
Abstract
Given a sequence of integers, we want to find a longest increasing subsequence of the sequence. It is known that this problem can be solved in \(O\left (n \log n\right )\) time and space. Our goal in this paper is to reduce the space consumption while keeping the time complexity small. For \(\sqrt {n} \le s \le n\), we present algorithms that use \(O\left (s \log n\right )\) bits and \(O\left (\frac {1}{s} \cdot n^{2} \cdot \log n\right )\) time for computing the length of a longest increasing subsequence, and \(O\left (\frac {1}{s} \cdot n^{2} \cdot \log ^{2} n\right )\) time for finding an actual subsequence. We also show that the time complexity of our algorithms is optimal up to polylogarithmic factors in the framework of sequential access algorithms with the prescribed amount of space.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Given a sequence of integers (possibly with repetitions), the problem of finding a longest increasing subsequence (LIS, for short) is a classic problem in computer science which has many application areas including bioinfomatics and physics (see [38] and the references therein). It is known that LIS admits an O(n log n)-time algorithm that uses O(n log n) bits of working space [2, 17, 37], where n is the length of the sequence.
A wide-spread algorithm achieving these bounds is Patience Sorting, devised by Mallows [24,25,26]. Given a sequence of length n, Patience Sorting partitions the elements of the sequence into so-called piles. It can be shown that the number of piles coincides with the length of a longest increasing subsequence (see Section 3 for details). Combinatorial and statistical properties of the piles in Patience Sorting are well studied (see [2, 8, 33]).
However, with the dramatic increase of the typical data sizes in applications over the last decade, a main memory consumption in the order of Θ(n log n) bits is excessive in many algorithmic contexts, especially for basic subroutines such as LIS. We therefore investigate the existence of space-efficient algorithms for LIS.
Our Results
In this paper, we present the first space-efficient algorithms for LIS that are exact. We start by observing that when the input is restricted to permutations, an algorithm using O(n) bits can be obtained straightforwardly by modifying a previously known algorithm (see Section 3.3). Next, we observe that a Savitch type algorithm [36] for this problem uses O (log2n) bits and thus runs in quasipolynomial time. However, we are mainly interested in space-efficient algorithms that also behave well with regard to running time. To this end we develop an algorithm that determines the length of a longest increasing subsequence using \(O\left (\sqrt {n} \log n\right )\) bits which runs in O (n1.5 log n) time. Since the constants hidden in the O-notation are negligible, the algorithm, when executed in the main memory of a standard computer, may handle a peta-byte input on external storage.
More versatile, in fact, our space-efficient algorithm is memory-adjustable in the following sense. (See [3] for information on memory-adjustable algorithms). When a memory bound s with \(\sqrt {n} \le s \le n\) is given to the algorithm, it computes with O (s log n) bits of working space in \(O\left (\frac {1}{s} \cdot n^{2} \log n\right )\) time the length of a longest increasing subsequence. When s = n our algorithm is equivalent to the previously known algorithms mentioned above. When \(s = \sqrt {n}\) it uses, as claimed above, \(O\left (\sqrt {n} \log n\right )\) bits and runs in O (n1.5 log n) time.
The algorithm only determines the length of a longest increasing subsequence. To actually find such a longest increasing subsequence, one can run the length-determining algorithm n times to successively construct the sought-after subsequence. This would give us a running time of \(O\left (\frac {1}{s}\cdot n^{3} \log n\right )\). However, we show that one can do much better, achieving a running time of \(O\left (\frac {1}{s} \cdot n^{2} \log ^{2} n\right )\) without any increase in space complexity, by recursively finding a near-mid element of a longest increasing subsequence.
To design the algorithms, we study the structure of the piles arising in Patience Sorting in depth and show that maintaining certain information regarding the piles suffices to simulate the algorithm. Roughly speaking, our algorithm divides the execution of Patience Sorting into O(n/s) phases, and in each phase it computes in O (n log n) time information on the next O(s) piles, while forgetting previous information.
Finally, we complement our algorithm with a lower bound in a restricted computational model. In the sequential access model, an algorithm can access the input only sequentially. We also consider further restricted algorithms in the multi-pass model, where an algorithm has to read the input sequentially from left to right and can repeat this multiple (not necessarily a constant number of) times. Our algorithm for the length works within the multi-pass model, while the one for finding a subsequence is a sequential access algorithm. Such algorithms are useful when large data is placed in an external storage that supports efficient sequential access. We show that the time complexity of our algorithms is optimal up to polylogarithmic factors in these models.
Related Work
The problem of finding a longest increasing subsequence (LIS) is among the most basic algorithmic problems on integer arrays and has been studied continuously since the early 1960’s. It is known that LIS can be solved in O(n log n) time and space [2, 17, 37], and that any comparison-based algorithm needs Ω(n log n) comparisons even for computing the length of a longest increasing subsequence [17, 32]. For the special case of LIS where the input is restricted to permutations, there are O(n loglog n)-time algorithms [6, 12, 20]. Patience Sorting, an efficient algorithm for LIS, has been a research topic in itself, especially in the context of Young tableaux [2, 8, 24,25,26, 33].
Recently, LIS has been studied intensively in the data-streaming model, where the input can be read only once (or a constant number of times) sequentially from left to right. This line of research was initiated by Liben-Nowell, Vee, and Zhu [22], who presented an exact one-pass algorithm and a lower bound for such algorithms. Their results were then improved and extended by many other groups [15, 18, 19, 28, 34, 35, 38]. These results give a deep understanding on streaming algorithms with a constant number of passes even under the settings with randomization and approximation. (For details on these models, see the recent paper by Saks and Seshadhri [35] and the references therein). On the other hand, multi-pass algorithms with a non-constant number of passes have not been studied for LIS.
While space-limited algorithms on both RAM and multi-pass models for basic problems have been studied since the early stage of algorithm theory, research in this field has recently intensified. Besides LIS, other frequently studied problems include sorting and selection [7, 16, 27, 30], graph searching [4, 9, 14, 31], geometric computation [1, 5, 10, 13], and k-SUM [23, 39].
2 Preliminaries
Let τ = 〈τ(1),τ(2),…,τ(n)〉 be a sequence of n integers, possibly with repetitions. For 1 ≤ i1 < … < iℓ ≤ n, we denote by τ[i1,…,iℓ] the subsequence 〈τ(i1),…,τ(iℓ)〉 of τ. A subsequence τ[i1,…,iℓ] is an increasing subsequence of τ if τ(i1) < … < τ(iℓ). If τ(i1) ≤… ≤ τ(iℓ), then the sequence τ is non-decreasing. We analogously define decreasing subsequences and non-increasing subsequences. By lis(τ), we denote the length of a longest increasing subsequence of τ.
For example, consider a sequence τ1 = 〈2,8,4,9,5,1,7,6,3〉. It has an increasing subsequence τ1[1,3,5,8] = 〈2,4,5,6〉. Since there is no increasing subsequence of τ1 with length 5 or more, we have lis(τ1) = 4.
In the computational model in this paper, we use the RAM model with the following restrictions that are standard in the context of sublinear space algorithms. The input is in a read-only memory and the output must be produced on a write-only memory. We can use an additional memory that is readable and writable. Our goal is to minimize the size of the additional memory while keeping the running time fast. We measure space consumption in the number of bits used (instead of words) within the additional memory.
3 Patience Sorting
Since our algorithms are based on the classic Patience Sorting, we start by describing it in detail and recalling some important properties regarding its internal configurations.
Internally, the algorithm maintains a collection of piles. A pile is a stack of integers. It is equipped with the procedures push and top: the push procedure appends a new element to become the new top of the pile; and the top procedure simply returns the element on top of the pile, which is always the one that was added last.
We describe how Patience Sorting computes lis(τ). See Algorithm 1. The algorithm scans the input τ from left to right (Line 2). It tries to push each newly read element τ(i) to a pile with a top element larger than or equal to τ(i). If on the one hand there is no such a pile, Patience Sorting creates a new pile to which it pushes τ(i) (Line 4). On the other hand, if at least one such pile exists, Patience Sorting pushes τ(i) to the oldest pile that satisfies the property (Line 6). After the scan, the number of piles is the output, which happens to be equal to lis(τ) (Line 8).

We return to the sequence τ1 = 〈2, 8, 4, 9, 5, 1, 7, 6, 3〉 for an example. The following illustration shows the execution of Algorithm 1 on τ1. In each step the bold number is the newly added element. The underlined elements in the final piles form a longest increasing subsequence τ1[1, 3, 5, 8] = 〈2, 4, 5, 6〉, which can be extracted as described below.
Proposition 3.1 ([2, 17, 37])
Given a sequenceτof lengthn,Patience Sortingcomputeslis(τ) inO(n log n) time usingO(n log n) bits of working space.
3.1 Correctness of Patience Sorting
It is observed in [8] that when the input is a permutation π, the elements of each pile form a decreasing subsequence of π. This observation easily generalizes as follows.
Observation 3.2
Given a sequence τ, the elements of each pile constructed by Patience Sorting form a non-increasing subsequence of τ.
Hence, any increasing subsequence of τ can contain at most one element in each pile. This implies that lis(τ) ≤ ℓ.
Now we show that lis(τ) ≥ ℓ. Using the piles, we can obtain an increasing subsequence of length ℓ, in reversed order, as follows [2]:
- 1.
Pick an arbitrary element of Pℓ;
- 2.
For 1 ≤ i < ℓ, let τ(h) be the element picked from Pi+ 1. Pick the element τ(h′) that was the top element of Pi when τ(h) was pushed to Pi+ 1.
Since h′ < h and τ(h′) < τ(h) in each iteration, the ℓ elements that are selected form an increasing subsequence of τ. This completes the correctness proof for Patience Sorting.
The proof above can be generalized to show the following characterization for the piles.
Proposition 3.3 ([8])
τ(i) ∈ Pjif and only if a longest increasing subsequence ofτending atτ(i) has lengthj.
3.2 Time and Space Complexity of Patience Sorting
Observe that at any point in time, the top elements of the piles are ordered increasingly from left to right. Namely, \(\texttt {top}(P_{k}) < \texttt {top}(P_{k^{\prime }})\) if k < k′. This is observed in [8] for inputs with no repeated elements. We can see that the statement holds also for inputs with repetitions.
Observation 3.4
At any point in time during the execution of Patience Sorting and for any k and k′ with 1 ≤ k < k′≤ ℓ, we have \(\texttt {top}(P_{k}) < \texttt {top}(P_{k^{\prime }})\) if Pk and \(P_{k^{\prime }}\) are nonempty.
Proof
We prove the statement by contradiction. Let i be the first index for which Patience Sorting pushes τ(i) to some pile Pj, so that the statement of the observation becomes false.
First assume that \(\texttt {top}(P_{j}) \ge \texttt {top}(P_{j^{\prime }})\) for some j′ > j. Let τ(i′) be the element in Pj pushed to the pile right before τ(i). By the definition of Patience Sorting, it holds that
This contradicts the minimality of i because τ(i′) was the top element of Pj before τ(i) was pushed to Pj.
Next assume that \(\texttt {top}(P_{j^{\prime }}) \ge \texttt {top}(P_{j})\) for some j′ < j. This case contradicts the definition of Patience Sorting since \(\tau (i) = \texttt {top}(P_{j}) \le \texttt {top}(P_{j^{\prime }})\) and thus τ(i) actually has to be pushed to a pile with an index smaller or equal to j′. □
The observation above implies that Line 6 of Algorithm 1 can be executed in O(log n) time by using binary search. Hence, Patience Sorting runs in O(n log n) time.
The total number of elements in the piles is O(n). By storing its position in the sequence, each element in the piles can be represented with O(log n) bits (instead of O(log |Σ|) bits, where Σ is the alphabet from which the input elements are taken). Thus Patience Sorting consumes O(n log n) bits in total. If it maintains all elements in the piles, it can compute an actual longest increasing subsequence in the same time and space complexity as described above. Note that to compute lis(τ), it suffices to remember the top elements of the piles. However, the algorithm still uses Ω(n log n) bits when lis(τ) ∈Ω(n).
3.3 A Simple O(n)-bits Algorithm for Permutations
Here we observe that, when the input is a permutation π of {1,…,n}, lis(π) can be computed in O(n2) time with O(n) bits of working space. The algorithm maintains a used/unused flag for each element of {1,…,n} assuming that each element appears exactly once in the sequence. Hence, this algorithm cannot be applied to general inputs where repetitions may happen and the alphabet size |Σ| can be much larger than the input length n.
Let τ be a sequence of integers without repetitions. A subsequence τ[i1,…,iℓ] is the left-to-right minima subsequence if {i1,…,iℓ} = {i : τ(i) = min{τ(j) : 1 ≤ j ≤ i}}. In other words, the left-to-right minima subsequence is made by scanning τ from left to right and greedily picking elements to construct a maximal decreasing subsequence.
Burstein and Lankham [8, Lemma 2.9] showed that the first pile P1 is the left-to-right minima subsequence of π and that the i th pile Pi is the left-to-right minima subsequence of a sequence obtained from π by removing all elements in the previous piles P1,…,Pi− 1.
Algorithm 2 below uses this characterization of piles. The correctness follows directly from the characterization. It uses a constant number of pointers of O(log n) bits and a Boolean table of length n for maintaining “used” and “unused” flags. Thus it uses n + O(log n) bits working space in total. The running time is O(n2): each for-loop takes O(n) time and the loop is repeated at most n times.

4 An Algorithm for Computing the Length
In this section, we present our main algorithm that computes lis(τ) with O(s log n) bits in \(O\left (\frac {1}{s} \cdot n^{2} \log n\right )\) time for \(\sqrt {n} \le s \le n\). Note that the algorithm here outputs the length lis(τ) only. The next section discusses efficient solutions to actually compute a longest sequence.
In the following, by Pi for some i we mean the i th pile obtained by (completely) executing Patience Sorting unless otherwise stated. (We sometimes refer to a pile at some specific point of the execution). Also, by Pi(j) for 1 ≤ j ≤|Pi| we denote the j th element added to Pi. That is, Pi(1) is the first element added to Pi and Pi(|Pi|) is the top element of Pi.
To avoid mixing up repeated elements, we assume that each element τ(j) of the piles is stored with its index j. In the following, we mean by “τ(j) is in Pi” that the j th element of τ is pushed to Pi. Also, by “τ(j) is Pi(r)” we mean that the j th element of τ is the r th element of Pi.
We start with an overview of our algorithm. It scans over the input O(n/s) times. In each pass, it assumes that a pile Pi with at most s elements is given, which has been computed in the previous pass. Using this pile Pi, it filters out the elements in the previous piles P1,…,Pi− 1. It then basically simulates Patience Sorting but only in order to compute the next 2s piles. As a result of the pass, it computes a new pile Pj with at most s elements such that j ≥ i + s.
The following observation, that follows directly from the definition of Patience Sorting and Observation 3.4, will be useful for the purpose of filtering out elements in irrelevant piles.
Observation 4.1
Let τ(y) ∈ Pj with j≠i. If τ(x) was the top element of Pi when τ(y) was pushed to Pj, then j < i if τ(y) < τ(x), and j > i if τ(y) > τ(x).
Using Observation 4.1, we can obtain the following algorithmic lemma that plays an important role in the main algorithm.
Lemma 4.2
Having storedPiexplicitly in the additional memory and given an indexj > i, the size |Pk| for alli + 1 ≤ k ≤ min{j,lis(τ)} can be computed inO(n log n) time withO((|Pi| + j − i)log n) bits. Iflis(τ) < j, then we can computelis(τ) in the same time and space complexity.
Proof
Recall that Patience Sorting scans the sequence τ from left to right and puts each element to the appropraiate pile. We process the input in the same way except that we filter out, and thereby ignore, the elements in the piles Ph for which h < i or h > j.
To this end, we use the following two filters whose correctness follows from Observation 4.1.
(FilteringPhwithh < i). To filter out the elements that lie in Ph for some h < i, we maintain an index r that points to the element of Pi read most recently in the scan. Since Pi is given explicitly to the algorithm, we can maintain such a pointer r.
When we read a new element τ(x), we have three cases.
If τ(x) is Pi(r + 1), then we increment the index r.
Else if τ(x) < Pi(r), then τ(x) is ignored since it is in Ph for some h < i.
Otherwise we have τ(x) > Pi(r). In this case τ(x) is in Ph for some h > i.
(FilteringPhwithh > j). The elements in Ph for h > j can be filtered without maintaining additional information as follows. Let again τ(x) be the newly read element.
If no part of Pj has been constructed yet, then τ(x) is in Ph for some h ≤ j.
Otherwise, we compare τ(x) and the element τ(y) currently on the top of Pj.
If τ(x) > τ(y), then τ(x) is in Ph for some h > j, and thus ignored.
Otherwise τ(x) is in Ph for some h ≤ j.
We simulate Patience Sorting only for the elements that pass both filters above. While doing so, we only maintain the top elements of the piles and additionally store the size of each pile. This requires at most O((j − i)log n) space, as required by the statement of the lemma. For details see Algorithm 3.
The running time remains the same since we only need constant number of additional steps for each step in Patience Sorting to filter out irrelevant elements. If Pj is still empty after this process, we can conclude that lis(τ) is the index of the newest pile constructed. □
The proof of Lemma 4.2 can be easily adapted to also compute the pile Pj explicitly. For this, we simply additionally store all elements of Pj as they are added to the pile.
Lemma 4.3
GivenPiand an indexj such thati < j ≤ lis(τ), we can computePjinO(n log n) time withO((|Pi| + |Pj| + j − i)log n) bits.
Assembling the lemmas of this section, we now present our first main result. The corresponding pseudocode of the algorithm can be found in Algorithm 4.
Theorem 4.4
There is an algorithm that, given an integers satisfying\(\sqrt {n} \le s \le n\)anda sequenceτof length n, computes lis(τ) in\(O\left (\frac {1}{s} \cdot n^{2} \log n\right )\)timewithO(s log n) bits of space.

Proof
To apply Lemmas 4.2 and 4.3 at the beginning, we start with a dummy pile P0 with a single dummy entry P0(1) = −∞. In the following, assume that for some i ≥ 0 we computed the pile Pi of size at most s explicitly. We repeat the following process until we find lis(τ).

In each iteration, we first compute the size |Pk| for i + 1 ≤ k ≤ i + 2s. During this process, we may find lis(τ) < i + 2s. In such a case we output lis(τ) and terminate. Otherwise, we find an index j such that i + s + 1 ≤ j ≤ i + 2s and |Pj|≤ n/s. Since \(s \ge \sqrt {n}\), it holds that \(|P_{j}| \le n/\sqrt {n} = \sqrt {n} \le s\). We then compute Pj itself to replace i with j and repeat.
By Lemmas 4.2 and 4.3, each pass can be executed in O(n log n) time with a working space of O(s log n) bits. There are at most lis(τ)/s iterations, since in each iteration the index i increases by at least s or lis(τ) is determined. Since lis(τ) ≤ n, the total running time is \(O\left (\frac {1}{s} \cdot n^{2} \log n\right )\). □
In the case of the smallest memory consumption we conclude the following corollary.
Corollary 4.5
Given a sequenceτof lengthn,lis(τ) can be computed inO (n1.5 log n) time with\(O\left (\sqrt {n} \log n\right )\)bitsof space.
5 An Algorithm for Finding a Longest Increasing Subsequence
It is easy to modify the algorithm in the previous section in such a way that it outputs an element of the final pile Plis(τ), which is the last element of a longest increasing subsequence by Proposition 3.3. Thus we can repeat the modified algorithm n times (considering only the elements smaller than and appearing before the last output) and actually find a longest increasing subsequence.Footnote 1 The running time of this naïve approach is \(O\left (\frac {1}{s} \cdot n^{3} \log n\right )\).
As we claimed before, we can do much better. In fact, we need only an additional multiplicative factor of O(log n) instead of O(n) in the running time, while keeping the space complexity as it is. In the rest of this section, we prove the following theorem.
Theorem 5.1
There is an algorithm that, given an integers satisfying\(\sqrt {n} \le s \le n\)anda sequenceτof length n, computes a longest increasing subsequence ofτin\(O(\frac {1}{s} \cdot n^{2} \log ^{2} n)\)timeusingO(s log n) bits of space.
Corollary 5.2
Given a sequenceτof lengthn, a longest increasing subsequence ofτcan be found inO (n1.5 log2n) time with\(O\left (\sqrt {n} \log n\right )\)bitsof space.
We should point out that the algorithm in this section is not a multi-pass algorithm. However, we can easily transform it without any increase in the time and space complexity so that it works as a sequential access algorithm.
5.1 High-Level Idea
We first find an element that is in a longest increasing subsequence roughly in the middle. As we will argue, this can be done in \(O\left (\frac {1}{s} \cdot n^{2} \log n\right )\) time with O(s log n) bits by running the algorithm from the previous section twice, once in the ordinary then once in the reversed way. We then divide the input into the left and right parts at a near-mid element and recurse.
The space complexity remains the same and the time complexity increases only by an O(log n) multiplicative factor. The depth of recursion is O(log n) and at each level of recursion the total running time is \(O\left (\frac {1}{s} \cdot n^{2} \log n\right )\). To remember the path to the current recursion, we need some additional space, but it is bounded by O (log2n) bits.
5.2 A Subroutine for Short Longest Increasing Sequences
We first solve the base case in which lis(τ) ∈ O(n/s). In this case, we use the original Patience Sorting and repeat it O(n/s) times. We present the following general form first.
Lemma 5.3
Letτbe a sequences of lengthn andlis(τ) = k. Then a longest increasing subsequence ofτcan be found inO(k ⋅ n log k) time withO(k log n) bits.
Proof
Without changing the time and space complexity, we can modify the original Patience Sorting so that
it maintains only the top elements of the piles;
it ignores the elements larger than or equal to a given upper bound; and
it outputs an element in the final pile.
We run the modified algorithm lis(τ) times. In the first run, we have no upper bound. In the succeeding runs, we set the upper bound to be the output of the previous run. In each run the input to the algorithm is the initial part of the sequence that ends right before the last output. The entire output forms a longest increasing sequence of τ.Footnote 2
Since lis(τ) = k, modified Patience Sorting maintains only k piles. Thus each run takes O(n log k) time and uses O(k log n) bits. The lemma follows since this is repeated k times and each round only stores O(log n) bits of information from the previous round. □
The following special form of the lemma above holds since n/s ≤ s when \(s \ge \sqrt {n}\).
Corollary 5.4
Letτbe a sequence of lengthn andlis(τ) ∈ O(n/s) for somes with\(\sqrt {n} \le s \le n\). A longest increasing subsequence ofτcan be found in\(O\left (\frac {1}{s} \cdot n^{2} \log n\right )\)timewithO(s log n) bits.
5.3 A Key Lemma
As mentioned above, we use a reversed version of our algorithm. Reverse Patience Sorting is the reversed version of Patience Sorting: it reads the input from right to left and uses the reversed inequalities. (See Algorithm 5). Reverse Patience Sorting computes the length of a longest decreasing subsequence in the reversed sequence, which is a longest increasing subsequence in the original sequence. Since the difference between the two algorithms is small, we can easily modify our algorithm in Section 4 for the length so that it simulates Reverse Patience Sorting instead of Patience Sorting.

Let Qi be the i th pile constructed by Reverse Patience Sorting as in Algorithm 5. Using Proposition 3.3, we can show that for each τ(i) in Qj, the longest decreasing subsequence of the reversal of τ ending at τ(i) has length j. This is equivalent to the following observation.
Observation 5.5
τ(i) ∈ Qj if and only if a longest increasing subsequence of τ starting at τ(i) has length j.
This observation immediately gives the key lemma below.
Lemma 5.6
Pk ∩ Qlis(τ)−k+ 1 ≠ ∅for allk with 1 ≤ k ≤lis(τ).
Proof
Let 〈τ(i1),…,τ(iℓ)〉 be a longest increasing subsequence of τ. Proposition 3.3 implies that τ(ik) ∈ Pk. The subsequence 〈τ(ik),…,τ(iℓ)〉 is a longest increasing subsequence of τ starting at τ(ik) since otherwise 〈τ(i1),…,τ(iℓ)〉 is not longest. Since the length of 〈τ(ik),…,τ(iℓ)〉 is iℓ − k + 1 = lis(τ) − k + 1, it holds that τ(k) ∈ Qlis(τ)−k+ 1. □
Note that the elements of Pk and Qlis(τ)−k+ 1 are not the same in general. For example, by applying Reverse Patience Sorting to τ1 = 〈2,8,4,9,5,1,7,6,3〉, we get Q1 = 〈3,6,7,9〉, Q2 = 〈1,5,8〉, Q3 = 〈4〉, and Q4 = 〈2〉 as below. (Recall that P1 = 〈2,1〉, P2 = 〈8,4,3〉, P3 = 〈9,5〉, and P4 = 〈7,6〉). The following diagram depicts the situation. The elements shared by Pk and Qlis(τ)−k+ 1 are underlined.
5.4 The Algorithm
We first explain the subroutine for finding a near-mid element in a longest increasing subsequence.
Lemma 5.7
Lets be an integer satisfying\(\sqrt {n} \le s \le n\). Given a sequenceτof length n, thekth element of a longest increasing subsequence ofτfor somek withlis(τ)/2 ≤ k < lis(τ)/2 + n/scan be found in\(O\left (\frac {1}{s} \cdot n^{2} \log n\right )\)timeusingO(s log n) bits of space.
Proof
We slightly modify Algorithm 4 so that it finds an index k and outputs Pk such that |Pk|≤ s and lis(τ)/2 ≤ k ≤lis(τ)/2 + n/s. Such a k exists since the average of |Pi| for lis(τ)/2 ≤ i < lis(τ)/2 + n/s is at most s. The time and space complexity of this phase are as required by the lemma.
We now find an element in Pk ∩ Qlis(τ)−k+ 1. Since the size |Qlis(τ)−k+ 1| is not bounded by O(s) in general, we cannot store Qlis(τ)−k+ 1 itself. Instead use the reversed version of the algorithm in Section 4 to enumerate it. Each time we find an element in Qlis(τ)−k+ 1, we check whether it is included in Pk. This can be done with no loss in the running time since Pk is sorted and the elements of Qlis(τ)−k+ 1 arrive in increasing order. □
The next technical but easy lemma allows us to split the input into two parts at an element of a longest increasing subsequence and to solve the smaller parts independently.
Lemma 5.8
Letτ(j) be thekth element of a longest increasing subsequence of asequenceτ. LetτLbe the subsequence ofτ[1,…,j − 1] formed by the elements smaller thanτ(j). Similarly letτRbe the subsequence ofτ[j + 1,…,|τ|] formed by the elements larger thanτ(j). Then, a longest increasing subsequence ofτcan be obtained by concatenating a longest increasing subsequence ofτL, τ(j), and a longest increasing subsequence ofτR, in this order.
Proof
Observe that the concatenated sequence is an increasing subsequence of τ. It suffices to show that lis(τL) + lis(τR) + 1 ≥lis(τ). Let τ[i1,…,ilis(τ)] be a longest increasing subsequence of τ such that ik = j. From the definition, τ[i1,…,ik− 1] is a subsequence of τL, and τ[ik+ 1,…,ilis(τ)] is a subsequence of τR. Hence lis(τL) ≥ k − 1 and lis(τR) ≥lis(τ) − k, and thus lis(τL) + lis(τR) + 1 ≥lis(τ). □
As Lemma 5.8 suggests, after finding a near-mid element τ(k), we recurse into τL and τR. If the input τ′ to a recursive call has small lis(τ′), we directly compute a longest increasing subsequence. See Algorithm 6 for details of the whole algorithm. Correctness follows from Lemma 5.8 and correctness of the subroutines.

5.5 Time and Space Complexity
In Theorem 5.1, the claimed running time is \(O\left (\frac {1}{s} \cdot n^{2} \log ^{2} n\right )\). To prove this, we first show that the depth of the recursion is O(log n). We then show that the total running time in each recursion level is \(O\left (\frac {1}{s} \cdot n^{2} \log n\right )\). The claimed running time is guaranteed by these bounds.
Lemma 5.9
Given a sequenceτ, the depth of the recursions invoked byRecursiveLISof Algorithm 6 is atmost log6/5lis(τ′), whereτ′is the subsequence ofτcomputed in Line3.
Proof
We proceed by induction on lis(τ′). If lis(τ′) ≤ 3|τ′|/s, then no recursive call occurs, and hence the lemma holds. In the following, we assume that lis(τ′) = ℓ > 3|τ′|/s and that the statement of the lemma is true for any sequence τ″ with lis(τ″) < ℓ.
Since ℓ > 3|τ′|/s, Algorithm 6 recurses into two branches on subsequences of τ′. From the definition of k in Line 8 of Algorithm 6, the length of a longest increasing subsequence is less than ℓ/2 + |τ′|/s in each branch. Since ℓ/2 + |τ′|/s < ℓ/2 + ℓ/3 = 5ℓ/6, each branch invokes recursions of depth at most log6/5(5ℓ/6) = log6/5ℓ − 1. Therefore, the maximum depth of the recursions invoked by their parent is at most log6/5ℓ. □
Lemma 5.10
Given a sequenceτof lengthn, the total running time at each depth ofrecursion excluding further recursive calls in Algorithm 6 takes\(O\left (\frac {1}{s} n^{2} \log n\right )\)time.
Proof
In one recursion level, we have many calls of RecursiveLIS on pairwise non-overlapping subsequences of τ. For each subsequence τ′, the algorithm spends time \(O\left (\frac {1}{s} |\tau ^{\prime }|^{2} \log |\tau ^{\prime }|\right )\). Thus the total running time at a depth is \(O\left ({\sum }_{\tau ^{\prime }} \frac {1}{s} |\tau ^{\prime }|^{2} \log |\tau ^{\prime }|\right )\), which is \(O\left (\frac {1}{s} n^{2} \log n\right )\) since \({\sum }_{\tau ^{\prime }} |\tau ^{\prime }|^{2} \le |\tau |^{2} = n^{2}\). □
Finally we consider the space complexity of Algorithm 6.
Lemma 5.11
Algorithm 6 usesO(s log n) bits of working space on sequences of length n.
Proof
We have already shown that each subroutine uses O(s log n) bits. Moreover, this space of working memory can be discarded before another subroutine call occurs. Only a constant number of O(log n)-bit words are passed to the new subroutine call. We additionally need to remember the stack trace of the recursion. The size of this additional information is bounded by O(log2n) bits since each recursive call is specified by a constant number of O(log n)-bit words and the depth of recursion is O(log n) by Lemma 5.9. Since log2n ∈ O(s log n) for \(s \ge \sqrt {n}\), the lemma holds. □
6 Lower Bound for Algorithms with Sequential Access
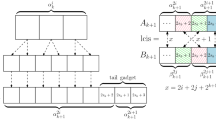
An algorithm is a sequential access algorithm if it can access elements in the input array only sequentially. In our situation this means that for a given sequence, accessing the i th element of the sequence directly after having accessed the j th element of the sequence costs time at least linear in |i − j|. As opposed to the RAM, any Turing machine in which the input is given on single read-only tape has this property. Note that any lower bound for sequential access algorithms in an asymptotic form is applicable to multi-pass algorithms as well since every multi-pass algorithm can be simulated by a sequential access algorithm with the same asymptotic behavior. Although some of our algorithms are not multi-pass algorithms, it is straightforward to transform them to sequential access algorithms with the same time and space complexity.
To show a lower bound on the running time of sequential access algorithms with limited working space, we need the concept of communication complexity (see [21] for more details). Let f be a function. Given \(\alpha \in \mathcal {A}\) to the first player Alice and \(\beta \in \mathcal {B}\) to the second player Bob, the players want to compute f(α,β) together by sending bits to each other (possibly multiple times). The communication complexity of f is the maximum number of bits transmitted between Alice and Bob over all inputs by the best protocol for f.
Consider the following variant of the LIS problem: Alice gets the first half of a permutation π of {1,…,2n} and Bob gets the second half. They compute lis(π) together. It is known that this problem has high communication complexity [19, 22, 38].
Proposition 6.1Proposition 6.1 ([19, 38])
Letπbe a permutation of {1,…,2n}. Given the first half ofπto Alice and the second half to Bob, they needΩ(n) bits of communication to compute lis(π) in the worst case (even with 2-sided error randomization).
Now we present our lower bound. Note that the lower bound even holds for the special case where input is restricted to permutations.
Theorem 6.2
Given a permutationπof {1,…,4n}, any sequential access (possibly randomized) algorithm computinglis(π) using b bits takes Ω(n2/b) time.
Proof
Given an arbitrary n > 1, let π′ be a permutation of {1,…,2n}. We construct a permutation π of {1,…,4n} as follows. Let \({\pi }_{1}^{\prime } = \langle {\pi (1),\dots ,\pi (n)}\rangle \) be the first half of π′, define \({\pi }_{2}^{\prime } = \langle {4n,4n-1,\dots , 2n + 2}\rangle \) and let \({\pi }_{3}^{\prime } =\langle {\pi (n + 1),\pi (n + 2),\ldots ,\pi (2n)}\rangle \) be the second half of π′. Then we define π to be the concatenation of \({\pi }_{1}^{\prime }\), \({\pi }_{2}^{\prime }\), \({\pi }_{3}^{\prime }\) and the one element sequence \({\pi }_{4}^{\prime } =\langle {2n + 1}\rangle \), in that order.
It is not difficult to see that π is a permutation and that lis(π) = lis(π′) + 1. To see the latter, observe that the concatenation of \({\pi }_{2}^{\prime }\) and \({\pi }_{4}^{\prime }\) is a decreasing subsequence of π. Hence any increasing subsequence of π can contain at most one element not in π′. On the other hand, any increasing subsequence of π′ of length ℓ can be extended with the element 2n + 1 of \({\pi }_{4}^{\prime }\) to an increasing subsequence of π of length ℓ + 1.
We say a sequential access algorithm traverses the middle if it accesses a position in \({\pi }_{1}^{\prime }\) and then accesses a position in \({\pi }_{3}^{\prime }\) or vice versa with possibly accessing elements in \({\pi }_{2}^{\prime }\) but only such elements in meantime. Since each traversal of the middle takes Ω(n) time, it suffices to show that the number of traversals of the middle is Ω(n/b).
Suppose we are given a sequential access algorithm M that computes lis(π) with t traversals of the middle. Using M, we construct a two-player communication protocol for computing lis(π′) with at most tb bits of communication. (A similar technique is described for streaming algorithms in [38]).
Recall that the first player Alice gets the first half \({\pi }_{1}^{\prime }\) of π′ and the second player Bob gets the second half \({\pi }_{3}^{\prime }\) of π′. They compute lis(π′) together as follows.
Before starting computation, Alice computes πA by concatenating \({\pi }_{1}^{\prime }\) and \({\pi }_{2}^{\prime }\) in that order, and Bob computes πB by concatenating \({\pi }_{2}^{\prime }\), \({\pi }_{3}^{\prime }\), and \({\pi }_{4}^{\prime }\) in that order.
They first compute lis(π) using M by repeating the following phases:
Alice starts the computation by M and continues while M stays in π[1,…,3n − 1] = πA. When M tries to access π[3n,…,4n], and thus a traversal of the middle occurs, Alice stops and sends all b bits stored by M to Bob.
Bob restores the b bits received from Alice to the working memory of M and continues computation while M stays in π[n + 1,…,4n] = πB. A traversal of the middle is occurred when M tries to access π[1,…,n]. Bob then stops and sends the b bits currently stored by M back to Alice.
When M outputs lis(π) and terminates, the currently active player outputs lis(π) − 1 as lis(π′) and terminates the protocol.
The two players correctly simulate M and, as a result, compute lis(π′) together. Since the algorithm M invokes t traversals, the total number of bits sent is at most tb. Since tb ∈Ω(n) holds by Proposition 6.1, we have t ∈Ω(n/b) as required. □
Recall that our algorithms for the LIS problem use O(s log n) bits and run in \(O(\frac {1}{s} n^{2} \log n)\) time for computing the length and in \(O(\frac {1}{s} n^{2} \log ^{2} n)\) time for finding a subsequence, where \(\sqrt {n} \le s \le n\). By Theorem 6.2, their time complexity is optimal for algorithms with sequential access up to polylogarithmic factors of log2n and log3n, respectively.
7 Concluding Remarks
Our results in this paper raise the following question:
Can we solve LIS with \(o\left (\sqrt {n}\right )\)-space in polynomial time?
Observe that an unconditional ‘no’ implies that SC ≠ P ∩PolyL, where SC (Steve’s Class) is the class of problems that can be solved by an algorithm that simultaneously runs in polynomial-time and polylogarithmic-space [11, 29]. As a conditional lower bound, we can use the (hypothetical) hardness of Longest Common Subsequence (LCS). Given two strings, LCS asks to find a longest sequence that is a subsequence of both strings. It is easy to see that a longest increasing subsequence of a sequence τ can be computed as a longest common subsequence of τ and the sequence obtained by sorting τ. The other direction is not that obvious, but there is a reduction from LCS on strings of length n to LIS on a string of length at most n2 [20]. The reduction can be easily implemented in log-space. This implies that an O(f(n))-space polynomial-time algorithm for LIS can be used as an O(f(n2))-space polynomial-time algorithm for LCS. In particular, an \(O(\sqrt {n}^{1-\epsilon })\)-space polynomial-time algorithm for LIS gives an O(n1−𝜖)-space polynomial-time algorithm for LCS for any 𝜖 > 0, and a log-space algorithm for LIS implies a log-space algorithm for LCS.
To make the presentation simple, we used the length n of τ to bound lis(τ) in the time complexity analyses of the algorithms. If we analyze the complexity in terms of lis(τ) instead of n when possible, we can obtain the following output-sensitive bounds.
Theorem 7.1
Lets be an integer satisfying\(\sqrt {n} \le s \le n\), and letτbe a sequence of lengthn withlis(τ) = k. UsingO(s log n) bits of space,lis(τ) can be computed in\(O\left (\frac {1}{s} \cdot k n \log k\right )\)timeand a longest increasing subsequence ofτcan be found in\(O\left (\frac {1}{s} \cdot k n \log ^{2} k\right )\)time.
Notes
This algorithm outputs a longest increasing subsequence in the reversed order. One can access the input in the reversed order and find a longest decreasing subsequence to avoid this issue.
Again this output is reversed. We can also compute the output in nonreversed order as discussed before.
References
Ahn, H.-K., Baraldo, N., Oh, E., Silvestri, F.: A time-space trade-off for triangulations of points in the plane. In: COCOON 2017, pp 3–12 (2017). https://doi.org/10.1007/978-3-319-62389-4_1
Aldous, D., Diaconis, P.: Longest increasing subsequences: from patience sorting to the Baik-Deift-Johansson theorem. Bull. Am. Math. Soc. 36 (4), 413–432 (1999). https://doi.org/10.1090/S0273-0979-99-00796-X
Asano, T., Elmasry, A., Katajainen, J.: Priority queues and sorting for read-only data. In: TAMC 2013, pp 32–41 (2013). https://doi.org/10.1007/978-3-642-38236-9_4
Asano, T., Izumi, T., Kiyomi, M., Konagaya, M., Ono, H., Otachi, Y., Schweitzer, P., Tarui, J., Uehara, R.: Depth-first search using O(n) bits. In: ISAAC 2014, pp 553–564 (2014). https://doi.org/10.1007/978-3-319-13075-0_44
Banyassady, B., Korman, M., Mulzer, W., Van Renssen, André, Roeloffzen, M., Seiferth, P., Stein, Y.: Improved time-space trade-offs for computing Voronoi diagrams. In: STACS 2017, vol. 66, pp 9:1–9:14 (2017). https://doi.org/10.4230/LIPIcs.STACS.2017.9
Bespamyatnikh, S., Segal, M.: Enumerating longest increasing subsequences and patience sorting. Inf. Process. Lett. 76(1–2), 7–11 (2000). https://doi.org/10.1016/S0020-0190(00)00124-1
Borodin, A., Cook, S.: A time-space tradeoff for sorting on a general sequential model of computation. SIAM J. Comput. 11(2), 287–297 (1982). https://doi.org/10.1137/0211022
Burstein, A., Lankham, I.: Combinatorics of patience sorting piles. Séminaire Lotharingien de Combinatoire 54A, B54Ab (2006). http://www.mat.univie.ac.at/~slc/wpapers/s54Aburlank.html
Chakraborty, S., Satti, S.R.: Space-efficient algorithms for maximum cardinality search, stack BFS, queue BFS and applications. In: COCOON 2017, pp 87–98 (2017). https://doi.org/10.1007/978-3-319-62389-4_8
Chan, T.M., Chen, E.Y.: Multi-pass geometric algorithms. Discret. Comput. Geom. 37(1), 79–102 (2007). https://doi.org/10.1007/s00454-006-1275-6
Cook, S.A.: Deterministic CFL’s are accepted simultaneously in polynomial time and log squared space. In: STOC 1979, pp 338–345 (1979), https://doi.org/10.1145/800135.804426
Crochemore, M., Porat, E.: Fast computation of a longest increasing subsequence and application. Inf. Comput. 208(9), 1054–1059 (2010). https://doi.org/10.1016/j.ic.2010.04.003
Darwish, O., Elmasry, A.: Optimal time-space tradeoff for the 2D convex-hull problem. In: ESA 2014, pp 284–295 (2014). https://doi.org/10.1007/978-3-662-44777-2_24
Elmasry, A., Hagerup, T., Kammer, F.: Space-efficient basic graph algorithms. In: STACS 2015, vol. 30, pp 288–301 (2015). https://doi.org/10.4230/LIPIcs.STACS.2015.288
Ergun, F., Jowhari, H.: On the monotonicity of a data stream. Combinatorica 35(6), 641–653 (2015). https://doi.org/10.1007/s00493-014-3035-1
Frederickson, G.N.: Upper bounds for time-space trade-offs in sorting and selection. J Comput Syst Sci 34(1), 19–26 (1987). https://doi.org/10.1016/0022-0000(87)90002-X
Fredman, M.L.: On computing the length of longest increasing subsequences. Discret. Math. 11(1), 29–35 (1975). https://doi.org/10.1016/0012-365X(75)90103-X
Gál, A., Gopalan, P.: Lower bounds on streaming algorithms for approximating the length of the longest increasing subsequence. SIAM J. Comput. 39(8), 3463–3479 (2010). https://doi.org/10.1137/090770801
Gopalan, P., Jayram, T.S., Krauthgamer, R., Kumar, R.: Estimating the sortedness of a data stream. In: SODA 2007, pp 318–327 (2007). http://dl.acm.org/citation.cfm?id=1283417
Hunt, J.W., Szymanski, T.G.: A fast algorithm for computing longest common subsequences. Commun. ACM 20(5), 350–353 (1977). https://doi.org/10.1145/359581.359603
Kushilevitz, E., Nisan, N.: Communication complexity. Cambridge University Press, Cambridge (1997)
Liben-Nowell, D., Vee, E., An, Z.: Finding longest increasing and common subsequences in streaming data. J. Comb. Optim. 11(2), 155–175 (2006). https://doi.org/10.1007/s10878-006-7125-x
Lincoln, A., Williams, V.V., Wang, J.R., Ryan Williams, R.: Deterministic time-space trade-offs for k-SUM. In: ICALP 2016, pp 58:1–58:14 (2016), https://doi.org/10.4230/LIPIcs.ICALP.2016.58
Mallows, C.L.: Problem 62-2, patience sorting. SIAM Rev. 4(2), 143–149 (1962). http://www.jstor.org/stable/2028371
Mallows, C.L.: Problem 62-2. SIAM Rev. 5(4), 375–376 (1963). http://www.jstor.org/stable/2028347
Mallows, C.L.: Patience sorting. Bulletin of the Institute of Mathematics and its Applications 9, 216–224 (1973)
Munro, J.I., Paterson, M.S.: Selection and sorting with limited storage. Theor. Comput. Sci. 12(3), 315–323 (1980). https://doi.org/10.1016/0304-3975(80)90061-4
Naumovitz, T., Saks, M.: A polylogarithmic space deterministic streaming algorithm for approximating distance to monotonicity. In: SODA 2015, pp 1252–1262 (2015). https://doi.org/10.1137/1.9781611973730.83
Nisan, N.: RL \(\subseteq \) SC. In: STOC 1992, pp 619–623 (1992). https://doi.org/10.1145/129712.129772
Pagter, J., Rauhe, T.: Optimal time-space trade-offs for sorting. In: FOCS 1998, pp 264–268 (1998). https://doi.org/10.1109/SFCS.1998.743455
Pilipczuk, M., Wrochna, M.: On space efficiency of algorithms working on structural decompositions of graphs. In: STACS 2016, vol. 47, pp 57:1–57:15 (2016). https://doi.org/10.4230/LIPIcs.STACS.2016.57
Ramanan, P.: Tight \(\Omega (n \lg n)\) lower bound for finding a longest increasing subsequence. Int. J. Comput. Math. 65(3–4), 161–164 (1997). https://doi.org/10.1080/00207169708804607
Romik, D.: The surprising mathematics of longest increasing subsequences. Cambridge University Press, Cambridge (2015). https://doi.org/10.1017/CBO9781139872003
Saks, M., Seshadhri, C.: Space efficient streaming algorithms for the distance to monotonicity and asymmetric edit distance. In: SODA 2013, pp 1698–1709 (2013). https://doi.org/10.1137/1.9781611973105.122
Saks, M., Seshadhri, C: Estimating the longest increasing sequence in polylogarithmic time. SIAM J. Comput. 46(2), 774–823 (2017). https://doi.org/10.1137/130942152
Savitch, W.J.: Relationships between nondeterministic and deterministic tape complexities. J. Comput. Syst. Sci. 4(2), 177–192 (1970). https://doi.org/10.1016/S0022-0000(70)80006-X
Schensted, C.: Longest increasing and decreasing subsequences. Can. J. Math. 13(2), 179–191 (1961). https://doi.org/10.4153/CJM-1961-015-3
Su, X., Woodruff, D.P.: The communication and streaming complexity of computing the longest common and increasing subsequences. In: SODA 2007, pp 336–345 (2007). http://dl.acm.org/citation.cfm?id=1283383.1283419
Wang, J.R.: Space-efficient randomized algorithms for K-SUM. In: ESA 2014, pp 810–829 (2014). https://doi.org/10.1007/978-3-662-44777-2_67
Acknowledgments
The authors are grateful to William S. Evans for bringing the reduction from LCS to LIS mentioned in the concluding remarks to their attention.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article is part of the Topical Collection on Special Issue on Theoretical Aspects of Computer Science (2018)
Partially supported by MEXT/JSPS KAKENHI grant numbers JP17H01698, JP18H04091, JP18K11168, JP18K11169, JP24106004. A preliminary version appeared in the proceedings of the 35th International Symposium on Theoretical Aspects of Computer Science (STACS 2018), vol. 96 of Leibniz International Proceedings in Informatics, pp. 44:1-44:15, 2018.
Rights and permissions
About this article

Cite this article
Kiyomi, M., Ono, H., Otachi, Y. et al. Space-Efficient Algorithms for Longest Increasing Subsequence. Theory Comput Syst 64, 522–541 (2020). https://doi.org/10.1007/s00224-018-09908-6
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00224-018-09908-6