantage in term of the HV indicator, especially comparing with the EIMe, the LCBMe, and the VFEIMh method. Figure 15 illustrates the Pareto frontier with the lowest HV indicator in 10 runs. It can be seen that the Pareto frontier obtained from proposed method is better than other methods obtained.

Pareto frontier with the lowest HV indicator in 10 runs on the engineering problem
5 Conclusion
A bi-fidelity Bayesian optimization method for multi-objective optimization is proposed. In the proposed method, the LCB functions are adopted to utilize the uncertainty of surrogate model. On this basis, a novel acquisition function is defined, in which a cost coefficient balances the computational expense and accuracy of new sample points with different fidelity levels. Then, the new sample can be determined by maximizing the proposed acquisition function.
Four numerical test problems with different dimensions and two real-world engineering design optimization problems are applied to investigate the feasibility and efficiency of the proposed method. Some conclusions are drawn as follows:
-
1)
The effect of samples with different fidelities for improving the quality of the current Pareto set is quantified in the proposed method;
-
2)
The proposed method balances the cost and effect of samples with different fidelities, which can utilize the LF samples to potentially further reduce the computational expense;
-
3)
Compared with other two state-of-the-art single-fidelity methods and two bi-fidelity methods, the proposed method shows prominent performance in computational cost and improving of Pareto solutions, especially for solving high-dimension problems.
In the future, several potential directions are worth exploring. First, the acquisition function of choosing new samples from multiple fidelities (> 2) still remains to be researched and tested. Second, combined with the research from Foumani et al. (2022), other acquisition functions like EI and PI can be utilized in multi-objective optimization with multi-fidelity model. Last but not the least, the proposed method can be extended to solve multi-objective robust optimization problems.
Abbreviations
- \(CR\) :
-
Cost ratio of samples with different fidelity
- \(F(x)\) :
-
Objective of multi-objective optimization
- \(f_{l} (x)\) :
-
Predicted mean of low-fidelity surrogate model
- \(f_{i}^{j}\) :
-
jTh Pareto solution of the ith objective
- \(f_{LCB} (x)\) :
-
LCB function at sample x
- \(f_{LCB}^{l} (x)\) :
-
Low-fidelity LCB function at sample x
- \(f_{LCB}^{h} (x)\) :
-
High-fidelity LCB function at sample x
- \(g_{j} (x)\) :
-
jTh Constrain of multi-objective optimization
- \(H(p)\) :
-
Hypervolume indicator
- \(I(x)\) :
-
Improvement function at sample x
- \(I_{LCB} (x)\) :
-
Improvement of LCB function at sample x beyond current Pareto set
- \(I_{LCB}^{l} (x)\) :
-
Improvement of low-fidelity LCB at sample x beyond current Pareto set
- \(I_{LCB}^{h} (x)\) :
-
Improvement of high-fidelity LCB at sample x beyond current Pareto set
- \(I(x,t)\) :
-
The novel improvement function with different fidelity
- \(N_{l}\) :
-
Quantity of the low-fidelity samples
- \(N_{h}\) :
-
Quantity of the high-fidelity samples
- \({\text{R}}\) :
-
Covariance matrix of the hierarchical Kriging model
- \({\text{R}}_{l}\) :
-
Covariance matrix of the low-fidelity Kriging model
- \(s_{l}^{2} (x)\) :
-
Mean-squared error of the low-fidelity Kriging model at unobserved points
- \(t\) :
-
Fidelity level
- \(X_{j}\) :
-
jTh Pareto solution
- \(Z( \cdot ),Z_{l} ( \cdot )\) :
-
Gaussian random process
- \(\beta_{0,l} {,}\,\beta_{0}\) :
-
Scaling factor of trend model
- \({\text{r}}\) :
-
Correlation vector of the hierarchical Kriging model
- \({\text{r}}_{l}\) :
-
Correlation vector of the low-fidelity Kriging model
- \(\theta\) :
-
“Roughness” parameter
- \(\sigma^{2}\) :
-
Process variance
- \(LCB\) :
-
Function associated with LCB
- \(l\) :
-
Low-fidelity value
- \(h\) :
-
High-fidelity value
- \(lb\) :
-
Lower bound of the value
- \(ub\) :
-
Upper bound of the value
- \(h\) :
-
High-fidelity value
- \(l\) :
-
Low-fidelity value
- \(\mu\) :
-
Value associated with predicted mean
References
Chen S, Jiang Z, Yang S, Chen W (2016) Multimodel fusion based sequential optimization. AIAA J 55(1):241–254
Choi S, Alonso JJ, Kroo IM (2009) Two-level multifidelity design optimization studies for supersonic jets. J Aircr 46(3):776–790
Deb K, Pratap A, Agarwal S, Meyarivan T (2002) A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans Evol Comput 6(2):182–197
Emmerich MTM, Deutz AH, Klinkenberg JW (2011) Hypervolume-based expected improvement: Monotonicity properties and exact computation. Paper presented at the 2011 IEEE congress of evolutionary computation (CEC)
Eweis-Labolle JT, Oune N, Bostanabad R (2022) Data fusion with latent map gaussian processes. J Mech Des 144(9):091703
Han ZH, Görtz S (2012) Hierarchical kriging model for variable-fidelity surrogate modeling. AIAA J 50:1885–1896
He Y, Sun J, Song P, Wang X (2022) Variable-fidelity hypervolume-based expected improvement criteria for multi-objective efficient global optimization of expensive functions. Eng Comput 38(4):3663–3689
Jeong S, Obayashi S (2005) Efficient global optimization (EGO) for multi-objective problem and data mining. Paper presented at the 2005 IEEE congress on evolutionary computation
Jerome S, William JW, Toby JM, Henry PW (1989) Design and analysis of computer experiments. Stat Sci 4(4):409–423
Jiang P, Cheng J, Zhou Q, Shu L, Hu J (2019) Variable-fidelity lower confidence bounding approach for engineering optimization problems with expensive simulations. AIAA J 57(12):5416–5430
Jin Y (2011) Surrogate-assisted evolutionary computation: recent advances and future challenges. Swarm Evol Comput 1(2):61–70
Jones DR (2001) A taxonomy of global optimization methods based on response surfaces. J Global Optim 21(4):345–383
Jones DR, Schonlau M, Welch WJ (1998) Efficient global optimization of expensive black-box functions. J Global Optim 13(4):455–492
Keane AJ (2006) Statistical improvement criteria for use in multiobjective design optimization. AIAA J 44(4):879–891
Kennedy MC, O’Hagan A (2000) Predicting the output from a complex computer code when fast approximations are available. Biometrika 87(1):1–13
Knowles J (2006) ParEGO: a hybrid algorithm with on-line landscape approximation for expensive multiobjective optimization problems. IEEE Trans Evol Comput 10(1):50–66
Leifsson L, Koziel S, Tesfahunegn YA (2015) Multiobjective aerodynamic optimization by variable-fidelity models and response surface surrogates. AIAA J 54(2):531–541
Li X, Qiu H, Jiang Z, Gao L, Shao X (2017) A VF-SLP framework using least squares hybrid scaling for RBDO. Struct Multidiscip Optim 55(5):1629–1640
Liu H, Ong YS, Cai J, Wang Y (2018) Cope with diverse data structures in multi-fidelity modeling: a Gaussian process method. Eng Appl Artif Intell 67:211–225
Lophaven SN, Nielsen HB, Søndergaard J (2002) DACE: a Matlab kriging toolbox (Vol. 2): Citeseer
Perdikaris P, Venturi D, Royset JO, Karniadakis GE (2015) Multi-fidelity modelling via recursive co-kriging and Gaussian–Markov random fields. Proc R Soc a: Math, Phys Eng Sci 471:20150018
Qian J, Cheng Y, Zhang A, Zhou Q, Zhang J (2021) Optimization design of metamaterial vibration isolator with honeycomb structure based on multi-fidelity surrogate model. Struct Multidiscip Optim 64(1):423–439
Ruan X, Jiang P, Zhou Q, Hu J, Shu L (2020) Variable-fidelity probability of improvement method for efficient global optimization of expensive black-box problems. Struct Multidiscip Optim 62(6):3021–3052
Schonlau M, Welch W, Jones D (1998) Global versus local search in constrained optimization of computer models. Inst Math Stat Lect Notes Monograph Ser 34:11–25
Shahriari B, Swersky K, Wang Z, Adams RP, Freitas Nd (2016) Taking the human out of the loop: a review of bayesian optimization. Proc IEEE 104(1):148–175
Shi M, Lv L, Sun W, Song X (2020) A multi-fidelity surrogate model based on support vector regression. Struct Multidiscip Optim 61(6):2363–2375
Shu L, Jiang P, Zhou Q, Xie T (2019) An online variable-fidelity optimization approach for multi-objective design optimization. Struct Multidiscip Optim 60(3):1059–1077
Shu L, Jiang P, Shao X, Wang Y (2020) A new multi-objective bayesian optimization formulation with the acquisition function for convergence and diversity. J Mech Design. https://doi.org/10.1115/14046508
Shu L, Jiang P, Wang Y (2021) A multi-fidelity Bayesian optimization approach based on the expected further improvement. Struct Multidiscip Optim 63(4):1709–1719
Singh P, Couckuyt I, Elsayed K, Deschrijver D, Dhaene T (2017) Multi-objective geometry optimization of a gas cyclone using triple-fidelity co-kriging surrogate models. J Optim Theory Appl 175(1):172–193
Sóbester A, Leary SJ, Keane AJ (2005) On the design of optimization strategies based on global response surface approximation models. J Global Optim 33(1):31–59
Srinivas N, Krause A, Kakade SM, Seeger MW (2012) Information-theoretic regret bounds for Gaussian process optimization in the bandit setting. IEEE Trans Inf Theory 58(5):3250–3265
Sun G, Li L, Fang J, Li Q (2021) On lower confidence bound improvement matrix-based approaches for multiobjective Bayesian optimization and its applications to thin-walled structures. Thin Walled Struct 161:107248
Svenson J, Santner T (2016) Multiobjective optimization of expensive-to-evaluate deterministic computer simulator models. Comput Stat Data Anal 94:250–264
Tran A, Tran M, Wang Y (2019) Constrained mixed-integer Gaussian mixture Bayesian optimization and its applications in designing fractal and auxetic metamaterials. Struct Multidiscip Optim 59(6):2131–2154
Wang GG (2003) Adaptive response surface method using inherited Latin hypercube design points. J Mech Des 125(2):210–220
Williams B, Cremaschi S (2021) Selection of surrogate modeling techniques for surface approximation and surrogate-based optimization. Chem Eng Res Des 170:76–89
Williams CK, Rasmussen CE (2006) Gaussian processes for machine learning. MIT press Cambridge, MA
Yang K, Emmerich M, Deutz A, Bäck T (2019) Multi-objective Bayesian global optimization using expected hypervolume improvement gradient. Swarm Evol Comput 44:945–956
Zanjani Foumani Z, Shishehbor M, Yousefpour A, Bostanabad R (2022). Multi-Fidelity Cost-Aware Bayesian Optimization. arXiv:2211.02732
Zhan D, Cheng Y, Liu J (2017) Expected improvement matrix-based infill criteria for expensive multiobjective optimization. IEEE Trans Evol Comput 21(6):956–975
Zhan D, Meng Y, Xing H (2022) A fast multi-point expected improvement for parallel expensive optimization. IEEE Trans Evol Comput. https://doi.org/10.1109/TEVC.2022.3232776
Zhang Y, Han ZH, Zhang KS (2018) Variable-fidelity expected improvement method for efficient global optimization of expensive functions. Struct Multidiscip Optim 58(4):1431–1451
Zhang Y, Kim NH, Park C, Haftka RT (2018) Multifidelity surrogate based on single linear regression. AIAA J 56(12):4944–4952
Zheng J, Li Z, Gao L, Jiang G (2016) A parameterized lower confidence bounding scheme for adaptive metamodel-based design optimization. Eng Comput 33(7):2165–2184
Zhou Q, Jiang P, Shao X, Hu J, Cao L, Wan L (2017) A variable fidelity information fusion method based on radial basis function. Adv Eng Inform 32:26–39
Funding
This research has been supported by the National Natural Science Foundation of China (NSFC) under Grant No. 52105256 and No. 52188102.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Replication of results
The main step of the proposed method is introduced in Sect. 3. The Matlab codes can be available from the website: https://pan.baidu.com/s/1B0vf4QaWByIoNUvoa9vFUA by using the password: 0ubx.
Additional information
Responsible Editor: Ramin Bostanabad.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Xu, K., Shu, L., Zhong, L. et al. A bi-fidelity Bayesian optimization method for multi-objective optimization with a novel acquisition function. Struct Multidisc Optim 66, 53 (2023). https://doi.org/10.1007/s00158-023-03509-9
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00158-023-03509-9