
Abstract
In different engineering processes, the reliability of systems is increasingly evaluated to ensure that the safety–critical process systems will operate within their expected operational boundary for a certain mission time without failure. Different methodologies used for reliability analysis of process systems include Failure Mode and Effect Analysis (FMEA), Fault Tree Analysis (FTA), and Bayesian Networks (BN). Although these approaches have their own procedures for evaluating system reliability, they rely on exact failure data of systems’ components for reliability evaluation. Nevertheless, obtaining exact failure data for complex systems can be difficult due to the complex behavior of their components, and the unavailability of precise and adequate information about such components. To tackle the data uncertainty issue, this chapter proposes a framework by combining intuitionistic fuzzy set theory and expert elicitation that enables the reliability assessment of process systems using FTA. Moreover, to model the statistical dependencies between events, we use the BN for robust probabilistic inference about system reliability under different uncertainties. The efficiency of the framework is demonstrated through application to a real-world system and comparison of the results of analysis produced by the existing approaches.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others

Keywords
10.1 Introduction
Chemical process industries are one of the most hazardous sectors where the potential of occurrence of serious undesirable events, rare accidents, mishaps, or near misses is significant. Such unexpected events can directly or indirectly cause serious injuries like loss of life, serious and immutable environmental damage, loss of material and equipment assets, and decrease the forgotten factor as the reputation of the company. Fire and explosion, the release of toxic, and hazardous materials are common examples of the abovementioned events [1]. Catastrophic accidents such as the Piper Alpha fire and explosion in 1988, BP explosion in 2005, and Deepwater Horizon tragedy in 2010 reveal the tragic effects of major accidents in the chemical process industry [2]. Thus, the prediction of the occurrence of unexpected events and subsequent consequences has a high necessity to assure the safe operation of the system and to prevent the upcoming occurrence of similar events. In this regard, safety and risk analysis can help to prevent the occurrence of unwanted events and develop operational mitigation actions [3]. Several qualitative and quantitative methods, including fault tree analysis (FTA), event tree analysis (ETA), failure mode and effect analysis (FMEA), hazard and operability study (HAZOP), and risk matrix, have been widely used in the risk analysis of chemical process industries. Among the available techniques, FTA is a well-established technique, which can graphically describe the relationships between the cause and effects of different events in the form of Basic Events (BEs), Intermediates Events (IEs), and Top Event (TE). FTA can provide both qualitative and quantitative analysis by presenting undesired events and giving probabilistic analysis from root causes to the consequence [4].
FTA uses the probabilities of BEs (located at bottom of the tree) as quantitative input to calculate the probability of the undesired event as TE (located at the top of the tree). Therefore, the probability of all BEs as crisp values or probability density functions (PDF) is required for quantitative analysis [5]. However, in the real-world industry, because of the lack of knowledge and missing data or systematic bias, the availability of all necessary data cannot be guaranteed. Thus, collecting data from varieties of sources having different features such as dissimilar operating environments, industrial sectors, and experts from diverse backgrounds is an important solution, which has been widely used to obtain the known probability. In addition, even with consideration of exact probabilities or PDFs, intrinsic uncertainties may remain because of different failure modes, lack of knowledge of the mechanism of the failure process, and ambiguity of system experiences. Therefore, a robust method is required for calculating the probability of BEs and addressing the uncertainty among the data collection and analysis procedure [6, 7].
Experts’ knowledge has been used to obtain the BEs probability when objective data are limited, incomplete, imprecise, or unknown [8]. The fuzzy set theory (FST) introduced by Zadeh [9] has been demonstrated to be effective and efficient in data uncertainty handling and computing the probability of BEs utilizing multi-expert opinions. The previous studies generally used FST to acquire the probability of BEs from impression and subjectivity in expert judgment. For example, Yazdi and Kabir [10] proposed a framework to obtain the known failure rates from the reliability data handbook and the unknown failure rate according to the experts’ opinions. Due to the elicitation procedure considering the unavailability of sufficient data, fuzzy set theory is used to transform linguistic expressions provided by experts into fuzzy numbers. Subsequently, fuzzy possibility, crisp possibility, and failure probability of each BEs are calculated. The risk matrix analysis framework proposed by Yan et al. [11] considered potential risk influences such as controllability, manageability, criticality, and uncertainty. The likelihood in the risk matrix has been calculated by obtaining the probability of the TE of a fault tree. In the TE probability computation process, the probabilities of the BEs of the fault tree have been obtained through expert elicitation. The analytical hierarchy process (AHP) is utilized to improve the accuracy of the failure probability data by minimizing the subjective biases of the experts by quantifying their weightings. Yazdi and Kabir [12] revised Yan et al.’s methodology as a new framework using fuzzy AHP and similarity aggregation procedure (SAM) in the fuzzy environment to cope with available ambiguities of identified BEs. All mentioned papers used a combination of FST and multi-expert knowledge to approximate the BEs’ probabilities. However, the FST suffers from several shortages. The one worth mentioning is related to the uncertainty or hesitation about the degree of membership. The FST cannot include the hesitation in the membership functions. In this regard, Atanassov [13] extended conventional fuzzy set to propose the intuitionistic fuzzy set (IFS), in which non-membership degrees and hesitation margin groups have been included with the membership degrees. The IFS data are more complete than the conventional fuzzy data that considers membership function only [14]. In another example, it is demonstrated the use of IFSs to handle uncertainties in FMEA [15]. Yazdi [16] utilized IFS and specifically intuitionistic fuzzy numbers (IFNs) to develop a conventional risk matrix.
To the best of the authors’ knowledge, limited research has been conducted to combine IFNs and multi-expert knowledge to address the issues of data uncertainty in FTA. For instance, Shu et al. [17] utilized IFNs to analyze the failure behavior of the printed circuit board assembly. A vague FTA approach has been proposed [18] by integrating experts’ judgment into the analysis to calculate the fault interval of system components. Afterward, for fuzzy reliability evaluation of a “liquefied natural gas terminal emergency shutdown system”, Cheng et al. [19] used IFS with FTA. The weakest t-norm-based IFS has been used with FTA [20] to evaluate system reliability. Recently, Kabir et al. [21] have utilized IFS for dynamic reliability analysis.
On the other hand, traditional FTA as well as fuzzy FTA are well known to have a static structure and cannot consider the variation of risk due to the dynamic behavior of the system. In addition, BEs are assumed to be independent in both methods and they are considered to have binary states—failed and non-failed, whereas, in practice, events can be in more than two states. Moreover, the effects of common cause failure (CCF) in the reliability of systems are usually not considered in traditional FTA. Such mentioned issues are commonly named as model uncertainty in risk analysis [22]. Thus, model uncertainty is recognized as a considerable limitation of risk analysis methods. In this regard, a dependency coefficient method is introduced by Ferdous et al. [23] to evaluate the interdependencies of BEs in static FT. The joint likelihood function in the hierarchical Bayesian network is developed [24] to consider the interdependencies among BEs in conventional FT. Besides, Hashemi et al. [25] used the copula function technique to evaluate and model the interdependencies of BEs to improve uncertainty analysis.
Bayesian networks (BN) have become a popular method, which has been widely used to incorporate a variety of information types such as extrapolated data, experts’ judgment, or partially related data in risk analysis of process industries [26, 27]. Kabir and Papadopoulos [22] provided a review of the applications of BNs in reliability and risk assessment areas. Examples of such applications include risk analysis of fire and explosion [28, 29], leakage [30, 31], human error [32,33,34], maintenance activity [35, 36], and offshore and drilling operations [37,38,39] utilized BN as a probabilistic interface tool for reasoning under uncertainty. BN used a chain rule or d-separation to represent the causal relationships between a set of variables (in case of FTA is BEs) considering the dependencies [40]. BN is also able to cope with the limitations of conventional FTA as well as having a flexible structure. Several scholars have used BN in parallel with FTA and addressed the shortages of the conventional FTA by mapping FT into the corresponding BN [41,42,43,44]. Because of the modeling flexibility provided by BN, the interdependencies of BEs can be effortlessly modeled by using BN. BN can also model multiple states for BEs and common cause failure (CCF) scenarios. Furthermore, to deal with the model uncertainty, BN can perform the probability updating mechanism using Bayes’ theorem by adding new information about the system over time.
The novelty and contribution of this work are utilizing the advantages of IFNs over traditional FST to evaluate the TE probability of an FT. Besides, this chapter adopts BN to allow dynamic risk assessment under uncertainty, where the BEs’ probabilities are calculated based on the combination of subjective opinions and IFNs, and BN is used to take into account the interdependencies of BEs as well as CCF. The rest of the chapter is organized as follows. In Sect. 10.2, the uncertainty sources in chemical process industries are reviewed. A short overview of the IFS theory is presented in Sect. 10.2. In Sect. 10.3, the proposed methodology is described. Section 10.4 demonstrates the feasibility and efficiency of the proposed approach via a numerical example with sensitivity analysis. Lastly, the concluding statements are presented in Sect. 10.5.
10.2 Background
10.2.1 Uncertainty Sources in Chemical Process Industries
The term uncertainty is widely used with a different meaning in the literature on risk analysis. Several scholars claimed that uncertainty is equal to risk about the future and accordingly risk is equal to uncertainty. Others stated that uncertainty and risk are from two different schools and it has not been complicated to each other [40]. In this chapter, it is assumed the terms risk and uncertainty are two different concepts. There exist two distinct concepts of uncertainty in chemical process industries including (i) uncertainty caused by physical unpredictability (aleatory uncertainty) and (ii) uncertainty caused by insufficient knowledge (epistemic uncertainty) [45, 46].
The existence of aleatory and epistemic uncertainties in risk analysis of chemical process industries implies that the probability of numerous risk factors cannot be measured in an appropriate way when they are ambiguous and unknown. Referring to aleatory uncertainty, the random behavior of some parameters in a system or its environment should be stated such as inconsistency in weather conditions and experimental data variability for BEs in FT. In contrast, epistemic uncertainty is related to fuzziness, vagueness, or imprecision regarding the quality of chemical process safety, particularly in the accident scenario identification and consequence modeling. In reality, it is difficult to reduce aleatory uncertainty because of the intrinsic nature of a system, whereas it is possible to reduce epistemic uncertainty when more knowledge about the system is available over time. More information about the characteristics of aleatory and epistemic uncertainties can be found in [47]. This study concentrates on epistemic uncertainty.
During analysis, a certain explanation or assumption about the models leads to model uncertainty. Moreover, mathematical and other analytical tools are utilized to reduce properties of interest, ranging from structural, stochastic, human behavior, accident, evacuation, dispersion model, etc. This study concentrates on the model uncertainty caused by the independence assumptions among BEs in FTA. Thus, the modeling capability of BN is used to assess the dependency among events to address the abovementioned issue.
Parameter uncertainties are caused by the imprecisions and inaccuracies in the input data used in the process safety analysis. These uncertainties are intrinsic due to the imperfect nature of the available data, and the analysis process requires to be based on partial knowledge. Nonetheless, it is believed that parameter uncertainty is the easiest one to be quantified [48]. In the literature, to cope with parameter uncertainty, it is commonly expressed by PDFs and Monte Carlo simulation-based probability theory [49,50,51]. However, as mentioned earlier, PDFs are rarely easy to obtain. In this chapter, IFNs are utilized to deal with parameter uncertainty, where the probabilities of BEs are treated as IFNs that are derived from multi-experts’ knowledge.
10.2.2 IFS Theory
The concept of the classical fuzzy sets has been generalized by Atanassov [13] into IFS through the introduction of a non-membership function \(v_{{\tilde{A}}} \left( x \right)\) indicating the evidence against \(x \in X\) along with the membership value \(\mu_{{\tilde{A}}} \left( x \right)\) indicating evidence for \(x \in X\) and this admits an aspect of indeterminacy.
An IFS \(\tilde{A}\) in the universe of discourse X is given by
where \(\mu_{{\tilde{A}}} :X \to \left[ {0,1} \right]\) and \(v_{{\tilde{A}}} :X \to \left[ {0,1} \right]\) are membership and non-membership functions, respectively, where
For every value \(x \in X\), the values \(\mu_{{\tilde{A}}} \left( x \right)\) and \(v_{{\tilde{A}}} \left( x \right)\) represent, respectively, the degree of membership and degree of non-membership to \(\tilde{A} \subseteq X\) Moreover, the uncertainty level or hesitation degree of the membership of \(x\) in \(\tilde{A}\) is denoted as:
If \(\pi_{{\tilde{A}}} \left( x \right) = 0,\forall x \in X\), then the IFS becomes a classical fuzzy set.
If the membership and non-membership functions of an IFS \(\tilde{A}\) (i.e., \(\mu_{{\tilde{A}}} \left( x \right)\) and \(v\left( {_{{\tilde{A}}} \left( x \right)} \right)\) satisfy the following conditions given by Eqs. (10.4) and (10.5), then \(\tilde{A}\) in X is considered as IF-convex
If there exist at least two points \(x_{1} ,x_{2} \in X\) such that \(\mu_{{\tilde{A}}} \left( {x_{1} } \right) = 1\) and \(v_{{\tilde{A}}} \left( {x_{2} } \right) = 1\), then the IFS \(\tilde{A}\) in X is considered as IF-normal [52]:
An IFS \(\tilde{A} = \left\{ {\left\langle {x,\mu_{{\tilde{A}}} \left( x \right),v_{{\tilde{A}}} \left( x \right)} \right\rangle :x \in R} \right\}\) is called an IFN if
-
(i)
\(\tilde{A}\) is IF-normal and IF-convex.
-
(ii)
\(\mu_{{\tilde{A}}} \left( x \right)\) is an upper and \(v_{{\tilde{A}}} \left( x \right)\) is a lower semi-continuous.
-
(iii)
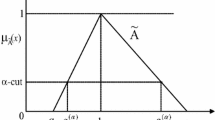
\(Supp \tilde{A} = \left\{ {x \in X:v_{{\tilde{A}}} \left( x \right) < 1} \right\}\) is bounded (see Fig. 10.1).
Fig. 10.1 
Graphical representation of IFNs

A Triangular-IFN is an IFN given by
and
where \(a_{1}^{\prime } \le a_{1} \le a_{2} \le a_{3} \le a_{3}^{\prime }\). This TIFN is denoted by \(\tilde{A} = \left( {a_{1} ,a_{2} ,a_{3} ; a_{1}^{\prime } ,a_{2} ,a_{3}^{\prime } } \right).\)
10.3 Material and Method
To introduce the methodology developed in this chapter, this section briefly describes the framework as can be seen in Fig. 10.2.

The structure of the proposed method
10.3.1 Hazard Analysis
There are numerous methods available for hazard analysis in different types of industrial sectors. The initial step of all hazard analysis methods is identifying all possible hazards. Therefore, well understanding of process function has a high necessity for this purpose. All information about a process system should be collected to understand its functionality appropriately. Then, any hazards which have enough potential to destroy the industrial equipment, surrounding environment, or harm to the public should be considered [40]. HAZOP technique is based on the brainstorming method that has enough capability to recognize hazardous systems and sub-systems by employing a group of specialists, commonly a third-party company. Thus, this study considers the outcome of HAZOP as a highly probable and severe event. In fact, the HAZOP study is commonly in conducted process-based industries to identify the deviation as a pre-step fault tree analysis. However, considering the inherent features process, FMEA or other types of risk assessment method can also be carried out.
10.3.2 Developing a Fault Tree and Collecting Data
After identifying an event as the TE of a fault tree, the rest of the tree is developed from top to bottom in a downward direction. It should be noted that further analysis of the FT is performed based on the TE. Therefore, the TE of the FT must be chosen appropriately for further analysis. The TE is commonly specified as an accident or hazardous event which can potentially be a cause of asset loss or harm to the public. After finalizing the development of an FT, the BEs that are put at the bottom level of the tree (leaves) should be identified to facilitate further analysis. The logic relationship between BEs, IEs, and TE is defined using Boolean OR and AND gates.
The reliability data such as the ones from OREDA [53] can be used to obtain the failure rate of known BEs. Nevertheless, when there is a difficulty in using a reliability handbook to obtain failure rates of rare events with unknown or limited failure data, three popular methods, including expert judgment, extrapolation, and statistical methods, can be utilized to estimate the failure rates [54]. The statistical method estimates the failure rates by estimating the failure probabilities by performing a short test on the practical data. In addition, statistical methods can be distinguished with deterministic methods, which are suitable where observations are precisely reproducible or are expected to be in this manner. The extrapolation method denotes the utilization of a predicting model, equal condition, or the available reliability data sources. The expert judgment method directly calculates probabilities based on experts’ opinions on the occurrence of BEs. This study employs the expert judgment method to estimate BEs’ occurrence probability. In this regard, a combination of subjective opinions expressed by experts and IFNs can help assessors to deal with the uncertainty that may arise during the analysis. In the following subsection, the procedure of using an expert system is presented.
10.3.3 Use of the Expert System
Expert systems are convenient to use in quantitative analysis models in circumstances where the available situations make it difficult or even more impossible to make enough observation to quantify the models using real data. Thus, expert systems are commonly used to approximate the model parameter under ambiguous conditions. Expert systems can also be used to improve the estimation, which is gained from real data.
An expert provides his/her judgment about a subject based on knowledge and experience according to his/her background. Thus, an employed expert will require to respond to a predefined set of questions related to a subject, which can include personal information, probabilities, rating, weighting factor, uncertainty estimation, and so on. The experts’ opinions can be collected during an eliciting. An important issue related to the elicitation process is that experts’ opinions should not be used instead of rigorous reliability and risk analysis approaches, whereas it can be used to supplement them where reliability and risk analytical approaches are inconsistent or inappropriate.
10.3.3.1 Experts’ Opinion Elicitation
Due to the increased complexity of systems and the subjective nature of expert judgment, no officially renowned approach has been developed for treating expert opinion. Once the elicitation process is finished, opinions are analyzed by combining them to obtain an aggregated result to be used in the reliability analysis. Clemen and Winkler [55] divided the elicitation and aggregation processes into two categories—behavioral and mathematical methods. Behavioral methods aim to create some sort of group agreement between the employed experts. While, in mathematical methods, the experts expressed their opinion about an uncertain quantity in the form of subjective probabilities. Afterward, suitable mathematical methods are used to combine these opinions. The rationale behind using mathematical approaches for the processing of experts’ opinions was provided in [56, 57]. Hence, in this study, one of the mathematical methods is used to analyze experts’ opinions.
According to [58], probability can be considered as a numerical representation of uncertainty because it offers a way to quantify the likelihood of occurrence of an event. Therefore, it is much easier for the employed experts to use linguistic expressions like high probable, low probable, and so on to express their opinions. Three elicitation methods that have been widely used for subjective analysis are Indirect, Direct, and Delphi. The basis of the Indirect method is to utilize the betting rates of experts to reach a point of indifference between obtainable choices according to an issue. The Direct method is the direct estimation of the degree of confidence of an expert on some subject. The Delphi technique is the first organized tool for methodologically collecting opinions on a specific subject using a cautiously defined ordered set of questionnaires mixed with summarized information and feedback resulting from previously received responses [59, 60]. The selection of each method for a particular purpose should fulfill the rational consensus principles such as accountability and fairness. In this study, among the abovementioned methods, Delphi, because of having enough capacity for expert opinion elicitation, is selected for eliciting process.
10.3.3.2 Experts Weighting Evaluation
Once the experts’ opinion elicitation process is completed, the expert weighting calculation is started. This step is necessary because, in real life, each employed expert has a different weight according to his/her experience and background. Thus, to obtain realistic results for the probability of each BE, the weight (importance of the judgment outcome) of the employed experts should be identified. There are many methods such as simple averaging besides many unmethodical techniques that may be used for giving specific weighting to the experts. However, they cannot diminish subjective bias and help domain experts to carry out the eliciting procedure in an effective way.
AHP (analytical hierarchy process) introduced by Saaty [61] is a widely used process in multi-criteria decision-making. This process breaks large decision problems into smaller ones and then uses a hierarchy of decision layers to handle the complexity of the problems. This allows focusing on a smaller set of the decision at a time. There exist criticism regarding AHP’s use of lopsided judgmental scales and its inability to appropriately reflect the characteristic uncertainty and imprecision of pair comparisons [62]. The verbal statements provided by the decision-makers in AHP could be unclear. Moreover, they regularly would choose to provide their preferences as oral expressions instead of numerical quantities and the type of pair comparisons used cannot properly reflect their decisions about priorities [63,64,65,66]. The abovementioned shortages represent that in most cases, the nature of decision-making is full of ambiguities and complexities, and accordingly it is denoted that most decisions are made in a fuzzy environment.
Let \(O = \left\{ {o_{1} , o_{2} , \ldots , o_{n} } \right\}\) is a set of objects and \(W = \left\{ {w_{1} , w_{2} , \ldots , w_{m} } \right\}\) is a set of goals. Therefore, the extent analysis values for \(m\) goals for each object can be denoted as:
where each of \(M_{gi}^{m}\) is a triangular fuzzy set.
Step 1. The fuzzy synthetic extent concerning the i-th object is denoted as:
To get \(\mathop \sum\nolimits_{j = 1}^{m} {\text{\rm M}}_{gi}^{j}\) the fuzzy addition operation of \(m\) extent analysis values for a particular matrix is achieved as:
and afterward, the inverse of the vector is calculated as follows:
Step 2. The degree of likelihood of \({\text{\rm M}}_{2} = \left( {l_{2} ,m_{2} ,u_{2} } \right) \ge {\text{\rm M}}_{1} = \left( {l_{1} ,m_{1} ,u_{1} } \right)\) is calculated as:
It can be represented by Eq. (10.13).
As seen in Fig. 10.3, \(d\) is the highest intersection point between \(\mu_{{M_{1} }}\) and \(\mu_{{M_{2} }}\).

The intersection between \(M_{1}\) and \(M_{2}\)
Step 3. The degree of likelihood that a convex fuzzy number is greater than \(k\) convex fuzzy \(M_{i} \left( {i = 1,2, \ldots ,k} \right)\) numbers can be obtained by:
Suppose that \(d^{\prime} ( A_{i} ) = \min V\left( {S_{i} \ge S_{k} } \right)\) for \(k = 1,2, \ldots ,n;k \ne i\). Now, the given weight vector is denoted by:
where \(A_{i} \left( {i = 1,2, \ldots ,n} \right)\) are n elements.
Step 4. Using normalization, the normalized weight vectors are:
where W is a non-fuzzy number.
The fuzzy linguistic variables are used to allow experts to provide their subjective opinions reflecting nine-point essential scale. In this chapter, the linguistic variables and their equivalent fuzzy numbers are used.
10.3.3.3 Experts’ Opinion Aggregation
The experts’ opinion aggregation process can be completed in three phases including (i) obtaining linguistic terms from experts describing the likelihood of occurrence of BEs, (ii) mapping linguistic variables into the corresponding fuzzy numbers, and (iii) applying an aggregation process under fuzzy environment.
Firstly, the engaged experts provided their judgements about the likelihood of occurrence of each BE in the fault tree. Their opinions can be obtained in the form of linguistic variables represented as IFNs.
As experts may have dissimilar opinions about a subject due to having a different level of experience, background, and expertise, it is essential to aggregate multi-expert opinions to reach an agreement. Different kinds of aggregation methods like the arithmetic averaging method and similarity aggregation method (SAM) can be utilized for this purpose. However, Yazdi and Zarei [56] pointed out the benefits of such methods in the context of fuzzy FTA. It is concluded that SAM has enough capability for this purpose. Therefore, an extension of SAM as described in [67] is used in this chapter for the aggregation of IFNs. The SAM method contains the following steps.
Step A. Mapping of linguistic variables into equivalent IFNs:
After each expert, \(E_{k} \left( {k = 1, 2, \ldots , n} \right)\) provides his/her judgment about the occurrence possibility of each BE in the form of linguistic variables; accordingly, it is transformed into the equivalent IFNs.
Step B. Degree of similarity computation:
The similarity \(S_{uv} \left( {\tilde{A}_{u} ,\tilde{A}_{v} } \right)\) between the opinions \(\tilde{A}_{u}\) and \(\tilde{A}_{v}\) of experts \(E_{u}\) and \(E_{v}\) is evaluated as:
where \(S_{uv} \left( {\tilde{A}_{u} ,\tilde{A}_{v} } \right) \in \left[ {0,1} \right]\) is the function to measure similarity, where \(\tilde{A}_{u}\) and \(\tilde{A}_{v}\) are two regular intuitionistic fuzzy numbers, \(EV_{u}\) and \(EV_{v}\) are the expectancy evaluation for \(\tilde{A}_{u}\) and \(\tilde{A}_{v}\). The \(EV\) of a triangular IFN \(\tilde{A} = \left( {a,b,c; a^{\prime}, b^{\prime}, c^{\prime} } \right)\) is calculated as:
A similarity matrix \(\left( {SM} \right)\) for m experts is defined as:
where \(S_{uv} = s\left( {\tilde{A}_{u} ,\tilde{A}_{v} } \right)\), if \(u = v\) then \(S_{uv} = 1\).
Step C. Degree of agreement computation:
The average agreement degree \(AA\left( {E_{m} } \right)\) for each expert is calculated as
where \(m = 1,2, \ldots ,n\).
Step D. The relative agreement computation:
The \({\text{RAD}} \left( {E_{m} } \right)\) is the relative agreement degree, which can be calculated as:
where \(m = 1,2, \ldots ,n\).
Step E. Consensus degree computation:
The aggregation weight \(\left( {w_{m} } \right)\) of an expert \(E_{m}\) is computed using \({\text{RAD}} \left( {E_{m} } \right)\), and the weight of each expert (\(W_{{{\text{FAHP}}}}\)) is obtained by FAHP as follows.
where \(\alpha \left( {0 \le \alpha \le 1} \right)\) is the weighting factor also known as a relaxation factor that can be assigned to \(W_{{{\text{FAHP}}}} \left( {E_{m} } \right)\) \({\text{RAD}} \left( {E_{m} } \right)\) to define their relative importance.
Step F. Aggregated result computation:
The aggregated result for each basic event can be computed as:
where \(\tilde{P}_{j}\) is the aggregated possibility of basic event j in the form of IFNs.
So far, the aggregation possibility of each BE based on IFNs is computed. In the next section, the procedure of TE computation is explained.
10.3.4 Calculation of Probability of TE
Once the occurrence possibilities of all BEs are obtained, these values are translated into the equivalent probabilities using the following equation introduced by [68]:
where FP and FPS represent failure probability and failure possibility, respectively, and
Once the intuitionistic fuzzy failure probabilities of the BEs are obtained, they are used to calculate the IF probability of the TE. Intuitionistic fuzzy arithmetic operations are adopted to evaluate the probabilities of the minimal cut sets of the FT and the same for the TE probability.
A set of minimal cut sets of a fault tree can be denoted as:
where \(C_{i}\) is the i-th minimal cut set of order \(k\) and is denoted as \(C_{i} = e_{1} .e_{2} \ldots e_{k}\).
Let the probability \(\tilde{P}_{j}\) of event \(e_{j} :i = 1,2, \ldots ,n\) be characterized by triangular IFNs \(\left( {a_{j} ,b_{j} ,c_{j} ;a_{j}^{\prime } ,b_{j} ,c_{j}^{\prime } } \right)\), then the failure probability of \(\tilde{P}_{{C_{i} }}\) of the minimal cut set \(C_{i}\) is estimated using the following expressions.
As the TE of an FT is represented by an OR gate, the failure probability of the TE can be calculated using the following equation:
where \(\tilde{P}_{{C_{1} }} , \tilde{P}_{{C_{2} }} , \ldots , \tilde{P}_{{C_{m} }}\) denoted the failure probabilities of all MCSs \(C_{i} :i = 1,2, \ldots ,m\).
Through IF-defuzzification process an IFN can be converted to a single scalar quantity. The failure probability of the TE obtained as triangular IFN \(\tilde{A} = \left( {a,b,c;\mathop {a,}\limits^{\prime } b,\mathop c\limits^{\prime } } \right)\) can be defuzzified as follows.
10.3.5 Different Approach Comparison
To understand the efficiency of the proposed model, the results are compared with the common approaches. Firstly, conventional FFTA based on the FST which is widely used in different engineering applications is applied. Then, an approach based on the integration of the BN and FST which was introduced in [12] is utilized.
As mentioned in the literature, the procedure of conventional FFTA is utilizing triangular or trapezoidal fuzzy numbers for the probability expression of all BEs in FT. Then, fuzzy arithmetic operations are utilized to compute the TE probability in terms of a fuzzy number.
In the second approach, after [69] that compared conventional FTA and BN, many studies have been performed by mapping FT into the corresponding BN for different applications. A list of such works can be found in literature [70], which makes use of the advantages of multi-expert opinions and FST for uncertainty handling in the data and BN for modeling dependency between events. According to their approach, the probability of each BE is computed in five key steps as collecting experts’ opinions in qualitative terms, fuzzification, aggregation, defuzzification, and probability computation. Once the probability of each BEs is obtained, then FT is mapped into the corresponding BN. According to the Bayes theorem, the TE probability can be calculated as follows.
In a BN, the joint probability distribution of a set of variables can be denoted using the conditional dependency of variables and chain rules as follows:
where \(U = \left\{ {X_{1} ,X_{2} , \ldots ,X_{n} } \right\}\) and \(X_{i + 1}\) is the parent of \(X_{i}\). Consequently, the probability of \(X_{i}\) can be calculated as:
Using Bayes theorem as seen in Eq. (10.32), the prior probability of an event (E) can be updated.
To get further details, readers can refer to [71].
10.3.6 Sensitivity Analysis
Once the relative competency of each expert’s opinion is predicted, it is better to determine the consensus coefficient. Thus, the decision-maker needs to allocate a proper value for the relaxation factor \(\alpha\) in Eq. (10.22); otherwise, sensitivity analysis (SA) should be performed to evaluate the reliability of the system when \(\alpha\) has been given different values ranging from 0 to 1. In this study, the relaxation factor is considered as 0.5 to give equal weights to both factors on the right side of the Eq. (10.22). However, to identify the sensitivity of the BEs, we have performed the sensitivity analysis by varying the values of \(\alpha .\) This helped to understand which of the BEs are more sensitive to uncertainty.
Using BIM, the criticality of an event is identified as follows:
As seen in the above equation, the criticality of the basic event \({\text{BE}}_{i}\) is computed by taking the difference between the top event probabilities when the \({\text{BE}}_{i}\) is assumed to have occurred and non-occurred, respectively.
10.4 Application to the Case Study
The developed methodology is applied to the risk analysis of an ethylene oxide (EO) production plant that is a component of an ethylene transportation line to demonstrate its effectiveness. The detail of the system is shown in Fig. 10.4. A prior study performed on the abovementioned system by [72] identified the most hazardous components of the system, including the ethylene oxide storage and reaction unit, ethylene oxide distillation column, transportation line, and ethylene re-boiler. It was recommended that further risk assessment is essential for the declared units. Therefore, Khan and Haddara [73] found optimal maintenance in the above case study using a risk-based maintenance method. Additionally, the ethylene transportation line component was recognized as the third key hazard in the available units. In this regard, [12] applied their proposed approach to EO Transportation line as a case study.

Schematic diagram of the EO plant [72]
10.4.1 Probabilistic Risk Assessment
An ignition of vapor cloud that may lead to a fireball is selected as the TE of the FT. The developed FT is shown in Fig. 10.5. As seen in the fault tree, there are 25 BEs (represented as circles) and details of these BEs are presented in Table 10.1. To compute the occurrence probability of each BE, the heterogeneous group of experts used in [12] has been used in this chapter. Using the Delphi method, employed experts were asked to provide their judgements in relevant linguistic terms. The weights of experts have been computed using the FAHP method, and the calculated weights of experts 1, 2, 3, and 4 are 0.249, 0.126, 0.495, and 0.128, respectively [12].

FT for the ethylene transportation line (reworked and modified from [12])
To show the aggregation procedure of expert’s judgment; consider the case of BE24 (Corrosion) as an example. Concerning the characterization of IFNs, the linguistic variables, obtained from four experts, are categorized as “L”, “M”, “FH”, and “M”. The detailed computation of aggregation for BE24 is shown in Table 10.2. The aggregated results for all BEs are presented in Table 10.3.
To calculate the TE of the FT of Fig. 10.5, it was qualitatively analyzed to obtain 102 MCSs. Each of the MCSs is a combination of a number of BEs that can cause the TE. Using the Eqs. (10.22), (10.23) and the IF-probabilities of the BEs from Table 10.3, the TE probability as IFN is calculated as: {3.296E-11, 8.270E-10, 1.132E-08, 1.804E-11, 8.270E-10, 1.922E-08}. After defuzzification, the crisp probability of the TE obtained is 5.715E-09. We have also used the crisp probabilities of the BEs (see the last column of Table 10.3) to evaluate the TE probability and the value obtained was 1.620E-09. As can be seen, this value is close to the value obtained through the defuzzification of the IF-probabilities.
According to step 11 of the framework shown in Fig. 10.2, the TE probability has been evaluated using the BN-based approach for comparison of the result. Figure 10.6 shows the BN model of the FT illustrated in Fig. 10.5. In this BN, the prior probabilities of the root nodes are specified based on the crisp probabilities of the BEs as shown in Table 10.3. Conversely, the conditional probabilities of nodes representing logic gates are characterized according to the specification of the gates. After running a query on this BN model, the probability of TE obtained was 1.576E-9, which is quite close to the value of TE probability calculated by the algebraic formulation.

BN model of the FT of Fig. 10.5
10.4.2 Sensitivity Analysis
As discussed in Sect. 3.6, a SA can be applied to show the validity of the proposed method, as well as highlight some features of the method. By varying the value of \(\alpha\) from 0 to 1, the probability of each BE is computed. Accordingly, the TE probability is estimated using BN. The probabilities of all BEs based on the corresponding value of \(\alpha\) are provided in Table 10.4.
It should be added that the sensitivity analysis assists experts to allocate priorities and make it flexible to perform the risk assessment. Figure 10.7 shows the results of the sensitivity analysis.

The probability of basic events based on the variation of \(\alpha\)
The SA specifies that the estimated probability for all the basic events is not pretty sensitive to the variations in the value of \(\alpha\). Using different values of \(\alpha\) ranging from 0 to 1, we can see that the risk probability of only 4 of the 25 basic events (16%) is quite different and these BEs are BE4, BE9, BE11, and BE20. Therefore, in this study, the differences between the rankings concerning different \(\alpha\) values are low.
In addition, choosing an adequate value of \(\alpha\) illustrates an important role in the top event probability computation. The value of \(\alpha\) can have an effect on the probability of each BE and accordingly top event. Thus, the value of \(\alpha\) should be allocated taking into account the following issues. As an initial subject, decision-makers can consult any existing historical data from similar operation conditions and risk assessment, which have received feedback from them earlier. Next, using a questionnaire or other available methods, the value of \(\alpha\) can be obtained based on the decision-makers’ opinions. If a decision-maker has a high confidence regarding his/her judgment about the probability of basic events, the value of \(\alpha\) can be set to a higher value, on the contrary, a smaller value can be assigned to \(\alpha\). Finally, the value of \(\alpha\) can be assigned according to a realistic circumstance, meaning that the value of \(\alpha\) should be allocated a higher value when it is easy to get the consensus of decision-makers’ judgements on the probability of basic events or when the appropriately selected decision-makers are present.
The above SA illustrates that the presented model can offer vital data to analysts and other involved parties in the risk assessment process. Accordingly, the probability of the top event is computed by varying the value of \(\alpha\).
According to the new estimated probability of BEs, the probability of the TE is also updated and provided in Table 10.5.
10.4.3 Identification of Critical BEs and Corrective Actions for the Most Critical BEs
As we all know, one of the important outputs of FTA and correspondingly BN is recognizing the critical basic events. Based on this recognition, decision-makers can provide corrective and/or preventive actions to reduce the probability of critical basic events. As a result, the TE probability will be reduced; subsequently, the probability reduction will lead to improved performance of the system.
By following the criticality calculation approach shown in Sect. 3.6, the criticality of the BEs is estimated and conveyed in Table 10.6. As seen in the table, Flame arrestor A failed (BE4), Flame arrestor B failed (BE5), Ignition source present (BE6), Flammable gas detector fail (BE1), Flow sensor failed (BE11), and Leak from bends (four bends) (BE9) are recognized to be the most critical events (in the descending order of criticality), which are also recognized as top six critical events in [12]. This chapter provides corrective actions for the first five critical basic events because in the realistic case, the system cannot apply any interpretative actions to all BEs. The existing control measures for the aforementioned BEs can fall into the process safety management system since the construction of the complex plant. However, the performance of the control measures needs to be upgraded based on all requirements and changed after a couple of years.
Several control measures as corrective actions are recommended for the critical basic events. It is believed that any corrective actions need to satisfy the three main criteria as (i) it should have acceptable efficiency, (ii) it should fall into the acceptable economic perspective, and (iii) the recommended corrective actions should be environmentally friendly. Keeping these criteria in our mind, to control the Flame arrestors A and B, increasing the number of inspection can effectively reduce the probability of failure. In addition, cleaning, as an important part of the Flame arrestor maintenance procedure, is required to be continuously considered. The Ignition source present event can properly be eliminated by providing natural or in some specific cases of a fireproof ventilation system. The ventilation system has been widely used and accepted method in the oil and gas industries. It can prevent smoke and fire propagation through the air ducts even in case of fire. To reduce the failure probability of a flammable gas detector, one possible and applicable way is using an updated version of a gas detector. The flammable gas detector may fail due to some identical causes. These causes also need to be identified. Thus, the failure can be eliminated only and only by some simple modifications. According to this, continual maintenance to preserve the detector in operational conditions is recommended. To deal with another critical basic event as “Flow sensor failed”, a potential acceptable solution is by introducing redundancy, i.e., changing the current system into the parallel one by adding one more sensor. In this case, one sensor is operating and the second sensor is in a standby mode. In case of the failure of the operating sensor, the standby sensor can take over the operational responsibility of the failed sensor, thus preventing the failure. Finally, the “Leak from bends” is controlled by bare-eye inspection. To cope with this failure, electrical testing such as voltage and resistance measurement, physical testing like drop test, bending test, and pull test can be applied. Also, such visual inspection including optical microscope and X-ray microscope is also possible to be used.
Adding to this, the risk assessment is a continuous procedure to improve the safety performance of the studied system. Therefore, continuous review and revision must be taken into account.
10.5 Conclusion
This chapter presents a framework for FTA and BN-based reliability analysis of process systems using IFS theory where there exists uncertainty with the availability of precise failure data. The proposed approach enables the gathering of uncertain data by combining IFS theory with expert elicitation. The IFS theory differs from the traditional fuzzy set theory in the sense that it considers both the membership and non-membership of an element in the set. Therefore, the utilization of the IFS theory would allow us to model situations where a varying level of confidence is associated with the fuzziness of numerical data. Therefore, by using IFS theory together with expert judgment as presented in this chapter, the analysts would get increased flexibility while expressing failure data in the form of fuzzy numbers.
The sensitivity analysis performed within the proposed framework would help the analysts to determine the events that are more sensitive to uncertainty, thus allowing to make informed decision to improve the data quality of the associated events. Furthermore, the criticality analysis of the events followed by the recommendation of corrective actions would greatly help to increase the reliability of the studied system. The efficiency of the proposed framework has been verified by applying it to a practical system. The experimentations illustrate that the IFS-based method offers a valuable way of reliability assessment of process systems when the fuzzy failure data of system components cannot be defined with high confidence. It should be added that, as a direction for future works, the same approach can be integrated using much more advanced fuzzy set theory such as but not limited PFS.
References
Mannan, S., Lees, F.P., Lees’ Loss Prevention in the Process Industries: Hazard Identification, Assessment, and Control. Elsevier Butterworth-Heinemann (2005)
Amyotte, P.R., Berger, S., Edwards, D.W., Gupta, J.P., Hendershot, D.C., Khan, F.I., Mannan, M.S., Willey, R.J.: Why are major accidents still occurring? Process Saf. Prog. 35, 253–257 (2016). https://doi.org/10.1002/prs.11795
Khan, F.I., Abbasi, S.A.: Risk analysis of a typical chemical industry using ORA procedure. J. Loss Prev. Process Ind. 14, 43–59 (2000). https://doi.org/10.1016/S0950-4230(00)00006-1
Kabir, S.: An overview of fault tree analysis and its application in model based dependability analysis. Expert Syst. Appl. 77, 114–135 (2017). https://doi.org/10.1016/j.eswa.2017.01.058
Markowski, A.S., Mannan, M.S., Bigoszewska, A.: Fuzzy logic for process safety analysis. J. Loss Prev. Process Ind. 22, 695–702 (2009). https://doi.org/10.1016/j.jlp.2008.11.011
Omidvar, M., Zarei, E., Ramavandi, B., Yazdi, M.: Fuzzy Bow-Tie Analysis: Concepts, Review, and Application BT—Linguistic Methods Under Fuzzy Information in System Safety and Reliability Analysis. In: Yazdi, M. (ed.) Springer International Publishing, Cham, pp. 13–51 (2022). https://doi.org/10.1007/978-3-030-93352-4_3
Yazdi, M., Adumene, S., Zarei, E.: Introducing a Probabilistic-Based Hybrid Model (Fuzzy-BWM-Bayesian Network) to Assess the Quality Index of a Medical Service BT—Linguistic Methods Under Fuzzy Information in System Safety and Reliability Analysis. In: Yazdi, M. (ed.) Springer International Publishing, Cham, pp. 171–183 (2022). https://doi.org/10.1007/978-3-030-93352-4_8
Cooke, R.: Experts in Uncertainty: Opinion and Subjective Probability in Science. Oxford University Press (1991)
Zadeh, L.: Fuzzy sets. Inf. Control. 8, 338–353 (1965)
Yazdi, M., Kabir, S.: Fuzzy evidence theory and Bayesian networks for process systems risk analysis. Hum. Ecol. Risk Assess. 26, 57–86 (2020). https://doi.org/10.1080/10807039.2018.1493679
Wang, D., Zhang, Y., Jia, X., Jiang, P., Guo, B.: Handling uncertainties in fault tree analysis by a hybrid probabilistic-possibilistic framework. Qual. Reliab. Eng. Int. 32, 1137–1148 (2016). https://doi.org/10.1002/qre.1821
Yazdi, M., Kabir, S.: A fuzzy Bayesian network approach for risk analysis in process industries. Process Saf. Environ. Prot. 111 (2017). https://doi.org/10.1016/j.psep.2017.08.015
Atanassov, K.T.: Intuitionistic fuzzy sets. Fuzzy Sets Syst. 20, 87–96 (1986). https://doi.org/10.1016/S0165-0114(86)80034-3
Govindan, K., Khodaverdi, R., Vafadarnikjoo, A.: Intuitionistic fuzzy based DEMATEL method for developing green practices and performances in a green supply chain. Expert Syst. Appl. 42, 7207–7220 (2015). https://doi.org/10.1016/j.eswa.2015.04.030
Sayyadi Tooranloo, H., Sadat Ayatollah, A.: A model for failure mode and effects analysis based on intuitionistic fuzzy approach. Appl. Soft Comput. J. 49, 238–247 (2016). https://doi.org/10.1016/j.asoc.2016.07.047
Yazdi, M.: Risk assessment based on novel intuitionistic fuzzy-hybrid-modified TOPSIS approach. Saf. Sci. 110, 438–448 (2018). https://doi.org/10.1016/j.ssci.2018.03.005
Ming-Hung, S., Ching-Hsue, C., Chang, J.-R.: Using intuitionistic fuzzy sets for fault-tree analysis on printed circuit board. Assembly 46, 2139–2148 (2006). https://doi.org/10.1016/j.microrel.2006.01.007
Chang, J.R., Chang, K.H., Liao, S.H., Cheng, C.H.: The reliability of general vague fault-tree analysis on weapon systems fault diagnosis. Soft Comput. 10, 531–542 (2006). https://doi.org/10.1007/s00500-005-0483-y
Cheng, S.R., Lin, B., Hsu, B.M., Shu, M.H.: Fault-tree analysis for liquefied natural gas terminal emergency shutdown system. Expert Syst. Appl. 36, 11918–11924 (2009). https://doi.org/10.1016/j.eswa.2009.04.011
Kumar, M., Yadav, S.P.: The weakest t-norm based intuitionistic fuzzy fault-tree analysis to evaluate system reliability. ISA Trans. 51, 531–538 (2012). https://doi.org/10.1016/j.isatra.2012.01.004
Kabir, S., Walker, M., Papadopoulos, Y.: Dynamic system safety analysis in HiP-HOPS with Petri nets and Bayesian networks. Saf. Sci. 105, 55–70 (2018). https://doi.org/10.1016/j.ssci.2018.02.001
Kabir, S., Papadopoulos, Y.: Applications of Bayesian networks and Petri nets in safety, reliability, and risk assessments: a review. Saf. Sci. 115, 154–175 (2019). https://doi.org/10.1016/j.ssci.2019.02.009
Ferdous, R., Khan, F., Veitch, B., Amyotte, P.R.: Methodology for computer aided fuzzy fault tree analysis. Process Saf. Environ. Prot. 87, 217–226 (2009). https://doi.org/10.1016/j.psep.2009.04.004
Yu, H., Khan, F., Veitch, B.: A flexible hierarchical Bayesian modeling technique for risk analysis of major accidents. Risk Anal. 37, 1668–1682 (2017). https://doi.org/10.1111/risa.12736
Hashemi, S.J., Khan, F., Ahmed, S.; Multivariate probabilistic safety analysis of process facilities using the Copula Bayesian network model. Comput. Chem. Eng. 93, 128–142 (2016). https://doi.org/10.1016/j.compchemeng.2016.06.011
Yazdi, M., Nikfar, F., Nasrabadi, M.: Failure probability analysis by employing fuzzy fault tree analysis. Int. J. Syst. Assur. Eng. Manag. 8, 1177–1193 (2017). https://doi.org/10.1007/s13198-017-0583-y
Yazdi, M.: Footprint of knowledge acquisition improvement in failure diagnosis analysis. Qual. Reliab. Eng. Int. 405–422 (2018). https://doi.org/10.1002/qre.2408
Wang, Y.F., Qin, T., Li, B., Sun, X.F., Li, Y.L.: Fire probability prediction of offshore platform based on dynamic Bayesian network. Ocean Eng. 145, 112–123 (2017). https://doi.org/10.1016/j.oceaneng.2017.08.035
Xin, P., Khan, F., Ahmed, S.: Dynamic hazard identification and scenario mapping using Bayesian network. Process Saf. Environ. Prot. 105, 143–155 (2017). https://doi.org/10.1016/j.psep.2016.11.003
Liu, X., Zheng, J., Fu, J., Nie, Z., Chen, G.: Optimal inspection planning of corroded pipelines using BN and GA. J. Pet. Sci. Eng. 163, 546–555 (2018). https://doi.org/10.1016/j.petrol.2018.01.030
Yan, F., Xu, K., Yao, X., Li, Y.: Fuzzy Bayesian network-bow-tie analysis of gas leakage during biomass gasification. PLoS ONE 11, e0160045 (2016). https://doi.org/10.1371/journal.pone.0160045
Pasman, H., Rogers, W.: The bumpy road to better risk control: a Tour d’Horizon of new concepts and ideas. J. Loss Prev. Process Ind. 35, 366–376 (2015). https://doi.org/10.1016/j.jlp.2014.12.003
Naderpour, M., Lu, J., Zhang, G.: An abnormal situation modeling method to assist operators in safety-critical systems. Reliab. Eng. Syst. Saf. 133, 33–47 (2015). https://doi.org/10.1016/j.ress.2014.08.003
Ren, J., Jenkinson, I., Wang, J., Xu, D.L., Yang, J.B.: A methodology to model causal relationships on offshore safety assessment focusing on human and organizational factors. J. Safety Res. 39, 87–100 (2008). https://doi.org/10.1016/j.jsr.2007.09.009
Cai, B., Zhang, Y., Wang, H., Liu, Y., Ji, R., Gao, C., Kong, X., Liu, J.: Resilience evaluation methodology of engineering systems with dynamic-Bayesian-network-based degradation and maintenance. Reliab. Eng. Syst. Saf. 209, 107464 (2021). https://doi.org/10.1016/j.ress.2021.107464
Li, X., Zhu, H., Chen, G., Zhang, R.: Optimal maintenance strategy for corroded subsea pipelines. J. Loss Prev. Process Ind. 49, 145–154 (2017). https://doi.org/10.1016/j.jlp.2017.06.019
Abimbola, M., Khan, F., Khakzad, N., Butt, S.: Safety and risk analysis of managed pressure drilling operation using Bayesian network. Saf. Sci. 76, 133–144 (2015). https://doi.org/10.1016/j.ssci.2015.01.010
Khakzad, N., Khan, F., Amyotte, P.: Quantitative risk analysis of offshore drilling operations: a Bayesian approach. Saf. Sci. 57, 108–117 (2013). https://doi.org/10.1016/j.ssci.2013.01.022
Khakzad, N., Khan, F., Amyotte, P.: Quantitative risk analysis of offshore drilling operations: a Bayesian approach. Saf. Sci. 57, 108–117 (2013). https://doi.org/10.1016/j.ssci.2013.01.022
Rausand, M., Haugen, S.: Risk Assessment: Theory, Methods, and Applications. Wiley, Hoboken (2020)
Mohammadfam, I., Zarei, E., Yazdi, M., Gholamizadeh, K.: Quantitative risk analysis on rail transportation of hazardous materials. Math. Probl. Eng. 2022, 6162829 (2022). https://doi.org/10.1155/2022/6162829
Adumene, S., Adedigba, S., Khan, F., Zendehboudi, S.: An integrated dynamic failure assessment model for offshore components under microbiologically influenced corrosion. Ocean Eng. 218, 108082 (2020). https://doi.org/10.1016/j.oceaneng.2020.108082
Adumene, S., Okwu, M., Yazdi, M., Afenyo, M., Islam, R., Orji, C.U., Obeng, F., Goerlandt, F.: Dynamic logistics disruption risk model for offshore supply vessel operations in Arctic waters. Marit. Transp. Res. 2, 100039 (2021). https://doi.org/10.1016/j.martra.2021.100039
Li, F., Wang, W., Dubljevic, S., Khan, F., Xu, J., Yi, J.: Analysis on accident-causing factors of urban buried gas pipeline network by combining DEMATEL, ISM and BN methods. J. Loss Prev. Process Ind. 61, 49–57 (2019). https://doi.org/10.1016/j.jlp.2019.06.001
Yazdi, M., Kabir, S., Walker, M.: Uncertainty handling in fault tree based risk assessment: state of the art and future perspectives. Process. Saf. Environ. Prot. 131, 89–104 (2019). https://doi.org/10.1016/j.psep.2019.09.003
Yazdi, M., Golilarz, N.A., Adesina, K.A., Nedjati, A.: Probabilistic risk analysis of process systems considering epistemic and aleatory uncertainties: a comparison study. Int. J. Uncertainty Fuzziness Knowl.-Based Syst. 29, 181–207 (2021). https://doi.org/10.1142/S0218488521500098
Verma, A.K., Srividya, A., Karanki, D.R.: Reliability and Safety Engineering. Springer London (2010). https://doi.org/10.1007/978-1-84996-232-2
Markowski, A.S., Mannan, M.S.: Fuzzy risk matrix. J. Hazard. Mater. 159, 152–157 (2008). https://doi.org/10.1016/j.jhazmat.2008.03.055
Nadjafi, M., Farsi, M.A., Jabbari, H.: Reliability analysis of multi-state emergency detection system using simulation approach based on fuzzy failure rate. Int. J. Syst. Assur. Eng. Manag. 8, 532–541 (2016). https://doi.org/10.1007/s13198-016-0563-7
Abdo, H., Flaus, J.-M.: Monte Carlo simulation to solve fuzzy dynamic fault tree*. IFAC-PapersOnLine 49, 1886–1891 (2016). https://doi.org/10.1016/j.ifacol.2016.07.905
Abdo, H., Flaus, J.M., Masse, F.: Uncertainty quantification in risk assessment—representation, propagation and treatment approaches: application to atmospheric dispersion modeling. J. Loss Prev. Process Ind. 49, 551–571 (2017). https://doi.org/10.1016/j.jlp.2017.05.015
Garg, H.: A novel approach for analyzing the behavior of industrial systems using weakest t-norm and intuitionistic fuzzy set theory. ISA Trans. 53, 1199–1208 (2014). https://doi.org/10.1016/j.isatra.2014.03.014
OREDA: Offshore Reliability Data Handbook, 4th edn. Trondheim (2015)
Preyssl, C.: Safety risk assessment and management-the ESA approach. Reliab. Eng. Syst. Saf. 49, 303–309 (1995). https://doi.org/10.1016/0951-8320(95)00047-6
Clemen, R.T., Winkler, R.L.: Combining probability distributions from experts in risk analysis. Risk Anal. 19, 155–156 (1999). https://doi.org/10.1023/A:1006917509560
Yazdi, M., Zarei, E.: Uncertainty handling in the safety risk analysis: an integrated approach based on fuzzy fault tree analysis. J. Fail. Anal. Prev. 18, 392–404 (2018). https://doi.org/10.1007/s11668-018-0421-9
Yazdi, M., Korhan, O., Daneshvar, S.: Application of fuzzy fault tree analysis based on modified fuzzy AHP and fuzzy TOPSIS for fire and explosion in the process industry. Int. J. Occup. Saf. Ergon. 26, 319–335 (2020)
Berni, R.: Quality and reliability in top-event estimation: quantitative fault tree analysis in case of dependent events. Commun. Stat. Theor. Methods 41, 3138–3149 (2012). https://doi.org/10.1080/03610926.2011.621574
Yazdi, M., Khan, F., Abbassi, R., Rusli, R.; Improved DEMATEL methodology for effective safety management decision-making. Saf. Sci. 127, 104705 (2020). https://doi.org/10.1016/j.ssci.2020.104705
Jiang, G.-J., Chen, H.-X., Sun, H.-H., Yazdi, M., Nedjati, A., Adesina, K.A.: An improved multi-criteria emergency decision-making method in environmental disasters. Soft Comput. (2021). https://doi.org/10.1007/s00500-021-05826-x
Saaty, T.L.: Decision Making with Dependence and Feedback: The Analytic Network Process: The Organization and Prioritization of Complexity. RWS Publications (1996)
Deng, H.: Multicriteria analysis with fuzzy pairwise comparison. Int. J. Approx. Reason. 21, 215–231 (1999). https://doi.org/10.1016/S0888-613X(99)00025-0
Rezaei, J.: Best-worst multi-criteria decision-making method. Omega (United Kingdom) 53, 49–57 (2015). https://doi.org/10.1016/j.omega.2014.11.009
Rezaei, J.: Best-worst multi-criteria decision-making method: Some properties and a linear model. Omega (United Kingdom) 64, 126–130 (2016). https://doi.org/10.1016/j.omega.2015.12.001
Li, H., Guo, J.-Y., Yazdi, M., Nedjati, A., Adesina, K.A.: Supportive emergency decision-making model towards sustainable development with fuzzy expert system. Neural Comput. Appl. 33, 15619–15637 (2021). https://doi.org/10.1007/s00521-021-06183-4
Yazdi, M.: Acquiring and sharing tacit knowledge in failure diagnosis analysis using intuitionistic and pythagorean assessments. J. Fail. Anal. Prev. 19, 369–386 (2019). https://doi.org/10.1007/s11668-019-00599-w
Kabir, S., Geok, T.K., Kumar, M., Yazdi, M., Hossain, F.: A method for temporal fault tree analysis using intuitionistic fuzzy set and expert elicitation. IEEE Access 8 (2020). https://doi.org/10.1109/ACCESS.2019.2961953
Onisawa, T.: An application of fuzzy concepts to modelling of reliability analysis. Fuzzy Sets Syst. 37, 267–286 (1990). https://doi.org/10.1016/0165-0114(90)90026-3
Khakzad, N., Khan, F., Amyotte, P.: Safety analysis in process facilities: comparison of fault tree and Bayesian network approaches. Reliab. Eng. Syst. Saf. 96, 925–932 (2011). https://doi.org/10.1016/j.ress.2011.03.012
Yazdi, M.: A review paper to examine the validity of Bayesian network to build rational consensus in subjective probabilistic failure analysis. Int. J. Syst. Assur. Eng. Manag. 10, 1–18 (2019). https://doi.org/10.1007/s13198-018-00757-7
Jensen, F.V., Nielsen, T.D.: Bayesian Networks and Decision Graphs (2007). https://doi.org/10.1007/978-0-387-68282-2
Khan, F.I., Husain, T., Abbasi, S.A.: Design and evaluation of safety measures using a newly proposed methodology “SCAP.” J. Loss Prev. Process Ind. 15, 129–146 (2002). https://doi.org/10.1016/S0950-4230(01)00026-2
Khan, F.I., Haddara, M.: Risk-based maintenance (RBM): a new approach for process plant inspection and maintenance. Process Saf. Prog. 23, 252–265 (2004). https://doi.org/10.1002/prs.10010
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this chapter

Cite this chapter
Yazdi, M., Kabir, S., Kumar, M., Ghafir, I., Islam, F. (2023). Reliability Analysis of Process Systems Using Intuitionistic Fuzzy Set Theory. In: Garg, H. (eds) Advances in Reliability, Failure and Risk Analysis. Industrial and Applied Mathematics. Springer, Singapore. https://doi.org/10.1007/978-981-19-9909-3_10
Download citation
DOI: https://doi.org/10.1007/978-981-19-9909-3_10
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-19-9908-6
Online ISBN: 978-981-19-9909-3
eBook Packages: Mathematics and StatisticsMathematics and Statistics (R0)