
Abstract
This work is based on meta-heuristic optimization (MOT) techniques that are currently used to optimize various problems. Known for its simplicity and stochastic nature, MOT is used to solve complex engineering problems. There are different categories of MOT, but this article will focus on techniques from artificial bee colony (ABC) and grey wolf optimizer (GWO). In this paper, an optimal feedback linearization control (FLC) for active and reactive powers control of a doubly fed induction generator (DFIG) is considered. The adopted controller is based on metaheuristic optimization techniques (MOTs) such as ABC and GWO. MOTs algorithms are proposed for tuning and generating optimal gains for PI controller to overcome the imperfections of the traditional tuning method, in order to enhance the performance of FLC-DFIG response. The control strategy is tested via a 1.5 MW DFIG wind turbine using MATLAB-SIMULINK. The simulation results confirm the improved performance of the DFIG wind system controlled by the optimal feedback linearization control compared to the classical feedback linearization control in terms of maximum overshoot, steady-state error, and settling time. The comparative results show the efficiency of the proposed improvement approach which provided the best overshoot value, outperforming the classical method by 6.82% and 43.85%, respectively. For the settling time, the superiority was in the order of approximately 9.38% and 87.85%. Considering the steady-state error, the proposed approach's superiority is 210% and more than 3e3% respectively.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Sustainable energy sources are clean and constitute an alternative resolution to meet the needs of the actual society. These renewable energy sources offer advantages because they are sustainable and reduce the CO2 coming from the combustion of fossil fuels [1].Among these energy sources, we find wind energy. The doubly fed Induction generator (DFIG) has an important role in modern wind energy conversion systems [2] because it can generate reactive current and produces constant-frequency electric power at variable speed operation. In this perspective, various techniques have been employed to control wind turbine systems based on DFIG by applying field oriented control (FOC) also known as the vector control technique, its principle is to make DFIG similar to a DC machine, where the flux and torque are independently controlled. Various control schemes adopted the field oriented control (FOC). In [3], classical PI controllers are used for the decoupled control of the active and reactive powers; the controller lacks strong dynamics and is not fully resistant to wind a fluctuation [1], which reduces the quality of energy produced. In [4], the fuzzy PI controllers are investigated to enhance the performance of the PI controller. Sliding mode control is used in [5], the controller can easily control instantaneous active and reactive power without a rotor current control loop and synchronous coordinate transformation [5]. However, these strategies do not consider the dynamics of DFIG-based wind energy systems because these systems are complex and nonlinear. In this control approach, the changes in wind speed have a negative impact on system performance. Therefore, the field oriented control scheme becomes powerless, unable to account for certain phenomena and, often gives less efficient results. To overcome this problem, the current research trend has been carried out in the field of nonlinear control systems. Many methods have been proposed in this field. The feedback linearization technique has been and still is one of the most used. This technique is used to cancel the nonlinear terms and linearize the system [6]. In this context, several works have shown that this nonlinear control technique has revealed interesting properties regarding decoupling and parametric robustness. In [7], a feedback linearization technique is used to control DC-based DFIG systems, to ameliorate the dynamic response of the system [7].In [8], the same control strategy is used to control the stator power of the DFIG wind turbine under unbalanced grid voltage in which the oscillations of generator torque and active power can be considerably reduced. While [9] proposes a mathematical formulation of the feedback linearization control technique of the DFIG wind turbine considering magnetic saturation which gives better dynamic performance. A Sliding mode control combined with feedback linearization is presented in [10] to improve the system's robustness. The searches presented in [7,8,9,10] are based on the simplified model of DFIG (The currents, the stator voltage, and the stator flux are expressed in the stator flux-oriented reference frame) and controlled by feedback linearization algorithm combined with the classical PI controller. The success of these controllers counts on the suitable choice of PI gains [11]. The adjustment of the PID gains using conventional trial and error techniques to achieve the best performance takes time and is almost tiring, particularly for non-linear systems [12].Recently, intelligent optimization techniques have been effectively applied as optimization tools in various applications such as grey wolf optimizer (GWO), particle swarm optimization (PSO), and artificial bee colony (ABC) [13].In [14], the author used a cuckoo search algorithm (CSA) for maximum power point tracking of solar PV systems under partial shading conditions. In [15], a genetic algorithm (GA), GWO and ABC algorithm are employed for the optimal control of the pitch angle of the wind turbine.
In this paper, feedback linearization controller based on the proposed MOTs algorithm is investigated and tested in control for DFIG Wind turbine. The feedback linearization strategy is applied to the nonlinear mathematical model of DFIG to independently control the active and reactive power. The difference between the current method and the methods in previous studies is to propose MOTs algorithms to tune and generate the optimal gains (\(K_{P}\) and \(K_{I}\)) of the feedback linearization controller, to overcome the drawbacks of the old tuning methods, which rely on conventional trial and error techniques, in order to improve the performance of FLC-DFIG response such as reducing overshoot and minimizing the steady-state errors and settling time.
The main contributions of this research can be summarized are as:
-
To design and use a feedback linearization controller (FLC) based on the nonlinear model of the DFIG integrated into a wind system to control the active and reactive powers, in order to capture the maximum power from the wind.
-
To apply MOTs algorithms (GWO, ABC) to determine and generate the optimal gains (\(K_{P}\) and \(K_{I}\)) of the feedback linearization controller of wind turbines in order to achieve maximum performance.
-
To compare the simulation results obtained using optimized feedback linearization control FLC tuned by GWO and ABC with the conventional feedback linearization control which is based on traditional tuning methods.
2 Problem Formulation
The correct tuning of the PI gains is necessary to obtain the required performances according to the characteristics of the system. The transfer function of a PI controller is:
where \(K_{P}\) and \(K_{I}\) are the proportional and integral gains respectively. These parameters for active and reactive powers control of the DFIG according to the criterion of the performance index. The problem of optimization is formulated in the form of objective function for adjusting the gains controllers of rotor side converter (RSC) to track the reference values of the stator powers and to ameliorate the dynamic behavior of the system [13].
The objective function is to improve the overall system dynamic behavior via minimizing the error objective function that refers to the performance index [16].
This function is based on the relation of the system performance when analyzing a set point response, criteria used to describe how well the system responds to the change including the steady state error, settling time, rise time, and the maximum overshoot ratio [13]. The Integration of the time weighted square error (ITWSE) is objective function. In this paper, the error signal is the active power and reactive power errors respectively.
where the \(P_{sre}\) and \(Q_{sre}\) are the RSC active and reactive powers regulation error, \(C_{1}\) and \(C_{2}\) are positive, their values are selected according to optimization technique. Fig. 1 shows the successive steps for estimating the values of the optimal gain for the PI controller [16]. PI controllers are then taken into account in the loop to regulate the stator powers [17] then, ABC and GWO algorithms are used for estimating the optimal values of PI controller via the performance index minimization [18]. The results of the different optimization algorithms will be compared through the overall system dynamic response.

Steps for optimal gain search
3 Studied System Modeling
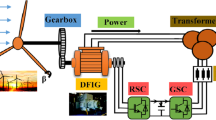
The studied system (Fig. 2) consists in a wind turbine comprising three blades of length \(R\), fixed on a drive shaft which is connected to a gain multiplier \(G\). This multiplier drives DFIG. Its stator is connected to the electric grid, while its rotor is connected to the electric grid but via a back-to-back two-level converter. The rotor side converter RSC is used to control the active and reactive stator powers issued by the WECS to the electric grid. The regulation of DC voltage to the desired value is assured by the grid side converter (GSC).

DFIG Wind turbine system
3.1 Turbine Model
The general expression of the aerodynamic power produced by the turbine is given by:
where:\(\rho\) is the air density,\(Cp\left( {\lambda ,\beta } \right)\) is the power coefficient of the turbine,\(\lambda\) is the tip speed ratio and \(\beta\) is the pitch angle (deg),\(V\) is the wind speed (m/s).
The tip speed ratio is defined by:
where: \(\omega_{t}\) is the speed turbine (rad/s).
Figure 3 shows the \(Cp\left( {\lambda ,\beta } \right)\) characteristic for different values of \(\beta\).

Typical \(Cp\left( {\lambda ,\beta } \right)\) curve
where
3.2 Dynamique Model of DFIG
The DFIG is modeled in Park frame by the following equations
The DFIG stat model according to the rotor components is given by
where
The mechanical equation is given by
where \(P\),\(J\),\(C_{G}\), \(C_{vis}\) represents the number of pole pairs, the inertia of the shaft, the torque on the generator, all frictions on the shaft, respectively.
We put
The system (8) is then written in the form:
where
and
4 Feedback Linearization Control
This strategy uses an inverse transformation to get the required control law for the nonlinear system and attain a decoupled power control [19].
The command vector is \(\left[ {\begin{array}{*{20}c} {v_{qr} } & {v_{dr} } \\ \end{array} } \right]^{T}\) and the output vector is \(\left[ {\begin{array}{*{20}c} {P_{s} } & {Q_{s} } \\ \end{array} } \right]^{T}\) defined by:
Substituting \(i_{ds}\) and \(i_{qs}\) in (14) by their counterparts extracted from the two last equations of (7), one has [20]:
Arranging (15)
Differentiating (16) until an input appears
From (12) and (17), we obtain:
The objective is to force the output \(P_{s}\) and \(Q_{s}\) to follow their references values \(P_{sref}\) and \(Q_{sref}\),respectively.
The power errors are defined as follows:
The control input is defined as:
Rewriting (18) in the matrix form
A new control input is defined as
The expression of control will be defined as
where
and
The goal is stabilized the output at \(\left[ {\begin{array}{*{20}c} {P_{sref} } & {Q_{sref} } \\ \end{array} } \right]^{T}\), a PI controller is used to the system (23). Hence, the new control is given by
The control is stable if the gains \(K_{pP - reg}\),\(K_{iP - reg}\), \(K_{pQ - reg}\), \(K_{iQ - reg}\) of the polynomial (25) obtained by Eqs. (22) and (24) are greater than zero. The tracking error converges and the system remains stable [21].
5 Meta-Heuristic Optimization Techniques
Recently, several meta-heuristic optimization algorithms have been used to resolve complex computational problems [15]. Some of the most famous are: genetic algorithm (GA), particle swarm optimization (PSO), gravitational search algorithm (GSA), magnetic optimization algorithm (MOA), charged system search (CSS), ant colony optimisation (ACO), teaching learning-based optimization (TLBO) and biogeography-based optimisation (BBO). The classical optimization techniques cannot resolve effectively and flexibly deal different problems. For this cause, the metaheuristic optimisation techniques (MOTs) have been applied to several domains. In addition, it has been proved that there is no MOT that can resolve all optimization problems [22]. The existing methods give good results in solving some problems, but not all.Therefore, various new heuristic algorithms are proposed every year, and research in this discipline is active [22].
5.1 Grey Wolf Optimization
GWO has been developed by Seyedali Mirjalili et al. [23].The principle of this algorithm is detailed in [23].This is simulate by democratic behaviour and the hunting mechanism of grey wolves [24]. Grey wolves favor to dwell in a group of 5–12 members they have a very strict hierarchy as in Fig. 4 [25]. It consists of four levels as follows.

Hierarchy of grey wolf
The leader wolf is called α. He is responsible for making decisions concerning predatory and defensive activities and resting [26].β wolf helps α to make decisions and the main responsibility of the β is the feedback suggestions. δ performs as sentinels scouts caretakers elders and hunters. The δ wolves have to submit to α and β, but they control the ω. The omega wolves must obey all the pack. α, β, and δ, orientates the hunting operation and ω follows them [27].
The encircle behaviour of GWO can be given as [16].
where \(t\) is the iterations number, \(\mathop A\limits^{ \to }\) and \(\mathop C\limits^{ \to }\) are coefficient vectors, \(\overrightarrow{{\mathrm{X}}_{\mathrm{p}}}\) is the position vector of the prey and \(\overrightarrow{\mathrm{X}}\) denotes the position vector of a wolf [28]. The vectors \(\mathop A\limits^{ \to }\) and \(\mathop C\limits^{ \to }\) are denoted as:
where \(\mathop a\limits^{ \to }\) is linearly decreased from 2 to 0 over the course of iterations. \(\mathop {r_{1} }\limits^{ \to }\) and \(\mathop {r_{2} }\limits^{ \to }\) are random vectors in [0,1].
The other research agents (including the ω wolves) must adjust their placements in accordance with the research agents' best positions provided the first best solutions. Figure 5 depicts the GWO algorithm's position updating [15].

Position updating in GWO
Figure 5 depicts how a search agent updates its location in the search region based on, α, β and δ. The final location of the search agent in the search area will be in a random position based on α, β and δ placements. Evidently, the prey's position is determined by α, β, δ and other wolves modify their places around the prey randomly [15].
The social hierarchy associated with the GWO hunting technique is mathematically simulated in a flowchart as shown in Fig. 6.

GWO algorithm
5.2 Artificial Bee Colony Algorithm
Artificial bee colony algorithm (ABC) has been developed by Karaboga in 2005.The principle of this algorithm is detailed in [29] is motivated by the intelligent behavior of the bee swarm [30]. In this optimization method, the bees are divided into three groups based on their tasks: employed, scout bee groups and onlooker [18]. 50% of the colony is possessed by employed bees and the other 50% composed of onlooker bees [30].
While other bees wait in the hive, the employed bees locate the food. Moreover, the onlookers’process the information and determine the best food place [16]. While the task of scout bees is the launch random search of the food source.The search could be done in three dimensions with the three groups, with the results being shared between them to reach an optimal solution rapidly and facilely [18].The ABC flowchart are shown in Fig. 7.

ABC algorithm
To transfer the onlooker bee to the position of the employed bee, we can use the Eq. (33)
where k denotes to the iteration number, i and j are randomly chosen indexes (i ≠ j), ∅ randomly variable. In [−1 1]. Each employed bee's location is updated in the neighborhood using:
The scheme of the optimized control system is shown in Fig. 8.

Optimized control scheme of the DFIG
6 Simulations Results
To validate the feedback linearization controller designed by PI,simulations were performed using Matlab™/Simulink. The proposed control strategy of the DFIG's RSC, using the ABC and GWO algorithms based feedback linearization PI control is tested.
The ABC-PI and GWO-PI are used on the system of the 1.5 MW WT-DFIG the parameters of DFIG are given in the Appendix. In this test, the system's controller parameters can be separated into four proportional-integral gains for RSC controllers, namely. (\(K_{pP - reg}\),\(K_{iP - reg}\)), (\(K_{pQ - reg}\), \(K_{iQ - reg}\)) that deal with the controller gains of the active and reactive powers regulator respectively. The optimal gain scheduling of the DFIG as shown in Table 1.
Figure 9 clearly shows the area of high agent density where the optimal gains of the PI controllers will be found.

Trace of search agents for different MOTs
Figures 10 and 11 illustrate(s) the performance of feedback linearization controller. These figures show(s) the stator active and reactive powers responses when the speed varies from 1450 to 1600 rpm at 8 s.The optimization algorithms ABC-PI and GWO-PI achieve excellent tracking of the control variables and close to zero steady state error. The active and reactive powers ripples are reduced considerably with the GWO-PI compared with that of ABC-PI and conventional PI controller and the GWO-PI has best dynamic performance than the ABC-PI concerning the steady state error and overshoot adequate.

Active power of the DFIG

Reactive power of the DFIG
Figures 12 and 13 show the DFIG rotor current time responses (\(i_{dr}\),\(i_{qr}\)) respectively for GWO-PI and ABC-PI. The rotor current damping with GWO tuned PI controller is decreased as compared with that of ABC-PI and the conventional PI controller or the over-current in the rotor circuit is reduced when using GWO-PI comprehensible.

Direct rotor current

Quadrature rotor current
In [9] and [31],the success of controllers counts on the suitable choice of PI gains (\(K_{p}\) and \(K_{I}\)).The adjustment of the PI coefficients using conventional trial and error techniques to achieve the best performance takes time and is almost tiring. Same remark for the choice of the gains for the fuzzy controller presented in [20].
Table 2 summarizes the comparison of previous researchs and our proposal. It should be noted that it is very difficult to find numerical results for the proposed technique in previous research to compare with the results of the current paper because they do not refer to the same conditions.
7 Conclusion
In this paper, the nonlinear control using a feedback linearization based on MOTs has been used to obtain the best performance for nonlinear control of DFIG active/ reactive power. The importance of this work is the determination of the optimal proportional integral (PI) controller’s gains for the control of DFIG Wind system.
The ABC and GWO techniques are introduced in order to ameliorate the dynamic performance WT-DFIG. The introduced GWO-PI and ABC-PI have provided more efficiency in seeking for the global optimum PI parameters with respect to the desired performance indices compared to the conventional PI controller. Therefore, both GWO and ABC are successfully used for optimizing the control parameters of the RSC for DFIG-based WECS under variable speed conditions.These two optimization techniques give better performance compared to the classical method. For the overshoot, the ABC algorithm provided the best overshoot value, outperforming GWO and the manual method by 6.82% and 43.85%, respectively. For the settling time, the GWO algorithm yielded the best settling time value, outperforming ABC and the manual method by 9.38% and 87.85% respectively. An identical observation is made for the steady-state error, the GWO algorithm provided the best steady-state error value, outperforming ABC and the manual method by 210% and more than 3e3% respectively. According to the simulation results based on the newly proposed tuning method using MOTs, the main improvements presented in this paper are:
-
Reduction of the maximum overshoot of the response of the active and reactive powers in a transient state.
-
Minimization of the settling time.
-
Decreasing the steady-state error of the system's dynamic behavior.
References
Nasef SA, Hassan AA, Elsayed HT, Zahran MB, El-Shaer MK, Abdelaziz AY (2022) Optimal tuning of a new multi-input multi-output fuzzy controller for doubly fed induction generator-based wind energy conversion system. Arab J Sci Eng 47(3):3001–3021
Zamzoum O, El Mourabit Y, Errouha M, Derouich A, El Ghzizal A (2018) Power control of variable speed wind turbine based on doubly fed induction generator using indirect field-oriented control with fuzzy logic controllers for performance optimization. Energy Sci Eng 6(5):408–423
Tamaarat A, Benakcha A (2014) Performance of PI controller for control of active and reactive power in DFIG operating in a grid-connected variable speed wind energy conversion system. Front Energy 8(3):371–378
Hamane B, Benghanemm M, Bouzid AM, Belabbes A, Bouhamida M, Draou A (2012) Control for variable speed wind turbine driving a doubly fed induction generator using Fuzzy-PI control. Energy Procedia 18:476–485
Hu J, Nian H, Hu B, He Y, Zhu ZQ (2010) Direct active and reactive power regulation of DFIG using sliding-mode control approach. IEEE Trans Energy Convers 25(4):1028–1039
Li J, Pan H, Long X, Liu B (2022) Objective holographic feedbacks linearization control for boost converter with constant power load. Int J Electr Power Energy Syst 134:107310
Yuliang SUN, Shaomin YAN, Bin CAI, Yuqiang WU (2018) Feedback linearization control for DC-based DFIG systems. In: 2018 Chinese automation congress. IEEE. (CAC) pp 1677–1680
Van TL, Nguyen H, Tran MT (2017) Feedback-linearization-based direct power control of DFIG wind turbine systems under unbalanced grid voltage. In: international conference on advanced engineering theory and applications, pp 830–839. Springer, Cham
Jose JT, Chattopadhyay AB (2020) Mathematical formulation of feedback linearizing control of doubly fed induction generator including magnetic saturation effects. Math Problems Eng 2020
Li P, Xiong L, Wu F, Ma M, Wang J (2019) Sliding mode controller based on feedback linearization for damping of sub-synchronous control interaction in DFIG-based wind power plants. Int J Electr Power Energy Syst 107:239–250
Askaria HM, Eldessouki MA, Mostaf MA (2015) Optimal power control for distributed DFIG based WECS using genetic algorithm technique. Am J Renew Sustain Energy 1(3):115–127
Soued S, Chabani MS, Becherif M, Benchouia MT, Ramadan HS, Betka A, Zouzou SE (2019) Experimental behaviour analysis for optimally controlled standalone DFIG system. IET Electr Power Appl 13(10):1462–1473
Osman AA, El-Wakeel AS, Kamel A, Seoudy HM (2015) Optimal tuning of PI controllers for doubly-fed induction generator-based wind energy conversion system using grey wolf optimizer. Int J Eng Res Appl 5(11):81–87
Bentata K, Mohammedi A, Benslimane T (2021) Development of rapid and reliable cuckoo search algorithm for global maximum power point tracking of solar PV systems in partial shading condition. Arch Control Sci, 31
Soued S, Ebrahim MA, Ramadan HS, Becherif M (2017) Optimal blade pitch control for enhancing the dynamic performance of wind power plants via metaheuristic optimisers. IET Electr Power Appl 11(8):1432–1440
Ramadan HS (2017) Optimal fractional order PI control applicability for enhanced dynamic behavior of on-grid solar PV systems. Int J Hydrog Energy 42(7):4017–4031
Shehata EG (2014) Direct power control of wind turbine driven DFIG during transient grid voltage unbalance. Wind Energy 17(7):1077–1091
Zhao J, Ramadan HS, Becherif M (2019) Metaheuristic-based energy management strategies for fuel cell emergency power unit in electrical aircraft. Int J Hydrog Energy 44(4):2390–2406
Boureguig K, Chouya A, Mansouri A (2021) Power improvement of DFIG wind turbine system using fuzzy-feedback linearization control. In: Advances in green energies and materials technology. Springer, Singapore. (pp 63–72)
Boureguig K, Mansouri A, Chouya A (2020) Performance enhancements of DFIG wind turbine using fuzzy-feedback linearization controller augmented by high-gain observer. Int J Power Electron Drive Syst 11(1):10
Chen G, Zhang L, Cai X, Zhang W, Yin C (2011) Nonlinear control of the doubly fed induction generator by input-output linearizing strategy. In: Electronics and signal processing. Springer, Berlin, Heidelberg. (pp 601–608)
Luo Q, Zhang S, Li Z, Zhou Y (2015) A novel complex-valued encoding grey wolf optimization algorithm. Algorithms 9(1):4
Mirjalili S, Mirjalili SM, Lewis A (2014) Grey wolf optimizer. Adv Eng Softw 69:46–61
Sakthi SS, Santhi RK, Krishnan NM, Ganesan S, Subramanian S (2017) Wind integrated thermal unit commitment solution using Grey Wolf optimizer. Int J Electr Comput Eng 7(5):2088–8708
Al-Tashi Q, Rais H, Jadid S (2018) Feature selection method based on grey wolf optimization for coronary artery disease classification. In: International conference of reliable information and communication technology. Springer, Cham. pp 257–266
Wang X, Zhao H, Han T, Zhou H, Li C (2019) A grey wolf optimizer using Gaussian estimation of distribution and its application in the multi-UAV multi-target urban tracking problem. Appl Soft Comput 78:240–260
Al-Tashi Q, Kadir SJA, Rais HM, Mirjalili S, Alhussian H (2019) Binary optimization using hybrid grey wolf optimization for feature selection. IEEE Access 7:39496–39508
Mittal N, Singh U, Sohi BS (2016) Modified grey wolf optimizer for global engineering optimization. Appl Comput Intell Soft Comput, 2016
Karaboga D (2005) An idea based on honey bee swarm for numerical optimization. Technical report-tr06, Erciyes University, engineering faculty, computer engineering department. Vol. 200, pp 1–10
Pilakkat D, Kanthalakshmi S (2019) An improved P&O algorithm integrated with artificial bee colony for photovoltaic systems under partial shading conditions. Sol Energy 178:37–47
Djilali L, Sanchez EN, Belkheiri M (2019) Real-time neural input-output feedback linearization control of DFIG based wind turbines in presence of grid disturbances. Control Eng Pract 83:151–164
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
Parameters | Value | Unit |
|---|---|---|
Nominal power | 1.5 | MW |
Turbine radius | 35.25 | m |
Gearbox gain | 90 | |
Stator Voltage | 398/690 | v |
Stator frequency | 50 | Hz |
Number of pairs poles | 2 | |
Nominal speed | 150 | rad/sec |
Stator resistance | 0.012 | Ω |
Rotor resistance | 0.021 | Ω |
Stator inductance | 0.0137 | H |
Rotor inductance | 0.0136 | H |
Mutual inductance | 0.0135 | H |
Inertia | 1000 | kg.m2 |
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Boureguig, K., Soued, S., Ouagueni, F. et al. Optimal Metaheuristic-Based Feedback Linearization Control of DFIG Wind Turbine System. J. Electr. Eng. Technol. (2023). https://doi.org/10.1007/s42835-023-01386-2
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s42835-023-01386-2